

Abstract
In statistical modelling, it is often important to know how much parameter estimates are influenced by particular observations. An attractive approach is to re-estimate the parameters with each observation deleted in turn, but this is computationally demanding when fitting models by using Markov chain Monte Carlo (MCMC), as obtaining complete sample estimates is often in itself a very time-consuming task. Here we propose two efficient ways to approximate the case-deleted estimates by using output from MCMC estimation. Our first proposal, which directly approximates the usual influence statistics in maximum likelihood analyses of generalised linear models (GLMs), is easy to implement and avoids any further evaluation of the likelihood. Hence, unlike the existing alternatives, it does not become more computationally intensive as the model complexity increases. Our second proposal, which utilises model perturbations, also has this advantage and does not require the form of the GLM to be specified. We show how our two proposed methods are related and evaluate them against the existing method of importance sampling and case deletion in a logistic regression analysis with missing covariates. We also provide practical advice for those implementing our procedures, so that they may be used in many situations where MCMC is used to fit statistical models. Copyright © 2011 John Wiley & Sons, Ltd.
Keywords: Bayesian methods, generalised linear models, influence, Markov chain Monte Carlo
1. Introduction
Measures of leverage, influence and residuals are well-established tools in data analysis. Influence refers to how sensitive inferences are to the presence of particular observations and has proved its usefulness in maximum likelihood and least squares analyses.
It is therefore of interest to explore efficient algorithms for measuring influence in Bayesian analyses. Our interest in this was motivated by examples such as the sudden unexpected death in infancy (SUDI) analysis described in detail in Section 2. Here we wish to fit a standard model and examine the usual diagnostics such as influence and residuals, but some observations have missing covariates. A natural way to incorporate these observations into the analysis is to posit a model for the missing data and use maximum likelihood, but this is computationally intensive in all but the simplest of situations. In particular, this type of approach becomes increasingly difficult as the dimension of the integrals with respect to the missing data and the parameter space over which the maximisation is performed become large.
In order to overcome these difficulties, Markov chain Monte Carlo (MCMC) 1 can be used. MCMC is a powerful but computationally intensive method for fitting Bayesian models. It has the nice feature of yielding a random sample from the posterior distribution of the parameters of interest, from which means and credible intervals can be readily calculated. Although relatively simple models present few difficulties, the iteration times for complex and hence more realistic models may be long. If the mixing is poor, many iterations can be required to obtain estimates to within an appropriate degree of Monte Carlo error. Numerical estimation of influence by directly removing observations is therefore extremely tedious at best.
Here the simplest definition of influence will be taken as the difference between whole sample parameter estimates and case-deleted estimates, where each case-deleted estimate can be obtained by removing the observation in question and refitting the model 2. Although alternative measures of influence are possible, such as distances between posterior distributions of parameters of interest and the corresponding case-deleted distributions 3, these are not developed further here.
An established way to obtain influence statistics by using MCMC is importance sampling 3, 4. Here we take advantage of the relationship between the full data posterior distribution and case-deleted posterior distributions; their ratio is the likelihood of the removed observation. Hence, case-deleted posterior summaries can be obtained from weighted summaries of the sampled values by using the importance weight which is proportional to the reciprocal of the likelihood of the deleted observation evaluated at the simulated parameter values. Although this procedure is effective in many situations, it has its limitations. If the weights are very variable, then extremely large numbers of iterations may be needed; highly unusual and hence influential observations can provide surprisingly volatile weights. Hence, the problem is that, if deleting an observation causes a big change in an estimate, then the importance sampling influence statistic depends heavily on very few MCMC draws and sometimes only one. Perhaps the other main difficulty is that importance sampling requires the repeated computation of the observations' contributions to the likelihood. This becomes particularly computationally demanding as the model becomes more complex, and as a consequence importance sampling is unfeasible for very complicated models. These concerns provided additional motivation for our work which provides influence statistics that do not make any further likelihood-based computations and, in contrast to the alternatives, do not become more computationally intensive as the model complexity increases.
The routine evaluation of influence statistics was firmly established in the context of linear regression in Cook's seminal paper 5. As emphasised by Cook, ‘On the surface it might seem that any desirability this measure [a standardised measure of influence] has would be overshadowed by the computations necessary for the determination of n+ 1 regressions’. However, Cook shows how influence statistics can be obtained using only quantities calculated from the original regression involving the complete sample, and this also provides the foundation of approximate influence measures for the generalised linear model (GLM) introduced by Pregibon 6 and Williams 7. Hence, approximate case-deleted estimates can be obtained for any GLM without the need to fit additional regressions. In particular, the case-deleted influence statistics for GLMs given by Williams provide the justification for the procedures for obtaining these using MCMC developed here.
Although the use of MCMC to fit models with missing data provides our motivation, our methods may be used much more generally. We do however require that the likelihood dominates the prior, so that Bayesian and likelihood-based analyses provide inferences that are in good numerical, but not necessarily philosophical, agreement. This is to ensure that the established likelihood-based influence statistics are similar to their Bayesian counterparts. Here we use models that either are a standard single-level GLM or comprise a collection of connected GLMs, so we can ignore the prior specification asymptotically. Many Bayesian models are specified in this way, and this type of approach is emphasised by the models typically fitted using WinBUGS 8 (http://www.mrc-bsu.cam.ac.uk/bugs/winbugs/contents.shtml). ‘Vague’ or ‘uninformative’ priors help to ensure that their role is negligible but, provided the sample size is sufficiently large and truly dogmatic priors are avoided, are not required by the methods and models that follow. We return to the additional issues presented by more complicated models, such as hierarchical and mixed effects models, in the discussion.
