

Abstract
With ever-increasing available data, predicting individuals' preferences and helping them locate the most relevant information has become a pressing need. Understanding and predicting preferences is also important from a fundamental point of view, as part of what has been called a “new” computational social science. Here, we propose a novel approach based on stochastic block models, which have been developed by sociologists as plausible models of complex networks of social interactions. Our model is in the spirit of predicting individuals' preferences based on the preferences of others but, rather than fitting a particular model, we rely on a Bayesian approach that samples over the ensemble of all possible models. We show that our approach is considerably more accurate than leading recommender algorithms, with major relative improvements between 38% and 99% over industry-level algorithms. Besides, our approach sheds light on decision-making processes by identifying groups of individuals that have consistently similar preferences, and enabling the analysis of the characteristics of those groups.
Introduction
Humans generate information at an unprecedented pace, with some estimates suggesting that in a year we now produce on the order of 1021 bytes of data, millions of times the amount of information in all the books ever written [1]. In this context, predicting individuals' preferences and helping them locate the most relevant information has become a pressing need. This explains the outburst, during the last years, of research on recommender systems, which aim to identify items (movies or books, for example) that are potentially interesting to a given individual [2]–[4].
However, understanding and ultimately predicting human preferences and behaviors is also important from a fundamental point of view. Indeed, the digital traces that we leave with all sorts of everyday activities (shopping, communicating with others, traveling) are ushering in a new kind of computational social science [5], [6], which aims to shed light on human mobility [7], [8], activity patterns [9], decision-making processes [10], social influence [11]–[13], and the impact of all these in collective human behavior [14], [15].
Existing recommender systems are good at solving the practical problem of providing quick estimates of individuals' preferences, but they often emphasize computational performance over other important questions such as whether the algorithms are mathematically well-grounded or whether the implicit models and assumptions are easy to interpret (and therefore to modify and fine tune). In contrast, algorithms that are based on plausible, easily-interpretable assumptions and that are based on solid mathematical grounds are useful in themselves and, arguably, hold the most potential to advance in the solution of the problem at the fundamental and practical levels. Here we present one such approach and show that it performs better than state-of-the-art recommender systems.
In particular, we focus on what is called collaborative filtering [16], namely making predictions about preferences based on preferences previously expressed by users. The underlying assumption in virtually all collaborative filtering approaches is that similar people have similar “interactions” with similar items. This consideration is usually taken into account heuristically. For example, in memory-based methods [16], one tries to identify users that are similar to the one for which we seek a prediction; or items that are similar to the target item. From these “neighbors” one then obtains a weighted average. In matrix factorization approaches [17], one assumes that each user and item can be characterized by a low-dimensional “feature vector,” and that the rating of an item by a user is the product of their feature vectors.
In contrast, we base our predictions in a family of models [18]–[21] that have been developed and are widely used by sociologists as plausible models of complex social networks, that is, of how social actors establish relationships (friendship relationships with each other, or membership relationships with institutions, for example). In this family of models, social actors are divided into groups and relationships between two actors are established depending solely on the groups to which they belong. Because of their simplicity and their explanatory power, these models are increasingly being studied as general models of complex (not necessarily social) networks [22]–[24].
In the context of predicting human preferences, block models assume that users and items can be simultaneously classified into categories, and that the category of the user and the category of the item fully determine the rating. Therefore, the model is extremely easy to interpret. Additionally, our algorithm is mathematically sound because it uses a Bayesian approach that deals rigorously with the uncertainty associated with the models that could potentially account for observed users' ratings. Indeed, our approach averages over the ensemble of all possible groupings of users and items, exploiting the formal analogies that exist between statistical inference and statistical physics [25].
Finally, our algorithm sheds light on the factors determining preferences because it allows one to study the groupings that have the most explanatory power or that accurately account for certain features of the users' ratings.
Bayesian Predictions Based on the Ensemble of Stochastic Block Models
Consider the observed ratings 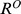 , whose element
, whose element 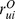 represents the rating of user u on item i (Fig. 1). Note that not all elements in this “matrix” are defined, since only some pairs
represents the rating of user u on item i (Fig. 1). Note that not all elements in this “matrix” are defined, since only some pairs 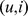 are actually observed; we call O the set of observed
are actually observed; we call O the set of observed 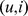 pairs. Like in collaborative filtering approaches [2], [3], we assume that these observations are all the information that the algorithm can use to make predictions about unobserved ratings (in other words, we do not use any information about users or items other than past ratings). Our problem is then to estimate the probability
pairs. Like in collaborative filtering approaches [2], [3], we assume that these observations are all the information that the algorithm can use to make predictions about unobserved ratings (in other words, we do not use any information about users or items other than past ratings). Our problem is then to estimate the probability 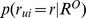 that the unobserved rating of item i by user u is
that the unobserved rating of item i by user u is 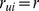 , given the observation
, given the observation 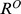 .
