

Abstract
The present study addressed the effects of aging on auditory serial-recall performance for natural and synthetic words. Word difficulty, measured in terms of frequency of occurrence and phonological similarity, and rate of presentation were also manipulated in an effort to determine which processes underlying serial-recall performance, if any, were affected by aging. Results indicated that age per se had little effect on short-term (working) memory as measured by the serial recall of monosyllabic words. Rate of presentation had little effect on recall for either subject group. Word difficulty, on the other hand, affected recall for both groups, with easy words being more readily recalled than hard words.
Keywords: aging, memory, hearing loss, synthetic speech
In many listening situations, short-term storage and retrieval of a sequence of words is crucial to normal communication. There are many such situations, for example, in telephone communication, which includes the acquisition of directory-assistance information from operators, recorded time and weather information, and computer-based customer-service switchboards for use with touch-tone telephones. Normal short-term memory capacity is assumed in the design of many of these communication systems. A recent trend in the development of such systems has been the use of high-quality computer-synthesized speech to present the auditory information to the listener. It has been demonstrated previously in young people with normal hearing and in elderly people with impaired hearing that even high-quality synthetic speech does not yield speech recognition or identification performance that is equivalent to that achieved with natural speech (Humes, Nelson & Pisoni, 1991; Logan, Greene & Pisoni, 1989). In addition, Luce, Feustel, and Pisoni (1983) have demonstrated that short-term storage and retrieval of word sequences is poorer for synthetic speech than for natural speech in young adults with normal hearing.
The primary issue addressed in the present study is whether aging affects the short-term recall of natural or synthetic speech. Accuracy of serial recall has been used frequently as a measure of short-term (or working) memory and was used in this study as our measure of short-term memory capacity. In an auditory serial-recall task, a sequence of words, typically 10 or fewer in number, is presented acoustically to the listener at a fixed rate of presentation. The listener is then asked to recall the sequence of words in the same order it was presented. The accuracy of serial recall is typically depicted as a serial-recall function that displays the percentage of words recalled correctly as a function of the word position in the sequence. Such functions are typically U-shaped, with better recall of both the earliest and most recent portions of the word sequence. The superior recall of early items in the list represents the so-called primacy portion of the serial-recall function, whereas the high-performance portion of the function associated with the most recently presented words is referred to as the recency portion of the function.
Processes used in the serial-recall task include encoding, storage, and retrieval of information. That is, the acoustic input must be converted to a unique pattern of sensory activity that is identified and labeled appropriately (encoding), stored temporarily in memory (until completion of the sequence of words), and then retrieved from memory for recall. A decline in serial recall, therefore, can be due to difficulties with one or more of these underlying processes. Humans, as processors of information, are believed to have a finite or limited capacity to do so. If more attentional resources are required for the encoding process in a certain condition, then fewer resources will be available for other tasks, such as storage and retrieval. In the present context, it is hypothesized that additional resources will be required for the encoding process when the intelligibility of the speech signal has been degraded through use of impoverished synthetic speech, rather than natural speech. Assuming limited resources and the allocation of extra resources to the encoding process, it is hypothesized that the storage and retrieval processes will be diminished or less efficient when the intelligibility of the speech signal has been degraded.
To evaluate further the role of storage and retrieval processes in the recall performance measured in this study, serial-recall measures were obtained for two different rates of presentation (or interword intervals) and for words that varied in difficulty. It was hypothesized that the manipulation of the rate of presentation should have little effect on the nearly instantaneous encoding process, but should affect the storage of information and its subsequent retrieval. A faster rate of presentation would allow less time for rehearsal of items than presentation at a slower rate. This would most likely have a larger affect on the early or primacy portion of the serial-recall function. Measures of intelligibility for the stimulus items used in the recall task are used frequently to evaluate the encoding process independent of storage and retrieval.
