

Abstract
Are 15-month-old infants able to detect a violation in the consistency of an event sequence that involves pretense? In Experiment 1, infants detected a violation when an actor pretended to pour liquid into one cup and then pretended to drink from another cup. In Experiment 2, infants no longer detected a violation when the cups were replaced with objects not typically used in the context of drinking actions, either shoes or tubes. Experiment 3 showed that infants’ difficulty in Experiment 2 was not due to the use of atypical objects per se, but arose from the novelty of seeing an actor appearing to drink from these objects. After receiving a single familiarization trial in which they observed the actor pretend to drink from either a shoe or a tube, infants now detected a violation when the actor pretended to pour into and to drink from different shoes or tubes. Thus, at an age (or just before the age) when infants are beginning to engage in pretend play, they are able to show comprehension of at least one aspect of pretense in a violation-of-expectation task: specifically, they are able to detect violations in the consistency of pretend action sequences.
Keywords: Cognitive development, Infancy, Pretense comprehension, Theory of mind
1. Introduction
As adults we understand that others act on the basis of their intentions and interpretations of the world and not directly on the basis of how the world is. Recent evidence suggests that infants in the first year also regard other people as acting with goals (e.g., Guajardo & Woodward, 2004; Király, Jovanovic, Prinz, Aschersleben, & Gergely, 2003; Sommerville & Woodward, 2005; Thoermer & Sodian, 2001; Woodward, 1998, 1999; Woodward & Guajardo, 2002; Woodward & Sommerville, 2000) and will interpret appropriate motion patterns even in inanimate objects as goal-directed, such as the intention to choose or attend to one object rather than another (e.g., Bíró & Leslie, in press; Csibra, Bíró, Koós, & Gergely, 2003; Csibra, Gergely, Bíró, Koós, & Brockbank, 1999; Gergely, Nádasdy, Csibra, & Bíró, 1995; Johnson, Slaughter, & Carey, 1998; Kamewari, Kato, Kanda, Ishiguro, & Hiraki, 2005; Kuhlmeier, Wynn, & Bloom, 2003; Shimizu & Johnson, 2004), and do so even as young as five months of age (Luo & Baillargeon, 2005). The nature and development of the infant’s understanding of intentional action have become central issues in infancy research. To date, this research has focused on how infants come to understand intentional action that is consistent with the actual state of the world. However, we are not limited to understanding world-consistent intentional action but, perhaps uniquely among species, we can also understand world-inconsistent action as intentional. Infants show the first striking signs of this emerging ability during the second year of life in shared pretense play.
Learning about the relation between goals and actions is already a difficult computational problem when the relation is world consistent (see Csibra & Gergely, 2007, for an insightful discussion). This problem can only be made more difficult when, for example, the infant observes an adult pretending to pour liquid from an empty container or pretending to drink from an empty cup, because the actions do not involve real substances and have no real effects. Yet infants appear to solve these problems and do so without undermining emerging knowledge or representations (Leslie, 1987). If infants learn about goals by associating actions with their effects, then actions with pretend intentions will typically defeat this strategy because there are usually no effects of pretend actions. According to one view, in order to learn about actions and goals, infants must first become familiar with a specific action and its effects in their own repertoire before they can recognize that specific intention in other people (e.g., Meltzoff, 2005, 2007; Woodward, 1999). Must one depend on the other in the case of pretense actions? Can infants who have little or no experience at producing a specific pretend action nevertheless recognize that intention in another person? According to another view, perceiving an efficient or rational relation between an action and the end achieved is critical for understanding the intention underlying the action (e.g., Csibra & Gergely, 2007; Gergely, Bekkering, & Király, 2002; Gergely et al., 1995). Because pretense play often achieves no obvious ends, it is unclear on this account how infants would learn about pretense intentions.
We explore these questions by using, for the first time, a violation-of-expectation pretense task with 15-month-old infants—an age at which productive pretense play is uncommon or even absent. Violation-of-expectation pretense tasks can provide a more direct way to investigate the recognition and comprehension of pretense than the measures used heretofore, which have usually relied upon the infants’ ability to produce pretend acts.
1.1. Goals of the present research
The nature and origins of our capacity for pretense has been actively studied since Piaget’s classic works on infancy (especially Piaget, 1962). Early work focused exclusively on the infant’s ability to produce various kinds of pretend-play acts (e.g., Bates, Benigni, Bretherton, Camaioni, & Volterra, 1979; Fenson & Ramsay, 1980, 1981; Huttenlocher & Higgins, 1978; McCune-Nicolich, 1981). Following Leslie (1987), early pretend play began to be conceptualized as part of social cognition, specifically, as a ‘theory of mind’ ability, and focus shifted toward the infant’s ability to recognize pretending in other people and to share pretense with play partners (e.g., Bosco, Friedman, & Leslie, 2006; Harris & Kavanaugh, 1993; Harris, Kavanaugh, & Dowson, 1997; Leslie, 1988, 1994a; Walker-Andrews & Harris, 1993; Walker-Andrews & Kahana-Kalman, 1999). In a recent development, Lillard and colleagues have begun to study the nature of the signals that are given by an adult pretend-play partner and to which the infant is sensitive, on the assumption that these signals will be critical to infant recognition of pretense (Lillard & Witherington, 2004). Despite this shift of theoretical focus toward pretense recognition, the measure of recognition and comprehension has remained the infant’s production of pretend-play actions. Our first goal in the present research was to investigate whether looking-time measures within the violation-of-expectation paradigm (Baillargeon, 2004) could be used to test infants’ recognition and comprehension of pretense, without requiring infants to produce pretend acts themselves.
Productive pretense first reliably appears between 18 and 24 months (e.g., Leslie, 1987; Piaget, 1962), though earlier pretense has occasionally been found in free play (e.g., Fenson & Ramsay, 1981; Haight & Miller, 1993; Tamis-LeMonda & Bornstein, 1994) and in experimental settings (e.g., Bosco et al., 2006; Walker-Andrews & Kahana-Kalman, 1999). At 15 months, Bosco et al. (2006) found evidence for only the simplest forms of pretense recognition when production was used as the measure and suggested that at very young ages the performance demands on action planning and control systems were a major limiting factor. If looking-time measures can be used successfully at this age, then they open an avenue for studying pretense comprehension that is freer of these performance demands. A second goal of the present research, then, was to allow a more accurate determination of underlying competence and its development and, in conjunction with studies of production, a better understanding of the nature of pretense performance demands. Both of these are key long-term goals of ‘theory of mind’ research and indeed of cognitive development research in general (e.g., Csibra & Gergely, 1998; Leslie, 2000; Leslie, Friedman, & German, 2004).
A third goal of the present research followed from recent findings suggesting that 15-month-old infants form expectations regarding an actor’s behavior that are appropriate to the actor’s, but not to the infant’s, beliefs about the situation (Onishi & Baillargeon, 2005). Infants were familiarized to an actor who hid an object in one of two boxes. The actor then either left the scene (false-belief condition) or remained watching (true-belief condition) while the object moved by itself from the original box into the other box. This recapitulates the essentials of what became the standard ‘Sally and Anne’ false-belief task (Baron-Cohen, Leslie, & Frith, 1985), but is entirely non-verbal. Infants’ looking times to one of two test events were then recorded: either the actor reached into the original box or into the other box where the object really was. In the false-belief condition, infants looked longer when the actor reached into the box that currently hid the object and shorter when she reached into the original box, where she wrongly believed the object to be. Infants in the true-belief condition showed the opposite pattern, looking longer if the actor reached into the original box. Looking times therefore reflected the violation of an expectation based on the actor’s belief states rather than on the actual location of the object. These findings are unexpected on those views of ‘theory of mind’ development that postulate a long learning process that leads to a false-belief concept only during the fifth year of life, and are thus highly controversial (see e.g., Perner & Ruffman, 2005; also the exchange between Leslie, 2005 and Ruffman & Perner, 2005). Because belief and pretense (make-believe) are cognate concepts, a looking-time study of pretense could provide background evidence relevant to Onishi and Baillargeon’s findings on false belief. For example, Perner and Ruffman (2005) suggested that these findings may have simply reflected infants’ expectation that an actor will behave toward the last seen location of an object. Pretend scenarios allow us to test whether infants can form expectations with regard to an actor’s pretend intentions toward an object or a property that does not exist and therefore was never seen.