The paper is set out as follows. In Section 2, we analyse the SUDI data. In Section 3, we review existing classical/frequentist methods for obtaining influence statistics for GLMs that lead us directly to our first proposal for obtaining these. In Section 4, we develop a procedure for obtaining influences using perturbed regression parameters, which, unlike our first proposal, does not require the form of the GLM to be specified. In Section 5, we describe the results from a simulation study, and in Section 6, we explain why our methods apply to models that comprise a collection of connected GLMs. In Section 7, we apply our methods to our example and compare the results with importance sampling and direct case deletion. We conclude in Section 8 with a discussion.
2. Sudden unexpected death in infancy
We will examine an illustrative analysis of a case control study exploring risk factors for SUDI in families with a previous SUDI 9. We have information for 137 Care of Next Infants (CONI) infants, of whom 33 are cases. This was analysed using logistic regression with key matching variables as covariates. WinBUGS 8, via the R package BRugs, was used to perform all MCMCs.
We found four variables to be especially good predictors of death in this sample by using a logistic model: Income Deprivation Affecting Children Index (DEP; a low score indicates high deprivation), mother's age in years (MAGE), birthweight in grams (BWT) and the number of previous terminations and miscarriages (TERMIN). All covariates were centred, and continuous variables were standardised, so we fit the model
| (1) |
From a standard complete case maximum likelihood analysis, we obtain the following (standard errors in parentheses): 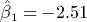 (0.55),
(0.55), 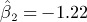 (0.47),
(0.47), 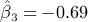 (0.29),
(0.29), 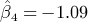 (0.33) and
(0.33) and 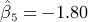 (0.58).
(0.58).
This complete case analysis discards 15% of the data: 21 observations have missing TERMIN values, four of which also have missing MAGE; DEP and BWT are complete. To include the incomplete cases, we fit model (1) jointly with models for the incomplete covariates. Specifically, we use a linear model for MAGE conditional on DEP and BWT and a log linear Poisson model for TERMIN on DEP, BWT and MAGE. We also use WinBUGS' truncation command to truncate TERMIN at 20. Without this, a few of the simulated TERMIN values can be unrealistically large, which has unfortunate implications for the model fit.
We place uniform priors on all regression parameters and a Gamma (0.001,0.001) prior on the precision of the variance in the linear model for MAGE. We used a burn in of 103 iterations and a further 105 iterations to make inferences. This MCMC took around 10 min on a Windows Terminals Server and provided 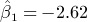 (0.54),
(0.54), 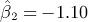 (0.42),
(0.42), 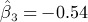 (0.28),
(0.28), 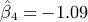 (0.33) and
(0.33) and 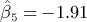 (0.60), where the estimates are given by the simulated sample means. This analysis adds further weight to the conclusion that the four variables considered are good predictors of death. We also obtained the correlation matrix of these estimates and therefore
(0.60), where the estimates are given by the simulated sample means. This analysis adds further weight to the conclusion that the four variables considered are good predictors of death. We also obtained the correlation matrix of these estimates and therefore 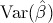 . We use the notation
. We use the notation 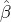 for both Bayesian and maximum likelihood estimates because we assume that they are in good numerical agreement. In particular, we use the hat notation to denote the posterior mean in all Bayesian analyses that follow, where we obtain these quantities as the sample mean of the simulated values from the MCMC.
for both Bayesian and maximum likelihood estimates because we assume that they are in good numerical agreement. In particular, we use the hat notation to denote the posterior mean in all Bayesian analyses that follow, where we obtain these quantities as the sample mean of the simulated values from the MCMC.
This analysis has successfully incorporated all data but makes it difficult to assess issues such as influence. With the additional assumptions made about the missing data, coupled with the fact that there is a large amount of variation in the observed covariates, there is the natural concern that a few unusual observations might be driving the inferences. We now turn our attention to methods for deriving influences using MCMC output and begin by considering the simpler case where there is just a single GLM and no missing data.
3. Case-deleted estimates for generalised linear models
We condition inference on X, an n by p matrix of explanatory variables. The observations, denoted by y, are an n by 1 vector of conditionally independent responses. We assume for now that the data are complete but return to the possibility of missing data in Sections 6 and 7. Denote μi = E[Y
i | Xi], where μi depends on the ith row of X, 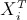 , through the linear predictor
, through the linear predictor 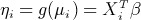 , where g(⋅) denotes the link function and β is the p by 1 vector of regression parameters. We assume that Y
i is a member of the exponential family with variance vi and dispersion parameter ϕ. Fitting the model in a Bayesian framework, and assuming that the likelihood dominates the prior, implies that the posterior means, medians and modes will all be close to the maximum likelihood point estimates, obtained using iterated weighted least squares 10, 11, with agreement as the sample size tends to infinity.
, where g(⋅) denotes the link function and β is the p by 1 vector of regression parameters. We assume that Y
i is a member of the exponential family with variance vi and dispersion parameter ϕ. Fitting the model in a Bayesian framework, and assuming that the likelihood dominates the prior, implies that the posterior means, medians and modes will all be close to the maximum likelihood point estimates, obtained using iterated weighted least squares 10, 11, with agreement as the sample size tends to infinity.
