

Abstract
Bilinguals who are fluent in American Sign Language (ASL) and English often produce code-blends - simultaneously articulating a sign and a word while conversing with other ASL-English bilinguals. To investigate the cognitive mechanisms underlying code-blend processing, we compared picture-naming times (Experiment 1) and semantic categorization times (Experiment 2) for code-blends versus ASL signs and English words produced alone. In production, code-blending did not slow lexical retrieval for ASL and actually facilitated access to low-frequency signs. However, code-blending delayed speech production because bimodal bilinguals synchronized English and ASL lexical onsets. In comprehension, code-blending speeded access to both languages. Bimodal bilinguals’ ability to produce code-blends without any cost to ASL implies that the language system either has (or can develop) a mechanism for switching off competition to allow simultaneous production of close competitors. Code-blend facilitation effects during comprehension likely reflect cross-linguistic (and cross-modal) integration at the phonological and/or semantic levels. The absence of any consistent processing costs for code-blending illustrates a surprising limitation on dual-task costs and may explain why bimodal bilinguals code-blend more often than they code-switch.
Keywords: bilingualism, lexical access, sign language
Bimodal bilinguals who are fluent in American Sign Language (ASL) and English rarely switch languages, but frequently code-blend, producing ASL signs and English words at the same time (Bishop, 2006; Baker & van den Bogaerde, 2008; Emmorey, Borinstein, & Thompson, 2005). For the vast majority of code-blends (> 80%), the ASL sign and the English word are translation equivalents; for example, a bimodal bilingual may manually produce the sign CAT1 while simultaneously saying “cat” (Emmorey, Borinstein, Thompson, & Gollan, 2008; Petitto et al., 2001). In contrast, articulatory constraints force unimodal bilinguals to either speak just one language or switch between their languages because it is physically impossible to say two words at the same time (e.g., simultaneously saying mesa in Spanish and table in English). The ability to produce both languages simultaneously introduces a unique opportunity to investigate the mechanisms of language production and comprehension, and raises questions about the possible costs or benefits associated with accessing two lexical representations at the same time.
Bimodal bilinguals’ strong preference for code-blending over code-switching provides some insight into the relative processing costs of lexical inhibition versus lexical selection, implying that inhibition is more effortful than selection. For a code-blend, two lexical representations must be selected (an English word and an ASL sign), whereas for a code-switch, only one lexical item is selected, and production of the translation equivalent must be suppressed (Green, 1998; Meuter & Allport, 1999). If lexical selection were more costly than inhibition, then one would expect bimodal bilinguals to prefer to code-switch. Instead, bimodal bilinguals prefer to code-blend, which suggests that dual lexical selection is less difficult than single lexical selection plus inhibition.
No prior studies have investigated the psycholinguistic mechanisms underlying bimodal bilinguals’ ability to simultaneously produce two lexical items and to comprehend two lexical items simultaneously, and this unique capacity can provide a new lens into mechanisms of lexical access. For unimodal bilinguals, many studies have documented processing costs associated with switching between languages for both production (e.g., Meuter & Allport, 1999; Costa & Santesteban, 2004) and comprehension (e.g., Grainger & Beauvillian, 1987; Thomas & Allport, 2000). For bimodal bilinguals, however, the potential costs associated with code-blending must involve controlling simultaneous, rather than serial production or comprehension of lexical representations in two languages. By establishing of the costs or advantages of code-blending, we can begin to characterize how bilinguals control two languages that are instantiated within two distinct sensory-motor systems.
To examine the potential processing costs/benefits of code-blending for both language production and comprehension, we conducted two experiments. For production (Experiment 1), we used a picture-naming task and compared naming latencies for ASL signs and English words produced in a code-blend with naming latencies for signs or words produced in isolation. Naming latencies for ASL were measured with a manual key-release and for English by a voice-key response. For language comprehension (Experiment 2), we used a semantic categorization task (is the item edible?) and compared semantic decision latencies for ASL-English code-blends with those for ASL signs and audiovisual English words presented alone.
Code-blend production might incur a processing cost because the retrieval of two lexical representations may take longer than retrieval of a single representation – particularly if dual lexical retrieval cannot occur completely in parallel (i.e., is at least partially serial). On the other hand, production of an English word or an ASL sign could facilitate retrieval of its translation equivalent, thus speeding picture-naming latencies or reducing error rates for signs or words in a code-blend. Translation priming effects have been reported for unimodal bilinguals in picture naming tasks (e.g., Costa and Caramazza, 1999).
For comprehension, a processing cost for code-blending is less likely because the perception of visual and auditory translation equivalents converge on a single semantic concept, which could facilitate rapid comprehension. However, there is some evidence that simultaneous perception of translation equivalents across modalities can interfere with processing (e.g., Mitterer & McQueen, 2009; Duran, 2005). For example, Duran (2005) assessed the simultaneous comprehension of auditory and visual words presented in Spanish and English. Proficient Spanish-English bilinguals heard and read two words simultaneously (e.g, hearing “apple” while seeing the written translation manzana), and then were cued unpredictably to report either what they had heard or what they had read. Bilinguals were slower to respond and made more errors for the simultaneous condition than when processing one language alone. However, such cross-language interference effects may only occur for unimodal bilinguals because written words in one language provide misleading phonological information about the words being spoken in the other language. Thus, while code-blend production might incur a processing cost related to dual lexical retrieval, code-blend comprehension might facilitate lexical access because the phonological representations of signed and spoken languages do not compete. Further, unlike bimodal bilinguals, unimodal bilinguals do not habitually process both languages simultaneously, and thus results from cross-modal comprehension experiments cannot speak to the cognitive mechanisms that might develop to support simultaneous dual language comprehension when it occurs regularly and spontaneously.
An important phenotypic characteristic of natural code-blend production is that the articulation of ASL signs and English words appears to be highly synchronized. For the majority (89%) of code-blends in a sentence context, the onset of an ASL sign was articulated simultaneously with the onset of the associated English word (Emmorey et al., 2008). When naming pictures in an experimental task, participants may also synchronize the production of ASL signs and English words. If so, then bilinguals must wait for the onset of the ASL sign before producing the English word – even if both lexical items are retrieved at the same time. This is because the hand is a larger and slower articulator than the vocal cords, lips, and tongue (the speech articulators), and it takes longer for the hand to reach the target sign onset than for the speech articulators to reach the target word onset. For example, it will take longer for the hand to move from a rest position (e.g., on the response box) to a location on the face than for the tongue to move from a resting position (e.g, the floor of the mouth) to the alveolar ridge. To produce a synchronized code-blend the onset of speech must be delayed while the hand moves to the location of the sign. Delayed speech during picture-naming would indicate a type of “language coordination cost” for English that reflects the articulatory dependency between the vocal and manual elements of a code-blend.
If lexical onsets are synchronized, then only ASL responses can provide insight into whether dual lexical retrieval incurs a processing cost and more specifically, whether lexical retrieval is serial or simultaneous during code-blend production. For example, if lexical access is at least partially serial and the English word is retrieved before accessing the ASL sign, then RTs should be slower for ASL signs within a code-blend than for signs produced alone. The English word is expected to be retrieved more quickly than the ASL sign because English is the dominant language for hearing ASL-English bilinguals (see Emmorey et al., 2008).
The possible patterns of results for Experiment 1 (code-blend production) and their corresponding implications are as follows:
Longer RTs and/or increased error rates for ASL signs produced in a code-blend than for signs produced alone would indicate a processing cost for code-blending. Longer RTs would also imply that it is not possible to retrieve and select two lexical representations fully in parallel.
Equal RTs and equal error rates for ASL alone and in a code-blend would indicate that dual lexical retrieval can occur in parallel during code-blend production with no associated processing cost.
Longer RTs for English in a code-blend would signal a dual lexical retrieval cost but may also reflect a language coordination cost, i.e., speech is delayed – perhaps held in a buffer – in order to coordinate lexical onsets within a code-blend.
Increased error rates for English words produced in a code-blend than for English words produced alone would indicate a cost for dual lexical retrieval.
