

Abstract
A growing body of evidence suggests that semantic access is obligatory. Several studies have demonstrated that brain activity associated with semantic processing, measured in the N400 component of the event-related brain potential (ERP), is elicited even by meaningless, orthographically illegal strings, suggesting that semantic access is not gated by lexicality. However, the downstream consequences of that activity vary by item type, exemplified by the typical finding that N400 activity is reduced by repetition for words and pronounceable nonwords but not for illegal strings. We propose that this lack of repetition effect for illegal strings is caused not by lack of contact with semantics, but by the unrefined nature of that contact under conditions in which illegal strings can be readily categorised as task-irrelevant. To test this, we collected ERPs from participants performing a modified Lexical Decision Task, in which the presence of orthographically illegal acronyms rendered meaningless illegal strings more difficult lures than normal. Confirming our hypothesis, under these conditions illegal strings elicited robust N400 repetition effects, quantitatively and qualitatively similar to those elicited by words, pseudowords, and acronyms.
Keywords: N400, Semantic access, Lexical decision, ERPs
INTRODUCTION
Within a single language, only some strings of letters are deemed meaningful; in English, for example, the string DOG is meaningful but the string DTG is not. It might seem intuitive, then, that only strings known to be associated with a meaning are actually processed for semantics, and that the clearly non-meaningful strings are “filtered out” prior to semantic access. This intuition about how visual word recognition proceeds is formalised in models that employ staged processing, and has been influential both classically and contemporarily (e.g., classically: Forster, 1999; Forster & Davis, 1984; Forster & Veres, 1998; more contemporarily: Borowsky & Besner, 2006). Under the Entry Opening Model of Forster and colleagues (e.g., Forster & Davis, 1984), for example, the semantics corresponding to an input cannot be retrieved until that input has been matched with a lexical entry, an explicit, internal representation of a single wordform*this constitutes semantic staging. Thus, nonwords, which are postulated not to have lexical entries, can never make it past the lexical lookup process to semantics. The existence of a lexical level of representation is thus also a typical property of staged theories, as without it there is no clear basis for determining whether an input is eligible for semantic processing (or for making lexical decisions; see Forster & Hector, 2002).
The strongly staged view is moderated by findings from the event-related potential (ERP) literature showing that word-like nonwords (pronounceable pseudowords, such as GORK) elicit brain potentials*in particular, the N400 component of the ERP* that have been shown to be functionally specific markers of semantic processing (e.g., Deacon, Dynowska, Ritter, & Grose-Fifer, 2004; Rugg & Nagy, 1987; see Kutas and Federmeier, in press, for a review of the N400 literature). These results suggest a modification of strongly staged views wherein strings that are similar to items with lexical entries can accumulate evidence for the entry or entries that they are similar to and thereby allow the semantics of those entries to be accessed. The metric for “similarity” is often orthographic regularity (Deacon et al., 2004; Rugg & Nagy, 1987).
A natural extension of the idea that weak staging may be better able to account for the N400 nonword data than strong staging is to question whether staging is necessary at all. Indeed, an alternative theoretical framework exists in which all inputs are eligible to make contact with semantics, and, consequently, there is no need for a formal lexical level of representation. This theoretical stance is instantiated in models of reading from the Parallel Distributed Processing (PDP) tradition (e.g., Harm & Seidenberg, 2004; Plaut, McClelland, Seidenberg, & Patterson, 1996). Because information flow is cascaded in such models, the evidence for a particular semantics stemming from a particular input can cascade forward from orthography to semantics for every input, regardless of whether that input is actually a word or not. The explanation in a PDP framework for why nonwords elicit semantic effects is therefore actually quite similar to that for a staged framework: when presented with a particular input, the semantics of items similar to that input will become activated. However, because there is no staging at all in PDP models, there is nothing to prevent any input from contacting at least some semantics, regardless of its orthographic or lexical properties.
Inspired by the PDP approach, we have recently argued on the basis of several ERP studies that semantic access is an obligatory process, which is engaged even by meaningless, orthographically illegal letter strings (Laszlo & Fedemeier, 2008, 2009, 2011). This obligatory-semantics view is based on a series of findings demonstrating that, both in unconnected text (Laszlo & Federmeier, 2011) and in sentences (Laszlo & Federmeier, 2008, 2009), the N400 component can be elicited not only by pronounceable pseudowords but also by illegal strings (e.g., consonant strings, XFQ), with the same time course and distribution as N400s elicited by words. For example, illegal strings and words show precisely the same effects of sentence congruity (Laszlo &Federmeier, 2008) and of orthographic relationship to an expected sentence completion (Laszlo & Federmeier, 2009).
One difference between the N400 activity elicited by words and illegal strings is that N400s to illegal strings tend to be notably more positive than those to words* explaining, in part, why many past ERP studies that employed such strings did not observe marked N400 activity and therefore concluded that illegal strings do not engage semantic access processes (e.g., Rugg & Nagy, 1987). However, we have shown that this difference is not a categorical one but is instead driven by the fact that illegal strings have, on average, much lower orthographic neighbourhood size (operationalised using Coltheart’s N, the number of words that can be made by changing one letter of a target item). In fact, the N400 response to orthographically illegal strings varies with orthographic neighbourhood size in precisely the same way that responses to words do (Laszlo & Federmeier, 2011): high N illegals (e.g., MPD) elicit larger N400s than low N illegals (e.g., KHS), just as high N words (e.g., BAT) elicit larger N400s than low N words (e.g., SKI). Indeed, in an item level regression analysis (Laszlo & Federmeier, 2011), we have shown that, for strings presented in lists, the function relating N to N400 mean amplitude is indistinguishable for nonlexical items (illegal strings and pseudowords) and lexical items (words and acronyms). Thus, it is not the case that N400s are either present or absent in a manner determined by lexical status (as would be suggested by strongly staged theories) or even by orthographic regularity. Rather, the data suggest that the amount of N400 activity elicited by a given string lies along a continuum and is interactively determined by a variety of lexical variables, such as frequency, orthographic neighbourhood size, and number of lexical associates (Laszlo & Federmeier, 2011)—an account more consonant with weakly staged or fully cascaded theories.
Although these data indicate that illegal strings, like words, elicit N400 activity (and, by inference, make contact with semantics) whenever they are encountered—in contrast to predictions of strongly staged views—it is nevertheless also the case that strikingly different patterns of N400 effects can be observed in response to words and illegal strings across tasks. As mentioned above, similar N400 effect patterns have been reported for illegal strings and words when these are embedded as completions of highly constraining sentences. For instance, N400 activity is reduced (to the same degree) for illegal strings and words that are orthographic neighbours of an expected sentence completion (Laszlo & Federmeier, 2009). However, in other tasks, N400 effects are not identical for words and illegal strings. When embedded in a list of unconnected text, for example, words elicit large N400 repetition effects (a reduction in N400 amplitude for a second presentation shortly following a first), but illegal strings typically elicit none (e.g., Laszlo & Federmeier, 2007; Rugg & Nagy, 1987). The lack of repetition effect for illegal strings is particularly striking given that pseudowords (which are similarly meaningless) and acronyms (which are similarly orthographically illegal) both do elicit repetition effects (Laszlo & Federmeier, 2007).
