

Abstract
Graphical models appear well suited for inferring brain connectivity from fMRI data, as they can distinguish between direct and indirect brain connectivity. Nevertheless, biological interpretation requires not only that the multivariate time series are adequately modeled, but also that there is accurate error-control of the inferred edges. The PCfdr algorithm, which was developed by Li and Wang, was to provide a computationally efficient means to control the false discovery rate (FDR) of computed edges asymptotically. The original PCfdr algorithm was unable to accommodate a priori information about connectivity and was designed to infer connectivity from a single subject rather than a group of subjects. Here we extend the original PCfdr algorithm and propose a multisubject, error-rate-controlled brain connectivity modeling approach that allows incorporation of prior knowledge of connectivity. In simulations, we show that the two proposed extensions can still control the FDR around or below a specified threshold. When the proposed approach is applied to fMRI data in a Parkinson's disease study, we find robust group evidence of the disease-related changes, the compensatory changes, and the normalizing effect of L-dopa medication. The proposed method provides a robust, accurate, and practical method for the assessment of brain connectivity patterns from functional neuroimaging data.
1. Introduction
The interaction between macroscopic brain regions has been increasingly recognized as being vital for understanding the normal brain function and the pathophysiology of many neuropsychiatric diseases. Brain connectivity patterns derived from neuroimaging methods are therefore of great interest, and several recently published reviews have described different modeling methods for inferring brain connectivity from fMRI data [1, 2]. Specifically, graphical models which represent statistical dependence relationships between time series derived from brain regions, such as structural equation models [3], dynamic causal models [4], and Bayesian networks [5], appear to be well suited for assessing connectivity between brain regions.
Graphical models, when applied to functional neuroimaging data, represent brain regions of interest (ROIs) as nodes and the stochastic interactions between ROIs as edges. However, in most nonbrain imaging graphical model applications, the primary goal is to create a model that fits the overall multivariate data well, does not necessarily accurately reflect the particular connections between nodes. Yet in the applications of graphical models to brain connectivity, the neuroscientific interpretation is largely based on the pattern of connections inferred by the model. This places a premium on accurately determining the “inner workings” of the model such as accounting for the error rate of the edges in the model.
The false discovery rate (FDR) [6, 7], defined as the expected ratio of spurious connections to all learned connections, has been suggested as a suitable error-rate control criterion when inferring brain connectivity. Compared with traditional type I and type II statistical error rates, the FDR is more informative in bioinformatics and neuroimaging, since it is directly related with the uncertainty of the reported positive results. When selecting candidate genes for genetic research, for example, researchers may want 70% of selected genes to be truly associated with the disease, that is, an FDR of 30%.
Naively controlling traditional type I and type II error rates at specified levels may not necessarily result in reasonable FDR rates, especially in the case of large, sparse networks. For example, consider an undirected network with 40 nodes, with each node interacting, on average, with 3 other nodes; that is, there are 60 edges in the network. An algorithm with the realized type I error rate of 5% and the realized power of 90% (i.e., the realized type II error rate = 10%) will recover a network with 60 × 90% = 54 correct connections and [40 × (40 − 1)/2 − 60] × 5% = 36 false connections, which means that 36/(36 + 54) = 40% of the claimed connections actually would not exist in the true network! This example, while relatively trivial, demonstrates that the FDR may not be kept suitably low by simply controlling traditional type I and type II error rates.
Recent work in the machine learning field has started to investigate controlling the FDR in network structures using a generic Bayesian approach and classical FDR assessment [8]. This work was subsequently extended to look specifically at graphical models where the FDR was assessed locally at each node [9].
Li and Wang proposed a network-learning method that allows asymptotically control of the FDR globally. They based their approach on the PC algorithm (named after Peter Spirtes and Clark Glymour), a computationally efficient and asymptotically reliable Bayesian network-learning algorithm. The PC algorithm assesses the (non)existence of an edge in a graph by determining the conditional dependence/independence relationships between nodes [10]. However, different from the original PC algorithm, which controls the type I error rate individually for each edge during conditional independence testing, the Li and Wang algorithm, referred as the PCfdr algorithm, is capable of asymptotically controlling the FDR under prespecified levels [11]. The PCfdr algorithm does this by interpreting the learning of a network as testing the existence of edges, and thus the FDR control of edges becomes a multiple-testing problem, which has a strong theoretical basis and has been extensively studied by statisticians [11].
Beside giving an introduction of these recent advancements, this paper will present two extensions to the original PCfdr algorithm, the combination of which leads to a multisubject brain connectivity modeling approach incorporating FDR control, a priori knowledge and group inference. One extension is an adaptation of a priori knowledge, allowing users to specify which edges must appear in the network, which cannot and which are to be learned from data. The resulting algorithm is referred to as PCfdr + algorithm in this paper. Many applications require imposing prior knowledge into network learning. For example, analyzing causal relationship in time series may forbid backward connections from time t + 1 to t, such as that in dynamic Bayesian networks. In some situations, researchers may want to exclude some impossible connections based on anatomical knowledge. Incorporating a priori knowledge into PCfdr algorithm allows for more flexibility in using the method and potentially leads to greater sensitivity in accurately discovering the true brain connectivity.
The second extension to PCfdr algorithm is a combination of the PCfdr algorithm and a mixed-effect model to robustly deal with intersubject variability. As neuroimaging research typically involves a group of subjects rather than focusing on an individual subject, group analysis plays an important role in final biological interpretations. However, compared with the extensive group-level methods available for analysis of amplitude changes in blood-oxygen-level-dependent (BOLD) signals (e.g., Worsley et al. [12], Friston et al. [13]), the problem of group-level brain connectivity analysis is less well studied. This is likely due to the fact that it requires not only accommodating the variances and the correlations across subjects, but also accounting for the potentially different structures of subject-specific brain connectivity networks. The proposed group-level exploratory approach for brain connectivity inference combines the PCfdr algorithm (or the extended PCfdr + algorithm if a priori knowledge is available) and a mixed-effect model, a widely used method for handling intersubject variability.
Several methods have been proposed to infer group connectivity in neuroimaging. Bayesian model selection [14] handles intersubject variability and error control; however, its current proposed implementation does not scale well, making it more suitable for confirmatory, rather than an exploratory research. Varoquaux et al. [15] propose a data-driven method to estimate large-scale brain connectivity using Gaussian modeling and deals with the variability between subjects by using optimal regularization schemes. Ramsey et al. [16] describe and evaluate a combination of a multisubject search algorithm and the orientation algorithm.
