

Abstract
OBJECTIVE
This study aimed to provide guidelines to optimize perception of soft speech and speech in noise for Advanced Bionics cochlear implant (CI) users.
DESIGN
Three programs differing in T-levels were created for ten subjects. Using the T-level setting that provided the lowest FM-tone, sound-field threshold levels for each subject, three additional programs were created with input dynamic range (IDR) settings of 50, 65 and 80 dB.
STUDY SAMPLE
Subjects were postlinguistically deaf adults implanted with either the Clarion CII or 90K CI devices.
RESULTS
Sound-field threshold levels were lowest with T-levels set higher than 10% of M-levels and with the two widest IDRs. Group data revealed significantly higher scores for CNC words presented at a soft level with an IDR of 80 dB and 65 dB compared to 50 dB. Although no significant group differences were seen between the three IDRs for sentences in noise, significant individual differences were present.
CONCLUSIONS
Setting Ts higher than the manufacturer’s recommendation of 10% of M-levels and providing IDR options can improve overall speech perception; however, for some users, higher Ts and wider IDRs may not be appropriate. Based on the results of the study, clinical programming recommendations are provided.
Keywords: Cochlear implant, input dynamic range, speech processor program, speech perception
INTRODUCTION
As the cochlear implant (CI) population grows, guidelines to efficiently and effectively optimize patient benefit from a CI are valuable to audiologists as well as to CI users. Providing guidelines to optimize CI recipients’ ability to understand soft speech and speech in noise is of particular importance as these are difficult listening situations for the majority of CI users.
A number of research studies have shown that access to low-level speech cues can improve CI recipients’ ability to understand soft speech (Skinner et al, 1997; Skinner et al, 1999; Skinner et al, 2002; James et al, 2003; Firszt et al, 2004; Holden et al, 2007; Dawson et al, 2007; Davidson et al, 2009). The intensity of the softest components of every-day speech is around 25 dB SPL; therefore, it is important that CI users have access to low-level sound in order to maximally understand speech in difficult listening situations encountered in every-day life. Examples of these situations include: listening to someone speak from another room, trying to understand soft spoken individuals such as children, and trying to understand the asides of a conversation. In addition, CI users who have access to low-level speech cues expend less effort in listening throughout the day.
Firszt et al (2004) evaluated a group of 78 CI users (26 each with the Advanced Bionics, Nucleus and MedEl CI systems) at three presentation levels in quiet (70, 60 and 50 dB SPL) and at a single presentation level in noise (60 dB SPL, +8 signal-to-noise ratio [SNR]). The results revealed a significant correlation between frequency-modulated (FM) tone sound-field threshold levels and performance on monosyllabic words, sentences in quiet and sentences in noise at the lower presentation levels. That is, lower FM-tone, sound-field threshold levels were correlated with better speech recognition at both 50 and 60 dB SPL.
Spahr et al (2007) found that CI users have particular difficulty understanding speech in noise as well as soft speech. They evaluated a group of 39 CI recipients using three different behind-the-ear (BTE) speech processors (13 each with the Advanced Bionics CII, the Nucleus 24 Esprit3G and the Med El Tempo+). All subjects had considerable open-set speech recognition, scoring between 50% and 90% on the Consonant-Vowel Nucleus-Consonant (CNC) Monosyllabic Word Test (Peterson & Lehiste, 1962) presented at 74 dB SPL. Each group of 13 scored significantly higher on AzBio sentences (Spahr & Dorman, 2005) in quiet presented at 74 dB SPL than on sentences presented at the same level in four-talker babble (+10 and +5 SNRs). Group mean scores for the AzBio sentences in quiet were high at 85%, 82% and 79% for the CII, Tempo+ and 3G speech processors, respectively. Group mean AzBio sentence scores at a +10 dB SNR dropped to 64%, 58%, and 42%, and at a +5 SNR, scores dropped to 44%, 38% and 22% for the CII, Tempo+, and 3G processors, respectively. Spahr and his colleagues point out that these same SNRs do not cause degradation to speech understanding for individuals with normal hearing. In addition, when the AzBio sentences were presented in quiet at three presentation levels (74, 64 and 54 dB SPL), all subjects had significantly better scores at the two higher presentation levels than at the lower presentation level.
The fact that CI users are challenged by difficult listening situations is well-known to audiologists who work with these patients on a regular basis. CI patients who perform well on word and sentence tests presented in quiet at a comfortable listening level often report substantial difficulty understanding in most noisy environments encountered in daily life (Donaldson et al, 2009). Moreover, they report difficulty understanding soft speech spoken by children and individuals speaking from another room. If optimizing patient performance in daily life is the goal, then it is essential that clinical fitting address the ability of CI users to understand soft speech as well as speech in noise.
Significant improvements in CI users’ perception of soft speech and speech in noise were seen in a study by Holden et al, 2007. Two speech processor maps were compared in a group of ten, postlingual, adult Nucleus Freedom™ CI recipients. One map used an input dynamic range (IDR) of 30 dB and the other used an IDR of 40 dB. The IDR is the range of the incoming acoustic signal which is mapped into the CI user’s electrical dynamic range (range between minimum stimulation levels [T-levels] and maximum stimulation levels [C-levels]). Theoretically, a wide IDR will capture more of the incoming acoustic signal than a narrow IDR allowing the CI user to hear soft, medium and loud sound. A narrow IDR may restrict the CI user’s ability to hear soft speech and sound because less of the incoming acoustic signal is being mapped into the CI user’s electrical dynamic range. A narrow IDR may be beneficial when listening in noise because low-level background noise may not be mapped into the CI user’s electrical dynamic range. The results from the study by Holden and colleagues revealed that FM-tone, sound-field threshold levels were significantly lower from 250–6000 Hz with the wider IDR (40 dB) than with the narrower IDR (30 dB). Sound-field threshold levels were approximately 20 dB HL across the frequency range with 40 dB IDR providing the group of subjects with an articulation index (AI; Mueller & Killion, 1990) of 0.97. Sound-field threshold levels were between 25 and 30 dB HL across the frequency range with 30 dB IDR providing an AI of 0.75 (See Figure 2, Holden et al, 2007). Therefore, more low-level acoustic cues were made audible with the wider IDR than with the narrower IDR. This was consistent with the group scoring significantly higher on the CNC word test presented at a soft level of 50 dB SPL with 40 dB IDR compared to 30 dB IDR. Moreover, the group scored significantly higher on the City University of New York (CUNY) sentence test (Boothroyd et al, 1988) presented at 65 dB SPL in background babble with the 40 dB IDR compared to the 30 dB IDR. This small but significant increase in the group score for sentences in noise with the wider IDR was unexpected; however, the authors hypothesized that it was likely due to the increased speech cues provided by the wider IDR.
Figure 2.
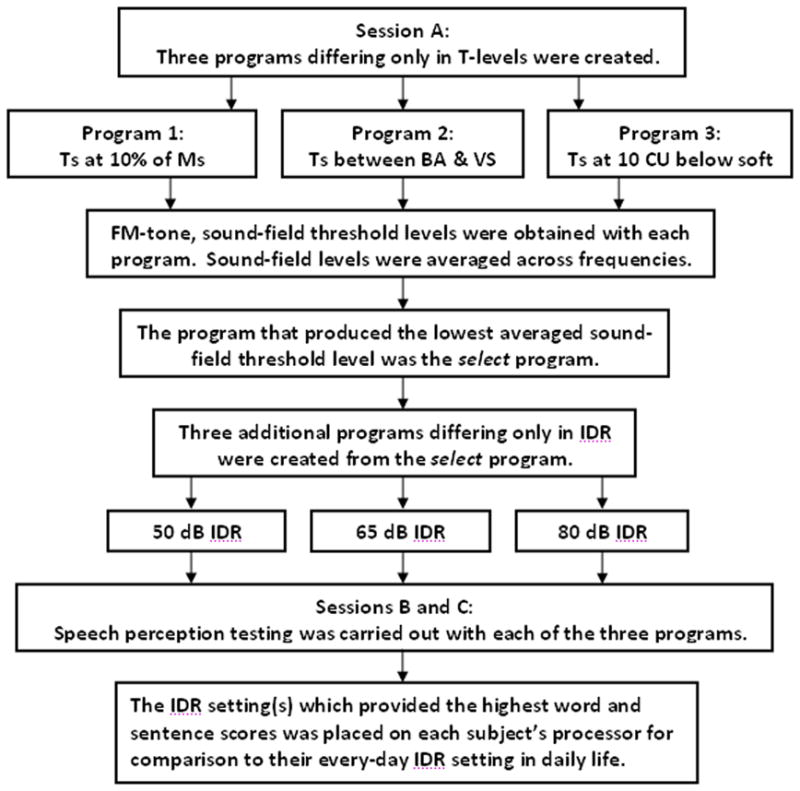
Summary of procedures performed at test sessions A, B, and C.
