

Abstract
Why do the equally spaced dots in figure 1 appear regularly spaced? The answer ‘because they are’ is naive and ignores the existence of sensory noise, which is known to limit the accuracy of positional localization. Actually, all the dots in figure 1 have been physically perturbed, but in the case of the apparently regular patterns to an extent that is below threshold for reliable detection. Only when retinal pathology causes severe distortions do regular grids appear perturbed. Here, we present evidence that low-level sensory noise does indeed corrupt the encoding of relative spatial position, and limits the accuracy with which observers can detect real distortions. The noise is equivalent to a Gaussian random variable with a standard deviation of approximately 5 per cent of the inter-element spacing. The just-noticeable difference in positional distortion between two patterns is smallest when neither of them is perfectly regular. The computation of variance is statistically inefficient, typically using only five or six of the available dots.
Keywords: vision, texture, camouflage
1. Introduction
The idea that perceptual systems are tuned to look for regularities and structures in the environment was proposed by the Gestalt psychologists [1], but we know little about the mechanisms for perceiving regularities, or their limits. Patterns such as those in figure 1 are perceived by normal observers as more-or-less regular, but we do not know what mechanisms they use to decide whether the patterns are completely regular or not. In particular, it is not clear how the observer treats sensory noise in the representation of regularity. The existence of this noise can be demonstrated using dots similar to the individual texture elements in figure 1. When observers are shown three dots in a row and have to decide whether the centre one is ‘up’ or ‘down’ relative to the position of the flankers, they do not always give the same answer at a given physical displacement of the centre dot. Sensory noise is responsible for this variability [2].
Figure 1.

All three patterns contain 11 × 11 dots spaced on a regular grid with individual dot positions independently perturbed by addition of a random positional shift. (a) The random perturbation is so small as to be invisible. (b) It is twice as great and just visible. (c) It is twice that of the middle panel and is clearly visible.
It is conventional to represent performance with a ‘psychometric function’ that relates response probabilities to the physical stimulus. An example for the alignment of three dots is shown in figure 2. Good fits to psychometric functions for such alignment tasks are usually obtained by assuming the sensory noise is Gaussian, with a standard deviation equal to a size difference of approximately 5 per cent [3,4].
Figure 2.
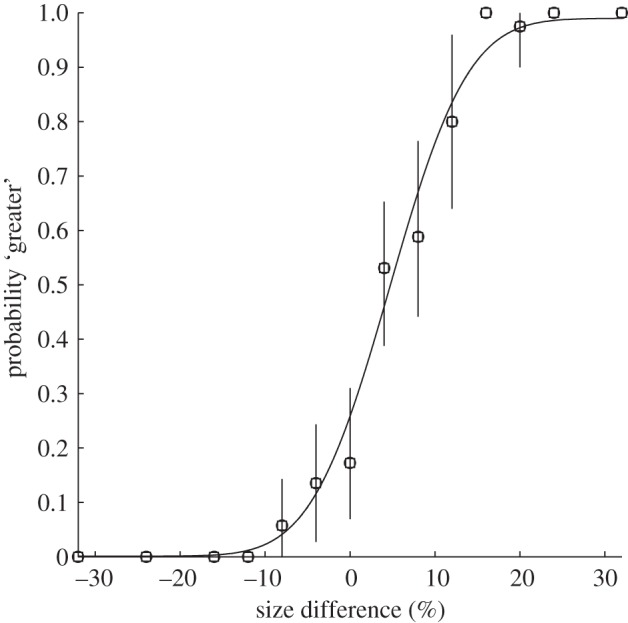
An example of a psychometric function for discrimination with the best-fitting cumulative Gaussian fit (solid curve) to the data points. The observer decided whether the centre dot in a row of three dots was displaced ‘up’ or ‘down’ relative to the flanking dots. Each data point shows the probability of responding ‘up’ (ordinate) as a function of the actual physical displacement (abscissa). The vertical bars represent 95% confidence limits from the binomial distribution.
If this sensory noise were included in the perceptual representation of a pattern with regularly spaced elements, then we would expect to see local irregularities throughout the pattern, even when none is physically present. The alignments between elements would all seem different. Some of the differences, by chance, would be larger than the standard deviation of the noise, and should thus be conspicuous. However, this is not what happens. Instead, a regular pattern appears regular. We now consider two alternative hypotheses to account for this finding.
