

Abstract
A fundamental and frequently overlooked aspect of animal learning is its reliance on compatibility between the learning rules used and the attentional and motivational mechanisms directing them to process the relevant data (called here data-acquisition mechanisms). We propose that this coordinated action, which may first appear fragile and error prone, is in fact extremely powerful, and critical for understanding cognitive evolution. Using basic examples from imprinting and associative learning, we argue that by coevolving to handle the natural distribution of data in the animal's environment, learning and data-acquisition mechanisms are tuned jointly so as to facilitate effective learning using relatively little memory and computation. We then suggest that this coevolutionary process offers a feasible path for the incremental evolution of complex cognitive systems, because it can greatly simplify learning. This is illustrated by considering how animals and humans can use these simple mechanisms to learn complex patterns and represent them in the brain. We conclude with some predictions and suggested directions for experimental and theoretical work.
Keywords: evolution of learning, comparative cognition, language acquisition, learning of structured data, data acquisition, innate template
1. Introduction
Just like morphological traits, we would expect that cognitive traits have evolved over time, and thus are best understood in the light of evolutionary theory. However, while it is relatively easy to see how natural selection acts on clearly defined morphological traits, such as limbs, bones or blood vessels, with cognitive traits that in themselves are not well understood, it is difficult to tell what is actually evolving. While attempts to integrate evolutionary theory and cognition are increasingly common, they are largely based on explaining the adaptive value of behavioural mechanisms already studied by psychologists [1–4], or on modelling the evolution of particular learning rules [5–9] that are far too simple to capture complex cognition. We believe that in order to model the evolution of more complex learning or cognitive mechanisms, it is necessary to make some additional assumptions about how they work and how their components can gradually be modified by natural selection. Over the past few years, we have developed a model of learning and cognitive development and explored its ability to explain a range of phenomena [10,11]. Here, we take an evolutionary approach to examine the model's plausibility and its potential use for the study of cognitive evolution.
The model focuses on two aspects of cognition: learning and data acquisition. In many cases, learning and data acquisition have been studied independently. For example, when studying learning, a subject is typically presented with a set of stimuli that can be viewed as a dataset; experiments are done to see whether the subject can learn rules [12,13], or whether it can learn the relative value of different data items [14,15]. But where does this dataset come from? There are many studies of attentional mechanisms and the use of innate templates to direct the learning process (e.g. input mechanisms in social learning [16]), but these mechanisms are usually not incorporated into learning models as a way of guiding data selection. For example, computational models for language acquisition use large datasets of child-directed speech without using attentional or communicational cues for data selection [17–19]. We believe that much of the learning is already determined by the selection of data to acquire. Our model involves mechanisms for both learning and data acquisition—mechanisms that involve a number of parameters. We argue that the parameters for these learning and data-acquisition mechanisms must coevolve to become coordinated so as to result in a system for learning and representing structured data that is evolutionarily and computationally plausible.
Our model assumes that, at all times, an agent has some representation of the information it has acquired this far. This representation is then used for search, prediction, goal-directed behaviour and so on. The model represents the information in terms of a network where nodes (data units) and edges (the links between them) have weights. While the details were critical to our earlier work [10] and its implementation [20], they do not matter for our present discussion. Roughly speaking, we assume that there is a mechanism that, given new information, modifies the representation—this is what learning means in our setting (see also [21]). Exactly how it does so depends on certain learning parameters in our model, parameters that are subject to evolutionary pressures. As far as data acquisition goes, note that, at any given time, there is a great wealth of potential information that the agent could acquire. An agent is exposed to a large variety of sensory data: visual, auditory, olfactory and tactile. There is far too much data for anyone to absorb; somehow the agent must decide what to focus on, or treat as relevant, while ignoring the rest. Part of this decision is clearly determined by the agent's sensory mechanisms. Humans, for example, can hear only certain frequencies, and their sense of smell is far more limited than a dog's. But we claim that the rest (i.e. the decision of what to focus on, or to pay attention to) is determined by the representation itself. Data input are recognized as relevant, and thus receive attention, if part of them match or are sufficiently similar to the data that have already been represented, either because they are innate or were acquired through previous experience (the other part of the input can be arbitrary, and hence completely novel). What counts as a match or as ‘sufficiently similar’, and how much data can be acquired along with the matching part are clearly important questions. While the details are beyond the scope of this paper, again, how this data-acquisition mechanism works depends in part on parameter settings, which are subject to evolutionary pressures. It is these parameters for data acquisition that coevolve with the mechanisms that determine what we can sense and with the learning parameters that determine how the network is modified when new data are acquired.
The power of allowing the learning and data-acquisition mechanisms to coevolve should become clearer after we give a number of examples in §2 and §3, but we can already sketch the main ideas. In our model, acquired data items and the links between them have weights in the memory representation; these weights increase with further observations of those items, and decrease (decay) otherwise. If its weight becomes sufficiently large, a data item becomes fixated in memory; decay then becomes improbable. The probability that a data item is learned is thus determined by how frequently it is observed (or acquired), and by the parameters of weight increase and decrease. These parameters create a window for learning, during which data can either be learned or ‘disappear’ from the network. We believe that, during this window, additional processes are at work that compare data sequences, segment them based on commonalities and update their weight and link structure in memory representation [10,11]. We thus get a mechanism for learning the statistical significance of data items and their associations with other items: data items or associations that are rare will decay, while those that are frequent will get fixated and thus learned.
The mechanism as described equates statistical frequency with biological importance. This may not always be appropriate. We thus expect the mechanism to be modified by evolution. This can happen in (at least) two ways. First, the weight increase parameters may evolve to become state-sensitive. For example, a frightening event (rare but important) may result in the weights increasing after only a few observations (even one may suffice), allowing important data to get fixated sooner. Motivational or emotional states may influence learning in this way. Second, the data-acquisition mechanism will evolve to focus on the biologically important events, ignoring those that are less relevant. The combined effect of the learning and data-acquisition mechanisms is that the agent receives less data, much of which decays. However, the selection of data received is not random. It is guided by parameters that have evolved to facilitate effective learning under the animal's ecological conditions, which are characterized by a particular distribution of data items. If these parameters are well tuned, irrelevant data will be filtered out, spurious patterns will eventually decay, and significant data items and the link structure between them will be learned correctly.