The fact that illegal strings have not been found to elicit N400 repetition effects was unsurprising on the strong staging assumption that such inputs do not engage semantic processing at all. However, given growing evidence that illegal strings do routinely elicit N400 activity and that N400 effects are obtained for illegal strings under some conditions, the lack of a repetition effect for these items becomes notable. Of course, the possibility that all strings make contact with semantics does not mean that the outcome of semantic analysis will be the same for all input types. Indeed, given that people can easily categorise strings as meaningful or not, it must be the case that at some point theprocessing of items with and without known meanings diverges. One question, then, is when and how does this processing diverge, and under what circumstances?
An obvious difference between the circumstances in which N400 modulations have and have not been observed for illegal strings is the presence of context. Illegal strings in sentences (such as those in Laszlo & Federmeier, 2008, 2009) may benefit from the contextual semantics that those sentences provide, which can essentially be imputed onto unfamiliar sentence completions. In fact, we have suggested that assigning contextual semantics to unfamiliar items may be an adaptive feature of obligatorysemantics, allowing the learning of new vocabulary from context. Obligatory semantic processing obviates the need for the system to recognise that it does not know what an input means in order to launch some sort of word-learning mechanism, and instead ensures that unfamiliar items will always be assigned a meaning that is consonant with whatever context they were encountered in. In fact, prominent models of the acquisition of semantic features (e.g., Latent Semantic Analysis, Landauer & Dumais, 1997; Hyperspace Analogue to Language, Lund & Burgess, 1996) behave in precisely this way—assigning semantic features to an input based on its co-occurrence with contextually relevant items.
In contrast, the contextual semantics available when an illegal string is encountered in a list of unconnected text (where repetition effects are typically measured; e.g., Laszlo & Federmeier, 2007) is too incoherent to result in the successful imputation of any particular semantics onto the novel input. This, then, could at least partially explain why illegal strings have been found to elicit N400 effects in sentences but not in word lists. However, the absence of a learned meaning combined with absence of contextual semantics is not sufficient to explain why illegal strings do not elicit repetition effects, since pseudowords in lists do produce such effects (Laszlo & Federmeier, 2007; Rugg & Nagy, 1987). Pseudoword repetition effects are typically interpreted as being the result of the activation of semantic features associated with items similar to the pseudoword (e.g., the activation of semantic features of FORK and PORK in response to GORK; Deacon et al., 2004; Laszlo & Federmeier, 2007; Rugg & Nagy, 1987)—this is true for both weakly staged and fully cascaded models. Illegal strings are indeed similar to fewer known items; in Laszlo and Federmeier (2007), for example, pseudowords had an average neighbourhood size of 10.0 whereas illegal strings had an average neighbourhood size of 1.14. However, whether more facilitation would be expected for re-retrieval of an item with many, diverse associations or one with only a few associations is unclear. In at least some circumstances, it is known that having many neighbours can make processing of an item more difficult—for example, lexical decision accuracies are often lower to high N than low N pseudowords (e.g., Coltheart, Davelaar, Jonasson, & Besner, 1977). Based on this sort of finding, one might have predicted that activating the many neighbours of high N pseudowords would create deficits in processing on subsequent presentations, not facilitation. Given that, on some accounts, pseudowords might have been expected to fare more poorly with repetition than illegal strings, it is especially interesting to attempt to identify other factors (besides N alone) that might be participating in creating differential repetition effects for the two item types.
Another difference between pseudowords and illegal strings is the role that they play in the context of the typical experimental task in ERP studies with unconnected text. These tasks have generally involved some kind of lexical decision (e.g., Rugg & Nagy, 1987) or semantic categorisation judgment (e.g., Laszlo & Federmeier, 2007). In such tasks, pseudowords are much more competitive lures for the target items (e.g., words or names) than illegal strings. For example, in our own semantic categorisationtask, wherein participants were asked to identify proper English first names, a pseudoword like KOF is more difficult to reject as a name than an illegal string of letters like NHK. Task demands, therefore, may require that some stimulus types (e.g., pseudowords) command more attention or are processed more extensively than others (e.g., illegal strings), which, in turn, may affect how or how much those items are processed on repetition. That is, although the emerging data strongly suggest that all orthographic inputs always engage semantic processing to some extent, the degree to which effects of that processing will be observed when an item is repeated may depend on how fully or attentively stimuli are processed, as a function of task demands.
If it is, in fact, task demands—not inherent differences in the representation or processing of different item types—that determine whether repetition effects will be observed, then there must be task circumstances under which even meaningless, illegal letter strings in unconnected text can be shown to elicit repetition effects. Therefore, in designing the present experiment, we set out to find just such circumstances. Since our hypothesis was that in previous tasks pseudowords have been more competitive lures than illegal strings, we attempted to create a situation in which pseudowords and illegal strings were equally good lures, and, thus, would presumably have to be attended and processed to a similar extent. As it is well known that in the lexical decision task (LDT), items that are more similar to words (the “target” items) are more difficult to process (e.g., Ratcliff, Gomez, & McKoon, 2004; Wagenmakers et al., 2004), we chose to employ a modified LDT wherein some of the target items were orthographically very similar to corresponding illegal string lures. Specifically, we presented participants with words, pseudowords, and illegal strings (as is typical) but also with orthographically illegal but highly familiar acronyms (e.g., VCR, AAA). Thus, our task differed from the “classic” LDT, which includes only words and nonwords, by including both orthographically legal and illegal items that are meaningful (words and acronyms) as well as legal and illegal items that are not meaningful (pronounceable pseudowords and illegal strings), and, as fillers, proper names. Participants were required to give the same response for words and acronyms (i.e., indicate that both were familiar and meaningful). In this scenario, just as high N pseudowords are difficult foils for words, illegal strings are difficult foils for acronyms, as rough orthographic characteristics alone (i.e., the lack of a central vowel or the lack of a consonant, bigram frequency) cannot discriminate an illegal string from an acronym in this set of items.
We predicted that if easy rejection of illegal strings as task-irrelevant in past studies of list reading caused the lack of N400 repetition effects, then the more extensive processing necessary to discriminate illegals from acronyms might allow robust N400 repetition effects to illegal strings to emerge in this context, even in the absence of contextual semantics. To make a strong test of this prediction, we used exactly the same items as those that, when used in a previous study with a semantic categorisation task (Laszlo & Federmeier, 2011), elicited negligible N400 repetition effects. Thus, any N400 effects we may observe here must necessarily be a function of task, not of item. To enable examination of repetition effects, we repeated all critical items (words, pseudowords, acronyms, and illegal strings) at an inter-item lag of 0, 2, or 3. If illegal strings are processed more extensively when first presented in this variant of the LDT, processing of the same items on subsequent presentations should benefit in a way it does not when illegal strings are more easily dismissed. Correspondingly, we would then expect to find similar N400 repetition effects for illegal items as for pseudowords (and words and acronyms), instead of the item type interaction that has been reported in the past (e.g., Deacon et al., 2004; Laszlo & Federmeier, 2007; Rugg & Nagy, 1987).
