

Abstract
Researchers use community-detection algorithms to reveal large-scale organization in biological and social networks, but community detection is useful only if the communities are significant and not a result of noisy data. To assess the statistical significance of the network communities, or the robustness of the detected structure, one approach is to perturb the network structure by removing links and measure how much the communities change. However, perturbing sparse networks is challenging because they are inherently sensitive; they shatter easily if links are removed. Here we propose a simple method to perturb sparse networks and assess the significance of their communities. We generate resampled networks by adding extra links based on local information, then we aggregate the information from multiple resampled networks to find a coarse-grained description of significant clusters. In addition to testing our method on benchmark networks, we use our method on the sparse network of the European Court of Justice (ECJ) case law, to detect significant and insignificant areas of law. We use our significance analysis to draw a map of the ECJ case law network that reveals the relations between the areas of law.
Introduction
Network theory provides a good framework for studying systems composed of many interacting components. Recently, researchers have been interested in highlighting highly interconnected structures, communities, in biological and social networks [1]–[8], because often communities correspond to behavioral or functional components. For example, in social networks, communities can represent friendship groups; on the web, they can represent related pages on a specific topic; and in metabolic networks, they can represent cycles or other functional groupings. Here we show that communities can also capture disciplines of judgements in case law systems [9]. However, similar to many real-world networks, the network of ECJ case law is sparse because of missing links. The challenge in finding significant structures in sparse networks is twofold: random noise directly propagates to the community results, and communities easily shatter because of missing links. To find reliable communities in sparse networks with missing links, here we propose a simple method based on link prediction. First we show that our method performs well on benchmark networks. Then we apply our method to the ECJ case law network and generate a significance map of EU law.
Researchers use two main approaches to find statistically significant communities in networks: approaches based on explicit underlying null models in the clustering algorithms and approaches based on perturbation techniques. In the null-model approaches, communities are significant if the probability of finding them in a random network is lower than a given threshold [10]–[12]. This is a solid approach when we are interested in how a network was formed. But when researchers are interested in highlighting functional aspects of an instantiated network, such as dynamics on a given network, they often use perturbation techniques [13]–[16]. Taking this approach, researchers assume random noise in the data. When they perform the statistical analysis, they repeatedly perturb and cluster the data and then aggregate the results. Therefore, they can use any clustering algorithm and are not restricted to a particular null model. But for many sparse networks, the main source of error is not random noise in the data, but rather missing links with different effects on the clustering. For example, many clustering algorithms identify more clusters in sparse networks than in the corresponding networks without missing links [17], [18]. Accordingly, we consider a network to be sparse if a clustering algorithm finds significantly more modules after a fraction of the links have been removed. To take this shattering effect into account when we perform significance analysis on sparse networks with missing links, we introduce resampling based on link prediction.
To assess the significance of sparse networks with missing links, we combine perturbation techniques and link prediction. In practice, we resample sparse networks by completing triangles. For undirected networks, completing triangles corresponds to the simple and effective link prediction method called common neighbor [19]. With this approach, our aim is to add links that are missing because of insufficient data but avoid connecting nodes that factually are disconnected. After explaining our approach in detail, first we show that we can recover shattered modules in benchmark networks as long as the mixing between modules is moderate and not too many links are deleted. Then we apply the method to identify significant areas in the network of ECJ case law. This network consists of more than 8,000 court cases connected by about 32,000 citations over the time period 1954–2010, clearly a sparse network. We create a significance map and connect several insignificant clusters into complete areas of EU law.
