

Abstract
In applications to dependent data, first and foremost relational data, a number of discrete exponential family models has turned out to be near-degenerate and problematic in terms of Markov chain Monte Carlo simulation and statistical inference. We introduce the notion of instability with an eye to characterize, detect, and penalize discrete exponential family models that are near-degenerate and problematic in terms of Markov chain Monte Carlo simulation and statistical inference. We show that unstable discrete exponential family models are characterized by excessive sensitivity and near-degeneracy. In special cases, the subset of the natural parameter space corresponding to non-degenerate distributions and mean-value parameters far from the boundary of the mean-value parameter space turns out to be a lower-dimensional subspace of the natural parameter space. These characteristics of unstable discrete exponential family models tend to obstruct Markov chain Monte Carlo simulation and statistical inference. In applications to relational data, we show that discrete exponential family models with Markov dependence tend to be unstable and that the parameter space of some curved exponential families contains unstable subsets.
Keywords: social networks, statistical exponential families, curved exponential families, undirected graphical models, Markov chain Monte Carlo
1 Introduction
We consider discrete exponential families (Barndorff-Nielsen 1978) with emphasis on applications to relational data (Wasserman and Faust 1994). Examples of relational data are social networks, terrorist networks, the world wide web, intra- and inter-organizational networks, trade networks, and cooperation and conflict between nations. A common form of relational data is discrete-valued relationships Yij between pairs of nodes i, j = 1, …, n. Let Y be the collection of relationships Yij given n nodes and
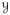 be the sample space of Y. Any distribution with support
can be expressed in exponential family form (Besag 1974, Frank and Strauss 1986). Discrete exponential families of distributions with support
were introduced by Frank and Strauss (1986), Wasserman and Pattison (1996), Snijders et al. (2006), Hunter and Handcock (2006), and others.
be the sample space of Y. Any distribution with support
can be expressed in exponential family form (Besag 1974, Frank and Strauss 1986). Discrete exponential families of distributions with support
were introduced by Frank and Strauss (1986), Wasserman and Pattison (1996), Snijders et al. (2006), Hunter and Handcock (2006), and others.
In terms of statistical computing, the most important obstacle is the fact that relational data tend to be dependent and discrete exponential families for dependent data come with intractable likelihood functions. Therefore, conventional maximum likelihood and Bayesian algorithms (e.g., Geyer and Thompson 1992, Snijders 2002, Handcock 2002a, Hunter and Handcock 2006, Møller et al. 2006, Koskinen et al. 2010) exploit draws from distributions with support
to maximize the likelihood function and explore the posterior distribution, respectively. As Markov chain Monte Carlo (MCMC) is the foremost means to generate draws from distributions with support
, MCMC is key to both simulation and statistical inference.
In practice, MCMC simulation from discrete exponential family distributions with support
has brought to light some serious issues: first, Markov chains may mix extremely slowly and hardly move for millions of iterations (Snijders 2002, Handcock 2003a); and second, the extremely slow mixing of Markov chains may be rooted in the stationary distribution: the stationary distribution may be near-degenerate in the sense of placing almost all probability mass on a small subset of the sample space
(Strauss 1986, Jonasson 1999, Snijders 2002, Handcock 2003a, Hunter et al. 2008, Rinaldo et al. 2009). The most troublesome observation, though, is that the subset of the natural parameter space corresponding to non-degenerate distributions may be a negligible subset of the natural parameter space. These troublesome observations raise at least two questions. First, why is the effective natural parameter space of some discrete exponential families (e.g., Frank and Strauss 1986) negligible, while the effective natural parameter space of others (e.g., the Bernoulli model, under which the Yij are i.i.d. Bernoulli random variables) is non-negligible? Second, which sufficient statistics can induce such problematic behavior?
Handcock (2002a, 2003a,b) adapted and extended results of Barndorff-Nielsen (1978, pp. 185–186) and pointed out that, as the natural parameters tend to the boundary of the natural parameter space, the probability mass is pushed to the boundary of the convex hull of the space of sufficient statistics (cf. Rinaldo et al. 2009, Geyer 2009, Koskinen et al. 2010). However, these results are applicable to both the Bernoulli model and Frank and Strauss (1986) and neither explain the striking contrast between them nor clarify which sufficient statistics can induce problematic behavior.
We introduce the notion of instability along the lines of statistical physics (Ruelle 1969) with an eye to characterize, detect, and penalize problematic discrete exponential families. Strauss (1986) was the first to observe that the problematic behavior of the discrete exponential families of Frank and Strauss (1986) is related to lack of stability of point processes in statistical physics (Ruelle 1969, p. 33). We adapt the notion of stability of point processes in the sense of Ruelle (1969, p. 33) to discrete exponential families and introduce the notions of unstable discrete exponential family distributions and unstable sufficient statistics. We show that unstable exponential family distributions are characterized by excessive sensitivity and near-degeneracy. In special cases, the subset of the natural parameter space corresponding to non-degenerate distributions and mean-value parameters far from the boundary of the mean-value parameter space turns out to be a lower-dimensional subspace of the natural parameter space. In applications to relational data, it turns out that the parameter space of exponential families with Markov dependence (Frank and Strauss 1986) tends to be unstable and that the parameter space of some curved exponential families (Snijders et al. 2006, Hunter and Handcock 2006) contains unstable subsets.
We introduce the notion of instability and its implications in Section 2, discuss its impact on MCMC simulation and statistical inference in Sections 3 and 4, respectively, and present applications to relational data and simulation results in Sections 5 and 6, respectively.
