

Abstract
When evaluating causal influence from one time series to another in a multivariate data set it is necessary to take into account the conditioning effect of the other variables. In the presence of many variables and possibly of a reduced number of samples, full conditioning can lead to computational and numerical problems. In this paper, we address the problem of partial conditioning to a limited subset of variables, in the framework of information theory. The proposed approach is tested on simulated data sets and on an example of intracranial EEG recording from an epileptic subject. We show that, in many instances, conditioning on a small number of variables, chosen as the most informative ones for the driver node, leads to results very close to those obtained with a fully multivariate analysis and even better in the presence of a small number of samples. This is particularly relevant when the pattern of causalities is sparse.
1. Introduction
Determining how the brain is connected is a crucial point in neuroscience. To gain better understanding of which neurophysiological processes are linked to which brain mechanisms, structural connectivity in the brain can be complemented by the investigation of statistical dependencies between distant brain regions (functional connectivity) or of models aimed to elucidate drive-response relationships (effective connectivity). Advances in imaging techniques guarantee an immediate improvement in our knowledge of structural connectivity. A constant computational and modelling effort has to be done in order to optimize and adapt functional and effective connectivity to the qualitative and quantitative changes in data and physiological applications. The paths of information flow throughout the brain can shed light on its functionality in health and pathology. Every time that we record brain activity we can imagine that we are monitoring the activity at the nodes of a network. This activity is dynamical and sometimes chaotic. Dynamical networks [1] model physical and biological behaviour in many applications; also, synchronization in dynamical network is influenced by the topology of the network itself [2]. A great need exists for the development of effective methods of inferring network structure from time series data; a dynamic version of the Bayesian networks has been proposed in [3]. A method for detecting the topology of dynamical networks, based on chaotic synchronization, has been proposed in [4].
Granger causality has become the method of choice to determine whether and how two time series exert causal influences on each other [5, 6]. This approach is based on prediction: if the prediction error of the first time series is reduced by including measurements from the second one in the linear regression model, then the second time series is said to have a causal influence on the first one. This frame has been used in many fields of science, including neural systems [7–10], reochaos [11], and cardiovascular variability [12].
From the beginning [13, 14], it has been known that if two signals are influenced by third one that is not included in the regressions, this leads to spurious causalities, so an extension to the multivariate case is in order. The conditional Granger causality analysis (CGCA) [15] is based on a straightforward expansion of the autoregressive model to a general multivariate case including all measured variables. CGCA has been proposed to correctly estimate coupling in multivariate data sets [16–19]. Sometimes though, a fully multivariate approach can entrain problems that can be purely computational or even conceptual: in the presence of redundant variables the application of the standard analysis leads to underestimation of causalities [20].
Several approaches have been proposed in order to reduce dimensionality in multivariate sets, relying on generalized variance [16], principal components analysis [19], or the Granger causality itself [21].
In this paper we will address the problem of partial conditioning to a limited subset of variables, in the framework of information theory. Intuitively, one may expect that conditioning on a small number of variables should be sufficient to remove indirect interactions if the connectivity pattern is sparse. We will show that this subgroup of variables might be chosen as the most informative for the driver variable and describe the application to simulated examples and a real data set.
2. Materials and Methods
We start by describing the connection between the Granger causality and information-theoretic approaches like the transfer entropy in [22]. Let {ξ n}n=1,…,N+m be a time series that may be approximated by a stationary Markov process of order m, that is, p(ξ n | ξ n−1,…, ξ n−m) = p(ξ n | ξ n−1,…, ξ n−m−1). We will use the shorthand notation X i = (ξ i,…,ξ i+m−1)⊤ and x i = ξ i+m, for i = 1,…, N, and treat these quantities as N realizations of the stochastic variables X and x. The minimizer of the risk functional
| (1) |
represents the best estimate of x, given X, and corresponds [23] to the regression function f*(X) = ∫dxp(x | X)x. Now, let {η n}n=1,…,N+m be another time series of simultaneously acquired quantities, and denote Y i = (η i,…,η i+m−1)⊤. The best estimate of x, given X and Y, is now g*(X, Y) = ∫dxp(x | X, Y)x. If the generalized Markov property holds, that is,
| (2) |
then f*(X) = g*(X, Y) and the knowledge of Y does not improve the prediction of x. Transfer entropy [22] is a measure of the violation of 2: it follows that the Granger causality implies nonzero transfer entropy [24]. Under the Gaussian assumption it can be shown that the Granger causality and transfer entropy are entirely equivalent and just differ for a factor two [25]. The generalization of the Granger causality to a multivariate fashion, described in the following, allows the analysis of dynamical networks [26] and to discern between direct and indirect interactions.
