

Abstract
Stochastic Differential Equations (SDE) are often used to model the stochastic dynamics of biological systems. Unfortunately, rare but biologically interesting behaviors (e.g., oncogenesis) can be difficult to observe in stochastic models. Consequently, the analysis of behaviors of SDE models using numerical simulations can be challenging. We introduce a method for solving the following problem: given a SDE model and a high-level behavioral specification about the dynamics of the model, algorithmically decide whether the model satisfies the specification. While there are a number of techniques for addressing this problem for discrete-state stochastic models, the analysis of SDE and other continuous-state models has received less attention. Our proposed solution uses a combination of Bayesian sequential hypothesis testing, non-identically distributed samples, and Girsanov's theorem for change of measures to examine rare behaviors. We use our algorithm to analyze two SDE models of tumor dynamics. Our use of non-identically distributed samples sampling contributes to the state of the art in statistical verification and model checking of stochastic models by providing an effective means for exposing rare events in SDEs, while retaining the ability to compute bounds on the probability that those events occur.
Background
The dynamics of biological systems are largely driven by stochastic processes and subject to random external perturbations. The consequences of such random processes are often investigated through the development and analysis of stochastic models (e.g., [1-4]). Unfortunately, the validation and analysis of stochastic models can be very challenging [5,6], especially when the model is intended to investigate rare, but biologically significant behaviors (e.g., oncogenesis). The goal of this paper is to introduce an algorithm for examining such rare behaviors in Stochastic Differential Equation (SDE) models. The algorithm takes as input the SDE model, 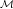 , and a high-level description of a dynamical behavior, ϕ (e.g., a formula in temporal logic). It then computes a statistically rigorous bound on the probability that the given model exhibits the stated behavior using a combination of biased sampling and Bayesian Statistical Model Checking [7,8].
, and a high-level description of a dynamical behavior, ϕ (e.g., a formula in temporal logic). It then computes a statistically rigorous bound on the probability that the given model exhibits the stated behavior using a combination of biased sampling and Bayesian Statistical Model Checking [7,8].
Existing methods for validating and analyzing stochastic models often require extensive Monte Carlo sampling of independent trajectories to verify that the model is consistent with known data, and to characterize the model's expected behavior under various initial conditions. Sampling strategies are either unbiased or biased. Unbiased sampling strategies draw trajectories according to the probability distribution implied by the model, and are thus not well-suited to investigating rare behaviors. For example, if the actual probability that the model will exhibit a given behavior is 10-10, then the expected number of samples need to see such behaviors is about 1010 (See Figure 1). Biased sampling strategies, in contrast, can be used to increase the probability of observing rare events, at the expense of distorting the underlying probability distribution/measure. If the change of measure is well-characterized (as in importance sampling), these distortions can be corrected when computing properties of the distribution.
Figure 1.

Observing rare behaviors in i.i.d. sampling is challenging. A toy model with a one low-probability state. An unbiased sampling algorithm may require billions of samples in order to observe the 'bad' state. Statistical algorithms based on i.i.d. algorithms are not suitable for analyzing such models with rare interesting behaviors.
Our method uses a combination of biased sampling and sequential hypothesis testing [9,10] to estimate the probability that the model satisfies the property. Briefly, the algorithm randomly perturbs the computational model prior to generating each sample in order to expose rare but interesting behaviors. These perturbations cause a change of measure. We note that in the context of SDEs, a change of measure is itself a stochastic process and so importance sampling, which assumes that the change of measure with respect to the biased distribution is known, cannot be used. Our technique does not require us to know the exact magnitudes of the changes of measure, nor the Radon-Nikodym derivatives [11]. Instead, it ensures that that the geometric average of these derivatives is bounded. This is a much weaker assumption than is required by importance sampling, but we will show that it is sufficient for the purposes of obtaining bounds via sequential hypothesis testing.
Related work
Our method performs statistical model checking using hypothesis testing [12,13], which has been used previously to analyze in a variety of domains (e.g., [14-19,19]), including computational biology (e.g., [7,8,20-22]). There are two key differences between the method in this paper and existing methods. First, existing methods generate independently and identically distributed (i.i.d.) samples. Our method, in contrast, generates independent but non-identically distributed (non-i.i.d.) samples. It does so to expose rare behaviors. Second, whereas most existing methods for statistical model checking use classical statistics, our method employs Bayesian statistics [23,24]. We have previously shown that Bayesian statistics confers advantages in the context of statistical verification in terms of efficiency and flexibility [7,8,19,25].