If our model is correct, it can help in the study of cognitive evolution in a number of ways. First, it suggests what is evolving: the set of parameters that adjust the weights on data items (and hence the window for learning), and the mechanisms of data acquisition that determine the type and distribution of data acquired by the animal. Simply put, our model suggests that genetic differences in these traits would eventually result in different brains (with various consequences in terms of required size, structure, resources and supporting mechanisms). Second, our model may explain how learning of complex patterns may be feasible even for animals that have little memory and computational power. Many computational models that deal with complex learning tasks need a great deal of memory and computational power because they acquire all the data without forgetting, and then run the statistical analysis. Our model builds in techniques for removing data—they decay away if, roughly speaking, they do not occur frequently enough to be viewed as statistically significant. Third, our model makes a set of testable predictions. It predicts that because learning parameters have evolved to handle a typical rate and distribution of data input in nature, manipulating this input can impair learning in some specific ways that can be tested experimentally.
In the rest of the paper, we use our model to explain a set of learning and cognitive mechanisms and how they might have evolved. We start with basic examples from imprinting and associative learning, and continue with more challenging tasks of learning patterns in time and space (which is needed, for example, in language acquisition). Our observations show how our simple model can lead to significant insight regarding a wide range of phenomena, without requiring complex assumptions or adaptation to specific settings.
We conclude with some predictions and suggested directions for experimental and theoretical work.
2. Imprinting
The principle of coevolving learning and data-acquisition mechanisms may be easiest to explain in the context of imprinting. In filial imprinting, for example, a newly hatched duckling searches for an image that resembles its innate template of a ‘mother duck’, and then follows this image until it becomes imprinted on it [22,23]. To some extent, this innate template of a mother works in much the same way as an innate attraction to the characteristics of food types. In both cases, the animal looks for something that matches its innate template; finding a match is rewarding, and shapes future interaction with the environment. Imprinting, however, has a unique feature: it provides a time window for learning—the sensitive period [23,24]. During this time, the duckling takes the closest, most frequently observed match to its template to be its mother. While this may not always be correct, in practice, it almost always is. It is usually assumed that the template and the sensitive period coevolved in this way to facilitate correct imprinting [23,25].
In terms of our model, the innate template can be viewed as the data-acquisition mechanism. It directs the duckling to pay attention to objects that can potentially match the innate template of a mother, and to ignore objects that do not match it well. The sensitive period is the window for learning; the best match (usually the mother) is followed and observed repeatedly, gains weight in memory representation and eventually reaches fixation. Competing stimuli, on the other hand, are gradually neglected, and their weight in memory is likely to decay. There are obviously more specific mechanistic details in any type of imprinting; these can be viewed as different modifications of the learning parameters or the data-acquisition mechanism.
To better understand the evolutionary advantage of such coevolving mechanisms, consider an alternative to filial imprinting which provides an innate template but has no sensitive period. In theory this should work, but the cost of such a mechanism is that the duckling must keep paying attention to all images that resemble the innate template and keep assessing which of them is the best match. This is a wasteful process; in nature, no better mother is likely to be encountered after the first few days, and it could even be risky to keep looking for one (because another adult duck may reject or even brutally attack the duckling). Thus, the combined action of the innate template and the sensitive period offers a better solution. Moreover, it can be highly reliable and it simplifies the learning process by restricting it to a small time window. As a result, fewer data are acquired, less memory is required and less computation is needed for comparing possible candidate matches.
The idea that sensitive periods are adaptive and that their time, duration and intensity are under selection is not new (see discussions in [23,26,27]). It is also well known that because the innate template is not very specific, animals can easily be imprinted on the wrong stimulus if exposed to conditions that are different than those under which they have evolved (e.g. when raised in captivity). This fragility of the imprinting process highlights the fact that its success depends on seeing the right things at the right time. More precisely, imprinting evolved to encounter certain data with a certain distribution. Imprinting would not have evolved if its sensitive period did not lead to an increase in the likelihood of learning the correct stimuli. A situation like this can be demonstrated in some hosts of parasitic birds that use an imprinting-like process to learn to recognize their eggs or nestlings based on what they see during their first breeding [26,28,29]. Under some conditions, these birds face the risk of being imprinted on the parasite chick, and consequently rejecting their own offspring. Theoretical models and recent experiments suggest that birds learn to recognize nestlings only when the risk of miss-imprinting is not too high [29,30]. Thus, in the case of imprinting, it is quite easy to see that the success of the coevolving learning and data-acquisition mechanism depends on their ability to cope with the expected distribution of data in nature. The process can be simple and reliable because evolution has already provided it with appropriate filters and learning parameters.
3. Associative learning
Associative learning has been well studied [31]; see also recent reviews in this volume [32,33]. Our goal in this section is to demonstrate that associative learning can be viewed in terms of coevolving learning and data-acquisition mechanisms. We then show in §4 that thinking in these terms may help explain how associative learning can gradually evolve into more complex cognitive mechanisms.
Learning to associate data in the environment with a probability of finding food presents two problems. The first is how to decide which data items should be learned and monitored; the second is to determine how to monitor and represent the reward probability predicted by the data items that are learned/monitored. Most learning models deal with the second problem and ignore the first. It is usually assumed in such models that the subject already knows the alternatives that should be sampled (e.g. buttons or levers to press, keys to peck or flowers to visit); the model captures only the process of sampling and updating the expected value of each alternative [5,9] or the associative strength between items [31]. In practice, however, the first problem—what to learn—is equally significant. Psychologists and animal trainers are well aware of the fact that the stimulus to be learned must be close to the reward, in time or in space, in order to be learned [34–37]. In terms of our model, this closeness requirement is not merely a technical constraint on the neuronal system, but an adaptive part of the data-acquisition mechanism. We say that this is only part of the data-acquisition mechanism because the other, more basic, part is the innate template of the reward itself: the range of shapes, smells and tastes that determine what the animal perceives as food. This template is similar to the innate template in imprinting mechanisms (and, similarly, may be more- or less-specific, depending on selection pressures), but here the goal is not only to learn to recognize food, but also to learn to associate it with relevant data in the environment. For that goal, we believe that an additional data-acquisition mechanism is required, one that captures the required proximity between the reinforcer and the stimuli.