Williams 7 provides an approximation to the ith case-deleted maximum likelihood estimate, 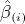 , obtained by using the complete sample estimate
, obtained by using the complete sample estimate 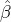 as an initial value and one step of the weighted least squares algorithm:
as an initial value and one step of the weighted least squares algorithm:
| (2) |
where 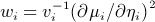 , W = diag(wi), ri denotes the residual (yi −μi) and hi is the ith diagonal element of the ‘hat’ matrix H = W1/2X(XTWX)−1XTW1/2; all terms on the right-hand side are evaluated at the complete sample estimates. Let θi denote the canonical parameter for the regression. The density of yi is exp((b(θi) + yiθi)/ϕ+ c(yi,ϕ)), where μi = −b′ (θi) and vi = −ϕb″(θi). Furthermore, the matrix
, W = diag(wi), ri denotes the residual (yi −μi) and hi is the ith diagonal element of the ‘hat’ matrix H = W1/2X(XTWX)−1XTW1/2; all terms on the right-hand side are evaluated at the complete sample estimates. Let θi denote the canonical parameter for the regression. The density of yi is exp((b(θi) + yiθi)/ϕ+ c(yi,ϕ)), where μi = −b′ (θi) and vi = −ϕb″(θi). Furthermore, the matrix 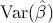 is approximately (XTWX)−1.
is approximately (XTWX)−1.
We suggest omitting the term involving hi in (2). The sum of the positive hi equals the number of regression parameters p, and we assume that the sample size n is much greater than p. Hence, although the relative magnitudes of hi play an important role in determining the observations' leverages, they are much less important when obtaining influence statistics using (2); (1 −hi) ≍ 1 for all i in large samples with no grossly outlying values. With this simplification and substitution of ∂μi/∂ηi = ∂θi/∂ηi ×∂μi/∂θi, where ∂μi/∂θi = vi/ϕ, Williams' formula (2) becomes
| (3) |
This further approximation is useful as we routinely obtain 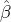 and
and 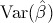 when fitting the model to the full dataset. In particular, for the SUDI data, we have already obtained
when fitting the model to the full dataset. In particular, for the SUDI data, we have already obtained 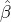 and
and 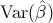 as described and reported in Section 2.
as described and reported in Section 2.
Any procedure for obtaining the rest of the right-hand side of (3) may be used to provide approximate case-deleted estimates. In particular, we can obtain influence statistics, 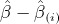 , directly from (3). If the canonical link is used, ∂θi/∂ηi and (3) simplifies further.
, directly from (3). If the canonical link is used, ∂θi/∂ηi and (3) simplifies further.
3.1. Our first proposal
Assuming a particular GLM, and that the impact of the prior specification is negligible, we propose additionally defining and storing the simulated values of
when running the MCMC. The derivatives ∂θi/∂ηi can be evaluated in terms of ηi and are unity if a canonical link has been adopted. Hence, the δi are easily computed in terms of the covariates, β and ϕ. Replacing δi with its estimate (the mean of the simulated values) from the MCMC in (3), and 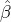 and
and 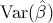 with theirs, immediately yields an approximate influence for the ith observation. All of the unobserved quantities that we define in this article are evaluated at every iterate of the MCMC, including derivatives, and so all of these vary between MCMC draws, but only the estimates
with theirs, immediately yields an approximate influence for the ith observation. All of the unobserved quantities that we define in this article are evaluated at every iterate of the MCMC, including derivatives, and so all of these vary between MCMC draws, but only the estimates 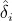 ,
, 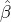 and
and 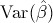 are used to compute influence statistics in (3) when using our first proposal. An assessment of the MC error for
are used to compute influence statistics in (3) when using our first proposal. An assessment of the MC error for 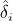 is equally important, but just as straightforward, as for
is equally important, but just as straightforward, as for 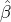 when obtaining influence statistics in this way.
when obtaining influence statistics in this way.
4. Obtaining influence statistics using perturbations
Our first proposal avoids any further evaluation of the likelihood and so can be expected to be more computationally efficient than importance sampling but requires the form of the GLM to be known. In this section, we propose a second method based on perturbing the regression parameters. Although we use the theory of GLMs to justify the procedure, ultimately we use just the variance/covariance matrix of the complete sample point estimates and the posterior means of the perturbations.
We will define an n by p random matrix ε of ‘perturbations’ and replace the jth regression coefficient in the model, for the ith observation, by βij = βj + εij. The entries εij are to be given independent (of each other, β and ϕ) normal priors with mean 0. Otherwise, the regression is to be fitted using MCMC in the usual way. This essentially introduces a random effect component (over observations) on the regression parameters. By making the prior precisions of the random perturbations extremely large, we obtain approximately the same estimates 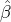 and
and 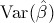 as in the usual perturbation-free regression model. We use the quantities σij to denote the prior standard deviations of εij.
as in the usual perturbation-free regression model. We use the quantities σij to denote the prior standard deviations of εij.
We next show in the case of a GLM that the posterior distributions of the εij relate to influential outcomes in the model. The intuition is that, if an observation is directly influential for a particular parameter, then the corresponding posterior εij distribution will move further from zero than its less influential counterparts, reflecting the ‘pull’ or influence that this observation exerts on the fitted model.
