

Abstract
High content screening (HCS) has emerged an important tool for drug discovery because it combines rich readouts of cellular responses in a single experiment. Inclusion of cell cycle analysis into HCS is essential to identify clinically suitable anticancer drugs that disrupt the aberrant mitotic activity of cells. One challenge for integration of cell cycle analysis into HCS is that cells must be chemically synchronized to specific phases, adding experimental complexity to high content screens. To address this issue, we have developed a rules-based method that utilizes mitotic phosphoprotein monoclonal 2 (MPM-2) marker and works consistently in different experimental conditions and in asynchronous populations. Further, the performance of the rules-based method is comparable to established machine learning approaches for classifying cell cycle data, indicating the robustness of the features we use in the framework. As such, we suggest the use of MPM-2 analysis and its associated expressive features for integration into HCS approaches.
Introduction
High content screening (HCS) enables the simultaneous characterization of multiple on- and off-target effects of chemical treatments within cell populations. An off-target effect that requires attention when developing clinical therapeutics is cell cycle disruption, as changes in the cell cycle modulate cancer development and progression.1
Automated imaging techniques coupled with quantitative analysis routines that classify cells into different cell cycle stages have been shown to be accurate and reproducible.2 Since many clinically important disruptions occur during mitosis—the phase in which the replicated genome is divided into two daughter cells—efforts have been made to classify stages of mitosis with a high degree of temporal resolution.3–5
One common experimental approach involves using a fluorescent histone marker or nuclear stain (e.g., 4′,6-diamidino-2-phenylindole [DAPI] or Hoechst) to provide a nuclear marker.6,7 After image acquisition, images are processed into individual nuclei, and measurements from the labeling pattern within each nucleus are made. Finally, statistical learning approaches are used to determine cell cycle stage based on subnuclear and nuclear patterns. One challenge to these approaches is that treatment conditions often change from experiment to experiment; for example, drug treatment can lead to diverse mitotic chromosome morphologies in one dataset that may not be represented in another set.
In this work we seek to develop and evaluate a rules-based classification framework that can be applied to both synchronous and asynchronous populations of cells. Our framework reduces the need for synchronized cell populations and would simplify high content screens. Moreover, we seek to make this framework robustly to different compound treatments, making it suitable for HCS applications. To this end, we have also defined unique features for high content analysis that refines our framework across different types of experimental treatments.
Materials and Methods
Cell Lines and Culture
The quantitative cell cycle approaches developed here arose from previous mitotic progression studies of Aurora kinase family members and engineered cell lines.8 The single thymidine block experiment and the unsynchronized cell experiments were performed with HeLa cells cultured in Dulbecco's modified Eagle's medium (DMEM; Invitrogen) supplemented with 10% fetal bovine serum (FBS), 50 units/mL penicillin, and 50 μg/mL streptomycin (Invitrogen). The double thymidine block experiment was performed with HeLa Tet-On Aurora-C-wild type (HTO-AurC-WT) cells. HTO-AurC-WT cells are modified HeLa Tet-On cells (BD Biosciences) that have been stably transfected with a pTRE-regulated expression construct for Flag-Aurora-C.8 Flag-Aurora-C expression is negligible in the absence of doxycycline, which was not used in the experiments described here, and moderate Aurora-C overexpression has no overt effect on cell cycle progression.9 HTO-AurC-WT cells were cultured in a 1:1 combination of DMEM and McCoy's 5A medium (Invitrogen) with 10% tet system-approved FBS (Hyclone), 50 units penicillin and 50 μg streptomycin, 100 μg/mL G-418 (Invitrogen), and 100 μg/mL hygromycin B (Invitrogen). All cells were cultured at 37°C in 5% CO2.
Cell Seeding and Synchronizations
Cells were manually seeded into black-walled, optical glass-bottom, 96-well trays (Matrical; double thymidine block experiment), into 384-well optical plastic-bottom trays (Greiner; unsynchronized experiment) or onto poly-D-lysine-coated coverslips (single thymidine block experiment). Where indicated, cells were synchronized at the G1/S border by single or double thymidine block. Specifically, 30 h after seeding, cells were blocked by exchanging the medium in the well for medium containing 4 mM thymidine and incubated for 14 h. Cells were then released from this block by three changes of thymidine-free media. For single thymidine block, cells were incubated for 8 h, and then fixed. For double thymidine block, cells were incubated for 10 h, blocked again for 15 h, and then released again into S phase in synchrony. Cells were then fixed after the second release as the peak of the synchronized wave of cells passed through mitosis.
Cell Fixation, DNA Staining, and Immunolabeling
Cells were fixed by the gentle addition of an equal volume of ice-cold 8% EM-grade formaldehyde in Dulbecco's phosphate-buffered saline (PBS) plus Ca2+ and Mg2+ directly to the media already in the well for a final concentration of 4% formaldehyde, and incubated on ice for 30 min. Cells were briefly permeablized in PBS containing 0.5% Triton X-100 (PBS-TX) and then treated with blocking buffer (1% bovine serum albumin in PBS-TX) for 15 min at room temperature. Cells were immunolabeled with 1:100–1:500 mouse mitotic phosphoprotein monoclonal 2 (MPM-2) antibody [GeneTex (clone 0.T.181) or Millipore] and either 1:200 rabbit anti-Aurora-B antibody (Bethyl Labs) or 1:1,000 rat anti-tubulin (Abcam) diluted in blocking buffer for 1 h at room temperature. Cells were then washed two times for 10 min each in PBS-TX. Next, secondary antibodies diluted in blocking buffer (1:1,000 Alexa Fluor 488–conjugated goat anti-mouse and 1:500 Alexa Fluor 647–conjugated goat anti-rabbit or 1:1,000 Alexa Fluor 568–conjugated goat anti-rat from Invitrogen) were applied for 1 h at room temperature. About 1 μg/mL DAPI and 10 μg/mL CellMask™ Deep Red (Invitrogen; single thymidine block experiment only) in PBS-TX was applied to cells for 10 min. Cells were washed in PBS-TX for 10 min, followed by PBS for 10 min. To ensure stable imaging, cells were postfixed in 4% formaldehyde in PBS for 30 min at room temperature or 37°C and then rinsed several times in PBS. Cells in 96-well or 384-well plates were stored at 4°C in PBS until imaging, and they were also imaged while in PBS. Cells on coverslips were mounted on slides with SlowFade Gold Antifade reagent (Invitrogen).
