

Abstract
We investigate the dynamic relationship between residential choices of individuals and resulting long-term aggregate segregation patterns, allowing for feedback effects of macrolevel neighborhood conditions on residential choices. We reinterpret past survey data on whites’ attitudes about desired neighborhoods as revealing large heterogeneity in whites’ tolerance of black neighbors. Through agent-based modeling, we improve on a previous model of residential racial segregation by introducing individual-level heterogeneity in racial tolerance. Our model predicts, in the long run, a lower level of residential racial segregation than would be true with homogeneous racial tolerance. Further analysis shows that whites’ tolerance of black neighbors is closely associated with their overall racial attitudes toward blacks.
Keywords: population heterogeneity, Schelling model, Guttman scale, Detroit Area Study, segregation index
Racial residential segregation is an enduring social phenomenon in American society that has a negative impact on the black population (1). One proximate cause of this phenomenon is whites’ widespread attitude of preferring not to live in the same neighborhoods with blacks (2, 3). Although there are signs that racial residential segregation has lessened in recent decades, it remains very strong in many American metropolitan areas today (4). A common measure of segregation is the dissimilarity index (denoted as D), with 0 representing no segregation and 1 representing complete segregation. According to the latest data from the 2010 US decennial census, blacks and whites are still severely segregated in many large metropolitan areas, with D exceeding 0.7 in Detroit, Milwaukee, New York, Newark, Chicago, Philadelphia, Miami, Cleveland, and St. Louis (5). If racial segregation results from whites’ racially based residential preferences, do these very high levels of racial residential segregation indicate whites’ strong opposition to having blacks as neighbors?
This is not necessarily the case. In a highly influential work, Thomas Schelling (6, 7) demonstrated that even a very mild ingroup preference for one’s racial group not making up less than 50% of the population in a neighborhood could lead to a high level of racial segregation in the aggregate through a dynamic process. When a white family moves from one neighborhood to another, for example, it changes the racial composition of both the origin neighborhood (i.e., making it slightly less white) and the destination neighborhood (i.e., making it slightly whiter), and these changes in neighborhood racial composition could cause other families to move in response. Thus, severe racial segregation may result even though the population does not have a strong race-based preference.
Demonstrated with coins and graph paper, Schelling’s model was simple. However, it proved powerful in illustrating that small individual preferences can lead to the unexpected emergence of severe segregation in a population. Schelling’s model contained two important features that make it a crude precursor to today’s agent-based modeling (ABM) that relies on modern computers (8). First, each individual’s residential behavior affects the surrounding environment through “feedback.” Second, accumulation of individuals’ small-scale behaviors leads to dramatic social outcomes through “micro-macro interaction.” Recently, with the aid of modern computing techniques, the robustness of Schelling’s remarkable finding has been shown with various modifications (9–15). An analytical model has been developed to understand conditions under which stable segregation, as in Schelling’s model, would result in equilibrium (16).
Of the several ABM implementations of the Schelling model, the study by Bruch and Mare (13, 15), henceforth referred to as the Bruch–Mare study, is notable for its attempt to incorporate survey data on residential preference. For simplicity of illustration, Schelling originally assumed that neither whites nor blacks would want to live in a neighborhood in which their racial group makes up less than 50% of the total population. Obviously, such a preference model, with a sharp threshold at 50%, is unrealistic. To improve the Schelling model with more realism, the Bruch–Mare study used survey data in two Detroit area studies (DAS) on residential preferences for neighborhoods with different racial compositions. Instead of a threshold, it was found that the preference function depends, continuously, on neighborhood racial composition. As will be discussed below, the DAS data reveal that whites’ preferences for neighborhoods decline monotonically with the proportion of blacks in a neighborhood.
The Bruch–Mare study assumed, within each race, a homogeneous preference function and estimated the function with the DAS survey data. Thus, the Bruch–Mare study, as in the original Schelling model, assumed a representative agent, the typical decision maker, for each race. Under this assumption, all agents in a population act in probabilistically the same way in a given situation. What differs among them is their circumstances rather than their intrinsic differences. The same preference function applies to all agents of the same race.
