

Abstract
The complexity of different components of the grammars of human languages can be quantified. For example, languages vary greatly in the size of their phonological inventories, and in the degree to which they make use of inflectional morphology. Recent studies have shown that there are relationships between these types of grammatical complexity and the number of speakers a language has. Languages spoken by large populations have been found to have larger phonological inventories, but simpler morphology, than languages spoken by small populations. The results require further investigation, and, most importantly, the mechanism whereby the social context of learning and use affects the grammatical evolution of a language needs elucidation.
Keywords: language, phonology, morphology, language evolution, cultural evolution, social structure
1. Introduction
A productive recent strategy in comparative anthropology has been to examine whether relationships that hold across species in non-human animals have analogues across populations in humans. For example, classic analyses in evolutionary biology showed that there is a strong relationship between life expectancy and age at first reproduction, across mammalian species [1]. This relationship is produced by the power of natural selection to tune life histories to prevailing ecological conditions. Recent studies have shown that there is also a strong relationship across human societies between life expectancy and age at first reproduction [2,3]. Here, the ultimate reasons for the relationship are the same as in the non-human case, but the tuning between ecological conditions and life history is brought about by the processes of behavioural plasticity and social learning, which are often referred to as cultural evolution, rather than as the selection on genes [4].
Several recent studies have uncovered the patterns of covariation between social and communicative complexity at the species level, with more complex communication systems found in species with more complex social groups (sciurids [5]; bats [6] and primates [7]). Social complexity is often proxied here by the size of social groups. This naturally raises the question of whether there is any analogous relationship across human populations. Human ethnolinguistic communities vary enormously in scale, from isolated small bands to populations of many millions of people. Is there, then, any association between the size of a society and the complexity of its communication system?
The primary communication system of any human population is its spoken language. The idea that there might be an association of any kind between social scale and linguistic complexity has not, until recently, been pursed with much enthusiasm by linguists. There are a number of reasons for this. First, there is an important sense in which all normal human languages (i.e. languages which are the native communication system of a community of people) should be conceptualized as equally complex. Languages can be viewed as systems that allow recombination of a finite number of elements in such ways to produce an unboundedly large set of possible meanings. Given that the set of possible meanings is unbounded in all languages, it is necessarily equally large in all languages. However, the overall equality of potential messages across languages does not mean that the different means whereby messages are encoded are equally complex across all languages, as we shall see in the following text.
A second reason for the neglect of the topic is historical. Anecdotal claims concerning a relationship between the history of some particular people, and the grammar of the language they speak, are all too easy to make. Nineteenth and early-twentieth century comparative linguistics was not short of them, and their essentially unfalsifiable nature led them to be abandoned as the discipline developed. Although the study of the structure of languages, and the study of how languages are used in social context, both thrived, it became an axiom in linguistics that there was little relationship between the two. Kaye [8, p. 48] represented the mainstream view when he stated: ‘there is no correlation whatever between … any aspect of linguistic structure and the environment. Studying the structure of a language reveals absolutely nothing about either the people who speak it or the physical environment in which they live’. This strictly autonomous view may have represented a reasonable disciplinary tactic at a time when fundamental work on how to characterize and catalogue human languages had yet to be done, but it was a statement of presumption rather than a research finding.
A third reason for a lack of research on linguistic complexity and social scale stemmed from a lack of appropriate datasets. With comparative linguists generally working qualitatively rather than quantitatively, often working on a single language or language family, and not necessarily presenting their findings in a common format, convincing comparative analyses were hard to do. This began to change with pioneering individual scholars assembling databases of grammatical parameters from global samples of already described languages [9–11]. The initial foci of this work were on structural and historical questions rather than on interrelationships between linguistic and social parameters, but they laid an important foundation, which was to be built upon by more recent collaborative projects such as the World Atlas of Language Structures (WALS) [12]. WALS presents structural information on up to 2678 languages from all of the major continents and families in a common, quantifiable format. It thus provides the kind of sample required to be able to test hypotheses about social scale and linguistic complexity with sufficient power and generality. The availability of datasets such as WALS has led to a profusion of high-impact publications in comparative linguistics [13–15], including those on linguistic structure and social scale reviewed later.
The final reason for scepticism about relationships between linguistic structure and social scale is the lack of well-characterized mechanisms whereby social scale would actually affect language change in interesting ways. Languages are not organisms that show purposive behaviour. Nor are they deliberately designed. Thus, it is not immediately clear why they would be tuned to the type of society using them. However, there has been a recent surge of theoretical and empirical interest in how the mechanisms of social transmission may affect the cultural evolution of linguistic systems [16–18], and, somewhat independently, several different hypotheses for how social context could affect linguistic structure have been proposed in the linguistic literature [19–25]. Some of these will be reviewed later.
The purpose of this paper, then, is to review the evidence for associations between linguistic complexity and social scale, with social scale measured for most purposes by the size of the speaker population. In §2, I briefly describe a few key ways in which languages vary in their complexity. In §3, I review the recent studies demonstrating that structural complexity is indeed related to the speaker population size. In §4, I consider various proposals about what the mechanisms driving these associations could be, if they are real. Section 5 concludes.