Manipulations of word difficulty, as defined by the model of Goldinger, Pisoni, and Logan (1991) (see also Luce, 1986), should affect storage and retrieval processes, but not the encoding process. Briefly, according to these authors, hard words are defined as words that (a) have many phonological neighbors or words that differ from the target word by only one phoneme, and (b) are low in frequency of occurrence. Easy words, on the other hand, do not have many similar-sounding neighbors and occur frequently in the language. Although more details concerning the criteria for the easy/hard distinction are provided in the following section, two examples may be helpful at this point to illustrate the distinction being made here. The word gad, for example, is a hard word according to this taxonomy because it has many similar sounding neighbors (bad, mad, fad, had, dad, sad, gab, gag, gal, etc.) and is not a frequently occurring word. An example of an easy word, on the other hand, is word. This monosyllable occurs frequently, yet has a restricted neighborhood of similar sounding monosyllables (bird, curd, worm, work, etc.). Goldinger et al. (1991) showed that hard words are more difficult to recall than easy words, despite equivalent high levels of intelligibility for both sets of words. Thus, the recall difference for easy versus hard words appears to reflect differences in the storage or retrieval processes for these two categories of words and not encoding (i.e., item-by-item intelligibility was high). It is hypothesized that the recall difference between easy and hard words will be reduced for degraded speech because all of the words will be more difficult to discriminate and encode as a result of the degradation. This will require allocation of more attentional resources to the encoding process at the expense of the other processes of storage and retrieval.
In summary, the present study addressed the effects of aging on auditory serial-recall performance for natural and synthetic words. Word difficulty and interword interval also were manipulated in an effort to determine which processes, if any, underlying serial-recall performance were affected by aging.
Method
Subjects
A total of 24 subjects participated in this study. They were divided into two groups on the basis of their age. Group YNH subjects were young normal-hearing adults (N = 12) aged 21–24 years (M = 22.4 years). Group ENH subjects were elderly normal-hearing adults (N = 12) aged 61–76 years (M = 69.8 years). All subjects had pure tone air-conduction thresholds < or = 20 dB HL from 500–4000 Hz (ANSI, 1989) and normal immittance measurements bilaterally.
All subjects were tested monaurally with the test ear randomly determined for all subjects. All subjects were in good health and were native speakers of English.
Materials/Apparatus
The stimulus materials consisted of 120 monosyllabic words selected from the Modified Rhyme Test (House, Williams, Hecker, & Kryter, 1965) and divided into 12 lists of 10 words each. In each condition, 2 10-word lists were used as practice and the 10 remaining 10-word lists were used to measure recall performance.
A total of four variables were examined in this study; one between-subjects variable (subject group) and three within-subject variables (talker, presentation rate, and word difficulty). The talker variable refers to the use of speech materials generated either by a real talker (natural speech) or by a machine (DECtalk synthetic speech). The word lists for each condition were produced by either the text-to-speech system DECtalk 1.8 (DECPaul) or a native speaker of English.
The presentation-rate variable assumed one of two interword-interval values for the 10 words on each list: 1 or 2 sec. This interval was measured from offset to onset for successive words in the list. For all recall conditions, each 10-word list was separated by a silent interval of 60 sec.
Additionally, the word lists varied depending on whether the words within a list were easy or hard (Goldinger et al., 1991). Easy words have few phonological neighbors and are higher in frequency of occurrence than their neighbors. Hard words have many similar-sounding neighbors and tend to be lower in frequency of occurrence than their neighbors. Five 10-word test lists within each condition consisted of easy words, and five lists consisted of hard words. The mean frequency of occurrence and its standard deviation were 228.0 and 288.5, respectively, for the easy words and 10.3 and 8.2, respectively, for the hard words. That is, based on the data of Kucera and Francis (1967) on the frequency of occurrence of words in printed text, the easy words used in this study occurred an average of 228 times per million words, whereas the hard words occurred only 10.3 times. Similarly, the mean neighborhood density and its standard deviation for the easy words were 17.4 and 3.9, respectively, whereas these values were 30.3 and 3.8, respectively, for the hard words. That is, for the easy words there were approximately 17 similar sounding words that could be constructed by changing one phoneme, whereas, on average, about 30 such words could be constructed for the hard words.