4.1. The mathematical consequences of introducing the perturbations
Let 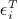 denote the ith row of the perturbation matrix. With the assumption that each of the n observations, conditional on all εij, β and ϕ, are independent (equivalent to assuming that they are exchangeable in the original model),
denote the ith row of the perturbation matrix. With the assumption that each of the n observations, conditional on all εij, β and ϕ, are independent (equivalent to assuming that they are exchangeable in the original model),
| (4) |
Note that we include the prior P(β,ϕ) for completeness, but we assume that its role is negligible in practice. We show in the Appendix that, provided the prior perturbation variances (denoted by 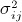 ) are made sufficiently small, the posterior mean of εij is given by
) are made sufficiently small, the posterior mean of εij is given by 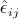 , where
, where
| (5) |
Xij denotes the jth entry of 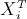 , and all quantities are on the right-hand side of (5) are evaluated at their posterior modes.
, and all quantities are on the right-hand side of (5) are evaluated at their posterior modes.
4.2. An approximation
We assume that the magnitude of the posterior mode of si is small in relation to that of ri. We can check this, provided that the form of the GLM is known, as shown for our example in Section 7. As 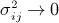 , si → 0, and we can ignore si. Hence,
, si → 0, and we can ignore si. Hence,
| (6) |
where δij is the jth entry in δi and is evaluated at full sample estimates in exactly the same way as in Williams' approximation for case-deleted estimates. For models where the variance vi is unbounded, extra care must be taken to ensure that si is small in relation to the residuals because si is linear in vi. For example, for datasets with large Poisson counts, very small 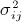 may be required to ensure that we can ignore si in this way.
may be required to ensure that we can ignore si in this way.
We can therefore obtain the term δi ≈ {∂θi/∂ηi}(Xiri/ϕ) using MCMC by adding the perturbations and monitoring the simulated εi or equivalently by defining the random variables 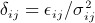 and monitoring the δi. With the combination of (6) and (3), the case-deleted estimates are
and monitoring the δi. With the combination of (6) and (3), the case-deleted estimates are
from which we can obtain the influences, 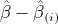 .
.
4.3. Implementation and Monte Carlo error
A practical issue is that, although it is possible to implement this method in a single stage as presented above, this is computationally demanding and frequently results in ‘trap errors’ in WinBUGS. We suggest a two-stage procedure that avoids these difficulties in practice. In the first stage, the original model is fitted without perturbations in the usual way in order to obtain 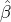 ,
, 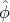 and
and 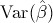 .
.
In the second stage, to simplify the MCMC algorithms, we suggest constraining β and ϕ to their estimates from the first stage and then introducing the perturbations. With β and ϕ fixed in this way, the posterior for the ε vectors becomes (4) with P(β,ϕ) = 1 and P(yi | εi,β,ϕ) replaced by 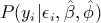 , and a similar
, and a similar 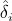 is obtained. This simplification is made purely for computational convenience because suitable
is obtained. This simplification is made purely for computational convenience because suitable 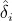 are evaluated regardless of whether a one-stage or a two-stage procedure is adopted.
are evaluated regardless of whether a one-stage or a two-stage procedure is adopted.
Now that β and ϕ are to be held fixed in this second stage, the only observation which is used to update the prior of εi, and therefore δi, is yi. Hence, we can add the εi to a single observation (but to all regression coefficients) at a time, providing yi as the only observation, and run n additional analyses. In practice, we found it convenient and computationally efficient to add the perturbations in this manner, so that 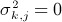 for all k ≠ i when obtaining the ith influence statistic. It is then a very simple task to update the vector εi
en bloc using a Gibbs' sampler, and, because there are no other random variables, we simulate directly from the posterior εi | yi and the simulated εi, and hence δi are independent. The resulting MCMC mixes and converges extremely rapidly.
for all k ≠ i when obtaining the ith influence statistic. It is then a very simple task to update the vector εi
en bloc using a Gibbs' sampler, and, because there are no other random variables, we simulate directly from the posterior εi | yi and the simulated εi, and hence δi are independent. The resulting MCMC mixes and converges extremely rapidly.
Monte Carlo error is inherent in the influences obtained using equation (6), which is a little more difficult to assess because of the indirect manner in which influence statistics are obtained when using the perturbations. The error in 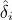 is approximately normally distributed, centred at the origin with
is approximately normally distributed, centred at the origin with 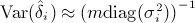 , where
, where 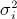 is the vector of
is the vector of 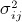 associated with observation i, and m is the number of iterations. This is because δi has a prior variance of
associated with observation i, and m is the number of iterations. This is because δi has a prior variance of 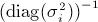 , and in the two-stage approach, the simulated δi are independent as explained above; the posterior variance of δi is therefore very similar to its prior. Hence, the Monte Carlo error of the influence of the ith observation, obtained as
, and in the two-stage approach, the simulated δi are independent as explained above; the posterior variance of δi is therefore very similar to its prior. Hence, the Monte Carlo error of the influence of the ith observation, obtained as 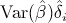 , is approximately
, is approximately 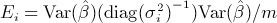 , so that a good indication of this Monte Carlo error can easily be obtained. Small values of
, so that a good indication of this Monte Carlo error can easily be obtained. Small values of 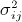 , which improve the accuracy of the approximations, also increase Monte Carlo error of the influence statistics, and some kind of tradeoff is needed in practice. If the perturbations are made quite large in this Monte Carlo error/approximation tradeoff, then they do not affect the primary analysis because this is performed in the first ‘perturbation free’ stage. Large entries of
, which improve the accuracy of the approximations, also increase Monte Carlo error of the influence statistics, and some kind of tradeoff is needed in practice. If the perturbations are made quite large in this Monte Carlo error/approximation tradeoff, then they do not affect the primary analysis because this is performed in the first ‘perturbation free’ stage. Large entries of 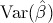 also have an unfortunate implication for the Monte Carlo error, so we suggest centring data before fitting models to reduce the variance of intercept terms.
also have an unfortunate implication for the Monte Carlo error, so we suggest centring data before fitting models to reduce the variance of intercept terms.
