

Abstract
This paper deals with the complex unit roots representation of archea DNA sequences and the analysis of symmetries in the wavelet coefficients of the digitalized sequence. It is shown that even for extremophile archaea, the distribution of nucleotides has to fulfill some (mathematical) constraints in such a way that the wavelet coefficients are symmetrically distributed, with respect to the nucleotides distribution.
1. Introduction
In some recent papers the existence of symmetries in nucleotide distribution has been studied for several living organisms [1–6] including mammals, fungi [1–4], and viruses [5, 6]. Thus showing that any (investigated) DNA sequence, when converted into a digital sequence, features some fractal shape of its DNA walk and an apparently random-like distribution. However, when the short wavelet transform maps the digital sequence into the space of wavelet coefficients, and these coefficients are clustered then they are located along some symmetrical shapes.
One of the main tasks of this paper is to show that although the distribution of nucleotide, in any DNA sequence, can be considered as randomly given, when we compare a random sequence (and the corresponding random walk) with a DNA sequence (and walk) it can be seen that there exists some distinctions. So that the nucleotides distribution seems to side with a random distribution with some constraints. These constraints (rules) are singled out in the following, by showing the existence of hidden geometry which underlies the structure of a DNA sequence.
In other words, nucleotides are distributed along any DNA sequence at first apparently randomly but at second analysis according to some (statistical) mathematical constraints which does not allow a given nucleotide to be arbitrarily followed by any other remaining nucleotides.
It is interesting to notice that even in the primitives organisms which billions of years ago have been colonizing the earth under extreme conditions of life, their DNA has to fulfill the same constraints of the more evolved DNAs.
In order to achieve this goal some fundamental steps have to be taken into consideration and discussed.
Since DNA is a sequence of symbols, a map of these symbols into numbers has to be defined. In the following we will consider the complex unit roots map, which has the advantage of being unitary and distributed along the unit circle.
The indicator matrix is defined on the the indicator map. This matrix is important in order to draw the dot plot of the DNA sequence and from this plot we can see that apparently nucleotides seem to be randomly distributed. However, we will show by wavelet analysis that they look randomly distributed, while they are not.
The Ulam spiral adapted to DNA sequences is defined in order to single out some geometrical patterns.
Random walks on DNA, or short DNA walks, show that the random walks look like fractals.
The analysis of clusters of wavelet coefficients show that DNA walks have to fulfill some geometrical constraints.
In all DNA sequences, analyzed so far, for different kinds of living organisms, this geometrical symmetry [1–6] has been detected. In the following this analysis is extended also to archaea, since they might be considered at the early stage of life and their DNA is compared with more evolved microorganisms as bacteria.
It will be shown that, inspite of the many similarities with random sequences, only the wavelet analysis makes it possible to single out some distinctions. In particular, the wavelet coefficients of all (analyzed) organisms tend to fulfill a minimum principle for the energy of the signal. Also the archaea which often live in extreme environments have to fulfill the same geometrical rule of any other living organism.
The analysis of DNA by wavelets [7–9], as seen in [8–12], helps to single out local behavior and singularities [7, 13] or to express the scale invariance of coefficients [14]. Also multifractal nature of the time series [15–17] can be easily detected by wavelet analysis.
Some previous paper have studied various sequences of DNA such as leukemia tet variants, influenza viruses such as the A (H1N1) variant, mammalian, and a fungus (see [1–3, 14]) provided by the National Center for Biotechnology Information [18–21]. In all these papers it was observed that DNA has to fulfill not only some chemical steady state given by the chemical ligands but also some symmetrical distribution of nucleotide along the sequence. In other words, base pairs have to be placed exactly in some positions.
According to previous results, it will be shown that as any other living organisms also these elementary organisms have DNA walks with fractal shape and wavelet coefficients bounded on a short-range wavelet transform. In other words, also anaerobic organism which should be understood as the most elementary at the first step of life have the same symmetries on wavelet coefficients as for more evolved organism, so that life has to fulfill some constrained distribution of nucleotides in order to give rise to some organism even at the most elementary step.
In particular, in Section 2, some remarks about the analysed data are given. Section 3 deals with some elementary plots which can easily visualize the distribution of nucleotides. The Ulam spiral plot is also proposed for the first time and it is observed a different distribution of weak/strong hydrogen bonds. Section 4 provides some definitions about parameters of complexity. We will notice that all these parameters give rise to the same classification of organism. Section 4 proposes a complex numerical representation of DNA chains and random walks, while in final Section 6 the short wavelet trasform is given in order to single out some symmetries at the lower order of transform.
2. Materials and Methods
In the following we will take into consideration some genome, complete sequences of DNA, concerning the following archaea:
-
h1:
Aeropyrum pernix K1, complete genome. DNA, circular, 1669696 bp, [18–21], accession BA000002.3. Lineage: Archaea; Crenarchaeota; Thermoprotei; Desulfurococcales; Desulfurococcaceae; Aeropyrum; Aeropyrum pernix; Aeropyrum pernix K1. This organism, which was the first strictly aerobic hyperthermophilic archaeon sequenced, was isolated from sulfuric gases in Kodakara-Jima Island, Japan in 1993.
-
h2:
Acidianus hospitalis W1, complete genome. DNA, circular, 2137654 bp, [18–21], accession CP002535. Lineage: Archaea; Crenarchaeota; Thermoprotei; Sulfolobales; Sulfolobaceae; Acidianus; Acidianus hospitalis; Acidianus hospitalis W1
-
h3:
Acidilobus saccharovorans 345-15. complete genome. DNA, circular, 2137654 bp, [18–21], accession CP001742.1. Lineage: Archaea; Crenarchaeota; Thermoprotei; Acidilobales; Acidilobaceae; Acidilobus; Acidilobus saccharovorans; Acidilobus saccharovorans 345-15. Anaerobic bacteria found in hot springs.
to be compared with the following (aerobic/anaerobic) bacteria/fungi:
-
b1:
Mycoplasma putrefaciens KS1 chromosome, complete genome. DNA, circular, length 832603 bp, [18–21], accession NC 015946,. Lineage: Bacteria; Tenericutes; Mollicutes; Mycoplasmatales; Mycoplasmataceae; Mycoplasma; Mycoplasma putrefaciens; Mycoplasma putrefaciens KS1.
