

Abstract
We consider the semiparametric proportional hazards model for the cause-specific hazard function in analysis of competing risks data with missing cause of failure. The inverse probability weighted equation and augmented inverse probability weighted equation are proposed for estimating the regression parameters in the model, and their theoretical properties are established for inference. Simulation studies demonstrate that the augmented inverse probability weighted estimator is doubly robust and the proposed method is appropriate for practical use. The simulations also compare the proposed estimators with the multiple imputation estimator of Lu and Tsiatis (2001). The application of the proposed method is illustrated using data from a bone marrow transplant study.
Keywords: Asymptotic property, Augmented inverse probability weighted estimator, Cause-specific hazard function, Double robust property, Inverse probability weighted estimator, Missing cause of failure, Multiple imputation
1. Introduction
Competing risks data are commonly encountered in medical studies. Typically the responses to a treatment can be classified in terms of failure from disease of interest or from non-disease-related causes. Hence, in the competing risks framework, each individual is exposed to K distinct types of risks and the eventual failure can be attributed to precisely one of the risks. Let T* denote the time to failure, Δ* the cause of failure, and Z a p-dimensional vector of possibly time-dependent covariates. Then a principal estimable quantity in competing risks data is the cause-specific hazard function of cause k, defined, in the absence of censoring, by
which is the instantaneous rate of experiencing the event of type k at time t, having not experienced any of the K competing events until time t. Without loss of generality in our study, we consider only two causes of failure, the cause of interest as cause 1 and the other as cause 2 (i.e. Δ* = 1 or 2). In many applications involving follow-up studies, however, individuals may be subject to censoring. Let C be a censoring time and , where and denote the latent failure times from causes 1 and 2, respectively. Then the observed data consist of observations of (T, Δ, Z), where T = min(T*, C) and Δ = Δ*I(T* ≤ C). If the failure time T* is observed, Δ is the cause of failure and Δ = 0 otherwise. The observable cause-specific hazard function of cause k in the presence of censoring is given by
Throughout the paper, we assume that Z is an external covariate process (Kalbfleish and Prentice, 2002) and the censoring time C is conditionally independent of (T*, Δ*) given Z (Lu and Tsiatis, 2001; Gao and Tsiatis, 2005; Lu and Liang, 2008). Under this assumption, it can be shown that if the distribution of C is continuous at t. A number of statistical models for the relationship between the cause-specific hazard function of interest and regression covariates have been studied, among others, by Benichou and Gail (1990); Prentice et al. (1978); Cheng et al. (1998); Shen and Cheng (1999); Scheike and Zhang (2003). In this article we study the proportional hazards model for describing the relationship,
| (1) |
where λ0(·) is a nonnegative, but otherwise unspecified baseline hazard function and β0 is a p-dimensional vector of regression parameters. The parameter β0 can be consistently estimated by treating all the failure times with Δ ≠ 1 as censored observations and using the partial likelihood score equation proposed by Cox (1972, 1975). The estimator will be called the full-case estimator, denoted by β̂F in the paper.
In practice, however, the information needed for the cause of failure may be lost, or it may be difficult to determine the cause of disease or death for some individuals (Andersen et al., 1996). When we have missing causes in data, a naive method for estimating the regression parameter β0 is to simply ignore the missing data and use the partial likelihood score equation to the complete data only. The so-called complete-case estimator, denoted by β̂C, is clearly inefficient and can lead to serious bias. Thus, analysis of competing risks data with missing cause of failure has received considerable attention and a number of models have been proposed. Dinse (1982, 1986) considered nonparametric estimation for incomplete cause of death data with no covariate. Goetghebeur and Ryan (1990) proposed a modified log-rank test to compare survival in two groups, Dewanji (1992) suggested a modification of that approach, and Goetghebeur and Ryan (1995) extended the results of Goetghebeur and Ryan (1990) to proportional hazards regression model. More recently, Lu and Tsiatis (2001) proposed a parametric model to model the probability that the missing cause is the cause of interest while allowing the inclusion of additional auxiliary covariates and then estimated the regression parameters by using a multiple imputation method (Rubin, 1987, 1996). Gao and Tsiatis (2005) considered linear transformation models and Lu and Liang (2008) considered the additive hazards model for analysis of competing risks data with missing cause of failure.
For right-censored survival data in which the censoring indicator is missing, Lo (1991) considered the problem of nonparametric maximum likelihood estimation of a survival function in the absence of covariates, McKeague and Subramanian (1998) developed a survival function estimator assuming that the censoring indicators are missing completely at random. Subramanian (2000) considered further development of efficient estimation of the regression parameters under proportionality assumptions of the conditional hazards, and Gijbels et al. (2007) proposed a class of estimating functions for the regression parameters of the Cox proportional hazard model, among others.
In this study of analysis of competing risks data with missing cause of failure, we derive two different estimators for the regression parameters in model (1), namely the inverse probability weighted estimator and augmented inverse probability weighted estimator, and establish their theoretical properties. The first approach, following the idea of Horvitz and Thompson (1952), uses the inverse probability weighted complete-case technique to estimate the regression parameter. This approach uses only the complete cases and relies on correct modeling for the probability of missing causes. It has been shown that the inverse probability weighted estimator is inconsistent when the respective parametric model is misspecified, and is inefficient (Gao and Tsiatis, 2005; Lu and Liang, 2008; Scharfstein et al., 1999). It would be desirable, therefore, to obtain improved efficiency over the inverse probability weighted estimator. The second approach, adapting the idea of Robins et al. (1994), augments the inverse probability weighted complete-case estimating equation with a consistent estimator of the conditional distribution of the cause of interest that incorporates information available for individuals whose cause of failure is missing. See Subramanian and Bandyopadhyay (2010) for homogeneous right censored data with missing censoring indicators.