To be more precise, we can say that the data-acquisition mechanism that guides associative learning is the one that determines how close in time or space a data item should be to the reinforcer in order to be acquired as a candidate for association. The reinforcer can either be a food item or a previously learned data item that can now function as a secondary reinforcer. Note that, in this sense, the reinforcers reinforce not only the act of foraging, but also the act of data acquisition. More generally, in our model, the reinforcer can be any data that match data already represented in memory and that indicate that the new input is important or relevant (see [10] for more details). As a result, a data sequence of a certain length is processed; this ‘certain length’ helps determine which data are deemed relevant and which are ignored. (We use the term ‘length’ here for simplicity; it can also be a certain radius or neighbourhood around the reinforcer.)
The occurrence of two data items within this acquired sequence (e.g. a food item and a visual cue) is then represented by a link that increases in weight every time that they are observed together again within an acquired data sequence. The weight of this association link can also decay (i.e. decrease). This can happen if the second item in the pair (e.g. the visual cue) is not observed again, or if it is observed, but without the first one (i.e. without food). Thus, there are two tests to pass for a cue to be learned. First, the cue must be sufficiently close in time or space to the reinforcer in order to be included in an acquired data sequence; this is the data-acquisition test. Second, the link between the two items must gain a sufficient level of weight; this is the learning test. The details of how the weight of an item is increased in the learning test may not be simple; various learning rules may determine exactly how experience increases the associative strength of data items (reviewed in [31]). In terms of our model, they can all be viewed as mechanisms that adjust the weights of nodes and links in the data representation, and they all must coevolve with the proximity requirement in the data-acquisition test.
As in the previous section, to understand the evolutionary advantage of a mechanism that restricts the amount of data, we should consider the alternative possibility. In theory, the subject can acquire and try to remember all the data that can be absorbed by its senses during foraging, and then compare the correlation between each data item and the data representing the experience of receiving food. The problem, however, is that this method is costly in terms of memory and computation, and may produce spurious correlations that can only be identified and eliminated by yet more data and computation. And indeed, as mentioned already, research on learning suggests that humans and animals do not behave this way. Instead, they tend to acquire much less data, and pay attention only to stimuli that are sufficiently close in time or space to the rewarding event.
There is also evidence that the degree of proximity that is required between the learned data and the reinforcer for data acquisition to occur evolves to fit the statistical distribution of the data that should be learned. In taste aversion, for example, animals can associate nausea and vomiting with food eaten hours before [38]. This makes sense because it takes a few hours for the food to be digested and to cause the aversive symptoms. This example demonstrates that a long delay between the reinforcer and the data can evolve when it is adaptive. In most other forms of associative learning, the required proximity is usually on the order of a few seconds [35]; when spatial proximity is considered, the associated data must be a short distance from the reinforcer [36], as would be expected if most useful cues for predicting the presence of food are likely to be experienced within this range. If the animal looks only for relevant data in too small a neighbourhood of the reinforcer, it may miss opportunities to learn useful cues. On the other hand, expanding the neighbourhood too much would increase the number of candidate cues significantly, and would complicate the learning task enormously. Note that, in this respect, the relatively long delay in taste aversion is not very costly because this process is focused on data related to food types; in nature, the number of such food types encountered during a few hours or a day is not too high. The situation is completely different when the target for learning is a subtle visual cue that must be sorted out from many dozens of potential cues encountered during only a few hours of foraging activity.
Our model suggests that different types of associative learning can often be viewed as outcomes of learning and data-acquisition mechanisms that coevolve. One obvious source of variation in these outcomes is in the innate reinforcers themselves. Changing them would certainly change the type of data that is learned. Another one, as explained earlier, is in the parameter that determines the required proximity of data to the reinforcer in the data-acquisition mechanism. And finally, differences in the parameters of weight increase and decrease may be expressed as differences between learning that requires a single versus repeated experiences, or between learning that occurs within a few seconds or a few weeks. Furthermore, learning types that have been traditionally classified as different may not be viewed as such by our model. For example, according to our model, classical and operant conditioning differ only in the fact that the first is based on external sensory data, while the second is focused on the data that represent the animal's own actions. In our model, such differences matter only if these data types differ systematically in their likelihood of being acquired or in their learning parameters, issues that are still debated (see also [39,40]).
According to our model, imprinting can also be viewed as no more than a variant of associative learning (see also [24]). Links between the innate template and the observed features of the imprinted object eventually reach fixation, while links with competing stimuli decay. An interesting distinction between the links established in imprinting and those in associative learning is that, in imprinting, the links are mainly (or at least initially) based on similarity—that is, similarity of the data item to the template, while in associative learning, they are based on co-occurrence (in time or space) of the data item to the reinforcer. This distinction is not as large as it may appear. Similarity links are also involved in associative learning. As mentioned earlier, the initial response to the innate reinforcer is based on recognizing similarity between data input (smell, taste and shape) and a template (as in imprinting), and additional data acquisition can also be based on recognizing similarity to additional learned items that are now acting as secondary reinforcers.
4. Learning structure in time and space
There seems to be a large gap between the associative learning described earlier and the mechanisms required for higher cognitive abilities, such as the ability to construct cognitive maps, to acquire language, or to represent the knowledge held by others [41–44]. To develop such abilities, humans and animals must learn the statistical regularities in the data, which in turn will enable them to learn how the data are structured, both spatially and temporally. As mentioned in §1, in our previous work, we suggested that during learning, additional processes are at work that compare data sequences, segment them based on commonalities and update their weight and link structure in memory representation [10,11]. We also described in more detail how such processes can facilitate advanced cognitive abilities such as language acquisition or theory of mind and what evidence is currently available to support the existence of such processes. (See [10, §3.1] for details of an associative learning account of theory of mind that involves data segmentation, network construction and generalization.) Here we focus on the evolution of these learning processes. We suggest that they can evolve from the simple associative principles that we described in the previous sections (see also Heyes [32] for a similar view).