-
b2:
Mortierella verticillata mitochondrion, complete genome. dsDNA, circular, length 58745 bp, [18–21], accession NC 006838. Lineage: Eukaryota; Opisthokonta; Fungi; Fungi incertae sedis; Basal fungal lineages; Mucoromycotina; Mortierellales; Mortierellaceae; Mortierella; Mortierella verticillata.
-
b3:
Blattabacterium sp. (Periplaneta Americana) str. BPLAN, complete genome. DNA, circular, length 636994 nt, [18–21], accession NC 013418. Lineage: Bacteria; Bacteroidetes/Chlorobi group; Bacteroidetes; Flavobacteria; Flavobacteriales; Blattabacteriaceae; Blattabacterium; Blattabacterium sp. (Periplaneta Americana); Blattabacterium sp. (Periplaneta Americana) str. BPLAN.
Moreover we will compare DNA sequences with artificial sequences of nucleotides randomly taken (see Section 4).
2.1. Archaea
Archaea are a group of elementary single-cell microorganisms, having no cell nucleus or any other membrane-bound organelles within their cells. They are similar to bacteria, since they have the same size and shape (apart few exceptions) and the generally similar cell structure. However, the evolutionary history of archaea and their biochemistry has significant differences with regard to other forms of life. Therefore they are considered as members of a phylogenetic group distinct from bacteria and eukaryota.
Archaea during their evolution have been spreading all over the Earth in almost all habitats [22, 23] existing in a broad range of habitats, being one of the major contribution (20%) to earth's biomass. The most peculiar feature of archaea is that they can live in some environments with extreme life conditions (thus being considered as extremophiles [22, 24]). Indeed, some archaea survive to high temperatures, over 100°C, while others can live in very cold habitats or highly saline, acidic, or alkaline water. Nevertheless some archaea are living in mild conditions.
It has been also recognized that the archaea may be the most ancient organisms on the Earth, so that archaea, and eukaryotes are probably diverged early from an ancestral colony of organisms.
We will see, in the following, that archaea DNA it looks very close to random sequences so that we can assume that the ancestral organism were evolving by random permutations from a primitive assembly of nucleotides. So that the evolution can be seen as a tendency to a steady state far from the randomness. Therefore, the bacteria's DNA (and other eukaryotes' [1–6]), as a result of the evolution, shows the existence of some hidden stability.
3. Correlation Plots
In this section we will consider some elementary plots from where it is possible to visualize autocorrelation, distribution law of nucleotides and to measure some fundamental parameters by using frequency count.
Let
| (1) |
be the finite set (alphabet) of nucleotides (nucleic acids): adenine (A), cytosine (C), guanine (G), thymine (T), and x ∈ 𝒜 any member of the alphabet. Nucleic acids are further grouped according to their ligand properties as
purine {A, G}, pyrimidine {C, T},
amino {A, C}, keto {G, T},
weak hydrogen bonds {A, T}, strong hydrogen bond {G, C}.
A DNA sequence is the finite symbolic sequence
| (2) |
so that
| (3) |
with
| (4) |
being the nucleotide x at the position h.
In general we can define an ℓ-length alphabet as follows: let the ℓ-length DNA word be defined by the ℓ-combination of the 4 nucleotides (1). For each fixed length ℓ there are 4ℓ words, however not all of them can be considered, from biological point of view, as independent instances (see, e.g., Table 1), for this we define the ℓ-length alphabet as the set of ℓ-length independent words:
Table 1.
Correspondence codons to amino acids.
| Amino acid | Codon | ||
|---|---|---|---|
| 1 | M | Methionine | ATG |
| 2 | E | Glutamic acid | GAA, GAG |
| 3 | Q | Glutamine | CAA, CAG |
| 4 | D | Aspartic acid | GAT, GAC |
| 5 | R | Arginine | CGT, CGC, CGA, CGG, AGA, AGG |
| 6 | T | Threonine | ACT, ACC, ACA, ACG |
| 7 | N | Asparagine | AAT, AAC |
| 8 | H | Histidine | CAT, CAC |
| 9 | V | Valine | GTT, GTC, GTA, GTG |
| 10 | G | Glycine | GGT, GGC, GGA, GGG |
| 11 | L | Leucine | TTA, TTG, CTT, CTC, CTA, CTG |
| 12 | S | Serine | TCT, TCC, TCA, TCG, AGT, AGC |
| 13 | P | Proline | CCT, CCC, CCA, CCG |
| 14 | F | Phenylalanine | TTT, TTC |
| 15 | I | Isoleucine | ATT, ATC, ATA |
| 16 | C | Cysteine | TGT, TGC |
| 17 | A | Alanine | GCT, GCC, GCA, GCG |
| 18 | K | Lysine | AAA, AAG |
| 19 | Y | Thyroxine | TAT, TAC |
| 20 | W | Tryptophan | TGG |
| Stop | TAA, TAG, TGA | ||
| (5) |
with |⋯| cardinality of the set and
| (6) |
For instance with ℓ = 1, the alphabet is 𝒜 1 = 𝒜 = {A, C, G, T}, with ℓ = 3 the alphabet is given by the 20 amino acids
| (7) |
each amino acid being represented by a 3-length word of Table 1.
Let 𝒮 N be an N-length ordered sequence of nucleotides {A, C, G, T} and 𝒜 ℓ the chosen alphabet, a DNA sequence of words is the finite symbolic sequence
| (8) |
so that
| (9) |
with
| (10) |
being the word x at the position h.
3.1. Indicator Matrix
The 2D indicator function, based on the 1D definition given in [25], is the map
| (11) |
such that
| (12) |
with
| (13) |
and, where for short, we have assumed
| (14) |
According to (12), the indicator of an N-length sequence can be easily represented by the N × N sparse symmetric matrix of binary values {0,1} which results from the indicator matrix (see also [3–5])
| (15) |
being, explicitly
| (16) |
This squared matrix can be plotted in 2 dimensions by putting a black dot where u hk = 1 and white spot when u hk = 0 (Figure 1) thus giving rise to the two-dimensional dot plot, which is a special case of the recurrence plot [26].
Figure 1.

