

Abstract
Musical training strengthens speech perception in the presence of background noise. Given that the ability to make use of speech sound regularities, such as pitch, underlies perceptual acuity in challenging listening environments, we asked whether musicians’ enhanced speech-in-noise perception is facilitated by increased neural sensitivity to acoustic regularities. To this aim we examined subcortical encoding of the same speech syllable presented in predictable and variable conditions and speech-in-noise perception in 31 musicians and nonmusicians. We anticipated that musicians would demonstrate greater neural enhancement of speech presented in the predictable compared to the variable condition than nonmusicians. Accordingly, musicians demonstrated more robust neural encoding of the fundamental frequency (i.e., pitch) of speech presented in the predictable relative to the variable condition than non-musicians. The degree of neural enhancement observed to predictable speech correlated with subjects’ musical practice histories as well as with their speech-in-noise perceptual abilities. Taken together, our findings suggest that subcortical sensitivity to speech regularities is shaped by musical training and may contribute to musicians’ enhanced speech-in-noise perception.
Keywords: Auditory, Brainstem, Musical training, Speech in noise
Human communication rarely occurs in optimal listening environments; rather, we are often surrounded by background noise. Despite the frequent presence of noise, humans are remarkably adept at disentangling target sounds from a complex soundscape. A key mechanism thought to underlie accurate perception in noise is the auditory system’s ability to extract regularities from an ongoing acoustic signal (Strait, Hornickel, & Kraus, in press; Chandrasekaran, Hornickel, Skoe, Nicol, & Kraus, 2009; Winkler, Denham, & Nelken, 2009). This is accomplished through the neural fine-tuning of responses based on a sound’s predictability–a phenomenon that is observed in humans, non-human primates and rodents, underscoring its importance for auditory function throughout the animal kingdom (Baldeweg, 2006; Bendixen, Roeber, & Schröger, 2007; Bendixen, Schroger, & Winkler, 2009; Chandrasekaran et al., 2009; Dean, Harper, & McAlpine, 2005; Dean, Robinson, Harper, & McAlpine, 2008; Malmierca, Cristaudo, Perez-Gonzalez, & Covey, 2009; Perez-Gonzalez, Malmierca, & Covey, 2005; Pressnitzer, Sayles, Micheyl, & Winter, 2008; Skoe & Kraus, 2010b; Wen, Wang, Dean, & Delgutte, 2009; Winkler et al., 2009). Neural adaptation to regularly occurring sounds does not require overt attention (Muller, Metha, Krauskopf, & Lennie, 1999; Pressnitzer et al., 2008; Webster, Kaping, Mizokami, & Duhamel, 2004), reinforcing the idea that this sensitivity to acoustic regularities is a basic tenet of auditory processing. Consistent with the notion that regularity detection is a basic function of the auditory system, failure to take advantage of acoustic regularities has been linked to poor music aptitude (Strait, Hornickel et al., in press) and language impairments such as developmental dyslexia (Ahissar, Lubin, Putter-Katz, & Banai, 2006; Chandrasekaran et al., 2009; Kujala et al., 2000; Kujala & Naatanen, 2001; Schulte-Korne, Deimel, Bartling, & Remschmidt, 1999) and specific language impairment (Evans, Saffran, & Robe-Torres, 2009).
Pitch is a particularly important form of regularity that the auditory system employs to promote auditory object formation and speaker identification (Baumann & Belin, 2010; Clarke & Becker, 1969; Kreiman, Gerratt, Precoda, & Berke, 1992), two key elements required for extracting speech from a noisy environment (Oxenham, 2008; Shinn-Cunningham & Best, 2008). Pitch is the perceptual correlate of a sound’s fundamental frequency (F0), the slowest repeating periodic element of that sound. Increasing the pitch difference between two auditory streams improves a listener’s ability to perceive them as two distinct auditory objects, resulting in better perception of their acoustic content (Assmann & Summerfield, 1987; Bird & Darwin, 1998; Brokx & Nooteboom, 1982; Culling & Darwin, 1993; Drullman & Bronkhorst, 2004). Indeed, these results highlight the important role that voice pitch plays for speech-in-noise perception. Recently, the relationship between F0 and speech-in-noise perception was extended to neurobiological processes whereby the robustness of an individual’s subcortical encoding of the F0 correlates with speech-in-noise perceptual ability (Anderson, Skoe, Chandrasekaran, Zecker, & Kraus, 2010; Song, Skoe, Banai, & Kraus, 2010).
Music, like language, is a highly structured system that relies on the grouping of a finite number of sounds (notes) according to specific rules. Given that musical skill requires the rapid online detection of sound regularities, it is not surprising that musicians demonstrate advantages for detecting pitch patterns (Brattico, Näätänen, & Tervaniemi, 2001; van Zuijen, Sussman, Winkler, Näätänen, & Tervaniemi, 2004; van Zuijen, Sussman, Winkler, Näätänen, & Tervaniemi, 2005). Musicians are also more adept at using rhythmic and tonal regularities to extract rhythmic hierarchies (Drake, Jones, & Baruch, 2000), to detect incongruous melodic endings (Besson & Faita, 1995; Besson, Faita, & Requin, 1994), and to structure temporal (Tervaniemi, Ilvonen, Karma, Alho, & Näätänen, 1997) and tonal sequences (van Zuijen et al., 2004). Evidence suggests that musicians’ sensitivity to acoustic regularities extends to the domain of language, in which musicians are more sensitive to deviations in speech patterns than nonmusicians (Jentschke & Koelsch, 2009; Magne, Schön, & Besson, 2006; Nikjeh, Lister, & Frisch, 2009; Schon, Magne, & Besson, 2004; Tervaniemi et al., 2009). To date, this work has only focused on perceptual abilities and cortical processes. It remains to be determined whether the musician advantage for detecting sound patterns and acoustic regularities extends to other aspects of neural processing in the auditory pathway–namely, the auditory brainstem.
The auditory brainstem response (ABR) provides a noninvasive method to study subcortical sensitivity to acoustic regularities. While the ABR represents acoustic features of the evoking stimulus with considerable fidelity (Galbraith, Arbagey, Branski, Comerci, & Rector, 1995; Skoe & Kraus, 2010a), it is also modulated by stimulus predictability and the behavioural relevance of the evoking sound. Enhanced subcortical responses to meaningful acoustic features have been noted to occur on multiple time scales, such as over the course of a 90-min recording session (Skoe & Kraus, 2010b), with short-term auditory training (Russo, Nicol, Zecker, Hayes, & Kraus, 2005; Song, Skoe, Wong, & Kraus, 2008), and as a function of life-long musical or linguistic experience (Bidelman, Gandour, & Krishnan, 2011; Kraus & Chandrasekaran, 2010; Krishnan & Gandour, 2009; Krishnan, Xu, Gandour, & Cariani, 2005; Lee, Skoe, Kraus, & Ashley, 2009; Parbery-Clark, Skoe, & Kraus, 2009; Strait, Kraus, Skoe, & Ashley, 2009; Wong, Skoe, Russo, Dees, & Kraus, 2007). As such, the auditory brainstem offers a unique window through which we can explore the relative impacts of stimulus predictability and musical expertise on auditory processing and their influences on speech-in-noise perception.
