

Abstract
We have developed a new method for classifying 3D reconstructions with missing data obtained by electron microscopy techniques. The method is based on principal component analysis (PCA) combined with expectation maximization. The missing data, together with the principal components, are treated as hidden variables that are estimated by maximizing a likelihood function. PCA in 3D is similar to PCA for 2D image analysis. A lower dimensional subspace of significant features is selected, into which the data are projected, and if desired, subsequently classified. In addition, our new algorithm estimates the missing data for each individual volume within the lower dimensional subspace. Application to both a large model data set and cryo-electron microscopy experimental data demonstrates the good performance of the algorithm and illustrates its potential for studying macromolecular assemblies with continuous conformational variations.
Keywords: image processing, Electron Microscopy, single particle reconstruction, missing cone/missing wedge, Multivariate Statistical Analysis, Principal Component Analysis, Expectation Maximization
1. Introduction
Electron tomography can be used to determine the 3D structures of individual subcellular components and to reconstruct complete specimen areas containing many macromolecules (Hoppe et al. 1968, 1976a, b, c). While the technique is ideally suited for the analysis of heterogeneous samples, the low signal-to-noise ratio found in electron tomographic reconstructions of individual objects limits its efficacy.
Averaging techniques have been extensively used for more than four decades to increase the signal-to-noise ratio for 2D image analysis (Markham et al. 1963, 1964; Saxton and Frank 1977; Frank et al. 1978). Major progress was achieved through the introduction of correspondence analysis with associated classification tools (Bretaudiere et al. 1981; van Heel and Frank 1981; Frank and van Heel 1982; Bretaudiere and Frank 1986). This enabled the objective classification of the data into sets of images showing identical particles before averaging, which results in average images with substantially higher resolution and increased signal-to-noise ratio.
Several single particle 3D reconstruction methods incorporate some form of 2D averaging techniques in their algorithms, which results implicitly in 3D averaging. The first method developed was the random conical reconstruction technique, in which one micrograph at high specimen tilt, showing many single particles, is recorded, followed by a second micrograph of the same specimen area without tilt (Radermacher et al. 1986, 1987, 1988). The images extracted from the 0°-micrograph are used for alignment and classification of the particles, and reconstructions are calculated from the corresponding tilt images. The orthogonal tilt reconstruction technique is based on a similar principle. Images are collected at ±45° and one of the tilts is used for alignment and classification, and the other for computing the 3D reconstructions (Leschziner and Nogales 2006). An alternative method used for single particle reconstruction is angular reconstitution (van Heel 1987) where the reconstruction is calculated entirely from micrographs without tilt and the orientation of the particles is calculated by common line methods (Crowther et al. 1970).
Most 3D averaging methods, with either explicit or implicit averaging, work reliably when applied to sets of identical aligned particles. If multiple copies of identical objects are present in a tomogram, averaging of subtomograms can increase the signal-to-noise ratio of the final 3D structures (Knauer et al. 1983; Oettl et al. 1983; Grünewald et al. 2003; Förster & Hegerl 2007). When data are heterogeneous, a classification step is necessary before averaging. For tomographic data, the classification can only be applied to 3D volumes or subvolumes. On the other hand, the random conical reconstruction technique allows for a classification into sets of particles with identical conformation and orientation by applying one of the many methods developed for 2D classification and averaging to the 0°-images. The classification results are imposed onto the tilt images, and then reconstructions are calculated separately for each class. While heterogeneous particles are separated in the resulting 3D reconstructions, identical particles in different orientations are also separated into different classes. Identical 3D structures (originally in different orientations) can be aligned and averaged. However, even after 3D alignment of volumes calculated using any 3D electron microscopy technique, visual classification can be inaccurate. Missing data can result in structural distortions that might lead to misclassifications (Fig. 1). Thus, mathematical methods that can classify volumes irrespective of missing data need to be employed.
Figure 1.
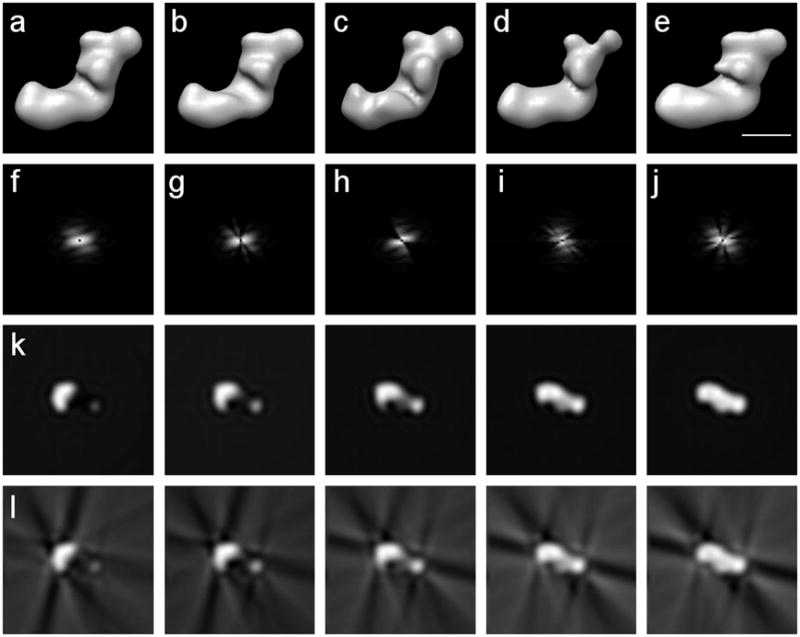
Reconstructions from complete and incomplete sets of noise-free projections of complex I from Y. lipolytica forming a single-axis tilt series around the y-axis; volume size 64×64×64 voxels; voxel size 9Å; low-pass filtered to 36Å. (a) Reconstruction from a complete set. (b)-(e) Reconstructions with 30% missing data using four different subsets of projections. (f)-(j) Power spectra of the central slices of the Fourier transforms of (a)-(e) respectively. (k) Five consecutive x-z slices around the center of the complete reconstruction in (a). (l) Five consecutive x-z slices around the center of the reconstruction with missing data in (b). Clearly visible are the artifacts caused by the missing data. Scale bar 100Å.
3D classification of volumes with missing data has been used for more than a decade (Walz et al. 1997; Winkler and Taylor 1999; Winkler 2007). Only recently have these methods been extended to classify volumes with missing data in different orientations (Bartesaghi et al. 2008; Förster et al. 2008; Scheres et al. 2009). The core of the classification scheme in Bartesaghi et al. (2008) is a hierarchical ascendant classification based on pairwise distances between volumes. The calculation of the distances is restricted to the Fourier areas common to each pair of volumes, which minimizes the influence of the missing data. An algorithm based on principal component analysis, presented later, eliminates the influence of the missing data by excluding it from the calculation of the cross-correlation matrix (Förster et al. 2008). Here, the correlation coefficients are renormalized depending on the amount of overlapping data in each pair of volumes. Both algorithms allow for the recovery of missing data by calculating 3D class averages provided that the data exist in at least one class member.
We present here a robust feature extraction method for the application to 3D reconstructions with missing data, PPCA-EM, based on Probabilistic Principal Component Analysis using Expectation Maximization (Roweis 1997; Tipping and Bishop 1999; Yu et al. 2008). The algorithm extracts the main features of the structure independently of the existence and specific geometry of the missing data as it estimates the latter for each individual volume. In the end, the algorithm represents the data set in a lower dimensional subspace. Once the dimensionality has been reduced, the data can be classified by any standard algorithm, including Diday's method of moving centers (Diday 1971), k-means (MacQueen 1967), fuzzy c-means (Dunn 1973; Bezdek 1981; Carazo et al. 1990) and hierarchical ascendant classification (Johnson 1967).
PPCA-EM has two major advantages over earlier approaches. First, the algorithm finds an approximate principal subspace and the approximate principal component projections regardless of the missing data. Second, the algorithm estimates the missing data for each individual volume. Therefore, the missing data can be estimated even if a data set exhibits only continuous variations without relying on class averages.
2. Background
Principal component analysis (PCA) is a multivariate statistical technique that reduces the dimensionality of the data while maintaining the maximum variance. Let the observation vector t ∈ ℝd represent a 2D image or a 3D volume, rearranged as a one-dimensional vector so that each component in t corresponds to a pixel or voxel, with d being the number of pixels or voxels. In a set of well aligned images, the components of t vary when the represented structures vary or when noise corrupts the data.