— The undersampling model. Observers are unable to measure the spatial relationships between all the elements during a brief glimpse of the pattern. Instead, they take a restricted sample of elements, and use these elements only to calculate the positional variance. They can use the computed variance to decide whether one pattern is more regular than another. However, the variance is represented in perception only if it exceeds the amount expected from sensory noise. Thus, all patterns with physical variances smaller than the sensory noise will appear completely regular, even if they can be discriminated. It may seem paradoxical that an observer could discriminate differences in patterns that ‘look’ the same, but there are many examples of this in the ‘discrimination without awareness’ literature [5–7]. The key to this dissociation is that in the discrimination case the observer is forced to decide which of two patterns is more regular: a decision they can make without adopting any absolute standard of complete regularity. In the ‘appearance’ case, they have to decide whether a given pattern is completely regular or not. To make this decision, they have to adopt some criterion, and this may well depend upon their own sensory noise.
— The sensory threshold model. The observer calculates a variance signal from all or some of the pattern elements, but all variances falling below some arbitrary ‘sensory threshold’ are set to zero. This is not the same as the threshold implicit in the undersampling model, because the threshold in the latter case does not affect the discrimination process, only the conscious decision whether a pattern is, or is not, regular.
To decide between these two models on a quantitative basis, we measured the ability of observers to discriminate between pairs of patterns such as those in figure 1 when they were both irregular, but to different extents. One of the patterns had a variance σ2 and the other a variance σ2 + Δσ2. A key prediction of the sensory threshold model is that the best performance (the lowest Δσ) will be obtained when V is non-zero. In other words, two patterns will be more easily discriminated when both are slightly irregular than when one of them is completely regular. Exactly this effect, referred to as ‘pedestal facilitation’, has been reported for the discrimination of luminance contrast, and has been conventionally explained by a sensory threshold [8]; for recent review, see Solomon [9]. The undersampling model does not predict pedestal facilitation of variance, although as we shall see, this depends on the exact measure we take of the threshold. The final decision between the two models can be taken only by their goodness-of-fit to the data, which we assess using the calculation of maximum likelihood.
A second question we addressed in these experiments is how the presence of task-irrelevant variance in the patterns would affect variance discrimination along the relevant dimension. In all cases, the relevant dimension was the positional variance of the dots. In one manipulation, we added irrelevant variance of contrast between the elements comprising the patterns. In another manipulation, we arranged the dots around a circle and instructed observers to report the variance in either their angular separation or their distance from the centre, ignoring the other dimension. These investigations bear on the general theory of camouflage. Previous psychophysical investigations of camouflage have used variance in an irrelevant dimension to mask a pattern defined by its mean difference from the background [10]. Here, we see if this generalizes to the masking of variance by variance.
2. Methods
(a). Observers
The observers were two of the authors (M.M. and I.M.), and a third (G.M.) who was unaware of the specific aims of the experiment.
(b). Apparatus
Stimuli were presented on the LCD screen of a Sony Vaio (PGC-TR5MP) laptop computer using Matlab and the PsychToolbox [11] for Windows. Screen size was 1280 × 768 pixels (230 × 14 mm). Only the green LCDs were used, and the mean luminance was 56 Cd m−2. The viewing distance was approximately 57 cm, so that the pixel size was approximately 0.018° of visual angle.
(c). Stimuli
Different kinds of regular patterns were used in different experiments. In square arrays, the dots were regularly spaced in an 11 × 11 lattice (figure 1). In circular patterns, 11 dots were equally spaced around a notional circle. In linear patterns, 11 dots were equally spaced along a notional line. The position of each dot in the array was selected from a uniform probability density function (PDF) with mean μ and range ω, where μ was the position it would have if the pattern were completely regular. In the square arrays, the spatial perturbation was independently sampled in dimensions x and y. In the circular patterns, the perturbation was either radial or angular in different experiments. We also included ‘camouflage’ conditions where (i) observers had to ignore irrelevant variation to the radial position of the dots while responding to variation in their angle and (ii) observers ignored random contrast polarity (black versus white) of the dots in the circular array while responding to variance in angular position. All dots had a Gaussian profile with a space constant of one quarter of the inter-dot separation, making them look slightly fuzzy.