Hearing in noise depends on the auditory system’s ability to segregate a target signal from competing input. The pitch cues of a person’s voice provide not only a means to distinguish between the target and the noise, but they also act as a unifying percept that enables elements with the same pitch to be grouped into a single acoustic stream. In fact, the ability to hear in noise relates with the magnitude of pitch, or F0, encoding (Anderson et al., 2010; Song et al., 2010). Given this, we were surprised to find that musicians, who demonstrate a heightened ability to hear in noise, do not demonstrate enhanced subcortical F0 encoding for speech in noise compared to nonmusicians (Parbery-Clark, Skoe, & Kraus, 2009). While musicians’ enhanced speech-in-noise perception (Parbery-Clark, Skoe, & Kraus, 2009; Parbery-Clark, Skoe, Lam, & Kraus, 2009; Parbery-Clark, Strait, Anderson, Hittner, & Kraus, 2011) suggests a potential advantage for locking on to the acoustic regularities of a target speaker’s voice, mechanisms other than general F0 enhancement must underlie their heightened perceptual performance. Here, we ask whether musicians’ speech-in-noise perception is founded on a greater neural sensitivity to acoustic regularities within an ongoing stream of speech sounds.
1. Methods
1.1. Participants
Thirty-one young adults ages 18–30 (mean = 22.4, s.d. = 3.4) participated in this study. All participants were native English speakers, had normal hearing thresholds (<20 dB HL at octave frequencies 0.125–8 kHz) and demonstrated normal IQ as measured by the Test of Nonverbal Intelligence (TONI) (Brown, Sherbenou, & Johnsen, 1982). No participants reported histories of learning or neurological disorders. All participants gave their written informed consent according to principles set forth by Northwestern University’s Institutional Review Board. Sixteen participants were classified as musicians (11 females), all of whom had begun musical training at or before age seven (mean = 5.1, s.d. = 1.2) and had consistently played a musical instrument throughout their lives up until the time of study participation (mean = 16.4, s.d. = 3.4). Fifteen subjects were classified as nonmusicians (11 females) and reported fewer than three years of musical training at any point in their lives. The two groups did not differ according to IQ (F(1,29) = 2.25, p = 0.144), age (F(1,29) = 0.643, p = 0.429), or hearing thresholds (F(1,29) = 1.059, p = 0.312).
1.2. Stimuli
The speech stimulus was a 170 ms six-formant speech syllable (/da/) synthesized using a Klatt-based synthesizer at a 20 kHz sampling rate. This syllable has a steady fundamental frequency (F0 = 100 Hz) except for an initial 5 ms stop burst. During the first 50 ms (transition between the stop burst and the vowel), the first, second and third formants change over time (F1, 400–720 Hz; F2, 1700–1240 Hz; F3, 2580–2500 Hz) but stabilize for the subsequent vowel, which is 120 ms in duration. The fourth, fifth and sixth formants are constant throughout (F4, 3300 Hz; F5, 3750 Hz; F6, 4900 Hz). In the predictable condition, the /da/ was presented 100% of the time. In the variable condition, the same /da/ was randomly presented within the context of seven other speech sounds at a probability of 12.5% (Fig. 1). The seven other speech sounds varied by formant structure (/ba/, /ga/, /du/), voice-onset time (/ta/), F0 (/da/ with a dipping contour, /da/ with an F0 of 250 Hz), and duration (163 ms /da/) (see Chandrasekaran et al., 2009 for further descriptions of the stimuli and the experimental paradigm).
Fig. 1.

To investigate subcortical sensitivity to stimulus regularities, the speech sound /da/ was presented in predictable (top) and variable (bottom) conditions. In the predictable condition, /da/ was presented 100% of the time. In the variable condition, /da/ was randomly presented at a frequency of 12.5%, in the context of seven other speech sounds. Auditory brainstem responses to /da/ were event-matched between the two conditions (represented by highlighted bars) so as to avoid the potential confound of presentation order.
1.3. Auditory brainstem measures
Brainstem responses were differentially recorded at a 20 kHz sampling rate using Ag–AgCl electrodes in a vertical montage (Cz active, forehead ground and linked-earlobe references) using Scan 4.3 (Compumedics, Charlotte, NC) under the two different conditions (i.e., predictable and variable). In both conditions, a total of 6100 individual responses were collected. The speech stimuli were presented in alternating polarities, a common technique used in subcortical recordings to minimize the contribution of stimulus artifact and cochlear microphonic (Aiken & Picton, 2008; Gorga, Abbas, & Worthington, 1985). The speech stimuli were presented binaurally at 80 dB SPL with an inter-stimulus interval of 83 ms through insert ear phones (ER-3; Etymotic Research, Elk Grove Village, IL) at a rate of 3.95 Hz. Contact impedance was 2 kΩ or less across all electrodes. Each condition lasted ~ 26 ± 2 min. To facilitate a wakeful yet relaxed state for the recording session, participants watched a silent, captioned movie of their choice. Artifact rejection was monitored during the recording session and maintained at <10% for all participants.
Responses were band-pass filtered offline from 70 to 2000 Hz (12 dB roll-off, zero phase-shift) using NeuroScan Edit 4.3 to maximize the contribution of the auditory brainstem nuclei in the recording and to reduce the inclusion of low-frequency cortical activity (Akhoun et al., 2008; Chandrasekaran & Kraus, 2010). Responses were epoched from –40 to 213 ms (stimulus onset occurring at 0 ms) and events with amplitudes beyond ±35 μV were rejected as artifact. To compare the neural response to /da/ across the two conditions, responses were trial matched (Fig. 1). This was achieved by ranking the presentation of the /da/ in the variable condition to its presentation number to create a presentation event template from which the responses to the /da/ at the same location in the predictable condition could be selected. The individual trials selected from each condition were then summed to create trial-matched averages. While this method results in a large number of trials being disregarded in the predictable condition, trial-matching between the two conditions facilitates the comparison of neural responses to the same stimulus recorded in two conditions without the potential confound of presentation order or differing numbers of trials. The final response average for each condition consisted of 700 artifact-free neural responses to /da/.
1.4. Frequency analyses
The spectral energy of the neural responses was analyzed using MATLAB 7.5.0 (The Mathworks, Inc., Natick, MA) by computing fast Fourier transforms. Spectral amplitudes were calculated for the portion of the response corresponding to the vowel (60–170 ms) using 40 Hz-wide bins centered at the F0 (100 Hz) and its second through fifth harmonics (200–500 Hz). The differences between the spectral amplitudes of the F0 and its harmonics in the two conditions were then calculated by subtracting the spectral amplitudes of the frequencies of interest in the variable condition from the spectral amplitudes of these same frequencies in the predictable condition.