Methods
Resampling based on Completing Triangles
To generate resamples of inherently sensitive sparse networks, we need a method that efficiently adds extra links while preserving the core structure of the network. That is, if we apply community detection algorithms for partitioning sparse networks with missing links, we will often find small shattered modules. On the other hand, if we just add links randomly to prevent shattering, most likely we will connect nodes that should be disconnected because they are not directly related. Accordingly, we note that the problem of aggregating shattered modules by adding links is similar to the problem of predicting missing links. Missing links prediction methods operate by estimating the likelihood of a link between a pair of vertices based on their similarity. To evaluate the similarity between vertices based on the structural properties of the network, indices like common neighbors [19], Jaccard coefficient [20], degree product, shortest paths, and hierarchical structure [21] have been proposed and used to predict future links on real data [22]. All similarity indices use specific assumptions about the positions of the missing links that often make them complicated and computationally expensive to calculate. But these assumptions might not reveal meaningful information in all real networks. To significantly analyze networks’ communities by generating resampled networks, however, we do not need to exactly predict missing links; we only need to add extra links in a non-destructive way so we can measure the robustness of the communities. Therefore, we perturb sparse networks with a simple and general method: triangle completion. That is, we complete a fraction of open triangles that exist in the original data, see Figure 1. By adopting triangle completion, we assume that communities should have high density of triangles. With this implicit null model, we can aggregate related shattered communities with a simple and general assumption about the network. Triangles are the smallest unit of communities, and completing them strengthens local connections and the important core of the communities. As a result, shattered communities combine with each other and the community size grows. Figure 1 shows an example network in which black links indicate existing links in the network and the four inner circles correspond to communities in the network. When we add links by completing the triangles (dashed lines), we aggregate the small communities into two big communities. Of course, by completing triangles we might add links between nodes that should not be connected. If more information is available about the network, other more sophisticated null models that may work better can be applied [21], [22]. But as we show in the next section, the simple and general triangle completion method performs well on benchmark networks.
Figure 1. Completing triangles followed by clustering aggregate shattered communities.

Dashed lines show different possibilities for completing triangles.
Benchmark Networks
To validate our method, we tested triangle completion followed by clustering with the infomap algorithm [23] on artificial networks with a built-in community structure. The benchmark graphs that we use resemble real-world network and was introduced by Lancichinetti et al.
[24]. The benchmark networks have tunable exponents and we use exponent 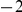 for the degree distribution and exponent
for the degree distribution and exponent  for the community size distribution. Further, the mixing parameter
for the community size distribution. Further, the mixing parameter 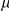 determines the ratio between the external degree of a node with respect to its community and the total degree of that node. We use this framework to generate undirected networks with built-in community structures. Figure 2A schematically shows a network with 100 nodes and four built-in communities. By removing 50% of the links, communities fall apart and small modules are detected (Figure 2B), But with triangle completion, related shattered modules are combined with each other (Figure 2C).
determines the ratio between the external degree of a node with respect to its community and the total degree of that node. We use this framework to generate undirected networks with built-in community structures. Figure 2A schematically shows a network with 100 nodes and four built-in communities. By removing 50% of the links, communities fall apart and small modules are detected (Figure 2B), But with triangle completion, related shattered modules are combined with each other (Figure 2C).
Figure 2. Triangle completion aggregates shattered modules.

Original network with 4 communities in A, removing links leads to small shattered communities in B, and completing triangles in the shattered network integrates small communities in C.
To quantitatively show that triangle completion perturbs the network in a non-destructive way, we used normalized mutual information (NMI) to measure the similarity between the community structure of the original network and the community structure of the perturbed network [25], [26].
Figure 3 shows the result of using the perturbation method on benchmark networks with 1000 nodes, average degree 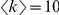 , community sizes between 10 and 50, and two different levels of mixing between communities. We generated sparse networks with missing links by randomly removing 30 and 60 percent of the links in the benchmark networks. In the figure, we use relative link perturbation to refer to the normalized difference between the number of links in the perturbed and unperturbed network. The first row shows the result of triangle completion for low mixing,
, community sizes between 10 and 50, and two different levels of mixing between communities. We generated sparse networks with missing links by randomly removing 30 and 60 percent of the links in the benchmark networks. In the figure, we use relative link perturbation to refer to the normalized difference between the number of links in the perturbed and unperturbed network. The first row shows the result of triangle completion for low mixing, 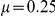 , and well-defined communities. Low
, and well-defined communities. Low 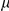 , less than 0.5, means that, on average, each node has more links going to nodes within the same community than to nodes in other communities. So when we use our triangle completion method for perturbing such networks, we strengthen the structure inside the communities more than the structure between the communities. Therefore, we amplify the coarse-grain structure of the network, and the community structure of the perturbed network will be similar to the community structure of the original network, disregarding the number of extra links that we added. This reasoning is valid both when we perturb the original raw network and when we perturb the reduced networks. By adding extra links to the reduced networks, shattered and weakly connected modules aggregate and module sizes grow. For reference, the gray lines in Figure 3 show that if we randomly add links, we completely destroy the community structure of the network.
