

Abstract
Objective
The frequency modulation (FM) of speech can convey linguistic information and also enhance speech-stream coherence and segmentation. Using a clinically oriented approach, the purpose of the present study was to examine the effects of age and hearing loss on the ability to discriminate between stochastic patterns of low-rate FM and determine whether difficulties in speech perception experienced by older listeners relate to a deficit in this ability.
Design
Data were collected from 18 normal-hearing young adults, and 18 participants who were at least 60 years old, nine normal-hearing and nine with a mild-to-moderate sensorineural hearing loss. Using stochastic frequency modulators derived from 5-Hz lowpass noise applied to a 1-kHz carrier, discrimination thresholds were measured in terms of frequency excursion (ΔF) both in quiet and with a speech-babble masker present, stimulus duration, and signal-to-noise ratio (SNRFM) in the presence of a speech-babble masker. Speech perception ability was evaluated using Quick Speech-in-Noise (QuickSIN) sentences in four-talker babble.
Results
Results showed a significant effect of age, but not of hearing loss among the older listeners, for FM discrimination conditions with masking present (ΔF and SNRFM). The effect of age was not significant for the FM measures based on stimulus duration. ΔF and SNRFM were also the two conditions for which performance was significantly correlated with listener age when controlling for effect of hearing loss as measured by pure-tone average. With respect to speech-in-noise ability, results from the SNRFM condition were significantly correlated with QuickSIN performance.
Conclusions
Results indicate that aging is associated with reduced ability to discriminate moderate-duration patterns of low-rate stochastic FM. Furthermore, the relationship between QuickSIN performance and the SNRFM thresholds suggests that the difficulty experienced by older listeners with speech-in-noise processing may in part relate to diminished ability to process slower fine-structure modulation at low sensation levels. Results thus suggest that clinical consideration of stochastic FM discrimination measures may offer a fuller picture of auditory processing abilities.
Keywords: aging, frequency modulation, hearing loss, speech perception
INTRODUCTION
Older listeners often experience difficulty understanding speech, especially in adverse listening environments (e.g., Plomp & Mimpen 1979; CHABA 1988; Dubno et al. 2008). Although peripheral hearing loss has been shown to be a dominant factor contributing to this difficulty (van Rooij & Plomp 1990; Humes & Christopherson 1991), the extent of the speech-processing deficits can exceed expectations based on hearing thresholds alone (for a review, see Pichora-Fuller & Souza 2003). Aspects of auditory temporal processing by older listeners have been evaluated in different attempts to account for the discrepancy. For examle, deficits associated with listener age have been reported for measures of gap detection (Strouse et al. 1998; Phillips et al. 2000; Snell et al. 2002; Helfer & Vargo 2009), detection of amplitude and frequency modulation (He et al. 2007, 2008), forward masking (Gifford et al. 2007), discrimination of interaural time and phase differences (Divenyi & Haupt 1997; Grose & Mamo 2010; Hopkins & Moore 2011), gap, voice-onset-time, and duration discrimination (Gordon-Salant & Fitzgibbons 1993,1999; Fitzgibbons & Gordon-Salant 1995; Strouse et al. 1998;Tremblay et al. 2003), and discrimination of temporal order and rhythm (Trainor & Trehub 1989; Humes & Christopherson 1991; Gordon-Salant & Fitzgibbons 1999; Fitzgibbons et al. 2006). Despite age-related deficits in measures of temporal processing and speech perception in studies which measured both, a strong relationship between the two has been obtained in only some (Gordon-Salant & Fitzgibbons 1993; Snell et al. 2002; Gifford et al. 2007; Helfer & Vargo 2009) but not all of the work (van Rooij & Plomp 1990; Humes & Christopherson 1991; Divenyi & Haupt 1997; Strouse et al. 1998; Gordon-Salant & Fitzgibbons 1999; Phillips et al. 2000; Grose et al. 2009). This contrast among findings has led to speculation that the effect of age on the relationship between temporal processing and speech perception is most apparent in situations involving complexity in terms of stimuli or auditory task (Gordon-Salant & Fitzgibbons 1999; Pichora-Fuller & Souza 2003).
Once processed through the frequency-selective channels of the auditory system, the complexity of speech is represented by changes in the short-term amplitude and phase spectra (Flanagan & Golden 1966), or in other words, in terms of fluctuation of the temporal envelope and temporal fine structure of bandlimited signals. As variations in periodicity, dynamic fine-structure information can be expressed as frequency modulation (FM) of the band center frequency. Effect of listener age on the processing of speech FM has been obtained in measures of discrimination of formant transitions (Elliott et al. 1989) and voicing intonation patterns (Souza et al. 2010), with age-related deficits in phonetic identification based on dynamic spectral information reported by Dorman et al. (1985) and Fox et al. (1992).
Potential involvement of FM in speech processing is not limited to conveying phonetic information. Speech utterances are a sequence of diverse acoustic events. Perception, however, is generally of a coherent stream in which events from a single talker are linked together. FM, as represented through the pattern of intonation and formant transitions, may serve to maintain this signal coherence (Lackner & Goldstein 1974; Dorman et al. 1975). Along with enhancing coherence, modulation of the voicing fundamental can aid in the necessary segmentation of the syllable and word boundaries of the ongoing speech stream (Cutler 1976; Spitzer et al. 2007). Finally, this modulation has been shown to benefit speech intelligibility in the presence of competing interference (Laures & Bunton 2003; Binns & Culling 2007; Miller et al. 2010).
The effect of FM rate on auditory streaming is lowpass with coherence dropping rapidly with increasing rate above 1–2 Hz (Anstis & Saida 1985). Analysis of the FM spectrum of speech follows a similar lowpass characteristic. Figure 1 shows the average modulation spectra of the fine structure and envelope of 300 monosyllabic words spoken by a female talker.1 Both functions exhibit greatest amplitude at lower modulation rates. The importance of the low-rate envelope modulation spectrum of speech is well known (Houtgast & Steeneken 1985). Though the similarity between the fine-structure and envelope modulation spectra of speech in the present analysis is anticipated due to correlation between the two temporal modulations for bandlimited stimuli (Papoulis 1983), the analysis highlights the potential importance of low-rate speech FM.
Fig. 1.
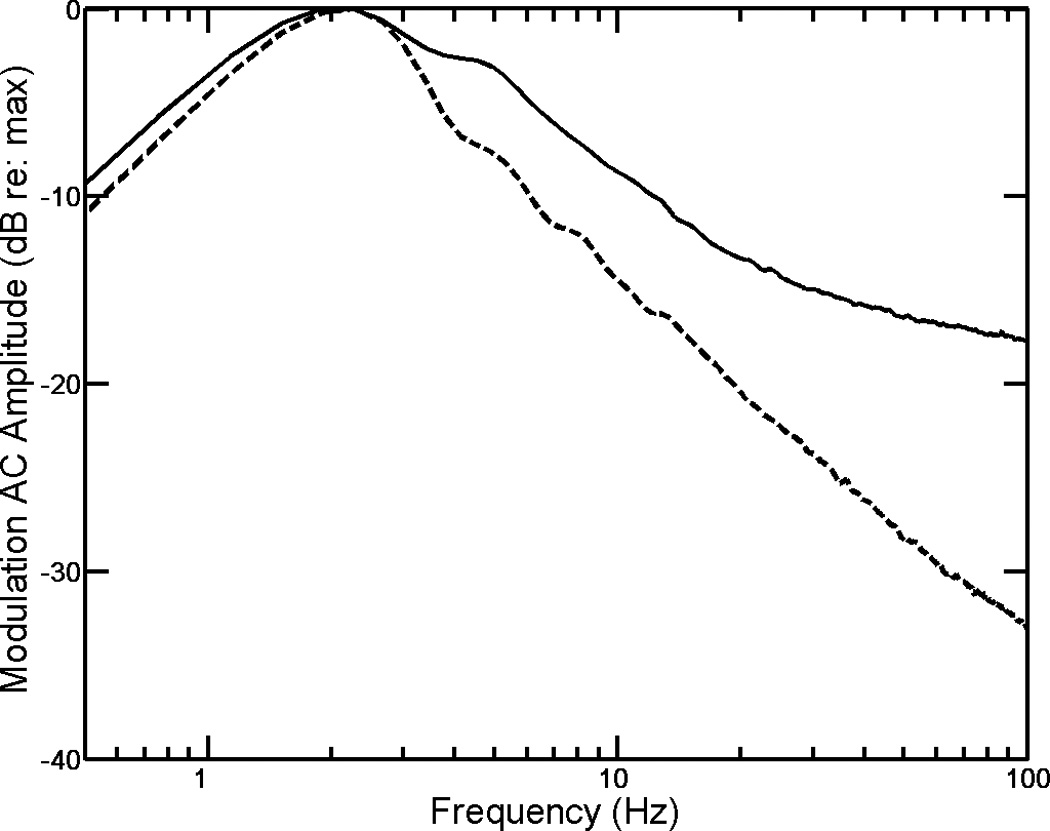
Average modulation spectra of the fine structure (solid line) and envelope (dashed line) of 300 monosyllabic words spoken by a female talker. Functions were derived by passing stimuli through a compressive-dynamic gammachirp filterbank, extracting the amplitude and frequency modulation for each channel, and then separately averaging the two across channels and speech tokens.