Indicator matrix for: (a1) pseudorandom 70-length sequence; (a2) pseudo-periodic 70-length sequence with period π = 35; (b1) 70-length DNA sequence of Mycoplasma KS1 bacter; (h3) 70-length DNA sequence of Acidilobus Archaea.
A simple generalization of this matrix can be considered for the alphabets 𝒜 ℓ, as follows. By choosing the 3 alphabet of amino acids, the 2D indicator function is the map
| (17) |
such that
| (18) |
with
| (19) |
According to (12), the indicator, on the 3-alphabet of amino acids of an N-length sequence can be easily represented by the N × N sparse symmetric matrix of binary values {0,1}:
| (20) |
being, explicitly
| (21) |
With the graphical representation of this matrix we can also show the correlation of amino acids.
3.2. Test Sequences
In the following, in order to single out the main features of biological sequences, we will compare the DNA sequence with some test sequences.
- Pseudorandom N-length sequence of nucleotides is the sequence {ℛ i}i=1,…,N ℓ where r i is a symbol randomly chosen in the alphabet 𝒜 ℓ, like for example, (ℓ = 1):
(22) - Pseudoperiodic N-sequence of nucleotides with period π is the direct sum of a given π-length pseudorandom sequence, such that N = kπ, (k ∈ ℕ) and ℛ i = ℛ i+π, for example,
When π = 1 we have a pseudorandom sequence.(23)
If we plot the indicator matrix of some bacteria and compare it with a pseudorandom and periodic sequence, we can see that (Figure 1)
the main diagonal is a symmetry axis for the plot;
there are some motifs which are repeated at different scales like in a fractal;
periodicity is detected by parallel lines to the main diagonal (Figure 1(a2));
empty spaces are more distributed than filled spaces, in the sense that the matrix u hk is a sparse matrix (having more 0's than 1's);
it seems that there are some square-like islands where black spots are more concentrated; these islands show the persistence of a nucleotide (Figures 1(a2) and 1(b1));
the dot plot of archaea is very similar to the dot plot of a random sequence (Figures 1(a1) and 1(h3)).
It can be noticed that DNA sequences of a living organism resemble (Figure 1) random sequences, with some short range influence, built on the same alphabet. This has been taken as an axiom of nucleotides distribution, so that DNA sequences are often considered as Markov chain [27]. However, there are some hidden rules in combining the nucleotides and these rules lead, during the evolution, to a steady distribution. In fact, the more primitive the sequence is, the more randomly distributed the nucleotides are. It seems that as a consequence of the evolution, nucleotides move from a disordered aggregation toward a more organized structure, shown by the growing islands in the dot plot. The biological evolution is such that the challenge for the self-organization might follow from random permutations of a primitive disordered sequence so that the organization, that is, the complexity, is only the result of many arbitrary permutations of randomness. During the challenge for complexity, DNA sequence becomes “less random” and it loses some kind of energy.
From the graphical representation of the indicator matrix for bacteria and amino acids we can see a more sparse matrix, but with some typical plots (Figure 2).
Figure 2.

Indicator matrix for the first 100 amino acids of (h1) Aeropyrum pernix K1, (h2) Acidianus hospitalis W1, (h3) Acidilobus saccharovorans 345-15 (b1) Mycoplasma putrefaciens KS1, (b2) Mortierella verticillata, and (b3) Blattabacterium sp.
3.3. Spiral Plot
In this section we consider a 2D distribution of nucleotides, following the idea given by Ulam for the distribution of primes, along an Ulam-like spiral [28]. In order to find some patterns in their distribution, nucleotides are arranged along a rectangular spiral. This is equivalent to mapping the 1D sequence of integers into a 2D sequence as follows:
| (24) |
For instance the sequence
| (25) |
distributed along the spiral looks like Figure 3.
Figure 3.
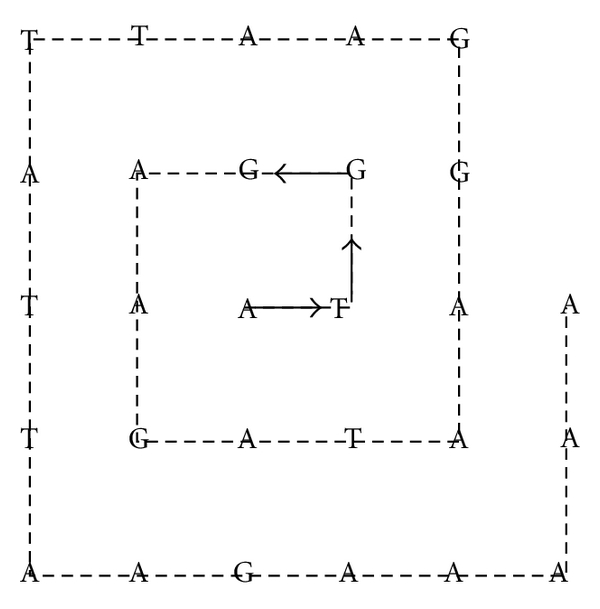
Distribution of nucleotides on a rectangular spiral.
For each nucleotide we can draw a spiral containing the distribution of only one acid nucleic. To each organism there correspond four plots, for A, C, G, T, respectively.
Let us first note that on a random sequence (Figure 4) the four distribution are equivalent.
Figure 4.

Spiral distribution of the first 3752 nucleotides for the random sequence.
By comparing the spirals of bacteria, random and archaea (Figures 4, 5, 6, 7, 8, 9, 10) we can see that there is a different distribution of each nucleotide. However the more evolved organism tends to have a higher percentage of weak hydrogen bonds (Figures 5, 6 and 7), so that we can assume the following.
Figure 5.

Spiral distribution of the first 3752 nucleotides for Mycoplasma putrefaciens KS1.
Figure 6.

Spiral distribution of the first 3752 nucleotides for Mortierella verticillata.
Figure 7.

Spiral distribution of the first 3752 nucleotides for Blattabacterium sp.
Figure 8.

Spiral distribution of the first 3752 nucleotides for Aeropyrum pernix K1..
Figure 9.

Spiral distribution of the first 3752 nucleotides for Acidianus hospitalis W1.
Figure 10.

Spiral distribution of the first 3752 nucleotides for Acidilobus saccharovorans 345-15.
Conjecture 1 —
During the evolution, the distribution of nucleotides changes in a such way that strong hydrogen bonds tend to become weak.
