

Abstract
The transition between B- and A-DNA was first observed nearly 50 years ago. We have now mapped this transformation through a set of single-crystal structures of the sequence d(GGCGCC)2, with various intermediates being trapped by methylating or brominating the cytosine bases. The resulting pathway progresses through 13 conformational steps, with a composite structure that pairs A-nucleotides with complementary B-nucleotides serving as a distinct transition intermediate. The details of each step in the conversion of B- to A-DNA are thus revealed at the atomic level, placing intermediates for this and other sequences in the context of a common pathway.
The transformation from B-DNA in fibers (1) to dehydrated A-DNA (2) was one of the first reversible structural transitions observed in a biomolecule. Although B-DNA is recognized as the standard form of the double helix, the junction between B- and A-DNA appears as a target for the anticancer drug cisplatin (3), and an A-conformation with exaggerated base-pair inclinations is induced by TATA-binding protein, the transcriptional promoter in eukaryotes (4, 5). Consequently, an understanding of how B-DNA converts to A-DNA (the B-A transition) is significant both for its history and for understanding how DNA structure affects cellular function. In the current study, methylated and brominated variants of the sequence d(GGCGCC)2 were crystallized as standard A-DNA and several intermediate conformations, the most important being a composite structure in which each strand is half A-DNA and half B-DNA, with the A-nucleotides paired with complementary B-nucleotides across the duplex. Thus, along with structures from previous work (6), we have assembled 13 single-crystal structures that define a pathway for the B-A transition in this single sequence.
In a B-A transition, the long and narrow B-duplex—with its 10- to 10.5-bp repeat, 3.4-Å rise, and base pairs stacked at the center of the helix—is converted to the underwound and compact A-DNA structure, characterized by an 11-bp repeat, a 2.6-Å rise, and base pairs that are inclined up to 20° and displaced by ≈4 Å so they essentially wrap around the helix axis (7). The geometries of the deoxyribose sugars are also converted from C2′-endo in B-DNA (with the C2′-carbon puckered above the furanose plane toward the nucleobase) to C3′-endo in A-DNA. Molecular mechanics simulations suggest that many of these structural features are transformed in a concerted manner (8–10), leading to the question of whether a discrete intermediate exists in the B-A transition.
There is a growing number of DNA crystal structures that exhibit properties of both A- and B-DNA. These include d(CCCCGGGG)2, an A-DNA with a relatively extended rise of 3.1 Å (11), and d(CGCCCGCGGGCG)2, a kinked A-DNA structure with B-type helices at the ends (12). More recently, the central six base pairs of d(CATGGGCCCATG)2 were defined as an A/B-intermediate conformation in which the base pairs are displaced but not highly inclined relative to the helix axis (13). Our own studies have shown that methylating or brominating cytosines in d(GGCGCC)2 induce a unique extended conformation that is neither B- nor A-DNA (6). The sequence d(GGCGCC)2 crystallized as standard B-DNA, whereas the structures of d(GGCGm5CC)2 and d(GGCGBr5CC)2 (m5C and Br5C are 5-methylcytosine and 5-bromocytosine, respectively) have longer rises than B-DNA and are broader, with a larger slide between base pairs, than A-DNA. All of these conformations, however, have C3′-endo sugars and therefore are generally considered to be allomorphic forms of A-DNA rather than true transition intermediates. We present here a set of single-crystal structures that represent the missing conformational links required to define a common B-A transition pathway for a single DNA sequence.
Methods
All deoxyoligonucleotides were synthesized by using phosphoramidite chemistry on an Applied Biosystems DNA synthesizer in the Center for Gene Research and Biotechnology at Oregon State University. The oligonucleotides were filtered through a Sephadex G-25 (Sigma–Aldrich) column, lyophilized, redissolved in 15 mM sodium cacodylate buffer (pH 7.0), and used for crystallization without further purification. Crystals were grown at room temperature by vapor diffusion in sitting drop setups with initial solutions containing 0.7 mM DNA, 25 mM sodium cacodylate buffer (pH 6), 0.8 mM MgCl2, and 0.1–1.2 mM spermine tetrahydrochloride, and were equilibrated against a reservoir of 15% (vol/vol) 2-methyl-2,4-pentanediol. The crystal of d(GGCGCC)2 was grown, as above, with the addition of 2 mM Co(NH3)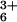 . These conditions are similar to those of previous studies (6).