The paper is structured as follows. In Section 2, the inverse probability weighted estimator and augmented inverse probability weighted estimator are developed. The asymptotic properties of the corresponding estimators are established in Section 3. In Section 4, we investigate the finite sample properties of the proposed estimators through simulations, including comparisons with the multiple imputations estimator proposed by Lu and Tsiatis (2001). A bone marrow transplant data set is analyzed in Section 4. Some conclusions and discussions are given in Section 5. Technical derivations are detailed in Appendix.
2. Estimating equations
Since the cause of failure may not be observed for some individuals, we define the missingness indicator R as follows. If an individual’s death is observed, then R = 1 when the cause of failure information Δ* is observed and R = 0 otherwise. If an individual is censored, we always define R = 1. We also introduce auxiliary covariates A which are not of interest for modelling the cause-specific hazard function but may be used to describe the missingness mechanism. The utilization of auxiliary information has been considered by Lu and Tsiatis (2001), Gao and Tsiatis (2005), Lu and Liang (2008), Gilbert, McKeague, and Sun (2008), among others. Then the observed data will consist of
for i = 1, …, n. We assume that {Oi, i = 1, …, n} are independent identically distributed. The possible choices are {Ti, Zi, Ai, 1, 0, 1, 0} for the individual who died from the cause 1, {Ti, Zi, Ai, 1, 0, 0, 1} for the individual who died from the cause 2, {Ti, Zi, Ai, 0, 0, 0, 0} for the individual who died with missing cause, and {Ti, Zi, Ai, 1, 1, 0, 0} for the censored individual.
We also assume that the cause of failure is missing at random (MAR) (Rubin, 1976); that is, the probability that the cause of failure is missing given Δ > 0 and W = (T, Z, A) depends only on the observed W, but not on the unobserved Δ,
| (2) |
The assumption implies that
and likewise for the case involving Δ = 2. See also Lu and Tsiatis (2001), Gao and Tsiatis (2005), and Lu and Liang (2008).
2.1. Inverse probability weighted estimator
Following the inverse selection probability idea of Horvitz and Thompson (1952), the method of inversely weighting the probability of complete-case has been commonly used in missing data problems. To do that, we need to estimate the probability of a complete case, π(Q) ≡ P (R = 1|Q), where Q = (W, Δ). By the MAR assumption and R = 1 when Δ = 0, we have
| (3) |
where r(W) = P (R = 1|W, Δ > 0). We consider that the probability of complete-case r(Wi) may be specified as a parametric model r(Wi, ψ0), in terms of a few unknown parameters ψ0. Accordingly, let π(Qi, ψ0) = r(Wi, ψ0)I(Δ > 0) + I(Δ = 0). Since R is binary, one can posit the logistic model , though other parametric models can also be used. By (2) and (3), the likelihood L regarding to π(Q, ψ0) is
This implies that the maximum likelihood estimator ψ̂ of ψ can be estimated by maximizing the likelihood based on uncensored data
It is known that for a correctly specified model r(Wi, ψ), ψ̂ consistently estimates ψ0, the true value of the parametric component of r(Wi, ψ) (Haberman, 1974, 1977; Gourieroux and Monfort, 1981).
We define the counting process Ni(t) = I(Δi = 1)I(Ti ≤ t) and at-risk process Yi(t) = I(Ti ≥ t). Let a⊗0 = 1, a⊗1 = a, and a⊗2 = aa⊤ for a vector a. Let
for m = 0, 1, 2. Then we consider the following inverse probability weighted estimating equation for β0:
| (4) |
where τ > 0 is the end of follow-up time. The inverse probability weighted estimator (IPW) of β solves the above equation and is denoted by β̂I. When there is no missing cause, the equation (4) consequently becomes the partial likelihood score equation proposed by Cox (1972, 1975). The cumulative baseline hazard function can be estimated by
2.2. Augmented inverse probability weighted estimator
The inverse probability weighted estimator β̂I uses only complete cases. Thus, it is inefficient. In addition, its consistency relies on correct modelling of the probability r(Wi, ψ0). To improve the robustness and efficiency over β̂I, we adapt the idea of Robins et al. (1994) and propose to augment the inverse probability weighted estimating equation with a consistent estimator of the conditional distribution of the cause of interest that utilizes available information for individuals with missing cause of failure.
Consequently, we estimate the probability that the cause of failure is the cause of interest ρ(W) ≡ P (Δ = 1| Δ > 0, W). Let f(t, Δ = 1| Δ > 0, z, a) be the conditional joint density of T and Δ = 1 given (Δ > 0, Z = z, A = a). Then for w = (t, z, a),
where λ̃k(t|z, a) is the conditional cause-specific hazard function of T at t due to cause Δ = k given (Z, A) = (z, a) for k = 1, 2. Here, instead of directly estimating ρ(Wi) which requires the estimation of two unknown cause-specific hazard functions, we posit a parametric model ρ(Wi, γ0) for ρ(Wi) in terms of a few unknown parameters γ0. It is natural to use a logistic regression model , but other parametric models can also be accommodated.
There is, however, an issue with obtaining estimates for γ in the presence of missingness. The MAR assumption implies that given Δ > 0 and W, R is independent of Δ; that is,
| (5) |
By (5), ρ(Wi) can be deduced from the complete cases with Ri = 1 and Δi > 0. This suggests that the maximum likelihood estimator γ̂ of γ can be obtained by maximizing the likelihood based on complete-case data
Since γ̂ is the maximum likelihood estimator, then for a correctly specified model ρ(Wi, γ), γ̂ consistently estimates γ0, the true value of the parametric component model ρ(Wi, γ) (Haberman, 1974, 1977; Gourieroux and Monfort, 1981).