Let us consider n time series {x α(t)}α=1,…,n; the state vectors are denoted:
| (3) |
m being the window length (the choice of m can be done using the standard cross-validation scheme). Let ϵ(x α | X) be the mean squared error prediction of x α on the basis of all the vectors X (corresponding to linear regression or nonlinear regression by the kernel approach described in [24]). The multivariate Granger causality index c(β → α) is defined as follows: consider the prediction of x α on the basis of all the variables but X β and the prediction of x α using all the variables, then the causality measures the variation of the error in the two conditions, that is,
| (4) |
Note that in [24] a different definition of causality has been used,
| (5) |
The two definitions are clearly related by a monotonic transformation:
| (6) |
Here, we first evaluate the causality δ(β → α) using the selection of significative eigenvalues described in [26] to address the problem of overfitting in (5); then we use (6) and express our results in terms of c(β → α) because it is with this definition that causality is twice the transfer entropy, equal to I{x α; X β | X∖X β}, in the Gaussian case [25].
Turning now to the central point of this paper, we address the problem of coping with a large number of variables, when the application of the multivariate Granger causality may be questionable or even unfeasible, whilst bivariate causality would detect also indirect causalities. Here, we show that conditioning on a small number of variables, chosen as the most informative for the candidate driver variable, is sufficient to remove indirect interactions for sparse connectivity patterns. Conditioning on a large number of variables requires a high number of samples in order to get reliable results. Reducing the number of variables, that one has to condition over, would thus provide better results for small data sets. In the general formulation of the Granger causality, one has no way to choose this reduced set of variables; on the other hand, in the framework of information theory, it is possible to individuate the most informative variables one by one. Once that it has been demonstrated [25] that the Granger causality is equivalent to the information flow between the Gaussian variables, partial conditioning becomes possible for the Granger causality estimation; to our knowledge this is the first time that such approach is proposed.
Concretely, let us consider the causality β → α; we fix the number of variables, to be used for conditioning, equal to n d. We denote by Z = (X i1,…, X ind) the set of the n d variables, in X∖X β, most informative for X β. In other words, Z maximizes the mutual information I{X β; Z} among all the subsets Z of n d variables. Then, we evaluate the causality
| (7) |
Under the Gaussian assumption, the mutual information I{X β; Z} can be easily evaluated, see [25]. Moreover, instead of searching among all the subsets of n d variables, we adopt the following approximate strategy. Firstly, the mutual information of the driver variable, and each of the other variables, is estimated, in order to choose the first variable of the subset. The second variable of the subsets is selected among the remaining ones as those that, jointly with the previously chosen variable, maximize the mutual information with the driver variable. Then, one keeps adding the rest of the variables by iterating this procedure. Calling Z k−1 the selected set of k − 1 variables, the set Z k is obtained adding, to Z k−1, the variable, among the remaining ones, with the greatest information gain. This is repeated until n d variables are selected. This greedy algorithm, for the selection of relevant variables, is expected to give good results under the assumption of sparseness of the connectivity.
3. Results and Discussion
3.1. Simulated Data
Let us consider linear dynamical systems on a lattice of n nodes, with equations, for i = 1,…, n
| (8) |
where a's are the couplings, s is the strength of the noise, and τ's are unit variance i.i.d. Gaussian noise terms. The level of noise determines the minimal amount of samples needed to assess that the structures recovered by the proposed approach are genuine and are not due to randomness as it happens for the standard Granger causality (see discussions in [24, 26]); in particular noise should not be too high to obscure deterministic effects. Firstly we consider a directed tree of 16 nodes depicted in Figure 1; we set a ij equal to 0.9 for each directed link of the graph thus obtained and zero otherwise. We set s = 0.1. In Figure 2 we show the application of the proposed methodology to data sets generated by (8), 100 samples long, in terms of quality of the retrieved network, expressed in terms of sensitivity (the percentage of existing links that are detected) and specificity (the percentage of missing links that are correctly recognized as nonexisting). The bivariate analysis provides 100% sensitivity and 92% specificity. However, conditioning on a few variables is sufficient to put in evidence just the direct causalities while still obtaining high values of sensitivity. The full multivariate analysis (obtained as n d tends to 16) gives here a rather low sensitivity due to the low number of samples. This is a clear example where conditioning on a small number of variables is better than conditioning on all the variables at hand.
Figure 1.