Methods
Our method draws on concepts from several different fields. We begin by briefly surveying the semantics of stochastic differential equations, a language for formally specifying dynamic behaviors, Girsanov's theorem on change of measures, and results on consistency and concentration of Bayesian posteriors.
Stochastic differential equation models
A stochastic differential equation (SDE) [26,27] is a differential equation in which some of the terms evolve according to Brownian Motion [28]. A typical SDE is of the following form:
where X is a system variable, b is a Riemann integrable function, v is an Itō integrable function, and W is Brownian Motion. The Brownian Motion W is a continuous-time stochastic process satisfying the following three conditions:
1. W0 = 0
2. Wt is continuous (almost surely).
3. Wt has independent normally distributed increments:
• Wt - Ws and Wt' - Ws' are independent if 0 ≤ s <t <s' <t'.
• , where denotes the normal distribution with mean 0 and variance t - s. Note that the symbol ~ is used to indicate "is distributed as".
Consider the time between 0 and t as divided into m discrete steps 0, t1, t2 ... tm = t. The solution to a stochastic differential equation is the limit of the following discrete difference equation, as m goes to infinity:
In what follows, 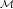 will refer to a system of stochastic differential equations. We note that a system of stochastic differential equations comes equipped with an inherent probability space and a natural probability measure μ. Our algorithm repeatedly and randomly perturbs the probability measure of the Brownian motion in the model
will refer to a system of stochastic differential equations. We note that a system of stochastic differential equations comes equipped with an inherent probability space and a natural probability measure μ. Our algorithm repeatedly and randomly perturbs the probability measure of the Brownian motion in the model 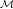 which, in turn, changes the underlying measure in an effort to expose rare behaviors. These changes can be characterized using Girsanov's Theorem.
which, in turn, changes the underlying measure in an effort to expose rare behaviors. These changes can be characterized using Girsanov's Theorem.
Girsanov's theorem for perturbing stochastic differential equation models
Given a process {θt | 0 ≤ t ≤ T} satisfying the Novikov condition [29], such as an SDE, the following exponential martingale Zt defines the change from measure P to new measure :
Here, Zt is the Radon-Nikodym derivative of with respect to P for t <T. The Brownian motion under is given by: . The non-stochastic component of the stochastic differential equation is not affected by change of measures. Thus, a change of measure for SDEs is a stochastic process (unlike importance sampling for explicit probability distributions).
Specifying dynamic behaviors
Next, we define a formalism for encoding high-level behavioral specification that our algorithm will test against 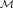 .
.
Definition 1 (Adapted Finitely Monitorable). Let σ be a finite-length trace from the stochastic differential equation 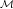 . A specification ϕ is said to be adapted finitely monitorable (AFM) if it is possible to decide whether σ satisfies ϕ, denoted ϕ ⊨ ϕ.
. A specification ϕ is said to be adapted finitely monitorable (AFM) if it is possible to decide whether σ satisfies ϕ, denoted ϕ ⊨ ϕ.
Certain AFM specifications can be expressed as formulas in Bounded Linear Temporal Logic (BLTL) [30-32]. Informally, BLTL formulas can capture the ordering of events.
Definition 2 (Probabilistic Adapted Finitely Monitorable). A specification ϕ is said to be probabilistic adapted finitely monitorable (PAFM) if it is possible to (deterministically or probabilistically) decide whether 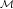 satisfies ϕ with probability at least θ, denoted .
satisfies ϕ with probability at least θ, denoted .
Some common examples of PAFM specifications include Probabilistic Bounded Linear Temporal Logic (PBLTL) (e.g., see [19]) and Continuous Specification Logic. Note that temporal logic is only one means for constructing specifications; other formalisms can also be used, like Statecharts [33,34].
Semantics of bounded linear temporal logic (BLTL)
We define the semantics of BLTL with respect to the paths of 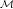 . Let σ = (s0, Δ0), (s1, Δ1),... be a sampled execution of the model along states s0, s1,... with durations Δ0, Δ1, .. . ∈ ℝ. We denote the path starting at state i by σi (in particular, σ0 denotes the original execution σ). The value of the state variable x in σ at the state i is denoted by V (σ, i, x). The semantics of BLTL is defined as follows:
. Let σ = (s0, Δ0), (s1, Δ1),... be a sampled execution of the model along states s0, s1,... with durations Δ0, Δ1, .. . ∈ ℝ. We denote the path starting at state i by σi (in particular, σ0 denotes the original execution σ). The value of the state variable x in σ at the state i is denoted by V (σ, i, x). The semantics of BLTL is defined as follows:
1. σk ⊨ x ~ v if and only if V(σ, k, x) ~ v, where v ∈ ℝ and ~ ∈ {>, <, =}.
