

Abstract
We define a new measure of variable importance of an exposure on a continuous outcome, accounting for potential confounders. The exposure features a reference level x0 with positive mass and a continuum of other levels. For the purpose of estimating it, we fully develop the semi-parametric estimation methodology called targeted minimum loss estimation methodology (TMLE) [23, 22]. We cover the whole spectrum of its theoretical study (convergence of the iterative procedure which is at the core of the TMLE methodology; consistency and asymptotic normality of the estimator), practical implementation, simulation study and application to a genomic example that originally motivated this article. In the latter, the exposure X and response Y are, respectively, the DNA copy number and expression level of a given gene in a cancer cell. Here, the reference level is x0 = 2, that is the expected DNA copy number in a normal cell. The confounder is a measure of the methylation of the gene. The fact that there is no clear biological indication that X and Y can be interpreted as an exposure and a response, respectively, is not problematic.
Keywords and phrases: Variable importance measure, non-parametric estimation, targeted minimum loss estimation, robustness, asymptotics
1. Introduction
Consider the following statistical problem: One observes the data structure O = (W, X, Y) on an experimental unit of interest, where W ∈
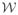 stands for a vector of baseline covariates, and X ∈ ℝ and Y ∈ ℝ respectively quantify an exposure and a response; the exposure features a reference level x0 with positive mass (there is a positive probability that X = x0) and a continuum of other levels (a first source of difficulty); one wishes to investigate the relationship between X on Y, accounting for W (a second source of difficulty) and making few assumptions on the true data-generating distribution (a third source of difficulty). Taking W into account is desirable when one knows (or cannot rule out the possibility) that it contains confounding factors, i.e., common factors upon which the exposure X and the response Y may simultaneously depend.
stands for a vector of baseline covariates, and X ∈ ℝ and Y ∈ ℝ respectively quantify an exposure and a response; the exposure features a reference level x0 with positive mass (there is a positive probability that X = x0) and a continuum of other levels (a first source of difficulty); one wishes to investigate the relationship between X on Y, accounting for W (a second source of difficulty) and making few assumptions on the true data-generating distribution (a third source of difficulty). Taking W into account is desirable when one knows (or cannot rule out the possibility) that it contains confounding factors, i.e., common factors upon which the exposure X and the response Y may simultaneously depend.
We illustrate our presentation with an example where the experimental unit is a set of cancer cells, the relevant baseline covariate W, the exposure X and response Y are, respectively, is a measure of DNA methylation, the DNA copy number and the expression level of a given gene. Here, the reference level is x0 = 2, that is, the expected copy number in a normal cell. The fact that there is no clear biological indication that X and Y can be interpreted as an exposure and a response, respectively, is not problematic. Associations between DNA copy numbers and expression levels in genes have already been considered in the literature (see e.g., [11, 26, 1, 17, 10]). In contrast to these earlier contributions, we do exploit the fact that X features both a reference level and a continuum of other levels, instead of discretizing it or considering it as a purely continuous exposure.
We focus on the case that there is very little prior knowledge on the true data-generating distribution P0 of O, although we know/assume that (i) O takes its values in the bounded set
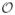 (we will denote ||O|| = max{|W|, |X|, |Y|}), (ii) P0(X ≠ x0) > 0, and finally (iii) P0(X ≠ x0|W) > 0 P0-almost surely. Accordingly, we see P0 as a specific element of the non-parametric set
(we will denote ||O|| = max{|W|, |X|, |Y|}), (ii) P0(X ≠ x0) > 0, and finally (iii) P0(X ≠ x0|W) > 0 P0-almost surely. Accordingly, we see P0 as a specific element of the non-parametric set
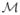 of all possible data-generating distributions of O satisfying the latter constraints. We define the parameter of interest as Ψ (P0), for the non-parametric variable importance measure Ψ:
→ ℝ characterized by
of all possible data-generating distributions of O satisfying the latter constraints. We define the parameter of interest as Ψ (P0), for the non-parametric variable importance measure Ψ:
→ ℝ characterized by
| (1) |
for all P ∈
. Thus, Ψ (P)(X − x0) is the best linear approximation of the form β (X − x0) to (Y − EP (Y|X = x0, W)), hence also to (EP(Y|X, W) − EP (Y|X = x0, W)). Parameter Ψ quantifies the influence of X on Y on a linear scale, using the reference level x0 as a pivot and accounting for W. Note that this expression conveys the notion that the role of X and Y are not symmetric. As its name suggests, Ψ belongs to the family of variable importance measures, which was introduced in [21]. However, its case is not covered by the latter article because X is continuous. We will see how Ψ naturally relates to an excess risk, a prototypical variable importance measure of a binary exposure, when X takes only two distinct values.
The methodology presented in this article straightforwardly extends to situations where one would prefer to replace the expression β(X − x0) in (1) by βf (X, W) for any f such that f(x0, W) = 0 and EP {f (X, W)2} > 0 for all P ∈
. We emphasize that in contrast to [15, 14, 28, 21, 20], we do not assume a semi-parametric model (which would here be written as Y = β (X − x0) + η (W) + U with unspecified η and U such that EP (U|X, W) = 0). This fact bears important implications. The parameter of interest, Ψ (P0), is universally defined no matter what properties the unknown true data-generating distribution P0 enjoys, or does not enjoy. This justifies the expression “non-parametric variable importance measure of a continuous exposure” in the title.
An obvious substitution estimator of Ψ (P0) is
an expression derived from (1) by substituting the empirical measure Pn for P0 and the Nadaraya-Watson estimator θ̂n(X, W) of EP0 (Y|X, W) for it. Under regularity conditions of order k on the true conditional expectation, the optimal bandwith hn for θ̂n satisfies hn = cn−1/(2k+d) where d = 2 is the dimension of (X, W). Now it is possible to characterize a P0 ∈
such that
. In particular, ψ̂n cannot achieve
-consistency under that P0. We see that ψ̂n suffers from the fact that the bias-variance trade-off, which is at the core of the construction of θ̂n, is optimized for the sake of estimating the infinite-dimensional parameter EP0 (Y|X, W) whereas we are eventually interested in estimating the one-dimensional parameter Ψ (P0).