We start by explaining briefly why learning structure in time and space is challenging, and how it can be simplified by the joint action of learning and data-acquisition mechanisms. It is quite common to view cognitive representation as a complex network of data items and their associations in time and space. The problem is how such a network can be constructed by learning. The field of statistical learning offers several possible methods [17,18,45], but they all require much memory and computation. One approach that has been suggested is that of comparing a stimulus stream with other streams or with space- or time-shifted versions of itself, in order to reveal commonalities and differences from which regularities can be inferred [46,47] that can then be tested for statistical significance [18]. However, two complications arise. First, comparing a sequence with all shifted versions of that sequence and that of all previously acquired sequences is clearly computationally demanding. Second, when testing for statistical significance, we must somehow distinguish between true commonalities and ‘coincidental commonalities’ in the data. This requires a large corpus of experience. As we have seen, both the first and the second problem arise in the context of associative learning as well. We can deal with them using the same techniques: using the data-acquisition mechanism to limit the data input, and using the learning mechanism to control which data items can be ignored (thanks to decay).
Restricting the process of comparison to the learning window—the time during which the weight is greater than zero but has not reached fixation—has a number of advantages. For one thing, we reduce the amount of data to be processed. We also obtain a powerful test for the statistical significance of data items and their associations. Patterns of co-occurrences that are rare will decay, while those that are frequent will get fixated, and thus learned. This seems appropriate; if an event occurs multiple times in a data window, it is unlikely to be coincidental. Social and contextual cues can modify the rate of weight increase and decrease, thus shaping the size of the learning window during which the search for commonalities is conducted. Finally, data input are restricted to what is deemed relevant by the data-acquisition mechanisms. As discussed earlier for imprinting and associative learning, the ability to learn the patterns that are indeed useful (such as words in a sentence or natural objects or structures in the environment) is greatly improved by the coevolved coordination between the data-acquisition and the learning parameters. Given a certain distribution of data input, the parameters of weight increase and decrease that will be selected are those that facilitate the learning of the most useful patterns and network representation.
We now explain how the proposed process of learning structure could have evolved from simple associative learning. Our goal is not to advocate a particular historical sequence of events, but to demonstrate how the evolutionary transition between such mechanisms could occur. It seems likely that associative learning preceded the ability to learn structure, but the transition could have happened several times, and relatively early in the evolution of sensory systems.
Recall that in our view of associative learning, when an animal recognizes a food item it also acquires a certain amount of ‘nearby’ data (near in time and/or space). This ‘acquisition’ of nearby data is modelled by links between ‘food’ and the acquired data items in the data representation. Most of these links are likely to decay, but those that are based on associations that are experienced repeatedly will increase in weight and survive. Note that this process can already be described as a simple version of the search for commonalities described earlier. First, sensory input is compared with data already represented in memory (a template for food); when food is recognized, a sequence of nearby data is acquired. For example, recognizing FOOD can initiate the acquisition of the unsegmented data sequence 3459FOOD2731. An animal that recognizes FOOD will segment the data sequence as 3459—FOOD—2731 (represented as three nodes with links between them). Suppose that the next time food is observed, it occurs in the data sequence 3450FOOD6680. Again, this sequence is segmented as 3450—FOOD—6680. If the node labelled ‘3459’ from the earlier sequence has not decayed, the animal will recognize the common subsequence ‘345’ in ‘3459’ and ‘3450’. The resulting data representation may then look like this:
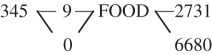
Following repeated co-occurrences, if the item ‘345’ and its links to FOOD gain sufficient weight, ‘345’ itself can become a secondary reinforcer for data acquisition. This means that the data-acquisition mechanism can now acquire data sequences that include ‘345’ even if they do not include ‘FOOD’. Thus, a sensory input such as 55713459844 that includes ‘345’ will be segmented into 5571—345—9844, and added to the representation with appropriate links and weights. As a result of this process, the network grows. Some of its nodes and links will increase in weight following repeated occurrences and co-occurrences, while other nodes and links will decay and disappear from the network. The nodes that increase in weight can become secondary reinforcers for data acquisition as described earlier for the node ‘345’. Secondary reinforcers for data acquisition may not be as strong as (i.e. might have lower weight than) innate ones (e.g. food). The extent to which secondary reinforcers increase the likelihood of acquiring additional data should depend on the extent to which such data can contribute to survival. The parameters adjusting the weights of the secondary reinforcers as a function of experience should evolve to optimize the data-acquisition process.
Before we continue, let us note that the process described earlier can also facilitate a search for commonality within a sequence (i.e. commonalities between a sequence and a space- or time-shifted version of itself). For example, suppose that the sequence 3159FOOD3148 is acquired, and the animal not only recognizes FOOD, but can also recognize the subsequence 31 at different locations within the sequence. This results in the sequence being segmented as 31—59—FOOD—31—48. Whether the node representing 31 decays or reaches fixation depends on further observations.
Only a few steps are still needed to make the earlier-mentioned process be virtually the same as the process of learning structure that was described earlier. Consider a primitive animal that crawls along while searching for food by occasionally digging or probing the soil at random. When food is found, it acquires some nearby data as described earlier, using associative learning, and thus learns some cues that can direct its future decisions as to whether to dig or to keep crawling. However, a relatively simple modification can facilitate an important transition: imagine that instead of acquiring nearby data only when food is found, it now acquires some nearby data every time it moves a step forward. In other words, instead of using food as a reinforcer for data acquisition, the animal is now reinforced to acquire nearby data around its path of movement, receiving streams of data from the environment. A simple accumulation of such data streams could have been counterproductive. However, since the animal already searches for commonalities within and between data sequences, the data will not be accumulated as is. Instead, most of it will be added to the agent's network, and will soon decay, while features that are observed repeatedly and are therefore likely to represent real objects or features in the environment will increase in weight and eventually be learned. Learning such objects and features may help to make sense of the world even if they are not associated with a particular reinforcer. For example, an animal that can easily recognize that the area in front of it contains a mixture of pebbles and branches may benefit precisely because it can learn that these objects are normally not associated with food, and it is best to move forward.
