

Abstract
Objective
To determine the effect of chronic (recurrent) otitis media with effusion (OME) on frequency weighting in the perception of speech in noise. It was hypothesized that children with a history of OME weight speech information in the mid frequency region higher than control children.
Design
This is a matched cohort study looking at differences in frequency weighting in 12 children with a history of OME 1–2 weeks following placement of tympanostomy tubes compared to 21 control children. Children were tested on their ability to identify key words in sentences presented in speech-shaped noise. The frequency content of the sentences was manipulated in order to determine the relative importance of frequencies in the regions of 1, 2, and 4 kHz. The frequency bands selected were 798–1212 Hz (low band), 1575–2425 Hz (mid band), and 3000–5000 Hz (high band). Initial testing involved adaptive runs where a speech-shaped masker was held at a constant level and the level of the speech with all three bands present varied. Once a level corresponding to 85–90% correct was identified, novel sentences were then presented at this signal-to-noise ratio in fixed block runs, with all bands present, or with one of the three bands omitted.
Results
The children in the OME group achieved 85–90% correct at a lower signal-to-noise ratio than controls in the adaptive testing, where all three speech bands were present. Fixed block testing indicated that children with OME history gave more weight to speech frequencies in the region of 2000 Hz compared to the age-matched control group.
Conclusions
The results are consistent with an interpretation that the development of frequency weighting in the perception of speech can be affected by a history of OME.
Keywords: frequency weighting, otitis media with effusion, speech perception
INTRODUCTION
It is known that acute otitis media can result in conductive hearing impairment. Additionally, several previous studies have indicated that the perception of speech can be abnormal in children with a history of otitis media with effusion (OME) even after pure tone detection thresholds return to normal. These abnormalities include poor recognition of sentences masked by a competing talker (Gravel & Wallace, 1992; Jerger, Jerger, Alford et al., 1983), worse identification of words masked by speech-shaped noise (Schilder, Snik, Straatman et al., 1994), immature weighting of speech features (Nittrouer, 1996a, 1996b), and relatively poor perception of particular features of speech (Clarkson, Eimas, & Marean, 1989; Groenen, Crul, Maassen et al., 1996; Petinou, Schwartz, Gravel et al., 2001). In some children with a significant history of OME in their first year of life, phonetic coding can remain worse than normal even in the later school years (Mody, Schwartz, Gravel et al., 1999).
The present study investigated the effect of chronic OME on the development of frequency weights in the perception of speech. Our study is similar in some respects to the previous work by Nittrouer aimed at understanding weighting of formant transition information. Nittrouer (1996a) showed that 3-year-old children and adults weight speech cues differently. Labeling data from young children showed that their judgments about syllable-initial fricatives were more affected by the dynamic vowel formant transition portion of the stimuli than the static noise-simulated consonant when compared to adults. A later study (Nittrouer, 1996b) extended this approach to the study of children with a history of OME. Those data suggest that 8-year-old children with OME weight dynamic speech cues more than their normal-hearing peers. In that way the OME group at 8 years of age resembles the previously studied 3-year-old group. Weighting functions were significantly correlated with scores on a test of phonetic awareness, suggesting that speech weighting develops in a way that is contingent upon exposure to language. These findings were consistent with the idea that the development of mature speech weighting strategies requires sufficient auditory language exposure during the preschool years. Chronic OME prevents complete access to auditory language, which may limit the development of mature speech weighting strategies.
Whereas Nittrouer’s studies examined the weighting of dynamic and static cues, the focus of the present study on frequency weighting in the perception of speech has a basis in the audiometric configuration that is typical of OME. Several investigators (Fria, Cantekin, & Eichler, 1985; Hunter, Margolis, & Giebink, 1994; Kokko, 1974) have reported that OME is often associated with an audiogram where sensitivity at 2000 Hz is better (by 7–10 dB) than at lower and higher frequencies. Dobie and Berlin (1979) speculated that the peak in sensitivity at 2000 Hz may be a result of intrinsic properties of the middle ear system, i.e. a crossover point between separate mass and stiffness components of the hearing loss. They noted that even mild alterations in the speech spectrum could result in changes in speech perception in children with OME, particularly at poor signal-to-noise ratios. The present study investigated whether a history of OME is associated with abnormal spectral weighting of the different frequency regions of speech. We hypothesize that the spectral region around 2000 Hz, where sensitivity is usually best and least variable over time in children with recurrent episodes of OME, is given more weight than lower and higher spectral regions. This hypothesis is based upon the idea that the abnormal spectral input experienced by children with chronic OME may result in adaptation of the neural structures that underlie the processing of speech.