Automated Microscopy
For automated cell cycle classification, high-throughput imaging was performed with a 20×/0.75 NA or 0.50 NA Plan Nikon objective on a Beckman-Coulter IC-100 Image Cytometer. At least 30 fields were imaged per treatment. Image-based auto-focusing was performed for each field in the DAPI channel, and one image was collected for each channel at the autofocus z-plane, plus two additional images 5 μm above and below the autofocus plane (double thymidine block and unsynchronized experiments) or six additional planes, three above and three below the autofocus plane, every 2 μm (single thymidine block experiment). DAPI, MPM-2, and either Aurora-B or tubulin and CellMask channel images were collected at each plane.
Image Preprocessing
Raw images were processed by background subtraction of the median pixel value from the entire image, except for CellMask images, in which case the mode pixel value was subtracted. Resulting negative intensity pixels were set to zero. Further image analysis was performed on background-subtracted images. To correct for chromatic aberrations, channels were registered by manually determining optimal vertical and horizontal translations and expansions for additional channels relative to the DAPI channel. These translations and expansions were then automatically applied to all fields from an experiment, and the resulting padding was then cropped. Implementation of the custom workflow was performed using the Advanced Imaging Collection in Pipeline Pilot 7.5.2 (Accelrys, Inc.).
Image Segmentation
A multi-step method was developed for the delineation of nuclei from DAPI images that is tolerant of the disparity in signal intensity, axial thickness, shape, and size between interphase nuclei and mitotic chromosome masses (Appendix Fig. A1); these details become significant when using high numerical aperture objectives.
A binary nucleus mask was created from the DAPI channel. The image was smoothed by filling intensity holes in the image, applying Gaussian smoothing, and then filling intensity holes again. The smoothed DAPI image was transformed to a gradient image to highlight nuclear/chromosomal edges. Watershed segmentation was then performed on the gradient image to break it into watershed basins. In general, each nucleus consisted of numerous watershed basins, with boundaries of a subset of the basins corresponding to the true boundaries of the nuclei. Intensity peaks were then identified in the smoothed DAPI image and used as seed regions for the formation of nuclei. All watershed regions overlapping with a seed region became a nuclear seed. Watershed regions were merged with adjacent seed regions if their median DAPI pixel intensity was within 50% of that of the adjacent seed. The merging process was reiterated until no new watershed regions were added to seed regions. Resulting seed regions defined a binary nuclear mask. This produced nuclear object boundaries that overlaid steep transitions from bright to dim DAPI signals, and that also adjusted to the brightness of each individual nuclear/chromosomal object, whether interphase or mitotic.
Closely adjacent nuclei that merge into a single nuclear object with this binary mask are a common occurrence, especially in samples with high cell density. To separate touching nuclei, we applied watershed segmentation to the inverse of the distance transform of the binary mask. The peaks of the distance transform were used as water sources for the watershed segmentation. This frequently resulted in over-segmentation of nuclei. To recombine over-segmented nuclei, the peak markers of the distance transform image within each watershed segmentation region were expanded to include all pixels with an intensity difference from the peak less than an empirically determined threshold (e.g., 3). If this expanded peak marker encountered the boundary between its watershed region and an adjacent watershed region, then one of two paths would be followed. First, if the peak marker from the adjacent region also expanded to the same boundary, then the two peak markers were merged into a single peak marker. Alternatively, if the first peak marker was the only one that expanded to the boundary, then it was eliminated from the peak marker image. The new expanded peak markers image was then used as the water source for another watershed segmentation, and the process was repeated iteratively until no additional peaks could be merged or eliminated. This produced a labeled nucleus mask that correctly segmented most cells (Appendix Fig. A2b). The only cells that proved problematic were nonlinear clusters, cells exhibiting a high degree of overlap, and narrow metaphase, anaphase, or cytokinetic nuclei with end-on abutments to other cells.
A cellular mask was created by dilating the nuclear mask using an empirically determined structuring element with a 20-pixel radius (Appendix Fig. A2c). Cytoplasm masks were produced by the subtraction of the nucleus masks from the cellular masks. The custom segmentation workflow was implemented using imaging components within Pipeline Pilot 7.5.2 (Accelrys, Inc.).
Feature Extraction
Intensity and morphology-based features were extracted from the DAPI and MPM-2 channels of each segmented cell using the Image Region Shape Statistics, Advanced Image Region Shape Statistics, Image Intensity Statistics, and Advanced Image Intensity Statistics components in the Advanced imaging Collection in Pipeline Pilot 7.5.2 (Accelrys, Inc.).
Manual Cell Cycle Classification
Segmented cells were scored by an expert both to serve as a training set for automated classification and for validation of the automated classifier and rules-based classifiers. About 1,000 to 2,000 nuclear objects were manually classified from each nondrug-treated sample, and from 200 to 1,000 objects for each drug-treated sample, into the following classes: interphase, prophase, prometaphase, metaphase, anaphase, cytokinesis, telophase, multi-nuclear cluster—all interphase, multi-nuclear cluster—mixed (i.e., contained at least one mitotic cell), apoptotic/necrotic, fragment, and noncell. All acquired z-planes were used to achieve best possible manual classification, whereas only the optimally focused planes of each channel were employed for automated classification. Whereas only the DAPI and MPM-2 channels were used for automated classification, the fluorescence channels used for manual classification varied by experiment. In the double thymidine blocked and released experiment, DAPI and Aurora-B channels were used, blind to the MPM-2 channel. In the single thymidine blocked and released experiment, DAPI, tubulin, and CellMask channels were used, blind to the MPM-2 channel. In the unsynchronized experiment, DAPI and MPM-2 were used for manual classification.
Automated Classification
One-against-one support vector machine (SVM) classification was performed using a radial-basis-function kernel.10 The kernel parameter, g, and slack penalty, C, were tuned using a grid search over the range of 0.5–128 and 1–1,024, respectively (in increments increasing by a factor of four) with fivefold cross-validation. To account for unbalanced class sizes, sampling without replacement was used on the entire training dataset to create 30 sub-training sets, each containing the same number (one less than the size of the class with fewest samples) of cell samples per class. A classifier was trained on each of these sub-training sets to create an ensemble of classifiers. Each classifier in the ensemble produces a probability of a sample belonging to a class; therefore, for each testing sample, a class label was defined as the class with the maximum summed probability across the ensemble. Before classifier training, each sub-training set data was standardized by feature and normalized by sample, linearly dependent features were removed, and then stepwise discriminant analysis was performed to select for informative features.11 This was performed in Python 2.6.5, with SVM implementation from the LIBSVM toolbox (www.csie.ntu.edu.tw/∼cjlin/libsvm).