In this paper, we extend the Bruch–Mare study by relaxing this unrealistic assumption. Indeed, it has been long known in the literature on racial residential segregation that individuals’ neighborhood preferences vary greatly, with some whites being willing to tolerate some representation of black neighbors (2, 6, 17, 18). We capitalize on this knowledge and empirically estimate the heterogeneity of whites’ attitudes toward having black neighbors, using survey data collected in four large metropolitan areas (Detroit, Atlanta, Los Angeles, and Boston). We present the results on the heterogeneity of whites’ neighborhood preferences in Section 1. In Section 2, we use the estimated heterogeneity pattern in whites’ neighborhood preferences in an extended ABM to explore its long-term implications for racial residential segregation. In Section 3, we estimate social determinants of the heterogeneity of whites’ neighborhood preferences. Section 4 concludes.
1. Heterogeneity of Whites’ Neighborhood Preferences
Between 1992 and 1994, the Multi-City Study of Urban Inequality (MCSUI) conducted coordinated social surveys in four large metropolitan areas: Detroit, Atlanta, Los Angeles, and Boston. The Detroit part of the MCSUI was also the 1992 DAS. A major mission of the MCSUI was to understand racial attitudes and racial residential segregation in contemporary urban America. Adult respondents (21 y of age and older) in census tracts with varying rates of poverty were interviewed in their homes by trained interviewers. More than 8,900 household interviews were completed in the four metropolitan areas.
The MSCUI asked white respondents to express their willingness to live in five hypothetical neighborhoods with a varying representation of blacks: 0, 1, 3, 5, and 8 of 14 immediate neighbors. The actual graphic representations of the five hypothetical neighborhoods is presented in column 2 of Table 1, along with the corresponding proportions of blacks in column 3. The respondent was told that he or she had been looking for a house and had found an attractive and affordable one in the middle of the hypothetical neighborhood. The respondent was then asked if he or she would move into this house. The percentage of white respondents willing to move into each type of neighborhood, as an indicator of whites’ neighborhood preferences, is given in the subsequent four columns for the four metropolitan areas.
Table 1.
MSCUI results on whites’ neighborhood preferences
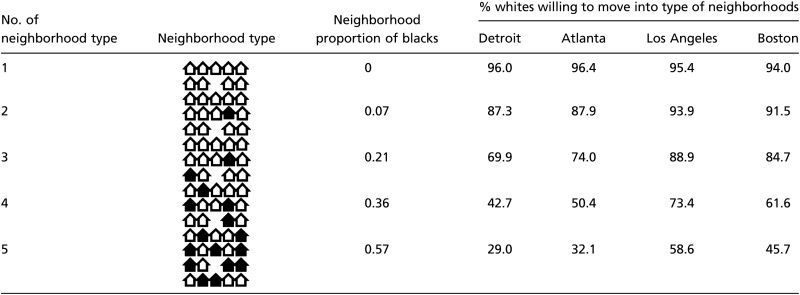 |
The survey data reveal whites’ overall unwillingness to live in neighborhoods with a substantial presence of blacks. There is a clear pattern that whites’ overall neighborhood preference declines monotonically with blacks’ presence. The pattern is the most pronounced in Detroit and is similarly sharp in Atlanta, but it is flatter in Los Angeles and Boston, reflecting more deeply divided racial tensions in Detroit and Atlanta than in Los Angeles and Boston.
The Bruch–Mare study interpreted the monotonic pattern in the Detroit survey to mean that whites’ individual-level probability of moving to a neighborhood declines with blacks’ presence and assumed a homogeneity model of neighborhood preferences for all whites (13). In this study, we take a different approach and treat the pattern as revealing heterogeneous groups of whites, each with a different level of tolerance of black neighbors. Our approach is sensible because the original survey items, as displayed in Table 1, were designed purposely with different intensities of black presence, and thus can be considered a Guttman scale (19).
