

Abstract
Sound for the human voice is produced via flow-induced vocal fold vibration. The vocal folds consist of several layers of tissue, each with differing material properties 1. Normal voice production relies on healthy tissue and vocal folds, and occurs as a result of complex coupling between aerodynamic, structural dynamic, and acoustic physical phenomena. Voice disorders affect up to 7.5 million annually in the United States alone 2 and often result in significant financial, social, and other quality-of-life difficulties. Understanding the physics of voice production has the potential to significantly benefit voice care, including clinical prevention, diagnosis, and treatment of voice disorders.
Existing methods for studying voice production include in vivo experimentation using human and animal subjects, in vitro experimentation using excised larynges and synthetic models, and computational modeling. Owing to hazardous and difficult instrument access, in vivo experiments are severely limited in scope. Excised larynx experiments have the benefit of anatomical and some physiological realism, but parametric studies involving geometric and material property variables are limited. Further, they are typically only able to be vibrated for relatively short periods of time (typically on the order of minutes).
Overcoming some of the limitations of excised larynx experiments, synthetic vocal fold models are emerging as a complementary tool for studying voice production. Synthetic models can be fabricated with systematic changes to geometry and material properties, allowing for the study of healthy and unhealthy human phonatory aerodynamics, structural dynamics, and acoustics. For example, they have been used to study left-right vocal fold asymmetry 3,4, clinical instrument development 5, laryngeal aerodynamics 6-9, vocal fold contact pressure 10, and subglottal acoustics 11 (a more comprehensive list can be found in Kniesburges et al. 12)
Existing synthetic vocal fold models, however, have either been homogenous (one-layer models) or have been fabricated using two materials of differing stiffness (two-layer models). This approach does not allow for representation of the actual multi-layer structure of the human vocal folds 1 that plays a central role in governing vocal fold flow-induced vibratory response. Consequently, one- and two-layer synthetic vocal fold models have exhibited disadvantages 3,6,8 such as higher onset pressures than what are typical for human phonation (onset pressure is the minimum lung pressure required to initiate vibration), unnaturally large inferior-superior motion, and lack of a "mucosal wave" (a vertically-traveling wave that is characteristic of healthy human vocal fold vibration).
In this paper, fabrication of a model with multiple layers of differing material properties is described. The model layers simulate the multi-layer structure of the human vocal folds, including epithelium, superficial lamina propria (SLP), intermediate and deep lamina propria (i.e., ligament; a fiber is included for anterior-posterior stiffness), and muscle (i.e., body) layers 1. Results are included that show that the model exhibits improved vibratory characteristics over prior one- and two-layer synthetic models, including onset pressure closer to human onset pressure, reduced inferior-superior motion, and evidence of a mucosal wave.
Keywords: Bioengineering, Issue 58, Vocal folds, larynx, voice, speech, artificial biomechanical models
Protocol
The fabrication sequence (see Fig. 1) consists of making molds for vocal fold model layers, sequentially casting silicone layers, and mounting the models for testing. The model has four distinct layers: body, ligament, superficial lamina propria, and epithelium, in addition to a single fiber. A backing layer is added to facilitate the accurate placement of individual layers to the vocal fold model. The model geometric parameter definitions are shown in Fig. 2, with parameter values for the current model given in Table 1. In the following sections, different silicone mixing ratios are specified for the different layers; these produce material properties that are similar to those reported for human vocal fold tissue in the small strain regime 13 (see Table 2).
1. Mold fabrication and preparation
Create solid models of three vocal fold layers: superficial lamina propria, ligament, and body layers. This is typically done by creating 3D computer-aided design (CAD) models with the desired geometries, exporting the CAD models as stereolithography (STL) files, and sending the STL files to a custom machine shop for rapid prototyping.
Create a box-shaped mold form using thin pieces of acrylic material. Approximate dimensions (not critical) are 2.54 cm high × 5.72 cm wide × 6.35 cm deep. Make the bottom of the form by adhering it to a flat acrylic plate. Seal all interior edges with vacuum grease.
Place a small amount of vacuum grease on the lateral side of the solid model of desired geometry (i.e., the body, the ligament, or the superficial lamina propria). Press model into bottom of mold form cavity, vacuum grease side down, so that the vacuum grease holds the part in place. Liberally coat mold form and solid model with release agent. Using a paint brush, ensure release agent reaches into all corners of the mold form cavity.
Mix 10 parts A and one part B of Smooth-Sil 950 platinum silicone rubber (parts measured by weight) in a container that has sufficient room for expansion. To remove air bubbles place mold form with uncured silicone rubber in a vacuum chamber and reduce pressure (e.g., to around 26 inches Hg below atmospheric pressure) for approximately three minutes (or more or less as necessary). Remove degassed silicone from chamber and pour into mold form cavity. Place mold with uncured silicone into vacuum chamber and degas again. Remove from vacuum chamber and place on level surface. Allow to cure for 24 hours and remove mold from mold form.