Word lists were generated by accessing a large database of previously digitized speech materials housed in the Speech Research Laboratory at Indiana University. Once the set of 100 words meeting our criteria was identified, these words were used to generate lists of 10 words for the recall task. Stimulus files for each word in a given list were output from the computer at a sampling rate of 10 kHz, low-pass filtered at 4.8 kHz, and recorded on digital audiotapes. The vowel /a/ was recorded at the beginning of each tape for calibration of sound levels at playback. The calibration vowel had an rms amplitude equal to that of the test items.
Twelve lists of 10 words each were created. The 2 lists presented first in each condition were practice lists and included the same 20 words for each condition. However, the order of the practice words varied across conditions. The remaining 10 lists (5 lists of easy words and 5 lists of hard words) were constituted of the same 100 words. Within each 10-word list, the same words were presented across conditions. The order in which the words were presented within each list, however, was randomized separately for each condition. In addition, the order of the 10 lists was randomized for each condition.
The tapes were played back using a Digital Audio Tape (DAT) deck (Panasonic SV-3500) and presented monaurally through headphones (TDH-39) mounted in supra-aural cushions (MX-41/AR). The lists were presented at a level of 75 dB SPL as specified in an NBS-9A coupler. An intelligibility test, consisting of the same 100 test words used in the recall conditions, was created for each speaker’s voice. There was a 5-sec response interval between the presentation of each word.
All testing was completed in a large room designed for headphone testing of groups of subjects. Octave-band ambient noise levels were within 15 dB of those specified in ANSI S3.1–1977 for “ears covered” (headphone) threshold testing.
Procedure
Following subject selection, subjects were given written instructions explaining the experiment. Initially, a short sample of the synthetic and natural speech was played for all subjects, familiarizing them with the speech quality of the talkers to be used. A written copy of the sample was provided for the subjects to follow along as they heard the sample of each talker. The subjects were then instructed to listen to each list of 10 words. At the completion of the presentation of each list, a short 1-kHz tone of moderate level was presented. This tone signaled the beginning of the recall period. Subjects were instructed to write those words heard, in the order in which they were presented, on the numbered answer sheets provided for each condition. After 60 sec, a second short tone signaled the end of the recall period. Lastly, a third short tone signaled the beginning of the next list of 10 words. This sequence was repeated 12 times, once for each of the 12 10-word lists (2 practice, 10 test), in each of the four conditions (2 rates × 2 talkers) for a total of 48 presentations of the 10-item lists.
After the completion of the four recall conditions, the intelligibility of each talker’s voice was evaluated. The same 100 words used in the recall task were randomly presented in two different orders (one order for each talker). Subjects were instructed to write each word immediately after it was heard on numbered answer sheets. All subjects had the intelligibility test for the synthetic talker’s voice prior to the intelligibility test for the natural talker’s voice in an attempt to minimize learning effects.
Approximately 2 hours were required for each subject to complete the experiment. All subjects were paid for their participation.
Results and Discussion
Table 1 presents the means and standard deviations of the intelligibility scores obtained from both subject groups and for both talkers. Individual scores were arcsine transformed to stabilize the error variance and then subjected to analysis of variance (ANOVA). Significant effects of talker (F (1, 22) = 93.6, p < .001) were observed. The main effect of subject group and the interaction between group and talker were not significant (F (1, 22) = 3.6, F (1, 22) = 0.6, p > .05, respectively). We interpret these results to indicate that it was more difficult to encode the synthetic speech than the natural speech, but that the two age groups do not differ in their encoding abilities.
TABLE 1.
Means and standard deviations of percent-correct intelligibility scores for both subject groups and both talkers.
YNH = young normal hearing.