Here we fully develop a version of the semi-parametric estimation methodology called targeted minimum loss estimation (TMLE) [23, 22] tailored to the inference of Ψ (P0). This involves iteratively updating an initial estimator such as ψ̂n in order to produce another substitution estimator. Because the latter is targeted at the estimation of Ψ (P0), it achieves -consistency under mild assumptions. Specifically, Corollary 1 on asymptotic normality only requires that the product of the convergence rate of by the minimum of the convergence rates of and be faster than . In particular, this condition may hold even in situations where none of the three above estimators achieves -consistency.
We cover the whole spectrum of the TMLE theoretical study, practical implementation, simulation study, and application to the aforementioned genomic example.
In Section 2, we study the fundamental properties of parameter Ψ. In Section 3 we provide an overview of the TMLE methodology tailored for the purpose of estimating Ψ (P0). In Section 4, we state and comment on important theoretical properties enjoyed by the TMLE (convergence of the iterative updating procedure at the core of its definition; its consistency and asymptotic normality). The specifics of the TMLE procedure are presented in Section 5 (this section may be skipped on first reading). The properties considered in Section 4 are illustrated by a simulation study inspired by the problem of assessing the importance of DNA copy number variations on expression level in genes, accounting for their methylation (the real data application we are ultimately interested in), as described in Section 6. All proofs are postponed to the appendix.
We assume from now on, without loss of generality, that x0 = 0. Following [25], for any measure λ and measurable function f, λf = ∫ fdλ. We set
. Moreover, the following notation are used throughout the article: for all P ∈
, θ(P)(X, W) = EP (Y|X, W), μ(P)(W) = EP (X|W), g(P)(0|W) = P(X = 0|W), and σ2(P) = EP {X2}. In particular, Ψ (P) can also be written as
2. The non-parametric variable importance parameter
It is of paramount importance to study the parameter of interest in order to better estimate it. Parameter Ψ actually enjoys the following properties (see Section A.2 for definitions and van der Vaart [25, Chapter 25, ] for an introduction to the theory of semiparametric models).
Proposition 1
For all P ∈
,
| (2) |
Parameter Ψ is pathwise differentiable at every P ∈
with respect to the maximal tangent set
. Its efficient influence curve at P is
, where the two components
and
are
-orthogonal and characterized by
Furthermore, the efficient influence curve is double-robust: for any (P, P′) ∈
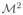 , if either (μ(P′) = μ(P) and g(P′) = g(P)) or θ (P′)(0, ·) = (P)(0, ·) holds, then PD★(P′) = 0 implies Ψ (P′) = Ψ (P).
, if either (μ(P′) = μ(P) and g(P′) = g(P)) or θ (P′)(0, ·) = (P)(0, ·) holds, then PD★(P′) = 0 implies Ψ (P′) = Ψ (P).
The proof of Proposition 1 is relegated to Section A.2.
We emphasize again that we do not assume a semi-parametric model Y = βX + η(W)+U (with unspecified η and U such that EP (U|X, W) = 0). Setting R(P, β)(X, W) = θ (P)(X, W) − θ (P)(0, W) − βX for all (P, β) ∈
× ℝ, the latter semi-parametric model holds for P ∈
if there exists a unique β(P) ∈ ℝ such that R(P, β(P)) = 0. Note that β is always solution to the equation βEP {X2} = EP {X (θ (P)(X, W) − θ (P)(0, W) − R(P, β)(X, W))}. In particular, if the semi-parametric model holds for a certain P ∈
, then β(P) = Ψ (P) by (2). On the contrary, if the semi-parametric model does not hold for P, then it is not clear what β(P) could even mean whereas Ψ (P) is still a well-defined parameter worth estimating. We discuss in Section 4.2 what happens if one estimates β(P) when assuming wrongly that the semi-parametric holds. The discussion allows to identify the awkward non-parametric extension of parameter β(P) that one then estimates.
Equality (2) also teaches us that
| (3) |
for the functional
 :
→ ℝ characterized by
:
→ ℝ characterized by
| (4) |
(all P ∈
). We see that
(P) X is the best linear approximation of the form βX to Y, hence also to EP (Y|X). In view of (1),
overlooks the role played by W. The second term in the right-hand side of (3) is a correction term added to
(P) in order to take W into account. We do not claim that Ψ (P) is superior to
(P): they just do not quantify the same features of P. In the real data application of Section 6.7, we compare the estimators of Ψ (P0) and
(P0) to illustrate that they target two different unknown quantities, and to check across genes whether accounting for W has an impact or not.
Whereas the roles of X and Y are symmetric in the numerator of
(P), they are obviously not in that of the correction term. Less importantly, (2) also makes clear that there is a connection between Ψ and an excess risk. Indeed, consider P ∈
such that P(X ∈ {0, x1}) = 1 for x1 ≠ 0. Then Ψ (P) satisfies
for h(P)(W) = P(X = x1|W), i.e., Ψ (P) appears as a weighted excess risk (the prototypical excess risk would be here EP {θ (P)(x1, W) − θ (P)(0, W)}).
Since Ψ is pathwise differentiable, the theory of semi-parametric estimation is applicable, providing a notion of asymptotically efficient estimation. Remarkably, the asymptotic variance of a regular estimator of Ψ (P0) is lower-bounded by the variance VarP0D★ (P0)(O) under P0 of the efficient influence curve at P0 (a consequence of the convolution theorem). The TMLE procedure takes advantage of the properties of Ψ described in Proposition 1 in order to build a consistent and possibly asymptotically efficient substitution estimator of Ψ (P0). In view of (3), this is a challenging statistical problem because, whereas estimating
(P0) is straightforward (the ratio of the empirical means of XY and X2 is an efficient estimator of
(P0)), estimating the correction term in (3) is more delicate, notably because this necessarily requires estimating the infinite-dimensional features θ (P0)(0, ·) and μ(P0).
3. Overview of the TMLE procedure tailored to the estimation of the non-parametric variable importance measure
We observe n independent copies O(i) = (W(i), X(i), Y
(i)) (i = 1, …, n) of the observed data structure O ~ P0 ∈
. The empirical measure is denoted by Pn. The TMLE procedure iteratively updates an initial substitution estimator
of Ψ (P0) (based on an initial estimator
of the data-generating distribution P0), building a sequence
(with
the kth update of
) which converges to the targeted minimum loss estimator (TMLE)
as k increases. This iterative scheme is visually illustrated in Figure 1, and we invite the reader to consult its caption now.
Fig 1.