Although an advantage of this approach is that we merely require the model to be some (unspecified) GLM, the form of the GLM does have implications for how small the perturbations' variances have to be, which in turn has implications for m. In practice, it may be desirable to use a variety of small σij and large m in order to determine if reliable influence statistics have been obtained. Alternatively, and if known, the properties of the GLM in question can be examined and suitable criterion chosen. Despite this, the difficulties associated with choosing appropriate values of σij and m, so that both the approximations are accurate and the MC error is small, are a disadvantage of this method. Our first proposal may therefore be considered preferable in situations where the form of the GLM is known.
5. A simulation study
In order to assess the accuracy of the two proposed methods, we performed a simulation study. Here we simulated 100 datasets, each with n = 100 observations, by using the linear model Y ∼ N(β0 + β1x1 + β2x2,1), where β0 = 0, β1 = 1 and β3 = 3. Burn ins of 103 iterations were used. A further 105 iterations were used when implementing our first proposal, and m = 106 iterations were used when obtaining influences using the perturbations to ensure that these had stabilised.
By using normally distributed data, exact frequentist influence statistics 5 can be obtained which provide a ‘gold standard’ to compare our methods with. Because we used a linear model with a canonical link, our simulation study does not assess the accuracy of the approximations described in the Appendix; rather, it assesses how well our proposals work when these approximations are valid. Flat priors over very wide ranges were used for the β parameters, and a Gamma (0.001,0.001) prior was used for the precision of the variance.
Perturbations with σij = min(0.05/ | Xij |, 1) were used. These values have been found to ensure as large perturbations as possible are used, without compromising the accuracy of any approximation, when a canonical link is used in either a linear (with variance of around 1 or greater) or logistic regression involving a moderate number of parameters. For a GLM with a canonical link, the approximations described in the Appendix only require that values of 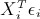 are small and the posterior modes of the si are small in relation to the residuals ri;
are small and the posterior modes of the si are small in relation to the residuals ri; 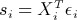 for a standard linear regression. For example, for p = 6 as in our main example, using | Xij | σij = 0.05 ensures that
for a standard linear regression. For example, for p = 6 as in our main example, using | Xij | σij = 0.05 ensures that 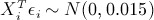 , so that probable values of
, so that probable values of 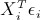 are small on the log odds scale. Numerical difficulties (‘trap errors’ in WinBUGS) can, however, be obtained if instead σij = 0.05/ | Xij | is used because this results in very large σij if covariates are close to zero and hence potential numerical instability. We suggest considering the use of σij = min(a/ | Xij |, b) in practice and have found a = 0.05 and b = 1 to be suitable for our examples.
are small on the log odds scale. Numerical difficulties (‘trap errors’ in WinBUGS) can, however, be obtained if instead σij = 0.05/ | Xij | is used because this results in very large σij if covariates are close to zero and hence potential numerical instability. We suggest considering the use of σij = min(a/ | Xij |, b) in practice and have found a = 0.05 and b = 1 to be suitable for our examples.
By combining the influence statistics across all simulated observations and datasets, we have 100 ×100 = 10 000 exact frequentist influence statistics for each regression parameter to compare our methods with. Both our proposed methods provided influence statistics that were in good agreement with these standard influence statistics. To give an indication of this, the coefficients of the least squares regression lines of the proposed influence statistics on the standard frequentist influence statistics are given for each parameter in Table 1, where the correlations between the proposed and standard influence statistics are also shown. The correlations are given to five decimal places so that they are distinguishable. The gradients of the regression lines are all between 0.95 and 0.99 suggesting that, compared with the exact frequentist influences, the proposed methods have a slight tendency to understate the influence of observations in this simulation study, but the overall picture is that all three methods are in good agreement. This tendency can be explained by the omittance of the (1 −hi) terms in (2), so this will lessen in larger samples.
Some results from the simulation study: c1 and m1 denote the intercepts and gradients of the least squares regression lines of influence statistics from our first proposal (Section 3.1) on the frequentist influence statistics; ρ1 denotes the correlation between these influence statistics. c2, m2 and ρ2 denote these same quantities for influences obtained using perturbations
| Parameter | c1 | m1 | ρ1 | c2 | m2 | ρ2 |
|---|---|---|---|---|---|---|
| β0 | 0.0000 | 0.9832 | 0.99979 | 0.0002 | 0.9761 | 0.99978 |
| β1 | 0.0000 | 0.9648 | 0.99964 | 0.0000 | 0.9578 | 0.99963 |
| β2 | 0.0000 | 0.9726 | 0.99962 | −0.0001 | 0.9655 | 0.99957 |
6. Obtaining influences for models comprising a collection of connected generalised linear models and in situations where there are missing data
The above analysis assumes a single GLM (with complete data), but as explained in the introduction, Bayesian models are commonly defined as a collection of connected GLMs. For example, the model for the SUDI data is such a collection of three GLMs, where the logistic regression of death on all the covariates is of real interest. There are also some missing data, which motivated our methods as we explained in the introduction.