It should be noticed that along these spirals, there is a one-to-one map λ between ℕ and the points of the spiral (with integer coordinates) in ℜ 2
| (26) |
so that
| (27) |
This bijective map can be considered also between ℕ and the complex space ℂ so that each natural number corresponds to a complex number (with integer coefficients)
| (28) |
Since these spirals seem to fill in a finite region of the plane we can evaluate the complexity of each curve by typical fractal measures.
4. Parameters of Complexity
In this section we define some parameters, based on frequency distribution, which can measure the complexity of a DNA by computing the complexity of its representation in the complex plane (for a more detailed analysis see [29] and references therein).
Let 𝒮 N be an N-length-ordered sequence of nucleotides, and
| (29) |
be the probability to find the nucleotide x at the position h, 1 ≤ h ≤ N. According to (12) we define
| (30) |
as the number of nucleotides in the h-length segment of 𝒮 N, so that
| (31) |
The corresponding frequencies are
| (32) |
so that
| (33) |
We can assume that for large sequences
| (34) |
4.1. Randomness
Since for a random sequence the frequencies of nucleotides coincide for large n,
| (35) |
we can define as randomness index the following:
| (36) |
with σ being the variance, so that ℛ = 1 for random sequence and ℛ = 0 for a nonrandom sequence. Over the first 10000 nucleotides we have the randomness value of Table 2.
Table 2.
Randomness.
| Mycoplasma putrefaciens | 0.696 | |||||
|
| ||||||
| Mortierella verticillata | 0.779 | |||||
|
| ||||||
| Blattabacterium | 0.743 | |||||
|
| ||||||
| Aeropyrum pernix | 0.982 | |||||
|
| ||||||
| Acidianus hospitalis | 0.828 | |||||
|
| ||||||
| Acidilobus saccharouorans | 0.934 | |||||
|
| ||||||
| pseudorandom | 0.999 | |||||
However, if we compute the randomness index over the frequencies of amino acids in the 𝒜 3 alphabet then we can observe a different distribution of values. Over the first 30000 nucleotides corresponding to 10000 amino acids, we have the randomness value of Table 3.
Table 3.
Randomness of amino acids distribution.
| Mycoplasma putrefaciens | 0.946 | ||||||
|
| |||||||
| Mortierella verticillata | 0.938 | ||||||
|
| |||||||
| Blattabacterium | 0.953 | ||||||
|
| |||||||
| Aeropyrum pernix | 0.962 | ||||||
|
| |||||||
| Acidianus hospitalis | 0.916 | ||||||
|
| |||||||
| Acidilobus saccharouorans | 0.950 | ||||||
|
| |||||||
| pseudorandom | 0.963 | ||||||
So that we can comment that the arising complexity of the words and alphabets shows a different randomness in each alphabet.
4.2. Complexity
As a simple measure of complexity [30–32], for an n-length sequence, the following has been proposed [33]:
| (37) |
In Table 4 the complexity of the first 100-length segment of the DNA sequences is computed. It is interesting to notice the more similarities between the archaea Acidilobus with the pseudorandom sequence than with the pseudoperiodic. Nucleotide distribution in primitive biosequences is more likely random than pseudodeterministic. Moreover, the evolution reduces the complexity of the sequence.
Table 4.
Complexity.
| Mycoplasma putrefaciens | 1.151 | ||||||
|
| |||||||
| Mortierella verticillata | 1.285 | ||||||
|
| |||||||
| Blattabacterium | 1.197 | ||||||
|
| |||||||
| Aeropyrum pernix | 1.212 | ||||||
|
| |||||||
| Acidianus hospitalis | 1.231 | ||||||
|
| |||||||
| Acidilobus saccharouorans | 1.296 | ||||||
|
| |||||||
| Pseudorandom | 1.295 | ||||||
4.3. Fractal Dimension
The fractal dimension is computed on the dot plot, by the box counting algorithm [34, 35], as the average of the number p(n) of 1's in the randomly taken n × n minors of the N × N indicator matrix u hk or equivalently the number p(n) of black dots in the randomly taken n × n squares over the dot plot
| (38) |
The explicit computation enables us to compare the fractal dimension on the first 100-length segments of DNA chains, with an approximation up to 10−3 (see Table 5).
Table 5.
Fractal dimensions.
| Mycoplasma putrefaciens | 1.283 | |||||||
|
| ||||||||
| Mortierella verticillata | 1.296 | |||||||
|
| ||||||||
| Blattabacterium | 1.287 | |||||||
|
| ||||||||
| Aeropyrum pernix | 1.288 | |||||||
|
| ||||||||
| Acidianus hospitalis | 1.290 | |||||||
|
| ||||||||
| Acidilobus saccharouorans | 1.297 | |||||||
|
| ||||||||
| pseudorandom | 1.298 | |||||||
|
| ||||||||
| pseudoperiodic | 1.285 | |||||||
If we compare the fractal dimensions of the bacteria with pseudorandom and pseudoperiodic we can see that the fractal dimension of nucleotide distribution ranges, for all variants, in the interval [1.28–1.30]. As expected, the more “random” sequences have higher fractal dimension.
4.4. Entropy
Another fundamental parameter, related to the information content of a sequence which measures the heterogeneity of data, is the information entropy (or Shannon entropy) [36–42]. Based on the axiom that less information implies a larger uncertainty and vice versa that more information leads us to a more deterministic model, the entropy concept has been recently offering some interesting interpretations about uncertainty in DNA. In fact, DNA as any other signal has been considered as a sequence of symbols carrying chemical-functional information.
The normalized Shannon entropy [39, 40, 42] is defined, over the alphabet 𝒜 ℓ, as
| (39) |
where p x(n) should be computed for large sequences. According to (32), (34), we will approximate its value with
| (40) |
However, the entropy is a parameter very similar to the complexity. In fact, it can be easily seen that (for the proof see [29]) the entropy H and the measure of complexity K differ for a factor. There follows that the entropy does not give any new information comparing with the previous parameters. As expected also the table of entropies classifies bacteria and archaea in the same way (Table 6).
Table 6.