A set of n observation vectors, {ti,i=1,2,…,n}, forms a scattered cloud in a d-dimensional space. PCA searches for the directions with the highest variance, (e.g., Lebart 1984). The classical method to derive the principal components is eigendecomposition (Pearson 1901) or singular value decomposition (Golub and Loan 1996) of the covariance matrix of the data.
The covariance matrix is defined as Σ = E[(t−μ)(t−μ)T] ∈ ℝd×d, where E denotes the expectation with respect to the probability distribution of t; the superscript “T”, the transpose operator; and μ = E[t] ∈ ℝd, the mean of t. In practice, the covariance matrix is estimated using the scatter matrix, , where the sample mean, is an estimation of the true mean.
By definition, the eigenvectors ωj ∈ ℝd and the eigenvalues λj ∈ ℝ of the scatter matrix satisfy
where q′ is the rank of S and q′ ≤ min(d,n). The values of λj describe the variance of the observations in the direction of the corresponding eigenvectors ωj and are arranged in descending order, λ1 ≥ λ2 ≥ … λq′ ≥ 0. Thus the corresponding eigenvectors, ω1, ω2,…,ωq′ , are sorted in descending order of significance. Each eigenvector is normalized so that , where δij is the Kronecker delta (which is 1 for i = j and 0 otherwise).
The original observations ti can be projected into the subspace defined by the q most significant eigenvectors ωj, j = 1,2,…q (where q ≤ q′):
The xi approximately represent the ti in a q-dimensional space while retaining the variance of the data set as much as possible.
The relationships between xi and ti can be formulated in a linear form,
| (1) |
where W = (ω1, ω2,…,ωq) and the εi are the residuals: the difference between the approximation and the observed data. Tipping & Bishop (1999) proposed a probabilistic model for the variables in Equation 1. In their model, the latent variables xi, are assumed to have a normal distribution,
| (2) |
where I denotes the identity matrix. The residuals, εi, are assumed to be independent and normally distributed with a mean of zero and an isotropic variance of σ2,
| (3) |
These probabilistic assumptions are consistent with other eigendecomposition methods: PCA is a special case in the limit when σ2 →0 (Roweis 1997).
The introduction of a probabilistic model facilitates the use of the expectation maximization (EM) algorithm (Dempster et al. 1977) to estimate the latent variables. We first present the PPCA-EM algorithm for complete data sets. This framework was established by Tipping & Bishop (1999) using an iterated, two-step process.
In the expectation (E) step, the hidden (unknown) variables are estimated from the observations and the current values of the parameters. Statistical moments of the latent variables, 〈xi〉 and , are estimated using p(xi | ti, W, σ2), the conditional probability density of xi given the observations ti and the current values of W and σ2, (Little and Rubin 1987). Following the probability assumptions made in Equations 2 and 3, one obtains,
| (4) |
where the superscript “−1” denotes matrix inversion. Equation 4 is used to update the value of the xi.
In the maximization (M) step, new estimates of the parameters, W and σ2, are computed by maximizing the conditional expectation of the log-likelihood, 〈ℓ〉, with respect to the conditional probability density of the unknown variables xi given the known variables ti, p(xi ∣ ti, W, σ2). The log-likelihood is defined in terms of the joint probability of the observed variables and the latent variables,
| (5) |
where the joint probability density
can be computed from Equation 1 combined with the probabilistic assumptions in Equations 2 and 3. The conditional expectation of the log-likelihood (Eq. 5) then becomes
| (6) |
Maximizing the conditional expectation defined in Equation 6 with respect to W and σ2 yields a new estimate for W,
| (7) |
and using the above quantity for σ2,
| (8) |
In Equation 7, we assume min(n, d) ≥ q so that the matrix inversion can be carried out.
The E-step and M-step are iterated using the most recent estimates of 〈xi〉 and (for i = 1,2…,n), and of W and σ2 until no major change occurs in the estimation. It has been shown analytically that this procedure converges to the maximum-likelihood estimation (Dempster et al. 1977). The limiting values of Equations 4, 7 and 8 correspond to the final estimates of the latent variables xi which are the estimates of the q principal components of ti; the matrix W which spans the estimated eigenspace; and σ2, the variance of the residuals.
3. Methods
3.1 PPCA-EM algorithm
Probabilistic principal component analysis using expectation maximization (PPCA-EM) is readily adapted to observations with missing data (Tipping and Bishop 1999; Roweis 1997). We have extended the technique to encompass 3D reconstructions from electron micrographs with missing data, either originating from tomographic tilt series (single-axis, dual-axis or conical), random conical tilting, or any other technique with incomplete angular coverage(Yu et al. 2008). Different tilting schemes result in different geometries of missing data: single-axis tilting has a missing wedge; dual-axis tilting has a missing pyramid; while conical and random conical tilting have a missing cone that after angular refinement may assume an irregular shape (Radermacher 1980; Radermacher and Hoppe 1980). However, the presence of the coefficients in the Fourier transform of 3D reconstructions can be traced based on the projection-slice-theorem, which states that the 2D Fourier transform of a projection is a central section through the 3D Fourier transform of the object. This is most straightforward in a polar coordinate system, since each radial line is either completely determined or completely missing. Each radial line can easily be indexed, and therefore no special geometrical restrictions to the shape of the missing data need to be considered. Our 3D reconstruction algorithm using Radon transforms maintains a counter of the actual number of radial lines averaged in each direction (Radermacher 1994, 1997). This counter is currently used to properly calculate the average of each radial line in the reconstruction.
We have further extended the PPCA-EM algorithm to complex space to facilitate the application to 3D reconstructions in different forms. Hence ti ∈ ℂd, for all i = 1,2,…,n. In addition, for each ti we can store the counter from the reconstruction algorithm in a vector ρi ∈ ℝd, where either ρi,j ≥ 1 if ti,j is present; or ρi,j = 0 if ti,j is missing. These vectors can be used as an index for every component of ti, indicating the presence or absence of the component. In addition to its use as a Boolean indicator, in PPCA-EM, the value can be used for a more accurate calculation of the weighted mean in Equation 11.
The PPCA-EM algorithm can be extended to incomplete data sets with the above information. The relationship between the observations ti and the latent variables xi in Equation 1 then becomes
| (9) |
where the indices of ti have been permutated so that denotes the present data in the ith observation, and , the missing data, with for all i = 1,2,…n. The superscript indicates either present (p) or missing (m) data. In general, each volume has different subsets of present and missing data, and consequently requires a different permutation of its indices. The jth component of ti is in if and only if ρi,j ≥ 1, otherwise it is in . Likewise, the transform matrix W separates by rows into two parts and , and the means μi into and for each volume, for i = 1,2,…n, in accordance with the above permutation.
The model (Eq. 9) is simplified by introducing the centered variable yi = ti − μ,
| (10) |
Here, μ is estimated using the sample mean μ̂ properly weighted to account for the missing data. Each component μ̂j is calculated as
| (11) |
The missing components have 0 weights and do not contribute to the mean.
Based on the probabilistic assumptions (Eqs. 2 and 3) and the linearity of the Gaussian distribution, the model (Eq. 10) yields the conditional probability density yi|xi ∼ N(Wxi, σ2I) and the marginal probability density yi ∼ N(0, WWH + σ2I). Here the superscript “H” denotes the Hermitian conjugate, which is the transpose of the complex conjugate, since the algorithm is valid for either real or complex data.
The expectation maximization algorithm can be used to estimate the latent variables xi, the model parameter W and σ2, and the missing data , which are treated as additional hidden variables. Specifically, for each i = 1,2,…n, the values of xi and can be estimated by their statistical mean, 〈xi〉 and , taken with respect to the conditional probability density . In this context, the iterative, two-step process described in Section 2 can be extended as follows.
In the E-step, the first-and second-order statistical moments of xi and are directly evaluated using . Whence, for i = 1,2,…n,
| (12) |
| (13) |
Note that these moments depend explicitly only upon the current values of , , σ2 and the present data . Instead of the entire volumes, only the present data are used to estimate the latent variables xi, which eliminates any artifacts caused by the missing data (Eq. 12). The missing data are estimated at the same time from the model given the value of the latent variables xi and the corresponding rows in the transform matrix (Eq. 13).