Finally, a fourth goal of the present research was to test a new way to examine physical reasoning in infants. According to Leslie’s model of pretense (Leslie, 1987, 1994a), infants do not need to learn special pretend transformations (Fein, 1975), but can simply apply their regular real world knowledge albeit in an abstract form to draw inferences about what should happen next in a pretend scenario. For example, if infants understand that upturning a cup will cause any (real) water it contains to fall out, then they can apply that same knowledge to compute what will ‘happen’, if an actor, who is pretending that a cup contains (imaginary) ‘water’, upturns that cup: namely, the ‘water’ will ‘fall out’. As long as the infant’s representation of the scenario, together with any inferential processing of those representations, remains decoupled, as indicated in the example by the quotation marks, then there need be no confusion with reality. Indeed, because in this pretend scenario there is no actual water in the cup, this kind of inference is an elementary form of counterfactual causal reasoning (Leslie, 1987, 1994a). There is now a substantial literature on factual physical reasoning in infancy stemming mainly from looking-time studies (for a recent review, see Baillargeon, 2004). In this paper, we extend this approach to study early counterfactual (pretense) physical reasoning.
2. Experiment 1
Are 15-month-old infants able to interpret the actions of an actor even when her actions involve an imaginary liquid? In Experiment 1, infants received a single test trial in which they saw a female actor sitting at a window in the back wall of an apparatus; in front of her were an empty jug and two upside-down cups, a blue one on the left and a red one on the right (see Fig. 1). The actor first turned the cups right-side up (thus demonstrating that they were empty), and then lifted the jug and pretended to pour into one of the cups. Finally, the actor lifted the blue cup up to her lips and pretended to drink from it. We explored infants’ understanding of this pretend pouring and drinking sequence by showing two versions of the sequence. Half of the infants saw a consistent sequence in which the actor pretended to pour into the blue cup and then pretended to drink from that cup (expected event). The other infants saw an inconsistent sequence in which the actor pretended to pour into the red cup and then pretended to drink from the blue cup (unexpected event).
Fig. 1.

Schematic drawing of the expected and unexpected test events shown in Experiment 1.
We reasoned that if 15-month-old infants could make sense of the actor’s behavior even when it involved an imaginary liquid, then they should expect her to pretend to pour into and drink from the same cup, rather than from different cups. The infants who saw the unexpected event should thus look reliably longer than those who saw the expected event.
2.1. Method
2.1.1. Participants
Participants were 24 healthy, term infants, 11 male and 13 female, ranging in age from 14 months, 13 days to 15 months, 27 days (M = 15 months, 8 days). An additional 8 infants were tested but not included in the analyses, because they were overly active (4) or talkative (1), because their looking times during the test trial were over 2.5 SD from the mean of their condition (2), or because of observer difficulties (1). Half of the infants saw the expected event, and half saw the unexpected event.
The infants’ names in this and in the following experiments were obtained from birth announcements in the local newspaper. Parents were contacted by letters and follow-up phone calls; they were offered reimbursement for travel expenses but were not otherwise compensated for their participation.
2.1.2. Apparatus
The apparatus consisted of a wooden display booth 128 cm high, 101 cm wide, and 52 cm deep that was mounted 76 cm above the room floor. The infant faced an opening 43 cm high and 93.5 cm wide in the front of the apparatus. Before the test trial, a curtain consisting of a muslin-covered frame 61 cm high and 99.5 cm wide was lowered in front of this opening. The side walls of the apparatus were painted white and the floor was covered with pastel patterned contact paper. The back wall was made of white foam board and had a window 43 cm high and 43 cm wide extending from its lower edge, 10 cm from the right wall (from the infants’ perspective).
The actor sat on a wooden chair behind the window; a muslin curtain behind the actor hid the testing room. The actor wore a long-sleeved dark blue shirt with thin white horizontal stripes and a tan visor, which covered her eyes. At the start of the test trial, the actor’s bare hands rested on the apparatus floor, 15 cm in front of the window. The tips of her middle fingers lay about 10 cm apart, with the left positioned 19.5 cm from the right edge of the window, and the right 13.5 cm from the left edge of the window.
The stimuli used in the test trial were a jug and two cups. The jug was an empty half-gallon milk jug made of translucent white plastic, with no labels and no lid. Its body was roughly rectangular and was 23 cm high, 9.5 cm wide, and 9.5 cm deep; its opening was 2 cm high and 3.5 cm in diameter. Along one edge, just below the jug’s opening, was a hollow handle 9.5 cm tall. At the start of the test trial, the jug was positioned 8 cm to the right and 1 cm in front of the actor’s hands, 12 cm from the right wall; its handle was on the right at the back and was not visible to the infants. The two cups, one blue and one red, were made of plastic and were 9.5 cm tall; each cup was 5 cm in diameter at the base and flared out to a 7.5 cm opening at the top. At the start of the test trial, the cups rested upside-down on the apparatus floor, 8.5 cm apart; the blue cup was on the left and the red cup was on the right. The cups were positioned 10 cm in front of the actor’s hands, 8.5 cm to the left of the jug.
The testing room was brightly lit, and three additional 20-W fluorescent bulbs in the apparatus provided additional light. Standing at an angle on either side of the apparatus were two frames, each 183 cm high, 69 cm wide, and covered with dark blue cloth; the frames helped isolate the infants from the testing room.
2.1.3. Events
In the following text, the numbers in parentheses indicate the number of seconds taken to perform each action. The events are described from the infant’s point of view. To help the actor follow the events’ scripts, a metronome beat softly once per second. A camera mounted behind and next to the infant projected an image of the events onto a TV screen in a different part of the testing room; a supervisor monitored the events to confirm that they followed the prescribed scripts.
Infants received a single test trial in which they saw either the expected or the unexpected event. Each test trial consisted of a 14-s pre-trial followed by a main-trial.
Expected event
At the start of the pre-trial for the expected event, the infants could see the actor, the jug, and the two upside-down cups. After a pause (1 s), the actor used her right hand to turn the blue cup (2 s) and then the red cup (2 s) right-side up. She then returned her right hand to its starting position on the apparatus floor (1 s). Next, the actor used her left hand to grasp the handle of the jug (1 s). She then lifted the jug and upended it at a steep angle over the red cup as though to pour into it (1 s); she then paused (2 s), holding the opening of the jug about 5 cm above the cup (the infants could clearly see that no liquid flowed from the jug into the cup). The actor then returned the jug (1 s) and her left hand (1 s) to their starting positions on the apparatus floor. Finally, the actor grasped the blue cup with her right hand (1 s), brought it to her mouth as though to drink from it (1 s), and then paused. During the main-trial, the actor remained in the same paused position—with the blue cup in front of her mouth—until the trial ended (see below).
Unexpected event
The unexpected event was identical to the expected event except that, instead of pretending to pour into the blue cup, the actor pretended to pour into the red cup. The actor thus pretended to pour into and to drink from different cups.
2.1.4. Procedure
Each infant sat on a parent’s lap centered in front of the apparatus; the infant’s head was about 50 cm from the curtain. Parents were instructed to close their eyes and to remain silent and neutral during the test trial.
Prior to the test trial, the actor knelt next to the parent’s chair and interacted with the infant for a few seconds. She first called the infant’s attention to her shirt. She then showed the infant the two cups, one at a time, tapping their solid bottoms and putting her hand into their openings, to demonstrate that they were cups.
During the test trial, each infant saw either the expected or the unexpected test event. Looking times during the pre-trial and main-trial portions of the trial were computed separately. The infants’ mean looking time during the 14-s pre-trial was 13.9 s (ranging from 12.8 to 14.0 s), indicating that they tended to look continuously during the pre-trial. The main-trial ended when the infant either (1) looked away from the paused scene for two consecutive seconds after having looked for at least two cumulative seconds, or (2) looked for 40 cumulative seconds without looking away for two consecutive seconds.
Each infant’s looking behavior was monitored by two hidden observers who watched the infant through peepholes in the cloth-covered frames on either side of the apparatus. Each observer held a button linked to a computer and depressed the button when the infant looked at the event. The computer used the looking times registered by the primary (typically more experienced) observer to determine the end of the trial. To calculate inter-observer agreement, the main-trial portion of the test trial was divided into 100-ms intervals, and the computer determined within each interval whether the two observers agreed as to whether the infant was or was not looking at the event. Percent agreement was calculated by dividing the number of intervals in which the observers agreed by the total number of intervals in the trial. Agreement was calculated for all 24 infants in Experiment 1 and averaged 95% per infant.
Preliminary analysis of the data revealed no reliable main effect of sex and no reliable interaction between sex and test event, both Fs(1, 20) < 1.03, ps > .32; the data were therefore collapsed across sex in subsequent analyses.