Illustration of the TMLE procedure (with its general one-step updating procedure). We intentionally represent the initial estimator
closer to P0 than its kth and (k +1)th updates
and
, heuristically because
is as close to P0 as one can possibly get (given Pn and the specifics of the super-learning procedure) when targeting P0 itself. However, this obviously does not necessarily imply that
performs well when targeting Ψ (P0) (instead of P0), which is why we also intentionally represent
closer to Ψ (P0) than
. Indeed,
is obtained by fluctuating its predecessor
in the direction of Ψ ”, i.e., taking into account the fact that we are ultimately interested in estimating Ψ (P0). More specifically, the fluctuation {
} of
is a one-dimensional parametric model (hence its curvy shape in the large model
) such that (i)
, and (b) its score at ε = 0 equals the efficient influence curve
at
(hence the dotted arrow). An optimal stretch
is determined (e.g. by maximizing the likelihood on the fluctuation), yielding the update
.
It is not necessary to estimate the whole distribution P0 in order to perform the estimation of Ψ (P0). Only some features of P0 must be estimated. One of the purposes of Section 3 is to identify the list of these features. To do so, it proves convenient (from notational and conceptual points of view) to rely on a sequence of estimators of the whole distribution P0, even though we are eventually only interested for each k ≥ 0 in the determined list of features of .
We determine what initializing the TMLE procedure boils down to in Section 3.1. A general one-step targeted updating procedure is described in Section 3.2. How to conduct specifically these initialization and update (as well as two alternative tailored two-step updating procedures) will be addressed in Section 5.
3.1. Initial estimator
In this subsection, we describe what it takes to construct an initial substitution estimator of Ψ (P0). Of course, how one derives the substitution estimator Ψ (P) from the description of (certain features of) P is relevant even if P is not literally an initial estimator of P0.
By (2), building an initial substitution estimator of Ψ (P0) requires the estimation of θ (P0), of σ2 (P0), and of the marginal distribution of (W, X) under P0. Given , initial estimator of P0 with known and marginal distribution of (W, X) under can indeed be obtained (or, more precisely, evaluated accurately) by the law of large numbers, as discussed below. We emphasize that such an initial estimator may very well be biased. In other words, one would need strong assumptions on the true data-generating distribution P0 (which we are not willing to make; typically, assuming that P0 belongs to a given regular parametric model) and adapting the construction of based on those assumptions (typically, relying on maximum likelihood estimation) in order to obtain the consistency of .
For B a large integer (say B = 105), evaluating accurately (rather than computing exactly) the initial substitution estimator of Ψ (P0) boils down to simulating B independent copies (W̃ (b), X̃(b)) of (W, X) under , then using the approximation
| (5) |
Knowing the marginal distribution of (W, X) under amounts to knowing (i) the marginal distribution of W under , (ii) the conditional distribution of Z ≡ 1{X = 0} given W under , and (iii) the conditional distribution of X given (W, X ≠ 0) under . Firstly, we advocate for estimating initially the marginal distribution of W under P0 by its empirical version, or put in terms of likelihood, to build in such a way that . Secondly, the conditional distribution of Z given W under is the Bernoulli law with parameter , so it is necessary that be known too (and such that, -almost surely, . Thirdly, the conditional distribution of X given (W, X ≠ 0) under can be any (finite variance) distribution, whose conditional mean can be deduced from :
| (6) |
and whose conditional second order moment satisfies
| (7) |
In particular, it is also necessary that be known too.
In summary, the only features of we really care for in order to evaluate accurately (rather than compute exactly) are , and the marginal distribution of W under , which respectively estimate θ (P0), μ(P0), g(P0), σ2 (P0), and the marginal distribution of W under P0. We could for instance rely on a working model where the conditional distribution of X given (W, X ≠ 0) is chosen as the Gaussian distribution with conditional mean as in (6) and any conditional second order moment (which is nothing but a measurable function of W) such that (7) holds. We emphasize that we do use here expressions from the semantical field of choice, and not from that of assumption; a working model is just a tool we use in the construction of the initial estimator, and we do not necessarily assume that it is well-specified. Although such a Gaussian working model would be a perfectly correct choice, we advocate for using another one for computational convenience, as presented in Section 5.1.
3.2. A general one-step updating procedure of the initial estimator
The next step consists in iteratively updating . Assuming that one has already built (k − 1) updates of , resulting in (k − 1) updated substitution estimators , it is formally sufficient to describe how the kth update is derived from its predecessor in order to fully determine the iterative procedure. Note that the value of are derived as , by following (5) in Section 3.1 with substituted for .
We present here a general one-step updating procedure (two alternative tailored two-step updating procedures are also presented in Section 5.2). We invite again the reader to refer to Figure 1 for its visual illustration.
Set ρ ∈ (0, 1) a constant close to 1 (in Section 6, we use ρ = 0.999) and consider the path { } characterized by
| (8) |
where
is the current estimator of the efficient influence curve at P0 obtained as the efficient influence curve at
(see Proposition 1). The path is a one-dimensional parametric model that fluctuates
(i.e.,
) in the direction of
(i.e., the score of the path at ε = 0 equals
). Here, we choose minus the log-likelihood function as a loss function (i.e., we choose L:
×
→ ℝ characterized by L(P)(O) = −log P(O)). Consequently, the optimal update of
, corresponds to the maximum likelihood estimator (MLE)
The MLE is uniquely defined (and possibly equal to , hence the introduction of the constant ρ in the definition of the path) provided for instance that
(this statement is to be understood conditionally on Pn, i.e. it is a statement about the sample). Under mild assumptions on P0, targets such that is the Kullback-Leibler projection of P0 onto the path { }. We now set , thus concluding the description of the iterative updating step of the TMLE procedure. Finally, the TMLE is defined as , assuming that the limit exists, or more generally as for a conveniently chosen sequence {kn}n≥0 (see Sections 4.1 and 4.2 regarding this issue).
This is a very general way of dealing with the updating step of the TMLE methodology. The key is that it is possible to determine how the fundamental features of (i.e., the components of involved in the definition of and in the definition of Ψ) behave (exactly) as functions of ε relative to their counterparts at ε = 0 (i.e., with respect to (wrt) ), as shown in the next Lemma (its proof is relegated to Section A.2).
Lemma 1
Set with ||s||∞ < ∞ and consider the path characterized by
| (9) |
The path has score function s. For all and all measurable functions f of W,
| (10) |
| (11) |
| (12) |
| (13) |
| (14) |
Regarding the computation of , it is also required to know how to sample independent copies of (W, X) under , see Section 3.1. Finally, we emphasize that by (14), the marginal distribution of W under typically deviates from its counterpart under (i.e., from its empirical counterpart).