.
Figure 1. Predicting preferences using stochastic block models.

(A) Users A–H rate movies a–h as indicated by the colors of the links. (B-C) Matrix representation of the ratings; patterned gray elements represent unobserved ratings. Different partitions of the nodes into groups (indicated by the dashed lines) provide different explanations for the observed ratings. The partition in (B) has much explanatory power (low 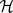 ) because ratings in each pair of user-item groups are very homogeneous. For example, it seems plausible that C would rate item a with a 2, given that all users in the
) because ratings in each pair of user-item groups are very homogeneous. For example, it seems plausible that C would rate item a with a 2, given that all users in the 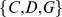 group give a 2 to all items in group
group give a 2 to all items in group 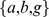 . Conversely, the partition in (C) has very little explanatory power. According to Eq. 4, the predictions of (B) contribute much more than those of (C) to the inference of unobserved ratings.
. Conversely, the partition in (C) has very little explanatory power. According to Eq. 4, the predictions of (B) contribute much more than those of (C) to the inference of unobserved ratings.
Let's assume that the observed ratings can be explained by one of the models in a family 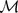 of generative models. Then,
of generative models. Then,
| (1) |
where 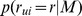 is the probability that
is the probability that 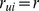 if the ratings where actually generated using model M, and
if the ratings where actually generated using model M, and 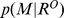 is the plausibility of model M given the observation. Using Bayes theorem Eq. (1) becomes
is the plausibility of model M given the observation. Using Bayes theorem Eq. (1) becomes
| (2) |
where 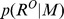 is the probability that model
is the probability that model 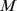 gives rise to
gives rise to 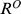 among all possible ratings (or the likelihood of the model), and
among all possible ratings (or the likelihood of the model), and 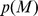 is the a priori probability that model
is the a priori probability that model 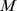 is the correct one (or prior). This equation is formally equivalent to those derived in the context of network inference [22] and, more broadly, to those used in Bayesian model averaging [26].
is the correct one (or prior). This equation is formally equivalent to those derived in the context of network inference [22] and, more broadly, to those used in Bayesian model averaging [26].
Although Eq. (2) is the correct probabilistic treatment of 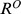 for inference of unobserved ratings, in practice predictions will only be accurate if the models in
for inference of unobserved ratings, in practice predictions will only be accurate if the models in 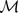 (or at least some of them) correctly describe how users actually rate items. Additionally, the models need to be simple enough that they are analytically or computationally tractable.
(or at least some of them) correctly describe how users actually rate items. Additionally, the models need to be simple enough that they are analytically or computationally tractable.
We consider the family 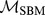 of stochastic block models [19]–[22]. In a stochastic block model, users and items are partitioned into groups and the probability that a user rates an item with
of stochastic block models [19]–[22]. In a stochastic block model, users and items are partitioned into groups and the probability that a user rates an item with 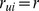 depends, exclusively, on the groups
depends, exclusively, on the groups 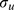 and
and 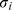 to which the user and the item belong, that is
to which the user and the item belong, that is
| (3) |
with 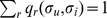 .
.
Consider the case in which ratings can take K different values  (we use the labels
(we use the labels 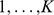 for simplicity, but the only requirement is that there are K non-overlapping classes, which do not need to be ordinals). Under the assumption of no prior knowledge about the models (
for simplicity, but the only requirement is that there are K non-overlapping classes, which do not need to be ordinals). Under the assumption of no prior knowledge about the models (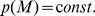 ), one can partially integrate Eq. (2) (see Methods) to obtain
), one can partially integrate Eq. (2) (see Methods) to obtain
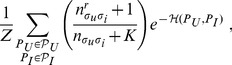 |
(4) |
where the sum is over all possible partitions of users and items into groups (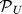 and
and 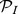 , respectively),
, respectively), 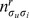 is the number of r-ratings observed from users in group
is the number of r-ratings observed from users in group 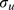 to items in group
to items in group 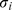 , and
, and 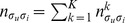 is the total number of observed ratings from users in
is the total number of observed ratings from users in 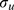 to items in
to items in 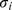 . The “Hamiltonian”
. The “Hamiltonian” 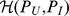 , which weights the contribution of each partition, depends only on the partition
, which weights the contribution of each partition, depends only on the partition
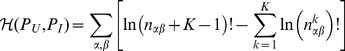 |
(5) |
and 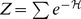 is the partition function.
is the partition function.
