

Abstract
Nature, technology and society are full of complexity arising from the intricate web of the interactions among the units of the related systems (e.g., proteins, computers, people). Consequently, one of the most successful recent approaches to capturing the fundamental features of the structure and dynamics of complex systems has been the investigation of the networks associated with the above units (nodes) together with their relations (edges).
Most complex systems have an inherently hierarchical organization and, correspondingly, the networks behind them also exhibit hierarchical features. Indeed, several papers have been devoted to describing this essential aspect of networks, however, without resulting in a widely accepted, converging concept concerning the quantitative characterization of the level of their hierarchy.
Here we develop an approach and propose a quantity (measure) which is simple enough to be widely applicable, reveals a number of universal features of the organization of real-world networks and, as we demonstrate, is capable of capturing the essential features of the structure and the degree of hierarchy in a complex network. The measure we introduce is based on a generalization of the m-reach centrality, which we first extend to directed/partially directed graphs. Then, we define the global reaching centrality (GRC), which is the difference between the maximum and the average value of the generalized reach centralities over the network.
We investigate the behavior of the GRC considering both a synthetic model with an adjustable level of hierarchy and real networks. Results for real networks show that our hierarchy measure is related to the controllability of the given system. We also propose a visualization procedure for large complex networks that can be used to obtain an overall qualitative picture about the nature of their hierarchical structure.
Introduction
The last decade has witnessed an explosive growth of interest in the analysis of complex natural, technological and social systems that permeate many aspects of everyday life. These systems are typically made of many units. Complexity arises from either the structure of the interactions between very similar units or, alternatively, the units and the interactions themselves can have specific characteristics. In both cases, the abstract representation of a complex system can be achieved by a collection of nodes (units) and edges (representing interactions between the units) forming a network (or graph).
Research on networks has considerably profited from using both the standard and novel techniques developed in the field of statistical mechanics [1]–[3]. Although a remarkable body of knowledge has accumulated about the statistical properties of networks [4], a number of questions are still open. The issue of hierarchy has attracted the attention of a great number of social and natural scientists [5]. It has been argued that hierarchy is present in a wide range of complex systems: such as physical, chemical, biological, and social systems [6]. Recent empirical findings demonstrate that hierarchy is present in many of the related networks: in the dominant-subordinate hierarchy among animals [7], in the hierarchy of the leader-follower network of pigeon flocks [8], in rhesus macaque kingdoms [9], in the structure of the transcriptional regulatory network of Escherichia coli [10], or in a wide range of social and technological networks [5]. All of these examples suggest that hierarchy is an important feature of natural, artificial and social networks.
It is important to distinguish between the three major types of hierarchies: the order, the nested and the flow hierarchies. In case of an order hierarchy, hierarchy is regarded to be basically only an “ordered set”, and it is understood to be “equivalent to an ordering induced by the values of a variable defined on some set of elements” [11] (i.e., generally there is no network behind this concept). In case of a nested hierarchy higher level elements consist of and contain lower level elements, or, as [12] has formulated “larger and more complex systems consist of and are dependent upon simpler systems and essential system-component entities”. When a network is structured in a flow hierarchy (mostly directed graphs), the nodes can be layered in different levels so that the nodes that are influenced by a given node (are connected to it through a directed edge) are at lower levels.
Our observation is that the notions of “hierarchy” and the “level of hierarchy” are very closely related. In fact, without a proper measure of hierarchy the notion of hierarchy cannot be complete. Indeed, there are various definitions of hierarchy, or, in other words, there is no unique, widely accepted definition of the notion of hierarchy itself. Correspondingly, we propose that a good measure of hierarchy can serve as a starting point for finding the best definition of hierarchy.
In this paper, we are interested in flow hierarchy for the following reasons. First, order hierarchy is a single-valued function over the population and there is no underlying network of interactions attached to the hierarchy. Secondly, uncovering a nested hierarchy is analogous to community detection, for which there are known methods [13], [14]. Finally, both order and nested hierarchies can be converted to flow hierarchies. In an order hierarchy, a directed edge can be assigned to each pair of adjacent members in the hierarchy and this produces a chain of directed edges. In a nested hierarchy, a virtual node is assigned to every subgraph, and if a subgraph contains another, then the two corresponding virtual nodes are connected with a directed link, which produces a flow hierarchy on the network of virtual nodes.
Among the many exciting questions related to hierarchy [5] is concerned with its origin. Several studies have approached this problem from a historical viewpoint [15], [16] but without any quantitative description. The best known quantitative model for the evolution of hierarchies is the Bonabeau model [17]. According to this model, a hierarchy can emerge as the result of the outcomes of competitions between pairs of participating units, and a hierarchy itself is defined by a rank (order) assigned to each participating unit [17]. Another interesting result comes from game theory: simulations of prisoners dilemma type dynamics on adaptive networks showed that cooperation combined with imitation can lead to a hierarchical structure [18]. Note, however, that in this model every node can imitate at most one other, and therefore, the emerging hierarchy is by definition a directed tree.
Usually, a hierarchy is the consequence of the different roles, significances and histories of the nodes [17], [19]. In other words, if the influence of the nodes on others (and thence, on the whole system) differs, then a hierarchy can emerge. Nodes with the strongest influence can denote the leaders of a group (as in the structure of a company or hidden groups [20], [21]; or amongst homing pigeons [8]), central proteins in transcription regulatory networks [10], [22] or opinion leaders [23], [24]. These nodes can have a major impact on the system, and thus, finding them and quantifying the extent of hierarchy at the same time is an important step in the understanding of functionality and controlling of networks.
In most cases networks contain all sorts of edges (both directed and undirected, various edge weights [strength]) making the detection of hierarchy a difficult challenge. When one looks at real-life networks the picture is often much more complicated than for the simple treelike hierarchy: there can be (i) relations between entities on the same level, (ii) “shortcuts” when a step in the hierarchy is bypassed, (iii) ties which, instead of going downward on the hierarchy, go upward, (iv) even cycles of connected nodes [25] and (v) clusters [26], etc. It can even happen that some or all of the levels of hierarchy cannot be clearly defined (are not well-separated).
The hierarchy measures proposed so far have various undesirable properties that make their application to all classes of complex networks problematic: they (i) use free parameters that are unknown for many networks [20], [27], (ii) quantify only the deviation of the network from the tree and penalize loops or multiple edges [28], and (iii) are applicable only to fully directed or fully undirected graphs [20], [27]–[29]. Here we are aiming at introducing a measure which can be equally used for all sorts of networks and thus, used for uncovering universal features of the hierarchical organization of the relations within a complex system.
Visualizing the structure of networks has been a widely used approach to obtain a qualitative picture about some of their features (e.g., clusters/modules). At present, the hierarchical visualization of networks is mostly based on the Sugiyama method [30], which offers an informative and clear hierarchical layout for small networks. However, (i) for networks with more than 2–300 nodes the generated layout becomes difficult to understand; (ii) the meaning of the levels is not defined at all; (iii) independently of the presence or absence of a hierarchy in the given network, the method generates a hierarchical layout that is often misleading; (iv) all steps of the Sugiyama method are NP-complete or NP-hard [31], [32], which makes the usage of several different heuristics necessary and thus, results become less well-defined.
Clearly, there is a need for (a) a measure of hierarchy that is free of the above-mentioned undesired properties and (b) a method for the hierarchical visualization of networks that is unbiased, unambiguous and easily applicable even to large graphs. Thus, the two main goals of our paper are to provide a universally applicable measure and a visualization technique of the hierarchical structure of complex large networks.
Results
Definition of the global reaching centrality
Unweighted directed networks
We are looking for a measure that is expected to satisfy the following natural and reasonable conditions:
Absence of free parameters and a priori metrics in the definition.
The definition should be for unweighted directed graphs (digraphs) and it should be easily extendable to both weighted and undirected graphs.
The hierarchy measure should be helpful for generating a layout of the graph.
To arrive at an appropriate definition, we quantify the concept of flow hierarchy, where nodes contribute to the dynamics of the system differently. We first define the local reaching centrality of node i in an unweighted directed graph, G, as the generalization of the m-reach centrality
[33] to m = N (where N is the number of nodes in G). The local reaching centrality,  , of node i is the proportion of all nodes in the graph that can be reached from node i via outgoing edges. In other words,
, of node i is the proportion of all nodes in the graph that can be reached from node i via outgoing edges. In other words,  is the number of nodes with a finite positive directed distance from node i divided by N - 1, i.e., the maximum possible number of nodes reachable from a given node. We aim to define hierarchy as a heterogeneous distribution of the local reaching centrality. Thus, in graph G we denote by
is the number of nodes with a finite positive directed distance from node i divided by N - 1, i.e., the maximum possible number of nodes reachable from a given node. We aim to define hierarchy as a heterogeneous distribution of the local reaching centrality. Thus, in graph G we denote by 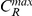 the highest local reaching centrality and define the global reaching centrality (GRC) as:
the highest local reaching centrality and define the global reaching centrality (GRC) as:
| (1) |
Here, V denotes the set of nodes in G. For normalization, the sum is divided by N - 1, as this is the maximal value of the enumerator. In the GRC = 1 case the graph has only one node with nonzero local reaching centrality (i.e., it is a star graph). Throughout this paper, for the model networks and real networks we use this directed, unweighted type of 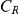 .
.
It is worth mentioning that in the special case of a tree graph, a recursive equation can be derived for  . This equation has some formal similarities with the one for the complexity measure introduced by Huberman et al. [34], [35], but with some important differences related to the motivation, details of the recursive equations involved, etc.
. This equation has some formal similarities with the one for the complexity measure introduced by Huberman et al. [34], [35], but with some important differences related to the motivation, details of the recursive equations involved, etc.
Weighted and undirected networks
Generalizations to weighted or undirected graphs are straightforward based on the definition of the local reaching centrality. For the generalization of the GRC to weighted directed graphs, we introduce a simple variant of the local reaching centrality:
 |
(2) |
Here 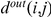 is the length of the directed path that goes from i to j via out-going edges and
is the length of the directed path that goes from i to j via out-going edges and  is the weight of the k-th edge along this path (link weight is assumed to be proportional to connection strength). If nodes i and j are connected by more than one directed shortest path, then the one with the maximum weight (i.e., maximum strength) should be used. This extension of the local reaching centrality measures the average weight of a given directed path starting from node i in a weighted directed graph. If we set
is the weight of the k-th edge along this path (link weight is assumed to be proportional to connection strength). If nodes i and j are connected by more than one directed shortest path, then the one with the maximum weight (i.e., maximum strength) should be used. This extension of the local reaching centrality measures the average weight of a given directed path starting from node i in a weighted directed graph. If we set  for every i, j and k, then the original local reaching centrality (defined for unweighted directed graphs) is recovered.
for every i, j and k, then the original local reaching centrality (defined for unweighted directed graphs) is recovered.
To generalize the local reaching centrality to undirected unweighted graphs, we remove the  term from the previous definition and obtain
term from the previous definition and obtain
| (3) |
This quantity is very similar to the local closeness centrality defined by Sabidussi in [36]. In fact, this is equivalent to the generalization of the closeness centrality for disconnected graphs given by Opsahl [37].
Classical random networks
In order to demonstrate the basic features of the GRC, we briefly discuss its behavior for a few well-known network types. For Erdös–Rényi (ER) graphs [38], [39], scale-free (SF) [40]–[42] graphs and directed trees (more precisely arborescences with random branching number [43], [44]), the distribution of 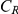 is markedly different (the curves in Figure 1 are averages for 1000 random graphs of each type). In every case, the exponent for the SF networks was set to
is markedly different (the curves in Figure 1 are averages for 1000 random graphs of each type). In every case, the exponent for the SF networks was set to 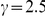 . For the directed tree, the distribution follows a power-law that is distorted due to the random branching numbers. Directed trees have a maximally heterogeneous distribution of
. For the directed tree, the distribution follows a power-law that is distorted due to the random branching numbers. Directed trees have a maximally heterogeneous distribution of 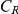 , thus, based on our arguments above, they are maximally hierarchical. Note that the hierarchical tree (directed tree) has very few nodes with local reaching centrality close to 1.
, thus, based on our arguments above, they are maximally hierarchical. Note that the hierarchical tree (directed tree) has very few nodes with local reaching centrality close to 1.
Figure 1. An adjustable hierarchical network with the different edge types.