If responses to the five survey items indeed conform to a Guttman scale, we would expect that any respondent willing to move to a neighborhood with a higher level of blacks’ presence would also be willing to move to a neighborhood with a lower level of blacks’ presence. This rank-order condition would partition a sample into six classes, with five classes conforming to a Guttman hierarchical scale of varying tolerance of black neighbors and a residual class not satisfying the Guttman scale requirement. The classes are shown in the first six columns of Table 2. For example, class 1 consists of whites who cannot tolerate a single black out of 14 neighbors; class 2 consists of whites who can only tolerate 1 black neighbor but not 2 or more black neighbors; and so forth. In the next four columns, we present percentages of whites who fall into the classes for the four metropolitan areas in the MSCUI data. The last row of Table 2 shows that the Guttman scale hypothesis is well supported, because the percentage of respondents not conforming to it, in class 6, is very small at around 5%. We also observe, as in Table 1, that whites in Detroit and Atlanta are less tolerant of black neighbors than those in Los Angles and Boston, because the percentage of class 1 is much higher in the former than in the latter and the percentage of class 5 is also lower in the former than in the latter.
Table 2.
Whites in the MCSUI (1992–1994) are divided into six classes by the Guttman scale
| % whites |
|||||||||
| Class | Resp 1 | Resp 2 | Resp 3 | Resp 4 | Resp 5 | Detroit | Atlanta | Los Angeles | Boston |
| 1 | 1 | 0 | 0 | 0 | 0 | 10.47 | 9.34 | 3.10 | 4.92 |
| 2 | 1 | 1 | 0 | 0 | 0 | 18.10 | 15.08 | 6.84 | 8.01 |
| 3 | 1 | 1 | 1 | 0 | 0 | 26.73 | 22.95 | 15.22 | 22.22 |
| 4 | 1 | 1 | 1 | 1 | 0 | 13.86 | 18.20 | 14.19 | 14.39 |
| 5 | 1 | 1 | 1 | 1 | 1 | 26.59 | 30.00 | 55.87 | 44.26 |
| 6 | Not following a Guttman scale | 4.25 | 4.43 | 4.77 | 6.19 | ||||
Resp, response.
In summary, we have presented evidence that whites’ neighborhood preferences are highly heterogeneous. This confirms a finding in the previous literature that “while the majority of whites would not remain in a neighborhood that is mostly black, there are many whites who are willing to tolerate some representation of blacks in their neighborhoods” (ref. 2, p. 336). Although alternative interpretations of the observed survey data are possible, we think that the evidence for heterogeneous preferences in these data is very strong if not overwhelming.
2. Racial Residential Segregation Under Heterogeneous Neighborhood Preferences
2.1. Baseline Model.
We now incorporate what we learned in the previous section into ABM and explore its long-term implications for racial residential segregation. Because our model extends the Bruch–Mare study, we retain the same computational model and initial parameters as in the original work (13, 15). Specifically, the computational model uses a 2D 500 × 500 lattice, that is, a grid of 250,000 cells. This lattice is populated with a mixture of “agents” that are 50% white and 50% black. Each agent can occupy 1 cell on the lattice at a time but can move to any vacant cell. To allow agents to move relatively freely on the lattice, 15% of the cells on the lattice are vacant. At the beginning of the simulation, all agents are evenly distributed throughout the lattice. Next, one agent is sampled from the population using simple random sampling with replacement. With one of the preference functions described below, we compute the selected agent’s transition probabilities for his/her current neighborhood and the neighborhoods surrounding all available vacancies. Based on these probabilities, the agent moves into another neighborhood in the city or remains in his/her current residence. Any agent who moves leaves his/her current cell vacant for another agent to move into. In the next time period, another agent is sampled, and the process continues. After 2 million iterations, we measure segregation using the D, based on 2,500 equally sized “tracts” that contain 100 cells.