, less than 0.5, means that, on average, each node has more links going to nodes within the same community than to nodes in other communities. So when we use our triangle completion method for perturbing such networks, we strengthen the structure inside the communities more than the structure between the communities. Therefore, we amplify the coarse-grain structure of the network, and the community structure of the perturbed network will be similar to the community structure of the original network, disregarding the number of extra links that we added. This reasoning is valid both when we perturb the original raw network and when we perturb the reduced networks. By adding extra links to the reduced networks, shattered and weakly connected modules aggregate and module sizes grow. For reference, the gray lines in Figure 3 show that if we randomly add links, we completely destroy the community structure of the network.
Figure 3. Test of triangle completion on unweighted undirected benchmark networks.

The panels show the similarity between the community structure of the original and the perturbed networks as a function of relative link perturbation, in A and B for low module mixing and in C and D for high module mixing. Panels A and C quantifies the similarity in terms of the normalized mutual information (NMI) and panels B and D quantifies the similarity in terms of the module size ratio. Filled circles correspond to the similarity after link removal. Open symbols correspond to the similarity after subsequently adding links by triangle completion (colored circles) and random link addition (gray squares). Link addition starts at 0, 30, and 60 percent link removal. Each point corresponds to an average over 100 networks.
We use the ratio between the average module size of the perturbed network, 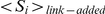 , and the average module size of the original network,
, and the average module size of the original network, 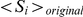 , to quantify module growth:
, to quantify module growth:
| (1) |
When the built-in community structure is well-defined for low 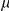 , the module size ratio does not exceed one and the community structure never collapses. On the other hand, in networks with high
, the module size ratio does not exceed one and the community structure never collapses. On the other hand, in networks with high 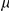 and comparable number of links within and between communities, we destroy the community structure. That is, when we use triangle completion to perturb the network, module sizes grow quickly and finally collapse (Figure 3C,D). We have also analyzed networks with large communities, varying in size between 20 and 100 nodes, and found similar results. When completing triangles, the mutual information remains approximately constant and module sizes grow toward the original sizes as long as the mixing parameter is sufficiently low. In general, we find that
and comparable number of links within and between communities, we destroy the community structure. That is, when we use triangle completion to perturb the network, module sizes grow quickly and finally collapse (Figure 3C,D). We have also analyzed networks with large communities, varying in size between 20 and 100 nodes, and found similar results. When completing triangles, the mutual information remains approximately constant and module sizes grow toward the original sizes as long as the mixing parameter is sufficiently low. In general, we find that 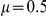 is the threshold at which triangle completion works (Figure 4). When
is the threshold at which triangle completion works (Figure 4). When 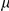 is higher than 0.5, there are not enough regularities in the network to use for non-destructive perturbation. Figure 4 also shows that for denser and less challenging networks, the difference between triangle completion and random link addition decreases. For sufficiently dense networks, other methods, including link removal, can be used. But the more sparse the network is, the better is triangle completion over random link addition.
is higher than 0.5, there are not enough regularities in the network to use for non-destructive perturbation. Figure 4 also shows that for denser and less challenging networks, the difference between triangle completion and random link addition decreases. For sufficiently dense networks, other methods, including link removal, can be used. But the more sparse the network is, the better is triangle completion over random link addition.
Figure 4. The success of triangle completion depends on the module mixing.