The major distinguishing feature of the proposed approach compared to these aforementioned approaches is that the current data-driven approach aims at controlling the FDR directly at the group-level network. We demonstrate that in simulations that, with a sufficiently large subject size, the proposed group-level algorithm is able to reliably recover network structures and still control the FDR around prespecified levels. When the proposed approach, referred as the gPCfdr + algorithm, is applied to real fMRI data with Parkinson's disease, we demonstrate evidence of direct and indirect (i.e., compensatory) disease-related connectivity changes, as well as evidence that L-dopa provides a “normalizing” effect on connectivity in Parkinson's disease, consistent with its dramatic clinical effect.
2. Materials and Methods
2.1. Preliminaries
Graphical models, such as Bayesian networks, encode conditional independence/dependence relationships among variables graphically with nodes and edges according to the Markov properties [17]. The concept of conditional (in)dependence is very important for the inference of brain connectivity, as it assists in distinguishing between direct and indirect connectivity. For example, the activities in two brain regions are initially correlated, but become independent after all possible influences from other brain regions are removed, then this is an example of indirect connectivity, as the initial activity was actually induced by common input from another region(s). On the other hand, if the activities of two brain regions are correlated even after all possible influences from other regions are removed, then very likely there is a direct functional connection between them and hence is an example of direct connectivity. Conditional dependence is the real interest in learning brain connectivity because it implies that two brain regions are directly connected.
Since a graphical model is a graphical representation of conditional independence/dependence relationships, the nonadjacency between two nodes is tested by inspecting their conditional independence given all other nodes. As multiple edges are tested simultaneously, FDR-control procedures should be applied to correct the effect of multiple testing.
Given two among N random variables, there are 2N−2 possible subsets of the other N − 2 variables upon which the two variables could be conditionally independent. To avoid exhaustively testing such an exponential number of conditional independence relationships, the following proposition [10] can be employed [9, 11].
Proposition 1 —
Given a multivariate probability distribution whose conditional independence relationships can be perfectly encoded as a Bayesian network according to the Markov property, two nodes a and b are nonadjacent if and only if there is a subset C of nodes either all in the neighbors of a or all in the neighbors of b such that a and b are conditionally independent on given C.
Based on Proposition 1, nodes a and b can be disconnected once they are found conditionally independent upon a conditional node set C. As the tests of adjacency progress for every node pair, the neighborhood of nodes keeps shrinking, so an exhaustive search of the conditional node set C is avoided. This greatly reduces computation, especially for a sparse network.
2.2. Brain Connectivity Inference Incorporating False Discovery Rate Control and A Priori Knowledge
2.2.1. PCfdr + Algorithm
The initial version of Li and Wang's [11] method, called the PCfdr algorithm, was proved to be capable of asymptotically controlling the FDR. Here we present an extension of the PCfdr algorithm which can incorporate a priori knowledge, which was not specified in the original PCfdr algorithm. We name the extension as the PCfdr + algorithm where the superscript “+” indicates that it is an extension. The pseudocode of the PCfdr + algorithm is given in Algorithm 1, and its Matlab implementation is downloadable at http://www.junningli.org/software. It handles prior knowledge with two inputs: E must, the set of edges assumed to appear in the true graph, and E test, the set of edges to be tested from the data. The original PCfdr algorithm can thus be regarded as a special case of the extended algorithm, by setting E must = ∅ and E test = {all possible edges}.
Algorithm 1.

The PCfdr + algorithm.
2.2.2. Asymptotic Performance
Before we present theorems about the asymptotic performance of the PCfdr + algorithm and its heuristic modification, let us first introduce the assumptions related to the theorems.
-
(A1)
The multivariate probability distribution P is faithful to a directed acyclic graph (DAG) whose skeleton is G true.
-
(A2)
The number of vertices is fixed.
-
(A3)
Given a fixed significance level of testing conditional independence, the power of detecting conditional dependence approaches 1 at the limit of large sample sizes.
-
(A4)
The union of E must, the edges assumed to be true, and E test, the edges to be tested, covers E true, all the true edges; that is, E test ∪ E must⊇E true.
Assumption (A1) is generally assumed when graphical models are applied, and it restricts the probability distribution P to a certain class. Assumption (A2) is usually implicitly stated, but here we emphasize it because it simplifies the proof. Assumption (A3) may seem overly restrictive, but actually can be easily satisfied by standard statistical tests, such as the likelihood ratio test introduced by Neyman and Pearson [18] and the partial-correlation test by Fisher [19], if the data are identically and independently sampled. Assumption (A4) relates to prior knowledge, which interestingly does not require that the assumed “true” edges E must be a subset of the true edges E true, but just that all true edges are included in the union of the assumed “true” edges and the edges to be tested.
The detection power of the PCfdr + algorithm and its heuristic modification at the limit of large sample sizes is elucidated in Theorem 2.
Theorem 2 —
Assuming (A1), (A2), and (A3), both the PC fdr + algorithm and its heuristic modification, the PC fdr* + algorithm, are able to recover all the true connections in E test with probability one as the sample size approaches infinity:
(1) where E true′ denotes the set of true edges in E test; that is, E true′ = E true∩E test, E stop′ denotes the set of edges inferred by the algorithm about E test; that is, E stop′ = E stop∩E test, and m denotes the sample size.
It should be noted that Theorem 2 does not need Assumption (A4), which implies that the true edges in E test are still able to be recovered by the algorithms with probability one at the limit of large sample sizes, even if the edges assumed to be present by users are not completely correctly specified.
The FDR of the PCfdr + algorithm at the limit of large sample sizes is elucidated in Theorem 3.
Theorem 3 —
Assuming (A1), (A2), (A3), and (A4), the FDR of the set of edges inferred by the PC fdr + algorithm about E test approaches a value not larger than the user-specified level q as the sample size m approaches infinity:
(2) where FDR(E stop′, E true′) is defined as
(3)
Theorem 3 concerns the PCfdr + algorithm, and it requires Assumption (A4). We are still not sure whether similar FDR performance can be proved for the PCfdr* + algorithm. Assumption (A4) does not require that the assumed “true” edges E must is a subset of the true edges E true but only that all true edges are included in the union of the assumed “true” edges and the edges to be tested. This is particularly useful in practice, since it does not require users' prior knowledge to be absolutely correct, but allows some spurious edges to be involved in E must, once all true edges have been included in either E must or E test. Assumption (A4) can be satisfied by making E test ∪ E must large enough to cover all the true edges, but as shown in (4) this will increase the computational cost of the algorithm.
Theorems 2 and 3 address the performance of the PCfdr + algorithm and its heuristic modification at the limit of large sample sizes. Because the PCfdr + algorithm is derived from the PCfdr algorithm, its performance should be very similar. The numerical examples of the PCfdr algorithm in Li and Wang's [11] work may provide helpful and intuitive understanding on the performance of the PCfdr + algorithm with moderate sample sizes.
The detailed proofs of Theorems 2 and 3 are provided in Appendix A.