Results
Selection of a Mitosis Marker Suitable for Classification
To distinguish between interphase and the mitotic sub-phases prophase, prometaphase, metaphase, anaphase, cytokinesis, and telophase (Fig. 1), we chose MPM-2 phospho-epitope as a cell cycle protein marker. MPM-2 is a well-described mitotic marker antibody used in cell cycle studies that labels phospho-epitopes present on numerous hyperphosphorylated mitotic proteins.12 This redundancy of reactive proteins means that it is unlikely that labeling of mitotic cells could be lost due to experimental depletion of a single epitope-carrying protein. MPM-2 intensely labels mitotic cells from a wide variety of species ranging from mosquitoes to humans,12 indicating that the presence of the reactive epitope is an evolutionarily conserved characteristic of mitotic cells. Further, there is strong evidence that creation of MPM-2 reactive phosphoproteins is essential for entry into the mitotic state.13–18 Importantly, to our knowledge, MPM-2 has not been experimentally uncoupled from mitosis.
Fig. 1.

Example cell cycle patterns in HeLa cells. Each image contains DAPI (red) and MPM-2 (green) signal. Representative images are shown of interphase (a), prophase (b), prometaphase (c), metaphase (d), anaphase (e), cytokinesis (f), and telophase (g) in untreated HeLa cells. Treatments that block cells in prometaphase produce differing DAPI staining patterns, whereas MPM-2 staining is consistent: nocodazole (h), paclitaxel (i), ZM447439 (j, k), and monastrol (l). MPM-2, mitotic phosphoprotein monoclonal 2; DAPI, 4′,6-diamidino-2-phenylindole.
Using MPM-2 in Anaphase and Cytokinesis Recognition
Anaphase is characterized by chromosomal division. Cytokinesis is the process of cellular division, and it begins during late anaphase and completes during telophase (Fig. 1e, f). DAPI staining alone is insufficient for recognizing cells undergoing cytokinesis, and it can variably segment anaphase cells as one or two distinct nuclear objects per cell, depending upon the extent of chromatid separation. However, because MPM-2 labeling is diffuse and cytoplasmic after nuclear envelope breakdown (NEBD), we were able to segment the MPM-2 image and thereby delineate cellular boundaries of post-NEBD mitotic cells (including prometaphase, metaphase, anaphase, and cytokinesis; see A rules-based classifier that distinguishes between mitotic stages section). This was done exactly as for nuclear segmentation from the DAPI image, except that post-NEBD mitotic nuclei were used as object seed regions. By this process, cells undergoing cytokinesis were automatically segmented into two distinct MPM-2 objects, each associated with a single internal nuclear object. In contrast, precytokinetic anaphase cells were segmented as a single MPM-2 object. All nuclear objects within a single MPM-2-segmented cell were considered to belong to the same cell. Thus, for the purposes of our classification, the birth of two daughter cells from a single parent cell is considered to take place at the onset of cytokinesis.
Defining a Set of Mitosis Features
Images were automatically processed into single cell regions using the DAPI channel. A trained expert manually labeled a subset of images from each experiment using the established cell cycle markers as a supplemental reference. Separately, a commonly used set of intensity features were extracted from the DAPI and MPM-2 channels and commonly used shape features were extracted from the nucleus masks.2 This set includes the DAPI intensity per cell measurement, which has been shown to be suitable for 2N/4N analysis.19 Additionally, we defined additional DAPI and MPM-2-derived features to distinguish between sub-mitotic phases: (a) the cytoplasm-to-nucleus MPM-2 intensity, (b) the misalignment score, the degree to which a cell has aligned its chromosomes at the spindle equator, and (c) the pairing score, a measure that relates the alignment between two plates in a cell and therefore is indicative of anaphase (see Appendix).
Datasets of Cell Populations Under Different Mitotic Indices
We collected three datasets using three approaches: untreated, single thymidine block and release, and double thymidine block and release. Each dataset consists of cells that were antibody labeled for MPM-2 and counterstained with DAPI. Additionally, mitotic markers Aurora-B and tubulin were antibody labeled in some cells for further reference. For each dataset we determined the mitotic index (MI), which is the percentage of cells in mitosis, through visual analysis of the Aurora-B and tubulin markers. Unsynchronized cells have an MI of 7% (low MI) and single thymidine block; release cells have an MI of 16% (medium MI) and double thymidine block; release populations have an MI of 36% (high MI). Using the total DAPI per cell measurement, we used 2N/4N analysis to further identify population shifts in the different datasets (Fig. 2).
Fig. 2.

Separation of cells by DNA content. (a) The unsynchronized population has a mitotic index (MI) of 7%. (b) The single thymidine block and release treatment produces a 16% MI population. (c) The double thymidine block and release treatment population has an MI of 36%. Gray vertical lines in all panels represent thresholds (from left to right) separating Sub2N cells, 2N cells, 4N cells, and Super4N cells.
A Rules-Based Classifier That Distinguishes Between Mitotic Stages
We defined a rules-based classifier (Fig. 3) using features that capture observable characteristics of MPM-2 immunolabeling and DAPI staining. The first rule determines whether cells are in interphase (Fig. 1a) or mitosis, and it is predicated on the observation that MPM-2 immunolabeling in interphase is low in both the nucleus and cytoplasm.12 DNA content was used to define 2N (e.g., anaphase, cytokinesis, telophase, G1, and S) or 4N cells (e.g., S, G2, prophase, prometaphase, metaphase, and anaphase). For each individual 4N cell, we calculated the median nuclear MPM-2 channel pixel intensity. From these values, we visually determined a threshold that separated mitotic 4N cells above from interphase 4N cells below. Similarly, we calculated the median cytoplasmic MPM-2 channel pixel intensity from each individual 2N cell, and we used these values to set a threshold that separated mitotic 2N cells above from interphase 2N cells below (Appendix Fig. A3).
Fig. 3.

Decision tree for mitotic stage classification. Nodes (blank ovals) and leaves (filled ovals) represent intermediate and final decisions, respectively. T1–T5, thresholds; X, median MPM-2 pixel intensity in the nucleus; Y, median MPM-2 pixel intensity in the cytoplasm.
The second rule distinguishes cells with intact nuclei from those having undergone NEBD (Appendix Fig. A4). It has been observed that NEBD and cytoplasmic MPM-2 immunolabeling mark the prophase-to-prometaphase transition (Fig. 1c).20 Moreover, we routinely observed that MPM-2 immunolabeling is recruited back into the nucleus during telophase before reactivity was lost, presumably due to potential translocation of phosphorylated MPM-2 antigens or the kinases that phosphorylate them. With this in mind, we defined an NEBD feature to distinguish prophase and telophase (late phase) from the other sub-mitotic stages. We used the ratio of cytoplasmic to nuclear MPM-2 intensity to capture this property, as cells expressing MPM-2 without a nuclear envelope have a higher proportion of signal in the cytoplasm. From visual analysis of cell population data (Appendix Fig. A4a), we found that a ratio of 1 separates post-NEBD from non-NEBD cells. As before, we manually adjusted this threshold to give better separation of prophase and prometaphase cells.