METHODS
Participants
Data were analysed from 24 participants (13 female, age range 18 22 yeras, mean age 19 years).1 Data from two additional participants were discarded due to unsatisfactory levels of ocular artifact. All participants were right-handed, monolingual speakers of English with normal or corrected-to-normal vision and no history of neurological disease or defect. Participants were students at the University of Illinois. The experimental protocol was approved by the Internal Review Board of the University of Illinois, and all participants were compensated with course credit.
Stimuli
Critical stimuli were identical to those used in Laszlo and Federmeier (2011). They consisted of 75 each words (e.g., HAT, MAP), pseudowords (e.g., DAWK, KAK), meaningless, illegal strings (e.g., CKL, KKB), and familiar but orthographically illegal acronyms (e.g., VCR, AAA). Additionally, 150 common proper English first names (e.g., SARA, KARA) were used as fillers. All items were between three and five letters long (mean 3.19). Illegal strings and acronyms were composed of all consonants or all vowels.
Table 1 displays mean lexical characteristics of each critical item type (i.e., length, written frequency, and N—the three lexical variables known to account for the most variance in word reading latency; Spieler & Balota, 1997), along with examples. Written frequency was estimated as the logarithm of an item’s token count in the Wall Street Journal Corpus (Marcus, Santorini, & Marcinkiewicz, 1993). Orthographic neighbourhood size was computed as the total number of words that could be formed by replacing one letter of a target item, as indicated by the Medical College of Wisconsin Orthographic Wordform Database (Medler & Binder, 2005).
TABLE 1.
Selected lexical characteristics: N was estimated from the Medical College of Wisconsin Orthographic Wordform Database (Medler & Binder, 2005). All frequency estimates were drawn from the Wall Street Journal Corpus (Marcus et al., 1993)
| Item type | Examples | Length | Log written frequency |
N |
|---|---|---|---|---|
| Word | HAT, MAP | 3.2 | 2.39 | 12.99 |
| Pseudoword | DAWK, KAK | 3.2 | – | 1.04 |
| Acronym | VCR, AAA | 3.2 | 0.96 | 1.93 |
| Illegal string | CKL, KKB | 3.2 | – | 2.4 |
Critical experimental items (words, pseudowords, acronyms, and illegal strings) were each repeated one time at a lag of 0, 2, or 3 intervening items, allowing us to examine N400 repetition effects. Each level of repetition lag occurred an equal number of times both within and across item types. Correct responses to the critical items in the modified LDT were “yes” for words and acronyms and “no” for illegal strings and pseudowords. Incorrect responses were not included in averaged ERPs. The experiment included 750 trials (2 × 300 critical items + 150 proper name fillers). These 750 trials were broken up into 5 blocks of 150 trials with rest breaks between each block. A random selection of 24 of the 120 possible permutations of 5 blocks was presented (one different random permutation to each participant).
Procedure
Participants were seated 100 cm away from a computer monitor and instructed that their task was to determine whether the series of letter strings they were about to be presented was or was not “familiar and meaningful”,2 and to minimise blinks and eye movements except during a blink interval indicated on the screen by the presence of a white cross. After a demonstration of trial structure and examples of the correct response to be paired with each of the critical item types, participants were presented with a short block of practice trials consisting of items similar to those in the experiment proper. Behavioural responses were monitored during the practice block, and participants were given feedback about their performance and additional instruction, if necessary, before the beginning of the experimental blocks.
In both the practice and experimental blocks, a fixation arrow was continuously present in the centre of the screen. Participants were instructed to keep their eyes on the fixation arrow as much as possible. Stimuli were presented one at a time in white directly above the fixation arrow on the black background of a 22-inch CRT computer monitor with resolution 640 480. Trial structure was as follows: 500 ms warning stimulus (red cross above the fixation arrow), 500 ms stimulus presentation, 1,000 ms response interval (fixation arrow present only), 1,000 ms blink interval (white cross above the fixation arrow). The stimulus presentation control scripts (and thus stimulus timing and order and all presentation parameters) were identical to those used in Laszlo and Federmeier (2011). Thus, the only difference between the experiments was the task—which, in Laszlo and Federmeier (2011) was to indicate whether each item in the stream of text was a common English proper name.
Electroencephalogram (EEG) recording
EEG was recorded from 6 Ag/AgCl electrodes embedded in an electrocap. We sampled from middle prefrontal, middle parietal, middle central, left middle central, right middle central, and middle occipital electrode sites. We used this reduced electrode montage because we were interested in comparing results across tasks and studies, so wherever possible we used exactly the same setup as in Laszlo and Federmeier (2011). In that study, the same reduced electrode montage was used to permit the collection of data from a large number of participants (N = 120). Since the hypotheses in both Laszlo and Federmeier (2011) and the present study revolve around the N400 and Late Positive Complex (LPC) components, which are both maximal at centralposterior channels, even this reduced montage provides ample coverage of the sites where the expected effects should be largest.
All EEG electrodes were referenced online to the left mastoid process and digitally re-referenced offline to the average of the left and right mastoids. The electrooculogram (EOG) was recorded using a bipolar montage of electrodes placed at the outer canthi of the left and right eyes; blinks were monitored with an electrode at the suborbital ridge. EEG and EOG were recorded with a bandpass of 0.02 100 Hz, and sampled at a rate of 250 Hz with a gain of 10,000 × . All electrode impedances were kept below 2.0 kω. ERPs were computed by averaging the EEG at each electrode timelocked to the onset of each trial for each critical item type for each presentation (resulting in, for example, averaged ERPs to words on the first presentation). Trials containing eye movement or drift artifact were rejected with a threshold individualised to each participant by inspection of that participant’s raw waveforms, and blinks were corrected using a procedure described by Dale (1994). Artifact rejection resulted in an average loss of 5% of trials per participant. All ERPs consisted of a 100 ms prestimulus baseline and continued for 920 ms after stimulus onset. Measurement of ERP mean amplitude was conducted on data digitally filtered off-line with a bandpass of 0.2–20 Hz. EEG recording and postprocessing procedures were again identical to those in Laszlo and Federmeier (2011).
RESULTS
Behaviour
Accuracy in the modified LDT for each critical item type on each presentation is displayed in Table 2. A two-way Analysis of Variance (ANOVA) with factors of item type (word, pseudoword, acronym, or illegal string) and presentation (first or second) revealed a main effect of item type, F(3, 184) = 17.2, p<.0001, and a main effect of presentation, F(1, 184) = 8.11, p = .005, but no interaction between the two, F(3, 184) = 1.43, p =.236. As shown in Table 2, responses to words were most accurate, then illegal strings, then pseudowords, then acronyms, and this was true on both first and second presentation. As also shown in Table 2, the main effect of repetition was driven by the fact that responses to all item types—especially words and acronyms— were more accurate on second presentation. Most importantly, the overall high level of behavioural accuracy indicates that participants were able to successfully perform the modified LDT.