2.2.3. Computational Complexity
The majority of the computational effort in the PCfdr + is utilized in performing statistical tests of conditional independence at step 7 and the FDR at step 11. If the algorithm stops at the depth d = d max, then the number of conditional independence tests required is bounded by
| (4) |
where |E test| is the number of edges to be tested, Δ is the maximum degree of graph G init (the graph formed at step 1) whose edges are E must∩E test, and C Δ−1 d is the number of combinations of choosing d unordered and distinct elements from Δ − 1 elements. The bound usually is very loose, because it assumes that no edge has been removed until d = d max.
The computational complexity of the FDR procedure, Algorithm 2, invoked at step 11 of the PCfdr + algorithm is O(Hlog(H)) when it is invoked for the first time, where H = |E test| is the number of input p values and is O(H) later, with the optimization suggested in Appendix B. In the worst case that p a⊥b∣C is always larger than p a~b max, the complexity of the computation spent on the FDR control in total is bounded by O(|E test|log(|E test|) + T|E test|) where T is the number of performed conditional independence tests (see (4)). This is a very loose bound because it is rare that p a⊥b∣C is always larger than p a~b max.
Algorithm 2.

FDR setup [6].
In practice, the PCfdr + algorithm runs very quickly, especially for sparse networks. In our experiments (see Section 3.1), it took about 10 seconds to infer the structure of a first-order dynamic network with 20 nodes from data of 1000 time points.
2.2.4. Miscellaneous Discussions
It should be noted that controlling the FDR locally is not equivalent to controlling it globally. For example, if it is known that there is only one connection to test for each node, then controlling the FDR locally in this case will degenerate to controlling the point-wise error rate, which cannot control the FDR globally.
Listgarten and Heckerman [8] proposed a permutation method to estimate the number of spurious connections in a graph learned from data. The basic idea is to repetitively apply a structure learning algorithm to data simulated from the null hypotheses with permutation. This method is generally applicable to any structure learning method, but permutation may make the already time-consuming structure learning problem even more computationally cumbersome, limiting its use in practical situations.
2.3. FDR-Controlled Group Brain Connectivity Inference with or without A Priori Knowledge
In this section, we propose another extension to the PCfdr algorithm: from the single subject level to the group level. Assessing group-level activity is done by considering a mixed-effect model (Step 7 of Algorithm 3), and we name it the gPCfdr algorithm where “g” indicates that it is an extension at the group level. When also incorporating a priori knowledge, the resulting algorithm is named the gPCfdr + algorithm.
Algorithm 3.

The gPCfdr algorithm.
Suppose we have m subjects within a group. Then for subject i, the conditional independence between the activities of two brain regions a and b given other regions C can be measured by the partial correlation coefficient between X a(i) and X b(i) given X C(i), denoted as r ab∣C(i). Here X • denotes variables associated with a vertex or a vertex set, and index i indicates that these variables are for subject i. By definition, the partial correlation coefficient r ab∣C(i) is the correlation coefficient between the residuals of projecting X a(i) and X b(i) onto X C(i) and can be estimated by the sample correlation coefficient as
| (5) |
where
| (6) |
For clarity, in the following discussion we omit the subscript “ab | C” and simply use index “i” to emphasize that a variable is associated with subject i.
To study the group-level conditional independence relationships, a group-level model should be introduced for r i. Since partial correlation coefficients are bounded and their sample distributions are not Gaussian, we apply Fisher's z-transformation to convert (estimated) partial correlation coefficients r to a Gaussian-like distributed z-statistic z, which is defined as
| (7) |
where r is a (estimated) partial correlation coefficient and z is its z-statistic.
The group model we employ is
| (8) |
where e i follows a Gaussian distribution N(0, σ g 2) with zero mean and σ g 2 variance. Consequently, the group-level testing of conditional independence is to be used to test the null hypothesis z g = 0.
Because z i is unknown and can only be estimated, the inference of z g should be conducted with . If X a(i), X b(i), and X C(i) jointly follow a multivariate Gaussian distribution, then asymptotically follows a Gaussian distribution N(z i, σ i 2) with σ i 2 = 1/(N i − p − 3), where N i is the sample size of subject i's data and p represents the number of variables in X C(i). Therefore, based on (8), we have
| (9) |
where ϵ i follows N(0, σ i 2) and e i follows N(0, σ g 2). This is a mixed-effect model where ϵ i denotes the intrasubject randomness and e i denotes the intersubject variability. At the group level, follows a Gaussian distribution N(z g, σ i 2 + σ g 2). Note that unlike regular mixed-effect models, the intrasubject variance σ i 2 in this model is known, because N i and p are known given the data X(i) and C. In general, σ i 2 = 1/(N i − p − 3) is not necessarily equal to σ j 2 for i ≠ j, and the inference of z g should be conducted in the manner of mixed models, such as estimating σ g 2 with the restricted maximum likelihood (ReML) approach. However, if the sample size of each subject's data is the same, then σ i 2 equals σ j 2. For this balanced case, which is typically true in fMRI applications and as well the case in this paper, we can simply apply a t-test to 's to test the null hypothesis z g = 0.
Replacing Step 7 of the single-subject PCfdr algorithm (i.e., the intrasubject hypothesis test) with the test of z g = 0, we can extend the single-subject version of the algorithm to its group-level version. We will employ this t-test in our simulations and in the real fMRI data analysis presented later in this paper. Such a testing approach significantly simplifies the estimation process, and our simulation results presented later demonstrate that this method can still control the FDR at a user specified error rate level.
3. Experiments
3.1. Simulations for the PCfdr + Algorithm
Here we compare the performances of the proposed PCfdr + algorithm and the original PCfdr algorithm, using time series generated from two dynamic Bayesian networks in Figure 1. One network has 20 nodes (10 channels) and 23 edges, and the other has 40 nodes (20 channels) and 56 edges. The dynamic Bayesian networks are assumed Gaussian, with connection coefficients uniformly distributed in [0.2,0.6] with Gaussian noise whose amplitudes are uniformly distributed in [0.5, 1.1]. We use partial correlation coefficients to test conditional independence relationships. The target FDR for both methods is set as 5%. For the PCfdr + algorithm, one-third of the nonexisting connections are excluded as prior knowledge.
Figure 1.
