

Summary
In high-dimensional data analysis, feature selection becomes one means for dimension reduction, which proceeds with parameter estimation. Concerning accuracy of selection and estimation, we study nonconvex constrained and regularized likelihoods in the presence of nuisance parameters. Theoretically, we show that constrained L0-likelihood and its computational surrogate are optimal in that they achieve feature selection consistency and sharp parameter estimation, under one necessary condition required for any method to be selection consistent and to achieve sharp parameter estimation. It permits up to exponentially many candidate features. Computationally, we develop difference convex methods to implement the computational surrogate through prime and dual subproblems. These results establish a central role of L0-constrained and regularized likelihoods in feature selection and parameter estimation involving selection. As applications of the general method and theory, we perform feature selection in linear regression and logistic regression, and estimate a precision matrix in Gaussian graphical models. In these situations, we gain a new theoretical insight and obtain favorable numerical results. Finally, we discuss an application to predict the metastasis status of breast cancer patients with their gene expression profiles.
Keywords: Coordinate decent; continuous but non-smooth minimization; general likelihood; graphical models; nonconvex; (p, n)-asymptotics
1 Introduction
Feature selection is essential to battle the inherited “curse of dimensionality” in high-dimensional analysis. It removes non-informative features to derive simpler models for interpretability, prediction and inference. In cancer studies, for instance, a patient’s gene expression is linked to her metastasis status of breast cancer, for identifying cancer genes. In a situation as such, our ability of identifying cancer genes is as critical as a model’s predictive accuracy, where selection accuracy becomes extremely important to reproducible findings and generalizable conclusions. Towards accuracy of selection and parameter estimation, we address several core issues in high-dimensional likelihood-based selection.
Consider a selection problem with nuisance parameters, based on a random sample Y = (Y1, ···, Yn) with each Yi following probability density g(θ0, y), where θ0 = (β0, η0) is a true parameter vector, and are the parameters of interest and nuisance parameters respectively, is a set of nonzero coefficients of β0 with size |A0| = p0, and is a vector of 0’s with c denoting the set complement. Here we estimate (β0, A0), where p may greatly exceed n, and q = 0 is permitted.
For estimation and selection, a likelihood is regularized with regard to β, particularly when p > n. This leads to an information criterion:
| (1) |
where is the log-likelihood based on Y, λ > 0 is a regularization parameter, and is the L0-function penalizing an increase in a model’s size. In (1), when θ = β without nuisance parameters, λ = 1 is Akaike’s information criterion, is Bayesian information criterion [21], among others. In fact, essentially all selection rules can be cast into the framework of (1).
Regularization (1) has been of considerable interest for its interpretability and computational merits. Yet its constrained counterpart (2) has not received much attention, which is
| (2) |
where K ≥ 0 is a tuning parameter corresponding to λ in (1). Minimizing (1) or (2) in θ gives a global minimizer leading to an estimate β̂ = (β̂Â, 0Âc)T, with  the estimated A0, where η is un-regularized and possibly profiled out. Note that (1) and (2) may not be equivalent in their global minimizers, which is unlike a convex problem.
This article systematically investigates constrained and regularized likelihoods involving nuisance parameters, for estimating zero components of β0 as well as nonzero ones of θ0. This includes, but is not limited to, estimating nonzero entries of a precision matrix in graphical models.
There is a huge body on parameter estimation through L1-regularization in linear regression; see, for instance, [16] for a comprehensive review. For feature selection, consistency of the Lasso [26] has been extensively studied under the irrepresentable assumption; c.f., [15] [34]. Other methods such as the SCAD [6] have been studied. Yet L0-constrained or regularized likelihood remain largely unexplored. Despite progress, many open issues remain. First, what is the maximum number of candidate features allowed for a likelihood method to reconstruct informative features? Results, such as [13], seem to suggest that the capacity of handling exponentially many features may be attributed primarily to the exponential tail of a Gaussian distribution, which we show is not necessary. Second, can parameter estimation be enhanced through removal of zero components of β? Third, can a selection method continue to perform well for parameters of interest in the presence of a large number of nuisance parameters, as in covariance selection for off-diagonal entries of a precision matrix?
This article intends to address the foregoing three issues. First, we establish finite-sample mis-selection error bounds for constrained L0-likelihood as well as its computational surrogate, given (n, p0, p), where the surrogate–a likelihood based on a truncated L1-function (TLP) approximating the L0-function, permits efficient computation; see Section 2.1 for a definition. On this basis, we establish feature selection consistency for them as n, p → ∞, under one key condition that is necessary for any method to be selection consistent:
| (3) |
where , d0 > 0 is a constant, |·| and \ denote the size of a set and that of set difference, respectively, is the Hellinger-distance for with respect to a dominating measure μ, and g(θ, y) is a probability density for Y1. As one consequence, exponentially many candidate features are permitted for selection consistency with a broad class of constrained likelihoods. This challenges the well established result that the maximum number of candidate features permitted for selection consistency depends highly on a likelihood’s tail behavior, c.f., [4]. In fact, selection consistency continues to hold even if the error distribution does not have an exponential tail; see Proportion 1 for linear regression. Second, sharper parameter estimation results from accurate selection by L0-likelihood and its surrogate as compared to that without such selection. For feature selection in linear regression and logistic regression, the optimal Hellinger risk of the oracle estimator, the maximum likelihood estimate (MLE) based on A0 as if the true A0 were known a priori, is recovered by these methods, which is of order of and is uniform over a certain L0-band of θ0 excluding the origin. This is in contrast to the minimax rate with u ≥ p0 for estimation without feature selection in linear regression [17]. In other words, accurate selection by L0-likelihood and its surrogate over the L0-band improves accuracy of estimation after non-informative features are removed, without introducing additional bias to estimation. Moreover, in estimating a precision matrix in Gaussian graphical models, the foregoing conclusions extend but with a different rate at , where a log p factor is due to estimation of 2p nuisance parameters as compared to logistic regression. Third, two difference of convex (DC) methods are employed for computation of (1) and (2), which relax nonconvex minimization through a sequence of convex problems.
Two disparate applications are considered, namely, feature selection in generalized linear models (GLMs), as well as estimation of a precision matrix in Gaussian graphical models. In GLMs, feature selection in nonlinear regression appears more challenging than linear regression for a high-dimensional problem. In statistical modeling of a precision matrix in Gaussian graphical models, two major approaches have emerged to exploit matrix sparsity by likelihood selection and neighborhood selection. Papers based on these two approaches include [15] [12] [28] [2] [8] [19] [20] [18], among others. As suggested by [19], existing methods may not perform well when the dimension of a matrix exceeds the sample size n, although they give estimates better than the sample covariance matrix. In addition, theoretical aspects for a likelihood approach remain to be under studied. In these situations, the proposed method compares favorably against its competitors in simulations, and novel theoretical results provide an insight into a selection process.
This article is organized as follows. Section 2 develops the proposed method for L0-regularized and constrained likelihoods. Section 3 presents main theoretical results for selection consistency and parameter estimation involving selection, followed by a necessary condition for selection consistency. Section 4 applies the general method and theory to feature selection in GLMs. Section 5 is devoted to estimation of a precision matrix in Gaussian graphical models. Section 6 presents an application to predict the metastasis status of breast cancer patients with their gene expression profiles. Section 7 contains technical proofs.