Sheft and Lorenzi (2008) showed that the region of best FM discriminability coincides with the lowpass characteristic of speech FM, allowing for significant contribution to speech perception. Conditions evaluated the ability of normal-hearing listeners to discriminate among stochastic patterns of FM generated by frequency modulating pure-tone carriers with random samples of lowpass noise. For all values of the maximum frequency excursion following modulation (ΔF), discriminability of the stochastic FM patterns decreased with increasing average FM rate. Past work studying frequency discrimination in the context of speech perception has used frequency glides. Results indicated a performance decrement with increasing glide excursion beyond a critical bandwidth (Madden and Fire, 1997; Thyer and Mahar, 2006). In studies of auditory streaming, coherence drops with increasing frequency span between sequential elements (e.g., Bregman, 1990). In contrast to both sets of findings, Sheft and Lorenzi found that performance improved with increasing ΔF. For the stochastically modulated stimuli of that work, increasing ΔF enhances pattern distinction which in turn aids discrimination. This is not the case for discrimination of monotonic frequency glides. Furthermore, pattern distinction would not be expected as a factor that enhances sequence coherence per se. However, discrimination based on distinctive features of a complex time-varying stimulus is a central aspect of speech processing. This discrimination can help to distinguish phonemic contrasts and guide segmentation of the speech stream into meaningful units (e.g., Stevens, 2002; Li & Loizou, 2008).
To evaluate whether FM discrimination cues remain effective in background noise to allow for possible contribution to speech-in-noise processing, Sheft and Lorenzi (2008) also evaluated performance in a number of masking conditions. The addition of an unmodulated noise masker at a signal-to-noise ratio (SNR) of 6 dB had little effect on FM pattern discrimination. Furthermore, neither sinusoidally amplitude modulating the masker at a low rate (4 or 20 Hz) nor reducing the SNR to −2 dB significantly altered the amount of masking. Results thus indicated viability of low-rate FM cues to aid speech perception in the presence of modulated maskers, even at low sensation levels.
The present study directly evaluated the relationship between the ability to discriminate among stochastic patterns of low-rate FM and speech perception in both normal-hearing young adults and older listeners with either near-normal hearing thresholds or a mild-to-moderate sensorineural hearing loss. The hypothesis was that difficulty experienced by older listeners understanding speech against background interference would relate in significant part to impaired processing of FM. Experimental protocol was clinically oriented. As such, the procedure was not focused on determining asymptotic performance levels, but rather on providing a basis for subsequent development of a clinically feasible approach for assessment of listener abilities. For a fuller understanding of auditory processing of stochastic FM, discrimination ability was measured in five separate tasks which estimated thresholds in terms of frequency excursion, stimulus duration, or SNR in the presence of a speech-babble masker. For each listener, speech discrimination ability was measured both in quiet and in the presence of a speech-babble masker.
Discrimination of stochastic FM introduces uncertainty into the procedure through the sampling of independent noise modulators. Collins et al. (1994) suggested that by incorporating aspects of natural speech, use of stimulus uncertainty in psychoacoustic paradigms increases predictive power regarding listener performance in speech tasks. Most past work involving stimulus uncertainty has been conducted in the context of informational masking (for a review, see Kidd et al. 2008). With frequency patterns, informational-masking studies have generally manipulated a single target element of the pattern. For speech perception, intelligibility relies not on the processing of a single target element, but rather on the entire temporal pattern (Remez et al. 1994). In contrast to the earlier work involving frequency uncertainty, the present study evaluated the ability to discriminate a change in the whole pattern in order to bring the psychoacoustic procedure closer to a central aspect of speech processing.
PARTICIPANTS AND METHODS
Participants
Three groups of listeners participated in the study. The first consisted of 18 young adults (16 women; age range: 22–33 yrs; mean: 23.7 yrs) who had normal audiometric thresholds (≤15 dB HL re: ANSI 2004) for the octave frequencies between 0.25–8.0 kHz. The second and third groups consisted of nine older listeners each, with groups distinguished by pure-tone average (PTA) audiometric thresholds at 0.5, 1.0, and 2.0 kHz as either normal hearing (NH) or hearing impaired (HI). The nine participants in the second group (5 women; age range: 61–72 yrs; mean: 65.3 yrs) in each ear had a PTA of 20 dB HL or less. For the third group, the nine listeners (4 women; age range: 61–84 yrs; mean: 70.6 yrs) had a mild-to-moderate sloping hearing loss confirmed as sensorineural by bone-conduction thresholds and tympanometry. Hearing loss was symmetric with PTAs varying by no more than 12 dB between ears (for seven of the listeners, the difference was ≤5 dB) and binaural PTAs ranging from 22–53 dB HL. Average group audiograms are shown in Figure 2. Despite labeling of the second group as older normal-hearing listeners based on PTA, all but two of the participants exhibited at least a mild hearing loss at 4 and 8 kHz. All study participants achieved a score of 25 or greater on the Mini Mental Status Examination (Folstein et al. 1975) and spoke English as their first and primary language.
Fig. 2.

Average left (L) and right (R) ear audiograms for the three subject groups. Error bars are one standard deviation (SD) of the mean threshold.
Psychoacoustic Stimuli and Procedure
Five conditions measured discrimination thresholds between pairs of stimuli that were frequency modulated by lowpass noise. If n(t) is the zero-mean noise modulator with the absolute value of peak amplitude scaled to 1.0, the general form of the discrete stimulus is given by:
where t is time, f is carrier frequency, N(t) is the cumulative integral of n(t), ΔF is the maximum frequency excursion due to modulation, and sr is sampling rate. A consequence of the modulation is that the instantaneous frequency of the stimulus follows the amplitude pattern of the noise modulator. This is illustrated in the top two panels of Figure 3 for a 5-Hz lowpass-noise modulator and 400-Hz ΔF. The bandwidth of the noise modulator determines the average rate of frequency modulation (equal to ~0.78 the lowpass cutoff frequency in Hz).2 Due to the stochastic modulation, the long-term stimulus spectrum is continuous with a bandwidth that reflects modulator peak amplitude (see Fig. 3, bottom panel). In all conditions, modulator bandwidth was fixed at 5 Hz and FM carrier frequency at 1 kHz. Using random assignment of coefficients in an inverse fast Fourier transform, noise modulators were digitally generated with 0.25- Hz frequency resolution.
Fig. 3.
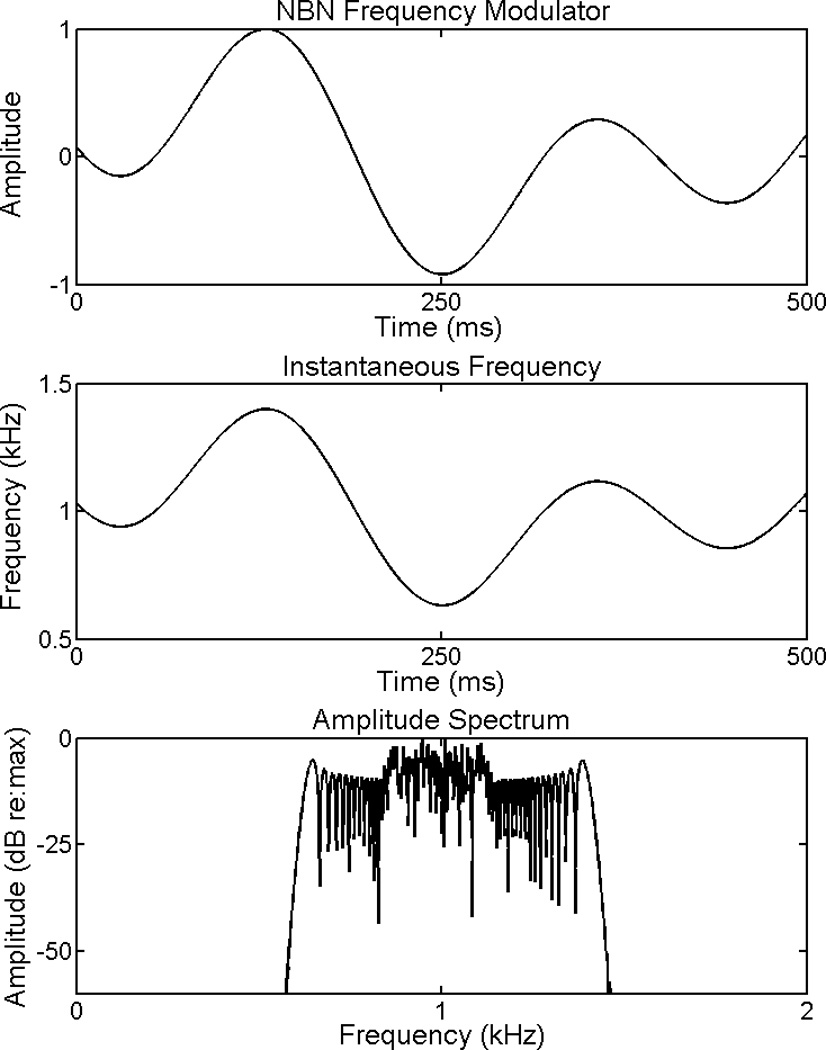
Analysis of stochastic FM. Top panel: time waveform of a 5-Hz lowpass noise modulator. Middle panel: instantaneous-frequency function when the modulator is applied to a 1-kHz pure-tone carrier with ΔF equal to 400 Hz. Bottom panel: long-term amplitude spectrum of the modulated stimulus.