. These conditions are similar to those of previous studies (6).
X-ray diffraction data for the Co3+ form of d(GGCGCC)2, d(GGm5CGm5CC)2, d(GGm5CGCC)2, and d(GGBr5CGBr5CC)2 were collected at room temperature by using CuKα radiation from a RUH3R generator and R-AXIS IV image plate detector (Rigaku, Tokyo). Multiwavelength x-ray diffraction data for d(GGBr5CGCC)2 were collected on beamline 5.0.2 at the Advanced Light Source in Berkeley, CA, at liquid nitrogen temperature by using an ADSC Quantum IV detector (San Diego). Three wavelengths corresponding to the peak of bromine absorption (0.92052Å), the inflection (0.92065Å), and a remote (0.90836Å) were used in cns (14) to determine the phases for d(GGBr5CGCC)2. Diffraction data collected at the peak wavelength were used in SHELXL-97 (15) for refinement.
The crystals of d(GGm5CGCC)2 and d(GGm5CGm5CC)2 were isomorphous with those of d(GGBr5CGCC)2; consequently, their structures were solved by molecular replacement by using the four unique duplexes of the d(GGBr5CGCC)2 structure as the starting model. The bromine atoms were removed and methyl groups added to the appropriate cytosines. The initial values of Rcryst and Rfree were 42.6 and 41.6%, respectively, for d(GGm5CGCC)2, and 51.2 and 51.0% for d(GGm5CGm5CC)2. The structures were then refined in cns (14) by using the maximum likelihood target while maintaining the same crossvalidation set as d(GGBr5CGCC)2, yielding the final refinement statistics in Table 1. The structure of d(GGBr5CGBr5CC)2 was solved by molecular replacement by using the previously solved extended structure of d(GGCGBr5CC)2 (6) and refined by using the same technique. The structure of the Co3+-form of d(GGCGCC)2 was rerefined with higher-resolution data by using the previously solved and refined structure (6). All datasets were reduced by using the programs denzo and scalepack from the hkl package (18) and structures, with the exception of d(GGBr5CGCC)2, were refined with cns (14) incorporating nucleic acid specific parameters (19).
Table 1.
Data collection and refinement statistics
| Sequence: | GGBr5CGCC | GGm5CGCC | GGm5CGm5CC | GGBr5CGBr5CC | GGCGCC + Co3+ |
|---|---|---|---|---|---|
| Structure(s): | f, i, j, l | e, i, k, m | a | ||
| Data collection | |||||
| Space Group | P3221 | P3221 | P3221 | P43212 | P4122 |
| Unit Cell Dimensions | a = b = 41.1 Å, | a = b = 41.9 Å, | a = b = 42.3 Å, | a = b = 60.7 Å, | a = b = 42.6 Å, |
| c = 175.1 Å, γ = 120° | c = 176.7 Å, γ = 120° | c = 179.4 Å, γ = 120° | c = 24.6 Å | c = 63.5 Å | |
| Resolution, Å | 20.0 − 1.45 | 20.0 − 1.9 | 20.0 − 2.4 | 20.0 − 2.8 | 20.0 − 2.0 |
| Total reflections (unique) | 628,716 (58,430) including Bijvoets | 107,358 (14,930) | 49,399 (7,269) | 10,777 (1,215) | 18,846 (4,207) |
| Completeness (%)* | 99.9 (99.6) | 99.0 (96.5) | 91.7 (61.5) | 95.2 (99.1) | 97.5 (95.0) |
| Rmeas (%)*† | 11.0 (66.8) | 4.5 (47.5) | 6.3 (40.0) | 8.1 (54.4) | 6.9 (51.8) |
| Refinement | |||||
| Rcryst (Rfree) (%)‡ | 13.8 (18.7) | 18.5 (20.4) | 17.3 (20.0) | 21.1 (25.7) | 22.8 (24.5) |
| DNA (solvent) atoms | 968 (234) | 968 (115) | 976 (75) | 244 (2) | 240 (37) |
| rms deviation bond lengths, Å | 0.015 | 0.003 | 0.003 | 0.005 | 0.003 |
| rms deviation bond angles, ° | 2.29 | 0.81 | 0.82 | 0.95 | 1.01 |
Values in parentheses refer to the highest-resolution shell.