The original Schelling model can be written as a statistical model in which agent i moves into the jth neighborhood at time t with probability:
 |
where 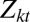 = 1 when the kth neighborhood has at least 50% agents of the same race at time t, and 0 otherwise, and k indexes all possible destination neighborhoods. To improve the Schelling model with more realism, Bruch and Mare (ref. 13, p. 678) allowed neighborhood attractiveness to vary gradually with the proportion of neighbors who are of the same race. Their model can be expressed as a logistic probability model in the form of:
= 1 when the kth neighborhood has at least 50% agents of the same race at time t, and 0 otherwise, and k indexes all possible destination neighborhoods. To improve the Schelling model with more realism, Bruch and Mare (ref. 13, p. 678) allowed neighborhood attractiveness to vary gradually with the proportion of neighbors who are of the same race. Their model can be expressed as a logistic probability model in the form of:
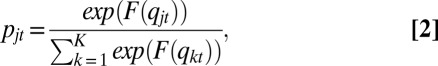 |
where 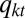 is the proportion of one’s own group in neighborhood k at time
is the proportion of one’s own group in neighborhood k at time 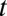 , and
, and 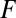 denotes the response function, estimated from the DAS data shown in Table 1. Note that this model assumes the same probabilistic destination function for all agents. We call this setup the Bruch–Mare model.
denotes the response function, estimated from the DAS data shown in Table 1. Note that this model assumes the same probabilistic destination function for all agents. We call this setup the Bruch–Mare model.
Our baseline model departs from the Bruch–Mare model in assuming that the entire population, separately for whites and blacks, consists of six distinct classes with their own destination probabilities depending on neighborhood conditions and respective representations, estimated from white respondents in the Detroit data (shown in Table 2). We start with six classes because five neighborhood types presented to the respondents allow us to identify only six classes. We build our baseline model using six heterogeneous classes and also refer to it as the categorical heterogeneous model. For simplicity, we assume that agents in the first five classes follow threshold preferences, such that for the gth class (g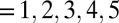 ),
), 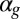 represents the upper threshold of tolerating the proportion of persons of the other race in a neighborhood (shown in column 3 of Table 1, namely, 0.07, 0.21, 0.36, 0.57 for g = 1, 2, 3, 4). Thus, we modify the basic Schelling model of Eq. 1 into:
represents the upper threshold of tolerating the proportion of persons of the other race in a neighborhood (shown in column 3 of Table 1, namely, 0.07, 0.21, 0.36, 0.57 for g = 1, 2, 3, 4). Thus, we modify the basic Schelling model of Eq. 1 into:
where 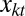 is the proportion of the other race in the kth neighborhood at time t. In other words, when an agent in class g moves, he/she randomly chooses a neighborhood where the proportion of the other race is less than
is the proportion of the other race in the kth neighborhood at time t. In other words, when an agent in class g moves, he/she randomly chooses a neighborhood where the proportion of the other race is less than 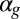 . For simplicity of illustration, we assume that agents in class 5 are indifferent toward neighborhood racial composition (i.e.,
. For simplicity of illustration, we assume that agents in class 5 are indifferent toward neighborhood racial composition (i.e., 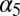 = 1).
= 1).
For agents in class 6, not conforming to the Guttman scale, we estimate their destination choice function by fitting the rank-ordered logit model as in the Bruch–Mare study. Under their model, the probability that an agent moves into neighborhood j is:
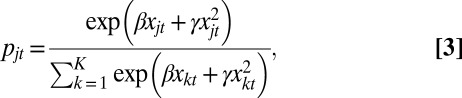 |
where 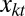 is the proportion of the other race in the kth neighborhood at time t and K is the total number of possible destination neighborhoods. Estimating the model with the Detroit data via maximum likelihood, we obtain:
is the proportion of the other race in the kth neighborhood at time t and K is the total number of possible destination neighborhoods. Estimating the model with the Detroit data via maximum likelihood, we obtain:
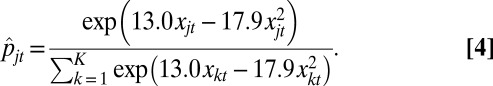 |
Thus, we use Eq. 4 as the neighborhood destination model for class 6: 4.25% of the hypothetical population.
In Fig. 1, we present our simulation results for long-term segregation, measured by the D. The segregation trends under the Schelling model* and under the Bruch–Mare model† are shown by the green line and the red line, respectively. The two trends are not markedly different from each other. However, the blue line representing the segregation trend under the categorical heterogeneity model is significantly lower in the long term.
Fig. 1.

Lower segregation under the categorical heterogeneity model.