Finally, we included a frequency manipulation within the stimuli, which will allow us to consider the possible locus of any observed code-blending effects. Specifically, if these effects are modulated by lexical frequency, it would imply they have a lexical locus (Almeida, Knobel, Finkbeiner, & Caramazza, 2007).
Experiment 1: Code-blend production
Methods
Participants
Forty ASL-English bilinguals (27 female) participated in Experiment 1. We included both early ASL-English bilinguals, often referred to as Codas (children of deaf adults), and late ASL-English bilinguals who learned ASL through instruction and immersion in the Deaf community. Two participants (one early and one late bilingual) were eliminated from the analyses because of a high rate of sign omissions (>20%).
Table 1 provides participant characteristics obtained from a language history and background questionnaire. The early ASL-English bilinguals (N = 18) were exposed to ASL from birth, had at least one deaf signing parent, and eight were professional interpreters. The late ASL-English bilinguals (N = 20) learned ASL after age six (mean = 16 years; range: 6 – 26 years), and 13 were professional interpreters. All bilinguals used ASL and English on a daily basis. Both groups classified themselves as English-dominant, rating their English proficiency as higher than their ASL proficiency, F(1,26) = 24.451, MSE = 0.469, p < .001, ηp2 = .485. In addition, there was an interaction between bilingual group and language proficiency rating, F(1,26) = 5.181, MSE = 0.469, p = .031, ηp2 = .166. Self-ratings of ASL proficiency (1 = “not fluent” and 7 = “very fluent”) were significantly lower for late bilinguals (mean = 5.7, SD = 0.8) than for early bilinguals (mean = 6.4, SD = 0.8), t(35) = 2.397, p = .022. The two groups did not differ in their English proficiency ratings, t(26) = 1.256, p = .220.
Table 1.
Means for participant characteristics. Standard deviations are given in parentheses.
| Age (years) | Age of ASL exposure | ASL self-rating a | English self-rating a | Years of education | |
|---|---|---|---|---|---|
| Early ASL-English bilinguals (N = 18) | 27 (6) | birth | 6.4 (0.8) | 6.8 (0.6) | 16.2 (2.8) |
| Late ASL-English bilinguals (N = 20) | 36 (10) | 16.4 (7.0) | 5.7 (0.8) | 7.0 (0.0) | 17.7 (2.7) |
Based on a scale of 1–7 (1 = “not fluent” and 7 = “very fluent”)
Materials
Participants named 120 line drawings of objects taken from the UCSD Center for Research on Language International Picture Naming Project (Bates et al., 2003; Székely et al., 2003). For English, the pictures all had good name agreement based on Bates et al. (2003): mean percentage of target response = 91% (SD = 13%). For ASL, the pictures were judged by two native deaf signers to be named with lexical signs (English translation equivalents), rather than by fingerspelling, compound signs, or phrasal descriptions, and these signs were also considered unlikely to exhibit a high degree of regional variation. Half of the pictures had low-frequency English names (mean ln-transformed CELEX frequency = 1.79, SD = 0.69) and half had high-frequency names (mean = 4.04, SD = 0.74). Our lab maintains a database of familiarity ratings for ASL signs based on a scale of 1 (very infrequent) to 7 (very frequent), with each sign rated by at least 4 deaf signers. The mean ASL sign-familiarity rating for the ASL translations of the low-frequency words was 3.04 (SD = 0.86) and 4.15 (SD = 1.19) for the high-frequency words.
Procedure
Pictures were presented using Psyscope Build 46 (Cohen, MacWhinney, Flatt, & Provost 1993) on a Macintosh PowerBook G4 computer with a 15-inch screen. English naming times were recorded using a microphone connected to a Psyscope response box. ASL naming times were recorded using a pressure release key (triggered by lifting the hand) that was also connected to the Psyscope response box. Within a code-blend, separate naming times were recorded simultaneously for English and ASL using the microphone and key release mechanisms. Participants initiated each trial by pressing the space bar. Each trial began with a 1000-ms presentation of a central fixation point (“+”) that was immediately replaced by the picture. The picture disappeared when either the voice-key or the release-key triggered. All experimental sessions were videotaped.
Participants named 40 pictures in ASL only, 40 pictures in English only, and 40 pictures with an ASL-English code-blend. The order of language blocks was counter-balanced across participants, such that all pictures were named in each language condition, but no participant saw the same picture twice. Participants were instructed to name the pictures as quickly and accurately as possible, and six practice items preceded each naming condition. Participants were told: For each object you see, you will name it in English/in ASL/in English and ASL simultaneously, as appropriate for each testing block.
Results
Reaction times that were two standard deviations above or below the mean for each participant for each language were eliminated from the RT analyses. This procedure eliminated 5.3% of the data for the early bilinguals and 5.6% for the late bilinguals.
English responses in which the participant produced a vocal hesitation (e.g., “um”) or in which the voice key was not initially triggered were eliminated from the RT analysis, but were included in the error analysis. ASL responses in which the participant paused or produced a manual hesitation gesture (e.g., UM in ASL) after lifting their hand from the response key were also eliminated from the RT analysis, but were included in the error analysis. Occasionally, a signer produced a target sign (e.g., SHOULDER) with their non-dominant hand after lifting their dominant hand from the response key; such a response was considered correct, but was not included in the RT analysis. In addition, if either the ASL or the English response was preceded by a hesitation (“um”, UM, or a manual pause) or the voice key was not initially triggered, neither the ASL nor the English response was entered into the code-blend RT analysis. These procedures eliminated 0.6 % of the English alone data, 1.8 % of the ASL alone data, and 3.4 % of the code-blend data.
Only correct responses were included in the RT analyses. Responses that were acceptable variants of the intended target name (e.g., Oreo instead of cookie, COAT instead of JACKET, or fingerspelled F-O-O-T instead of the sign FOOT) were considered correct and were included in both the error and RT analyses. Fingerspelled responses were not excluded from the analysis because a) fingerspelled signs constitute a non-trivial part of the ASL lexicon (Brentari & Padden, 2001; Padden, 1998) and b) fingerspelled signs are in fact the correct response for some items because either the participant always fingerspells that name or the lack of context in the picture-naming task promotes use of a fingerspelled name over the ASL sign (e.g., the names of body parts were often fingerspelled). Non-responses and “I don’t know” responses were considered errors.
We did not directly compare RTs for ASL and English due to the confounding effects of manual vs. vocal articulation. For each language, we initially conducted a 2 × 2 × 2 ANOVA that included bilingual group (early, late), naming condition (alone, in a code-blend), and lexical frequency (high, low) as the independent variables and RT and error rate as the dependent variables. However, these analyses revealed no main effects of participant group and no significant interactions between participant group and naming condition or frequency.2 Therefore, we report the results of 2 (naming condition) × 2 (frequency) ANOVAs for RT and error rate for each language. The results are shown in Figures 1 and 2.
Figure 1.

Naming latencies for high- and low-frequency ASL signs and English words produced alone or in a code-blend. Error bars indicate standard error of the mean. Response time for ASL was measured from key release and from voice onset for English (see Figure 3).
Figure 2.

Error rates for high- and low-frequency ASL signs and English words produced alone or in a code-blend. Error bars indicate standard error of the mean.
American Sign Language
For ASL, there was no difference in picture-naming latencies when signs were produced in a code-blend compared to when signs were produced alone, Fs < 1. As expected, participants named pictures with high frequency ASL signs (those with high familiarity ratings) more quickly than pictures with low frequency signs (those rated as less familiar), F1(1,37) = 37.43, MSE = 28,006, p < .001, ηp2 = .503; F2(1,118) = 25.779, MSE = 87,222, p < .001, ηp2 = .179. Lexical frequency did not interact with naming condition for ASL, F1(1,37) = 1.218, MSE = 15,334, p = .277, ηp2 = .032; F2(1,118) = 1.576, p = 0.212, ηp2 = .013.