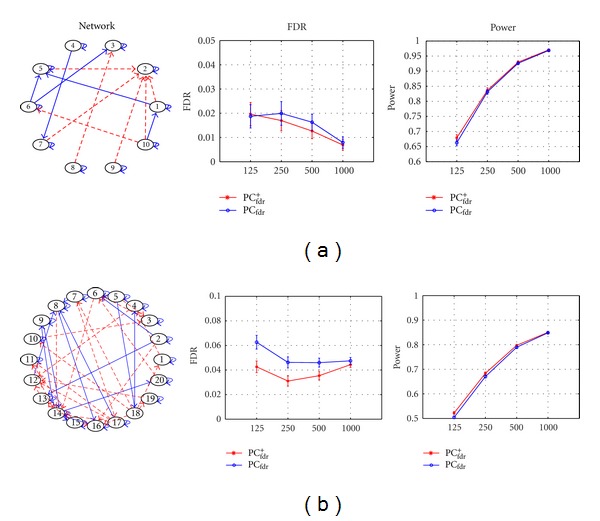
Simulation results for the PCfdr + algorithm. (a) Simulation results for the network with 10 nodes and 23 edges. (b) Simulation results for the network with 20 nodes and 56 edges. In the networks, solid arrows represent edges from time t to t + 1, and dashed arrows represent edges with no time lag (i.e., from time t to t). For the FDR and detection power curves, the blue solid lines represent the PCfdr algorithm, the red solid lines represent the PCfdr + algorithm, the x-axis means the sample sizes, and the y-axis means the FDR or detection power.
Figure 1 shows the estimated FDR and detection power results, at sample sizes of 125, 250, 500, and 1000 time points and with 50 repetitive trials for each sample size. As shown in graphs (a) and (b), the PCfdr + and PCfdr algorithms can both control the FDR under or around 5%. For both methods, the detection power increases as the sample size increases. However, we can see that the PCfdr + algorithm yields higher detection power and lower FDR than the original PCfdr algorithm does. As mentioned earlier in the Introduction Section, the PCfdr + algorithm has the advantage of providing researchers more flexibility in using the method and higher accuracy in discovering brain connectivity.
3.2. Simulations for the gPCfdr Algorithm
The simulations here serve two purposes: first, to verify whether the proposed gPCfdr algorithm for modeling brain connectivity can control the FDR at the group level, and second, to compare the gPCfdr algorithm with the single-subject PCfdr algorithm proposed in [11] and the state-of-art IMaGES algorithm investigated in Ramsey et al. [16] for inferring the structure of the group connectivity network.
The simulations were conducted as follows. First, a connectivity network is generated as the group-level model. Individual subject-level networks are then derived from the group-level model by randomly adding or deleting connections with a small probability, and subject-specific data are generated according to individual subject networks. Next, the network-learning methods, that is, the proposed gPCfdr algorithm, the single-subject PCfdr method with pooling together the data from all subjects, and the IMaGES algorithm, are applied to the simulated data. Finally, the outputs of the algorithms are compared with the true group-level network to evaluate their accuracy.
The data generation process is as follows.
Randomly generate a directed acyclic graph (DAG) as the group-level network and associate each connection with a coefficient. The DAG is generated by randomly connecting nodes with edges and then orienting the edges according to a random order of the nodes. The connection coefficients are assigned as random samples from the uniform distribution U(β 1, β 2), where β 1 and β 2 characterize the coefficient strength.
For each subject, a subject-level network is derived from the group-level network by randomly adding and deleting connections. More specifically, for each of the existing connections, the connection is deleted with probability 0.05, and for each of the absent connections, a connection is added with probability 0.01. The corresponding connection coefficients are randomly sampled from the uniform distribution U(β 1, β 2).
Given a subject-level network, the subject-specific data are generated from a Gaussian Bayesian network, with the additional Gaussian noise following the standard Gaussian distribution N(0,1).
In the first simulation, we compare the performances of the proposed gPCfdr algorithm, the original PCfdr algorithm, and the IMaGES algorithm [16], when using different connection coefficient strengths. In this example, the group-level network is the DAG in Figure 2(a). From this model, twenty subject-level models are derived, and for each subject, data with three hundred samples are simulated. To test the performances of the algorithms with a range of connection strengths, we vary the connection coefficient generating distribution U(β 1, β 2) gradually from U(0.2, 0.3) to U(0.7, 0.8). At the network-learning stage, we set the target FDR to be 5% for the gPCfdr algorithm. For reliable assessment, this procedure is repeated thirty times.
Figure 2.
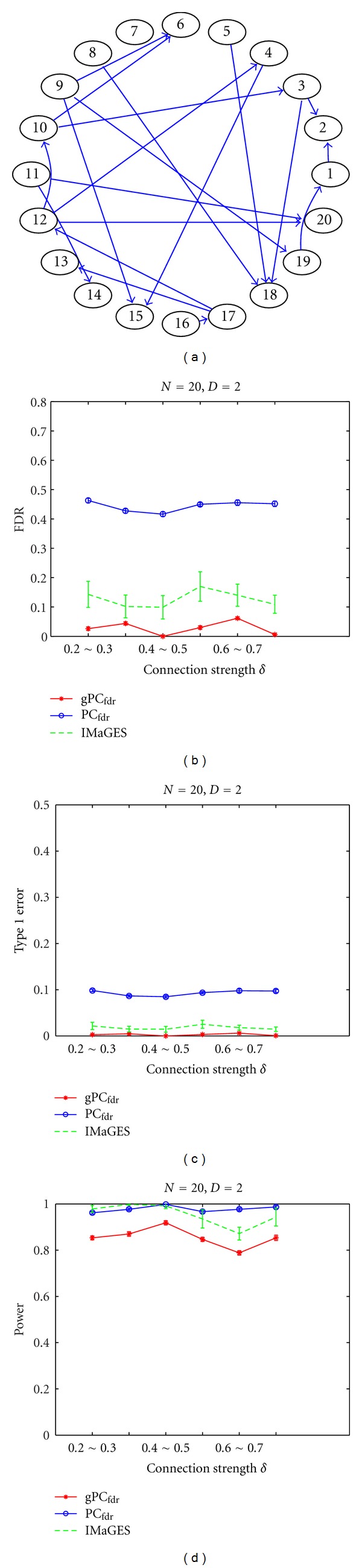
Simulation 1: assessing the effects of connection strength on the learned group networks. (a) The group-level network, with 20 nodes and an average of two connections per node. (b) The FDR curves (with standard deviation marked) of the gPCfdr algorithm, the original PCfdr algorithm by pooling all subject data together, and the IMaGES algorithm. (c) The type I error rate curves. (d) The detection power curves. The x-axis represents the generating distribution U(β 1, β 2) for sampling the connection coefficients.
Figures 2(b), 2(c), and 2(d) show the FDR and the type I error rate, and the detection power results as a function of connection strength. We note that all methods are relatively invariant to connection strength. The proposed gPCfdr algorithm steadily controls the FDR below or around the desired level and accurately makes the inference at the group level. The detection power of IMaGES algorithm is higher than that of gPCfdr algorithm, but it fails to control the FDR under the specified 5% level. Its higher detection power is achieved by sacrificing FDR. This is reasonable, since IMaGES is not specifically designed to control the FDR error rate.