Similarity between the community structure of the original network and the perturbed networks for three different average degrees 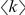 as a function of the module mixing parameter
as a function of the module mixing parameter 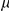 . In panel A the similarity is quantified in terms of the normalized mutual information (NMI) and in panel B the similarity is quantified in terms of the module size ratio. Filled lines and circles correspond to triangle completion and dashed lines and open circles correspond to random link addition. No links were removed prior link addition and the number of links were doubled in all networks by link addition. Each point corresponds to an average over 100 networks.
. In panel A the similarity is quantified in terms of the normalized mutual information (NMI) and in panel B the similarity is quantified in terms of the module size ratio. Filled lines and circles correspond to triangle completion and dashed lines and open circles correspond to random link addition. No links were removed prior link addition and the number of links were doubled in all networks by link addition. Each point corresponds to an average over 100 networks.
By repeatedly completing triangles and clustering link-added networks, we can generate bootstrap resamples for assessing significant communities in sparse networks with missing links. In the next section, we use this resampling technique to identify significant and insignificant communities in the network of ECJ case law.
Results and Discussion
ECJ case Law Network
Case law is continuously evolving and changing over time. New cases build on old cases and areas of law emerge, vanish, evolve or remain constant over time. Citation patterns between cases allow us to track and capture the evolution of areas of law. For example, Bommarito II et al. used a dynamic citation network to find meaningful clusters in the network of the United Supreme Court by means of a distance measure [27]. Here we use approximately 32,000 citations between more than 8,000 court cases (1954–2010) from the Court of Justice of the EU to better understand the overall structure of ECJ case law.
The European Court of Justice ensures the correct interpretation and application of EU law [28]. When it comes to the judgments of the ECJ, legal scholars traditionally begin by distinguishing cases primarily concerning substantive issues from cases primarily concerning constitutional issues. Substantive issues regard questions about specific rights and obligations of individuals, Member States, and EU institutions under EU law. However, constitutional issues regard questions about the division of power between EU and Member States or the duties of Member States to enforce substantive rights. We find that the distinction between substantive and constitutional issues is supported by the network of ECJ case law. In addition to being substantive or constitutional, every judgment has also a procedural dimension in the sense that the ECJ enjoys jurisdiction over each case on one of eleven possible grounds [29]. More information about the Court’s cases is available on the EU law website [30].
We generated and clustered bootstrap networks from the network of ECJ case law to detect significant areas of law and to better understand the overall structure. In the time-directed network of ECJ case law, each vertex corresponds to a court case and an arc from case A to case B shows that the newer case A cites the older case B, as schematically illustrated in Figure 5. Similar to many other time-directed networks, the network of ECJ case law is sparse, as, in the beginning, there were few cases to cite. However, because the number of cases increases with time, new cases have more options to cite. Completing the triangles in the time-directed network of ECJ case law corresponds to one of the three situations depicted in Figure 5. In all three situations, the added citation corresponds to a potential citation that we predict could have been considered and materialized in the first place.
Figure 5. Three possibilities for completing triangles in the time-directed network of ECJ case law.

Given two citations between three cases, A being more recent than B, which in turn is more recent than C, we can complete triangles in three different situations. Panel A: If a new case A cites two older cases B and C, but B does not cite C, we can make B cite C. Panel B: If a new case A cites B, and B cites C but A does not cite C, we can make A cite C. Panel C: If two new cases A and B both cite an old case C and the newest case A does not cite B, we can make A cite B.
To show that our perturbation method does not destroy the core structure of the law network, we would like to compare the community structure of the link-added network to the community structure of the original raw network in terms of NMI. But the actual community structure of the original raw network is not known in this case. To overcome this problem, we use the case law directory code, the official classification system of the court, as our reference point. With this reference point, the NMI will be low but when we complete triangles we can use the trend of the NMI to validate our method. As Figure 6 shows, perturbing the ECJ case law network by completing triangles does not destroy the core structure of the network. For example, even when we make the network 12 times denser, NMI stays almost constant, but at the same time, the module sizes grow as we desire.