(d). Procedure
A 2AFC (two-alternative forced-choice) procedure was used. On each trial, two patterns were shown, each for 200 ms and with a 200 ms blank interval in between. Observers had to decide which of the two had the greater degree of spatial irregularity. The reference pattern with pedestal range ω was presented randomly either first or second. The standard deviation of the range is related to its width ω by the expression 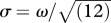 . The position of each dot in the other pattern, the test, had a range of ω + Δω, where
. The position of each dot in the other pattern, the test, had a range of ω + Δω, where 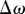 was varied by an adaptive procedure [12] to determine the just-noticeable Δω (JND) at which the observer was 84 per cent correct. There was no feedback to indicate whether the response was correct or not. The pedestal range was randomly selected on each trial from a set of preset values. A block of trials terminated when each of these preset values had been presented 50 times. Confidence limits for the JND (95%) were determined by exactly simulating the experiment 80 times with a bootstrapping procedure [13].
was varied by an adaptive procedure [12] to determine the just-noticeable Δω (JND) at which the observer was 84 per cent correct. There was no feedback to indicate whether the response was correct or not. The pedestal range was randomly selected on each trial from a set of preset values. A block of trials terminated when each of these preset values had been presented 50 times. Confidence limits for the JND (95%) were determined by exactly simulating the experiment 80 times with a bootstrapping procedure [13].
(e). Modelling
The model assumes that the observer samples elements (dots) from the grid and compares their positions with those predicted from a template. We admit that this version of the model is unrealistic. It is more likely that the observer has access to sensory signals representing the alignment between pairs of dots (figure 2) or their separations. However, such a model is difficult to compute, particularly in the two dimensions of a grid. The model we actually use should be thought of as an ideal observer model in which the observer knows the positions of all the dots in a template.
In the undersampling model, the observer on each trial samples ν dot positions from each of the two patterns and selects the pattern having the greater sample variance of these positions from the template positions. In the case of the standard pattern, each of the ν dots is taken from a distribution with variance ω2/12 + ι2, where ι is the standard deviation of the internal noise; and in the case of the test pattern, each is taken from a distribution with variance 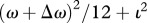 . Recall that the external perturbations were taken from a uniform distribution of width ω that has variance ω2/12). The units of ω are the distance between elements in the unperturbed pattern. When the underlying PDF for signal, pedestal and noise are Gaussian it is easy to compute the probability that var(test)/var(ref) > 1 and thus that the observer is correct [14]. However, departures from regularity in our stimuli did not form Gaussian distributions, so we resorted to simulation to produce the fits shown in figure 2. The fits had only two free parameters, the number of dots per sample (ν) and the range of the internal noise in the same units as ω. The sensory threshold model was the same as the undersampling model, except that all internal variances below a threshold value were set to zero before the two stimuli were compared. This latter model has three parameters: the internal noise, the number of dots per sample and the threshold.
. Recall that the external perturbations were taken from a uniform distribution of width ω that has variance ω2/12). The units of ω are the distance between elements in the unperturbed pattern. When the underlying PDF for signal, pedestal and noise are Gaussian it is easy to compute the probability that var(test)/var(ref) > 1 and thus that the observer is correct [14]. However, departures from regularity in our stimuli did not form Gaussian distributions, so we resorted to simulation to produce the fits shown in figure 2. The fits had only two free parameters, the number of dots per sample (ν) and the range of the internal noise in the same units as ω. The sensory threshold model was the same as the undersampling model, except that all internal variances below a threshold value were set to zero before the two stimuli were compared. This latter model has three parameters: the internal noise, the number of dots per sample and the threshold.
(f). Significance testing
The experimental data for each condition consisted of a 3 × N matrix, where N was the number of trials in the condition to be analysed. The first row of the matrix contained the pedestal value ω, the second the value of Δω and the third the observer's response (0 for wrong, and 1 for correct). The model used the values of ω and Δω along with the estimated values for the number of dots per sample, and the internal noise to predict the probability correct, which was then compared with the actual observer's responses to calculate the joint likelihood over all N trials.
The Matlab function fminsearch was the used to find values of internal noise (ι) and sample size (ν) to maximize the joint likelihood. In practice, to avoid non-integral values of ν, we used fixed values of sample size to find the best-fitting internal noise, and repeated this procedure over a range of sample sizes to find the best overall fit.