Rmeas = Σhkl √(n/n − 1)Σi|〈I〉hkl − Ihkl,i|/ΣhklΣi|Ihkl,i|, where Ihkl is the intensity of a reflection, 〈I〉hkl is the average of all observations of this reflection and its symmetry equivalents, and n is the multiplicity (16).
Rcryst = Σhkl|Fobs − kFcalc|/Σhkl|Fobs|. Rfree = Rcryst for 10% of the reflections that were not used in refinement (17).
Results
Single-Crystal Structures of d(GGBr5CGCC)2 and d(GGm5CGCC)2.
For the current study, we have grown crystals of the sequences d(GGm5CGm5CC)2, d(GGm5CGCC)2, and d(GGBr5CGCC)2, which are all isomorphous to each other but differ from all previous oligonucleotide sequences (Table 1). The crystal structures of these sequences were seen to include a conformation that is a composite of A- and B-DNA. The structure of d(GGBr5CGCC)2 was solved to 1.6-Å resolution by using multiwavelength anomalous diffraction phasing with bromine as the anomalous scatterer (20). The resulting experimental electron density maps allow unbiased interpretations of four independent DNA double helices in the asymmetric unit of the crystal, as well as the detailed conformational features of the individual nucleotides (Fig. 1A). This structure was subsequently used to determine the structures of d(GGm5CGm5CC)2 and d(GGm5CGCC)2 by molecular replacement (Table 1). The DNAs of these sequences are arranged with three duplexes forming a planar canopy in the a–b plane, whereas a fourth duplex extends perpendicularly from near the center of this planar assembly. One duplex in the plane is a classic A-DNA structure, characterized by C3′-endo sugar puckers, and highly inclined and displaced base pairs. The remaining two helices in the plane have C3′-endo sugars and base pairs that are displaced from but not highly inclined relative to the helix axis, similar to the A/B intermediate of d(CATGGGCCCATG)2 (13).
Figure 1.

Single-crystal structures of d(GGBr5CGCC)2 and d(GGm5CGCC)2. (A) Experimental electron density map derived from the 1.6-Å multiwavelength anomalous diffraction phased x-ray diffraction data of d(GGBr5CGCC)2. The electron density, after density modification, of one base pair is shown with the final refined model of this GC base pair included for reference [figure created with bobscript (21)]. (B) Comparison of the δ- and χ-torsion angles and the sugar conformations of the nucleotides in d(GGBr5CGCC)2 (open symbols) and d(GGm5CGCC)2 (closed symbols). Nucleotides with C2′-endo type sugars are indicated by circles, with the C3′-endo sugars by squares, and those with intermediate O4′-endo sugars by diamonds. Nucleotides in the two structures are numbered 1–6 for one strand and 7–12 for the complementary strand (both in the 5′ to 3′ directions). The values of δ and χ for previous single-crystal structures [comprising high resolution—better than 2 Å—crystal structures deposited in the Nucleic Acid Database (22)] of B-DNA are defined by the hashed oval, and those of A-DNA are defined by the open oval [adapted from Lu et al. (23)].
The fourth duplex that bridges these planes of A-like structures is a composite double-helical conformation. The three nucleotides at the 5′-end of each strand have A-type C3′-endo sugars (Fig. 1B), whereas the last three nucleotides have C2′-endo and C1′-exo sugars, which fall within the B-type C2′-endo family, and an O4′-endo sugar, which is the lowest-energy intermediate between the C2′- and C3′-endo conformations. In addition, the δ and χ dihedral angles show the three nucleotides at the 5′-end of each strand to be A-DNA and those of the three 3′-nucleotides to be B-DNA. Thus, the A-type nucleotides at the 5′-end of each strand are paired with B-type nucleotides at the 3′-end of the complementary strand. This mixture of A- and B-DNA base pairing is similar to the A-RNA/B-DNA chimera seen by fiber diffraction (24), but differs from the A-RNA structures of DNA/RNA hybrids (25, 26). The composite conformation seen here is analogous to the junction between B- and A-DNA first proposed by Arnott and colleagues (27), and to the intermediate for the B-A transition in poly(dG)⋅poly(dC) suggested from Raman spectroscopy (28).