The blue edges belong to the original arborescence graph that is used as the backbone of the adjustable hierarchical (AH) network. There are three type of possible edges added to the graph: down edges (green), horizontal edges (orange) and up edges (red). They have different effects on the hierarchical structure of the directed tree. Down edges conserve the hierarchy, horizontal edges has a slight influence and up edges make strong changes in the structure.
This is in contrast with the ER and SF graphs in which most of the nodes have a large local reaching centrality. Since almost every node has the same centrality, the contribution of the nodes in Eq. 1 for the ER and SF graphs is negligible. Note that not only the GRC, but also the standard deviation of 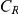 increases with the heterogeneity of the graph. The values of GRC are shown in Table 1 together with the standard deviation of the distribution. However, the GRC itself is more suitable for quantifying the heterogeneity of the graph for two reasons. On the one hand, the accuracy of the standard deviation of
increases with the heterogeneity of the graph. The values of GRC are shown in Table 1 together with the standard deviation of the distribution. However, the GRC itself is more suitable for quantifying the heterogeneity of the graph for two reasons. On the one hand, the accuracy of the standard deviation of  is worse than that of the GRC (it has larger deviation on the ensemble of graphs). On the other hand, the standard deviation of
is worse than that of the GRC (it has larger deviation on the ensemble of graphs). On the other hand, the standard deviation of  is much smaller for the directed tree than for the ER, which is in contrast to our definition making the tree maximally hierarchical. In summary, we find that, based on their reaching centralities, ER graphs are not hierarchical at all, as expected, and SF graphs are slightly hierarchical.
is much smaller for the directed tree than for the ER, which is in contrast to our definition making the tree maximally hierarchical. In summary, we find that, based on their reaching centralities, ER graphs are not hierarchical at all, as expected, and SF graphs are slightly hierarchical.
Table 1. Heterogeneity of the distribution of the local reaching centrality for different network types.
| Graph |
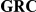
|