MATERIALS AND METHODS
Listeners
The control group consisted of 21 children, ranging in age from 4.8 to 8.4 years old (mean= 6.7 years). Pure tone air conduction audiometry indicated that thresholds in quiet were equal to or better than 20 dB HL for octave frequencies between 250 Hz and 8000 Hz. No listeners had a known history of significant ear disease. The experimental group was composed of 12 children ranging in age from 5.1 to 7.6 years (mean = 6.5 years) with a diagnosis of active OME at the time of recruitment and plans to undergo tympanostomy tube placement. Eleven of the twelve OME listeners had a history of bilateral OME, and the ear of test was chosen at random. The remaining listener had a history of unilateral OME and, in this case, the ear with a history of hearing loss was tested.
In this study, only listeners having documented hearing loss of 25 dB HL or worse at one or more frequencies between 250 and 4000 Hz and Type B tympanograms prior to surgery were included in the experimental group. In addition, the presence of OME was supported by otoscopy performed by an otolaryngologist. Audiometric pure-tone thresholds were obtained for each ear, using the descending Hughson-Westlake method. Table 1 shows mean, pre-surgery air conduction audiometric thresholds and standard deviations; post-surgical audiometric thresholds measured just prior to data collection all fell at or below 20-dB HL, confirming that the hearing loss document for the OME group was due solely to middle ear effusion. The pattern of thresholds was consistent with previous reports of listeners with OME indicating better sensitivity at 2 kHz than at lower and higher frequencies (Fria, Cantekin, & Eichler, 1985; Hunter, Margolis, & Giebink, 1994; Kokko, 1974). The UNC Medical School Institutional Review Board approved all experimental procedures prior to their initiation. The children with OME history were tested approximately 1–2 weeks after the placement of tympanostomy tubes.
TABLE 1.
Average pre- and postsurgical air conduction audio-metric thresholds and standard deviations
| Preoperative frequency (Hz)
|
|||||
|---|---|---|---|---|---|
| 250 | 500 | 1000 | 2000 | 4000 | |
| Preop threshold (dB) | 36.1 | 32.1 | 30.4 | 24.6 | 31.7 |
| Standard deviation | 11.1 | 8.7 | 11 | 12.2 | 18.4 |
| Postoperative frequency (Hz)
|
|||||
| 250 | 500 | 1000 | 2000 | 4000 | |
| Preop threshold (dB) | 14.17 | 11.3 | 11.3 | 7.9 | 10.8 |
| Standard deviation | 7 | 5.7 | 4.8 | 4.5 | 5.6 |
Postsurgical audiometric thresholds measured just before to data collection, all fell at or below 20 dB HL, confirming that the hearing loss documented for the OME group was solely because of middle ear effusion.
Stimuli
Target speech was a male voice speaking BKB sentences (AUDiTEC, St. Louis; Bench, Kowal, & Bamford, 1979). Each sentence contained from three to five key words, with an average of approximately 3.6 key words per sentence. These sentences have been shown to be an appropriate measure of speech perception in young children (Uchanski, Geers, & Protopapas, 2002). The sentences were filtered into three bands: a low band from 798–1212 Hz, a mid band from 1575–2425 Hz, and a high band from 3000–5000 Hz. In some conditions all three bands were presented together, and in other conditions one of the three bands was omitted; energy outside the spectral regions defined by these bands was never presented. Although these bands differ somewhat as estimated by the intelligibility associated with the articulation index for short passages (Studebaker, Pavlovic, & Sherbecoe, 1987), pilot testing suggested similar intelligibility across bands for the material used here, and also suggested performance near 100% when all bands were presented together in quiet. The level of speech stimuli is reported below as the peak equivalent of the original, unfiltered recordings, defined in units of dB SPL. A speech-shaped noise was used as the masker, generated based on the long-term average spectrum of the BKB sentences. The speech-shaped noise was presented at an overall level of 70 dB SPL and was played throughout the threshold run. The stimuli were delivered monaurally to the listeners through one earphone of a circumaural headset (Sony MDR V6).