2. Some dimensions of variation in language complexity
Languages encode an open-ended set of meanings from a small set of basic elements by repeated composition or modification of those elements. Contrasting sound segments are combined into lexical items (for example, walk is a distinct word from talk or baulk). More complex meanings can then be produced from lexical items both by morphological processes (e.g. producing walks and walked from walk) and by syntactic ones (creating chains of items where the meaning depends on both the identity of the individual items and the order in which they are put together, such as The man went for a walk, and The walk went by the house). Although all languages use these processes with, as we have seen, the same overall result, they vary considerably in where within their structure the complexity resides.
(a). Phonological complexity versus word length
Languages vary in the number of contrasting sound segments of which they make use, from around one dozen to (depending exactly how the calculation is done) somewhere between 100 and 200 [11]. Clearly, the use of more contrasting segments makes available many more possible word-forms of a given length, and, indeed, across languages, there is a robust inverse relationship between the number of sound contrasts available in the inventory, and the average length of a word ([26–28]; figure 1a). This is one example of how paradigmatic complexity (the information carried by each unit in a string of units) is traded off against syntagmatic complexity (crudely, the number of units of which the string is made up). Thus, a language such as Vute, which has a very complex phonological inventory, need only have a simple lexicon, in the sense that most lexical items are monosyllables, whereas a language like Hawai'ian with a simple phonological inventory has relatively long, multi-syllabic words. Phonological inventory size has been quantified for a large number of languages [11], and estimated from word lists for many more [28].
Figure 1.

(a) The relationship between the number of segments in the phonological inventory, and the mean length of words, for 10 languages of diverse families. Data from Nettle [19]. (b) The relationship between the number of word-forms that occur in a translation of the New Testament, and the number of word-tokens in that translation, for six languages. Data from Juola [29].
(b). Morphological complexity versus phrase length
Languages differ greatly in the use they make of inflectional morphology. At one extreme are so-called isolating languages, where word forms undergo little or no morphological modification, and grammatical relations and other aspects of meaning must be conveyed by additional independent words and by word order. An example is Vietnamese, where distinctions such as plurality and tense are made by adding separate words with meanings such as ‘two’ or ‘yesterday’, rather than by any morphological modification of nouns or verbs. At the other extreme are synthetic languages, which make extensive use of inflection and other morphological operations to convey meaning distinctions. For example, in Chuckchee, a single word suffices for the meaning ‘we saw you’ [30, p. 534]:
ninelGumuri
imperfective–2 pers. singular object-see-1 pers. plural subject
‘We saw you’
The effect of increasing morphological complexity is partly due to an increased redundancy in language [31]. For example, inflections made on nouns are often redundantly repeated on their modifiers or on verbs, or encode information predictable from word order and context. However, it is a plausible claim that the net effect of extensive morphology is to reduce the necessary length of phrases, again by increasing paradigmatic complexity in such a way as to reduce syntagmatic complexity. Juola [29] showed that there was a remarkably strong inverse relationship between the number of words taken up by the translation of the New Testament in a language, and the diversity of word-forms used in that translation (figure 1b). Morphologically complex languages have more word-forms than morphologically simpler languages, as each word can be realized in many different ways, and the consequence is that they require fewer words to convey a given amount of meaning.
Various approaches have been proposed to measuring a language's morphological complexity. Juola created indices based on the information theory and the compressibility of texts under different conditions [29], while Nichols pioneered an index derived from the descriptive grammar of the language based on which constituents of the sentence were morphologically marked [10]. More recently, Lupyan & Dale [31] have scored a number of indices of morphological complexity for the languages of the WALS. They also provide an overall metric, which sums the number from a set of key features, such as plurality, tense, etc., that are encoded morphologically in the language rather than by a separate lexical item. I discuss this index in §3.
This section has briefly and by no means exhaustively introduced some of the key ways in which components of languages can differ quantifiably in their complexity. Quantification of such differences provides us with the possibility of testing for associations between different aspects of linguistic complexity, and social scale.
3. Covariation of linguistic parameters with social scale
This section reviews the associations that have recently been reported between speaker population size and different measures of linguistic complexity.
(a). Phonological inventory size
Hay & Bauer [32] showed for an opportunity sample of 250 languages from diverse families that there was a robust positive correlation between speaker population size and the size of the phonological inventory. Atkinson replicated this result using WALS data [15], and most recently, Wichmann et al. [28] further replicated it using word lists from over 3100 languages, close to half the known languages of the world. This has the advantage of being probably the largest comparative dataset ever studied, and also having data on mean word length, although it has limitations in terms of the type of data recorded. These limitations were partly addressed by validating a subset of the data points against the more detailed UPSID database [11]. Wichmann et al. [28] found that phonological inventory size and word length both correlated with the log speaker population size. The best estimate of effect size for the association between the log number of speakers and the size of phonological inventory was r = 0.18. Thus, there is a robustly non-zero but weak tendency for languages with few speakers to have few phonological contrasts and relatively long words.