TMLE and one-step estimation methodologies
By being based on an iterative scheme, the TMLE methodology naturally evokes the one-step estimation methodology introduced by Le Cam [8] (see [25, Sections 5.7 and 25.8] for a recent account). The latter estimation methodology draws its inspiration from the method of Newton-Raphson in numerical analysis, and basically consists in updating an initial estimator by relying on a linear approximation to the original estimating equation.
Yet, some differences between the TMLE and one-step estimation methodologies are particularly striking. Most importantly, because the TMLE methodology only involves substitution estimators, how one updates (in the parameter space ℝ) the initial estimator
of Ψ (P0) into
is the consequence of how one updates (in model
) the initial estimator
of P0 into
. In contrast, the one-step estimator is naturally presented as an update (in the parameter space ℝ) of the initial estimator, for the sake of solving a linear approximation (in Ψ (P)) to the estimating equation PnD★ (P) = 0. The TMLE methodology does not involve such a linear approximation; it nevertheless guarantees by construction
for large k (see Section 4.1 on that issue). Furthermore, on a more technical note, the asymptotic study of the TMLE
does not require that the initial estimator
be
-consistent (i.e., that
be uniformly tight), whereas that of the one-step estimator typically does.
However, there certainly exist interesting relationships between the TMLE and one-step estimation methodologies too. Such relationships are not obvious, and we would like to investigate them in future work.
4. Convergence and asymptotics
In this section, we state and comment on important theoretical properties enjoyed by the TMLE. In Section 4.1, we study the convergence of the iterative updating procedure which is at the core of the TMLE procedure. In Section 4.2, we derive the consistency and asymptotic normality of the TMLE. By building on the statement of consistency, we also argue that it is more interesting to estimate our non-parametric variable importance measure Ψ (P0) than its semi-parametric counterpart.
4.1. On the convergence of the updating procedure
Studying the convergence of the updating procedure has several aspects to it. We focus on the general one-step procedure of Section 3.2. All proofs are relegated to Section A.4.
On one hand, the following result (very similar to Result 1 in [23]) holds:
Lemma 2
Assume (i) that all the paths we consider are included in
 ⊂
such that supP∈
⊂
such that supP∈
 ||D★ (P)||∞ = M < ∞, and (ii) that their fluctuation parameters ε are restricted to [−ρ, ρ] for ρ = (2M)−1. If
then
.
||D★ (P)||∞ = M < ∞, and (ii) that their fluctuation parameters ε are restricted to [−ρ, ρ] for ρ = (2M)−1. If
then
.
Condition (i) is weak, and we refer to Lemma 4 for a set of conditions which guarantee that it holds. Lemma 2 is of primary importance. It teaches us that if the TMLE procedure “converges” (in the sense that ) then its “limit” is a solution of the efficient influence curve equation (in the sense that for any arbitrary small deviation from 0, it is possible to guarantee by choosing k large enough). This is the key to the proofs of consistency and asymptotic linearity, see Section 4.2. Actually, the condition can be replaced by a more explicit condition on the class of the considered data-generating distributions, as shown in the next lemma.
Lemma 3
Under the assumptions of Lemma 2, suppose additionally that the sample satisfies (iii) , and (iv) that the log-likelihood of the data is uniformly bounded on . Then it holds that and .
On the other hand, it is possible to obtain another result pertaining to the “convergence” of the updating procedure directly put in terms of the convergence of the sequences and , provided that goes to 0 quickly enough. Specifically,
Lemma 4
Suppose that for some finite C > 0. Then we have for all k ≥ 0. Suppose moreover that for all k ≥ 0, and are bounded away from 0. Then condition (i) of Lemma 2 holds. Assume now that . Then the sequence converges in total variation (hence in law) to a data-generating distribution . Simultaneously, the sequence converges to .
It is necessary to bound and away from 0 because conditions (i) and (ii) of Lemma 2 only imply that and . Now, it makes perfect sense from a computational point of view to resort to lower-thresholding in order to ensure that and cannot be smaller than a fixed constant. Assuming that the series converges ensures that converges in total variation rather than weakly only. Interestingly, we do draw advantage from this stronger type of convergence in order to derive the second part of the lemma. In conclusion, note that Newton-Raphson-type algorithms converge at a k−2-rate, which suggests that the condition is not too demanding.
4.2. Consistency and asymptotic normality
We now investigate the statistical properties of the TMLE . We actually consider a slightly modified version of the TMLE, henceforth denoted by , in order to circumvent the issue of the convergence of the sequence as k goes to infinity. The modified version is perfectly fine from a practical point of view. All proofs are relegated to Section A.5.
Consistency
Under mild assumptions, the TMLE is consistent. Specifically:
Proposition 2 (consistency)
We assume (i) that there exist finite values C > c > 0 such that and for all n ≥ 1, (ii) that and respectively converge to θ0 such that ||θ0||∞ ≤ C, μ0, g0 and in such a way that and , and (iii) that and belong to a P0-Donsker class with P0-probability tending to 1. In addition, we suppose that all assumptions of Lemma 3 are met, and that the (possibly random) integer kn ≥ 0 is chosen so that .
Define . If the limits satisfy either θ (0, ·) = θ (P0)(0, ·) or (μ0 = μ(P0) and g0 = g(P0)) then consistently estimates Ψ (P0).
It is remarkable that the consistency of the TMLE is granted essentially when the estimators converge and that one only of the limits θ0 (0, ·) of and (μ0, g0) of ( ) coincides with the corresponding truth θ (P0)(0, ·) or (μ (P0), g(P0)). This property is mostly inherited from the double-robustness of the efficient influence curve D★ of parameter Ψ (i.e., PD★ (P′) = 0 implies Ψ (P′) = Ψ (P)) and from the fact that the TMLE solves the efficient influence curve equation (i.e., .