At the next decision level, we separated cells based on their DNA content. First, we applied the MPM-2 cytoplasmic segmentation to post-NEBD cells as described above (see Using MPM-2 in anaphase and cytokinesis recognition). Then, 2N/4N analysis was performed on all cells using the total DAPI intensity per cell (Fig. 2).19 We used this to separate the non-NEBD cells into telophase (2N) and prophase (4N). For post-NEBD-positive cells, we identified 2N cells as being in cytokinesis. The thresholds to identify 2N and 4N were determined manually from the DAPI distributions (Fig. 2, Appendix Fig. A5).
The fourth rule utilizes the misalignment score to identify metaphase cells in the 4N post-NEBD population (Appendix Fig. A6). We then sorted cells based on this score, and manually chose the threshold that produced good separation between metaphase and the remaining stages. Cells that were at or below the threshold were determined to be metaphase.
The final decision rule distinguishes between anaphase and prometaphase using the pairing score (Appendix Fig. A7). As before, the threshold was manually chosen to separate the two phases.
Evaluation of Rules-Based Classifier
The classifier performed best at determining the interphase and metaphase classes (Fig. 4). Interphase sensitivity was at least 95% and precision was at least 80% across the three experiments. Metaphase sensitivity (TPR) and precision (PR) were at least 88% in all experiments. Sensitivity (also called recall) and precision are commonly used to assess classifier performance and are defined as
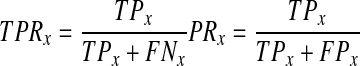 |
Fig. 4.

Performance of classifier in different cell cycle-disruptive drug treatments. Values are in percentages. Each box in the table is a separate plot of classification precision (PR) versus sensitivity (TPR) for the cell cycle class listed at the top of the corresponding column and the drug treatment listed at the left of the corresponding row. Solid symbols are rules-based classifier results, and empty symbols are SVM classifier results. Symbol shape indicates the experiment: circle, high MI; square, medium MI; triangle, low MI. Data are only shown for experiments in which there were at least five members of the corresponding manually identified ground truth class. The error bars represent 95% confidence intervals of the sensitivity/precision as determined by the Wilson Score, and the positions of the symbols themselves represent the centers of the intervals. SVM, support vector machine.
where x is the mitosis stage (or class); TP, or true positives, is the number of correct classifications within x; FP, or false positives, is the number of samples misclassified as x; and FN, or false negatives, is the number of samples incorrectly classified as x. Prometaphase classification was more variable from experiment to experiment; sensitivity ranged from 75% to 89% and precision from 60% to 84%. Anaphase sensitivity hovered around 50%, but precision was at least 84% in all experiments. Cytokinesis precision ranged from 63% to 73% and sensitivity ranged from 57% to 84%. Prophase and telophase classifications were lowest. While prophase recognition sensitivity was around 50%, precision ranged from 20% to 78%. Telophase classification maintained fairly constant precision from experiment to experiment, ranging from 50% to 67%, but ranged widely in sensitivity, with values from 3% to 56%.
Notably, most misclassifications were assigned to one of the two classes temporally adjacent to the true class, and most of these misclassifications were of cells in transition between classes that had near-threshold values. Such misclassifications were ascribed to the gradual change in patterns between some sub-mitotic phases. An exception to this rule was the low frequency confusion by the classifier of prometaphase and anaphase cells that failed the pairing score test. Another was the misclassification of clear-cut anaphase cells as cytokinesis due to the isolation of one of the segregating sister chromatid masses from the other, which often occurred due to imperfections in segmentation.
Comparison of Framework to SVM Classification
We compared our framework results to an SVM classifier (Fig. 4), which has been used in various cell cycle studies.2 The classifier was trained on a set of stepwise discriminant analysis (SDA)-selected features extracted from the images (excluding the cytoplasm-to-nucleus, misalignment, and pairing measures). We evaluated this approach by cross validation, and found that it performed best on the double thymidine block dataset, followed by the single thymidine block and then unsynchronized sets (Appendix Table A1).
We then compared the effectiveness of the SVM approach to that of the rules-based classifier on the same datasets (Fig. 4, no drug). We found that SVM performed comparably to the rules-based method in the classification of interphase cells, prophase cells, cytokinetic cells, and telophase cells, whereas the rules-based method outperformed the SVM in the classification of prometaphase, metaphase, and anaphase cells. Interestingly, in these latter three classes we observed that quality of classification by the SVM was affected by the MI of the training set, whereas the rules-based method was not. The SVM classified prometaphase and metaphase cells almost as effectively as the rules-based method for the high MI experiment, but not for the medium and low MI experiments. We also observed a greater tendency for the SVM-based method to misclassify cells to classes that were not temporally adjacent to their true class.
Robustness to Drug Treatments
Treatment of cells with mitosis-disrupting drugs can produce unusual phenotypes that may not be properly classified. To evaluate the robustness of the rules-based classifier to different treatments, we tested the framework on cells treated with cell cycle disrupting drugs (Table 1), which block cells in prometaphase with unusual morphology (Fig. 1h–l). We found that the quality of interphase and prometaphase rules-based classifications were not decreased by treatment of cells with 2 μM ZM447439, an Aurora-B kinase inhibitor21 or 100 ng/mL nocodazole, a microtubule depolymerizing agent.22 In contrast, we found that the quality of prometaphase classification by the SVM classifier decreased after treatment of cells with ZM447439 and nocodazole.
Table 1.
Performance of Classification Approaches on Different Drug Treatments in a Double Thymidine Block and Release Experiment
| Method | Class | Control | ZM447439 | Nocodazole |
|---|---|---|---|---|
| Rules | Interphase | 97/80 | 90/88 | 96/87 |
| Prometaphase | 89/84 | 96/82 | 65/82 | |
| SVM | Interphase | 80/98 | 77/95 | 75/96 |
| Prometaphase | 82/80 | 61/88 | 3/33 |
Values are sensitivity/precision, and are given in percentages.
SVM, support vector machine.