Our methods are, however, immediately applicable to any GLM component within the full model. When implementing our first proposal (Section 3.1), we simply define δi = {∂θi/∂ηi}(Xiri/ϕ) for the GLM for which influences are desired and combine these with the resulting regression estimates, 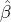 and
and 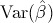 , for this same GLM. Neglecting any prior dependence between regression parameters that might have been specified, and if there is no missing data, the parameter estimates for each GLM are independent, and hence, the standard theory described in Section 3 ensures that influence statistics are obtained from our methods.
, for this same GLM. Neglecting any prior dependence between regression parameters that might have been specified, and if there is no missing data, the parameter estimates for each GLM are independent, and hence, the standard theory described in Section 3 ensures that influence statistics are obtained from our methods.
There is, however, the issue of missing covariates, which is ignored in the above argument. This is in fact of little concern provided the fraction of missing data is not too severe because our procedures average the influences over the posterior distributions of any missing data, and hence, suitable influences are obtained. This way of handling missing data may be considered an advantage of our methods. We may therefore handle missing data by entering them as ‘NA’ in the usual way when using WinBUGS, for example.
The perturbations are justified as they obtain δi in a different way and hence are also appropriate. Here we constrain all parameters to their estimated values after fitting the model comprising a collection of connected GLMs in the first stage and then add the perturbations to the GLM in question and monitor the simulated δi in the same manner as before.
7. Influence statistics in the sudden unexpected death in infancy analysis
We used the proposed methods, and the alternatives, to estimate the influences in the SUDI analysis. Our first proposal is suitable because the form of the model of interest (the logistic regression for the probability of death) is known, but our second proposal will also be used so that the results can be compared.
There are some missing covariates, but otherwise model (1) is a standard logistic regression. We therefore also monitored 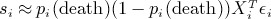 when adding the corresponding perturbation to ensure that the role of si is negligible in (5). The average absolute posterior mean of
when adding the corresponding perturbation to ensure that the role of si is negligible in (5). The average absolute posterior mean of 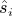 was just 0.0006, and its maximum was 0.0024. These are small values in relation to the residuals resulting from logistic regression, and we are reassured that approximation (6) is accurate. A burn in of 103 iterations was used. A further 105 iterations were used to obtain influences using our first proposal, and the influences from the perturbations-based method appeared to stabilise (small MC error) using m = 106. Perturbations with | Xij | σij = 0.05 were initially used, but some numerical difficulties were encountered for the three data points where the mother's age was 29 years; this corresponds to a covariate of zero in the regression as written above and, hence, with the decision to use | Xij | σij = 0.05, an infinite σij. In fact, covariates were centred at exact means rather than the approximate ones given above, but the three very large σij arising from this strategy presented problems. Following the procedure used in the simulation study to avoid these problems, σij was therefore reduced to unity when used in conjunction with the mother's age covariate for these three observations.
was just 0.0006, and its maximum was 0.0024. These are small values in relation to the residuals resulting from logistic regression, and we are reassured that approximation (6) is accurate. A burn in of 103 iterations was used. A further 105 iterations were used to obtain influences using our first proposal, and the influences from the perturbations-based method appeared to stabilise (small MC error) using m = 106. Perturbations with | Xij | σij = 0.05 were initially used, but some numerical difficulties were encountered for the three data points where the mother's age was 29 years; this corresponds to a covariate of zero in the regression as written above and, hence, with the decision to use | Xij | σij = 0.05, an infinite σij. In fact, covariates were centred at exact means rather than the approximate ones given above, but the three very large σij arising from this strategy presented problems. Following the procedure used in the simulation study to avoid these problems, σij was therefore reduced to unity when used in conjunction with the mother's age covariate for these three observations.
7.1. Comparison of methods
A gold standard influence analysis was performed by removing each of the 137 observations in turn. Only 20 000 iterations were used to obtain estimates for each case-deleted sample to reduce the time taken (to around 5 h). The resulting case-deleted influences were standardised (divided by the standard error of the corresponding complete sample parameter estimate) and are shown as solid points in Figure 1 for the first 20 observations, where standardised influences for β2 and β3 are shown in the top two panels and those for β4 and β5 are shown in the bottom two panels. The 95% intervals describing Monte Carlo uncertainty, from normal approximations, are only slightly wider than the solid points which can thus be taken to be accurate. Hollow circles show the corresponding estimates obtained by importance sampling 3, 4; triangles show these from our first proposal (Section 3.1), and diamonds show influences obtained using perturbations (our second proposal).
Figure 1.
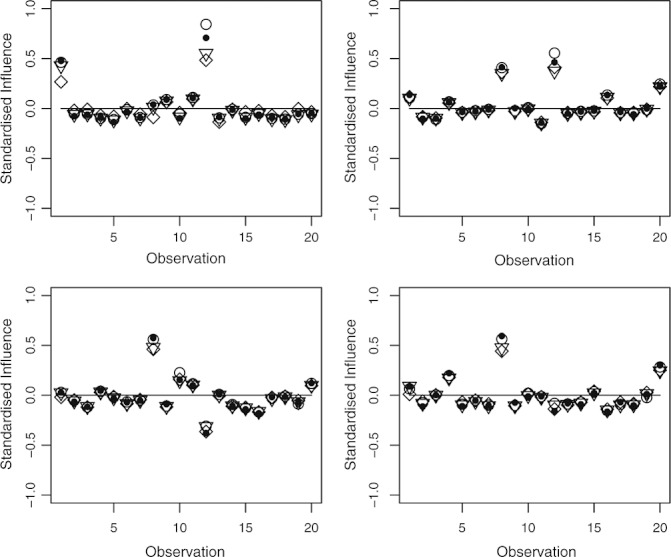
Standardised influence statistics for the first 20 observations. The top two panels show influences for β2 and β3, whilst the bottom two panels show these for β4 and β5. Solid points show the influence statistics obtained by case deletion; hollow circles show the corresponding estimates obtained by importance sampling; triangles show these using our first proposal (Section 3.1); and diamonds show influences obtained using perturbations.