2.2. Results
The infants’ looking times during the main-trial portion of the test trial (see Fig. 2) were analyzed by means of a one-way analysis of variance (ANOVA) with test event (expected or unexpected) as a between-subjects factor. The main effect of test event was reliable, F(1, 22) = 13.18, p < .0025, indicating that the infants who saw the unexpected event (M = 30.7, SD = 9.1) looked reliably longer than those who saw the expected event (M = 18.2, SD = 7.8).
Fig. 2.
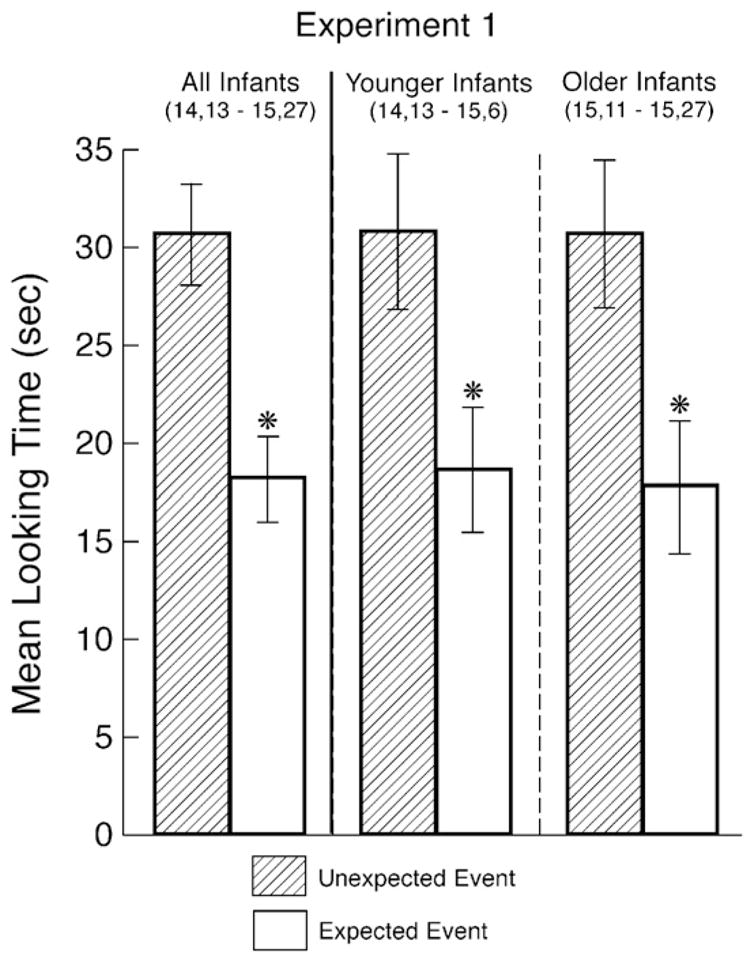
Mean looking times of the infants to the unexpected and expected test events in Experiment 1. Error bars represent standard error.
A non-parametric Wilcoxon rank-sum test confirmed this positive result, WS = 101, p < .01.
Age comparisons
To determine whether the younger as well as the older infants in Experiment 1 showed the same response pattern, the sample was divided into two age groups: there were 12 younger infants, 5 male and 7 female, ranging from 14 months, 13 days to 15 months, 6 days (M = 14 months, 26 days), and 12 older infants, 6 male and 6 female, ranging in age from 15 months, 11 days to 15 months, 27 days (M = 15 months, 20 days). Half of the infants in each age group saw the expected event, and half saw the unexpected event.
The infants’ looking times during the main-trial portion of the test trial (see Fig. 2) were analyzed by means of a 2 × 2 ANOVA with age (younger or older) and test event (expected or unexpected) as between-subjects factors. Neither the main effect of age nor the interaction between age and test event was reliable, both Fs(1, 20) < 1. However, the main effect of test event was reliable, F(1, 20) = 12.00, p < .0025. Planned comparisons indicated that (1) in the younger group, the infants who saw the unexpected event (M = 30.8, SD = 9.7) looked reliably longer than those who saw the expected event (M = 18.6, SD = 7.9), F(1, 20) = 5.68, p < .05; and (2) in the older group, the infants who saw the unexpected event (M = 30.7, SD = 9.4) also looked reliably longer than those who saw the expected event (M = 17.8, SD = 8.4), F(1, 20) = 6.33, p < .025.
2.3. Discussion
The infants in Experiment 1 who saw the actor pretend to pour into and drink from different cups looked reliably longer than those who saw the actor pretend to pour into and drink from the same cup. Although there was visibly and audibly no liquid present, the infants were able to detect the violation in the unexpected event. These results suggest that infants, from as young as 15 months of age, expect an actor to act consistently within an event sequence, even when her actions were only pretend. Although she was only pretending to pour and drink, she should do so consistently, rather than inconsistently, despite the fact that as there was no actual liquid, there were no real effects and it did not matter from which cup she ‘drank’.
The results of Experiment 1 thus suggested that infants as young as 15 months of age can make sense of pretend action sequences and expect them to be consistent. However, an alternative interpretation of the results was that the infants simply detected a deviation from familiar action scripts. By 15 months, infants are likely to already know something about pouring and drinking (e.g., Reid, Csibra, Belsky, & Johnson, 2007). In particular, they may have learned that when an individual holds a container over a cup and pours liquid into it, then a likely subsequent action is for that individual to lift that cup, and not some other cup, to her mouth. Thus, perhaps the infants in Experiment 1 who saw the unexpected event looked reliably longer because an activated pour-to-cup script activated a linked drink-from-cup script—and the actor’s behavior deviated from that script.
In Experiment 2 we sought to address this alternative explanation. We reasoned that if the events in Experiment 1 simply activated linked pour-to-cup and drink-from-cup action scripts, then infants should no longer detect violations if the cups were replaced with substitute objects not typically used in the context of pouring and drinking actions. For example, if the actor pretended to pour into one of two shoes, there should be no violation if the actor then pretended to drink from the other shoe. Infants should have stored neither pouring nor drinking scripts for shoes, nor learned to link such scripts, on the assumption that such events, in real or pretend versions, would occur infrequently in most infant environments.
Alternatively, if infants could recognize pretense in other people, then they might be able to detect the violation in consistency even when unsuitable objects were used. If the actor was pretending, then she ought to be able to pretend with cups or shoes or any other objects she cared to use. We thus explored the robustness of infants’ understanding of the actor’s pretense by showing sequences similar to those in Experiment 1, but with two types of unsuitable objects (see Fig. 3). Specifically, instead of the blue and the red cups, we used blue and red shoes (shoe condition) or blue and red tubes (tube condition).
Fig. 3.

Schematic drawing of the expected and unexpected test events shown in the shoe and tube conditions of Experiment 2.
3. Experiment 2
The infants in Experiment 2 saw expected and unexpected test events similar to those shown in Experiment 1, except that the cups were replaced with shoes or tubes. Shoes could conceivably hold liquids, but infants were unlikely to ever have seen adults pour into and drink from shoes. Tubes could not hold liquids, and so infants could never have seen adults pour into and drink from tubes. Infants were thus unlikely to have had experiences that would result in the formation of linked pour and drink scripts involving either shoes or tubes.
3.1. Method
3.1.1. Participants
Participants were 24 healthy, term infants, 12 male and 12 female, ranging in age from 14 months, 16 days to 15 months, 29 days (M = 15 months, 9 days). An additional 3 infants were tested but not included in analyses, because they were overly active (2) or drowsy (1). Half of the infants were assigned to the shoe condition (M = 15 months, 10 days), and half to the tube condition (M = 15 months, 9 days). Within each condition, half of the infants saw the expected event, and half saw the unexpected event.
3.1.2. Apparatus
The apparatus and stimuli used in Experiment 2 were the same as in Experiment 1, except that the cups were replaced with shoes or tubes. The shoes were girl slip-on shoes for toddlers, with the straps removed. Each shoe was about 5 cm high (at its highest point), 15 cm long, and 6.5 cm wide. The sole of each shoe was ivory colored, and its upper (which was originally white) was painted with poster paint; one shoe was painted blue and one red. At the start of the test trial, the shoes lay on their sides 1 cm apart, with their tops facing the infant and with their toes pointing to the right. The shoes were positioned 11.5 cm in front of the actor’s hands, 3.5 cm to the left of the jug. Each tube was a cylindrical cardboard tube, 9 cm tall and 6.5 cm in diameter, with walls 2 mm thick. One tube was covered inside and out with blue contact paper, and one with red contact paper. At the start of the test trial, the tubes stood 9.5 cm apart, 10 cm in front of the actor’s hands and 9 cm to the left of the jug.