All conditions were intended to measure the ability to discriminate stimuli based on differences in the temporal pattern of frequency fluctuation about the carrier frequency rather than variations in long-term or peak stimulus characteristics. To maintain a constant ΔF, modulator peak amplitude was the same for all stimuli of a given discrimination trial. The contrasting modulators of each discrimination trial were either independent samples drawn from the same underlying noise distribution, or a single random sample paired with its time reversal scaled by −1.0 following cumulative integration. In the first approach, across stimuli the average long-term amplitude spectra are identical due to the common sampling distribution. The time reversal and sign change of the second approach leads to a time reversal of the instantaneous-frequency function between the contrasting stimuli of each trial, with long-term amplitude spectra of the stimuli always the same. In the second approach, however, the correlation between the instantaneous-frequency functions of a stimulus pair is generally nonzero due to the modulators not being independent noise samples. Figure 4 illustrates the instantaneous frequency functions of a contrasting stimulus pair generated with independent sampling. The average rate of frequency fluctuation (i.e., modulator bandwidth) and maximum frequency deviation from the carrier frequency (i.e., ΔF) are the same for the two stimuli so that discrimination must rely on only the temporal pattern of frequency deviation.
Fig. 4.
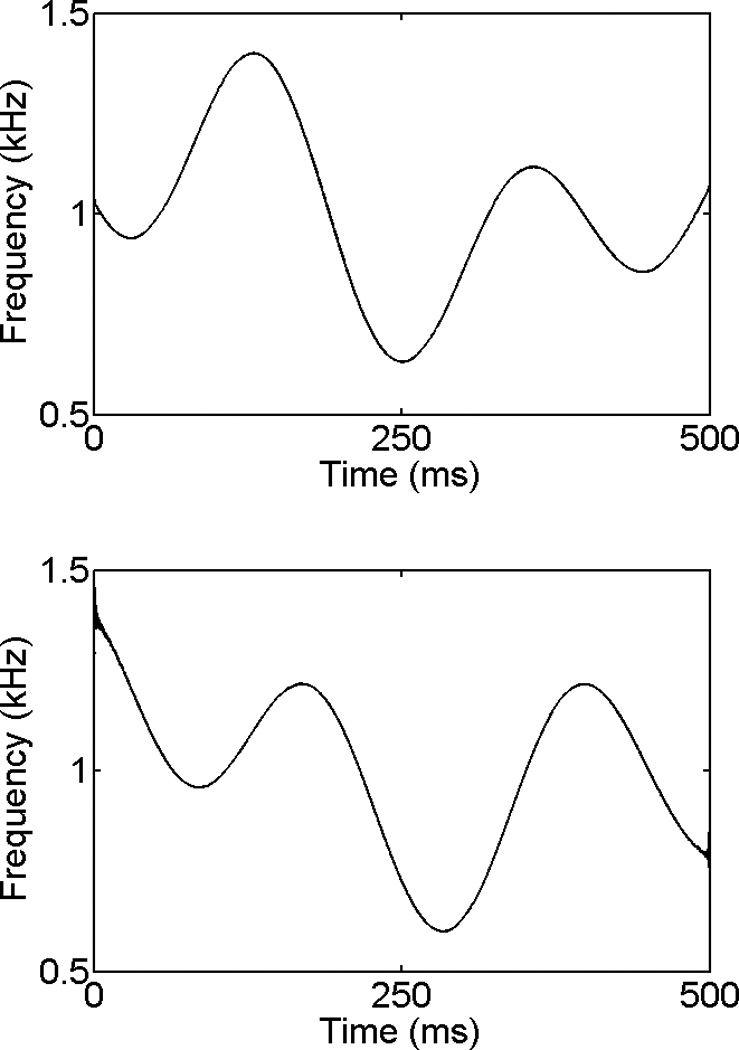
Schematic illustration of two examples of stochastic FM on a typical trial showing the contrasting instantaneous-frequency functions of the stimuli. With independent noise samples used as modulators across trials, instantaneous-frequency functions also varied across trials.
The ability to discriminate stochastic FM was measured with a cued two-interval forced-choice (2IFC) adaptive procedure. Five-hundred ms separated the three stimulus presentations of a trial. On each trial, a randomly selected noise modulator was used as the cue modulator of the 1-kHz carrier. With random selection, one of the two observation intervals that followed the cue was identical to the cue; the other interval was generated with a contrasting modulator. The listener’s task was to indicate which observation interval differed from the cue with feedback provided after each trial. Across the five conditions, thresholds were estimated in terms of three independent variables described below. Using a two-down one-up tracking rule that converged on 70.7% (Levitt 1971), threshold estimates were based on the average of the last eight of the required minimum of twelve tracking reversals with run length always at least 40 trials. Concerned with clinical feasibility of the psychoacoustic measures, all data from each listener were collected in a single session with one threshold estimate per condition. Results thus represent neither trained nor asymptotic performance levels. For practice, listeners initially completed the first condition without scoring; thereafter each subsequent run was scored. All scored runs began with eight practice trials. Each run took roughly five to six minutes.
There were five FM conditions with the first three using the independent-samples method of generating contrasting modulators, and the last two using the time-reversal method. The second and third conditions used a continuous four-talker speech-babble masker spoken by one male and three female talkers. The masker was continuous in that it began roughly 10 s before the first trial of a run and remained on until feedback was provided for the final trial. The average power spectrum of the masker is shown in Figure 5. A two-minute sample of the masker output over Etymotic ER-3A insert earphones was recorded through a KEMAR manikin. Based on Fourier transform coefficients, level was determined in consecutive one-third-octave bands. Results are expressed in dB relative the power of a 1-kHz pure-tone (the FM carrier in all discriminations conditions) with both the masker and pure tone presented separately at 80 dB SPL. For band center frequencies ranging from roughly 0.6 to 1.6 kHz that approximate the widest frequency excursion of stimuli in the discrimination conditions, average band power level varied from −15.3 to −10.3 dB relative the FM carrier.
Fig. 5.
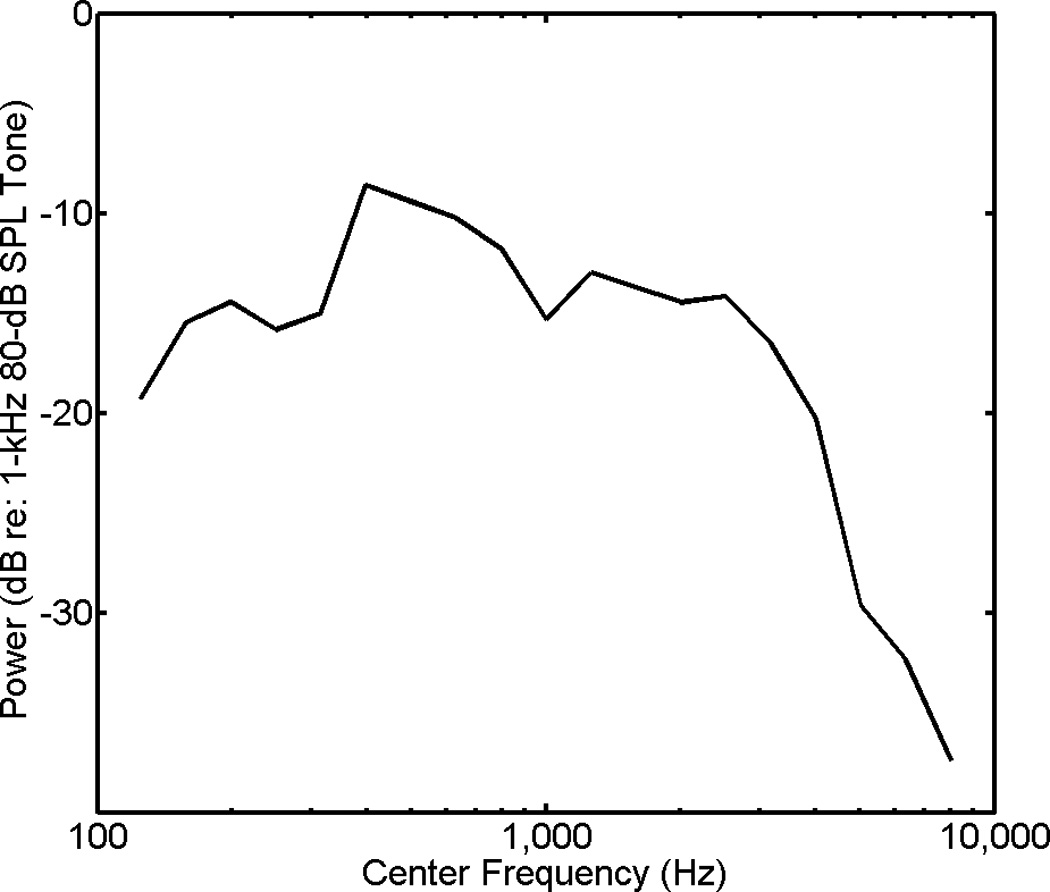
Average power spectrum of the speech-babble masker recorded through a KEMAR manikin as a function of the center frequency of the consecutive one-third-octave bands used in analysis. Levels are expressed in dB relative the power of a 1-kHz pure-tone with both the masker and pure tone presented separately at 80 dB SPL.