TABLE 2.
Accuracy in the lexical decision task: accuracy of behavioural response for each critical item type on each of two presentations
| Item type | First presentation | Second presentation |
|---|---|---|
| Word | 0.88 | 0.94 |
| Pseudoword | 0.80 | 0.82 |
| Acronym | 0.67 | 0.78 |
| Illegal string | 0.85 | 0.86 |
Event-related potentials
Three components were of interest: the P2, N400, and LPC. The N400 was of primary interest, but given that meaningful and meaningless item types were differentiated in behaviour (as expected), we were also interested in examining later components for ERP differences corresponding to the behavioural differences, as well as looking for indications of form-based facilitations with repetition, which have been reported on the P2 (e.g., Evans & Federmeier, 2007; Misra & Holcomb, 2003). All components were measured as the mean amplitude of participant average waveforms elicited by each of the four critical item types (word, pseudoword, acronym, and illegal string) across all six EEG channels over the time window of interest, relative to a 100 ms prestimulus baseline. The P2 was measured from 175 to 225 ms, the N400 from 300 to 500 ms, and the LPC from 600 to 900 ms. In what follows, main effects of electrode are not reported, as they were of no theoretical significance. All ERP ANOVAs utilise a repeated measures design and have had their degrees of freedom adjusted by the Greenhouse-Geisser correction for violation of the assumption of sphericity.
N400 repetition effects
We began by affirming that in this study, as in all others that we are aware of, words, pseudowords, and familiar acronyms elicited N400 repetition effects. To do so, we conducted individual ANOVAs with factors of presentation (first or second) and electrode (one level for each of 6 channels) for each item type. All showed reliable effects of repetition [for words, F(1, 23) = 50.78, p<.0001; for pseudowords, F(1, 23) = 46.47, p<.0001; and for acronyms, F(1, 23) = 70.73, p<.0001]. These repetition effects are visible in Figure 1, which displays first and second presentation waveforms for each item type over the middle parietal electrode site. Each pairwise comparison also displayed an interaction of repetition with electrode [for words F(5, 115) = 44.79, p<.0001; for pseudowords, F(5, 115) = 26.12, p<.0001; for acronyms, F(5, 115) = 30.07, p<.0001]. Table 3 displays mean N400 repetition effect amplitude for each of the four critical item types over each of the six available scalp channels, confirming that the interactions with electrode are driven by repetition effects in this window being largest over central-posterior channels, as is typical for N400 effects.
Figure 1.
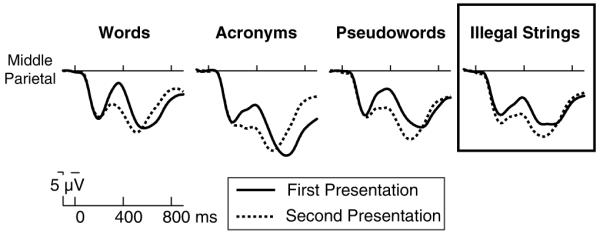
Grand averaged ERPs over the middle parietal electrode site are displayed for the first and second presentation of each item type (words, acronyms, pseudowords, and illegal strings). In this figure, as in all ERP figures, negative is plotted up. Notice the robustly evident N400 component and N400 repetition effect in the illegal string waveforms (boxed).
TABLE 3.
Repetition Effect Magnitudes by Electrode Site: Mean N400 repetition effect magnitude at each of ethe six available scalp electrode channels, in microvolts
| Item type | Middle prefrontal |
Left middle central |
Right middle central |
Middle central |
Middle parietal |
Middle occiptal |
|---|---|---|---|---|---|---|
| Word | 0.31 | −2.84 | −2.54 | −2.49 | −2.96 | −1.93 |
| Pseudoword | 0.04 | −2.64 | −2.42 | −2.49 | −2.93 | −1.87 |
| Acronym | −0.14 | −3.12 | −3.15 | −3.15 | −3.40 | −2.27 |
| Illegal string | −0.82 | −2.28 | −2.25 | −2.46 | −2.51 | −1.26 |
Note: The channel with the largest repetition effect for each item type is bolded (the middle parietal channel for all four item types), highlighting the fact that for all item types, the repetition effect in this time window is centro-posteriorly distributed, as is typical for an N400 effect.
For additional verification of the data, we confirmed that we had replicated the common finding that larger N400 repetition effects are observed with immediate repetition than with delayed repetition. To this end, we conducted an ANOVA with factors of immediacy (immediate or nonimmediate repetition), lexicality (lexical items: words and acronyms, nonlexical items: pseudowords and illegal strings), and electrode. This analysis revealed a main effect of immediacy, F(1, 23) = 15.16, p = .0007, driven by the fact that repetition effects were larger for immediate repetitions, as expected. There was no interaction of immediacy and lexicality, F(1, 23) = 0.02, and no three-way interaction, F(5, 115) = 0.84. For this reason, we collapse across immediate and nonimmediate repetitions in what follows.
Of critical interest was whether or not illegal strings would elicit similar N400 repetition effects to those elicited by words, pseudowords, and acronyms, under these task conditions. Thus we conducted an ANOVA identical to those exploring individual item type repetition effects above (i.e., having factors of repetition and electrode) on the illegal string mean amplitude data in the N400 window. This analysis revealed a reliable effect of repetition, F(1, 23) = 50.41, p<.0001, and an interaction with electrode, F(5, 115) = 9.70, p .0004, driven by the fact that the effect of repetition was largest over posterior channels for this item type, as for all the others (see Table 3). The illegal string repetition effect can be observed in detail in Figure 2, which displays the waveforms elicited by first and second presentation of illegal strings at each of the six available scalp electrode sites. It is clear from Figure 2 that, in addition to the statistically reliable repetition effect in the N400 window, waveforms elicited by illegal strings appear to have the morphological characteristics of an N400 component (i.e., a negative voltage deflection in the 300 500 ms epoch). Figure 3 shows the corresponding data from the semantic categorisation task with the same items in Laszlo and Federmeier (2011), where it is clear that there is very little N400 reduction on second presentation for illegal strings (different from the pattern for the other item types).
Figure 2.

Grand averaged ERPs representing the response elicited by meaningless, illegal strings on first presentation (bold line) and second presentation (dotted line), at each of the six available scalp electrode sites. Note that in the N400 window, the illegal string repetition effect is largest over posterior sites, as is typical of an N400 effect.
Figure 3.
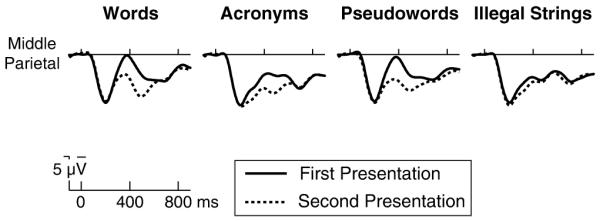
Grand averaged ERPs over the middle parietal electrode site are displayed for the first and second presentation of each item type (words, acronyms, pseudowords, and illegal strings), from a random selection of 24 subjects from Laszlo and Federmeier (2011), where a semantic categorisation task was used instead of the LDT used in the present experiment. The exact same illegal strings that elicit a strong N400 repetition effect in the present LDT elicit a negligible N400 repetition effect in the semantic categorisation task.