In the M-step, the log-likelihood is again defined by Equation 5, and the conditional expectation of the log-likelihood with respect to is
Maximizing 〈ℓ〉 with respect to each element wjk of W yields two different solutions depending if wjk belongs to or , which usually differs for each i = 1,2,…n. We create a set of composite matrices, Gi ∈ℂd×q for each i = 1,2,…n. Each element gi,jk of Gi is either an element of if the jth component of the ith observation is present, or an element of if the jth component of the ith observation is missing. Hence,
| (14) |
where the superscript “C” denotes the complex conjugate. Here, j′ is the index in that corresponds to the jth component of yi and j″ is the index in that corresponds to the jth component of yi. The indices j′ and j″ can be obtained using the same permutations as in Equation 9. Introducing Gi enables a concise formulation for the new estimate of W,
| (15) |
Under the assumption that σ2 → 0, Equations 12 and 13 in the E-step simplify to
| (16) |
| (17) |
Likewise, the new estimate of W (Eq. 15) in the M-step simplifies to
| (18) |
where 〈yi〉 is constructed similarly as Gi (Eq. 14),
| (19) |
where j′ and j″ are the same as in Equation 14. Note that during the E-step, the most recent estimates of W are entered into the right-hand sides of Equations 16 and 17. Likewise, during the M-step, the most recent estimates of 〈xi〉 and are entered into the right-hand side of Equation 18.
Equations 16, 17 and 18 are iterated until a predefined convergence criterion is met or a maximum number of iterations is reached. As a convergence criterion we used the condition that the normalized change of the square error falls below a critical value. We defined the square error in the kth iteration as , and the normalized change of the square error as
| (20) |
The current version of the PPCA-EM algorithm was implemented in Python 2.5, using the numpy package, a Python interface for the LAPACK subroutine library (Numpy 2009).
3.2 Performance Measure
Three statistical tests were carried out to investigate the performance of the PPCA-EM algorithm: First, Fisher's Least Significant Difference (LSD) test to measure the separation between known classes; second, k-means to demonstrate how our algorithm facilitates clustering or classification; and finally, discrepancy comparisons to evaluate the estimation of the missing data.
Fisher's LSD test is a widely used statistical inference method to measure the separation between multiple classes, which is an extension of Student's t-test to multiple classes, (Ott and Longnecker 2003). Here we grouped the xi's, representing the volumes, according to the known classes, and measured the separation between groups by calculating
where m is the number of classes in the data set, n is the number of total volumes, ni is the number of members in ith class and x̅i is the mean of the ith class. The minimum LSD score,
which indicates the least separation between two classes, was used as the performance score of the algorithm. The difference D̂ was compared to a critical value, Dc, obtained from Student's t-distribution at α = 0.005, with n − m degrees of freedom. The class separation was considered successful when the difference between the class means was statistically significant at α = 0.005, i.e., D̂ > Dc. For each experimental condition, the success rate was defined as the ratio of the number of successful trials over the total number of trials, expressed as a percentage.
The k-means algorithm, one of the widely used classification/clustering algorithms, was used to demonstrate how our PPCA-EM algorithm facilitates classification and clustering. PCA is typically followed by a classification algorithm applied to the representation of the data in the principal component subspace. Likewise, classification techniques can be applied to the results of PPCA-EM. The combination of the k-means algorithm and the known classes of the data set allows for easy identification of any misclassified reconstructions. A paucity of misclassified reconstructions provides an additional indicator of an appropriate extraction of the main features of the data.
The accuracy of the estimation of the missing data was evaluated by calculating the normalized distance between the complete 3D Fourier volumes reconstructed from all projections and the volumes with the missing data estimated. As a distance measure we used the Fourier discrepancy, based on the real space discrepancy (Herman et al. 1973; Colsher 1977),
| (21) |
Here, is the jth component of the ith complete volume, t̅i is the mean of the ith volume, and t̃i,j = 〈yi〉i + μ̂j (Eqs. 19 and 11) is the jth component of the ith volume with the missing data estimated.
4. Test Data
4.1 Model Data
We applied the PPCA-EM algorithm to a synthetic problem based on a binary version of a 3D reconstruction of complex I from Yarrowia lipolytica (Radermacher et al. 2006; Clason et al. 2007). We chose a model derived from a 3D reconstruction of complex I with the motivation that the results obtained here may advance the understanding of the variations we observed earlier. Using a binary version of the structure ensured that the starting volume was complete and had no missing data. The test data set consisted of a set of 3D volumes containing four classes obtained by applying the skew transform
| (22) |
to the binary volume. Here (x, y, z) denote the coordinates of the voxel in the original volume; (x′, y′, z′), the coordinates of the voxel in the skewed volume; and a,b,c, the parameters that define the skew operation. Specifically, we used a = 0,b = 0, c = 0 for class 1, a = 0.25,b = 0.1,c = 0.1 for class 2, a = 0.1,b = 0.25,c = 0.1 for class 3 and a = 0.1,b = 0.1,c = 0.25 for class 4. These four structures were then resized to 64×64×64 voxels resulting in a voxel size of 9Å (Fig. 2).
Figure 2.
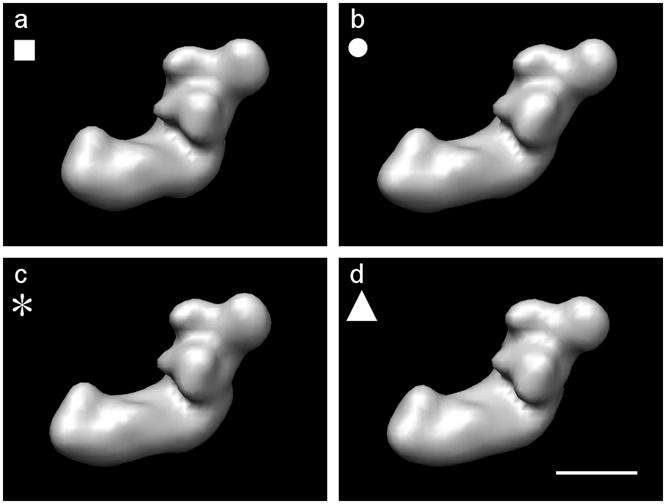
The four starting models derived from a binary volume of complex I from Y. lipolytica, calculated by shearing using Eq. 22, low-pass filtered to 36Å. (a) Original volume a = 0,b = 0.c = 0 (class 1). (b) Volume sheared by a = 0.25,b = 0.1,c = 0.1 (class 2). (c) Volume sheared by a = 0.1,b = 0.25,c = 0.1 (class 3). (d) Volume sheared by a = 0.1,b = 0.1,c = 0.25 (class 4). The symbols (■, ●, *, ▲) are used to identify the classes in subsequent Figures 6 and 7. Even though the parameters have the same values in three of the transformations, the visibility of the differences changes depending on the viewing direction. A skew along either the x-axis or the y-axis is more obvious, since we are viewing along the z-direction. Scale bar 100Å.
Single-axis tilt projections were calculated with 2° angular interval and low-pass filtered to 36Å resolution. Gaussian noise was generated, low-pass filtered to the same resolution as the signal and added to every projection separately before calculating each of the reconstructions. The signal-to-noise ratio was measured as the ratio between the standard deviation of the signal and the standard deviation of the noise out to 36Å resolution. From these projections, multiple 3D reconstructions with missing data were calculated using randomly selected subsets of the projections. We used the 3D Radon inversion algorithm as the reconstruction algorithm (Radermacher 1994, 1997). The angular increments for the 3D Radon transforms were the same as for the single axis tilt series. Therefore, the summation of the 2D Radon transforms of the projections into 3D Radon transforms corresponded to a simple stacking of each 2D transform into the corresponding angular slice of the 3D transform. No averaging occurred, and the signal-to-noise ratio in the 3D transforms is the same as the signal-to-noise ratio in the 2D Radon transform of the projections. 3D polar Fourier transforms were calculated by a 1D Fourier transform of each radial line in the 3D Radon transforms (Deans 1983).
One hundred experimental conditions were created by using all possible combinations of the following three parameters: signal-to-noise ratio (2.0, 1.5, 1.0 and 0.5 at 36Å resolution; corresponding to 0.81, 0.58, 0.41 and 0.19 at full resolution (18Å), respectively) (see supplementary Fig. s1); percentage of missing data (10%, 15%, 20%, 25% and 30%) and total number of volumes in a data set (20, 40, 60, 80 and 100), equally distributed over the four classes. Each combination was repeated 27 times varying the noise and the random selection of missing data. A total of 2700 data sets were created to test the algorithm.