Figure 6. Completing triangles in the court case network generates non-destroyed resample networks.

Panel A: Normalized mutual information (NMI) between the original network and the link-added networks as a function of the relative link perturbation. Panel B: Module size ratio between the original network and the link-added networks as a function of the relative link perturbation. Each point corresponds to an average over 100 runs.
For a significance analysis of the ECJ case law network, we first partition the network with a clustering algorithm to capture regularities in the raw network. To cluster with respect to citation flow between the court cases, we use the map equation framework with a generalized flow model for time-directed networks [23]. However, we emphasize that the significance analysis method works for any clustering algorithm. To assess the significance of detected clusters, we generate 100 resample networks by the triangle completion method without making any assumption about the underlying distribution of the resampled networks. Each resample network has twice the number of links as the raw network. Then we partition all resampled networks by using the same clustering method we used for the raw network. To identify significant clusters, cluster cores, we search for the biggest subset of nodes in each cluster that gathered together in more than 90% of the resampled networks. We define the size of a subset to correspond to the number of nodes in the subset and also to the volume of flow through the subset, weighted equally. So by finding the core of each cluster, we can assess which nodes significantly belong to a cluster and which do not. In addition to identifying significant and insignificant nodes within each cluster, the resampled networks can provide us with information about which clusters are significantly stand-alone and which are probably subsets of other clusters. We consider a cluster as significantly stand-alone if its core is not partitioned with another cluster in at least 90% of the resampled networks. That is, two clusters are mutually insignificant if their cores are partitioned together in more than 10% of the resampled networks. In this regard, each cluster could be insignificant with more than one other cluster, which means there is not enough support from the data for these clusters to exist as significantly stand-alone.
Figure 7 shows the map of the ECJ case law network illustrating the 40 top clusters, which we have manually named by analyzing which cases are clustered together. The size of nodes and links represent the citation flow within and between clusters, and we have highlighted mutually insignificant clusters by blue shaded areas.
Figure 7. Map of ECJ case law.

We partitioned 8,200 court case documents with 32,000 citations. Afterwards, we generated 100 resampled networks using the triangle completion method. By clustering these resampled networks and comparing them to the clustering of the raw network, we can estimate how much support the data provide in partitioning the raw network. The map represents the 40 top modules. Insignificant clusters and their mutually insignificant friends are shaded with blue areas.
Several of the identified clusters represent well-established areas of law. One example is Equal treatment (125 cases with 25 cases in the significant core, or 25/125 cases for short), which aggregates cases concerning discrimination of individuals based on nationality. Less intuitive, but seemingly valid, is the clustering of cases concerning the justification of such discrimination into a separate cluster, Justifying unequal treatment of persons (113/134 cases). Interestingly, completing triangles aggregates not these two clusters but the latter with cases concerning Members States’ (MS) justification of other violations of substantive rights in the highlighted area MS justifying restrictions of basic freedoms in Figure 7. Legal scholars have speculated in a convergence of these areas of law without being able to conclusively demonstrate this trend. Another example of a structure that does not fit squarely into the traditional legal classification is Borderline cases in the internal market (36/74 cases). The cluster works as a hub between different areas of law, bringing together cases involving several different substantive issues, including inter alia equal treatment.
The significance map in Figure 7 demonstrates that a single clustering of the sparse network is insufficient and can be misleading. For example, the map contains two clusters representing cases concerning Value Added Tax (VAT) (83/113 and 89/101 cases, respectively), even though there are no considerable differences between cases belonging to the two clusters. The significance analysis reveals that the two clusters are not significantly stand alone, because the significant cores are clustered together in 80 percent of all bootstrap networks. By completing triangles and aggregating the clusters, we can resolve the problem caused by missing links. The same is true for Public service contracts (33/60 and 25/46 cases with 83 percent co-clustering of significant cores). The same is also true for Infringement proceedings (10/58, 34/44, and 2/51 cases with 31 percent co-clustering between the least co-clustered pair of significant cores) and Adoption & review of EU legislation (51/116, 31/43, and 5/38 cases with 31 percent co-clustering between the least co-clustered pair of significant cores). These clusters are also interesting because the cases are clustered based on the grounds for jurisdiction (procedural clusters), which would likely be absent in a more traditional legal categorization of the case law.