Merit of the non-parametric variable importance measure over its semi-parametric counterpart
Again, we do not assume a semi-parametric model Y = βX + η (W) + U (with unspecified η and U such that EP (U |X, W) = 0). However, if P ∈
is such that θ (P)(X, W) = β(P)X + θ (P)(0, W) (i.e., if the semi-parametric model holds under P) then Ψ (P) = β(P). Denote
 ⊂
the set of all such data-generating distributions. It is known (see for instance [28]) that β:
→ ℝ is a pathwise differentiable parameter (wrt the corresponding maximal tangent space), and that its efficient influence curve at P ∈
is given by
⊂
the set of all such data-generating distributions. It is known (see for instance [28]) that β:
→ ℝ is a pathwise differentiable parameter (wrt the corresponding maximal tangent space), and that its efficient influence curve at P ∈
is given by
with v2(P)(X, W) = EP ((Y − θ (P)(X, W)) 2|X, W) is the conditional variance of Y given (X, W) under P. Note that the second factor in the right-hand side expression reduces to (X − μ (P)(W)) whenever v2(P)(X, W) only depends on W.
For the purpose of emphasizing the merit of the non-parametric variable importance measure over its semi-parametric counterpart, say that one estimates β(P0) assuming (temporarily) that P0 ∈
(hence Ψ (P0) = β(P0)). Say that one builds
such that (i)
does not depend on (X, W), and (ii)
. Assume that
and
respectively converge to β1,
, μ1 and θ1 (such that θ1(X, W) = β1X + θ1(0, W)), and finally that one solves in the limit the efficient influence curve equation:
| (15) |
(this is typically derived from (ii) above; see the proof of Proposition 2 for a typical derivation). Then (by double-robustness of ), the estimator of β(P0) is consistent (i.e., β1 = β(P0)) if either θ1 = θ (P0) (that is obvious) or μ1 = μ (P0). For example, suppose that μ1 = μ (P0). In particular, one can deduce from equalities EP0 {X (X − μ(P0)(W))} = EP0 {(X − μ(P0)(W))2} and (15) that
(provided that X does not coincide with μ (P0)(W) under P0). Equivalently, β1 = b(P0) for the functional b:
=
\{P ∈
: X = μ(P)(W)} → ℝ such that, for every P ∈
,
Note that one can interpret parameter b as a non-parametric extension of the semi-parametric parameter β (non-parametric, because its definition does not involve a semi-parametric model anymore). Now, we want to emphasize that b arguably defines a sensible target if θ1(0, ·) = θ (P)(0, ·) (in addition to μ1 = μ (P0)), but not otherwise! This illustrates the danger of relying on a semi-parametric model when it is not absolutely certain that it holds, thus underlying the merit of targeting the non-parametric variable importance measure rather than its semi-parametric counterpart.
Asymptotic normality
In addition to being consistent under mild assumptions, the TMLE is also asymptotically linear, and thus satisfies a central limit theorem. We start with a partial result:
Proposition 3
Suppose that the assumptions of Proposition 2 are met. If then it holds that
| (16) |
Expansion (16) sheds some light on the first order properties of the TMLE . It notably makes clear that the convergence of is affected by how fast the estimators and converge to their limits (see second term). If the rates of convergence are collectively so slow that they only guarantee for some r ∈ [0, 1/2[, then expansion (16) becomes
and asymptotic linearity fails to hold. On the contrary, we easily deduce from Proposition 3 what happens when θ0(0, ·) = θ (P0)(0, ·), μ0 = μ (P0), g0 = g(P0), with fast rates of convergence:
Corollary 1 (asymptotic normality)
Suppose that the assumptions of Proposition 3 are met. If in addition it holds that θ0(0, ·) = θ (P0)(0, ·), μ0 = μ (P0), g0 = g(P0) and
then
i.e., the TMLE is asymptotically linear with an influence function equal to D★ (σ2(P0), θ0, μ0, g0, Ψ (P0)).
Thus, is asymptotically distributed from a centered Gaussian law with variance P0D★ (σ2 (P0), θ0, μ0, g0, Ψ (P0))2. In particular, if θ0 = θ(P0) then the TMLE is efficient.
Corollary 1 covers a simple case in the sense that, by being , the second right-hand side term in (16) does not significantly contribute to the linear asymptotic expansion. In other words, the influence curve actually is D★ (σ2(P0), θ0, μ0, g0, Ψ (P0)). Depending on how and are obtained (we recommend relying on super-learning, cf. Section 5.3), the contribution to the linear asymptotic expansion may be significant (but determining this contribution would be a very difficult task to address on a case by case basis when relying on super-learning).
5. Specifics of the TMLE procedure tailored to the estimation of the non-parametric variable importance measure
In this section, we present practical details on how we conduct the initialization and updating steps of the TMLE procedure as described in Section 3. We introduce in Section 5.1 a working model for the conditional distribution of X given (W, X ≠ 0) which proves very efficient in computational terms. In Section 5.2, we introduce two alternative two-step updating procedures which can be substituted for the general one-step updating procedure presented in Section 3.2. Finally, we describe carefully what are all the features of interest of P0 that must be considered for the purpose of targeting the parameter of ultimate interest, Ψ (P0), via the construction of the TMLE.
5.1. Working model for the conditional distribution of X given (W,X ≠ 0)
The working model for the conditional distribution of X given (W, X ≠ 0) under that we build relies on two ideas:
-
we link the conditional second order moment to the conditional mean (both under ) through the equality
(17) where ϕn, λ (t) = λt2+(1 − λ)(t(mn+Mn)− mnMn) (with mn = mini≤n X(i), Mn = maxi≤n X(i)), and λ ∈ [0, 1] is a tuning parameter;
under and conditionally on (W, X ≠ 0), X takes its values in the set {X(i): i ≤ n}\{0} of the observed X’s different from 0.
As the conditional distribution of X given (W, X ≠ 0) under is subject to two constraints, X cannot take fewer than three different values in general. Elegantly, it is possible (under a natural assumption on ) to fine-tune λ and to select three values in {X(i): i ≤ n}\{0} in such a way that X only takes the latter values:
Lemma 5
Assume that
guarantees that
-almost surely, and X ∈ [mn + c, Mn − c] for some c > 0 when X ≠ 0. It is possible to construct
in such a way that (i) W has the same marginal distribution under
and
and (ii) for all W ∈
, there exist three different values x(1), x(2), x(3) ∈ {X(i): i ≤ n}\{0} and three non-negative weights p1, p2, p3 summing up to 1 such that, conditionally on (W, X ≠ 0) under
, X = x(k) with conditional probability pk.