Procedure
Listeners sat with an experimenter in a double-walled sound booth. The experimenter was positioned in front of a visual display that showed the current sentence. The child was seated such that the display was not visible. The child was instructed to repeat as many words as possible after each sentence presentation, and to guess when unsure of any words. No feedback was provided. The experimenter recorded errors following each listener response. There were 21 lists of 16 sentences each; this large corpus allowed testing with novel sentences on every presentation, preventing familiarity with the test materials from affecting performance.
The testing procedure involved two steps. In the first step, all three bands of speech were always present and sentences were presented sequentially, starting with the first sentence of the first list. Testing was completed using an adaptive staircase procedure that was broadly based on Levitt (1971). If any key word of a sentence presentation was missed, the speech presentation level was increased by 2 dB on the next trial. If all key words were correctly identified for two consecutive presentations at a particular speech level, then the speech presentation level was decreased by 2 dB on the subsequent trial. The run was stopped following 6 reversals in speech level adjustment, and the masked speech reception threshold (SRT) was taken as the average of the last 4 reversals. Pilot testing indicated that the S/N ratio so estimated was associated with approximately 85–90% key words correct when lists of sentences filtered into the three bands were presented in fixed blocks. This relatively high level of performance was desirable in order to allow measurement of reductions in performance when one of the three bands was omitted.
The second procedural step involved presentation of different sentences in fixed blocks of 16 sentences (one list) at the fixed S/N ratio determined in the first step. Four conditions were run where all bands were present or one of the bands was omitted. These fixed-block conditions are referred to as all-present, omit-low, omit-mid, and omit-high. The four conditions were run in a quasi-random order, with one list of 16 sentences presented in each of the conditions. The four conditions were then repeated in a new quasi-random order. Performance in each condition was then estimated by applying an arcsine transformation (Studebaker, 1985) to the two replicate data points, averaging these values, and then converting the result back to percent correct.
RESULTS
The results of the control and OME groups differed for the first step of speech testing, where the speech reception threshold was determined for all three bands of filtered speech presented in a speech shaped noise background. The average speech reception thresholds for the control and OME history groups were 90.6 dB SPL and 88.9 dB SPL, respectively, with associated standard deviations of 3.1 and 2.1 dB. This difference of 1.7 dB was statistically significant (t31=2.26; p=0.038).
Summary results for fixed S/N ratio conditions for all listeners are shown in Figure 1. All listeners showed the expected relatively good performance in the all-present condition. The percent correct scores for the all-present condition ranged between 84% and 96% for the normal-hearing group (mean 91.2) and between 83% and 93% for the OME history group (mean 87.4%). A t-test performed on the arcsine-transformed percent correct data indicated a significant difference between the groups (t31= −2.94; p=0.006). Inspection of Figure 1 reveals that the omission of any one of the bands resulted in some reduction in performance for both groups. Of particular interest here was whether omission of the mid-band resulted in a greater decline in performance for the OME group than for the control group. This was examined in a repeated measures ANOVA comparing performance for each condition in which one band was omitted. An analysis of the arcsine-transformed percent correct scores indicated a significant effect of band omission (F2, 62=60.71; p<0.005), no significant effect of group (F1, 31=1.462; p=0.236), and a significant interaction between band omission and group (F2, 62=3.596; p=0.033). Because the interaction between band omission and experimental group was significant, simple effects testing was performed (Kirk, 1968). Transformed percent correct scores were significantly lower in the OME group for the omit-mid condition (F1,31=6.479, p=0.016), but not for the omit-low (F1,31=0.003, p= 0.958) or the omit-high (F1,31=0.020, p=0.889) conditions. There was no correlation within the OME group between the percent correct scores for the omit-mid condition and the audiometric threshold at 2 kHz measured prior to insertion of tympanostomy tubes (r=0.482; p=0.113).
Figure 1.