Although carrying out the exhaustive summation over all partitions in Eq. (4) is unfeasible, one can estimate 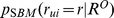 using Metropolis sampling [22], [25], [27]. Given these probabilities, our prediction for a given rating is the one that maximizes the probability
using Metropolis sampling [22], [25], [27]. Given these probabilities, our prediction for a given rating is the one that maximizes the probability
| (6) |
Benchmark Algorithms
To test how accurately our stochastic block model (SBM) algorithm predicts human preferences, we compare its performance to that of some of the most accurate algorithms in the literature of collaborative filtering recommender systems (see Methods for details) [4]. First, we consider a matrix factorization method [17] based on singular value decomposition (SVD) [28], which uses stochastic gradient descent to minimize the deviations between model predictions and observed ratings [17]. We use two implementations of this algorithm: our own implementation (SVD1) as well as a highly optimized implementation provided by LensKit framework (SVD2) [4]. Second, we consider an algorithm based on the similarity between items [4], [29], and again use the LensKit implementation (Item-Item). Additionally, we consider a baseline naive recommender, where the rating of an item by a user is simply the average rating of the item by all users that have rated it before [4].
Results
Performance Comparison on Model Ratings
To investigate how our approach performs compared to the benchmark algorithms, and in what situations it works better or worse, we start by generating model dichotomous like/dislike ratings as follows. First, each item i is assigned an intrinsic quality 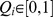 . Additionally, items and users are partitioned into groups, and each user u has an a priori preference
. Additionally, items and users are partitioned into groups, and each user u has an a priori preference 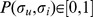 for item i, where
for item i, where 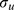 and
and 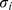 are the user and item groups, respectively. Then, the probability that u rates i with
are the user and item groups, respectively. Then, the probability that u rates i with 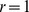 (“like”, as opposed to
(“like”, as opposed to 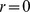 , “dislike”) is
, “dislike”) is
| (7) |
where 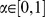 is a parameter that enables us to interpolate between a situation in which the intrinsic quality of the item is the only relevant factor (
is a parameter that enables us to interpolate between a situation in which the intrinsic quality of the item is the only relevant factor (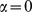 ) and a situation in which a priori preferences are the only relevant factor (
) and a situation in which a priori preferences are the only relevant factor (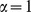 ).
).
In Fig. 2, we show the performance of the different algorithms when applied to model ratings. When the intrinsic quality is the dominant factor in user ratings (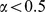 ), all algorithms perform similarly well. Of note, in the limiting case where intrinsic quality is the only relevant factor (
), all algorithms perform similarly well. Of note, in the limiting case where intrinsic quality is the only relevant factor (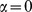 ), the naive recommender is the optimal predictor and does indeed perform slightly better than the others.
), the naive recommender is the optimal predictor and does indeed perform slightly better than the others.
Figure 2. Algorithm comparison for model ratings.

We show the prediction accuracy (that is, the fraction of correct rating predictions) as a function of the parameter  that measures the importance of a priori preferences as opposed to intrinsic item quality (see text for details). The black line represents the optimal prediction accuracy, which would be obtained if the algorithms were able to estimate exactly the probability of each rating. For all the simulations we use:
that measures the importance of a priori preferences as opposed to intrinsic item quality (see text for details). The black line represents the optimal prediction accuracy, which would be obtained if the algorithms were able to estimate exactly the probability of each rating. For all the simulations we use: 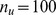 users organized in 5 groups;
users organized in 5 groups; 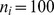 items organized in 5 groups;
items organized in 5 groups; 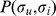 uniformly distributed in
uniformly distributed in 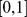 ; 4,000 observed ratings; and 1,000 ratings in the test set.
; 4,000 observed ratings; and 1,000 ratings in the test set.
Conversely, when a priori preferences start playing a significant role (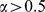 ) algorithms start to differ in their performance. As expected, the naive recommender performs poorly in this regime and becomes totally uninformative when
) algorithms start to differ in their performance. As expected, the naive recommender performs poorly in this regime and becomes totally uninformative when 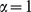 . The performances of the other algorithms are closer, but SBM is significantly and consistently the most accurate.
