

Abstract
Not only the levels of individual metabolites, but also the relations between the levels of different metabolites may indicate (experimentally induced) changes in a biological system. Component analysis methods in current ‘standard’ use for metabolomics, such as Principal Component Analysis (PCA), do not focus on changes in these relations. We therefore propose the concept of ‘Between Metabolite Relationships’ (BMRs): common changes in the covariance (or correlation) between all metabolites in an organism. Such structural changes may indicate metabolic change brought about by experimental manipulation but which are lost with standard data analysis methods. These BMRs can be analysed by the INdividual Differences SCALing (INDSCAL) method. First the BMR quantification is described and subsequently the INDSCAL method. Finally, two studies illustrate the power and the applicability of BMRs in metabolomics. The first study is about the induced plant response of cabbage to herbivory, of which BMRs are a considerable part. In the second study—a human nutritional intervention study of green tea extract—standard data analysis tools did not reveal any metabolic change, although the BMRs were considerably affected. The presented results show that BMRs can be easily implemented in a wide variety of metabolomic studies. They provide a new source of information to describe biological systems in a way that fits flawlessly into the next generation of systems biology questions, dealing with personalized responses.
Electronic supplementary material
The online version of this article (doi:10.1007/s11306-011-0316-1) contains supplementary material, which is available to authorized users.
Keywords: Correlations, Covariance, Relationships, Individual differences, Component models, Chemometrics, Inter-individual variation, Natural variation
Introduction
The relationships between different anatomical measurements are a fundamental aspect of human physiology, as has been elegantly depicted by Leonardo da Vinci in his seminal work ‘The Vitruvian Man’ (da Vinci 1487; Vitruvius 25 BC). This work shows these relationships are highly conserved, even for men of variable length. This ancient idea of describing relationships between different properties has reached many other fields of research, for example quantitative genetics (Steppan et al. 2002) and individual differences psychology (Goldberg 1990).
Also the levels of many metabolites in a biological system may be highly interrelated through the biochemical pathways. Perturbations of these biological systems (e.g. diet or disease) may alter enzyme activity and therefore the link between different metabolites. However, the extent of such alterations may also differ between individuals. Thereby also in- or decreases of the inter-individual metabolite level differences may indicate system change. Then not only absolute metabolite level differences between experimental groups, but also the relationships between the metabolites may indicate change. Such Between Metabolite Relationships (BMRs) therefore describe an aspect of metabolism that is complementary to the changes that are common to all individuals (Weckwerth et al. 2004).
Recent advances in ‘omics’-research brought the study of BMRs closer, because metabolomics emerges more and more as a system-wide approach to observe metabolism (Bino et al. 2004; Fiehn 2002; Hall 2006). The data of a metabolomics study usually consists of a list of numerous metabolites, of which the levels are given for every measured sample (e.g. individual and/or time-point). Of prime interest to metabolomics studies may be to find the in- or decrease of specific metabolite levels between different groups of individuals (e.g. before and after an experimental perturbation) (Fig. 1a). However, this paradigm holds a major shortcoming for the system-wide view provided by metabolomics analyses, because it may disregard metabolite combinations that show interesting variation where the individual metabolites do not.
Fig. 1.

Three paradigms to observe metabolic differences between two groups: a Level difference of an individual metabolite (e.g. ANOVA), b Level difference in a combination of, i.e. a component of more metabolites (e.g. PLS), c Changes in the combined relationship between metabolites (INDSCAL)
Univariate methods that quantify level changes of individual metabolites (e.g., ANalysis Of VAriance, ANOVA (Sokal and Rohlf 1995)) disregard the interrelations between levels of different metabolites and thereby the system-wide aspect of metabolism. Therefore in general multivariate methods are used to analyse data generated in metabolomics studies, mostly those from the ‘Component Analysis’ family such as PCA and PLS-DA (Barker and Rayens 2003, Jolliffe 2002). These summarize data into a small number of ‘components’—latent variables that gather information about the importance of all measured metabolites. These profiles are constructed based on the levels of all metabolites and express the relative importance of every metabolite in combination with all other metabolites. PCA or PLS-DA models in e.g. case–control studies enable to describe differences in metabolite combinations between groups, even if the levels of single metabolites are not significantly different (Fig. 1b).
However, neither ANOVA nor PLS-DA explicitly reveals the changes in the relationships between metabolites in different experimental groups. Also unsupervised methods like PCA (Jolliffe 2002) may be insufficient to describe BMRs, because these methods cover all metabolic variation simultaneously. The BMRs—schematically depicted in Fig. 1c—usually remain entangled with other sources of metabolic change and remain beyond reach of any method in these two metabolomic paradigms.
Several studies focus on relations between metabolites (Steuer 2006), enzymes and genes (van Erk et al. 2010; Zhai et al. 2010). These studies visualise such relations by Correlation Networks that show the relationships between all metabolite/enzymes/genes pairs (Steuer et al. 2003). However, as already mentioned ‘Due to the sheer number of pairwise metabolic correlations, large overview network graphs easily get incomprehensible’ (Weckwerth et al. 2004) which is specifically relevant in metabolomics. Therefore a method that both specifically focuses on BMRs and is based on interpretable components that describe the behaviour of the entire system (i.e. all pairwise metabolite relations together) is required. It will provide a novel and complementary view on metabolism.