2. σk ⊨ ϕ1 ∨ϕ2 if and only if σk ⊨ ϕ1 or σk ⊨ ϕ2.
3. σk ⊨ ϕ1 ∧ ϕ2 if and only if σk ⊨ ϕ1 and σk ⊨ ϕ2;
4. σk ⊨ ¬ϕ1 if and only if σk ⊨ ϕ1 does not hold.
5. σk ⊨ ϕ1Utϕ2 if and only if there exists i ∈ ℕ such that: (a) 0 ≤ Σ0 ≤ l <iΔk+l≤ t; (b) σk+i⊨ ϕ2; and (c) for each 0 ≤ j < i, σk+j⊨ ϕ1;
Statistical model validation
Our algorithm performs statistical model checking using Bayesian sequential hypothesis testing [23] on non-i.i.d. samples. The statistical model checking problem is to decide whether a model 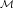 satisfies a probabilistic adapted finitely monitorable formula ϕ with probability at least θ. That is, whether where θ ∈ (0, 1).
satisfies a probabilistic adapted finitely monitorable formula ϕ with probability at least θ. That is, whether where θ ∈ (0, 1).
Sequential hypothesis testing
Let ρ be the (unknown but fixed) probability of the model satisfying ϕ. We can now re-state the statistical model checking problem as deciding between the two composite hypotheses: H0 : ρ ≽ θ and H1 : ρ < θ. Here, the null hypothesis H0 indicates that 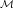 satisfies the AFM formula ϕ with probability at least θ, while the alternate hypothesis H1 denotes that
satisfies the AFM formula ϕ with probability at least θ, while the alternate hypothesis H1 denotes that  satisfies the AFM formula ϕ with probability less than θ.
satisfies the AFM formula ϕ with probability less than θ.
Definition 3 (Type I and II errors). A Type I error is an error where the hypothesis test asserts that the null hypothesis H0 is false, when in fact H0 is true. Conversely, a Type II error is an error where the hypothesis test asserts that the null hypothesis H0 is true, when in fact H0 is false.
The basic idea behind any statistical model checking algorithm based on sequential hypothesis testing is to iteratively sample traces from the stochastic process. Each trace is then evaluated with a trace verifier [32], which determines whether the trace satisfies the specification i.e. σi ⊨ ϕ. This is always feasible because the specifications used are adapted and finitely monitorable. Two accumulators keep track of the total number of traces sampled, and the number of satisfying traces, respectively. The procedure continues until there is enough information to reject either H0 or H1.
Bayesian sequential hypothesis testing
Recall that for any finite trace σi of the system and an Adapted Finitely Monitorable (AFM) formula ϕ, we can decide whether σi satisfies ϕ. Therefore, we can define a random variable Xi denoting the outcome of σi ⊨ ϕ. Thus, Xi is a Bernoulli random variable with probability mass function , where xi = 1 if and only if σi ⊨q ϕ, otherwise xi = 0.
Bayesian statistics requires that prior probability distributions be specified for the unknown quantity, which is ρ in our case. Thus we will model the unknown quantity as a random variable u with prior density g(u). The prior probability distribution is usually based on our previous experiences and beliefs about the system. Non-informative or objective prior probability distribution [35] can be used when nothing is known about the probability of the system satisfying the AFM formula.
Suppose we have a sequence of independent random variables X1,..., Xn defined as above, and let d = (x1,..., xn) denote a sample of those variables.
Definition 4. The Bayes factor  of sample d and hypotheses H0 and H1 is .
of sample d and hypotheses H0 and H1 is .
The Bayes factor may be used as a measure of relative confidence in H0 vs. H1, as proposed by Jeffreys [36]. The Bayes factor is the ratio of two likelihoods:
| (1) |
We note that the Bayes factor depends on both the data d and on the prior g, so it may be considered a measure of confidence in H0 vs. H1 provided by the data x1,..., xn, and "weighted" by the prior g.