2 Method and computation
2.1 Method
In a high-dimensional situation, it is computationally infeasible to minimize a discontinuous cost function involving the L0-function in (1) and (2). As a surrogate, we seek a good approximation of the L0-function by the TLP, defined as , with τ > 0 a tuning parameter controlling the degree of approximation; see Figure 1 for a display. This τ decides which individual coefficients to be shrunk towards zero. The advantages of J(|z|) are fourfold, although J(z) has been considered in other contexts [9]:
Figure 1.

Truncated L1 function Jt (|βj|) with τ = 1 in (a), and its DC decomposition into a dfference of two convex functions JL and JT,2 in (b).
(Surrogate) It performs the model selection task of the L0-function, while providing a computationally efficient means. Note that the approximation error of the TLP function to the L0-function becomes zero when τ is tuned such that , seeking the sparsest solution by minimizing the number of non-zero coefficients.
(Adaptive model selection through adaptive shrinkage) It performs adaptive model selection [23] through a computationally efficient means when λ is tuned. Moreover, it corrects the Lasso bias through adaptive shrinkage combining shrinkage with thresholding.
(Piecewise linearity) It is piecewise linear, gaining computational advantages.
(Low resolutions) It discriminates small from large coefficients through thresholding. Consequently, it is capable of handling many low-resolution coefficients, through tuning τ.
To treat nonconvex minimization, we replace the L0-function by its surrogate J(·) to construct an approximation of (2) and that of (1):
| (4) |
| (5) |
where (5) is a dual problem of (4). To solve (5) and (4), we develop difference convex methods for the primal and dual problems, for efficient computation.
2.2 Unconstrained dual and constrained primal problems
Our DC method for the dual problem (5) begins with a DC decomposition of S(θ): S(θ) = S1(θ) − S2(β), where , and . Without loss of generality, assume that −L is convex in θ; otherwise, a DC decomposition of −L is required and can be treated similarly. Given this DC decomposition, a sequence of upper approximations of S(θ) is constructed iteratively, say, at iteration m, with ∇S2 a subgradient of S2 in |β|: S(m)(θ) = S1(θ) − (S2(β̂(m − 1))+(|β| − |β̂(m-1)|)T∇S2 (|β̂(m-1)|)), by successively replacing S2(β) by its minorization, where |·| for a vector takes the absolute value in each component. After ignoring that is independent of θ, the problem reduces to
| (6) |
Minimizing (6) in θ yields its minimizer θ̂(m). The process continues in m until termination occurs. Our unconstrained DC method is summarized as follows.
Algorithm 1
-
Step 1.
(Initialization) Supply a good initial estimate θ̂(0), such as the minimizer of S1(θ).
-
Step 2.
(Iteration) At iteration m, compute θ̂(m) by solving (6).
-
Step 3.
(Termination) Terminate when S(θ̂(m−1)) − S(θ̂(m)) ≤ ε, and no components of β̂(m) is at ±τ. Otherwise, add ε to that components whose absolute value is τ, and go to Step 2, where ε is the square root of the machine precision. Then the estimate θ̂ = θ̂(m*), where m* is the smallest index at the termination criterion.
In Algorithm 1, (6) reduces to a general weighted Lasso problem: , with . Therefore any efficient software is applicable.
For (4), we decompose the nonconvex constraint into a difference of two convex functions to construct a sequence of approximating convex constraints. This amounts to solving the mth subproblem in a parallel fashion as in (6):
| (7) |
This leads to a constrained DC algorithm—Algorithm 2 for solving (4) by replacing (5) in Algorithm 1 by (4).
Algorithms 1 and 2 are a generalization of those in [24] for a general likelihood, where all the computational properties there extend to the present situation, including equivalence of the DC solutions of the two algorithms and their convergence. Next we shall work with (5) due to its computational advantage. For instance, a coordinate decent method that works well with (5) breaks down for (4), c.f., [24].
3 Theory
This section presents a general theory for accuracy of reconstruction of the oracle estimator θ̂ml = (β̂ml, η̂ml) with given A0, which is the MLE provided that the knowledge about A0 were known a priori. As direct consequences, feature selection consistency is studied as as well as optimal parameter estimation defined by the oracle estimator. In addition, a necessary condition for feature selection will be established as well. A parallel theory for regularized likelihood is similar and thus is omitted.
3.1 Constrained L0-likelihood
In (2), assume that a global minimizer exists, denoted by θ̂L0 = (β̂L0, η̂L0) with . Write β as (βA, 0|Ac|), with βA being (β1, …, β|A|)T for any subset A ⊂ {1, ···, p} of nonzero coefficients.
Before proceeding, we define a complexity measure for the size of a space
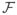 . The bracketing Hellinger metric entropy of
, denoted by the function H(·,
), is defined by logarithm of the cardinality of the u-bracketing (of
) of the smallest size. That is, for a bracket covering
satisfying
and for any f ∈
, there exists a j such that
, a.e. P, then H(u,
) is log(min{m : S(u, m)}), where ||f||2 = ∫ f2(z)dμ. For more discussions about metric entropy of this type, see [14].
. The bracketing Hellinger metric entropy of
, denoted by the function H(·,
), is defined by logarithm of the cardinality of the u-bracketing (of
) of the smallest size. That is, for a bracket covering
satisfying
and for any f ∈
, there exists a j such that
, a.e. P, then H(u,
) is log(min{m : S(u, m)}), where ||f||2 = ∫ f2(z)dμ. For more discussions about metric entropy of this type, see [14].
Assumption A (Size of parameter space)
For some constant c0 > 0 and any
, H(t,
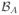 ) ≤ c0(log p)2|A| log(2ε/t), with |A| ≤ p0, where
=
) ≤ c0(log p)2|A| log(2ε/t), with |A| ≤ p0, where
=
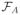 ∩ {h(θ, θ0) ≤ 2ε} is a local parameter space, and
= {g1/2(θ, y) : θ = (β, η), β = (βA, 0)} be a collection of square-root densities.
∩ {h(θ, θ0) ≤ 2ε} is a local parameter space, and
= {g1/2(θ, y) : θ = (β, η), β = (βA, 0)} be a collection of square-root densities.
Theorem 1 (Error bound and oracle properties)
Under Assumption A, if K = p0, then, there exists a constant c2 > 0, say , such that for (n, p0, p),
| (8) |
Moreover, under (3) with , θ̂L0 reconstructs the oracle estimator θ̂ml with probability tending to one as n, p → ∞. Three oracle properties hold as n, p → ∞:
(Selection consistency) Estimator ÂL0 is selection consistent, that is, P(ÂL0 ≠ A0) → 0.
- (Optimal parameter estimation) For θ0, and , provided that Eh2(θ̂ml, θ0) does not tend to zero too fast in that , where εn,p0p is any solution for ε:
(9) (Uniformity over a L0-band) The reconstruction holds uniformly over B0(u, l), namely, supθ0∈B0(u,l) P(θ̂L0 ≠ θ̂ml) → 0, where B0(u,l) is a L0-band, defined as with 0 < u ≤ min(n, p), , and u < min(n, p). This implies feature selection consistency supθ0∈B0(u,l) P(ÂL0 ≠ A0) → 0, and optimal parameter estimation , with , provided that Eh2(θ̂ml, θ0) does not tend to zero too fast in that .