Data were collected from each listener in the following order.
Delta F. The maximum frequency excursion of the FM tones was varied in the first condition to determine the minimum ΔF needed to discriminate 500-ms stochastic FM patterns. Stimulus level was 80 dB SPL. In the adaptive threshold procedure, ΔF was varied geometrically. Beginning at 400 Hz, ΔF was initially changed by a factor of 1.46 with factor size reduced to 1.10 following the second tracking reversal. With thresholds in terms of frequency excursion, the procedure provides a measure of sensitivity in terms of the magnitude of pattern deviation from the carrier frequency.
Masked Delta F. The second condition repeated condition 1 in the presence of the continuous speech-babble masker. A high SNR of 16 dB was used to minimize energetic masking so effects might relate more directly to factors such as attention and distraction.
-
SNRFM. Using the continuous speech-babble masker at 80 dB SPL and with ΔF fixed at 400 Hz, the level of the FM tones was varied in the third condition to determine the SNR needed to discriminate pattern of frequency fluctuation. Initial tracking step size was 6 dB which was reduced to 2 dB following the second reversal. The fixed ΔF of 400 Hz extends well beyond the bandwidth of the auditory filter tuned to the 1-kHz carrier frequency allowing for significant involvement of cross-channel processing of the stochastic modulation. Results obtained with this metric offer evaluation of discrimination ability at low sensation levels, a characteristic of many adverse listening environments in which speech processing is difficult.
The fourth and fifth conditions measured discrimination thresholds without masking in terms of stimulus duration. At briefer durations, listeners do not follow the frequency fluctuations of the stimuli, but rather perceive stimuli globally in terms of overall characteristics such as timber. Support for involvement of duration-specific cues comes from conditions of Sheft and Lorenzi (2008) in which carrier frequency was randomized between the cue and observation intervals of a trial. Results showed little effect of randomization with a 500-ms stimulus duration, but near-chance performance if duration was less than 50 ms. These findings are consistent with the interpretation that at long durations, discrimination is cued by the pattern of frequency fluctuation which in a relative sense is not affected by carrier randomization. However, if cued by timbre or pitch at brief durations, randomization would severely impair discrimination. To avoid discrimination based on within-trial differences in the long-term amplitude spectra, the time-reversal method for generating contrasting modulators was used. With this method, the three stimuli of a given trial shared a common amplitude spectrum, differing only in terms of their phase spectra. In these two final conditions, stimulus level was 80 dB SPL for trials on which stimulus duration was 100 ms or longer. Once duration tracked below 100 ms, level was adjusted to maintain the energy level (i.e., sum of the squared discrete signal values) at that of a 100-ms stimulus (e.g., level was increased by roughly 3 dB for each halving of duration from 100 ms). To limit peak amplitudes, this correction assumed a minimum duration of 3 ms.
Duration Descending. For the fourth condition, ΔF was fixed at 400 Hz and the duration of the FM tones was adaptively varied, beginning at 500 ms, to estimate the shortest duration needed for discrimination. Duration was initially changed by a factor of 1.46 with factor size reduced to 1.10 following the second tracking reversal.
Duration Ascending. As noted above, discrimination cues in condition 4 can change with duration from following the frequency fluctuations to a global stimulus percept. To perform well in the task, a listener must, dependent on stimulus duration, focus on different cues. While trial-by-trial feedback helps subjects to adapt listening strategy as duration changes, it does not ensure that they will attend to the appropriate cue at the respective duration. To better estimate performance limits with duration as the independent variable, condition 5 repeated condition 4, but began the tracking procedure at a brief 11-ms duration. The fifth condition was added to the study after data collection from the younger subjects had begun. Consequently, only 10 of the 18 young listeners participated in this condition.
In all conditions, stimuli were shaped with 50-ms cosinusoidal rise/fall ramps, unless stimulus duration was less than 100 ms. In those cases, rise/fall time was equal to half the stimulus duration. A Hewlett Packard personal computer and an Edirol UA25 24-bit soundcard with on-board anti-alias filtering were used for stimulus generation and experimental control. Following analog conversion at a 22.05-kHz sampling rate, modulated stimuli and continuous maskers when used were presented diotically through Etymotic ER-3A insert earphones with the listeners seated in a double-walled soundproof booth.
Speech Measures
Speech perception was evaluated in terms of discrimination of NU-6 words in quiet and sentences from the Quick Speech-in-Noise Test (QuickSIN;Killion et al. 2004) in the presence of four-talker babble. Using a 50-item word list spoken by a male talker, NU-6 words were presented at the subject’s most comfortable listening level with discrimination scores obtained for the left and right ears separately. QuickSIN testing was conducted with diotic presentation. Following QuickSIN protocol, sentence level was 70 dB HL if the listener’s PTA was 45 dB HL or less; otherwise level was adjusted to one judged as “loud, but ok.” Spoken by a female talker, each QuickSIN list contains six sentences in the presence of the same four-talker babble used in the psychoacoustic conditions. Across the six sentences of each list, the SNR decreases in 5-dB steps from 25 to 0 dB. Based on the number of key words correctly repeated, results are converted to the metric SNR Loss, the estimated SNR needed for 50% correct relative to the performance of normal-hearing listeners. For each subject, results were obtained on four QuickSIN sentence lists to allow for estimation of the intelligibility-function slope at P(c) of 0.5 along with measurement of the SNR Loss. To ensure that subjects understood the task, a separate practice list was administered before scored testing. Speech testing was conducted in a double-walled soundproof booth using Etymotic ER-3A insert earphones.
RESULTS
Stochastic FM
In data figures, box plots indicating performance of the younger listeners are shown along with individual results from both the older NH and HI participants. Threshold measures of Delta F are shown in Figure 6. With or without the speech-babble masker present (right and left figure panels, respectively), thresholds from both NH and HI older listeners were generally equal to or greater than the median thresholds of the young NH subjects. The one exception to this trend, a 63 year-old subject whose thresholds in both tasks were the lowest among all participants, had PTAs in both ears of less than 10 dB HL. With exclusion of this one subject, the threshold distributions of the NH and HI older listeners roughly coincide in both Delta F conditions. Comparing performance between the two Delta F conditions, a greater relative deficit due to the addition of the speech-babble masker was obtained from the older listeners. On average, masking increased thresholds by a factor of 1.31 and 1.84 for the younger and older listeners, respectively.
Fig. 6.

For the three subject groups, thresholds from the Delta F and Masked Delta F conditions in the left and right panels, respectively. The box plot at the left in each panel shows the median threshold from the younger listeners; the upper and lower box edges indicate the 25th and 75th percentiles with error bars showing the 10th and 90th percentiles. Individual results from the older NH and HI subjects are displayed as circles and triangles, respectively.
Analysis of variance (ANOVA) on the log transformed Delta F thresholds confirmed these observations. The effect of subject group was significant for the dependent variables Delta F [F(2,33)=6.248, p=.005] and Masked Delta F [F(2,33)=15.323, p<.001]. In both cases, post-hoc comparisons with Tukey’s Honestly Significant Difference (HSD) test showed no significant difference between the two groups of older listeners. In the Delta F condition, only the comparison between the older HI and younger participants was significant (p=.004), while both older groups were significantly different (p<.001) than younger participants in the Masked Delta F condition. To evaluate the effect of masking, a mixed-design ANOVA was performed using Delta F (with vs. without the masker present) as the within-subjects factor and age category (young vs. older) as the between-subjects factor. The within-subject effect of masking was significant [F(1,34)=25.197, p<.001] as were the factor age category [F(1,34)=19.835, p<.001] and the interaction between masking and age category [F(1,34)=4.988, p=.032].