3.1.3. Events
The infants received a single test trial in which they saw an expected or an unexpected event similar to those shown in Experiment 1, with the following exceptions. In the shoe condition, shoes were used instead of cups; at the start of the pre-trial, the shoes lay on their sides (instead of upside-down, to make them more recognizable), and the actor turned them upright from that position. In the tube condition, tubes were used instead of cups; at the start of the pre-trial, the actor turned the tubes over, even though they looked identical in either position, to keep her actions similar across conditions.
3.1.4. Procedure
The procedure used in the shoe and tube conditions was similar to that of Experiment 1. Prior to the test trial, the actor again knelt next to the parent’s chair, showed the infant her shirt, and then introduced the two objects to be used in the trial. In the shoe condition, the actor showed the infant each shoe one at a time, tapping on its sole and slipping her hand inside its open top. In the tube condition, the actor showed each tube one at a time, putting her hand in both open ends to demonstrate that it was indeed a tube.
During the test trial, the infants saw either the expected or the unexpected test event appropriate for their object condition (shoe or cup condition). The infants’ mean looking time during the 14-s pre-trial at the start of the trial was 13.9 s (ranging from 13.7 to 14.0 s in the shoe condition, and from 13.4 to 14.0 s in the tube condition); the infants thus tended to be highly attentive during the pre-trial. Interobserver agreement was calculated for all 24 infants in Experiment 2 and averaged 96% per infant.
Preliminary analysis of the data revealed no reliable main effect of sex and no reliable interaction between sex and test event, both Fs(1, 20) < 1.12, ps > .30; the data were therefore collapsed across sex in subsequent analyses.
3.2. Results
The infants’ looking times during the main-trial portion of the test trial (see Fig. 4) were analyzed by means of a 2 × 2 ANOVA with object condition (shoe or tube) and test event (expected or unexpected) as between-subjects factors. Neither the main effect of object condition nor the interaction between object condition and test event was reliable, both Fs(1, 20) < 1. The main effect of test event was also not reliable, F(1, 20) < 1, suggesting that the infants who saw the unexpected (M = 17.9, SD = 10.8) and the expected (M = 22.6, SD = 12.2) events tended to look equally overall. Planned comparisons indicated that the same pattern held in each object condition: (1) in the shoe condition, the infants who saw the unexpected (M = 20.8, SD = 13.8) and the expected (M = 22.7, SD = 10.2) events looked about equally, F(1, 20) < 1; and (2) in the tube condition, the infants who saw the unexpected (M = 15.1, SD = 6.6) and the expected (M = 22.5, SD = 15.0) events also looked about equally, F(1, 20) < 1.18, p > .29.
Fig. 4.
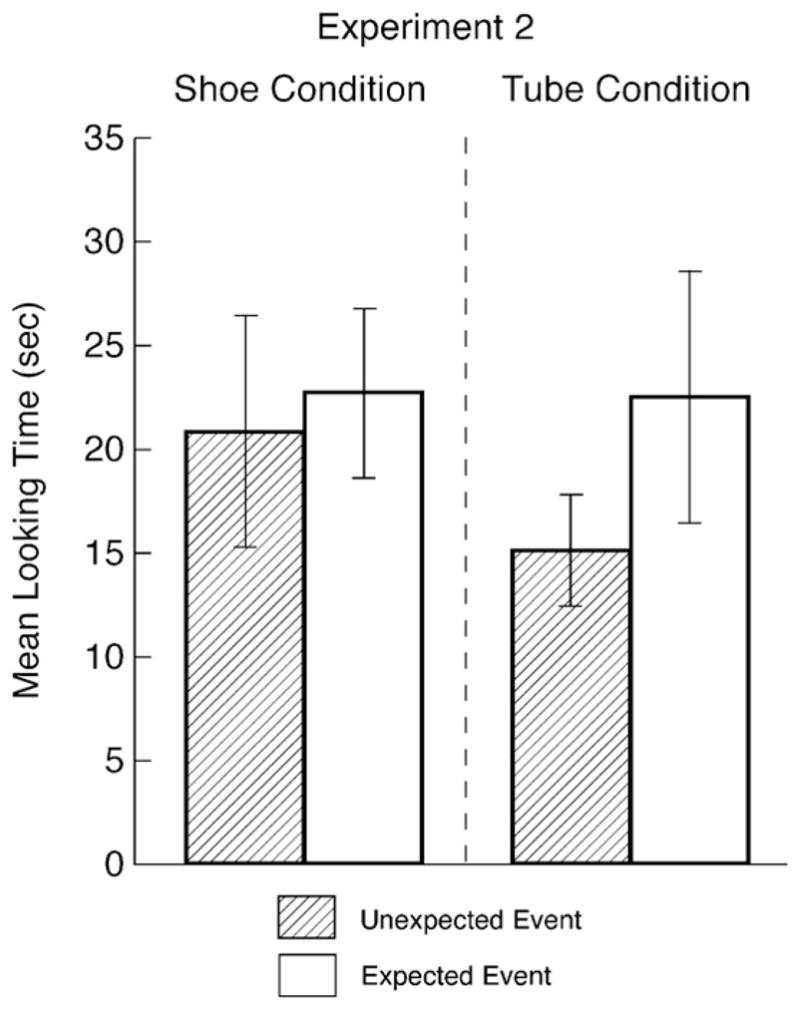
Mean looking times of the infants to the unexpected and expected test events for the two object conditions in Experiment 2. Error bars represent standard error.
Non-parametric Wilcoxon rank-sum tests confirmed the negative results of the shoe (WS = 37, p > .20) and tube (WS = 36, p > .20) conditions.
Comparison to Experiment 1
In an additional analysis, the looking times of the infants in Experiments 1 and 2 were compared by means of a 2 × 2 ANOVA with Experiment (1 or 2) and test event (expected or unexpected) as between-subjects factors (in this analysis, the data from the shoe and tube conditions in Experiment 2 were collapsed). The only reliable effect was the interaction between Experiment and test event, F(1, 44) = 8.68, p < .01. Planned comparisons confirmed that, whereas in Experiment 1 the infants who saw the unexpected event looked reliably longer than those who saw the expected event, F(1, 44) = 9.24, p < .005, in Experiment 2 the infants tended to look equally at the two events, F(1, 44) = 1.26, p > .26.
3.3. Discussion
In Experiment 1, the infants detected a violation when the actor pretended to pour into and to drink from different cups; in Experiment 2, in contrast, the infants failed to detect a violation when the actor pretended to pour into and to drink from different shoes or tubes.
The negative results of Experiment 2 allowed us to rule out one alternative interpretation of the positive results of Experiment 1, namely, that the infants who saw the unexpected event looked reliably longer than those who saw the expected event simply because of perceptual highlighting. In the unexpected event, the actor first pretended to pour into the red cup, drawing the infants’ attention to that cup; next, the actor pretended to drink from the blue cup, causing the infants to shift the focus of their attention from the red to the blue cup, and thus perhaps resulting in longer looking times. In the expected event, in contrast, the actor pretended to pour into and to drink from the blue cup, so that the infants did not have to change the focus of their attention—it simply remained on the blue cup, leading to shorter looking times. According to this perceptual-highlighting hypothesis, the infants in the shoe and tube conditions of Experiment 2 who saw the unexpected event should also have looked reliably longer than those who saw the expected event, because they again had to shift the focus of their attention from the red to the blue shoe, or from the red to the blue tube. The fact that the infants in each condition tended to look equally at the unexpected and expected events thus casts doubt on the notion that the positive results of Experiment 1 were simply due to perceptual highlighting.
How, then, should we explain the discrepant results of Experiments 1 and 2? One possible explanation, raised earlier, was that the infants in Experiment 1 simply evaluated the events they were shown in terms of familiar action scripts. From repeatedly observing adults pour and drink liquids in everyday life, the infants could have learned that when someone pours liquid into a cup, a likely subsequent action is to drink from that cup and not some other cup. Thus, the infants in Experiment 1 could have responded to the unexpected event with increased attention simply because an activated pour-to-cup script triggered a linked drink-from-cup script, and the actor’s behavior deviated from that script. In Experiment 2, in contrast, the infants had no analogous basis for evaluating the test events, because they had never observed adults pour into and drink from shoes or tubes and hence lacked relevant action scripts.
