

Abstract
The robustness of image features is a very important consideration in quantitative image analysis. The objective of this paper is to investigate the robustness of a range of image texture features using hematoxylin stained breast tissue microarray slides which are assessed while simulating different imaging challenges including out of focus, changes in magnification and variations in illumination, noise, compression, distortion, and rotation. We employed five texture analysis methods and tested them while introducing all of the challenges listed above. The texture features that were evaluated include co-occurrence matrix, center-symmetric auto-correlation, texture feature coding method, local binary pattern, and texton. Due to the independence of each transformation and texture descriptor, a network structured combination was proposed and deployed on the Rutgers private cloud. The experiments utilized 20 randomly selected tissue microarray cores. All the combinations of the image transformations and deformations are calculated, and the whole feature extraction procedure was completed in 70 minutes using a cloud equipped with 20 nodes. Center-symmetric auto-correlation outperforms all the other four texture descriptors but also requires the longest computational time. It is roughly 10 times slower than local binary pattern and texton. From a speed perspective, both the local binary pattern and texton features provided excellent performance for classification and content-based image retrieval.
Keywords: Cloud computing, tissue microarray, texture features
INTRODUCTION
It has been reported that one in seven women in the United States has a risk of developing breast cancer during her lifetime. Breast cancer is one of the most frequently diagnosed cancers in women. Breast cancer is expected to account for 28% (207, 090) of all new cases among women in the US during 2010.[1] Tissue microarrays (TMAs) consist of small histological sections (histospots) arranged in a matrix configuration on a recipient paraffin block.[2] TMAs provide an efficient approach to preserve tissues while facilitating high-throughput analysis and experiments. Digital microscopy and open microscopy environment[3,4] have become extremely valuable tools for visualizing, archiving and quantitatively analyzing pathology specimens.
Image texture analysis has been widely investigated for pathology images.[5–10] There are three principal approaches to represent image texture: statistical methods, structural methods and model based methods.[11,12] For statistical approaches, the relationships between each pixel and its neighboring pixels are quantified by the spatial distribution of their intensities. For structural approaches, an image is modeled as a set of texture units or primitives, and image texture is a representation of the geometric properties of these texture units. Model based texture analysis methods rely on utilizing the model parameters to describe the essential perceived qualities of texture, such as Markov random fields, fractals, et al. Statistical and structural approaches are often combined to extract texture features.[12] When texture analysis algorithms are applied to large image sets, it is generally time-consuming. CometCloud[13,14] is an autonomic computing engine that enables the dynamic and on-demand federation of clouds and grids as well as the deployment and execution of applications in such federated environments. It supports highly heterogeneous and dynamic cloud/grid infrastructures, enabling the integration of public/private clouds and autonomic cloudbursts, i.e., dynamic scale-out to clouds to address dynamic workloads, spikes in demands, and other extreme requirements. Since a single cloud/grid/cluster has finite resources (nodes) it may not satisfy all types of heterogeneous jobs. In such cases a computing middleware which provides a flexible architecture which can federate heterogeneous computing environments and deploy heterogeneous jobs on the federated computing environments is required. The CometCloud is very well suited for such efforts.
CometCloud supports the dynamic addition or removal of master and/or worker nodes from any of the federated environments (i.e., clouds, grids, local clusters, etc.) to enable on-demand scale up/down or scale out/in. It provides two classes of workers, the secure worker and the unsecured (isolated) worker as shown in Figure 1. Secure workers can access and possibly host part of the Comet virtual coordination space as well as provide computational cycles, while isolated workers only provide computational cycles. CometCloud supports both pull-based and push-based task scheduling models as appropriate to the specific computing environment. For example, traditional high performance computing grids such as TeraGrid uses batch queues to submit jobs, and in such an environment, CometCloud pushes jobs into the queue. However, for public clouds such as Amazon EC2, each node can be started on-demand and workers on these nodes pull tasks whenever they become idle. The pull-based model is especially well suited for cases where the capabilities of the workers and/or the computational requirements of the tasks are heterogeneous. The Comet virtual coordination space is used to host application tasks and possibly small amounts of data associated with the tasks. Secure workers can connect to the space and pull tasks from the space directly whileunsecured workers receive tasks only through a proxy.
Figure 1.
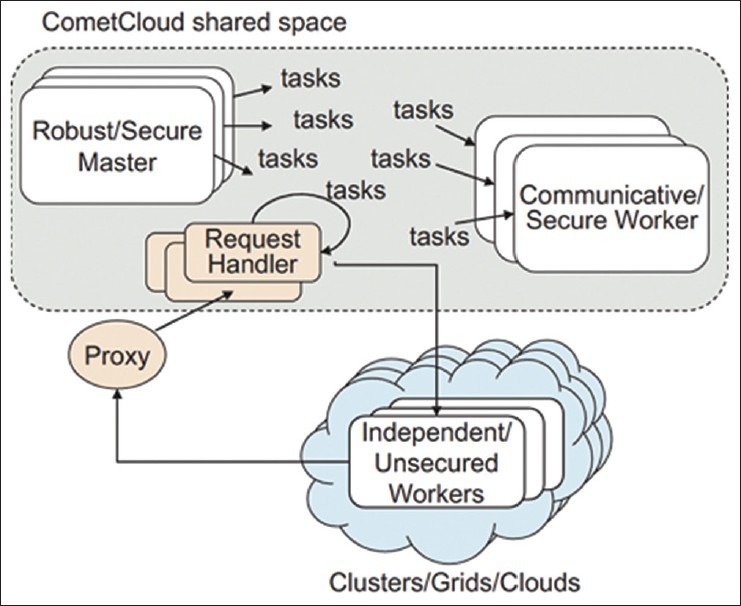
Overview of the scale-out to clouds using CometCloud
IMAGE FEATURE ROBUSTNESS
Image feature robustness is a general problem and an extremely important characteristic to measure in image analysis applications. The objective of our work was to investigate the robustness of a spectrum of texture features under different image transformations and deformations. This study includes a random selection of ten normal and ten cancer cores from 122 hematoxylin stained breast TMA discs. The corresponding images were evaluated by domain experts to confirm the fact that they were representative of normal and abnormal samples after multiple random runs. All the images were taken using a Nikon microscope. Figure 2 shows one representative normal breast TMA core acquired while varying the magnification, focus, illumination, speckle noise, compression, distortion and rotation, respectively. A robust texture descriptor should generate similar texture features under all these deformations and transformations. Thanks to the contribution of cloud computing, it enabled our team to conduct this study reliably and efficiently. In the following section we explain the transformations and deformations we utilized to test the robustness of the texture descriptors.