In order to compare the magnitude of the N400 repetition effects elicited by the four critical item types, we formed difference waves by computing a point-by-point subtraction of second presentation waveforms of each item type from first presentation waveforms of the same item type. Thus, difference waves represent a continuous time depiction of the effect of repetition on each item type. Figure 4 displays difference waves computed in this way for each of the four critical item types. We then performed an ANOVA with factors of item type (word, acronym, pseudoword, or illegal string) and electrode on mean amplitude over the 300 500 ms N400 window. This ANOVA revealed no effect of item type, F(3, 69) = 0.91, indicating no appreciable difference in the magnitude of repetition effects elicited by the four item types. Pairwise follow up tests comparing repetition effect magnitude for words with those for each of the other three item types revealed that the absent main effect of lexical type was not observable even in direct comparisons (all p >.20).
Figure 4.

Grand average difference waves representing the point-by-point subtraction of waveforms elicited on the first presentation of each item type from the waveforms elicited on the second presentation of each item type. All four item types elicit a clear repetition effect in the N400 time window; words and acronyms only (i.e., lexical items) also elicit a marked positivity in the later LPC window.
It was of interest to compare the repetition effects elicited in the present experiment directly with those elicited in the semantic categorisation task of Laszlo and Federmeier (2011). Therefore, we computed mean N400 repetition effect sizes for each of the four item types for a random selection of 24 of the 120 participants in that study. We then conducted a mixed-model ANOVA with a between-subjects factor of task (semantic categorisation or modified LDT), and a within-subjects factor of item type (word, acronym, pseudoword or illegal string). Since repetition effect magnitudes were largest over the middle parietal channel in both studies, we focused our analysis on that channel. This analysis revealed a main effect of task, F(1, 46) = 5.85, p = .02, a main effect of item type, F(3, 138) = 6.51, p = .0004, and an interaction between the two, F(3, 138) = 3.40, p = .02. The main effect of task results from larger repetition effects, in general, being observed in the modified LDT. The interaction between task and item type is driven by the fact that only acronyms and illegal strings elicited reliably larger repetition effects in the LDT than in the semantic categorisation task [for acronyms, t(46) = 2.48, p = .017; for illegal strings, t(46) = 1.97, p = .055]. Table 4 enumerates the magnitude of repetition effects for each item type over the middle parietal electrode site in each of the two tasks.
TABLE 4.
Interaction of task with repetition effect magnitudes: size (in microvolts) of the mean N400 repetition effect elicited by each item type in each task
| Item type | Semantic categorisation repetition effect size |
Lexical decision repetition effect size |
|---|---|---|
| Word | −1.79 | −2.64 |
| Pseudoword | −1.61 | −2.57 |
| Acronym | −1.78 | −3.10 |
| Illegal string | −0.93 | −2.18 |
P2 effects
As it was possible that differences in N400 repetition effects between item types were obscured by processing differences in the preceding P2 window, we conducted another set of four pairwise ANOVAs identical to those conducted testing for a repetition effect for each item type in the N400 window, this time in the 175 225 ms P2 window. This analysis revealed that only illegal strings elicited P2 repetition effects [for illegal strings, F(1, 23) = 32.42, p<.0001; for words F(1, 23) = 0.77; for acronyms F(1, 23) = 1.25; for pseudowords F(1, 23) <0.01). In light of this selective P2 effect for illegal strings only, it was important to verify that illegal strings would still elicit an N400 repetition effect if differences in the preceding P2 window were taken into account. Therefore, we repeated the ANOVA testing for an N400 repetition effect on illegal strings, this time baselined to the P2 (175–225 ms). The results of the P2-baselined ANOVA in the N400 window indicated that illegal string repetition effects remain on the N4 even if differences in the preceding P2 window are taken into consideration, F(1, 23) = 7.41, p = .01.
LPC effects
We expected that the lexical items (words and acronyms) and nonlexical items (pseudowords and illegal strings) would be affected differently by repetition in the LPC window, reflecting participants’ ability to consciously decide whether items from each type were meaningful or not. We therefore conducted a three-way ANOVA with factors of lexicality (lexical: words and acronyms, nonlexical: pseudowords and illegal strings), repetition (first or second), and electrode in the 600 900 ms LPC window. This analysis revealed a main effect of repetition, F(1, 23) = 15.44, p = .0007, driven by the fact that responses to second presentation tended to be less positive than responses to first presentation in this time window. The main effect of lexicality was not reliable, F(1, 23) = 0.59, p = .45. However, there was a significant interaction between lexicality and repetition, F(1, 23) = 19.28, p = .0002, driven by the fact that the repetition effect was much larger for lexical items than nonlexical items, with little apparent effect at all for the nonlexical items. The three-way interaction between lexicality, repetition, and electrode was also reliable, F(5, 115) = 4.00, p = .025, as repetition effects, especially those for lexical items, tended to be larger over the back of the head, consistent with typical LPC distribution. The same pattern of interactive effects is observed if the same ANOVA is conducted in a slightly earlier window (500 700 ms). LPC repetition effects for both nonlexical and lexical items are highlighted in Figure 5, and are also clearly visible for individual item types (words and acronyms) in Figure 4. Thus, although the lexical types did not elicit discriminable repetition effects in the N400 window, they were discriminated in the LPC window.
Figure 5.
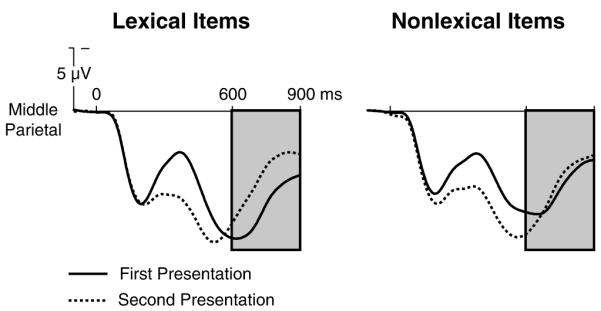
Grand averaged ERPs over the middle parietal electrode site are displayed for the first and second presentation of both lexical items (words and acronyms, averaged) and nonlexical items (pseudowords and illegal strings, averaged. The nonlexical items thus represent the “no” responses and the lexical items the “yes” responses. While N400 repetition effects are similar for the two lexical classes, there is a decreased positivity on second presentation for lexical but not nonlexical items in the LPC window (boxed).
In light of the interaction between repetition effect magnitude and lexicality in the early (500–700 ms) LPC window, we investigated whether or not the absent main effect of lexicality on repetition effect magnitudes in the N400 window would still be absent in a narrower, earlier time window (i.e., we wanted to determine whether the later onsetting differences between lexical types were perhaps obscuring differences between lexical types in the N400 window). Thus, we repeated the ANOVA with factors of lexical type and electrode, originally computed on the repetition effect difference waves in the 300–500 ms N400 window, this time using a 350–400 ms (thus, narrowly around the N400 peak). In this narrower, earlier window, as in the full 300–500 ms N400 window, there was no main effect of lexical type on repetition effect magnitude, F(3, 69) = 1.80, p = .15.