In the SNRFM condition, thresholds from the older listeners were generally equal to or greater than the median threshold of the younger subjects (Fig. 7). Based on pilot results obtained from a subset of the younger participants, the mean discrimination threshold of −18 dB is roughly 10–20 dB above detection threshold. Thus, FM pattern discrimination can be quite robust at very low presentation levels. An ANOVA confirmed that for the SNRFM measure, the effect of subject group was significant [F(2,33)=18.836, p<.001] with post-hoc comparisons using Tukey’s HSD test showing significant differences only between the younger and the two older subject groups, in both cases with p<.001.
Fig. 7.

For the three subject groups, thresholds from the SNRFM condition. The median threshold from the younger listeners is indicated by the box plot to the left; the upper and lower box edges indicate the 25th and 75th percentiles with error bars showing the 10th and 90th percentiles. The circles and triangles show individual results from the older NH and HI subjects, respectively.
Results from the Duration conditions are shown in Figure 8. Across conditions, Duration Descending showed the most consistent effect of hearing loss among the older listeners (Fig. 8, left panel). In the Duration conditions, discrimination cues vary with stimulus duration. At longer durations, cues are based on following the pattern of frequency fluctuation, while at brief durations, differences in a global stimulus percept (e.g., timber or pitch) cue discrimination. For both the younger and older NH participants, the threshold range from roughly 5 to 130 ms in the Duration Descending condition may in part reflect differing ability to adjust listening strategy as the discrimination cues change. Beginning with an 11-ms stimulus duration, the Duration Ascending condition was run to obtain a better estimate of performance as a function of duration with results shown in the right panel of Figure 8. Between the Duration Descending and Duration Ascending conditions, the geometric mean of thresholds dropped by a factor of 4.5, 4.6, and 6.3 for the younger, older NH, and older HI subject groups, respectively. This result is consistent with better utilization of the short-duration global cues in the Duration Ascending condition. However, the threshold range across listeners in all subject groups remained large in the Duration Ascending condition, indicating that some listeners remained unable to use short-duration discrimination cues.
Fig. 8.

For the three subject groups, thresholds from the Duration Descending and Duration Ascending conditions in the left and right panels, respectively. The box plot at the left in each panel shows the median threshold from the younger listeners; the upper and lower box edges indicate the 25th and 75th percentiles with error bars showing the 10th and 90th percentiles. Individual results from the older NH and HI subjects are displayed as circles and triangles, respectively.
For both the Duration Descending and Duration Ascending conditions, ANOVAs on the log transformed Duration thresholds showed that the effect of subject group was not significant. To evaluate the effect of procedure in the Duration conditions, a mixed-design ANOVA was conducted which compared within-subject Duration Descending to Duration Ascending results with the between-subjects factor age category (young or older). The effect of procedure was significant [F(1,26)=71.544, p<.001] while age category was not, confirming the overall trend for lower thresholds in the Duration Ascending condition.
Speech Measures
Average NU-6 word discrimination in quiet, based on the between-ear average for the individual listeners, was close to ceiling with 98, 93, and 94% correct for the young, older NH, and older HI subject groups, respectively. In all but four cases, the between-ear difference in performance was four percentage points or less. Summary results from QuickSIN testing with the speech-babble masker are displayed in Figure 9. The lower panel shows the mean SNR Loss for the three subject groups with mean thresholds of −0.5, 0.83, and 4.75 dB for the young, older NH, and older HI listeners, respectively. An ANOVA showed that the effect of subject group was significant for SNR Loss [F(2,33)=12.947, p<.001] with Tukey’s HSD post-hoc comparisons indicating significant differences only between the performance of the older HI listeners and the younger (p<.001) and older NH (p=.007) subject groups.
Fig. 9.

QuickSIN results. Top panel: for the three subject groups, mean speech-in-noise intelligibility transformed into rationalized arcsine units (rau) as a function of SNR. The function fits are illustrative and do not represent the third-degree polynomials used to fit individual subject data (see text for details). Along the right axis, data points indicate the mean intelligibility-function slope at the 50% point of the individual subject data in units of percent change in performance per dB of SNR. Bottom panel: mean SNR Loss for the three subject groups with error bars representing 1 SD.
The top panel of Figure 9 shows the mean intelligibility functions for the three subject groups transformed into rationalized arcsine units (rau; Studebaker 1985). Along with indicating the between-group change in SNR needed to achieve a specific performance level, the slope of the intelligibility function appears shallowest for the older HI listeners. Following the approach of Wilson et al. (2007), a best-fit third-degree polynomial was used to estimate the function slope at the 50% point of the individual subject data. With performance always above 50% correct at all SNRs, results from three young NH listeners were excluded from this analysis. Estimated mean function slopes at the 50% point are shown along the right axis of the upper panel of Figure 9 in units of percent change in performance per dB of SNR. Mean function slopes were nearly identical at roughly 14% per dB change in SNR for the young and older NH listeners, with the mean slope slightly less than 10% per dB for the older HI group. An ANOVA on the arcsine transformed intelligibility-function slopes showed that the effect of subject group was significant [F(2,30)=7.533, p=.002] with Tukey’s HSD post-hoc comparisons indicating significant differences only between the performance of the older HI listeners and the younger (p=.004) and older NH (p=.006) subject groups.
Correlation Analysis
Experimental and clinical measures were submitted to a pair-wise Pearson correlation analysis with results shown in Table 1. With no past work indicating a beneficial effect of age or hearing loss on either FM or speech-in-noise abilities, one-tailed significance testing was used. The resampling method of Troendle (1995) was used to control for family-wise error with multiple hypothesis testing. In the iterative procedure, the data matrix was repeatedly shuffled with the minimum p value saved for each random ordering. Following 10,000 iterations, the proportion of times that these saved values were less than the p value of the original data was used as the p value adjusted for multiple comparisons. As a stepwise procedure across comparisons from highest to lowest correlation, the procedure was stopped once a correlation was no longer significant with the adjusted p value. Adjusted p values for significant correlations are shown as the lower entry in the cells of Table 1. For the clinical measures, PTA was based on between-ear averages for each listener, while the variable 4-kHz threshold used from each participant the better of the left- or right-ear audiometric threshold. Correlations were significant for both PTA and 4-kHz threshold with Delta F, Masked Delta F, SNRFM, and QuickSIN SNR Loss. For the Duration conditions, the only significant correlation was between Duration Descending and 4-kHz threshold. When using partial correlation to control for lower frequency hearing thresholds as estimated by the PTA, 4-kHz threshold remained significantly correlated with the SNRFM (r=.386, p=.022) and Masked Delta F (r=.403, p=.017) thresholds. A high correlation between 4-kHz thresholds and listener age is commonly observed with an r of .819 (p<.001) obtained in the present work. This correlation suggests that the basis of the relationship between FM results and 4-kHz thresholds may not be high-frequency hearing sensitivity per se, but rather some other factor related to aging.
TABLE 1.
Pair-wise Pearson correlations among experimental and clinical measures
| Delta F | Masked Delta F |
SNRFM | Duration Descending |
Duration Ascending |
QSIN SNR Loss |
|
|---|---|---|---|---|---|---|
| Age | .466 .020 |
.663 <.001 |
.743 <.001 |
.220 | .112 | .576 .002 |
| PTA | .399 .046 |
.534 .005 |
.625 <.001 |
.348 | .226 | .810 <.001 |
| 4-kHz Threshold |
.451 .022 |
.627 <.001 |
.693 <.001 |
.406 .044 |
.202 | .694 <.001 |
| QSIN SNR Loss |
.200 | .281 | .489 .013 |
.189 | .340 | 1 |
In individual cells, Pearson correlation with adjusted p value underneath in cases where the one-tailed correlation was significant at the 0.05 level or lower. p values were corrected for multiple comparisons with an iterative resampling procedure (see text for additional details). Number of subjects was 36 for all measures except Duration Ascending for which data were obtained from only 28 listeners with missing data from the younger subject group.
Listener PTA showed the highest correlation with QuickSIN SNR Loss (r=.810, p<.001), a result consistent with SNR Loss being the only measure that showed a significant difference between the older NH and HI subject groups. For listener age, the highest correlation was with the SNRFM results (r=.743, p<.001). When controlling for effect of PTA with partial correlation, age remained significantly correlated with only the two FM measures that used the speech-babble masker [SNRFM (r=.534, p=.001); Masked Delta F (r=.471, p=.004)]. The effect of hearing loss was further evaluated using a between-subjects analysis of covariance (ANCOVA) with age category (young and older) as a fixed factor and PTA as a covariate. In line with correlation results, the effect of covariate PTA was significant only for QuickSIN SNR Loss [F(1,33)=39.526, p<.001, and the effect of age category was significant only for the SNRFM [F(1,33)=12.137, p=.001] and Masked Delta F [F(1,33)=12.803, p=.001] measures. Results thus indicate that the two measures of FM processing in the presence of interference provide information regarding the effect of aging not obtained with the other procedures.
