

Abstract
Objectives. We assessed how frequently researchers reported the use of statistical techniques that take into account the complex sampling structure of survey data and sample weights in published peer-reviewed articles using data from 3 commonly used adolescent health surveys.
Methods. We performed a systematic review of 1003 published empirical research articles from 1995 to 2010 that used data from the National Longitudinal Study of Adolescent Health (n = 765), Monitoring the Future (n = 146), or Youth Risk Behavior Surveillance System (n = 92) indexed in ERIC, PsycINFO, PubMed, and Web of Science.
Results. Across the data sources, 60% of articles reported accounting for design effects and 61% reported using sample weights. However, the frequency and clarity of reporting varied across databases, publication year, author affiliation with the data, and journal.
Conclusions. Given the statistical bias that occurs when design effects of complex data are not incorporated or sample weights are omitted, this study calls for improvement in the dissemination of research findings based on complex sample data. Authors, editors, and reviewers need to work together to improve the transparency of published findings using complex sample data.
Secondary data analysis of nationally representative health surveys is commonly conducted by health science researchers and can be extremely useful when they are investigating risk and protective factors associated with health-related outcomes. By providing access to a vast array of variables on large numbers of individuals, large-scale health survey data are enticing to many researchers. Many researchers, however, lack the methodological skills needed for effective access to and use of such data. Traditional statistical methods and software analysis programs assume that data were generated through simple random sampling, with each individual having equal probability of being selected. With large, nationally representative health surveys, however, this is often not the case. Instead, from the perspective of statistical analysis, data from these complex sample surveys differ from those obtained via simple random sampling in 4 respects.
First, the probabilities of selection of the observations are not equal; oversampling of certain subgroups in the population is often employed in survey sample design to allow reasonable precision in the estimation of parameters. Second, multistage sampling results in clustered observations in which the variance among units within each cluster is less than the variance among units in general. Third, stratification in sampling ensures appropriate sample representation on the stratification variable(s), but yields negatively biased estimates of the population variance. Fourth, unit nonresponse and other poststratification adjustments are usually applied to the sample to allow unbiased estimates of population characteristics.1 If these aspects of complex survey data are ignored, standard errors and point estimates are biased, thereby potentially leading to incorrect inferences being made by the researcher.
SAMPLE WEIGHTS
Typically, observations from complex sample surveys are weighted such that an observation's weight is equal to the reciprocal of the probability of selection. That is, observations more likely to be selected (e.g., from oversampling) receive a smaller weight than do observations less likely to be selected. In data available from large-scale surveys, weights are provided such that the sum of the weights equals either the sample size (relative weights)
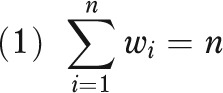 |
or the population size (raw weights)
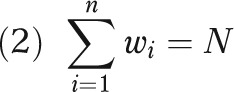 |
Sample weights are then applied in the computation of statistics from the sample observations. For example, the sample mean is computed as
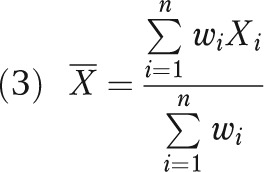 |
When researchers omit sample weights from the analysis of complex survey data, parameter estimates are biased and incorrect inferences can be drawn. Further, when sample weights are not used, findings are not representative of the larger population of interest. Instead, findings are only generalizable to the sample used.
ESTIMATION OF VARIANCES
The estimation of sampling error is a critical component of survey analysis. Sampling error provides an index of the precision of point estimates (e.g., sample means or proportions) and is used for the calculation of both confidence intervals and hypothesis tests. For complex sample surveys (involving stratification, multistage sampling, and unequal probabilities of selection), the calculation of sampling error differs from the calculation used in simple random sampling. Unfortunately, software designed for general data analysis, including common SAS procedures such as PROC GLM or PROC LOGISTIC (SAS Institute, Cary, NC), calculate standard errors under the assumption of simple random sampling. However, for researchers using complex sample data, a variety of methods are available for appropriate estimation of sampling error, including Taylor series linearization, replication methods (balanced repeated replications, jackknife, and bootstrap), and the use of design effects (DEFFs).
Taylor series linearization is used in many statistical applications to obtain approximate values of functions that are difficult to calculate precisely. Details on the calculations are beyond the scope of this article, but a clear explanation can be found in Skinner et al.2 The Taylor series approach tends to be computationally fast (compared with replication methods) but carries the limitation that a separate formula must be developed for each variance estimate of interest.