We have just explained how acquiring streams of data and processing them using the basic principles of associative learning results in a process that is virtually the same as our general model for learning structure [10,11]. We demonstrated this with a specific example in which an animal acquires data along its path of movement, and suggested that this is likely to be adaptive because such data streams include useful things to learn, even though they are not immediately related to food. For similar reasons, it might be useful for a young animal to continuously follow the actions of its parent, regardless of whether the parent finds food. This is because the data surrounding the actions or the foraging sites of an experienced parent are likely to include data items that should be learned. A similar argument can certainly be made for song learning or language acquisition, where the sounds uttered by the parent are clearly the target for learning. In such cases, the data-acquisition mechanism includes the parent's actions or voice as the reinforcer for data acquisition, and a set of parameters that determine the range of nearby data that is deemed relevant for acquisition. The learning parameters (of weight increase and decrease) should then evolve to handle the acquired data input in a way that optimizes learning of useful patterns and structure.
We have argued elsewhere that by recursively applying these principles of comparison of data streams within a restricted learning window, further associations can be detected and hierarchical structure can be constructed in the data representation [10,11,20]. We also suggested that, as part of this process, similarity can be identified at the level of link structure, which facilitates generalization and the use of context. For example, a child may classify as ‘similar’ items that are visually different, such as apples and bananas, because they have many similar links (e.g. they are associated with being picked from trees, eaten by people, have a juicy sweet taste and mentioned together with the word fruits). Thus, commonalities in incoming data may be identified at higher levels of organization; consequently, associations between more abstract concepts or ideas can be represented in the network [10,20]. Here, however, we attempt to demonstrate that using the framework of coevolving data-acquisition and learning mechanisms, all these processes can evolve from the same set of simple principles as those used in associative learning.
5. Evolving brains
What is the difference between the brain of a sparrow and a crow, or a dog and a child? Can it be explained in terms of different data-acquisition and learning parameters? Obviously, there is much more to a brain than what we have captured so far in our model. The processes described in our model must eventually be explained in terms of neuronal structures and activities, and the proposed network should exist within brain organs that store and handle the relevant types of data (e.g. visual, acoustic, motor, spatial). The network must also be structured in a way that allows efficient search; moreover, a whole set of processes is required to explain how the network can be used to produce and execute behaviours. We have suggested elsewhere how some of this might be done [10], but these are clearly questions awaiting future research. However, regardless of exactly how these additional tasks are performed, they all must be supported by the network. And because the network is constructed through the joint action of data-acquisition and learning mechanisms, these mechanisms and their parameters should be responsible for many of the evolved differences in cognitive abilities. We have already suggested this possibility briefly in §1; we are now in a position to evaluate this idea better.
At the simplest level, relating cognitive differences to data-acquisition mechanisms is quite intuitive. It results naturally from different innate templates, which direct individuals to search for particular types of food, or to follow their parents and group members, or to listen to particular sounds. Such differences will eventually produce a particular type of representation of the world that is likely to vary across different species. However, the idea goes deeper than that. A house sparrow will probably not be able to make tools like a New Caledonian crow [48] even if it pays careful attention to twigs and leaves, and tries to accumulate data about them. This is almost like expecting that a dog will be able to understand English if it only listens carefully to its owners and acquires long enough strings of spoken language. Acquiring more relevant data is necessary and can help (and some dogs can certainly understand some English [49]), but is not enough. The reason for this, according to our model, is not only that sparrows or dogs do not have the additional systems required for producing or practicing the behaviour (e.g. the motor skills). It is primarily because the acquired data must be processed using learning parameters that coevolved with the data-acquisition mechanism (i.e. that evolved to handle a certain flow rate and distribution of data input). It is not enough for a dog to acquire all the sentences uttered by its owners and search for commonalities. It must also have the appropriate rates of weight increase and decrease (and their possible modification by state or social cues) that would result in a sensible segmentation of sentences into words, and a correct representation of their structural relationships [11]. Thus, in terms of our model, at least some cognitive differences across species (as well as individual differences within a species [50]) may be based on specific coevolved combinations of data-acquisition and learning parameters.
Are there evolved differences in brain and cognition that cannot be captured in terms of data-acquisition and learning parameters? Obviously, there are many evolved differences in brain size, anatomy and morphology across different taxa [51], and there are probably many additional differences in working memory and other cognitive aspects that are still hard to quantify [52]. We cannot argue that all of them can be explained in terms of data-acquisition and learning parameters, but we believe that many of them might be. For example, if the mechanisms of data acquisition and the rate of weight increase and decrease determine the type and the amount of data that are eventually stored in long-term memory, they may also determine the size of specialized brain areas. Similarly, the rate of weight increase and decrease that determines the learning window during which search for commonalities and updating of the network can occur may be related to the capacity of working memory.
6. Predictions, supportive evidence and future work
As mentioned in §1, our model predicts that because learning parameters have evolved to handle a typical rate and distribution of data input in nature, manipulating this input can impair learning in some specific ways. We already discussed the most obvious example of this prediction in the case of miss-imprinting: if the right type of data was not acquired during the learning window (or was not acquired at a sufficient rate), imprinting on an ‘inappropriate’ object will result. Another simple prediction arises naturally in the context of associative learning: reducing the rate of encountering a particular data item may prevent it from gaining enough weight, and thus prevent it from being learned; similarly, manipulating the data stream so that certain data items appear unnaturally often (within the data-acquisition range) should result in successful learning of data that are normally not relevant. This prediction is repeatedly (and unsurprisingly) verified by the fact that animals can easily be conditioned on artificial stimuli and be prevented from learning natural ones. It should also hold for data streams that are acquired while moving along or following a parent (as discussed earlier), as indicated, for example, from research on song learning [53].