In Table 1, a significant correlation between the SNRFM thresholds and QuickSIN performance (r=.489, p=.013) suggests that an FM processing deficit may contribute to difficulty with speech-in-noise intelligibility. The absence of a significant relationship between the QuickSIN SNR Loss and either Delta F or Masked Delta F indicates a limitation on the relationship between FM and speech-in-noise processing. For the metrics used, the relationship was most apparent when incorporating the low sensation levels of the modulated stimuli in the SNRFM condition.
DISCUSSION
The ability to discriminate stochastic FM was investigated for both young and older listeners with thresholds measured in terms of peak frequency excursion or ΔF, stimulus duration, and SNR in the presence of a four-talker speech-babble masker. Experimental protocol was clinically oriented and did not attempt estimate asymptotic performance levels. Results showed a significant effect of age, but not of hearing loss among the older listeners, in the Masked Delta F and SNRFM conditions, the only two psychoacoustic conditions that used a speech-babble masker. These were also the two conditions for which performance was significantly correlated with listener age when controlling for effect of PTA. These common effects in the two masking conditions were obtained despite the 16-dB difference in masker level. Previous studies have shown that thresholds for detection of periodic low-rate FM are elevated for both elderly and hearing-impaired listeners ( Moore & Skrodzka 2002; Buss et al. 2004; He et al. 2007; Strelcyk & Dau 2009). Though FM detection is requisite, FM pattern discrimination must also underlie any robust contribution to speech processing. Souza et al. (2010) recently reported that for subjects with normal to near-normal hearing thresholds, discrimination of voicing intonation patterns, represented as a monotonic frequency glide over 620 ms, was poorer among older (mean age 70 yrs) than younger (mean age 24 yrs) listeners. The fluctuation of the stochastic FM of the current work is nonmonotonic, extending the finding of an effect of age to more complex pattern discrimination.
The correlation analysis indicated a significant relationship between 4-kHz thresholds and both the Masked Delta F and SNRFM results, even when controlling for effect of PTA. With a 1-kHz FM carrier frequency and ΔF at most 400 Hz, the correlation between the FM measures and auditory thresholds at 4 kHz was not expected. The result is consistent with the findings of Lorenzi et al. (2009) and Strelcyk and Dau (2009) that when accompanied by a high-frequency hearing loss, processing of temporal fine structure can be impaired in a lower frequency region of normal hearing sensitivity. However, the high correlation between age and 4-kHz thresholds suggests that for the current work, the basis of the relationship between FM results and 4-kHz thresholds may be some factor related to aging other than hearing sensitivity. Detection of low-rate FM in part depends on temporal information conveyed by the pattern of neural phase locking (Moore & Sek 1996; Moore and Skrodzka 2002). Assuming a similar basis for supra-threshold discrimination of low-rate FM, a decline in performance due to a deficit in phase locking is consistent with age-related neural degeneration (Frisina 2001; Clinard et al. 2010).
In the Masked Delta F condition, psychoacoustic performance was measured in the presence of continuous four-talker speech-babble interference at an SNR of 16 dB. Masker type was selected to approximate a common type of interference of real-world listening situations. The high SNR was used to minimize energetic masking so effects would relate more directly to factors such as attention or distraction. Results showed a significant effect of age group on the extent of masking with no effect of a mild-to-moderate hearing loss among the older participants.
The effect of listener age was not significant for the two measures of FM discrimination based on stimulus duration. In the Duration conditions, contrasting modulators used on a given trial were time reversals of one another to eliminate differences in the long-term amplitude spectra. Therefore discrimination could not be based on integration over the entire stimulus duration. Phase-spectra differences, the distinction that remains when contrasting modulators have identical long-term amplitude spectra, lead to differences in arrival time by frequency for the two stimuli. To serve as a discrimination cue, auditory processing must in some way window stimuli to preserve arrival-time differences. Once stimulus duration is shorter than the processing window, discrimination is no longer possible. Working with Huffman sequences which differ in terms of phase but not amplitude spectra, Patterson and Green (1970) assessed auditory temporal acuity in terms of the minimum stimulus duration that allowed for discrimination. Results indicated that highly trained listeners were able to discriminate stimuli as brief as 2.5 ms. In the present work, median Duration Ascending thresholds from untrained NH young and older listeners were 6.1 and 6.2 ms, respectively. Effect of training on discrimination of transient stimuli was observed by Jesteadt et al. (1976). For listeners with an asymmetric hearing loss between ears, Jesteadt et al. also reported that performance was often better in the ear with the greater loss. The median Duration Ascending threshold from the older HI participants was 8.2 ms, highest of all groups. However, effect of subject group was not significant in the current study. Results thus indicate that older listeners often show normal temporal resolution based on the Duration Ascending metric.
Results from QuickSIN testing indicated an effect of hearing loss but not of listener age. Comparison of present results to other measures of speech-reception thresholds (SRTs) from the literature is complicated by differences in test material, masker type, level, procedure, and criterion for group selection (Dubno et al. 1984; George et al. 2007). With sentences from the Speech Perception in Noise test, the effect of age among listeners with normal to near-normal hearing thresholds on SRTs can be roughly 2–3 dB (Dubno et al. 1984; Gelfand et al. 1988), a range just slightly larger than the current 1.33 dB difference. Using QuickSIN sentences and maskers as in the present study but a higher presentation level of 100 dB SPL, Wilson et al. (2007) evaluated the effect of hearing loss on performance, with average audiometric thresholds and age range of HI participants roughly coinciding to the older HI subject group of the current work. Between the younger NH and older HI listeners, the average SRT increased 7.9 dB in the study of Wilson et al as compared to the 5.25 change in SNR Loss in the present work.
Along with the effect on SNR Loss, hearing loss was associated with a shallower slope of the speech-intelligibility function. At the 50% correct point, both younger and older NH listeners showed a mean slope of roughly 14% per dB of SNR, while the mean slope for the older HI participants was 10% per dB. This difference in slope agrees well with the 6.1% per dB difference reported by Wilson et al. (2007) between comparable subject groups. In general, a decrease in psychometric-function slope indicates an increase in processing variance from either noise or distortion. Plomp (1978) argued that hearing impairment shows combined effects of attenuation and distortion. As with speech perception, distortion in auditory processing would impair the ability to discriminate FM stimuli. Results showed that the effect of hearing loss was not significant in the FM measures obtained from the older participants, suggesting that possible distortion associated with hearing loss was not a factor affecting psychoacoustic results from these listeners. It thus appears that possible involvement of distortion in the QuickSIN results of the older HI listeners does not reflect a change in overall processing ability of low-rate stochastic FM.
Results showed a significant correlation between performance in the SNRFM condition and masked speech perception as measured by QuickSIN SNR Loss. For young to middle-age listeners who varied in degree of hearing loss, Buss et al. (2004) reported significant correlations between speech perception and measures of 2-Hz FM detection. For a subject group composed of primarily older hearing-impaired listeners, Strelcyk and Dau (2009) found that speech reception in the presence of a two-talker babble masker was significantly correlated with 2-Hz FM detection in which low-rate amplitude modulation was also imposed on the stimulus carrier. Working with subjects that included both young and older normal-hearing and hearing-impaired listeners, Hopkins & Moore (2011) found a significant relationship between SRTs in modulated noise and the ability to discriminate between complex tones which differed only in terms of temporal fine structure but not envelope. The relationship between speech perception and temporal fine-structure processing has also been evaluated in studies which measured the intelligibility of speech stimuli processed to control fine-structure cues. Results from this work indicated that the ability to use the temporal fine-structure cues of speech is reduced or abolished in most listeners with a mild-to-moderate cochlear hearing loss irrespective of age, although younger listeners tended to show better ability to use these cues than did older listeners (Lorenzi et al. 2006; Hopkins et al. 2008; Ardoint et al. 2010). Hearing-impaired listeners showing best speech intelligibility in a non-stationary noise background also showed residual ability to use temporal fine-structure speech cues (Lorenzi et al. 2006). Individual differences in this residual ability accounted for about 70% of the variance in speech intelligibility scores in fluctuating noise. If the contribution of temporal fine-structure cues to speech perception is most evident in masking conditions, present results suggest that the difficulty experienced by older listeners with speech-in-noise processing may in part relate to diminished ability to process slower fine-structure modulation at low SNRs.
In summary, results indicate that measures of stochastic FM processing show effects of listener age. Among older listeners with up to a moderate hearing loss, degree of loss did not significantly affect performance. Furthermore, the relationship between QuickSIN performance and the SNRFM thresholds suggests that a FM processing deficit may hinder speech-in-noise intelligibility. Most hearing aids include some form of amplitude compression to restrict dynamic range. The analysis of Sheft et al. (2008) conducted with vocoded speech signals demonstrated that any alteration in the fidelity of temporal-envelope transmission also affects the fidelity of temporal fine-structure transmission. This suggests strongly that though hearing-aid compression is set by temporal-envelope values, it affects the fidelity of transmission of the temporal fine-structure cues of speech. Correlations obtained in the present study indicate that evaluation of hearing-aid compression algorithms needs to consider impact on the FM of speech. Current work is developing a clinically feasible approach for assessment of the SNR measure of stochastic FM processing. Along with offering a fuller picture of the auditory difficulties experienced in an adverse noisy environment, the procedure will potentially help in determining appropriate settings for prosthetic devices and in monitoring rehabilitation progress.