The calculation of probability correct for a particular combination of {ν,ι,ω,Δω} was calculated from 10 000 simulated trials. To make possible an orderly gradient descent, we seeded the random number generator used by the simulator so that each combination of {ν,ι,ω,Δω} always produced exactly the same probability correct. To test the reliability of the fits, we carried out 80 independent fits with different seeds for the random number generator, and used the resulting distribution of fits to calculate 95% confidence limits. These were always well within the confidence limits of the thresholds estimated from the data by bootstrapping.
3. Results
(a). Discrimination thresholds as function of pedestal
We present first (figure 3) the results for one subject (M.M.) in one condition (11 × 11 grid) in order to establish some general points about the data and modelling. The figure shows, on the left, the JNDs in the standard deviation of the added noise, as a function of the standard deviation of the pedestal. Recall that the pedestal refers to the noise in the less variable stimulus, while the discrimination threshold is how much more noise the other stimulus needs for the two to be discriminable at the 84 per cent correct level. An important point to note is that the models are constrained not just by the points shown in this graph, but by all the points on the psychometric function (figure 1) amounting to several thousands of trials.
Figure 3.
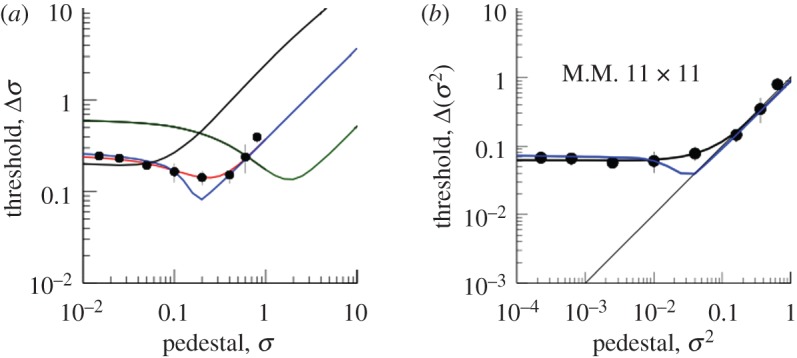
The results (filled circles) for observer MM in the 11 × 11 grid condition, and the fits of various models described more fully in the text. (a) The data as a function of the standard deviation of the uniform distribution from which the dot positions were sampled, in units of the canonical dot spacing. The red curve passing through all the data points is the best fit of the undersampling model, with six dots per sample. The blue curve is a fit of the sensory threshold model with the threshold constrained to be the same as the variance of the internal noise. The green curve is the best fit of the undersampling model with the number of samples constrained to be the total number of dots (11 × 11). The black curve with no dip is the fit of the undersampling model with n = 2. (b) Thresholds (σ2) as a function of pedestal (σ2). The black curve is the best fit of the undersampling model. The blue curve is a fit of the sensory threshold model with the threshold constrained to be the same as the variance of the internal noise.
The data points show a clear ‘dipper’ effect with a minimum threshold (best discrimination) at a non-zero value of the pedestal. Thereafter, they show an increase as a function of pedestal level, approximating a slope of unity. This effect is conventionally called ‘masking’ of the added signal by the pedestal and is related to Weber's Law, which states that the JND between two stimuli is proportional to their absolute magnitude (review by Solomon [9] and Laming [15]).
The best fit to the data is the solid curve running through all the data points. This is the fit of the undersampling model, which contains two parameters, the internal noise of the observer and the number of dots per sample used by the observer to calculate the variance (in this case, six out of the 11 × 11 available). Note that this model does not include a sensory threshold. It may seem puzzling, therefore, that it produces a ‘dip’, which is conventionally explained by a sensory threshold. The reason for this is shown in the graph on the right, which plots the same data in terms of the variance of the noise and the pedestal, rather than its standard deviation. The ‘dip’ now disappears, both from the data and from the model. The reason for the ‘dip’ in the standard deviations (figure 3a) is that in the model the internal noise of the observer and the external noise added to the stimulus are assumed to be additive. In a linear system, two independent noise sources are equivalent to a single noise having the sum of the two variances. This squaring means that the larger of the two noise sources is dominant. When the two stimuli being compared have no external noise, the internal noise predominates and the observer is relatively insensitive. When both stimuli have a pedestal equal to the internal noise, the latter is less dominant and discrimination is easier. For example, let the internal noise have unit standard deviation, let the pedestal be zero, and let the other stimulus have a standard deviation that is one more than the pedestal. The difference in standard deviation between the two stimuli is 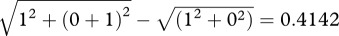 . Now let the pedestal also have unit standard deviation. The same calculation produces the difference
. Now let the pedestal also have unit standard deviation. The same calculation produces the difference 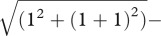
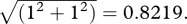 Therefore, the effect of the signal is greater with a non-zero pedestal.