However, there was another possible explanation for the discrepant results of Experiments 1 and 2. It could be that, whereas the infants in Experiment 1 succeeded in detecting the violation in the consistency of the pretend event sequence they were shown, the infants in Experiment 2 failed to do so because the processing demands of the task overwhelmed their limited information-processing resources (for related processing-load argument with older children see Eenshuistra, Ridderinkhof, Weidema, & van der Molen, 2007). A commonly reported developmental sequence in pretend play (e.g., Bretherton, O’Connell, Shore, & Bates, 1984; Fein, 1975) is for infants to begin by pretending with more realistic objects (e.g., having a tea party with toy cups and a toy teapot), and only later expanding to pretend with less-realistic substitute objects (e.g., using blocks as stand-ins for the cups and the teapot). It is possible that such a sequence occurs because realistic objects make fewer processing demands on infants, and that with age and practice infants gradually become better able to meet those demands. Thus, the infants in the shoe and tube conditions of Experiment 2 might have failed to detect the violation they were shown, not because they lacked relevant action scripts, but because they were confused or distracted by the novel sight of the actor pretending to drink from a shoe or a tube. As a result, they were unable to focus on the event as a whole and could not judge whether it unfolded in a consistent or an inconsistent manner.
The preceding analysis predicted that, by providing minimal familiarization with the actor pretending to drink from a shoe or a tube, we might help infants overcome their confusion and hence detect the violation shown in each condition. Experiment 3 was designed to test this possibility.
4. Experiment 3
Experiment 3 was identical to Experiment 2, with one exception: prior to the test trial, the infants received a single familiarization trial in which they saw the actor grasp a green shoe (shoe condition) or a green tube (tube condition) and bring it to her mouth, as though to drink from it (see Fig. 5). The jug was absent in this trial, and no pouring occurred; the red and blue shoes or tubes were also absent. The trial was intended solely to acquaint the infants with the sight of the actor pretending to drink from a shoe or tube.
Fig. 5.
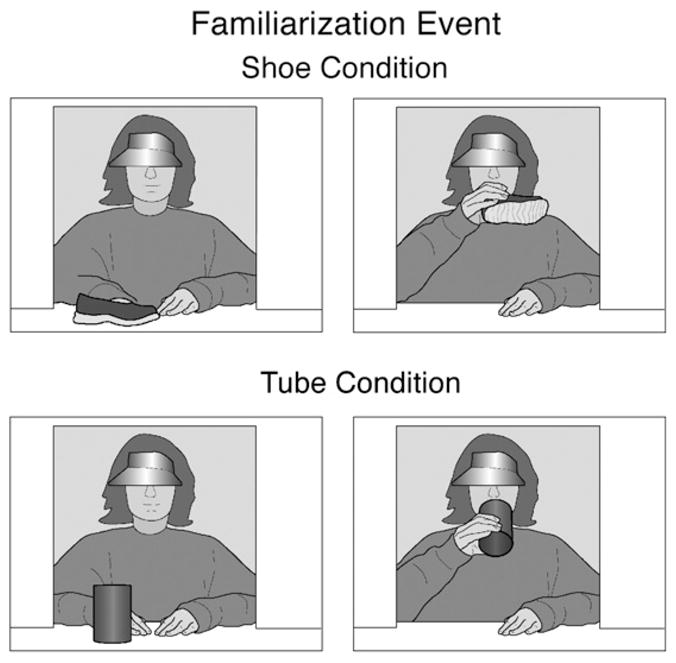
Schematic drawing of the familiarization event shown in the shoe and tube conditions of Experiment 3.
We reasoned that if the infants in the shoe and tube conditions of Experiment 2 failed to detect the violation in the unexpected event because they lacked relevant action scripts (e.g., pour-to-shoe linked to drink-from-shoe scripts), then seeing the actor pretend to drink from a shoe or tube in a single trial could not be sufficient to establish such scripts. As a result, the infants in Experiment 3 should respond like those in Experiment 2, and look about equally at the unexpected and expected events.
On the other hand, if the infants in the shoe and tube conditions of Experiment 2 failed to detect the violation in the unexpected event because (1) they had never seen a person drink (or pretend to drink) from shoes or tubes before and hence (2) they were distracted by the novelty or incongruity of this behavior, then the infants in Experiment 3, who were given a brief preview of the behavior, might be able to overcome their distraction and to focus on the consistency or inconsistency of the event. Thus, in each condition, the infants who saw the unexpected event should look reliably longer than those who saw the expected event, as in Experiment 1.
4.1. Method
4.1.1. Participants
Participants were 24 healthy, term infants, 12 male and 12 female, ranging in age from 14 months, 24 days to 16 months, 0 day (M = 15 months, 11 days). An additional 9 infants were tested but not included in the analyses, because they looked for the maximum amount of time allowed (60 s) during the familiarization trial thus showing a failure to disengage (3), because their looking times during the test trial were over 2.5 SD from the mean of their condition (3), because of observer difficulties (1), or because they were distracted (1) or talkative (1). As in Experiment 2, half of the infants were assigned to the shoe condition (M = 15 months, 8 days), and half to the tube condition (M = 15 months, 13 days). Within each condition, half of the infants saw the expected event, and half saw the unexpected event.
4.1.2. Apparatus
The apparatus and stimuli used in Experiment 3 were similar to those in Experiment 2, except that the familiarization trial involved a green shoe or a green tube; these were identical to the shoes and tubes used in Experiment 2, except for color. At the start of the familiarization trial, the green shoe rested right-side up on the apparatus floor, toe to the right; it stood 10 cm in front of the actor’s hands, with its center positioned 40.5 cm from the right wall of the apparatus. The green shoe thus occupied the midway position between those occupied by the blue and red shoes in the test trial. Similarly, the green tube stood 10 cm in front of the actor’s hands, with its center positioned 41.75 cm from the right wall of the apparatus; the green tube thus occupied the midway position between those occupied by the blue and red tubes in the test trial.
4.1.3. Events
The events shown in Experiment 3 were identical to those in Experiment 2, with one exception. Prior to the test trial, the infants received a single familiarization trial involving either a green shoe (shoe condition) or a green tube (tube condition). The familiarization trial consisted of a 3-s pre-trial followed by a main-trial. At the start of the pre-trial in the shoe condition, the actor sat at the window in the back wall of the apparatus, with her bare hands on the floor. After a pause (1 s), the actor used her right hand to grasp the shoe (1 s). She then lifted it to her mouth, as though to drink from it (1 s), and paused. During the main-trial, the actor remained in the same paused position, with the green shoe at her mouth, until the trial ended. In the tube condition, the green shoe was replaced with the green tube.
4.1.4. Procedure
The procedure used in Experiment 3 was similar to that in Experiment 2, with the following exceptions. Prior to the session, the actor knelt next to the parent’s chair, showed the infant her shirt, and then introduced the object to be used in the familiarization trial in addition to the two objects to be used in the test trial.
Next, the infants received one familiarization trial in which they saw the event appropriate for their object condition (shoe or tube). The infants’ mean looking time during the 3-s pre-trial at the start of the familiarization trial was 2.9 s (ranging from 2.5 to 3.0 s in the shoe condition, and from 2.2 to 3.0 s in the tube condition), indicating that the infants tended to watch during the entire pre-trial. The main-trial portion of the familiarization trial ended when the infants either (1) looked away from the paused scene for two consecutive seconds after having looked for at least two cumulative seconds or (2) looked for 60 cumulative seconds without looking away for two consecutive seconds.
Next, the infants saw either the expected or the unexpected test event appropriate for their object condition (shoe or tube condition). The infants’ mean looking time during the 14-s pre-trial at the start of the test trial was 14.0 s (ranging from 14.0 to 14.0 s in the shoe condition and from 13.6 to 14.0 s in the tube condition), indicating that the infants were highly attentive during the pre-trial.
Interobserver agreement during the familiarization and test trials was calculated for 23 of the 24 infants in Experiment 3 (only one observer was present for one infant) and averaged 96% per trial per infant.
Preliminary analysis of the test data revealed no reliable main effect of sex and no reliable interaction between sex and test event, both Fs(1, 20) < 1; the data were therefore collapsed across sex in subsequent analyses.