2 Instability, sensitivity, and degeneracy
Let YN be a discrete random variable with sample space
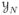 =
=
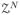 , where
, where
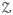 is a discrete set of M elements and N is the number of degrees of freedom. In applications to relational data (Wasserman and Faust 1994), YN may correspond to N ≤ n2 relationships among n nodes; in applications to spatial data (Besag 1974), N random variables located at N sites of a lattice; and in binomial sampling, N i.i.d. Bernoulli random variables.
is a discrete set of M elements and N is the number of degrees of freedom. In applications to relational data (Wasserman and Faust 1994), YN may correspond to N ≤ n2 relationships among n nodes; in applications to spatial data (Besag 1974), N random variables located at N sites of a lattice; and in binomial sampling, N i.i.d. Bernoulli random variables.
We consider discrete exponential families of distributions {Pθ, θ ∈ Θ} with probability mass functions of the form
| (1) |
where ηN: Θ ↦ ℝL is a vector of natural parameters and gN:
↦ ℝL is a vector of sufficient statistics,
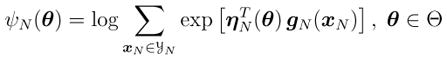 |
(2) |
is the cumulant generating function, and Θ = {θ ∈ ℝK: ψN(θ) < ∞} is the parameter space. The vector of natural parameters ηN(θ) may be a linear or non-linear function of parameter vector θ. If is a linear function of θ, where AN is a K × L matrix, the non-uniqueness of the canonical form of exponential families can be exploited to absorb AN into gN(yN), so that ηN(θ) = θ can be assumed without loss of generality. If ηN(θ) is a non-linear function of θ and K < L, the exponential family is curved (Efron 1978).
Let
, and IN(θ) = minyN∈
[qθ(yN)] and SN(θ) = maxyN∈
[qθ(yN)] be the minimum and maximum of qθ(yN), respectively. Since pθ(yN) is invariant to translations of qθ(yN) by −IN(θ), let IN(θ) = 0 without loss of generality.
Definition: stable, unstable distributions
A discrete exponential family distribution Pθ, θ ∈ Θ, is stable if there exist constants C > 0 and NC > 0 such that
| (3) |
and unstable if, for any C > 0, however large, there exists NC > 0 such that
| (4) |
In general, instability may be induced by ηN(θ) or gN(yN). In the important special case where ηN(θ) is a linear function of θ, in which case ηN(θ) = θ can be assumed without loss of generality, gN(yN) is the exclusive source of instability. Let ηN,k(θ) and gN,k(yN) be the k-th coordinate of ηN(θ) and gN(yN), respectively, LN,k = minyN∈
[gN,k(yN)] and UN,k = maxyN∈
[gN,k(yN)] be the minimum and maximum of gN,k(yN), respectively, and LN,k = 0 without loss of generality, owing to the invariance of pθ(yN) to translations of qθ(yN) by −ηN,k(θ) LN,k (k = 1, …, L).
Definition: stable, unstable sufficient statistics
A sufficient statistic gN,k(yN) is stable if there exists constants C > 0 and NC > 0 such that
| (5) |
and unstable if, for any C > 0, however large, there exists NC > 0 such that
| (6) |
While the notion of unstable discrete exponential families holds intuitive appeal, the parameter space Θ of most discrete exponential families of interest includes subsets indexing stable distributions. With a wide range of applications in mind, it is therefore preferable to study the characteristics of unstable sufficient statistics and unstable distributions and to detect in applications unstable sufficient statistics and subsets of Θ indexing unstable distributions. It is worthwhile to note that Handcock (2002a, b, 2003a) discussed an alternative, but unrelated notion of stability, calling discrete exponential families stable if small changes in natural parameters result in small changes of the probability mass function.
To demonstrate instability and its implications, we introduce two classic examples in Section 2.1. In Sections 2.2 and 2.3, we show that unstable exponential family distributions are characterized by excessive sensitivity and near-degeneracy.
2.1 Examples
A simple but common form of relational data is undirected graphs yN, where the relationships yij ∈ {0, 1} satisfy the linear constraints yij = yji (all i < j) and yii = 0 (all i), which reduces the number of degrees of freedom N from n2 to n(n−1)/2. Two classic models of undirected graphs are the Bernoulli model with natural parameter θ and stable sufficient statistic Σi<j yij and the 2-star model with natural parameter θ and unstable sufficient statistic Σi, j<k yijyik. The Bernoulli model arises from the assumption that the random variables Yij are i.i.d. Bernoulli (all i < j), while the 2-star model can be motivated by Markov dependence (Frank and Strauss 1986). The Bernoulli model implies SN(θ) = |θ|N and is therefore stable for all θ, while the 2-star model implies SN(θ) = |θ| (n − 2)N and is therefore unstable for all θ ≠ 0.
2.2 Instability and sensitivity
Unstable discrete exponential family distributions are characterized by excessive sensitivity.
Consider the smallest possible changes of yN, that is, changes of one element of yN, and let
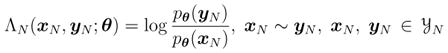 |
(7) |
be the log odds of pθ(yN) relative to pθ(xN), where xN ~ yN means that xN and yN are nearest neighbors in the sense that xN and yN match in all but one element. The following theorem shows that, if an exponential family distribution is unstable, then the probability mass function is characterized by excessive sensitivity in the sense that the nearest neighbor log odds are unbounded and therefore even the smallest possible changes can result in extremely large log odds.