However, the more interesting and powerful prediction of our model is related to the process of searching for commonalities and segmenting the data. Recall that the weight increase and decrease parameters create a learning window during which these processes can take place. Thus, to recognize a common subsequence in two sequences, the second sequence must be acquired before the first one decays. Only then can the two sequences be segmented properly. For example, we would expect GOODMORNING and VERYGOOD to be segmented into GOOD—MORNING and VERY—GOOD. According to our framework, such segmentation is more likely if the phrases to be segmented are heard repeatedly in different sentences uttered in close temporal proximity. Indeed, a recent experimental study showed that word learning of artificial language by students is improved significantly under such conditions. Onnis et al. [54] showed that when sentences that include common words are presented sequentially or only one sentence apart, segmentation is better than when the same corpus of sentences is presented in a scrambled random order. Note that this result would not follow in models that did not require a learning window, for example, in models where all the data are first acquired and then analysed, as in most computational models for word learning [17–19]. Moreover, recent analyses of child-directed speech show that parents and carers behave as if they know that this proximity of sentences with common words is necessary. About one-fifth of the sentences in child-directed speech take part in sets of sentences (termed variation sets) that include partial repetitions (such as: ‘look at the ball; what a nice ball; look’) [11,55,56].
Our model also predicts that manipulating the data stream so that one of the sequences is acquired repeatedly and reaches fixation before the other one is acquired can impair segmentation. Each sequence may then be learned as a complete unique sequence rather than a composition of a few smaller ones. Interestingly, segmentation errors of this kind are common in autistic children, who frequently use an entire phrase rather than a single appropriate word when they see an object or a person related to this phrase (cf. echolalia [57,58]). As we suggested in earlier work [10,11], autistic children are likely to ‘observe’ quite different data streams than normal children, because they do not pay attention to human speech anywhere near as much as typical children do [57,59]; so according to our model, the inappropriate segmentation would be expected.
There is not much work on data segmentation by animals, but the potential for such research is exciting. If our model is correct, many of the advanced cognitive abilities exhibited by animals, such as the ability to learn patterns and rules, to predict chains of consequences or to construct cognitive maps, all arise from the same processes of segmenting data during a learning window and constructing a network representation. Accordingly, we predict that manipulating the distribution of data sequences in such learning tasks should result in atypical outcomes. Furthermore, the analysis of such experimental results, and exactly what type of manipulation is needed to obtain certain types of atypicality, should reveal the parameters of the learning window of such cognitive tasks, illustrating how they coevolved with their data-acquisition mechanisms in different taxa or under different ecological conditions. Combining such work with computer simulations of such data-acquisition and learning mechanisms should help us understand the computational feasibility and evolutionary plausibility of our model.
Acknowledgements
We thank O. Kolodny, S. Edelman, R. Katzir, A. Thornton and two anonymous reviewers for comments on the manuscript. A.L. was supported in part by the Israel Science Foundation grant no. 1312/11, and J.Y.H. was supported in part by NSF grants IIS-0534064, IIS-0812045 and IIS-0911036, by AFOSR grants FA9550-08-1-0438 and FA9550-09-1-0266, and by ARO grant W911NF-09-1-0281.
References
- 1.Real L. A. 1991. Animal choice behaviour and the evolution of cognitive architecture. Science 253, 980–986 10.1126/science.1887231 (doi:10.1126/science.1887231) [DOI] [PubMed] [Google Scholar]
- 2.Shettleworth S. J. 1998. Cognition, evolution and behaviour. New York, NY: Oxford University Press [Google Scholar]
- 3.Dudai Y. 2009. Predicting not to predict too much: how the cellular machinery of memory anticipates the uncertain future. Phil. Trans. R. Soc. B 364, 1255–1262 10.1098/rstb.2008.0320 (doi:10.1098/rstb.2008.0320) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Dukas R. 2009. Learning: mechanisms, ecology, and evolution. In Cognitive ecology II (eds Dukas R., Ratcliffe J. M.), pp. 7–26 Chicago, IL: University of Chicago Press [Google Scholar]
- 5.McNamara J. M., Houston A. I. 1987. Memory and the efficient use of information. J. Theor. Biol. 125, 385–395 10.1016/S0022-5193(87)80209-6 (doi:10.1016/S0022-5193(87)80209-6) [DOI] [PubMed] [Google Scholar]
- 6.Niv Y., Joel D., Meilijson I., Ruppin E. 2002. Evolution of reinforcement learning in uncertain environments: a simple explanation for complex foraging behaviours. Adap. Behav. 10, 5–24 10.1177/10597123020101001 (doi:10.1177/10597123020101001) [DOI] [Google Scholar]
- 7.Groß R., Houston A. I., Collins E. J., McNamara J. M., Dechaume-Moncharmont F. X., Franks N. R. 2008. Simple learning rules to cope with changing environments. J. R. Soc. Interface 5, 1193–1202 10.1098/rsif.2007.1348 (doi:10.1098/rsif.2007.1348) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Lange A., Dukas R. 2009. Bayesian approximations and extensions: optimal decisions for small brains and possibly big ones too. J. Theor. Biol. 259, 503–516 10.1016/j.jtbi.2009.03.020 (doi:10.1016/j.jtbi.2009.03.020) [DOI] [PubMed] [Google Scholar]
- 9.Arbilly M., Motro U., Feldman M. W., Lotem A. 2010. Co-evolution of learning complexity and social foraging strategies. J. Theor. Biol. 267, 573–581 10.1016/j.jtbi.2010.09.026 (doi:10.1016/j.jtbi.2010.09.026) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Lotem A., Halpern J. Y. 2008. A data-acquisition model for learning and cognitive development and its implications for autism. Cornell Computing and Information Science Technical Reports. See http://hdl.handle.net/1813/10178.