Shannon entropy.
| Mycoplasma putrefaciens | 0.877 | |||||
|
| ||||||
| Mortierella verticillata | 0.976 | |||||
|
| ||||||
| Blattabacterium | 0.911 | |||||
|
| ||||||
| Aeropyrum pernix | 0.922 | |||||
|
| ||||||
| Acidianus hospitalis | 0.937 | |||||
|
| ||||||
| Acidilobus saccharovorans | 0.984 | |||||
|
| ||||||
| pseudorandom | 0.984 | |||||
5. Complex Root Representation of DNA Words
The complex (digital) representation of a DNA sequence of words is the map of the symbolic sequence of words into a set of complex numbers and it is defined as
| (41) |
such that for each x h ∈ 𝒟 ℓ(S N) it is ρ(x h) ∈ ℂ.
The complex root representation of the sequence S N is the sequence 𝒟 ℓ(S N) of complex numbers {y h}h=1,…,N defined as
| (42) |
with being the imaginary unit. There follows that, independently on the alphabet, it is
| (43) |
being all complex roots, of the unit, located on the unit circle of the complex plane ℂ 1.
For instance, with 𝒜 1 = {A, C, G, T}, the cardinality of the alphabet is |𝒜 1 | = 4 and
| (44) |
Analogously, with 𝒜 3 = {M, E,…, W} it is |𝒜 3 | = 20 and the 20 complex roots of unit
| (45) |
so that explicitly is
| (46) |
Therefore the complex representation of a DNA sequence is a sequence of complex numbers
| (47) |
with y h given by (42).
An n-length pseudorandom (white noise) complex sequence belonging to the unit circle can be defined directly by using some random exponents
| (48) |
with r n, s n being random values in the set {0, ℕ}.
5.1. Random Walks
Random walk on the complex sequence Y N is defined as the series Z N = {z n}n=1,…,N
| (49) |
which is the cumulative sum
| (50) |
When y k = ρ(x k) with x k ∈ 𝒜 ℓ and X k ∈ S N we will properly call these walks as DNA walk. When the y k are randomly generated we will call them random walks.
By remembering the definition of frequencies, DNA walk is the complex value signal {Z n}n=0,…,N−1 with
| (51) |
where the coefficients a n, g n, t n, c n given by (12) fulfill the condition (31).
If we compare the DNA walks (Figure 11) some primitive archaea such as h3 are very similar to a random walk (Figure 13). In particular archaea seem to grow less than other bacteria (with the exception of b2).
Figure 11.

Walks on the first 200 nucleotides: (b1) Mycoplasma putrefaciens, (b2) Mortierella verticillata, (b3) Blattabacterium, (h1) Aeropyrum pernix, (h2) Acidianus hospitalis, and (h3) Acidilobus saccharovorans.
Figure 13.
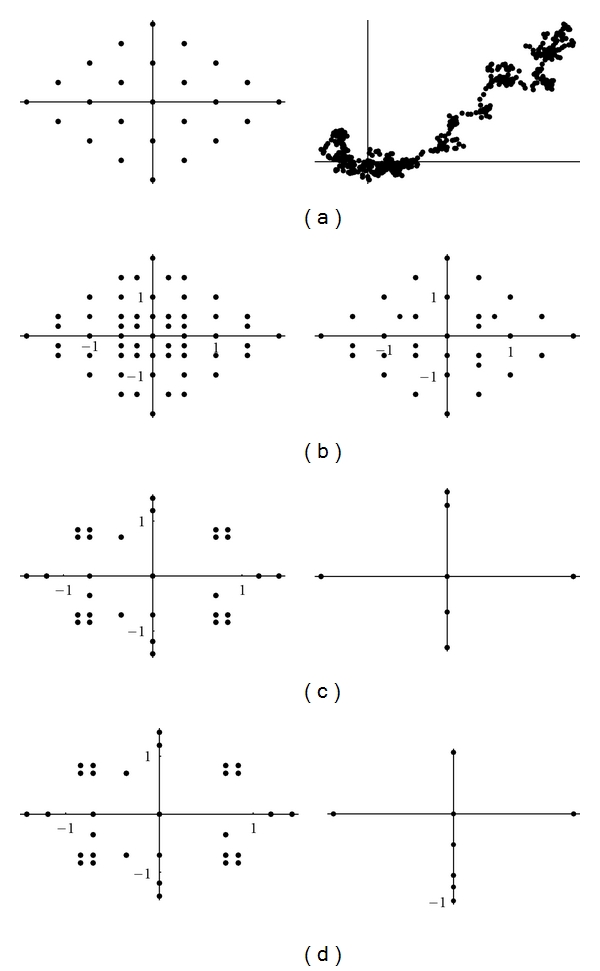
Cluster analysis of the 4th short Haar wavelet transform of a 4000-length random sequence (left) and its 2000-length random walk (right): (a) (α, α*); (b) (β 0 0, β*0 0); (c) (β 0 1, β*0 1); (d) (β 1 1, β*1 1).
It is interesting also to notice that the random walks on amino acids (Figure 12) show that more evolved organisms have some “periodic” behavior, while the absolute value of walks on archaea is growing fast.
Figure 12.

Absolute value of walks on the first 100 amino acids: (b1) Mycoplasma putrefaciens, (b2) Mortierella verticillata, (b3) Blattabacterium, (h1) Aeropyrum pernix, (h2) Acidianus hospitalis, (h3) Acidilobus saccharovorans.
6. Wavelet Analysis
Wavelet analysis is a powerful method extensively applied to the analysis of biological signals [12, 43–45] aiming to single out the most significant parameters of complexity and heterogeneity in a time series and, in particular, in a DNA sequence. This method is based on the analysis of wavelet coefficients which are obtained by the wavelet transform.
We will consider in the following the Haar wavelet basis (see, e.g., [3, 4, 29]) made by scaling functions:
| (52) |
and the Haar wavelets:
| (53) |
The discrete Haar wavelet transform is the N × N matrix 𝒲 N : 𝕂 N ⊂ ℓ 2 → 𝕂 N ⊂ ℓ 2 which maps the vector
| (54) |
into the vector of wavelet coefficients β N = {α, β k n}:
| (55) |
The matrix 𝒲 N can be easily computed by some recursive product [3, 4, 13, 29, 46] so that with N = 4, M = 2, we have [3, 4, 29]
| (56) |
From (55) with M = 2, N = 4, by explicit computation, we have
| (57) |
| (58) |
Thus the first wavelet coefficient α represents the average value of the sequence and the other coefficients β the finite differences. The wavelet coefficients β's, also called details coefficients, are strictly connected with the first-order properties of the discrete time series.