In contrast to the Taylor series linearization approach, replication methods rely on the power of computers rather than the mathematics of statistics. These approaches to variance estimation take repeated subsamples from the observed data, calculate the desired statistic in each subsample, and estimate the variance of the statistic by computing the variability of the subsample values.2 The different methods that are subsumed under the replication umbrella simply represent different approaches to forming these subsamples. The most popular methods of replication are balanced repeated replication, the jackknife, and the bootstrap.
The balanced repeated replication approach divides each sampling stratum into 2 primary sampling units and creates subsamples by randomly selecting 1 of the units from each stratum to represent the entire stratum.2 By contrast, the jackknife method removes 1 primary sampling unit at a time to create each replicate. Finally, the bootstrap approach generates replicates by randomly sampling with replacement from the obtained sample responses. Each bootstrap replicate is drawn with the same sample size and the same sample structure (number of observations sampled with replacement from each stratum) as the total sample.2
Some complex health surveys also provide estimates of DEFFs, which are different from both the linearization and replication approaches and may be used to adjust the sampling error calculated by techniques that assume simple random sampling. The DEFF is simply the ratio of the variance that would be obtained in simple random sampling (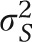 ) to the variance obtained under the sampling method used (
) to the variance obtained under the sampling method used (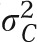 , c for complex):
, c for complex):
 |
The value of the DEFF differs across variables measured in sample surveys, and estimates of DEFF are typically provided for the major variables of interest. The obtained standard error of a statistic, computed assuming simple random sampling, is multiplied by the square root of the DEFF (often called the design factor) to obtain an improved estimate of the actual standard error. When the design effect of complex data sources is not accounted for and variances are not estimated appropriately, standard errors are often too small, thereby increasing type I errors.
In the early days of complex survey data, when concepts such as design effects and sample weights were relatively new to the applied researcher and took more of a statistical background to calculate, lack of awareness of the importance of design effects and sample weights might have been understandable. But today, with the advent of numerous statistical software packages and procedures developed to account for the design effects of complex survey data (e.g., SUDAAN [RTI International, Research Triangle Park, NC], Stata [StataCorp LP, College Station, TX], Mplus [Mplus, Los Angeles, CA], SAS SURVEY PROCEDURES, WesVar [Westat, Rockville, MD], IVEware [University of Michigan, Ann Arbor]) and the inclusion of calculated sample weights as variables in the data provided to researchers, omission of these important analytic techniques is not justifiable. Not only have articles and books detailing the methodological importance of these issues been published,3–7 but they have even been referred to as “basic ingredients needed for a complete analysis of survey data.”3(p45) Moreover, all large health survey databases available to researchers come with users’ guides and technical reports outlining the sampling methods used as well as instructions on how to account appropriately for the design effect of the survey and incorporate sample weights into the analysis. Yet the question remains, how often do health researchers account for design effects and include sample weights when conducting secondary data analysis of nationally representative health surveys?
To answer this question, we reviewed scientific, peer-reviewed articles published between 1995 and 2010 using data from 3 commonly used nationally representative adolescent health surveys: National Longitudinal Study of Adolescent Health (Add Health),8 Monitoring the Future (MTF),9 and Youth Risk Behavior Surveillance System (YRBS).10 More specifically, we reviewed articles to assess how frequently researchers reported the use of design effects and sampling weights when publishing findings based on data derived from these complex health surveys. We decided to focus on the reporting of the use of these “basic ingredients” of secondary analysis of complex health survey data because that is the only way for readers to ascertain if the necessary analytic techniques were included in the analysis of the survey data.
METHODS
Unlike primary research studies, in which the population of interest is a population of individuals, the population of interest for systematic reviews is a specified group of research studies. For the current study, the population of interest consisted of scientific, peer-reviewed, published articles using data from Add Health, MTF, and YRBS during the 16-year period from January 1995 to December 2010. We searched PubMed, PsychINFO, ERIC, and Web of Science using different key terms specific to each survey. For Add Health, we searched each electronic database using “National Longitudinal Study of Adolescent Health” and “Add Health” as key terms; for MTF, we searched using “Monitoring the Future” and “MTF”; for YRBS, we searched using “Youth Risk Behavior Surveillance System” and “YRBS.” We read the abstract for each article generated from our searches to determine whether the article met our inclusion criteria.