ACKNOWLEDGMENTS
The authors thank Erica Hegland for her assistance with data collection.
This work was supported by NOHR and NIH-NIDCD (R15 DC011916 and R03 DC008676). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institute on Deafness and Other Communication Disorders or the National Institutes of Health.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
The functions shown in Figure 1 were derived by first passing the stimuli through a compressive-dynamic gammachirp filterbank simulating peripheral auditory filtering (see Irino & Patterson 2006). The fine-structure and envelope modulations of each channel were separately derived. The FM function was the temporal variation from mean value of the time derivative of the unwrapped instantaneous phase, and the envelope function was the magnitude of the analytic signal (see Sheft et al. 2008 for additional details). Finally, the two modulation functions were separately averaged across channels.
With narrowband noise modulators, both fine-structure and envelope periodicities of the modulator contribute to average rate of FM. The relationship between modulator bandwidth and average FM rate was determined empirically by analyzing 5,000 stimulus samples at each of the modulator bandwidths used in the Sheft and Lorenzi (2008) study.
REFERENCES
- ANSI (American National Standards Institute) Specifications for audiometers (ANSI S3.6-2004. New York: ANSI; 2004. [Google Scholar]
- Anstis S, Saida S. Adaptation to auditory streaming of frequency-modulated tones. J Exp Psych Human Percept Perf. 1985;11:257–271. [Google Scholar]
- Ardoint M, Sheft S, Fleuriot P, et al. Perception of temporal fine-structure cues in speech with minimal envelope cues for listeners with mild-to-moderate hearing loss. Int J Audiol. 2010;49:823–831. doi: 10.3109/14992027.2010.492402. [DOI] [PubMed] [Google Scholar]
- Binns C, Culling JF. The role of fundamental frequency contours in the perception of speech against interfering speech. J Acoust Soc Am. 2007;122:1765–1776. doi: 10.1121/1.2751394. [DOI] [PubMed] [Google Scholar]
- Bregman A. Auditory Scene Analysis. Cambridge MA: MIT Press; 1990. [Google Scholar]
- Buss E, Hall JW, Grose JH. Temporal fine-structure cues to speech and pure tone modulation in observers with sensorineural hearing loss. Ear Hear. 2004;25:242–250. doi: 10.1097/01.aud.0000130796.73809.09. [DOI] [PubMed] [Google Scholar]
- CHABA (Committee on Hearing, Bioacoustics, and Biomechanics) Speech understanding and aging. J Acoust Soc Am. 1988;83:859–895. [PubMed] [Google Scholar]
- Clinard CG, Tremblay KL, Krishnan AR. Aging alters the perception and physiological representation of frequency: Evidence from human frequency-following response recordings. Hear Res. 2010;264:48–55. doi: 10.1016/j.heares.2009.11.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins LM, Wakefield GH, Feinman GR. Temporal pattern discrimination and speech recognition under electrical stimulation. J Acoust Soc Am. 1994;96:2731–2737. doi: 10.1121/1.411279. [DOI] [PubMed] [Google Scholar]
- Cutler A. Phoneme-monitoring reaction time as a function of preceding intonation contour. Percept Psychophys. 1976;20:55–60. [Google Scholar]
- Divenyi PL, Haupt KM. Audiological correlates of speech understanding deficits in elderly listeners with mild-to-moderate hearing loss. II. Correlation analysis. Ear Hear. 1997;18:100–113. doi: 10.1097/00003446-199704000-00002. [DOI] [PubMed] [Google Scholar]
- Dorman MF, Cutting JE, Raphael LJ. Perception of temporal order in vowel sequences with and without formant transitions. J Exp Psych Hum Percept Perf. 1975;104:121–129. [PubMed] [Google Scholar]
- Dorman MF, Marton K, Hannley MT, et al. Phonetic identification by elderly normal and hearing-impaired listeners. J Acoust Soc Am. 1985;77:664–670. doi: 10.1121/1.391885. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Dirks DD, Morgan DE. Effects of age and a mild hearing loss on speech recognition in noise. J Acoust Soc Am. 1984;76:87–96. doi: 10.1121/1.391011. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Lee F, Matthews LJ, et al. Longitudinal changes in speech recognition in older persons. J Acoust Soc Am. 2008;123:462–475. doi: 10.1121/1.2817362. [DOI] [PubMed] [Google Scholar]
- Elliott LL, Hammer MA, Scholl ME, et al. Age differences in discrimination of simulated single-formant frequency transitions. Percept Psychophys. 1989;46:181–186. doi: 10.3758/bf03204981. [DOI] [PubMed] [Google Scholar]
- Flanagan JL, Golden RM. Phase vocoder. Bell System Tech J. 1966;45:1493–1509. [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Age effects on duration discrimination with simple and complex stimuli. J Acoust Soc Am. 1995;98:3140–3145. doi: 10.1121/1.413803. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S, Friedman SA. Effects of age and sequence presentation rate on temporal order recognition. J Acoust Soc Am. 2006;120:991–999. doi: 10.1121/1.2214463. [DOI] [PubMed] [Google Scholar]
- Folstein MF, Folstein SE, McHugh PR. "Mini-mental state" A practical method for grading the cognitive state of patients for the clinician. J Psychiatr Res. 1975;12:189–198. doi: 10.1016/0022-3956(75)90026-6. [DOI] [PubMed] [Google Scholar]
- Fox RA, Wall LG, Gokcen J. Age-related differences in processing dynamic information to identify vowel quality. J Speech Hear Res. 1992;35:892–902. doi: 10.1044/jshr.3504.892. [DOI] [PubMed] [Google Scholar]
- Frisina RD. Possible neurochemical and neuroanatomical bases of age-related hearing loss—presbycusis. Seminars Hear. 2001;22:213–225. [Google Scholar]
- Gelfand SA, Ross L, Miller S. Sentence reception in noise from one versus two sources: Effects of aging and hearing loss. J Acoust Soc Am. 1988;83:248–256. doi: 10.1121/1.396426. [DOI] [PubMed] [Google Scholar]
- George ELJ, Zekveld AA, Kramer SE, et al. Auditory and nonauditory factors affecting speech reception in noise by older listeners. J Acoust Soc Am. 2007;121:2362–2375. doi: 10.1121/1.2642072. [DOI] [PubMed] [Google Scholar]
- Gifford RH, Bacon SP, Williams EJ. An examination of speech recognition in a modulated background and of forward masking in younger and older listeners. J Speech Lang Hear Res. 2007;50:857–864. doi: 10.1044/1092-4388(2007/060). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon-Salant S, Fitzgibbons PJ. Temporal factors and speech recognition performance in young and elderly listeners. J Speech Hear Res. 1993;36:1276–1285. doi: 10.1044/jshr.3606.1276. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Fitzgibbons PJ. Profile of auditory temporal processing in older listeners. J Speech Lang Hear Res. 1999;42:300–311. doi: 10.1044/jslhr.4202.300. [DOI] [PubMed] [Google Scholar]
- Grose JH, Mamo SK. Processing of temporal fine structure as a function of age. Ear Hear. 2010;31:755–760. doi: 10.1097/AUD.0b013e3181e627e7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grose JH, Mamo SK, Hall JW. Age effects in temporal envelope processing: Speech unmasking and auditory steady state responses. Ear Hear. 2009;30:568–575. doi: 10.1097/AUD.0b013e3181ac128f. [DOI] [PMC free article] [PubMed] [Google Scholar]
- He N, Mills JH, Dubno JR. Frequency modulation detection: Effects of age, psychophysical method, and modulation waveform. J Acoust Soc Am. 2007;122:467–477. doi: 10.1121/1.2741208. [DOI] [PubMed] [Google Scholar]
- He N, Mills JH, Ahlstrom JB, et al. Age-related differences in the temporal modulation transfer function with pure-tone carriers. J Acoust Soc Am. 2008;124:3841–3849. doi: 10.1121/1.2998779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer KS, Vargo M. Speech recognition and temporal processing in middle-aged women. J Am Acad Audiol. 2009;20:264–271. doi: 10.3766/jaaa.20.4.6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hopkins K, Moore BCJ. The effects of age and cochlear hearing loss on temporal fine structure sensitivity, frequency selectivity, and speech reception in noise. J Acoust Soc Am. 2011;130:334–349. doi: 10.1121/1.3585848. [DOI] [PubMed] [Google Scholar]