Repeat steps 1.1 through 1.4 to create molds for each of the superficial lamina propria, ligament, and body layers.
Cut ligament layer mold at the center of the medial surface in the anterior-posterior direction with a straight razor to allow for fiber insertion.
2. Casting of each layer
Body Layer: Apply thin layer of release agent to body mold cavity with paint brush. Mix one part B and one part A of Ecoflex 00-30 Supersoft Platinum Silicone (by weight). Add one part Silicone Thinner (by weight) to reduce the eventual cured stiffness of the material. Mix together for 30 seconds and place in vacuum chamber for one minute to remove entrapped air. Remove mixture from vacuum and pour into the body mold cavity, but do not fill to the top of the entire mold cavity. Place in oven at 250 °F for 30 minutes. Remove from oven and cool.
Backing: Mix one part B and one part A of Dragon Skin and add one part Silicone Thinner (by weight). Mix vigorously for 30 seconds, place in vacuum for 1 minute, and pour into the body mold cavity until full. Place in oven at 250 °F for 30 minutes. Remove mold from oven and cool. Remove model from mold, allow to cool to room temperature, and remove any release agent on the surface of the body layer with paper towel.
Ligament Layer: Apply thin layer of release agent on ligament mold cavity surface with paint brush. Place a 30 cm thread in the mold by pushing it into the cut from the straight razor. Thoroughly mix one part B and one part A of Ecoflex 00-30 and four parts of Silicone Thinner (by weight). Place in vacuum chamber to remove air bubbles and pour mixture into ligament mold cavity.
Ligament Layer (continued): Press body-backing model (from Steps 2.1.1 and 2.1.2) into the ligament mold cavity. Begin insertion at one side and gently move to the other so that the model pushes the excess uncured silicone and air bubbles out of the mold cavity. If air bubbles are present, remove the model from the mold cavity, refill with uncured silicone, and repeat pressing model into the mold. Place mold in oven for 30 minutes, remove, and cool to room temperature. Remove model from mold. Remove excess release agent with paper towel.
Superficial Lamina Propria Layer: Apply thin layer of release agent on superifical lamina propria (SLP) mold cavity surface with paint brush. Mix one part B, one part A of Ecoflex 00-30, and 8 parts Silicone Thinner by weight. Vacuum as done previously and pour into SLP mold cavity. Use the same process described in Step 2.1.4 to insert the ligament-body-backing model into the superficial lamina propria mold cavity. Place in an oven at 250 °F and cure for one hour. Remove from oven and allow to cool. Remove model slowly and with extreme care so that the superficial lamina propria remains intact.
Epithelium Layer: Place vocal fold model on a flat surface with the backing down. Remove support material with a straight razor. Suspend threads in air by attaching them to an object of greater height than the model. Mix one part B and one part A of Dragon Skin with one part of Silicone Thinner, mix, vacuum, then pour over the model and allow to cure for one hour. Repeat the process to create a thicker layer. Remove excess material with a straight razor.
Optional: If each layer is desired to be a different color (for visible inspection of different layers), add dye to part B of either the Ecoflex or Dragon Skin during the mixing process.
Optional: If material property data will be collected, create tensile and rheological specimens simultaneously with fabrication of each model layer. Do this by pouring extra uncured material into release agent-treated molds of desired material property specimen shape and size.
Optional: If measurements of layer thickness are desired, cut a cross section of the model with a straight razor and inspect with microscope.
3. Final model preparation for testing
Mount each completed vocal fold model into an acrylic mounting plate by first applying a thin layer of silicone glue on the back (lateral) and side (anterior-posterior) model surfaces. Insert model into recessed cut of mounting plate. Align the model medial surface with the top of the acrylic plate. Wipe away excess glue. Allow glue to cure for one hour.
Apply talc powder to the model surface to reduce surface tackiness.
For medial surface tracking use a fine-point Sharpie pen to mark dots on the model. Best results occur if marking is done after application of talc powder.
Place long bolts through holes of the mounting plate with the threaded ends pointing toward the model to which the existing model will be paired. Lay threads over the bolts. Put closed cell foam over the bolts to close any air gaps.
Pair this prepared model with another vocal fold model that has been similarly mounted to an acrylic holder using Steps 3.1 and 3.2. Tighten screws to compress the foam and bring the medial surfaces together until the desire pre-vibratory gap is reached. Ensure both sets of threads are placed over the bolts and extend outward from the acrylic plates in the anterior-posterior direction.
Mount vocal fold pair on air supply tube.