4.2. Results
Familiarization trial
The infants’ looking times during the main-trial portion of the familiarization trial (see Fig. 6) were analyzed by means of a 2 ×2 ANOVA with object condition (shoe or tube) and test event condition (expected or unexpected) as between-subjects factors. The main effect of object condition was marginally reliable, F(1, 20) = 3.56, p < .08, suggesting that the infants in the shoe condition (M = 27.3, SD = 12.4) tended to look longer overall than those in the tube condition (M = 18.8, SD = 8.2). No other effect was reliable, both Fs(1, 20) < 1. The infants thus appeared to find the sight of the actor pretending to drink from the green shoe somewhat more novel or interesting than the sight of the actor pretending to drink from the green tube.
Fig. 6.

Mean looking times of the infants in the two object conditions and the two event conditions of Experiment 3 during the familiarization trial (top) and test trial (bottom).
Test trial
The infants’ looking times during the main-trial portion of the test trial (see Fig. 6) were analyzed in the same manner as the familiarization trial. Neither the main effect of object condition, F(1, 20) = 2.70, p > .11, nor the object condition × test event interaction, F(1, 20) < 1, was reliable. However, the main effect of test event was reliable, F(1, 20) = 19.10, p < .0005, indicating that the infants who saw the unexpected event (M = 24.2, SD = 8.0) looked reliably longer overall than those who saw the expected event (M = 11.9 SD = 5.7). Planned comparisons revealed that the same pattern held in each object condition: (1) in the shoe condition, the infants who saw the unexpected event (M = 22.0, SD = 8.4) looked reliably longer than those who saw the expected event (M = 9.5, SD = 4.1), F(1, 20) = 10.08, p < .005; and (2) in the tube condition, the infants who saw the unexpected (M = 26.3, SD = 7.7) again looked reliably longer than those who saw the expected event (M = 14.4, SD = 6.4), F(1, 20) = 9.04, p < .01.
Non-parametric Wilcoxon rank-sum tests confirmed the positive results of the shoe (WS = 23, p < .01) and tube (WS = 24, p < .025) conditions.
The test data in Experiment 3 were also subjected to an analysis of covariance (ANCOVA), using as a covariate the infants’ looking time during the familiarization trial. The results of the ANCOVA replicated those of the ANOVA: the only reliable effect was the main effect of test event, F(1, 16) = 7.31, p < .025; and planned comparisons confirmed that the infants who saw the unexpected event looked reliably longer than those who saw the expected event in both the shoe condition, F(1, 16) = 10.72, p < .005, and the tube condition, F(1, 16) = 9.62, p < .01.
Comparison to Experiment 2
In a final analysis, the looking times of the infants in Experiments 2 and 3 were compared by means of a 2 × 2 × 2 ANOVA with Experiment (2 or 3), object condition (shoe or tube), and test event (expected or unexpected) as between-subjects factors. Recall that the only difference between the two experiments was that the infants in Experiment 3 received a familiarization trial prior to the test trial. The only reliable effect was the interaction between Experiment and test event, F(1, 40) = 9.07, p < .005. Planned comparisons confirmed that, whereas in Experiment 2 the infants who saw the unexpected and expected events tended to look equally, F(1, 40) = 1.38, p > .24, in Experiment 3 the infants who saw the unexpected event looked reliably longer than those who saw the expected event, F(1, 40) = 9.52, p < .005. Additional planned interaction comparisons revealed that this interaction pattern was marginally reliable when the data from the shoe conditions in Experiments 2 and 3 were examined separately, F(1, 40) = 3.30, p < .08, and was reliable for the tube conditions, F(1, 40) = 5.97, p < .025.
4.3. Discussion
The infants in Experiment 3 detected the violation in the consistency of the pretend event sequences they were shown, suggesting that they were able to make sense of the actor’s pretend actions even when substitute objects were used.
The results from Experiment 3 are consistent with our hypothesis that the infants in Experiment 2 failed to detect the violation in the unexpected event they were shown because they were distracted by the novelty or incongruity of seeing the actor ‘drink’ from a shoe or tube. After seeing the actor pretend to drink from a shoe or tube in the familiarization trial, the infants in Experiment 3 were able to follow and process the entire event sequence shown in the test trial: they now looked reliably longer when the actor pretended to pour into and to drink from different objects, than when she pretended to pour into and to drink from the same object.
The results of Experiment 3 are also inconsistent with the notion that the infants in Experiment 1 responded to the unexpected event with increased attention simply because it deviated from familiar action scripts. The infants in the shoe and tube conditions of Experiment 3 also responded to the unexpected event with increased attention, and the single familiarization trial they received is unlikely to have resulted in the formation of appropriate scripts (e.g., pour-to-shoe and drink-from-shoe scripts). Not only are such scripts assumed to require repeated experiences (e.g., Schank & Abelson, 1977), but we did not familiarize the infants with a pouring action, so they could not have formed a pour-to-object script, nor could they have linked it to a drink-from-object script.
Finally, the results of Experiment 3 suggest that infants are able to detect a violation in the consistency of a pretend sequence even when it involves substitute objects very different from those usually associated with the sequence. The shoes were physically appropriate as substitute objects in that they could hold liquid, but they were contextually inappropriate in that shoes are rarely used for drinking purposes (apart perhaps from champagne now and then). The tubes were both physically and contextually inappropriate, since tubes cannot hold liquid and hence are never used for drinking activities. The fact that the infants in the present research were able to detect violations in the consistency of pretend pour-and-drink sequences involving cups, shoes, or tubes suggests that their ability to comprehend pretend sequences was quite robust. Once the infants had minimal opportunity to observe that the actor was willing to ‘drink’ from shoes or tubes—no such opportunity was needed with cups, as the infants were already familiar with their use in the context of drinking activities—they were able to monitor the pretend sequences as they unfolded and to detect inconsistencies when they occurred. If the actor chose to ‘drink’ from shoes or tubes, then she should ‘drink’ from the one she had just ‘poured’ into, and not from another, empty one.
5. General discussion
In Experiment 1, 15-month-old infants readily detected a violation in a highly familiar event sequence when common objects were used, looking longer when an actor pretended to pour into one cup and then inconsistently pretended to drink from another cup, than when she pretended to pour into and to drink from the same cup. This finding suggests that at an age before infants are commonly engaging in pretend play, they have some expectations about how others should engage in pretense. In Experiment 2, infants failed to detect violations in the same event sequences when substitute objects were used, suggesting that perhaps infants did not understand the pretend sequences of Experiment 1, but merely had specific scripted expectations tied to sequences of actions involving jugs and cups. However, in Experiment 3, infants detected violations in the test events from Experiment 2 after they had been familiarized with the actor performing pretend drinking actions on a similar object. This pattern of results demonstrated that the infants were able to detect the violation in the sequences involving the substitute objects, but needed a little more time or exposure to do so.
The particular pretend sequences we used were closely comparable to those in the ‘simple’ pretend tasks of Bosco et al. (2006) that required infants to produce a play action or to point in response to a question. In that study, 16-month-olds also passed pretend pouring-and-drinking scenarios. The present results are consistent with these previous results but extend them to younger infants using a looking-time measure. The present results indicate that violation-of-expectation tasks can be a useful addition to traditional measures of pretend-play ability. Traditional measures require the child to enter into and share pretense with another person, often the experimenter, by producing a playful response or by answering a question, or to produce play actions in solitary pretense. Such measures require the child to produce a voluntary response or produce play; they often require some language ability at the same time. Looking-time measures do not require infants to produce a play action and are usually entirely non-verbal. Such measures may be especially useful with special populations such as children with autism or with language delays. Bosco et al. found that 16-month-olds failed on more complex pretense, such as a task in which an imaginary filling-emptying-bowls sequence was followed by a pretend feeding of a hungry dog from either of two bowls, only one of which should contain imaginary food. With normally developing infants, it will be interesting to see if infants of this age can pass such a scenario in a violation-of-expectation task.
By 15 months, infants can follow a pretend sequence. They expect a pretend pouring event to be followed by a pretend drinking event from the same cup, shoe, or tube. Experiment 2 ruled out perceptual highlighting as an explanation for these results. Experiment 3 ruled out simple knowledge of scripts, because infants are unlikely to have a script for pouring or drinking with shoes or tubes, let alone a script for pouring into and drinking from the same shoe or tube. The infants were able to reason about pretend sequences involving these substitute objects, but found them harder. However, a single trial to acquaint, or perhaps to prime, the infants with the idea of pretend drinking from a shoe or tube was all that was required in order to establish a subsequent expectation that the actor should ‘drink’ from the same shoe or tube that she had ‘poured something into’ earlier. Our results therefore extend the existing literature on goal detection in infancy. Previous findings have shown that by the second year of life, infants detect a wide range of agents’ intentions in action or goals (e.g., Elsner, 2007; Gergely et al., 2002; Song & Baillargeon, 2007; see also Bíró & Leslie, in press, for a recent review). The present findings indicate that by 15 months of age, infants can also form expectations regarding actors’ intentions towards objects or properties that do not actually exist.