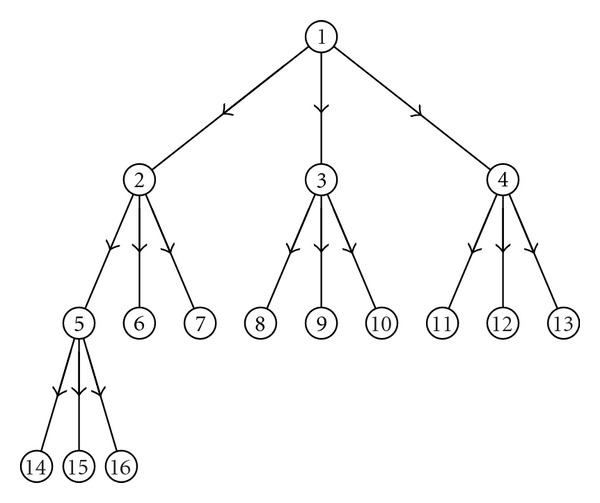
A directed rooted tree of 16 nodes.
Figure 2.
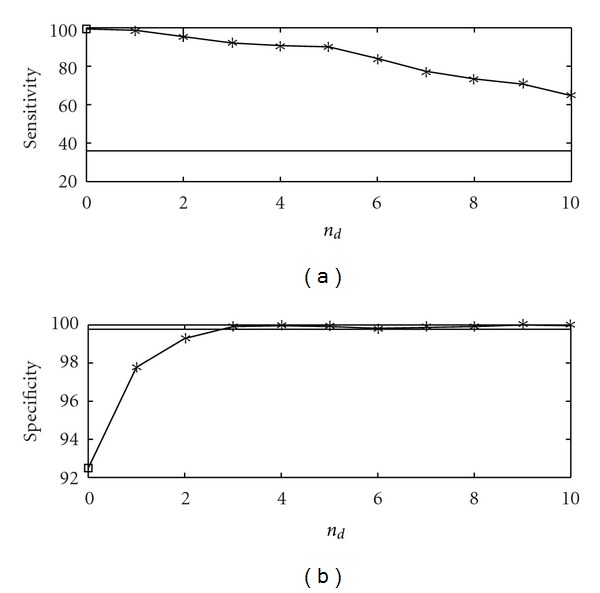
The sensitivity (a) and the specificity (b) are plotted versus n d, the number of variables selected for conditioning, for the first example, the rooted tree. The number of samples N is 100, and the order is m = 2; similar results are obtained varying m. The results are averaged over 100 realizations of the linear dynamical system described in the text. The empty square, in correspondence to n d = 0, is the result from the bivariate analysis. The horizontal line is the outcome from multivariate analysis, where all variables are used for conditioning.
As another example, we now fix n = 34 and construct couplings in terms of the well-known Zachary data set [27], an undirected network of 34 nodes. We assign a direction to each link, with equal probability, and set a ij equal to 0.015, for each link of the directed graph thus obtained, and zero otherwise. The noise level is set as s = 0.5. The network is displayed in Figure 3: the goal is again to estimate this directed network from the measurements of time series on nodes.
Figure 3.
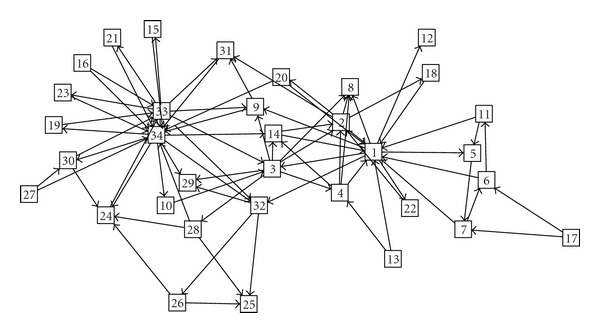
The directed network of 34 nodes obtained assigning randomly a direction to links of the Zachary network.
In Figure 4 we show the application of the proposed methodology to data sets generated by (8), in terms of sensitivity and specificity, for different numbers of samples. The bivariate analysis detects several false interactions; however, conditioning on a few variables is sufficient to put in evidence just the direct causalities. Due to the sparseness of the underlying graph, we get a result that is very close to the one by the full multivariate analysis; the multivariate analysis here recovers the true network, and indeed the number of samples is sufficiently high. In Figure 5, concerning the stage of selection of variables upon which conditioning is performed, we plot the mutual information gain as a function of the number of variables included n d: it decreases as n d increases.
Figure 4.