For ASL error rates, there was again no difference between naming conditions, F1(1,37) = 2.068, MSE = .005, p = .159, ηp2 = .053; F2 < 1, and participants made fewer errors for pictures named with high-frequency than with low-frequency signs, F1(1,37) = 63.478, MSE = .004, p < .001, ηp2 = .632; F2(1,118) = 16.529, MSE = .021, p < .001, ηp2 = .123. Of particular interest, there was a significant interaction between ASL frequency and naming condition, F1(1,37) = 7.093, MSE = .003, p = .011, ηp2 = 0.161; F2 (1,118) = 5.156, MSE = 0.006, p = .025, ηp2 = .042. Retrieving English during a code-blend appeared to facilitate retrieval of low-frequency ASL signs compared to producing ASL signs alone, t(36) = 2.337, p = .025, but facilitation was not observed for high-frequency signs, t < 1.
English
As seen in Figure 1, English response latencies for words produced in a code-blend were much longer (mean = 655 ms) than for words produced alone, F1(1,37) = 217.037, MSE = 75,519, p < .001, ηp2 = .854; F2(1,118) = 848.410, MSE = 32,278, p < .001, ηp2 = .878. As discussed in the introduction, speech may be delayed during code-blend production so that lexical onsets in English and ASL can be coordinated. Below, we investigate this hypothesis by measuring the amount of time it took bilinguals to move their hand from the response key to the onset of the ASL sign (the ASL transition time in a code-blend).
As expected, participants named pictures more quickly with high-frequency words than with low-frequency words, F1(1,37) = 64.066, MSE = 8,891, p < .001, ηp2 = .634; F2(1,118) = 17.283, MSE = 71,680, p < .001, ηp2 = .128. In addition, word frequency interacted with naming condition, F1(1,37) = 24.944, MSE = 10,011, p < .001, ηp2 = .403; F2(1,118) = 11.973, MSE = 32,278, p = .001, ηp2 = .092. The frequency effect was much larger when English was produced in a code-blend: the mean RT difference between low- and high-frequency words was 203 ms compared to 41 ms when English was produced alone. This result suggests that the frequency effect observed for English in a code-blend actually reflects the ASL frequency effect because participants did not respond until they had retrieved both the ASL sign and the English word for the code-blend response (perhaps holding the English word in a buffer). Note that the frequency effect is expected to be larger for ASL than for English because ASL is the non-dominant language (Gollan, Montoya, Cera, & Sandoval, 2008). Supporting our hypothesis, the size of the frequency effect for English in a code-blend as a function of total RT (12% or 203 ms frequency effect/1619 ms total RT) was identical to the size of the frequency effect for ASL in a code-blend (also 12%: 144 ms/1157 ms).
For English error rates, as for ASL error rates, code-blending seemed to reduce retrieval failures compared to English words produced alone (see Figure 2), but the difference was not significant, F1(1,37) = 1.816, MSE = .002, p = .186, ηp2 = .047; F2(1,118) = 1.040, MSE = .003, p = .310, ηp2 = .009. Participants made fewer errors naming pictures with high-frequency words than low-frequency words, F1(1,37) = 13.255, MSE = 0.002, p = .001, ηp2 = .264; F2(1,118) = 2.624, MSE = .015, p = .108, ηp2 = .022. In contrast to ASL, the interaction between word frequency and naming condition was not significant for English error rates, F1(1,37) = 0.545, MSE = 0.002, p = .465, ηp2 = .015; F2(1,118) = 0.535, MSE = 0.003, p = 0.466, ηp2 = .005, possibly because retrieval failures are less likely for the dominant language. The error rate for low-frequency English words produced alone (7%) was half that observed for low-frequency ASL signs produced alone (14%).
ASL transition time analyses
To investigate whether the apparent cost to English naming times in a code-blend can be explained by a “language coordination cost,” we measured the transition time from when each participant lifted his/her hand from the response box to the onset of the ASL sign (see Figure 3). Based on this coordination hypothesis, we predicted that English RT in a code-blend should be equal to the sum of the ASL RT in a code-blend and the sign transition time.
Figure 3.

Illustration of the timing of an ASL-English code-blend response in the picture-naming task.
In addition, it is possible that during code-blend production, lexical retrieval is serial such that the English word is accessed during the transitional movement of the ASL sign. If so, then ASL transition times might be longer in the code-blend condition than in the ASL alone condition, reflecting the additional processing cost of retrieving the English word. To test this hypothesis, we also measured the transition time for ASL signs produced in isolation.
ASL transition time measurements were conducted using the videotape data from the experimental sessions. The ASL response onset/transition onset was defined as the first video frame in which movement from the response key could be detected. The transition offset/sign onset was defined as follows: 1) the first video frame in which the hand contacted the body for body-anchored or two-handed signs (e.g., GIRL, CHAIR) and 2) if the sign did not have contact (e.g., LION, F-O-O-T), then sign onset was defined as the first video frame in which the hand arrived at the target location near the body or in neutral space, before starting the phonologically specified sign movement or handshape change. For each correct item for each participant, transition time was calculated as the number of video frames between the response/transition onset and the sign onset, multiplied by 33 (the frame rate for NTSC format video is 30 frames per second). Data from four participants were excluded because the response box had been positioned such that their hand release could not be easily seen on the video. The video coding was done by five hearing ASL signers. All coders were first trained to measure transition time using the criteria above for video data from 2 participants. To obtain a measure of inter-rater reliability, the coders independently measured transition times for a second pair of bilinguals. The coders were very consistent in their measurements: 87% of transition time measurements differed by just three or fewer video frames across all five coders, and no single coder was consistently different from the others (i.e., consistently 1 or 2 frames off).
For each participant, we summed the ASL response time in a code-blend (mean = 1165 ms; SE = 66 ms) and the sign transition time (mean = 460 ms; SE = 14 ms) to obtain a combined ASL code-blend RT plus transition time measure. This combined measure (mean = 1625 ms; SE = 66 ms) did not differ significantly from the code-blend English response time (mean = 1639 ms; SE = 67 ms), t < 1. In other words, the English naming time within a code-blend did not differ from the ASL naming time plus the transition time to arrive at the beginning of the ASL sign.
To further examine whether English and ASL naming latencies were yoked, we correlated – for each participant - English RTs in a code-blend with the sum of the ASL code-blend RT plus the ASL transition time in a code-blend. These correlations were quite high, with an average r of .82 (SE = .03), and a one-sample t test against zero (after Fisher transformation) was significant, t(31) = 20.970, p < .001. These high correlations indicate that the variation in English code-blend RTs within a participant can be largely explained by the combination of their ASL RTs and sign transition times.
Finally, the comparison of transition times for ASL produced alone versus in a code-blend revealed that the transition times for ASL within a code-blend (mean = 460 ms, SE = 14) were actually faster than for ASL produced alone (mean = 483 ms, SE = 16 ms), t(32) = 2.333, p = .026. Thus, if retrieval of the English word occurred after initiation of the ASL response, it did not slow the movement to sign onset. Rather, bilinguals may have transitioned more quickly to the ASL sign onset in order to produce the English word they had already retrieved.
Discussion
The pattern of results observed in Experiment 1 suggests that ASL-English bilinguals can simultaneously retrieve two lexical representations with no processing cost to ASL and further that code-blending may actually facilitate retrieval of low frequency ASL signs. A possible mechanism for this facilitation effect is translation priming, analogous to cross-linguistic priming reported for unimodal bilinguals. For example, Costa and Caramazza (1999) found that presentation of translation equivalents during picture naming accelerated lexical production in a picture-word interference paradigm. For Spanish-English bilinguals, seeing the (L1) English word table facilitated naming the picture in (L2) Spanish (producing mesa). In the case of code-blend production, retrieving the English word during picture-naming may prime the ASL translation and render it more accessible, thus reducing the number of ASL non-responses or “don’t know” naming errors for less frequent ASL signs.