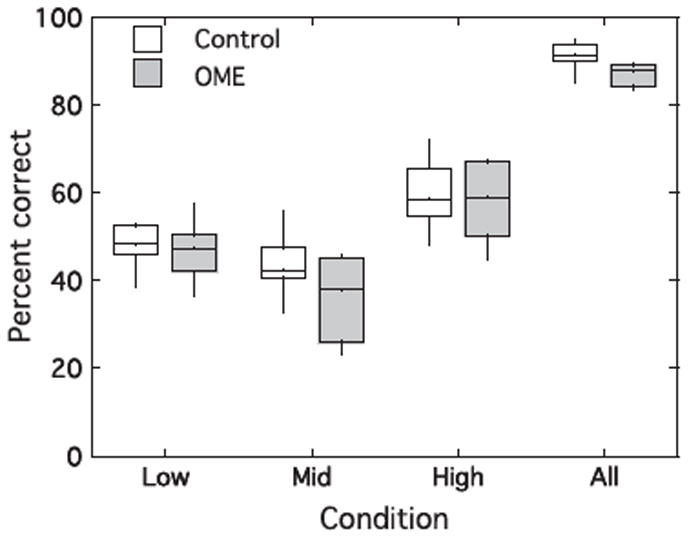
A comparison of percent correct for normal hearing listeners (open rectangles) and OME listeners (shaded rectangles) in the omit-low, omit-mid, omit-high, and all-present conditions. Rectangles span the 25th to 75th percentiles, and the middle horizontal bar indicates the median. Vertical bars represent the 10th to 90th percentiles.
Percent correct data for individual control and OME listeners are plotted in Figure 2 as a function of age, with each omit-band condition shown in a separate panel. Unfilled circles represent the control data and filled circles represent the OME data. The shaded band represented the 95% prediction interval (Kleinbaum & Kupper, 1978) for the control group and the line in the center of this band is the best-fitting regression line fitted to the data of the control group. Examination of these data reveals that the data of the OME listeners were relatively symmetrically distributed around the normal regression line for the omit-low and omit-high conditions. However, in the omit-mid condition, the data of the OME listeners tended to fall below the normal regression line, and three of the OME listeners fell below the associated prediction interval. This pattern of results is consistent with the significant interaction between group and band omitted noted above.
Figure 2.
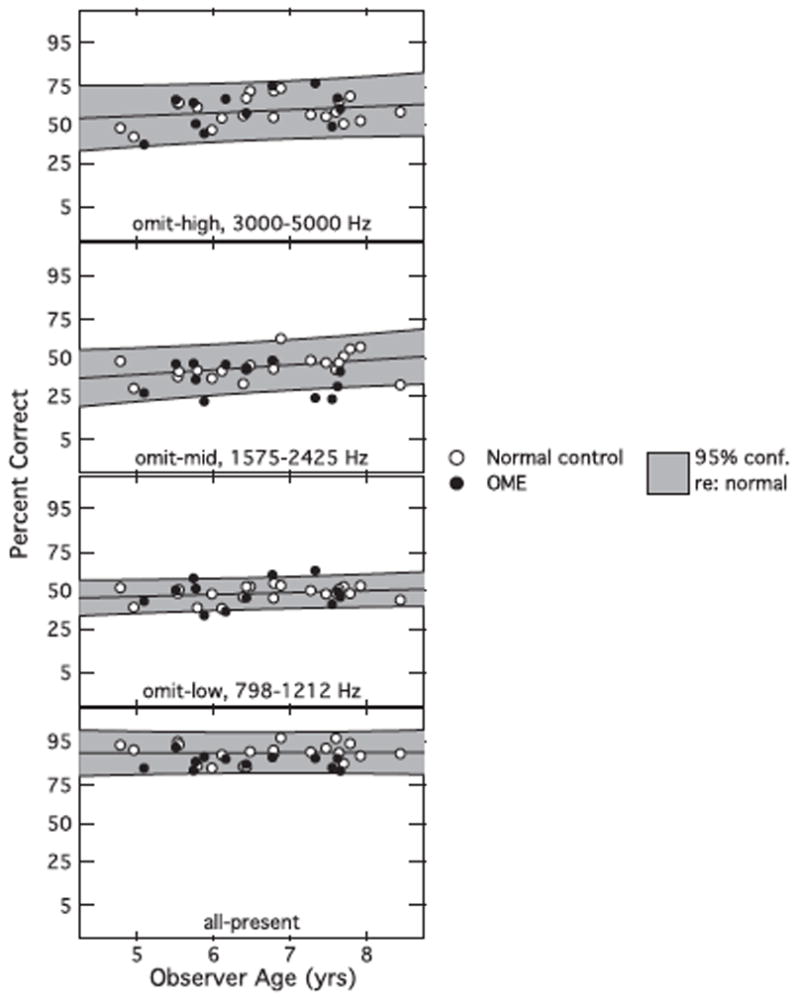
Individual control (unfilled circles) and OME (filled circles) data are plotted as a function of age, with each omit-band condition shown in a separate panel. The shaded area represents the 95% prediction interval based on the data of the normal-hearing listeners. The data are plotted as arcsine transformed percent correct values. The graph is labeled in terms of the equivalent percent correct.
