

Assembling objects from building blocks by means of predefined combination rules leads to combinatorial explosions. Indeed, it does not matter how many classes of building blocks or alternatives of combination rules are given, provided one of both is two or larger, because then the number of possible objects commonly increases exponentially with the number of elements and soon exceeds the realizations that can be sustained by taking together all available resources (for a few simple examples, see Fig. 1). Problems of this kind are encountered in biophysical chemistry when biopolymer molecules are built from several classes of monomers, in combinatorial chemistry when new molecules are formed through combination of several reactions, or in molecular genetics when regulation and control networks are considered. Thus, combinatorial explosion is a universal threat to biopolymer sequences and structures as well as reaction and controlling networks. Examples are known from biology, in particular metabolic, genetic, developmental, signaling, and neural networks. If this is true, how, then, can organized objects originate? Must not all processes that are not regulated externally end up in a highly diverse mess of molecular species, each one at best realized only in a few molecules? The frequently given answers invoke self-organization as a (universal) principle introducing order into diverse manifolds. In general, self-organization requires non-equilibrium conditions and some kind of self-enhancement. Both criteria are often fulfilled and commonly met in biology under realistic conditions. The main questions, nevertheless, remain: Which are the chemical driving forces or reaction mechanisms that shape organized networks: for example, those we see in nature? What limits the size, the diversity, and the complexity of chemical reaction networks or, in particular, what determines the properties of the ones that operate in living organisms?
Figure 1.

Examples of combinatorial explosion and a catalytic cycle reducing the numbers of possible objects. A shows polynucleotide sequences with increasing chain length n. The number of possibilities is 4n and thus increases exponentially with n. B presents the numbers of possible CmHnOp compounds, computed from simple minded combinatorial expressions assigning three, two, and one possibilities for introducing oxygen containing functions into CH3, CH2, and CH groups, respectively. Clearly, we see an indication of exponential increase. These numbers are compared with those derived in ref. 1 through selection of compounds suitable for a primitive metabolism in early evolution. C presents diagrams for interactions. Here we are dealing with a single class of elements represented by squares. The elements are coupled through their edges to the neighboring squares. We show possible patterns on a two-dimensional (square) lattice. The numbers of these patterns, related to “polyominoes” or “animals” defined in discrete mathematics, increase exponentially with the numbers of squares (2). D, ultimately, represents a cycle of catalytic reactions (3). The catalysts, the enzymes En, are synthesized from substrates Sn. Closure of the cycle leads to an autocatalytic ensemble. Self-enhancement discriminates against molecules that are not members of the cycle and reduces the numbers of possibilities.
Morowitz et al. (1) present in this issue of PNAS a study on the origin of intermediary metabolism that can be interpreted as an illustrative example of a new strategy reducing complexity and undesirable diversity. They start from the Beilstein, the well known source of information in organic chemistry, which represents the most comprehensive database of organic molecules and contains more than 3.5 million entries, and apply a small number of simple and plausible selection rules: (i) The compounds considered contain six or less carbon atoms combined with an arbitrary (or in principle unlimited) number of hydrogen and oxygen atoms.† (ii) Compounds showing too low solubility in water are eliminated. (iii) Compounds with heats of combustion exceeding a predefined threshold value are not considered. These three rules are readily converted into practically equivalent restrictions on the numbers and ratios of atoms, #C, #C/#O, and #H/#O. Then follows a combination of more specific rules (iv), which exclude structural elements that are characteristic of low stability in a prebiotic or biological scenario. These are radicals, energetically rich ions as well as molecules containing highly reactive bonds, C⩵C⩵C, C C, or O—O, respectively. The final result is a subset of 153 molecules, and, not unexpectedly, all members of the citric cycle are in this subset. In case no restrictions except the specific rules (iv) were made, the numbers of compounds would have been almost as large as 7,500 (Fig. 1).