In the following we will consider the short wavelet transform which consists in the subdivision of the DNA sequence into 4-length segments and apply the wavelet transform to each segment. As a result, from the N = 2M-length complex vector Y, which is subdivided into 2M−2 segments, the 4-parameter short Haar wavelet transform gives the cluster of points
| (59) |
in the 8-dimensional space ℝ4 × ℝ4, that is,
| (60) |
This algorithm enables us to construct clusters of wavelet coefficients and to study the correlation between the real and imaginary coefficients of the DNA representation and DNA walk. It has been observed [3, 4, 29] that some symmetry arises from the plots of wavelet coefficients of DNA walks.
6.1. Cluster Analysis of the Wavelet Coefficients of the Complex DNA Representation
Let us first compute the clusters of wavelet coefficients for the random sequence (48). As can be seen the wavelet coefficients both for the sequence and for its series range in some discrete set of values (see Figure 13).
The cluster algorithm applied to the complex representation sequence shows that the values of the wavelet coefficients belong to some discrete finite sets (Figure 14).
Figure 14.
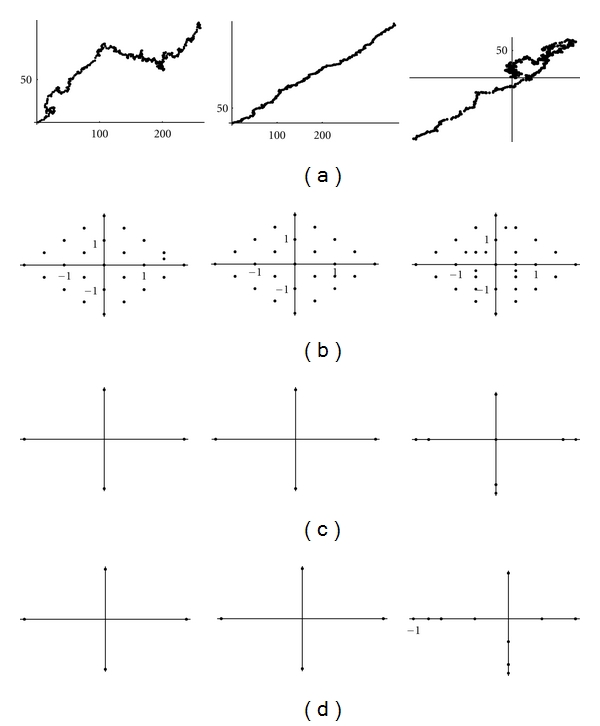
Cluster analysis of the 4th short Haar wavelet transform of the complex representation for a DNA walk on the first 2000 nucleotides of (h1) Aeropyrum, (h2) Acidianus, (h3) Acidilobus saccharovorans in the planes: (a) (α, α*); (b) (β 0 0, β*0 0); (c) (β 0 1, β*0 1); (d) (β 1 1, β*1 1).
It should be noticed that this symmetry on detail coefficients is lost for wavelet transform on longer segments (Figures 15, 16 and 17).
Figure 15.
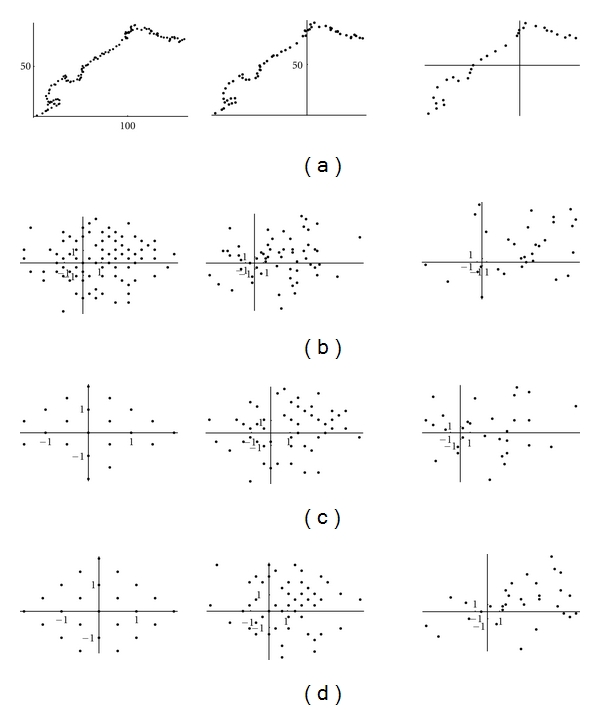
Cluster analysis of the 8th (left), 16th (middle column), 32th (right) short Haar wavelet transform of the DNA walk on the first 1000 nucleotides of h1 (Aeropyrum) in the planes: (a) (α, α*); (b) (β 0 0, β*0 0); (c) (β 0 1, β*0 1); (d) (β 1 1, β*1 1).
Figure 16.
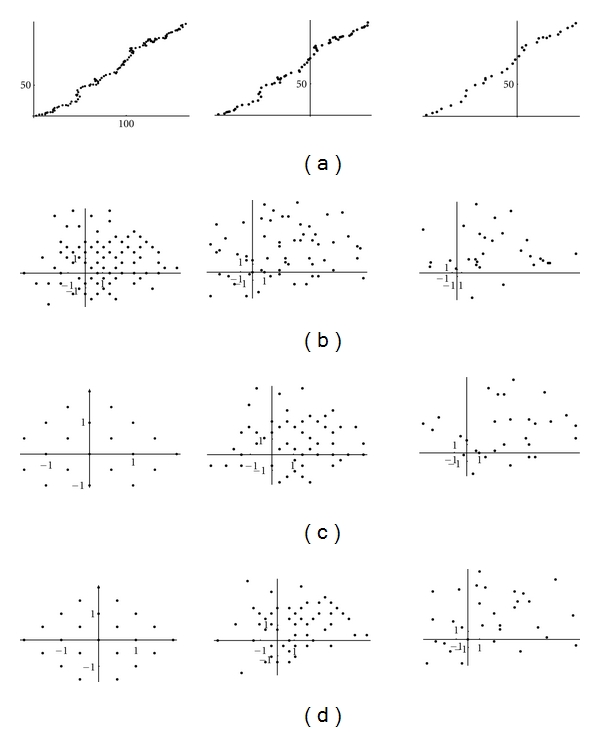
Cluster analysis of the 8th (left), 16th (middle column), 32th (right) short Haar wavelet transform of the DNA walk on the first 1000 nucleotides of h2 (Acidianus) in the planes: (a) (α, α*); (b) (β 0 0, β*0 0); (c) (β 0 1, β*0 1); (d) (β 1 1, β*1 1).