Discussion
We have defined a rules-based classification approach with several favorable characteristics for integration into HCS approaches. First, it produces classification results that are comparable to machine learning-based methods in synchronized populations. Second, as with machine learning approaches, this framework is scalable to large experiments, as the image processing routines and decisions by a trained classifier are highly reproducible. Third, and most significant, the rules framework performs similarly across different types of experiments, including asynchronous populations of cells and drug-treated cells. Removing the need to synchronize cells can simplify a cell cycle experiment and make its incorporation into HCS feasible. The final important attribute of the rules-based classifier is that when it disagrees with the manual label, it routinely assigns a label that is temporally adjacent to the correct assignment. This property may be useful in efforts to re-label data for manual annotations that may not be sufficient.
Classifier confusion with the telophase class may have arisen because the MPM-2 distribution may not reliably characterize telophase cells. Thus, it may be advantageous to re-annotate cells that have 2N DNA content and high levels of MPM-2 within the nucleus simply as late mitosis, rather than as telophase.
The analysis presented also highlights the utility of MPM-2 as a robust mitotic marker, and we envision that the knowledge-derived features from MPM-2 can be integrated into future machine learning approaches to produce more meaningful cell cycle decisions. Coupled with additional biomarkers, this enables robust high content screens that produce richer, multifaceted readouts.
Abbreviations
- DAPI
4′,6-diamidino-2-phenylindole
- DMEM
Dulbecco's modified Eagle's medium
- FBS
fetal bovine serum
- HCS
high content screening
- HTO-AurC-WT
HeLa Tet-On Aurora-C-wild type
- MI
mitotic index
- MPM-2
mitotic phosphoprotein monoclonal 2
- NEBD
nuclear envelope breakdown
- PBS
phosphate-buffered saline
- PBS-TX
PBS plus 0.1% Triton X-100
- SVM
support vector machine.
Appendix Fig. A1.

Segmentation of the binary nuclear mask from the DAPI channel image. Example images of the segmentation steps are shown and description of each step is below the image. DAPI, 4′,6-diamidino-2-phenylindole.
Appendix Fig. A2.

Additional cell segmentation steps. (a) The boundaries of the binary nuclear mask produced as described in Supplementary Figure 1 are shown overlaid in red on the DAPI channel of a sample image region. (b) The boundaries of the labeled nuclear mask produced by separation of touching nuclei (as described in the Materials and Methods section) is overlaid in red on the DAPI channel. (c) The expanded cell mask is obtained by dilating the nuclear mask in B by 20 pixels. The expanded cell mask is overlaid in green, and the nuclear mask in red, on the DAPI channel (left) and the MPM-2 channel (right). MPM-2 median pixel intensity measurements are then taken from the resulting cytoplasmic and nuclear regions to classify objects into interphase/mitosis classes and post-NEBD mitotic/non-post-NEBD mitotic classes. (d) Cells of the post-NEBD mitotic class are used as seed regions to create the post-NEBD cell mask. Post-NEBD cell mask boundaries are overlaid in green, and nuclear mask boundaries in red, on the DAPI channel (left) and MPM-2 channel (right). The post-NEBD mask is used to discriminate between cytokinetic and anaphase cells, and to recombine overly segmented post-NEBD cells. NEBD, nuclear envelope breakdown.
Appendix Fig. A3.

Separation of mitotic cells from interphase cell by MPM-2 labeling intensity. (a) All cells with 2N or 4N DNA content are plotted on a two-dimensional density plot, with median cytoplasmic MPM-2 pixel intensity on the y-axis and median nuclear MPM-2 pixel intensity on the x-axis. The frequency of cells falling in particular bin is indicated by its color, with black meaning no cells, then with increasing frequency from blue to green to yellow to red to white. (b) A portion of the same cells were manually classified into cell cycle stages, and the total cellular DAPI sum of pixel intensities for cells of each stage were plotted as on a scatterplot with the same axes as in (a), with spots color coded by stage (interphase, black; prophase, aqua; prometaphase, blue; metaphase, red; anaphase, yellow; cytokinesis, purple; telophase, olive). In both (a) and (b), red lines represent nuclear and cytoplasmic median MPM-2 pixel intensity thresholds that separate cells of the mitotic class above either threshold from cells of the interphase class below both thresholds. (c) The percentage of each manually determined cell cycle phase or mitotic stage (row headings) to fall into each automatic class (column headings) is shown.
Appendix Fig. A4.

Separation of post-NEBD cells from prophase and telophase cells by the cytoplasmic:nuclear ratio of MPM-2 labeling. (a) The cytoplasmic:nuclear ratio of median MPM-2 pixel intensities (after background subtraction as described in text) was measured for all cells of the mitotic automated class and plotted as a line histogram. (b) A portion of the same cells were manually classified into cell cycle stages, and the cytoplasmic:nuclear MPM-2 ratios for cells of each stage were plotted as line histograms as in (a), color coded by stage (prophase, aqua; prometaphase, blue; metaphase, red; anaphase, yellow; cytokinesis, purple; telophase, olive). In both (a) and (b), red vertical lines represent the threshold that separates cells of the post-NEBD class above from cells of the prophase or prometaphase class below. (c) The percentage of each manually determined cell cycle phase or mitotic stage (row headings) to fall into each automatic class (column headings) is shown.
Appendix Fig. A5.

Separation of cells by DNA content. (a) A portion of the cells shown in A were manually classified into cell cycle stages, and the total cellular DAPI sum of pixel intensities for cells of each stage were plotted as line histograms color coded by stage (interphase, black; prophase, aqua; prometaphase, blue; metaphase, red; anaphase, yellow; cytokinesis, purple; telophase, olive). Each cell cycle stage is individually scaled by normalized frequency. Red vertical lines in (a) represent thresholds (from left to right) separating Sub2N cells, 2N cells, 4N cells, and Super4N cells. (b) The percentage of each manually determined cell cycle phase or mitotic stage (row headings) to fall into each automatic class (column headings) is shown.
Appendix Fig. A6.

Calculation of the misalignment score. (a) Original DAPI channel images of an example metaphase cell and prometaphase cell. (b) DAPI image pixels are clustered into 3 brightness levels, dark (black), dim (gray), and bright (white) by k-means clustering. (c) The long axis of the bright k-means cluster object is determined to be the spindle equator and is shown overlaid in red on the original DAPI image. (d) The distance transform from the spindle equator is determined, and then squared, such that pixel intensity increases as the square of the distance from the equator. (e) The original DAPI image pixels that fall within the dim and bright k-means cluster regions are multiplied by the squared distance transform image, then normalized by dividing by the sum intensity of all the pixels in the original DAPI image falling within the dim and bright k-means cluster regions. (f) The misalignment scores for each cell are shown. Higher scores indicate poorer alignment.