Hence, we choose to directly construct a satisfying the constraints of in Lemma 5. Note that, by (8), because the conditional distribution of X given (W, X ≠ 0) under has its support included in {X(i): i ≤ n}\{0}, then so do the conditional distributions of X given (W, X ≠ 0) under (all k ≥ 1) obtained by following the general one-step updating procedure of Section 3.2. Similarly, because we initially estimate the marginal distribution of W under P0 by its empirical counterpart, then the marginal distributions of W under and (all k ≥ 1) have their supports included in {Wi: i ≤ n}.
We discuss in Section 5.4 why it is computationally more interesting to consider such a working model (instead of a Gaussian working model for instance). We emphasize that assuming X ∈ [mn + c, Mn − c] when X ≠ 0 (for a possibly tiny c > 0) is hardly a constraint, and that the latter must be accounted for while estimating μ(P0), g(P0), and σ2 (P0). The proof of the lemma is relegated to Section A.2.
5.2. Two tailored alternative two-step updating procedures
We present in Section 3.2 a general one-step updating procedure. Alternatively, it is also possible to decompose each update into a first update of the conditional distribution of Y given (W, X), followed by a second update of the marginal distribution of (W, X).
First update: fluctuating the conditional distribution of Y given (W, X)
We actually propose two different fluctuations for that purpose: a Gaussian fluctuation on one hand and a logistic fluctuation on the other hand, depending on what one knows or wants to impose.
Gaussian fluctuation
We use minus the log-likelihood function as a loss function, as we did for the general one-step updating procedure. First fluctuate only the conditional distribution of Y given (W, X), by introducing the path {
} such that (i) (W, X) has the same distribution under
as under
, and (ii) under
and given (W, X), Y is distributed from the Gaussian law with conditional mean
and conditional variance 1, where the so-called clever covariate (an expression taken from [22]) H(P) is characterized for any P ∈
by
This definition guarantees that the path fluctuates (i.e., , provided that Y is conditionally Gaussian given (W, X) under ) in the direction of (i.e., the score of the path at ε = 0 equals ). Introducing the MLE
the first intermediate update bends into .
Logistic fluctuation
There is yet another interesting option in the case that Y ∈ [a, b] is bounded (or in the case that one wishes to impose Y ∈ [a, b], typically then with a = mini≤n Y(i) and b = maxi≤n Y(i), which allows to incorporate this known fact (or wish) into the procedure. Assume that θ (P0) takes its values in (a, b) and also that is constrained in such a way that . Introduce for clarity the function on the real line characterized by Fa,b(t) = (t − a)/(b − a). Here, we choose the loss function characterized by −La,b(P)(O) = Fa,b(Y) log Fa,b∘ θ(P)(X, W) + (1 − Fa,b(Y)) log(1 − Fa,b ∘ θ (P)(X, W)), with the convention La,b(P)(O) = + ∞ if θ (P)(X, W) ∈ {a, b}. Note that the loss La,b(P) depends on the conditional distribution of Y given (W, X) under P only through its conditional mean θ (P). This straightforwardly implies that in order to describe a fluctuation { } of , it is only necessary to detail the form of the marginal distribution of (W, X) under and how depends on and ε. Specifically, we first fluctuate only the conditional distribution of Y given (W, X), by making be such that (i) (W, X) has the same distribution under as under , and (ii)
Now, introduce the La,b-minimum loss estimator
which finally yields the first intermediate update . The following lemma (whose proof is relegated to Section A.2) justifies our interest in the loss function La,b and fluctuation { }:
Lemma 6
Assume that the conditions stated above are met. Then La,b is a valid loss function for the purpose of estimating θ (P0) in the sense that
Moreover, it holds that
The second inequality is the counterpart of the fact that, when using the Gaussian fluctuation, the score of the path at ε = 0 equals .
Second update: fluctuating the marginal distribution of (W, X)
Next, we preserve the conditional distribution of Y given (W, X) and only fluctuate the marginal distribution of (W, X), by introducing the path { } such that (i) Y has the same conditional distribution given (W, X) under as under , and (ii) the marginal distribution of (W, X) under is characterized by
| (18) |
This second path fluctuates (i.e., ) in the direction of (i.e., the score of the path at ε = 0 equals ). Consider again minus the log-likelihood as loss function, and introduce the MLE
the second update bends into , concluding the description of how we can alternatively build based on .
Note that, by (18), because the conditional distribution of X given (W, X ≠ = 0) under has its support included in {X(i): i ≤ n}\{0} (a consequence of our choice of working model, see Section 5.1), then so do the conditional distributions of X given (W, X ≠ 0) under (all k ≥ 1) obtained by following either one of the tailored two-step updating procedure. Furthermore, it still holds that the marginal distributions of W under and (all k ≥ 1) have their supports included in {Wi: i ≤ n} (because we initially estimate the marginal distribution of W under P0 by its empirical counterpart).
5.3. Super-learning of the features of interest
It still remains to specify how we wish to carry out the initial estimation and updating of the features of interest θ (P0), μ(P0), g(P0), and σ2 (P0). As for σ2(P0) = EP0{X2}, we simply estimate it by its empirical counterpart i.e., construct in such a way that . The three other features θ (P0), μ(P0) and g(P0) are estimated by super-learning, and constructed in such a way that and equal their corresponding estimators. Super-learning is a cross-validation based aggregation method that builds a predictor as a convex combination of base predictors [24, 22] (we briefly describe in Section 6.5 the specifics of the super-learning procedure that we implement for our application to simulated and real data). The weights of the convex combination are chosen so as to minimize the prediction error, which is expressed in terms of the non-negative least squares (NNLS) loss function [7] and estimated by V -fold cross-validation. Heuristically the obtained predictor is by construction at least as good as the best of the base predictors (this statement has a rigorous form implying oracle inequalities, see [24, 22]).
Lemma 1 teaches us what additional features of must be known in order to derive the kth update from its predecessor , starting from k = 1.
Specifically, if we rely on the general one-step updating procedure of Section 3.2 then we need to know:
and for the update of (see (10));
for the updates of , and the marginal distribution of W under (see the right-hand side denominators in (11), (12), (14));
for the update of μ (Pk−1) (see the right-hand side numerator in (11));
for the update of (see the right-hand side numerator in (12));
for the update of (see (13)).
It is noteworthy that if either one of the two-step updating procedures of Section 5.2 is used then the first two conditional expectations do not need to be known, because updating relies on the clever covariate , which is entirely characterized by the current estimators and of the features μ (P0), g(P0), and σ2 (P0), respectively. In the sequel of this sub-section, we focus on the general one-step updating procedure of Section 3.2. How to proceed when relying on either of the two-step updating procedures of Section 5.2 can be easily deduced from that case.