(b). Morphological complexity
The most complete study of morphological complexity across languages is by Lupyan & Dale [31], who used the WALS dataset of over 2200 languages (although given the varying amount of data available on particular languages within WALS, the actual n for particular comparisons was generally far lower). They recorded a large set of grammatical features that languages may or may not encode morphologically, including case, tense, aspect, negation, possession, person and evidentiality marking. The results were striking: across many different kinds of marker, languages spoken by fewer people are likely to be more morphologically complex. The findings are best visualized by using Lupyan & Dale's overall index of morphological complexity, which scores how many of 18 possible distinctions within the language make use of morphological operations (the index is scored from −18 for none, to 0 for all of them). The more morphologically complex a language is, the fewer speakers it tends to have (figure 2).
Figure 2.

Mean speaker population sizes for languages of different degrees of morphological complexity. Bars represent 95% CI of the median, and their width is proportional to the sample size for that degree of complexity. Reproduced from Lupyan & Dale [31].
These studies show that there are patterns of covariation across the world's languages between speaker population size, and both phonological and morphological complexity. Note that the associations run in opposite directions: for phonology, languages with more speakers show greater paradigmatic, and less syntagmatic, complexity, whereas for morphology, languages with more speakers tend to have less paradigmatic complexity, and thus presumably more syntagmatic complexity.
One issue with these studies concerns whether speaker population size is indeed the causally relevant variable. Language size is generally distributed along a latitudinal gradient [33–35], and thus languages spoken by small populations are also spoken by populations occupying more tropical environments, and in countries at a lower level of economic development [36]. It is as yet untested whether some of these other factors are more causally relevant than speaker population size per se [37,38]. The weakness of the associations suggests either that the crude population size is only rather weakly correlated with the causally important factors, and/or, that language evolution is affected by many influences and a considerable amount of contingency and phylogenetic inertia.
A further limitation of these studies lies in their treatment of statistical non-independence among data points. This issue, known in anthropology as Galton's problem [39], is essentially the same as that involved in cross-species comparisons of traits in biology. The authors of the papers reviewed earlier do take account of Galton's problem, using simple strategies such as controlling for language family or geographical region, or taking family-level averages for the traits of interest. However, these controls do not use all of the information known about the variation in historical relatedness among the world's languages, and are not as powerful as the phylogenetic corrections that are available in the biological literature, and that can be fruitfully applied to linguistic data [13].
The observed associations may well prove robust to more sophisticated treatment of non-independence: because the sample sizes are large, many different families are represented, and the various heuristic strategies the researchers adopt for controlling for shared history are generally statistically conservative. In this case, the most intriguing follow-up question is what mechanism could cause these patterns to emerge. Understanding the link between the micro-scale of individual behaviour (speech in this case), and the macro-scale of historically enduring shared patterns of culture (the grammars of languages in this case), is the most challenging issue in the study of cultural evolution, and indeed in anthropology more generally [4]. Section 4 reviews some of the possible mechanisms that may be relevant in this instance.
4. Mechanisms generating covariation between social and linguistic structure
To clarify how associations between linguistic complexity and social scale could come about, it is first necessary to review basic ideas about the cycle of replication of languages. The grammatical structure of languages is encoded in the brains of speakers, and passed from one generation of a speech community to the next. However, and importantly, this transmission is not direct. That is, the linguistic knowledge of one generation does not replicate directly into the linguistic knowledge of the next. Rather, the linguistic knowledge held by the members of generation 1 leads the members of generation 1 to produce sets of speech that serve as inputs to learning processes in the brains of members of generation 2 (figure 3). Each member of generation 2 will then construct a personal linguistic system that is adduced from this input, but not identical to the system in the brain of any individual in generation 1. This is why languages change over historical time. At any one time, there will be variation (within and between speakers) in the realization of communicative strategies present in the set of utterances to which each learner is exposed. If some of those variants are easier to hear, easier to understand or more easily learnable, they will be differentially likely to be incorporated into the linguistic knowledge of the next generation. This is the sense in which language change is an evolutionary process, as Darwin himself noted in The descent of man [40, pp. 465–466].
Figure 3.