Theorem 1
If a discrete exponential family distribution Pθ, θ ∈ Θ, is unstable, then there exist no constants C > 0 and NC > 0 such that
| (8) |
Theorem 1 implies that some, but not necessarily all, nearest neighbor log odds are unbounded. It indicates that the probability mass function is excessively sensitive to small changes in subsets of
and that some elements of
dominate others in terms of probability mass. A walk through
resembles a walk through a rugged, mountainous landscape: small steps in
can result in dramatic increases or decreases in probability mass. An example is given by the 2-star model of Section 2.1: for all θ ≠ 0, the nearest neighbor log odds satisfy |ΛN(xN, yN; θ)| ≤ 2 |θ| (n − 2) (all xN ~ yN) and are therefore O(n). The excessive sensitivity of the 2-star model is well-known (Handcock 2003a), but Theorem 1 indicates that all unstable exponential family distributions suffer from excessive sensitivity.
Section 3 shows that the unbounded nearest neighbor log odds of unstable exponential family distributions have a direct impact on MCMC simulation.
2.3 Instability and degeneracy
Discrete exponential family distributions with support
cannot be degenerate in the strict sense of the word. However, unstable discrete exponential family distributions turn out to be near-degenerate. Worse, in the important special case of discrete exponential families with unstable sufficient statistics, the subset of the natural parameter space corresponding to non-degenerate distributions turns out to be a lower-dimensional subspace of the natural parameter space.
Let
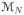 = {yN ∈
: qθ(yN) = SN(θ)} be the subset of modes and, for any 0 < ε < 1, let
= {yN ∈
: qθ(yN) = SN(θ)} be the subset of modes and, for any 0 < ε < 1, let
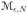 = {yN ∈
: qθ(yN) > (1 − ε) SN(θ)} be the subset of ε-modes of the probability mass function pθ(yN). The following theorem shows that unstable exponential family distributions tend to concentrate almost all probability mass on the modes of the probability mass function.
= {yN ∈
: qθ(yN) > (1 − ε) SN(θ)} be the subset of ε-modes of the probability mass function pθ(yN). The following theorem shows that unstable exponential family distributions tend to concentrate almost all probability mass on the modes of the probability mass function.
Theorem 2
If a discrete exponential family distribution Pθ, θ ∈ Θ, is unstable, then it is degenerate in the sense that, for any 0 < ε < 1, however small,
| (9) |
A related result was reported by Strauss (1986) and Handcock (2003a). In general, the fact that almost all probability mass tends to be concentrated on the modes of the probability mass function is troublesome: first, because the effective support, the subset of the support
with non-negligible probability mass, is reduced; and second, because in most applications the modes do not resemble observed data.
In the important special case of exponential families with unstable sufficient statistics, it is possible to gain more insight into near-degeneracy. Consider one-parameter exponential families {Pθ, θ ∈ Θ} with natural parameter ηN(θ) = θ and sufficient statistic gN(yN). Let LN = 0 (without loss of generality) and UN be the minimum and maximum of gN(yN), respectively, and, for any 0 < ε < 1, let
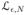 = {yN ∈
: gN(yN) < ε UN} and
= {yN ∈
: gN(yN) < ε UN} and
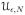 = {yN ∈
: gN(yN) > (1 − ε) UN} be the subset of the sample space
close to the minimum and maximum of gN(yN), respectively. The following result shows that one-parameter exponential families with unstable sufficient statistics gN(yN) tend to be degenerate with respect to gN(yN).
= {yN ∈
: gN(yN) > (1 − ε) UN} be the subset of the sample space
close to the minimum and maximum of gN(yN), respectively. The following result shows that one-parameter exponential families with unstable sufficient statistics gN(yN) tend to be degenerate with respect to gN(yN).
Theorem 3
A one-parameter exponential family {Pθ, θ ∈ Θ} with natural parameter θ and unstable sufficient statistic gN(yN) is degenerate with respect to gN(yN) in the sense that, for any 0 < ε < 1, however small, and for any θ < 0,
| (10) |
and, for any θ > 0,
| (11) |
Thus, the probability mass is pushed to the minimum of gN(yN) for all θ < 0 and the maximum of gN(yN) for all θ > 0, and the subset of the natural parameter space Θ corresponding to non-degenerate distributions is a lower-dimensional subspace of Θ: the point θ = 0. An example of a one-parameter exponential family with unstable sufficient statistic is given by the 2-star model of Section 2.1.
Consider K-parameter exponential families {Pθ, θ ∈ Θ} with natural parameters ηN,1(θ) = θ1, …, ηN,K(θ) = θK and K − 1 stable sufficient statistics gN,1(yN), …, gN,K−1(yN) as well as one unstable sufficient statistic gN,K(yN). In accordance with the preceding paragraph, let
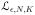 and
and
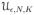 be the subset of the sample space
close to the minimum and maximum of the unstable sufficient statistic gN,K(yN), respectively. The following result shows that K-parameter exponential families with K − 1 stable and one unstable sufficient statistic tend to be degenerate with respect to the unstable sufficient statistic.
be the subset of the sample space
close to the minimum and maximum of the unstable sufficient statistic gN,K(yN), respectively. The following result shows that K-parameter exponential families with K − 1 stable and one unstable sufficient statistic tend to be degenerate with respect to the unstable sufficient statistic.
Theorem 4
A K-parameter exponential family {Pθ, θ ∈ Θ} with natural parameters θ1, …, θK and K − 1 stable sufficient statistics gN,1(yN), …, gN,K−1(yN) as well as one unstable sufficient statistic gN,K(yN) is degenerate with respect to gN,K(yN) in the sense that, for any 0 < ε < 1, however small, and for any θK < 0,
| (12) |
and, for any θK > 0,
| (13) |
In general, it is not straightforward to see where the probability mass of K-parameter exponential families with multiple unstable sufficient statistics ends up. In special cases, though, insight can be gained. Consider a K-parameter exponential family {Pθ, θ ∈ Θ} with natural parameters θ1, …, θK and sufficient statistics gN,1(yN), …, gN,K(yN), where gN,1(yN), …, gN,K−1(yN) may be unstable while gN,K(yN) is unstable and dominates gN,1(yN), …, gN,K−1(yN) in the sense that, for any D > 0, however large, there exists ND > 0 such that
| (14) |
A K-parameter exponential family with multiple unstable sufficient statistics, including an unstable, dominating sufficient statistic gN,K(yN), tends to be degenerate with respect to gN,K(yN).