Non-i.i.d. Bayesian sequential hypothesis testing
Traditional methods for hypothesis testing, including those outlined in the previous two subsection*s, assume that the samples are drawn i.i.d.. In this section* we show that non-i.i.d. samples can also be used, provided that certain conditions hold. In particular, if one can bound the change in measure associated with the non-identical sampling, one can can also bound the Type I and Type II errors under a change of measure. Our algorithm bounds the change of measure, and thus the error.
We begin by reviewing some fundamental concepts from Bayesian statistics including KL divergence, KL support, affinity, and δ-separation, and then restate an important result on the concentration of Bayesian posteriors [35,37].
Definition 5 (Kullback-Leibler (KL) Divergence). Given a parameterized family of probability distributions {fθ}, the Kullback-Leibler (KL) divergence K(θ0, θ) between the distributions corresponding to two parameters θ and θ0 is: . Note that is the expectation computed under the probability measure .
Definition 6 (KL Neighborhood). Given a parameterized family of probability distributions {fθ}, the KL neighborhood Kε (θ0) of a parameter value θ0 is given by the set {θ : K (θ0, θ) < ε}.
Definition 7 (KL Support). A point θ0 is said to be in the KL support of a prior Π if and only if for all ε >0, Π (Kε (θ0)) >0.
Definition 8 (Affinity). The affinity Aff(f, g) between any two densities is defined as .
Definition 9 (Strong δ-Separation). Let A ⊂ [0, 1] and δ >0. The set A and the point θ0 are said to be strongly δ-separated if and only if for any proper probability distribution v on A, .
Given these definitions, it can be shown that the Bayesian posterior concentrates exponentially under certain technical conditions [35,37].
Bounding errors under a change of measure
Next, we develop the machinery needed to compute bounds on the Type-I/Type-II errors for a testing strategy based on non-i.i.d. samples.
A stochastic differential equation model 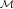 is naturally associated with a probability measure μ. Our non-i.i.d. sampling strategy can be thought of as the assignment of a set of probability measures μ1, μ2,... to
is naturally associated with a probability measure μ. Our non-i.i.d. sampling strategy can be thought of as the assignment of a set of probability measures μ1, μ2,... to 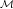 . Each unique sample σi is associated with an implied probability measure μi and is generated from
. Each unique sample σi is associated with an implied probability measure μi and is generated from 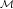 under μi in an i.i.d. manner. Our proofs require that all the implied probability measures are equivalent. That is, an event is possible (resp. impossible) under a probability measure if and only if it is possible (resp. impossible) under the original probability measure μ.
under μi in an i.i.d. manner. Our proofs require that all the implied probability measures are equivalent. That is, an event is possible (resp. impossible) under a probability measure if and only if it is possible (resp. impossible) under the original probability measure μ.
We use the following result regarding change of measures. Suppose a given behavior, say ϕ, holds on the original model with an (unknown) probability ρ.
Here, Xi is a Bernoulli random variable denoting the event that ith sample satisfies the given behavior ϕ. Note that the Xi s must be independent of one another. Now, we can rewrite the above expression as:
Note that the term denotes the probability of observing the event Xi under the modified probability measure μi if the unknown probability ρ were u. In order to ensure the independence assumption, the new probability measures μi are chosen independently of one another. The ratio is the implied Radon-Nikodym derivative for the change of measure between two equivalent probability measures. Suppose, the testing strategy has made n observations X1, X2,... Xn. Then,
A sampling algorithm can compute by drawing independent samples from a stochastic differential equation model under the new "modified" probability measure. We note that it is not easy to compute the change of measure algebraically or numerically. However, our algorithm does not need to compute this quantity explicitly. It simply establishes bounds on it.
Consider the following expression that is computable without knowing the implied Radon-Nikodym derivative or change of measure explicitly.
Now, we can rewrite the above expression as:
Our result will exploit the fact that we do not allow our testing or sampling procedures to have arbitrary implied Radon-Nikodym derivatives. This is reasonable as no statistical guarantees should be available for an intelligently designed but adversarial test procedure that (say) tries to avoid sampling from the given behavior. Suppose that the implied Radon-Nikodym derivative always lies between a constant c and another constant 1/c. That is, the change of measure does not distort the probabilities of observable events by more than a factor of c. Then, we observe that:
Furthermore,
Thus, by allowing the sampling algorithm to change measures by at most c, we have changed the posterior probability of observing a behavior by at most c2.