Therefore, the effect of the signal is greater with a non-zero pedestal.
The apparent ‘dip’ disappears when variances are plotted instead. The ‘dip’ on the left-hand side of figure 3 is therefore not evidence for a sensory threshold. To see what the effect of a sensory threshold would actually be, we plot the case where there is a sensory threshold equal to the variance of internal noise. This produces the steeply dipped function in figure 1a. It also produces a dip in the variance plot (figure 1b).
Note that the undersampling model also predicts the ‘masking’ region of the dipper function, where thresholds rise with the pedestal value. This is particularly clear in the variance plot (figure 3b). The reason for this is that the sampling variance of the variance rises with the true variance. On each trial, the observer is comparing two sample variances. The greater the true variance (the pedestal) the more likely the two samples are to differ by chance, and the larger the signal will have to be in order to be reliably detected. All this is as predicted by the model.
Figure 3 also plots functions when the number of samples is equal to the total number available (11 × 11) or equal to only 2. These are significantly poor fits to the data, as verified by a bootstrapping test based on likelihoods.
The model fits to the data for all conditions (e.g. 11 dots in a circle; single row of 11 dots) are shown in table 1, and illustrative examples are shown in figure 4. Table 1 shows that observers always used fewer than the number of dots available, typically approximately 6, and that the sensory threshold model was never a significantly better fit to the data than the simple undersampling model. In no case was the fitted threshold as high or higher than the fitted internal noise.
Table 1.
Best-fitting values for internal noise (ι), sample size (ν) and threshold (t) to the data for different observers and conditions (key in second column) along with the log-likelihoods of these fits (column 6). The unit for ι is the proportion of nearest-neighbour spacings in each array. The final column (χ2) shows the values for twice the difference in log-likelihoods of two fits. Fits with a threshold such as row 2 are compared with fits without in the row above. Fits that combine two conditions, such as row 5, which combines 1 and 3, are compared with the summed likelihoods of the two separate fits.
| condition | ι | threshold | ν | log-likelihood | χ2 | |
|---|---|---|---|---|---|---|
| 1 | M.M. circ rad 1 | 0.07 | 5 | −940.10 | ||
| 2 | M.M. circ rad 2 | 0.07 | 0.02 | 5 | −940.15 | |
| 3 | M.M. circ rad rand ang 1 | 0.09 | 4 | −833.71 | ||
| 4 | M.M. circ rad rand ang 2 | 0.09 | 0.01 | −833.00 | ||
| 5 | M.M. 1 and 3 combined | 0.07 | 4 | −1785.60 | −23.58 | |
| 6 | G.M. circ rad 1 | 0.06 | 4 | −699.59 | ||
| 7 | G.M. circ rad 2 | 0.06 | 0.00 | 5 | −699.20 | |
| 8 | G.M. circ rad rand ang 1 | 0.09 | 4 | −821.34 | ||
| 9 | G.M. circ rad rand ang 2 | 0.09 | 0.06 | 6 | −821.27 | |
| 10 | G.M. 6 and 8 combined | 0.08 | 4 | −1534.80 | −27.74 | |
| 11 | M.M. circ ang 1 | 0.11 | 5 | −1371.30 | ||
| 12 | M.M. circ ang 2 | 0.20 | 0.38 | 5 | −1371.30 | |
| 13 | M.M. circ ang rand b/w 1 | 0.15 | 5 | −1895.40 | ||
| 14 | M.M. circ ang rand b/w 2 | 0.15 | 0.12 | 5 | −1895.30 | |
| 15 | M.M. 11 and 13 combined | 0.13 | 5 | −3350.70 | −168.00 | |
| 16 | I.M. circ ang 1 | 0.11 | 5 | −661.30 | ||
| 17 | I.M. circ ang 2 | 0.11 | 0.08 | 5 | −661.28 | |
| 18 | I.M. circ ang rand b/w 1 | 0.13 | 5 | −703.17 | ||
| 19 | I.M. circ ang rand b/w 2 | 0.13 | 0.05 | 6 | −703.17 | |
| 20 | I.M. 16 and 18 combined | 0.12 | 6 | −1370.70 | −12.46 | |
| 21 | G.M. circ ang 1 | 0.11 | 6 | −753.02 | ||
| 22 | G.M. circ ang 2 | 0.11 | 0.08 | 6 | −753.02 | |
| 23 | G.M. circ ang rand b/w 1 | 0.12 | 5 | −792.96 | ||
| 24 | G.M. circ ang rand b/w 2 | 0.12 | 0.11 | 5 | −792.84 | |