In the field of individual differences psychology, a component method appropriate for the analysis of BMRs called Individual Differences Scaling (INDSCAL) is already available (Carroll 1981). This method translates the changes in covariance or correlations between metabolites upon experimental manipulation into a series of scores and loadings, analogous to those from PCA or PLS-DA. A voluminous yet well-readable publication reveals that INDSCAL is a special version of Parallel Factor Analysis (PARAFAC) (Harshman and Lundy 1984).1 The PARAFAC model has been used earlier to solve a range of questions in metabolomics studies that focused on changes in metabolite profiles, see e.g. (Montoliu et al. 2009; Jansen et al. 2008; Forshed et al. 2007; Sinha et al. 2004; Verouden et al. 2009) and will therefore provide a view on BMRs intuitive to metabolomics researchers.
First BMRs and the INDSCAL model are presented. Then two metabolomics data sets are analysed with INDSCAL, one with a very prominent response of plant chemistry to herbivory and another with a much more subtle response of obese humans to catechin-enriched green tea extract (GTE). The results of standard data analysis methods used in metabolomics, such as ANOVA, PCA, and PLS-DA are compared to that of INDSCAL.
Theory
In metabolomics experiments, one or more experimental factors can be manipulated (e.g. doses of a toxicant, different populations) to observe their effect on the metabolites present in an organism, often on different time-points after the manipulation. Metabolomic data consists of comprehensive biochemical descriptions of each sample as a list of metabolites with their corresponding levels. An ‘experimental group’ of multiple individuals—called biological replicates—undergo a combination of experimental factors. Technical and financial limitations usually lead to considerably more measured metabolites than the number of biological replicates.
The ‘conceptual model’ underlying most metabolomics experiments states that an experimental manipulation may change the levels of several metabolites. When this manipulation is performed on several biological replicates, their response should be similar to the other replicates, up to a certain deviation caused by natural and technical variation. When quantified in a linear model for one factor with groups 1…k…K, this leads to Eq. 1.
| 1 |
where X k is the (I k × J) matrix containing the levels of each metabolite, indicated by 1…j…J in the biological replicates 1k…i k…I k of experimental group k, μ is the length J ‘centroid’ vector of all samples, vector μ k the centroid vector for group k expressed as a deviation from μ; matrix S k contains the deviation of each individual biological replicate from vector μ k; see Supplementary Table 1 for a list of symbols used throughout the paper.
Equation 1 is generally used to quantify the significance of this experimental manipulation on levels of a small subset of single metabolites. This can be done by ANOVA (Sokal and Rohlf 1995) that estimates the treatment effects expressed in a series of vectors 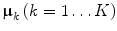 : interesting putative biomarkers are then identified as variables j for which variation across the j-th elements of
: interesting putative biomarkers are then identified as variables j for which variation across the j-th elements of 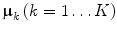 is high relative to the natural and technical variation of the biological replicates derived from S
k. The model in Eq. 1 does not make any assumptions about the relationships between metabolites, which falls in the realm of the component analysis paradigm.
is high relative to the natural and technical variation of the biological replicates derived from S
k. The model in Eq. 1 does not make any assumptions about the relationships between metabolites, which falls in the realm of the component analysis paradigm.
Multivariate components
A major objective in metabolomics is to understand the underlying biochemical system, which makes observation of the variations in each individual metabolite insufficient. The relations between different metabolites may both lead to a more parsimonious model—the biochemical system will constrain the complexity of the metabolic changes resulting from the experiment—and may lead to hitherto unknown relations between the metabolites that will provide a better insight into the observed system (Jansen et al. 2009c).
To model these system-wide relationships metabolomics embraced the multivariate ‘component’ paradigm that models the relationships between all J metabolite descriptors (Fig. 1b). The ‘standard’ methods in this field may also be expressed using the partitioning of the variation in Eq. 1. Principal Component Analysis simultaneously describes μ k and S k, so that this model will give a convoluted description of the paradigms in Fig. 1b, c. The often-used method Partial Least Squares-Discriminant Analysis (PLS-DA) aims—like ANOVA—to describe μ k at the expense of the ‘biological variation’ (inter-individual variation, natural variation) in matrix S k. Clearly, thereby PLS-DA does exactly the opposite of what is of interest to BMRs.
The analysis of BMRs requires separation of the variation in μ k from that in S k, because the BMR-related information (between the individual biological replicates) is contained only in the latter matrix. Therefore a component analysis method needs to be developed that focuses on the relations between the metabolites within this contribution.
Between Metabolite Relationships
In characterising BMRs, the strength of relationship between metabolites is of high interest. However, also how much variation in each experimental group is associated with this relationship is important. Although Pearson correlations are widely used in metabolomics, they overlook this aspect, because in Pearson correlations the variation in the levels of both metabolites is scaled by their standard deviations. Therefore covariances are the preferred measure for BMRs.
A BMR-describing component model should focus upon the differences between groups in the systematic part of the biological variation. This information is hidden in S k, specifically in the relationships between the metabolites. A view on BMRs therefore necessarily revolves around quantifying relations between the columns of S k. This can be done by covariances, like in Eq. 2.
| 2 |
where R k is the covariance matrix of experimental group k with dimensions (J × J).
Because interpreting R k may be tedious for many metabolite covariances, the holistic and simple view of a component model of BMRs may be highly desirable.
Individual differences scaling
A component model for BMRs needs to describe the relations between metabolites, rather than the levels themselves as well as possible. An existing component model that does just this is INdividual Differences SCALing (INDSCAL) model (Kruskal and Wish 1978; Harshman and Lundy 1984; Carroll 1981; Carroll and Chang, 1970), which is given in Eq. 3.
| 3 |
where G k is an (R × R) score matrix of group k; matrix A of size (J × R) contains the chemical loadings; E k contains the residuals of which the sum-of-squares is minimized. The constraints are imposed to arrive at identified and meaningful solutions.