Figure 2.
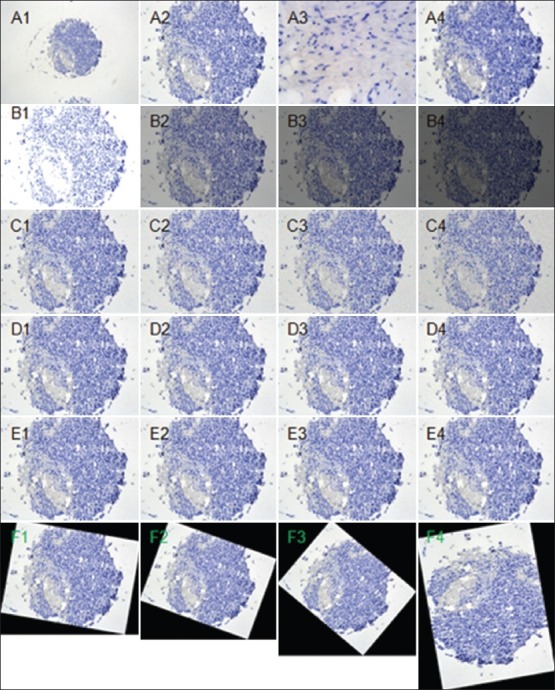
One representative normal breast TMA core taken at different magnification objectives 10× (A1), 20× (A2), and 40× (A3). A4 represents out of focus under 20x. B1 to B4 represent different levels of illumination; C1 to C4 denote different levels of speckle noise with zero mean and variance at 0.02, 0.04, 0.08 and 0.16, respectively; D1 to D4 represent different levels of compression; E1 to E4 denote different levels of B-spline distortion; F1 to F4 show the transformed images under different rotation angles at 10, 20, 40 and 80 degrees using the center of the image as the origin
Transformation Methods
Each TMA core was physically imaged at 3 different magnifications (10×, 20×, 40×) using the same center of the core. Out of focus was performed under 20× magnification with using an even illumination. The other transformations including different levels of illumination, speckle noise, compression, distortion and rotation were performed after digital acquisition. All digital and physical transformations were introduced to simulate the artifacts and variations that are often introduced during the preparation of TMA slides and different imaging conditions. All the transformed images were compared with images taken at 20× magnification under an even illumination light condition and within a focal plane.
For images at 20× magnification objective within a focal plane, we transformed the color image from RGB space to CIE xyY space. Within the xyY space, each image was transformed at 2,1/2,1/4 and 1/8 times of the original images’ luminance. Speckle noise is a random pattern in an image caused by coherent process of back scattered signals from multiple distributed targets. It is directly proportional to the local intensity. Define J = I + n*I, where I is an original image, J is the noisy image, and n represents the uniformly distributed random noise with zero mean and variance at different levels. In order to test the speckle noise, we set the variance to 0.02, 0.04, 0.08 and 0.16, respectively.
Singular value decomposition is used to model the compression. The singular values of the original image are ranked in a decreasing order, and the sum of the first several principle components were used to reconstruct the original images. In the experiments the first 100, 200, 400 and 800 ranked components were tested to reconstruct the original images, respectively.
Region distortion is implemented using a B-splines transformation, which deforms a specific region in the image by manipulating an underlying mesh of control points.[15] In our experiments, B-spline transformations with different parameters were applied to 60% of the original images from the center of each TMA image. For rotation experiments, we tested at angles of 10, 20, 40 and 80 degrees respectively, using the center of the image as its origin.
Texture Analysis Methods
The five texture analysis methods evaluated in this paper are: co-occurrence matrix (COOC), center-symmetric auto-correlation (CSAC), texture feature coding method (TFCM), local binary pattern (LBP), and texton. COOC[16,17] and CSAC[18] belong to statistical methods. TFCM[19] and LBP[20] are combined statistical and structural approaches. The texton is a model based texture method.[21] Previous studies[22,23] had shown that some texture features can capture the underlying variations that exist in normal and cancer tissues. In recent studies, texture has been successfully characterized through textons.[21,23–25] We chose to investigate those five image analysis algorithms for this study because they capture rotation- and intensity- invariant texture features and are not sensitive to region of interest size.
COOC (also called spatial gray-level dependence matrices) were first proposed by Haralick et al,[16,17] and are based on the estimation of the intensity second-order joint conditional probability density functions for various distances and for four specified directions (0°, 45°, 90° and 135°) between two pixels. Texture features calculated using the COOC quantify the distribution of gray-level values within an image. For this study, four texture features including contrast, correlation, energy and homogeneity were calculated from the co-occurrence matrices within the segmented ROIs from four specified directions within a 3 × 3 local window. Contrast is a measure of the gray-level variation between pairs of image elements. Correlation is sensitive to uniform and repeated structures. Energy is sensitive to image regions that have only a small number of intensity distribution patterns; it is an indicator of uniformity or smoothness. Homogeneity is sensitive to images with lower contrast values.