ENH = elderly normal hearing.
Tables 2 and 3 present the mean percentage of words recalled correctly for each of the 10 serial positions for the young normal-hearing (YNH) and elderly normal-hearing (ENH) groups, respectively. In each table, the results are presented for the eight factorial combinations of the three within-group variables: talker (natural/synthetic), difficulty (easy/hard), and rate (1 sec/2 sec interword interval). Standard deviations are also provided in these tables.
TABLE 2.
Means and standard deviations (in parentheses) of percent-correct scores for serial-recall task for the YNH group.
| Talker | Difficulty | Rate | Serial position
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| N | E | 2 | 71.7 (31.3) | 56.7 (26.7) | 48.3 (32.4) | 38.3 (32.4) | 41.7 (28.8) | 38.3 (32.4) | 53.3 (32.3) | 58.3 (24.8) | 76.7 (25.4) | 90.0 (13.5) |
| N | H | 2 | 53.3 (33.4) | 47.6 (31.1) | 36.7 (28.1) | 28.3 (27.6) | 25.0 (24.3) | 26.7 (23.1) | 33.3 (23.1) | 46.7 (28.7) | 70.0 (16.0) | 60.0 (12.1) |
| N | E | 1 | 75.0 (29.7) | 55.0 (36.3) | 43.3 (30.6) | 51.7 (33.5) | 30.0 (28.9) | 16.7 (16.7) | 35.0 (27.1) | 41.7 (31.3) | 56.7 (32.8) | 85.0 (29.7) |
| N | H | 1 | 68.3 (24.8) | 26.7 (15.6) | 28.3 (27.6) | 25.0 (25.8) | 13.3 (15.6) | 16.7 (22.3) | 13.3 (24.6) | 33.3 (28.7) | 45.0 (27.1) | 66.7 (38.5) |
| D | E | 2 | 78.3 (21.7) | 56.7 (25.4) | 53.3 (31.1) | 33.3 (23.1) | 28.3 (19.9) | 23.3 (18.8) | 31.7 (23.3) | 36.7 (28.1) | 66.7 (28.7) | 80.0 (17.1) |
| D | H | 2 | 51.7 (18.0) | 21.7 (15.9)) | 40.0 (25.6 | 16.7 (28.1) | 16.7 (18.8) | 16.7 (14.4) | 23.3 (23.9) | 21.7 (26.2) | 48.3 (21.7) | 60.0 (12.1) |
| D | E | 1 | 71.7 (27.6) | 51.7 (26.2) | 38.3 (24.8) | 18.3 (18.0) | 26.7 (19.7) | 20.0 (17.1) | 26.7 (30.0) | 31.7 (28.9) | 35.0 (25.8) | 70.0 (31.3) |
| D | H | 1 | 33.3 (19.7) | 20.0 (24.1) | 13.3 (9.85) | 15.0 (15.1) | 6.67 (13.0) | 15.0 (15.1) | 25.0 (25.8) | 11.7 (13.4) | 35.0 (25.8) | 50.0 (27.6) |
Data are shown for each serial position (1–10), each talker (N = natural; D = DECtalk), each level of word difficulty (E = easy; H = hard), and each presentation rate (2 = 2-sec interword interval; 1 = 1-sec interword interval).
TABLE 3.
Means and standard deviations (in parentheses) of percent-correct scores for serial-recall task for the ENH group.