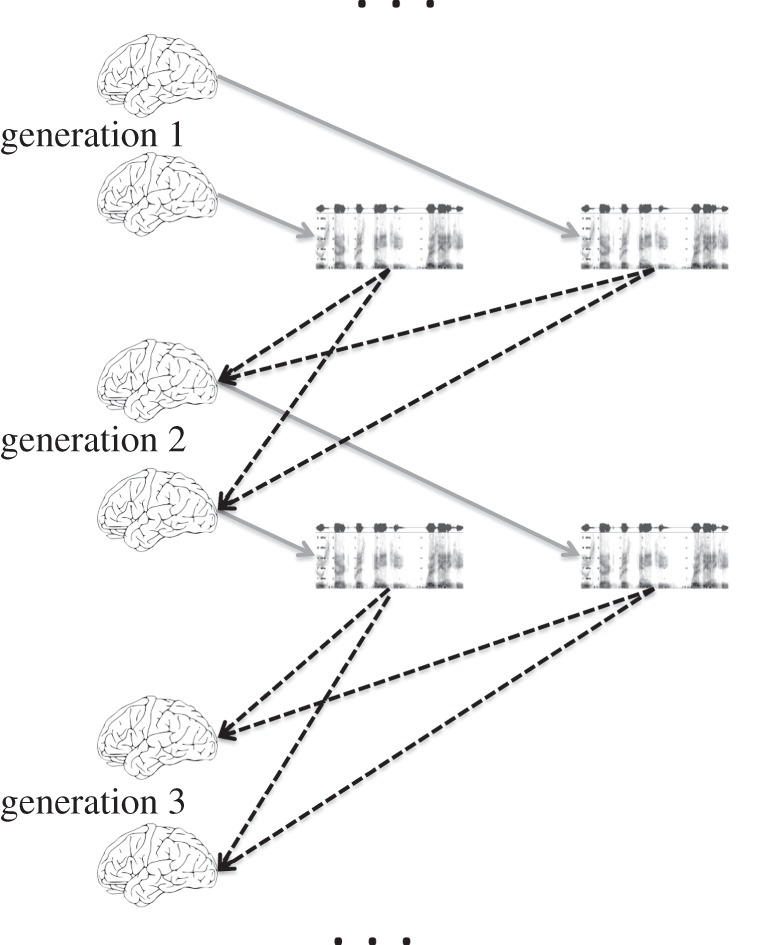
The cycle of replication of languages. Stored linguistic knowledge in the brains of the first generation of speakers is used in communicative utterances. These utterances serve as the data input for learning processes by the next generation, which build their stored linguistic knowledge. Thus, linguistic, and more generally cultural, transmission is a much more indirect process than the replication of DNA. Solid grey arrows represent production and black dashed arrows denote learning.
The schematic in figure 3 immediately allows us to see some ways that the social context could affect language change. Properties of the learners will affect the cycle of replication. Are the learners typically children or adults? Are they learning only one language, or several concurrently? Properties of the input set will also be important. From how many different models is a learner sampling? Are those models very similar to each other (did they, in their turn, all learn from the same sample set)? What kinds of speech contexts are those models producing their input utterances in? Each of these will affect which phonological and grammatical variants are represented and survive through each iteration of ‘generate and learn’ involved in the cycle of replication.
(a). Heterogeneity in the learning set
The first two proposed mechanisms rely on the idea that in communities where the total speaker population is small, the networks of speakers from which individuals acquire language are more restricted. In general, this is a reasonable contention. After all, small languages would not have diverged and remained separate from their neighbours if the social networks of their speakers were not somehow socially and geographically restricted [19,35]. There are two slightly distinct versions of the idea. One is that in small communities, each learner acquires language from a smaller set of individuals than they would in a larger community [32]. There is no direct evidence for this proposition, but it may be plausible, given that small languages are generally spoken in isolated subsistence communities with low levels of political organization and economic development. A variant is that individuals in small communities acquire language from the same number of models as in large communities, but their social networks are more clustered. That is, if individual A is exposed to the speech of individuals B and C, then there is a high degree of expected overlap in the speech sample to which B and C were exposed as they learned. The consequence of either of these mechanisms will be that in small communities, learners will experience less variation in the sample of utterances to which they are exposed than will learners in large communities.
Why would the degree of variation in the input systematically affect which grammatical items persist? Many morphological distinctions rely on a single segment or even sub-segmental phonological change (as in many African languages that use tonal contrasts to signal plurality). It could be that when the input to language learning is very heterogeneous, these fine distinctions are more likely to fail to be acquired, with the learner not able to discriminate the pattern among the noise. The learner would then develop a grammar lacking the morphological means to make a semantically important distinction, and would spontaneously innovate with a lexical strategy such as adding a word for ‘two’ or ‘yesterday’ to fulfil the appropriate communicative function. Thus the morphological complexity of the language would be reduced. Such a process would be an instance of the general result that has been shown using theoretical models: a greater error rate in signal transmission leads to the evolution of a smaller number of more distinct signals, but this requires chaining together of longer signal strings in order to convey the same number of meanings [41,42].
An explanation is needed of why heterogeneity in the learning set would tend to increase rather than decrease the complexity of the phonological inventory. By analogy with the morphological case, it would seem that the opposite might be true. However, there is experimental evidence that sound contrasts are more reliably acquired if multiple distinct training voices are used [43], and simulation work suggests that larger sets of learning models will lead to the maintenance of finer phonological distinctions [44], presumably because the effects of individual idiosyncracies are minimized, producing cleaner phonetic distributions from which the learner can adduce the phonological boundaries. Thus, it is possible that heterogeneity of learning models could account for the opposing effects of the speaker population size on phonology and morphology (see also §4c).