Theorem 5
A K-parameter exponential family {Pθ, θ ∈ Θ} with natural parameters θ1, …, θK and sufficient statistics gN,1(yN), …, gN,K(yN), where gN,1(yN), …, gN,K−1(yN) may be unstable while gN,K(yN) is unstable and dominates gN,1(yN), …, gN,K−1(yN), is degenerate with respect to gN,K(yN) in the sense that, for any 0 < ε < 1, however small, and for any θK < 0,
| (15) |
and, for any θK > 0,
| (16) |
It is worthwhile to point out that whether most probability mass tends to be concentrated on one element of the sample space
and the entropy of the distribution tends to 0 depends on the sufficient statistics. An exponential family that is degenerate with respect to sufficient statistics is as degenerate as it can be.
As we will see in Section 4, the degeneracy of exponential families with unstable sufficient statistics tends to push the mean-value parameters to the boundary of the mean-value parameter space, which tends to obstruct statistical inference.
3 Impact of instability on MCMC simulation
If a Markov chain with unstable stationary distribution is constructed by MCMC methods, the excessive sensitivity and near-degeneracy of the stationary distribution tend to have a direct impact on MCMC simulation.
The excessive sensitivity of unstable stationary distributions, excessive in the sense that the nearest neighbor log odds are unbounded, affects the probabilities of transition between nearest neighbors: e.g., in applications to undirected graphs (cf. Section 2.1), Gibbs samplers sample elements yij from full conditional distributions of the form
| (17) |
where y−ij denotes the collection of elements yN excluding yij, and the log odds of πij(y−ij; θ) is given by
| (18) |
A Metropolis-Hastings algorithm moves from xN to yN, generated from a probability mass function f with support {yN: yN ~ xN}, with probability
| (19) |
Since the nearest neighbor log odds satisfy ΛN (xN, yN; θ) = −ΛN(yN, xN; θ) (all xN ~
yN) and are unbounded by Theorem 1, Markov chains with unstable stationary distributions can move extremely fast from some subsets of the sample space
to other subsets and extremely slowly back. In addition, if the mode of the probability mass function is not unique, multiple Markov chains may be required, because Theorems 1 and 2 indicate that one Markov chain may be trapped at one of the modes. Worse, Theorems 3 and 4 suggest that MCMC simulation from exponential families with unstable sufficient statistics may be a waste of time and resources in the first place.
The most important conclusion, though, is that mixing problems of MCMC algorithms tend to be rooted in the unstable stationary distribution rather than the design of the MCMC algorithms, as is evident from the unbounded nearest neighbor log odds and the near-degeneracy of unstable stationary distributions. A related result and conclusion was reported by Handcock (2003a).
4 Impact of instability on statistical inference
The degeneracy of exponential families with unstable sufficient statistics tends to push the mean-value parameters to the boundary of the mean-value parameter space and therefore tends to obstruct maximum likelihood estimation.
Let μN: Θ ↦ int(
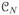 ) be the map from parameter space Θ to the mean-value parameter space int(
) (Barndorff-Nielsen 1978, p. 121) given by
) be the map from parameter space Θ to the mean-value parameter space int(
) (Barndorff-Nielsen 1978, p. 121) given by
| (20) |
where int(
) denotes the interior of the convex hull
of {gN(yN): yN ∈
}.
We start with one-parameter exponential families {Pθ, θ ∈ Θ} with natural parameter θ and unstable sufficient statistic gN(yN). Let LN = 0 (without loss of generality) and UN be the minimum and maximum of gN(yN), respectively, and
| (21) |
be the mean-value parameter, where re-scaling by 1/UN ensures that the range of μN(θ)/UN is (0, 1). The following result shows that one-parameter exponential families with unstable sufficient statistics gN(yN) push the mean-value parameter μN (θ) to its infinum for all θ < 0 and its supremum for all θ > 0.
Corollary 1
The mean-value parameter μN(θ) of a one-parameter exponential family {Pθ, θ ∈ Θ} with natural parameter θ and unstable sufficient statistic gN(yN) tends to the boundary of the mean-value parameter space in the sense that, for any θ < 0, however small,
| (22) |
and, for any θ > 0, however small,
| (23) |
By Corollary 1, the subset of the natural parameter space Θ corresponding to mean-value parameters far from the boundary of the mean-value parameter space tends to be a lower-dimensional subpace of Θ: the point θ = 0. In addition, the mean-value parameter μN(θ) can be expected to be extremely sensitive to changes of the natural parameter θ around 0.
The relationship between the natural parameter θ and the mean-value parameter μN(θ) is problematic in terms of maximum likelihood estimation. If gN(yN) ∈ int(
) denotes an observation in the interior of
, the maximum likelihood estimate of θ exists and is unique (Barndorff-Nielsen 1978, p. 150) and is given by the root of the estimating function
| (24) |
The estimating function δN(θ) depends on θ through μN(θ), and since μN(θ) tends to be extremely sensitive to changes of θ around 0, so does δN(θ). If the observation gN(yN) is not close to the boundary of
, the maximum likelihood estimate of θ tends to be close to 0, since only values of θ close to 0 map to values of μN(θ) which are not close to the boundary of
. As a result, maximum likelihood algorithms tend to search for the maximum likelihood estimate of θ in a small neighborhood of 0, but are hampered by the extreme sensitivity of the estimating function δN(θ) around θ = 0 and tend to make small steps in the natural parameter space Θ around θ = 0 and large steps in the mean-value parameter space int(
) and struggle to converge. A related result and conclusion was reported by Handcock (2003a).