The INDSCAL model loadings A describe the important relations between metabolites and the scores G k describe the magnitude of the variation of these relations within each experimental group, such that both important aspects of the BMRs are described.
The INDSCAL model is strongly related to Parallel Factor Analysis (PARAFAC) (Bro 1997; Harshman 1970; Smilde et al. 2004), an often-used component model in metabolomics. The INDSCAL model can be fitted by modelling the covariance matrices R k (arranged in a (R × J × J) three-way array) by PARAFAC (ten Berge and Kiers 1991). The additional nonnegativity constraint on G k can be straightforwardly imposed by publicly available software (Andersson and Bro 2000). Like PARAFAC, the components of an INDSCAL model are unique.
Model visualization and interpretation
Conventionally, the INDSCAL loadings A are shown in such a way that high loading values relate to the relevance of those metabolites in the BMRs important on each component. However, it may be better interpretable to rearrange the loadings following the structure of the covariance matrices, i.e. 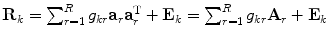 , where the matrices A
r of dimensions J × J are symmetric. Then high values in A
r directly indicate important relations between metabolites. It may therefore be easier to interpret a heat map of A
r than a conventional loading plot of A to identify relevant metabolites. However, since such heat maps do not allow comparison between components in one figure, both may be of value to gain insight in the BMRs. The scores G
k (or rather the diagonal elements gkr) show for which group k the relations in A
r are important. A score of zero implies that the corresponding relations are absent in group k.
, where the matrices A
r of dimensions J × J are symmetric. Then high values in A
r directly indicate important relations between metabolites. It may therefore be easier to interpret a heat map of A
r than a conventional loading plot of A to identify relevant metabolites. However, since such heat maps do not allow comparison between components in one figure, both may be of value to gain insight in the BMRs. The scores G
k (or rather the diagonal elements gkr) show for which group k the relations in A
r are important. A score of zero implies that the corresponding relations are absent in group k.
Just like in PARAFAC, the components fitted for INDSCAL are not orthogonal. The amount of information explained by the model can therefore only be calculated for the entire model. Furthermore, adding INDSCAL components modifies all other components (Smilde et al. 2004), which means a proper number of components has to be chosen before interpreting the model.
Number of components, stability and validation
The amount of information each component adds to the model may be used to determine the appropriate number of INDSCAL components, by comparing the information explained in a model to those with fewer components.
Whether the fitted model is prone to local optima can be tested by using multiple random starting values: the models need to be comparable, otherwise the model may contain too many components, thereby covering technical or other non-systematic variation.
Because the INDSCAL model describes entire experimental groups rather than individual biological replicates, the significance of observed effects is not expressed in the scores G k. An earlier-proposed jack-knife approach relies heavily on distributional assumptions (Weinberg et al. 1984), not likely fulfilled by metabolomics data. Therefore we quantify this significance by resampling: the results (i.e. scores and loadings) of models where individual biological replicates are left out are compared to the original model, which shows how individual replicates influence the model. This resampling strategy is fully explained in the supplementary material. Also a schematic pipeline to describe BMRs by INDSCAL is given there (Supplementary Fig. 1).
Materials and methods
Induced plant response study data set
This experiment studied the ‘induced plant response’ of cabbage plants to simulated herbivory to the plant shoot (SJA) or root (RJA), by the plant hormone jasmonic acid. These plants were compared to control (CON) plants, not treated with the hormone. The defense was characterized by the glucosinolate compound class: 11 compounds were profiled in plants harvested at 1, 7 and 14 days after the simulated attacks. The dataset contains 6–10 replicate plants per herbivory type/harvest time. This study was described in much more detail in an earlier paper (Jansen et al. 2009b).
Human nutritional intervention study data set
In a double-blinded, placebo-controlled nutritional intervention study with a parallel design, 186 human subjects with abdominal obesity (BMI 25–35 kg/m2 and a waist circumference of over 80 cm for women or 95 cm for men) consumed either catechin-enriched green tea extract drink (GTE; 600 mg catechins/day, 87 subjects) or a placebo drink (placebo, green tea-flavoured drink without any active ingredients, 99 subjects) over a period of 12 weeks. The experiment was conducted at University of Nottingham and approved by the University of Nottingham Medical School Ethics Committee. Fasted serum samples were collected at the baseline (start of the experiment; T0) and after 4, 8 and 12 weeks of intervention (T4, T8 and T12). For each serum sample a metabolic profile was obtained, composed of 136 lipid metabolites expressed as ratios between the peak areas of the metabolite and internal standard. The supplementary material contains a description of the analytical method and Supplementary Table 2 lists the measured metabolites.
Software
All statistical analyses were carried out in MATLAB 2009a (The Mathworks Inc., Natick, Massachusetts, USA), using in-house routines, partly based on the N-way Toolbox (Andersson and Bro 2000). They have been made available on www.bdagroup.nl.
Results and discussion
Induced plant response study—comparison of PCA and INDSCAL results
In the “induced plant response” study, the metabolic effect of shoot herbivory (SJA) or root herbivory (RJA) are of interest. Initially a PCA model was fitted, slightly modified to exclude the average time-profile of all plants related to uninteresting chemical variation (see earlier paper: Jansen et al. 2009b). The results of this analysis are given (again) in Supplementary Fig. 2.