CSAC can be regarded as a generalization of Laws’ kernel method.[26] It measures covariance of any local center-symmetric patterns. Two local center-symmetric auto-correlations, linear and rank-order (SAC and SRAC), together with a related covariance measure (SCOV) and variance ratio (SVR), within-pair variance (WVAR) and between-pair variance (BVAR) were calculated. All of these are rotation-invariant measures.[18]
TFCM[19] is a coding scheme in which each pixel is represented by a texture feature number (TFN). The TFN of each pixel is generated based on a 3 × 3 texture unit as well as the gray-level variations of its eight surrounding neighbor pixels. The TFNs are used to generate a TFN histogram from which texture feature descriptors are quantified. In this work, we calculated coarseness, homogeneity, mean convergence and variance. Coarseness measures drastic intensity change in the 8-connective neighborhood. Homogeneity measures the total number of pixels whose intensity have no significant change in the 8-connective neighborhood. Mean convergence indicates how closely the texture approximates the mean intensity within a texture unit. Variance measures deviation of TFNs from the mean. Code entropy, which measures the information content of coded TFNs, was also calculated, in four Orientations 0°, 45°, 90° and 135°.
The local binary pattern (LBP) method is a multi-resolution approach for gray-scale and rotation invariant texture extraction based on local binary patterns.[20] Its principle is analogous to TFCM. Each pixel is labeled with the code of the texture primitive that best matches the local neighborhood. Thus each LBP code can be regarded as a micro-texton. The derivation of the LBP follows that represented by Ojala et al.[20] Texture T in a local neighborhood of a gray-scale image can be defined as the joint distribution of the gray levels of P + 1 image pixels. Based on the assumption that the intensity differences between center pixel and its neighbors are independent to the intensity of center pixel, the joint distribution can be factorized as
T ≈ t(gc)t(g0 – gc,…,gp-1 – gc) (1)
Where gc corresponds to the gray values of the center pixel of a local neighborhood. gp(p = 0, ␎ , p – 1) corresponds to the gray values of P equally spaced pixels on a circle of radius R that form a circularly symmetric set of neighbors. Because t(gc) describes the overall luminance of an image which is unrelated to local image texture and to achieve invariance with respect to any monotonic transformation of the gray scale, only the signs of the differences are applied. After a binomial weight 2p is assigned to each sign of the difference transforming the differences in a neighborhood into a unique LBP code. The code characterizes the local image texture around (xc, yc).
![]()
So the texture of the image can be approximately described with a 2p-bin discrete distribution of LBP code as T ≈ t(LBPp, R(xc, yc))
The local binary pattern (LBP) method was applied to extract rotation-invariant, uniform patterns for each image. Within the segmented ROI, three different radii (R) of a circle with corresponding numbers (N) of local neighbors of center pixel for the circle were calculated using a multi-resolution approach to gray-scale and rotation invariant texture extraction based LBP. The radii (R) of circles used in the experiments and corresponding numbers (N) of local neighbors were R = 1 and N = 8; R = 2 and N = 12; R = 4 and N = 16 respectively.
In more recent studies, texture has been characterized through textons, which are basic repetitive elements of textures.[21,24,25] Due to characteristics of expressiveness and generalization of textons,[21] a texton library can be built through responses to a set of well-defined linear filters using randomly selected image data from whole data set, and clustering of the resulting filter responses gives centers that represent the texton library of the whole dataset. In our studies, we randomly selected 30 normal discs and cancerous discs respectively to construct a texton reference library. First, each of the TMA images were filtered using a filter bank containing 48 filters,[21] including 36 oriented filters with 6 orientations, 3 scales and 2 phases, 8 center-surround derivative Gaussian filters, and 4 low-pass Gaussian filters. Allowing Nm to represent the number of pixels within the mask region for each disc. After filtering, each pixel within the mask region is transformed to a 48-dimensional vector. For each image, each pixel is mapped to a 48 x (Nm × 3)-dimensional space. Next, the resulting vectors were clustered using a vector quantization algorithm, (we chose a k-means clustering algorithm[27] for this purpose). Here, we set k equal to 25 empirically. After clustering, each image was represented by 25 centers with 48 filter responses. Subsequently the textons of all the normal and cancerous TMA images were concatenated to form two large texton sets separately. After applying k-means clustering again on those two texton sets separately using k = 250 (here using a much larger value than the number of training dataset), we built texton libraries of 500 centers with 48 filter responses for the whole dataset of TMA images. Finally the texton histogram library of images was used to compute the texton histogram of each TMA image. For TMA image, using the same filter bank, the histograms were created by assigning the filter responses of each pixel within the mask to the closest texton in the library.
Performance Evaluation
The robustness of the features is evaluated using two matrices. Type I is to evaluate each texture method's own robustness under different levels of transformations, which we called generative power. A more robust texture analysis algorithm should produce similar feature vectors under different transformations, and therefore has more generative power. The χ2 distance is utilized to measure the similarity of feature vectors. Type II is to evaluate the discriminative power under different levels of transformations. The texture analysis algorithm with higher discriminative power should maximize the inter-class disparity while minimizing the intra-class similarity. Define the following measurement,
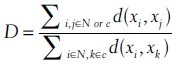
where N is the normal TMA image features and C is the cancer TMA image features, x represents a feature vector at different transformation levels for a specific texture method. A texture feature with higher discriminative power should produce smaller D value by definition.