DISCUSSION
An emerging body of work points to obligatory contact between incoming perceptual forms and semantic memory, even when those forms are novel and dissimilar from other known forms, as in the case of orthographically illegal strings. On this view, however, it is striking that N400 repetition effects, indicative of facilitated semantic access upon re-encountering an item in a short time frame, have typically not been found for illegal strings, despite being present for similarly meaningless items, if they are orthographically regular (pseudowords), as well as for similarly orthographically illegal items, if they are meaningful (acronyms). Thus, the goal of the present experiment was to investigate how task demands modulate the outcome of semantic processing, affecting subsequent semantic access for items that are repeated. In particular, we set out to examine the hypothesis that there are task circumstances under which illegal strings in an unstructured list will elicit N400 repetition effects. We noted that prior work that had not found N400 effects for these items—including our own study using exactly the same items used here—often used tasks wherein illegal strings can rapidly be rejected as task-irrelevant based on low-level characteristics such as bigram frequency.
Therefore, in order to attempt to elicit N400 repetition effects on illegal strings, in the present study we presented participants with a modified LDT, in which words, pseudowords, and illegal strings were joined by orthographically illegal, yet meaningful acronyms. We hypothesised that the presence of the acronyms would make the illegal strings more difficult to reject on the basis of low-level characteristics alone, meaning that the strings would have to be processed with more attention than in the name detection task, which might lead to downstream effects in the form of facilitated processing upon repetition. Indeed, in this task context, we observed robust repetition effects on the exact same illegal strings that elicited negligible repetition effects in our prior study using a name detection task (Laszlo & Federmeier, 2011). Figures 1 and 3 contrast the illegal string repetition effects in the present study (Figure 1) and Laszlo and Federmeier (2011; Figure 3). For illegal strings (alone among the item types in our study), repetition effects began in the P200 time window. P2 repetition effects have also been observed for other item types (such as words) in prior work, and have been linked in particular to form based processing (e.g., Evans & Federmeier, 2007; Petit, Midgley, Holcomb, & Grainger, 2006). The P2 repetition effect was then followed by a repetition effect on the N400. We consider the clear differences in N400 processing of illegal strings between the modified LDT and the previously conducted name detection task to be confirmation of our hypothesis that illegal strings would be more competitive lures in the modified LDT—especially in light of the fact that only illegal strings and acronyms elicited larger N400 repetition effects in the modified LDT.
To our knowledge, this is the first time that N400 repetition effects have been observed for meaningless, illegal strings. Although we have shown previously that effects of sentence context can be observed on illegal strings (Laszlo & Federmeier, 2008, 2009), past work has unanimously observed a lack of N400 repetition effect for this item type in unstructured lists (e.g., Deacon et al., 2004; Laszlo & Federmeier, 2007; Rugg & Nagy, 1987). Thus, one critical contribution of the present work is the demonstration that meaningless, illegal strings of letters can elicit N400 effects outside of a sentence context. Different from the N400 effects that have been seen for illegal strings in sentences, here context information did not implicitly or explicitly suggest a meaning for these strings to participants: the items were simply presented without comment mixed in with words, pseudowords, and acronyms. Thus, the N400 effects observed here are not likely to be the result of attributing contextual semantics to the meaningless strings, as there is no coherent context in an unconnected stream of text. Instead, it seems that the additional attention required to differentiate illegal strings from orthographically similar acronyms in order to successfully perform the modified LDT resulted in enhanced repetition effects for the illegal strings, even in the absence of context. This explanation is consistent with past findings that N400 priming and repetition effects are enhanced for attended items (McCarthy & Nobre, 1993).
These data thus suggest that attention is important for the elicitation of N400 repetition effects (but not N400 components). If an item is not attended to, as for illegal strings in our name-recognition task, there will be little or no benefit with repetition—with much larger repetition effects being observed for other item types which do require attention, such as words, pseudowords, and acronyms in our previous studies (Laszlo & Federmeier, 2008, 2011). Indeed, previous work has shown that repetition effects can be absent even for words, if they are attended only shallowly (i.e., in making a judgment about lettercase; Rugg, Furda, & Lorist, 1988), suggesting that not only spatial attention but also attention to meaning features of an item is required for the elicitation of repetition effects. Furthermore, acronyms elicited larger repetition effects in the LDT than they did in the name detection task, where their low level properties (low bigram frequency and lack of a central vowel) made them less likely to be targets. In contrast, when some type of semantic analysis is necessary even for meaningless items—as with pseudowords in our name-recognition task and both pseudowords and illegals in the modified LDT—the downstream consequence of this semantic analysis is observed as a repetition effect on the N400. Converging results have been observed for repeated novel shapes (“squiggles”), wherein only items rated as meaningful on a participant by participant basis elicited repetition effects on the N400 (Voss & Paller, 2007; Voss, Schendan, & Paller, 2010). Thus, although all inputs elicit activity in the semantic system, the consequences of that activity for future processing of an item is a function of a number of factors, including attention, as necessitated by task demands.
The finding that strings in unconnected lists can elicit N400 repetition effects that are qualitatively and quantitatively similar to those elicited by other item types constitutes additional evidence that semantic processing can unfold similarly for unfamiliar, orthographically irregular inputs and meaningful, regular ones. One interesting venue for future research will be to determine at a more fine-grained level whether the topological distribution of N400 repetition effects is similar for illegal strings and other item types; because the present study made use of a reduced electrode montage (in order to enable precise comparisons with Laszlo & Federmeier, 2011), the data available about the scalp distribution of the illegal string repetition effect is limited. However, the available data, when taken together with evidence that illegal strings elicit other classic N400 effects such as sensitivity to sentence context information (Laszlo & Federmeier, 2008, 2009) and sensitivity to lexical variables such as orthographic neighbourhood size (Laszlo & Federmeier, 2011), provide strong converging evidence for our obligatory-semantics view. In context and out of it, illegal strings seem able to engage attempts at semantic processing despite their lack of associated semantics or similarity to (large numbers of) items that do have associated semantics. This account of word recognition is thus similar to views of object recognition wherein all incoming perceptual information is automatically assessed by the semantic system in an attempt to match perceived objects with pre-existing object representations (e.g., Humphreys, Price, & Riddoch, 1999; Plaut & Shallice, 1993).
As evidence for the obligatory-semantics view, the present findings also constitute evidence against some prominent alternative views of what the N400 represents. Some have argued that the N400 indexes processes involved in integrating an input’s semantics into the larger sentence or discourse context—processes that are postulated to occur only after an input has been recognised and its specific semantics accessed (e.g., Hagoort, Baggio, & Willems, 2009). However, such “postlexical” views of the N400 seem difficult to reconcile with the finding that illegal strings, which are both unfamiliar and irregular, elicit N400 activity and show word-like N400 effects.