Age effects were examined by computing the correlation between transformed percent correct scores for sentence identification under the three ‘omit band’ stimulus conditions and age of listener (significance reported for a two-tailed test). For the normal-control group, this correlation was not significant for the cases where the low or high band was omitted (p>0.12), and was weak but significant (r=0.39;p=0.004) in the case where the mid band was omitted. Performance of the OME group was not significantly correlated with age for any of the three conditions in which one band was omitted (p>=0.21).
DISCUSSION
The discussion begins with the question that was of central interest in this study, the effect of removing one of three frequency bands on speech perception performance and its relation to a history of OME. The results from conditions where one of the three speech bands was omitted can be interpreted in terms of the auditory experience in children with an OME history. Studies by Nittrouer and colleagues (Nittrouer 1996b; Nittrouer & Burton, 2005) showed that the development of speech cue weights related to formant transitions was affected by a history of OME, presumably due to reduced auditory experience or degraded quality of speech exposure in these children with intermittent hearing loss. Our results suggest that the fluctuating hearing loss associated with a history of OME may also affect the development of frequency weighting in the perception of sentence material. Specifically, frequency weighting examined by observing the influence of omitting one of three filtered bands of speech indicated that the 2 kHz region was weighted relatively highly by children with a history of OME (Figure 1). This result was consistent with the hypothesis that children with an OME history may place more weight in this frequency region due to the fact that hearing thresholds are relatively better and more stable at 2 kHz than at other frequencies. It should noted that the spectral region around 2 kHz is associated with important speech information (particularly in terms of F2 and formant transitions involving F2) for many speakers (e.g., Peterson and Barney, 1952). The pre-surgery audiograms of the children tested here showed better hearing thresholds at 2 kHz than 1 kHz and 4 kHz, consistent with earlier findings (Fria, Cantekin, & Eichler, 1985; Hunter, Margolis, & Giebink, 1994; Kokko, 1974). However, it should be noted that a significant correlation between the speech frequency weighting result and the pre-surgery audiogram was not observed here. It is possible that this correlation was not significant because the pre-surgery audiogram was not sufficiently representative of the long-term history of hearing sensitivity. We cannot assess this question further in the present data set because we do not have records of the long-term audiometric sensitivity of the children tested.
The results of this study can be interpreted in terms of the detrimental effects of omitting one spectral region of the speech signal, quantifying the contribution of that band in terms of the reduction in percent correct. A related way to interpret these results is in terms of the ability of the listener to integrate the information in the remaining two bands. For example, the relatively poor performance of the OME listeners in the condition where the mid band was omitted could be interpreted as relative dominance of that band in speech recognition or, alternatively, as a poor ability to integrate the speech information contained in the low and high bands. Difficulty in integrating the low and high bands could be due to the unreliable auditory information present in these bands during active OME infections. By this interpretation, children with normal hearing may demonstrate more mature integration ability because of stable auditory cues from all bands.
As noted above, the children with an OME history performed worse than normal in the omit-mid condition but not in the omit-low or omit-high conditions (Figures 1&2). This might seem puzzling from the standpoint of frequency weighting, because if the mid band is weighted more than normal in children with OME history, the low band and the high band would therefore be weighted proportionately less than normal. If this were true, it might be expected that the children with OME history would do better than the control children in the omit-low and omit-high conditions. This was not the case, as the children with an OME history performed at the same level as normal children when the low band or the high band was omitted (Figures 1&2). A plausible explanation for this finding is related to the lower average presentation level for speech in the OME group. OME children were, on average, presented with a lower speech level than the normal controls in the fixed block conditions due to the fact that the SRTs obtained in the adaptive, initial stage of testing were lower for the OME group than the control group (see further discussion of this below). This lower presentation level could make the task more challenging for the OME group when listening to the omit-low or omit-high conditions. It is possible that if the presentation levels for the two groups were equal, the children with OME would perform better for the low band and high band omitted speech than their normal counterparts.