We also find, somewhat surprising from a legal perspective, that substantive, constitutional, and procedural clusters are closely related. For example, we find that there is a strong relationship between National procedural autonomy (28/77 cases), which aggregates cases concerning the constitutional issue of procedural adequacy of national courts enforcing EU law, and The principle of equal pay (74/84 cases), a cluster representing the substantive issue of the right of men and women to equal pay for equal work. The pattern of interconnected substantive and constitutional clusters remains on the level of aggregated clusters. Completing triangles and aggregating mutually insignificant clusters reveal a strong relationship between the highlighted constitutional area Effective enforcement and the highlighted substantive area Equality between men and women.
These results confirm that combining our resampling method with the significance analysis of the preliminary clusters can provide reliable aggregated clusters that help us better understand the modular organization of a system with missing information.
To summarize, using communities as the principal component of complex systems is reliable only if the communities are statistically significant and not the result of noisy or incomplete data. To assess the significance of communities in networks with missing links, we have suggested a simple approach that perturbs the sparse networks in a constructive way by adding links based on triangle completion. The remaining challenge is to estimate the optimal number of links to be added, but our benchmark tests indicate that results are insensitive to the number of added links. We used our method to identify significantly stand-alone communities and aggregate mutually insignificant communities in the sparse network of European Court of Justice case law. With a significance map of ECJ case law, for the first time we can analyze the large-scale organization of European law. We have, for example, identified structures and relationships that do not fit into the traditional legal classification system and empirically confirmed trends that legal scholars have only speculated in.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: MR was supported by Swedish Research Council grant 2009-5344. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Girvan M, Newman MEJ. Community structure in social and biological networks. Natl Acad Sci USA. 2002;99:7821–7826. doi: 10.1073/pnas.122653799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Radicchi F, Castellano C, Cecconi F, Loreto V, Parisi D. Defining and identifying communities in networks. Natl Acad Sci USA. 2004;101:2658–2663. doi: 10.1073/pnas.0400054101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Newman MEJ. Fast algorithm for detecting community structure in networks. Phys Rev E. 2004;69:066133. doi: 10.1103/PhysRevE.69.066133. [DOI] [PubMed] [Google Scholar]
- 4.Danon L, Díaz-Guilera A, Arenas A. Stat Mech 2006: P11010; 2006. The effect of size heterogeneity on community identification in complex networks.P11010 [Google Scholar]
- 5.Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E. Stat Mech 2008: P10008; 2008. Fast unfolding of communities in large networks.P10008 [Google Scholar]
- 6.Hastings MB. Community detection as an inference problem. Phys Rev E. 2006;74:035102. doi: 10.1103/PhysRevE.74.035102. [DOI] [PubMed] [Google Scholar]
- 7.Rosvall M, Bergstrom CT. An information-theoretic framework for resolving community structure in complex networks. Natl Acad Sci USA. 2007;104:7327–7331. doi: 10.1073/pnas.0611034104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Palla G, Derenyi I, Farkas I, Vicsek T. Uncovering the overlapping community structure of complex networks in nature and society. Nature. 2005;435:814–818. doi: 10.1038/nature03607. [DOI] [PubMed] [Google Scholar]