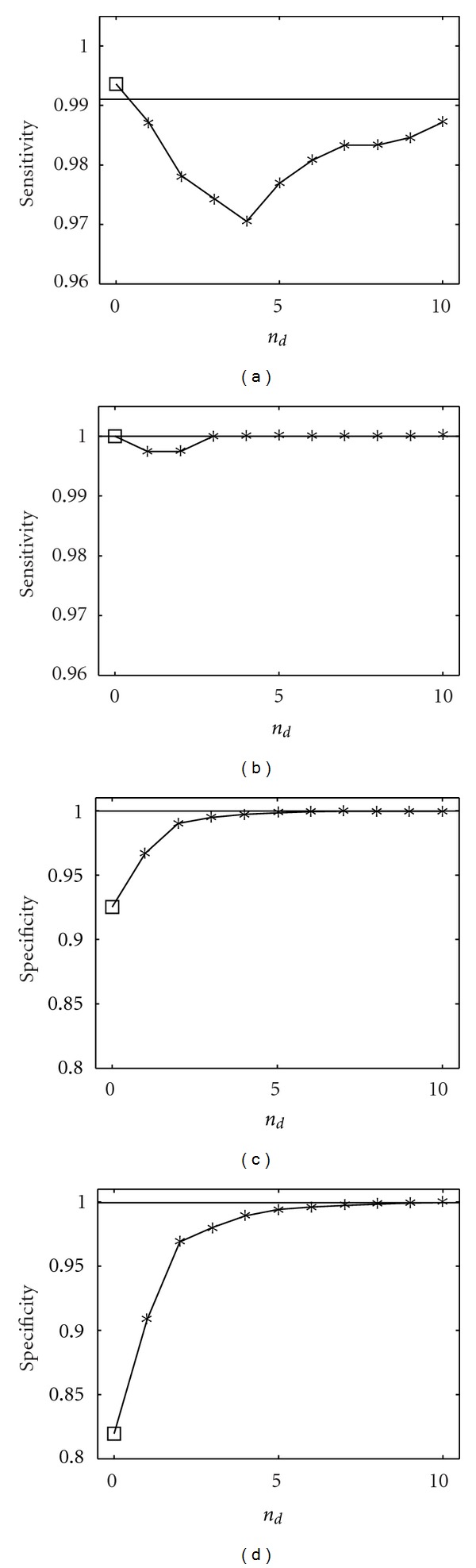
Sensitivity and specificity are plotted versus n d, the number of variables selected for conditioning, for two values of the number of samples N, 500 (left) and 1000 (right). The order is m = 2, similar results are obtained varying m. The results are averaged over 100 realizations of the linear dynamical system described in the text. The empty square, in correspondence to n d = 0, is the result from the bivariate analysis. The horizontal line is the outcome from multivariate analysis, where all variables are used for conditioning.
Figure 5.
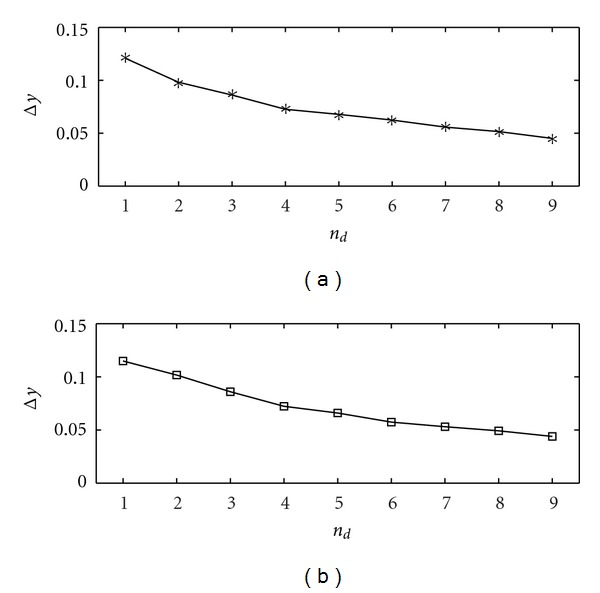
The mutual information gain, when the (n d + 1)th variable is included, is plotted versus n d for two values of the number of samples N, 500 (a) and 1000 (b). The order is m = 2. The information gain is averaged over all the variables.
3.2. EEG Epilepsy Data
We consider now a real data set from an 8 × 8-electrode grid that was implanted in the cortical surface of the brain of a patient with epilepsy [28]. We consider two 10-second intervals prior to and immediately after the onset of a seizure, called, respectively, the preictal period and the ictal period. In Figure 6 we show the application of our approach to the preictal period; we used the linear causality. The bivariate approach detects many causalities between the electrodes; most of them, however, are indirect. According to the multivariate analysis there is just one electrode that is observed to influence the others, even in the multivariate analysis: this electrode corresponds to a localized source of information and could indicate a putative epileptic focus. In Figure 6 it is shown that conditioning on n d = 5 or n d = 20 variables provides the same pattern corresponding to the multivariate analysis, which thus appears to be robust. These results suggest that the effective connectivity is sparse in the preictal period. As a further confirmation, in Figure 7 we plot the sum of all causalities detected as a function of the number of conditioning variables, for the preictal period; a plateau is reached already for small values of n d.
Figure 6.