Now, we define the counting process . Let
Then we propose the following augmented inverse probability weighted estimating equation
| (6) |
where ψ̂ and γ̂ are the maximum likelihood estimators defined earlier. The augmented inverse probability weighted estimator (AIPW) of β solves the above equation (6) and is denoted by β̂A. The cumulative baseline hazard function can be estimated by
3. Asymptotic results
When the model for r(Wi) is correctly specified, we let ψ0 be the true value of ψ such that r(Wi) = r(Wi, ψ0). Under Condition (A.4) stated in the Appendix, . When the model for ρ(Wi) is correctly specified, we let γ0 be the true value of γ such that ρ(Wi) = ρ(Wi, γ0). In this case, . In general, under Condition (A.4), there exist ψ* and γ* such that and (White, 1982). We have ψ* = ψ0 if r(Wi) is correctly specified, and γ* = γ0 if ρ(Wi) is correctly specified.
Let s(m)(t, β) = E[Y1(t)eβ⊤Z1(t) Z1(t)⊗m], z̄(t, β) = s(1)(t, β)/s(0)(t, β), and v(t, β) = s(2)(t, β)/s(0)(t, β) − z̄(t, β)⊗2.
Theorem 1
Assume Condition A given in the Appendix. If r(Wi, ψ0) is correctly specified for r(Wi), then and converges in distribution to a zero-mean Gaussian random vector with covariance matrix , where
, Vψ is given in (8), Iψ and Sψi are given in (11) in the Appendix.
The asymptotic covariance matrix can be consistently estimated by
where
and . Here V̂ψ, Îψ and Ŝψi are obtained by replacing with their respective sample estimators and substituting (β̂I, ψ̂) for (β0, ψ0) in Vψ, Iψ, and Sψi.
The following establishes the asymptotic properties of β̂A.
Theorem 2
Assume Condition A given in the Appendix. If at least one of r(Wi, ψ0) and ρ(Wi, γ0) is correctly specified for r(Wi) and ρ(Wi), then and converges in distribution to a zero-mean Gaussian random vector with covariance matrix , where
and
Here M*(t) is defined in (17), and Pψ, , Pγ, and are given in (15) and (19) in the Appendix.
It is interesting to notice that if r(Wi, ψ0) = r(Wi), then Pγ = 0, and if ρ(Wi, γ0) = ρ(Wi), then Pψ = 0. When both the models for r(Wi) and ρ(Wi) are correctly specified, we have Pψ = 0 and Pγ = 0 and hence, .
The asymptotic covariance matrix can be consistently estimated by
where
and
Here P̂ψ, , P̂γ, and are the empirical counterparts of Pψ, , Pγ, and given in (15) and (19) in the Appendix, obtained by replacing with their respective sample estimators and substituting (β̂A, ρ̂, γ̂) for (β0, ψ*, γ*).
4. Numerical results
4.1. Simulation studies
We present simulation studies conducted to evaluate the performance of our proposed methods. We set τ = 2.0 and consider a univariate covariate Z, where Z follows a uniform distribution on [0, 1]. Given Z, the latent failure time of interest is generated from the proportional hazards model , where λ = 1 and β = −0.5. The other latent failure time is generated from a Gompertz distribution with a hazard function , where θ = −0.5 and ν = 0.2. The censoring time C is generated from an exponential distribution which yields about 20% censoring level. We consider a single auxiliary covariate A which follows a Bernoulli distribution with success probability of 0.5. We also consider a logistic regression model logit{r(W, ψ)} = ψ1 + ψ2T + ψ3Z + ψ4A for missing cause of failure. We have about 20% missingness with ψ = (0.7, 1, −1, 1) and about 45% missingness with ψ = (−0.8, 1, −1, 1). In the settings we consider here, the true model ρ(W) is given by a logistic regression model logit{ρ(W)} = −θ − νT +βZ. To study the performance of the estimators when r(W) is misspecified, we posit two different parametric models of r(W, ψ), where one is a correctly specified logistic model and the other is a misspecified constant model r0 ∈ (0, 1) independent of W. To study the behavior when ρ(W) is misspecified, we consider various model specifications. We posit a correctly specified logistic model logit{ρ(W, γ)} = γ1 + γ2T + γ3Z (Model 1), a misspecified logistic model logit{ρ(W, γ)} = γ1 + γ2Z (Model 2), a misspecified logistic model logit{ρ(W, γ)} = γ1 + γ2T (Model 3) and a misspecified constant model ρ0 ∈ (0, 1) independent of W (Model 4). The simulation studies consist of 1000 runs with the sample size n = 200 and n = 400. We also conduct comparison with the multiple imputation estimators, studied by Lu and Tsiatis (2001), with the number of imputation m = 1 and m = 5.
The results from Table 1 and Table 2 show that the complete-case estimator β̂C shows large biases in all the settings. When the parametric model for r(W) is correctly specified, both the IPW estimator β̂I and AIPW estimator β̂A show small biases, but the AIPW estimator has smaller standard errors than the corresponding IPW estimator. When the parametric model for ρ(W) is correctly specified, the multiple imputation estimator has small biases, but the multiple imputation estimator tends to have larger biases when ρ(W) is misspecified. As expected, the AIPW estimator is clearly not sensitive to the misspecification if one of the parametric models for r(W) and ρ(W) is misspecified. In fact, the AIPW estimator performs quite well even when both the parametric models r(W) and ρ(W) are misspecified. The standard errors of the multiple imputation estimator decrease as the number of imputation increases. The standard errors of the multiple imputation estimator and the AIPW estimator are comparable when ρ(W) is correctly specified. However, the multiple imputation estimator seems to have small standard errors than the AIPW estimator under misspecified ρ(W). The estimated standard errors of the AIPW estimator are close to the sample standard errors, and the 95% confidence intervals have reasonable coverage probabilities.
Table 1.