1.5. Speech perception in noise
Speech perception in noise was measured using the Hearing in Noise Test (HINT, Bio-logic Systems Corp; Mundelein, IL) (Nilsson, Soli, & Sullivan, 1994). During this test participants repeat short, semantically and syntactically simple sentences (e.g., she stood near the window) taken from the Bamford–Kowal–Bench corpus of male-produced sentences (Bench, Kowal, & Bamford, 1979). These sentences are presented in free-field within speech-shaped background noise from a loud speaker located one meter at a 0° azimuth from the participant. The noise presentation level is fixed at 65 dB SPL and the program automatically adjusts perceptual difficulty by increasing or decreasing the intensity level of the target sentences until the signal-to-noise ratio (SNR) threshold is determined. This SNR threshold is defined as the dB level difference between the speech and the noise at which 50% of sentences are correctly repeated. A lower SNR indicates better performance.
1.6. Statistical analyses
Group differences in the neural encoding of the F0 and its second through fifth harmonics (H2–H5) in the predictable and variable conditions were explored with a repeated measure ANOVA. To quantify relationships among stimulus predictability, speech-in-noise perception and musicians’ musical practice histories, Pearson and Spearman correlations were employed as appropriate (SPSS, Chicago, IL). All results reflect two-tailed significance values.
2. Results
Consistent with previous results, musicians demonstrated better perception of speech in noise than nonmusicians (F(1,29) = 18.04, p < 0.005) (Parbery-Clark, Skoe, Lam et al., 2009). Musicians also showed greater subcortical enhancement of the F0 presented in the predictable compared to the variable condition than nonmusicians (Fig. 2). A RMANOVA (condition × group) demonstrated a significant interaction between stimulus condition and musician/nonmusician groups for the F0 (F(1,29) = 7.288, p = 0.01) but not for its harmonics (H2–H5, all p > 0.5). We did not observe a main effect of musical training on F0 encoding in that musicians did not demonstrate enhanced F0 encoding relative to nonmusicians within either the predictable or the variable conditions (predictable: F(1,30) = 0.659, p = 0.423; variable: F(1,30) = 0.375 p = 0.545). Post hoc, within-group, paired samples t-tests, however, revealed that musicians had a greater representation of the F0 in the predictable relative to the variable condition (t(15) = −2.336, p = 0.034) whereas nonmusicians did not (t(14) = 1.717, p = 0.11) (Fig. 2).
Fig. 2.

Subcortical enhancement of predictable speech in musicians. (A) Group average responses for musicians (left) and nonmusicians (right) in predictable (grey) and variable (black) stimulus conditions. (B) Grand average spectra and (C) corresponding frequency amplitude bar graphs for the predictable and variable conditions for the fundamental frequency (F0) and its harmonics (H2–H5). (D) Musicians, but not nonmusicians, demonstrate enhanced subcortical representation of the fundamental frequency (F0) in the predictable condition relative to the variable condition. *p < 0.05; **p < 0.01; error bars represent 1 standard error.
2.1. Subcortical enhancement of predictable speech relates with speech-in-noise perception
Across all subjects, the degree of enhancement in auditory brainstem responses to the F0 between the two conditions correlated with speech-in-noise (SIN) perception, with better SIN perception relating to a greater F0 enhancement in the predictable compared to the variable condition (r = −0.533, p = 0.002). Within-group analyses revealed that this relationship was mainly driven by the musicians (rho = −0.567, p = 0.02) and was not significant among nonmusicians only (rho = −0.348, p = 0.204) (Fig. 3). No other measure of spectral magnitude (i.e., H2–H5) between the predictable and variable conditions related with SIN perception across all subjects or within each group separately (p > 0.2).
Fig. 3.

The difference between the F0 representation in the predictable compared to the variable condition (F0predictable – F0variable) correlates with speech-in-noise perception among musicians, in which greater subcortical sensitivity to speech regularities relates to better speech-in-noise perception (rho = −0.567, p = 0.02). This same relationship is not present in the nonmusician group (rho = −0.348, p = 0.204).
2.2. Subcortical enhancement of predictable speech relates with music experience
We observed a positive correlation between years of musical experience and the extent of F0 enhancement within musicians, with more years of practice relating to a greater enhancement of the F0 in the predictable relative to the variable condition (Fig. 4; rho = 0.672, p = 0.004).
Fig. 4.
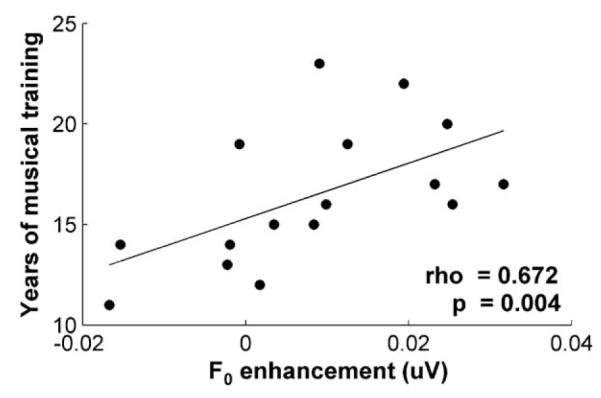
The difference between the F0 representations in the predictable compared to the variable condition (F0predictable – F0variable) correlates with years of musical practice for the musician group. The more years musicians consistently practiced their instrument, the greater the neural sensitivity to speech sound regularities (rho = 0.672, p = 0.004).
3. Discussion
Here, we demonstrate the facilitation of neural encoding according to regularities in an ongoing speech stream. In musicians, the representation of voice pitch in the auditory brainstem response is enhanced to predictably occurring speech relative to a variable, or unpredictable, context. This result highlights the potential role that musical training plays in improving the detection of acoustic regularities. Furthermore, the extent of subcortical enhancement to predictably occurring speech in musicians relates to the ability to hear speech in background noise. These findings demonstrate a neural advantage for detecting regularities within an ongoing speech stream in musicians, underscoring their enhanced ability to track the voice of a target speaker in background noise.
3.1. Musical experience tunes neural sensitivity to acoustic regularities
Music, like language, is highly patterned, with both music and language demonstrating acoustic organization that unfolds over time. Within a musical context, repetition and regularity play fundamental roles, contributing to the perception of rhythm, meter (Hannon, Snyder, Eerola, & Krumhansl, 2004; Large & Jones, 1999) and tonality (Krumhansl, 1985, 1990). Given the common use of sound patterns in music and that musicians are trained to detect them, it is not surprising that musicians are more adept at distinguishing pitch (Brattico et al., 2001; van Zuijen et al., 2004), rhythmic (van Zuijen et al., 2005) and melodic (Fujioka, Trainor, Ross, Kakigi, & Pantev, 2004; Fujioka, Trainor, Ross, Kakigi, & Pantev, 2005) patterns. In addition, musicians are more sensitive to harmonic relationships between chords, with musicians demonstrating greater effects of harmonic expectancy than nonmusicians (Koelsch, Jentschke, Sammler, & Mietchen, 2007).