The behavior of K-parameter exponential families {Pθ, θ ∈ Θ} with natural parameters θ1, …, θK and K − 1 stable sufficient statistics gN,1(yN),…, gN,K−1(yN) as well as one unstable sufficient statistic gN,K(yN) resembles the behavior of one-parameter exponential families with unstable sufficient statistic gN,K(yN). Let LN,K = 0 (without loss of generality) and UN,K be the minimum and maximum of the unstable sufficient statistic gN,K(yN), respectively, and
| (25) |
be the coordinate of the vector of mean-value parameters μN(θ) corresponding to gN,K(yN).
Corollary 2
The vector of mean-value parameters μN(θ) of a K-parameter exponential family {Pθ, θ ∈ Θ} with natural parameters θ1, …, θK and K − 1 stable sufficient statistics gN,1(yN), …, gN,K−1(yN) as well as one unstable sufficient statistic gN,K(yN) tends to the boundary of the mean-value parameter space in the sense that, for any θK < 0, however small,
| (26) |
and, for any θK > 0, however small,
| (27) |
To conclude, while some maximum likelihood algorithms may outperform others, Corollaries 1 and 2 indicate that all maximum likelihood algorithms can be expected to suffer from degeneracy with respect to sufficient statistics (cf. Handcock 2003a, Rinaldo et al. 2009).
5 Applications to relational data
The intention of the present section is to detect unstable subsets of the parameter space of discrete exponential families, because unstable discrete exponential family distributions are characterized by excessive sensitivity and near-degeneracy (cf. Section 2), which tends to obstruct MCMC simulation (cf. Section 3) as well as statistical inference (cf. Section 4).
We focus on applications to relational data, but note that in applications to lattice systems (Besag 1974) and binomial sampling, exponential family models (with suitable neighborhood assumptions) tend to be stable (Ruelle 1969). We consider undirected graphs and the most widely used exponential family models of undirected graphs, so-called exponential family random graph models (ERGMs) with Markov dependence and curved exponential family random graph models (curved ERGMs). It is worthwhile to note that the number of degrees of freedom N is O(n2) and is therefore large even when the number of nodes n is small, suggesting that the large-N results of Sections 2–4 shed light on the behavior of ERGMs even when n is not large.
A simple and appealing class of ERGMs with Markov dependence (Frank and Strauss 1986) is given by
| (28) |
where sN,k(yN) = Σi, j1<…<jk yij1 · · ·yijk is the number of k-stars (k = 1, …, n − 1) and Σi<j<k yijyjkyik is the number of triangles. Since the number of natural parameters of (28) is n, it is common to impose linear or non-linear constraints on the natural parameters of (28) with an eye to reduce the number of parameters to be estimated. The following ERGMs are special cases of (28) obtained by imposing suitable linear constraints on the natural parameters of (28).
Result 1
ERGMs with 2-star terms of the form
| (29) |
are unstable for all θ2 ≠ 0.
Result 2
ERGMs with triangle terms of the form
| (30) |
are unstable for all θ2 ≠ 0.
Results 1 and 2 are in line with existing results: both ERGMs are known to be near-degenerate and problematic in terms of MCMC simulation and statistical inference (Strauss 1986, Jonasson 1999, Snijders 2002, Handcock 2003a, Rinaldo et al. 2009). The most striking conclusion is that in both cases the subset of the natural parameter space ℝ2 corresponding to non-degenerate distributions is a lower-dimensional subspace of ℝ2: the line (θ1, 0). In terms of MCMC, the nearest neighborhood log odds |ΛN(xN, yN; θ)| are O(n), which suggests that MCMC algorithms tend to suffer from extremely slow mixing, as is well-known (Snijders 2002, Handcock 2002a, 2003a).
To reduce the problematic behavior of ERGMs of the form (29) and (30), it has sometimes been suggested to counterbalance positive instability-inducing terms by negative instability-inducing terms.
Result 3
ERGMs with 2-star and triangle terms of the form
| (31) |
are unstable for all θ2 and θ3 excluding θ2 = θ3 = 0 and θ2 = − θ3/3.
Result 3 demonstrates that counterbalancing instability-inducing terms does not, in general, work: the subset of ℝ3 corresponding to non-degenerate distributions is severely constrained by the linear constraints θ2 = θ3 = 0 and θ2 = − θ3/3.
We turn to the curved ERGMs of Snijders et al. (2006) and Hunter and Handcock (2006), which were motivated by the problematic behavior of ERGMs with Markov dependence. Three of the best-known curved ERGM terms are geometrically weighted degree (GWD), geometrically weighted dyadwise shared partner (GWDSP), and geometrically weighted edgewise shared partner (GWESP) terms (cf. Hunter et al. 2008).
Result 4
Curved ERGMs with GWD terms of the form
| (32) |
where DN,k(yN) is the number of nodes i with degree Σj≠i yij = k, are unstable for all θ2 ≠ 0 and θ3 < −log 2.
Result 5
Curved ERGMs with GWDSP terms of the form
| (33) |
where DSPN,k(yN) is the number of pairs of nodes {i, j} with Σh≠i,j yihyjh = k dyadwise shared partners, are unstable for all θ2 ≠ 0 and θ3 < −log 2.