. The performances of the other algorithms are closer, but SBM is significantly and consistently the most accurate.
Of course, for 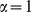 model ratings are generated according to a block model, so the SBM approach is expected to work best. However, it is worth pointing out that at least for these model ratings, the most advanced collaborative filtering approaches are never the most accurate, regardless of the value of
model ratings are generated according to a block model, so the SBM approach is expected to work best. However, it is worth pointing out that at least for these model ratings, the most advanced collaborative filtering approaches are never the most accurate, regardless of the value of  –either they perform slightly worse than the naive recommender, or they perform significantly worse than the SBM. Since these collaborative filtering approaches are known to be much more accurate in real data than the naive approach (indeed, they are consistently the most accurate among collaborative filtering methods in the literature [4]), our results on model ratings suggest that the SBM algorithm has the potential to provide good estimates on real data. Additionally, our approach also seems to be the most robust because it never provides estimates that are significantly worse than those produced by any other algorithm.
–either they perform slightly worse than the naive recommender, or they perform significantly worse than the SBM. Since these collaborative filtering approaches are known to be much more accurate in real data than the naive approach (indeed, they are consistently the most accurate among collaborative filtering methods in the literature [4]), our results on model ratings suggest that the SBM algorithm has the potential to provide good estimates on real data. Additionally, our approach also seems to be the most robust because it never provides estimates that are significantly worse than those produced by any other algorithm.
Performance Comparison on the MovieLens Dataset
The MovieLens dataset is one of the gold-standards for testing collaborative filtering algorithms [4]. It contains 100,000 real ratings (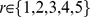 ) from 943 users on 1,682 movies, which were collected through the MovieLens web site (movielens.umn.edu) during the seven-month period from September 19th, 1997 through April 22nd, 1998. For purposes of validation, the dataset is organized in five different splits, each containing a training set
) from 943 users on 1,682 movies, which were collected through the MovieLens web site (movielens.umn.edu) during the seven-month period from September 19th, 1997 through April 22nd, 1998. For purposes of validation, the dataset is organized in five different splits, each containing a training set 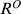 with 80,000 ratings and a test set with 20,000 ratings.
with 80,000 ratings and a test set with 20,000 ratings.
As we show in Fig. 3, our algorithm is the most accurate for all and each of the test sets, both in terms of the classification accuracy (that is, the fraction of predictions that are exactly correct) and in terms of the mean absolute error (the mean of the absolute value of the difference between the predicted and the real ratings).
Figure 3. Algorithm comparison for real ratings from the MovieLens dataset.

Each test set corresponds to a split of the 100,000 ratings in the complete dataset into 80,000 observed ratings and 20,000 test ratings. (A) Classification accuracy is the fraction of 1–5 ratings that are exactly predicted by each algorithm. (B) Mean absolute error is the mean absolute deviation of the prediction from the actual rating.
To fully appreciate the importance of our improvement over existing algorithms, it is worth noting that, in terms of classification accuracy, the average improvement of the SBM approach over the best recommender (the Item-Item algorithm) represents a 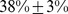 of the improvement of the best recommender over the baseline (naive recommender). The improvement of SBM over SVD, relative to the improvement of SVD over the baseline, is
of the improvement of the best recommender over the baseline (naive recommender). The improvement of SBM over SVD, relative to the improvement of SVD over the baseline, is 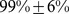 . These are major improvements, especially when compared to the differences that could be attributed to implementation details, which are small as shown by the difference in performance between SVD1 and SVD2 (Fig. 3).
. These are major improvements, especially when compared to the differences that could be attributed to implementation details, which are small as shown by the difference in performance between SVD1 and SVD2 (Fig. 3).
Characteristics of Sampled Partitions
As we have pointed out before, our approach offers the opportunity to study the collections of groupings that have the most explanatory power, namely, those that the Metropolis sampler visits. The MovieLens dataset includes some demographic information about users (such as gender and age) as well as some characteristics of the movies (such as genre). We use this information to assess whether the groupings we sample are indeed correlated with these user and movie characteristics, even when the stochastic block model does not take this information into account.
In particular, we study the co-classification of users [30], that is, the probability that two users belong to the same group
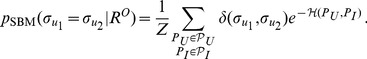 |
(8) |
We then plot the probability that a pair of users have the same gender and their average age difference as a function of their co-classification probability (Fig. 4A). We observe that user co-classification is strongly correlated with both demographic properties. For example, a pair of users that are very unlikely to belong to the same group have the same gender 58% of the times, whereas pairs of nodes that are almost surely in the same group have the same gender 83% of the times.