We have also shown that the sequence d(GGBr5CGBr5CC)2 is nearly identical to the previously solved structures of d(GGCGm5CC)2 and d(GGCGBr5CC)2, both of which had extended helical rises compared with both A- and B-DNAs (6). Finally, we have resolved the B-DNA structure of d(GGCGCC)2 in its cobalt form to a higher (2.0-Å) resolution than reported (6).
The B-A Transition Pathway.
The structures of d(GGm5CGCC)2 and d(GGBr5CGCC)2, along with the previous B-conformations of d(GGCGCC)2 and extended conformations of d(GGCGm5CC)2 and d(GGCGBr5CC)2, form a set of 13 unique structures (designated a to m, Table 2) that define a common transition pathway (Fig. 2). The structures were sorted according to their increasingly negative x-displacement, starting with the structure that most closely resembles fiber B-DNA (a), and ending with the structure that most closely resembles fiber A-DNA (m) (Fig. 3). This yields a continuous and monotonic transformation of duplexes with progressively deeper major grooves. Central to this transition pathway are the composite intermediates (e and f) that bridge the gap between the B- and A-type conformations. The structures arranged in this way also show a continuous progression of the conformations away from standard B-DNA. The rms deviation of the atoms for each conformation relative to standard B-DNA (a) systematically increases as the structures proceed from a to m. Sorting these structures according to other parameters, for example by increasing inclination of the base pairs, results in nonlogical pathways that intermix B- and A-DNAs throughout the transition.
Table 2.
Crystallized sequences and duplex conformations
| Sequence | Resolution, Å | Conformation | Structure | Rise/Patterson rise*, Å | Twist, ° |
|---|---|---|---|---|---|
| GGCGCC | Fiber B-DNA | B | 3.38 | 36.0 | |
| GGCGCC + Co3+ | 2.0 | B-DNA | a | 3.38 ± 0.08/3.5 | 35.0 ± 2.3 |
| GGCGCC + spermine4+ | 2.7 | B-DNA | b | 3.33 ± 0.28/3.4 | 33.9 ± 1.1 |
| c | 3.35 ± 0.28/3.5 | 35.9 ± 4.7 | |||
| d | 3.17 ± 0.47/3.5 | 33.6 ± 2.8 | |||
| GGm5CGCC | 1.9 | Composite | e | 3.36 ± 0.46/3.1 | 31.7 ± 4.9 |
| A/B | i | 2.93 ± 0.24 | 31.3 ± 2.5 | ||
| A/B | k | 3.06 ± 0.11 | 30.4 ± 2.2 | ||
| A-DNA | m | 2.68 ± 0.27 | 30.9 ± 3.7 | ||
| GGBr5CGCC | 1.4 | Composite | f | 3.07 ± 0.30/3.2 | 31.9 ± 3.4 |
| A/B | i | 2.78 ± 0.26 | 31.5 ± 3.0 | ||
| A/B | j | 3.02 ± 0.11 | 31.0 ± 0.9 | ||
| A-DNA | l | 2.63 ± 0.33 | 31.0 ± 2.9 | ||
| GGCGBr5CC | 2.25 | Extended | g | 3.57 ± 0.40/3.7 | 30.0 ± 4.7 |
| GGCGm5CC | 2.2 | Extended | h | 3.55 ± 0.35/3.7 | 28.4 ± 4.9 |
| GGCGCC | Fiber A-DNA | A | 2.56 | 32.7 |
The crystal structures of d(GGCGCC)2, d(GGCGm5CC)2, and d(GGCGBr5CC)2 have been described (6). We have resolved the Co3+ form of d(GGCGCC)2 here to higher resolution than before.
Figure 2.

The 13 unique conformations (a to m) seen in the single-crystal structures of d(GGCGCC)2, d(GGm5CGCC)2, d(GGBr5CGCC)2, d(GGCGm5CC)2, and d(GGCGBr5CC)2 arranged as described in the text and Table 2. Each structure is viewed down the helix axis (purple dot), and into the helix axis (purple line). Conformations a–d are B-type helices (green labels), e and f are composite helices (blue labels), g and h are extended intermediates (purple labels), i–m are A-DNA allomorphs, starting with A/B-intermediates (red labels) and progressing continuously to standard A-DNA (orange labels). The overall transition through each structure is shown in Movie 1, which is published as supplemental data on the PNAS web site, www.pnas.org.