Might the present results be explained simply by saying that, as Woodward (1998) showed, even young infants expect an actor who intentionally interacts with one of two objects to later act again on this rather than the other object? The difference in the present case, of course, is that the actor did not actually interact with or act upon either of the objects during the test event. During the pre-trials, the actor acted only upon the jug, merely holding it above one or the other of the objects without further consequence. Infants in the Woodward paradigm require there to be a known cause-effect relation between the act and the target object; without a known effect, infants will not interpret the act as directed toward that object (Bíró & Leslie, in press; Király et al., 2003; Woodward, 1999). In our pretend sequences the actor’s actions had no effects on the test object; at least, no actual effects. However, the results do suggest that the infants interpreted these actions as if they did have effects; this, we suggest, is because they interpreted the sequences as pretend scenarios. Future research should examine more closely the specificity of the infants’ interpretations of pretense: for example, are their expectations as specific in looking-time studies as they were with the production measures used by Bosco et al. (2006)?
The ability to interpret agents’ behavior in relation to intentional states that have a counterfactual or imaginary content has been held to be a hallmark of mentalistic understanding (e.g., Leslie, 1987, 1994b). In this regard, the present results comport with recent findings by Onishi and Baillargeon (2005) that 15-month-olds expect an actor to behave according to the actor’s belief about the state of the world, even when the actor’s belief is false. Perner and Ruffman (2005); also Ruffman and Perner, 2005 suggested that the results of Onishi and Baillargeon sprang from a simple innate rule infants may have, rather than from any mentalistic notion. The proposed rule, that an actor should behave toward an object in the last location in which the actor saw the object, will not account for the present results. The ‘object’ toward which our actor acted was imaginary and was therefore never seen.
As adults, when we slip into a world of pretense or fiction, though we expect to encounter novel events and imaginary objects and people, we also expect an entire episode to have internal consistency. For example, if we read about the regicidal Macbeth ascending the Scottish throne in one scene, we do not expect Macbeth to be working in a bank in California in the next. Likewise, if Amanda pretends to be ill so as not to go to school, she should not be found running around outside playing basketball. In the present research, we demonstrated that 15-month-old infants have at least an elementary understanding that even pretend event sequences should be internally consistent.
Such expectations of consistency do not necessarily require sophisticated understanding but may simply follow from the basic processing mechanisms of pretense. For example, according to the model presented by Leslie (1987, 1994a), pretense begins by stipulating a state of affairs, for example, ‘there is water in this jug’. This stipulated state of affairs is only imaginary (because the jug is empty), but developing this stipulation into a sequence or game can proceed by mentally applying real-world knowledge. For example, in the real world, if you turn a jug of water upside down, then the water will come out and pour in a downward direction. In a reasoning process, real-world knowledge as in the previous if-then rule can be applied to the stipulated (pretend) situation ‘there is water in this jug’. Thus, as long as the inferred consequent is also marked as a pretend situation ‘the water pours into the cup’, no confusion or representational abuse will arise.
Of course, it is possible to pretend, for example, that water poured out of a jug goes in an upward direction. But because this outcome departs from real-world knowledge, it will have to be stipulated rather than inferred. The upshot is that unless some imaginary situation is either stipulated or inferred from something that has been stipulated, the pretense will retain real-world assumptions. Put another way, real-world assumptions are maintained unless otherwise specified. This mode of operation is just economy of effort, a kind of ‘representational inertia’: the pretend world will be represented as minimally different from the (assumed) real world. One interpretation, then, of our finding that 15-month-olds expect pretend event sequences to be internally consistent is simply that this is the most economical representation to compute—the representation with the greatest ‘inertia’. However, it constitutes an extension of the primary physical reasoning that is the achievement of infants in the first year. It is the birth of counterfactual reasoning.
Finally, according to some accounts, the social aspects of interactions are of central importance for learning about intentionality (Rochat, 2007) and about pretend play (Les-lie, 1987). In the real world, pretend play is very often shared between partners as a type of intentional communication (Leslie & Happé, 1989). It is possible to think of the present experiments in this light where the infant spontaneously assumes the actor is trying to communicate with her about a pretense in which she then shares. Such speculations could be addressed in future research.
The research reported here will need to be extended to many other kinds of pretend scenarios. Until then, our findings and conclusions must remain somewhat tentative. However, the extension of the violation-of-expectation method to the study of pretense and other issues long central to ‘theory of mind’ development (e.g., Onishi & Baillargeon, 2005) holds out great promise of opening up new routes to understanding the structure of infant social intelligence.
Acknowledgments
This research was supported by a grant from NICHD to Renée Baillargeon (HD-21104) and from Fonds québécois de la recherche sur la société et la culture (FQRSC) and the Natural Sciences and Engineering Research Council of Canada (NSERC) to Kristine H. Oni-shi. We thank the staff of the University of Illinois Infant Cognition Laboratory for their help with the data collection, and the parents and infants who participated in the research.
References
- Baillargeon R. Infants’ reasoning about hidden objects: evidence for event-general and event-specific expectations. Developmental Science. 2004;7:391–424. doi: 10.1111/j.1467-7687.2004.00357.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baron-Cohen S, Leslie AM, Frith U. Does the autistic child have a “theory of mind”? Cognition. 1985;21:37–46. doi: 10.1016/0010-0277(85)90022-8. [DOI] [PubMed] [Google Scholar]
- Bates E, Benigni L, Bretherton I, Camaioni L, Volterra V. The emergence of symbols: Cognition and communication in infancy. New York: Academic Press; 1979. [Google Scholar]
- Bíró S, Leslie AM. Infants’ perception of goal-directed actions: development through cue-based bootstrapping. Developmental Science. doi: 10.1111/j.1467-7687.2006.00544.x. in press. [DOI] [PubMed] [Google Scholar]
- Bosco FM, Friedman O, Leslie AM. Recognition of pretend and real actions in play by 1- and 2-year-olds: early success and why they fail. Cognitive Development. 2006;21:3–10. [Google Scholar]
- Bretherton I, O’Connell B, Shore C, Bates E. The effect of contextual variation on symbolic play: development from 20 to 28 months. In: Bretherton I, editor. Symbolic play and the development of social understanding. New York: Academic Press; 1984. pp. 271–298. [Google Scholar]
- Csibra G, Bíró S, Koós O, Gergely G. One-year-old infants use teleological representations of actions productively. Cognitive Science. 2003;27:111–133. [Google Scholar]
- Csibra G, Gergely G. The teleological origins of mentalistic action explanations: a developmental hypothesis. Developmental Science. 1998;1:255–259. [Google Scholar]
- Csibra G, Gergely G. ‘Obsessed with goals’: Functions and mechanisms of teleological interpretation of actions in humans. Acta Psychologica. 2007;124(1):60–78. doi: 10.1016/j.actpsy.2006.09.007. [DOI] [PubMed] [Google Scholar]
- Csibra G, Gergely G, Bíró S, Koós O, Brockbank M. Goal attribution without agency cues: the perception of ‘pure reason’ in infancy. Cognition. 1999;72:237–267. doi: 10.1016/s0010-0277(99)00039-6. [DOI] [PubMed] [Google Scholar]