Figure 4. Characteristics of sampled partitions.

We calculate how often each pair of users (A) or movies (B) are co-classified in the same group in the sampled partitions. (A) Probability that a pair of users have the same gender (circles), and their age difference (squares), as a function of their co-classification frequency. (B) Overlap between the genres of a pair of movies (see Methods) as a function of their co-classification frequency.
Similarly, we plot the genre overlap (see Methods) between two movies as a function of their co-classification probability (Fig. 4B). Again, we observe a strong correlation, which indicates that the stochastic block model correctly picks groups that are related to movie content, even without having access to such information.
Discussion
We have shown that a Bayesian approach based on the block structure of social networks gives predictions of human preferences that are significantly and considerably more accurate than leading collaborative filtering recommender algorithms.
Like any other approach, ours has shortcomings. In particular, it is worth noting that the gain in accuracy comes at the expense of computational cost–Metropolis sampling of the user and item partition space is computationally demanding. Although we are able to run the algorithm on the MovieLens dataset with approximately 1,000 users and items and 100,000 ratings, handling even one order of magnitude more might be challenging. Besides parallelizing the sampling process (which is straightforward), we think that two approaches could significantly reduce the computational cost: (i) finding analytical approximations to Eq. (4), or even an exact series expansion in terms of the ratings matrix; (ii) implementing a believe propagation algorithm [23], [31] to replace Monte Carlo sampling.
In any case, we consider that the advantages of our approach outweigh its shortcomings. Not only does our algorithm provide better predictions, but also has some desirable features: it is mathematically rigorous, it is based on plausible social models, and it sheds light on decision-making processes.
With respect to mathematical rigor, the Bayesian approach is the complete and correct probabilistic treatment of the observations. As a result, we obtain an estimate of the whole probability distribution for each rating 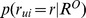 . From this, we can choose how to make predictions (the most likely rating, the mean, the median, an others). In contrast, recommender systems like those based on matrix factorization give predictions that, in general, are not feasible ratings (for example,
. From this, we can choose how to make predictions (the most likely rating, the mean, the median, an others). In contrast, recommender systems like those based on matrix factorization give predictions that, in general, are not feasible ratings (for example, 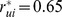 when
when 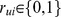 ) or that may even be outside the rating range (for example,
) or that may even be outside the rating range (for example, 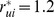 when
when 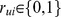 ). Additionally, these algorithms assume that ratings are linearly spaced in the “psychological scale” of users (that is, that the difference between
). Additionally, these algorithms assume that ratings are linearly spaced in the “psychological scale” of users (that is, that the difference between 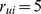 and
and 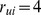 is the same as between
is the same as between 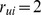 and
and 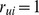 ), which is known not to be true [4].
), which is known not to be true [4].
Finally, our approach is based on models that were originally defined and are widely used to explain how social agents establish relationships, and is therefore in a better position to illuminate which social and psychological factors determine human preferences. As an interesting byproduct of this, we note that it is possible to use our approach to infer demographic properties from ratings alone, a subject that is of much current interest [32].
Methods
Derivation of the Rating Equations
Here, we show how we derive the expressions for the probability of a given rating (Eq. (4)) starting from the general Bayesian formulation of the problem (Eq. (2)). In a stochastic block model, users and items are partitioned into groups and the probability that a user rates an item with 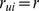 depends, exclusively, on the groups
depends, exclusively, on the groups 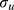 and
and 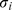 to which the user and the item belong, that is
to which the user and the item belong, that is
| (9) |
with 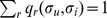 . Other than this normalization constraint,
. Other than this normalization constraint, 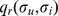 can take any value between 0 and 1.
can take any value between 0 and 1.
As in the main text, we consider the case in which ratings can take K different values  . In this case, a model
. In this case, a model 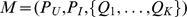 is completely specified by a partition
is completely specified by a partition 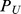 of the users, a partition
of the users, a partition 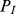 of the items, and K matrices
of the items, and K matrices 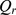 ,
, 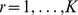 , whose elements are
, whose elements are 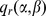 . Then the likelihood of a model is
. Then the likelihood of a model is
| (10) |
where 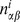 is the number of i-ratings observed from users in group
is the number of i-ratings observed from users in group  to items in group
to items in group 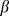 .
.