In the second simulation, we test the performances of the algorithms as a function of the number of subjects within the group. The group-level network is the DAG in Figure 3(a), and the number of subjects increases from eight to twenty-five. At the network-learning stage, we set the target FDR to be 5%. This procedure is repeated thirty times.
Figure 3.
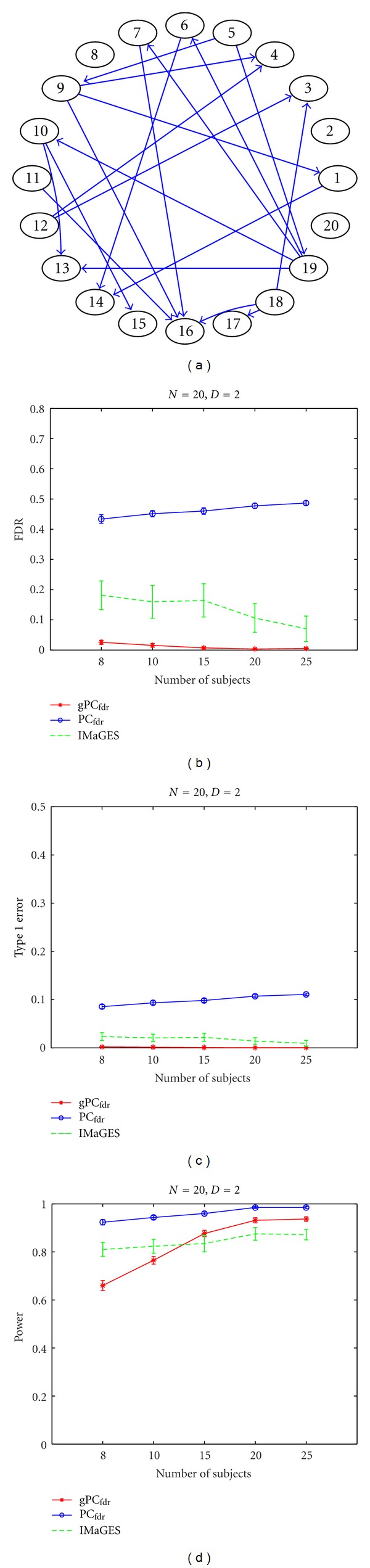
Simulation 2: assessing the effects of increasing the number of subjects on the learned group networks. (a) The group-level network, with 20 nodes and an average of two connections per node. (b) The FDR curves (with standard deviation marked) of the proposed gPCfdr algorithm, the original PCfdr algorithm by pooling all subject data together, and the IMaGES algorithm. (c) The type I error rate curves. (d) The detection power curves. The x-axis represents the number of subjects within the group.
Figure 3(b) demonstrates the FDR results as a function of the number of subjects within the group. It is noted that the proposed gPCfdr algorithm is able to keep the FDR below or around the specified level. The detection power gradually increases as the number of subjects increases. When there are more than 15 subjects, the gPCfdr algorithm seems that it can achieve higher (better) detection power and lower (better) FDR and type I error rate than the IMaGES algorithm does. It suggests that when the number of subjects is large enough, the proposed gPCfdr algorithm can jointly address efficiency, accuracy, and intersubject variability. The original PCfdr algorithm of simply pooling the data together fails to control the FDR, and the resulting FDR does not decrease as the number of subject increases, probably due to the increasing heterogeneity within the group. In order to investigate the effects of the number of ROIs, we also investigate two networks with 15 and 25 nodes, respectively, and repeat the simulations (not shown here). The results are qualitatively similar to what we show here.
3.3. fMRI Application
In order to assess the real-world application performance of the proposed method, we apply the gPCfdr + algorithm for inferring group brain connectivity network to fMRI data collected from twenty subjects. All experiments were approved by the University of British Columbia Ethics Committee. Ten normal people and ten Parkinson's disease (PD) patients participated in the study. During the fMRI experiment, each subject was instructed to squeeze a bulb in their right hand to control an “inflatable” ring so that it smoothly passed through a vertically scrolling a tunnel. The normal controls performed only one trial, while Parkinson's subjects performed twice, once before L-dopa medication and the other approximately an hour later, after taking medication.
Three groups were categorized: group N for the normal controls, group Ppre for the PD patients before medication, and group Ppost for the PD patients after taking L-dopa medication. For each subject, 100 observations were used in the network modeling. For details of the data acquisition and preprocessing, please refer to Palmer et al. [20]. 12 anatomically defined regions of interest (ROIs) were chosen based on prior knowledge of the brain regions associated with motor performance (Table 1).
Table 1.
Brain regions of interest (ROIs).
| Full name of brain region | Abbreviation |
|---|---|
| Left/right lateral cerebellar hemispheres | lCER, rCER |
| Left/right globus pallidus | lGLP, rGLP |
| Left/right putamen | lPUT, rPUT |
| Left/right supplementary motor cortex | lSMA, rSMA |
| Left/right thalamus | lTHA, rTHA |
| Left/right primary motor cortex | lM1, rM1 |
“l” or “r” in the abbreviations stands for “Left” or “Right,” respectively.
We utilized the two extensions of the PCfdr algorithm and learned the structures of first-order group dynamic Bayesian networks from fMRI data. Because the fMRI BOLD signal can be considered as the convolution of underlying neural activity with a hemodynamic response function, we assumed that there must be a connection from each region at time t to its mirror at time t + 1. We also assumed that there must be a connection between each region and its homologous region in the contralateral hemisphere. The TR interval (i.e., sampling period) was a relatively long, 1.985 seconds; we restricted ourselves to learn only connections between ROIs without time lags. In total, there are 12 + 6 = 18 pre-defined connections and 12 × (12 − 1) ÷ 2 − 6 = 60 candidate connections to be tested. The brain connectivity networks (with the target FDR of 5%) learned for the normal (group N) and PD groups before (group Ppre) and after (group Ppost) medication are compared in Figure 4. Note the connection between the cerebellar hemisphere and contralateral thalamus in the normal subjects and between the supplementary motor area (SMA) and the contralateral putamen, consistent with prior knowledge. Interestingly, in Ppre subjects, the left cerebellum now connects with the right SMA, and the right SMA ↔ left putamen connection is lost. Also, there are now bilateral primary motor cortex (M1) ↔ putamen connections seen in the Ppre group, presumably as a compensatory mechanism. After medication (Ppost), the left SMA ↔ left thalamus connection is restored back to be normal.
Figure 4.