(b). Drift
An idea related to the previous one is that stochastic change, analogous to genetic drift, has a more severe effect in small communities than in large ones. One variant of this idea was developed for the cultural evolution of technologies by Henrich [45]. He argued that the skills underlying useful technologies, which are rather hard to develop, and are maintained by social learning once they have been developed, are more easily lost by chance in small populations of learners than in large ones. This leads to a greater likelihood of technological atrophy in small populations. Relatedly, in small communities or restricted social networks, phonological distinctions may be more likely to be lost by chance, leading to a tendency towards phonological reduction in small communities or those that have gone through population bottlenecks [15]. Why this would apply to phonological distinctions but not morphological ones is unclear.
A related idea was proposed by Nettle [21] and Trudgill [25]. By analogy with the nearly neutral theory of molecular evolution [46], Nettle argued that the turnover of linguistic change would be faster in small communities, and, relatedly, that communicatively suboptimal grammatical strategies were more likely to drift to fixation in small communities than in larger ones. Trudgill's argument is slightly different but makes a similar prediction of disfavoured structures being more likely to persist in small communities. Assuming that intermediate sizes of phonological inventory, and intermediate levels of morphological complexity, represent the communicatively optimal language system, this predicts that languages spoken in small communities should be more extreme than those spoken in large ones. That is, a small language should be more likely to have a very large or very small phonological inventory, a very low or very high level of morphological complexity, with languages of large communities more likely to be in the middle. The empirical evidence thus far has not supported the proposal of a faster rate of change in smaller communities [47,48], or of small languages having more extreme levels of complexity than large languages, because the relationships between linguistic parameters and population size are linear, rather than inflected [28,31,32].
(c). Adult versus child learners
Perhaps the most compelling mechanism yet discussed involves the relative proportions of learners of a language who acquire it as adults rather than as children. Adult language learning is fundamentally different from that of children. Adult language learners find complex morphological paradigms hard to acquire, and rely extensively on transparent compositional form-meaning relationships (strategies such as using a word meaning ‘yesterday’ alongside the verb stem to mark past tense). On the other hand, adults are adept at using extralinguistic cues and context to infer meaning distinctions that are grammatically unspecified. Children acquiring their native language, by contrast, use pattern recognition strategies to eventually acquire arbitrary high levels of paradigmatic complexity and irregularity. Thus, the greater the extent to which the utterances in the community are produced by individuals who only began learning the language as adults, the greater the extent to which morphological distinctions might be expected to disappear, to be replaced with simple, regular, transparent, lexical rules or simply left grammatically unspecified.
This raises the question of why morphological complexity evolves where learners are typically children, given that languages can function effectively with essentially no inflectional morphology at all. One possibility is that paradigmatic morphology increases the overall rate of information transmission, as suggested in §2b. This would mean that using more morphological strategies allows speakers to communicate efficiently and concisely, and will thus tend to be incrementally favoured in speech wherever the simplifying consequences of adult language acquisition are not in force. Morphological operations do indeed often develop historically from separate lexical items, in a contraction process known as grammaticalization. Here, successive generations reinterpret previously separate content words as grammatical modifications of other words, often contracting them in the process. Thus, paradigmatic complexity is gained and syntagmatic complexity is lost.
An alternative possibility is that much morphology is not directly communicatively advantageous, but rather enhances the learnability of language by children [31]. It would do this by providing redundant cues for the parsing of sentences, thus aiding the process of first-language acquisition, given that children are less adept than adults at using pragmatic cues and context to fill in speaker meaning in the absence of grammatical specification. At the margin, then, a slightly more morphologically inflected form would be more likely to be acquired by a generation of children than a slightly less morphologically inflected one, even though the additional inflection might be redundant from the perspective of adult communication. Lupyan & Dale [31] do indeed show, by analysing translations of a standard text into over 100 languages, that languages with more speakers (and hence, by inference, a higher proportion of adult learners) contain more redundancy.
The adult/child learner mechanism is probably the best supported of the various possible mechanisms discussed here. First, it is reasonable to assume that the more widespread a language, the more likely it is to be used by adult learners, for example because it is a regional or national lingua franca, although systematic data on this relationship have not been presented. Languages with larger speaker populations also overlap and adjoin more other languages, leading to the potential for adult learning and use [31]. One obvious hypothesis is that languages that have large populations but no adult learners—for example, because the population is that of an isolated island—should look like small languages in terms of their complexity. The corollary is that languages that are small but for some exceptional reason spoken by a large proportion of adult learners should look grammatically like large languages. These hypotheses are clearly testable.
A second argument for the importance of the adult/child learner mechanism is that there is plenty of qualitative historical evidence for the effect of adult learning on the development of languages [24]. In particular, creolization, the process by which a novel language develops via a bottleneck during which no speakers are speaking the language they acquired as a child, involves radical morphological simplification [22,49]. Creole languages are highly isolating and have very transparent form-meaning mappings.