The PCA results have been described in great detail in the earlier paper and are only briefly repeated here. The induced response to jasmonic acid consists of an increase in Glucobrassicin (GBC) and Neoglucobrassicin (NEO) for both treatments, but considerably larger for SJA. The RJA plants have higher levels of Progoitrin (PRO) and Glucobrassicanapin (GBN) after 7 and 14 days (PC 3). These changes are consistent for all the plants in the relevant treatment-time combinations and will therefore end up in μ k in Eq. 1. The increase in NEO and GBC will differ between plants, but the model also revealed that SJA plants harvested after 7 and 14 days with more NEO, contain less GBC, this will typically end up in matrix S k of Eq. 1 and therefore be the target of INDSCAL analysis. The earlier study also showed the increase in PRO and GBN levels in RJA plants after 7 and 14 days is preceded by an increase in the natural variation of these levels, which should also be revealed by INDSCAL.
A 4-component INDSCAL model explains a highly unstable amount of information (see Table 1), leading to three-components. This INDSCAL model (Fig. 2) corresponds very well to the PCA results. The first component explains a BMR in the SJA plants that increases from absence to an enormous contribution 14 days after harvest and explains the high NEO with low GBC levels (see Fig. 2c). The positive relation between PRO and GBN, expected to be high specifically high 1 day after RJA is indeed present in the second INDSCAL component (Fig. 2d). The component is also important 14 days after SJA, which after further inspection of the large confidence interval on the PCA scores. The third INDSCAL component describes the consistently larger variation in NEO and in GBC related to the natural variation between the different SJA (1–14 days) and RJA plants (1–7 days) described by the first PCA component (Fig. 2e). In this data set, the qualitatively observed BMRs in the earlier PCA model could be quantified in the INDSCAL model.
Table 1.
Number of components for INDSCAL model of plant data set
| # components | % convergence | % variance explained |
|---|---|---|
| 1 | 100 | 92 |
| 2 | 100 | 97 |
| 3 | 100 | 99 |
| 4 | 80 | 99.5 |
| 5 | 55 | 99.7 |
The second column shows how many models converged to a stable solution and the third how much information is described by the model
Fig. 2.

INDSCAL model of plant data set. a Group scores for component 1 vs. component 2, b Group scores for component 2 vs. component 3, circles refer to control group (CON), squares to root herbivory (RJA) and crosses to shoot herbivory (SJA). Loading are presented as heatplots separately for each component: c loadings for component 1, d loadings for component 2 and e loadings for component 3
Example of human nutritional metabolomics study and BMRs
In this section, BMR analysis is applied on lipid profiles from obese human subjects consuming either green tea extract (GTE) or placebo during 12 weeks. Changes in the lipidome were expected, because dietary supplementation of GTE has been proposed as a strategy for weight loss (Maki et al. 2009; Kovacs and Mela 2006). It has been hypothesized to promote lipolysis as a mechanism by which GTE stimulates fat oxidation (Westerterp-Plantenga 2010) and to affect lipid metabolism by inhibiting lipid absorption and digestion (Koo and Noh 2007).
The effect of GTE on the lipid profiles was analysed by investigating changes in individual metabolite levels, in multi-metabolite profiles and in BMR components fitted by INDSCAL. Variables were not scaled and INDSCAL was performed with covariances to compare all results to each other.
Changes in individual metabolite levels
Univariate, nonparametric U-Mann–Whitney statistic tests (Sokal and Rohlf 1995) did not reveal any statistically significant changes in individual metabolite levels between T12 (end of intervention period) and T0 (baseline) (see Supplementary Table 3), for either GTE or placebo. This indicates GTE did not induce an effect stronger than the inter-individual variation. This is frequently observed in dietary intervention studies within healthy human subjects, where effects are typically subtle and obscured by large inter-individual variations.
Profiles of multiple metabolites
An unsupervised PCA model did not reveal any relevant difference between GTE and placebo groups (see Supplementary Fig. 3). A supervised PLS-DA model also did not provide statistically significant differences between the GTE and placebo group metabolite profiles between T0 and T12 (see Supplementary Table 4). A multiway-PLS-DA (N-PLS-DA) was employed to simultaneously evaluate time-related metabolic changes induced by GTE at all four time points (Bro 1996; Castro and Manetti 2007), while retaining the structure of the repeated measurements on the same individuals (Smilde et al. 2010). The diagnostic outcome of this model was very weak: e.g. 47.1% of the samples were misclassified (see Supplementary Table 4). This shows GTE intervention did not change the serum lipid profiles significantly as observed by the ‘standard’ multivariate data analysis methods most widely used in metabolomics (Jansen et al. 2009c; Trygg et al. 2007; Lindon et al. 2000; Holmes et al. 2000).
Between Metabolite Relationships
To include all available a priori knowledge about the experimental design into the INDSCAL model, a ‘baseline’ group (BL) was constructed of all individuals measured at the start of the experiment (T0), assuming all subjects to belong to a homogeneous population before the nutritional intervention. For the remaining samples, covariance matrices were calculated for each experimental groups, i.e. treatment and measurement time-point combination: GTE-T4, GTE-T8, GTE-T12, placebo-T4, placebo-T8 and placebo-T12.
To determine the number of INDSCAL components appropriate to model these covariance matrices, one to five components were fitted 20 times, starting from random values. Table 2 shows the percentages of explained information and of converged models. This table shows that the model requires two components, because 20% of the models with three components did not converge to a stable solution.
Table 2.