| Talker | Difficulty | Rate | Serial position
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| N | E | 2 | 75.0 (22.8) | 63.3 (16.7) | 33.3 (26.1) | 25.0 (21.1) | 16.7 (30.6) | 15.0 (24.3) | 23.3 (28.1) | 38.3 (31.3) | 71.7 (19.9) | 85.0 (12.4) |
| N | H | 2 | 41.7 (32.4) | 31.7 (31.3) | 20.0 (25.6) | 16.7 (31.7) | 13.3 (23.1) | 16.7 (26.7) | 23.3 (23.9) | 31.7 (21.7) | 66.7 (31.1) | 83.3 (20.6) |
| N | E | 1 | 70.0 (34.6) | 43.3 (40.8) | 28.3 (33.5) | 21.7 (19.9) | 13.3 (197) | 6.70 (9.90) | 10.0 (23.4) | 30.0 (34.6) | 36.7 (30.6) | 91.7 (13.4) |
| N | H | 1 | 50.0 (39.5) | 18.3 (21.7) | 15.0 (21.1) | 6.70 (13.0) | 1.70 (5.80) | 1.70 (5.80) | 8.30 (23.3) | 16.7 (29.3) | 31.7 (27.6) | 66.7 (17.8) |
| D | E | 2 | 75.0 (29.7) | 51.7 (26.2) | 43.3 (25.4) | 26.7 (23.1) | 10.0 (23.4) | 18.3 (27.6) | 16.7 (30.6) | 35.0 (28.4) | 56.7 (28.1) | 86.7 (17.8) |
| D | H | 2 | 41.7 (30.1) | 21.7 (26.2) | 25.0 (25.8) | 18.3 (26.2) | 16.7 (18.8) | 18.3 (24.8) | 13.3 (24.6) | 13.3 (23.1) | 35.0 (22.8) | 56.7 (30.6) |
| D | E | 1 | 60.0 (28.3) | 28.3 (27.6) | 26.7 (23.1) | 10.0 (13.5) | 8.33 (18.0) | 11.7 (23.3) | 16.7 (18.8) | 26.7 (30.0) | 46.7 (38.5) | 73.3 (19.7) |
| D | H | 1 | 25.0 (22.8) | 15.0 (19.3) | 5.00 (12.4) | 8.33 (13.4) | 3.33 (11.6) | 0.00 (0.00) | 10.0 (16.0) | 11.7 (13.4) | 28.3 (18.0) | 71.7 (19.9) |
Data are shown for each serial position (1–10), each talker (N = natural; D = DECtalk), each level of word difficulty (E = easy; H = hard), and each presentation rate (2 = 2-sec interword interval; 1 = 1-sec interword interval).
The percent-correct recall scores from each subject were arcsine transformed prior to statistical analysis. To facilitate a meaningful interpretation of the analysis, the 10-item serial-position functions for each talker (natural and synthetic) were divided into two 5-item halves. The data for serial positions 1 through 5 were designated as the primacy portion of the function, whereas the data for positions 6 through 10 were labeled as the recency portion of the function. Further, given the previously established differences in intelligibility between high-quality synthetic speech (DECtalk) and natural speech (Humes et al., 1991; Logan et al., 1989), confirmed again in this study, and the likely influence of these intelligibility differences on recall, the effects of talker per se were not of interest. Rather, we included natural and synthetic speech in this study to evaluate how readily conclusions drawn from the data with natural speech could be generalized to synthetic speech.
A total of four multivariate analyses of variance (ANOVAs) were performed on the arcsine-transformed data. A separate ANOVA was conducted for each half of the serial-position curve (primacy/recency) and for each talker (natural/synthetic). Each ANOVA examined the effects of the between-subject factor of subject group and the within-subject factors of rate, difficulty, and serial position. The results of these four ANOVAs are summarized in Table 4.
TABLE 4.
Summary of the F values from four analyses of variance (ANOVAs) conducted on the serial-recall data. The four ANOVAs result from factorial combination of two talkers (Natural vs. DECtalk speech) with two portions of the serial-recall function (primacy vs. recency).