HIGH THROUGHPUT FEATURE CALCULATION ON THE COMETCLOUD
Because of the independence of each transformation and texture feature method, this can be parallelized on clusters. Figure 3 shows all the possible executions for image transformation and feature extraction. The application was implemented with master/worker programming model using CometCloud. A master generates each of the combination of image transformation and feature extraction as a task and inserts it into the CometCloud shared space. Then, a worker picks up a task from the space, executes it, and sends the results back to the master. Whenever a worker completes a task, it consumes a next task immediately from the space so as to minimize the idle time.
Figure 3.
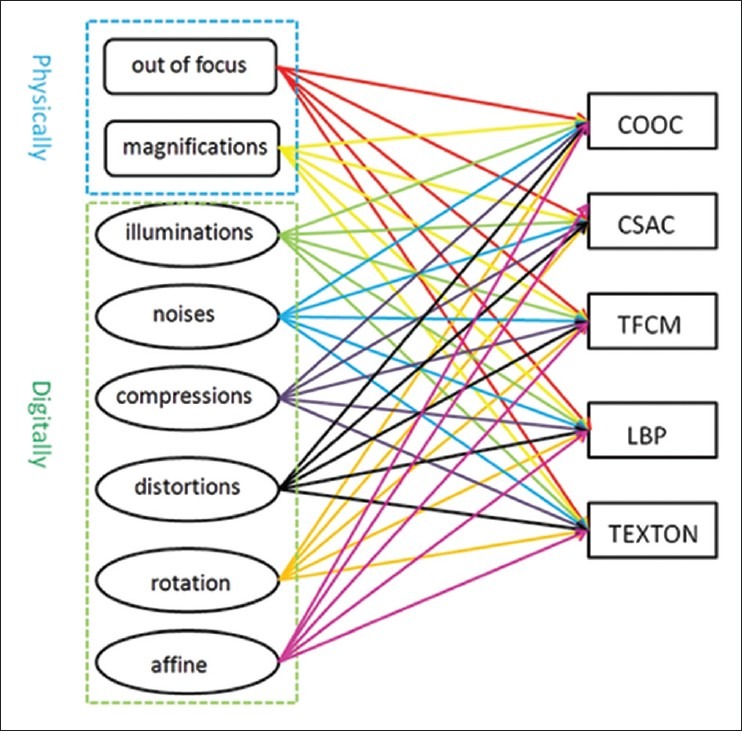
A workflow of the procedures of image transformations and feature extractions
EXPERIMENTAL RESULTS
Feature Robustness
Figures 4a and b show the type I and type II evaluations at different magnifications (10×, 20× and 40×) with even illumination under focal plane. Figure 5 and show the type I and type II evaluations at 20× magnification objective with even illumination but out of focus. Figures 6a and b show the type I and type II evaluations at different levels of illumination with its corresponding luminance at 2, 1/2, 1/4 and 1/8, respectively. Figures 7 and show the type I and type II evaluations at different levels of zero mean speckle noise with its corresponding variance at 0.02, 0.04, 0.08 and 0.16 respectively. Figures 8a and b show the type I and type II evaluations at different levels of compression with its corresponding singular value at 800, 400, 200 and 100 respectively. Figures 9a and b show the type I and type II evaluations at different levels of B-spline distortion degree (2, 4, 8, and 16). Figures 10a and b show the type I and type II evaluations at different rotation angles (10°, 20°, 40° and 80°) using center of the image as the origin.
Figure 4.
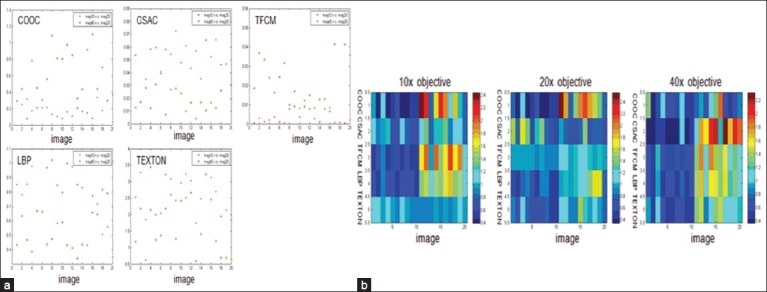
(a) type I evaluation of each texture method at 10×, 20× and 40× magnification objectives with even illumination under focal planet; (b) Type II evaluation of each texture method at 10×, 20× and 40× magnification objectives with even illumination under focal plane
Figure 5.
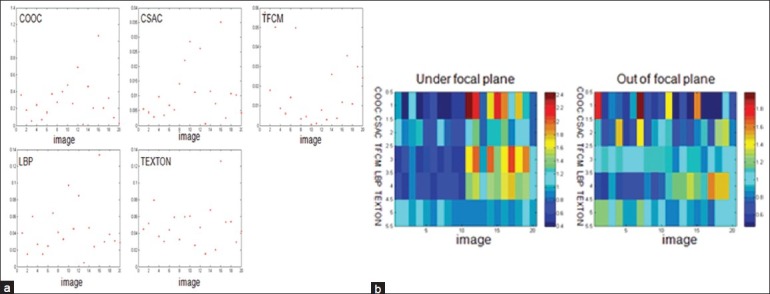
(a) Type I evaluation of each texture method at 20× magnification objective with even illumination but out of focus purposely; (b) Type II evaluation of each texture method at 20× magnification objective with even illumination under focal plane and out of focal plane purposely
Figure 6.