Why is segregation lower under the heterogeneity model? To understand the underlying dynamics for the results, we examine some auxiliary results from our baseline model. Earlier, we defined five types of neighborhoods in Table 1 and six classes of agents in Table 2. Type 5 neighborhoods are those where the proportion of the other race exceeds 57%. With a high tolerance of the different race, class 5 agents are indifferent concerning neighborhood racial composition. In our ABM, we begin with a random distribution of agents into neighborhoods, such that the class of agents is unrelated to the types of neighborhoods. Over time (ticks), however, there emerges a pattern of sorting of agents by class into types of neighborhoods. In Fig. 2, we present the proportions of class 5 agents in different types of neighborhoods over time. Type 5 neighborhoods become more and more populated by class 5 agents (i.e., those agents who are indifferent concerning neighborhood racial composition). This is because other agents, those who are sensitive to neighborhood racial composition, have left type 5 neighborhoods in high proportions. As classes of agents are selectively sorted into types of neighborhoods, agents become relatively satisfied with their neighborhood racial composition. This is the main reason why population heterogeneity in neighborhood preference leads to lower racial segregation: A small proportion of agents who are highly tolerant of the other race helps to lower long-term segregation levels.
Fig. 2.

Proportion of class 5 agents by neighborhood type in categorical heterogeneity model.
2.2. Continuous Heterogeneous Preference.
One limitation of our baseline model is that we are constrained by the survey data to divide heterogeneity in preference into six distinct classes. In reality, heterogeneity in preference is more likely to be continuous than categorical, as Schelling himself considered it to be (6). To consider the more realistic case of continuous heterogeneous preference, we impose a piecewise linearity structure on tolerance function. For example, we make agents in class 1 follow a continuous distribution of the threshold of tolerance from 0 to 7% with a linear cumulative distribution function. We similarly identify the distributions of tolerance from classes 2 through 5. Fig. 3 shows the cumulative distribution function of tolerance from 0 to 100% by this method of interpolation. For agents in class 6, the 4.25% who do not follow a Guttman scale, we use the same destination choice function (Eq. 4).
Fig. 3.

Cumulative distribution function of the threshold of tolerance (class 6 agents excluded) under the continuous heterogeneity model.
2.3 Segregation Trends Under Continuous Heterogeneous Preference.
We now modify our baseline model by changing the specification for heterogeneous preference from categorical classes into a continuous function, as in Fig. 3. We show long-term segregation trends after we modified the ABM in Fig. 4. The blue line in Fig. 4 represents the segregation trend under the continuous heterogeneity model, whereas the green line and the red line again correspond to the Schelling model and the Bruch–Mare model. Again, it is apparent that segregation is less severe under the heterogeneity model than under the Bruch–Mare model. However, comparing Fig. 4 with Fig. 2, we also observe that long-term segregation under the continuous heterogeneous model is higher than that under the categorical heterogeneous model. Recall earlier that we assumed in the categorical heterogeneity model a class of agents who are indifferent to neighborhood racial composition (i.e., class 5 agents). In reality, it is unlikely to be true that there exists such a large indifferent class. The continuous heterogeneity model imposes a linear interpolation of tolerance within each class, including class 5 (whose thresholds lie between 57% and 100% black). The results show a higher level of segregation under the continuous heterogeneity model than under the categorical heterogeneity model. More realistic models specifying lower thresholds than linear interpolation would lead to higher levels of segregation.
Fig. 4.

Lower segregation under the continuous heterogeneity model.
We further examine the dynamics of sorting under the continuous heterogeneity model. At any given point in the long-term process, we extract the “neighborhood other race proportion” for each agent, who has an individual-specific “tolerance threshold.” Thus, we are able to calculate a correlation coefficient between these two measures across different agents (with class 6 agents excluded) at any given time. In Fig. 5, we present the trend of this correlation over time. An increasing pattern is apparent, with the increase tapering off at the end of the simulation. This pattern indicates a trend of self-selection, agents who are more tolerant of the different race being more systematically sorted into neighborhoods with higher concentrations of persons of the different race. This gradual process of self-selection, or sorting, explains why segregation is less severe under continuous heterogeneous preference than under homogeneous preference.
Fig. 5.