Thus far, we have considered accounts of the results where one of the three bands was omitted in terms of frequency weighting of bands and in terms of the ability to integrate information across speech bands. Another possible interpretation of these findings involves the idea that increasing the difficulty of a task adversely impacts performance of OME listeners more than normal control listeners. If OME and normal-hearing groups differed only in their ability to effectively process a degraded signal where one band was omitted, then group differences should be negatively correlated with scores for the normal-hearing listeners. In other words, group differences should be larger in conditions where normal-hearing listeners did more poorly. Within the normal listeners, removal of the low band or the mid band resulted in a similar reduction in percent correct when contrasted with the all-present condition, while removal of the high band did not impact performance to the same extent (Figure 1). The OME listeners showed a different pattern of results, with their worst performance occurring in the omit-mid condition. If greater task difficulty acted to accentuate group differences, then the OME listeners would be expected to perform equally poorly in the omit-low and omit-mid conditions. The finding of a significant group difference for the omit-mid condition but not the omit-low condition suggests that the groups do not differ simply on their ability to process speech under difficult listening conditions. Further, if task difficulty more adversely affects the performance of OME listeners when compared to normal control children, then the speech reception threshold in the first, adaptive stage of testing should have likewise indicated poorer performance in children with OME; the finding of the opposite pattern of results, with lower thresholds for the OME group, suggests that task difficulty, per se, played little or no role in the group differences observed for the omit-mid condition.
The discussion now turns to the SRT obtained in the adaptive, first stage of testing where all three bands were present. The results from this condition indicate that the children with a history of OME require a lower speech presentation level than normal to achieve an SRT that corresponded to approximately 85–90% correct. At first glance, this might appear to be at odds with previous results indicating that children with a history of OME sometimes require a higher S/N ratio to understand speech in a noise background (Gravel & Wallace, 1992). However, one potentially important difference between most previous studies and the present experiment is that the speech used here was filtered into three, non-overlapping bands such that the speech signal was degraded even when all three bands were present. This degraded signal included the mid band (1575–2425 Hz) region which we hypothesize to be integral to speech perception in OME listeners. In a previous study by Schilder, Snik, and Straatman (1994), children with an OME history were found to have poorer than normal speech perception for unfiltered speech in noise, but performance of the OME and normal groups was not significantly different when the speech was low-pass filtered at 1kHz (with a slope of 24dB per octave). In contrast, Welsh, Welsh, and Healy (1983), reported that many children with OME history demonstrated poorer than normal perception of speech low-pass filtered at 500 Hz (with a slope of 18dB per octave). It may be possible to reconcile these disparate results for speech perception in OME listeners by considering the differences in the information present in each of the speech signals, particularly with regard to the presence of frequencies in the mid band region (1575–2425 Hz) employed in the present study. For example, the study of Schilder et al., which used a low-pass cutoff of 1 kHz would have allowed more access to information in the 1575–2425 mid band, than the study of Welsh et al., where the low-frequency cutoff was 500 Hz. It is possible that this factor can help to account for the fact that the Welsh et al. study showed poorer than normal performance for low-pass filtered speech but that the study of Schilder et al. did not. The present study used a very different form of processing where speech was filtered into discrete bands. The present finding that children with a significant history of otitis media were relatively adept at listening to the speech filtered into three non-overlapping bands is consistent with the possibility that performance of this task is related to prior listening experience. In their daily lives, children with chronic OME are faced with the need to understand speech in the context of the different spectral shapes imposed by their ever-changing middle ear conditions. This experience could provide the OME listener with an opportunity to learn strategies which support better speech understanding for the stimuli used here in comparison to a normal-hearing peer. It is known that children with normal hearing are more deleteriously affected than adults when asked to process spectrally degraded speech sounds (Eisenberg, Shannon, Martinez et al., 2000). It is possible that a significant history of exposure to spectrally altered speech signals and access to the 1575–2425 Hz mid band enabled the OME listeners of the present study to process filtered speech relatively well in comparison to children with normal hearing.