An unsolved question, however, is how the adult/child learner mechanism relates to the increased phonological complexity of the languages of large communities. Again, one might suppose that extensive adult learning would lead to the loss of unfamiliar phonological distinctions, rather than their gain, and thus to smaller rather than larger inventories. One possible solution might be via word length. Isolating languages may require more word-tokens to convey a given amount of information than do synthetic ones (figure 1b). Speakers may thus seek to make speech strings more economical in other ways. This would be facilitated by any process whereby the set of paradigmatic phonological options increases, allowing words to be truncated (for example, the replacement of word-final nasals with distinctions of nasality on the preceding vowels). Thus, short words and large inventories might stem from compensatory strategies speakers use in morphologically simple languages. Some aspects of this could easily be tested. The associations between the morphological typology of a language and its phonological inventory have not been investigated to date, although this would be eminently possible in the WALS.
5. Conclusion
The evidence reviewed in this paper shows that there are correlations between social scale (as measured by speaker population size), and different types of complexity in human languages. Languages of small communities tend to have smaller phonological inventories, longer words and greater morphological complexity than languages spoken in larger communities. The results need more sophisticated multivariate and comparative analysis, and perhaps most pressingly, the cultural-evolutionary mechanisms involved need to be isolated and identified. Lest it seem that this is a hopeless task, which will always involve using the correlational data to try to speculate about past social processes, we should note that an important body of work has recently developed using experimental artificial languages in the laboratory [16,50]. These paradigms have investigated how fundamental linguistic patterns such as compositionality evolve culturally through cycles of ‘generate and learn’ (figure 3) among laboratory participants. Some of the results of this work are relevant to current concerns. For example, where a graphical communication system is used repeatedly among the same individuals, it evolves towards economy of expression, whereas when it often has to be transmitted to novel learners, it retains iconicity, and thus is laborious to produce but easy to learn [51]. These experiments point the way to possible experimental tests of the kinds of mechanisms outlined in §4.
The associations described in §3 represent very recent, controversial and non-obvious findings. The interest they have generated appears to be part of a somewhat new direction in the study of human language. For some decades, the study of the formal structure of language has been pursued rather independently from the study of the social context in which language is used and learned, and the qualitative identification of formal universal patterns has been the conceptual priority. This appears to be giving way to a greater centrality accorded to linguistic diversity [19,52], the development of much more sophisticated quantitative methods [13,14] and a focus on the role of social transmission in the emergence and persistence of linguistic structure [17,18]. This can be studied both theoretically and in silico [17,44,53,54], and, increasingly, experimentally in the laboratory [50]. These new directions in the study of language mean that our understanding of how social context relates to grammatical complexity in human language may be much further advanced in 10 years hence than it was 10 years ago.
References
- 1.Promislow D. E. L., Harvey P. H. 1990. Living fast and dying young: a comparative analysis of life-history variation amongst mammals. J. Zool. 220, 417–437 10.1111/j.1469-7998.1990.tb04316.x (doi:10.1111/j.1469-7998.1990.tb04316.x) [DOI] [Google Scholar]
- 2.Low B. S., Hazel A., Parker N., Welch K. B. 2008. Influences of women's reproductive lives: unexpected ecological underpinnings. Cross Cult. Res. 42, 201–219 10.1177/1069397108317669 (doi:10.1177/1069397108317669) [DOI] [Google Scholar]
- 3.Nettle D. 2011. Flexibility in reproductive timing in human females: integrating ultimate and proximate explanations. Phil. Trans. R. Soc. B 36, 357–365 10.1098/rstb.2010.0073 (doi:10.1098/rstb.2010.0073) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Nettle D. 2009. Ecological influences on human behavioural diversity: a review of recent findings. Trends Ecol. Evol. 24, 618–624 10.1016/j.tree.2009.05.013 (doi:10.1016/j.tree.2009.05.013) [DOI] [PubMed] [Google Scholar]