The absence of any significant cost to ASL is a striking result given that code-blends require planning, retrieval, and coordinated production of twice as many lexical representations as producing ASL alone. This finding also stands in contrast to the significant switch-costs observed during unimodal language mixing. Although switch costs tend to be smaller for the non-dominant language, no studies (to our knowledge) report a complete absence of switch costs for the non-dominant language. Of course, a major difference between unimodal and bimodal language mixing is that unimodal bilinguals ultimately must produce one language and specifically not produce the other. In contrast, code-blending requires the overt production of both languages. Thus, processing costs that are associated with language inhibition, or single language selection, simply may not be relevant for code-blend production. Furthermore, code-blending differs from code-switching with respect to the amount of information retrieved. That is, the same semantic content is retrieved in a code-blend, whereas in a code-switch, speakers first produce information in one language followed by different information in the other language. Any processing cost associated with this shift in information content is not present for code-blends (although in a minority of spontaneous code-blends, distinct information is produced in each language; Emmorey et al., 2008).
In contrast to ASL, English RTs were significantly longer in a code-blend. However, the ASL transition time analysis revealed that these exceptionally long naming times were most likely not due to very slow lexical retrieval for English. Rather, English RTs in a code-blend can be largely accounted for by summing the ASL code-blend RT and the transition time to arrive at sign onset. This analysis also revealed that ASL transition times were faster (not slower) for signs produced in a code-blend compared to signs produced in isolation. This finding implies that bilinguals had already retrieved the English word when they initiated the ASL response, and thus transitioned more rapidly to the sign onset in order to synchronize English and ASL lexical onsets. Given this pattern of data, however, it is possible that code-blend production did in fact slow lexical retrieval for English, but that this processing cost was obscured by the coordination of lexical onsets in a code-blend. Nevertheless, code-blending did not increase error rates for English – in fact, error rates were numerically lower for English in a code-blend than for English produced alone.
Bimodal bilinguals were not instructed to coordinate their sign and speech productions – they did so spontaneously. This result is consistent with recent research demonstrating robust neural and functional connections between the hand and mouth (e.g., Gentilucci & Dalla Volta, 2008) and with studies that show a strong tendency to coordinate vocal and manual articulation in non-linguistic tasks (Kelso, 1995; Spencer, Semjen, Yang, & Ivry, 2006). The synchronous timing of code-blends is also parallel to the vocal-manual coordination that occurs with co-speech gesture (McNeill, 1992).
Like code-blending, the production of co-speech gesture does not appear to incur a processing cost for spoken language. On the contrary, some studies suggest that representational co-speech gestures (i.e., iconic, non-conventionalized gestures) facilitate retrieval of spoken words (Krauss, 1998; Krauss & Hadar, 1999; Morsella & Krauss, 2004; Frick-Horbury & Guttentag, 1998). However, signs, unlike gestures, are stored as lexical representations with semantic, morphosyntactic, and phonological specifications. For example, we suggest that code-blend facilitation for ASL occurs because retrieval of the more accessible English word facilitates access to its ASL translation, perhaps via lexical links between languages (e.g., Kroll & Stewart, 1994). In contrast, co-speech gestures do not have translation equivalents, and the mechanism by which co-speech gesture might facilitate word retrieval during language production remains controversial and unclear (e.g., Alibali, Kita, & Young, 2000; Hostetter, Alibali, & Kita, 2008).
Finally, the early and late bilinguals did not differ from each other, and bilingual type did not interact significantly with naming condition or lexical frequency. These findings suggest that the early and late bilinguals in this study were relatively well matched for ASL proficiency and that age of ASL acquisition does not have a significant impact on code-blend production. Baus, Gutiérrez-Sigut, Quer, and Carreiras (2008) also found no difference between early and late deaf signers in a picture-naming study with Catalan Sign Language (CSL), and their participants were all highly skilled signers. With sufficient proficiency, age of acquisition may have little effect on the speed or accuracy of lexical retrieval, at least as measured by picture naming tasks.
We now turn to the potential processing costs or benefits of code-blending for language comprehension. Cross-linguistic facilitation effects may be more likely for language comprehension given the robustness of translation priming in lexical recognition for unimodal bilinguals (e.g., Gollan, Forster, & Frost, 1997; Duyck & Warlop, 2009). On the other hand, for unimodal bilinguals simultaneous perception of two lexical items in different modalities is slower than perception of one language alone (Duran, 2005). Thus, code-blend interference effects in comprehension may occur, constituting a type of dual task effect that results from the need to process two different languages at the same time.
Experiment 2: Code-blend perception
To assess code-blend comprehension, we chose a semantic categorization task in which participants determined whether or not a sign, word, or code-blend referred to an item that was edible. We selected the edible/non-edible semantic category because it is a natural and early acquired category that requires lexical access and semantic processing.
Methods
Participants
Forty-five ASL-English bilinguals (30 female) participated in Experiment 2. Two participants were eliminated from the analyses because of high error rates (> 20%). Thirteen early bilinguals and 10 late bilinguals participated in both Experiments 1 and 2. Order of experiment was counter-balanced across participants, and no stimulus appeared in both experiments. Table 2 provides participant characteristics obtained from a language history and background questionnaire.
Table 2.
Means for participant characteristics. Standard deviations are given in parentheses.
| Age (years) | Age of ASL exposure | ASL self-rating a | English self-ratinga | Years of education | |
|---|---|---|---|---|---|
| Early ASL-English bilinguals (N = 18) | 27 (6) | birth | 6.1 (0.7) | 6.9 (0.3) | 16.0 (2.6) |
| Late ASL-English bilinguals (N = 25) | 34 (9) | 17.0 (4.6) | 5.7 (0.7) | 7.0 (0.0) | 18.5 (3.4) |
Based on a scale of 1–7 (1 = “not fluent” and 7 = “very fluent”)
The early ASL-English bilinguals (N = 18) were exposed to ASL from birth, had at least one deaf signing parent, and 11 were professional interpreters. The late ASL-English bilinguals (N = 25) learned ASL after age six (mean = 17 years, range: 6 – 26 years), and 16 were professional interpreters. All participants used ASL on a daily basis. Self-ratings of ASL proficiency trended in the same direction as in Experiment 1, but did not differ significantly for late bilinguals (mean = 5.7, SD = 0.7) compared to early bilinguals (mean = 6.1, SD = 0.7), t(38) = 1.628, p = .112. In addition, both bilingual groups rated their proficiency in English as higher than in ASL, F(1,33) = 58.052, MSE = 0.296, p < .001, ηp2 = .638. There was no interaction between bilingual group and language proficiency rating, F(1,33) = 2.113, MSE = 0.296, p = .156, ηp2 = .060.
Materials
Ninety nouns that denoted either edible objects (e.g., bacon, cracker, french fries; N = 45) or non-edible objects (e.g., badge, flag, sweater; N = 45) were produced by a model who is an early ASL-English bilingual (a Coda). The model was filmed producing the ASL signs, saying the English words, or producing ASL-English code-blends for each of the 90 items. For code-blends, the model naturally (without instruction) synchronized the onsets of the word and the sign (within 2 video frames). The film was edited using Final Cut Express (Apple, Inc.) to create separate video clips for each item. For ASL and for ASL-English code-blends, the beginning of a video clip was the first frame in which the hand appeared on the screen (the model was filmed from the waist to just above the top of the head), and the end of the clip was 5 frames (165 ms) after the hand began to move back to resting position on the lap. For English, the onset of the video clip was 9 frames (300 ms) prior to the voice onset of the word; this delay was chosen to avoid a startling and abrupt onset to the video clips of audio-visual speech. The English alone video clips ended 9 frames (300 ms) after the offset of the word.
The video clips in each language condition (ASL alone, English alone, and ASL-English code-blends) were divided into three lists of 30 items each. The three lists were balanced for English frequency (frequency per million from CELEX: list1 = 40.7, list2 = 42.4, list3 = 39.1) and for ASL familiarity ratings (mean ratings: list1 = 3.9, list2 = 4.0, list3 = 3.9). The lists were counter-balanced across participants, such that all items were viewed in each language condition, but no participant saw the same item twice.