Example: Suppose, the testing strategy has made n observations X1, X2,... Xn. Then,
Similarly,
Termination conditions for non-i.i.d. sampling
Traditional (i.e., i.i.d.) Bayesian Sequential Hypothesis Testing is guaranteed to terminate. That is, only a finite number of samples are required before the test selects one of the hypotheses. We now consider the conditions under which a Bayesian Sequential Hypothesis Testing based procedure using non-i.i.d. samples will terminate. To do this, we first need to show that the posterior probability distribution will concentrate on a particular value as we see more an more samples from the model.
To consider the conditions under which our algorithm will terminate after observing n samples, note that the factor introduced due to the change of measure c2n can outweigh the gain made by the concentration of the probability measure e-nb. This is not surprising because our construction thus far does not force the test not to bias against a sample in an intelligent way. That is, a maliciously designed testing procedure could simply avoid the error prone regions of the design. To address this, we define the notion of a fair testing strategy that does not engage in such malicious sampling.
Definition 10. A testing strategy is η-fair (η ≥ 1) if and only if the geometric average of the implied Radon-Nikodym derivatives over a number of samples is within a constant factor η of unity, i.e.,
Note that a fair test strategy does not need to sample from the underlying distribution in an i.i.d. manner. However, it must guarantee that the probability of observing the given behavior in a large number of observations is not altered substantially by the non-i.i.d. sampling. Intuitively, we want to make sure that we bias for each sample as many times as we bias against it. Our main result shows that such a long term neutrality is sufficient to generate statistical guarantees on an otherwise non-i.i.d. testing procedure.
Definition 11. An η-fair test is said to be eventually fair if and only if 1 ≤ η4 <eb, where b is the constant in the exponential posterior concentration theorem.
The notion of a eventually fair test corresponds to a testing strategy that is not malicious or adversarial, and is making an honest attempt to sample from all the events in the long run.
Algorithm
Finally, we present our Statistical Verification algorithm (See Figure 2) in terms of a generic non-i.i.d. testing procedure sampling with random "implied" change of measures. Our algorithm is relatively simple and generalizes our previous Bayesian Statistical verification algorithm [8] to non-i.i.d. samples using change of measures. The algorithm draws non-i.i.d. samples from the stochastic differential equation under randomly chosen probability measures. The algorithm ensures that the implied change of measure is bounded so as to make the testing approach fair. The variable n denotes the number of samples obtained so far and x denoted the number of samples that satisfy the AFM specification ϕ. Based upon the samples observed, we compute the Bayes Factor under the new probability measures. We know that the Bayes Factor so computed is within a factor of the original Bayes Factor under the natural probability measure. Hence, the algorithm divides the Bayes Factor by the factor η2n if the Bayes Factor is larger than one. If the Bayes Factor is less than one, the algorithm multiplies the Bayes Factor by the factor η2n.
Figure 2.

Non-i.i.d. Statistical Verification Algorithm. The figure illustrated the non-i.i.d. Bayesian model validation algorithm. The algorithm builds upon Girsanov's theorem on change of measure and Bayesian model validation.
Results and discussion
We applied our algorithm to two SDE models of tumor dynamics from the literature. The first model is a single dimensional stochastic differential equation for the influence of chemotherapy on cancer cells, and the second model is a pair of SDEs that describe an immunogenic tumor.
Lefever and Garay model
Lefever and Garay [38] studied the growth of tumors under immune surveillance and chemotherapy using the following stochastic differential equation:
Here, x is the amount of tumor cells, A0cos(ωt) denotes the influence of a periodic chemotherapy treatment, r0 is the linear per capita birth rate of cancer cells, K is the carrying capacity of the environment, and β represents the influence of the immune cells. Note that Wt is the standard Brownian Motion, and default model parameters were those used in [38]..
We demonstrate our algorithm on a simple property of the model. Namely, starting with a tumor consisting of a billion cells, is there at least a 1% chance that the tumor could increase to one hundred billion cells under under immune surveillance and chemotherapy. The following BLTL specification captures the behavioral specification:
Figure 3 contrasts the number of samples needed to decide whether the model satisfies the property using i.i.d. and non-i.i.d.. As expected, the number of samples required increases linearly in the logarithm of the Bayes factor regardless of whether i.i.d. or non-i.i.d. sampling is used. However, non-i.i.d. sampling always requires fewer samples than i.i.d. sampling. Moreover, the difference between the number of samples increases with the Bayes factor. That is, the lines are diverging.