|
| ER |

|

|
| SF |

|

|
| Tree |

|

|
The two measures of heterogeneity presented here are the global reaching centrality ( ) and
) and  (standard deviation of
(standard deviation of 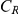 ). Means and variances are shown for an ensemble of 1000 networks.
). Means and variances are shown for an ensemble of 1000 networks.
Adjustable hierarchical network
We study the behavior of the GRC in a model with adjustable hierarchy as well (see Methods for a detailed description of the model). The parameter  tunes between the completely random and the totally hierarchical states. In the
tunes between the completely random and the totally hierarchical states. In the 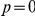 limit, the topology of the AH graph is close to that of an ER graph, but, as one can see, the distribution of the local reaching centrality values of the AH is similar to that of the SF network (Figure 2): a little wider at small centralities than in the ER case. By increasing p, the distribution further widens around the origin and at p = 1, it resembles the one for the directed tree, but it is even closer to a power-law. The global reaching centrality as function of the parameter p is shown in Figure 3. The GRC monotonously increases with p and sweeps through the (0,1) interval in the synthetic model, indicating that it is suitable for measuring the level of hierarchy. As seen in the figures, the global reaching centrality at a given value of p is less for larger average degrees. This observation is confirmed with the results on ER and SF networks (Figure 4). For large densities the GRC vanishes for both the ER and the SF networks.
limit, the topology of the AH graph is close to that of an ER graph, but, as one can see, the distribution of the local reaching centrality values of the AH is similar to that of the SF network (Figure 2): a little wider at small centralities than in the ER case. By increasing p, the distribution further widens around the origin and at p = 1, it resembles the one for the directed tree, but it is even closer to a power-law. The global reaching centrality as function of the parameter p is shown in Figure 3. The GRC monotonously increases with p and sweeps through the (0,1) interval in the synthetic model, indicating that it is suitable for measuring the level of hierarchy. As seen in the figures, the global reaching centrality at a given value of p is less for larger average degrees. This observation is confirmed with the results on ER and SF networks (Figure 4). For large densities the GRC vanishes for both the ER and the SF networks.
Figure 2. Distribution of the local reaching centrality for the adjustable hierarchical network.

Distribution of the local reaching centrality in the adjustable hierarchical (AH) network model at different  parameter values. Each distribution is averaged over 1000 AH networks with
parameter values. Each distribution is averaged over 1000 AH networks with  and
and  . The standard deviations of the distributions are comparable to the averages only for relative frequencies less than 0.002. Note that from the
. The standard deviations of the distributions are comparable to the averages only for relative frequencies less than 0.002. Note that from the 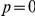 (highly random) to the
(highly random) to the  (fully hierarchical) state the distribution changes continuously and monotonously with
(fully hierarchical) state the distribution changes continuously and monotonously with  .
.
Figure 3. The global reaching centrality at different p values in the adjustable hierarchical model.

All curves show averages over an ensemble of 1000 networks with  and different average degrees. Standard deviations grow with
and different average degrees. Standard deviations grow with  , but they are clearly below the average values of the GRC. Note that for larger density, it is less likely to obtain the same level of hierarchy.
, but they are clearly below the average values of the GRC. Note that for larger density, it is less likely to obtain the same level of hierarchy.
Figure 4. The global reaching centrality versus average degree in the Erdös–Rényi and scale-free networks.

Dots show averages for 1000 graphs with  nodes. In the Erdös–Rényi and scale-free networks, standard deviations of the GRC are comparable with its averages only for
nodes. In the Erdös–Rényi and scale-free networks, standard deviations of the GRC are comparable with its averages only for  and
and  , respectively.
, respectively.
Real networks
We now turn our attention to the hierarchical properties of real networks. The global reaching centralities for different types of networks are shown in Table 2. For each network we show the average degree ( ) and the GRC of the real network. It is important to point out that the direction of the edges in real networks had to be well-defined before calculating the reaching centrality. In every case, the networks were directed so that the source of an edge had a larger effect on the target than conversely. This choice of directedness originates in the observation that the higher a node is in the hierarchy, the more impact it has on the network. According to Table 2, the GRC can have values from a broad range, depending on the average degree and the structure of the networks. For graphs with higher average degree, the GRC is usually smaller. This indicates that for a dense network it is harder to achieve a large reaching centrality, as seen with the ER, SF and AH graphs. The value of the GRC shows how hierarchical the structure of the network is. Food webs have the largest GRC and networks of intra-organizational trust have the smallest. This is in good agreement with the extremely low number of loops in food webs and the high number of loops in email-based organizational networks.
) and the GRC of the real network. It is important to point out that the direction of the edges in real networks had to be well-defined before calculating the reaching centrality. In every case, the networks were directed so that the source of an edge had a larger effect on the target than conversely. This choice of directedness originates in the observation that the higher a node is in the hierarchy, the more impact it has on the network. According to Table 2, the GRC can have values from a broad range, depending on the average degree and the structure of the networks. For graphs with higher average degree, the GRC is usually smaller. This indicates that for a dense network it is harder to achieve a large reaching centrality, as seen with the ER, SF and AH graphs. The value of the GRC shows how hierarchical the structure of the network is. Food webs have the largest GRC and networks of intra-organizational trust have the smallest. This is in good agreement with the extremely low number of loops in food webs and the high number of loops in email-based organizational networks.
Table 2. Hierarchical properties of real networks.
| Type | Meaning of 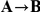
|
Network |