Procedure
Video clips were presented using Psyscope Build 46 (Cohen et al.,1993) on a Macintosh PowerBook G4 computer with a 15-inch screen. Participants initiated each trial by pressing the space bar. Each trial began with a 500-ms presentation of a central fixation point (“+”) that was immediately replaced by the video clip. Participants responded with a key press. Video clips disappeared if a response was made before the video clip ended.
Participants were instructed to determine whether the items named in the video clips were edible or not. Using the computer keyboard, they responded by pressing the B key marked “yes” and the M key marked “no.” Between responses they rested their finger on the N key which lies between the two. They were also instructed to respond as quickly and accurately as possible. The order of language blocks (ASL alone, English alone, code-blend) was counter-balanced across participants. Four practice items preceded each language condition.
For ASL alone, RT was measured from the start of each video clip because articulation of the sign began at the onset of the video clip; that is, the hand began to move toward the location of the sign, and information about hand configuration may be available within the first few frames (see Emmorey & Corina, 1990). For English alone, RT was measured from the voice onset of the English word, rather than from the start of the video clip. For ASL-English code-blends, two RT measurements were obtained. For ASL within a code-blend, RT was measured from the onset of the video clip as in the ASL alone condition, and for English within a code-blend, RT was measured from the voice onset of the English word, as in the English alone condition.
Results
Reaction times that were two standard deviations above or below the mean for each participant for each language condition were eliminated from the RT analyses. This procedure eliminated 5.7% of the data for early bilinguals and 5.3% for late bilinguals. Only correct responses were entered into the RT analysis.
Response Times
As in Experiment 1, we did not directly compare RTs for ASL and English because similar confounding effects of language modality were present in the stimuli (i.e., visual-manual signs vs. auditory-oral words). Thus, for each language, we conducted a 2 × 2 ANOVA with bilingual group (early, late) and presentation condition (alone, within a code-blend) as the independent variables, and RTs as the dependent variable.3 The RT results are shown in Figure 4.4
Figure 4.
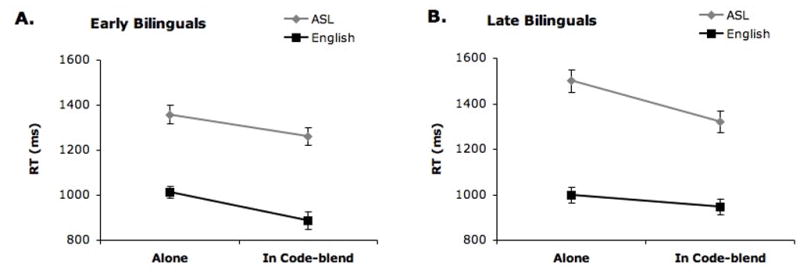
Response times (RTs) for early bilinguals (A) and late bilinguals (B) for making semantic categorization decisions (edible/non-edible) to each language produced alone or in a code-blend. Error bars indicate standard error of the mean. For ASL, RTs were measured from the beginning of the video clip when the hand became visible; for English, RTs were measured from voice onset.
For ASL, response times were significantly faster (by a mean of 138 ms) when signs were presented within a code-blend than when presented alone, F1(1,41) = 46.288, MSE = 8522.3, p < .001, ηp2 = .53; F2(1,87) = 100.998, MSE = 22,954, p < .001, ηp2 = .537. Late bilinguals tended to respond more slowly than early bilinguals, but this effect was only significant by items, F1(1,41) = 2.613, MSE = 80,246.3, p = .114, ηp2 = .06; F2(1,87) = 86.110, MSE = 7,972, p < .001, ηp2 = .497. In addition, the interaction between naming condition and bilingual type was significant and indicated that the late bilinguals showed a larger code-blend facilitation effect for ASL (mean effect = 12% or 178 ms/1499 ms) than the early bilinguals (mean effect = 7% or 97 ms/1358 ms), F1(1,41) = 4.063, MSE = 8522.3, p = .050, ηp2 = .090; F2(1,87) = 12.990, MSE = 9,523, p = .001, ηp2 = .130.
For English, response times were also significantly faster (by a mean of 93 ms) when words were presented within a code-blend than alone, F1(1,41) = 25.914, MSE = 6464.9, p < .001, ηp2 = .39; F2(1,88) = 51.016, MSE = 15,039, p < .001, ηp2 = .367. There was no main effect of bilingual group, F1(1,41) = 0.163, MSE = 59,364.8, p = .689, ηp2 = .004; F2(1,88) = 3.912, MSE = 4,008, p = .051, ηp2 = .043; however, the interaction between naming condition and bilingual group was significant, F1(1,41) = 4.642, MSE = 6464.9, p = .037, ηp2 = .10; F2(1,88) = 21.462, MSE = 6,132, p < .001, ηp2 = .196. In contrast to the pattern observed for ASL, the early bilinguals showed a larger code-blend benefit for English (mean effect = 13% or 127 ms/1014 ms) than the late bilinguals (mean effect = 5% or 52 ms/998 ms). Thus, both languages seem to exhibit a code-blend facilitation effect, and the size of the facilitation effect for each language is modulated by bilingual type. Early bilinguals exhibit greater code-blend facilitation for English than late bilinguals, whereas late bilinguals exhibit greater code-blend facilitation for ASL than early bilinguals. This interaction provides some clues to the locus of code-blend facilitation effects, as we will discuss below.
Error Rates
For error data (see Table 3; note that ASL and English means are not calculated separately for code-blends because participants only made one response to each code-blend stimulus), we conducted a two-way ANOVA with bilingual group (early, late) and presentation condition (ASL alone, English alone, Code-blend) as the independent variables. There was no main effect of bilingual group, F1(1,41) = 1.618, MSE =.002, p = .211, ηp2 =.04; F2(1,89) = 1.407, MSE = .005, p = .239, ηp2 = .016, but there was a main effect of condition, F1(1,41) = 40.367, MSE = 0.002, p < .001, ηp2 = .50; F2(1,89) = 20.930, MSE = .017, p < .001, ηp2 = .190. Error rates for ASL alone were significantly higher than for English alone, t(41) = 6.197, p < .001, indicating that ASL is the non-dominant language for these bilinguals. In addition, error rates were reduced for ASL in the code-blend condition, t(41) = 6.491, p < .001, probably because if the ASL sign was not known, the semantic decision could be made on the basis of English alone. The error rates for the code-blend and the English alone conditions did not differ from each other, t(41) = 0.324, p = .747. There was no interaction between naming condition and bilingual group, F1(1,41) = 1.403, MSE = .003, p = .243, ηp2 =.08; F2 < 1.
Table 3.
Error Rates for semantic categorization decisions (edible/non-edible) to ASL signs, English words, and ASL-English Code-blends
| Bilingual Group | ASL M (SE) |
English M (SE) |
Code-blend M (SE) |
|---|---|---|---|
| Early Bilinguals | 8.9% (1.9%) | 2.0% (0.6%) | 1.5% (0.4%) |
| Late Bilinguals | 6.3% (0.5%) | 1.5% (0.4%) | 1.6% (0.5%) |
Discussion
The results of Experiment 2 revealed that simultaneously perceiving and accessing two lexical representations (translation equivalents) is significantly faster than processing either language alone. Thus, code-blending speeds lexical access during language comprehension for both the dominant and the non-dominant language. In contrast, for unimodal bilinguals, there is no evidence that code-switching facilitates word recognition. In fact, it is likely that the unimodal analogy to code-blending would slow comprehension because the simultaneous perception of spoken translation equivalents would compete for auditory attention or might be blended into a single (uninterpretable) percept (i.e., a fusion effect). Further, simultaneous cross-modal (written and auditory) presentation of two spoken languages appears to slow comprehension for unimodal bilinguals (Duran, 2005). Thus, code-blend perception, like code-blend production, is a linguistic phenomenon that is unique to bimodal bilinguals.