To be selected, an article must have (1) presented findings based on original empirical research using data from at least 1 of the 3 health surveys of interest (Add Health, MTF, or YRBS) and (2) been published in a scientific, peer-reviewed journal. For the purposes of this review, articles published in the Morbidity and Mortality Weekly Report (MMWR) were excluded. Although the MMWR is a scientific publication, articles included in each issue are not subjected to the standard peer-review process, so they did not meet the inclusion criteria. Through this selection process, we identified and reviewed a total of 1003 articles that met the inclusion criteria: 765 articles using Add Health data, 146 articles using MTF data, and 92 articles using YRBS data.
Before reviewing the articles, we developed and pilot tested a code sheet. Each author independently reviewed the same article and then met as a group to discuss coding decisions. There was no discrepancy in the coding decisions; therefore, all reviewers felt comfortable proceeding to review independently their assigned articles. The article that the lead author selected for the pilot test was one in which she felt it was moderately difficult to determine whether the authors reported accounting for design effects and the use of sample weights (i.e., an article that did not include “model” language that clearly identified these 2 elements in the Methods section). Reviewers also collaboratively developed the list of key words used in the electronic search of each article.
All articles were available in PDF format and were reviewed both electronically and manually. To determine whether researchers reported the use of appropriate statistical techniques that accounted for the complex sampling structure of the survey data and the use of sample weights in their analyses, we electronically searched articles, using the “search” function available in PDF documents, for the following key words: “weight,” “complex,” “sampling,” “SUDAAN,” “Stata,” “surveyreg,” “surveyfreq,” “surveymeans,” and “surveylogistic.” Because the list of electronic key search words was not exhaustive, we also manually reviewed the Methods and Results sections of each article.
Articles were credited with reporting the use of appropriate statistical techniques that accounted for the complex sampling structure of the survey data if the authors included sentences that either explicitly named a procedure (e.g., SVY procedures in Stata) or indicated that standard errors were adjusted to account for the complex sample design of the data. To credit an article for reporting use of sample weights, we looked for either explicit statements such as “the data were weighted for all analyses” or a more general sentence that reflected the notion that the authors addressed the issue of unequal probability of selection and poststratification adjustments (i.e., implying the use of sample weights). We also gave articles credit for reporting sample weights when the authors explicitly stated that sample weights were not used in the study. Because the focus of the review was on the transparency of reporting practices, explicitly stating that sample weights were not used is just as important as clearly stating when they are used; the key point is that the authors shared the nature of the analyses with the reader.
Each article was coded independently by a single researcher. We also conducted reliability checks and established interrater reliability. For the reliability checks, random samples of 10% of articles assigned to each researcher were reviewed by a second researcher. Over the course of the study, reviewers met weekly as a group to discuss the articles included in that week's reliability check. Overall, interrater reliability was initially 89% for design effects and 96% for sample weights. However, it is important to note that by the last round of reliability checks, there was 100% agreement for both design effects and sample weights.
RESULTS
Of the articles included in the review, 76% reported results from Add Health data, 14% included results from MTF data, and 10% used YRBS data. Collectively, 60% of articles reported accounting for the design effect of these complex data and 61% reported using sample weights. However, the clarity in the reporting of this information varied across articles. We have presented examples of informative and vague ways in which researchers reported use of sample weights and accounting for the design effects.
Informative:
All analyses were estimated with sampling weights that corrected for nonresponse and sample design. Standard errors were adjusted for clustering at the school level (schools were the primary sampling unit) using Stata's (version 8.0) SVYLOGIT command.11(p427)
Vague:
We restricted our sample to the 13 568 adolescents who participated in both the Wave I (1995) and Wave II (1996) in-home data collection, and for whom sample weights were available.12(p199)
In the informative quote, the researchers are explicit in the use of sample weights and accounting for the design effect of the complex data. In the vague quote, however, although the fact that the sample was restricted to participants for whom sample weights were available implies that sample weights were used, the reader does not know the extent to which sampling weights were included in statistical analyses.
As displayed in Table 1, when examined by data source approximately two thirds of Add Health and YRBS articles reported accounting for the design effect, compared with roughly one quarter of MTF articles. A slightly better pattern emerged in terms of sample weights; Add Health and YRBS articles still reported on the use, or nonuse, of sample weights in their statistical analyses more often than did MTF articles, although half of these articles also reported this information. However, as shown in Table 1, not all articles reported accounting for both design effects and use of sample weights. For example, one quarter of MTF articles and nearly one fifth of YRBS articles reported information on sample weights but not on accounting for design effects in terms of standard error adjustments.