|

|

|
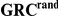
|
| Food web | A eats B | Ythan [48] | 135 | 4.452 | 0.814 
|
0.507 |
| Seagrass [49] | 49 | 4.612 | 0.723 
|
0.253 | ||
| LittleRock [50] | 183 | 13.628 | 0.811 
|
0.045 | ||
| GrassLand [48] | 88 | 1.557 | 0.961 
|
0.695 | ||
| Electric | B depends on the value at A | s1488 [51] | 667 | 2.085 | 0.482 
|
0.298 |
| s1494 [51] | 661 | 2.116 | 0.482 
|
0.289 | ||
| s5378 [51] | 2993 | 1.467 | 0.231 
|
0.062 | ||
| s9234 [51] | 5844 | 1.4 | 0.424 
|
0.050 | ||
| s35932 [51] | 17828 | 1.683 | 0.459 
|
0.015 | ||
| Metabolic | B is an end product of A | C. elegans [52] | 1173 | 2.442 | 0.048 | 0.052 |
| E. coli [52] | 2275 | 2.533 | 0.043 | 0.058 | ||
| S. cerevisiae [52] | 1511 | 2.537 | 0.037 | 0.042 | ||
| Neuronal | A synapse goes from A to B | C. elegans [53], [54] | 297 | 7.943 | 0.133 
|
0.023 |
| Macaque brain [55] | 45 | 10.289 | 0.000 | 0.000 | ||
| Internet | A communicates with B | p2p-1 [56], [57] | 10876 | 3.677 | 0.598 | 0.597 |
| p2p-2 [56], [57] | 8846 | 3.599 | 0.600 | 0.599 | ||
| p2p-3 [56], [57] | 8717 | 3.616 | 0.607 | 0.605 | ||
| Organization | B trusts in A | Enron [58], [59] | 156 | 10.699 | 0.038 
|
0.044 |
| Consulting [60] | 46 | 19.109 | 0.043 
|
0.032 | ||
| Manufacturing [60] | 34 | 18.935 | 0.013 | 0.013 | ||
| B knows A | Freemans-1 [61] | 34 | 18.971 | 0.028 
|
0.041 | |
| Freemans-2 [61] | 77 | 24.412 | 0.000 | 0.000 | ||
| Trust | B trusts in A | WikiVote [62] | 7115 | 14.573 | 0.494 
|
0.534 |
| College [63], [64] | 32 | 3 | 0.275 | 0.273 | ||
| Prison [64,64] | 67 | 2.716 | 0.172 
|
0.111 | ||
| Language | B follows A | English [65] | 7724 | 5.992 | 0.128 
|
0.238 |
| French [65] | 9424 | 2.578 | 0.657 
|
0.875 | ||
| Spanish [65] | 12642 | 3.57 | 0.951 | 0.939 | ||
| Japanese [65] | 3177 | 2.613 | 0.054 
|
0.206 | ||
| Regulatory | A regulates B | TRN-Yeast-1 [66] | 4441 | 2.899 | 0.934 
|
0.968 |
| TRN-Yeast-2 [67] | 688 | 1.568 | 0.116 
|
0.670 | ||
| TRN-EC [67] | 419 | 1.239 | 0.261 
|
0.679 |
We show the order ( ), average degree (
), average degree ( ), and global reaching centrality for the original (
), and global reaching centrality for the original ( ) and for the randomized networks (
) and for the randomized networks (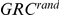 ). References to data sources are included. Suits next to the GRC values show comparison to the randomized networks: whether the original networks are more hierarchical than their randomization (club suit) or they are more egalitarian (diamond suit) with a 98% confidence level. The meaning of edges is also indicated.
). References to data sources are included. Suits next to the GRC values show comparison to the randomized networks: whether the original networks are more hierarchical than their randomization (club suit) or they are more egalitarian (diamond suit) with a 98% confidence level. The meaning of edges is also indicated.
While the actual value of the GRC provides information about the hierarchical properties of the network, we can also compare the results to the randomized versions of the original networks to see how consistent the value we obtained is with the expectations. In order to do this, for each network we generated 100 random networks with the same degree (the details of randomization is explained in the Methods section): the mean values of the global reaching centralities for these randomized networks are shown in Table 2 ( ). The color of the networks' names indicates the relation of each original network to its randomized version: the names of statistically significantly (with a confidence interval of 98%) hierarchical networks are in red while the names of non-hierarchical ones (same confidence) are in blue. Apart from the actual GRC values, the comparison to randomized networks by
). The color of the networks' names indicates the relation of each original network to its randomized version: the names of statistically significantly (with a confidence interval of 98%) hierarchical networks are in red while the names of non-hierarchical ones (same confidence) are in blue. Apart from the actual GRC values, the comparison to randomized networks by  shows slight differences between the analyzed network types. For the food webs
shows slight differences between the analyzed network types. For the food webs 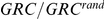 is remarkably high. Although the electronic circuits have low GRC values, they are significantly more hierarchical than their randomized versions. In contrast, although the Internet networks have larger reaching centralities than most other listed networks, these values do not differ significantly from the values of the corresponding randomized networks. Also note that the regulatory networks are significantly less hierarchical, mostly because biochemical systems contain many feedbacks keeping the processes stabilized.
is remarkably high. Although the electronic circuits have low GRC values, they are significantly more hierarchical than their randomized versions. In contrast, although the Internet networks have larger reaching centralities than most other listed networks, these values do not differ significantly from the values of the corresponding randomized networks. Also note that the regulatory networks are significantly less hierarchical, mostly because biochemical systems contain many feedbacks keeping the processes stabilized.
The emergence of hierarchy in many human-made organizations and networks raises the question whether conscious control over these systems plays a role in the origin of hierarchy? In order to investigate this question, we compared the global reaching centralities with the controllability of networks as defined by Liu et al. [45]. They show that the minimal number of driver nodes (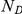 ) is related to the maximum matching of the network and they also provide an algorithm for determining
) is related to the maximum matching of the network and they also provide an algorithm for determining  . In a network with N nodes the relative number of driver nodes is
. In a network with N nodes the relative number of driver nodes is 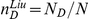 . Driver nodes are the nodes that have to be controlled in order to take full control over the network. Full control means that one can drive the system from any initial state to any other desired final state. Since the networks listed in Table 2 have different original functions (food web, electric, etc.), and in many cases their controllability and hierarchical properties are not yet well understood, we compared these two quantities separately within each group of networks. The Pearson correlations of the GRC and
. Driver nodes are the nodes that have to be controlled in order to take full control over the network. Full control means that one can drive the system from any initial state to any other desired final state. Since the networks listed in Table 2 have different original functions (food web, electric, etc.), and in many cases their controllability and hierarchical properties are not yet well understood, we compared these two quantities separately within each group of networks. The Pearson correlations of the GRC and  are shown in Table 3. In most of the listed real networks, the correlation is above 0.5, which is a relatively small value but still indicates a weak relation between the two quantities. Next, we compared the hierarchy measure, GRC, to the ratio of driver nodes in our synthetic model. Interestingly, for high link densities (
are shown in Table 3. In most of the listed real networks, the correlation is above 0.5, which is a relatively small value but still indicates a weak relation between the two quantities. Next, we compared the hierarchy measure, GRC, to the ratio of driver nodes in our synthetic model. Interestingly, for high link densities ( ) the ratio of driver nodes is very close to the value of the GRC and they differ significantly only for highly hierarchical graphs (i.e., for
) the ratio of driver nodes is very close to the value of the GRC and they differ significantly only for highly hierarchical graphs (i.e., for  ). In an easily (hardly) controllable network, i.e., where
). In an easily (hardly) controllable network, i.e., where  is low (high), few (many) nodes need to be controlled for a total control over the network. According to the results shown in Table 3 for real graphs and the results with the synthetic model (for a wide range of p) the GRC and
is low (high), few (many) nodes need to be controlled for a total control over the network. According to the results shown in Table 3 for real graphs and the results with the synthetic model (for a wide range of p) the GRC and  are moderately positively correlated. In other words, hierarchical networks are harder to control. This result contradicts our initial intuitive concept that hierarchy emerges because it is the optimal structure with respect to controllability. This contradiction can be traced back to an assumption in the node-based definition of controllability given in [45] where each node is assumed to send the same signal to all of its neighbors. If, however, the network's dynamics is defined on the edges [46], then the definition of controllability differs from the definition by Liu et al. Therefore, as an alternative, we compared hierarchy to controllability defined under the switchboard dynamics
[46] (correlations are shown in Table 4). In the case of switchboard dynamics edges are controlled and nodes are simple devices converting the signals arriving on their in-edges to signals leaving on their out-edges. The driver nodes in this dynamics are those that one has to control for controlling the state of every edge. Based on the correlations between the GRC and the number of driver nodes, we conclude that under the switchboard dynamics hierarchical networks are better controllable.
are moderately positively correlated. In other words, hierarchical networks are harder to control. This result contradicts our initial intuitive concept that hierarchy emerges because it is the optimal structure with respect to controllability. This contradiction can be traced back to an assumption in the node-based definition of controllability given in [45] where each node is assumed to send the same signal to all of its neighbors. If, however, the network's dynamics is defined on the edges [46], then the definition of controllability differs from the definition by Liu et al. Therefore, as an alternative, we compared hierarchy to controllability defined under the switchboard dynamics
[46] (correlations are shown in Table 4). In the case of switchboard dynamics edges are controlled and nodes are simple devices converting the signals arriving on their in-edges to signals leaving on their out-edges. The driver nodes in this dynamics are those that one has to control for controlling the state of every edge. Based on the correlations between the GRC and the number of driver nodes, we conclude that under the switchboard dynamics hierarchical networks are better controllable.
Table 3. The Pearson correlation of the GRC and 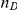 defined by Liu et al.
defined by Liu et al.
| Type of the networks |
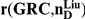
|
| Regulatory | 0.843 |
| Trust | 0.974 |
| Food web | 0.69 |
| Metabolic | −0.225 |
| Electric | 0.503 |
| Internet | 0.632 |
| Organizational | 0.337 |
| Language | 0.933 |
With only one exception, all correlations are positive and many of them are above 0.6, i.e., the GRC and  are positively correlated.
are positively correlated.
Table 4. Pearson correlation of the GRC and  in the switchboard dynamics.
in the switchboard dynamics.
| Type of the networks |