In a recent study by Davidson et al (2009), similar results were found for 30 children implanted with the Nucleus 24 device and using the Freedom™ speech processor. Two speech processor maps were compared. The maps were identical except one map was programmed using 30 dB IDR and the other 40 dB IDR. The results revealed significantly lower sound-field threshold levels from 250–6000 Hz with 40 dB IDR compared to 30 dB IDR. Sound-field threshold levels with 40 dB IDR were approximately 20 dB HL across the frequency range. Sound-field thresholds with the 30 dB IDR were between 20 and 30 dB HL across the frequency range. Furthermore, the results showed significantly higher scores for CNC words presented at 50 dB SPL with 40 dB IDR compared to 30 dB IDR. Speech understanding in noise was evaluated with the Bamford-Kowal-Bench Speech in Noise Test (BKB-SIN; Killion et al, 2004) in which an SNR-50 score was obtained, that is, an SNR for which 50% of the sentences were repeated correctly. No significant difference between the two IDRs was seen for the BKB-SIN for this group of children. Based on the improvement in audibility and CNC scores, it was recommended by Holden et al (2007) and Davidson et al (2009) that all Freedom™ CI recipients use the wider 40 dB IDR setting for all listening situations.
Spahr et al (2007) evaluated the effects of increasing the IDR from 30 to 60 dB on the ability to understand soft speech and speech in noise with the Advanced Bionics (AB) CII BTE. AzBio sentences were presented at 57 dB SPL using four IDR settings, 30, 40, 50 and 60 dB. As the IDR was increased, scores significantly improved. In addition, AzBio sentences were presented at 77 dB SPL with a +10 SNR using the same four IDR settings. Significantly higher scores were seen with an increase in IDR from 30 to 40 dB. No significant difference for sentences in noise was seen between the IDR settings of 40, 50 and 60 dB. Because 60 dB IDR provided the best perception of soft speech and no detriment to understanding speech in noise, Spahr and colleagues recommended use of the 60 dB IDR setting.
Research by Skinner and colleagues examined how to optimize the perception of soft speech for users of earlier Nucleus CI devices (Skinner et al, 1999). The results of this study revealed that raising T-levels above a counted level (100% detection level) lowered sound-field threshold levels and improved CNC word scores at soft presentation levels for users of the Nucleus 22 device. This method of setting Ts worked well for obtaining low FM-tone, sound-field threshold levels for the group of 30 children using the Nucleus 24 device and Freedom™ processor (See Figure 3; Davidson et al, 2009). Holden et al (2007) found that with the wider IDR of the Freedom™ device (40 dB IDR compared to 30 dB IDR with previous Nucleus devices), raising Ts above a counted level was not necessary to obtain sound-field threshold levels around 20 dB HL from 250–6000 Hz for the group of ten adults participating in that study. Spahr and Dorman (2005) evaluated the speech perception of 15 Med El Tempo+ CI recipients. Subjects were tested with three different speech processor programs that varied only in T-level settings. T-levels for each electrode were set at 0, at 10% of a most comfortable loudness (MCL) percept, or at a behavioral threshold level (a percept of barely audible). Group scores revealed no significant differences between the three programs for sentences in quiet presented at a relatively soft level of 54dB SPL or for sentences in noise presented at 74 dB SPL with a +10 dB SNR. The authors concluded that setting T-levels at behavioral thresholds rather than at 10% of MCL or 0 is time consuming and does not necessarily improve the perception of softer speech with the Med El Tempo+ speech processor. However, sound-field threshold levels were not obtained with any of the programs, and subjects reported that sound was softer when using the programs with Ts set at 10% of MCL or 0. Spahr and Dorman (2005) noted that some patients may prefer programs with T-levels set higher in order to better detect soft speech and sound in daily life; moreover, access to soft speech cues can be beneficial for children in incidental learning situations.
Figure 3.

Group mean sound-field threshold levels in dB HL from 250–6000 Hz with each of the three T-level settings (Ts at 10% of Ms, Ts between BA and VS, and Ts at 10 CU below soft). Error bars represent ± 1 standard deviation.
Given the results of the above studies, the objectives of the present study were two-fold. The first was to determine programming procedures that would allow CI recipients using the Advanced Bionics cochlear implant and speech processor to obtain sound-field threshold levels of approximately 20 dB HL across the frequency range permitting audibility of soft speech cues. The second objective was to evaluate the upper range of IDR settings (50 to 80 dB) available in the clinical software to determine the setting or settings that provide the best perception of soft speech and speech in noise. The overall goal of the study was to provide guidelines for audiologists to efficiently and effectively optimize performance of CI recipients using the Advanced Bionics cochlear implant system for two difficult listening situations, understanding soft speech and speech in noise.
METHODS
This study was approved by the Human Research Protection Office at Washington University School of Medicine (WUSM). Ten postlinguistically deafened adults participated in the study. All were implanted with either the AB Clarion CII or 90K cochlear implant devices and were patients in the Adult Cochlear Implant and Hearing Rehabilitation Program at WUSM. Demographic information is shown in Table 1. The subjects ranged in age from 49 to 80 years at the time of the study with a mean age of 59.7 years (standard deviation = 8.8). The duration of deafness for each subject ranged from 3 to 35 years with a mean duration of 5.8 years (standard deviation = 10.5). Length of implant use ranged from 5 months to 5 years with a mean length of 2.9 years (standard deviation = 1.4). Three-dimensional reconstructions of spiral CT scans (Skinner et al, 2007) showed that all subjects had complete insertions of the electrode array into the cochlea.
Table 1.
Subject demographic information.
| Subject | Sex | Etiology | Age at Study (yrs) | Duration of Deafness (yrs) | Implanted Ear | Length of Implant Use (yrs) |
|---|---|---|---|---|---|---|
| 1 | F | Familial | 63 | 5 | R | 2.5 |
| 2 | F | Familial | 62 | 4 | R | 1.8 |
| 3 | M | Familial & Noise | 65 | 3 | R | 4.0 |
| 4 | F | Unknown | 54 | 35 | R | 2.5 |
| 5 | F | Familial | 52 | 8 | R | 5.0 |
| 6 | F | Familial | 49 | 5 | L | 0.4 |
| 7 | F | Ototoxicity | 60 | 3 | L | 4.0 |
| 8 | F | Unknown | 58 | 5 | R | 1.5 |
| 9 | M | Middle Ear Disease | 80 | 5 | R | 3.0 |
| 10 | F | Familial | 54 | 15 | R | 4.0 |
Subjects used either the High Resolution (HiRes) or HiRes 120 speech processing strategies (Firszt et al, 2009) and all had open-set speech recognition. The subjects’ CNC word scores obtained at their most recent clinical evaluation (presentation level = 60 dB SPL) ranged from 32% to 88% with a mean of 65% (standard deviation = 20.2). Table 2 shows the specific cochlear implant device, speech processor, speech coding strategy and programming parameters that each subject used in their every-day program prior to the study. Each subject’s every-day program was created during routine clinical post-operative visits at WUSM. When creating a speech processor program, minimum levels (T-levels) and most comfortable levels (M-levels), were determined for each active electrode. At WUSM an ascending loudness judgment (ALJ) procedure is used to set both T- and M-levels. During the ALJ procedure, the patient reports the loudness of the sound on a seven-point scale (barely audible, very soft, soft, medium soft, most-comfortable, loud but comfortable, and maximum comfort). M-levels are usually set at a most comfortable level and T-levels at a percept of barely audible. Advanced Bionics recommends setting T-levels to 10% of M-levels noting that measurement of behavioral threshold levels on each electrode is time consuming and may be a difficult task for patients, especially those with tinnitus. Setting T-levels to 10% of Ms is based on the assumption that the typical CI user has an electrical dynamic range of loudness of approximately 20 dB which corresponds to an M-level to T-level ratio of 10 (Advanced Bionics Corporation, 2003). Based on prior research at WUSM (Skinner et al, 1997; Skinner et al, 1999; Firszt et al, 2004), we seek to maximize the perception of soft speech; therefore, behavioral thresholds are measured for each electrode and assigned to the T-levels. Nonetheless, we are not aware of any peer-reviewed, published data comparing AB CI users’ perception of soft speech with T-levels set to behavioral thresholds and T-levels set at 10% of M-levels. The current study addresses this issue.
Table 2.