Nonetheless, our results could be analogous to studies of visual word recognition in unimodal bilinguals that reported facilitation when both languages were relevant to the task (see Dijkstra, 2005, for review). For example, Dijkstra, Van Jaarsveld, and Ten Brinke (1998) found that when Dutch-English bilinguals were asked to make lexical decisions to letter strings that could be words in either Dutch or English (responding “yes” to both English and Dutch words), response times were facilitated for interlingual homographs (words such as brand that occur in both Dutch and English but that have different meanings) compared to words that exist only in one language. Based on frequency data, Dijkstra et al. (1998) argued that bilinguals made their lexical decisions based on whichever reading of the interlingual homograph became available first. Similarly, it is possible that ASL-English bilinguals made their semantic decisions for the code-blend stimuli based on whichever lexical item (ASL sign or English word) was recognized first in the code-blend.
According to this “race” explanation of code-blend comprehension, lexical recognition occurs independently for each language such that sometimes the English word is recognized first and sometimes the ASL sign is recognized first. However, a different possibility is that code-blend comprehension involves the integration of lexical material from both languages, which facilitates lexical recognition and semantic processing. During code-blend processing, lexical cohort information from both languages could be combined to constrain lexical recognition for each language. For example, the English onset “ap” activates several possible words (“apple,” “aptitude,” “apricot,” …), but only “apple” is consistent with the onset of the ASL sign; similarly, the ASL onset (a hooked 1 handshape; cheek/chin location) activates several possible signs (APPLE, COOL/NEAT, RUBBER, …), but only APPLE is consistent with the onset of the English word “apple.” In addition, integration could also occur at the semantic level. In this case, code-blend facilitation occurs because both languages provide congruent and confirmatory information regarding the semantic decision. Thus, for any given item, an integration account predicts code-blend facilitation for both languages, whereas the race explanation predicts facilitation only for one of the languages in the code-blend (the language that loses the race).
To tease apart the race versus integration accounts of code-blend comprehension, we conducted an analysis in which we first determined whether the English word or the ASL sign should “win” the lexical recognition race by comparing RTs for words and signs produced alone.5 For example, the mean RT for the word “apple” in the English alone condition was 114 ms faster than the mean RT for the ASL sign APPLE in the ASL alone condition, whereas the mean RT for the sign FRUIT (ASL alone) was 169 ms faster than the mean RT for the word “fruit” (English alone). For the lexical items where English was faster (N = 110), the race model predicts that in a code-blend, we should only observe facilitation for ASL and not for English (because English won the race). However, significant English facilitation in a code-blend is still observed for these items (mean facilitation effect = 109 ms), t(109) = 8.096, p < 001. Similarly, for those items where ASL won the race (N = 70), we still observed significant facilitation for ASL in a code-blend (mean facilitation effect = 39 ms), t(69) = 2.598, p = .011.
These results provide evidence that code-blend facilitation effects are not solely due to one language being recognized before the other. Rather, the findings imply that lexical integration may occur either at the phonological level or during semantic processing (or both). Further research using a lexical recognition task that is less dependent on semantic processing (e.g., lexical decision) will help determine precisely where lexical integration occurs during code-blend comprehension.
Finally, we found that the code-blend facilitation effect interacted with age of ASL acquisition. The early bilinguals exhibited a larger benefit for English words within a code-blend (mean = 127 ms) than was observed for the late bilinguals (mean = 52 ms), while the late bilinguals exhibited a larger benefit for ASL signs within a code-blend (mean = 178 ms) than was observed for the early bilinguals (mean = 97 ms). This pattern of results may reflect a superior ability of early bilinguals to process phonetic and phonological information that is available early in the ASL signal.
Previous research with deaf early and late learners of ASL has shown that early learners need less visual information to recognize ASL signs (Emmorey & Corina, 1990; Morford & Carlson, 2011) and that late learners allocate more attention to identifying phonological features compared to early learners (Mayberry & Fischer, 1989). If the same is true for hearing early and late ASL learners, then early bilinguals may be better able to process early visual cues to the phonological and lexical representations of ASL signs. Thus, for these bilinguals, early identification of an ASL sign onset can constrain the initial cohort for the English word, such that recognition of English words is faster within a code-blend than in isolation (where no ASL-translation cues are present). Late learners, on the other hand, are less able to quickly and efficiently process the visual cues that are present in the transition and the sign onset and therefore show a smaller benefit to English word recognition. Similarly, the late bilinguals exhibited a greater benefit to ASL sign recognition from an accompanying English word because they are relatively slow to process ASL signs. Thus, the presence of an English translation equivalent speeds ASL sign recognition to a greater degree than for early bilinguals because English word onset cues can constrain sign identity. Sign recognition for early bilinguals benefits less from the presence of a spoken English word because they have already processed many of the early visual cues to sign identity by the time they hear the onset of the English translation.
A question that arises is whether stronger code-blend facilitation effects for English could be obtained in late-learners if they were sufficiently proficient in ASL, or if only native ASL-English bilinguals can process visual cues sufficiently early. Our choice of semantic category (edible/non-edible) did not allow us to include a manipulation of word frequency. Nonetheless, a post-hoc division of our materials into 37 high (M=4.2, SD=0.7) versus 53 low-frequency (M=1.8, SD=0.9) targets revealed that late bilinguals exhibited a significant code-blend facilitation effect for English for code-blends with high-frequency words (p = .017), but not for code-blends with low-frequency words (p = .104). At the same time, the size of this facilitation effect was smaller (72 ms) when compared with the facilitation effects observed for the same high-frequency targets in early bilinguals (118 ms), although this difference was not significant (p = .291). Thus, it seems that ASL proficiency is an important factor in allowing code-blend facilitation effects to occur, but these analyses leave open the possibility that part of the code-blend facilitation effect may depend upon early exposure to ASL, perhaps to “tune” the visual system to sign-specific phonetic cues (e.g., Krentz & Corina, 2008).
General Discussion
Together Experiments 1 and 2 represent the first experimental investigation of a behavior that is ubiquitous in communication between speaking-signing bilinguals. In prior work (Emmorey et al., 2008), we suggested that when mixing languages, bimodal bilinguals prefer to code-blend because doing so is easier than code-switching which involves suppressing the production of one language. The results of our code-blend production study (Experiment 1) support this hypothesis. Although code-blending is effectively a dual-task (bilinguals process two lexical representations instead of just one), we found no evidence of processing costs for the nondominant language (ASL), and code-blending actually facilitated access to low-frequency signs, preventing naming failures (see Figures 1 and 2). In this respect, code-blend production is strikingly different from unimodal code-switching, which incurs significant costs to both languages.
The results of our code-blend comprehension study (Experiment 2) revealed that code-blending facilitated comprehension of both languages (see Figure 4). Code-blend facilitation during language comprehension may be analogous to a more general cognitive phenomenon known as the redundant signals effect (RSE). The RSE refers to the fact that participants respond more quickly when two stimuli with the same meaning are presented in different modalities (e.g., a tone and a light that both signal “go”) compared to when just one stimulus is presented (Miller, 1986). Several studies suggest that the RSE occurs because information from the redundant stimuli are combined and together coactivate a response (Miller, 1982; Miller & Ulrich, 2003). The code-blend facilitation effects reported here could operate in an analogous manner, with the combined activation of “redundant” lexical representations in ASL and in English speeding semantic decisions.
Additional analyses suggested that code-blend facilitation effects were not simply due to parallel lexical access in which one lexeme was recognized before the other. Rather, semantic integration may speed comprehension for code-blends, just as co-speech gestures may facilitate comprehension of spoken words via semantic integration (e.g., Kelly, Özyürek, & Maris, 2010; Özyürek, Willems, Kita, & Hagoort, 2007). It is also possible that – unlike co-speech gestures – phonological cues from ASL and from English within a code-blend can be combined to constrain lexical cohorts within each language. In fact, the finding that early bilinguals exhibited a larger facilitation effect for English than late bilinguals suggests that phonological integration may occur during code-blend comprehension. Specifically, we hypothesize that early bilinguals are better able to utilize early visual phonological information from ASL to constrain recognition of English.