Appendix Fig. A7.

Separation of metaphase cells from prometaphase and anaphase cells by determining the misalignment score. (a) The misalignment score was calculated for all post-NEBD cells with 4N DNA content and they were plotted as a line histogram. (b) A portion of the same cells were manually classified into cell cycle stages, and the misalignment scores of prometaphase, metaphase, and anaphase cells were plotted as line histograms as in (a), color coded by stage (prometaphase, blue; metaphase, red; anaphase, yellow). All stages are on the same absolute frequency scale. In both (a) and (b), red vertical lines represent the misalignment score threshold that separates the metaphase class below from cells of the prometaphase or anaphase class above. (c) The percentage of each manually determined cell cycle phase or mitotic stage (row headings) to fall into each automatic class (column headings) is shown. (d) A sample of cells from the medium MI experiment is shown in order of misalignment score. The misalignment score of each cell is in the top left of each image, and its manual classification is in the bottom left. Pm, prometaphase; M, metaphase; A, anaphase.
Appendix Table A1.
Cross-Validation of Support Vector Machine Classification on Different Treatment Types
| Unsynchronized | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |
Classifier output |
|
|
|
||||||||
| True class | Ana | Cyto | Inter | Meta | Multi-nuc | Noncell | Prom | Pro | Telo | # | TPR | PR |
| Anaphase | 6 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 9 | 0.67 | 0.55 |
| Cytokinesis | 1 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 14 | 0.79 | 0.35 |
| Interphase | 0 | 3 | 649 | 0 | 103 | 86 | 0 | 8 | 25 | 874 | 0.74 | 0.97 |
| Metaphase | 3 | 1 | 0 | 9 | 0 | 0 | 16 | 2 | 0 | 31 | 0.29 | 0.60 |
| Multi-Nuclear | 0 | 0 | 10 | 0 | 23 | 1 | 0 | 1 | 0 | 35 | 0.66 | 0.18 |
| Noncell | 0 | 1 | 3 | 0 | 0 | 12 | 0 | 0 | 1 | 17 | 0.71 | 0.11 |
| Prometaphase | 1 | 0 | 0 | 4 | 0 | 0 | 7 | 0 | 0 | 12 | 0.58 | 0.29 |
| Prophase | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 5 | 1 | 7 | 0.71 | 0.28 |
| Telophase | 0 | 14 | 5 | 0 | 0 | 3 | 0 | 2 | 12 | 36 | 0.33 | 0.29 |
| Single thymidine block and release | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |
Classifier output |
|
|
|
|||||||||
| True class | Ana | Cyto | Frag | Inter | Meta | Multi-nuc | Noncell | Prom | Pro | Telo | # | TPR | PR |
| Anaphase | 6 | 1 | 0 | 0 | 3 | 0 | 0 | 5 | 0 | 0 | 15 | 0.40 | 0.21 |
| Cytokinesis | 2 | 41 | 0 | 0 | 1 | 0 | 0 | 1 | 3 | 6 | 54 | 0.76 | 0.69 |
| Fragment | 0 | 0 | 32 | 1 | 2 | 1 | 2 | 0 | 0 | 0 | 38 | 0.84 | 0.73 |
| Interphase | 0 | 1 | 10 | 1,163 | 0 | 111 | 99 | 0 | 7 | 112 | 1,503 | 0.77 | 0.98 |
| Metaphase | 7 | 4 | 0 | 0 | 26 | 0 | 0 | 6 | 0 | 0 | 43 | 0.60 | 0.63 |
| Multi-nuclear | 1 | 1 | 0 | 9 | 1 | 100 | 0 | 3 | 0 | 10 | 125 | 0.80 | 0.46 |
| Noncell | 0 | 0 | 2 | 2 | 0 | 0 | 8 | 0 | 1 | 0 | 13 | 0.62 | 0.07 |
| Prometaphase | 12 | 0 | 0 | 0 | 8 | 1 | 0 | 28 | 7 | 0 | 56 | 0.50 | 0.62 |
| Prophase | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 15 | 4 | 21 | 0.71 | 0.36 |
| Telophase | 0 | 11 | 0 | 8 | 0 | 3 | 1 | 1 | 9 | 95 | 128 | 0.74 | 0.42 |
| Double thymidine block and release | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |
Classifier output |
|
|
|
|||||||||
| True class | Ana | Apop | Cyto | Inter | Meta | Multi-nuc | Noncell | Prom | Pro | Telo | # | TPR | PR |
| Anaphase | 24 | 0 | 5 | 0 | 0 | 1 | 0 | 7 | 0 | 0 | 37 | 0.65 | 0.63 |
| Apoptotic/Necrotic | 1 | 29 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 32 | 0.91 | 0.91 |
| Cytokinesis | 5 | 0 | 50 | 0 | 0 | 2 | 0 | 0 | 0 | 13 | 70 | 0.71 | 0.77 |
| Interphase | 0 | 1 | 0 | 415 | 0 | 12 | 2 | 0 | 36 | 37 | 503 | 0.83 | 0.98 |
| Metaphase | 2 | 0 | 0 | 0 | 42 | 0 | 0 | 2 | 0 | 0 | 46 | 0.91 | 0.89 |
| Multi-nuclear | 1 | 1 | 0 | 2 | 0 | 54 | 0 | 0 | 3 | 0 | 61 | 0.89 | 0.74 |
| Noncell | 0 | 1 | 0 | 0 | 0 | 0 | 39 | 0 | 0 | 0 | 40 | 0.98 | 0.91 |
| Prometaphase | 5 | 0 | 0 | 0 | 5 | 0 | 1 | 71 | 2 | 0 | 84 | 0.85 | 0.82 |
| Prophase | 0 | 0 | 0 | 4 | 0 | 2 | 0 | 7 | 38 | 0 | 51 | 0.75 | 0.48 |
| Telophase | 0 | 0 | 10 | 4 | 0 | 1 | 0 | 0 | 1 | 53 | 69 | 0.77 | 0.51 |
Numbers in confusion matrices show the number of cells counted as a particular class by the classifier. # represents the total number of cells hand-scored as belonging to that class. Specificity (TPR) and precision (PR) are represented as ratios.
Defining the Misalignment Score
To assist in M-phase classification, we developed a measurement, called the misalignment score, designed to indicate the degree to which a cell has aligned its chromosomes at the spindle equator. Among the postnuclear envelope breakdown (NEBD) cell class, a threshold misalignment score can then be used to separate metaphase cells with low misalignment from prometaphase, and anaphase cells with high misalignment. The image processing steps for obtaining the misalignment score are illustrated in Appendix Fig. A8. The misalignment score represents the degree to which 4′,6-diamidino-2-phenylindole (DAPI) staining intensity is distributed about a line that serves as an estimate of the metaphase plate long axis, and is calculated as
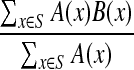 |
Appendix Fig. A8.