| Effect (df) | Nat- Primacy F | Nat- Recency F | DEC- Primacy F | DEC- Recency F |
|---|---|---|---|---|
| Group(G) (1,22) | 2.91 | 2.51 | 3.09 | 0.17 |
| Rate(R) (1,22) | 0.45 | 13.40* | 9.84* | 3.05 |
| Difficulty(D) (1,22) | 64.60* | 17.01* | 62.20* | 24.60* |
| Position(P) (4,88) | 58.50* | 74.46* | 45.60* | 83.50* |
| G × R (1,22) | 0.05 | 0.06 | 0.28 | 0.03 |
| G × D(1,22) | 0.02 | 3.32 | 1.68 | 0.06 |
| G × P (4,88) | 0.84 | 1.87 | 0.26 | 2.28 |
| R × D (1,22) | 0.51 | 0.04 | 0.06 | 1.08 |
| R × P (4,88) | 2.24 | 8.11* | 2.00 | 2.00 |
| D × P (4,88) | 2.55 | 5.10* | 19.46* | 4.18* |
| R × D × P (4,88) | 1.90 | 0.87 | 1.45 | 1.52 |
| G × R × D (1,22) | 0.24 | 4.80 | 0.77 | 0.02 |
| G × R × P (4,88) | 0.56 | 1.73 | 0.59 | 1.40 |
| G × D × P (4,88) | 2.22 | 0.87 | 0.84 | 0.64 |
| G × R × D × P (4,88) | 0.65 | 3.88* | 0.71 | 2.51 |
p< .01.
All four ANOVAs revealed that the main effect of subject group was not significant. Moreover, as indicated in Table 4, all four ANOVAs failed to reveal a significant group-by-position interaction. This lack of between-group differences in recall is apparent in Figures 1 and 2, which plot the results for both subject groups in each of the four panels. Figure 1 presents the data for natural speech, whereas Figure 2 shows the results for synthetic speech. The top panels in each figure represent the results for easy words, whereas the bottom panels present comparable results for hard words. The left panels in both figures contain the data for the slow rate of presentation (2-sec interword interval), whereas the right panels represent the data for the fast rate of presentation (1-sec interword interval). It is clear from these data that the YNH and ENH groups perform similarly, except possibly in the middle portion of the serial-recall curves, where the younger subjects tend to outperform the older normal-hearing subjects.
FIGURE 1.
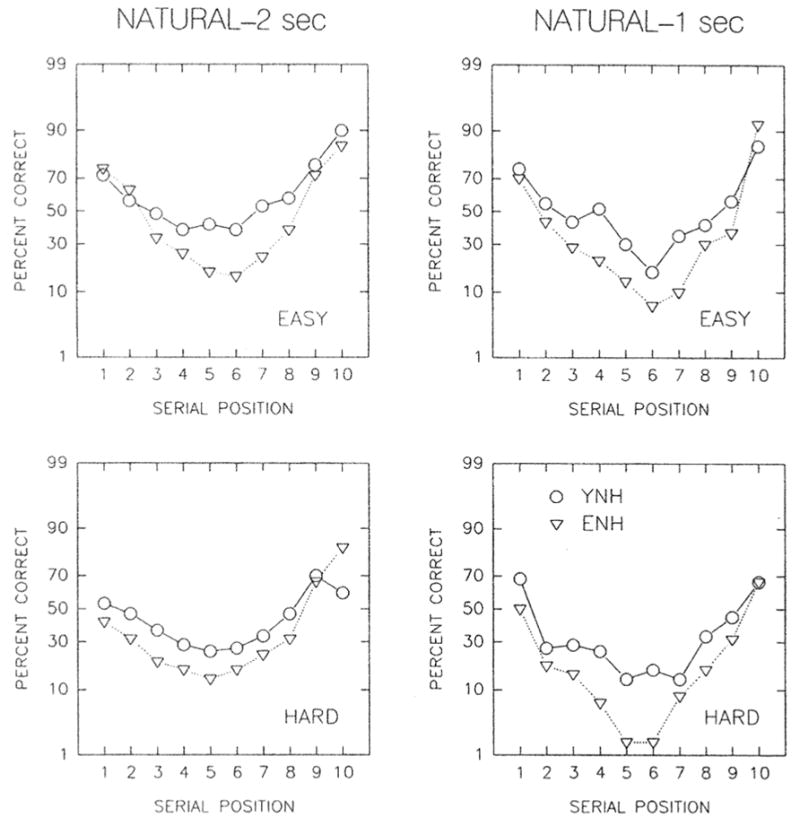
Mean serial-recall functions obtained from both subject groups for natural speech. The two left panels display results for the 2-sec interword interval, whereas the two right panels display the results for the 1-sec interword interval. The top panels present results for easy words, and the bottom panels provide the results for hard words. Each symbol type represents the mean data from a different subject group as follows: circles = young normal-hearing adults (YNH); and inverted triangles = elderly normal-hearing adults (ENH).