In addition, our code-blend production experiment indicated that the retrieval of two lexical representations from two distinct languages occurs in parallel and is not a completely serial process. Equal RTs for ASL produced alone and in a code-blend argues against a pattern of serial retrieval in which English is retrieved before ASL. Furthermore, the ASL transition time analysis indicated that English was not retrieved after ASL (i.e., during the transition to sign onset). The fact that retrieval failures were significantly reduced for low-frequency ASL signs also argues against a pattern of serial retrieval in which English is retrieved after ASL because retrieval of the English word likely facilitated retrieval of the low-frequency ASL sign. Thus, partial serial access may occur when a lexical item in one language is more readily available, but the overall pattern of results indicates parallel lexical access during code-blend production.
The finding that simultaneous retrieval of translation equivalents is not costly is surprising, given theoretical characterizations of lexical selection as a competitive process (e.g., Levelt, Roelofs, & Meyer, 1999) and could be taken as evidence to support arguments against such competition. Although phonological representations are unlikely to compete for ASL-English bilinguals given modality differences across languages, lemma-level competition is certainly still possible (Pyers, Gollan, & Emmorey, 2009). However, Mahon, Costa, Peterson, Vargas, and Caramazza (2007) showed that selection of a target word did not become more difficult in the presence of highly similar distractor words in a series of picture-word interference experiments, and they argued that lexical selection therefore does not involve competition among semantically similar representations. At a minimum, our findings imply that the language system is either fully equipped with (or can be trained to develop) a mechanism for turning competition off to allow simultaneous selection and production of close competitors. We suggest that when biology does not force single language production for bilinguals, translation equivalents do not need to compete for selection and lexical retrieval is not slowed (at least not for the nondominant language) during simultaneous language production.
Code-blending did cause a modality-specific “cost” for spoken word production because speech was delayed in order to synchronize vocal and manual articulation. Thus, the articulators for signs and words within a code-blend are not independent of each other, but rather must be coupled such that lexical onsets are aligned. The fact that bimodal bilinguals preferred to coordinate lexical onsets in the absence of an addressee suggests that articulatory coordination is not accomplished primarily for the benefit of the perceiver. Instead, vocal-manual coordination appears to be driven by pressure to synchronize linguistic articulations during production.
In conclusion, code-blending is a commonly occurring linguistic behavior that is unique to bimodal bilinguals but that can also inform psycholinguistic models of language processing by uncovering both bottlenecks and facilitatory processes that occur when elements from two languages are produced and perceived simultaneously. Our results suggest that linguistic articulators must be coupled, that accessing and retrieving two highly related lexical representations is sometimes easier than retrieving just one, and thus that lexical selection is, or at least can be, a non-competitive process.
We examined the ability of bimodal bilinguals to simultaneously process signs and words
No processing costs for production suggests lexical access is non-competitive
Comprehension facilitation indicates cross-linguistic/cross-modal lexical integration
Acknowledgments
This research was supported by NIH Grant HD047736 awarded to Karen Emmorey and San Diego State University and NIH Grant HD050287 awarded to Tamar Gollan and the University of California San Diego. The authors thank Lucinda Batch, Helsa Borinstein, Shannon Casey, Rachael Colvin, Ashley Engle, Mary Kane, Franco Korpics, Heather Larrabee, Danielle Lucien, Lindsay Nemeth, Erica Parker, Danielle Pearson, Dustin Pelloni, and Jennie Pyers for assistance with stimuli development, data coding, participant recruitment, and testing. We thank Marcel Giezen for help with the statistical analyses in Experiment 2. We would also like to thank all of the ASL-English bilinguals, without whom this research would not be possible.
Footnotes
By convention, words in capital letters represent English glosses (the nearest equivalent translation) for ASL signs.
We also determined that for RT, interpreters did not differ significantly from non-interpreters and interpreting experience did not interact with naming condition or frequency. For error rate, interpreters were more accurate than non-interpreters for ASL, but no interactions between interpreter group and naming condition or frequency were significant.
Yes (edible) and No (non-edible) responses were collapsed in the analyses. Although consideration of response type revealed main effects of type of answer, with faster Yes than No responses (ps < .001), including response type as a variable did not alter the overall pattern of results.
As for Experiment 1, interpreting experience did not impact the results. In addition, interpreters did not differ significantly from non-interpreters for either RT or for error rate.
For this analysis, we adjusted the ASL RTs by subtracting the transition time to lexical onset, which is the only way to directly compare ASL and English RTs.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Karen Emmorey, Email: kemmorey@mail.sdsu.edu.
Jennifer Petrich, Email: jpetrich@projects.sdsu.edu.
Tamar H. Gollan, Email: tgollan@ucsd.edu.
References
- Alibali MW, Kita S, Young AJ. Gesture and the process of speech production: we think, therefore we gesture. Language and Cognitive Processes. 2000;15:593–613. [Google Scholar]
- Almeida J, Knobel M, Finkbeiner M, Caramazza A. The locus of the frequency effect in picture naming: When recognizing is not enough. Psychonomic Bulletin and Review. 2007;14(6):1177–1182. doi: 10.3758/bf03193109. [DOI] [PubMed] [Google Scholar]
- Baker A, van den Bogaerde B. Codemixing in signs and words in the input to and output from children. In: Plaza-Pust C, Morales Lopéz E, editors. Sign bilingualism: Language development, interaction, and maintenance in sign language contact situations. Amsterdam: Benjamins; 2008. pp. 1–27. [Google Scholar]
- Bates E, D’Amico S, Jacobsen T, Szekely A, Andonova E, Devescovi A, Herron D, Lu CC, Pechmann T, Pleh C, Wicha N, Federmeier K, Gerdjikova I, Gutierrez G, Hung D, Hsu J, Iyer G, Kohnert K, Mehotcheva T, Orozco-Figueroa A, Tzeng A, Tzeng O. Timed picture naming in seven languages. Psychonomic Bulleting and Review. 2003;10(2):344–380. doi: 10.3758/bf03196494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baus C, Gutiérrez-Sigut E, Quer J, Carreiras M. Lexical access in Catalan Signed Language (LSC) production. Cognition. 2008;108:856–865. doi: 10.1016/j.cognition.2008.05.012. [DOI] [PubMed] [Google Scholar]
- Bishop M. Unpublished doctoral dissertation. Gallaudet University; 2006. Bimodal bilingualism in hearing, native users of American Sign Language. [Google Scholar]
- Brentari D, Padden C. A lexicon of multiple origins: native and foreign vocabulary in American Sign Language. In: Brentari D, editor. Foreign vocabulary in sign languages: A cross-linguistic investigation of word formation. Mahwah, NJ: Lawrence Erlbaum Associates; 2001. pp. 87–119. [Google Scholar]
- Cohen JD, MacWhinney B, Flatt M, Provost J. PsyScope: A new graphic interactive environment for designing psychology experiments. Behavioral Research Methods, Instruments, and Computers. 1993;25(2):257–271. [Google Scholar]
- Costa A, Caramazza A. Is lexical selection in bilingual speech production language-specific? Further evidence from Spanish-English and English-Spanish bilinguals. Bilingualism: Language and Cognition. 1999;2(3):231–244. [Google Scholar]