| 25 | G.M. 21 and 23 combined | 0.11 | 5 | −1550.30 | −8.64 | |
| 26 | M.M. 11 × 11 1 | 0.08 | 6 | −1321.80 | ||
| 27 | M.M. 11 × 11 2 | 0.13 | 0.07 | 6 | −736.40 | |
| 28 | I.M. 11 × 11 1 | 0.13 | 11 | −736.41 | ||
| 29 | I.M. 11 × 11 2 | 0.13 | 0.11 | 11 | −736.37 | |
| 30 | M.M. 1 × 11 1 | 0.07 | 5 | −671.97 | ||
| 31 | M.M. 1 × 11 2 | 0.07 | 0.00 | 5 | −671.96 | |
| 32 | I.M. 1 × 11 1 | 0.07 | 5 | 1327.10 | ||
| 33 | I.M. 1 × 11 2 | 0.07 | 0.00 | 5 | 1327.10 |
Figure 4.

(a) Show results for two observers (M.M., left; I.M., right) with two kinds of stimulus array: 11 × 11 dot matrices (top) and a single line of 11 dots (bottom). The solid line is the best fit of the sampling model. (b) Show results for two observers (M.M., left; G.M., right) with arrays of 11 dots arranged in a circle. In the top two panels, the signal the observer was instructed to compare between the two patterns in the 2AFC design was the difference in variance of the radial distance of the dots. In the bottom two panels, observers detected differences in angular separation of the dots. In the condition indicated by square symbols, only the relevant dimension was varied. In the condition indicated by circles, an additional source of variation (camouflage) was introduced. In the top two panels, this was variation in angular position; in the bottom two panels, it was random variation in contrast polarity (white/black).
(b). Camouflage
We collected two kinds of data relevant to camouflage. In the first, a circular array of dots was used, and the elements were perturbed in their angle from the centre. Either all had the same contrast, or were randomly black or white. The observers were M.M., G.M. and I.M. As table 1 and figure 4 show, the contrast variation caused an increase in thresholds, even though it was irrelevant to the task. The effect on the model fits was that contrast variation was equivalent to an increase in sensory noise. This is also true of the second test, where a radial variation in dot position was camouflaged by an irrelevant perturbation in the angle (observers M.M. and G.M.), except that there was a decrease in the number of samples from five to four for M.M. in the camouflage condition.
4. Discussion
We suggest two related conclusions. The first is that the observer's discrimination performance is limited by low-level noise equivalent to physical perturbation in the position of the dots. This means that a completely regular pattern is not discriminable from one having a marked degree of physical perturbation. However, both such patterns appear completely regular (figure 1). The low-level noise is not represented in awareness. We infer from this that the internal noise in individual dot position is not represented in the conscious perception of a regular pattern. Rather, what is represented is a regular template for the pattern. If the computed perturbation from the template does not exceed the internal noise level, then the pattern is seen as regular.
This conclusion is reinforced by our estimates of the number of dots (ν) the observer is using in computing variability. We estimate this number as approximately 6, which is strikingly inefficient for a pattern with 11 × 11 elements. The efficiency is higher (approx. 50%) for the circular patterns but ν is still approximately 6, suggesting a fixed sample size rather than a fixed efficiency. The only exception to the ‘ν = 6’ rule is observer I.M., who manages an impressive 11 dots for the 11 × 11 pattern. The conclusion that observers use only a small amount of the available information to compute irregularity is further evidence that the perception of a regular pattern is the perception of a template, because the actual physical position of most of the dots is not being represented at all. In other words, we see a regular arrangement of dots, even though the noisy position of many of them has not been sampled.