Result 6
Curved ERGMs with GWESP terms of the form
| (34) |
where ESPN,k(yN) is the number of pairs of nodes {i, j} with yijΣh≠i,j yihyjh = k edgewise shared partners, are unstable for all θ2 ≠ 0 and θ3 < −log 2.
Thus, the parameter space of curved ERGMs with GWD, GWDSP, and GWESP terms contains unstable subsets. In terms of MCMC, in unstable subsets of the parameter space the curved ERGMs tend to be worse than the ERGMs with Markov dependence: if θ2 ≠ 0 and θ3 < −log 2, the nearest neighborhood log odds |ΛN(xN, yN; θ)| are O(exp[n]). On the other hand, the curved ERGMs with GWD, GWDSP, and GWESP terms are stable provided θ2 ≠ 0 and θ3 ≥ −log 2, which is encouraging and indicates that the effective parameter space is non-negligible, in contrast to ERGMs with Markov dependence. The unstable subsets of the parameter space of curved ERGMs should be penalized by specifying suitable penalties in a maximum likelihood framework and suitable priors in a Bayesian framework.
6 Simulation results
To demonstrate that unstable discrete exponential family distributions are characterized by excessive sensitivity and near-degeneracy (cf. Section 2) and tend to obstruct MCMC simulation (cf. Section 3) and statistical inference (cf. Section 4), we resort to MCMC simulation of undirected graphs with n = 32 nodes and N = 496 degrees of freedom from the ERGMs of Results 1–6 (cf. Section 5). Since the computational cost of MCMC simulation is prohibitive, we exploit the fact that Results 1–6 hold regardless of the value of θ1, the natural parameter corresponding to the sufficient statistic Σi<j yij, and fix the value of θ1 at −1 and the value of θ2 of the ERGMs of Results 3–6 at 1. For every ERGM and every non-fixed parameter, we consider 200 values in the interval [−5, 5]. At every such value, we generate an MCMC sample of size 2,000,000, discarding 1,000,000 draws as burn-in and recording every 1,000th post-burn-in draw. The MCMC samples were generated by a Metropolis-Hastings algorithm of the form (19) (Hunter et al. 2008).
We start with two classic examples: the Bernoulli model with stable sufficient statistic gN(yN) = Σi<j yij and the 2-star model with unstable sufficient statistic gN(yN) = Σi, j<k yijyik (cf. Section 2.1). Figure 1 plots the MCMC sample estimates of the mean-value parameters μN(θ) = Eθ [gN(YN)] of these models against the corresponding natural parameters θ. The MCMC sample estimate of the mean-value parameter μN(θ) of the Bernoulli model is close to the exact value μN(θ) = N/(1+exp[−θ]) (within two standard deviations of the sample average based on random samples of size 1,000), demonstrating that MCMC simulation from the Bernoulli model is hardly problematic. The MCMC sample estimate of the mean-value parameter μN(θ) of the 2-star model is, in line with Corollary 1, close to its infinum for all θ < 0 and close to its supremum for all θ > 0, and extremely sensitive to small changes of θ around 0.
Figure 1.

MCMC sample estimate of mean-value parameter μN(θ) plotted against natural parameter θ of Bernoulli model and 2-star model, where CN ensures that the range of μN(θ)/CN is (0, 1); shaded regions indicate unstable regions
The ERGMs with Markov dependence (Results 1–3) are expected to be degenerate with respect to the unstable sufficient statistics, the number of 2-stars (Result 1), the number of triangles (Result 2), and the number of triangles (Result 3 with 2-star parameter equal to 1), and the corresponding mean-value parameters are expected to be close to the boundary of the mean-value parameter space. Figure 2 plots the proportion of 2-stars (Result 1) and triangles (Results 2 and 3) against the corresponding natural parameter and confirms these considerations.
Figure 2.

MCMC sample proportion of 2-stars (Result 1) and triangles (Results 2 and 3) plotted against corresponding natural parameter; shaded regions indicate unstable regions
Concerning the curved ERGMs with GWD, GWDSP, and GWESP terms (Results 4–6), since the number of sufficient statistics is linear in n, we focus on the sufficient statistic Σi<j yij, one of the most fundamental functions of undirected graphs yN. We take the coefficient of variation CVN, defined as the standard deviation of Σi<j yij divided by the mean of Σi<j yij, as an indicator of mixing and near-degeneracy: low coefficients of variation indicate slow mixing and near-degeneracy. We divide the coefficients of variation CVN by the coefficient of variation CVN(Bernoulli) under the corresponding ERGM with θ1 = −1 and θ2 = 0, which corresponds to the Bernoulli model of Section 2.1 with θ = −1. Figure 3 plots the MCMC sample coefficients of variation CVN/CVN(Bernoulli) against the critical parameter θ3 of the ERGMs of Results 4–6. The simulation results indicate that in the unstable subset of the parameter space, corresponding to θ3 < −log 2, the coefficients of variation are close to 0, as expected, and around θ3 = −log 2, the coefficients of variation rise to a value comparable to the coefficient of variation CVN(Bernoulli) under the corresponding Bernoulli model.
Figure 3.

MCMC sample coefficient of variation CVN of curved ERGM with GWD term (Result 4), GWDSP term (Result 5), and GWESP term (Result 6), re-scaled by 1/CVN(Bernoulli); shaded regions indicate unstable regions
7 Discussion
Building on the work of Strauss (1986) and Handcock (2002a, 2003a,b), we have introduced the notion of instability and shown that unstable discrete exponential family distributions are characterized by excessive sensitivity and near-degeneracy. In the important special case of exponential families with unstable sufficient statistics, the subset of the natural parameter space corresponding to non-degenerate distributions and mean-value parameters far from the boundary of the mean-value parameter space turns out to be a lower-dimensional subspace of the natural parameter space. These characteristics of instability tend to obstruct MCMC simulation and statistical inference. In applications to relational data, we find that exponential families with Markov dependence tend to be unstable and that the parameter space of some curved exponential families contains unstable subsets. We conclude that unstable subsets of the parameter space of curved exponential families should be penalized by specifying suitable penalties in a maximum likelihood framework and suitable priors in a Bayesian framework.