In this study, we show that musicians’ sensitivity to sound patterns transfers to the speech domain, with musicians demonstrating a greater representation of pitch cues in a predictable than a variable context relative to nonmusicians. Furthermore, we provide evidence that this skill is differentiated within the musician group in that musicians with more years of musical training show greater sensitivity to stimulus regularities. This correlation between the degree of subcortical sensitivity to stimulus regularities and years of musical practice provides compelling evidence that our results may be induced, at least in part, by training rather than being driven solely by genetic factors. Additional support for this premise comes from Moreno et al. (2009), who conducted a longitudinal study with random assignment of nonmusician children to music or painting training. Results showed that those children who received musical training demonstrated enhanced pitch processing for both music and speech, again highlighting the role of musical training, rather than genetic predispositions alone, in engendering musicians’ enhanced processing of pitch. As such, our results contribute to a growing literature demonstrating a link between musicians’ musical practice histories (Margulis, Mlsna, Uppunda, Parrish, & Wong, 2009; Pantev, Roberts, Schulz, Engelien, & Ross, 2001; Strait, Chan, Ashley, & Kraus, in press) and the number of years of musical practice or age of onset of musical training with the extent of neural enhancement observed (Gaser & Schlaug, 2003; Hutchinson, Lee, Gaab, & Schlaug, 2003; Lee et al., 2009; Musacchia, Sams, Skoe, & Kraus, 2007; Strait & Kraus, 2011; Strait et al., 2009; Wong et al., 2007).
3.2. Neural enhancement to acoustic regularities: the role of the descending auditory system
The brain is an active, adaptive system that generates predictions about the environment (Engel, Fries, & Singer, 2001; Friston, 2005; Winkler et al., 2009). Neural representation of the external world is not context-invariant; rather, experience (short- and long-term) and immediate environmental conditions modulate neural function. Out of a constant barrage of sensory information, cortical centers are thought to continually predict which features are behaviourally relevant and fine-tune the neural encoding of these features accordingly, thus facilitating their perception (Ahissar & Hochstein, 2004; Ahissar, Nahum, Nelken, & Hochstein, 2009; Bajo, Nodal, Moore, & King, 2010; Engel et al., 2001; Fritz, Elhilali, & Shamma, 2005; Tzounopoulos & Kraus, 2009). One way this may be accomplished is through the generation of predictions in cortical centers that are, in turn, used to bias neural encoding occurring earlier in the auditory processing stream. This process improves the representation of salient or predictable acoustic features. The modification of subcortical response properties is thought to occur via a series of reciprocal feedback loops originating in the cortex and terminating at subcortical nuclei (Suga & Ma, 2003). The descending branches of the auditory system modify subcortical responses by sharpening neural tuning and increasing response magnitudes for frequently occurring signals (Gao & Suga, 1998; Yan & Suga, 1998) or the most behaviourally relevant auditory information while suppressing irrelevant input (Gao & Suga, 1998; Luo, Wang, Kashani, & Yan, 2008).
Continually generated predictions also serve another important role: they enable the formation of templates that can be used to facilitate interpretation of incoming information. When the incoming stimulus matches the internally generated pattern, sensory processing can be accomplished more rapidly (i.e., because it was expected) (Haenschel, Vernon, Dwivedi, Gruzelier, & Baldeweg, 2005). If, on the other hand, the incoming stimulus does not match the internally generated pattern, it is flagged as a violation of the predicted sound sequence. When this occurs, the auditory system must determine whether to modulate the current expectation or to treat the violation as a unique event (Näätänen & Winkler, 1999; Winkler, Karmos, & Näätänen, 1996). Our results indicate that musicians benefit from regularity to a greater extent than nonmusicians. This result highlights the potential presence of strengthened top-down control mechanisms in musicians, as has been previously proposed (Kraus & Chandrasekaran, 2010; Strait, Chan et al., in press; Strait, Kraus, Parbery-Clark, & Ashley, 2010; Tervaniemi et al., 2009), that enable musicians to tailor subcortical structures for the maximal extraction and neural encoding of important acoustic information. An alternate but not mutually exclusive mechanism is that musical training may bolster stimulus-driven, bottom-up statistical learning. Increased modulation of subcortical processes according to statistical properties of incoming sounds can stem from top-down and/or bottom-up mechanisms and would result in an enhancement of regularities within a speech stream. While both of these mechanisms may be at play, the present data cannot disambiguate their relative contributions.
3.3. Subcortical sensitivity to acoustic regularities improves SIN perception
A key component of SIN perception is the ability to distinguish a target voice from background noise. The pitch of a target voice is a salient cue that contributes to the extraction of a voice from its surrounding acoustic environment (Assmann & Summerfield, 1987; Bird & Darwin, 1998; Brokx & Nooteboom, 1982; Culling & Darwin, 1993; Drullman & Bronkhorst, 2004). Because the pitch of a person’s voice is relatively constant and changes smoothly over time (Darwin, 2005), pitch cues are typically easy to follow. Pitch can also provide a means to group sequential sounds into an acoustic stream, contributing to object formation that facilitates speech perception in noise. Still, how does this translate into a neural code? One idea is that the auditory system enhances its representation of the target stimulus’ spectral cues to positively contribute to object formation (Chandrasekaran et al., 2009; Ulanovsky, Las, & Nelken, 2003). Here, we document a musician advantage for neurally representing the F0, an acoustic correlate of pitch, in a predictable context and show that the extent of this repetition-induced enhancement relates to SIN perceptual ability. These findings highlight the possibility that musicians’ abilities to detect and lock on to regularities within an auditory environment contribute to their enhanced ability to perceive speech in noise.
3.4. Future directions
In this study, we explored the effect of stimulus regularity on the neural processing of an isolated speech sound. While we interpret our results as indicative of a greater impact of stimulus regularity on the neural encoding of speech in musicians relative to nonmusicians, future work using additional speech sounds and words will aid in the generalization of these findings. It will also be important to determine whether these effects extend to other acoustic domains, such as to music. Given that musicians demonstrate enhancements in the neural processing of pitch in both speech and music (Bidelman et al., 2011; Magne et al., 2006; Moreno et al., 2009; Musacchia et al., 2007), exploration of the impact of stimulus regularity on the neural encoding of speech and music may provide a powerful approach for elucidating the extent to which cross-domain neural functions undergird music and language processing.
While the detection of acoustic regularities is an important aspect of auditory scene analysis, the ability to detect unexpected novel stimuli is also necessary for an individual to respond to behaviourally relevant changes in the environment. In addition to tracking sensory regularities, the brain also has the capacity to act as a novelty detector (e.g., the mismatch negativity response, or MMN (Näätänen, Gaillard, & Mäntysalo, 1978)). We propose that regularity and novelty detection within an ongoing sound stream may not be distinct processes; rather, they reflect different faces of the same coin. For example, a sound can only be deemed novel if it violates predictions generated by identified regularities. In this study, we document enhanced neural encoding of a predictably relative to a variably presented speech sound. Future work employing a more diverse range of speech sound probabilities is needed to more explicitly define the effect of statistical regularity on subcortical response properties. Further work might also vary the behavioural relevance of eliciting stimuli (e.g., behaviourally relevant regularities in language versus irrelevant regularities occurring in a steady hum of traffic, enabling it to be easily ignored). This may permit the definition of how behavioural relevance alters the neural encoding of acoustic regularities.