Our findings also suggest a general theory of pattern camouflage. In its most general form, the principle of camouflage is that irrelevant variation along one-dimension masks detection of variation along another. For example, a region of high-orientation variance if a texture is harder to see in the texture elements that are randomly coloured red and green [10,16]. This is analogous to what we find in our experiments for variance. The ability of observers to detect perturbations of radial position in circular patterns is compromised by irrelevant contrast variation or by angular variation. This is what we would expect if observers were computing variance from a fixed internal template.
Acknowledgements
We thank the UK EPSRC Research Council (grant no. EP/H033955/1) and the Max Planck Society for support.
References
- 1.Koffka K. 1935. Principles of Gestalt psychology. London, UK: Lund Humphries [Google Scholar]
- 2.Green D. M., Swets J. A. 1966. Signal detection theory and psychophysics, 1st edn New York, NY: Wiley [Google Scholar]
- 3.Westheimer G. 1981. Visual hyperacuity. Prog. Sensory Physiol. 1, 2–29 [Google Scholar]
- 4.Morgan M. J. (ed.) 1990. Hyperacuity. London, UK: Macmillan [Google Scholar]
- 5.He S., Cavanagh P., Intriligator J. 1996. Attentional resolution and the locus of visual awareness. Nature 383, 334–337 10.1038/383334a0 (doi:10.1038/383334a0) [DOI] [PubMed] [Google Scholar]
- 6.Parkes L., Lund J., Angelluci A., Solomon J., Morgan M. 2001. Compulsory averaging of crowded orientation signals in human vision. Nat. Neurosci. 4, 739–744 10.1038/89532 (doi:10.1038/89532) [DOI] [PubMed] [Google Scholar]
- 7.Smallman H. S., MacLeod D. I. A., He S., Kentridge R. W. 1996. Fine-grain of the neural representation of human spatial vision. J. Neurosci. 16, 1852–1859 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Nachmias J., Sansbury R. 1974. Grating contrast: discrimination may be better than detection. Vision Res. 14, 1039–1042 10.1016/0042-6989(74)90175-8 (doi:10.1016/0042-6989(74)90175-8) [DOI] [PubMed] [Google Scholar]
- 9.Solomon J. A. 2009. The history of dipper functions. Attent. Percept. Psychophys. 71, 435–443 10.3758/APP.71.3.435 (doi:10.3758/APP.71.3.435) [DOI] [PubMed] [Google Scholar]
- 10.Callaghan T. 1984. Dimensional interaction of hue and brightness in preattentive field segregation. Percept. Psychophys. 36, 25–34 10.3758/BF03206351 (doi:10.3758/BF03206351) [DOI] [PubMed] [Google Scholar]
- 11.Brainard D. H. 1997. The psychophysics toolbox. Spat. Vis. 10, 433–436 10.1163/156856897X00357 (doi:10.1163/156856897X00357) [DOI] [PubMed] [Google Scholar]
- 12.Watson A. B., Pelli D. G. 1983. QUEST: a Bayesian adaptive psychometric method. Percept. Psychophys. 33, 113–120 10.3758/BF03202828 (doi:10.3758/BF03202828) [DOI] [PubMed] [Google Scholar]
- 13.Efron B. 1982. The Jackknife, the Bootstrap and other resampling plans. Philadelphia, PA: Society for Industrial and Applied Mathematics [Google Scholar]
- 14.Morgan M., Chubb C., Solomon J. A. 2008. A ‘dipper’ function for texture discrimination based on orientation variance. J. Vision 8, 9.1–9.8 10.1167/8.11.9 (doi:10.1167/8.11.9) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Laming D. 1985. Some principles of sensory analysis. Psychol. Rev. 92, 462–485 10.1037/0033-295X.92.4.462 (doi:10.1037/0033-295X.92.4.462) [DOI] [PubMed] [Google Scholar]
- 16.Morgan M. J., Adam A., Mollon J. D. 1992. Dichromats break colour-camouflage of textural boundaries. Proc. R. Soc. Lond. B 248, 291–295 10.1098/rspb.1992.0074 (doi:10.1098/rspb.1992.0074) [DOI] [PubMed] [Google Scholar]