Correlation between neighborhood other race proportion and the threshold of tolerance (class 6 agents excluded) under the continuous heterogeneity model.
3. Social Determinants of Whites’ Neighborhood Preferences
If a population is heterogeneous with respect to preference for neighborhood racial composition, can we find social determinants predicting such heterogeneity? In this section, we attempt to uncover social characteristics that are associated with whites’ tolerance levels for black neighbors. We use survey data from the MCSUI.
In Table 3, we present results from an ordered logit model (20) predicting the membership in a higher (i.e., more tolerant) class, separately for the four metropolitan areas. In estimating the ordered logit model, we are interested in a single latent dimension, racial tolerance, as the essential outcome variable underlying the five hierarchical classes. We exclude class 6 from the analysis. In addition to a set of indicator variables absorbing the marginal distribution of the classes, we include sex, years of education, marital status, the presence of children under 18 y of age at home, and home ownership as predictors. We hypothesize that age, marriage, the presence of children, and home ownership should be negatively associated with racial tolerance and that years of education should be positively associated with racial tolerance. The estimated coefficients, when they are statistically significant, are all in the expected directions. For example, the years of education variable is positively associated with tolerance in Detroit, Atlanta, and Boston. Age is negatively associated with tolerance in Detroit, Los Angeles, and Boston. Being married is negatively associated with tolerance in Detroit, and so is house ownership in Boston.
Table 3.
Ordered logit model for predicting latent class membership
| Regression coefficients |
||||
| Detroit | Atlanta | Los Angeles | Boston | |
| y ≥ 2 | 2.539*** | 1.995*** | 4.873*** | 3.575*** |
| y ≥ 3 | 1.208** | 0.839 | 3.592*** | 2.462*** |
| y ≥ 4 | −0.010 | −0.250 | 2.413*** | 1.042* |
| y ≥ 5 | −0.666 | −1.064* | 1.706*** | 0.370 |
| Female | −0.040 | −0.045 | −0.139 | −0.143 |
| Years of education | 0.078** | 0.054* | −0.008 | 0.072** |
| Married | −0.398** | −0.251 | −0.215 | −0.162 |
| Living with children under 18 y of age | 0.072 | −0.010 | 0.170 | −0.043 |
| Age | −0.021*** | −0.006 | −0.022*** | −0.023*** |
| House ownership | −0.245 | −0.096 | −0.233 | −0.579*** |
| No. of observations | 700 | 562 | 515 | 736 |
| Model D.F. | 6 | 6 | 6 | 6 |
| Model L.R. | 58.89 | 10.82 | 39.76 | 53.00 |
In this analysis, we excluded cases belonging to class 6 or with any missing values. D.F., degrees of freedom; L.R., likelihood ratio test statistic.
*P < 0.1; **P < 0.05; ***P < 0.001 (two-tailed tests).
The above regression results suggest that population heterogeneity in neighborhood preference is not purely a result of chance but is driven, in part, by social determinants, personal and demographic characteristics, in the white population. In fact, it seems plausible that these social determinants affect neighborhood preference because they are associated with whites’ overall racial attitudes toward blacks. Fortunately, the MCSUI collected a wealth of information on whites’ racial attitudes about blacks. Thus, we test our proposition by examining the pattern of variation in whites’ racial attitudes about blacks as a function of their neighborhood preference. We present the results in Table 4.
Table 4.
Class-specific average racial attitudes from pooled data
| Non-Hispanic whites’ rating of blacks |
||||
| Class membership | Economic poverty** | Welfare dependence*** | Intelligence*** | Easiness to get along*** |
| 1 | 5.17 | 5.21 | 2.86 | 2.71 |
| 2 | 5.17 | 4.84 | 2.79 | 2.99 |
| 3 | 5.08 | 4.49 | 3.01 | 3.09 |
| 4 | 5.06 | 4.16 | 3.26 | 3.42 |
| 5 | 4.99 | 3.71 | 3.39 | 3.55 |
Figures are means on a scale from 1–7, where 7 is the positive end of a bipolar rating continuum. The wording of the questions for the four measures is as follows:
Economic poverty: Now, I have some questions about different groups in our (US) society. I’m going to show you a seven-point scale on which the characteristics of people in a group can be rated. In the first statement, a score of 1 means that you think almost all the people in that group are “rich.” A score of 7 means that you think almost everyone in the group is “poor.” A score of 4 means that you think the group is not toward one end or the other, and, of course, you may choose any number in-between that comes closest to where you think people in the group stand. Where would you rate (GROUP) on this scale, where 1 means tends to be rich and 7 means tends to be poor?