Summary statistics of simulation results with 20% missingness under various model specifications of ρ(·).
| Estimator |
n = 200
|
n = 400
|
||||||
|---|---|---|---|---|---|---|---|---|
| Bias | SSE | MSE | CP | Bias | SSE | MSE | CP | |
| β̂C | −0.136 | 0.442 | 0.447 | 96.0 | −0.129 | 0.322 | 0.313 | 92.6 |
| β̂Ic | −0.007 | 0.422 | 0.426 | 96.4 | −0.002 | 0.313 | 0.299 | 93.9 |
| β̂Im | −0.107 | 0.430 | 0.430 | 96.1 | −0.182 | 0.392 | 0.385 | 92.2 |
| (Model 1) | (Model 1) | |||||||
| β̂Ac | −0.005 | 0.406 | 0.416 | 96.2 | 0.002 | 0.301 | 0.292 | 94.4 |
| β̂Am | −0.003 | 0.403 | 0.411 | 96.5 | 0.003 | 0.351 | 0.345 | 95.1 |
| β̂M1 | −0.003 | 0.427 | 0.437 | 96.3 | 0.003 | 0.313 | 0.306 | 94.3 |
| β̂M5 | −0.005 | 0.406 | 0.419 | 96.6 | 0.005 | 0.302 | 0.294 | 94.4 |
| (Model 2) | (Model 2) | |||||||
| β̂Ac | −0.005 | 0.406 | 0.416 | 96.1 | 0.002 | 0.301 | 0.292 | 94.4 |
| β̂Am | −0.007 | 0.403 | 0.412 | 96.4 | 0.001 | 0.297 | 0.290 | 94.3 |
| β̂M1 | −0.012 | 0.428 | 0.438 | 96.2 | −0.003 | 0.314 | 0.307 | 94.3 |
| β̂M5 | −0.011 | 0.408 | 0.420 | 96.6 | −0.001 | 0.303 | 0.295 | 94.0 |
| (Model 3) | (Model 3) | |||||||
| β̂Ac | −0.004 | 0.406 | 0.416 | 96.2 | 0.002 | 0.300 | 0.292 | 94.5 |
| β̂Am | 0.005 | 0.395 | 0.405 | 96.7 | 0.010 | 0.292 | 0.286 | 94.5 |
| β̂M1 | 0.061 | 0.370 | 0.383 | 96.3 | 0.066 | 0.273 | 0.269 | 93.8 |
| β̂M5 | 0.057 | 0.347 | 0.364 | 96.2 | 0.067 | 0.260 | 0.255 | 93.8 |
| (Model 4) | (Model 4) | |||||||
| β̂Ac | −0.005 | 0.406 | 0.416 | 96.2 | 0.002 | 0.301 | 0.292 | 94.5 |
| β̂Am | −0.001 | 0.397 | 0.406 | 96.7 | 0.009 | 0.341 | 0.336 | 95.2 |
| β̂M1 | 0.056 | 0.367 | 0.383 | 96.5 | 0.062 | 0.273 | 0.269 | 94.1 |
| β̂M5 | 0.054 | 0.348 | 0.364 | 96.5 | 0.064 | 0.261 | 0.256 | 93.5 |
Bias, the mean of the estimates of β; SSE, the sample standard error of the estimates of β; MSE, the mean of the standard error estimates; CP, the empirical coverage probability of the corresponding 95% confidence intervals; β̂C, the complete-case estimator; β̂Ic and β̂Im, the IPW estimators; β̂Ac and β̂Am, the AIPW estimators; β̂M1 and β̂M5, the multiple imputation estimators with m = 1 and m = 5 imputations. Here c denotes the correctly specified model and m the misspecified model for r(·), respectively.
Table 2.
Summary statistics of simulation results with 45% missingness under various model specifications of ρ(·).
| Estimator |
n = 200
|
n = 400
|
||||||
|---|---|---|---|---|---|---|---|---|
| Bias | SSE | MSE | CP | Bias | SSE | MSE | CP | |
| β̂C | −0.322 | 0.595 | 0.599 | 94.0 | −0.305 | 0.420 | 0.416 | 88.1 |
| β̂Ic | −0.014 | 0.583 | 0.554 | 93.7 | 0.002 | 0.411 | 0.394 | 94.7 |
| β̂Im | −0.194 | 0.561 | 0.552 | 94.6 | −0.182 | 0.392 | 0.385 | 92.2 |
| (Model 1) | (Model 1) | |||||||
| β̂Ac | −0.022 | 0.540 | 0.523 | 94.3 | 0.001 | 0.380 | 0.365 | 93.4 |
| β̂Am | −0.011 | 0.493 | 0.494 | 95.8 | 0.003 | 0.351 | 0.345 | 95.1 |
| β̂M1 | −0.007 | 0.534 | 0.539 | 96.2 | −0.006 | 0.377 | 0.376 | 95.2 |
| β̂M5 | −0.012 | 0.502 | 0.509 | 96.6 | 0.001 | 0.356 | 0.354 | 95.1 |
| (Model 2) | (Model 2) | |||||||
| β̂Ac | −0.021 | 0.539 | 0.523 | 94.0 | 0.001 | 0.379 | 0.365 | 93.6 |
| β̂Am | −0.017 | 0.495 | 0.496 | 95.9 | −0.003 | 0.352 | 0.347 | 94.8 |
| β̂M1 | −0.022 | 0.538 | 0.541 | 96.5 | −0.017 | 0.377 | 0.377 | 95.2 |
| β̂M5 | −0.025 | 0.506 | 0.510 | 96.7 | −0.010 | 0.356 | 0.355 | 94.8 |
| (Model 3) | (Model 3) | |||||||
| β̂Ac | −0.020 | 0.538 | 0.524 | 94.9 | 0.002 | 0.379 | 0.365 | 94.0 |
| β̂Am | 0.011 | 0.463 | 0.471 | 96.0 | 0.017 | 0.338 | 0.333 | 95.1 |
| β̂M1 | 0.137 | 0.368 | 0.383 | 94.6 | 0.133 | 0.266 | 0.268 | 92.3 |
| β̂M5 | 0.130 | 0.325 | 0.340 | 94.6 | 0.139 | 0.237 | 0.238 | 91.1 |
| (Model 4) | (Model 4) | |||||||
| β̂Ac | −0.020 | 0.536 | 0.525 | 94.6 | 0.002 | 0.379 | 0.365 | 94.2 |
| β̂Am | 0.004 | 0.469 | 0.476 | 96.2 | 0.009 | 0.341 | 0.336 | 95.2 |
| β̂M1 | 0.131 | 0.371 | 0.384 | 95.2 | 0.127 | 0.268 | 0.269 | 92.5 |
| β̂M5 | 0.126 | 0.327 | 0.340 | 94.7 | 0.134 | 0.239 | 0.239 | 91.5 |
Bias, the mean of the estimates of β; SSE, the sample standard error of the estimates of β; MSE, the mean of the standard error estimates; CP, the empirical coverage probability of the corresponding 95% confidence intervals; β̂C, the complete-case estimator; β̂Ic and β̂Im, the IPW estimators; β̂Ac and β̂Am, the AIPW estimators; β̂M1 and β̂M5, the multiple imputation estimators with m = 1 and m = 5 imputations. Here c denotes the correctly specified model and m the misspecified model for r(·), respectively.