Our documentation of subcortical enhancement to a repeated and, hence, predictable speech sound might appear at odds with the well-documented decrease in cortical evoked responses in which stimulus repetition leads to reduced neural response magnitudes (i.e., repetition suppression). Despite its widespread acknowledgement, the neural mechanisms underlying repetition suppression remain debated. Although some have proposed decreased neuronal activity with stimulus repetition, repetition may also engender a more precise neural representation of the evoking stimulus, facilitating certain aspects of the neural response while inhibiting others (e.g., more precise inhibitory sidebands surrounding a facilitated response to the physical dimensions of the stimulus) (Grill-Spector, Henson, & Martin, 2006). Indeed, stimulus repetition does not always lead to reduced cortical evoked response magnitudes; there are certain circumstances in which repetition (Loveless, Hari, Hämäläinen, & Tiihonen, 1989; Loveless, Levänen, Jousmäki, Sams, & Hari, 1996; Wang, Mouraux, Liang, & Iannetti, 2008) and stimulus predictability (Bendixen et al., 2009) result in greater cortical magnitudes. Subcortical responses also demonstrate this duality of enhancement (Chandrasekaran et al., 2009; Dean et al., 2005; Skoe & Kraus, 2010b) or attenuation (Anderson, Christianson, & Linden, 2009; Malmierca et al., 2009; Perez-Gonzalez et al., 2005) to repeated or predictable sounds. Although our results indicate enhanced subcortical responses with stimulus repetition, especially in musicians, whether this corresponds with cortical response suppression or augmentation is undetermined. Future work employing this experimental paradigm with the concurrent recording of subcortical and cortical responses may advance our understanding of the effect of repetition and predictability on the auditory system as a whole.
4. Conclusions
In order to deal with the enormous amount of sensory information received on a moment-to-moment basis, the brain must decide which elements are most relevant to the task in hand. To accomplish this goal, the nervous system continually generates predictions based on previous experiences to more efficiently extract the most relevant cues from the complex sensory environment. This adaptability is keenly displayed while attempting to hear in noise, when the auditory system’s goal is to segregate the target voice from the background noise. Pitch provides a good candidate for facilitating this process, as it can aid in distinguishing a specific voice from background noise. Here, we demonstrate that musicians are more sensitive to regularities within an ongoing speech stream, resulting in a greater neural representation of the fundamental frequency in a predictable compared to a variable context. In musicians, this increase in neural sensitivity to speech in a predictable context relates to SIN perception, thereby offering a neural basis for musicians’ behavioural advantage for hearing in noise. Furthermore, the extent of musical training relates to the degree of regularity-induced neural enhancement, suggesting that this is a malleable process that can be shaped by experience.
Acknowledgements
This work was funded by the National Science Foundation (SGER 0842376). The authors wish to thank Jane Hornickel for her assistance with data processing.
Footnotes
References
- Ahissar M, Hochstein S. The reverse hierarchy theory of visual perceptual learning. Trends in Cognitive Sciences. 2004;8:457–464. doi: 10.1016/j.tics.2004.08.011. [DOI] [PubMed] [Google Scholar]
- Ahissar M, Lubin Y, Putter-Katz H, Banai K. Dyslexia and the failure to form a perceptual anchor. Nature Neuroscience. 2006;9:1558–1564. doi: 10.1038/nn1800. [DOI] [PubMed] [Google Scholar]
- Ahissar M, Nahum M, Nelken I, Hochstein S. Reverse hierarchies and sensory learning. Philosophical Transactions of the Royal Society London B: Biological Sciences. 2009;364:285–299. doi: 10.1098/rstb.2008.0253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aiken SJ, Picton TW. Envelope and spectral frequency-following responses to vowel sounds. Hearing Research. 2008;245:35–47. doi: 10.1016/j.heares.2008.08.004. [DOI] [PubMed] [Google Scholar]
- Akhoun I, Gallégo S, Moulin A, Ménard M, Veuillet E, Berger-Vachon C, et al. The temporal relationship between speech auditory brainstem responses and the acoustic pattern of the phoneme /ba/ in normal-hearing adults. Clinical Neurophysiology. 2008;119:922–933. doi: 10.1016/j.clinph.2007.12.010. [DOI] [PubMed] [Google Scholar]
- Anderson LA, Christianson GB, Linden JF. Stimulus-specific adaptation occurs in the auditory thalamus. The Journal of Neuroscience. 2009;29:7359. doi: 10.1523/JNEUROSCI.0793-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Skoe E, Chandrasekaran B, Zecker S, Kraus N. Brainstem correlates of speech-in-noise perception in children. Hearing Research. 2010;270:151–157. doi: 10.1016/j.heares.2010.08.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Assmann PF, Summerfield Q. Perceptual segregation of concurrent vowels. Journal of the Acoustical Society of America. 1987;82:S120. [Google Scholar]
- Bajo VM, Nodal FR, Moore DR, King AJ. The descending corticocollicular pathway mediates learning-induced auditory plasticity. Nature Neuroscience. 2010;13:253–260. doi: 10.1038/nn.2466. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baldeweg T. Repetition effects to sounds: Evidence for predictive coding in the auditory system. Trends in Cognitive Sciences. 2006;10:93–94. doi: 10.1016/j.tics.2006.01.010. [DOI] [PubMed] [Google Scholar]
- Baumann O, Belin P. Perceptual scaling of voice identity: Common dimensions for different vowels and speakers. Psychological Research. 2010;74:110–120. doi: 10.1007/s00426-008-0185-z. [DOI] [PubMed] [Google Scholar]
- Bench J, Kowal Å, Bamford J. The BKB (Bamford–Kowal–Bench) sentence lists for partially-hearing children. British Journal of Audiology. 1979;13:108–112. doi: 10.3109/03005367909078884. [DOI] [PubMed] [Google Scholar]
- Bendixen A, Roeber U, Schröger E. Regularity extraction and application in dynamic auditory stimulus sequences. Journal of Cognitive Neuroscience. 2007;19:1664–1677. doi: 10.1162/jocn.2007.19.10.1664. [DOI] [PubMed] [Google Scholar]
- Bendixen A, Schroger E, Winkler I. I heard that coming: Event-related potential evidence for stimulus-driven prediction in the auditory system. Journal of Neuroscience. 2009;29:8447. doi: 10.1523/JNEUROSCI.1493-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Besson M, Faita F. An Event-Related Potential (ERP) study of musical expectancy: Comparison of musicians with nonmusicians. Journal of Experimental Psychology: Human Perception and Performance. 1995;21:1278–1296. [Google Scholar]