Number of components for INDSCAL model for human nutritional data set
| # components | % convergence | % variance explained |
|---|---|---|
| 1 | 100 | 97.1 |
| 2 | 100 | 99.0 |
| 3 | 80 | 99.4 |
| 4 | 60 | 99.6 |
| 5 | 70 | 99.8 |
The second column shows how many models converged to a stable solution and the third how much information is described by the model
The INDSCAL scores of the GTE group (black circles in Fig. 3a) differ from those of the placebo group (white circles) after 4, 8 and 12 weeks of intervention and from the BL group (grey circle). The first INDSCAL component mainly describes a systematic drift of the GTE group from the region of the plot covered by the placebo group and the second component shows an additional variation in the BMRs of the GTE group, prominent at T4 (Fig. 3a).
Fig. 3.
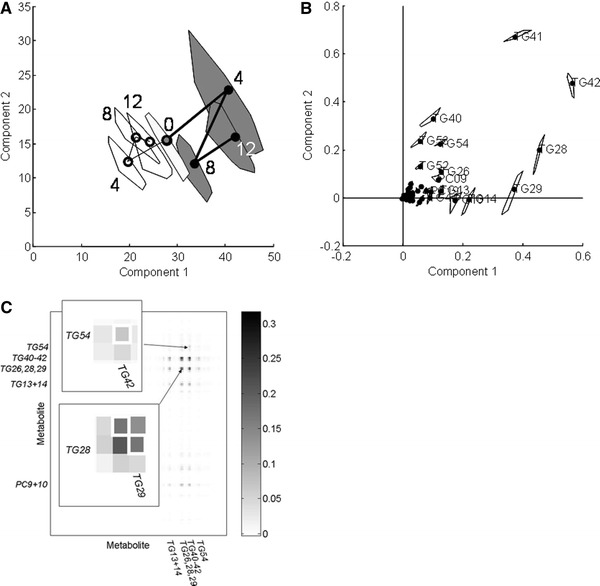
INDSCAL model of human nutrition data set. a Group scores: the white circles indicated the placebo group, the black the GTE group and the grey the common baseline group (sampled before start of intervention). The region around each score is obtained during model validation and refers to region of plot where 95% scores obtained from resampled models occurred. b Loadings with regions of confidence obtained during model validation analogously as for scores. c Heat plot of BMRs in greyscale; both inserts focus on the relations of TG28 with 29 and of TG54 with 42: these are indicated by the white frames
The resampling results (confidence intervals around the circles in Fig. 3a) show that the differences between GTE and placebo are highly significant after 4 and 12 weeks and that after 8 weeks the resampling interval of GTE has only very slight overlap with that of BL. The resampling results of the chemical loadings (intervals around the circles in Fig. 3b) show that the BMR response to GTE consists of the covariance between metabolites TG28, TG29, TG41 and TG42.
The first INDSCAL component is of most interest in this study, because it shows a consistent GTE-associated drift. The heat plot in Fig. 3c focuses upon these loadings. This heat plot shows BMRs rather than the contributions of the individual lipids to the loadings in Fig. 3b. The heat plot quantifies the BMRs in greyscale, showing for example that the covariance between TGs 28 and 29 is larger than between TGs 54 and 42, considerably less interpretable from Fig. 3b alone.
Selected lipids: level changes and BMRs
The effect of GTE on the plasma lipids is clearly visible in both INDSCAL model representations in Fig. 3. It is mainly associated with relations between a very small subset of lipids. Most important are the triacylglycerols TG28-29 and TG41-42. Figure 4a shows that the variance of TG29 (those for TGs 28, 41 and 42 are comparable and not shown) is significantly affected by GTE compared to the control and the BL groups, although the mean group levels of these metabolites did not change (Supplementary Fig. 4). The Pearson correlation coefficients for these lipids did not change between GTE and placebo (see Supplementary Table 5), but the covariances did (Fig. 4b; Supplementary Fig. 4). The barplot in Fig. 4b corresponds closely to the INDSCAL scores (Fig. 3a). The INDSCAL results and the (co)variance plots show that the effect of GTE manifested itself by a systematic increase of the covariance between TG28 and TG29 during the entire study period and an additional increase of the covariance between TG41 and TG42 during the first 4 weeks of intervention, described by the second INDSCAL component. The last is related to a large inter-individual difference in time and magnitude of response at the beginning of the intervention.
Fig. 4.

Variance and covariance of selected metabolites. a Variance of TG29 and b covariance between TG28 and TG29; BL baseline group, GTE catechin-enriched green tea extract group, placebo placebo group, significantly different: **P < 0.05 and ***P < 0.01
Interpretation of the observed GTE effect
The INDSCAL model shows that supplementation of GTE significantly affects relationships between a small subset of triacyloglycerols (see Supplementary Table 6 for the isomer composition). Similar TGs have been reported to play an important role in diet-induced weight loss for metabolic syndrome in a 33-week intervention (Schwab et al. 2008). These changes were not shown by the standard uni- and multivariate statistical analyses, because these focus upon responses in metabolite levels similar for all treated individuals (i.e. PLS-DA or Mann–Whitney tests). Figures 3 and 4 show the observed BMRs relate to an increase in the variation in the levels of selected triacyloglycerols between subjects that received the same intervention.