It is worthwhile, nevertheless, to investigate critically and in detail the assumptions applied by Morowitz et al. (1). The selection rules used to reduce diversity are of differing characters. Rule i, the restriction to compounds containing six or fewer carbon atoms, is a plausible ad hoc assumption because the tricarboxylic acids appearing in the citric acid cycle contain six carbon atoms. It is, however, rather difficult to justify the assumption on the basis of chemical reaction kinetics because there are many processes with high efficiency and sufficiently high rate constants that lead to larger organic compounds, which are, nevertheless, soluble in water and have small enough heats of combustion. On the other hand, it is evident that larger molecules are generally more difficult to obtain from precursor C1-compounds. Rule i thus appears to be a kind of “best compromise” bridging insufficient knowledge on the frequency of chemical transformations among CmHnOp compounds and the data on current cellular metabolism. In contrast, the other two rules, ii and iii, have a firm physical and chemical basis in the context of prebiotic evolution and present day cellular biology. Sufficient solubility in aqueous solution is a conditio sine qua non for reaction partners in the cytoplasm. A high heat of combustion implies a large distance in free energy between the compound and its equivalent in (xCO2 + yH2O). Such a large free energy distance is a hardly surmountable obstacle for prebiotic synthesis from CO2, H2O, and reduction equivalents, which after all must occur without enzymatic catalysis. Rules i–iv reduce the numbers of organic molecules from somewhat less than 10,000 to 153. The remaining molecules are good candidates for the partners in prebiotic reaction networks, and, thus, Morowitz et al. (1) set the stage for modeling plausible precursors of present day core metabolism.
Early autotrophic organisms, like most present-day bacteria, were unable to perform photosynthesis. Then, the reductive citric acid cycle can serve as the major source of carbon compounds with two or more carbon atoms, which are synthesized through reduction of carbon dioxide. How could it be avoided that this synthesis ends up in a mess of thousands of compounds, each one present at very low concentration only? The reductive citric acid cycle is autocatalytic and can be formally written as ([C6H5O7]3− = citrate):
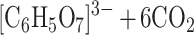 |
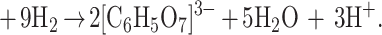 |
Autocatalytic reactions bind resources in the sense that they convert all available material into their products, and, thus, side reactions not belonging to the autocatalytic cycle are annihilated. Here the product is citrate, and it opens the pathway to a great variety of organic molecules. In other words, because of self-enhancement, the proposed cycle will canalize production of organic matter via its members. The reductive citric acid cycle, thus, represents a source of organic compounds, provided that enough reduction equivalents are available. This requires some early source of chemical energy that can be used for reducing carbon dioxide. Although the autocatalytic nature of the citric acid cycle is a convincing argument in favor of its role in a prebiotic scenario, we should keep in mind that the reactions are now carried out by highly specific proteins. At present, there is no clear experimental evidence that such a reaction cycle would work efficiently without enzyme catalysis. The paper by Morowitz et al. (1), nevertheless, identifies the molecular candidates for a metabolic reaction cycle in aqueous solution.
How could an early metabolism evolve toward the highly elaborate present-day reaction network? Or, in the sense of the initial question, how could evolution avoid being caught in “combinatorial explosion”? Let us consider two examples, one being a proposed mechanism of early evolution and the other an experimentally tested process, autocatalytic reaction networks (4–7), and replication induced by templates (3). Networks of catalytic reactions were introduced already in the 1960s and 1970s as models for self-organization of biological macromolecules as well as for genetic and epigenetic control (4–7). Independently of their possible role in early evolution, genetic regulatory networks became now a central issue in theoretical genome research (8–11). Reaction networks showing autocatalysis as an ensemble property were discussed as canalizing devices for the evolution of biopolymers (5, 6). The numbers of polymers, which play a role in such reaction networks, are drastically reduced through the occurrence of autocatalytic subsets. Thus, autocatalysis in the form of a reaction cycle is a possible strategy for taming combinatorial complexity, but there are more efficient and more powerful ways to do so. The “great invention of nature” is to reduce the catalytic cycle to one or two members. Autocatalysis is then a result of the logically simple but chemically difficult process of copying. Template induced synthesis is found with oligonucleotides (12) and oligopeptides (13). Oligo- and polynucleotides are ideal templates because their template action is built directly into the molecular structure and is independent of specific sequence requirements. Therefore, they may be characterized as obligatory templates. Polynucleotides are copied either directly or via an intermediate in the form of a uniquely defined negative copy. Template action of oligopeptides was found with specific sequences only, and, in this case, the capacity to perform autocatalysis is sequence-specific and thus “non-obligatory.” In particular, Reza Ghadiri's group (13) used sequences forming leucine zippers consisting of a ratchet-like arrangement of valine and leucine residues. After template-induced autocatalysis has been introduced, the numbers of alternatives are no longer important because self-enhancement and selection will lead automatically to a single or a few dominant species. Indeed, the exponentially exploding diversity of polynucleotides is not at all a restriction for the evolution of genes and genomes. In short, template-induced autocatalytic processes are excellent means for the taming of the combinatorial explosion.