- 5.Blumstein D. T., Armitage K. B. 1997. Does sociality drive the evolution of communicative complexity? A comparative test with ground-dwelling sciurid alarm calls. Am. Nat. 150, 179–200 10.1086/286062 (doi:10.1086/286062) [DOI] [PubMed] [Google Scholar]
- 6.Wilkinson G. S. 2003. Social and vocal complexity in bats. In Animal social complexity: intelligence, culture and individualized societies (eds de Waal F. B. M., Tyack P. L.), pp. 322–341 Cambridge, MA: Harvard University Press [Google Scholar]
- 7.McComb K., Semple S. 2005. Coevolution of vocal communication and sociality in primates. Biol. Lett. 1, 381–385 10.1098/rsbl.2005.0366 (doi:10.1098/rsbl.2005.0366) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kaye J. D. 1989. Phonology: a cognitive view. Hillsdale, NJ: Erlbaum [Google Scholar]
- 9.Dryer M. S. 1989. Large linguistic areas and language sampling. Anglais 13, 257–292 [Google Scholar]
- 10.Nichols J. 1992. Linguistic diversity in space and time. Chicago, IL: University of Chicago Press [Google Scholar]
- 11.Maddieson I. 1984. Patterns of sounds. Cambridge, UK: Cambridge University Press [Google Scholar]
- 12.Dryer M. S., Haspelmath M. 2011. The word atlas of language structures online. Munich, Germany: Max Planck Digital Library [Google Scholar]
- 13.Greenhill S. J., Atkinson Q. D., Meade A., Gray R. D. 2010. The shape and tempo of language evolution. Proc. R. Soc. B 277, 2443–2450 10.1098/rspb.2010.0051 (doi:10.1098/rspb.2010.0051) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Dunn M., Greenhill S. J., Levinson S. C., Gray R. D. 2011. Evolved structure of language shows lineage-specific trends in word-order universals. Nature 473, 79–82 10.1038/nature09923 (doi:10.1038/nature09923) [DOI] [PubMed] [Google Scholar]
- 15.Atkinson Q. D. 2011. Phonemic diversity supports a serial founder effect model of language expansion from Africa. Science 332, 346–349 10.1126/science.1199295 (doi:10.1126/science.1199295) [DOI] [PubMed] [Google Scholar]
- 16.Kirby S., Cornish H., Smith K. 2008. Cumulative cultural evolution in the laboratory: an experimental approach to the origins of structure in human language. Proc. Natl Acad. Sci. USA 105, 10 681–10 686 10.1073/pnas.0707835105 (doi:10.1073/pnas.0707835105) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Kirby S., Dowman M., Griffiths T. L. 2007. Innateness and culture in the evolution of language. Proc. Natl Acad. Sci. USA 104, 5241–5245 10.1073/pnas.0608222104 (doi:10.1073/pnas.0608222104) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Chater N., Christiansen M. H. 2010. Language acquisition meets language evolution. Cogn. Sci. 34, 1131–1157 10.1111/j.1551-6709.2009.01049.x (doi:10.1111/j.1551-6709.2009.01049.x) [DOI] [PubMed] [Google Scholar]
- 19.Nettle D. 1999. Linguistic diversity. Oxford, UK: Oxford University Press [Google Scholar]
- 20.Wray A., Grace G. W. 2007. The consequences of talking to strangers: evolutionary corollaries of socio-cultural influences on linguistic form. Lingua 117, 543–578 10.1016/j.lingua.2005.05.005 (doi:10.1016/j.lingua.2005.05.005) [DOI] [Google Scholar]
- 21.Nettle D. 1999. Is the rate of linguistic change constant? Lingua 108, 119–136 10.1016/S0024-3841(98)00047-3 (doi:10.1016/S0024-3841(98)00047-3) [DOI] [Google Scholar]
- 22.Trudgill P. 2002. Sociolinguistic variation and change. Georgetown, DC: Georgetown University Press [Google Scholar]
- 23.Trudgill P. 2001. Contact and simplification: historical baggage and directionality in linguistic change. Linguist. Typol. 5, 371–374 [Google Scholar]
- 24.McWhorter J. 2007. Language interrupted: signs of non-native acquisition in standard language grammars. New York, NY: Oxford University Press [Google Scholar]
- 25.Trudgill P. 2004. Linguistic and social typology: the Austronesian migrations and phoneme inventories. Linguist. Typol. 8, 305–320 [Google Scholar]
- 26.Nettle D. 1995. Segmental inventory size, word length, and communicative efficiency. Linguistics 33, 359–367 [Google Scholar]
- 27.Nettle D. 1998. Coevolution of phonology and the lexicon in twelve languages of West Africa. J. Quant. Linguist. 5, 240–245 10.1080/09296179808590132 (doi:10.1080/09296179808590132) [DOI] [Google Scholar]
- 28.Wichmann S., Rama T., Holman E. W. 2011. Phonological diversity, word length and population sizes across languages: the ASJP evidence. Linguist. Typol. 15, 177–197 10.1515/lity.2011.013 (doi:10.1515/lity.2011.013) [DOI] [Google Scholar]
- 29.Juola P. 1998. Measuring linguistic complexity: the morphological tier. J. Quant. Linguist. 5, 206–213 10.1080/09296179808590128 (doi:10.1080/09296179808590128) [DOI] [Google Scholar]
- 30.Muravyova I. M. 1998. Chukchee (Palaeo-Siberian). In The handbook of morphology (eds Spencer A., Zwicky A. M.), pp. 455–476 Oxford, UK: Blackwell [Google Scholar]