Putting together Eqs. (2), (9) and (10), and under the assumption of no prior knowledge about the models (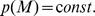 ), we have
), we have
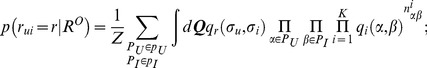 |
(11) |
where the integral is over all 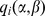 within the subspace that satisfies the normalization constraints
within the subspace that satisfies the normalization constraints 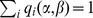 . These integrals factorize and one is left with only two types of integrals to solve. For
. These integrals factorize and one is left with only two types of integrals to solve. For 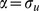 ,
, 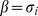 and
and  we have (without loss of generality we consider the case
we have (without loss of generality we consider the case 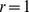 and, for clarity, we drop the dependence of
and, for clarity, we drop the dependence of  on
on  and
and 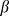 )
)
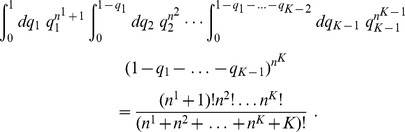 |
For all other terms we have
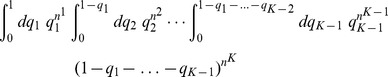 |
Using these expressions in Eq. (11), one obtains Eq. (4).
Sampling of the Partition Space
Uniformly sampling the space of users' and movies' partitions is necessary to get accurate estimates of 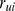 (Eq. (4)). The simplest way to sample users (or movies) partitions is by considering a random initial partition and then attempting moves of individual users from their current group to a new group, which is selected uniformly at random. However, this approach has the shortcoming of implicitly considering groups as distinguishable–for example, if node A is alone in group 1 and we move it to an empty group, the partition has not changed but the algorithm considers it as different.
(Eq. (4)). The simplest way to sample users (or movies) partitions is by considering a random initial partition and then attempting moves of individual users from their current group to a new group, which is selected uniformly at random. However, this approach has the shortcoming of implicitly considering groups as distinguishable–for example, if node A is alone in group 1 and we move it to an empty group, the partition has not changed but the algorithm considers it as different.
In fact, when there are as many potential user groups as there are users, considering groups as distinguishable has the effect of over-counting partitions by a factor 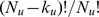 , where
, where 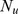 is the number of users and
is the number of users and 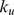 is the number of non-empty user groups in the partition.
is the number of non-empty user groups in the partition.
Since, as we have said, sampling over partitions with distinguishable groups is easiest to implement, in practice we use a modified Hamiltonian that “penalizes” partitions that are otherwise over-counted
| (12) |
where 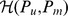 is given by Eq. (5).
is given by Eq. (5).
Note that the additional terms in Eq. (12) are not a priori penalties to avoid over-fitting by models with many groups, but rather corrections to a sampling process that would otherwise be biased. The over-fitting problem, which is common to other approaches to inference of block models [23], is automatically solved by our marginalization over the 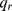 probabilities.
probabilities.
For infinitely long samplings of the space of partitions, the correction in Eq. (12) exactly cancels the over-counting of certain partitions that our sampling method causes. For finite sampling times, one cannot be sure that the whole partition space is uniformly sampled. To minimize this potential problem, we run short, parallel and independent sampling processes in different regions of the partition space, as opposed to a single long sampling process. This slightly improves our predictions of model and real ratings (although the improvement is small compared to the difference between our algorithm and other algorithms' performance).
Benchmark Algorithms
In the naive recommender (Naive), the rating of user u for item i is simply the average rating of i by all users:
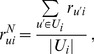 |
(13) |
where 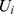 is the set of users that rated item i and
is the set of users that rated item i and 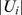 is the number of users in that set.
is the number of users in that set.
The matrix factorization method based on singular value decomposition (SVD) works as follows [17]. The matrix of ratings R (with a number of rows 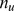 that coincides with the number of users, and a number of columns
that coincides with the number of users, and a number of columns 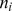 that coincides with the number of items) can be decomposed, using singular value decomposition, into
that coincides with the number of items) can be decomposed, using singular value decomposition, into
| (14) |
where P is a 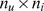 matrix and Q is a
matrix and Q is a 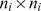 matrix.
matrix.