The L0-method consistently reconstructs the oracle estimator when the degree of separation exceeds the minimal level, precisely under (3). As a result, selection consistency is established for the L0-method. This, combined with that in Theorem 3, suggests that the L0-method is optimal in feature selection against any method, matching up with the lower bound requirement under the degree of separation with respect to (p, p0, n) except a constant factor d0 > 0 in Theorem 3. Moreover, the optimality extends further to parameter estimation, where sharper parameter estimation is obtained from accurate L0 selection, achieving the optimal Hellinger risk of the oracle estimator asymptotically. By comparison, such a result is not expected for L1-regularization. As suggested in [17], selection consistency of Lasso does not give sharper parameter estimation, where the rate of convergence of a L1-method in the L2 risk remains to be in linear regression. This is because a L1-method is nonadaptive and overpenalizes large coefficients as a result of shrinking small coefficients towards zero. Similarly, in feature selection in logistic regression, the L0-method is expected to give rise to better estimation precision than a L1-method, although a parallel result for a L1-method has not been available. Finally, the uniform result in (C) is over a L0-band B0(u, l), which is not expected over a L0-ball B0(u, 0) in view of the result of Theorem 3.
3.2 Constrained truncated L1-likelihood
For constrained truncated L1-likelihood, one additional regularity condition–Assumption B is assumed, which is generally met with a smooth likelihood; see Section 4 for an example. It requires the Hellinger-distance to be smooth so that the TLP approximation to the L0-function becomes adequate through tuning τ.
Assumption B
For some constants d1−d3 > 0,
| (10) |
where θτ+ = (β1I(|β1| ≥ τ), ···, βpI(|βp| ≥ τ), η1, ···, ηq).
Theorem 2 (Error bound and oracle properties)
Under Assumption A with
replaced by {g1/2(θ, y) : θ = (β, η) : β = (βA, βAc), ||βAc||ℓ∞ ≤ τ}, say 0 ≤ τ ≤ c′ε for some constant c′, and Assumption B, if K = p0 and τ ≤ max(c′, (d1Cmin(θ0)/2pd3)1/d2>), then there exists a constant c2 > 0, such that for any (n, p0, p),
| (11) |
Moreover, under (3) with sufficiently large constant d0 > 0, θ̂T has the three oracle properties (A)–(C) of θ̂L0, provided that . For (C), is required as well as .
Remark
Constants in Theorem 1 can be made precise. For instance, and .
Theorem 2 says that the oracle properties of the L0-function are attained by its computational surrogate when τ is sufficiently small.
3.3 Necessary condition for selection consistency
This section establishes the necessary condition (3) by estimating the minimal value d0 in (3), required for feature selection consistency.
Let K(θ1, θ2) = E log g(θ1, Y)/g(θ2, Y) be the Kullback-Leibler loss for θ1 versus θ2, where E is taken with regard to g(θ1, Y). Let .
Assumption C
For a constant r > 0, . Here {θj = (βj, η0), j = 1, ···, p} is a set of parameters, where ; j = 1, ···, p0}, and ; j = p0 + 1, ···, p, and . Assume that .
Theorem 3 (Necessary condition for feature selection consistency)
Under Assumption C, for any constant c* ∈ (0, 1), any (n, p0, p) with p0 ≤ p/2, and any η0, we have
| (12) |
with . Moreover,
| (13) |
where u ≤ min(p/2, n), , and .
Theorem 3 says that feature selection inconsistency occurs when in (3). There the minimal value yields a requirement for feature selection consistency in (3).
4 Generalized linear models
For GLMs, observations Yi = (Zi, Xi) are paired, response Zi is assumed to follow an exponential family with density function g(zi; θi, φ) = exp{[ziθi − b(θi)]/a(φ) + c(zi, φ)}, where θi is the natural parameter that is related to the mean μi = E(zi) = b′(θi), and φ is a dispersion parameter. With a link function g, a regression model becomes ηi = g(μi) = βTxi. The penalized likelihood for estimating regression coefficient vectors β is , where is the log-likelihood, and is the TLP penalty.
For parameter estimation and feature selection, we apply Algorithm 1, where (6) becomes a series of weighted lasso for GLMs, for which some existing routines are applicable, for simplicity. In implementation, we use the function wtlassoglm() in R package SIS.
Next we examine effectiveness of the proposed method through simulated examples in feature selection. In linear regression and logistic regression, the Lasso, SCAD [6], SCAD-OS, TLP and TLP-OS are compared in terms of predictive accuracy and identification of the true model, where SCAD-OS and TLP-OS are SCAD and TLP with only one iteration step in the DC iterative process, and SCAD-OS is proposed in [33]. The latter four methods use the Lasso as an initial estimate.
4.1 Simulations
For simulations predictors Xi’s are iid from N (0, V), where V is a p × p matrix whose ijth element is 0.5|i−j|. In linear regression, Zi = βTXi + εi, εi ~ N (0, σ2); i = 1, ···, n, and random error εi is independent of Xi; in logistic regression, a binary response is generated from logit Pr(Zi = 1) = βTXi. In both cases, β = (β1, ···, βp)T with β1 = 1, β2 = 0.5 and β5 = 0.75; βj = 0 for j ≠ 1, 2, 5. This set-up was similar to that considered in [33]; here we examine various situations with respect to p, n. Each simulation is based on 1000 independent replications.
For any given tuning parameter λ, all other methods use the Lasso estimate as an initial estimate. For each method, we choose its tuning parameter values by maximizing the log-likelihood based on a common tuning dataset with an equal sample size of the training data and independent of the training data. This is achieved through a grid search over 21 λ values returned by glmnet() for all the methods, and additionally over a grid of 10 τ values that are the 9th-, 19th-, 29th-, ···, 99th-percentiles of the final Lasso estimate for the TLP.
The model error (ME) is used to evaluate predictive performance of β̂, defined as ME(β̂) = (β̂ − β0)TV (β̂ − β0), which is the prediction error minus σ2 in linear regression, corresponding to the test error over an independent test sample of size T = ∞. In our context, the median ME’s are reported over 1000 simulation replications, due to possible skewness of the distribution of ME. In addition, the mean parameter estimates of the nonzero elements of β will be reported, together with the mean true positive (TP) and mean false positive (FP) numbers: and .
For linear regression, simulation results are reported for the cases of p = 12, 500, 1000, n = 50, 100, and σ2 = 1 in Table 1. As suggested by Table 1, the TLP performs best: it gives the smallest estimation and prediction error as measured by the ME, the smallest mean false positive number (FP) while maintaining a comparable mean number of true positives (TP) around 3. Most critically, as p increases, the TLP’s performance remains much more stable than its competitors. On a relative basis, the TLP outperforms its competitors more in more difficult situations.
Table 1.