Figure 3.

Helical parameters of the crystal structures of d(GGCGCC)2 and its methylated and brominated analogs. The x-displacement, inclination of the base pairs, pseudorotation phase angle, base-pair slide, and zP are plotted, from top to bottom, for the 13 unique helical conformations (a–m) arranged along a common transition pathway according to their x-displacement. Helical parameters were calculated with curves 5.2 (30), with the exception of zP, which was calculated by X3DNA (23). The average values for the parameters are shown for each structure, with the bars extending above and below the average reflecting the values for the individual base pairs or dinucleotide steps. Values for ideal B- and A-DNA in each plot are labeled B and A, respectively. Negative x-displacements reflect shifts of the base pairs away from the helix axis toward the minor groove; negative inclination angles arise from base pairs being tipped away from perpendicular of the helix axis and toward the 3′-end of each strand, and slide has the stacked base pairs displaced relative to each other along their long axes (30). Pseudorotation phase angles reflect the conformation of the deoxyribose sugars (labeled according to their respective endo-type families), with open circles representing the pseudorotation angle of the end nucleotides and closed circles the internal nucleotides of each strand. The parameter zP measures the displacement of the phosphates along each strand away from the midpoint between two stacked base pairs (31).
The pathway as we have defined it is consistent with a cooperative B-A transition according to the sugar puckers (as measured by the pseudorotation phase angle), the slide between base pairs, and the displacement of the phosphates reflected in the parameter zP (31) (zP, z-displacement of nucleotide phosphates) (Fig. 3). These three helical parameters, considered to be reliable discriminators between the B- and A-DNA forms (23), are highly correlated. All of the B-type duplexes (a to d) have C2′-endo type sugar puckers, small base-pair slides, and phosphates positioned equidistant between the stacked base pairs of each dinucleotide step (zP ≈ 0). The A-type structures (g to m) have C3′-endo sugars, large negative base-pair slides, and phosphates pushed toward the 3′-end of each dinucleotide (zP ≈ 2.5 Å). The composite conformations (e and f) are truly transition intermediates, mixing both C2′-endo and C3′-endo type sugars in the same duplex, and having intermediate slides. The intermediate values of zP reflect the phosphates being pushed toward the 3′-end for the A-type nucleotides, whereas the phosphates of the B-nucleotides remain at the midpoint between base pairs.
There is a simple relationship between displacement and inclination for the B-DNA structures (a to d): as the base pairs become displaced from the helix axis, they are more inclined. In the extreme case, the structure d is nearly halfway to A-DNA in terms of the displacement and inclination of its base pairs. A conformation with A-type base stacking but B-type sugars had been proposed as the intermediate for the B-A transition of d(CCCCGGGGG)2 in solution (32).
Displacement and inclination are also correlated in the A-type structures (g to m), but the trend is not simply an extension from the B-DNA structures. The first set of A-type structures (g and h) show no base-pair inclination. Indeed, the opposite trend is seen as the structures actually switch from B- to A-DNA (d to h), with the base pairs reset to the inclination of fiber B-DNA. From g to m, we see the DNA base pairs becoming more displaced, inclined, and compact in a near continuous manner, passing through a set of conformations that are similar to the A/B-intermediates of d(CATGGGCCCATG)2 (13).
All variants of this sequence were crystallized from nearly identical solutions, indicating that the conformations are associated with modifications to the cytosine bases and are not artifacts of crystallization. This provides the rationale for placing these structures along a common pathway. The coexistence of the composite and A/B-intermediates, and standard A-DNA within the crystals of d(GGm5CGCC)2 and d(GGBr5CGCC)2, indicates that these three forms are energetically related. The crystallization of both d(GGm5CGCC)2 and d(GGm5CGm5CC)2 as the composite intermediate and d(GGCGm5CC)2 as the extended intermediate shows that the two conformations depend only on methylation patterns; therefore, they are energetically similar and should be readily interconvertible. The extended conformation of d(GGCGm5CC)2 had previously been shown to be a kinetically trapped intermediate that leads ultimately to the formation of A-DNA (6). Finally, it is evident that d(GGCGCC)2 and its variants crystallize in conformations that assume several possible crystal lattices, and therefore the conformations are not defined explicitly by crystal packing.