The algorithm was applied to the 3D polar Fourier transforms weighted with to partially compensate for the uneven sampling in polar coordinates. Working in Fourier space, we can easily restrict the resolution by limiting the radius of the Fourier transforms, which also reduces the dimensions of ti, d. When a discrete polar Fourier transform is applied using a 2° sampling interval, 267300 Fourier components are needed to represent the structure to full resolution of 18Å (32 Fourier pixels). The resolution limit of 36Å (16 Fourier pixels) reduces the dimensions of ti to 137700.
The PPCA-EM algorithm was applied using a convergence criterion (Eq. 20) of Δk ≤ 10−6. For each data set, eight feature vectors ωi, i = 1,…8 (Eq. 1) were determined together with the latent variables xi (Eq. 10) which are the coordinates of the original volumes in the 8 dimensional subspaces. The missing data in each volume were additionally estimated based on the 8 feature vectors (Eq. 17).
4.2 Experimental Data
The algorithm was applied to cryo-electron microscopy data of Saccharomyces cerevisiae phosphofructokinase (PFK, EC 2.7.1.11, 835 kDa, 21S). PFK is a glycolytic enzyme that catalyses the phosphorylation of fructose-6-phosphate (F6P) in the presence of ATP and its activity is tightly regulated by many allosteric effectors (Sols 1981). In the presence of 3 mM F6P the enzyme is in the active state, while in the presence of 1 mM ATP and 3 mM MgCl2 the enzyme is in the inactive state. The octameric structure of S. cerevisiae PFK has been solved by a combination of Random Conical Tilt cryo-electron microscopy (Ruiz et al. 2001) and 3D reference based alignment of cryo-electron microscopy images without tilt in both states to better than 13Å resolution (Ruiz et al. 2003; Barcena et al. 2007).
The octameric enzyme in both states can be described as a dimer of tetramers, a top tetramer and a bottom tetramer. The F6P and the ATP states differ mainly in the rotation angle between the top and the bottom tetramers (75° rotation for PFK in the F6P-state and 46° rotation for PFK in the ATP-state). These differences, easily visualized in 3D (Fig. 3e-h), can only be observed in very specific 2D projections (Fig. 3a-d). In addition, even though each of the two tetramers in a given state contains 2α and 2β subunits, the tetramers do not possess identical conformations. Pseudo-symmetric PFK structures can be obtained by applying a rotation of 180° around the short axis of the molecule followed by a 75° rotation for the F6P-state or followed by a 46° rotation for the ATP-state. These symmetry operations bring the bottom tetramers to the positions previously occupied by the top tetramers. Both, ATP and F6P induce different structural changes to the top and bottom tetramers in the octamer thus introducing a slight asymmetry that is not visible in 2D projections of the enzyme and it is barely recognizable in 3D structures. The variations observed are mainly concentrated on the catalytic surface defined by the N-terminal domains of the α and β subunits, which exhibit different small relative shifts. These differences have been hypothesized as being part of the functional mechanism of PFK (Barcena et al. 2007).
Figure 3.

Experimental data of PFK in different states. (a)-(d) sample cryo-electron microscopy images each used to reconstruct the structures below in (e)-(h) respectively. (e) PFK in presence of F6P, where the bottom tetramer is in the F6P-bound state. (f) PFK in presence of ATP, where the bottom tetramer is in the ATP-bound state. (g) PFK in presence of F6P, where the top tetramer is in the F6P-bound state. (h) PFK in presence of ATP, where the top tetramer is in the ATP-bound state. The symbols (◆, ●, ▲, ■) are used to identify the classes in subsequent Figure 9. Scale bar 100Å.
The cryo-electron microscopy data set of the F6P bound state contained 16700 aligned projections extracted from 0°-micrographs and the cryo-electron microscopy data set of the ATP bound state contained 14500 aligned projections extracted from 0°-micrographs. Since PFK is an elongated molecule, the projections show PFK mainly rotating around its long axis. Thus, the data sets represent approximately a single axis tilt series with random tilt angles. For this analysis the projections were interpolated down to a pixel size of 7.2 Å. We have used the projections of PFK in the F6P and ATP states with the angular parameters obtained in the original reconstruction, which gives two states showing large conformational changes. By rotating the projections using the symmetry operations described above (180/75 for the F6P state and 180/46 for the ATP state), we were able to calculate PFK volumes in pseudo-symmetric states, in order to test the performance of the algorithm for detecting small conformational changes. 25 different subsets of only 100 randomly selected projections were used to calculate 25 reconstructions for each state. In addition to the missing data occuring in each reconstruction, randomly selected angular sections were removed from the 3D Radon/Fourier transforms, to insure that the volumes had at least 40% missing data in random directions. All reconstructions were aligned to each other prior to any multivariate statistical analysis.
The resulting data set contained 100 volumes, each reconstructed from 100 projections of vitrified PFK and exhibiting at least 40% missing data in their Fourier transforms. Test calculations were carried out in the same order as for the model data: standard PCA applied to the data-set set without missing data. Standard PCA and PCA-EM to the data set with missing data.
5. Results and Discussion
The PPCA-EM algorithm was applied to all 2700 model data sets. The results were calculated from the 27 experiments created for each of the 100 conditions defined by the multiple combination of SNR, percentage of missing data and number of volumes (Fig. 4).
Figure 4.
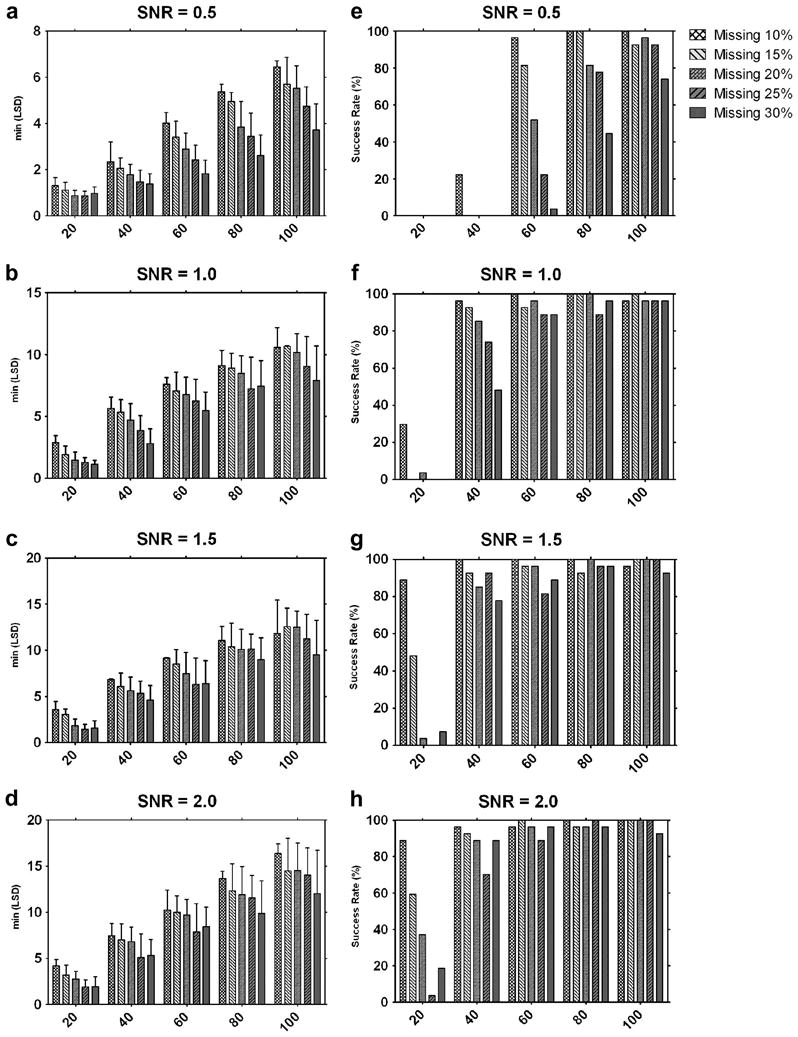
Results of the 2700 tests for 100 different combinations of the three parameters: signal-to-noise ratio, percentage of missing data, number of volumes in a data set. Left column (a)-(d): Each bar represents the mean of the 27 minimum LSD scores for each condition. Test combinations of missing data and number of volumes are represented in graphs for the different SNR used. Error bars show standard deviations. Right column (e)-(h): Each bar represents the success rates of the 27 experiments for each condition at different SNR.