|
| Regulatory | −0.922 |
| Trust | −0.983 |
| Food web | −0.406 |
| Metabolic | −0.916 |
| Electric | −0.969 |
| Internet | 0.57 |
| Organizational | −0.674 |
| Language | −0.812 |
The correlations are all negative (except for the Internet networks) and most of them are very close to −1. Thus, under the switchboard dynamics the GRC (strength of hierarchy) and  are strongly negatively correlated.
are strongly negatively correlated.
To show how the generalized reaching centralities can be applied to undirected networks, we tested our method on the networks of terrorists investigated by Memon et al. Our results are similar to those of [21]: the top of the hierarchy related to the Bojinka case contains Isamudin and K. S. Mehmood (known as Mohammed). In the London Bombings network [21] found that the mastermind of the 7/7 bombings was H. R. Awsat; he was identified by our analysis (based on  ) as a leader and M. S. Khan and I. M. Said as additional important participants. These results suggest that the above extensions of the local reaching centrality are effective quantities for the description of undirected graphs.
) as a leader and M. S. Khan and I. M. Said as additional important participants. These results suggest that the above extensions of the local reaching centrality are effective quantities for the description of undirected graphs.
Visualization of large networks
We use the method introduced in the Methods section for the hierarchical visualization of unweighted digraph by setting  . Since the local reaching centrality takes discrete values on the graph, we use
. Since the local reaching centrality takes discrete values on the graph, we use  , that is, nodes that have local reaching centralities very close to each other are in the same level. Figure 5 shows the layout of various graphs. ER graphs have only two layers close to each other and most of their nodes are in the top layer indicating an almost equal impact of every node and the absence of hierarchy. As opposed to this, an arborescence has many layers, the distances between the layers vary and the layers contain different numbers of nodes. At the topmost layer there is only one node and it is far from the other nodes. This structure is due to the fact that the roles of nodes in the graph vary on a wide range, in other words, the distribution of the local reaching centrality is strongly heterogeneous. The hierarchical structure of an SF graph is between those of an ER graph and an arborescence: although it has only a few layers, these layers are clearly separated.
, that is, nodes that have local reaching centralities very close to each other are in the same level. Figure 5 shows the layout of various graphs. ER graphs have only two layers close to each other and most of their nodes are in the top layer indicating an almost equal impact of every node and the absence of hierarchy. As opposed to this, an arborescence has many layers, the distances between the layers vary and the layers contain different numbers of nodes. At the topmost layer there is only one node and it is far from the other nodes. This structure is due to the fact that the roles of nodes in the graph vary on a wide range, in other words, the distribution of the local reaching centrality is strongly heterogeneous. The hierarchical structure of an SF graph is between those of an ER graph and an arborescence: although it has only a few layers, these layers are clearly separated.
Figure 5. Visualization of three network types based on the local reaching centrality.

Visualization of (A) an Erdös–Rényi (ER) network, (B) a scale-free (SF) network and (C) a directed tree with random branching number between 1 and 5. All three graphs have  nodes and the ER and SF graphs have
nodes and the ER and SF graphs have  . In each network
. In each network  was set to
was set to  .
.
Note that different realizations (single graphs) of the same graph model (e.g., the SF model) usually have different hierarchical layouts. In order to eliminate this bias and to compare the graph models themselves (instead of single graphs from each model), we apply the hierarchical layouts of single graphs to define the drawing (image) of graph ensembles. To do this, first we rescale the hierarchical layout of each single graph to unit height and width and center it in the unit square (Figure 6). Next, we overlay the hierarchical layouts of graphs from the same model. For each graph model the result of this process is a density distribution of the nodes (in the unit square) averaged over the different realizations of the given model. Figure 7 shows graph ensemble drawings: the ER model is visualized as a thin horizontal line at the bottom of the box, while the SF model has more levels and it is similar to the AH(0.3) network. The ensemble of arborescences is visualized in a small concentrated region at the bottom of the unit square indicating the presence of many close levels. The transition from egalitarianism to hierarchy can be clearly seen on the visualization of the AH graphs. At small p (proportion of edges pointing to a lower level) there is mostly one level, then with increasing p more and more other levels emerge, and finally, the network splits into two groups of levels that are moving away from each other. To illustrate the usefulness of our visualization method, we show results for four real graphs as well (Figure 8). The GrassLand network is highly hierarchical, while the Enron network is very egalitarian (only very few nodes are much lower than the majority). This is in good agreement with the global reaching centrality values. The electrical circuit and the biological regulatory network are between the two extreme cases. The first contains two major levels (further subdivided into smaller levels. In contrast, the regulatory network has only one wide bottom level and a few nodes in the top and they are close to each other.
Figure 6. Diagram illustrating the process of visualizing an ensemble of networks.

First, we compute the layout based on the selected 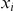 local quantity for each graph in the ensemble (top right). Next, we separate the levels logarithmically and scale each layout into the unit square (bottom left). Last, we overlay all rescaled layouts and plot the obtained density of nodes in the unit square (bottom right, see color scale also). In the heat maps, the color scale shows
local quantity for each graph in the ensemble (top right). Next, we separate the levels logarithmically and scale each layout into the unit square (bottom left). Last, we overlay all rescaled layouts and plot the obtained density of nodes in the unit square (bottom right, see color scale also). In the heat maps, the color scale shows  , where
, where  is the average density of the ensemble.
is the average density of the ensemble.
Figure 7. Visualization of network ensembles.