Discussion
We describe here the stepwise transition between two distinct conformations of a macromolecule, in this case from B- to A-DNA. This B-A transition shows many of the features first proposed by Drew and Calladine for this mechanism (33). Sugar pucker and slide are highly correlated throughout the transition, whereas inclination is highly variable. Indeed, the base pairs can be highly inclined in B-type DNAs, but they must be reset back to their noninclined geometries before continuing through the transformation to A-DNA. This is generally consistent with the Drew and Calladine mechanism, in which slide precedes inclination. However, the intermediate structures seen here also show that the change in sugar pucker is associated with an extension and unwinding of the helix.
The transition mapped through structures a to m incorporates a set of distinct conformational intermediates. We were able to trap these intermediates because the d(GGCGCC)2 sequence is resistant to forming A-DNA. This sequence was predicted from A-DNA propensity energies (34) to favor B-DNA, whereas a permutation of the sequence—(GCCGGC)2—was predicted to be and was crystallized only as canonical A-DNA (35).
In this transition pathway, B-DNA is first transformed to the composite intermediates in which half of each strand in the duplex is A-DNA (Fig. 4A). The C3′-endo sugars are associated with a slide between base pairs and extension of the backbone of the A-type nucleotides at the 5′-end of each strand. The complementary B-type nucleotides, however, oppose these perturbations; consequently, the composite A-B base pairs have only intermediate values for slide and are buckled to accommodate the backbone extension.
Figure 4.

Stereoview of the individual steps of the B- to A-DNA transition at the central base pairs of the double helix. A–D show the view into the major groove of the three base pairs (G2-C11, C3-G10, and G4-C9) from each conformational class superimposed on base pairs from the next conformational class along the transition pathway. The atoms of G4-C9 (lower base pairs) serve as the common reference to superimpose the structures. The carbons and phosphorus atoms of the base pairs are colored to distinguish between the conformations. (A) The transformation of standard B-DNA structure (d, green) to the composite intermediate (e, blue) shows the effect of changing half the sugars from C2′-endo to C3′-endo. (B) The transformation from e to the extended intermediate (g, purple) involves the complete conversion of the sugar puckers, resulting in the increase in the rise, slide, and unwinding of base pairs. (C) The transition to an A/B intermediate (j, red) results in the reduction of the rise and slide, but with very little inclination of the base pairs. (D) The final conversion to canonical A-DNA (m, orange) shows the compression of the major groove resulting from the inclination of the base pairs. These details for the individual base pairs are shown in Movie 2, which is published as supplemental data on the PNAS web site, www.pnas.org.
In the next series of steps, the transformation goes through the extended intermediates (g and h). With all nucleotides now adopting C3′-endo sugar conformations, the slide and extension between base pairs are no longer opposed, and both reach their maximum values (Fig. 4B). Although g and h could be considered A-type conformations, they are extended [Patterson rise, which measures the intrinsic rise between base pairs = 3.7 Å (29); Table 2], underwound (helical repeat ≥12 bp/turn), and have exaggerated base-pair slides; therefore, they should be considered to be at the interface between the transition intermediates and true A-DNA structures. It is not unreasonable that the transition between conformational states of DNA goes through an intermediate that bears little resemblance to either the starting or ending states. From this point, the DNA duplex becomes more compact, with a shortened rise, and rewinds itself to an 11-bp/turn repeat (Fig. 4C). In the final stages, the transition to the canonical A-DNA structure is nearly continuous, passing through the A/B-type intermediates along the way (Fig. 4D).
The detailed pathway is explicitly defined here for the B-A transition induced by methylation or bromination, but the common occurrences of a B-type conformation with A-like features and of the A/B intermediates in the current study and in previous unrelated sequences (13, 32) suggest that this pathway may generally be applicable to B-A transitions in other systems. For example, the A-DNA region of the cisplatin-bound A-B junction is located at the 5′-end of the crosslinked DNA strand (3), suggesting that A-type features propagate backwards from the point where the B-DNA helix is perturbed. Comparing d(GGm5CGCC)2, which has A-type nucleotides at the 5′-end of each strand, with d(GGCGm5CC)2, which has entirely A-type nucleotides, suggests that the A-conformation is initiated at the point of methylation and is propagated back toward the 5′-end of the strands. Finally, the transition to the conformation induced by TATA-binding protein requires only that the pathway be extended to even more exaggerated base-pair inclinations [from ≈20° for standard A-DNA to ≈40° for the promoter induced structure (36)].