It is worthwhile to point out that, while instability implies undesirable behavior such as near-degeneracy, stability is not—and cannot be—an insurance against near-degeneracy. Indeed, every discrete exponential family, with or without unstable sufficient statistics, includes near-degenerate distributions provided the natural parameters are sufficiently large (cf. Barndorff-Nielsen 1978, pp. 185–186, Handcock 2002a, 2003a,b). In addition, while unstable sufficient statistics can be stabilized, there are good reasons to be sceptical of simple stabilization strategies. Consider one-parameter exponential families with natural parameter θ and unstable sufficient statistic gN(yN). The unstable sufficient statistic gN(yN) can be transformed into the stable sufficient statistic gN(yN)/UN by dividing gN(yN) by its maximum UN. Since the canonical form of exponential families is not unique (Brown 1986, pp. 7–8), mapping gN(yN) to gN(yN)/UN is equivalent to mapping θ to θ/UN and can therefore be regarded as a reparameterization of the exponential family with unstable sufficient statistic gN(yN). Let ηN(θ) = θ/UN. By the parameterization invariance of maximum likelihood estimators, the maximum likelihood estimators θ̂ and of θ respectively ηN(θ) satisfy θ̂ = η̂N UN. The probability of data under the maximum likelihood estimator is the same under both parameterizations. The simple stabilization strategy therefore fails to address the problem of lack of fit: even under the maximum likelihood estimator, the probability of data may be extremely low relative to other elements of the sample space and the fit of the model thus unacceptable (cf. Hunter et al. 2008). The argument extends to K-parameter exponential families and linear transformations of sufficient statistics (Brown 1986, pp. 7–8).
Last, while the conditions under which maximum likelihood estimators of discrete exponential families for dependent data exist and are unique are well-understood (cf. Barndorff-Nielsen 1978, p. 151, Handcock 2002a, 2003a,b, Rinaldo et al. 2009), it is an open question which conditions ensure consistency and asymptotic normality of maximum likelihood estimators (cf. Hunter and Handcock 2006, Rinaldo et al. 2009). An anonymous referee suggested semi-group structure (cf. Lauritzen 1988, pp. 140–146). Semi-group structure implies stability and holds promise.
Acknowledgments
Support is acknowledged from the Netherlands Organisation for Scientific Research (NWO grant 446-06-029), the National Institute of Health (NIH grant 1R01HD052887-01A2), and the Office of Naval Research (ONR grant N00014-08-1-1015). The author is grateful to David Hunter and two anonymous referees for stimulating questions and suggestions.
A Appendix: proofs
Proof of Theorem 1
We prove Theorem 1 by contradiction. Given an unstable discrete exponential family distribution, suppose that there exist C > 0 and NC > 0 such that
| (35) |
Consider a given N ≥ 1. Let aN ∈ {yN ∈
: qθ(yN) = IN(θ)} and bN ∈ {yN ∈
: qθ(yN) = SN(θ)}, and let KN ≤ N be the number of non-matching elements of aN and bN. By changing the non-matching elements of aN and bN one by one, it is possible to go from aN to bN within KN ≤ N steps. Let yN,0, yN,1, …, yN,KN−1, yN,KN be a path from aN to bN such that yN,0 = aN and yN,KN = bN and yN,k−1 ~ yN,k (k = 1, …, KN). By Jensen’s inequality and (35), there exist C > 0 and NC > 0 such that, for any N > NC,
| (36) |
The left-hand side of (36) is, by definition of aN and bN, given by
| (37) |
Thus, (35) implies that there exist C > 0 and NC > 0 such that
| (38) |
which contradicts the assumption of instability.
Proof of Theorem 2
For any 0 < δ < ε < 1, however small, and any N ≥ 1,
| (39) |
using the fact that
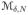 contains at least one element, and
contains at least one element, and
| (40) |
using the fact that
\
contains at most exp[N logM] −1 < exp[N logM] elements. Thus, the log odds of Pθ(YN ∈
) is given by
| (41) |
By instability, for any C > 0, however large, there exists NC > 0 such that
| (42) |
Since ε − δ > 0 and C > 0 can be as large as desired, ωε, N → ∞ as N → ∞ and (9) holds.
Proof of Theorems 3 and 4
We prove Theorem 4, since Theorem 3 can be considered to be a special case of Theorem 4.
Case 1: θK < 0. For any 0 < δ < ε < 1, however small, and any N ≥ 1,
| (43) |
and
| (44) |
Thus, the log odds of Pθ(YN ∈
) is given by
| (45) |
Since −θK > 0, ε − δ > 0, and the sufficient statistic gN,K(yN) is unstable, the term −θK (ε − δ) UN,K on the right-hand side of (45) is positive and not bounded by N, while the stability of the sufficient statistics gN,1(yN), …, gN,K−1(yN) implies that the other terms on the right-hand side of (45) are bounded by N. Thus, for any θK < 0, ωε,N,K → ∞ as N → ∞ and (12) holds.
Case 2: θK > 0. The case θK > 0 proceeds along the same lines as the case θK < 0, mutatis mutandis, to show that (13) holds.