A comparison of all the experiments shows the influence of the different parameters on the performance of the algorithm, measured by the minimum LSD scores (Fig. 4a-d). And the success rates at different SNR are shown in Figure 4e-h. For example, at a SNR of 0.5, with 30% percent missing data, and a data set of only 20 volumes, there was no single success in all 27 experiments (Fig. 4e). On the contrary, at a SNR of 2.0, with 10% percent data missing, and a data set of 100 volumes all 27 trials were successful (Fig. 4h).
Some rare success experiments were observed during the extensive testing of the algorithm. For instance, there was one successful experiment at SNR 1.0, with 20% missing data, and a data set of only 20 volumes (Fig. 4f). Close analysis of this data set showed that the area of missing data in this set of volumes had a substantial overlap, thus minimizing the influence of the missing data on the separation between classes. The statistical nature of the experiments causes other fluctuations visible in both SNR=1.5 and SNR=2.0 cases (Fig. 4g and 4h). An increase in performance is observed when the missing data increases from 25% to 30% in the cases of 20, 40, and 60 volumes, but not in the cases of 80 and 100 volumes. These are common statistical fluctuations that occur when only few data points are sampled (here less than 60) and that disappear when the number of samples increases.
Based on the test calculations, the minimum conditions required to obtain a certain reliability of the results can be estimated. A success rate above 70% can be observed for a SNR of 1 if the number of volumes is larger than 40 and the missing data are less than 25% (Fig. 4f). For a data set of 60 or more volumes, the success rate at a SNR of 1 was always above 70% for all percentages of missing data tested (Fig. 4f). When the data set contained 100 volumes, a 70% success rate was achieved for all modeled conditions, including those with a SNR of 0.5.
The three parameters that affect the results of PPCA-EM can be adjusted in various ways to improve the conditions for applying the algorithm. An increase in success rate can be achieved by increasing the number of volumes, by decreasing the percentage of the missing data, or by increasing the SNR for a given data set. The best method to improve the performance of the algorithm depends on the microscopy technique used for data collection. When electron tomography is used as reconstruction technique, an increase in the number of volumes can be easily achieved by collecting an additional tomography series, which usually contains a large number of subtomograms of the macromolecular structure of interest. In addition, the amount of missing data can be reduced by tilting to a higher angle, by collecting double-tilt series, or by using the conical tilt geometry (Radermacher 1980; Radermacher and Hoppe 1980), see Figure 5 and Table 1. Reconstructions from single-axis tilt series with ±60° angular range have 33.3% missing data. The performance of the PPCA-EM algorithm when applied to this data set can be approximately evaluated based on our tests under the condition of 30% missing data. A dual-axis tilt series also with ±60° angular range dramatically decreases the amounts of missing data to 16%, and our tests with 15% missing data provide a good reference for this condition. If the SNR is the limitation, it may be possible to increase the SNR by lowering the resolution while preserving sufficient detail for structural differentiation. When the random conical reconstruction technique is used, the easiest parameter to optimize is the SNR of the reconstructed volumes by collecting additional tilt pairs. Often the percentage of missing data can be reduced simply by using a higher tilt angle (Fig. 5 and Tab. 1). A large reduction in the percentage of missing data from 13.4% to 6.0% is achieved by increasing the tilt angle from 60° to 70°, which can be easily reached with modern specimen holders.
Figure 5.
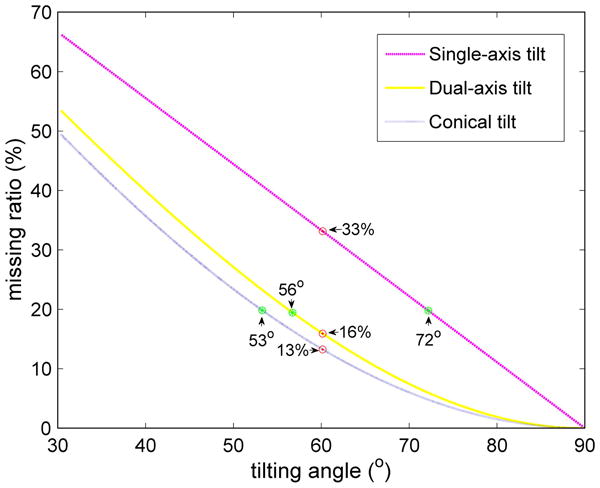
Graph representing the percentage of missing data for different tilting geometries. The x-axis indicates the maximum tilt angle for single-axis and dual-axis tilting, or the fixed tilt angle for conical tilting. Marked are the percentages of missing data for a tilt angle of 60° (red dots) and the tilt angles for 20% missing data (green stars) for each different geometry.
Table 1.
Tilt geometries and percentage of missing data. (a) The percentage of missing data for different tilt geometries and tilt angles. (b) The tilt angles for different tilt geometries and the percentage of missing data. * For conical/random conical (RC) the angular value represents the fixed tilt angle.
| a | |||
|---|---|---|---|
| single-axis | dual-axis | conical/RC | |
| ±30° | 66.7% | 53.9% | 50.0% |
| ±45° | 50.0% | 33.4% | 29.3% |
| ±60° | 33.3% | 16.0% | 13.4% |
| ±70° | 22.2% | 7.5% | 6.0% |
| ±80° | 11.1% | 1.9% | 1.5% |
| b | |||
| single-axis | dual-axis | conical/RC | |
| 10% | ∓81° | ∓67° | 64° |
| 15% | ∓77° | ∓61° | 58° |
| 20% | ∓72° | ∓56° | 53° |
| 25% | ∓68° | ∓52° | 49° |
| 30% | ∓63° | ∓48° | 44° |
The performance of the algorithm is illustrated in more detail for one of the data sets containing 100 volumes with a SNR of 0.5 and 30% missing data (Figs. 6, 7 and 8)1. Plots of the data in the subspace defined by the first three principal components are shown in Figure 6, in which symbols of the same shape and color identify the synthetic original classes. The scatter plots are represented using only the real part of the principal components, which most clearly show the separation of the data. The results of standard PCA when no data are missing demonstrate that PCA is able to capture the main features of the structures and shows an obvious separation into four classes (Fig. 6a). Figure 6b shows the results of standard PCA when the missing data are replaced with 0. The missing data dominate the analysis and no class separation can be detected. Even when eight principal components are visualized pairwise in all possible combinations, no class separation can be detected (results not shown). When the PPCA-EM is applied to the same data set with missing data (Fig. 6c), the correct clustering is achieved, however the volumes belonging to classes 3 and 4, localized at the two opposite ends of a single elongated cloud, are still loosely connected.
Figure 6.
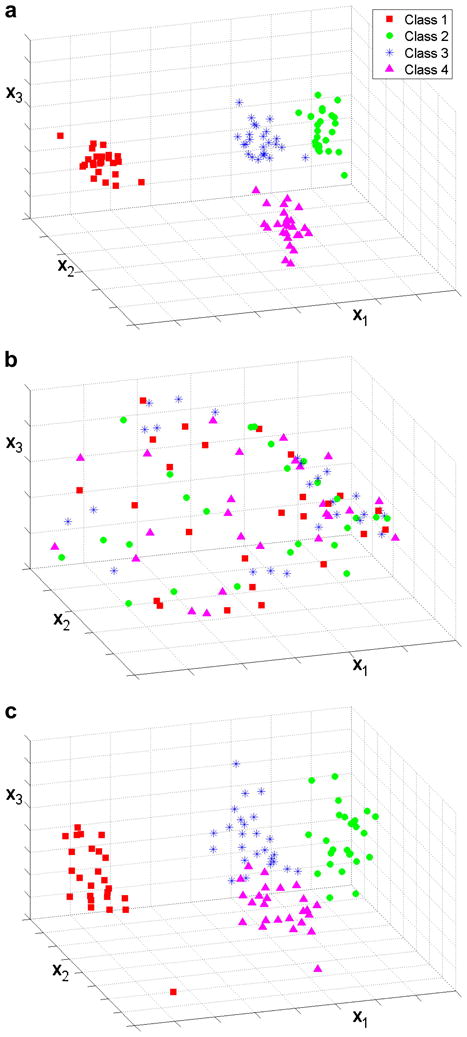
Scatter plots of the real part of the first three principal components, x1, x2 and x3, for a data set with 100 volumes and SNR of 0.5. Symbols correspond to the true classes of each volume. (a) Data set with no missing data, standard PCA. The four classes are clearly separated. (b) 30% missing data, standard PCA. The results are dominated by the missing data. (c) 30% missing data, PPCA-EM. Classes 1 and 2 are well separated. Classes 3 and 4 are loosely connected but easily separable.