- Besson M, Faita F, Requin J. Brain waves associated with musical incongruities differ for musicians and non-musicians. Neuroscience Letters. 1994;168:101–105. doi: 10.1016/0304-3940(94)90426-x. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Gandour JT, Krishnan A. Cross-domain effects of music and language experience on the representation of pitch in the human auditory brainstem. Journal of Cognitive Neuroscience. 2011;23:425–434. doi: 10.1162/jocn.2009.21362. [DOI] [PubMed] [Google Scholar]
- Bird J, Darwin CJ. Effects of a difference in fundamental frequency in separating two sentences. In: Almer AR, Rees A, Summerfield AQ, Meddis R, editors. Psychophysical and physiological advances in hearing. Whurr; London: 1998. pp. 263–269. [Google Scholar]
- Brattico E, Näätänen R, Tervaniemi M. Context effects on pitch perception in musicians and nonmusicians: Evidence from event-related-potential recordings. Music Perception. 2001;19:199–222. [Google Scholar]
- Brokx JP, Nooteboom S. Intonation and the perceptual separation of simultaneous voices. Journal of Phonetics. 1982;10:23–26. [Google Scholar]
- Brown L, Sherbenou R, Johnsen S. Test of nonverbal intelligence: TONI. Pro-ed; 1982. [Google Scholar]
- Chandrasekaran B, Hornickel J, Skoe E, Nicol T, Kraus N. Context-dependent encoding in the human auditory brainstem relates to hearing speech in noise: Implications for developmental dyslexia. Neuron. 2009;64:311–319. doi: 10.1016/j.neuron.2009.10.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chandrasekaran B, Kraus N. The scalp-recorded brainstem response to speech: Neural origins. Psychophysiology. 2010;47:236–246. doi: 10.1111/j.1469-8986.2009.00928.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clarke F, Becker R. Comparison of techniques for discriminating among talkers. Journal of Speech and Hearing Research. 1969;12:747–761. doi: 10.1044/jshr.1204.747. [DOI] [PubMed] [Google Scholar]
- Culling JF, Darwin CJ. Perceptual separation of simultaneous vowels: Within and across-formant grouping by F0. Journal of the Acoustical Society of America. 1993;93:3454–3467. doi: 10.1121/1.405675. [DOI] [PubMed] [Google Scholar]
- Darwin CJ. Pitch and auditory grouping. In: Plack CJ, Oxenham AJ, Fay RR, Popper AN, editors. Pitch: Neural coding and perception. Springer Handbook of Auditory Research; 2005. [Google Scholar]
- Dean I, Harper NS, McAlpine D. Neural population coding of sound level adapts to stimulus statistics. Nature Neuroscience. 2005;8:1684–1689. doi: 10.1038/nn1541. [DOI] [PubMed] [Google Scholar]
- Dean I, Robinson BL, Harper NS, McAlpine D. Rapid neural adaptation to sound level statistics. Journal of Neuroscience. 2008;28:6430–6438. doi: 10.1523/JNEUROSCI.0470-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Drake C, Jones M, Baruch C. The development of rhythmic attending in auditory sequences: Attunement, referent period, focal attending. Cognition. 2000;77:251–288. doi: 10.1016/s0010-0277(00)00106-2. [DOI] [PubMed] [Google Scholar]
- Drullman R, Bronkhorst A. Speech perception and talker segregation: Effects of level, pitch, and tactile support with multiple simultaneous talkers. The Journal of the Acoustical Society of America. 2004;116:3090–3098. doi: 10.1121/1.1802535. [DOI] [PubMed] [Google Scholar]
- Engel A, Fries P, Singer W. Dynamic predictions: Oscillations and synchrony in top-down processing. Nature Reviews Neuroscience. 2001;2:704–716. doi: 10.1038/35094565. [DOI] [PubMed] [Google Scholar]
- Evans J, Saffran J, Robe-Torres K. Statistical learning in children with specific language impairment. Journal of Speech, Language, and Hearing Research. 2009;52:321. doi: 10.1044/1092-4388(2009/07-0189). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston K. A theory of cortical responses. Philosophical Transactions of the Royal Society London B: Biological Sciences. 2005;360:815–836. doi: 10.1098/rstb.2005.1622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fritz JB, Elhilali M, Shamma SA. Differential dynamic plasticity of A1 receptive fields during multiple spectral tasks. Journal of Neuroscience. 2005;25:7623–7635. doi: 10.1523/JNEUROSCI.1318-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fujioka T, Trainor L, Ross B, Kakigi R, Pantev C. Musical training enhances automatic encoding of melodic contour and interval structure. Journal of Cognitive Neuroscience. 2004;16:1010–1021. doi: 10.1162/0898929041502706. [DOI] [PubMed] [Google Scholar]
- Fujioka T, Trainor L, Ross B, Kakigi R, Pantev C. Automatic encoding of polyphonic melodies in musicians and nonmusicians. Journal of Cognitive Neuroscience. 2005;17:1578–1592. doi: 10.1162/089892905774597263. [DOI] [PubMed] [Google Scholar]
- Galbraith G, Arbagey P, Branski R, Comerci N, Rector P. Intelligible speech encoded in the human brain stem frequency-following response. Neuroreport. 1995;6:2363–2367. doi: 10.1097/00001756-199511270-00021. [DOI] [PubMed] [Google Scholar]
- Gao E, Suga N. Experience-dependent corticofugal adjustment of midbrain frequency map in bat auditory system. Proceedings of the National Academy of Sciences of the United States of America. 1998;95:12663–12670. doi: 10.1073/pnas.95.21.12663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gaser C, Schlaug G. Brain structures differ between musicians and non-musicians. Journal of Neuroscience. 2003;23:9240–9245. doi: 10.1523/JNEUROSCI.23-27-09240.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gorga M, Abbas P, Worthington D. Stimulus calibration in ABR measurements. College-Hill Press; San Diego, CA: 1985. [Google Scholar]
- Grill-Spector K, Henson R, Martin A. Repetition and the brain: Neural models of stimulus-specific effects. Trends in Cognitive Sciences. 2006;10:14–23. doi: 10.1016/j.tics.2005.11.006. [DOI] [PubMed] [Google Scholar]
- Haenschel C, Vernon DJ, Dwivedi P, Gruzelier JH, Baldeweg T. Event-related brain potential correlates of human auditory sensory memory-trace formation. Journal of Neuroscience. 2005;25:10494–10501. doi: 10.1523/JNEUROSCI.1227-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hannon EE, Snyder JS, Eerola T, Krumhansl CL. The role of melodic and temporal cues in perceiving musical meter. Journal of Experimental Psychology: Human Perception and Performance. 2004;30:956–974. doi: 10.1037/0096-1523.30.5.956. [DOI] [PubMed] [Google Scholar]
- Hutchinson S, Lee LH, Gaab N, Schlaug G. Cerebellar volume of musicians. Cerebral Cortex. 2003;13:943–949. doi: 10.1093/cercor/13.9.943. [DOI] [PubMed] [Google Scholar]
- Jentschke S, Koelsch S. Musical training modulates the development of syntax processing in children. NeuroImage. 2009;47:735–744. doi: 10.1016/j.neuroimage.2009.04.090. [DOI] [PubMed] [Google Scholar]