To further study robustness of parameter estimates against misspecification of the parametric models for r(W) and ρ(W), we consider the same model for as described above, but here instead we generate from a Weibull distribution, log logistic distribution, exponential power distribution and gamma distribution. None of these distributions will induce a simple linear logistic regression model for ρ(W). For example, when is generated from a log logistic distribution with a hazard function , the true logistic model for ρ(W) is logit{ρ(W)} = −log(α) − log(λ) + βZ + log ((1 + λTα)/Tα−1). In all cases we misspecify ρ(W) by Model 1 to Model 4 described above. Although not presented here, the findings from these simulations are similar to those from Table 1 and Table 2.
In conclusion, the multiple imputation estimator of Lu and Tsiatis (2001) and the AIPW estimator have similar performance when the parametric models for r(W) and ρ(W) are correctly specified. The AIPW estimator has the advantage of double robustness such that the biases of the AIPW estimator remain small when the parametric model for r(W) or ρ(W) is misspecified. The bias of the multiple imputation estimator can be larger under misspecified ρ(W).
4.2. Bone marrow transplant data
Sierra et al. (2002) described the characteristics and outcomes of 452 patients with primary myelodysplasia (MDS) who received transplants from HLA-identical siblings and were registered with the International Bone Marrow Transplant Registry (IBMTR). The study has two competing risks; treatment related death defined as death in complete remission and relapse defined as recurrence of myelodysplasia. In this example, we consider 408 patients with complete covariate information obtained from the timereg package for R. Among these 408 patients, 161 patients died in complete remission, 87 patients relapsed, and 160 patients were censored. The covariates considered in our study are age of patient standardized at mean of 35 years old and platelet before transplantation (1 for more than 100 × 109 per L, or 0 for less). In the data set, the causes of failure are all known. For illustration purposes, we delete some failure causes by the three following missing mechanisms; missing completely at random (MCAR), missing at random (MAR), and not missing at random (NMAR).
For the MCAR, the causes of failure are randomly selected for missing with probability 23%. For the MAR, the logistic model is chosen as logit{r(W)} = 0.5 + 1.0 * T − 1.0 * age which yields about 23% missing causes, where T is the failure time. For the NMAR, the logistic model is chosen as logit{r(W)} = 0.5+1.0*T −1.0*age−0.5*I(Δ = 1) which yields about 26% missing causes, where Δ = 1 corresponds to the death in complete remission and Δ = 2 does to relapse. We posit the logistic models for both r(W) and ρ(W) with logit{r(W, ψ)} = ψ1 + ψ2 * T + ψ3 * age + ψ4 * platelet and logit{ρ(W, γ)} = γ1 + γ2 * log T + γ3 * age + γ4 * platelet.
The results of the estimation of β based on the AIPW estimator, the complete-case estimator and the multiple imputation estimator with the number of imputation m = 5 are summarized in Table 3. For comparison, Table 3 also includes the estimation of β based on the original data without artificial missing, namely, the full-case estimator. The results from the AIPW estimator and the multiple imputation estimator are very close under all the missingness mechanisms and they are closer to the full-case estimator than the complete-case estimator. The analyses using the AIPW estimator and the multiple imputation estimator are consistent with the findings from the earlier study; that is, patients with high platelet counts have a lower risk of treatment related mortality than those with low platelet counts, and a higher risk rate is seen among the older patients.
Table 3.
Estimation of the effects of platelet and age for the bone marrow transplant data.
| Missing | Estimator | Platelet | Age | ||||
|---|---|---|---|---|---|---|---|
| Est. | SEE | p-value | Est. | SEE | p-value | ||
| None | β̂F | −0.586 | 0.186 | 0.002 | 0.367 | 0.087 | <0.001 |
| MCAR | β̂C | −0.491 | 0.236 | 0.037 | 0.397 | 0.112 | <0.001 |
| β̂A | −0.520 | 0.203 | 0.010 | 0.387 | 0.091 | <0.001 | |
| β̂M5 | −0.530 | 0.205 | 0.010 | 0.380 | 0.096 | <0.001 | |
| MAR | β̂C | −0.504 | 0.238 | 0.034 | 0.241 | 0.107 | 0.024 |
| β̂A | −0.566 | 0.204 | 0.006 | 0.380 | 0.090 | <0.001 | |
| β̂M5 | −0.614 | 0.205 | 0.003 | 0.380 | 0.093 | <0.001 | |
| NMAR | β̂C | −0.390 | 0.253 | 0.123 | 0.156 | 0.114 | 0.171 |
| β̂A | −0.529 | 0.220 | 0.016 | 0.350 | 0.098 | <0.001 | |
| β̂M5 | −0.567 | 0.219 | 0.010 | 0.344 | 0.099 | <0.001 | |
Est., the estimate; SEE, the standard error estimate; p-value pertaining to testing no covariate effect; β̂F, the full-case estimator with no missing causes; β̂C, the complete-case estimator; β̂A, the AIPW estimator; β̂M5, the multiple imputation estimator with m = 5 imputations.