Tie the anterior threads together to form a loop. Repeat for the posterior threads. Hang desired weight on the loops simultaneously.
Models are now ready for testing and data collection.
4. Representative Results
Vibratory response data from one model created using this fabrication process are as follows; these results are typical. With tension of approximately 31 g applied to the fibers, the onset pressure was 400 Pa. At a subglottal pressure of 10% above onset pressure (440 Pa), the model vibrated at 115 Hz with a glottal flow rate of 210 ml/s. These values are in good agreement with values reported for those of humans (Table 3). Using high-speed videokymography to analyze model motion showed evidence of a phase difference between the superior and inferior margins, i.e., the superior margin concealed the inferior margin during the open phase of the vibration period (Fig. 3). Trajectories extracted from stereo images of the dots applied to the medial and inferior surfaces of the vocal fold model showed that the model exhibited an alternating convergent-divergent profile that is typical of human phonation, a mucosal wave-like motion, and a lower inferior-superior motion than in previous models (Fig. 4).
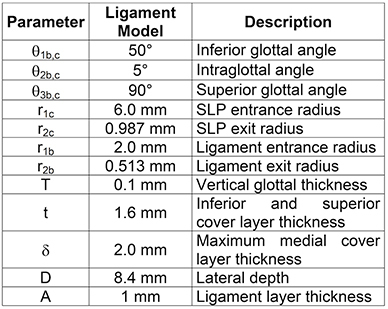
Table 1. Model geometric parameter values.
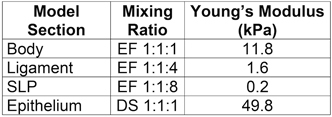
Table 2. Mixture ratios by weight and resulting Young's modulus of the individual sections of the vocal fold model. EF and DS designate silicone made from Ecoflex and Dragon Skin, respectively 14.
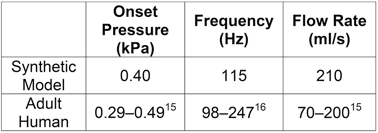
Table 3. Comparison between human and synthetic vocal fold vibratory responses.
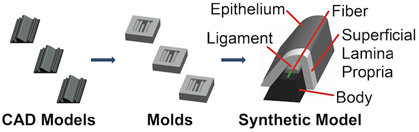
Figure 1. Synthetic vocal fold model fabrication process. CAD-derived solid models (left panel) are used to create molds (center panel) for each layer. Each layer is then cast, beginning with the body layer and ending with the epithelium layer (right panel, with each layer "peeled back" for visibility). After fabrication, models are mounted to acrylic plates for testing.
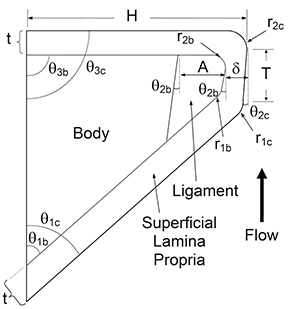
Figure 2. Synthetic vocal fold model cross section. Distinct body, superficial lamina propria, ligament, and epithelium layers are shown. Parameters define vocal fold model geometry. This figure is scaled for clear representation of geometric definitions. Application of the parameter values given in Table 1 will result in a slightly different shape than what is shown here.

Figure 3. High-speed kymogram of model vibration. Estimates for the location of the superior and inferior margins are shown in colored dotted lines. Phase differences between the inferior and superior margins are evident.
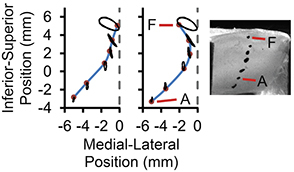
Figure 4. Medial surface profile of synthetic vocal fold model in a hemilarynx arrangement, captured at two different instances of time while vibrating. Ink markers were placed on the medial surface (as shown in the right image), imaged using two synchronized high-speed cameras, and tracked over the vibratory cycle. The left plot shows a convergent glottis during the opening phase and the right plot shows a divergent glottis during the closing phase.
Discussion
This method of fabricating synthetic vocal fold models yields models that exhibit vibratory behavior similar to that of human vocal folds. The multi-layer concept results in significant advantages over previous one- and two-layer model designs 3,6,8,15, in terms of reduced onset pressure and improved model motion (convergent-divergent profile during oscillation, mucosal wave-like motion, and reduced inferior superior displacement). The method presented here is demonstrated on a somewhat idealized model in terms of geometry, but it can be applied to models with different geometries. For example, a model based on human imaging geometric data (e.g., MRI 17, CT) could be fabricated using this method. Additionally, this fabrication process concept may find application in other research areas in which flow-induced vibrations and/or multiple layers of soft materials are central elements, e.g., investigations of flow through blood vessels, sleep apnea, and animal locomotion (particularly swimming and flying).