- Koelsch S, Jentschke S, Sammler D, Mietchen D. Untangling syntactic and sensory processing: An ERP study of music perception. Psychophysiology. 2007;44:476–490. doi: 10.1111/j.1469-8986.2007.00517.x. [DOI] [PubMed] [Google Scholar]
- Kraus N, Chandrasekaran B. Music training for the development of auditory skills. Nature Reviews Neuroscience. 2010;11:599–605. doi: 10.1038/nrn2882. [DOI] [PubMed] [Google Scholar]
- Kreiman J, Gerratt B, Precoda K, Berke G. Individual differences in voice quality perception. Journal of Speech and Hearing Research. 1992;35:512. doi: 10.1044/jshr.3503.512. [DOI] [PubMed] [Google Scholar]
- Krishnan A, Gandour J. The role of the auditory brainstem in processing linguistically-relevant pitch patterns. Brain and Language. 2009;110:135–148. doi: 10.1016/j.bandl.2009.03.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnan A, Xu Y, Gandour J, Cariani P. Encoding of pitch in the human brainstem is sensitive to language experience. Cognitive Brain Research. 2005;25:161–168. doi: 10.1016/j.cogbrainres.2005.05.004. [DOI] [PubMed] [Google Scholar]
- Krumhansl CL. Perceiving tonal structure in music. American Scientist. 1985;73:371–378. [Google Scholar]
- Krumhansl CL. Cognitive foundations of musical pitch. Oxford University Press; New York: 1990. [Google Scholar]
- Kujala T, Myllyviita K, Tervaniemi M, Alho K, Kallio J, Näätänen R. Basic auditory dysfunction in dyslexia as demonstrated by brain activity measurements. Psychophysiology. 2000;37:262–266. [PubMed] [Google Scholar]
- Kujala T, Naatanen R. The mismatch negativity in evaluating central auditory dysfunction in dyslexia. Neuroscience & Biobehavioral Reviews. 2001;25:535–543. doi: 10.1016/s0149-7634(01)00032-x. [DOI] [PubMed] [Google Scholar]
- Large EW, Jones MR. The dynamics of attending: How people track time-varying events. Psychological Review. 1999;106:119–159. [Google Scholar]
- Lee KM, Skoe E, Kraus N, Ashley R. Selective subcortical enhancement of musical intervals in musicians. Journal of Neuroscience. 2009;29:5832–5840. doi: 10.1523/JNEUROSCI.6133-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loveless N, Hari R, Hämäläinen M, Tiihonen J. Evoked responses of human auditory cortex may be enhanced by preceding stimuli. Electroencephalography and Clinical Neurophysiology/Evoked Potentials Section. 1989;74:217–227. doi: 10.1016/0013-4694(89)90008-4. [DOI] [PubMed] [Google Scholar]
- Loveless N, Levänen S, Jousmäki V, Sams M, Hari R. Temporal integration in auditory sensory memory: Neuromagnetic evidence. Electroencephalography and Clinical Neurophysiology/Evoked Potentials Section. 1996;100:220–228. doi: 10.1016/0168-5597(95)00271-5. [DOI] [PubMed] [Google Scholar]
- Luo F, Wang Q, Kashani A, Yan J. Corticofugal modulation of initial sound processing in the brain. Journal of Neuroscience. 2008;28:11615–11621. doi: 10.1523/JNEUROSCI.3972-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Magne C, Schön D, Besson M. Musician children detect pitch violations in both music and language better than nonmusician children: Behavioral and electrophysiological approaches. Journal of Cognitive Neuroscience. 2006;18:199–211. doi: 10.1162/089892906775783660. [DOI] [PubMed] [Google Scholar]
- Malmierca MS, Cristaudo S, Perez-Gonzalez D, Covey E. Stimulus-specific adaptation in the inferior colliculus of the anesthetized rat. Journal of Neuroscience. 2009;29:5483–5493. doi: 10.1523/JNEUROSCI.4153-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Margulis E, Mlsna LM, Uppunda AK, Parrish TB, Wong PCM. Selective neurophysiologic responses to music in instrumentalists with different listening biographies. Human Brain Mapping. 2009;30:267–275. doi: 10.1002/hbm.20503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moreno S, Marques C, Santos A, Santos M, Castro SL, Besson M. Musical training influences linguistic abilities in 8-year-old children: More evidence for brain plasticity. Cerebral Cortex. 2009;19:712–723. doi: 10.1093/cercor/bhn120. [DOI] [PubMed] [Google Scholar]
- Muller JR, Metha AB, Krauskopf J, Lennie P. Rapid adaptation in visual cortex to the structure of images. Science. 1999;285:1405–1408. doi: 10.1126/science.285.5432.1405. [DOI] [PubMed] [Google Scholar]
- Musacchia G, Sams M, Skoe E, Kraus N. Musicians have enhanced subcortical auditory and audiovisual processing of speech and music. Proceedings of the National Academy of Sciences of the United States of America. 2007;104:15894–15898. doi: 10.1073/pnas.0701498104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Näätänen R, Gaillard AWK, Mäntysalo S. Early selective-attention effect on evoked potential reinterpreted. Acta Psychologica. 1978;42:313–329. doi: 10.1016/0001-6918(78)90006-9. [DOI] [PubMed] [Google Scholar]
- Näätänen R, Winkler I. The concept of auditory stimulus representation in cognitive neuroscience. Psychological Bulletin. 1999;125:826–859. doi: 10.1037/0033-2909.125.6.826. [DOI] [PubMed] [Google Scholar]
- Nikjeh D, Lister J, Frisch S. Preattentive cortical-evoked responses to pure tones, harmonic tones, and speech: Influence of music training. Ear and Hearing. 2009;30:432. doi: 10.1097/AUD.0b013e3181a61bf2. [DOI] [PubMed] [Google Scholar]
- Nilsson M, Soli S, Sullivan J. Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. Journal of the Acoustical Society of America. 1994;95:1085–1099. doi: 10.1121/1.408469. [DOI] [PubMed] [Google Scholar]
- Oxenham A. Pitch perception and auditory stream segregation: Implications for hearing loss and cochlear implants. Trends in Amplification. 2008;12:316–331. doi: 10.1177/1084713808325881. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pantev C, Roberts LE, Schulz M, Engelien A, Ross B. Timbre-specific enhancement of auditory cortical representations in musicians. Neuroreport. 2001;12:169–174. doi: 10.1097/00001756-200101220-00041. [DOI] [PubMed] [Google Scholar]
- Parbery-Clark A, Skoe E, Kraus N. Musical experience limits the degradative effects of background noise on the neural processing of sound. Journal of Neuroscience. 2009;29:14100. doi: 10.1523/JNEUROSCI.3256-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parbery-Clark A, Skoe E, Lam C, Kraus N. Musician enhancement for speech-in-noise. Ear and Hearing. 2009;30:653. doi: 10.1097/AUD.0b013e3181b412e9. [DOI] [PubMed] [Google Scholar]
- Parbery-Clark A, Strait DL, Anderson S, Hittner E, Kraus N. Musical experience and the aging auditory system: Implications for cognitive abilities and hearing speech in noise. PLoS ONE. 2011;6:e18082. doi: 10.1371/journal.pone.0018082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perez-Gonzalez D, Malmierca MS, Covey E. Novelty detector neurons in the mammalian auditory midbrain. European Journal of Neuroscience. 2005;22:2879–2885. doi: 10.1111/j.1460-9568.2005.04472.x. [DOI] [PubMed] [Google Scholar]