Proof of Theorem 5
A proof of Theorem 5 proceeds along the same lines as the proof of Theorem 4, with the exception that the sufficient statistics gN,1(yN), …, gN,K−1(yN) may be unstable but are dominated by the unstable sufficient statistic gN,K(yN).
Proof of Corollaries 1 and 2
We prove Corollary 2, since Corollary 1 can be considered to be a special case of Corollary 1.
Case 1: θK < 0. For any 0 < γ < 1, however small, and any N ≥ 1, one can partition the sample space
into the subsets
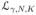 and
\
. Therefore,
and
\
. Therefore,
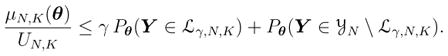 |
(46) |
By Theorem 4, for any 0 < δ < 1, however small, and any θK < 0, there exists Nδ > 0 such that
| (47) |
Since γ and δ can be as small as desired, (26) holds.
Case 2: θK > 0. The case θK > 0 proceeds along the same lines as the case θK < 0, mutatis mutandi, to show that (27) holds.
Proof of Results 1–6
Let 0N be the empty graph (0ij = 0, all i < j) and 1N be the complete graph (1ij = 1, all i < j) given n nodes and N = n(n − 1)/2 degrees of freedom. For every ERGM of Results 1–6, every θ ∈ Θ, and every n > 1, qθ(0N) = 0 and
| (48) |
Therefore, all θ ∈ Θ such that |qθ(1N)| is not bounded by N give rise to unstable distributions Pθ, proving Results 1–6.
References
- Barndorff-Nielsen OE. Information and Exponential Families in Statistical Theory. New York: Wiley; 1978. [Google Scholar]
- Besag J. Spatial interaction and the statistical analysis of lattice systems. Journal of the Royal Statistical Society, Series B. 1974;36:192–225. [Google Scholar]
- Brown L. Fundamentals of Statistical Exponential Families: With Applications in Statistical Decision Theory. Hayworth, CA, USA: Institute of Mathematical Statistics; 1986. [Google Scholar]
- Efron B. The geometry of exponential families. Annals of Statistics. 1978;6:362–376. [Google Scholar]
- Frank O, Strauss D. Markov graphs. Journal of the American Statistical Association. 1986;81:832–842. [Google Scholar]
- Geyer CJ. Likelihood inference in exponential families and directions of recession. Electronic Journal of Statistics. 2009;3:259–289. [Google Scholar]
- Geyer CJ, Thompson EA. Constrained Monte Carlo maximum likelihood for dependent data. Journal of the Royal Statistical Society, Series B. 1992;54:657–699. [Google Scholar]
- Handcock M. Degeneracy and inference for social network models. Paper presented at the Sunbelt XXII International Social Network Conference; New Orleans, LA. 2002a. [Google Scholar]
- Handcock M. Degeneracy and inference for social network models. Paper presented at the Joint Statistical Meetings; New York, NY. 2002b. [Google Scholar]
- Handcock M. Tech rep. Center for Statistics and the Social Sciences, University of Washington; 2003a. Assessing degeneracy in statistical models of social networks. http://www.csss.washington.edu/Papers. [Google Scholar]
- Handcock M. Statistical Models for Social Networks: Inference and Degeneracy. In: Breiger R, Carley K, Pattison P, editors. Dynamic Social Network Modeling and Analysis: Workshop Summary and Papers. Washington, D.C: National Academies Press; 2003b. [Google Scholar]
- Hunter DR, Goodreau SM, Handcock MS. Goodness of fit of social network models. Journal of the American Statistical Association. 2008;103:248–258. [Google Scholar]
- Hunter DR, Handcock MS. Inference in curved exponential family models for networks. Journal of Computational and Graphical Statistics. 2006;15:565–583. [Google Scholar]
- Hunter DR, Handcock MS, Butts CT, Goodreau SM, Morris M. ergm: A Package to Fit, Simulate and Diagnose Exponential-Family Models for Networks. Journal of Statistical Software. 2008;24:1–29. doi: 10.18637/jss.v024.i03. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jonasson J. The random triangle model. Journal of Applied Probability. 1999;36:852–876. [Google Scholar]
- Koskinen JH, Robins GL, Pattison PE. Analysing exponential random graph (p-star) models with missing data using Bayesian data augmentation. Statistical Methodology. 2010;7:366–384. [Google Scholar]
- Lauritzen SL. Extremal Families and Systems of Sufficient Statistics. Heidelberg: Springer; 1988. [Google Scholar]
- Møller J, Pettitt AN, Reeves R, Berthelsen KK. An efficient Markov chain Monte Carlo method for distributions with intractable normalising constants. Biometrika. 2006;93:451–458. [Google Scholar]
- Rinaldo A, Fienberg SE, Zhou Y. On the geometry of discrete exponential families with application to exponential random graph models. Electronic Journal of Statistics. 2009;3:446–484. [Google Scholar]
- Ruelle D. Statistical mechanics Rigorous results. London and Singapore: Imperial College Press and World Scientific; 1969. [Google Scholar]
- Snijders TAB. Markov chain Monte Carlo Estimation of exponential random graph models. Journal of Social Structure. 2002;3:1–40. [Google Scholar]
- Snijders TAB, Pattison PE, Robins GL, Handcock MS. New specifications for exponential random graph models. Sociological Methodology. 2006;36:99–153. [Google Scholar]
- Strauss D. On a general class of models for interaction. SIAM Review. 1986;28:513–527. [Google Scholar]
- Wasserman S, Faust K. Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press; 1994. [Google Scholar]
- Wasserman S, Pattison P. Logit Models and Logistic Regression for Social Networks: I. An Introduction to Markov Graphs and p*. Psychometrika. 1996;61:401–425. [Google Scholar]