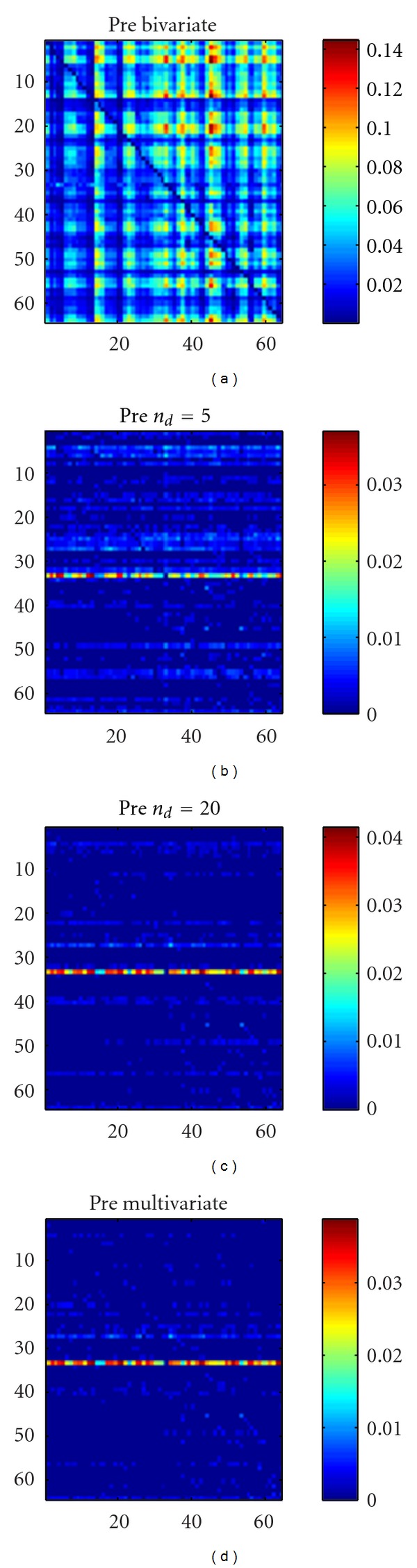
The causality analysis of the preictal period. The causality c(i → j) corresponds to the row i and the column j. The order is chosen as m = 6 according to the AIC criterion. (a) Bivariate analysis. (b) Our approach with n d = 5 conditioning variables. (c) Our approach with n d = 20 conditioning variables. (d) The multivariate analysis.
Figure 7.
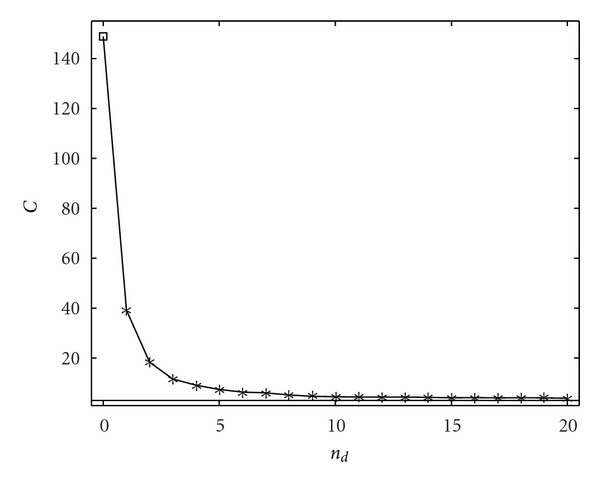
Concerning the preictal period, the sum of all causalities is plotted versus the number of conditioning variables.
In Figure 8 the same analysis is shown w.r.t. the ictal period: in this case conditioning on n d = 5 or n d = 20 variables does not reproduce the pattern obtained with the multivariate approach. The lack of robustness of the causality pattern w.r.t. n d seems to suggest that the effective connectivity pattern, during the crisis, is not sparse. In Figures 9 and 10 we show, for each electrode and for the preictal and ictal periods, respectively, the total outgoing causality (obtained as the sum of the causalities on all the other variables). These pictures confirm the discussion above: looking at how the causality changes with n d may provide information about the sparseness of the effective connectivity.
Figure 8.