If we denote the rows of matrix P as 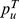 and the columns of Q as
and the columns of Q as 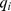 , then individual ratings satisfy
, then individual ratings satisfy 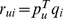 . For the purpose of making recommendations, it is convenient to pose the decomposition problem as an optimization one; indeed, one can prove that P and Q are the solution of
. For the purpose of making recommendations, it is convenient to pose the decomposition problem as an optimization one; indeed, one can prove that P and Q are the solution of
| (15) |
In practice, to estimate unobserverd ratings one needs to take into consideration a number of important issues. First, SVD factorization can have a prohibitive computational cost because we typically deal with large 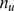 and
and 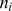 , so the problem has to be dimensionally reduced. Second, only some user-item pairs are observed (namely, those
, so the problem has to be dimensionally reduced. Second, only some user-item pairs are observed (namely, those 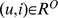 ). And third, users and items can have rating biases (for example, some users rate items higher than others, and some items are systematically highly rated).
). And third, users and items can have rating biases (for example, some users rate items higher than others, and some items are systematically highly rated).
Ultimately, unobserved ratings 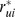 are estimated using
are estimated using
| (16) |
where 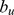 and
and 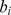 are the biases of users and items respectively and
are the biases of users and items respectively and 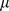 is the average rating in
is the average rating in 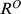 . The vectors
. The vectors 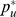 and
and 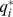 are dimensional reductions of the original
are dimensional reductions of the original 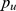 and
and 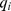 , and have length
, and have length 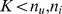 . They are obtained by solving the optimization problem
. They are obtained by solving the optimization problem
| (17) |
As Funks originally proposed [17] we solve this problem numerically using the stochastic gradient descent algorithm [33]. In our implementation of the algorithm (SVD1), we use 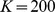 . In the LensKit implementation of the algorithm (SVD2) we set
. In the LensKit implementation of the algorithm (SVD2) we set 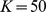 and a learning rate of 0.002 as suggested in Ref. [4].
and a learning rate of 0.002 as suggested in Ref. [4].
Finally, the algorithm based on the similarity between items (Item-Item) works as follows [29]. One starts by defining a similarity between items, which in our case is the cosine between the item rating vectors (conveniently adjusted to remove user biases towards higher or lower ratings [29]). The predicted rating 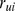 is the similarity-weighted average of the K closest neighbors of i that user u has rated. Once more, we use the default, optimized implementation of the algorithm in LensKit [4] (
is the similarity-weighted average of the K closest neighbors of i that user u has rated. Once more, we use the default, optimized implementation of the algorithm in LensKit [4] (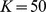 ).
).
Movie Genre Overlap
Each movie i in the MovieLens dataset is labeled with one or more genres 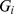 . We define the genre overlap
. We define the genre overlap 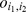 between two movies as the Jaccard index of the corresponding genre sets
between two movies as the Jaccard index of the corresponding genre sets
| (18) |
that is, the ratio between the number of genres shared by the two movies and the total number of genres with which they are labelled.
Funding Statement
This work was supported by a James S. McDonnell Foundation Research Award (RG and MSP), grants PIRG-GA-2010-277166 (RG) and PIRG-GA-2010-268342 (MSP) from the European Union, and grants FIS2010-18639 (RG and MSP), FIS2006-01485 (MOSAICO) (EM) and FIS2010-22047-C05-04 (EM) from the Spanish Ministerio de Economía y Competitividad. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.(2010) The data deluge. The Economist Feb. 25th.
- 2. Adomavicius G, Tuzhilin A (2005) Towards the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE T Knowl Data En 17: 734–749. [Google Scholar]
- 3.Melville P, Sindhwani V (2010) Encyclopedia of Machine Learning, Springer-Verlag, chapter Recommender systems.
- 4.Ekstrand MD, Ludwig M, Konstan JA, Riedl JT (2011) Rethinking the recommender research ecosystem: reproducibility, openness, and lenskit. Proceedings of the fifth ACM Conference on Recommender Systems : 133–140.