5. Conclusion
We propose the inverse probability weighted estimator and augmented inverse probability weighted estimator for analysis of competing risks data with missing cause of failure, where the Cox proportional hazard model is utilized to examine the covariate effects on the cause-specific hazard function for the failure type of interest. The augmented inverse probability weighted estimator posses the double robust property such that it is unbiased as long as one of the parametric models for r(W) and ρ(W) is correctly specified. The inverse probability weighted estimator is unbiased only when the parametric model for r(W) is correctly specified. Under the correctly specified models for r(W) and ρ(W), the augmented inverse probability weighted estimator is more efficient than the inverse probability weighted estimator.
The proposed estimators are compared with the multiple imputation estimator of Lu and Tsiatis (2001) through simulations. The multiple imputation estimator and augmented inverse probability weighted estimator have similar performance when the parametric models for r(W) and ρ(W) are correctly specified. The augmented inverse probability weighted estimator has the advantage of the double robustness over the multiple imputation estimator.
In the competing risks problem, another useful quantity is the cumulative incidence function which is the probability of occurrence by time t for a particular type of failure in the presence of other risks. It is known that the covariate effect on the cause-specific hazard for a particular type of failure can be quite different from its effect on the cumulative incidence function of that type of failure (Gray, 1988; Gaynor et al., 1993). Fine and Gray (1999) developed a direct Cox regression approach for the cumulative incidence curve based on earlier work by Gray (1988) and Pepe (1991). Recently, Andersen et al. (2003) and Klein and Andersen (2005) suggested pseudo-observation approach for direct modeling for cumulative incidence probabilities. It would be interesting to study models that relate the covariates directly to the cumulative incidence function for the failure type of interest in competing risks data with missing cause of failure.
Acknowledgments
The research of Yanqing Sun was partially supported by NSF DMS-0905777 and NIH grant R37 AI054165-09. The authors thank the reviewers for their constructive comments that have improved the paper.
Appendix
Condition A
-
(A.1)
λ0(t) is continuous on [0, τ]. The distribution of C is continuous on [0, τ] and P (C > τ) > 0. The covariate processes Zi(t) have paths that are left continuous and of bounded variation, and satisfy the moment condition E[||Zi(t)||4 exp(2M||Zi(t)||)] < ∞, where M is a constant such that β ∈ [−M, M]p and ||A|| = maxk,l |akl| for a matrix A = (akl).
-
(A.2)
Each component of s(j)(t, β) is continuous on [0, τ] × [−M, M]p for M > 0, j = 0, 1, 2 and s(0)(t, β) > 0 on [0, τ] × [−M, M]p. supt∈[0,τ],β∈[−M,M]p ||S(j)(t, β) − s(j)(t, β)|| = Op(n−1/2), and supψ∈[−L,L]q supt∈[0, τ],β∈[−M,M]p ||S̃(j)(t, β, ψ) − s(j)(t, β)|| = Op(n−1/2) for j = 0, 1, 2.
-
(A.3)
The matrix is positive definite.
-
(A.4)
There is a σ > 0 such that r(Wi) ≥ σ for all i with Δi > 0. Both r(Wi, ψ) and ρ(Wi, γ) are twice continuously differentiable with respect to ψ and γ, respectively. There exist ψ* and γ* satisfying the equations and , respectively, where and are the corresponding score functions for r(Wi, ψ) and ρ(Wi, γ) given in (19). The information matrices and also given in (19) are positive definite.
Proof of Theorem 1
Consistency of β̂I
Let ψ0 be the true value of ψ such that r(Wi) = r(Wi, ψ0) under the correctly specified model for r(Wi). Then . Let
When r(Wi, ψ0) is the correct model for r(Wi), z̃(t, β, ψ0) = z̄(t, β), where z̃(t, β, ψ0) is the limit of Z̃(t, β, ψ0). Under the conditions of Theorem 1, n−1 UI (β, ψ̂) = ξn(β, ψ0) + Op(n−1/2) uniformly in β ∈ [−M, M]p for M > 0.
By application of the Glivenko–Cantelli and Donsker theorems, ξn(β, ψ0) = ξ(β, ψ0) + Op(n−1/2) uniformly in β ∈ [−M, M]p, where
When r(Wi, ψ0) is the correct model for by the double expectation formula E[·] = E{E[·|Wi, Δi, Δi > 0]} and the missing at random assumption (2). Hence
uniformly in β ∈ [−M, M]p for M > 0.
Let
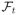 = σ{Ni(s), Yi(s), Zi(s), 0 ≤ s ≤ t, i = 1, …, n} be the σ-field generated by the observed information on the failure/censoring times and covariates up to time t. Then the intensity of the counting process Ni(t) is given by E{Ni(dt)|
} = λ1(t|Zi(t))Yi(t)dt. Under the independent censoring assumption stated in the introduction,
. Hence
is a martin-gale with respect to
. Since
, it follows that
. By Condition (A.3), β0 is the unique solution to ξ(β, ψ0) = 0. We have
by Theorem 5.9 of van der Vaart (1998).
= σ{Ni(s), Yi(s), Zi(s), 0 ≤ s ≤ t, i = 1, …, n} be the σ-field generated by the observed information on the failure/censoring times and covariates up to time t. Then the intensity of the counting process Ni(t) is given by E{Ni(dt)|
} = λ1(t|Zi(t))Yi(t)dt. Under the independent censoring assumption stated in the introduction,
. Hence
is a martin-gale with respect to
. Since
, it follows that
. By Condition (A.3), β0 is the unique solution to ξ(β, ψ0) = 0. We have
by Theorem 5.9 of van der Vaart (1998).