All three approximations perform least well for the more influential observations but are generally effective in obtaining influences. It is to be expected that large influences are obtained with the least precision, as these provide the biggest challenge to Williams' approximation (which two of the methods are based on) and the most volatile weights for importance sampling. Very similar results were obtained for the remaining 117 observations. Note in particular that all methods successfully detected the influential observation 12 for β2. It is not surprising that observation 12 is influential; this has the highest DEP score of the cases and one of the oldest MAGE values. Cook 5 suggests, in the context of linear regression, that if removing an observation results in an estimate at the edge of 50% of the whole sample confidence region, then this ‘may be cause for concern’. Observation 12 can therefore be interpreted as being worryingly influential for β2 but not excessively so.
Because all the procedures were successful, it is perhaps the additional computational burden required to obtain influences that determines which is to be recommended in practice. Importance sampling doubled the overall simulation time (from around 10 to 20 min). Using our first proposal only required an extra 5 min. Even for this relatively simple example, our first proposal was much faster than importance sampling. This relative efficiency will increase as the model complexity, and hence the difficulties associated with evaluating the observations' contributions to the likelihood, also increases.
The perturbations-based method required around 30 s for each observation, so that around an hour of computing time was needed to obtain influence statistics. Nevertheless, this method has the advantage that computation time does not increase with model complexity in the way it does with importance sampling and may prove useful for models where the precise form of the GLM cannot be specified. Indicative WinBUGS code for performing the analysis is available from the first author on request.
8. Discussion
This paper has developed novel ways of approximating established influence statistics, as used in classical methods, so that they can be used in the context of Bayesian analyses using MCMC. The two new approaches involve storing additional quantities and then use standard MCMC output to recover Williams' influence statistic. The type of analysis performed provided the motivation for this work, which can be applied much more generally. We have not, however, attempted to answer the much more difficult question of whether or not removing particular observations changes the conclusions qualitatively. Furthermore, we have not asked the even more difficult question of what we should do if we discover that an observation is very influential.
Direct case deletion, although easily implemented, is not a feasible option unless models can be fitted extremely quickly; even for the relatively simple model considered here, with just over a hundred observations, this took several hours. Importance sampling is a generally viable but fairly computationally intensive method for the type of models we have considered but becomes computationally prohibitive as the model becomes more complex and the repeated computation of the likelihood becomes less feasible. Even for our relatively simple example, the computational advantages of our first proposal are apparent. If any of the procedures that avoid direct case deletion highlight extremely influential observations, and an accurate indication of their influence is desired, it is necessary to remove the offending observations and refit the model. This is because all the approximate influences are less accurate for more influential observations. All that is typically needed in practice, however, is the identification of influential observations, and an indication of the extent of this influence and our procedures can be used for these purposes.
We have assumed that the model is a collection of connected single-level GLMs. Our methods might also be considered when the part of the model of interest is either known to be such a GLM or, at the very least, thought to behave similarly to one when using the perturbations. Bayesian Hierarchical models, where unobserved random effects present further issues 12, do not fit directly into our framework, however. Despite this, Hodges' 13 proposals for the assessment of case influence for hierarchical models, in his Section 4.4, bear some similarities to ours. Extensions or variations of our methods might be especially useful in this context and may form the subject of future work.
In particular, because the perturbations have the intuition that influential observations will exert more ‘pull’, it would be especially interesting to see if these are also useful for these and other types of statistical model. A difficulty in using the perturbations in practice is that we must ensure that all the various approximations used are appropriate. For models where the variance is unbounded, extra care must be taken to ensure that si is small in relation to the residuals because this is linear in vi. Furthermore, if a canonical link has not been used, we have a further criterion that must be satisfied in terms of the derivatives of the canonical parameter and the linear predictor.
In conclusion, we have proposed two new methods for estimating the influence of observations when fitting models by using MCMC. We have shown how these are related and given practical guidance. Both proposals have been shown, in an example, to give accurate measures of influence. Both proposals avoid any further computation of the likelihood and so can be used in some situations where the complexity of the model renders case deletion and importance sampling unfeasible.
Acknowledgments
The authors thank Shaun Seaman for his helpful comments on the use and implementation of importance sampling. We also thank Bob Carpenter for comments and for providing the data. D. J. and I. R. W. were supported by MRC grant U.1052.00.006. J. C. was supported by grant RES 063-27-0257.
Appendix
We assume a GLM so that the observations yi follow distributions from the natural exponential family with canonical parameter θi, so P(yi | θi) ∝ exp((b(θi) + yθi)/ϕ). With the perturbations and an arbitrary link function, we have 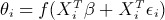 , where f(⋅) is a strictly increasing function; if this is the identity function, then we have assumed the canonical link. We also have the standard results
, where f(⋅) is a strictly increasing function; if this is the identity function, then we have assumed the canonical link. We also have the standard results
| (7) |
and
| (8) |
Using independent normal priors for the εij, and noting that all ε prior distributions are independent, gives
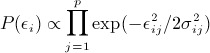 |
(9) |
The distributional assumptions of the GLM, with the perturbations introduced, gives
| (10) |
The product of (9) and (10) gives the posterior density of εi to within a constant of proportionality. Taking the logarithm of the resulting density and differentiating with respect to εij gives
| (11) |
where Xij denotes the jth entry of XiT; f′ (⋅) = ∂θi/∂ηi and b′ (⋅) are the derivatives of functions f(⋅) and b(⋅). In order to obtain the posterior distribution of εij, a series of approximations are required.