Previous experience may also be relevant to the results obtained in the fixed block testing for the condition where all three bands were present. Recall that, in this fixed block condition, the control group obtained a slightly higher percent correct than the OME group. Equivalent performance between the groups would have been expected, given that the speech presentation levels for fixed block testing were based upon an adaptive procedure that should have converged upon the same percent correct for all listeners. As argued above, the fact that the adaptive procedure used in the first stage of testing converged upon a lower SRT for the listeners in the OME group than the control group is consistent with the idea that the listeners with OME history benefited from prior experience in listening to degraded speech. It is possible that, when subsequently tested in the fixed block conditions where all bands were present, performance of the control children improved based on prior exposure to filtered speech in the first adaptive testing step. Such an improvement may not have occurred in the OME group because they were already using effective listening strategies due to their previous experience with degraded speech in their daily lives.
Finally, we will briefly consider a very general issue that concerns the effect of OME on hearing development. Most previous studies considering this issue have focused on the general result that the hearing loss associated with OME degrades the quality of auditory input and, as a consequence, delays auditory development adapted to process normal auditory input. Although the results of the present study are not inconsistent with this interpretation, they nevertheless highlight a slightly different perspective. Some of the present results suggest that, at least to some extent, auditory function in children with OME may adapt to facilitate processing of spectrally degraded signals and signals with spectral content that varies over time. Thus, although OME may slow auditory development for stimuli typically available to normal hearing listeners, it is important to consider the possibility that central auditory development continues to proceed in a way that exploits the changing information available at the output of a relatively unreliable periphery.
CONCLUSIONS
The present study supports the following conclusions:
OME listeners weighted the mid band (2 kHz region) more highly than normal-hearing listeners, possibly due to the increased stability of speech information in that frequency region.
In the adaptive stage of testing, OME listeners obtained speech reception thresholds at a lower than normal signal-to-noise ratio when listening to filtered speech with all three frequency bands present.
Some of the results of this investigation are consistent with the possibilities that listeners with OME may compensate for degraded auditory input by placing high weight upon spectral information that is relatively reliable and by learning to accommodate the range of spectral configurations that they encounter as a result of chronic, intermittent hearing loss.
Acknowledgments
This work was supported by grants from the NIH NIDCD, R01 00397 (JWH), T32 DC005360 (RJE).
References
- Bench J, Kowal A, Bamford J. The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children. Br J Audiol. 1979;13:108–112. doi: 10.3109/03005367909078884. [DOI] [PubMed] [Google Scholar]
- Clarkson RL, Eimas PD, Marean GC. Speech-Perception in Children with Histories of Recurrent Otitis-Media. Journal of the Acoustical Society of America. 1989;85:926–933. doi: 10.1121/1.397989. [DOI] [PubMed] [Google Scholar]
- Dobie RA, Berlin CI. Influence of otitis media on hearing and development. Annals of Otology, Rhinology, and Laryngology - Supplement. 1979;88:48–53. doi: 10.1177/00034894790880s505. [DOI] [PubMed] [Google Scholar]
- Eisenberg LS, Shannon RV, Martinez AS, Wygonski J, Boothroyd A. Speech recognition with reduced spectral cues as a function of age. J Acoust Soc Am. 2000;107:2704–2710. doi: 10.1121/1.428656. [DOI] [PubMed] [Google Scholar]