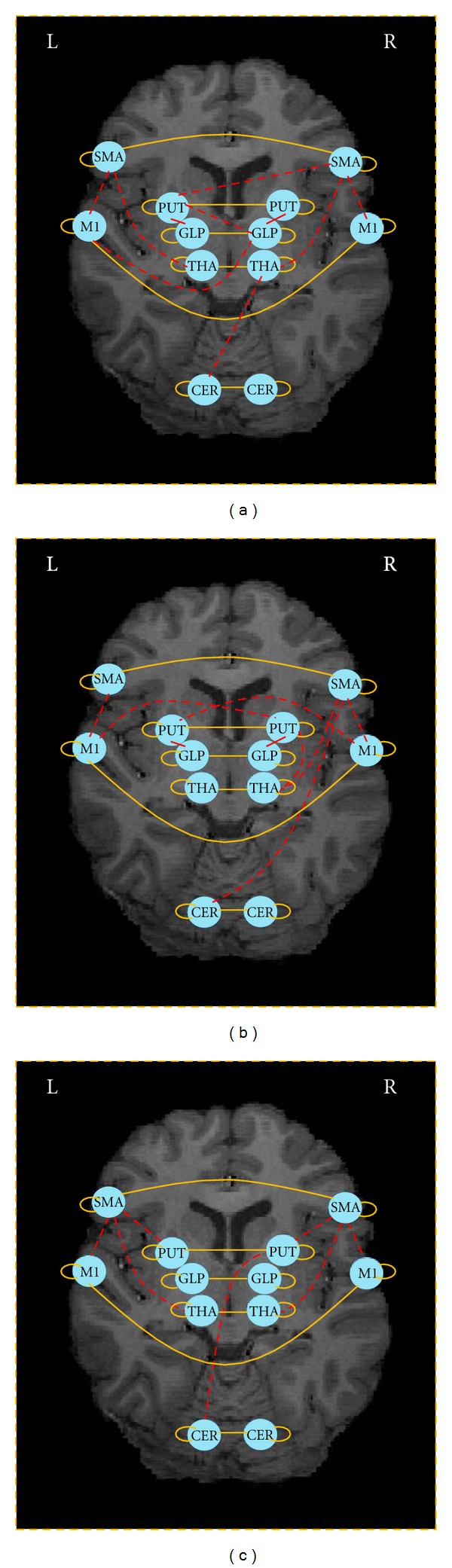
(a) Learned brain connectivity for the normal group (group N). (b) Learned brain connectivity for the PD group before medication (group Ppre). (c) Learned brain connectivity for the PD group after medication (group Ppost). Here “L” and “R” refer to the left and right sides, respectively. The solid lines are predefined connectivity, and the dashed lines are learned connectivity.
4. Discussion
Up to now, graphical models to infer brain connectivity from fMRI data have implicitly relied on the unrealistic assumption that if a model accurately represented the overall activity in several ROIs, the internal connections of such a model would accurately reflect underlying brain connectivity. The PCfdr algorithm was designed to loosen this overly restrictive assumption and asymptotically control the FDR of network connections inferred from data.
In this paper, we first presented the PCfdr + algorithm, an extension of the PCfdr algorithm, which allows for incorporation of prior knowledge of network structure into the learning process, greatly enhancing its flexibility in practice. The PCfdr + algorithm handles prior knowledge with two inputs: E must, which is the set of edges that are assumed to appear in the true graph, and E test, the set of edges that are to be tested from the observed data. We proved that, with mild assumptions and at the limit of large samples, the PCfdr + algorithm is able to recover all the true edges in E test and also curb the FDR of the edges inferred about E test.
It is interesting that the PCfdr + algorithm does not require the assumed “true” edges E must to be a subset of the true edges E true, but only that all true edges are included in the union of the assumed “true” edges and the edges to test. This is very useful in research practice, since it allows some spurious edges to be involved in E must, as long as all the true edges have been included in either E must or E test. Users can satisfy this requirement by making E test ∪ E must large enough to cover all the true edges.
When we compared the PCfdr + algorithm with the original PCfdr algorithm, both of them successfully controlled the FDR under the target threshold in simulations, providing a practical tradeoff between computational complexity and accuracy. However, the PCfdr + algorithm achieved better detection power and better FDR than the original PCfdr algorithm. Incorporating prior knowledge into PCfdr algorithm therefore enhances inference accuracy and improves the flexibility in using the method.
Another extension to PCfdr algorithm we described here was the ability to infer brain connectivity patterns at the group level, with intersubject variance explicitly taken into consideration. As a combination of the PCfdr algorithm and a mixed-effect model, the gPCfdr algorithm takes advantage of the error control ability of the PCfdr algorithm and the capability of handling intersubject variance. The simulation results suggest that the proposed method was able to accurately discover the underlying group network and steadily control the false discovery rate. Moreover, the gPCfdr algorithm was shown to be much more reliable than simply pooling together the data from all subjects. This may be especially important in disease states and older subjects. Compared with the IMaGES algorithm, gPCfdr demonstrated better control of the FDR.
As with all group models, a limitation of the proposed gPCfdr algorithm is the requirement of a sufficient number of subjects. While it is appreciated that in many biomedical applications data collection is resource intensive, and if the number of subjects is insufficient, the gPCfdr algorithm may give unreliable results. Nevertheless, the group extension to the PCfdr algorithm is one attempt to make brain connectivity inference using error-rate-controlled exploratory modeling.
When applying the proposed gPCfdr + to fMRI data collected from PD subjects performing a motor tracking task, we found group evidence of disease changes (e.g., loss of left cerebellar ↔ SMA connectivity), compensatory changes in PD (e.g., bilateral M1 ↔ contralateral putamen connectivity), and evidence of restoration of connectivity after medication (left SMA ↔ left thalamus). The tremendous variability in clinical progression of PD is likely due to variability not only in disease rate progression, but also in variability in the magnitude of compensatory changes. This highlights the importance of the proposed method, as it allows robust estimation of disease effects, compensatory effects, and effects of medication, all with a reasonable sample size, despite the enhanced intersubject variability seen in PD.
Acknowledgment
This work was partially supported by the Canadian Institutes of Health Research (CIHR) Grant (CPN-80080 MJM) and the Canadian Natural Sciences and Engineering Research Council (NSERC) Grant (STPGP 365208-08).
Appendices
A. Proof of Theorems
To assist the reading, we list below notations frequently used in the proof.
-
V:
all the nodes in a graph,
-
Gtrue:
the skeleton of the true underlying directed acyclic graph (DAG),
-
𝒜a~b:
the event that edge a ~ b is in the graph recovered by the PCfdr + algorithm,
-
𝒜Etrue′:
𝒜 Etrue′ = ⋂a~b∈Etrue′ 𝒜 a~b, the joint event that all the edges in E true′, the true edges in E test, are recovered by the PCfdr + algorithm,
-
pa~b:
the value of p a~b max when the PCfdr + algorithm stops,
-
Ca~b*:
a certain vertex set that d-separates a and b in the true DAG and that is also a subset of either adj(a, G true)∖{b} or adj(b, G true)∖{a}, according to Proposition 1. C a~b* is defined only for vertex pairs that are not adjacent in G true,
-
pa~b*:
the p value of testing X a⊥X b | X Ca~b*. The conditional independence relationship may not be really tested during the process of the PCfdr + algorithm, but p a~b* can still denote the value as if the conditional independence relationship was tested,
-
H*:
the value in (⋆) in Algorithm 2 that is either H or H(1 + 1/2,…, +1/H), depending on the assumption of the dependency of the p values.