Figure 3.

Comparison of i.i.d. and non-i.i.d. sampling. Non-i.i.d. vs i.i.d. sampling based verification for the Lefever and Garay model.
We note that there are circumstances when our algorithm may require more samples than one based on i.i.d. sampling. This will happen when the property being tested has relatively high probability. For example, we tested the property that the probability of eradicating the tumor is at most 1%. The i.i.d. algorithm required 1374 samples to deny this possibility while the non-i.i.d. algorithm required 1526 samples. Thus, our algorithm is best used to examine rare behaviors.
Nonlinear immunogenic tumor model
The second model we analyze studies immunogenic tumor growth [39,40]. Unlike the previous model, the immunogenic tumor model explicitly tracks the dynamics of the immune cells (variable x) in response to the tumor cells (variable y). The SDEs are as follows:
The parameters x1 an y1 denote the stochastic equilibrium point of the model. Briefly, the model assumes that the amount of noise increases with the distance to the equilibrium point.
For this model, we considered the following property: starting from 0.1 units each of tumor and immune cells, is there at least a 1% chance that the number of tumor cells could increase to 3.3 units. The property can be encoded into the following BLTL specification:
Default model parameters were those used in [39]. Figure 4 contrasts the number of samples needed to decide whether the model satisfies the property using i.i.d. and non-i.i.d.. The same trends are observed as in the previous model. That is, our algorithm requires fewer samples than i.i.d. hypothesis testing, and that the difference between these methods increases with the Bayes factor.
Figure 4.

Comparison of i.i.d. and non-i.i.d. sampling. Non-i.i.d. vs i.i.d. Sampling based verification for the nonlinear Immunogenic tumor model.
We also considered the property that the number of tumor cells increases to 4.0 units. We evaluated whether this property is true with probability at least 0.000005 under a Bayes Factor of 100, 000. The i.i.d. sampling algorithm did not produce an answer even after observing 10, 000 samples. The non-i.i.d. model validation algorithm answered affirmatively after observing 6, 736 samples. Once again, the real impact of the proposed algorithm lies in uncovering rare behaviors and bounding their probability of occurrence.
Discussion
Our results confirm that non-i.i.d. sampling reduces the number of samples required in the context of hypothesis testing -- when the property under consideration is rare. Moreover, the benefits of non-i.i.d. sampling increase with the rarity of the property, as confirmed by the divergence of the lines in Figures 2 and 3. We note, however, that if the property isn't rare then a non-i.i.d. sampling strategy will actually require a larger number of samples than an i.i.d. strategy. Thus, our algorithm is only appropriate for investigating rare behaviors.
Conclusions
We have introduced the first algorithm for verifying properties of stochastic differential equations using sequential hypothesis testing. Our technique combines Bayesian statistical model checking and non-i.i.d. sampling and provides guarantees in terms of termination, and the number of samples needed to achieve those bounds. The method is most suitable when the behavior of interest is the exception and not the norm.
The present paper only considers SDEs with independent Brownian noise. We believe that these results can be extended to handle SDEs with certain kinds of correlated noise. Another interesting direction for future work is the extension of these method to stochastic partial differential equations, which are used to model spatially inhomogeneous processes. Such analysis methods could be used, for example, to investigate properties concerning spatial properties of tumors, the propagation of electrical waves in cardiac tissue, or more generally, to the diffusion processes observed in nature.
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
SKJ and CJL contributed equally to all parts of the paper.
Contributor Information
Sumit Kumar Jha, Email: jha@eecs.ucf.edu.
Christopher James Langmead, Email: cjl@cs.cmu.edu.
Acknowledgements
The authors acknowledge the feedback received from the anonymous reviewers for the first IEEE Conference on Compuational Advances in Bio and Medical Sciences (ICCABS) 2011.
This article has been published as part of BMC Bioinformatics Volume 13 Supplement 5, 2012: Selected articles from the First IEEE International Conference on Computational Advances in Bio and medical Sciences (ICCABS 2011): Bioinformatics. The full contents of the supplement are available online at http://www.biomedcentral.com/bmcbioinformatics/supplements/13/S5.