Program parameters used by each subject in their every-day speech processor program.
| Subject | Electrode Array | Speech Processor | Strategy | Rate/channel (pps/ch) | Total Stimulation Rate | Number of Channels | Input Dynamic Range |
|---|---|---|---|---|---|---|---|
| 1 | 90K/Helix | Auria | HiRes | 1,371 | 19,194 | 14 | 60 |
| 2 | 90K/HiFocus 1j | Harmony | HiRes 120 | 3,712 | 44,544 | 13 | 60 |
| 3 | CII/HiFocus 1 | Harmony | HiRes 120 | 3,712 | 44,544 | 13 | 60 |
| 4 | 90K/HiFocus 1j | Harmony | HiRes 120 | 2,560 | 33,280 | 14 | 60 |
| 5 | CII/HiFocus 1 | Auria | HiRes | 1,933 | 30,928 | 16 | 60 |
| 6 | 90K/Helix | Harmony | HiRes 120 | 3,712 | 55,680 | 16 | 60 |
| 7 | CII/HiFocus 1 | Harmony | HiRes 120 | 2,184 | 26,208 | 13 | 60 |
| 8 | 90K/HiFocus 1j | Harmony | HiRes 120 | 3,712 | 51,968 | 15 | 70 |
| 9 | 90K/HiFocus 1j | Harmony | HiRes | 1,205 | 16,870 | 14 | 60 |
| 10 | CII/HiFocus 1 | PSP | HiRes 120 | 2,184 | 32,760 | 16 | 60 |
With the AB device, the maximum number of active electrodes is 16; however fewer electrodes can be used to create a program. The subjects in this study used between 13 and 16 active electrodes in their every-day program, depending on the electrodes removed during clinical programming. Most often, one or two basal electrodes were removed to reduce a reported high pitched sound quality or to improve sound-field threshold levels at 3000–6000 Hz. In addition, electrodes in the mid or apical section of the array were removed for some subjects due to their inability to discriminate pitch between adjacent electrodes. During clinical programming, T and M-levels as well as other programming parameters (i.e. speech processing strategy, pulse width, gain, IDR, and number of active electrodes) were set for each individual and then adjusted in order to make speech in daily life as intelligible as possible at both conversational and soft levels. FM-tone, sound-field threshold levels were routinely measured from 250–6000 Hz with the goal of obtaining levels less than 30 dB HL and as close to 20 dB HL as possible to increase the audibility of soft speech and sound (Holden et al, 2007; Davidson et al, 2009). As noted previously, the IDR is a parameter in the clinical software that can be set to optimize speech perception for different listening situations. Figure 1 shows the theoretical mapping of an acoustic input signal into a CI users’ electrical dynamic range as defined by T and M-levels for the Advanced Bionics cochlear implant system. This relationship linearly maps acoustic input in dB SPL to electrical output in clinical units (CU)1 such that an input level of 63 dB SPL produces an output at the M-level. The slope of this function is defined by the IDR value so that an input level of 63 minus the IDR value produces an output at the T-level. Increasing the IDR lessens the slope of the input-output function and allows for a broader range of input signal levels below 63 dB to be mapped into the electrical range of the stimulation channel. Figure 1 shows the input/output functions for IDRs of 50, 65 and 80 dB. Above 63 dB SPL the automatic gain control (AGC) of the system becomes active and higher acoustic input levels are compressed up to a point at which hard limiting occurs. The input/output functions may be modified by the implant user by manipulation of the volume (VOL) and sensitivity (SENS) controls on the processor. Changing volume increases or reduces the M-level used in calculation of the input/output function, whereas decreasing or increasing sensitivity changes the AGC activation point, effectively shifting the entire function to the right or left, respectively. Across stimulation channels the input/output functions are uniquely defined based on measured M-levels and T-levels that are either measured or set by a programming algorithm (Ts = 0 or Ts = 10% of Ms). In the SoundWave™ clinical software, the IDR values that can be selected range from 20 dB to 80 dB with 60 dB being the software’s default setting. Nine of the ten subjects in this study used the default IDR of 60 dB in their every-day program (Table 2). In addition, the majority of patients programmed at WUSM have a program placed on their speech processor with a decreased IDR, usually 50 dB, for use in noisy environments.
Figure 1.

The theoretical mapping of an acoustic input signal into the electrical dynamic range as defined by T and M-levels in the Advanced Bionics CI system. The input/output functions for three different IDR values (50, 65 and 80 dB) are shown.
As part of the study, subjects attended three different test sessions (sessions A, B and C) over a three-week period with one week between test sessions A and B and two weeks between test sessions B and C. At session A, FM-tone, sound-field threshold levels from 250–6000 Hz were obtained with each subject’s every-day program and most often used speech processor control settings. Subjects used the same control settings at each test session and were not allowed to change their settings during testing. Sound-field threshold levels were obtained in 2 dB steps using a standard Hughson-Westlake procedure (Carhart & Jerger, 1959). The FM tones were sinusoidal carriers modulated (modulation rate = 10 Hz) with a triangular function over the standard bandwidths recommended for use in the sound-field (Walker et al, 1984). In accordance with the ANSI standard for audiometers (ANSI S3.6-1996), a conversion in the sound-field from dB SPL to dB HL was made. For the conversion, the values subtracted from dB SPL values were: 13, 6, 4, 4, 2.5, 0.5, −4, −4.5, and 4.5 dB at 250, 500, 750, 1000, 1500, 2000, 3000, 4000, and 6000 Hz, respectively.
Ascending loudness judgments in response to electrical stimulation were then obtained for each active electrode used in the subjects’ every-day programs. Using the clinical programming software (SoundWave™ Version 1.4.77), “tone bursts” were selected as the stimulus. In this procedure, the stimulus (a biphasic pulse train, 200 msec in duration) measured in CU was set to 0 on each electrode. The stimulus was then slowly increased from 0 and the subject was asked to report the loudness of the sound on the seven-point scale from barely audible to maximum comfort. Subjects were familiar with this ALJ procedure as it was used to program their speech processors during routine clinical programming sessions.
From the information obtained with the ALJ procedure, three different programs were created for each subject. The M-levels were the same for each of the three programs and were similar to those currently used in each subject’s every-day program. Only minor adjustments to M-levels were made to ensure that levels were comfortably loud and were balanced for equal loudness between adjacent electrodes. The method used to set T-level in each of the three programs differed. In program one, T-levels were set, based on the manufacturer’s recommendation, at 10% of M-levels. In program two, T-levels for each active electrode were set at a level between each subject’s report of “barely audible” (BA) and “very soft” (VS) during the ALJ procedure. The CU for BA and the CU for VS were averaged and the T-level for each electrode was set to this number. T-levels were balanced between adjacent electrodes to ensure equal loudness. In program three, T-levels for each electrode were set at each subject’s judgment of “soft” during the ALJ procedure. Ts were balanced for equal loudness between adjacent electrodes at this “soft” level and then were globally decreased by 10 CU. With the exception of T-levels, all other parameters for all three programs as well as the subjects’ every-day program were the same.
FM-tone, sound-field threshold levels from 250–6000 Hz were obtained with each of the three programs. The sound-field thresholds were averaged across frequencies for each program and the program that produced the lowest averaged sound-field threshold was the select program. For subject one (S1), program one with Ts at 10% of Ms produced an averaged sound-field threshold level of 28.9 dB, program two with Ts between BA and VS produced an averaged sound-field threshold of 23.3 dB, and program three with Ts at 10 CU below soft produced a threshold of 24.4 dB; therefore, program two was the select program for S1. If sound-field threshold levels were not lower than 30 dB HL for the majority of frequencies from 250–6000 Hz with the select program, a combination of program manipulations (raising gains, T-levels, and/or M-levels) were performed on individual electrodes that fell within the frequency range where sound-field thresholds were greater than 30 dB HL. Gains were typically raised by 3–5 dB. One subject had the gain on a mid-frequency electrode raised by 8 dB to improve the sound-field threshold at 1000 Hz. T and M-levels were raised by 5–10 CU. Gains, Ts and Ms were primarily raised on basal electrodes as that is where subjects had highest sound-field thresholds. Five subjects (S1, S2, S3, S5, & S6) had manipulations made to the select program in order to optimize sound-field thresholds. Table 3 shows sound-field threshold levels from 250–6000 Hz for each subject with their select program after manipulations were made. Subjects 2 and 5 had a threshold at one frequency that was higher than 30 dB HL even after program manipulations were made. Subject 3 had thresholds at all frequencies higher than 30 dB HL as no program manipulations were successful at lowering thresholds without adversely affecting the sound quality of speech. Subjects 8 and 9 had a threshold at one frequency of 32 dB HL. No program manipulations were made with these two subjects.
Table 3.
FM tone, sound-field threshold levels for each of the subjects with the select program.
| Subject | 250 Hz | 500 Hz | 1000 Hz | 2000 Hz | 3000 Hz | 4000 Hz | 6000 Hz |
|---|---|---|---|---|---|---|---|
| 1 | 16 | 20 | 26 | 20 | 26 | 26 | 26 |
| 2 | 18 | 22 | 26 | 26 | 32 | 26 | 26 |
| 3 | 34 | 34 | 34 | 34 | 40 | 38 | 42 |
| 4 | 18 | 12 | 22 | 16 | 28 | 24 | 28 |
| 5 | 18 | 20 | 24 | 22 | 24 | 24 | 34 |
| 6 | 28 | 14 | 26 | 18 | 18 | 26 | 28 |
| 7 | 22 | 26 | 16 | 12 | 22 | 24 | 24 |
| 8 | 14 | 16 | 18 | 16 | 14 | 28 | 32 |
| 9 | 32 | 28 | 26 | 24 | 24 | 24 | 24 |
| 10 | 22 | 22 | 20 | 20 | 26 | 26 | 20 |
At the end of session A, three additional programs were created from the select program for each subject. These three programs were identical to each other with the exception of IDR. The three IDR settings used were 50 dB, 65 dB and 80 dB. These programs were only used by subjects in the laboratory; they did not take the programs home for use prior to testing.