- 11.Goldstein M. H., Waterfall H. R., Lotem A., Halpern J. Y., Schwade J., Onnis L., Edelman S. 2010. General cognitive principles for learning structure in time and space. Trends Cogn. Sci. 14, 249–258 10.1016/j.tics.2010.02.004 (doi:10.1016/j.tics.2010.02.004) [DOI] [PubMed] [Google Scholar]
- 12.Gentner T. Q., Fenn K. M., Margoliash D., Nusbaum H. C. 2006. Recursive syntactic pattern learning by songbirds. Nature 440, 1204–1207 10.1038/nature04675 (doi:10.1038/nature04675) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Murphy R. A., Mondragon E., Murphy V. A. 2008. Rule learning by rats. Science 319, 1849–1851 10.1126/science.1151564 (doi:10.1126/science.1151564) [DOI] [PubMed] [Google Scholar]
- 14.Marsh B., Kacelnik A. 2002. Framing effects and risky decisions in starlings. Proc. Natl Acad. Sci. USA 99, 3352–3355 10.1073/pnas.042491999 (doi:10.1073/pnas.042491999) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Keasar T., Rashkovich E., Cohen D., Shmida A. 2002. Bees in two-armed bandit situations: foraging choices and possible decision mechanisms. Behav. Ecol. 13, 757–765 10.1093/beheco/13.6.757 (doi:10.1093/beheco/13.6.757) [DOI] [Google Scholar]
- 16.Heyes C. 2011. What's social about social learning? J. Comp. Psychol. 126, 193–202 10.1037/a0025180 (doi:10.1037/a0025180) [DOI] [PubMed] [Google Scholar]
- 17.Brent M. R. 1999. Speech segmentation and word discovery: a computational perspective. Trends Cogn. Sci. 3, 294–301 10.1016/S1364-6613(99)01350-9 (doi:10.1016/S1364-6613(99)01350-9) [DOI] [PubMed] [Google Scholar]
- 18.Solan Z., Horn D., Ruppin E., Edelman S. 2005. Unsupervised learning of natural languages. Proc. Natl Acad. Sci. USA 102, 11 629–11 634 10.1073/pnas.0409746102 (doi:10.1073/pnas.0409746102) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.French R. M., Addyman C., Mareschal D. 2011. TRACX: a recognition-based connectionist framework for sequence segmentation and chunk extraction. Psychol. Rev. 118, 614–636 10.1037/a0025255 (doi:10.1037/a0025255) [DOI] [PubMed] [Google Scholar]
- 20.Kolodny O., Lotem A., Edelman S. In preparation Learning a generative probabilistic grammar of linguistic experience. [DOI] [PubMed]
- 21.Gallistel C. R. 1990. The organization of learning. Cambridge, MA: MIT Press [Google Scholar]
- 22.Bateson P. P. G. 1966. The characteristics and context of imprinting. Biol. Rev. 41, 177–220 10.1111/j.1469-185X.1966.tb01489.x (doi:10.1111/j.1469-185X.1966.tb01489.x) [DOI] [PubMed] [Google Scholar]
- 23.Bateson P. P. G. 1979. How do sensitive periods arise and what are they for? Anim. Behav. 27, 470–486 10.1016/0003-3472(79)90184-2 (doi:10.1016/0003-3472(79)90184-2) [DOI] [Google Scholar]
- 24.Bateson P. P. G. 1990. Is imprinting such a special case? Phil. Trans. R. Soc. Lond. B 329, 125–131 10.1098/rstb.1990.0157 (doi:10.1098/rstb.1990.0157) [DOI] [Google Scholar]
- 25.van Kampen H. 1996. A framework for the study of filial imprinting and the development of attachment. Psychon. B. Rev. 3, 3–20 10.3758/BF03210738 (doi:10.3758/BF03210738) [DOI] [PubMed] [Google Scholar]
- 26.Lotem A., Nakamura H., Zahavi A. 1995. Constraints on egg discrimination and cuckoo-host coevolution. Anim. Behav. 49, 1185–1209 10.1006/anbe.1995.0152 (doi:10.1006/anbe.1995.0152) [DOI] [Google Scholar]
- 27.Rodriguez-Gironez M., Lotem A. 1999. How to detect a cuckoo egg: a signal detection theory model for recognition and learning. Am. Nat. 153, 633–648 10.1086/303198 (doi:10.1086/303198) [DOI] [PubMed] [Google Scholar]
- 28.Rothstein S. I. 1974. Mechanisms of avian egg recognition: possible learned and innate factors. Auk 91, 796–807 [Google Scholar]
- 29.Shizuka D., Lyon B. E. 2010. Coots use hatch order to learn to recognize and reject conspecific brood parasitic chicks. Nature 463, 223–226 10.1038/nature08655 (doi:10.1038/nature08655) [DOI] [PubMed] [Google Scholar]
- 30.Lotem A. 1993. Learning to recognize nestlings is maladaptive for cuckoo Cuculus-canorus hosts. Nature 362, 743–745 10.1038/362743a0 (doi:10.1038/362743a0) [DOI] [Google Scholar]
- 31.Pearce J. M., Bouton M. E. 2001. Theories of associative learning in animals. Ann. Rev. Psychol. 52, 111–139 10.1146/annurev.psych.52.1.111 (doi:10.1146/annurev.psych.52.1.111) [DOI] [PubMed] [Google Scholar]
- 32.Heyes C. 2012. Simple minds: a qualified defence of associative learning. Phil. Trans. R. Soc. B 367, 2695–2703 10.1098/rstb.2012.0217 (doi:10.1098/rstb.2012.0217) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Dickinson A. 2012. Associative learning and animal cognition. Phil. Trans. R. Soc. B 367, 2733–2742 10.1098/rstb.2012.0220 (doi:10.1098/rstb.2012.0220) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Rescorla R. A., Cunningham C. L. 1979. Spatial contiguity facilitates Pavlovian second-order conditioning. J. Exp. Psycol. Anim. Behav. Process. 5, 152–161 10.1037/0097-7403.5.2.152 (doi:10.1037/0097-7403.5.2.152) [DOI] [PubMed] [Google Scholar]