- Pressnitzer D, Sayles M, Micheyl C, Winter IM. Perceptual organization of sound begins in the auditory periphery. Current Biology. 2008;18:1124–1128. doi: 10.1016/j.cub.2008.06.053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Russo N, Nicol T, Zecker S, Hayes E, Kraus N. Auditory training improves neural timing in the human brainstem. Behavioural Brain Research. 2005;156:95–103. doi: 10.1016/j.bbr.2004.05.012. [DOI] [PubMed] [Google Scholar]
- Schon D, Magne C, Besson M. The music of speech: Music training facilitates pitch processing in both music and language. Psychophysiology. 2004;41:341–349. doi: 10.1111/1469-8986.00172.x. [DOI] [PubMed] [Google Scholar]
- Schulte-Korne G, Deimel W, Bartling J, Remschmidt H. Pre-attentive processing of auditory patterns in dyslexic human subjects. Neuroscience Letters. 1999;276:41–44. doi: 10.1016/s0304-3940(99)00785-5. [DOI] [PubMed] [Google Scholar]
- Shinn-Cunningham B, Best V. Selective attention in normal and impaired hearing. Trends in Amplification. 2008;12:283–299. doi: 10.1177/1084713808325306. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Skoe E, Kraus N. Auditory brain stem response to complex sounds: A tutorial. Ear and Hearing. 2010a;31:302–324. doi: 10.1097/AUD.0b013e3181cdb272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Skoe E, Kraus N. Hearing it again and again: On-line subcortical plasticity in humans. PLoS ONE. 2010b;5:e13645. doi: 10.1371/journal.pone.0013645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song J, Skoe E, Banai K, Kraus N. Perception of speech in noise: Neural correlates. Journal of Cognitive Neuroscience. 2010 doi: 10.1162/jocn.2010.21556. doi:10.1162/jocn.2010.21556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song JH, Skoe E, Wong PC, Kraus N. Plasticity in the adult human auditory brainstem following short-term linguistic training. Journal of Cognitive Neuroscience. 2008;20:1892–1902. doi: 10.1162/jocn.2008.20131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait DL, Kraus N. Can you hear me now? Musical training shapes functional brain networks for selective auditory attention and hearing speech in noise. Frontiers in Psychology. 2011;2:1–10. doi: 10.3389/fpsyg.2011.00113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait DL, Chan K, Ashley R, Kraus N. Specialization among the specialized: Auditory brainstem function is tuned in to timbre. Cortex. doi: 10.1016/j.cortex.2011.03.015. (in press) doi:10.1016/j.cortex.2011.03.015. [DOI] [PubMed] [Google Scholar]
- Strait DL, Hornickel J, Kraus N. Subcortical processing of speech regularities predicts reading and music aptitude in children. Behavioral and Brain Functions. doi: 10.1186/1744-9081-7-44. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait DL, Kraus N, Parbery-Clark A, Ashley R. Musical experience shapes top-down auditory mechanisms: Evidence from masking and auditory attention performance. Hearing Research. 2010;261:22–29. doi: 10.1016/j.heares.2009.12.021. [DOI] [PubMed] [Google Scholar]
- Strait DL, Kraus N, Skoe E, Ashley R. Musical experience and neural efficiency: Effects of training on subcortical processing of vocal expressions of emotion. European Journal of Neuroscience. 2009;29:661–668. doi: 10.1111/j.1460-9568.2009.06617.x. [DOI] [PubMed] [Google Scholar]
- Suga N, Ma X. Multiparametric corticofugal modulation and plasticity in the auditory system. Nature Reviews Neuroscience. 2003;4:783–794. doi: 10.1038/nrn1222. [DOI] [PubMed] [Google Scholar]
- Tervaniemi M, Ilvonen T, Karma K, Alho K, Näätänen R. The musical brain: Brain waves reveal the neurophysiological basis of musicality in human subjects. Neuroscience Letters. 1997;226:1–4. doi: 10.1016/s0304-3940(97)00217-6. [DOI] [PubMed] [Google Scholar]
- Tervaniemi M, Kruck S, De Baene W, Schroger E, Alter K, Friederici AD. Top-down modulation of auditory processing: Effects of sound context, musical expertise and attentional focus. European Journal of Neuroscience. 2009;30:1636–1642. doi: 10.1111/j.1460-9568.2009.06955.x. [DOI] [PubMed] [Google Scholar]
- Tzounopoulos T, Kraus N. Learning to encode timing: Mechanisms of plasticity in the auditory brainstem. Neuron. 2009;62:463–469. doi: 10.1016/j.neuron.2009.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ulanovsky N, Las L, Nelken I. Processing of low-probability sounds by cortical neurons. Nature Neuroscience. 2003;6:391–398. doi: 10.1038/nn1032. [DOI] [PubMed] [Google Scholar]
- van Zuijen T, Sussman E, Winkler I, Näätänen R, Tervaniemi M. Grouping of sequential sounds-an event-related potential study comparing musicians and nonmusicians. Journal of Cognitive Neuroscience. 2004;16:331–338. doi: 10.1162/089892904322984607. [DOI] [PubMed] [Google Scholar]
- van Zuijen T, Sussman E, Winkler I, Näätänen R, Tervaniemi M. Auditory organization of sound sequences by a temporal or numerical regularity – A mismatch negativity study comparing musicians and non-musicians. Cognitive Brain Research. 2005;23:270–276. doi: 10.1016/j.cogbrainres.2004.10.007. [DOI] [PubMed] [Google Scholar]
- Wang AL, Mouraux A, Liang M, Iannetti GD. The enhancement of the N1 wave elicited by sensory stimuli presented at very short inter-stimulus intervals is a general feature across sensory systems. PLoS ONE. 2008;3:e3929. doi: 10.1371/journal.pone.0003929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webster MA, Kaping D, Mizokami Y, Duhamel P. Adaptation to natural facial categories. Nature. 2004;428:557–561. doi: 10.1038/nature02420. [DOI] [PubMed] [Google Scholar]
- Wen B, Wang GI, Dean I, Delgutte B. Dynamic range adaptation to sound level statistics in the auditory nerve. Journal of Neuroscience. 2009;29:13797–13808. doi: 10.1523/JNEUROSCI.5610-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winkler I, Denham SL, Nelken I. Modeling the auditory scene: Predictive regularity representations and perceptual objects. Trends in Cognitive Sciences. 2009;13:532–540. doi: 10.1016/j.tics.2009.09.003. [DOI] [PubMed] [Google Scholar]
- Winkler I, Karmos G, Näätänen R. Adaptive modeling of the unattended acoustic environment reflected in the mismatch negativity event-related potential. Brain Research. 1996;742:239–252. doi: 10.1016/s0006-8993(96)01008-6. [DOI] [PubMed] [Google Scholar]
- Wong PC, Skoe E, Russo NM, Dees T, Kraus N. Musical experience shapes human brainstem encoding of linguistic pitch patterns. Nature Neuroscience. 2007;10:420–422. doi: 10.1038/nn1872. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yan W, Suga N. Corticofugal modulation of the midbrain frequency map in the bat auditory system. Nature Neuroscience. 1998;1:54–58. doi: 10.1038/255. [DOI] [PubMed] [Google Scholar]