At the beginning of sessions B and C, the three programs with different IDR settings were loaded onto each subject’s speech processor in a pre-determined order that varied from subject to subject. FM-tone, sound-field threshold levels were obtained and speech perception tests were administered with each of the three programs. The CNC Monosyllabic Word Test and the CUNY Sentence Test were presented. The CNC word test consists of 10 lists of 50 words per list. Two lists were presented at 50 dB SPL with each of the three programs at each of the two test sessions. This soft presentation level (Pearsons et al, 1976) was used to determine if one IDR allowed subjects to perceive soft speech better than the other two IDRs. The CUNY Sentence Test consists of 72 lists of 12 sentences per list. Three lists of CUNY sentences were presented at 65 dB SPL in 4-talker babble (Auditec of St. Louis) with each of the three programs at each test session. The SNR was individually set for each subject to prevent ceiling or floor effects and was chosen for each subject so that the CUNY sentence recognition score would fall between 50% and 75% correct. The SNRs for Subjects 1–10 were +8, +7, +13, +10, +7, +10, +6, +5, +14, and +5 dB, respectively. Sentences in noise were administered to determine if one IDR allowed better understanding in noise than the other IDRs. All test lists were presented in a pseudo randomized order and each subject had a unique randomization.
Testing was performed in a double-walled sound booth (IAC; model 1204-A; 254 cm × 264 cm × 198 cm) through a loudspeaker placed at ear-level at 0 degrees azimuth and 1.5 meters from the center of the subjects’ heads. The test materials were presented via an IBM compatible, Pentium II computer that controlled a mixing and attenuation network (Tucker-Davis Technologies) to present stimuli through a power amplifier (Crown model D-150) and loudspeaker (JBL; model LSR32). FM tones as well as the speech recognition materials were stored as wave files on the hard disk played through a soundcard (Lynx Studio Technology; model LynxONE). All test materials were calibrated with the microphone of a B & K sound level meter (Model 2230) placed at what would be the center of the subject’s head during testing and used to measure the sound pressure level of the stimuli. A slow (250 ms integration time) RMS detector and wide band-pass filter (20 Hz to 20 kHz) were used to measure the SPL of the words and sentences for all test materials and an average overall SPL was computed for each of the test materials separately.
At the end of test session C, speech perception scores were averaged for each measure and the program or programs that provided the highest scores were loaded into each subject’s speech processor along with their every-day program for comparison in daily life. Subjects were asked to compare the programs in as many different listening situations as possible over a two-week period. In order to assist them with this process, the subjects were given a questionnaire to complete at home that described a number of listening situations. Subjects were asked to rate each program for as many of the listening situations as possible and then to choose their favorite overall program(s). A summary of procedures performed during test sessions A through C is provided in Figure 2.
RESULTS
Consistent with the goals of this study, the method of setting T-levels and choice of IDR setting were examined to determine programming procedures that would minimize sound-field thresholds, enhance audibility of soft speech, and improve speech perception in noise. First, the statistical dependence of sound-field thresholds on the three methods of setting T-levels (Ts at 10% of Ms, Ts between BA and VS, and Ts at 10 CU below soft) and the three choices of IDR (50, 65 and 80 dB) was examined. Second, the influence of the three IDR settings on the perception of soft speech and speech in noise was examined.
Group data were analyzed using repeated measure Analysis of Variance (ANOVA). A Greenhouse-Geisser adjustment was made to the degrees of freedom when sphericity could not be assumed and a p-value of ≤ 0.05 was used to determine statistical significance. Individual performance on speech recognition measures was analyzed using the Randomization Test (Edgington, 1967; Barlow & Hersen, 1984). This statistical test was applied to speech understanding measures for individual cases in a paper by Chmiel & Jerger (1995). Readers are referred to that paper for an in-depth discussion of the method and a comparison with other methods for evaluating single subject results under various test conditions. The strength of the Randomization Test is that variability in performance for the specific individual is used to determine a 95% confidence level when comparing conditions. Differences between conditions for an individual at the 95% confidence level are indicated on the graphs.
Table 4 shows mean T-levels across subjects for individual electrodes for the three programs differing in T-level settings. In addition, mean T-levels across subjects for each electrode in their every-day programs are shown along with the T-level for each program averaged across subjects and electrodes. Ts at 10% of Ms were lowest and Ts at 10 CU below soft were highest. Every-day program T-levels fell between Ts at 10% of Ms and Ts between BA and VS. Group mean sound-field threshold levels (250–6000 Hz) for each of the T-level settings are shown in Figure 3. A 3 (T-Level Setting) by 9 (Test Frequency) repeated measures ANOVA showed a significant main effect on sound-field thresholds for both T-Level Setting (F[2,18] = 7.31, p<0.01) and Test Frequency (F[8,72] = 7.48, p<0.001) with no significant interaction between T-Level Setting and Test Frequency. Post hoc pair-wise comparisons with a Bonferroni adjustment indicated sound-field thresholds were significantly lower when T-levels were set at 10 CU below soft than when T-levels were set at 10% of Ms (p<0.05). Other pair-wise differences between T-Level Settings were not significant.
Table 4.
Group mean T-level for individual electrodes for each of the three T-level settings as well as for each subject’s everyday program with standard deviations noted in parentheses. The last column shows the T-level averaged across electrodes for each setting with the standard deviation of the averages in parentheses.
| Electrode | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | Avg. T-level |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ts at 10% of Ms | 19 (6) | 19 (4) | 22 (7) | 22 (9) | 22 (8) | 22 (8) | 22 (8) | 22 (7) | 22 (7) | 22 (7) | 22 (7) | 21 (7) | 21 (7) | 21 (8) | 21 (9) | 21 (11) | 21.2 (0.9) |
| Ts between BA and VS | 59 (18) | 55 (16) | 63 (25) | 62 (26) | 66 (27) | 65 (25) | 66 (26) | 66 (25) | 68 (24) | 67 (27) | 72 (29) | 74 (29) | 79 (33) | 79 (36) | 83 (42) | 93 (49) | 69.8 (9.8) |
| CU below soft | 71 (19) | 70 (21) | 78 (29) | 78 (30) | 83 (31) | 83 (34) | 81 (33) | 85 (33) | 87 (33) | 86 (34) | 91 (36) | 93 (38) | 97 (41) | 98 (44) | 103 (54) | 112 (50) | 87.1 (11.4) |
| Ts in every-day map | 39 (18) | 40 (18) | 41 (23) | 43 (26) | 41 (25) | 41 (25) | 42 (27) | 44 (27) | 44 (27) | 44 (28) | 44 (29) | 48 (29) | 51 (38) | 44 (32) | 45 (34) | 20 (16) | 41.8 (6.4) |
Figure 3 shows an increase in sound-field thresholds in the high frequencies. Because of this increase, repeated measures ANOVAs were used to analyze sound-field thresholds at lower frequencies (250-1.5k Hz) separate from higher frequencies (2k–6k Hz). Results of a 3 (T-Level Setting) by 5 (Lower Test Frequencies) repeated measures ANOVA were consistent with the results of the analysis that included all frequencies; there was a significant main effect on sound-field thresholds for T-Level Setting (F[2,18] = 10.79, p<0.01) and Lower Test Frequencies (F[4,36] = 4.87, p<0.05). However, the results of a 3 (T-Level Setting) by 4 (Higher Test Frequencies) repeated measures ANOVA showed a main effect on sound-field thresholds for Higher Test Frequencies (F[3,27] = 5.62, p<0.01) but not for T-Level Setting. These results indicated that for the low to mid frequencies (250-1.5k Hz), there were small but significant differences in sound-field thresholds between T-Level Settings whereas in the higher frequencies (2k–6k Hz), the T-Level Setting had virtually no effect on sound-field thresholds. However, sound-field thresholds did increase as frequency increased from 2k–6k Hz (Figure 3). Recall that a select program for each subject was chosen from the three programs differing in T-levels. As previously stated, FM-tone, sound-field thresholds were averaged across frequencies for each of the three programs, and the program with the T-level setting that produced the lowest averaged sound-field threshold level was selected. As seen in Table 5, sound-field thresholds averaged across frequencies with each T-level setting were similar for the majority of subjects. For six subjects (S2, S4, S5, S6, S7, S10), the select program had Ts at 10 CU below soft. Subject 7’s lowest mean sound-field threshold level was the same for two of the three programs. After listening to conversational speech with both programs during Session A, S7 chose the program with Ts at 10 CU below soft as sounding clearer than the program with Ts between BA and VS; therefore, it was S7’s select program. The select program for S1 had Ts between BA and VS, and the select program for S3, S8 and S9 had Ts at 10% of Ms. Subject 9 reported static-like sound that interfered with listening when Ts were set at higher levels. Therefore, the select program for S9 had Ts set at 10% of Ms even though Ts between BA and VS provided the lowest averaged sound-field threshold level. Subjects 1, 3 and 5 had similar reports of static-like percepts with higher T-levels. However, none of these subjects needed modifications to their select program.
Table 5.