Visualizations of the (A) Erdös–Rényi, (B) scale-free, (C) directed tree and (D)–(L) AH network ensembles (subfigures (D)–(L) are for different values of the model parameter:  ). In each case the color scale shows
). In each case the color scale shows 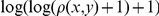 where
where  is the density averaged over 1000 graphs.
is the density averaged over 1000 graphs.  and
and 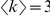 were set. In every network,
were set. In every network,  was set to
was set to  . The corresponding GRC values are: 0.997 (A), 0.058 (B), 0.127 (C), 0.135 (D), 0.161 (E), 0.194 (F), 0.238 (G), 0.290 (H), 0.361 (I), 0.452 (J), 0.581 (K) and 0.775 (L).
. The corresponding GRC values are: 0.997 (A), 0.058 (B), 0.127 (C), 0.135 (D), 0.161 (E), 0.194 (F), 0.238 (G), 0.290 (H), 0.361 (I), 0.452 (J), 0.581 (K) and 0.775 (L).
Figure 8. Visualization of real networks.

The hierarchy-based visualization of (A) the GrassLand food web, (B) the electrical circuit benchmark s9234, (C) the transcriptional regulatory network of yeast and (D) the core of the Enron network. In every network  was set to
was set to  .
.
Methods
Synthetic model
In order to show the behavior of GRC, we introduce a synthetic network model with tunable extent of hierarchy. The construction of the network is the following:
In a directed tree assign a level (
 ) to every node. The level of the root node is equal to the number of levels. If and only if a node has level
) to every node. The level of the root node is equal to the number of levels. If and only if a node has level  , then the level of its children will be
, then the level of its children will be  . These levels denote the natural layers in the hierarchy of the directed tree (the nodes at the bottom have
. These levels denote the natural layers in the hierarchy of the directed tree (the nodes at the bottom have  ).
).We put a given number of additional random directed edges in the graph according to the following rule. 1 - p proportion of the edges is totally random, i.e. we choose two nodes randomly (A and B) and if they are not already connected in the given (
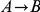 ) direction, we connect them. By p proportion of the edges, we put the
) direction, we connect them. By p proportion of the edges, we put the 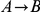 edge only if
edge only if  . In this way, p proportion of the random edges will not change the hierarchical structure of the directed tree.
. In this way, p proportion of the random edges will not change the hierarchical structure of the directed tree.
An example of a generated network with the different edge types is shown in Figure 9. Hereafter, we will refer to this synthetic model as the adjustable hierarchical network (AH).
Figure 9. Distributions of the local reaching centrality for different network types.