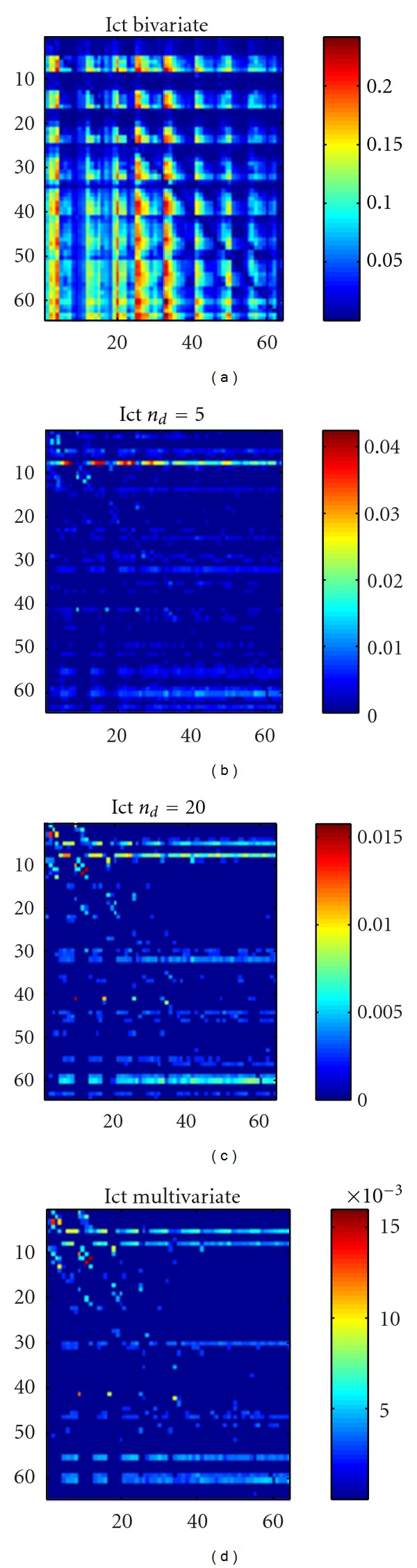
The sum of outgoing causality from each electrode in the EEG application, ictal period. (a) Bivariate analysis. (b) Our approach with n d = 5 conditioning variables. (c) Our approach with n d = 20 conditioning variables. (d) The multivariate analysis.
Figure 9.
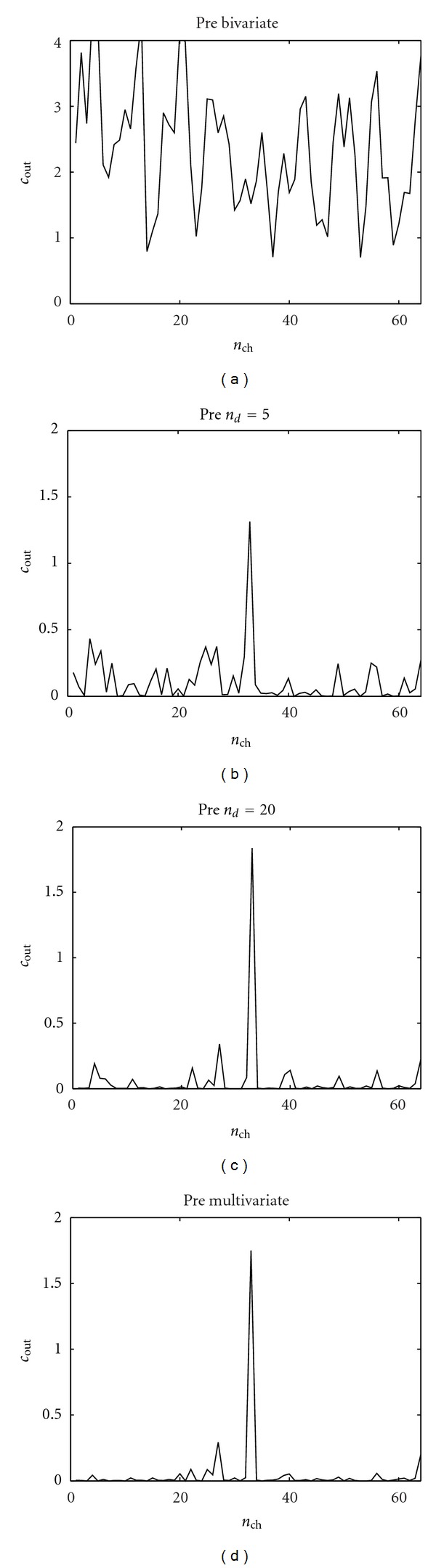
The sum of outgoing causality from each electrode in the EEG application, preictal period. (a) Bivariate analysis. (b) Our approach with n d = 5 conditioning variables. (c) Our approach with n d = 20 conditioning variables. (d) The multivariate analysis.
Figure 10.