Mean sound-field (SF) thresholds (dB HL) across frequencies for each subject with each T-level setting as well as the mean SF threshold across frequencies and subjects with each setting. The select program for each subject is in bold.
| Subjects | SF thresholds for Ts at 10% of Ms | SF thresholds for Ts between BA & VS | SF thresholds for Ts at 10 CU below soft |
|---|---|---|---|
| 1 | 28.9 | 23.3 | 24.4 |
| 2 | 32.4 | 27.6 | 27.3 |
| 3 | 34.9 | 35.3 | 35.1 |
| 4 | 23.1 | 24.0 | 18.9 |
| 5 | 24.7 | 22.7 | 22.0 |
| 6 | 23.3 | 23.3 | 22.2 |
| 7 | 25.6 | 20.0 | 20.0 |
| 8 | 18.2 | 18.4 | 18.9 |
| 9 | 25.1 | 21.8 | 23.3 |
| 10 | 24.9 | 24.2 | 21.8 |
|
| |||
| Group mean SF thresholds | 26.1 | 24.1 | 23.4 |
Three different IDR settings (50, 65 and 80 dB) were used to create three new programs for each subject from the select program. Sound-field thresholds were obtained at each of two test sessions with each IDR setting. The thresholds between the two test sessions were within 10 dB for all subjects at all frequencies with the average difference less than 1 dB (SD = 0.19). An average of the two test sessions was used for analysis. Figure 4 shows group mean sound-field threshold levels for all three IDRs. A 3 (IDR Setting) by 9 (Test Frequency) repeated measures ANOVA showed a significant main effect on sound-field thresholds for IDR Setting (F[1.1,10] = 12.6, p<0.01) and Test Frequency (F[3.5,31.5] = 6.7, p=0.001) with a significant interaction between IDR Setting and Test Frequency (F[5.5,49] = 3.7, p<0.01). Post hoc pair-wise comparisons with a Bonferroni adjustment indicated sound-field thresholds were significantly lower with 80 dB IDR and 65 dB IDR (p<0.05 for both) than with 50 dB IDR. There was not a significant difference in sound-field thresholds between 65 dB IDR and 80 dB IDR. Analysis of lower (250-1.5k Hz) and higher (2k–6k Hz) test frequencies were completed separately. Results of a 3 (IDR Setting) by 5 (Lower Test Frequencies) repeated measures ANOVA were consistent with the results of the analysis that included all frequencies; there was a significant main effect on sound-field thresholds for IDR Setting (F[2,18] = 18.25, p<0.001) and Test Frequency (F[4,36] = 5.13, p<0.01) with a significant interaction between IDR Setting and Test Frequency (F[8,72] = 2.72, p<0.05). Results of a 3 (IDR Setting) by 4 (Higher Test Frequencies) repeated measures ANOVA indicated a main effect on sound-field thresholds for Test Frequency (F[3,27] = 3.33, p<0.01) but not for IDR Setting. Similar to the results with T-level settings, IDR had a small effect on sound-field thresholds in the low-to-mid frequencies but no effect for higher frequencies. In addition, sound-field thresholds increased as frequency increased from 2k–6k Hz (Figure 4).
Figure 4.

Group mean sound-field threshold levels with the three IDR settings, 50 dB, 65dB and 80 dB. Error bars represent ± 1 standard deviation.
Individual as well as group mean CNC word scores for all three IDRs are shown in Figure 5. The CNC words were presented at a soft level of 50 dB SPL. Group mean scores were highest with 80 dB IDR and lowest with 50 dB IDR. A 3 (IDR Setting) by 4 (List Presentation Order [4 word lists presented]) repeated measures ANOVA indicated a significant main effect on group mean CNC word scores for IDR Setting (F[1.1, 9.8] = 12.63, p < 0.01). There was not a significant main effect on CNC word scores for List Presentation Order indicating no significant effect of practice from the presentation of the first word list to the presentation of the fourth word list. In addition, there was not a significant interaction between IDR Setting and List Presentation Order. Post-hoc pair-wise comparisons indicated significantly lower CNC word scores for 50 dB IDR compared to both 65 dB (p<0.05) and 80 dB IDR (p<0.05). Scores obtained with IDR settings of 65 dB and 80 dB were not different from each other. At the individual subject level, five subjects (S1, S2, S3, S8, & S9) had significantly higher word scores with 80 dB IDR than with 50 dB IDR. Subjects 2, 3, 8 and 10 had significantly higher word scores with 65 dB IDR than with 50 dB IDR, and S7 had a significantly higher score with 80 dB IDR than 65 dB IDR.
Figure 5.

Individual and group mean scores for CNC monosyllabic words presented at a soft level of 50 dB SPL with the three IDR settings (50 dB, 65 dB & 80 dB). Asterisks denote significantly different scores (* ≥ 95% confidence level). Error bars represent ± 1 standard deviation.
Figure 6 shows individual and group mean scores for CUNY sentences presented at 65 dB SPL in 4-talker babble for the three IDR settings. For sentences in noise, 50 dB IDR provided the highest group mean score while 80 dB IDR provided the lowest group mean score; however, a 3 (IDR Setting) by 6 (List Presentation Order [6 sentence lists presented]) repeated measures ANOVA indicated no significant main effect on group mean sentence in noise scores for IDR or List Presentation Order. There were, however, significant individual differences in scores. Subjects 1, 5, 6 and 9 had significantly higher sentence in noise scores with 50 dB IDR than with 80 dB IDR. In addition, S6 and S9 had had significantly higher scores with 50 than with 65 dB IDR.
Figure 6.

Individual and group mean scores for CUNY sentences presented in 4-talker babble with the three IDR settings (50 dB, 65 dB & 80 dB). The sentences were presented at 65 dB SPL with the SNR set individually for each subject. Asterisks denote significantly different scores (* ≥ 95% confidence level). Error bars represent ± 1 standard deviation.
Subjects were given the opportunity to compare their every-day program with the program(s) that on average provided them with the best speech perception scores during the study. Only two subjects (S3 & S10) scored highest with the same program for CNC words presented at a soft level and for CUNY sentences presented at a conversational level in noise. Table 6 shows the IDRs used in the programs that each subject compared in daily life over a two-week period. In addition the IDR(s) that each preferred overall after the two-week comparison are shown. When more than one program was preferred it was either because they were equally preferable or because they were preferred for different listening environments. For example S10 found the programs with 60 dB IDR (every-day program) and 65 dB IDR (study program) equivalent. Subject 7 preferred 60 dB IDR for every-day use, 80 dB IDR for listening in quiet, and 50 dB IDR for listening in background noise. All but two subjects selected 60 dB or 65 dB IDR as their preferred or among their preferred programs. In addition, three subjects chose 50 dB IDR among their preferred programs with one subject (S5) choosing 50 dB for all listening situations. Two subjects chose 80 dB IDR among their preferred programs with one subject choosing 80 dB as the single preferred program for all listening environments.
Table 6.
The IDR with which each subject scored highest for CNC words and sentences in noise as well as the IDR in their everyday program. The last row indicates each subject’s preferred IDR settings.
| Subjects | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| IDR providing highest CNC score | 80 | 80 | 80 | 65 | 80 | 80 | 80 | 80 | 80 | 65 |
| IDR providing highest sentence in noise score | 50 | 65 | 80 | 80 | 50 | 50 | 50 | 50 | 50 | 65 |
| IDR used in every-day program | 60 | 60 | 60 | 60 | 60 | 60 | 60 | 70 | 60 | 60 |
| Preferred IDR setting(s) | 60 | 65 | 60 | 65, 80 | 50 | 50, 60 | 50, 60, 80 | 80 | 50, 60 | 60, 65 |
DISCUSSION
This study has focused on optimizing the perception of soft speech and speech in noise for Advanced Bionics CI users. Because CI users encounter a variety of speakers and listening environments in daily life, it is important to program each individual’s speech processor to optimize speech understanding for these difficult listening situations. Previous literature has indicated that FM-tone, sound-field threshold levels less than 30 dB HL from 250–6000 Hz improves the audibility of soft sound, and therefore, the perception of soft speech (Firszt et al, 2004). For instance, sound-field threshold levels between 25 and 30 dB HL from 250–6000 Hz provides an AI of 0.75. However, sound-field threshold levels of approximately 20 dB HL from 250–6000 Hz provides an AI of 0.97 making almost all speech cues audible for CI users (Holden et al, 2007). If speech cues are audible, speech understanding is more likely to occur. Skinner et al (1999) decreased sound-field thresholds and improved the perception of soft speech by increasing T-levels so that low-level sounds were mapped to higher levels within Nucleus 22 CI users’ electrical dynamic range.
To optimize the perception of soft speech with the AB system in the current study, T-levels were adjusted to determine if manipulation of Ts had an effect on sound-field thresholds. Setting Ts to levels higher (10 CU below soft - Avg. T = 87.1 CU) than the manufacturer’s recommended setting of Ts (10% of Ms – Avg. T = 21.2 CU) resulted in small but significant decreases in sound-field threshold levels (Figure 3).
Consendai & Pelizone (2001) varied the IDR for a group of Ineraid CI users and found that an IDR of 45 dB provided the highest scores for vowels and consonants. Zeng et al (2002) found that an IDR between 50 and 60 dB provided the best vowel and consonant recognition for 10 Clarion CI users. Spahr et al (2007) recommended an IDR of 60 dB for use with the AB CII BTE speech processor. In that study, significantly higher sentence scores at soft presentation levels were seen with 60 dB IDR compared to 30, 40 and 50 dB IDRs. No significant difference was seen for sentences in noise between 40, 50 and 60 dB IDRs; however, sentences in noise were presented at a loud level of 77 dB SPL, and 60 dB was the widest IDR setting used. Within the AB SoundWave™ clinical software, a range of IDR settings from 20 to 80 dB is available with the default being 60 dB. In the present study, our objective was to evaluate the upper range of IDR settings (50 to 80 dB) and determine the setting or settings that provide the best perception of soft speech as well as speech in noise when using a presentation level in noise closer to conversational speech, namely 65 dB SPL (Pearsons et al, 1976).