Welfare dependence: Next, for each group, I want to know whether you think they tend to prefer to be self-supporting or tend to prefer to be on welfare. Where would you rate (GROUP) on this scale, where 1 means tends to prefer to be self-supporting and 7 means tends to prefer to be on welfare? A score of 4 means that you think the group is not toward one end or the other, and, of course, you may choose any number in-between that comes closest to where you think people in the group stand.
Intelligence (reverse-coded): Next, for each group, I want to know whether you think they tend to be intelligent or tend to be unintelligent. Where would you rate (GROUP) on this scale, where 1 means tends to be intelligent and 7 means tends to be unintelligent? A score of 4 means that you think the group is not toward one end or the other end, and, of course, you may choose any number in-between that comes closest to where you think people in the group stand.
Easiness to get along (reversed-coded): Next, for each group I want to know if you think they tend to be easy to get along with or tend to be hard to get along with. Where would you rate (GROUP) on this scale, where 1 means tends to be easy to get along with and 7 means tends to be hard to get along with? A score of 4 means that you think the group is not toward one end or the other, and, of course, you may choose any number in-between that comes closest to where you think people in the group stand.
**P < 0.05; ***P < 0.001 (two-tailed tests for correlation coefficients between class membership and racial attitudes).
In Table 4, we present means of four measures of whites’ racial attitudes about blacks by membership in neighborhood preference class. The four measures correspond to ratings of four characteristics: economic poverty, welfare dependence, intelligence, and easiness to get along. In the survey, respondents were asked to rate each characteristic of a given racial group on a scale ranging from 1 to 7. The wording of the questions for the four measures is given below the table. The table clearly shows a pattern: Whites in a class of more tolerance (i.e., a higher numbered class) have more favorable attitudes toward blacks than those in a class of less tolerance (i.e., a lower numbered class). For example, the average rating of blacks’ welfare dependence is as high as 5.21 for class 1 whites (the least tolerant class) but only 3.71 for class 5 whites (the most tolerant class). This pattern is true no matter what measures of racial attitudes are used. The association of racial attitude with class membership is statistically significant for all measures of racial attitudes.
4. Conclusion
In all areas of social science, population heterogeneity is the norm rather than the exception (21). Although previous work has effectively used ABM, or microlevel simulation, for understanding racial segregation (6, 7, 11–15), it has mostly suffered from assuming homogeneous, albeit probabilistic, agents, with some exceptions (11, 12). In this research, we contribute to the previous work first by revealing severe heterogeneity in neighborhood preference in survey data and then by demonstrating the social significance of heterogeneity in racial composition preference. Our work shows the following: (i) the heterogeneity in neighborhood preference serves to substantially lower racial segregation in the long run; and (ii) the heterogeneity in neighborhood preference should be interpreted as reflecting whites’ overall racial attitudes toward blacks.
Acknowledgments
We thank Michael Bader, Elizabeth Bruch, and Robert Mare for their comments on an earlier version of the paper. This work was supported by the National Institutes of Health (Grant R21 NR010856) as well as the Center for Social Epidemiology and Population Health and the Population Studies Center at the University of Michigan.
Footnotes
The authors declare no conflict of interest.
*For the Schelling model, we use the “median” threshold (at 36%) of those Detroit whites whose preferences follow a Guttman scale; that is, an agent is willing to move into a neighborhood only if it has no more than 36% of the other race.
†For the Bruch–Mare model, we use a linear utility function, 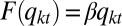 , where
, where 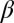 is estimated to be 10.99 from the 1992 Detroit area studies data. This functional specification corresponds to the “linear continuous model” in the Bruch–Mare study (ref. 15, p. 1185).
is estimated to be 10.99 from the 1992 Detroit area studies data. This functional specification corresponds to the “linear continuous model” in the Bruch–Mare study (ref. 15, p. 1185).