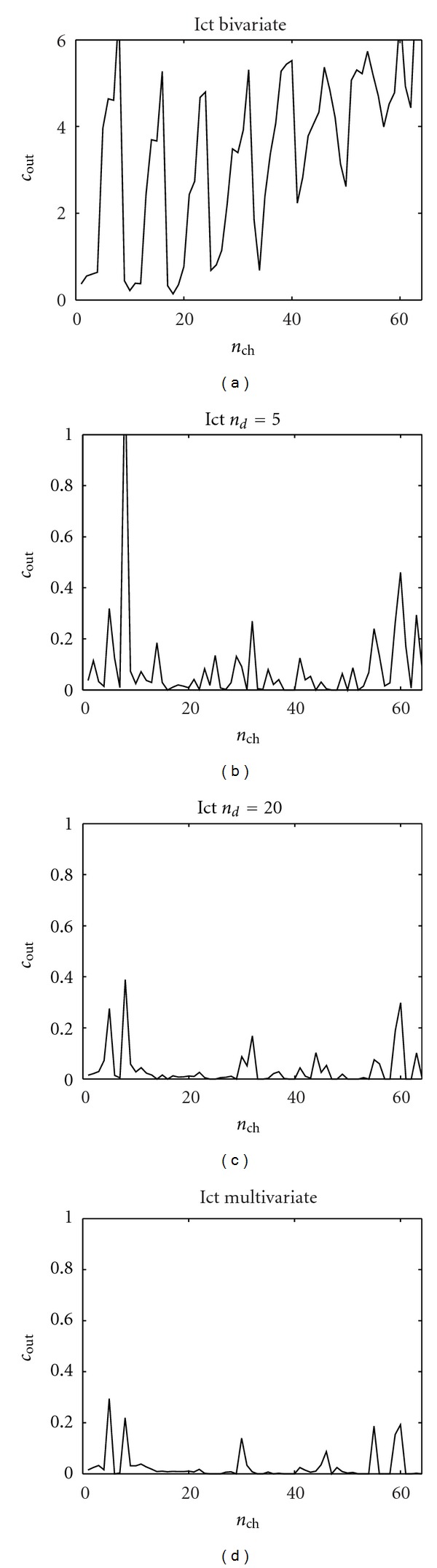
The causality analysis of the ictal period. The causality c(i → j) corresponds to the row i and the column j. The order is chosen as m = 6 according to the AIC criterion. (a) Bivariate analysis. (b) Our approach with n d = 5 conditioning variables. (c) Our approach with n d = 20 conditioning variables. (d) The multivariate analysis.
4. Conclusions
We have addressed the problem of partial conditioning to a limited subset of variables while estimating causal connectivity, as an alternative to full conditioning, which can lead to computational and numerical problems. Analyzing simulated examples and a real data set, we have shown that conditioning on a small number of variables, chosen as the most informative ones for the driver node, leads to results very close to those obtained with a fully multivariate analysis and even better in the presence of a small number of samples, especially when the pattern of causalities is sparse. Moreover, looking at how causality changes with the number of conditioning variables provides information about the sparseness of the connectivity.
References
- 1.Barabasi A. Linked. Perseus; 2002. [Google Scholar]
- 2.Boccaletti S, Hwang DU, Chavez M, Amann A, Kurths J, Pecora LM. Synchronization in dynamical networks: evolution along commutative graphs. Physical Review E. 2006;74(1):5 pages. doi: 10.1103/PhysRevE.74.016102. Article ID 016102. [DOI] [PubMed] [Google Scholar]
- 3.Gharhamani Z. Learning dynamic bayesian networks. Lecture Notes in Computer Science. 1997;1387:168–197. [Google Scholar]
- 4.Yu D, Righero M, Kocarev L. Estimating topology of networks. Physical Review Letters. 2006;97(18):4 pages. doi: 10.1103/PhysRevLett.97.188701. Article ID 188701. [DOI] [PubMed] [Google Scholar]
- 5.Hlaváčková-Schindler K, Paluš M, Vejmelka M, Bhattacharya J. Causality detection based on information-theoretic approaches in time series analysis. Physics Reports. 2007;441(1):1–46. [Google Scholar]
- 6.Bressler SL, Seth AK. Wiener-Granger causality: a well established methodology. NeuroImage. 2011;58(2):323–329. doi: 10.1016/j.neuroimage.2010.02.059. [DOI] [PubMed] [Google Scholar]
- 7.Kamiński M, Ding M, Truccolo WA, Bressler SL. Evaluating causal relations in neural systems: granger causality, directed transfer function and statistical assessment of significance. Biological Cybernetics. 2001;85(2):145–157. doi: 10.1007/s004220000235. [DOI] [PubMed] [Google Scholar]
- 8.Blinowska KJ, Kuś R, Kamiński M. Granger causality and information flow in multivariate processes. Physical Review E. 2004;70(5):4 pages. doi: 10.1103/PhysRevE.70.050902. Article ID 050902. [DOI] [PubMed] [Google Scholar]
- 9.Seth A. Causal connectivity of evolved neural networks during behavior. Network. 2005;16(1):35–54. doi: 10.1080/09548980500238756. [DOI] [PubMed] [Google Scholar]
- 10.Roebroeck A, Formisano E, Goebel R. Mapping directed influence over the brain using Granger causality and fMRI. NeuroImage. 2005;25(1):230–242. doi: 10.1016/j.neuroimage.2004.11.017. [DOI] [PubMed] [Google Scholar]
- 11.Ganapathy R, Rangarajan G, Sood AK. Granger causality and cross recurrence plots in rheochaos. Physical Review E. 2007;75(1):6 pages. doi: 10.1103/PhysRevE.75.016211. Article ID 016211. [DOI] [PubMed] [Google Scholar]