TABLE 1—
Reporting of Accounting for Design Effects and Use of Sample Weights in Published Articles That Used Data From 3 Commonly Used Adolescent Health Surveys
| Articles That Reported Accounting for Design Effects and Use of Sample Weights, by Data Source |
Articles That Reported Discordance Between Accounting for Design Effects and Use of Sample Weights, by Data Source |
Articles That Reported Accounting for Design Effects and Use of Sample Weights, by Author Affiliationa |
||||||
| Survey | Design Effects, % | Sample Weights, % | Design Effects, No Sample Weight, % | Sample Weights, No Design Effects, % | Design Effects, Internal Affiliate, % | Design Effects, No Affiliation, % | Sample Weights, Internal Affiliate, % | Sample Weights, No Affiliation, % |
| Add Health | 65 | 61 | 12 | 7 | 67 | 65 | 72 | 59 |
| MTF | 27 | 50 | 2 | 25 | 48 | 12 | 74 | 33 |
| YRBS | 65 | 80 | 1 | 16 | 97 | 50 | 100 | 71 |
Note. Add Health = National Longitudinal Study of Adolescent Health; MTF = Monitoring the Future; YRBS = Youth Risk Behavior Surveillance System. The articles (n = 1003) were published between 1995 and 2010.
“Internal affiliate” indicates that authors were part of the research team that designed the study or collected the data, or worked for an organization responsible for managing the research and data.
In addition, when we examined reporting practices over time, different reporting patterns across the 3 data sources also were noted. In general, the proportion of Add Health articles that reported use of design effects and sample weights noticeably increased after the late 1990s and then stayed relatively consistent, although there was a slight decrease over the last 5 years (Figure 1). Conversely, reporting of design effects and sample weights in MTF articles has continued to increase over the last 16 years (Figure 2). Moreover, unlike the reporting practices in both Add Health and MTF articles, the reporting practices seen in YRBS articles have remained relatively consistent across the last decade, after a slight increase after the late 1990s (Figure 3).
FIGURE 1—

Proportion of National Longitudinal Study of Adolescent Health (Add Health) articles that reported use of design effects and sample weights, by publication year.
FIGURE 2—

Proportion of Monitoring the Future (MTF) articles that reported use of design effects and sample weights, by publication year.
FIGURE 3—

Proportion of Youth Risk Behavior Surveillance System (YRBS) articles that reported use of design effects and sample weights, by publication year.
In addition to coding authors’ reports of accounting for design effects and use of sample weights, we also coded by author affiliation with the data source used in the article (internal affiliate or not). Internal affiliates consisted of authors who were part of the research team that designed the study or collected the data, as well as authors who worked for an organization responsible for managing the research and data (e.g., all employees of the Centers for Disease Control and Prevention were considered internal affiliates for YRBS data). Eighteen percent of Add Health articles, 42% of MTF articles, and 33% of YRBS articles were authored by internal affiliates. Of these, approximately two thirds of Add Health, one half of MTF, and all YRBS articles reported accounting for the design effect of the complex data structure, whereas three quarters of Add Health and MTF internal affiliate articles and almost all YRBS internal affiliate articles reported use of sample weights. Although these percentages appear low, they represent better reporting practices than those in articles written and published by researchers with no affiliation with the data (Table 1).
Finally, we examined the reporting of design effects and sample weights by journal source for the 10 most frequently cited journals (Table 2). These 10 journals published one third of the 1003 articles included in our study. Within these journals, 100% of articles published in 1 of the journals reported accounting for the design effect, with a range of 61% to 90% for the other 9 journals. Similarly, the range of the percentage of articles across these 10 journals that reported using sample weights was 58% to 84%.
TABLE 2—
Reporting Practices of Articles Published in the 10 Most Frequently Cited Journals in the Study
| Journal | No. of Articles | Articles Accounting for Design Effects, % | Articles Reporting Use of Sample Weights, % |
| Journal of Adolescent Health | 98 | 64 | 74 |
| Journal of Youth and Adolescence | 41 | 61 | 58 |
| American Journal of Public Health | 39 | 82 | 79 |
| Journal of Marriage and Family | 33 | 73 | 73 |
| Journal of School Health | 29 | 69 | 76 |
| Social Forces | 22 | 77 | 59 |
| Pediatrics | 21 | 90 | 81 |
| Archives of Pediatric and Adolescent Medicine | 20 | 80 | 75 |
| Journal of Family Issues | 19 | 79 | 84 |
| Perspectives on Sexual and Reproductive Health | 18 | 100 | 78 |
Note. The journals cited in the table published one third of the 1003 articles included in our study (year of publication = 1995–2010).