FIGURE 2.
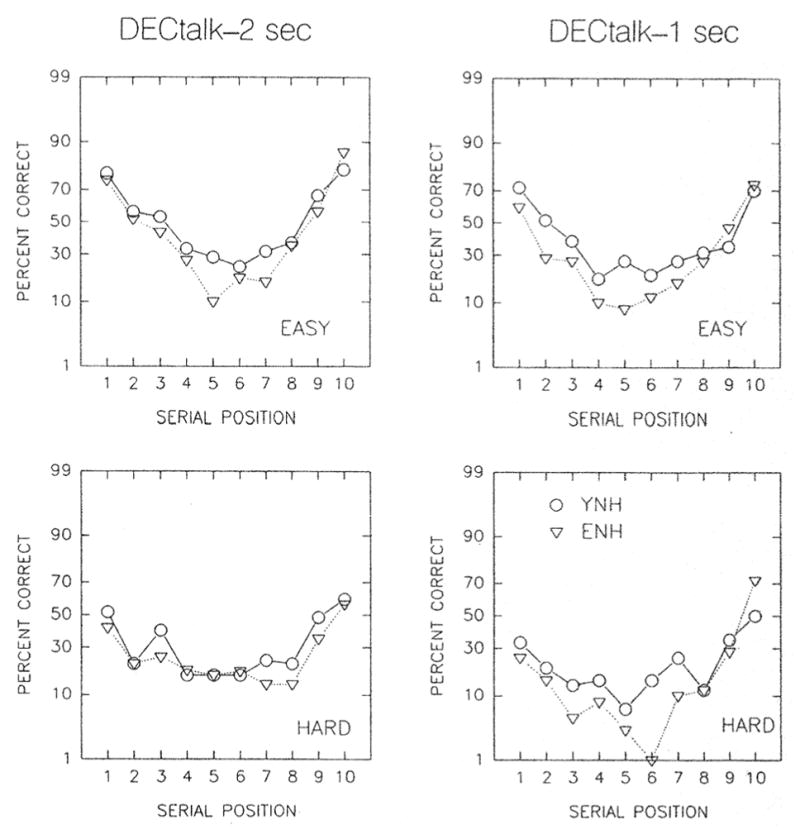
Mean serial-recall functions as in Figure 1, but for synthetic (DECtalk) speech.
Word difficulty had a significant effect on serial-recall performance across positions. This effect, moreover, was unaffected by subject group and rate of presentation, but not serial position (Table 4). In general, the interaction of word difficulty with position in three of the four ANOVAs reflects the presence of more shallow serial-position curves for hard words than for easy words. The lack of any significant interactions between word difficulty and subject group in Table 4 suggests that age alone has no influence on the effect of word difficulty on serial recall. Given the relatively high intelligibility scores for all words obtained from the YNH and ENH subjects, the significant main effect of word difficulty for both talkers and both halves of the serial-recall curves suggests that this factor exerts its primary influence on the storage or retrieval process, rather than the encoding process.
Rate of presentation had a significant effect on recall performance during the recency portion of the serial-position curve for natural speech and the primacy portion of the recall function for synthetic speech (Table 4). In both cases, poorer recall performance was associated with the faster rate of presentation. Given the high intelligibility of these words for subjects in the YNH and ENH groups, the effect of presentation rate on recall implies an effect on storage or retrieval processes rather than the encoding process.