Median ME’s, means (SD in parentheses) nonzero coefficients (β1, β2, β5), and true positive (TP) and false positive (FP) numbers of nonzero estimates, for linear regression, based on 1000 simulation replications.
| n | p | Method | ME | β1 = 1 | β2 = .5 | β5 = .75 | #TP | #FP |
|---|---|---|---|---|---|---|---|---|
| 50 | 12 | Lasso | .129 | .91(.17) | .41(.18) | .60(.16) | 2.98(0.14) | 3.82(2.39) |
| SCAD-OS | .109 | 1.02(.19) | .40(.22) | .68(.18) | 2.92(0.27) | 2.50(1.97) | ||
| SCAD | .118 | 1.04(.20) | .39(.24) | .71(.18) | 2.88(0.32) | 2.30(1.90) | ||
| TLP-OS | .088 | 1.01(.18) | .41(.20) | .68(.17) | 2.94(0.25) | 1.65(2.04) | ||
| TLP | .090 | 1.01(.19) | .41(.21) | .69(.17) | 2.92(0.27) | 1.57(1.98) | ||
|
| ||||||||
| 50 | 500 | Lasso | .431 | .76(.19) | .29(.18) | .41(.17) | 2.90(0.30) | 14.7(10.48) |
| SCAD-OS | .327 | 1.01(.24) | .25(.25) | .52(.24) | 2.70(0.47) | 14.81(8.69) | ||
| SCAD | .301 | 1.09(.26) | .21(.27) | .59(.26) | 2.53(0.53) | 12.25(7.63) | ||
| TLP-OS | .150 | 1.02(.21) | .39(.26) | .67(.22) | 2.75(0.45) | 4.27(6.86) | ||
| TLP | .143 | 1.02(.21) | .39(.26) | .68(.22) | 2.75(0.45) | 4.10(6.89) | ||
|
| ||||||||
| 50 | 1000 | Lasso | .501 | .72(.19) | .28(.18) | .37(.18) | 2.88(0.33) | 17.20(11.49) |
| SCAD-OS | .370 | .99(.25) | .26(.25) | .51(.26) | 2.67(0.49) | 18.76(9.60) | ||
| SCAD | .327 | 1.08(.26) | .20(.28) | .57(.29) | 2.49(0.54) | 15.19(8.41) | ||
| TLP-OS | .182 | 1.01(.20) | .40(.27) | .66(.25) | 2.72(0.47) | 5.43(8.69) | ||
| TLP | .175 | 1.02(.20) | .40(.27) | .66(.25) | 2.72(0.47) | 5.06(8.30) | ||
|
| ||||||||
| 100 | 12 | Lasso | .063 | .94(.12) | .44(.13) | .65(.11) | 3.00(0.00) | 3.94(2.42) |
| SCAD-OS | .042 | 1.01(.12) | .45(.14) | .72(.11) | 2.99(0.08) | 2.17(2.04) | ||
| SCAD | .042 | 1.02(.13) | .45(.15) | .74(.11) | 2.99(0.09) | 2.06(2.01) | ||
| TLP-OS | .037 | 1.01(.12) | .45(.13) | .71(.11) | 3.00(0.06) | 1.51(1.99) | ||
| TLP | .036 | 1.01(.12) | .45(.13) | .72(.11) | 3.00(0.07) | 1.46(1.95) | ||
|
| ||||||||
| 100 | 500 | Lasso | .186 | .84(.12) | .36(.12) | .52(.11) | 3.00(0.04) | 15.61(11.04) |
| SCAD-OS | .118 | 1.06(.14) | .32(.18) | .66(.14) | 2.94(0.24) | 14.92(10.45) | ||
| SCAD | .121 | 1.10(.15) | .30(.21) | .71(.12) | 2.89(0.31) | 14.20(10.00) | ||
| TLP-OS | .036 | 1.01(.12) | .47(.14) | .72(.11) | 2.99(0.12) | 3.64(6.57) | ||
| TLP | .035 | 1.01(.12) | .46(.14) | .72(.11) | 2.99(0.12) | 3.49(6.69) | ||
|
| ||||||||
| 100 | 1000 | Lasso | .211 | .83(.13) | .34(.13) | .51(.12) | 3.00(0.06) | 18.10(12.50) |
| SCAD-OS | .142 | 1.06(.15) | .30(.19) | .66(.15) | 2.91(0.29) | 19.70(13.35) | ||
| SCAD | .147 | 1.10(.15) | .27(.22) | .72(.14) | 2.83(0.38) | 18.80(12.74) | ||
| TLP-OS | .037 | 1.01(.13) | .46(.15) | .74(.12) | 2.97(0.18) | 3.93(7.04) | ||
| TLP | .037 | 1.01(.13) | .46(.15) | .74(.12) | 2.97(0.18) | 3.80(6.94) | ||
For logistic regression, simulation results are summarized for the cases of p = 12, 200, 500 and n = 100, 200 in Table 2. As expected, the TLP continues to outperform other methods with the smallest median ME’s. It gives less biased estimates than the Lasso estimates. The TLP’s superior performance remains strong over other methods, as p increases.
Table 2.
Median ME’s, means (SD in parentheses) nonzero coefficients (β1, β2, β5), and true positive (TP) and false positive (FP) numbers of nonzero estimates, for logistic regression, based on 1000 simulation replications.
| n | p | Method | ME | β1 = 1 | β2 = .5 | β5 = .75 | #TP | #FP |
|---|---|---|---|---|---|---|---|---|
| 100 | 12 | Lasso | .388 | .80(.27) | .35(.25) | .49(.27) | 2.8(0.4) | 3.8(2.2) |
| SCAD-OS | .416 | 1.03(.37) | .39(.36) | .61(.40) | 2.5(0.7) | 1.6(1.9) | ||
| SCAD | .472 | 1.10(.41) | .38(.39) | .67(.44) | 2.4(0.7) | 1.1(1.9) | ||
| TLP-OS | .350 | .98(.35) | .36(.32) | .59(.35) | 2.7(0.5) | 1.8(2.0) | ||
| TLP | .355 | .98(.35) | .35(.32) | .58(.35) | 2.6(0.6) | 1.8(2.0) | ||
|
| ||||||||
| 100 | 200 | Lasso | .947 | .57(.25) | .20(.19) | .26(.21) | 2.6(0.6) | 11.7(7.1) |
| SCAD-OS | .733 | .96(.45) | .23(.36) | .40(.41) | 2.0(0.7) | 3.1(2.9) | ||
| SCAD | .827 | 1.08(.53) | .23(.42) | .46(.53) | 1.7(0.6) | 1.1(1.4) | ||
| TLP-OS | .649 | .99(.42) | .31(.36) | .49(.46) | 2.2(0.7) | 3.8(5.2) | ||
| TLP | .664 | .99(.43) | .30(.37) | .48(.47) | 2.2(0.7) | 3.6(5.2) | ||
|
| ||||||||
| 100 | 500 | Lasso | 1.166 | .48(.24) | .18(.19) | .19(.19) | 2.4(0.7) | 13.6(9.1) |
| SCAD-OS | .867 | .84(.48) | .23(.35) | .29(.37) | 1.8(0.7) | 3.9(3.6) | ||
| SCAD | .847 | 1.00(.57) | .25(.46) | .34(.50) | 1.6(0.6) | 1.3(1.5) | ||
| TLP-OS | .791 | .93(.45) | .30(.39) | .38(.45) | 2.0(0.7) | 4.4(6.5) | ||
| TLP | .811 | .94(.46) | .29(.40) | .38(.45) | 2.0(0.7) | 4.1(6.4) | ||
|
| ||||||||
| 200 | 12 | Lasso | .203 | .87(.20) | .39(.20) | .57(.20) | 3.0(0.2) | 4.3(2.4) |
| SCAD-OS | .173 | 1.06(.25) | .44(.28) | .72(.26) | 2.8(0.4) | 1.6(2.2) | ||
| SCAD | .202 | 1.08(.25) | .45(.30) | .77(.25) | 2.8(0.5) | 1.2(2.1) | ||
| TLP-OS | .155 | 1.00(.24) | .40(.24) | .67(.24) | 2.9(0.3) | 1.8(2.1) | ||
| TLP | .157 | 1.00(.24) | .40(.24) | .67(.24) | 2.9(0.3) | 1.8(2.1) | ||
|
| ||||||||
| 200 | 200 | Lasso | .540 | .68(.18) | .27(.17) | .38(.17) | 2.9(0.3) | 14.1(8.9) |
| SCAD-OS | .271 | 1.07(.26) | .34(.32) | .64(.32) | 2.6(0.6) | 3.2(3.3) | ||
| SCAD | .262 | 1.12(.29) | .30(.37) | .68(.36) | 2.3(0.6) | 0.8(1.4) | ||
| TLP-OS | .204 | 1.04(.25) | .40(.29) | .68(.27) | 2.7(0.5) | 3.3(5.5) | ||
| TLP | .204 | 1.04(.26) | .39(.30) | .68(.28) | 2.7(0.5) | 3.2(5.8) | ||
|
| ||||||||
| 200 | 500 | Lasso | .651 | .64(.17) | .24(.16) | .33(.15) | 2.9(0.3) | 18.0(10.5) |