- 31.Lupyan G., Dale R. 2010. Language structure is partly determined by social structure. PLoS ONE 5, e8559. 10.1371/journal.pone.0008559 (doi:10.1371/journal.pone.0008559) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Hay J., Bauer L. 2007. Phoneme inventory size and population size. Language 83, 388–400 10.1353/lan.2007.0071 (doi:10.1353/lan.2007.0071) [DOI] [Google Scholar]
- 33.Mace R., Pagel M. 1995. A latitudinal gradient in the density of languages in North America. Proc. R. Soc. Lond. B 261, 117–121 10.1098/rspb.1995.0125 (doi:10.1098/rspb.1995.0125) [DOI] [Google Scholar]
- 34.Nettle D. 1996. Language diversity in West Africa: an ecological approach. J. Anthropol. Archaeol. 15, 403–438 10.1006/jaar.1996.0015 (doi:10.1006/jaar.1996.0015) [DOI] [Google Scholar]
- 35.Nettle D. 1998. Explaining global patterns of language diversity. J. Anthropol. Archaeol. 17, 354–374 10.1006/jaar.1998.0328 (doi:10.1006/jaar.1998.0328) [DOI] [Google Scholar]
- 36.Nettle D. 2000. Linguistic fragmentation and the wealth of nations: the Fishman–Pool hypothesis re-examined. Econ. Dev. Cult. Change 48, 335–348 10.1086/452461 (doi:10.1086/452461) [DOI] [Google Scholar]
- 37.Ember C. R., Ember M. 2007. Climate, econiche, and sexuality: influences on sonority in language. Am. Anthropol. 109, 180–185 10.1525/aa.2007.109.1.180 (doi:10.1525/aa.2007.109.1.180) [DOI] [Google Scholar]
- 38.Munroe R. L., Fought J. G., Macaulay R. K. S. 2009. Warm climates and sonority classes not simply more vowels and fewer consonants. Cross Cult. Res. 43, 123–133 10.1177/1069397109331485 (doi:10.1177/1069397109331485) [DOI] [Google Scholar]
- 39.Mace R., Pagel M. 1994. The comparative method in anthropology. Curr. Anthropol. 35, 549–564 10.1086/204317 (doi:10.1086/204317) [DOI] [Google Scholar]
- 40.Darwin C. 1871. The descent of man, and selection in relation to sex. London, UK: John Murray [Google Scholar]
- 41.Nowak M. A., Krakauer D. C., Dress A. 1999. An error limit for the evolution of language. Proc. R. Soc. Lond. B 266, 2131–2136 10.1098/rspb.1999.0898 (doi:10.1098/rspb.1999.0898) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Nowak M. A., Krakauer D. C. 1999. The evolution of language. Proc. Natl Acad. Sci. USA 96, 8028–8033 10.1073/pnas.96.14.8028 (doi:10.1073/pnas.96.14.8028) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Lively S., Logan J., Pisoni D. 1993. Training Japanese listeners to identify English /r/ and /l/. II: the role of phonetic environment and talker variability. J. Acoust. Soc. Am. 94, 1242–1255 10.1121/1.408177 (doi:10.1121/1.408177) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.de Boer B. 2001. The origins of vowel systems. Oxford, UK: Oxford University Press [Google Scholar]
- 45.Henrich J. 2004. Demography and cultural evolution: how adaptive cultural processes can produce maladaptive losses—the Tasmanian case. Am. Antiquity 69, 197–214 10.2307/4128416 (doi:10.2307/4128416) [DOI] [Google Scholar]
- 46.Ohta T. 1973. Slightly deleterious mutant substitutions in evolution. Nature 246, 96–98 10.1038/246096a0 (doi:10.1038/246096a0) [DOI] [PubMed] [Google Scholar]
- 47.Wichmann S., Stauffer D., Schulze C., Holman E. W. 2008. Do language change rates depend on population size? Adv. Complex Syst. 11, 357–369 10.1142/s0219525908001684 (doi:10.1142/s0219525908001684). [DOI] [Google Scholar]
- 48.Wichmann S., Holman E. W. 2009. Population size and rates of language change. Hum. Biol. 81, 259–274 10.3378/027.081.0308 (doi:10.3378/027.081.0308) [DOI] [PubMed] [Google Scholar]
- 49.McWhorter J. 2001. The world's simplest grammars are creole grammars. Linguist. Typol. 5, 125–126 [Google Scholar]
- 50.Scott-Phillips T. C., Kirby S. 2010. Language evolution in the laboratory. Trends Cogn. Sci. 14, 411–417 10.1016/j.tics.2010.06.006 (doi:10.1016/j.tics.2010.06.006) [DOI] [PubMed] [Google Scholar]
- 51.Garrod S., Fay N., Rogers S., Walker B., Swoboda N. 2010. Can iterated learning explain the emergence of graphical symbols? Interact. Stud. 11, 33–50 10.1075/is.11.1.04gar (doi:10.1075/is.11.1.04gar) [DOI] [Google Scholar]
- 52.Evans N., Levinson S. C. 2009. The myth of language universals: language diversity and its importance for cognitive science. Behav. Brain Sci. 32, 429–448 10.1017/s0140525x0999094x (doi:10.1017/s0140525x0999094x) [DOI] [PubMed] [Google Scholar]
- 53.Kirby S. 2001. Spontaneous evolution of linguistic structure—an iterated learning model of the emergence of regularity and irregularity. IEEE Trans. Evol. Comput. 5, 102–110 10.1109/4235.918430 (doi:10.1109/4235.918430) [DOI] [Google Scholar]
- 54.Nettle D. 1999. Using social impact theory to simulate language change. Lingua 108, 95–117 10.1016/s0024-3841(98)00046-1 (doi:10.1016/s0024-3841(98)00046-1) [DOI] [Google Scholar]