- 12.Faes L, Nollo G, Chon KH. Assessment of granger causality by nonlinear model identification: application to short-term cardiovascular variability. Annals of Biomedical Engineering. 2008;36(3):381–395. doi: 10.1007/s10439-008-9441-z. [DOI] [PubMed] [Google Scholar]
- 13.Granger CWJ. Investigating causal relations by econometric models and cross-spectral methods. Econometrica. 1969;37(3):424–438. [Google Scholar]
- 14.Wiener N. The Theory of Prediction. Vol. 1. New York, NY, USA: McGraw-Hill; 1996. [Google Scholar]
- 15.Geweke JF. Measures of conditional linear dependence and feedback between time series. Journal of the American Statistical Association. 1984;79(388):907–915. [Google Scholar]
- 16.Barrett AB, Barnett L, Seth AK. Multivariate Granger causality and generalized variance. Physical Review E. 2010;81(4):14 pages. doi: 10.1103/PhysRevE.81.041907. Article ID 041907. [DOI] [PubMed] [Google Scholar]
- 17.Chen Y, Bressler SL, Ding M. Frequency decomposition of conditional Granger causality and application to multivariate neural field potential data. Journal of Neuroscience Methods. 2006;150(2):228–237. doi: 10.1016/j.jneumeth.2005.06.011. [DOI] [PubMed] [Google Scholar]
- 18.Deshpande G, LaConte S, James GA, Peltier S, Hu X. Multivariate granger causality analysis of fMRI data. Human Brain Mapping. 2009;30(4):1361–1373. doi: 10.1002/hbm.20606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Zhou Z, Chen Y, Ding M, Wright P, Lu Z, Liu Y. Analyzing brain networks with PCA and conditional granger causality. Human Brain Mapping. 2009;30(7):2197–2206. doi: 10.1002/hbm.20661. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Angelini L, de Tommaso M, Marinazzo D, Nitti L, Pellicoro M, Stramaglia S. Redundant variables and granger causality. Physical Review E. 81;3:4 pages. doi: 10.1103/PhysRevE.81.037201. Article ID 037201. [DOI] [PubMed] [Google Scholar]
- 21.Marinazzo D, Liao W, Pellicoro M, Stramaglia S. Grouping time series by pairwise measures of redundancy. Physics Letters, Section A. 2010;374(39):4040–4044. [Google Scholar]
- 22.Schreiber T. Measuring information transfer. Physical Review Letters. 2000;85(2):461–464. doi: 10.1103/PhysRevLett.85.461. [DOI] [PubMed] [Google Scholar]
- 23.Papoulis A. Proability, Random Variables, and Stochastic Processes. New York, NY, USA: McGraw-Hill; 1985. [Google Scholar]
- 24.Marinazzo D, Pellicoro M, Stramaglia S. Kernel method for nonlinear Granger causality. Physical Review Letters. 2008;100(14):4 pages. doi: 10.1103/PhysRevLett.100.144103. Article ID 144103. [DOI] [PubMed] [Google Scholar]
- 25.Barnett L, Barrett AB, Seth AK. Granger causality and transfer entropy Are equivalent for gaussian variables. Physical Review Letters. 2009;103(23):4 pages. doi: 10.1103/PhysRevLett.103.238701. Article ID 238701. [DOI] [PubMed] [Google Scholar]
- 26.Marinazzo D, Pellicoro M, Stramaglia S. Kernel-Granger causality and the analysis of dynamical networks. Physical Review E. 2008;77(5):9 pages. doi: 10.1103/PhysRevE.77.056215. Article ID 056215. [DOI] [PubMed] [Google Scholar]
- 27.Zachary W. An information flow model for conflict and fission in small groups. Journal of Anthropological Research. 1977;33(2):452–473. [Google Scholar]
- 28.Kramer MA, Kolaczyk ED, Kirsch HE. Emergent network topology at seizure onset in humans. Epilepsy Research. 2008;79(2-3):173–186. doi: 10.1016/j.eplepsyres.2008.02.002. [DOI] [PubMed] [Google Scholar]