The group data in the present study showed significantly higher scores for CNC words presented at a soft level (50 dB SPL) with 65 dB IDR and 80 dB IDR compared to 50 dB IDR. However, group data showed no significant difference between the three IDR settings for sentences in noise presented at a conversational level (65 dB SPL). Analysis of individual subject data did reveal significant differences in scores between the three IDR settings for both words and sentences in noise (Figures 5 & 6). Nine subjects had significant differences in speech recognition based on the IDR setting for at least one of the test conditions. Seven subjects had significantly improved word recognition at the soft presentation level with a wider IDR (80 or 65 dB) than with the narrower IDR (50 dB). Four subjects scored significantly higher for sentences in noise with 50 dB IDR compared to 80 dB IDR, and for two of those four subjects, sentence in noise scores were also significantly higher with 50 dB IDR compared to 65 dB IDR. As would be expected from the speech recognition results, 80 dB IDR provided significantly lower sound-field thresholds than 50 dB IDR; however, the differences in sound-field thresholds across IDR settings were small (Figure 4). To determine the possible reasons for the small differences in sound-field thresholds for the three IDR settings as well as for the three T-level settings, two follow-up experiments were conducted.
EXPERIMENT A
The objective of Experiment A was to better understand the interaction between the static-like sound reported by some subjects, T-levels, and a range of IDR settings.
Methods: Experiment A
Two speech processor programs that differed only in T-level settings were created for each of three subjects (S6, S8, S10) who were able to return for additional testing. Program 1 had Ts for each active electrode set at levels producing percepts of BA and program 2 had Ts set at 0 CU. With each program, subjects were asked to listen with six different IDR settings, ranging from 35–80 dB. Subjects were seated in a double-walled sound booth (IAC) and their processors were connected to a laptop computer so that the IDR of each program could be changed easily using the SoundWave™ clinical fitting software. All wore their own Harmony™ processor with a T-mic™. Subject 10 was tested with her platinum sound processor (PSP) as well. Two questions were asked of the subjects when listening in quiet while seated in the sound booth with each program. Do you hear anything? If you do, how loud is it? The subjects reported the loudness using a 7-point rating scale (barely audible, very soft, soft, medium soft, medium, medium loud and loud).
Results: Experiment A
Table 7 shows the results from each of the three subjects. In this quiet setting when asked to listen for the presence of a sound, subjects 8 and 10 reported hearing noise with 40 dB IDR when Ts were set to BA, but not with Ts set at 0. At 50 dB IDR, all subjects reported hearing sound with both T-level settings when using the Harmony ™ processor. When Ts were set to 0, S10 did not report hearing sound with the PSP until the IDR was 60 dB. All reported an increase in the loudness of the sound as the IDR was widened to 80 dB. In addition, S8 and S10 reported the sound to be somewhat softer with Ts set to 0 than with Ts set at BA. At the end of the testing, each subject was asked to describe the sound that they heard. Subject 6 described the sound as static, S8 as a soft hum, and S10 as a sizzle.
Table 7.
Loudness ratings of the sound heard in the booth for a range of IDRs with two programs (P1: Ts = BA; P2: Ts = 0 CU) for three subjects. (None = no sound heard, VS = very soft, S = soft, MS = medium soft, M = medium.)
| S6: Harmony | 35 IDR | 40 IDR | 50 IDR | 60 IDR | 70 IDR | 80 IDR |
|---|---|---|---|---|---|---|
| Ts = BA | None | None | VS | S | MS | M |
| Ts = 0 | None | None | VS | S | MS | M |
|
| ||||||
| S8: Harmony | 35 IDR | 40 IDR | 50 IDR | 60 IDR | 70 IDR | 80 IDR |
|
| ||||||
| Ts = BA | None | VS | VS | S | MS | M |
| Ts = 0 | None | None | VS | VS | S | M |
|
| ||||||
| S10: Harmony | 35 IDR | 40 IDR | 50 IDR | 60 IDR | 70 IDR | 80 IDR |
|
| ||||||
| Ts = BA | VS | VS | S | MS | M | M |
| Ts = 0 | None | None | VS | VS | S | S |
|
| ||||||
| S10: PSP | 35 IDR | 40 IDR | 50 IDR | 60 IDR | 70 IDR | 80 IDR |
|
| ||||||
| Ts = BA | None | VS | VS | S | MS | M |
| Ts = 0 | None | None | None | VS | S | S |
In summary, subjects reported hearing static-like percepts which grew in loudness with wider IDR settings. At the narrower IDR settings most reported hearing no sound. Reducing T-levels from BA to 0 appears to have reduced the IDR threshold at which the sound was first perceived.
EXPERIMENT B
Experiment B was performed to determine the source of the static-like sound and explore why sound-field thresholds were elevated for high frequencies compared to low-to-mid frequencies. It was hypothesized that the source of the static-like sound may be related to low-level, intrinsic, electrical noise in the speech processing pathway. This pathway includes the microphone, amplifiers, and digital sampling circuitry of the speech processor hardware. In order to measure the speech processor noise floor in a manner that could be interpreted in the context of patient precepts, we measured the relative levels of the spontaneous output of each channel of a continuous interleaved sampler (CIS; Wilson et al, 1991) speech processor program under controlled acoustic input conditions. The goal was to make these measures from the electrode outputs of a bench-level, implantable receiver/stimulator which was being driven by an external speech processor running a program similar to that which a typical patient would use.
Methods: Experiment B
All measures were made in a double-walled sound booth (IAC). Third-octave, sound-field measures were made with a calibrated sound level meter (Larson-Davis Model 800B) and verified that ambient sound levels in the booth were lower than or equal to 3.5 dB HL from 250–8000 Hz. Three CIS programs that differed in T-level settings were created using the SoundWave™ clinical software. For the ten subjects in this study, the averaged T-level across subjects and electrodes for precepts between BA and VS was 69.8 CU (Table 4) and the averaged M-level across subjects and electrodes was approximately 200 CU; therefore, the first program had Ts set to 70 CU and Ms set to 200 CU. The second CIS program had Ts at 10% of Ms (20 CU), and the third program had Ts set to 0 CU. Ms remained at 200 CU for all programs. Each vocoder-based CIS program operated with 16 processing channels whose bandpass filters spanned 250 to 8000 Hz in total spectrum. By using the CIS processing strategy, the measures across channel outputs provided an estimate of the frequency spectrum of the intrinsic noise of the speech processor hardware.
To physically measure the relative noise levels across electrode channels while operating with a live or shorted microphone in quiet, the speech processor head-piece was coupled to a bench-level 90K implant receiver/stimulator terminated with 5 k-ohm loads on each channel output, thus converting stimulation currents into voltage signals. Each channel’s output voltage was then individually electrically buffered and processed through a precision full-wave rectifier, amplified by 10, and low-pass smoothed with a time constant of 2 msec. The average value of this resulting signal was measured in mVRMS for each channel over a five second period using a true-RMS multimeter operating in averaging mode (Tek TX3). In this manner, the output values are proportional to the average RMS energy of current pulses delivered spontaneously on each channel by the processor due to the mapping of intrinsic system noise. Under these operating conditions the stimulator outputs consisted of brief, sporadic, irregular bursts of small magnitude biphasic pulses. Channel six was not functional in this bench-level device so data were not available for that particular channel. Data were collected for active and shorted microphone conditions with a PSP and a standard head-piece microphone using four different IDR settings (30, 50, 65 and 80 dB) and the three different T-level settings (0, 20 and 70 CU). To obtain measures in the active microphone condition, the microphone-only option within the SoundWave™ clinical software was selected. The shorted microphone condition was approximated by selection of the auxiliary-only option in the SoundWave™ clinical software after plugging a shorted cable into the auxiliary input of the speech processor. Data were also collected using the same conditions for the Harmony™ processor with its internal microphone and then again with the T-Mic™.
Results: Experiment B
The top two rows of Figure 7 show the average RMS output voltage of each channel for the conditions of active microphone and shorted microphone in quiet. The bottom row shows the difference of these two conditions on an expanded scale and indicates the portion of the output that is attributable to the microphone alone. Each column contains data for a fixed T-level setting as indicated. Each panel shows the data sets for each of the IDR settings according to the legend in the upper left panel. In general, it is seen that the channel outputs in the active microphone condition increase with increasing T-levels, with wider IDR setting, and with increasing channel number (apical to basal or low-to-high frequency). When the microphone is shorted, the outputs are smaller but do persist in many cases and still increase with increasing T-level and IDR settings. However, when present, the outputs are relatively constant across channels for a given T-level and IDR combination, except for channel 16. The apparent increased noise in channel 16 is likely due to this channel having a three-fold relative bandwidth (~0.79 octaves) compared to other channels for the frequency bands used in this CIS program. Experiments with the Harmony™ processor using its internal microphone and using the T-Mic™ produced similar results, except the noise levels in the shorted microphone condition were not constant and increased with increasing channel number.
Figure 7.