Asymptotic Normality of β̂I
Since UI (β̂I, ψ̂) = 0, , where β̃ is on the line segment between β̂I and β0. We have
By (A.4), under correctly specified model for r(Wi). By Condition (A.2) and the consistency of β̂I, uniformly in t ∈ (0, τ]. We have
Thus
| (7) |
Let π̇(·, ψ) = ∂π(·, ψ)/∂ψ, ṙ(·, ψ) = ∂r(·,ψ)/∂ψ, r̈(·,ψ) = ∂ṙ(·, ψ)/∂ψ⊤, and
By the Taylor expansion of UI (β0, ψ̂) around ψ0,
Note that
where
| (8) |
It follows that
| (9) |
Since
we have
Under correctly specified r(Wi), E[Ri{π(Qi, ψ0)}−1Mi(t)] = 0. By Glivenko–Cantelli and Donsker theorems, converges weakly to a mean zero Gaussian process and uniformly in t under the correctly specified model for r(Wi). Applying Lemma 2 of Gilbert et al. (2008), we have
Hence
| (10) |
Let Sψi and Iψ be the score vector and the information matrix under the parametric model r(Wi, ψ), respectively. Specifically,
| (11) |
Under (A.4),
| (12) |
By (9), (10) and (12), we have
| (13) |
where
By the central limit theorem, n−1/2UI (β0, ψ̂) converges in distribution to a normal random vector with zero-mean and covariance matrix .
It follows by (7) and (13) that converges in distribution to a zero-mean Gaussian random vector with covariance matrix .
Proof of Theorem 2
Consistency of β̂A
Under (A.4), there exist ψ* and γ* such that and . Let
Under Condition A, n−1UA(β, ψ̂, γ̂) = ηn(β, ψ*, γ*) + Op(n−1/2) uniformly in β ∈ [−M, M]p for M > 0.
By application of the Glivenko–Cantelli and Donsker theorems, ηn(β, ψ*, γ*) = η(β, ψ*, γ*) + Op(n−1/2) uniformly in β ∈ [−M, M]p, where
If at least one of r(Wi, ψ0) and ρ(Wi, γ0) is correctly specified for r(Wi) and ρ(Wi), then by the missing at random assumption (2) and by using the double expectation formula E[·] = E{E[·|Wi, Δi, Δi > 0]} if r(Wi) is correctly specified and using E[·] = E{E[·|Wi, Ri, Δi > 0]} if ρ(Wi) is correctly specified. Hence
uniformly in β ∈ [−M, M] if at least one of r(Wi, ψ0) and ρ(Wi, γ0) is correctly specified for r(Wi) and ρ(Wi). Since η(β0, ψ*, γ*) = 0 and β0 is the unique solution to η(β0, ψ*, γ*) = 0 by Condition (A.3), we have by Theorem 5.9 of van der Vaart (1998).
Asymptotic Normality of β̂A
Since UA(β, ψ̂, γ̂) = 0, , where β̃ is on the line segment between β̂A and β0. We have
By Condition (A.2) and the consistency of β̂A, uniformly in t. Furthermore, by (A.4), and , we have
converges in probability to
which equals to if at least one of r(W) and ρ(W) is correctly specified. Thus
| (14) |
Let ṙ(·, ψ) = ∂r(·,ψ)/∂ψ, r̈(·, ψ) = ∂ṙ(·, ψ)/∂ψ⊤, ρ̇(·, γ) = ∂ρ(·, γ)/∂γ, and r̈(·, γ) = ∂ρ̇(·, γ)/∂γ⊤. By the Taylor expansion of UA(β0, ψ̂, γ̂) around ψ* and γ*,
Note that
where
| (15) |
It follows that
| (16) |
Let , and
| (17) |
Since , it follows that
Similar to the arguments given above, if at least one of r(Wi) and ρ(Wi) is correctly specified. By application of the Glivenko-Cantelli and Donsker theorems, converges weakly to a zero-mean Gaussian process and uniformly in t. Applying Lemma 2 of Gilbert et al. (2008), we have
Hence
| (18) |
Let and be the score vector and the information matrix under the parametric model r(Wi, ψ), respectively, and and the score vector and the information matrix under the parametric model ρ(Wi, γ). Specifically,
| (19) |
Under (A.4),
| (20) |
and
| (21) |
By (16), (18), (20), and (21), we have
| (22) |
where
By the central limit theorem, n−1/2UA(β0, ψ̂, γ̂) converges in distribution to a normal random vector with zero-mean and covariance matrix .
It follows by (14) and (22) that converges in distribution to a zero-mean Gaussian random vector with covariance matrix .
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Seunggeun Hyun, Email: shyun@uscupstate.edu.
Jimin Lee, Email: jlee@unca.edu.
Yanqing Sun, Email: yasun@uncc.edu.