Figure 17.
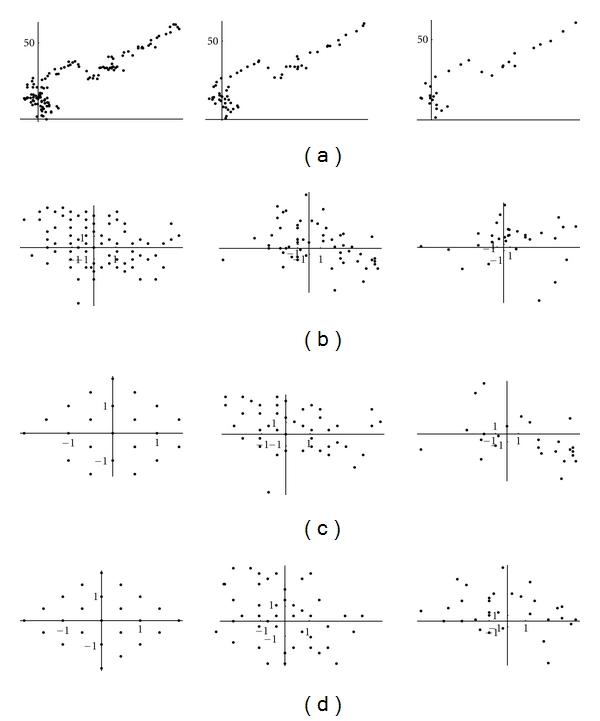
Cluster analysis of the 8th (left), 16th (middle column), 32th (right) short Haar wavelet transform of the DNA walk on the first 1000 nucleotides of h3 (Acidilobus saccharovorans) in the planes: (a) (α, α*); (b) (β 0 0, β*0 0); (c) (β 0 1, β*0 1); (d) (β 1 1, β*1 1).
There follows that DNA sequences have to be considered as Markov chain with short range dependence; in other words any acid nucleic is attached to the chain on the base of a correlation of the previous acid nucleic. In other words, if we look for a dependence rule on the DNA nucleotides this dependence might be summarized by a function as
| (61) |
7. Conclusions
In this paper archaea DNAs have been studied by focussing on the main parameters for complexity. It has been shown that more or less the main indices for complexity and heterogeneity, such as entropy, fractal dimension, and complexity do not differ too much when we have to classify the complexity of the sequence. However, some DNA sequences look more close to random sequences than others, thus suggesting that the evolution involves a process of complexity reduction: the more evolved a sequence is, the more far from a random distribution it is. In any case seems to be apparently impossible to distinguish between a random sequence and a DNA chain. By using the short wavelet transform instead we have shown that on short range (4-nucleotides) a DNA sequence shows some symmetries that slowly disappear by increasing the length of the analysed segment. Moreover, more evolved organisms have a more symmetrical distribution of wavelet coefficients.
References
- 1.Cattani C. Complex representation of DNA sequences. In: Elloumi M, et al., editors. In: Proceedings of the Bioinformatics Research and Development Second International Conference; July 2008; Vienna, Austria. Springer; [Google Scholar]
- 2.Cattani C. Complex representation of DNA sequences. Communications in Computer and Information Science. 2008;13:528–537. [Google Scholar]
- 3.Cattani C. Wavelet Algorithms for DNA Analysis. In: Elloumi M, Zomaya AY, editors. Algorithms in Computational Molecular Biology: Techniques, Approaches and Applications. chapter 35. New York, NY, USA: John Wiley & Sons; 2010. pp. 799–842. (Wiley Series in Bioinformatics). [Google Scholar]
- 4.Cattani C. Fractals and hidden symmetries in DNA. Mathematical Problems in Engineering. 2010;2010:1–31. Article ID 507056. [Google Scholar]
- 5.Cattani C, Pierro G. Complexity on acute myeloid leukemia mRNA transcript variant. Mathematical Problems in Engineering. 2011;2011:1–16. [Google Scholar]
- 6.Cattani C, Pierro G, Altieri G. Entropy and multi-fractality for the myeloma multiple TET 2 gene. Mathematical Problems in Engineering. 2011;2011:1–17. [Google Scholar]
- 7.Cattani C, Rushchitsky JJ. Wavelet and Wave Analysis as applied to Materials with Micro or Nanostructure, Series on Advances in Mathematics for Applied Sciences. Vol. 74. Singapore: World Scientific; 2007. [Google Scholar]
- 8.Murray KB, Gorse D, Thornton JM. Wavelet transforms for the characterization and detection of repeating motifs. Journal of Molecular Biology. 2002;316(2):341–363. doi: 10.1006/jmbi.2001.5332. [DOI] [PubMed] [Google Scholar]
- 9.Tsonis AA, Kumar P, Elsner JB, Tsonis PA. Wavelet analysis of DNA sequences. Physical Review E. 1996;53(2):1828–1834. doi: 10.1103/physreve.53.1828. [DOI] [PubMed] [Google Scholar]
- 10.Altaiski M, Mornev O, Polozov R. Wavelet analysis of DNA sequences. Genetic Analysis—Biomolecular Engineering. 1996;12(5-6):165–168. [PubMed] [Google Scholar]
- 11.Arneodo A, D’Aubenton-Carafa Y, Bacry E, Graves PV, Muzy JF, Thermes C. Wavelet based fractal analysis of DNA sequences. Physica D. 1996;96(1–4):291–320. [Google Scholar]
- 12.Zhang M. Exploratory analysis of long genomic DNA sequences using the wavelet transform: examples using polyomavirus genomes. In: Proceedings of the 6th Genome Sequencing and Analysis Conference; 1995; pp. 72–85. [Google Scholar]
- 13.Cattani C. Haar wavelet-based technique for sharp jumps classification. Mathematical and Computer Modelling. 2004;39(2-3):255–278. [Google Scholar]
- 14.Cattani C. Harmonic wavelet approximation of random, fractal and high frequency signals. Telecommunication Systems. 2010;43(3-4):207–217. [Google Scholar]
- 15.Li M. Fractal time series-a tutorial review. Mathematical Problems in Engineering. 2010;2010:1–26. Article ID 157264. [Google Scholar]
- 16.Li M, Li JY. On the predictability of long-range dependent series. Mathematical Problems in Engineering. 2010;2010:1–9. Article ID 397454. [Google Scholar]
- 17.Li M, Lim SC. Power spectrum of generalized Cauchy process. Telecommunication Systems. 2010;43(3-4):219–222. [Google Scholar]
- 18.National Center for Biotechnology Information. http://www.ncbi.nlm.nih.gov/genbank.