Image processing steps for calculation of pairing score. (a) Crop each nonmetaphase post-NEBD cell from the total DAPI image and mask with the post-NEBD cell mask. The DAPI image of an example early anaphase cell and its associated nuclear mask boundary (green) is shown. (b) Segment the masked single-cell DAPI image by k-means clustering into 4 brightness levels. (c) Threshold the k-means image at each of the 4 brightness levels and perform a binary open algorithm on each thresholded image to eliminate small isolated regions (i.e., one or two pixels). Continue if a total of two distinct objects are obtained at any threshold level. Otherwise, set pairing score to 0. (d) Label the two binary objects. (e) Invert the single-cell DAPI image to create “intensity basins” where the chromosomes are located, then set the region outside of post-NEBD cell mask boundary to zero intensity. (f) Perform “watershed from markers” algorithm on (f) using the two labeled objects (red) as the marker and the extra-cellular space as the background marker. This produces two objects which represent the extent of the intensity basins in the inverted DAPI image (white and gray). (g) Calculate sum of DAPI staining intensity within each resulting region boundary (green). If each region contains 2C DNA content, then continue to the next step. Otherwise, set pairing score to 0. (h) and (i) Calculate DAPI equality of the two regions, and parallelness and symmetry of the two objects, then calculate the pairing score from these values.
where A(x) is the pixel intensity of pixel x in the DAPI image and B(x) is the perpendicular distance from the pixel x to the long axis of the metaphase plate. S is the set of all pixels within a given radius of the centroid of the nuclear object, with each pixel receiving a value proportional to the DAPI fluorescence and to the square of the distance from the metaphase plate. The sum of all pixel scores is calculated and then normalized by dividing by the sum of all DAPI pixel intensities for the cell. Cells with poorly aligned chromosomes will have a higher score than cells with highly aligned chromosomes. To estimate the location of the metaphase plate, a single cell DAPI image was first isolated by masking with its cellular mask, and k-means clustering of pixel intensities was performed using three levels of brightness: dim, medium, and bright. The long axis line of the bright cluster region was used as a proxy for the metaphase plate long axis. This is useful because in cells with partial alignment of chromosomes, the regions containing overlapping, aligned chromosomes will be brighter than the regions containing dispersed misaligned chromosomes. The aligned chromosomes will fall into the bright cluster, and misaligned chromosomes will fall into the medium cluster and be ignored when determining the location and orientation of the metaphase plate.
Defining the Pairing Score
We developed a measurement based on symmetry, called the pairing score, designed to define the likelihood that a cell is in anaphase versus prometaphase. To calculate the pairing score, each nonmetaphase post-NEBD cell is scanned for paired sub-regions (Appendix Fig. A9). To do so, each cell is cropped from the whole field using the DAPI channel and masked by its post-NEBD mask. K-means clustering is performed on the pixel intensity values to segment the masked cell DAPI image into four intensity levels. The clustered image is then thresholded at each intensity value. If the number of resulting objects at any of the threshold levels is equal to two, then the cell is further processed. If not, the cell receives a pairing score of 0 and is not further processed. If a cell contains two objects after thresholding, then the masked cell DAPI image is inverted and watershed segmentation is performed using the two objects as water sources. DAPI sum of pixel intensities is calculated for each of the two resulting watershed regions. If either of the two regions falls outside of 2N DNA, then the cell is given a score of zero and not further processed. If both watershed regions have 2N DNA content, then three values are calculated. First, the DAPI equality is equal to the difference in DAPI sum of pixel intensities of the two watershed regions, divided by the larger of the two values. Second, a parallel quotient is calculated, equal to the 1 − a/π, where a is the angle between the long axes of the two k-means objects (in radians). Third, the symmetry is equal to
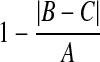 |
Appendix Fig. A9.

Separation of anaphase cells from prometaphase cells by pairing score. (a) For the high MI experiment, the DAPI equality, parallelness, and symmetry were calculated for each cell that was both automatically classified as nonmetaphase post-NEBD and manually classified as prometaphase or metaphase, and each of these three measurements was plotted in a separate line histogram, color coded by stage (prometaphase, blue; anaphase, yellow). (b) The pairing score was computed for the same cell types in all three experiments and plotted on histograms color coded by stage as in (a). Both stages are on the same absolute frequency scale. In both (a) and (b), red vertical lines represent the pairing score threshold that separates the prometaphase class below from the anaphase class above. (c) The percentage of each manually determined cell cycle phase or mitotic stage (row headings) to fall into each automatic class (column headings) is shown. (d) A sample of cells from the high MI experiment is shown in order of pairing score. The pairing score of each cell is in the top left of each image, and its manual classification is in the bottom left. Pm, prometaphase; A, anaphase.
where A is the centroid-to-centroid distance of the two k-means objects, and B and C are the distances from each centroid to the intersection of the long axes of the two objects. A value of one corresponds to perfect DAPI equality, parallel objects, or symmetry, whereas less perfect DAPI equality or symmetry will have values between zero and one. The pairing score equals the product of these three values, and also ranges between zero and one.
Acknowledgments
S.D.S., R.M.H., and B.R.B. were funded by the Huffington Foundation. J.Y.N. was supported by NIH K12DK083014 (PI, D.J. Lamb). A.T.S. was supported by the Medical Scientist Training Program (PI, J.R. Rosen). M.A.M. was supported by the ARRA Grand Opportunity award (1RC2ES018789-01) and John S. Dunn Foundation. Additional imaging resource support was provided by the John S. Dunn Gulf Coast Consortium for Chemical Genomics Screening Grant Program (PIs, P.J. Davis, University of Texas Health Science Center and M.A.M.), the Dan L. Duncan Cancer Center (P30 CA125123, PI, C.K. Osborne), the Center for Reproductive Biology (U54 HD007495, PI, B.W. O'Malley), and the Center for Digestive Diseases (P30 DK56338, PI, M.K. Estes). The authors thank T.-A.T. Nguyen and S.M. Hartig for critical review of the manuscript, I.P. Uray for performing high-throughput microscopy, D.R. Nash for expert analysis of cellular images, and T.J. Moran (Accelrys) and J.H. Price (Vala Sciences) for longstanding support in automated bioimaging techniques.
Disclosure Statement
No competing financial interests exist.