- Eenshuistra RM, Ridderinkhof KR, Weidema MA, van der Molen MW. Developmental changes in oculomotor control and working-memory efficiency. Acta Psychologica. 2007;124(1):139–158. doi: 10.1016/j.actpsy.2006.09.012. [DOI] [PubMed] [Google Scholar]
- Elsner B. Infants’ imitation of goal-directed actions: The role of movements and action effects. Acta Psychologica. 2007;124(1):44–59. doi: 10.1016/j.actpsy.2006.09.006. [DOI] [PubMed] [Google Scholar]
- Fein GG. A transformational analysis of pretending. Developmental Psychology. 1975;11:291–296. [Google Scholar]
- Fenson L, Ramsay DS. Decentration and integration of the child’s play in the second year. Child Development. 1980;51:171–178. [Google Scholar]
- Fenson L, Ramsay DS. Effects of modeling action sequences on the play of 12-, 15-, and 19-month-old children. Child Development. 1981;52:1028–1036. [PubMed] [Google Scholar]
- Gergely G, Bekkering H, Király I. Rational imitation in preverbal infants. Nature. 2002;415:755. doi: 10.1038/415755a. [DOI] [PubMed] [Google Scholar]
- Gergely G, Nádasdy Z, Csibra G, Bíró S. Taking the intentional stance at 12 months of age. Cognition. 1995;56:165–193. doi: 10.1016/0010-0277(95)00661-h. [DOI] [PubMed] [Google Scholar]
- Guajardo JJ, Woodward AL. Is agency skin-deep? Surface attributes influence infants’ sensitivity to goal-directed action. Infancy. 2004;6:361–384. [Google Scholar]
- Haight W, Miller P. Pretending at home: development in sociocultural context. Albany, NY: State University of New York Press; 1993. [Google Scholar]
- Harris PL, Kavanaugh RD. Young children’s understanding of pretense. Monographs of the Society for Research in Child Development. 1993;58:1–92. [Google Scholar]
- Harris PL, Kavanaugh RD, Dowson L. The depiction of imaginary transformations: early comprehension of a symbolic function. Cognitive Development. 1997;12:1–19. [Google Scholar]
- Huttenlocher J, Higgins ET. Issues in the study of symbolic development. In: Collins W, editor. Minnesota symposia on child psychology. Vol. 11. Hillsdale, NJ: Erlbaum; 1978. pp. 98–140. [Google Scholar]
- Johnson SC, Slaughter V, Carey S. Whose gaze will infants follow? Features that elicit gaze following in 12-month-olds. Developmental Science. 1998;1:233–238. [Google Scholar]
- Kamewari K, Kato M, Kanda T, Ishiguro H, Hiraki K. Six-and-a-half-month-old children positively attribute goals to human action and to humanoid-robot motion. Cognitive Development. 2005;20:303–320. [Google Scholar]
- Király I, Jovanovic B, Prinz W, Aschersleben G, Gergely G. The early origins of goal attribution in infancy. Consciousness and Cognition. 2003;12:752–769. doi: 10.1016/s1053-8100(03)00084-9. [DOI] [PubMed] [Google Scholar]
- Kuhlmeier VA, Wynn K, Bloom P. Attribution of dispositional states by 12-month-olds. Psychological Science. 2003;14:402–408. doi: 10.1111/1467-9280.01454. [DOI] [PubMed] [Google Scholar]
- Leslie AM. Pretense and representation: the origins of ‘theory of mind’. Psychological Review. 1987;94:412–426. [Google Scholar]
- Leslie AM. Some implications of pretense for mechanisms underlying the child’s theory of mind. In: Astington J, Harris P, Olson D, editors. Developing theories of mind. Cambridge: Cambridge University Press; 1988. pp. 19–46. [Google Scholar]
- Leslie AM. Pretending and believing: issues in the theory of ToMM. Cognition. 1994a;50:211–238. doi: 10.1016/0010-0277(94)90029-9. [DOI] [PubMed] [Google Scholar]
- Leslie AM. ToMM, ToBy, and agency: core architecture and domain specificity. In: Hirschfeld L, Gelman S, editors. Mapping the mind: Domain specificity in cognition and culture. New York: Cambridge University Press; 1994b. pp. 119–148. [Google Scholar]
- Leslie AM. ‘Theory of mind’ as a mechanism of selective attention. In: Gazzaniga M, editor. The new cognitive neurosciences. Cambridge, MA: MIT Press; 2000. pp. 1235–1247. [Google Scholar]
- Leslie AM. Developmental parallels in understanding minds and bodies. Trends in Cognitive Sciences. 2005;9:459–462. doi: 10.1016/j.tics.2005.08.002. [DOI] [PubMed] [Google Scholar]
- Leslie AM, Friedman O, German TP. Core mechanisms in ‘theory of mind’. Trends in Cognitive Sciences. 2004;8:528–533. doi: 10.1016/j.tics.2004.10.001. [DOI] [PubMed] [Google Scholar]
- Leslie AM, Happé F. Autism and ostensive communication: the relevance of metarepresentation. Development and Psychopathology. 1989;1:205–212. [Google Scholar]
- Lillard AS, Witherington DS. Mothers’ behavior modifications during pretense snacks and their possible signal value for toddlers. Developmental Psychology. 2004;40:95–113. doi: 10.1037/0012-1649.40.1.95. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo Y, Baillargeon R. Can a self-propelled box have a goal? Psychological reasoning in 5-month-old infants. Psychological Science. 2005;16:601–608. doi: 10.1111/j.1467-9280.2005.01582.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCune-Nicolich L. Toward symbolic functioning: structure of early use of early pretend games and potential parallels with language. Child Development. 1981;52:785–797. [Google Scholar]
- Meltzoff AN. Imitation and other minds: the ‘like me’ hypothesis. In: Hurley S, Chater N, editors. Perspectives on imitation: From neuroscience to social science. Vol. 2. Cambridge, MA: MIT Press; 2005. pp. 55–77. [Google Scholar]
- Meltzoff AN. The ‘like me’ framework for recognizing and becoming an intentional agent. Acta Psycho-logica. 2007;124(1):26–43. doi: 10.1016/j.actpsy.2006.09.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Onishi K, Baillargeon R. Do 15-month-old infants understand false beliefs? Science. 2005;308:255–258. doi: 10.1126/science.1107621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perner J, Ruffman T. Infants’ insight into the mind: How deep? Science. 2005;308:214–216. doi: 10.1126/science.1111656. [DOI] [PubMed] [Google Scholar]
- Piaget J. Play, dreams, and imitation in childhood. London: Routledge & Kegan Paul; 1962. [Google Scholar]
- Reid VM, Csibra G, Belsky J, Johnson MH. Neural correlates of the perception of goal-directed action in infants. Acta Psychologica. 2007;124(1):129–138. doi: 10.1016/j.actpsy.2006.09.010. [DOI] [PubMed] [Google Scholar]
- Rochat P. Intentional action arises from early reciprocal exchanges. Acta Psychologica. 2007;124(1):8–25. doi: 10.1016/j.actpsy.2006.09.004. [DOI] [PubMed] [Google Scholar]
- Ruffman T, Perner J. Do infants really understand false belief? Trends in Cognitive Sciences. 2005;10:462–463. doi: 10.1016/j.tics.2005.08.001. [DOI] [PubMed] [Google Scholar]
- Schank RC, Abelson R. Scripts, plans, goals, and understanding. Hillsdale, NJ: Erlbaum; 1977. [Google Scholar]
- Shimizu YA, Johnson SC. Infants’ attribution of a goal to a morphologicaly unfamiliar agent. Developmental Science. 2004;7:425–430. doi: 10.1111/j.1467-7687.2004.00362.x. [DOI] [PubMed] [Google Scholar]
- Sommerville JA, Woodward AL. Pulling out the intentional structure of action: the relation between action processing and action production in infancy. Cognition. 2005;95:1–30. doi: 10.1016/j.cognition.2003.12.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song H, Baillargeon R. Can 9.5-month-old infants attribute to an agent a disposition to perform a particular action on objects? Acta Psychologica. 2007;124(1):79–105. doi: 10.1016/j.actpsy.2006.09.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tamis-LeMonda CS, Bornstein MH. Specificity in mother-toddler language-play relations across the second year. Developmental Psychology. 1994;2:283–292. [Google Scholar]
- Thoermer C, Sodian B. Preverbal infants’ understanding of referential gestures. First Language. 2001;21:245–264. [Google Scholar]
- Walker-Andrews A, Harris PL. Young children’s comprehension of pretend causal sequences. Developmental Psychology. 1993;29:915–921. [Google Scholar]
- Walker-Andrews A, Kahana-Kalman R. The understanding of pretence across the second year of life. British Journal of Developmental Psychology. 1999;17:523–536. [Google Scholar]
- Woodward AL. Infants selectively encode the goal object of an actor’s reach. Cognition. 1998;69:1–34. doi: 10.1016/s0010-0277(98)00058-4. [DOI] [PubMed] [Google Scholar]
- Woodward AL. Infants’ ability to distinguish between purposeful and non-purposeful behaviors. Infant Behavior and Development. 1999;22:145–160. [Google Scholar]
- Woodward AL, Guajardo JJ. Infants’ understanding of the point gesture as an object-directed action. Cognitive Development. 2002;17:1061–1084. [Google Scholar]
- Woodward AL, Sommerville JA. Twelve-month-old infants interpret action in context. Psychological Science. 2000;11:73–77. doi: 10.1111/1467-9280.00218. [DOI] [PubMed] [Google Scholar]