A catalytic cycle, for example, the one shown in Fig.1D, as an ensemble behaves essentially like an autocatalyst. If a system contains several catalytic cycles, selection takes place between individual cycles and the result is again a drastic reduction in the diversity of molecular species. There are, however, two points that require attention: (i) The citric acid cycle is different from catalytic cycles shown in Fig.1D or discussed in refs. 3 and 5 because, in the former, the protein catalysts case are not synthesized through reactions within the cycle. (ii) Catalytic networks are non-obligatory autocatalysts like polynucleotide templates are. This means that mutations are not regularly conserved and produced further in the future by copying the variant template. Evolution of catalytic cycles is much more involved process than simple mutation (7). Coming back again to metabolic cycles, we remark that the evolution of specific catalysts for individual reactions is not intrinsic to the network. A metabolic cycle, like the citric acid cycle discussed in ref. 1, is a straightforward property of the entity carrying it, be it a functionally coupled ensemble or an organism. Because the enzymes are not synthesized through reactions within the cycle, they are not part of the set of molecules produced by the cycle. The enzymes, nevertheless, could be developed by the carrier of the cycle, and higher metabolic efficiency would be beneficial for the whole entity. After enzyme development came under control of a genetic regulatory system, the proteins could be improved by the conventional mechanics of mutation and selection. In other words, an early autonomous, eventually autocatalytic, precursor of the current citric acid cycle could evolve into the controlled core of present day metabolism through a gene regulated development of enzymes. What remains to be shown, however, is the existence and kinetic persistence of such a cycle of reactions without enzyme catalysis.
Footnotes
See companion article on page 7704.
The numbers of hydrogen and oxygen atoms are, of course, determined by the number of carbon atoms through the building principle of organic molecules (also see Fig. 1).
Article published online before print: Proc. Natl. Acad. Sci. USA, 10.1073/pnas.150237097.
Article and publication date are at www.pnas.org/cgi/doi/10.1073/pnas.150237097
References
- 1.Morowitz H J, Kostelnik J D, Yang J, Cody G D. Proc Natl Acad Sci USA. 2000;97:7704–7708. doi: 10.1073/pnas.110153997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Graham R L, Grötschel M, Lovász L, editors. Handbook of Combinatorics. Cambridge, MA: MIT Press; 1995. pp. 1938–1942. [Google Scholar]
- 3.Eigen M, Schuster P. Naturwissenschaften. 1977;64:541–565. doi: 10.1007/BF00450633. [DOI] [PubMed] [Google Scholar]
- 4.Kauffman S A. J Theor Biol. 1969;22:437–467. doi: 10.1016/0022-5193(69)90015-0. [DOI] [PubMed] [Google Scholar]
- 5.Kauffman S A. J Cybernetics. 1971;1:71–96. [Google Scholar]
- 6.Kauffman S A. The Origins of Order: Self-Organization and Selection in Evolution. Oxford: Oxford Univ. Press; 1993. [Google Scholar]
- 7.Frank S A. J Theor Biol. 1999;197:281–294. doi: 10.1006/jtbi.1998.0872. [DOI] [PubMed] [Google Scholar]
- 8.Thomas R, D'Ari R. Biological Feedback. Boca Raton FL: CRC; 1990. [Google Scholar]
- 9.Mestl T, Plahte E, Omholt S W. J Theor Biol. 1995;176:291–300. doi: 10.1006/jtbi.1995.0199. [DOI] [PubMed] [Google Scholar]
- 10.McAdams H H, Arkin A. Annu Rev Biophys Biomol Struct. 1998;27:199–224. doi: 10.1146/annurev.biophys.27.1.199. [DOI] [PubMed] [Google Scholar]
- 11.Mendoza L, Thieffry D, Alvarez-Buylla E R. Bioinformatics. 1999;15:593–606. doi: 10.1093/bioinformatics/15.7.593. [DOI] [PubMed] [Google Scholar]
- 12.Orgel L E. Nature (London) 1992;358:203–209. doi: 10.1038/358203a0. [DOI] [PubMed] [Google Scholar]
- 13.Lee D H, Granja J R, Martinez J A, Severin K, Ghadiri M R. Nature (London) 1996;382:525–528. doi: 10.1038/382525a0. [DOI] [PubMed] [Google Scholar]