References
- Andersen J, Goetghebeur E, Ryan L. Missing cause of death information in the analysis of survival data. Statistics in Medicine. 1996;15:2191–2201. doi: 10.1002/(SICI)1097-0258(19961030)15:20<2191::AID-SIM358>3.0.CO;2-D. [DOI] [PubMed] [Google Scholar]
- Andersen P, Klein J, Rosthøj S. Generalised linear models for correlated pseudo-observations, with applications to multi-state models. Biometrika. 2003;90:15–27. [Google Scholar]
- Benichou J, Gail M. Estimates of absolute cause-specific risk in cohort studies. Biometrics. 1990;46:813–826. [PubMed] [Google Scholar]
- Cheng S, Fine J, Wei L. Prediction of cumulative incidence function under the proportional hazards model. Biometrics. 1998;54:219–228. [PubMed] [Google Scholar]
- Cox D. Regression models and life tables (with discussion) Journal of the Royal Statistical Society Series B. 1972;34:187–220. [Google Scholar]
- Cox D. Partial likelihood. Biometrika. 1975;62:269–276. [Google Scholar]
- Dewanji A. A note on a test for competing risks with missing failure type. Biometrika. 1992;79:855–857. [Google Scholar]
- Dinse G. Nonparametric estimation for partially-complete time and of failure data. Biometrics. 1982;38:417–431. [PubMed] [Google Scholar]
- Dinse G. Nonparametric prevalence and mortality estimators for animal experiments with incomplete cause-of-death data. Journal of the American Statistical Association. 1986;81:328–336. [Google Scholar]
- Fine J, Gray R. A proportional hazards model for the subdistribution of a competing risk. Journal of the American Statistical Association. 1999;94:496–509. [Google Scholar]
- Gao G, Tsiatis A. Semiparametric estimators for the regression coefficients in the linear transformation competing risks model with missing cause of failure. Biometrika. 2005;92:875–891. [Google Scholar]
- Gaynor J, Feuer E, Tan C, Wu D, Little C, Straus D, Clarkson B, Brennan M. On the use of cause-specific failure and conditional failure probabilities: Examples from clinical oncology data. Journal of the American Statistical Association. 1993;88:400–409. [Google Scholar]
- Gijbels I, Lin D, Ying Z. Non- and semi-parametric analysis of failure time data with missing failure indicators. IMS Lecture Notes Monograph Series. 2007;54:203–223. [Google Scholar]
- Gilbert P, McKeague I, Sun Y. The two-sample problem for failure rates depending on a continuous mark: An application to vaccine efficacy. Biostatistics. 2008;9:263–276. doi: 10.1093/biostatistics/kxm028. [DOI] [PubMed] [Google Scholar]
- Goetghebeur E, Ryan L. A modified logrank test for competing risks with missing failure type. Biometrika. 1990;77:207–211. [Google Scholar]
- Goetghebeur E, Ryan L. Analysis of competing risks survival data when some failure types are missing. Biometrika. 1995;82:821–834. [Google Scholar]
- Gourieroux C, Monfort A. Asymptotic properties of the maximum likelihood estimator in dichotomous logit models. Journal of Econometrics. 1981;17:83–97. [Google Scholar]
- Gray R. A class of k-sample tests for comparing the cumulative incidence of a competing risk. Annals of Statistics. 1988;16:1040–1154. [Google Scholar]
- Haberman S. The Analysis of Frequency Data. University of Chicago Press; Chicago: 1974. [Google Scholar]
- Haberman S. Maximum likelihood estimates in exponential response models. Annals of Statistics. 1977;5:815–841. [Google Scholar]
- Horvitz D, Thompson D. A generalization of sampling without replacement from a finite universe. Journal of the American Statistical Association. 1952;47:663–685. [Google Scholar]
- Kalbfleish J, Prentice R. The Statistical Analysis of Failure Time Data. 2. Wiley; New York: 2002. [Google Scholar]
- Klein J, Andersen P. Regression modeling of competing risks data based on pseudovalues of the cumulative incidence function. Biometrics. 2005;61:223–229. doi: 10.1111/j.0006-341X.2005.031209.x. [DOI] [PubMed] [Google Scholar]
- Lo SH. Estimating a survival function with incomplete cause-of-death data. Journal of Multivariate Analysis. 1991;39:217–235. [Google Scholar]
- Lu K, Tsiatis A. Multiple imputation methods for estimating regression coefficients in the competing risks model with missing cause of failure. Biometrics. 2001;57:1191–1197. doi: 10.1111/j.0006-341x.2001.01191.x. [DOI] [PubMed] [Google Scholar]
- Lu W, Liang Y. Analysis of competing risks data with missing cause of failure under additive hazards model. Statistica Sinica. 2008;18:219–234. [Google Scholar]
- McKeague I, Subramanian S. Product-limit estimators and cox regression with missing censoring information. Scandinavian Journal of Statistics. 1998;25:589–601. [Google Scholar]
- Pepe M. Inference for events with dependent risks in multiple endpoint studies. Journal of the American Statistical Association. 1991;86:770–778. [Google Scholar]
- Prentice R, Kalbfleisch J, Peterson A, Flournoy N, Farewell V, Breslow N. The analysis of failure times in the presence of competing risks. Biometrics. 1978;34:541–554. [PubMed] [Google Scholar]
- Robins J, Rotnitzky A, Zhao L. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association. 1994;89:846–866. [Google Scholar]
- Rubin D. Inference and missing data. Biometrika. 1976;63:581–592. [Google Scholar]
- Rubin D. Multiple Imputation for Nonresponse in Surveys. Wiley; New York: 1987. [Google Scholar]
- Rubin D. Multiple imputation after 18+ years. Journal of the American Statistical Association. 1996;91:473–489. [Google Scholar]
- Scharfstein D, Rotnitzky A, Robins J. Adjusting for nonignorable drop-out using semiparametric nonresponse models: rejoinder. Journal of the American Statistical Association. 1999;94:1135–1146. [Google Scholar]
- Scheike T, Zhang M. Extensions and applications of the cox-aalen survival model. Biometrics. 2003;59:1036–1045. doi: 10.1111/j.0006-341x.2003.00119.x. [DOI] [PubMed] [Google Scholar]
- Shen Y, Cheng S. Confidence bands for cumulative incidence curves under the additive risk model. Biometrics. 1999;55:1093–1100. doi: 10.1111/j.0006-341x.1999.01093.x. [DOI] [PubMed] [Google Scholar]
- Sierra J, Perez W, Rozman W, Carreras C, Klein J, Rizzo J, Davies J, Lazarus S, Bredeson C, Marks D, Canals C, Boogaerts M, Goldman J, Champlin R, Keating A, Weisdorf D, deWitte T, Horowitz M. Bone marrow transplantation from hla-identical siblings as treatment for myelodysplasia. Blood. 2002;100:1997–2004. [PubMed] [Google Scholar]
- Subramanian S. Efficient estimation of regression coefficients and baseline hazard under proportionality of conditional hazards. Journal of Statistical Planning and Inference. 2000;84:81–94. [Google Scholar]
- Subramanian S, Bandyopadhyay D. Doubly robust semiparametric estimation for the missing censoring indicator model. Statistics and Probability Letters. 2010;80:621–630. [Google Scholar]
- van der Vaart A. Asymptotic Statistics. Cambridge University Press; Cambridge: 1998. [Google Scholar]
- White H. Maximum likelihood estimation of misspecified models. Econometrica. 1982;50:1–25. [Google Scholar]