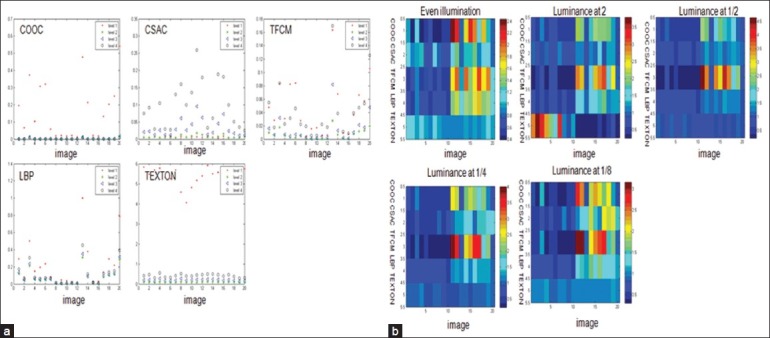
(a) Type I evaluation of each texture method with even illumination and with extra luminance at 2, 1/2, 1/4 and 1/8 at 20× magnification under focal plane; (b) Type II evaluation of each texture method with even illumination and with extra luminance at 2, 1/2, 1/4 and 1/8 at 20× magnification under focal plane
Figure 7.
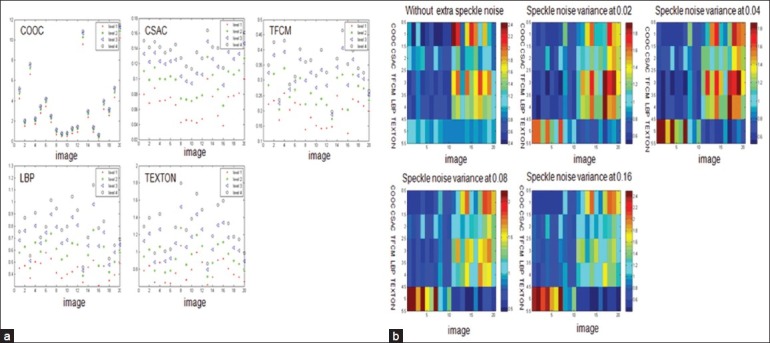
(a) Type I evaluation of each texture method without extra speckle noise and with added speckle noise with its corresponding zero mean and variance at 0.02, 0.04, 0.08 and 0.16 at 20× magnification under focal plane with even illumination; (b) Type II evaluation of each texture method without extra speckle noise and with added speckle noise with its corresponding zero mean and variance at 0.02, 0.04, 0.08 and 0.16 at 20× magnification under focal plane with even illumination
Figure 8.
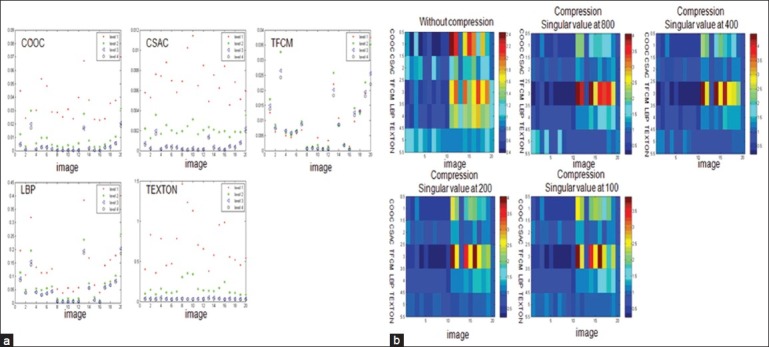
(a) Type I evaluation of each texture method at different levels of compression with its corresponding singular value at 800, 400, 200 and 100 at 20× magnification under focal plane with even illumination; (b) Type II evaluation of each texture method at different levels of compression with its corresponding singular value at 800, 400, 200 and 100 at 20× magnification under focal plane with even illumination
Figure 9.
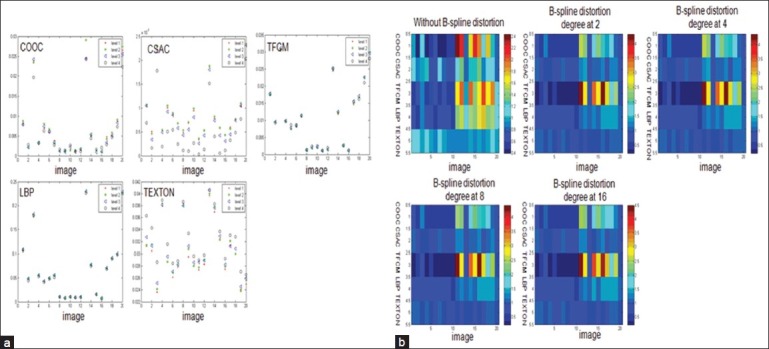
(a) Type I evaluation of each texture method at different levels of B-spline distortion degree at 2, 4, 8 and 16 at 20× magnification under focal plane with even illumination; (b) Type II evaluation of each texture method at different levels of B-spline distortion degree at 2, 4, 8 and 16 at 20× magnification under focal plane with even illumination
Figure 10.