| SCAD-OS | .289 | 1.07(.27) | .31(.32) | .57(.31) | 2.5(0.5) | 4.1(4.0) | ||
| SCAD | .262 | 1.13(.28) | .29(.37) | .66(.36) | 2.3(0.6) | 1.4(1.7) | ||
| TLP-OS | .231 | 1.04(.27) | .39(.30) | .65(.29) | 2.7(0.5) | 4.1(6.8) | ||
| TLP | .231 | 1.04(.27) | .38(.30) | .65(.30) | 2.7(0.5) | 3.8(6.8) | ||
4.2 Theory for feature selection
This section establishes some theoretical results to gain an insight into performance of the proposed method in feature selection. Let Y = (Z, X), and and g(β, Z) = pZ(1 − p)1−Z in linear and logistic regression. Assume that belongs to a compact parameter space for any model size |A| ≤ p0. In this case, selection does not involve nuisance parameters, where θ = β. Under (14), we establish feature selection consistency as well as optimal parameter estimation for the TLP:
| (14) |
where d0 > 0 is a constant independent of (n, p, p0), and ΣB is a sub-matrix given a subset B of predictors, of covariance matrix Σ with the jkth element Cov(Xj, Xk), independent of β0. A simpler but stronger condition can be used for verification of (14):
| (15) |
where is the resolution level of the true regression coefficients, , and cmin denotes the smallest eigenvalue. Note that (14) is necessary for any method to be selection consistent except constant d0 if .
Proposition 1
Under (14), the constrained MLE β̂T of (4) consistently reconstructs the oracle estimate β̂ml. As n, p → ∞, feature selection consistency is established for the TLP as well as optimal parameter estimation under the Hellinger distance h(·, ·). Moreover, the results hold uniformly over a L0-band , with 0 < u ≤ min(n, p), , that is, as n, p → ∞,
with for some d*.
Various conditions have been proposed for studying feature selection consistency in linear regression. In particular, a condition on γmin is usually imposed, in addition to assumptions on the design matrix X such as the sparse Riesz condition in [32]. To compare (14) with existing assumptions for consistent selection, note that these assumptions imply a fixed design version of (14) by necessity of consistent feature selection. For instance, as showed in [32], the sparse Riesz condition with dimension restriction and , required for the minimum concavity penalty to be consistent, imply (15) with p replaced by p − u thus (14) when p/u bounded away from 1, where u ≥ p0. Moreover, the number of over-selected variables is proved to be bounded but may not tend to zero for thresholding Lasso in Theorem 1.1 of [35], under a restrictive eigenvalue condition [1] and a requirement on γmin. Finally, in linear regression, only finite variance σ2 is required for the proposed method, which is in contrast to a commonly used assumption on sub-Gaussian distribution of εi.
In conclusion, the computational surrogate–the TLP method indeed shares desirable oracle properties of the L0-method, which is optimal against any selection method, for feature selection and parameter estimation.
5 Estimation of a precision matrix
Given n random samples from a p-dimensional normal distribution Y1, ···, Yn ~ N (μ, Σ), we estimate the inverse covariance matrix Ω = Σ−1 that is p × p positive definite, denoted by Ω ≻ 0. For estimation of (μ, Ω), the log-likelihood is proportional to
| (16) |
The profile log-likelihood for Ω, after μ is maximized out, is proportional to , where and are the corresponding sample mean and covariance matrix, det and tr denote the determinant and trace. In (16), the number of unknown parameters p2 in Ω can greatly exceed the sample size n in the presence of 2p nuisance parameters (μ, {Ωjj : j = 1, ···, p}), where Ωjk denotes the jkth elements of Ω. To avoid non-identifiability in estimation, we regularize off-diagonal elements of Ω in (16) through a nonnegative penalty function J(·) for the parameters of interest:
| (17) |
In estimation, the TLP function is employed for both parameter estimation and covariance selection in (17). Towards this end, we apply Algorithm 1 to solve (6) sequentially, which reduces to a series of weighted graphical lasso problems, and is solved by taking advantage of existing software. In implementation, we use R package glasso [8] for (6).
5.1 Simulations
Simulations are performed, where a tridiagonal precision matrix is used as in [7]. In particular, Σ is AR(1)-structured with its ij-element being σij = exp(−a|si − sj|), and s1 < s2 < ···< sp are randomly chosen: si − si−1 ~ Unif(0.5, 1), for some a > 0; i = 2, ···, p. The following situations are considered: (n, p) = (120, 30) or (n, p) = (120, 200), and a = 0.9 or a = 0.6, based on 100 replications.
Five competing methods are compared, including Lasso, adaptive Lasso (ALasso), SCAD-OS and SCAD, and TLP-OS and TLP. ALasso uses weight , where β̂(0) is an initial estimate and γ = 1/2 as in [7].
To measure performance of estimator Ω̂, we use the entropy loss and quadratic loss: loss1(Ω, Ω̂) = tr(Ω−1Ω̂) − log |Ω−1Ω̂| − p, and loss2(Ω, Ω̂) = tr(Ω−1Ω̂ − I)2, as well as the true positive (TP) and false positive (FP) numbers: #TP = Σi,j I(Ωij ≠ 0, Ω̂ij ≠ 0); #FP = Σi,j I(ωij = 0, Ω̂ij ≠ 0).
For small p = 30, TLP and TLP-OS are always among the winners. It is also confirmed that the one-step approximation to SCAD or TLP gives similar performance to that of the fully iterated SCAD or TLP, respectively. For large p, to save computing time, as advocated in [7], we only run SCAD-OS and TLP-OS. In such a situation, an improvement of TLP-OS over other methods is more substantial for large p = 200 than for small = 30. Overall, the proposed method delivers higher performance in low-dimensional and high-dimensional situations, respectively.