- 35.Rescorla R. A. 1988. Behavioural studies of Pavlovian conditioning. Ann. Rev. Neurosci. 11, 329–352 10.1146/annurev.ne.11.030188.001553 (doi:10.1146/annurev.ne.11.030188.001553) [DOI] [PubMed] [Google Scholar]
- 36.Christie J. 1996. Spatial contiguity facilitates Pavlovian conditioning. Psychon. B. Rev. 3, 357–359 10.3758/BF03210760 (doi:10.3758/BF03210760) [DOI] [PubMed] [Google Scholar]
- 37.Pryor K. 1999. Clicker training for dogs. Waltham, MA: Sunshine Books [Google Scholar]
- 38.Garcia J., Ervin F. R., Koelling R. A. 1966. Learning with prolonged delay of reinforcement. Psychon. Sci. 5, 121–122 [Google Scholar]
- 39.Blaisdell A. P., Sawa K., Leising K. J., Waldmann M. R. 2006. Causal reasoning in rats. Science 311, 1020–1022 10.1126/science.1121872 (doi:10.1126/science.1121872) [DOI] [PubMed] [Google Scholar]
- 40.Kutlu M. G., Schmajuk N. A. 2012. Classical conditioning mechanisms can differentiate between seeing and doing in rats. J. Exp. Psychol. Anim. Behav. Process. 38, 84–101 10.1037/a0026221 (doi:10.1037/a0026221) [DOI] [PubMed] [Google Scholar]
- 41.Gallistel C. R. 2008. Learning and representation. In Learning theory and behaviour (ed. Menzel R.), pp. 227–242 (vol. 1 of Learning and memory: a comprehensive reference (ed. J. Byrne)). Oxford, UK: Elsevier [Google Scholar]
- 42.Edelman S. 2011. On look-ahead in language: navigating a multitude of familiar paths. In Predictions in the brain (ed. Bar M.), pp. 170–189 Oxford, UK: Oxford University Press [Google Scholar]
- 43.Tenenbaum J. B., Kemp C., Griffiths T. L., Goodman N. 2011. How to grow a mind: statistics, structure, and abstraction. Science 331, 1279–1285 10.1126/science.1192788 (doi:10.1126/science.1192788) [DOI] [PubMed] [Google Scholar]
- 44.Ramnani N., Miall C. 2004. A system in the human brain for predicting the actions of others. Nat. Neurosci. 7, 85–90 10.1038/nn1168 (doi:10.1038/nn1168) [DOI] [PubMed] [Google Scholar]
- 45.Yuille A., Kersten D. 2006. Vision as Bayesian inference: analysis by synthesis? Trends Cogn. Sci. 10, 301–308 10.1016/j.tics.2006.05.002 (doi:10.1016/j.tics.2006.05.002) [DOI] [PubMed] [Google Scholar]
- 46.Harris Z. S. 1954. Distributional structure. Word 10, 146–162 [Google Scholar]
- 47.Harris Z. S. 1991. A theory of language and information. Oxford, UK: Clarendon [Google Scholar]
- 48.Bluff L. A., Weir A. A. S., Rutz C., Wimpenny J. H., Kacelnik A. 2007. Tool-related cognition in New Caledonian crows. Comp. Cogn. Behav. Rev. 2, 1–25 [Google Scholar]
- 49.Pilley J. W., Reid A. K. 2011. Border collie comprehends object names as verbal referents. Behav. Process. 86, 184–195 10.1016/j.beproc.2010.11.007 (doi:10.1016/j.beproc.2010.11.007) [DOI] [PubMed] [Google Scholar]
- 50.Sih A., Del Giudice M. 2012. Linking behavioural syndromes and cognition: a behavioural ecology perspective. Phil. Trans. R. Soc. B 367, 2762–2772 10.1098/rstb.2012.0216 (doi:10.1098/rstb.2012.0216) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Finlay B. L., Hinz F., Darlington R. B. 2011. Mapping behavioural evolution onto brain evolution: the strategic roles of conserved organization in individuals and species. Phil. Trans. R. Soc. B 366, 2111–2123 10.1098/rstb.2010.0344 (doi:10.1098/rstb.2010.0344) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Gray J. R., Thompson P. M. 2004. Neurobiology of intelligence: science and ethics. Nat. Rev. Neurosci. 5, 471–482 10.1038/nrn1405 (doi:10.1038/nrn1405) [DOI] [PubMed] [Google Scholar]
- 53.Payne R. B., Payne L. L., Woods J. L. 1998. Song learning in brood parasitic indigobirds Vidua chalybeata: song mimicry of their host species. Anim. Behav. 55, 1537–1553 10.1006/anbe.1997.0701 (doi:10.1006/anbe.1997.0701) [DOI] [PubMed] [Google Scholar]
- 54.Onnis L., Waterfall H. R., Edelman S. 2008. Learn locally, act globally: learning language from variation set cues. Cognition 109, 423–430 10.1016/j.cognition.2008.10.004 (doi:10.1016/j.cognition.2008.10.004) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Küntay A., Slobin D. 1996. Listening to a Turkish mother: some puzzles for acquisition. In Social interaction, social context, and language: essays in honor of Susan Ervin-Tripp (eds Slobin D., Gerhardt J., Kyratzis A., Jainsheng G.), pp. 265–286 Hillsdale, NJ: Lawrence Erlbaum Associates [Google Scholar]
- 56.Waterfall H. R., Sandbank B., Onnis L., Edelman S. 2010. An empirical generative framework for computational modeling of language acquisition. J. Child Lang. 37, 671–703 10.1017/S0305000910000024 (doi:10.1017/S0305000910000024) [DOI] [PubMed] [Google Scholar]
- 57.Frith U. 1989. Autism: explaining the enigma. Oxford, UK: Blackwell [Google Scholar]
- 58.Howlin P. 1998. Children with autism and Asperger syndrome: a guide for practitioners and carers. Oxford, NY: John Wiley and Sons [Google Scholar]
- 59.Klin A. 1991. Young autistic children's listening preferences in regard to speech: a possible characterization of the symptom of social withdrawal. J. Autism Dev. Disord. 21, 29–42 10.1007/BF02206995 (doi:10.1007/BF02206995) [DOI] [PubMed] [Google Scholar]