More generally, our data pattern is similarly inconsistent with staged word recognition models (e.g., Borowsky & Besner, 1993) that posit that higher-level representations, such as semantics, cannot be accessed until after orthographic processing of an input is complete, where “complete” implies matching an input with a specific lexical entity. Under such a view, it seems difficult to explain why brain activity linked to semantic processing could be observed to illegal strings—and facilitated upon repetition—since such strings presumably cannot be successfully recognised and hence should not engender semantic access. To explain the present data, a model of the word recognition system would have to allow even unfamiliar, low N items to make contact with semantics. This could be accomplished by setting an extremely weak threshold for semantic processing in a staged semantics model—but this results, then, in a staged model that essentially has no staging (as, in such a model, all inputs would be passed forward to semantics). To our knowledge, no such model has been proposed or implemented.
Instead, the present findings, taken together with past work that also showed N400 effects for illegal strings of letters (e.g., Laszlo & Federmeier, 2008, 2009, 2011), seem to provide support for cascaded, PDP-style models of word recognition. In such models (e.g., Harm & Seidenberg, 2004; Plaut et al., 1996) there is also no staged processing: information about an input flows forward (and backward) through the system continuously, again consistent with the unstaged nature of our results. Though it is potentially awkward for staged models to explain apparent semantic effects for such unfamiliar items as our illegal strings, PDP models can do so naturally, and an implemented PDP model demonstrating semantic access for illegal strings that is qualitatively and quantitatively similar to that for words, pseudowords, and acronyms, does exist (Laszlo & Plaut, 2011). In the ERP model, subcomponents of meaningless items activate semantics they are partially consistent with (e.g., the ORK in GORK activates the semantics of FORK, PORK, etc.). This property would seem critical for understanding what kind of semantics illegal strings activate—they activate the largely inchoate semantics of all the items that they partially overlap with, and as they tend to overlap with fewer items than pseudowords, they tend to engage less semantic activity and thus elicit smaller N400s in general.
Although we observed similar N400 repetition effects for all four of the critical item types, participants were, of course, able to perform the modified LDT and discriminate words and acronyms from nonwords. This differential behaviour for the lexical and nonlexical item classes was associated with differences in brain activity during the time period subsequent to the N400, continuously throughout the rest of the recording epoch, as effects on the LPC. The finding that differences observed on overt behavioural response patterns were mirrored in LPC waveforms is consistent with theories of the LPC that portray it as a marker of processing that is more explicit than that indexed by the N400 (e.g., Duzel, Yonelinas, Mangun, Heinze, & Tulving, 1997; Vissers, Chwilla, & Kolk, 2006). This pattern is further consistent with the dynamics of the ERP model (Laszlo & Plaut, under review), where a reliable signal for making lexical decisions is not available until the end of N400/beginning of LPC functional epoch. In the present study, words and acronyms elicited large LPC repetition effects, with reduced positivity on second presentation, but pseudowords and illegal strings did not. Words and acronyms elicited more positive LPCs on first presentation than on second, potentially indicating facilitated response selection at an explicit conscious level on second presentation. Similar findings have been observed in sentences, where words, pseudowords, and illegal strings elicit quite similar N400 effects but differing effects on the LPC (Laszlo & Federmeier, 2009). Thus, it is not the case that the ERP is not sensitive to lexicality (at least not when lexicality is task relevant, as it was in the modified LDT employed here), but rather that this sensitivity arises after the N400 time window.
Taken together, the findings on the N400 and LPC suggest a system in which the lexicality of an item has not been completely determined by the onset of the N400 epoch (contrary to the timecourse proposed by, for example, Sereno, Rayner, & Posner, 1998), during which time all inputs are still, obligatorily, attempting to activate a coherent semantics. When task demands can be met without allocation of attention to semantic analysis, as for illegal strings in the name detection task or words processed shallowly (Rugg et al., 1988), this attempt at semantics is not sufficiently strong or coherent to result in subsequent facilitation of semantic access upon repetition. However, when semantic access is augmented by attention, as in this modified LDT, where it is not possible to successfully respond to the illegal strings based on low-level features alone, repetition effects are enhanced, and can be observed even to wholly unfamiliar and irregular items. As the behavioural data demonstrate, neural activity associated with focused semantic analysis results in better performance on second presentation, suggesting that at least one consequence of the attention to meaning highlighted by the ERP data is that on the second presentation of items in a difficult task, readers are helped to “not get fooled again”.
Acknowledgments
The authors would like to acknowledge D. Plaut and E. Wlotko for insightful discussion, and S. Glazer, B. Milligan, and A. Rusthoven for their assistance with data collection. This research was supported by NIH Training Grants T32 MH019983 and T32 HD055272, NICHD F32 HD062043, NIA AG2630, and the James S. McDonnell Foundation 21st Century Science Initiative, Scholar Award in Understanding Human Cognition.
Footnotes
For purposes of comparison, a random selection of 24 (out of 120) participants from Laszlo and Federmeier (2011) were also analyzed. In that sample, there were also 13 females, age range 18 23 years, mean age 19 years.
This phrasing was used to provide a broad base for distinguishing words and acronyms, which are both familiar and meaningful, from pseudowords and illegal strings, which are neither, while also not causing confusion about how to respond to proper names, which are clearly familiar but may not always be considered “meaningful” in the same way.