The model described here has some limitations that could be subjects for future research and development. The materials have linear stress-strain response characteristics, and an anticipated future improvement includes the incorporation of nonlinear stress-strain materials. Use of biological rather than synthetic materials in this fabrication process is also possible. Because of the extreme flexibility of the lamina propria layer, the model is less robust under vibration than previous one- and two-layer models. However, keeping the subglottal pressure beneath approximately 1 kPa and occasionally applying talc powder to minimize surface adhesion should allow for the model to be used for durations on the order of days with minimal changes in model behavior, typically far exceeding those possible using excised larynges.
Disclosures
The authors have nothing to disclose.
Acknowledgments
The authors gratefully acknowledge Grants R03DC8200, R01DC9616, and R01DC5788 from the National Institute on Deafness and Other Communication Disorders for support of synthetic model development.
References
- Hirano M, Kakita Y. Cover-body theory of vocal fold vibration. Speech Science: Recent Advances. 1985. pp. 1–46.
- Voice, Speech, and Language Quick Statistics [Internet] Bethesda (MD): National Institute on Deafness and Other Communication Disorders; 2010. Available from: http://www.nidcd.nih.gov/health/statistics/vsl/Pages/stats.aspx. [Google Scholar]
- Pickup BA, Thomson SL. Influence of asymmetric stiffness on the structural and aerodynamic response of synthetic vocal fold models. Journal of Biomechanics. 2009;42(14):2219–2225. doi: 10.1016/j.jbiomech.2009.06.039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Z. Vibration in a self-oscillating vocal fold model with left-right asymmetry in body-layer stiffness. Journal of the Acoustical Society of America. 2010;128(5):EL279–EL285. doi: 10.1121/1.3492798. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Popolo PS, Titze IR. Qualification of a Quantitative Laryngeal Imaging System Using Videostroboscopy and Videokymography. Annals of Otology, Rhinology & Laryngology. 2008;117(6):4014–4412. doi: 10.1177/000348940811700602. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thomson SL, Mongeau L, Frankel SH. Aerodynamic transfer of energy to the vocal folds. Journal of the Acoustical Society of America. 2005;118(3):1689–1700. doi: 10.1121/1.2000787. [DOI] [PubMed] [Google Scholar]
- Neubauer J, Zhang Z, Miraghaio R, Berry DA. Coherent structures of the near field flow in a self-oscillating physical model of the vocal folds. Journal of the Acoustical Society of America. 2007;121(2):1102–1118. doi: 10.1121/1.2409488. [DOI] [PubMed] [Google Scholar]
- Drechsel JS, Thomson SL. Influence of supraglottal structures on the glottal jet exiting a two-layer synthetic, self-oscillating vocal fold model. Journal of the Acoustical Society of America. 2008;123(6):4434–4445. doi: 10.1121/1.2897040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Becker S, et al. Flow-structure-acoustic interaction in a human voice model. Journal of the Acoustical Society of America. 2009;125(3):1351–1361. doi: 10.1121/1.3068444. [DOI] [PubMed] [Google Scholar]
- Spencer M, Siegmund T, Mongeau L. Experimental study of the self-oscillation of a model larynx by digital image correlation. Journal of the Acoustical Society of America. 2007;123(2):1089–1103. doi: 10.1121/1.2821412. [DOI] [PubMed] [Google Scholar]
- Zhang Z, Neubauer J, Berry D. The influence of subglottal acoustics on laboratory models of phonation. Journal of the Acoustical Society of America. 2006;120(3):1558–1569. doi: 10.1121/1.2225682. [DOI] [PubMed] [Google Scholar]
- Kniesburges S, et al. In vitro experimental investigation of voice production. Current Bioinformatics. 2011. [DOI] [PMC free article] [PubMed]
- Titze IR. The Myoelastic Aerodynamic Theory of Phonation. National Center for Voice and Speech; 2006. pp. 82–101. [Google Scholar]
- Murray PR. Flow-Induced Responses of Normal, Bowed, and Augmented Synthetic Vocal Fold Models. Brigham Young University; 2011. [Google Scholar]
- Baken RJ, Orlikoff RF. Clinical Measurement of Speech and Voice. 2nd. Singular Publishing; 2000. [Google Scholar]
- Titze IR. Principles of Voice Production. National Center for Voice and Speech; 2000. [Google Scholar]
- Pickup BA, Thomson SL. Flow-induced vibratory response of idealized vs. magnetic resonance imaging-based synthetic vocal fold models. Journal of the Acoustical Society of America. 2010;128(3):EL124–EL129. doi: 10.1121/1.3455876. [DOI] [PMC free article] [PubMed] [Google Scholar]