Approximation 1
We use the linear approximation 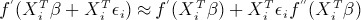 and note that this is exact if a canonical link is used and valid as
and note that this is exact if a canonical link is used and valid as 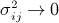 for all j = 1, ···, p. Hence,
for all j = 1, ···, p. Hence, 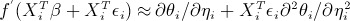 where the partial derivatives are evaluated at
where the partial derivatives are evaluated at 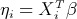 . We further assume
. We further assume 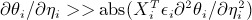 . Again as
. Again as 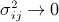 , this criterion is satisfied, and this is exact if a canonical link is used. Assuming sufficiently small perturbations, we approximate
, this criterion is satisfied, and this is exact if a canonical link is used. Assuming sufficiently small perturbations, we approximate 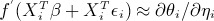 in (11).
in (11).
Approximation 2
We use two linear approximations, firstly for the function f(⋅), taken around 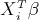 , and then for b′ (⋅), taken around
, and then for b′ (⋅), taken around 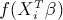 , to approximate
, to approximate 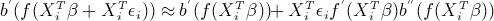 . From (7) and (8), this is equivalent to
. From (7) and (8), this is equivalent to 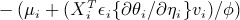 , where the partial derivative and the moments of Y
i are evaluated at
, where the partial derivative and the moments of Y
i are evaluated at 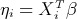 . The first of these linear approximations requires small
. The first of these linear approximations requires small 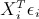 , and the second requires small
, and the second requires small 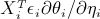 . For a canonical link, these requirements are the same, and the first linear approximation is exact. The second linear approximation is exact for a linear model and canonical link. All these approximations are justified for any GLM as
. For a canonical link, these requirements are the same, and the first linear approximation is exact. The second linear approximation is exact for a linear model and canonical link. All these approximations are justified for any GLM as 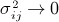 , however.
, however.
An approximate derivative
Upon making approximations 1 and 2, (11) becomes
| (12) |
where ri denotes the residual (yi −μi), and 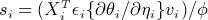 . We obtain the posterior mode by setting derivatives (12), j = 1, ···, p, to zero. Hence, denoting (for the moment) the posterior mode of εij using the ‘hat’ notation, we obtain (5). A linear approximation for b(⋅) in (3) further shows that the posterior of the εi are also approximately normal. Hence, the ‘hat’ notation in (5) can be taken to refer to any conventional measure of location, so we take this to indicate the posterior mean.
. We obtain the posterior mode by setting derivatives (12), j = 1, ···, p, to zero. Hence, denoting (for the moment) the posterior mode of εij using the ‘hat’ notation, we obtain (5). A linear approximation for b(⋅) in (3) further shows that the posterior of the εi are also approximately normal. Hence, the ‘hat’ notation in (5) can be taken to refer to any conventional measure of location, so we take this to indicate the posterior mean.
References
- 1.Gilks WR, Richardson S, Speigelhalter DJ. Markov Chain Monte Carlo in Practice. London: Chapman and Hall; 2006. [Google Scholar]
- 2.Bradlow ET, Zaslavsky AM. Case influence analysis in Bayesian influence. Journal of Computational and Graphical Statistics. 1997;6:314–331. [Google Scholar]
- 3.Weiss RE, Cho M. Bayesian marginal influence assessment. Journal of Statistical Planning and Inference. 1998;71:163–177. [Google Scholar]
- 4.Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. New York: Chapman and Hall; 2004. [Google Scholar]
- 5.Cook RD. Detection of influential observation in linear regression. Technometrics. 1977;19:15–18. [Google Scholar]
- 6.Pregibon D. Logistic regression diagnostics. The Annals of Statistics. 1981;9:705–724. [Google Scholar]
- 7.Williams DA. Generalized linear model diagnostics using the deviance and single case deletions. Applied Statistics. 1987;36:181–191. [Google Scholar]
- 8.Lunn DJ, Thomas A, Best N, Spiegelhalter D. Winbugs a Bayesian modelling framework: concepts, structure, and extensibility. Statistics in Computing. 2000;10:325–337. [Google Scholar]
- 9.Carpenter RG, Waite A, Coombs RC, Daman-Willems C, McKenzie A, Huber J, Emery JL. Repeat sudden unexpected and unexplained infant deaths: natural or unnatural? Lancet. 2005;365:29–35. doi: 10.1016/S0140-6736(04)17662-9. [DOI] [PubMed] [Google Scholar]
- 10.Lee Y, Nelder JA, Pawitan Y. Generalised Linear Models with Random Effects. London: Chapman and Hall; 2006. [Google Scholar]
- 11.McCullagh P, Nelder JA. Generalised Linear Models. London: Chapman and Hall; 1999. [Google Scholar]
- 12.Liu J, Hodges JS. Posterior bimodality in the balanced one-way random-effects model. Journal of the Royal Statistical Society, Series B. 2003;65:247–255. [Google Scholar]
- 13.Hodges JS. Some algebra and geometry for hierarchical models, applied to diagnostics (with discussion) Journal of the Royal Statistical Society, Series B. 1998;60:497–536. [Google Scholar]