For each network type 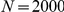 and for the Erdös–Rényi (ER) and scale-free (SF) networks
and for the Erdös–Rényi (ER) and scale-free (SF) networks  . All curves show averages of the distributions over an ensemble of 1000 graphs. Standard deviations are comparable with the averages only near the peaks in the ER and SF models. Although the standard deviations at the peaks are large, they do not change the positions of the peaks, and thus, do not affect the distributions.
. All curves show averages of the distributions over an ensemble of 1000 graphs. Standard deviations are comparable with the averages only near the peaks in the ER and SF models. Although the standard deviations at the peaks are large, they do not change the positions of the peaks, and thus, do not affect the distributions.
Randomization of real networks
During the analysis of the results with real networks, we also calculated the GRC after randomizing them: first, we generated a random network with the same in and out degree distribution according to the configuration model. The generated network is further randomized in the following way: we choose two random edges ( and
and 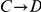 ) and change the endpoints of them (so that we get
) and change the endpoints of them (so that we get  and
and  ). In every case, the number of rewired edge pairs was ten times the number of edges.
). In every case, the number of rewired edge pairs was ten times the number of edges.
Visualization
We also propose a visualization method using an arbitrary local quantity on the graph. The algorithm is as follows:
Grade the nodes according to the local quantity
 .
.Add nodes to the first (lowermost) level of the layout in the increasing order of their
 values as long as
values as long as  . Here
. Here  is the standard deviation of
is the standard deviation of 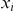 within the current (first) level,
within the current (first) level,  is the standard deviations of
is the standard deviations of  within the whole graph, and z is an adjustable coefficient.
within the whole graph, and z is an adjustable coefficient.When
 is reached, start a new level.
is reached, start a new level.Repeat 2nd and 3rd steps until every node is put in levels.
- For horizontal arrangement, align the center of every level to the same vertical line. In other words, in each level, the average of the horizontal positions of the nodes is the same:
Here,
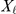 is the horizontal center of mass of level
is the horizontal center of mass of level 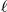 .
. - The levels are arranged vertically so that the distances between adjacent levels are proportional to the logarithm of the differences in the averages inside the corresponding levels, i.e.
where
 and is the vertical position of the
and is the vertical position of the  -th level and
-th level and  is the average of
is the average of 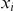 inside this level. First, set the vertical distances of levels proportionally to the differences between their average values of
inside this level. First, set the vertical distances of levels proportionally to the differences between their average values of  such that the smallest distance will be set to a given length (this length is the same as the horizontal distance between two adjacent nodes). Finally, set the distances to be proportional to the logarithm of the original differences so that the height of the graph is kept unchanged.
such that the smallest distance will be set to a given length (this length is the same as the horizontal distance between two adjacent nodes). Finally, set the distances to be proportional to the logarithm of the original differences so that the height of the graph is kept unchanged.
In the above steps we use the standard deviation in order to get clearly different layouts for different distributions of  . In a network with a localized distribution of
. In a network with a localized distribution of  the method produces few levels that are very close to each other. But if the distribution of
the method produces few levels that are very close to each other. But if the distribution of  is non-localized, the network will have many levels and a large vertical extension. If the distribution of
is non-localized, the network will have many levels and a large vertical extension. If the distribution of 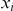 is continuous, then we can use z to adjust the extent to which every level contributes to the total variance. In other words, for large graphs, z tunes the vertical extension of the layout. If the distribution of
is continuous, then we can use z to adjust the extent to which every level contributes to the total variance. In other words, for large graphs, z tunes the vertical extension of the layout. If the distribution of 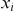 is discrete, then we can assign a level to each of its different values, which is mathematically equivalent to z = 0. In practice, we set z to a sufficiently small value,
is discrete, then we can assign a level to each of its different values, which is mathematically equivalent to z = 0. In practice, we set z to a sufficiently small value,  .
.
Implementation
For the graph generations, randomizations and shortest path calculations presented in this paper, we used the already implemented functions in the igraph software package [47]. An open-source implementation of the local and global reaching centrality calculations is provided at http://hal.elte.hu/~enys/grc.htm.
Discussion
Hierarchy is an essential feature of many natural and human-made networks and therefore, it is of high importance to have a measure quantifying it. Here we proposed a measure based on the assumption that the rank of the nodes should be related to their impact on the whole network, which is proportional to the number of all nodes reachable from them (local reaching centrality). The quantity we introduced, i.e., the global reaching centrality (GRC), measures the heterogeneity of the local reaching centrality distribution on the whole graph. In contrast to formerly proposed measures, the GRC does not penalize loops and undirected edges, but takes them into account by making bidirectionally connected pairs of nodes ( ,
, 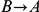 ) equivalent in the hierarchy. There are neither free parameters in the method, nor optimization, and the ranks of the nodes are a natural result of the GRC. Since the controllability (according to the switchboard dynamics) and the extent of hierarchy are positively correlated, our calculations indicated that hierarchical structures are more easily controllable.
) equivalent in the hierarchy. There are neither free parameters in the method, nor optimization, and the ranks of the nodes are a natural result of the GRC. Since the controllability (according to the switchboard dynamics) and the extent of hierarchy are positively correlated, our calculations indicated that hierarchical structures are more easily controllable.
Acknowledgments
We thank Illés Farkas and Gábor Vásárhelyi for their helpful comments on the early version of the manuscript. We also thank Tamás Nepusz for his technical and theoretical advices and suggestions on the simulations.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: This work was supported by the EU FP7 COLLMOT Grant No: 227878. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Castellano C, Fortunato S, Loreto V. Statistical physics of social dynamics. Phys Rev Lett. 2009;81:591–646. [Google Scholar]
- 2.Vicsek T, Zafiris A. Collective motion. 2010. arxiv:1010.5017.
- 3.Pastor-Satorras R, Vespignani A. Evolution and Strcuture of the Internet. Cambridge: Cambridge University Press; 2004. [Google Scholar]
- 4.Albert R, Barabási AL. Statistical Mechanics of Complex Networks. Phys Rev Lett. 2002;74:47–97. [Google Scholar]
- 5.Pumain D, editor. Hierarchy in Natural and Social Sciences. Dodrecht, The Netherlands: Springer; 2006. pp. 1–12. [Google Scholar]
- 6.Huseyn L, Whetten DA. The Concept of Horizontal Hierarchy and the Organization of Interorganizational Networks: a Comparative Analysis. Social Networks. 1984;6:31–58. [Google Scholar]
- 7.Goessmann C, Hemelrijk C, Huber R. The formation and maintenance of crayfish hierarchies: behavioral and self-structuring properties. Behavioral Ecology and Sociobiology. 2000;48:418–428. [Google Scholar]
- 8.Nagy M, Ákos Z, Biro D, Vicsek T. Hierarchical group dynamics in pigeon flocks. Nature. 2010;464:890–893. doi: 10.1038/nature08891. [DOI] [PubMed] [Google Scholar]
- 9.Fushing H, McAssey MP, Beisner B, McCowan B. Ranking network of captive rhesus macaque society: A sophisticated corporative kingdom. PLoS ONE. 2011;6:e17817. doi: 10.1371/journal.pone.0017817. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ma HW, Buer J, Zeng AP. Hierarchical sructure and modules in the Escherichia coli transcriptional regulatory network revealed by a new top-down approach. BMC Bioinformatics. 2004;5:199. doi: 10.1186/1471-2105-5-199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lane D. Hierarchy, complexity, society. Dodrecht, the Netherlands: Springer; 2006. pp. 81–120. [Google Scholar]
- 12.Wimberley ET. Nested ecology. The place of humans in the ecological hierarchy. Baltimore, MD: John Hopkins University Press; 2009. [Google Scholar]