Figure 7.
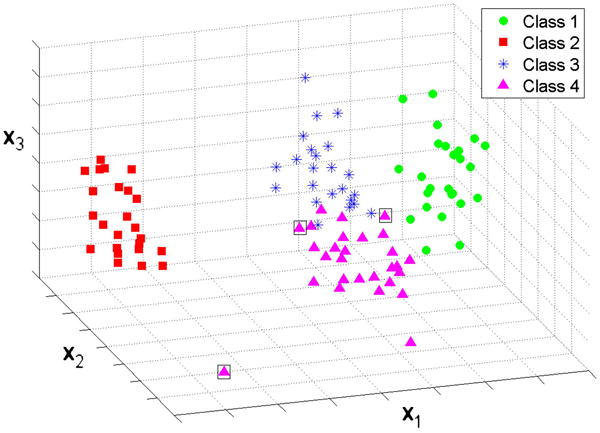
Classification results of the k-means algorithm applied to the results of PPCA-EM shown in Figure 6c. Only three misclassifications occur, enclosed in boxes. Here, the symbols correspond to the classes identified by the k-means algorithm.
Figure 8.
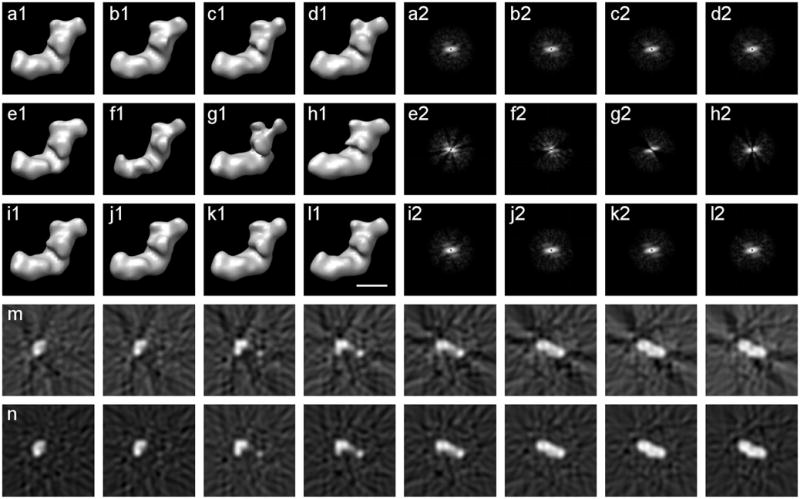
Reconstructions of class 1 with complete, incomplete, and estimated data, SNR=0.5. (a1)-(d1) Four reconstructions without missing data, any differences are caused by variation in noise. (a2)-(d2) Power spectra of the central slices of the Fourier transforms of (a1)-(d1) respectively. (e1)-(h1) Four reconstructions with 30% missing data. (e2)-(h2) Power spectra of the central slices of the Fourier transforms of (e1)-(h1) respectively. (i1)-(l1) Four reconstructions with estimated missing data from PPCA-EM. Each reconstruction closely resembles the corresponding complete reconstruction in (a1)-(d1). (i2)-(l2) Power spectra of the central slices of the Fourier transforms of (i1)-(l1) respectively, notice the filled-in estimated missing data. (m) Eight consecutive x-z slices around the center of the incomplete reconstruction in (e1). (n) Eight consecutive x-z slices around the center of the reconstruction with estimated missing data in (i1). Notice how the artifacts caused by the missing data are reduced by PPCA-EM. Scale bar 100Å.
When k-means clustering with k=4 was applied (Fig. 7), using the same coordinates as in Figure 6, the majority of the volumes were classified correctly into the original classes. Only 3 volumes out of 100 were misclassified (indicated by boxes in Figure 7). Note that no special attempt was made at this point to optimize the classification algorithm.
The PPCA-EM algorithm estimates not only the principal components but also the missing data for each single volume. The reconstructions with the estimated data (Fig. 8i1-l1) closely resemble the corresponding reconstructions without missing data (Fig. 8a1-d1). When the power spectra of the corresponding volumes are compared (Fig. 8i2-l2, a2-d2), the estimation appears better at lower resolution. However, a comparison of these power spectra with the power spectrum of a noise-free reconstruction (e.g., Fig. 1f) shows that the higher resolution spectrum contains mostly noise.
We compared three different methods for estimating the missing data by calculating Fourier discrepancies (Eq. 21) for the 100 volumes in the data set for each method (Tab. 2). The first method substitutes the missing data with the weighted mean of the total data set; the second method substitutes the missing data with the weighted mean of the class to which the volume belongs; and the third method uses the estimate from the PPCA-EM algorithm. The overall weighted mean is the worst estimation of the missing data, while the best estimation is obtained by PPCA-EM. The PPCA-EM algorithm aims at estimating the data including the variations originating from the noise, while the estimation from class averages implicitly includes a noise reduction. If a good classification can be obtained, the weighted class mean is a reasonable method for estimating the missing data. With a continuous distribution of the data, and no clear classification, the estimation by PPCA-EM is superior.
Table 2.
The Fourier discrepancy values for the three possible methods for estimating missing data.
| Fourier Discrepancy | |
|---|---|
| Total mean | 0.7301∓0.0010 |
| Class mean | 0.6015∓0.0002 |
| PPCA-EM | 0.5865∓0.0003 |
The application of the PPCA-EM algorithm to the cryo-electron microscopy PFK data set demonstrates the effectiveness of the algorithm applied to experimental data. The scatter plots of the volumes projected onto the first principal components are illustrated in Figure 9, in which the symbols are shaped and colored according to the different states of PFK. Without missing data, standard PCA is able to resolve the volumes into four well separated clusters (Fig. 9a). Thus, here PCA can capture the features that enable accurate volume classification, and can elucidate both the large and small variations in the data set. However, with at least 40% missing data, standard PCA neither captures the features nor separates the classes clearly (Fig. 9b). The PPCA-EM algorithm, when applied to the same data set with at least 40% missing data, is able to reproduce the correct clusters in the subspace of the largest principal components (Fig. 9c). Data clustering for both PCA and PPCA-EM was checked by examining 2D scatter plots of the volumes projected onto different combinations of the real and imaginary parts, and also the amplitudes of the largest principal components. Interestingly, for the PFK data the best separation was observed when the volumes were projected on the space defined by the real part versus the imaginary part of the first principal component. It should be noted that for the case of the model data of complex I, the best separation was observed in the 3D space defined by real parts of the first 3 principal components. Thus, once the principal components of a data set are obtained, the data should be analyzed in different 2D or 3D spaces, where the imaginary parts of the principal components are treated as additional principal components.
Figure 9.
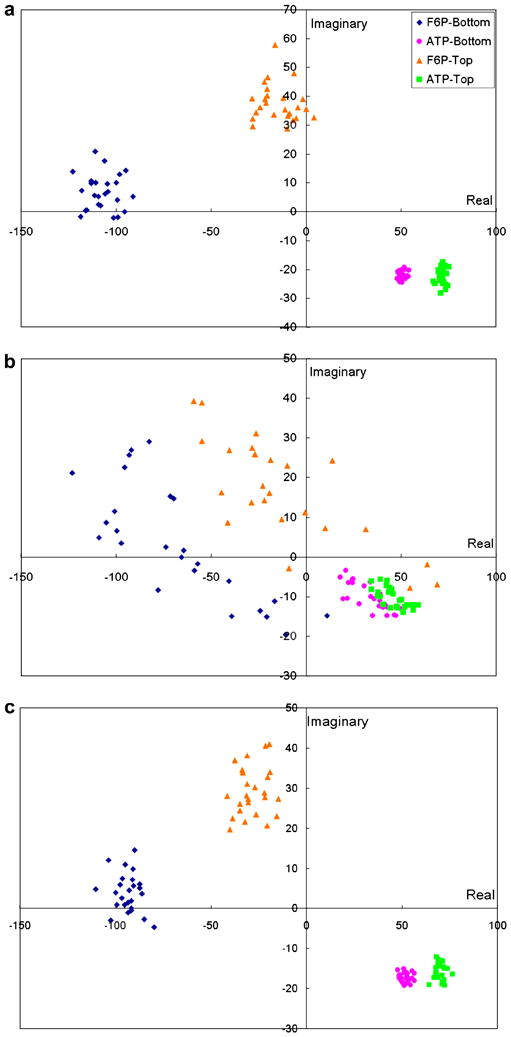
Scatter plots of the PFK volumes projected onto the first principal component, real part vs. imaginary part. Polar Fourier volumes reconstructed with 100 projections were used. Symbols correspond to different states of PFK. (a) No missing data, standard PCA. (b) 40% missing data, standard PCA. (c) 40% missing data, PPCA-EM.