5.2 Theory for precision matrix
To perform theoretical analysis, we specify a parameter space Θ in which Ω ❻ 0 with 0 < max1≤j≤p |Ωjj| ≤ M2, cmin(Ω) ≥ M1 > 0, for some constants M1, M2 > 0, independent of (n, p, p0). Let A = {(j, k) : j ≠ k, Ωjk ≠ 0} be the set of nonzero off diagonal elements of Ω, where |A| = p0 is an even number by symmetry of Ω, and Ω depends on A. Results in Theorem 1 imply that the constrained MLE yields covariance selection consistency under one assumption:
| (18) |
which is necessary for covariance selection consistency indeed for any method, up to constant d0 when cmin(H) > 0, where d0 > 0 is a constant independent of (n, p, p0), and is the p2 ×p2 Hessian matrix of −log det(Ω), whose (Ωjk, Ωj′k′) element is tr(Σ0ΔjkΣ0Δj′k′), c.f., [3], ΔjK is a p × p with the jk-element being 1 and 0 otherwise. Sufficiently, (18) can be verified using
| (19) |
with .
Proposition 2
Under (18), the constrained MLE Ω̂T of (4) consistently reconstructs the oracle estimator Ω̂ml. As n, p → ∞, covariance selection consistency is established for the TLP as well as optimal parameter estimation , where is the squared Hellinger distance for Ω versus Ω0. Moreover, the above results hold uniformly over a L0-band , with 0 < u ≤ min(n, p) and , that is, as n, p → ∞,
with for some d* > 0.
In short, the TLP method is optimal against any method in covariance selection, permitting p up to exponentially large in the sample size, or . Moreover, as a result of accurate selection of this method, parameter estimation can be sharply enhanced at an order of , as measured by the Hellinger distance, after zero off-diagonal elements are removed. Note that the log p factor is due to estimation of 2p nuisance parameters as compared to the rate of in logistic regression. In view of the result in Lemma 1, this result seems to be consistent with the minimax rate under the L∞ matrix norm [20].
6 Metastasis status of breast cancer patients
We apply the penalized logistic regression methods to analyze a microarray gene expression dataset of [29], where our objectives are (1) to develop a model predicting the metastasis status, and (2) to identify cancer genes, for breast cancer patients. Among the 286 patients, metastasis was detected in 106 patients during follow-ups within 5 years after surgery. Their expression profiles were obtained from primary breast tumors with Affymetrix HG-133a GeneChips.
In [29], a 76-gene signature was developed based on a training set of 115 patients, which yielded a misclassification error rate of 64/171=37.4% when applied to the remaining samples. [30] compared the performance of a variety of classifiers using a subset of 245 genes drawn from 33 cancer-related pathways: based on a 10-fold cross-validation (CV). Their non-parametric pathway-based regression method yielded the smallest error rate at 29%, while random forest, bagging and Support Vector Machine (SVM) had error rates of 33%, 35% and 42%.
In our analysis, we first performed a preliminary screening of the genes using a marginal t-test to select the top p genes with most significant p-values, based on the training data for each fold of a 10-fold-CV. Then the training data were split into two parts to fit penalized logistic models and to select tuning parameters, respectively. The results were summarized in Table 3, including the total misclassification errors and average model sizes (i.e. non-zero estimates) based on 10-fold CV. A final model is obtained by fitting the best model selected from a 10-fold CV to the entire data set.
With regard to prediction, no large difference is seen among various methods, with the error rates ranging from 102/286=35.7% (of TLP and TLP-OS with p = 200) to 118/286=41.3% (of ALasso with p = 200). The TLP performed similar to the TLP-OS, both were among the winners. In addition, the Lasso gave the least sparse models while the SCAD gave the most sparse models.
With regard to identifying cancer genes, the Lasso, TLP-OS and TLP yield the same model, identifying the largest number of cancer genes, whereas the SCAD and SCAD-OS give the most sparse models with only at most 2 cancer genes, and ALasso only yields 10 cancer genes. Here cancer genes are defined according to the Cancer Gene Database [10].
In summary, the TLP and TLP-OS identify a good proportion of cancer genes and lead to a model giving a reasonably good predictive accuracy of the metastasis status. In this sense, they perform well with regard to the foregoing two objectives.
Table 3.
Averaged (with SD in parentheses) entropy loss (loss1), quadratic loss (loss2), true positive (TP) and false positive (FP) numbers of nonzero parameters based on 100 simulations, for estimating a precision matrix in Gaussian graphical models in Section 4.
| Set-up | Method | loss1 | loss2 | #TP | #FP |
|---|---|---|---|---|---|
| p = 30, a = 0.9 | Lasso | 1.55(.15) | 2.96(.42) | 88.0(.0) | 314.0(41.6) |
| ALasso | 1.02(.15) | 1.99(.37) | 88.0(.0) | 95.5(30.2) | |
| SCAD-OS | 0.93(.16) | 1.99(.44) | 88.0(.0) | 126.0(39.4) | |
| SCAD | 0.74(.16) | 1.60(.42) | 87.9(.5) | 85.5(18.0) | |
| TLP-OS | 0.66(.18) | 1.47(.47) | 87.9(.5) | 28.1(21.4) | |
| TLP | 0.63(.18) | 1.39(.48) | 87.8(.7) | 22.4(17.0) | |
|
| |||||
| p = 30, a = 0.6 | Lasso | 1.69(.16) | 3.28(.46) | 88.0(.0) | 342.5(35.5) |
| ALasso | 1.01(.15) | 1.97(.37) | 88.0(.0) | 103.9(17.4) | |
| SCAD-OS | 0.75(.14) | 1.61(.36) | 88.0(.0) | 83.8(29.0) | |
| SCAD | 0.56(.12) | 1.20(.30) | 88.0(.2) | 26.1(15.0) | |
| TLP-OS | 0.57(.14) | 1.26(.37) | 88.0(.0) | 14.7(13.0) | |
| TLP | 0.54(.14) | 1.18(.36) | 88.0(.0) | 7.3(10.6) | |
|
| |||||
| p = 200, a = 0.9 | Lasso | 20.16(.50) | 34.50(1.85) | 597.9(.4) | 4847.8(614.7) |
| ALasso | 10.62(.53) | 19.64(1.20) | 597.3(1.2) | 936.8(37.9) | |
| SCAD-OS | 11.46(.60) | 24.03(1.67) | 597.7(.8) | 2453.6(251.2) | |
| TLP-OS | 6.16(.77) | 13.99(2.10) | 593.6(3.0) | 284.8(158.0) | |
|
| |||||
| p = 200, a = 0.6 | Lasso | 24.86(.54) | 46.18(3.72) | 598.0(.0) | 6161.7(863.0) |
| ALasso | 11.06(.48) | 21.53(1.18) | 598.0(.0) | 1526.1(118.6) | |
| SCAD-OS | 9.43(.49) | 20.871.77) | 598.0(.0) | 2754.8(523.6) | |
| TLP-OS | 4.45(.48) | 9.89(1.29) | 597.7(.7) | 185.5(76.3) | |
Table 4.