Supplementary Material
Acknowledgments
We thank P. A. Karplus and Z. A. Wood for a critical reading of this manuscript and Drs. X.-J. Lu and W. K. Olson at Rutgers University for discussion on the X3DNA analysis program. This work was supported by the National Science Foundation (MCB-0090615) and the National Institutes of Environmental Heath Sciences (ES00210). X-ray facilities were funded in part by the M. J. Murdock Charitable Trust and the Proteins and Nucleic Acids Research Core of the Environmental Health Sciences Center at Oregon State University.
Abbreviation
- zP
z-displacement of nucleotide phosphates
Footnotes
Data deposition: The atomic coordinates reported in this paper have been deposited in the Protein Data Bank, www.rcsb.org [PDB ID codes 1IH6 for d(GGBr5CGCC)2, 1IH2 for d(GGBr5CGBr5CC)2, 1IH3 for d(GGm5CGm5CC)2, 1IH4 for d(GGm5CGCC)2, and 1IH1 for the cobalt structure of d(GGCGCC)2 as B-DNA].
See commentary on page 6986.
References
- 1.Watson J D, Crick F H C. Nature (London) 1953;171:737–738. doi: 10.1038/171737a0. [DOI] [PubMed] [Google Scholar]
- 2.Franklin R E, Gosling R G. Nature (London) 1953;171:740–741. doi: 10.1038/171740a0. [DOI] [PubMed] [Google Scholar]
- 3.Takahara P M, Rosenzweig A C, Frederick C A, Lippard S J. Nature (London) 1995;377:649–652. doi: 10.1038/377649a0. [DOI] [PubMed] [Google Scholar]
- 4.Kim Y, Geiger J H, Hahn S, Sigler P B. Nature (London) 1993;365:512–520. doi: 10.1038/365512a0. [DOI] [PubMed] [Google Scholar]
- 5.Kim J L, Nikolov D B, Burley S K. Nature (London) 1993;365:520–527. doi: 10.1038/365520a0. [DOI] [PubMed] [Google Scholar]
- 6.Vargason J M, Eichman B F, Ho P S. Nat Struct Biol. 2000;7:758–761. doi: 10.1038/78985. [DOI] [PubMed] [Google Scholar]
- 7.Arnott S. In: Oxford Handbook of Nucleic Acid Structure. Neidle S, editor. New York: Oxford Univ. Press; 1999. pp. 1–38. [Google Scholar]
- 8.Cheatham T E, III, Kollman P A. J Mol Biol. 1996;259:434–444. doi: 10.1006/jmbi.1996.0330. [DOI] [PubMed] [Google Scholar]
- 9.Cheatham T E, III, Kollman P A. Structure (London) 1997;5:1297–1311. doi: 10.1016/s0969-2126(97)00282-7. [DOI] [PubMed] [Google Scholar]
- 10.Cheatham T E, III, Crowley M F, Fox T, Kollman P A. Proc Natl Acad Sci USA. 1997;94:9626–9630. doi: 10.1073/pnas.94.18.9626. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Wang A H-J, Fujii S, van Boom J H, Rich A. Proc Natl Acad Sci USA. 1982;79:3968–3972. doi: 10.1073/pnas.79.13.3968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Malinina L, Fernandez L G, Huynh-Dinh T, Subirana J A. J Mol Biol. 1999;285:1679–1690. doi: 10.1006/jmbi.1998.2424. [DOI] [PubMed] [Google Scholar]
- 13.Ng H-L, Kopka M L, Dickerson R E. Proc Natl Acad Sci USA. 2000;97:2035–2039. doi: 10.1073/pnas.040571197. . (First published February 25, 2000; 10.1073/pnas.040571197) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Brünger A T, Adams P D, Clore G M, DeLano W L, Gros P, Grosse-Kunstleve R W, Jiang J-S, Kuszewski J, Nilges M, Pannu N S, et al. Acta Crystallogr D. 1998;54:905–921. doi: 10.1107/s0907444998003254. [DOI] [PubMed] [Google Scholar]