Our PPCA-EM algorithm performs well on data with real noise as demonstrated by the results obtained with the experimental data set. Even though the Gaussian noise, assumed in the algorithm, is an approximation of the noise present in electron micrographs, the PPCA-EM algorithm is able to perform a principal component analysis on electron microscopy volumes with missing data. This is not surprising given the fact that standard PCA, where a Gaussian noise assumption is implied, has been highly successful as a multivariate statistical analysis method in the analysis of 2D electron microscopy images.
Currently, there are four algorithms available in electron microscopy that can analyze 3D volumes with missing data in different orientations. Förster's algorithm uses constrained cross-correlation to reduce the dimensionality of the volumes (Förster et al. 2008). Bartesaghi's algorithm is able to determine the translational and rotational alignments, and assign each volume to a class using a pairwise distance constrained in the commonly present part of the volumes (Bartesaghi et al. 2008). Neither algorithms estimate missing data for individual volumes. Scheres' algorithm, reported after the first submission of this paper, aligns, classifies and estimates missing data for 3D volumes based on expectation maximization (Scheres et al. 2009). None of the three algorithms estimate feature vectors. Our PPCA-EM algorithm extracts feature vectors, reduces the dimensionality of the data, and estimates the missing data for individual volumes. A specific classification algorithm is not included, leaving a wide choice of classification techniques. The technique best suited for a specific data set can be selected. When the data set exhibits continuous variations, these will be visible in the scatter plots produced in feature subspaces, and will not be obscured by a possibly artificial classification. Since our algorithm estimates missing data for individual volumes, averaging of subpopulation is not required.
In summary, we have derived the explicit formulations for the extension of the probabilistic principal component analysis to the application to 3D reconstructions with missing data. Extensive testing of the algorithm both with model and real data has demonstrated its high performance and illustrated its limitations. Most of these limitations can be overcome by increasing the information in the data set in a microscopy technique dependent fashion. The application to real data has shown that our algorithm can detect slight conformational differences that are not visible in 2D projections and barely visible in 3D. In addition to the separation of heterogeneous reconstructions, our algorithm estimates correctly the missing data for each single volume without requiring class averages. The importance of this feature will become prominent as more and more biological systems are studied that do not show well defined states but continuous variations.
Supplementary Material
Acknowledgments
This work was supported by NIH grant RO1 GM078202 (to M.R.), and has benefited from NIH grants RO1 GM068650 (to M.R.) and RO1 GM069551 (to T.R.). Additional computer resources provided by the Vermont Advanced Computing Center which is supported by NASA (Grant No. NNX 08A096G) are gratefully acknowledged.
Footnotes
Convergence criterion Δk ≤ 10−6, 158 iterations total 81 minutes (30 seconds per iteration) run on a single processor of a Quad-Core AMD Opteron™ Processor 2356.
References
- Barcena M, Radermacher M, Bar J, Kopperschlager G, Ruiz T. The structure of the ATP-bound state of S. cerevisiae phosphofructokinase determined by cryo-electron microscopy. Journal of Structure Biology. 2007;159:135–43. doi: 10.1016/j.jsb.2007.03.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartesaghi A, Sprechmann P, Liu J, Randall G, Sapiro G, Subramaniam S. Classification and 3D averaging with missing wedge correction in biological electron tomography. Journal of Structural Biology. 2008;162:436–450. doi: 10.1016/j.jsb.2008.02.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bezdek J. Pattern Recognition with Fuzzy Objective Function Algoritms. Plenum Press; New York: 1981. [Google Scholar]
- Bretaudiere J, Dumont G, Rej R, Bailly M. Suitability of control materials. General principles and methods of investigation. Clinical Chemistry. 1981;27:798–805. [PubMed] [Google Scholar]
- Bretaudiere J, Frank J. Reconstitution of molecule images analysed by correspondence analysis: a tool for structural interpretation [published erratum appears in J Microsc 1987 May;146(Pt 2):222] Journal of Microscopy. 1986;144:1–14. doi: 10.1111/j.1365-2818.1986.tb04669.x. [DOI] [PubMed] [Google Scholar]
- Carazo JM, Rivera FF, Zapata EL, Radermacher M, Frank J. Fuzzy Sets-Based Classification of Electron Microscopy Images of Biological Macromolecules With an Application to Ribosomal Particles. Journal of Microscopy. 1990;157:187–204. doi: 10.1111/j.1365-2818.1990.tb02958.x. [DOI] [PubMed] [Google Scholar]
- Clason T, Zickermann V, Ruiz T, Brandt U, Radermacher M. Direct localization of the 51 and 24kDa subunits of mitochondrial complex I by three-dimensional difference imaging. Journal Structure Biololgy. 2007;159:433–442. doi: 10.1016/j.jsb.2007.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Colsher JG. Iterative three-diminsional image reconstruction from tomographic projections. Computer Graphics and Image Process. 1977;6:513. [Google Scholar]
- Crowther RA, DeRosier DJ, Klug A. The reconstruction of a three-dimensional structure from projections and its application to electron microscopy. Proceedings of The Royal Society London Ser A. 1970;317:319–340. doi: 10.1098/rspb.1972.0068. [DOI] [PubMed] [Google Scholar]
- Deans SR. The Radon Transform and some of its Applications. John Wiley & Sons; New York: 1983. [Google Scholar]
- Dempster AP, Laird NM, Rubin DB. Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society Series B. 1977;39:1–38. [Google Scholar]
- Diday E. La méthode de nuées dynamiques. Revue Statistique Appliquée. 1971;19:19–34. [Google Scholar]
- Dunn J. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. Journal of Cybernetics. 1973;3:32–57. [Google Scholar]
- Förster F, Hegerl R. Structure Determination In Situ by Averaging of Tomograms. Methods in Cell Biology. 2007;79:741–767. doi: 10.1016/S0091-679X(06)79029-X. [DOI] [PubMed] [Google Scholar]
- Förster F, Pruggnaller S, Seybert A, Frangakis AS. Classification of cryo-electron sub-tomograms using constrained correlation. Journal of Structural Biology. 2008;161:276–286. doi: 10.1016/j.jsb.2007.07.006. [DOI] [PubMed] [Google Scholar]
- Frank J, Goldfarb W, Eisenberg D, Baker TS. Reconstruction of glutamine synthetase using computer averaging. Ultramicroscopy. 1978;3:283. doi: 10.1016/s0304-3991(78)80038-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frank J, van Heel M. Correspondence analysis of aligned images of biological particles. Journal of Molecular Biology. 1982;161:134–137. doi: 10.1016/0022-2836(82)90282-0. [DOI] [PubMed] [Google Scholar]
- Golub G, van Loan V. Matrix computations. The Johns Hopkins University Press; London: 1996. [Google Scholar]
- Grünewald K, Medalia O, Gross A, Steven AC, Baumeister W. Prospects of electron cryotomography to visualize macromolecular complexes inside cellular compartments: implications of crowding. Biophysical Chemistry. 2003;100:577–591. doi: 10.1016/s0301-4622(02)00307-1. [DOI] [PubMed] [Google Scholar]
- van Heel M. Angular reconstitution: a posteriori assignment of projection directions for 3D reconstruction. Ultramicroscopy. 1987;21:111. doi: 10.1016/0304-3991(87)90078-7. [DOI] [PubMed] [Google Scholar]