- Costa A, Santesteban M. Lexical access in bilingual speech production: Evidence from language switching in highly proficient bilinguals and L2 learners. Journal of Memory and Language. 2004;50:491– 511. [Google Scholar]
- Dijkstra T. Bilingual visual word recognition and lexical access. In: Kroll J, De Groot AMB, editors. Handbook of bilingualism: Psycholinguistic approaches. Oxford University Press; 2005. pp. 179–201. [Google Scholar]
- Dijkstra A, Van Jaarsveld H, Ten Brinke S. Interlingual homograph recognition: Effects of task demands and language intermixing. Bilingualism: Language and Cognition. 1998;1:51–66. [Google Scholar]
- Duran G. Masters Thesis. The University of Texas; El Paso: 2005. Hearing and reading two languages at the same time. [Google Scholar]
- Duyck W, Warlop N. Translation priming between the native language and a second language: New evidence from Dutch-French bilinguals. Experimental Psychology. 2009;56(3):173–179. doi: 10.1027/1618-3169.56.3.173. [DOI] [PubMed] [Google Scholar]
- Emmorey K, Borinstein HB, Thompson R, Gollan TH. Bimodal bilingualism. Bilingualism: Language and Cognition. 2008;11(1):43–61. doi: 10.1017/S1366728907003203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Emmorey K, Borinstein HB, Thompson R. Bimodal bilingualism: Code-blending between spoken English and American Sign Language. In: Cohen J, McAlister K, Rolstad K, MacSwan J, editors. Proceedings of the 4th International Symposium on Bilingualism. Somerville, MA: Cascadilla Press; 2005. [Google Scholar]
- Emmorey K, Corina D. Lexical recognition in sign language: Effects of phonetic structure and morphology. Perceptual and Motor Skills. 1990;71:1227–1252. doi: 10.2466/pms.1990.71.3f.1227. [DOI] [PubMed] [Google Scholar]
- Frick-Hornbury D, Guttentag RE. The effects of restricting hand gesture production on lexical retrieval and free recall. The American Journal of Psychology. 1998;111(1):43–62. [Google Scholar]
- Gentilucci M, Dalla Volta R. Spoken language and arm gestures are controlled by the same motor control system. The Quarterly Journal of Experimental Psychology. 2008;61(6):944–957. doi: 10.1080/17470210701625683. [DOI] [PubMed] [Google Scholar]
- Gollan TH, Forster KI, Frost R. Translation priming with different scripts: Masked priming with cognates and non-cognates in Hebrew-English bilinguals. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1997;23:1122–1139. doi: 10.1037//0278-7393.23.5.1122. [DOI] [PubMed] [Google Scholar]
- Gollan TH, Montoya R, Cera C, Sandoval T. More use almost always means a smaller frequency effect: Aging, bilingualism, and the weaker links hypothesis. Journal of Memory and Language. 2008;58:787–814. doi: 10.1016/j.jml.2007.07.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grainger J, Beauvillian C. Language blocking and lexical access in bilinguals. Quarterly Journal of Experimental Psychology. 1987;39A:295–319. [Google Scholar]
- Green DW. Mental control of the bilingual lexico-semantic system. Bilingualism: Language and Cognition. 1998;1:67–81. [Google Scholar]
- Hernandez AE, Kohnert KJ. Aging and language switching in bilinguals. Aging, Neuropsychology, and Cognition. 1999;6:69–83. [Google Scholar]
- Hostetter AB, Alibali MW, Kita S. I see it n my hand’s eye: representational gestures are sensitive to conceptual demands. Language and Cognitive Processes. 2007;22(3):313–336. [Google Scholar]
- Kelly SD, Özyürek A, Maris E. Two sides of the same coin: Speech and gesture mutually interact to enhance comprehension. Psychological Science. 2010;21(2):260–267. doi: 10.1177/0956797609357327. [DOI] [PubMed] [Google Scholar]
- Kelso JAS. Dynamic patterns: The self-organization of brain and behavior. Cambridge, MA: The MIT Press; 1995. [Google Scholar]
- Krauss RM. Why do we gesture when we speak? Current Directions in Psychological Science. 1998;7(2):54.60. [Google Scholar]
- Krauss RM, Hadar U. The role of speech-related arm/hand gestures in word retrieval. In: Campbell R, Lessing L, editors. Gesture, Speech and Sign. Oxford University Press; 1999. pp. 93–116. [Google Scholar]
- Krentz UC, Corina DP. Preference for language in early infancy: the human language bias is not speech-specific. Developmental Psychology. 2008;11(1):1–9. doi: 10.1111/j.1467-7687.2007.00652.x. [DOI] [PubMed] [Google Scholar]
- Kroll J, Stewart E. Category interference in translation and picture naming: Evidence for asymmetric connections between bilingual memory representations. Journal of Memory and Language. 1994;33:149–174. [Google Scholar]
- Levelt WJM, Roelofs A, Meyer AS. A theory of lexical access in speech production. Behavioral and Brain Sciences. 1999;22:1–75. doi: 10.1017/s0140525x99001776. [DOI] [PubMed] [Google Scholar]
- Mahon BZ, Costa A, Peterson R, Vargas KA. Lexical selection is not by competition: A reinterpretation of semantic interference and facilitation effects in the picture-word interference paradigm. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2007;33(3):503–535. doi: 10.1037/0278-7393.33.3.503. [DOI] [PubMed] [Google Scholar]
- Mayberry R, Fischer S. Looking through phonological shape to sentence meaning: The bottleneck of non-native sigh language processing. Memory and Cognition. 1989;17:740–754. doi: 10.3758/bf03202635. [DOI] [PubMed] [Google Scholar]
- McNeill D. Hand and Mind: What Gestures Reveal about Thought. Chicago, IL: University of Chicago Press; 1992. [Google Scholar]
- Meuter RFI, Allport A. Bilingual language switching in naming: Asymmetrical costs of language selection. Journal of Memory and Language. 1999;40(1):25–40. [Google Scholar]
- Miller J. Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology. 1982;14(2):247. doi: 10.1016/0010-0285(82)90010-x. [DOI] [PubMed] [Google Scholar]
- Miller J. Timecourse of coactivation in bimodal divided attention. Perception & Psychophysics. 1986;40(5):331. doi: 10.3758/bf03203025. [DOI] [PubMed] [Google Scholar]
- Miller J, Ulrich R. Simple reaction time and statistical facilitation: A parallel grains model. Cognitive Psychology. 2003;46(2):101. doi: 10.1016/s0010-0285(02)00517-0. [DOI] [PubMed] [Google Scholar]
- Mitterer H, McQueen JM. Foreign subtitles help but native-language subtitles harm foreign speech perception. PLoS ONE. 2009;4(11):e7785. doi: 10.1371/journal.pone.0007785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morford JP, Carlson ML. Sign perception and recognition in non-native signers of ASL. Language learning and development. 2011;7:149–168. doi: 10.1080/15475441.2011.543393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morsella E, Krauss RM. The role of gestures in spatial working memory and speech. The American Journal of Psychology. 2004;117(3):411–424. [PubMed] [Google Scholar]
- Özyürek A, Willems RM, Kita S, Hagoort P. On-line integration of semantic information from speech and gesture: Insights from event-related brain potentials. Journal of Cognitive Neuroscience. 2007;19(4):605–616. doi: 10.1162/jocn.2007.19.4.605. [DOI] [PubMed] [Google Scholar]
- Padden C. The ASL lexicon. Sign Language & Linguistics. 1998;1(1):39–60. [Google Scholar]
- Petitto LA, Katerelos M, Levy BG, Gauna K, Tetreault K, Ferraro V. Bilingual signed and spoken language acquisition from birth: implications for the mechanisms underlying early bilingual language acquisition. Journal of Child Language. 2001;28(2):453–496. doi: 10.1017/s0305000901004718. [DOI] [PubMed] [Google Scholar]
- Pyers J, Gollan TH, Emmorey K. Bimodal bilinguals reveal the source of tip-of-the-tongue states. Cognition. 2009;112:323–329. doi: 10.1016/j.cognition.2009.04.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spencer RMC, Semjen A, Yang S, Ivry RB. An event-based account of coordination stability. Psychonomic Bulletin & Review. 2006;13(4):702–710. doi: 10.3758/bf03193984. [DOI] [PubMed] [Google Scholar]
- Székely A, D’Amico S, Devescovi A, Federmeier K, Herron D, Iyer G, et al. Timed picture naming extended norms and validation against previous studies. Behavioral Research Methods, Instruments, & Computers. 2003;35(4):621–633. doi: 10.3758/bf03195542. [DOI] [PubMed] [Google Scholar]
- Thomas MSC, Allport A. Language switching costs in bilingual visual word recognition. Journal of Memory and Language. 2000;43:43–46. [Google Scholar]