Once , and are determined (see the first paragraph of this sub-section) hence is known, we therefore also estimate by super-learning the conditional expectations under P0 of and given (X, W) and those under P0 of and given W; we simply estimate by its empirical counterpart. Then we constrain in such a way that the conditional expectations of the same quantities under , and the expectation equal their corresponding estimators. This completes the construction of , and suffices for characterizing the features and of the first update .
Now, if one wished to follow exactly the conceptual road consisting in relying on Lemma 1 in order to derive the second update from its predecessor , one would have to describe how each conditional (and unconditional) expectation of the above list behaves, as a function of ε, on the path { }. This would in turn enlarge the above list of the features of interest of P0 that one would have to consider in the initial construction of . Note that the length of the list would increase quadratically in the number of updates. Instead, once is known, we estimate by super-learning the conditional expectations under P0 of and given (X, W), and the conditional expectations under P0 of , and given W; as for , we simply estimate it by its empirical counterpart. Then we proceed as if the conditional expectations of the same quantities under were equal to their corresponding estimators. By doing so, the length of the list of the features of interest of P0 is fixed, no matter how many steps of the updating procedure are carried out. Arguably, following this alternative road has little if no effect relative to following exactly the conceptual road consisting in relying on Lemma 1, because only second (or more) order expressions in ε are involved.
5.4. Merit of the working model for the conditional distribution of X given (W, X ≠ 0)
We explain here why (a) initially estimating the marginal distribution of W under P0 by its empirical counterpart and (b) relying on the working model for the conditional distribution of X given (W, X ≠ 0) that we described in Section 5.1 is computationally very interesting. The key is that, under and its successive updates (all k ≥ 1), the distributions of (W, X) have their supports included in {(W(i), X(j)): i ≤ j ≤ n} (we say they are “parsimonious”).
Indeed, Lemma 1 and a simple induction yield that, for each k ≥ 1, a single call to or involves a number of (nested) calls to the “past” features of interest and (0 ≤ k′ < k) which is O(k). Furthermore, the evaluation of (following (5) with substituted for ) requires in turn B calls (assuming for simplicity that the functions are not vectorized) to (in order to evaluate the numerator of the right-hand side term of (5)), and (in order to simulate {(W̃ (b), X̃(b)): b ≤ B}). Overall, at least O(Bk) calls to the set of all features of interest are performed at the kth updating step of the TMLE procedure. In practice (even if functions are vectorized) this leads to a large memory footprint and prohibitive running time of the algorithm, as each of these calls consists in the prediction of the corresponding feature, as described in Section 5.3.
By taking advantage of the “parsimony” of the distributions of (W, X) under the successive , we manage to alleviate dramatically the time and memory requirements of our implementation. Indeed, the “parsimony” implies that, at the kth step of the TMLE procedure (k ≥ 0), it is only required to compute and store O(n2) quantities (including, but not limited to, and for all 1 ≤ i, j ≤ n) — see Section 5.3). In particular, the evaluation of now requires retrieving O(B) values from a handful of vectors instead of performing O(Bk) memory and time-consuming (nested) function calls.
6. Application
We first present the genomic problem that motivated this study, in Section 6.1, and earlier contributions on the same topic, in Section 6.2. Two real datasets are described in Section 6.3. They play a central role in this article. We both (a) draw inspiration from one dataset and (b) use it in order to set up our simulation study, as presented in Section 6.4. We also apply the TMLE methodology directly to the other dataset. The specifics of the TMLE procedures that we undertake both on simulated and real data are given in Section 6.5, and their results are summarized in Section 6.6, for the simulation study, and in Section 6.7, for the real data application.
6.1. Association between DNA copy number and gene expression in cancers
The activity of a gene in a cell is directly related to its expression level (Y), that is, the number of messenger RNA (mRNA) fragments corresponding to this gene. Cancer cells are characterized by changes in their gene expression patterns. Such alterations have been shown to be caused directly or indirectly by genetic events, such as changes in the number of DNA copies (X), and epigenetic events, such as DNA methylation (W). Some changes in DNA copy number have been reported to be positively associated with gene expression levels [11]. Conversely, DNA methylation is a chemical transformation of cytosines (one of the four types of DNA nucleotides) which is thought to lead to gene expression silencing [5]. Therefore, DNA methylation levels are generally negatively associated with gene expression levels.
We propose to apply the methodology developed in the previous sections to the search for genes for which there exists an association between DNA copy number variation and gene expression level, accounting for DNA methylation.
6.2. Related works
In the context of cancer studies, various methods have been proposed in order to find associations between DNA copy number and gene expression at the level of genes. Because we cannot cite all of them, we try here to cite one relevant publication for each broad type of method. Most of them can be classified into two groups, depending on whether DNA copy number is viewed as a continuous or a discrete variable. When DNA copy number is viewed as a continuous variable, associations between X and Y are generally quantified using a correlation coefficient [11]. When it is viewed as a discrete variable, associations are typically quantified using a test of differential expression between DNA copy number states [26]. A common limitation to this two types of methods is that they are generally good at identifying genes that were already known, but less so at finding novel candidates. This is not surprising: for correlation-based methods, high correlation between X and Y requires both X and Y to vary substantially, in which case it is likely that these (marginal) variations have already been reported. For methods based on differential expression between copy number states, the latter often correspond to biological or clinical groups which are already known and for which differential expression analyses have already been carried out.
In the present paper, we acknowledge the fact that while DNA copy number is observed as a quantitative variable, the copy neutral state (two copies of DNA) generally has positive mass, in the sense that for a given gene, a positive proportion of samples have two copies of DNA.
Another major difference between our method and the ones cited above is that we explicitly incorporate DNA methylation into the analysis. Several papers where DNA copy number, gene expression and DNA methylation are combined have been published recently, but they typically analyze one dimension of (W, X, Y) at a time, and then use an ad hoc rule to merge or intersect the results [1, 17]. The CNAmet method [10] relies on two scores: a score of differential expression between copy number levels on the one hand, and between DNA methylation levels on the other hand. Then both scores are summed. In the method proposed here, the three dimensions are studied jointly.