This article is a PNAS Direct Submission.
References
- 1.Massey D, Denton N. American Apartheid Segregation and the Making of the Underclass. Cambridge, MA: Harvard Univ Press; 1993. [Google Scholar]
- 2.Farley R, Schuman H, Bianchi S, Colasanto D, Hatchett S. Chocolate city, vanilla suburbs: Will the trend toward racially separate communities continue? Soc Sci Res. 1978;7:319–344. [Google Scholar]
- 3.Farley R, Steeh C, Krysan M, Jackson T, Reeves K. Stereotypes and segregation: Neighborhoods in the Detroit area. AJS. 1994;100:750–780. [Google Scholar]
- 4.Farley R. The waning of American apartheid? Contexts. 2011;10(3):36–43. [Google Scholar]
- 5.Logan J, Stults B. 2011. The persistence of segregation in the metropolis: New findings from the 2010 census. Census Brief prepared for Project US2010. Available at http://www.s4.brown.edu/us2010. Accessed January 10, 2012.
- 6.Schelling T. Dynamic models of segregation. J Math Sociol. 1971;1:143–186. [Google Scholar]
- 7.Schelling T. Micromotives and Macrobehavior. New York: Norton; 1978. [Google Scholar]
- 8.Bonabeau E. Agent-based modeling: Methods and techniques for simulating human systems. Proc Natl Acad Sci USA. 2002;99(Suppl 3):7280–7287. doi: 10.1073/pnas.082080899. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Laurie A, Jaggi N. Role of “vision” in neighborhood racial segregation: A variant of the Schelling segregation model. Urban Stud. 2003;40:2687–2704. [Google Scholar]
- 10.Chen K. The emergence of racial segregation in agent-based model of residential location: The role of competing preferences. Comput Math Organ Theory. 2005;11:333–338. [Google Scholar]
- 11.Fossett M, Warren W. Overlooked implications of ethnic preferences for residential segregation in agent-based models. Urban Stud. 2005;42:1893–1917. [Google Scholar]
- 12.Fossett M. Ethnic preferences, social distance dynamics, and residential segregation: Theoretical explorations using simulation analysis. J Math Sociol. 2006;30:185–273. [Google Scholar]
- 13.Bruch E, Mare R. Neighborhood choice and neighborhood change. AJS. 2006;112:667–709. [Google Scholar]
- 14.Van de Rijt A, Siegel D, Macy M. Neighborhood chance and neighborhood change: A comment on Bruch and Mare. AJS. 2009;114:1166–1180. [Google Scholar]
- 15.Bruch E, Mare R. Preference and pathways to segregation: Reply to Van de Rijt, Siegel, and Macy. AJS. 2009;114:1181–1198. doi: 10.1086/597599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Tuljapurkar S, Bruch E, Mare R. Neighborhoods and individual preferences: A Markovian model. California Center for Population Research On-Line Working Paper Series. 2008. Available at http://papers.ccpr.ucla.edu/papers/PWP-CCPR-2008-038/PWP-CCPR-2008-038.pdf. Accessed April 15, 2012.
- 17.Clark WA. Residential preferences and neighborhood racial segregation: A test of the Schelling segregation model. Demography. 1991;28:1–19. [PubMed] [Google Scholar]
- 18.Krysan M, Bader M. Perceiving the metropolis: Seeing the city through a prism of race. Soc Forces. 2007;86:699–733. [Google Scholar]
- 19.Guttman L. The basis for scalogram analysis. In: Stouffer S, et al., editors. Measurement and Prediction: The American Soldier. Vol 4. New York: Wiley; 1950. [Google Scholar]
- 20.Powers D, Xie Y. Statistical Methods for Categorical Data Analysis. 2nd Ed. Bingley, UK: Emerald Group Publishing; 2008. [Google Scholar]
- 21.Xie Y. Otis Dudley Duncan’s legacy: The demographic approach to quantitative reasoning in social science. Res Soc Stratif Mobil. 2007;25:141–156. [Google Scholar]