The average RMS output voltage due to spontaneous output stimulation on each channel of a bench-level 90K implant receiver/stimulator and PSP using three CIS programs with three different T-level settings (separate columns) and four different IDR settings (see legend). The top row represents measures obtained with an active headpiece microphone. The middle row represents measures obtained with a shorted microphone, and the third row represents the difference in RMS output voltage between the two conditions. The acoustic center frequencies of the speech processor band-pass filters are 330, 450, 540,640,760, 900, 1.1k, 1.3k, 1.5k, 1.8k, 2.1k 2.5k, 3.0k, 3.6k, 4.3k, and 6.7k Hz for channels 1–16, respectively.
Discussion: Experiments A and B
In general the results from Experiments A and B are consistent with noise in the microphone and/or front-end circuitry of the speech processor hardware that may result in spontaneous electrical output stimulation even in quiet operating conditions for various T-level and IDR settings. This stimulation may result in audible noise-like percepts in quiet listening conditions. Much of this intrinsic noise appears to be due to the microphone alone. As such, the microphone noise may act as a lower boundary for how sound-field thresholds can be adjusted through manipulation of T-level and IDR settings. In a noise free system, it would be expected that increasing Ts and widening IDRs would decrease sound-field thresholds. However, when noise is present, increasing Ts and widening IDRs increases spontaneous stimulation output that may be perceived as noise-like percepts by CI users. Consequently, there may be a trade off between decreasing sound-field thresholds and hearing static-like sound for some individuals. From Experiments A and B, it appears that microphone noise or other front-end noise is mapped onto the subject’s electrical dynamic range. Consequently, a static-like sound is reported by some users, primarily when in a very quiet environment and may be more prevalent for the basal than apical electrodes (Figure 7). It is hypothesized that clinically the noise is masking FM tones when presented in the sound-field, thus elevating sound-field thresholds especially in the high frequencies. This explanation is consistent with the results found in the present study that revealed little difference in high frequency, sound-field thresholds between the three T-level settings (Figure 3) or between the three IDR settings (Figure 4). Moreover, it is consistent with our clinical observation that sound-field threshold levels increase as frequency increases from 2000–6000 Hz for AB CI users.
To explore further the hypothesis that the intrinsic noise is microphone related, we used a studio-quality, dynamic microphone in lieu of the standard PSP head-piece microphone with one subject in this study (S6). The low-noise microphone signal was delivered via the PSP’s auxiliary input and its level was adjusted to produce a comfortable listening level for live speech similar to that produced with the standard head-piece microphone. Sound-field thresholds were first obtained with the subject using her every-day program with the standard head-piece microphone and then using the studio-quality dynamic microphone connected to the PSP. Sound-field thresholds were approximately 10 dB lower (better) from 250–6000 Hz with the low-noise studio microphone than with the standard head-piece microphone.
We would expect that any device using a wide IDR would encounter similar system noise issues. Dawson et al (2007) alluded to this in a study that examined the differences in three IDR settings (31, 46 and 56 dB) with the Nucleus SPEAR3 research processor. The results revealed significantly higher group-mean scores for CNC words at soft presentation levels with the two wider IDRs used in the study; however, no significant difference in scores was found between 46 dB IDR and 56 dB IDR. Dawson hypothesized that subjects may have heard system noise when listening with 56 dB IDR which could have hampered their ability to understand speech at soft presentation levels explaining why no significant differences were seen between 46 and 56 dB IDR. However, Dawson noted that none of the subjects reported hearing noise in the sound booth.
Clinical Guidelines
The results of our study indicate that raising T-levels above 10% of Ms and using a wide IDR (65–80 dB) with the AB device can be beneficial in obtaining somewhat lower FM-tone, sound-field threshold levels and therefore, better detection of sound. In addition, improved perception of soft speech was observed for CNC words when using IDRs of 65 and 80 dB compared to 50 dB. However, caution needs to be used when raising T-levels and/or using a very wide IDR. Several subjects in this study reported hearing static-like sound in the sound booth when using higher T-level settings and/or wider IDRs. Consequently, we suggest using the manufacturer’s recommendation for setting T-levels (10% of Ms) and IDR (60 dB) for those patients who may not be able to report the presence of noise. In these cases, parameter manipulations such as raising gains and M-levels may help to improve sound-field threshold levels and enhance the perception of soft speech. Manipulations can be made on all active electrodes or on individual electrodes that correspond to the frequency region for which sound-field thresholds are highest. For older children and adults, we recommend setting Ts higher than 10% of Ms and providing wider IDR options to optimize the audibility of soft speech.
The results of the study were not conclusive as to the best IDR setting to use in noise. Group data did not show significant differences for sentences in noise scores between the three IDRs; however, four subjects did have significantly higher scores in noise with the 50 dB IDR compared to one or both of the wider IDR settings. Consequently, providing older children and adults with a program to use in noise (e.g., 50 IDR) and guidelines as to when to use this program may be beneficial. Options are needed to improve speech perception in noise since adult CI users continue to report understanding speech in noise as a primary area of dissatisfaction.
One might infer from the group and individual data that 80 dB IDR provides no greater benefit than 65 dB IDR for understanding soft speech and tends to provide similar or worse results for listening in noise than does 65 dB IDR (Figures 5 & 6). We hypothesize that these findings may be primarily due to the system’s internal noise limitations for many subjects at 80 dB IDR when listening in the sound booth. However, three of the ten subjects chose 80 dB IDR as either their preferred or one of their preferred programs (Table 6). An 80 dB IDR maps equivalent acoustic input signals to higher levels and over a more compressed range of the electrical dynamic range than does a 65 dB IDR (Figure 1) thus providing preferred speech representation for some subjects. Given that real world experience is often the best indicator of performance, we believe that 80 dB IDR should be provided as an option for older children and adults who can make competent decisions regarding speech processor program preferences. This study reiterates the fact that programming the CI is not a one size fits all process and optimizing speech processor programs for each individual patient is necessary in order for each patient to receive the greatest benefit possible from their device. Half of the subjects in this study preferred more than one IDR for use in every-day life. Moreover, only two subjects (S3 & S10) scored highest with the same program (i.e. same IDR setting) for CNC words presented at a soft level and for sentences in noise. The variety of IDR settings available in Advanced Bionics’ SoundWave™ clinical software can be used to optimize an individual’s speech perception for different listening environments. To optimize IDR settings in the very busy clinical environment, we suggest using the same basic program and varying the IDR (50 dB, 60/65 dB, 80 dB) to create three speech processor programs. The three programs can be placed on the speech processor for the CI user to try in different listening environments in every-day life. Discussing with the user the listening situations in which each program may perform best will be helpful in preparing the individual to be an informed and critical listener when evaluating the various IDR options.
CONCLUSION
The overall goal of this study was to provide audiologists with guidelines to efficiently and effectively optimize AB CI users’ performance for two difficult listening situations, understanding soft speech and understanding speech in noise. Group mean scores were significantly higher for CNC words presented at a soft level (50 dB SPL) with subjects using IDR settings of 80 dB and 65 dB compared to a narrower IDR of 50 dB. Group mean scores for sentences in noise were not significantly different with the three IDR settings; however, individual scores and subject preferences revealed that 50 dB IDR should be provided as an option for listening in noise. By raising T-levels higher than the manufacturer’s recommendation of 10% of Ms and using a wide IDR (80 dB), sound-field thresholds were near 20 dB HL from 250–2000 Hz with the AB devices used in this study. From 3000–6000 Hz, sound-field thresholds were between 25 and 30 dB HL. In order for the majority of speech cues to be audible, FM-tone, sound-field threshold levels need be approximately 20 dB HL from 250–6000 Hz. We hypothesize that front-end processor noise, primarily microphone noise, may be preventing the measurement of FM-tone, sound-field threshold levels around 20 dB HL in the high frequencies. Some subjects in this study spontaneously reported hearing noise while in the sound booth. Low-level, electrical noise in the speech processing pathway may be a consequence of any CI system using a wide IDR. Because of the low-level noise, providing guidelines for optimizing soft speech perception requires several considerations. Setting Ts at the manufacturer’s recommendation of 10% of Ms produced the highest sound-field thresholds but the fewest reports of static-like sound. Therefore, for young children or for those who cannot report on sound quality, raising T-levels above 10% of Ms should be done with caution. For older children and adults, setting Ts at higher levels may provide an improvement in sound-field thresholds and therefore, in the audibility of soft speech. The manufacturer’s recommendation of an IDR of 60 dB is suggested for very young children. Older children and adults, who are able to use multiple programs in different listening environments, should be provided a variety of IDR settings, specifically 65–80 dB IDR for quiet listening situations and 50 dB IDR for noise.
Acknowledgments
Appreciation is expressed to the ten subjects who graciously gave their time and effort to participate in this study. In addition, the authors are grateful to each of the reviewers for their thoughtful comments. Parts of this study were presented at the 10th International Conference on Cochlear Implants and Other Implantable Auditory Technologies, April 11, 2008, San Diego, CA. This research was supported in part by funds from Advanced Bionics Corporation and by Grant Number UL1 RR024992 from the National Center for Research Resources (NCRR), a component of the National Institutes of Health (NIH).