- van Heel M, Frank J. Use of multivariate statistics in analysing the images of biological macromolecules. Ultramicroscopy. 1981;6:187–194. doi: 10.1016/0304-3991(81)90059-0. [DOI] [PubMed] [Google Scholar]
- Herman G, Lent A, Rowland S. ART: Mathematics and applications (a report on the mathematical foundations and on the applicability to real data of the algebraic reconstruction techniques) Journal of Theoretical Biology. 1973;42:1–32. doi: 10.1016/0022-5193(73)90145-8. [DOI] [PubMed] [Google Scholar]
- Hoppe W, Langer R, Knech G, Poppe C. Proteinkristallstrukturanalyse mit Elektronenstrahlen. Naturwissenschaften. 1968;55:333. doi: 10.1007/BF00600449. [DOI] [PubMed] [Google Scholar]
- Hoppe W, Schramm HJ, Sturm M, Hunsmann N, Gaßβmann J. Three-dimensional electron microscopy of individual biological objects. I. Methods. Zeitschrift fuer Naturforschung. 1976a;31a:645–655. [Google Scholar]
- Hoppe W, Schramm HJ, Sturm M, Hunsmann N, Gaßβmann J. Three-dimensional electron microscopy of individual biological objects. II. Test calculations. Zeitschrift fuer Naturforschung. 1976b;31a:1370–1379. [Google Scholar]
- Hoppe W, Schramm HJ, Sturm M, Hunsmann N, Gaβmann J. Three-dimensional electron microscopy of individual biological objects. III. Experimental results on yeast fatty acid synthetase. Zeitschrift fuer Naturforschung. 1976c;31a:1380–1390. [Google Scholar]
- Johnson S. Hierarchical clustering schemes. Psychometrika. 1967;2:241–254. doi: 10.1007/BF02289588. [DOI] [PubMed] [Google Scholar]
- Knauer V, Hegerl R, Hoppe W. Three-dimensional reconstruction and averaging of 30 S ribosomal subunits of Escherichia coli from electron micrographs. Journal of Molecular Biology. 1983;163:409–30. doi: 10.1016/0022-2836(83)90066-9. [DOI] [PubMed] [Google Scholar]
- Lebart L. Multivariate Descriptive Statistical Analysis. John Wiley & Sons Inc; New York: 1984. [Google Scholar]
- Leschziner AE, Nogales E. The orthogonal tilt reconstruction method: An approach to generating single-class volumes with no missing cone for ab initio reconstruction of asymmetric particles. Journal of Structural Biology. 2006;153:284–299. doi: 10.1016/j.jsb.2005.10.012. [DOI] [PubMed] [Google Scholar]
- Little RJA, Rubin DB. Statistical Analysis with Missing Data. John Wiley; Chichester, UK: 1987. [Google Scholar]
- MacQueen J. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. University of California Press; Berkeley: 1967. Some methods for classification and analysis of multivariate observations; pp. 281–297. [Google Scholar]
- Markham R, Frey S, Hills G. Methods for the enhancement of image detail and accentuation of structure in electron microscopy. Virology. 1963;20:88–102. [Google Scholar]
- Markham R, Hitchborn J, Hills G, Frey S. The anatomy of the tobacco mosaic virus. Virology. 1964;22:342–359. doi: 10.1016/0042-6822(64)90025-x. [DOI] [PubMed] [Google Scholar]
- Numpy NumPy Reference. 2009 http://numpy.org.
- Oettl H, Hegerl R, Hoppe W. Three-dimensional reconstruction and averaging of 50 S ribosomal subunits of Escherichia coli from electron micrographs. Journal of Molecular Biology. 1983;163:431–50. doi: 10.1016/0022-2836(83)90067-0. [DOI] [PubMed] [Google Scholar]
- Ott L, Longnecker MT. A First Course in Statistical Methods. Cengage Learning 2003 [Google Scholar]
- Pearson K. On lines and planes of closest fit to systems of points in space. Philosophical Magazine. 1901;2:572–559. [Google Scholar]
- Radermacher M. Ph D Thesis, Technische Universität München. 1980. Dreidimensionale Rekonstruktion bei kegelfrörmiger Kippung im Elektronenmikroskop. [Google Scholar]
- Radermacher M. Three-dimensional reconstruction of single particles from random and nonrandom tilt series. Journal of Electron Microscopy Technique. 1988;9:359–394. doi: 10.1002/jemt.1060090405. [DOI] [PubMed] [Google Scholar]
- Radermacher M. Three-dimensional reconstruction from random projections: orientational alignment via Radon transforms. Ultramicroscopy. 1994;53:121–36. doi: 10.1016/0304-3991(94)90003-5. [DOI] [PubMed] [Google Scholar]
- Radermacher M. Radon transform techniques for alignment and 3D reconstruction from random projections. Scanning Microscopy. 1997;11:171–177. [Google Scholar]
- Radermacher M, Hoppe W. Properties of 3-D reconstruction from projections by conical tilting compared to single axis tilting compared to single axis tilting. Electron Microscopy; Proc. 7th Eur. Congr; 1980. pp. 132–133. [Google Scholar]
- Radermacher M, Ruiz T, Clason T, Benjamin S, Brandt U, Zickermann V. The three-dimensional structure of complex I from Yarrowia lipolytica: A highly dynamic enzyme. Journal of Structural Biology. 2006;154:269–279. doi: 10.1016/j.jsb.2006.02.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Radermacher M, Wagenknecht T, Verschoor A, Frank J. A New 3-Dimensional Reconstruction Scheme Applied to the 50s Ribosomal Subunit of E.Coli. Journal of Microscopy. 1986;141:Rp1–Rp2. doi: 10.1111/j.1365-2818.1986.tb02693.x. [DOI] [PubMed] [Google Scholar]
- Radermacher M, Wagenknecht T, Verschoor A, Frank J. Three-dimensional reconstruction from a single-exposure, random conical tilt series applied to the 50S ribosomal subunit of Escherichia coli. Journal of Microscopy. 1987;146:113–136. doi: 10.1111/j.1365-2818.1987.tb01333.x. [DOI] [PubMed] [Google Scholar]
- Roweis S. EM Algorithms for PCA and SPCA. Neural Information Processing Systems. 1997:626–632. [Google Scholar]
- Ruiz T, Kopperschläger G, Radermacher M. The first three-dimensional structure of phosphofructokinase from Saccharomyces cerevisiae determined by electron microscopy of single particles. Journal of Structural Biology. 2001;136:167–80. doi: 10.1006/jsbi.2002.4440. [DOI] [PubMed] [Google Scholar]
- Ruiz T, Mechin I, Bar J, Rypniewski W, Kopperschlager G, Radermacher M. The 10.8-A structure of Saccharomyces cerevisiae phosphofructokinase determined by cryoelectron microscopy: localization of the putative fructose 6-phosphate binding sites. Journal of Structural Biology. 2003;143:124–34. doi: 10.1016/s1047-8477(03)00140-0. [DOI] [PubMed] [Google Scholar]
- Saxton WO, Frank J. Motif detection in quantum noise-limited electron micrographs by cross-correlation. Ultramicroscopy. 1977;2:219–27. doi: 10.1016/s0304-3991(76)91385-1. [DOI] [PubMed] [Google Scholar]
- Scheres SH, Melero R, Valle M, Carazo J. Averaging of Electron Subtomograms and Random Conical Tilt Reconstructions through Likelihood Optimization. Structure. 2009;17:1563–1572. doi: 10.1016/j.str.2009.10.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sols A. Multimodulation of enzyme activity. Current topics in cellular regulation. 1981;19:77–101. doi: 10.1016/b978-0-12-152819-5.50020-8. [DOI] [PubMed] [Google Scholar]
- Tipping ME, Bishop CM. Probabilistic Principal Component Analysis. Journal of the Royal Statistical Society: Series B: Statistical Methodology. 1999;61:611–622. [Google Scholar]
- Walz J, Typke D, Nitsch M, Koster AJ, Hegerl R, Baumeister W. Electron Tomography of Single Ice-Embedded Macromolecules: Three-Dimensional Alignment and Classification. Journal of Structural Biology. 1997;120:387–395. doi: 10.1006/jsbi.1997.3934. [DOI] [PubMed] [Google Scholar]
- Winkler H. 3D reconstruction and processing of volumetric data in cryo-electron tomography. Journal of Structural Biology. 2007;157:126–137. doi: 10.1016/j.jsb.2006.07.014. [DOI] [PubMed] [Google Scholar]
- Winkler H, Taylor KA. Multivariate statistical analysis of three-dimensional cross-bridge motifs in insect flight muscle. Ultramicroscopy. 1999;77:141–152. [Google Scholar]
- Yu L, Snapp R, Radermacher M. Multivariate Statistical Analysis of Volumes with Missing Data. Proceedings of 35th Annual Meeting of the Microscopy Society of Canada; Montreal. 20-23 May.2008. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.