The manifestation of rate effects for different portions of the recall curve for natural versus synthetic speech suggests that this manipulation affects different processes for the two types of speech. We had hypothesized that the increased rate of presentation would have a negative effect on rehearsal processes. At fast presentation rates, less time is available for rehearsal. Thus, less information is maintained in short-term memory. Consequently, the early list items in the serial-recall task may not be maintained in memory at faster presentation rates, leading to decreased recall. Although this was the case for the synthetic speech, this was not observed for the natural speech. Had a third and faster rate of presentation been employed, however, it is possible that the hypothesized effect would have been observed for natural speech as well.
The effect of rate of presentation on the recency portion of the recall functions for natural speech is more difficult to explain. The faster rate of presentation may have resulted in more interference in the memory traces of successive words in short-term memory for natural speech.
Comparison of the results across talkers (Figure 1 vs. Figure 2) suggests that the recall of high-quality synthetic speech is slightly worse than that for natural speech. This is consistent with previous observations (Luce et al., 1983). Recall, however, that the intelligibility of the synthetic speech was significantly worse than that of natural speech for both subject groups (Table 1). It is unclear in this study, therefore, whether the poorer recall of synthetic speech is a consequence of the encoding of a degraded input (lower intelligibility) or deficient storage and retrieval of the synthetic speech.
In summary, age per se had little effect on the capacity or efficient use of short-term (working) memory as measured by the serial recall of spoken monosyllabic words. Rate of presentation, at least for the range of interword intervals used here, had little effect on recall for either subject group. Word difficulty, on the other hand, affected recall for both age groups. Easy words were recalled more readily than hard words.
Contributor Information
Larry E. Humes, Department of Speech and Hearing, Sciences, Indiana University, Bhomington
Kathleen J. Nelson, Department of Speech and Hearing, Sciences, Indiana University, Bhomington
David B. Pisoni, Department of Psychology, Indiana University, Bloomington
Scott E. Lively, Department of Psychology, Indiana University, Bloomington
References
- American National Standards Institute. Criteria for permissible ambient noise during audiometric testing. New York: ANSI; 1977. (ANSI 3.1-1977) [Google Scholar]
- American National Standards Institute. Specification for audiometers. New York: ANSI; 1989. (ANSI S3.6-1989) [Google Scholar]
- Goldinger SD, Pisoni DB, Logan JS. On the nature of talker variability effects on recall of spoken word lists. Journal of Experimental Psychology. 1991;17:152–162. doi: 10.1037//0278-7393.17.1.152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- House AS, Williams CE, Hecker MH, Kryter KD. Articulation-testing methods: Consonantal differentiation with a closed-response set. Journal of the Acoustical Society of America. 1965;77:1896–1906. doi: 10.1121/1.1909295. [DOI] [PubMed] [Google Scholar]
- Humes LE, Nelson KJ, Pisoni DB. Recognition of synthetic speech by hearing-impaired listeners. Journal of Speech and Hearing Research. 1991;34:1180–1184. doi: 10.1044/jshr.3405.1180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kucera F, Francis W. Computational analysis of present day American English. Providence, R.I: Brown University Press; 1967. [Google Scholar]
- Logan JS, Greene BG, Pisoni DB. Segmental intelligibility of synthetic speech produced by rule. Journal of the Acoustical Society of America. 1989;86:566–581. doi: 10.1121/1.398236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luce PA. Speech Research Laboratory Progress Report No 6. Bloomington: Indiana University; 1986. Neighborhoods of words in the mental lexicon. [Google Scholar]
- Luce PA, Feustel TC, Pisoni DB. Capacity demands in short-term memory for synthetic and natural speech. Human Factors. 1983;25:17–32. doi: 10.1177/001872088302500102. [DOI] [PMC free article] [PubMed] [Google Scholar]