- 19.Genome Browser. http://genome.ucsc.edu.
- 20.European Informatics Institute. http://www.ebi.ac.uk.
- 21.Ensembl. http://www.ensembl.org.
- 22.Howland JL. The Surprising Archaea. New York, NY, USA: Oxford University Press; 2000. [Google Scholar]
- 23.Woese CR, Fox GE. Phylogenetic structure of the prokaryotic domain: the primary kingdoms. Proceedings of the National Academy of Sciences of the United States of America. 1977;74(11):5088–5090. doi: 10.1073/pnas.74.11.5088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Madigan MT, Marrs BL. Extremophiles. Scientific American. 1997;276(4):82–87. doi: 10.1038/scientificamerican0497-82. [DOI] [PubMed] [Google Scholar]
- 25.Voss RF. Evolution of long-range fractal correlations and 1/f noise in DNA base sequences. Physical Review Letters. 1992;68(25):3805–3808. doi: 10.1103/PhysRevLett.68.3805. [DOI] [PubMed] [Google Scholar]
- 26.Eckmann JP, Kamphorst SO, Ruelle D. Recurrence plots of dynamical systems. Europhysics Letters. 1987;5:973–977. [Google Scholar]
- 27.Szczepański J, Michałek T. Random fields approach to the study of DNA chains. Journal of Biological Physics. 2003;29(1):39–54. doi: 10.1023/A:1022508206826. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Stein M, Ulam SM. An observation on the distribution of primes. American Mathematical Monthly. 1967;74(1):p. 4344. [Google Scholar]
- 29.Cattani C. Complexity and Simmetries in DNA sequences. In: Elloumi M, Zomaya AY, editors. Handbook of Biological Discovery. chapter 22. New York, NY, USA: John Wiley & Sons; 2012. pp. 700–742. (Wiley Series in Bioinformatics). [Google Scholar]
- 30.Gates MA. Simpler DNA sequence representations. Nature. 1985;316(6025):p. 219. doi: 10.1038/316219a0. [DOI] [PubMed] [Google Scholar]
- 31.Gates MA. A simple way to look at DNA. Journal of Theoretical Biology. 1986;119(3):319–328. doi: 10.1016/s0022-5193(86)80144-8. [DOI] [PubMed] [Google Scholar]
- 32.Hamori E, Ruskin J. H curves, a novel method of representation of nucleotide series especially suited for long DNA sequences. Journal of Biological Chemistry. 1983;258(2):1318–1327. [PubMed] [Google Scholar]
- 33.Berger JA, Mitra SK, Carli M, Neri A. Visualization and analysis of DNA sequences using DNA walks. Journal of the Franklin Institute. 2004;341(1-2):37–53. [Google Scholar]
- 34.Bernaola-Galván P, Román-Roldán R, Oliver JL. Compositional segmentation and long-range fractal correlations in DNA sequences. Physical Review E. 1996;55(5):5181–5189. doi: 10.1103/physreve.53.5181. [DOI] [PubMed] [Google Scholar]
- 35.Berthelsen CL, Glazier JA, Skolnick MH. Global fractal dimension of human DNA sequences treated as pseudorandom walks. Physical Review A. 1992;45(12):8902–8913. doi: 10.1103/physreva.45.8902. [DOI] [PubMed] [Google Scholar]
- 36.Aldrich PR, Horsley RK, Turcic SM. Symmetry in the language of gene expression: a survey of gene promoter networks in multiple bacterial species and non-σ regulons. Symmetry. 2011;3:1–20. [Google Scholar]
- 37.Ferrer-I-Cancho R, Forns N. The self-organization of genomes. Complexity. 2010;15(5):34–36. [Google Scholar]
- 38.Misteli T. Self-organization in the genome. Proceedings of the National Academy of Sciences of the United States of America. 2009;106(17):6885–6886. doi: 10.1073/pnas.0902010106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Shannon CE. A mathematical theory of communication. The Bell System Technical Journal. 1948;27:379–423. [Google Scholar]
- 40.Shannon CE. A mathematical theory of communication. The Bell System Technical Journal. 1948;27:623–656. [Google Scholar]
- 41.Solé RV. Genome size, self-organization and DNA’s dark matter. Complexity. 2010;16(1):20–23. [Google Scholar]
- 42.Yulmetyev RM, Emelyanova NA, Gafarov FM. Dynamical Shannon entropy and information Tsallis entropy in complex systems. Physica A. 2004;341(1–4):649–676. [Google Scholar]
- 43.Arneodo A, Bacry E, Graves PV, Muzy JF. Characterizing long-range correlations in DNA sequences from wavelet analysis. Physical Review Letters. 1995;74(16):3293–3296. doi: 10.1103/PhysRevLett.74.3293. [DOI] [PubMed] [Google Scholar]
- 44.Arneodo A, D’Aubenton-Carafa Y, Audit B, Bacry E, Muzy JF, Thermes C. What can we learn with wavelets about DNA sequences? Physica A. 1998;249(1–4):439–448. [Google Scholar]
- 45.Li W. The study of correlation structures of DNA sequences: a critical review. Computers and Chemistry. 1997;21(4):257–271. doi: 10.1016/s0097-8485(97)00022-3. [DOI] [PubMed] [Google Scholar]
- 46.Cattani C. Haar wavelets based technique in evolution problems. Proceedings of the Estonian Academy of Sciences: Physics & Mathematics. 2004;53(1):45–63. [Google Scholar]