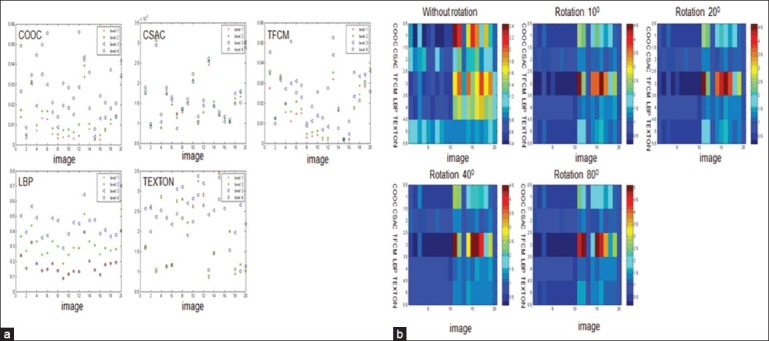
(a) Type I evaluation of each texture method at different rotation angles at 10°, 20°, 40° and 80° respectively using center of the image as the origin at 20× magnification under focal plane with even illumination; (b) Type II evaluation of each texture method at different rotation angles at 10°, 20°, 40° and 80° respectively using center of the image as the origin at 20× magnification under focal plane with even illumination
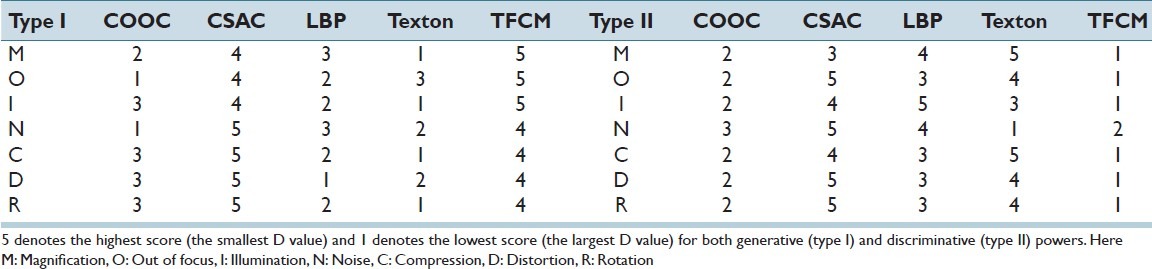
The type I and type II evaluation ranking results are shown in Table 1.
Table 1.
The performance evaluation ranking results
Type I Evaluation Results
At different magnification objectives, TFCM has the highest generative power while the Texton has the lowest; CSAC, LBP, and COOC have the middle level generative power. There is no significant difference among magnification 10×, 20×, and 40× for type I evaluation of CSAC, LBP and texton; but COOC and TFCM show significant difference.
For out of focus, TFCM has the highest generative power; COOC has the lowest generative power; CSAC, texton and LBP have the middle generative power.
At different illumination levels, TFCM has the highest generative power; Texton has the lowest generative power; CSAC, COOC and LBP have the medium generative power. There is no significant difference among each level of illumination for type I evaluation of CSAC, LBP and TFCM; but COOC and texton show significant difference among each level of illumination.
At different speckle noise levels, CSAC and TFCM have higher generative power; LBP and texton have the medium generative power; and COOC has the lowest generative power. With the noise level increased, each image texture feature shows decreased generative power as one might expect.
At different compression levels, CSAC and TFCM have the highest generative power; COOC and LBP have the medium generative power; and texton has the lowest generative power. With the compression level increased, each texture feature shows decreased generative power.
At different distortion levels, CSAC has the highest generative power; COOC, TFCM and texton have the medium level generative power; and LBP has the lowest generative power. With the distortion level increased, each feature extraction method shows the decreased generative power.
At different rotation angles, CSAC has the highest generative power; COOC, TFCM and LBP have the medium generative power; and texton has the lowest generative power. With the rotation angle increases, each feature extraction method shows a decreased generative power in general.
Type II Evaluation Results
At different magnification objectives, texton has the best discriminative power; LBP and CSAC are in the middle range. COOC and TFCM have the least classification power. Meanwhile there is no significant difference among different magnification objectives for type II evaluation.
For out of focus, CSAC has the best discriminative power, LBP and texton are in the middle. COOC and TFCM have the least discriminative power.
At different illumination levels, LBP, CSAC and texton show better discriminative powers compared to COOC and TFCM. Meanwhile, there is slight difference among various illumination levels among CSAC, LBP, texton and TFCM for type II evaluation except COOC.
At different speckle noise levels, texton, CSAC and LBP show better discriminative power than COOC, TFCM. With the speckle noise level increasing, CSAC and texton show a decreased discriminative power while LBP, TFCM and COOC are opposite.
Without compression, texton shows the best discriminative power; while TFCM has the least discriminative power. With the compression level increasing, texton shows the best discriminative power at various compression levels. CSAC and LBP show better classification power compared to COOC at different compression levels. TFCM shows the worst discriminative power at different compression levels.
Without distortion texton exhibits the best discriminative power; TFCM has the least discriminative power. With an increasing distortion level, CSAC has the best discriminative power at various distortion levels. Texton and LBP show better discriminative power compared to COOC at different compression levels. TFCM shows the worst discriminative power at various distortion levels.
Without rotation texton shows the best discriminative power; TFCM has the least discriminative power. When the rotation angle increases, CSAC shows the best discriminative power at different rotation angles. Texton and LBP show better discriminative power compared to COOC. TFCM has the worst discriminative power for rotation.
Feature Calculation on the CometCloud
We used Rutgers cluster with 30 nodes where each node has 8 cores, 6 GB memory, 146 GB storage and 1 GB Ethernet connection, and varied the number of workers from a single node to 30 nodes. Figure 11 shows the average runtime for each feature extraction method to execute an image on a single worker. CSAC and TFCM are the most computational expensive algorithms compared to other feature extraction methods. Figure 12 shows the time-to-completion (TTC) of all the combinations of image transformations and feature extractions varying the number of workers as well as the average number of tasks completed by a worker. When the number of workers increases, the TTC of the combinations of image transformations and feature extractions dramatically decreases accordingly. We found that parallelizing the task on 20 nodes achieved the best computational efficiency and the TTC increases slightly on 30 nodes. This is due to the increasing idle time of workers. When there is no task to consume in the space, the workers become idle and wait for a new task. This happens when the task generation rate is smaller than task consumption rate, which indicates that there are so many workers for small tasks than the master can generate. For example, the master generates tasks for LBP featuring, which has the smallest execution time as shown in Figure 11, and if there are too many workers than generated tasks, then the workers consume those small tasks quickly and become idle waiting for new tasks to be generated. In this experiment, the total idle time of all workers is 809 seconds at 20 nodes and 1,724 seconds at 30 nodes and this causes the slight increase of TTC.