Observed changes in metabolite covariances show that their changes are dependent between metabolites and therefore the observed effect of GTE can be explained on a system biology level. Inter-individual variation in the levels of selected triacylglycerols could be related to individual differences in the activities of transcription factors or enzymes regulating these metabolites (individual phenotype). Depending on the characteristics of the individual phenotype, GTE could induce the increase or decrease of these specific metabolite levels (see Supplementary material for a simulation example). For example, it has been stated that there is a wide variability in the flavonoid O-methylation by catechol-O-methyltransferase (COMT), a key enzyme that is hypothesized to be involved in fat oxidation and whose activity may differ between ethnic groups (Westerterp-Plantenga 2010). Alternatively, the increase of inter-individual variation in levels of selected triacyloglycerols can be explained by multiple mechanisms of actions and/or active compounds present in GTE. That may lead to opposing effects of GTE on a network of transcription factors and enzymes and thereby to up- and downregulation of the production of specific metabolites and less controlled ranges of metabolite levels. In this case, metabolic change might be the consequence of a superposition of e.g. changes in dietary fatty acid composition, different mechanisms of TG activation or different effects on the lipid species present in the TGs (Kovacs and Mela 2006; Westerterp-Plantenga 2010).
INDSCAL and BMRs in practice
To extract BMR-related information by standard data analysis methods may be difficult (i.e. PCA) and often even impossible (PLS-DA): these methods have a different focus. This paper shows, by two examples of metabolomic data sets from plant and human nutrition studies, that the BMR-related components of INDSCAL showed an essential aspect of metabolic change that was complementary to that obtained by standard methods. A PCA model of the plant “induced response study” only showed BMR-related change intermingled with level changes like those in Fig. 1b. However, with INDSCAL these were directly focused upon. In the human nutritional study, INDSCAL revealed increases in the inter-individual variation of four triacylglycerols upon GTE supplementation, while this (or any other) effect of GTE could not be observed by standard data analysis methods.
In this study, the BMRs were expressed and included in INDSCAL as covariances, but also other dissimilarity measures such as Pearson or Spearman correlation coefficients can be used for a different focus (Jansen et al. 2009a). In fact, multidimensional scaling methods like INDSCAL allow matrices R k to be filled with many dissimilarity measures, underlined by a valid distance metric (Borg and Groenen 2010). The choice of dissimilarity measure depends on the expected nature of the relationships, such that INDSCAL is a highly flexible tool to find BMRs.
Covariance analysis between metabolites, as opposed to correlations, is highly appropriate for studies where responses are expected to be inconsistent between individuals. For example, INDSCAL directly targets the expected variation in the response of different humans to dietary intervention, such as that of GTE. Because not all individuals respond to a dietary supplementation of GTE in the same fashion or degree, covariances rather than levels of these metabolites change when the entire experimental group is observed. The metabolites involved in this effect then also have a different role than in the conventional paradigms in Fig. 1a, b: triacylglycerols of which the covariances with other metabolites change during dietary intervention could be used a posteriori to select the individuals from the experimental group that have a similar metabolic response. This relates directly to the evolutionary constraints that were already discussed in the introduction: these also rely on responses only present in a subset of the population. The introduction of INDSCAL also makes such patterns available to metabolomics.
The literature concerning visualisation of INDSCAL models is sparse (with exceptions like (Chang and Carroll 1980)). The representation of A r in heat maps is—to our knowledge—new and considerably increases the insight into the metabolic relations described by the BMRs, compared to the conventional representation in Fig. 4. However, the relations between metabolites represent the biochemical reactions within the studied organisms, therefore the INDSCAL loadings would immensely benefit from an interpretation through biochemical pathways. This would connect the Correlation Networks that until now have observed metabolism as a series of pairwise correlations between metabolites (Steuer et al. 2003) with component analyses that simultaneously connect all metabolites to each other. The synergy between Correlation Networks and INDSCAL will be the topic of a follow-up paper.
The Between Metabolite Relationships, together with INDSCAL, will therefore greatly enhance the amount of biochemical information that can be obtained from ‘omics’ experiments.
Concluding remarks
Between Metabolite Relationships (BMRs) may reveal systematic changes in biological systems that remain elusive when only metabolite level changes are taken into account. The Individual Differences Scaling (INDSCAL) method is introduced here as a method to analyse these BMRs with component models, which give a system-wide view on the changes in relationships between all compounds measured in a metabolomics study.
The results of INDSCAL can support and explain already known metabolic changes, such as those in the “induced plant response” study. They can also provide information that lays beyond the reach of standard data analysis methods in use in metabolomics as in the human nutritional intervention study. The BMRs indicated which relations between metabolites are most prone to a variable response by the biological replicates e.g. by jasmonic acid application (subset of glucosinolates in “induced plant response” study) or by the GTE intervention (subset of triacyloglycerols in human nutritional intervention study). Identification of such changes in metabolite relationships will improve the understanding of possible mechanisms of action of tested interventions.
The BMRs, together with INDSCAL, thereby open the door to dedicated analysis of the next generation of questions in systems biology: those that deal with personalized medicine and individual or cohort-specific responses to dietary change.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Acknowledgments
This project was financed by the Netherlands Metabolomics Centre (NMC) which is a part of the Netherlands Genomics Initiative/Netherlands Organisation for Scientific Research. Authors gratefully acknowledge Jorne Troost (NMC, LACDR/Leiden University) for further experimental work on lipid identification and Adrie Dane (NMC, LACDR/Leiden University) for quality control of human nutritional intervention study data set. The ‘induced plant response’ study was funded by NWO, the Netherlands Organization for Scientific Research through VIDI grant, no. 864-02-001.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Footnotes
The book that this chapter appeared in is out-of-print and difficult to obtain. However, it can be found online in PDF format: http://publish.uwo.ca/~harshman/abstract.html.