REFERENCES
- Borowsky R, Besner D. Visual word recognition: A multistage activation model. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1993;19:813–840. doi: 10.1037//0278-7393.19.4.813. [DOI] [PubMed] [Google Scholar]
- Borowsky R, Besner D. Parallel distributed processing and lexical-semantic effects in visual word recognition: Are a few stages necessary? Psychological Review. 2006;113:181–195. doi: 10.1037/0033-295X.113.1.181. [DOI] [PubMed] [Google Scholar]
- Coltheart M, Davelaar E, Jonasson JT, Besner D. Access to the internal lexicon. In: Dornic S, editor. Attention and performance VI. Academic Press; New York: 1977. pp. 535–555. [Google Scholar]
- Dale AM. Unpublished doctoral dissertation. University of California, San Diego; La Jolla, CA: 1994. Source localization and spatial discriminant analysis of event-related potentials: Linear approaches. [Google Scholar]
- Deacon D, Dynowska A, Ritter W, Grose-Fifer J. Repetition and semantic priming of nonwords: Implications for theories of N400 and word recognition. Psychophysiology. 2004;41:60–74. doi: 10.1111/1469-8986.00120. [DOI] [PubMed] [Google Scholar]
- Duzel E, Yonelinas AP, Mangun GR, Heinze HJ, Tulving E. Event-related brain potential correlates of two states of conscious awareness in memory. Proceedings of the National Academy of Sciences USA. 1997;94:5973–5978. doi: 10.1073/pnas.94.11.5973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Evans KM, Federmeier KD. The memory that’s right and the memory that’s left: Event-related potentials reveal hemispheric asymmetries in the encoding and retention of verbal information. Neuropsychologia. 2007;45:1777–1790. doi: 10.1016/j.neuropsychologia.2006.12.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Forster KI. The microgenesis of priming effects in lexical access. Brain and Language. 1999;68:5–15. doi: 10.1006/brln.1999.2078. [DOI] [PubMed] [Google Scholar]
- Forster KI, Davis C. Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1984;10:680–698. [Google Scholar]
- Forster KI, Hector J. Cascaded versus noncascaded models of lexical and semantic processing: The turple effect. Memory & Cognition. 2002;30:1106–1117. doi: 10.3758/bf03194328. [DOI] [PubMed] [Google Scholar]
- Forster KI, Veres C. The prime lexicality effect: Form-pr Timing as a function of prime awareness, lexical status, and discrimination difficulty. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1998;24:498–514. doi: 10.1037//0278-7393.24.2.498. [DOI] [PubMed] [Google Scholar]
- Hagoort P, Baggio G, Willems RM. Semantic unification. In: Gazzaniga M, editor. The cognitive neurosciences. 4th ed MIT Press; Boston: 2009. pp. 819–836. [Google Scholar]
- Harm MW, Seidenberg MS. Computing the meaning of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review. 2004;111:662–720. doi: 10.1037/0033-295X.111.3.662. [DOI] [PubMed] [Google Scholar]
- Humphreys GW, Price C, Riddoch MJ. From objects to names: A cognitive neuroscience approach. Psychological Research. 1999;62:118–130. doi: 10.1007/s004260050046. [DOI] [PubMed] [Google Scholar]
- Kutas M, Federmeier KD. Thirty years and counting: Finding meaning in the N400 component of the event-related brain potential (ERP) Annual Review of Psychology. doi: 10.1146/annurev.psych.093008.131123. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Landauer TK, Dumais ST. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review. 1997;104:211–240. [Google Scholar]
- Laszlo S, Federmeier KD. Better the DVL you know: Acronyms reveal the contribution of familiarity to single word reading. Psychological Science. 2007;18:122–126. doi: 10.1111/j.1467-9280.2007.01859.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Federmeier KD. Minding the PS, queues, and PXQs: Uniformity of semantic processing across multiple stimulus types. Psychophysiology. 2008;45:458–466. doi: 10.1111/j.1469-8986.2007.00636.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Federmeier KD. A beautiful day in the neighborhood: An event-related potential study of lexical relationships and prediction in context. Journal of Memory and Language. 2009;61:326–338. doi: 10.1016/j.jml.2009.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Federmeier KD. The N400 as a snapshot of interactive processing: Evidence from regression analyses of orthographic neighbor and lexical associate effects. Psychophysiology. 2011;48:176–186. doi: 10.1111/j.1469-8986.2010.01058.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Plaut DC. Simulating event-related potential reading data in a neurally plausible parallel distributed processing model. Proceedings of the 33rd Annual Conference of the Cognitive Science Society; Mahwah, NJ. Lawrence Erlbaum Associates; 2011. [Google Scholar]
- Laszlo S, Plaut DC. A neurally plausible parallel distributed processing model of eventrelated potential reading data. doi: 10.1016/j.bandl.2011.09.001. (under review) Manuscript submitted for publication. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lund K, Burgess C. Producing high-dimensional semantic spaces from lexical co-occurrence. Behavior Research Methods, Instruments, Computers. 1996;28:203–208. [Google Scholar]
- Marcus M, Santorini B, Marcinkiewicz M. Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics. 1993;19:313–330. [Google Scholar]
- McCarthy G, Nobre AC. Modulation of semantic processing by spatial selective attention. Electroencephalograpy and Clinical Neurophysiology. 1993;88:210–219. doi: 10.1016/0168-5597(93)90005-a. [DOI] [PubMed] [Google Scholar]
- Medler DA, Binder JR. MCWord: An on-line orthographic database of the English language. 2005 Retrieved from http://www.neuro.mcw.edu/mcword/
- Misra M, Holcomb PJ. Event-related potential indices of masked repetition priming. Psychophysiology. 2003;40:115–130. doi: 10.1111/1469-8986.00012. [DOI] [PubMed] [Google Scholar]
- Petit JP, Midgley KM, Holcomb PJ, Grainger J. On the time course of letter perception: A masked priming ERP investigation. Psychonomic Bulletin and Review. 2006;13:674–681. doi: 10.3758/bf03193980. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plaut DC, McClelland JL, Seidenberg MS, Patterson K. Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review. 1996;103:56–115. doi: 10.1037/0033-295x.103.1.56. [DOI] [PubMed] [Google Scholar]
- Plaut DC, Shallice T. Perseverative and semantic influences on visual object naming errors in optic aphasia: A connectionist account. Journal of Cognitive Neuroscience. 1993;5:89–117. doi: 10.1162/jocn.1993.5.1.89. [DOI] [PubMed] [Google Scholar]
- Ratcliff R, Gomez P, McKoon G. A diffusion model account of the lexical decision task. Psychological Review. 2004;111:159–182. doi: 10.1037/0033-295X.111.1.159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rugg MD, Furda J, Lorist M. The effects of task on the modulation of event-related potentials by word repetition. Psychophysiology. 1988;25:55–63. doi: 10.1111/j.1469-8986.1988.tb00958.x. [DOI] [PubMed] [Google Scholar]
- Rugg MD, Nagy ME. Lexical contribution ot nonword repetition effects: Evidence from eventrelated potentials. Memory & Cognition. 1987;15:473–481. doi: 10.3758/bf03198381. [DOI] [PubMed] [Google Scholar]
- Sereno SC, Rayner K, Posner MI. Establishing a time-line of word recognition: Evidence from eye movements and event-related potentials. NeuroReport. 1998;9:2195–2200. doi: 10.1097/00001756-199807130-00009. [DOI] [PubMed] [Google Scholar]
- Spieler DH, Balota DA. Bringing computational models of word naming down to the item level. Psychological Science. 1997;8:411–416. [Google Scholar]
- Vissers C. Th. W. M., Chwilla DJ, Kolk HHJ. Monitoring in language perception: The effect of misspellings of words in highly constrained sentences. Brain Research. 2006;1106:150–163. doi: 10.1016/j.brainres.2006.05.012. [DOI] [PubMed] [Google Scholar]
- Voss JL, Paller KA. Neural correlates of conceptual implicit memory and their contamination of putative neural correlates of explicit memory. Learning & Memory. 2007;14:259–267. doi: 10.1101/lm.529807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Voss JL, Schendan HE, Paller KA. Finding meaning in novel geometric shapes influences electrophysiological correlates of repetition and dissociates perceptual and conceptual priming. Neuro-Image. 2010;49:2879–2889. doi: 10.1016/j.neuroimage.2009.09.012. [DOI] [PubMed] [Google Scholar]
- Wagenmakers E-J, Steyvers M, Raaijmakers JGW, Shiffrin RM, van Rijn H, Zeelenberg R. A model for evidence accumulation in the lexical decision task. Cognitive Psychology. 2004;48:332–367. doi: 10.1016/j.cogpsych.2003.08.001. [DOI] [PubMed] [Google Scholar]