Figure 11.
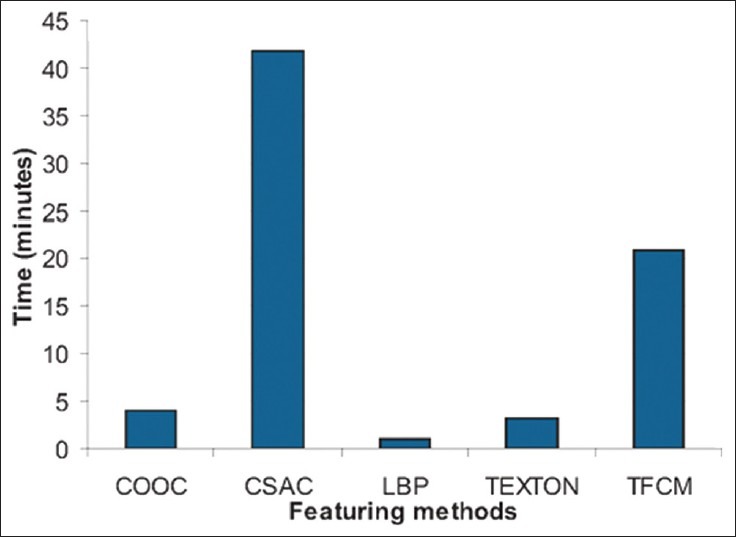
Average runtime per image for each feature extraction method
Figure 12.
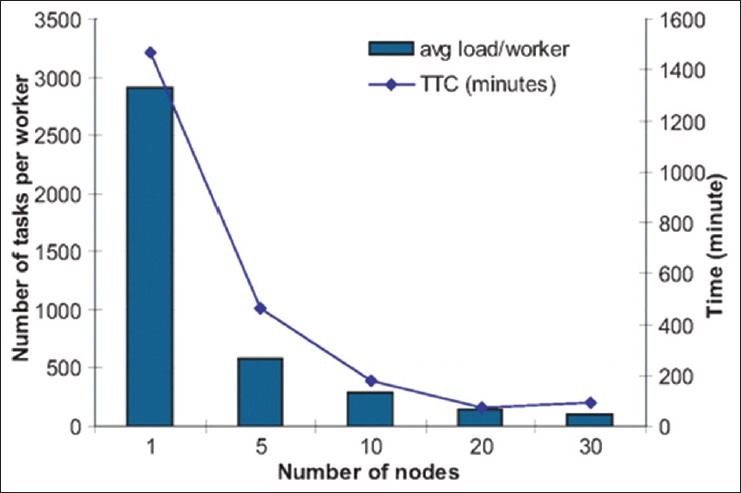
Time-to-completion of all the combination of image transformation and feature extraction varying the number of workers as well as the average number of tasks completed by a worker
We deployed the application on the Rutgers cluster (a private cloud) due to the static workloads of the application and to reduce data transfer overhead across networks; however, if the workloads increases and a shorter TTC is required, then public clouds such as Amazon EC2, etc. can be provisioned additionally to scale up resources and the workers on both private clouds and public clouds consume tasks.
DISCUSSION AND CONCLUSION
The aim of this study is to investigate feature robustness under different transformations and deformations. For type I evaluation (generative power), CSAC and TFCM outperforms the others; however, both features require longer computational time compared to other methods as shown in Figure 11. For type II evaluation (discriminative power), CSAC outperforms LBP or texton, which are better than COOC and TFCM. In general considering speed, LBP or texton would be the preferred methods.
Using CometCloud, the heavily over-loaded work can be easily parallelized on multiple nodes. We experimentally prove that CometCloud plays a critical role for large scale, computationally expensive applications. In addition to the CometCloud, a combination offederated high-performance computing cyber-infrastructure (Grids and Clouds) will be utilized in our future studies.
In our study, type I and type II evaluation metrics are utilized to select the most robust features for analyzing breast cancer tissue microarrays. Similar comparisons can be conducted for other types of images, such as lung cancer, colon cancer, etc. Our team also plans to apply similar procedures to investigate the robustness of image features across a wider range of pathology applications.