DISCUSSION
Improvement is needed in reporting the use of sample weights and accounting for design effects when disseminating research based on Add Health, MTF, and YRBS data. Nearly two thirds of Add Health and YRBS articles documented accounting for design effects compared with slightly more than one quarter of MTF articles; we observed the same variation across data sources for reporting use of sample weights. Furthermore, not only was variation evident in the reporting of these analytic techniques among researchers not affiliated with the data source, but differences were apparent among researchers affiliated with the 3 data sources. Such results are consistent with previous methodological reviews addressing other analytic issues, including the design and analysis of group-randomized trials,13 applications of multilevel modeling,14 reporting of analysis of variance and analysis of covariance results,15 and the use of propensity score matching methods.16
One plausible reason for some of the variation in reporting practices across the 3 data sources is differences in the technical documentation that is available to researchers for each of the data sources. For example, articles that were disseminating research from the MTF had the worst reporting practices for both design effects and sample weights. Similarly, although we found that both Add Health and YRBS provided easily accessible technical documentation about the complex nature of the data online, no such documentation was found for MTF data.
The quality of researchers’ reporting of these critical analytic techniques when using complex sample data also showed substantial inconsistency. Because reporting the use of sample weights and accounting for the design effects of complex data are the only ways to ascertain whether such analytic procedures are conducted, it is imperative that researchers include this information when disseminating findings based on research using complex sample data. The inconsistent and often vague reporting of these “key ingredients” is troublesome for a number of reasons.
For example, it is unclear if researchers are simply not reporting this information or if they are truly not accounting for design effects and sample weights in their analyses. When this information is not reported, a shadow of doubt is created on the accuracy of published secondary data analyses. Transparency is a key ethical guideline in reporting statistical information17,18; when they omit accounting for design effects and use of sample weights, researchers are not being transparent in their statistical analyses. More specifically, in the American Statistical Association's Ethical Guidelines for Statistical Practice, one item under “Responsibilities in Publication and Testimony” enjoins researchers to
Clearly and fully report the steps taken to guard validity. Address the suitability of the analytic methods and their inherent assumptions relative to the circumstances of the specific study. Identify the computer routines used to implement the analytic methods.17(section C.8)
Under this guideline, researchers who fail to mention design effects or sample weights when sharing findings based on complex sample data are not adequately addressing the inherent assumptions relative to the circumstances of their studies; this omission could then be considered a violation of research dissemination guidelines.
Whereas most scholars probably agree that the current reporting practices are troublesome, less agreement is likely regarding whose responsibility it is to improve the reporting practices of research conducted with complex sample data. We propose that the responsibility for improvement is shared by authors, reviewers, editors, and professors (through their graduate curricula). First and foremost, any researcher who conducts a secondary data analysis on complex sample data must read the users’ guide and methodological reports that accompany the data being used. Likewise, researchers must understand the nature of the data structure and have the skills to apply the necessary analytic techniques to help ensure accuracy of conclusions drawn on the basis of their findings. When sharing their findings, researchers must also include detailed information about the use or nonuse of sample weights or accounting for the design effects of complex sample data.
Although researchers should carry the primary responsibility for reporting of the accurate analysis of complex sample data, journal editors and reviewers are essential for improving such reporting practices. Editors should require all articles that present findings based on the analysis of complex sample data to include information regarding whether sample weights were used and if the design effect was accounted for. Similarly, editors should also train reviewers to evaluate these areas and, if necessary, solicit technical reviewers who are well versed in secondary data analysis of complex sample data. When an article does not contain this information, authors should be required to address the omission before an article is accepted for publication. Furthermore, in situations in which these analytic techniques are not used, authors should be required to state explicitly their nonuse, and editors and reviewers need to evaluate the nature of the inferences drawn (i.e., when sample weights are not used, it would be inappropriate for authors to discuss findings as if they were representative of the survey's intended population).
Additionally, with the increased use of large-scale complex health databases, graduate programs should include courses—or at the very least seminars—on secondary analysis of complex sample data. Although in-depth coverage of the intricacies of complex sample data would be the best curricular option, when this is not feasible, professors who teach statistics or research methods should at the minimum be encouraged to incorporate the topic into their existing courses. Graduate students can thereby be made aware of the methodological issues associated with complex sample data.