References
- 1.Katayama H. Sen S. Aurora kinase inhibitors as anticancer molecules. Biochim Biophys Acta. 2010;1799:829–839. doi: 10.1016/j.bbagrm.2010.09.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Tao CY. Hoyt J. Feng Y. A support vector machine classifier for recognizing mitotic subphases using high-content screening data. J Biomol Screen. 2007;12:490–496. doi: 10.1177/1087057107300707. [DOI] [PubMed] [Google Scholar]
- 3.Straight AF. Cheung A. Limouze J. Chen I. Westwood NJ. Sellers JR. Mitchison TJ. Dissecting temporal and spatial control of cytokinesis with a myosin II inhibitor. Science. 2003;299:1743–1747. doi: 10.1126/science.1081412. [DOI] [PubMed] [Google Scholar]
- 4.Harder N. Mora-Bermúdez F. Godinez WJ. Wünsche A. Eils R. Ellenberg J. Rohr K. Automatic analysis of dividing cells in live cell movies to detect mitotic delays and correlate phenotypes in time. Genome Res. 2009;19:2113–2124. doi: 10.1101/gr.092494.109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Neumann B. Walter T. Hériché J-K. Bulkescher J. Erfle H. Conrad C. Rogers P. Poser I. Held M. Liebel U. Cetin C. Sieckmann F. Pau G. Kabbe R. Wünsche A. Satagopam V. Schmitz MHA. Chapuis C. Gerlich DW. Schneider R. Eils R. Huber W. Peters J-M. Hyman AA. Durbin R. Pepperkok R. Ellenberg J. Phenotypic profiling of the human genome by time-lapse microscopy reveals cell division genes. Nature. 2010;464:721–727. doi: 10.1038/nature08869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Chen X. Zhou X. Wong STC. Automated segmentation, classification, and tracking of cancer cell nuclei in time-lapse microscopy. Biomed Eng IEEE Trans. 2006;53:762–766. doi: 10.1109/TBME.2006.870201. [DOI] [PubMed] [Google Scholar]
- 7.Walter T. Held M. Neumann B. Hériché J-K. Conrad C. Pepperkok R. Ellenberg J. Automatic identification and clustering of chromosome phenotypes in a genome wide RNAi screen by time-lapse imaging. J Struct Biol. 2010;170:1–9. doi: 10.1016/j.jsb.2009.10.004. [DOI] [PubMed] [Google Scholar]
- 8.Sasai K. Katayama H. Stenoien DL. Fujii S. Honda R. Kimura M. Okano Y. Tatsuka M. Suzuki F. Nigg EA. Earnshaw WC. Brinkley WR. Sen S. Aurora-C kinase is a novel chromosomal passenger protein that can complement Aurora-B kinase function in mitotic cells. Cell Motil Cytoskeleton. 2004;59:249–263. doi: 10.1002/cm.20039. [DOI] [PubMed] [Google Scholar]
- 9.Slattery SD. Mancini MA. Brinkley BR. Hall RM. Aurora-C kinase supports mitotic progression in the absence of Aurora-B. Cell Cycle. 2009;8:2984–2994. [PubMed] [Google Scholar]
- 10.Cortes C. Vapnik V. Support-vector networks. Machine Learn. 1995;20:273–297. [Google Scholar]
- 11.Jennrich RI. Stepwise discriminant analysis. Stat Methods Digit Comput. 1977;3:76–96. [Google Scholar]
- 12.Davis FM. Tsao TY. Fowler SK. Rao PN. Monoclonal antibodies to mitotic cells. Proc Natl Acad Sci USA. 1983;80:2926–2930. doi: 10.1073/pnas.80.10.2926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kuang J. Zhao J. Wright DA. Saunders GF. Rao PN. Mitosis-specific monoclonal antibody MPM-2 inhibits Xenopus oocyte maturation and depletes maturation-promoting activity. Proc Natl Acad Sci USA. 1989;86:4982–4986. doi: 10.1073/pnas.86.13.4982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Mueller PR. Coleman TR. Dunphy WG. Cell cycle regulation of a Xenopus Wee1-like kinase. Mol Biol Cell. 1995;6:119–134. doi: 10.1091/mbc.6.1.119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Mueller PR. Coleman TR. Kumagai A. Dunphy WG. Myt1: a membrane-associated inhibitory kinase that phosphorylates Cdc2 on both threonine-14 and tyrosine-15. Science. 1995;270:86–90. doi: 10.1126/science.270.5233.86. [DOI] [PubMed] [Google Scholar]
- 16.Kuang J. Ashorn CL. Gonzalez-Kuyvenhoven M. Penkala JE. cdc25 is one of the MPM-2 antigens involved in the activation of maturation-promoting factor. Mol Biol Cell. 1994;5:135–145. doi: 10.1091/mbc.5.2.135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Taagepera S. Rao PN. Drake FH. Gorbsky GJ. DNA topoisomerase II alpha is the major chromosome protein recognized by the mitotic phosphoprotein antibody MPM-2. Proc Natl Acad Sci USA. 1993;90:8407–8411. doi: 10.1073/pnas.90.18.8407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Renzi L. Gersch MS. Campbell MS. Wu L. Osmani SA. Gorbsky GJ. MPM-2 antibody-reactive phosphorylations can be created in detergent-extracted cells by kinetochore-bound and soluble kinases. J Cell Sci. 1997;110:2013–2025. doi: 10.1242/jcs.110.17.2013. [DOI] [PubMed] [Google Scholar]
- 19.Luther E. Kamentsky LA. Resolution of mitotic cells using laser scanning cytometry. Cytometry. 1996;23:272–278. doi: 10.1002/(SICI)1097-0320(19960401)23:4<272::AID-CYTO2>3.0.CO;2-J. [DOI] [PubMed] [Google Scholar]
- 20.Vandre DD. Davis FM. Rao PN. Borisy GG. Phosphoproteins are components of mitotic microtubule organizing centers. Proc Natl Acad Sci USA. 1984;81:4439–4443. doi: 10.1073/pnas.81.14.4439. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ditchfield C. Johnson VL. Tighe A. Ellston R. Haworth C. Johnson T. Mortlock A. Keen N. Taylor SS. Aurora B couples chromosome alignment with anaphase by targeting BubR1, Mad2, and Cenp-E to kinetochores. J Cell Biol. 2003;161:267–280. doi: 10.1083/jcb.200208091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Rieder CL. Palazzo RE. Colcemid and the mitotic cycle. J Cell Sci. 1992;102:387–392. doi: 10.1242/jcs.102.3.387. [DOI] [PubMed] [Google Scholar]