- 13.Girwan M, Newman ME. Community structure in social and biological networks. PNAS. 2002;99:7821–7826. doi: 10.1073/pnas.122653799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Palla G, Derényi I, Farkas I, Vicsek T. Uncovering the overlapping community structure of complex networks in nature and society. Nature. 2005;435:814–818. doi: 10.1038/nature03607. [DOI] [PubMed] [Google Scholar]
- 15.Smaje C. Natural Hierarchies. The Historical Sociology of Race and Caste. Hoboken, NJ: Blackwell Publishers; 2000. [Google Scholar]
- 16.Dubreuil B. Human Evolution and the Origins of Hierarchies. Cambridge: Cambridge University Press; 2010. [Google Scholar]
- 17.Theraulaz G, Bonabeau E, Deneubourg JL. Self-organization of Hierarchies in Animal Societies: The Case of the Primitively Eusocial wasp Polistes dominulus Christ. Journal of Theoretical Biology. 1995;174:313–323. [Google Scholar]
- 18.Eguíluz VM, Zimmermann MG, Cela-Conde CJ, Miguel MS. Cooperation and the Emergence of Role Differentiation in the Dynamics off Social Networks. American Journal of Sociology. 2005;110:977–1008. [Google Scholar]
- 19.Bonabeau E, Theraulaz G, Deneubourg JL. Dominance Orders in Animal Societies: The Self-organization Hypothesis Revisited. Bulletin of Mathematical Biology. 1999;61:727–757. doi: 10.1006/bulm.1999.0108. [DOI] [PubMed] [Google Scholar]
- 20.Rowe R, Creamer G, Hershkop S, Stolfo SJ. WebKDD/SNA-KDD 07: Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 workshop on Web mining and social network analysis. ACM; 2007. Automated social hierarchy detection through email network analysis. pp. 109–117. [Google Scholar]
- 21.Memon N, Larsen HL, Hicks DL, Harkiolakis N. Proceedings of the IEEE ISI 2008 PAISI, PACCF, and SOCO international workshops on Intelligence and Security Informatics. New York: Springer-Verlag; 2008. Detecting Hidden Hierarchy in Terrorist Networks: Some Case Studies. pp. 477–489. [Google Scholar]
- 22.Bhardwaj N, Kim PM, Gerstein MB. Rewiring of transcriptional regulatory networks: hierarchy, rather than connectivity, better reflects the importance of regulators. Science Signaling. 2010;3 doi: 10.1126/scisignal.2001014. [DOI] [PubMed] [Google Scholar]
- 23.Song X, Chi Y, Hino K, Tseng BL. Proceedings of the sixteenth ACM conference on Conference on information and knowledge man- agement. ACM, CIKM '07; 2007. Identifying Opinion Leaders in the Blogosphere. pp. 971–974. [Google Scholar]
- 24.Mak V. The Emergence of Opinion Leaders in Social Networks. 2008. Available: http://ssrn.com/abstract=1157285. Accessed 2012 Feb 24.
- 25.Hummon NP, Fararo TJ. Actors and networks as objects. Social Networks. 1995;17:1–26. [Google Scholar]
- 26.Johnsen EC. Network macrostructure models for the Davis-Leinhardt set of empirical sociomatrices. Social Networks. 1985;7:203–224. [Google Scholar]
- 27.Carmel L, Haren D, Koren Y. Drawing Directed Graphs Using One-Dimensional Optimization. Heidelberg: Springer; 2002. pp. 193–206. [Google Scholar]
- 28.Krackhardt D. Graph theoretical dimensions of informal organizatons. Mahwah, NJ: Lawrence Erlbaum Associates Inc; 1994. [Google Scholar]
- 29.Trusina A, Maslov S, Minnhagen P, Sneppen K. Hierarchi measures in complex networks. Phys Rev Lett. 2004;92:178702. doi: 10.1103/PhysRevLett.92.178702. [DOI] [PubMed] [Google Scholar]
- 30.Sugiyama K, Tagawa S, Toda M. Methods for visual understanding of hierarchical system structures. IEEE Transactions in Systems, Man and Cybernetics. 1981. pp. 109–125. volume 11.
- 31.Garey MR, Johnson DS. Computers and Intractability: A Guide to the Theory of NP-Completeness. New York: W. H. Freeman and Company; 1979. [Google Scholar]
- 32.Healy P, Nikolov NS. Hierarchical drawind algorithms. St Helier, NJ: CRC Press; 2004. [Google Scholar]
- 33.Borgatti SP. The Key Player Problem. Washington, D.C.: National Academy of Sciences Press; 2003. pp. 241–252. [Google Scholar]
- 34.Huberman BA, Hogg T. Complexity and adaption. Physica D. 1986;22:376–384. [Google Scholar]
- 35.Ceccatto HA, Huberman BA. The complexity of hierarchical systems. Physica Scripta. 1988;37:145. [Google Scholar]
- 36.Sabidussi G. The centrality index of a graph. Psychometrika. 1966;31:581–603. doi: 10.1007/BF02289527. [DOI] [PubMed] [Google Scholar]
- 37.Opsahl T, Agneessens F, Skvoretz J. Node centrality in weighted networks: Generalizing degree and shortest paths. Social Networks. 2010;32:245–251. [Google Scholar]
- 38.Erdős P, Rényi A. On the evolution of random graphs. Publ Math Inst Hung Acad Sci. 1960;5:17–60. [Google Scholar]
- 39.Bollobás B. Random Graphs. Cambridge: Cambridge University Press; 2001. [Google Scholar]
- 40.Barabási AL, Albert R. Emergence of scaling in random networks. Science. 1999;286:509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 41.Goh KI, Kahng B, Kim D. Universal behavior of load distribution in scale-free networks. Phys Rev Lett. 2001;87 doi: 10.1103/PhysRevLett.87.278701. [DOI] [PubMed] [Google Scholar]
- 42.Chung F, Lu L. Connected component in random graphs with given expected degree sequences. Annual Combinatorics. 2002;6:125–145. [Google Scholar]
- 43.Tutte WT. Graph Theory. Cambridge: Cambridge University Press; 2001. [Google Scholar]
- 44.Grinstead CM, Snell JL. Introduction to Probability, Second Revised Edition. Washington, D.C.: American Mathematical Society; 1997. [Google Scholar]
- 45.Liu YY, Slotine JJ, Barabási AL. Controllability of complex networks. Nature. 2011;473:167–173. doi: 10.1038/nature10011. [DOI] [PubMed] [Google Scholar]
- 46.Nepusz T, Vicsek T. Controlling edge dynamics in complex networks. 2011. arxiv:1112.5945.
- 47.Csárdi G, Nepusz T. The igraph software package for complex network research. InterJournal Complex Systems 1695. 2006. Available: http://igraph.sf.net. Accessed 2012 Mar 8.
- 48.Dunne JA, Williams RJ, Martinez ND. Food-web structure and network theory: The role of connectance and size. Proceedings of the National Academy of Sciences of the United States of America. 2002;99:12917–22. doi: 10.1073/pnas.192407699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Christian RR, Luczkovich JJ. Organizing and understanding a winter's seagrass foodweb network through effective trophic levels. Ecological Modelling. 1999;117:99–124. [Google Scholar]
- 50.Martinez N. Artifacts or attributes? Effects of resolution on the Little Rock Lake food web. Ecological Monographs. 1991;61:367–392. [Google Scholar]
- 51. Source: http://courses.engr.illinois.edu/ece543/iscas89.html. Accessed 2012 Feb 24. Networks available at http://hal.elte.hu/~enys/data.htm. Accessed 2012 Feb 24.
- 52.Jeong H, Tombor B, Albert R, Oltvai ZN, Barabási AL. The large-scale organization of metabolic networks. Nature. 2000;407:651–4. doi: 10.1038/35036627. [DOI] [PubMed] [Google Scholar]
- 53.Achacoso TB, Yamamoto WS. AY's Neuroanatomy of C. elegans for Computation. First edition. Boca Raton, FL: CRC Press; 1992. [Google Scholar]
- 54.Watts DJ, Strogatz SH. Collective dynamics of ‘small-world’ networks. Nature. 1998;393:440–2. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- 55.Négyessy L, Nepusz T, Kocsis L, Bazsó F. Prediction of the main cortical areas and connections involved in the tactile function of the visual cortex by network analysis. European Journal of Neuroscience. 2006;23:1919–1930. doi: 10.1111/j.1460-9568.2006.04678.x. [DOI] [PubMed] [Google Scholar]
- 56.Leskovec J, Faloutsos C. Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining. ACM; 2005. Graphs over time: densification laws, shrinking diameters and possible explanations. pp. 177–187. [Google Scholar]
- 57.Ripeanu M, Foster I, Iamnitchi A. Mapping the Gnutella network: Properties of large-scale peer-to-peer systems and implications for system design. IEEE Internet Computing Journal. 2002;6:50–57. [Google Scholar]
- 58.Leskovec J, Lang K, Dasgupta A, Mahoney M. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Mathematics. 2009;6:29–123. [Google Scholar]
- 59.Klimt B, Yang Y. 2004. Introducing the Enron corpus.
- 60.Cross R, Parker A. The Hidden Power of Social Networks. Boston, MA: Harvard Business School Press; 2004. [Google Scholar]
- 61.Freeman S, Freeman L. Social science research reports 46. 1979. Technical report, University of California, Irvine, CA.
- 62.Leskovec J, Huttenlocher D, Kleinberg J. Proceedings of the 28th international conference on Human factors in computing systems. ACM; 2010. Signed networks in social media. pp. 1361–1370. [Google Scholar]
- 63.Van Duijn MAJ, Huisman M, Stokman FN, Wasseur FW, Zeggelink EPH. Evolution of sociology freshmen into a friendship network. Journal of Mathematical Sociology. 2003;27:153–191. [Google Scholar]
- 64.Milo R, Itzkovitz S, Kashtan N, Levitt R, Shen-Orr S, et al. Superfamilies of evolved and designed networks. Science. 2004;303:1538–42. doi: 10.1126/science.1089167. [DOI] [PubMed] [Google Scholar]
- 65.Cancho RF, Solé RV. The small world of human language. Proceedings of the Royal Society of London Series B: Biological Sciences. 2001;268:2261–2265. doi: 10.1098/rspb.2001.1800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Balaji S, Babu MM, Iyer LM, Luscombe NM, Aravind L. Comprehensive analysis of combinatorial regulation using the transcriptional regulatory network of yeast. Journal of Molecular Biology. 2006;360:213–27. doi: 10.1016/j.jmb.2006.04.029. [DOI] [PubMed] [Google Scholar]
- 67.Milo R, Shen-Orr S, Itzkovitz S, Kashtan N, Chklovskii D, et al. Network motifs: simple building blocks of complex networks. Science. 2002;298:824–7. doi: 10.1126/science.298.5594.824. [DOI] [PubMed] [Google Scholar]