ACKNOWLEDGEMENT
This research was funded, in part, by grants from the National Institutes of Health through contract 5R01CA156386-06 and 1R01CA161375-01A1from the National Cancer Institute; and contracts 5R01LM009239-04 and 1R01LM011119-01 from the National Library of Medicine. Additional support was provided by a gift from the IBM International Foundation. CometCloud was developed as part of the NSF Cloud and Autonomic Computing Centre at Rutgers University. The project described was also partially supported by the National Centre for Research Resources, UL1RR033173, and the National Centre for Advancing Translational Sciences, UL1TR000117. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Footnotes
Available FREE in open access from: http://www.jpathinformatics.org/text.asp?2012/3/1/33/101782
REFERENCES
- 1.Jemal A, Siegel R, Xu J, Ward E. Cancer Statistics, 2010. CA Cancer J Clin. 2010;60:277–300. doi: 10.3322/caac.20073. [DOI] [PubMed] [Google Scholar]
- 2.Rimm DL, Camp RL, Charette LA, Costa J, Olsen DA, Reiss M. Tissue microarray: A new technology for amplification of tissue resources. Cancer J. 2001;7:24–31. [PubMed] [Google Scholar]
- 3.Swedlow JR, Goldberg I, Brauner E, Sorger PK. Informatics and quantitative analysis inbiological imaging. Science. 2003;300:100–2. doi: 10.1126/science.1082602. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Schiffmann DA, Dikovskaya D, Appleton PL, Newton IP, Creager DA, Allan C, et al. Open microscopy environment and findspots: Integrating image informatics with quantitative multidimensional image analysis. Biotechniques. 2006;41:199–208. doi: 10.2144/000112224. [DOI] [PubMed] [Google Scholar]
- 5.Diamond J, Anderson NH, Bartels PH, Montironi R, Hamilton PW. The use of morphological characteristics and texture analysis in the identification of tissue composition in prostataticneoplasia. Hum Pathol. 2004;35:1121–31. doi: 10.1016/j.humpath.2004.05.010. [DOI] [PubMed] [Google Scholar]
- 6.Tabesh A, et al. Automated prostate cancer diagnosis and gleason grading of tissue microarrays. Proc SPIE Medical Imaging - image processing. 2005 [Google Scholar]
- 7.Karacali B, Tozeren A. Automated detection of regions of interest for tissue microarray experiments: An image texture analysis. BMC Med Imaging. 2007;7:2. doi: 10.1186/1471-2342-7-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Qureshi H, Sertel O, Rajpoot N, Wilson R, Gurcan M. Adaptive discriminant wavelet packet transform and local binary pattern for meningioma subtype classificaiton. Med Image Comput ComputAssist Interv. 2008;11(Pt 2):196–204. doi: 10.1007/978-3-540-85990-1_24. [DOI] [PubMed] [Google Scholar]
- 9.Shuttleworth J, et al. Colour texture analysis using co-occurrence matrices for classificaition of colon cancer images. IEEE Canadian Conference on Electrical and Computer Engineering. 2002;2:1134–9. [Google Scholar]
- 10.Esgiar AN, Naguib RN, Sharif BS, Bennett MK, Murray A. Fractal analysis in detection of colonic cancer images. IEEE TransInf Technol Biomed. 2002;6:54–8. doi: 10.1109/4233.992163. [DOI] [PubMed] [Google Scholar]
- 11.Pitas I. Digital image processing algorithms and applications. Hoboken, New Jersey: John Wiley and Sons; 2000. [Google Scholar]
- 12.Tuceryan M, Jain AK. Texture analysis. The handbook of pattern recognition and computer vision. 1998:207–48. [Google Scholar]
- 13.Kim H. CometCloud: An autonomic cloud engine. Hoboken, New Jersey: John Wiley and Sons, Inc; 2011. [Google Scholar]
- 14.Kim H, el-Khamra Y, Jha S, Parashar M. Exploring application and infrastructure adaptation on hybrid grid-cloud infrastructure. Scientific Cloud Computing in conjunction with 19th ACM International Symposium on High Performance Distributed Computing. 2010 [Google Scholar]
- 15.Rueckert D, Sonoda LI, Hayes C, Hill DL, Leach MO, Hawkes DJ. Nonrigid registration using free-form deformations: Application to breast MR images. IEEE Trans Med Imaging. 1999;18:712–21. doi: 10.1109/42.796284. [DOI] [PubMed] [Google Scholar]
- 16.Haralick RM, Shanmugam K, Dinstein I. Textural features for image classification. IEEE Trans Syst Man Cybern C Appl Rev. 1973;SM-3:610–21. [Google Scholar]
- 17.Haralick RM. Statistical and structural approaches to texture. Proc SPIE. 1979;67:786–804. [Google Scholar]
- 18.Harwood D, Ojala T, Pietikainen M, Kelman S, Davis L. Texture classification by center-symmetric auto-correlation using Kullback discrimination of distributions. Pattern Recognit Lett. 1995;16:1–10. [Google Scholar]
- 19.Horng MH, Sun YN, Lin XZ. Texture feature coding method for classification of liver sonography. Comput Med Imaging Graph. 2002;26:33–42. doi: 10.1016/s0895-6111(01)00029-5. [DOI] [PubMed] [Google Scholar]
- 20.Ojala T, Pietikaninen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans Pattern Anal Mach Intell. 2002;24:971–87. [Google Scholar]
- 21.Leung T, Malik J. Representing and recognizing the visual appearance of materials using three-dimensional textons. Int JComput Vis. 2001;43:29–44. [Google Scholar]
- 22.Qi X, Cukierski W, Foran DJ. A comparative performance study characterizing breast tissue microarrays using standard RGB and multispectral imaging. Proc Photonics West SPIE. 2010;7557:32. [Google Scholar]
- 23.Qi X, Xing F, Foran DJ, Yang L. Comparative performance analysis of stained histopathology specimens using RGB and multispectral imaging. Proc SPIE Medical Imaging. 2011:7963–118. [Google Scholar]
- 24.Varma M, Zisserman A. Statistical approaches to material classification. Proc 7th European Conf on Computer Vision. 2002 [Google Scholar]
- 25.Cula O, Dana K. 3D texture recognition using bidirectional feature histograms. Int JComput Vis. 2004;59:33–60. [Google Scholar]
- 26.Laws K. Rapid texture identification. Proc SPIE. 1980;238:376–80. [Google Scholar]
- 27.Duda RO, Hart PE, Stork DG. Pattern classification. 2nd ed. New York: Wiley; 2001. [Google Scholar]