Jeroen J. Jansen and Ewa Szymańska contributed equally to the manuscript.
Contributor Information
Jeroen J. Jansen, Email: j.j.jansen@uva.nl
Huub C. J. Hoefsloot, Email: h.c.j.hoefsloot@uva.nl
References
- Andersson CA, Bro R. The n-way toolbox for matlab. Chemometrics and Intelligent Laboratory Systems . 2000;52:1–4. doi: 10.1016/S0169-7439(00)00071-X. [DOI] [Google Scholar]
- Barker M, Rayens W. Partial least squares for discrimination. Journal of Chemometrics. 2003;17:166–173. doi: 10.1002/cem.785. [DOI] [Google Scholar]
- Bino RJ, Hall RD, Fiehn O, et al. Potential of metabolomics as a functional genomics tool. Trends in Plant Science. 2004;9:418–425. doi: 10.1016/j.tplants.2004.07.004. [DOI] [PubMed] [Google Scholar]
- Borg I, Groenen PJF. Modern multidimensional scaling. New York: Springer; 2010. [Google Scholar]
- Bro R. Multiway calibration. Multilinear PLS. Journal of Chemometrics. 1996;10:47–61. doi: 10.1002/(SICI)1099-128X(199601)10:1<47::AID-CEM400>3.0.CO;2-C. [DOI] [Google Scholar]
- Bro R. Parafac: a tutorial. Chemometrics and Intelligent Laboratory Systems . 1997;38:149–171. doi: 10.1016/S0169-7439(97)00032-4. [DOI] [Google Scholar]
- Carroll JD. INDSCAL. In: Schiffmann SS, Reynolds ML, Young FW, editors. An introduction to multidimensional scaling. Orlando: Academic Press; 1981. [Google Scholar]
- Carroll JD, Chang JJ. Analysis of individual differences in multidimensional scaling via an n-way generalization of “Eckart-Young” decomposition. Psychometrika. 1970;35:283–319. doi: 10.1007/BF02310791. [DOI] [Google Scholar]
- Castro C, Manetti C. A multiway approach to analyze metabonomic data: A study of maize seeds development. Analytical Biochemistry. 2007;371:194–200. doi: 10.1016/j.ab.2007.08.028. [DOI] [PubMed] [Google Scholar]
- Chang JJ, Carroll JD. Three are not enough: An INDSCAL analysis suggesting that color space has seven dimensions. Color Research and Application. 1980;5:193–206. doi: 10.1002/col.5080050402. [DOI] [Google Scholar]
- Da Vinci, L. (1487). Vitruvian man. Venice.
- Fiehn O. Metabolomics—the link between genotypes and phenotypes. Plant Molecular Biology. 2002;48:155–171. doi: 10.1023/A:1013713905833. [DOI] [PubMed] [Google Scholar]
- Forshed J, Stolt R, Idborg H, Jacobsson SP. Enhanced multivariate analysis by correlation scaling and fusion of LC/MS and 1H-NMR data. Chemometrics and Intelligent Laboratory Systems . 2007;85:179–185. doi: 10.1016/j.chemolab.2006.06.012. [DOI] [Google Scholar]
- Goldberg LR. An alternative description of personality—the Big-5 factor structure. Journal of Personality and Social Psychology. 1990;59:1216–1229. doi: 10.1037/0022-3514.59.6.1216. [DOI] [PubMed] [Google Scholar]
- Hall RD. Plant metabolomics: From holistic hope, to hype, to hot topic. New Phytologist. 2006;169:453–468. doi: 10.1111/j.1469-8137.2005.01632.x. [DOI] [PubMed] [Google Scholar]
- Harshman, R. A. (1970). Foundations for the parafac procedure: Model and conditions for an ‘explanatory’ multi-mode factor analysis (Vol. 16, pp. 1–84). UCLA working papers in Phonetics.