- Fria TJ, Cantekin EI, Eichler JA. Hearing acuity of children with otitis media with effusion. Archives of Otolaryngology. 1985;111:10–16. doi: 10.1001/archotol.1985.00800030044003. [DOI] [PubMed] [Google Scholar]
- Gravel JS, Wallace IF. Listening and language at 4 years of age: effect of early otitis media. Journal of Speech and Hearing Research. 1992;35:588–595. doi: 10.1044/jshr.3503.588. [DOI] [PubMed] [Google Scholar]
- Groenen P, Crul T, Maassen B, van Bon W. Perception of voicing cues by children with early otitis media with and without language impairment. J Speech Hear Res. 1996;39:43–54. doi: 10.1044/jshr.3901.43. [DOI] [PubMed] [Google Scholar]
- Hunter LL, Margolis RH, Giebink GS. Identification of hearing loss in children with otitis media. Annals of Otology, Rhinology, & Laryngology - Supplement. 1994;163:59–61. doi: 10.1177/00034894941030s516. [DOI] [PubMed] [Google Scholar]
- Jerger S, Jerger J, Alford BR, Abrams S. Development of speech intelligibility in children with recurrent otitis media. Ear and Hearing. 1983;4:138–145. doi: 10.1097/00003446-198305000-00003. [DOI] [PubMed] [Google Scholar]
- Kirk RE. Experimental Design: Procedures for the Behavioral Sciences. Belmont, CA: Wadsworth; 1968. [Google Scholar]
- Kleinbaum DG, Kupper LL. Applied regression analysis and other multivariable methods. North Scituate: Duxbury Press; 1978. [Google Scholar]
- Kokko E. Chronic secretory otitis media in children. Acta Oto-Laryngologica, suppl. 1974;327:7–44. [PubMed] [Google Scholar]
- Levitt H. Transformed up-down methods in psychoacoustics. Journal of the Acoustical Society of America. 1971;49:467–477. [PubMed] [Google Scholar]
- Mody M, Schwartz RG, Gravel JS, Ruben RJ. Speech perception and verbal memory in children with and without histories of otitis media. Journal of Speech, Language, and Hearing Research. 1999;42:1069–1079. doi: 10.1044/jslhr.4205.1069. [DOI] [PubMed] [Google Scholar]
- Nittrouer S. Discriminability and perceptual weighting of some acoustic cues to speech perception by 3-year-olds. J Speech Hear Res. 1996a;39:278–297. doi: 10.1044/jshr.3902.278. [DOI] [PubMed] [Google Scholar]
- Nittrouer S. The relation between speech perception and phonemic awareness: evidence from low-SES children and children with chronic OM. J Speech Hear Res. 1996b;39:1059–1070. doi: 10.1044/jshr.3905.1059. [DOI] [PubMed] [Google Scholar]
- Nittrouer S, Burton LT. The role of early language experience in the development of speech perception and phonological processing abilities: evidence from 5-year-olds with histories of otitis media with effusion and low socioeconomic status. Journal of Communication Disorders. 2005;38:29–63. doi: 10.1016/j.jcomdis.2004.03.006. [DOI] [PubMed] [Google Scholar]
- Petinou KC, Schwartz RG, Gravel JS, Raphael LJ. A preliminary account of phonological and morphophonological perception in young children with and without otitis media. International Journal of Language and Communication Disorders. 2001;36:21–42. doi: 10.1080/13682820150217554. [DOI] [PubMed] [Google Scholar]
- Peterson GE, Barney HL. Control methods used in a study of the vowels. J Acoust Soc Am. 1952;24:175–184. [Google Scholar]
- Schilder AGM, Snik ADM, Straatman H, van den Broek P. The effect of otitis media with effusion at preschool age on some aspects of auditory perception at school age. Ear and Hearing. 1994;15:224–231. doi: 10.1097/00003446-199406000-00003. [DOI] [PubMed] [Google Scholar]
- Studebaker GA. A “rationalized” arcsine transform. J Speech Hear Res. 1985;28:455–462. doi: 10.1044/jshr.2803.455. [DOI] [PubMed] [Google Scholar]
- Studebaker GA, Pavlovic CV, Sherbecoe RL. A frequency importance function for continuous discourse. Journal of the Acoustical Society of America. 1987;81:1130–1138. doi: 10.1121/1.394633. [DOI] [PubMed] [Google Scholar]
- Uchanski RM, Geers AE, Protopapas A. Intelligibility of modified speech for young listeners with normal and impaired hearing. J Speech Lang Hear Res. 2002;45:1027–1038. doi: 10.1044/1092-4388(2002/083). [DOI] [PubMed] [Google Scholar]
- Welsh LW, Welsh JJ, Healy MP. Effect of sound deprivation on central hearing. Laryngoscope. 1983;93:1569–1575. doi: 10.1288/00005537-198312000-00010. [DOI] [PubMed] [Google Scholar]