- 15.Sheldrick G M, Schneider T R. Methods Enzymol. 1997;277:319–343. [PubMed] [Google Scholar]
- 16.Diederichs K, Karplus P A. Nat Struct Biol. 1997;4:269–275. doi: 10.1038/nsb0497-269. [DOI] [PubMed] [Google Scholar]
- 17.Brünger A T. Nature (London) 1992;355:472–475. doi: 10.1038/355472a0. [DOI] [PubMed] [Google Scholar]
- 18.Otwinowski Z, Minor W. Methods Enzymol. 1997;276:307–326. doi: 10.1016/S0076-6879(97)76066-X. [DOI] [PubMed] [Google Scholar]
- 19.Parkinson G, Vojtechovsky J, Clowney L, Brünger A T, Berman H M. Acta Crystallogr D. 1996;52:57–64. doi: 10.1107/S0907444995011115. [DOI] [PubMed] [Google Scholar]
- 20.Hendrickson W A, Ogata C M. Methods Enzymol. 1997;276:494–523. doi: 10.1016/S0076-6879(97)76074-9. [DOI] [PubMed] [Google Scholar]
- 21.Esnouf R M. Acta Crystallogr D. 1999;55:938–940. doi: 10.1107/s0907444998017363. [DOI] [PubMed] [Google Scholar]
- 22.Berman H M, Olson W K, Beveridge D L, Westbrook J, Gelbin A, Demeny T, Hsieh S-H, Srinivasan A R, Schneider B. Biophys J. 1992;63:751–759. doi: 10.1016/S0006-3495(92)81649-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Lu X-J, Shakked Z, Olson W K. J Mol Biol. 2000;300:819–840. doi: 10.1006/jmbi.2000.3690. [DOI] [PubMed] [Google Scholar]
- 24.Arnott S, Chandrasekaran R, Millane R P, Park H-S. J Mol Biol. 1986;188:631–640. doi: 10.1016/s0022-2836(86)80011-0. [DOI] [PubMed] [Google Scholar]
- 25.Horton N C, Finzel B C. J Mol Biol. 1996;264:521–533. doi: 10.1006/jmbi.1996.0658. [DOI] [PubMed] [Google Scholar]
- 26.Egli M, Usman N, Zhang S, Rich A. Proc Natl Acad Sci USA. 1992;89:534–538. doi: 10.1073/pnas.89.2.534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Selsing E, Wells R D, Alden C J, Arnott S. J Biol Chem. 1979;254:5417–5422. [PubMed] [Google Scholar]
- 28.Nishimura Y, Torigoe C, Tsuboi M. Nucleic Acids Res. 1986;14:2737–2748. doi: 10.1093/nar/14.6.2737. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Vargason J M, Ho P S. Nat Struct Biol. 2001;8:107–108. [Google Scholar]
- 30.Lavery R, Sklenar H. J Biomol Struct Dyn. 1989;6:655–667. doi: 10.1080/07391102.1989.10507728. [DOI] [PubMed] [Google Scholar]
- 31.El Hassan M A, Calladine C R. Philos Trans R Soc London A. 1997;355:43–100. [Google Scholar]
- 32.Trantírek L, Štefl R, Vorlíčková M, Koča J, Sklenář V, Kypr J. J Mol Biol. 2000;297:907–922. doi: 10.1006/jmbi.2000.3592. [DOI] [PubMed] [Google Scholar]
- 33.Calladine C R, Drew H R. J Mol Biol. 1984;178:773–782. doi: 10.1016/0022-2836(84)90251-1. [DOI] [PubMed] [Google Scholar]
- 34.Basham B, Schroth G P, Ho P S. Proc Natl Acad Sci USA. 1995;92:6464–6468. doi: 10.1073/pnas.92.14.6464. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Mooers B H M, Schroth G P, Baxter W W, Ho P S. J Mol Biol. 1995;249:772–784. doi: 10.1006/jmbi.1995.0336. [DOI] [PubMed] [Google Scholar]
- 36.Guzikevich-Guerstein G, Shakked Z. Nat Struct Biol. 1996;3:32–37. doi: 10.1038/nsb0196-32. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
{kind=link}
{kind=link}