Finally, the results from this study capture only a subsample of available health databases. Future research should investigate use of these important methodological issues in other commonly used large-scale health databases. Until then, however, the health science research community needs to start discussing ways to improve the reporting of analyses that account for design effects and use of sample weights when disseminating research findings based on complex sample data.
Acknowledgments
An earlier version of this article was presented at the American Public Health Association 135th Annual Meeting and Exposition; November 3–7, 2007; Washington, DC.
Human Participation Protection
Because the data included in the current study were obtained from secondary sources, institutional review board approval was not needed.
References
- 1.Brick JM, Kalton G. Handling missing data in survey research. Stat Methods Med Res. 1996;5(3):215–238 [DOI] [PubMed] [Google Scholar]
- 2.Skinner CJ, Holt D, Smith TMF, Analysis of Complex Surveys: Wiley Series in Probability and Mathematical Statistics. New York, NY: John Wiley & Sons; 1989 [Google Scholar]
- 3.Lee ES, Forthofer RN. Analyzing Complex Survey Data. 2nd ed. Newbury Park, CA: Sage Publications Inc; 2006. Sage University Paper Series on Quantitative Applications in the Social Sciences, series no. 07–071 [Google Scholar]
- 4.Korn EL, Graubard BI. Examples of differing weighted and unweighted estimates from a sample survey. Am Stat. 1995;49(3):291–295 [Google Scholar]
- 5.Johnson DR, Elliot LA. Sample design effects: do they affect the analyses of data from the National Survey of Families and Households? J Marriage Fam. 1998;60(4):993–1001 [Google Scholar]
- 6.Cohen SB. An evaluation of alternative PC-based software packages developed for the analysis of complex survey data. Am Stat. 1997;51(3):285–292 [Google Scholar]
- 7.Pfeffermann D. The role of sampling weights when modeling survey data. Int Stat Rev. 1993;61(2):317–337 [Google Scholar]
- 8.Chantala K. Introduction to Analyzing Add Health Data. Chapel Hill, NC: Carolina Population Center; 2003 [Google Scholar]
- 9.Monitoring the Future: A Continuing Study of American Youth (12th-Grade Survey), 2004: Description. Ann Arbor, MI: Inter-University Consortium for Political and Social Research; 2005 [Google Scholar]
- 10.Brener ND, Kann L, Kinchen SAet al. Methodology of the Youth Risk Behavior Surveillance System. MMWR Recomm Rep. 2004;53(RR-12):1–13 [PubMed] [Google Scholar]
- 11.Farrelly MC, Davis KC, Haviland ML, Messeri P, Healton CG. Evidence of a dose–response relationship between “truth” anti-smoking ads and youth smoking prevalence. Am J Public Health. 2005;95(3):425–431 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Dornbusch SM, Lin IC, Munroe PT, Bianchi AJ. Adolescent polydrug use and violence in the United States. Int J Adolesc Med Health. 1999;11(3–4):197–219 [DOI] [PubMed] [Google Scholar]
- 13.Murray DM, Pals SL, Blitstein JL, Alfano CM, Lehman J. Design and analysis of group-randomized trials in cancer: a review of current practices. J Natl Cancer Inst. 2008;100(7):483–491 [DOI] [PubMed] [Google Scholar]
- 14.Dedrick RF, Ferron JM, Hess MRet al. Multilevel modeling: a review of methodological issues and applications. Rev Educ Res. 2009;79(1):69–102 [Google Scholar]
- 15.Keselman HJ, Huberty CJ, Lix LMet al. Statistical practices of educational researchers: an analysis of their ANOVA, MANOVA, and ANCOVA analyses. Rev Educ Res. 1998;68(3):350–386 [Google Scholar]
- 16.Austin PC. A critical appraisal of propensity-score matching in the medical literature between 1996 and 2003. Stat Med. 2008;27(12):2037–2049 [DOI] [PubMed] [Google Scholar]
- 17.American Statistical Association, Committee on Professional Ethics Ethical guidelines for statistical practice. Available at: http://www.amstat.org/committees/ethics/index.cfm. Accessed September 1, 2009
- 18.Inverson C, Flanagin A, Fontananarosa PBet al. American Medical Association Manual of Style: A Guide for Authors and Editors. 9th ed. Philadelphia, PA: Lippincott, Williams, & Wilkins; 1998 [Google Scholar]