References
- Faeder JR, Blinov ML, Goldstein B, Hlavacek WS. Rule-based modeling of biochemical networks. Complexity. 2005;10(4):22–41. doi: 10.1002/cplx.20074. [DOI] [Google Scholar]
- Haigh J. Stochastic Modelling for Systems Biology by D. J. Wilkinson. Journal Of The Royal Statistical Society Series A. 2007;170:261–261. doi: 10.1111/j.1467-985X.2006.00455_14.x. http://ideas.repec. org/a/bla/jorssa/v170y2007i1p261-261.html [DOI] [Google Scholar]
- Iosifescu M, Tautu P, Iosifescu M. Stochastic processes and applications in biology and medicine [by] M. Iosifescu [and] P. Tautu. Editura Academiei; Springer-Verlag, Bucuresti, New York; 1973. [Google Scholar]
- Twycross J, Band L, Bennett MJ, King J, Krasnogor N. Stochastic and deterministic multiscale models for systems biology: an auxin-transport case study. BMC Systems Biology. 2010;4(34) doi: 10.1186/1752-0509-4-34. http://www. biomedcentral.com/17520509/4/34/abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kwiatkowska M, Norman G, Parker D. In: Formal Methods for the Design of Computer, Communication and Software Systems: Performance Evaluation (SFM'07) Bernardo M, Hillston J, editor. Vol. 4486. Springer; 2007. Stochastic Model Checking; pp. 220–270. LNCS (Tutorial Volume) [DOI] [Google Scholar]
- Kwiatkowska M, Norman G, Parker D. Proc 48th Annual Allerton Conference on Communication, Control and Computing. IEEE Press; 2010. Advances and Challenges of Probabilistic Model Checking. [Google Scholar]
- Langmead C. Generalized Queries and Bayesian Statistical Model Checking in Dynamic Bayesian Networks: Application to Personalized Medicine. Proc of the 8th International Conference on Computational Systems Bioinformatics (CSB) 2009. pp. 201–212.
- Jha SK, Clarke EM, Langmead CJ, Legay A, Platzer A, Zuliani P. In: CMSB Volume 5688 of Lecture Notes in Computer Science. Degano P, Gorrieri R, editor. Springer; 2009. A Bayesian Approach to Model Checking Biological Systems; pp. 218–234. [Google Scholar]
- Wald A. Sequential Analysis. New York: John Wiley and Son; 1947. [Google Scholar]
- Lehmann EL, Romano JP. Testing statistical hypotheses. 3. Springer Texts in Statistics, New York: Springer; 2005. [Google Scholar]
- Edgar GA. Radon-Nikodym theorem. Duke Mathematical Journal. 1975;42:447–450. doi: 10.1215/S0012-7094-75-04242-8. [DOI] [Google Scholar]
- Younes HLS, Simmons RG. In: CAV, Volume 2404 of Lecture Notes in Computer Science. Brinksma E, Larsen KG, editor. Springer; 2002. Probabilistic Verification of Discrete Event Systems Using Acceptance Sampling; pp. 223–235. [Google Scholar]
- Younes HLS, Kwiatkowska MZ, Norman G, Parker D. Numerical vs. Statistical Probabilistic Model Checking: An Empirical Study. TACAS. 2004. pp. 46–60.
- Lassaigne R, Peyronnet S. Approximate Verification of Probabilistic Systems. PAPM-PROBMIV. 2002. pp. 213–214.
- Hérault T, Lassaigne R, Magniette F, Peyronnet S. Proc 5th International Conference on Verification, Model Checking and Abstract Interpretation (VMCAI'04), Volume 2937 of LNCS. Springer; 2004. Approximate Probabilistic Model Checking. [Google Scholar]
- Sen K, Viswanathan M, Agha G. Statistical Model Checking of Black-Box Probabilistic Systems. CAV. 2004. pp. 202–215.
- Grosu R, Smolka S. Monte Carlo Model Checking. CAV. 2005. pp. 271–286.
- Gondi K, Patel Y, Sistla AP. Verification, Model Checking, and Abstract Interpretation, 10th International Conference, VMCAI 2009, Volume 5403 of LNCS. Springer; 2009. Monitoring the Full Range of omega-Regular Properties of Stochastic Systems; pp. 105–119. [Google Scholar]
- Jha SK, Langmead C, Ramesh S, Mohalik S. When to stop verification? Statistical Trade-off between Costs and Expected Losses. Proceedings of Design Automation and test In Europe (DATE) 2011. pp. 1309–1314.