Analysis results with various numbers (p) of predictors for the breast cancer data. The numbers of total classification errors (#Err), including false positives (#FP), and mean numbers of nonzero estimates (#Nonzero) from 10-fold CV, and the total numbers of nonzero estimates and cancer genes in the final models are shown.
| p | Method | 10-fold CV
|
Final model
|
|||
|---|---|---|---|---|---|---|
| #Err | #FP | #Nonzero | #Nonzero | #Cancer genes | ||
| 200 | Lasso | 107 | 17 | 40.1 | 62 | 13 |
| ALasso | 118 | 27 | 18.8 | 39 | 9 | |
| SCAD-OS | 107 | 4 | 9.5 | 15 | 2 | |
| SCAD | 107 | 1 | 4.7 | 2 | 0 | |
| TLP-OS | 102 | 8 | 33.5 | 62 | 13 | |
| TLP | 102 | 8 | 33.2 | 62 | 13 | |
|
| ||||||
| 400 | Lasso | 107 | 19 | 46.9 | 95 | 26 |
| ALasso | 112 | 19 | 14.4 | 32 | 10 | |
| SCAD-OS | 108 | 8 | 11.1 | 15 | 2 | |
| SCAD | 106 | 0 | 4.1 | 2 | 0 | |
| TLP-OS | 106 | 15 | 40.1 | 95 | 26 | |
| TLP | 106 | 14 | 38.2 | 95 | 26 | |
7 Appendix
Proof of Theorem 1
The proof uses a large deviation probability inequality of [27] to treat one-sided log-likelihood ratios with constraints. This enables us to obtain sharp results without a moment condition on both tails of the log-likelihood ratios.
When K = p0, |ÂL0| ≤ p0. If ÂL0 = A0, then β̂L0 = β̂ml. Let a class of candidate subsets be {A : A ≠ A0, |A| ≤ p0} for feature selection. Note that A ⊂ {1, ···, p} can be partitioned into (A \ A0) ∪ (A0 ∩ A). Let Bkj = {θ = (βA, 0, η) : A ≠ A0, |A0 ∩ A| = k, |A \ A0| = j, (p0 − k)Cmin(θ0) ≤ h2(θ, θ0)} ⊂
; k = 0, ···, p0 − 1, j = 1, ···, p0 − k. Note that Bkj consists of
different elements A’s of sizes |A0 ∩ A| = k and |A \ A0| = j. By definition,
. Hence
where P* is the outer measure and L(θ̂ml) ≥ L(θ 0) by definition.
For I, we apply Theorem 1 of [27] to bound each term. Towards this end, we verify the entropy condition (3.1) there for the local entropy over
. Note that under Assumption A
satisfies there with respect to ε > 0, that is,
| (20) |
for some constant c3 > 0 and c4, say c3 = 10 and . Moreover, by Theorem 2.6 of [25], for any integers a < b. By (3), implies (20), provided that . Using the facts about binomial coefficients: and , we obtain, by
Theorem 1 of [27], that for a constant c2 > 0, say , I is upper bounded by
where R(x) = x/(1 − x) is the exponentiated logistic function. Note, moreover, that I ≤ 1 and . Then
Finally, (A) follows from P(ÂL0 ≠ A0) ≤ P (θ̂L0 ≠ θ̂ml), (8) and (3) with , as n, p → ∞. For (B), let G = {θ̂L0 ≠ θ̂ml} and P(G) ≤ 8 exp(−c2nCmin/4) by (8) and (3). For the risk property, Eh2(θ̂L0, θ0) ≤ Eh2(θ̂ml, θ̂0) + Eh2(θ̂L0, θ0)I(G) is upper bounded by
using the fact that h(θ̂L0, θ0) ≤ 1. Then (B) is established. Similarly (C) follows. This completes the proof.
Proof of Theorem 2
The proof is basically the same as that in Theorem 1 with a modification that A is replaced by Aτ+. Now Bkj = {θτ+ : Aτ+ ≠ A0, |A0 ∩ Aτ+| = k, |Aτ+ \A0| = j, (d1(p0 − k)Cmin(θ0) − d3pτd2) ≤ h2(θτ+, θ0)}; j = 1, ···, p0. Then .
When K = p0, , implying that |Â+| ≤ p0. If |Â+| = p0, then , implying that θ̂T = θ̂ml. Then we focus our attention to the case of A+ ≠ A0. Note that, with θ = (β, η) and β = (βA, 0),
provided that τ ≤ (d1Cmin(θ 0)/2pd3)1/d2. The rest of the proof proceeds as in the proof of Theorem 1. This completes the proof.
Proof of Theorem 3
The main idea of the proof is the same as that for Theorem 1 of [24], which constructs an approximated least favorable situation for feature selection and uses Fano’s Lemma. According to Fano’s Lemma [11], for any mapping T = T(Y1, ···, Yn) taking values in S = {1, ···, ∣S∣}, , where K(qj, qk) = ∫ qj log(qj/qk) is the Kullback-Leibler information for densities qj versus qk corresponding Pj and Pk.
To construct an approximated least favorable set of parameters S for A0 versus , define β to be ( ). Let be a collection of parameters with components equal to γmin or 0 satisfying that for any 1 ≤ j, j′ = p, , as defined in Assumption C. Then for any θj, θk ∈ S, by Assumption C.
By Fano’s lemma, , implying that
bounded below by c* with . This yields (12). For (13), it follows that R* ≥ l with and , for any θ0 ∈ B0(u, l). This completes the proof.
Proof of Proposition 1
We now verify Assumptions A–C. Note that
for linear regression, and h2(β, β0) is
for logistic regression, where μ(s) = (1 + exp(s))−1.
Assumption A follows from [14]. Note that
and
, for 1 ≤ j ≤ p and β ∈
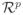 . Thus
. Thus
Then Assumption B is fulfilled with d1 = d2 = 1 and d3 = 2 maxj Σjj.
To simplify (3), we derive an inequality through some straightforward calculations: with β̃ = ((βA, 0) − (0, βA0))
for some constant , because the derivative of and (1 + exp(x))−1/2 are bounded away from zero under the compactness assumption. This leads to (14). By Theorem 2, the TLP has the properties (A)–(C) there, through tuning.
Finally, by the compactness assumption, where r = c max(Aj,Ak) E(βAj XAj − βAk XAk)2. By Theorem 3, (14) except a constant d0 > 0 is necessary for any method to be feature selection consistent. This completes the proof.
Proof of Proposition 2
To obtain the desired results, Theorems 1–3 are applied. First a lower bound of Cmin(θ0) is derived to simplify (3). Given the squared Hellinger distance , by strong convexity of −log det(Ω), c.f., [3], for any θ ∈ Θ and a constant c* > 0 depending on M1,
where A0 and A are as defined in Section 4.2, and Ω* is an intermediate value between Ω and Ω0; see A.4.3 of [3] of such an expansion. Moreover, Cmin(θ0) ≥ infΩAA≠A0,|A|≤p0 log (1 − h2(Ω, Ω0)), yielding (18).