Acronyms and Abbreviations
- AB
Advanced Bionics
- AGC
Automatic gain control
- AI
Articulation index
- ALJ
Ascending loudness judgments
- BA
Barely audible
- BKB-SIN
Bamford-Kowal-Bench Speech in Noise Test
- BTE
Behind-the-ear
- CIS
Continuous interleaved sampler
- C-levels
Maximum stimulation levels
- CI
Cochlear implant
- CNC
Consonant-vowel nucleus-consonant
- CU
Clinical units
- CUNY
City University of New York
- FM
Frequency modulated
- HL
Hearing level
- HINT
Hearing in Noise Test
- HiRes
High Resolution
- IDR
Input dynamic range
- MCL
Most comfortable loudness
- M-levels
Most comfortable levels
- PSP
Platinum sound processor
- SENS
sensitivity
- SNR
Signal-to-noise ratio
- SF
Sound-field
- T-levels
Minimum stimulation levels
- VOL
volume
- VS
Very soft
- WUSM
Washington University School of Medicine
Footnotes
In the Advanced Bionics SoundWave™ fitting software, stimulus amplitude is measured in Clinical Units (CU) which are linearly proportional to charge delivered in a single phase of a biphasic pulse. Specifically, stimulus amplitude (in CU) is defined as the duration of a single pulse phase (in μSec.) X the pulse peak amplitude current (in μAmp.) X a scaling constant of 0.0128447. In physical terms, electrical charge delivered per phase (in nCoulombs) equals CU divided by 12.8447, whereas net charge delivered for balanced biphasic pulses is zero (Advanced Bionics Corporation, 2003; Zwolan et al., 2008).
Declaration of Interest: Laura Holden and Jill Firszt serve as advisors on the Advanced Bionics Corporation Audiology Advisory Board. Charles Finley has in the past served as a consultant to Advanced Bionics. The subjects in this study were reimbursed for their participation, mileage and parking by funds provided by Advanced Bionics Corporation.
References
- Advanced Bionics Corporation. New methodology for fitting cochlear implants. A white paper published in June 2003. Advanced Bionics Corporation; Valencia, CA: 2003. [Google Scholar]
- Barlow D, Hersen M. Single Case Experimental Designs. 2. New York: Pergamon; 1984. [DOI] [PubMed] [Google Scholar]
- Boothroyd A, Hnath-Chisolm T, Hanin L, Kishon-Rabin L. Voice fundamental frequency as an auditory supplement to the speech reading of sentences. Ear Hear. 1988;9:306–312. doi: 10.1097/00003446-198812000-00006. [DOI] [PubMed] [Google Scholar]
- Carhart R, Jerger J. Preferred method for clinical determination of pure tone thresholds. J Speech Hear Dis. 1959;24:330–345. [Google Scholar]
- Chmiel R, Jerger J. Quantifying improvement with amplification. Ear Hear. 1995;16:166–175. doi: 10.1097/00003446-199504000-00004. [DOI] [PubMed] [Google Scholar]
- Cosendai G, Pelizzone M. Effects of acoustical dynamic range on speech recognition with cochlear implants. Audiol. 2001;40:272–281. doi: 10.3109/00206090109073121. [DOI] [PubMed] [Google Scholar]
- Davidson LS, Skinner MW, Holstad BA, Fears BT, Richter MK, et al. The effect of instantaneous input dynamic range setting on the speech perception of children with the Nucleus 24 implant. Ear Hear. 2009;30:340–349. doi: 10.1097/AUD.0b013e31819ec93a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donaldson GS, Chisolm TH, Blasco GP, Shinnick LJ, Ketter KJ, et al. BKB-SIN and ANL predict communication ability in cochlear implant users. Ear and Hear. 2009;30:401–410. doi: 10.1097/AUD.0b013e3181a16379. [DOI] [PubMed] [Google Scholar]
- Dawson PW, Vandali AE, Knight MR, Heasman JM. Clinical evaluation of expanded input dynamic range in Nucleus cochlear implants. Ear Hear. 2007;28:163–176. doi: 10.1097/AUD.0b013e3180312651. [DOI] [PubMed] [Google Scholar]
- Edington E. Statistical inference from N = 1 experiments. J Psychol. 1967;65:195–199. [PubMed] [Google Scholar]
- Firszt JB, Holden LK, Reeder RM, Skinner MW. Speech recognition in cochlear implant recipients: Comparison of standard HiRes and HiRes 120 sound processing. Otol Neurotol. 2009;30:146–152. doi: 10.1097/MAO.0b013e3181924ff8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Firszt JB, Holden LK, Skinner MW, Tobey EA, Peterson A, et al. Recognition of speech presented at soft to loud levels by adult cochlear implant recipients of three cochlear implant systems. Ear Hear. 2004;25:375–387. doi: 10.1097/01.aud.0000134552.22205.ee. [DOI] [PubMed] [Google Scholar]
- Holden LK, Skinner MW, Fourakis MS, Holden TA. Effect of increased IIDR in the Nucleus Freedom cochlear implant system. J Am Acad Audiol. 2007;18:778–791. doi: 10.3766/jaaa.18.9.6. [DOI] [PubMed] [Google Scholar]
- James CJ, Skinner MW, Martin LFA, Holden LK, Galvin KL, et al. An investigation of input level range for the Nucleus 24 cochlear implant system: Speech perception performance, program preference and loudness comfort ratings. Ear Hear. 2003;24:157–174. doi: 10.1097/01.AUD.0000058107.64929.D6. [DOI] [PubMed] [Google Scholar]
- Killion MC, Niquette PA, Gudmundsen GI, Revit LJ, Banerjee S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J Acoust Soc Am. 2004;116:2395–2405. doi: 10.1121/1.1784440. [DOI] [PubMed] [Google Scholar]
- Mueller HG, Killion MC. An easy method for calculating the articulation index. Hear J. 1990;43:15–17. [Google Scholar]
- Nilsson M, Soli S, Sullivan JA. Development of the hearing in noise test for measurement of speech reception thresholds in quiet and noise. J Acoust Soc Am. 1994;95:1085–1099. doi: 10.1121/1.408469. [DOI] [PubMed] [Google Scholar]
- Pearsons KS, Bennett RL, Fidel S. Bolt Beranek and Newman Report No 321. Canoga Park, CA: 1976. Speech levels in various environments. [Google Scholar]
- Peterson GE, Lehiste I. Revised CNC lists for auditory tests. J Speech Hear Dis. 1962;7:62–70. doi: 10.1044/jshd.2701.62. [DOI] [PubMed] [Google Scholar]
- Skinner M, Holden T, Whiting B, Voie A, Brunsden B, et al. In vivo estimates of the position of Advanced Bionics electrode arrays in the human cochlea. Ann Otol Rhinol Laryngol Suppl. 2007;197(116):2–24. [PubMed] [Google Scholar]
- Skinner MW, Binzer SM, Potts LG, Holden LK, Aaron RJ. Hearing rehabilitation for individuals with severe and profound hearing impairment: Hearing aids, cochlear implants, and counseling. In: Valente M, editor. Strategies for Selecting and Verifying Hearing Aid Fittings. 2. New York: Thieme Medical Publishers; 2002. pp. 311–344. [Google Scholar]
- Skinner MW, Holden LK, Holden TA, Demorest ME. Comparison of two methods for selecting minimum stimulation levels used in programming the Nucleus 22 cochlear implant. J Speech Lang Hear Res. 1999;42:814–828. doi: 10.1044/jslhr.4204.814. [DOI] [PubMed] [Google Scholar]
- Skinner MW, Holden LK, Holden TA. Speech recognition at simulated soft, conversational and raised-to-loud vocal efforts by adults with cochlear implants. J Acoust Soc Am. 1997;101:3766–3782. doi: 10.1121/1.418383. [DOI] [PubMed] [Google Scholar]
- Spahr AJ, Dorman MF, Loiselle LH. Performance of patients using different cochlear implant systems: Effects of input dynamic range. Ear Hear. 2007;28:260–275. doi: 10.1097/AUD.0b013e3180312607. [DOI] [PubMed] [Google Scholar]
- Spahr AJ, Dorman MF. Effects of minimum stimulation setting for the Med El Tempo+ speech processor on speech understanding. Ear Hear. 2005;26:2S–6S. doi: 10.1097/00003446-200508001-00002. [DOI] [PubMed] [Google Scholar]
- Walker G, Dillion H, Byrne D. Sound-field audiometry: Recommended stimuli and procedures. Ear Hear. 1984;5:13–21. doi: 10.1097/00003446-198401000-00005. [DOI] [PubMed] [Google Scholar]
- Wilson BS, Finley CC, Lawson DT, Wolford RD, Eddington DK, et al. Better speech recognition with cochlear implants. Nature. 1991;352:236–238. doi: 10.1038/352236a0. [DOI] [PubMed] [Google Scholar]
- Zeng F-G, Grant G, Niparko J, Galvin J, Shannon R, et al. Speech dynamic range and its effect on cochlear implant performance. J Acoust Soc Am. 2002;111:377–386. doi: 10.1121/1.1423926. [DOI] [PubMed] [Google Scholar]
- Zwolan TA, O’Sullivan MB, Fink NE, Niparko JK The CDACI Investigative Team. Electric charge requirements of pediatric cochlear implant recipients enrolled in the childhood development after cochlear implantation study. Otol Neurotol. 2008;29:143–148. doi: 10.1097/MAO.0b013e318161aac7. [DOI] [PubMed] [Google Scholar]