- Clarke EM, Faeder JR, Langmead CJ, Harris LA, Jha SK, Legay A. Statistical Model Checking in BioLab: Applications to the Automated Analysis of T-Cell Receptor Signaling Pathway. CMSB. 2008. pp. 231–250.
- Langmead CJ, Jha SK. In: WABI, Volume 4645 of Lecture Notes in Computer Science. Giancarlo R, Hannenhalli S, editor. Springer; 2007. Predicting Protein Folding Kinetics Via Temporal Logic Model Checking; pp. 252–264. [Google Scholar]
- Jha S, Langmead C. Synthesis and Infeasibility Analysis for Stochastic Models of Biochemical Systems using Statistical Model Checking and Abstraction Refinement
- Jeffreys H. Theory of Probability. Oxford University Press; 1939. [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. London: Chapman & Hall; 1995. [Google Scholar]
- Jha S, Langmead C. Exploring Behaviors of SDE Models of Biological Systems using Change of Measures. Proc of the 1st IEEE International Conference on Computational Advances in Bio and medical Sciences (ICCABS) 2011. pp. 111–117.
- Øksendal B. Stochastic Differential Equations: An Introduction with Applications (Universitext) 6. Springer; 2003. http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20\&path=ASIN/3540047581 [Google Scholar]
- Karatzas I, Shreve SE. Brownian Motion and Stochastic Calculus (Graduate Texts in Mathematics) 2. Springer; 1991. http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20\&path=ASIN/0387976558 [Google Scholar]
- Wang MC, Uhlenbeck GE. On the Theory of the Brownian Motion II. Reviews of Modern Physics. 1945;17(2-3):323. doi: 10.1103/RevModPhys.17.323. http://dx.doi.org/10.1103/RevModPhys. 17.323 [DOI] [Google Scholar]
- Girsanov IV. On Transforming a Certain Class of Stochastic Processes by Absolutely Continuous Substitution of Measures. Theory of Probability and its Applications. 1960;5(3):285–301. doi: 10.1137/1105027. [DOI] [Google Scholar]
- Pnueli A. FOCS. IEEE; 1977. The Temporal Logic of Programs; pp. 46–57. [Google Scholar]
- Owicki SS, Lamport L. Proving Liveness Properties of Concurrent Programs. ACM Trans Program Lang Syst. 1982;4(3):455–495. doi: 10.1145/357172.357178. [DOI] [Google Scholar]
- Finkbeiner B, Sipma H. Checking Finite Traces Using Alternating Automata. Formal Methods in System Design. 2004;24(2):101–127. [Google Scholar]
- Harel D. Statecharts: A Visual Formalism for Complex Systems. Science of Computer Programming. 1987;8(3):231–274. doi: 10.1016/0167-6423(87)90035-9. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.20.4799 [DOI] [Google Scholar]
- Ehrig H, Orejas F, Padberg J. Relevance, Integration and Classification of Specification Formalisms and Formal Specification Techniques. http://citeseerx.ist. psu.edu/viewdoc/summary?doi=10.1.1.42.7137
- Berger J. Statistical Decision Theory and Bayesian Analysis. Springer-Verlag; 1985. [Google Scholar]
- Jeffreys H. Theory of probability/by Harold Jeffreys. 3. Clarendon Press, Oxford; 1961. [Google Scholar]
- Choi T, Ramamoorthi RV. Remarks on consistency of posterior distributions. ArXiv e-prints. 2008.
- Lefever R, RGaray S. Biomathematics and Cell Kinetics. Elsevier, North-Hollan biomedical Press; 1978. chap. Local description of immune tumor rejection,:333. [Google Scholar]
- Horhat R, Horhat R, Opris D. Proceedings of the 2nd WSEAS international conference on Biomedical electronics and biomedical informatics. BEBI'09, Stevens Point, Wisconsin, USA: World Scientific and Engineering Academy and Society (WSEAS); 2009. The simulation of a stochastic model for tumour-immune system; pp. 247–252.http://portal.acm.org/citation.cfm?id = 1946539.1946584 [Google Scholar]
- Kuznetsov V, Makalkin I, Taylor M, Perelson A. Nonlinear dynamics of immunogenic tumors: Parameter estimation and global bifurcation analysis. Bulletin of Mathematical Biology. 1994;56:295–321. doi: 10.1007/BF02460644. http://dx. doi.org/10.1007/BF02460644 10.1007/BF02460644. [DOI] [PubMed] [Google Scholar]