For Assumption A, note that |Ωjk| ≤ (ΩjjΩkk) ≤ M2; j ≠ k, because Ω ≻ 0 and det(Ω) is bounded away from zero. To calculate the bracketing Hellinger metric entropy, we apply Proposition 1 of [22]. Let ΩA be a submatrix, consisting of p0 nonzero off-diagonal elements of Ω. Note that g(θ, y) of Y1 is proportional to h0(θA, y) Πj∈Ac hj(θj, y1), where , and yA and θA are the sub-vectors of y and θ corresponding to ΩA. Then for some constants kj > 0; j = 1, 2 and any Ω̄, Ω ∈ Θ,
This implies that H(t,
) = c0(|A| log(2εp/t)+log((p −|A|)p/t))) by [14] for some constant c0, which in turn yields Assumption A. For Assumption B, note that, for j ≠ k = 1, ···, p, for any θ ∈ Θ,
which is upper bounded by ; j ≠ k = 1, ···, p. With . This implies Assumption B with d1 = d2 = 1 and . For Assumption C, note that the Kullback-Leibler for θ0 versus θ is , which is upper bounded by h2(θ, θ0), because the likelihood ratios are uniformly bounded. An application of Taylor’s expansion as in verification of Assumption A yields that , where r = c*cmax(H), leading to Assumption C.
The results in (18) follow from Theorems 1–3 with by solving (9). This completes the proof.
Footnotes
Research supported in part by NSF grant DMS-0906616, NIH grants 1R01GM081535, 2R01GM081535, HL65462 and R01HL105397. The authors would like to thank the editor, the associate editor and anonymous referees for helpful comments and suggestions.
References
- 1.Bickel P, Ritov Y, Tsybakov A. Simultaneous analysis of lasso and dantzig selector. Ann Statist. 2008;37:1705–1732. [Google Scholar]
- 2.Benerjee O, Ghmoui LE, dAspremont A. Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J Mach Learn Res. 2008;9:485–516. [Google Scholar]
- 3.Boyd S, Vandenberghe L. Convex optimization. Cambridge Univ. Press; 2004. [Google Scholar]
- 4.Chen J, Chen Z. Extended Bayesian information criterion for model selection with large model space. Biometrika. 2008;95:759–771. [Google Scholar]
- 5.Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression. Ann Statist. 2004;32:407–499. [Google Scholar]
- 6.Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J Amer Statist Assoc. 2001;96:1348–1360. [Google Scholar]
- 7.Fan J, Feng Y, Wu Y. Network exploration via the adaptive Lasso and SCAD penalties. Ann Appl Statist. 2009;3:521–541. doi: 10.1214/08-AOAS215SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Friedman J, Hastie T, Tibshirani R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics. 2008;9:432–441. doi: 10.1093/biostatistics/kxm045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Gasso G, Raotomamonjy A, Canu S. Recovering sparse signals with nonconvex penalties and DC programming. 2009. Submitted. [Google Scholar]
- 10.Higgins ME, Claremont M, Major JE, Sander C, Lash AE. Cancer-Genes: a gene selection resource for cancer genome projects. Nucleic Acids Research. 2007;35 (suppl 1):D721–D726. doi: 10.1093/nar/gkl811. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ibragimov IA, Has’minskii RZ. Statistical estimation. Springer; New York: 1981. [Google Scholar]
- 12.Li H, Gui J. Gradient directed regularization for sparse Gaussian concentration graphs, with applications to inference of genetic networks. Biostat. 2006;7:302–317. doi: 10.1093/biostatistics/kxj008. [DOI] [PubMed] [Google Scholar]
- 13.Kim Y, Choi H, Oh HS. Smoothly clipped absolute deviation of high dimensions. J Amer Statist Assoc. 2008;103:1665–1673. [Google Scholar]
- 14.Kolmogorov AN, Tihomirov VM. ε-entropy and ε-capacity of sets in function spaces. Uspekhi Mat Nauk. 1959;14:3–86. [In Russian. English translation, Ameri. Math. Soc. transl. 2, 17, 277–364. (1961)] [Google Scholar]
- 15.Meinshausen N, Buhlmann P. High dimensional graphs and variable selection with the lasso. Ann Statist. 2006;34:1436–1462. [Google Scholar]
- 16.Negahban S, Wainwright M, Ravikumar P, Yu B. A unified framework for high-dimensional analysis of M-estimators with decomposable regularizers 2010 [Google Scholar]
- 17.Raskutti G, Wainwright M, Yu B. Tech Report. UC Berkeley: 2009. Minimax rates of estimation for high-dimensional linear regression over lq balls. [Google Scholar]
- 18.Rocha G, Zhao P, Yu B. Technical Report. UC Berkeley: 2008. A path following algorithm for sparse pseudo-likelihood inverse covariance estimation; p. 759. [Google Scholar]
- 19.Rothman A, Bickel P, Levina E, Zhu J. Sparse permutation invariant covariance estimation. Electronic J Statist. 2008;2:494–515. [Google Scholar]
- 20.Rothman A, Bickel P, Levina E, Zhu J. A new approach to Cholesky-based covariance regularization in high dimensions. Biometrika. 2009 To appear. [Google Scholar]
- 21.Schwarz G. Estimating the dimension of a model. Ann Statist. 1978;6:461–64. [Google Scholar]
- 22.Shen X, Wong WH. Convergence rate of sieve estimates. Ann Statist. 1994;22:580–615. [Google Scholar]
- 23.Shen X, Ye J. Adaptive model selection. J Amer Statist Assoc. 2002;97:210–221. [Google Scholar]
- 24.Shen X, Zhu Y, Pan W. Necessary and sufficient conditions towards feature selection consistency. 2010 Unpublished manuscript. [Google Scholar]
- 25.Stanica P, Montgomery AP. Good lower and upper bounds on binomial coefficients. J Ineq in Pure Appl Math. 2001;2:art 30. [Google Scholar]
- 26.Tibshirani R. Regression shrinkage and selection via the LASSO. JRSS-B. 1996;58:267–288. [Google Scholar]
- 27.Wong WH, Shen X. Probability inequalities for likelihood ratios and convergence rates of sieve MLEs. The Annals of Statistics. 1995;23:339–362. [Google Scholar]
- 28.Yuan M, Lin Y. Model selection and estimation in the Gaussian graphical model. Biometrika, bf. 2007;94:19–35. [Google Scholar]
- 29.Wang Y, Klijn JG, et al. Gene-expression profiles to predict distant metastasis of lymph-node-negative primary breast cancer. Lancet. 2005;365:671–679. doi: 10.1016/S0140-6736(05)17947-1. [DOI] [PubMed] [Google Scholar]
- 30.Wei Z, Li H. Nonparametric pathway-based regression models for analysis of genomic data. Biostatistics. 2007;8:265–284. doi: 10.1093/biostatistics/kxl007. [DOI] [PubMed] [Google Scholar]
- 31.Yuan M. High dimensional inverse covariance matrix estimation via linear programming. J Mach Learning Res. 2010;11:2261–2286. [Google Scholar]
- 32.Zhang CH. Nearly unbiased variable selection under minimax concave penalty. Ann Statist. 2010;38:894–942. [Google Scholar]
- 33.Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models (with discussion) Ann Statist. 2008;36:1509–1566. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Zhao P, Yu B. On model selection consistency of Lasso. JMLR. 2006;7:2541–2563. [Google Scholar]
- 35.Zhou S. Thresholded Lasso for high dimensional variable selection and statistical estimation. Technical report 2010 [Google Scholar]