Lemma A.1 —
If 𝒜 i(m),…, 𝒜 K(m) are a finite number of events whose probabilities each approach 1 as m approaches infinity
(A.1) then the probability of the joint of all these events approaches 1 as m approaches infinity:
(A.2)
For the proof of this lemma, please refer to Li and Wang's [11] work.
Lemma A.2 —
If there are F (F ≥ 1) false hypotheses among H tested hypotheses and the p values of the all the false hypotheses are smaller than or equal to (F/H*)q, where H* is either H or H(1 + 1/2,…, +1/H) depending on the assumption of the dependency of the p values, then all the F false hypotheses will be rejected by the FDR procedure, Algorithm 2.
For the proof of this lemma, please refer to Li and Wang's [11] work.
Proof of Theorem 2 —
If there is not any true edge in E true′, that is, E true′ = ∅, then the proof is trivially E true′ = ∅⊆E′.
In the following part of the proof, we assume E true′ ≠ ∅. For the PCfdr + algorithm and its heuristic modification, whenever the FDR procedure, Algorithm 2, is invoked, p a~b max is always less than maxC∈V∖{a,b}{p a⊥b∣C}, and the number of p values input to the FDR algorithm is always not more than |E test|. Thus, according to Lemma A.2, if
(A.3) then all the true connections will be recovered by the PCfdr + algorithm and its heuristic modification.
Let 𝒜 a⊥b∣C′ denote the event
(A.4) 𝒜 Etrue′′ denote the event of (A.3), and 𝒜 Etrue′ denote the event that all the true connections in E test are recovered by the PCfdr + algorithm and its heuristic modification.
∵𝒜 Etrue′′ is a sufficient condition for 𝒜 Etrue′, according to Lemma A.2.
∴𝒜 Etrue′⊇𝒜 Etrue′′.
∴P(𝒜 Etrue′) ≥ P(𝒜 Etrue′′).
(A.5) and limm→∞ P(𝒜 a⊥b∣C′) = 1 according to Assumption (A3).
∴ According to Lemma A.1, limm→∞ P(𝒜 Etrue′′) = 1.
∴1 ≥ limm→∞ P(𝒜 Etrue′) ≥ limm→∞ P(𝒜 Etrue′′) = 1.
∴limm→∞ P(𝒜 Etrue′) = 1.
Lemma A.3 —
Given any FDR level q > 0, if the p value vector P = [p 1,…, p H] input to Algorithm 2 is replaced with P′ = [p 1′,…, p H′], such that (1) for the those hypotheses that are rejected when P is the input, p i′ is equal to or less than p i, and (2) for all the other hypotheses, p i′ can be any value between 0 and 1, then the set of rejected hypotheses when P′ is the input is a superset of those rejected when P is the input.
For the proof of this lemma, please refer to Li and Wang's [11] work.
Corollary A.4 —
Given any FDR level q > 0, if the p value vector P = [p 1,…, p H] input to Algorithm 2 is replaced with P′ = [p 1′,…, p H′] such that p i′ ≤ p i for all i = 1,…, H, then the set of rejected hypotheses when P′ is the input is a superset of those rejected when P is the input.
The corollary can be easily derived from Lemma A.3.
Proof of Theorem 3 —
Let P stop = {p a~b} denote the value of P max when the PCfdr-skeleton algorithm stops.
∵ The FDR procedure is invoked whenever P max is updated, and P max keeps increasing as the algorithm progresses.
∴ According to Corollary A.4, E stop′ is the same as the edges recovered by directly applying the FDR procedure to P stop.
The theorem is proved through comparing the result of the PCfdr + algorithm with that of applying the FDR procedure to a virtual p value set constructed from P stop. The virtual p value set P* is defined as follows.
For a vertex pair a ~ b that is not adjacent in G true, let C a~b* denote a certain vertex set that d-separates a and b in the true graph and that is also a subset of either adj(a, G true)∖{b} or adj(b, G true)∖{a}. Let us define P* = {p a~b* | a ~ b ∈ E test} as
(A.6) Though p a⊥b|Ca~b* may not be actually calculated during the process of the algorithm, p a⊥b|Ca~b* still can denote the value as if it was calculated.
Let us design a virtual algorithm, called Algorithm*, that infers true edges in E test by just applying the FDR procedure to P*, and let E* denote the edges in E test claimed to be true by this virtual algorithm. This algorithm is virtual and impracticable because the calculation of P* depends on the unknown E true′, but this algorithm exists because E true′ exists.
For any vertex pair a and b that is not adjacent in G true, we have the following.
∵X a and X b are conditional independent given X Ca~b*.
∴p a⊥b|Ca~b* follows the uniform distribution on [0, 1].
∴ The FDR of Algorithm* is under q.
When all the true edges in the test set are recovered by the PCfdr + algorithm, that is, E true′⊆E stop′, all the edges in G true are included in E stop due to Assumption (A4). In this case, the conditional independence between X a and X b given X Ca~b* is tested for all the falsely recovered edges a ~ b ∈ E stop′∖E true′, because for these edges, subsets of adj(a, G true)∖{b} and subsets of adj(a, G true)∖{b} have been exhaustively searched and C a~b* is one of them. Therefore, p a~b ≥ p a~b* for all a ~ b ∈ E stop′ when event 𝒜 Etrue′ happens. Consequently, according to Lemma A.3,
(A.7) Let q(E′) denote the realized FDR of reporting E′ as the set of true edges in E test:
(A.8) The FDRs of the PCfdr + algorithm and Algorithm* are E[q(E stop′)] and E[q(E*)], respectively. Here E[x] means the expected value of x.
, where Q = E[q(E stop′) | 𝒜 Etrue′]P(𝒜 Etrue′).
∴.
∵limm→∞ P(𝒜 Etrue′) = 1, according to Theorem 2.
∴.
∴limsupm→∞ E[q(E stop′)] ≤ limsupm→∞ Q.
∵Q ≤ E[q(E stop′)].
∴limsupm→∞ Q ≤ limsupm→∞ E[q(E stop′)].
∴limsupm→∞ E[q(E stop′)] = limsupm→∞ Q = limsupm→∞ E[q(E stop′) | 𝒜 Etrue′]P(𝒜 Etrue′).
Similarly, limsupm→∞ E[q(E*)] = limsupm→∞ E[q(E*) | 𝒜 Etrue′]P(𝒜 Etrue′).
∵ Event 𝒜 Etrue′ implies E true′⊆E stop′⊆E*.