- Harshman RA, Lundy ME. The PARAFAC model for three-way factor analysis and multidimensional scaling. In: Law HG, Snyder CW, Hattie JA, Mcdonald RP, editors. Research methods for multimode data analysis. New York: Praeger Publishers; 1984. [Google Scholar]
- Holmes E, Nicholls AW, Lindon JC, et al. Chemometric models for toxicity classification based on NMR spectra of biofluids. Chemical Research in Toxicology. 2000;13:471–478. doi: 10.1021/tx990210t. [DOI] [PubMed] [Google Scholar]
- Jansen J, Allwood J, Marsden-Edwards E, et al. Metabolomic analysis of the interaction between plants and herbivores. Metabolomics. 2009;5:150–161. doi: 10.1007/s11306-008-0124-4. [DOI] [Google Scholar]
- Jansen JJ, Bro R, Hoefsloot HCJ, et al. PARAFASCA: ASCA combined with parafac for the analysis of metabolic fingerprinting data. Journal of Chemometrics. 2008;22:114–121. doi: 10.1002/cem.1105. [DOI] [Google Scholar]
- Jansen JJ, Smit S, Hoefsloot HCJ, Smilde AK. The photographer and the greenhouse: How to analyze plant metabolomics data. Phytochemical Analysis. 2009;21:48–60. doi: 10.1002/pca.1181. [DOI] [PubMed] [Google Scholar]
- Jansen J, Van Dam N, Hoefsloot H, Smilde A. Crossfit analysis: A novel method to characterize the dynamics of induced plant responses. BMC Bioinformatics. 2009;10:425. doi: 10.1186/1471-2105-10-425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jolliffe IT. Principal component analysis. New York: Springer; 2002. [Google Scholar]
- Koo SI, Noh SK. Green tea as inhibitor of the intestinal absorption of lipids: Potential mechanism for its lipid-lowering effect. Journal of Nutritional Biochemistry. 2007;18:179–183. doi: 10.1016/j.jnutbio.2006.12.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kovacs EMR, Mela DJ. Metabolically active functional food ingredients for weight control. Obesity Reviews. 2006;7:59–78. doi: 10.1111/j.1467-789X.2006.00203.x. [DOI] [PubMed] [Google Scholar]
- Kruskal JB, Wish M. Multidimensional scaling. Newbury Park: Sage Publications, Inc.; 1978. [Google Scholar]
- Lindon JC, Holmes E, Nicholson JK. Pattern recognition methods and applications in biomedical magnetic resonance. Progress in Nuclear Magnetic Resonance Spectroscopy. 2000;39:1–40. doi: 10.1016/S0079-6565(00)00036-4. [DOI] [Google Scholar]
- Maki KC, Reeves MS, Farmer M, et al. Green tea catechin consumption enhances exercise-induced abdominal fat loss in overweight and obese adults. Journal of Nutrition. 2009;139:264–270. doi: 10.3945/jn.108.098293. [DOI] [PubMed] [Google Scholar]
- Montoliu I, Martin FO-PJ, Collino S, Rezzi S, Kochhar S. Multivariate modeling strategy for intercompartmental analysis of tissue and plasma 1H-NMR spectrotypes. Journal of Proteome Research. 2009;8:2397–2406. doi: 10.1021/pr8010205. [DOI] [PubMed] [Google Scholar]
- Schwab U, Seppaanen-Laakso T, Yetukuri L, et al. Triacylglycerol fatty acid composition in diet-induced weight loss in subjects with abnormal glucose metabolism—the Genobin study. PLoS ONE. 2008;3:e2630. doi: 10.1371/journal.pone.0002630. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sinha AE, Hope JL, Prazen BJ, et al. Algorithm for locating analytes of interest based on mass spectral similarity in GC x GC-TOF-MS data: Analysis of metabolites in human infant urine. Journal of Chromatography A. 2004;1058:209–215. [PubMed] [Google Scholar]
- Smilde AK, Bro R, Geladi P. Multi-way analysis: Applications in the chemical sciences. New York: John Wiley & Sons; 2004. [Google Scholar]
- Smilde A, Westerhuis J, Hoefsloot H, et al. Dynamic metabolomic data analysis: A tutorial review. Metabolomics. 2010;6:3–17. doi: 10.1007/s11306-009-0191-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sokal RR, Rohlf FJ. Biometry. San Francisco: W.H.Freeman and company; 1995. [Google Scholar]
- Steppan SJ, Phillips PC, Houle D. Comparative quantitative genetics: Evolution of the g matrix. Trends in Ecology and Evolution. 2002;17:320–327. doi: 10.1016/S0169-5347(02)02505-3. [DOI] [Google Scholar]
- Steuer R. Review: On the analysis and interpretation of correlations in metabolomic data. Briefings in Bioinformatics. 2006;7:151–158. doi: 10.1093/bib/bbl009. [DOI] [PubMed] [Google Scholar]
- Steuer R, Kurths J, Fiehn O, Weckwerth W. Observing and interpreting correlations in metabolomic networks. Bioinformatics. 2003;19:1019–1026. doi: 10.1093/bioinformatics/btg120. [DOI] [PubMed] [Google Scholar]
- Ten Berge J, Kiers H. Some clarifications of the candecomp algorithm applied to indscal. Psychometrika. 1991;56:317–326. doi: 10.1007/BF02294465. [DOI] [Google Scholar]
- Trygg J, Holmes E, Lundstedt T. Chemometrics in metabonomics. Journal of Proteome Research. 2007;6:469–479. doi: 10.1021/pr060594q. [DOI] [PubMed] [Google Scholar]
- Van Erk M, Wopereis S, Rubingh C, et al. Insight in modulation of inflammation in response to diclofenac intervention: A human intervention study. BMC Medical Genomics. 2010;3:5. doi: 10.1186/1755-8794-3-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verouden MPH, Notebaart RA, Westerhuis JA, et al. Multi-way analysis of flux distributions across multiple conditions. Journal of Chemometrics. 2009;23:406–420. doi: 10.1002/cem.1238. [DOI] [Google Scholar]
- Weckwerth W, Loureiro ME, Wenzel K, et al. Differential metabolic networks unravel the effects of silent plant phenotypes. Proceedings of the National Academy of Sciences of the United States of America. 2004;101:7809–7814. doi: 10.1073/pnas.0303415101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weinberg S, Carroll J, Cohen H. Confidence regions for indscal using the jackknife and bootstrap techniques. Psychometrika. 1984;49:475–491. doi: 10.1007/BF02302586. [DOI] [Google Scholar]
- Westerterp-Plantenga MS. Green tea catechins, caffeine and body-weight regulation. Physiology and Behavior. 2010;100:42–46. doi: 10.1016/j.physbeh.2010.02.005. [DOI] [PubMed] [Google Scholar]
- Vitruvius. (25 BC). De architectura.
- Zhai G, Wang-Sattler R, Hart DJ, et al. Serum branched-chain amino acid to histidine ratio: A novel metabolomic biomarker of knee osteoarthritis. Annals of the Rheumatic Diseases. 2010;69:1227–1231. doi: 10.1136/ard.2009.120857. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.