- 9.Leicht EA, Clarkson G, Shedden K, Newman ME. Large-scale structure of time evolving citation networks. Eur Phys J B. 2007;59:75–83. [Google Scholar]
- 10.Spirin V, Mirny LA. Protein complexes and functional modules in molecular networks. Proceedings of the National Academy of Sciences. 2003;100:12123–12128. doi: 10.1073/pnas.2032324100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lancichinetti A, Radicchi F, Ramasco JJ. Statistical significance of communities in networks. Phys Rev E. 2010;81:046110. doi: 10.1103/PhysRevE.81.046110. [DOI] [PubMed] [Google Scholar]
- 12.Lancichinetti A, Radicchi F, Ramasco J, Fortunato S. Finding statistically significant communities in networks. PloS one. 2011;6:e18961. doi: 10.1371/journal.pone.0018961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Gfeller D, Chappelier JC, De Los Rios P. Finding instabilities in the community structure of complex networks. Phys Rev E. 2005;72:056135. doi: 10.1103/PhysRevE.72.056135. [DOI] [PubMed] [Google Scholar]
- 14.Karrer B, Levina E, Newman MEJ. Robustness of community structure in networks. Phys Rev E. 2008;77:046119. doi: 10.1103/PhysRevE.77.046119. [DOI] [PubMed] [Google Scholar]
- 15.Hu Y, Nie Y, Yang H, Cheng J, Fan Y, et al. Measuring the significance of community structure in complex networks. Phys Rev E. 2010;82:066106. doi: 10.1103/PhysRevE.82.066106. [DOI] [PubMed] [Google Scholar]
- 16.Rosvall M, Bergstrom CT. Mapping change in large networks. PLoS ONE. 2010;5:e8694. doi: 10.1371/journal.pone.0008694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Reichardt J, Leone M. (un)detectable cluster structure in sparse networks. Phys Rev Lett. 2008;101:078701. doi: 10.1103/PhysRevLett.101.078701. [DOI] [PubMed] [Google Scholar]
- 18.Lancichinetti A, Fortunato S. Community detection algorithms: A comparative analysis. Phys Rev E. 2009;80:056117. doi: 10.1103/PhysRevE.80.056117. [DOI] [PubMed] [Google Scholar]
- 19.Lorrain F, White HC, Math J. Structural equivalence of individual in social networks. Sociol. 1971;1:49. [Google Scholar]
- 20.Jaccard P. Distribution de la ore alpine: dans le bassin des dranses et dans quelques régions voisines. Bulletin de la Societe vaudoise des Sciences Naturelle. 1901;37:547. [Google Scholar]
- 21.Clauset A, Moore C, Newman MEJ. Hierarchical structure and the prediction of missing links in networks. Nature. 2008;453:98–101. doi: 10.1038/nature06830. [DOI] [PubMed] [Google Scholar]
- 22.Liben-Nowell D, Kleinberg J. The link-prediction problem for social networks. JASIST. 2007;58:1019–1031. [Google Scholar]
- 23.Rosvall M, Bergstrom CT. Maps of random walks on complex networks reveal community structure. Natl Acad Sci USA. 2008;105:1118–1123. doi: 10.1073/pnas.0706851105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Lancichinetti A, Fortunato S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities. Phys Rev E. 2009;80:016118. doi: 10.1103/PhysRevE.80.016118. [DOI] [PubMed] [Google Scholar]
- 25.Danon L, Díaz-Guilera A, Duch J, Arenas A. J Stat Mech; 2005. Comparing community structure identification.P09008 [Google Scholar]
- 26.Lancichinetti A, Fortunato S, Kertész J. Detecting the overlapping and hierarchical community structure in complex networks. New J Phys. 2009;11:033015. [Google Scholar]
- 27.II MJB, Katz DM, Zelner JL, Fowler JH. Distance measures for dynamic citation networks. Physica A 389: 2010;4201 - 4208 [Google Scholar]
- 28.EUR-Lex website. Article 19 (1) of the treaty on european union. 1 Available: http://eur-lex.europa.eu/en/treaties/index.htm. Accessed 2011 Sep. [Google Scholar]
- 29.EUR-Lex website. Articles 258–273 in treaty on the functioning of the european union. 1 Available: http://eur-lex.europa.eu/en/treaties/index.htm. Accessed 2011 Sep. [Google Scholar]
- 30.EUR-Lex website. Access to european union law. 1 Available: http://eur-lex.europa.eu Accessed 2011 Sep. [Google Scholar]