- Hopkins K, Moore BCJ, Stone MA. Effects of moderate cochlear hearing loss on the ability to benefit from temporal fine structure information in speech. J Acoust Soc Am. 2008;123:1140–1153. doi: 10.1121/1.2824018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Houtgast T, Steeneken HJM. A review of the MTF concept in room acoustics and its use for estimating speech intelligibility in auditoria. J Acoust Soc Am. 1985;77:1069–1077. [Google Scholar]
- Humes LE, Christopherson L. Speech identification difficulties of hearing-impaired elderly persons: The contributions of auditory processing deficits. J Speech Hear Res. 1991;34:686–693. doi: 10.1044/jshr.3403.686. [DOI] [PubMed] [Google Scholar]
- Irino T, Patterson RD. A dynamic compressive gammachirp auditory filterbank. IEEE Trans Audio Speech Lang Process. 2006;14:2222–2232. doi: 10.1109/TASL.2006.874669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jesteadt W, Bilger RC, Green DM, et al. Temporal acuity in listeners with sensorineural hearing loss. J Speech Hear Res. 1976;19:357–370. doi: 10.1044/jshr.1902.357. [DOI] [PubMed] [Google Scholar]
- Kidd G, Mason CR, Richards VM, et al. Informational masking. In: Yost WA, Popper AN, Fay RR, editors. Auditory Perception of Sound Sources. New York: Springer Science+Business; 2008. pp. 143–189. [Google Scholar]
- Killion MC, Niquette PA, Gudmundsen GI, et al. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J Acoust Soc Am. 2004;116:2395–2405. doi: 10.1121/1.1784440. [DOI] [PubMed] [Google Scholar]
- Lackner JR, Goldstein LM. Primary auditory stream segregation of repeated consonant-vowel sequences. J Acoust Soc Am. 1974;56:1651–1652. doi: 10.1121/1.1903493. [DOI] [PubMed] [Google Scholar]
- Laures JS, Bunton K. Perceptual effects of a flattened fundamental frequency at the sentence level under different listening conditions. J Comm Dis. 2003;36:449–464. doi: 10.1016/s0021-9924(03)00032-7. [DOI] [PubMed] [Google Scholar]
- Levitt H. Transformed up-down methods in psychoacoustics. J Acoust Soc Am. 1971;49:467–477. [PubMed] [Google Scholar]
- Li N, Loizou PC. The contribution of obstruent consonants and acoustic landmarks to speech recognition in noise. J Acoust Soc Am. 2008;124:3947–3958. doi: 10.1121/1.2997435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lorenzi C, Gilbert G, Carn H, et al. Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proc Natl Acad Sci USA. 2006;103:18866–18869. doi: 10.1073/pnas.0607364103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lorenzi C, Debruille L, Garnier S, et al. Abnormal processing of temporal fine structure in speech for frequencies where absolute thresholds are normal (L) J Acoust Soc Am. 2009;125:27–30. doi: 10.1121/1.2939125. [DOI] [PubMed] [Google Scholar]
- Madden JP, Fire KM. Detection and discrimination of frequency glides as a function of direction, duration, frequency span, and center frequency. J Acoust Soc Am. 1997;102:2920–2924. doi: 10.1121/1.420346. [DOI] [PubMed] [Google Scholar]
- Miller SE, Schlauch RS, Watson PJ. The effects of fundamental frequency contour manipulations on speech intelligibility in background noise. J Acoust Soc Am. 2010;128:435–443. doi: 10.1121/1.3397384. [DOI] [PubMed] [Google Scholar]
- Moore BCJ, Sek A. Detection of frequency modulation at low rates: Evidence for a mechanism based on phase locking. J Acoust Soc Am. 1996;100:2320–2331. doi: 10.1121/1.417941. [DOI] [PubMed] [Google Scholar]
- Moore BCJ, Skrodzka E. Detection of frequency modulation by hearing-impaired listeners: Effects of carrier frequency, modulation rate, and added amplitude modulation. J Acoust Soc Am. 2002;111:327–335. doi: 10.1121/1.1424871. [DOI] [PubMed] [Google Scholar]
- Papoulis A. Random modulation: A review. IEEE Trans Acoust Speech Signal Process. 1983;31:96–105. [Google Scholar]
- Patterson JH, Green DM. Discrimination of transient signals having identical energy spectra. J Acoust Soc Am. 1970;48:894–905. doi: 10.1121/1.1912229. [DOI] [PubMed] [Google Scholar]
- Phillips SL, Gordon-Salant S, Fitzgibbons PJ, et al. Frequency and temporal resolution in elderly listeners with good and poor word recognition. J Speech Lang Hear Res. 2000;43:217–228. doi: 10.1044/jslhr.4301.217. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK, Souza PE. Effects of aging on auditory processing of speech. Int J Audiol. 2003;42:2S11–2S16. [PubMed] [Google Scholar]
- Plomp R. Auditory handicap of hearing impairment and the limited benefit of hearing aids. J Acoust Soc Am. 1978;63:533–549. doi: 10.1121/1.381753. [DOI] [PubMed] [Google Scholar]
- Plomp R, Mimpen AM. Speech reception threshold for sentences as a function of age and noise level. J Acoust Soc Am. 1979;66:1333–1342. doi: 10.1121/1.383554. [DOI] [PubMed] [Google Scholar]
- Remez RE, Rubin PE, Berns SM, et al. On the perceptual organization of speech. Pyschologic Rev. 1994;101:129–156. doi: 10.1037/0033-295X.101.1.129. [DOI] [PubMed] [Google Scholar]
- Sheft S, Lorenzi C. Discrimination of stochastic patterns of frequency modulation relevant to speech perception. J Acoust Soc Am. 2008;123:3711. [Google Scholar]
- Sheft S, Ardoint M, Lorenzi C. Speech identification based on temporal fine structure cues. J Acoust Soc Am. 2008;124:562–575. doi: 10.1121/1.2918540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Snell KB, Mapes FM, Hickman ED, et al. Word recognition in competing babble and the effects of age, temporal processing, and absolute sensitivity. J Acoust Soc Am. 2002;112:720–727. doi: 10.1121/1.1487841. [DOI] [PubMed] [Google Scholar]
- Souza P, Arehart K, Miller CW, et al. Effects of age on F0 discrimination and intonation perception in simulated electric and electroacoustic hearing. Ear Hear. 2010;32:75–83. doi: 10.1097/AUD.0b013e3181eccfe9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spitzer SM, Liss JM, Mattys SL. Acoustic cues to lexical segmentation: A study of resynthesized speech. J Acoust Soc Am. 2007;122:3678–3687. doi: 10.1121/1.2801545. [DOI] [PubMed] [Google Scholar]
- Stevens KN. Toward a model for lexical access based on acoustic landmarks and distinctive features. J Acoust Soc Am. 2002;111:1872–1891. doi: 10.1121/1.1458026. [DOI] [PubMed] [Google Scholar]
- Strelcyk O, Dau T. Relations between frequency selectivity, temporal fine-structure processing, and speech perception in impaired hearing. J Acoust Soc Am. 2009;125:3328–3345. doi: 10.1121/1.3097469. [DOI] [PubMed] [Google Scholar]
- Strouse A, Ashmead DH, Ohde RN, et al. Temporal processing in the aging auditory system. J Acoust Soc Am. 1998;104:2385–2399. doi: 10.1121/1.423748. [DOI] [PubMed] [Google Scholar]
- Studebaker GA. A “rationalized” arcsine transform. J Speech Hear Res. 1985;28:455–462. doi: 10.1044/jshr.2803.455. [DOI] [PubMed] [Google Scholar]
- Troendle JF. A stepwise resampling method of multiple hypothesis testing. J Am Stat Assoc. 1995;90:370–378. [Google Scholar]
- Thyer N, Mahar D. Discrimination of nonlinear frequency glides. J Acoust Soc Am. 2006;119:2929–2936. doi: 10.1121/1.2191587. [DOI] [PubMed] [Google Scholar]
- Trainor LJ, Trehub SE. Aging and auditory temporal sequencing: Ordering the elements of repeating tone patterns. Percept Psychophys. 1989;45:417–426. doi: 10.3758/bf03210715. [DOI] [PubMed] [Google Scholar]
- Tremblay KL, Piskosz M, Souza P. Effects of age and age-related hearing loss on the neural representation of speech cues. Clinical Neurophysiol. 2003;114:1332–1343. doi: 10.1016/s1388-2457(03)00114-7. [DOI] [PubMed] [Google Scholar]
- van Rooij JCGM, Plomp R. Auditive and cognitive factors in speech perception by elderly listeners. II: Multivariate analyses. J Acoust Soc Am. 1990;88:2611–2624. doi: 10.1121/1.399981. [DOI] [PubMed] [Google Scholar]
- Wilson RH, McArdle RA, Smith SL. An evaluation of the BKB-SIN, HINT, QuickSIN, and WIN materials on listeners with normal hearing and listeners with hearing loss. J Speech Lang Hear Res. 2007;50:844–856. doi: 10.1044/1092-4388(2007/059). [DOI] [PubMed] [Google Scholar]