- 5. Watts DJ (2007) A twenty-first century science. Nature 445: 489. [DOI] [PubMed] [Google Scholar]
- 6. Lazer D, Pentland A, Adamic L, Aral S, Barabási AL, et al. (2009) Computational social science. Science 323: 721–723. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Brockmann D, Hufnagel L, Gaisel T (2006) The scaling laws of human travel. Nature 439: 462–465. [DOI] [PubMed] [Google Scholar]
- 8. Song C, Qu Z, Blumm N, Barabási AL (2010) Limits of predictability in human mobility. Science 327: 1018–1021. [DOI] [PubMed] [Google Scholar]
- 9. Malmgren RD, Stouffer DB, Campanharo ASLO, Amaral LA (2009) On universality in human correspondence activity. Science 325: 1696–1700. [DOI] [PubMed] [Google Scholar]
- 10. Salganik MJ, Dodds PS, Watts DJ (2006) Experimental study of inequality and unpredictability in an artificial cultural market. Science 311: 854–856. [DOI] [PubMed] [Google Scholar]
- 11. Christakis N, Fowler J (2007) The spread of obesity in a large social network over 32 years. New Engl J Med 357: 370–379. [DOI] [PubMed] [Google Scholar]
- 12. Cohen-Cole E, Fletcher J (2008) Is obesity contagious? Social networks vs. environmental factors in the obesity epidemic. J Health Econ 27: 1382–1387. [DOI] [PubMed] [Google Scholar]
- 13. Fowler J, Christakis N (2008) Estimating peer effects on health in social networks: A response to Cohen-Cole and Fletcher; and Trogdon, Nonnemaker, Pais. J Health Econ 27: 1400. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Vespignani A (2009) Predicting the behavior of techno-social systems. Science 325: 425–428. [DOI] [PubMed] [Google Scholar]
- 15. Iribarren JL, Moro E (2009) Impact of human activity patterns on the dynamics of information diffusion. Phys Rev Lett 103: 038702. [DOI] [PubMed] [Google Scholar]
- 16. Su X, Khoshgoftaar TM (2009) A survey of collaborative filtering techniques. Adv in Artif Intell 2009: 4 2–4: 2. [Google Scholar]
- 17. Koren Y, Bell R, Volinsky C (2009) Matrix factorization techniques for recommender systems. Computer 42: 30–37. [Google Scholar]
- 18. Breiger RL, Boorman SA, Arabie P (1975) An algorithm for clustering relational data with applications to social network analysis and comparison with multidimensional scaling. J Math Psychol 12: 328–383. [Google Scholar]
- 19. White HC, Boorman SA, Breiger RL (1976) Social structure from multiple networks. i. blockmodels of roles and positions. Am J Sociol 81: 730–780. [Google Scholar]
- 20. Holland PW, Laskey KB, Leinhardt S (1983) Stochastic blockmodels: First steps. Soc Networks 5: 109–137. [Google Scholar]
- 21. Nowicki K, Snijders TAB (2001) Estimation and prediction for stochastic blockstructures. J Am Stat Assoc 96: 1077–1087. [Google Scholar]
- 22. Guimerà R, Sales-Pardo M (2009) Missing and spurious interactions and the reconstruction of complex networks. Proc Natl Acad Sci U S A 106: 22073–22078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Decelle A, Krzakala F, Moore C, Zdeborová L (2011) Inference and phase transitions in the detection of modules in sparse networks. Phys Rev Lett 107: 065701. [DOI] [PubMed] [Google Scholar]
- 24. Newman MEJ (2011) Communities, modules and large-scale structure in networks. Nat Phys 8: 25–31. [Google Scholar]
- 25.Jaynes ET (2003) Probability Theory: The Logic of Science. Cambridge University Press. [Google Scholar]
- 26. Hoeting JA, Madigan D, Raftery AE, Volinsky CT (1999) Bayesian model averaging: A tutorial. Statistical Science 14: 382417. [Google Scholar]
- 27. Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E (1953) Equation of state calculations by fast computing machines. J Chem Phys 21: 1087–1092. [Google Scholar]
- 28.Paterek A (2007) Improving regularized singular value decomposition for collaborative filtering. In: Proc. KDD Cup Workshop at SIGKDD'07, 13th ACM Int. Conf. on Knowledge Discovery and Data Mining. 39–42. [Google Scholar]
- 29.Sarwar B, Karypis G, Konstan J, Riedl J (2001) Item-based collaborative filtering recommendation algorithms. In: Proceedings of the 10th international conference on World Wide Web. New York, NY, USA: ACM, WWW '01, 285–295. doi:10.1145/371920.372071. [Google Scholar]
- 30. Sales-Pardo M, Guimerà R, Moreira AA, Amaral LAN (2007) Extracting the hierarchical organization of complex systems. Proc Natl Acad Sci USA 104: 15224–15229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Yedidia JS, Freeman WT, Weiss Y (2003) Exploring artificial intelligence in the new millennium. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., chapter Understanding belief prop-agation and its generalizations. 239–269. [Google Scholar]
- 32.Malmgren RD, Hofman JM, Amaral LAN, Watts DJ (2009) Characterizing individual communication patterns. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 607–615.
- 33. Gardner W (2003) Learning characteristics of stochastic-gradient-descent algorithms: A general study, analysis, and critique. Signal Process 6: 113–133. [Google Scholar]