(A.9) ∴limsupm→∞ E[q(E stop′) | 𝒜 Etrue′]P(𝒜 Etrue′) ≤ limsupm→∞ E[q(E*) | 𝒜 Etrue′]P(𝒜 Etrue′).
∴limsupm→∞ E[q(E stop′)] ≤ limsupm→∞ E[q(E*)].
∵Algorithm* controls the FDR under q.
∴E[q(E*)] ≤ q.
∴limsupm→∞ E[q(E*)] ≤ q.
∴limsupm→∞ E[q(E stop′)] ≤ q.
B. Computational Complexity
The PCfdr + algorithm spends most of its computation on performing statistical tests of conditional independence at step 7 and controlling the FDR at step 11. If the algorithm stops at the depth d = d max, then the number of conditional independence tests required is bounded by
| (B.1) |
where |E test| is the number of edges to test, Δ is the maximum degree of graph G init (the graph formed at step 1 of the PCfdr + algorithm) whose edges are E must∩E test, and C Δ−1 d is the number of combinations of choosing d unordered and distinct elements from Δ − 1 elements. In the worst case that d max = Δ − 1, the complexity is bounded by 2 | E test | 2Δ−1 = |E test | 2Δ. The bound usually is very loose, because it assumes that no edge has been removed until d = d max. In real-world applications, the algorithm is very fast for sparse networks.
The computational complexity of the FDR procedure, Algorithm 2, invoked at step 11 of the PCfdr + algorithm, in general is O(Hlog(H) + H) = O(Hlog(H)) where H = |E test| is the number of input p values. The main complexity Hlog(H) is at the sorting (step 1). However, if it is recorded the sorted P max of the previous invocation of the FDR procedure, then the complexity of keeping the updated P max sorted is only O(H). With this optimization, the complexity of the FDR-control procedure is O(Hlog(H)) at its first operation and is O(H) later. The FDR procedure is invoked only when p a⊥b∣C > p a~b max. In the worst case that p a⊥b∣C is always larger than p a~b max, the complexity of the computation spent on the FDR control in total is bounded by O(|E test | log(|E test|) + T | E test|) where T is the number of performed conditional independence tests. This is a very loose bound because it is rare that p a⊥b∣C is always larger than p a~b max.
References
- 1.Smith SM, Miller KL, Salimi-Khorshidi G, et al. Network modelling methods for FMRI. NeuroImage. 2011;54(2):875–891. doi: 10.1016/j.neuroimage.2010.08.063. [DOI] [PubMed] [Google Scholar]
- 2.Friston KJ. Functional and effiective connectivity: a review. Brain Connectivity. 2011;1(1):13–36. doi: 10.1089/brain.2011.0008. [DOI] [PubMed] [Google Scholar]
- 3.McIntosh AR, Gonzalez-Lima F. Structural equation modeling and its application to network analysis in functional brain imaging. Human Brain Mapping. 1994;2(1-2):2–22. [Google Scholar]
- 4.Friston KJ, Harrison L, Penny W. Dynamic causal modelling. NeuroImage. 2003;19(4):1273–1302. doi: 10.1016/s1053-8119(03)00202-7. [DOI] [PubMed] [Google Scholar]
- 5.Li J, Wang ZJ, Eng JJ, McKeown MJ. Bayesian network modeling for discovering “dependent synergies” among muscles in reaching movements. IEEE Transactions on Biomedical Engineering. 2008;55(1):298–310. doi: 10.1109/TBME.2007.897811. [DOI] [PubMed] [Google Scholar]
- 6.Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. Annals of Statistics. 2001;29(4):1165–1188. [Google Scholar]
- 7.Storey JD. A direct approach to false discovery rates. Journal of the Royal Statistical Society B. 2002;64(3):479–498. [Google Scholar]
- 8.Listgarten J, Heckerman D. Determining the number of non-spuriousarcs in a learned DAG model: investigation of a Bayesian and a frequentist approach. Proceedings of the 23rd Conference on Uncertainty in Artificial Intelligence; 2007. [Google Scholar]
- 9.Tsamardinos I, Brown LE. Bounding the false discovery rate in local bayesian network learning. Proceedings of the 23rd AAAI Conference on Artificial Intelligence (AAAI '08); July 2008; pp. 1100–1105. [Google Scholar]
- 10.Spirtes P, Glymour C, Scheines R. Causation, Prediction, and Search. The MIT Press; 2001. [Google Scholar]
- 11.Li J, Wang ZJ. Controlling the false discovery rate of theassociation/causality structure learned with the pc algorithm. Journal of Machine Learning Research. 2009;10:475–514. [Google Scholar]
- 12.Worsley KJ, Liao CH, Aston J, et al. A general statistical analysis for fMRI data. NeuroImage. 2002;15(1):1–15. doi: 10.1006/nimg.2001.0933. [DOI] [PubMed] [Google Scholar]
- 13.Friston KJ, Stephan KE, Lund TE, Morcom A, Kiebel S. Mixed-effects and fMRI studies. NeuroImage. 2005;24(1):244–252. doi: 10.1016/j.neuroimage.2004.08.055. [DOI] [PubMed] [Google Scholar]
- 14.Stephan KE, Penny WD, Daunizeau J, Moran RJ, Friston KJ. Bayesian model selection for group studies. NeuroImage. 2009;46(4):1004–1017. doi: 10.1016/j.neuroimage.2009.03.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Varoquaux G, Gramfort A, Poline JB, Thirion B. Brain covariance selection: better individual functional connectivity models using population prior. Advances in Neural Information Processing Systems. 2010;23:2334–2342. [Google Scholar]
- 16.Ramsey JD, Hanson SJ, Glymour C. Multi-subject search correctly identifies causal connections and most causal directions in the DCM models of the Smith et al. simulation study. NeuroImage. 2011;58(3):838–848. doi: 10.1016/j.neuroimage.2011.06.068. [DOI] [PubMed] [Google Scholar]
- 17.Lauritzen SL. Graphical Models. Oxford University Press; 1996. [Google Scholar]
- 18.Neyman J, Pearson ES. On the use and interpretation of certaintest criteria for purposes of statistical inference: part I. Biometrika. 1928;20A:175–240. [Google Scholar]
- 19.Fisher RA. Frequency distribution of the values of the correlation 40 coefficients in samples from an indefinitely large population. Biometrika. 1915;10(4):507–521. [Google Scholar]
- 20.Palmer SJ, Ng B, Abugharbieh R, Eigenraam L, McKeown MJ. Motor reserve and novel area recruitment: amplitude and spatial characteristics of compensation in Parkinson’s disease. European Journal of Neuroscience. 2009;29(11):2187–2196. doi: 10.1111/j.1460-9568.2009.06753.x. [DOI] [PubMed] [Google Scholar]