6.3. Datasets
We exploit glioblastoma multiforme (GBM, the most common type of primary adult brain cancers) and ovarian cancers (OvCa, a cancerous growth arising from the ovary) data from The Cancer Genome Atlas (TCGA) project [2], a collaborative initiative to better understand several types of cancers using existing large-scale whole-genome technologies. TCGA has recently completed a comprehensive genomic characterization of these types of tumor, including DNA copy number (X), gene expression (Y), and DNA methylation (W) microarray experiments [18, 19].
Probe-level normalized GBM and OvCa data can be downloaded from the TCGA repository at http://tcga-data.nci.nih.gov/tcga/. In order to study associations between X, Y and W at the level of genes, these probe-level measurements first need to be aggregated into gene-level summaries. We choose to define X, Y and W as follows for a given gene:
DNA methylation W is the proportion of “methylated” signal at a CpG locus in the gene’s promoter region;
DNA copy number X is a locally smoothed total copy number relative to a set of reference samples;
expression Y is the “unified” gene expression level across three microarray platforms, as defined by [27].
After this pre-processing step, each gene is represented by a 3 × n matrix, where 3 is the number of data types and n is the number of samples. Figure 2(a) represents DNA methylation, DNA copy number, and gene expression data for one particular gene, EGFR, which is known to be altered in GBM. For this gene, the association between copy number and expression is non-linear, and high methylation levels are associated with low expression levels.
Fig 2.
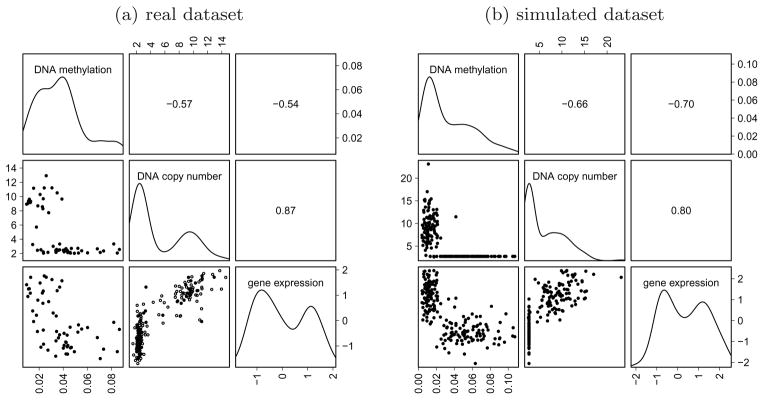
Illustrating DNA methylation, DNA copy number, and gene expression data. In both graphics, we represent kernel density estimates (diagonal panels), pairwise plots (lower panels), and report the pairwise Pearson correlation coefficients (upper panels). (a). Real dataset corresponding to the EGFR gene in 187 GBM tumor samples. For 130 among the 187 samples, only DNA copy number and gene expression data were available (circles in lower middle plot). (b). Simulated dataset consisting of n = 200 independent copies of the synthetic observed data structure described in Section 6.6. Note that the constant is added to each value of X so that graphics corresponding to real and simulated data can be more easily compared.
6.4. Simulation scheme
Because association patterns between copy number, expression and methylation are generally non-linear, setting up a realistic simulation model is a difficult task. We design here a simulation strategy based on perturbations of real observed data structures. It mimics situations such as the one observed in the Figure 2(a) for the EGFR gene in GBM. This strategy implements the following constraints:
there are generally up to three copy number classes: normal regions, and regions of copy number gains and losses;
in normal regions, expression is negatively correlated with methylation;
in regions of copy number alteration, copy number and expression are positively correlated.
Our simulation scheme relies on three real observed data structures corresponding to three samples from different copy number classes: loss (class 1), normal (class 2), and gain (class 3). We simulate a synthetic observed data structure O = (W, X, Y) ~ Ps as follows. Given a vector p = (p1, p2, p3) of proportions such that p1 + p2 + p3 = 1, we first draw a class assignment U from the multinomial distribution with parameter (1, p) (in other words, U = u with probability pu). Conditionally on U, a measure W of DNA methylation is drawn randomly as a perturbation of the DNA methylation in the corresponding real observed data structure OU: given a vector ω = (ω1, ω2, ω3) of positive numbers,
where Z is a standard normal random variable independent of U. Finally, a couple (X, Y) of DNA copy number and expression level is drawn conditionally on (U, W) as a perturbation of the couple ( ) in the corresponding real observed data structure OU (with an additional centering applied to X so that the pivot value be equal to 0): Given σ2 > 0, two variance-covariance 2 × 2-matrices Σ1 and Σ3 and a non-increasing mapping λ0: [0, 1] → [0, 1],
if U = 2, then , where Z′ is a standard normal random variable independent of (U, W);
if U ≠ 2, then (X, Y) is drawn conditionally on (U, W) from the bivariate Gaussian distribution with mean ( ) and variance-covariance matrix ΣU.
In particular, the reference/pivot value x0 = 0. Note that λ0 is chosen non-increasing in order to account for the negative association between DNA expression and methylation. Furthermore, the synthetic observed data structure O drawn from Ps is not bounded.
We easily derive closed-form expressions for the features of interest θ (Ps), μ(Ps), g(Ps), and σ2(Ps), which we report in the Appendix (see Lemma 7). Relying on Lemma 7 makes it possible to evaluate the value of Ψ (Ps), by following the procedure described in Section 3.1 (see details in Section 6.6).
Finally we provide in Figure 2(b), for the sake of illustration, a visual summary of a simulation run with n = 200 independent copies of the synthetic observed data structure O drawn from Ps and based on real observed data structure from two GBM samples for the EGFR gene which are described in Table 1. The parameters for this simulation were chosen as follows: p = (0, 1/2, 1/2), ω = (0, 3, 3), λ0: w ↦ −w, σ2 = 1, .
Table 1.
Real methylation, copy number and expression data used as a baseline for simulating the dataset according to the simulation scheme presented in Section 6.6. A visual of the simulated dataset is provided in Figure 2(b)
| sample name | methylation | copy number | expression |
|---|---|---|---|
| TCGA-02-0001 (i = 2) | 0.05 | 2.72 | −0.46 |
| TCGA-02-0003 (i = 3) | 0.01 | 9.36 | 1.25 |
6.5. Library of algorithms for super-learning
We have explained in Section 5.3 that we rely on super-learning [24, 22] in order to estimate some relevant infinite-dimensional features of P0, including (but not limited to) θ (P0), μ (P0) and g(P0). This algorithmic challenge is easily overcome, thanks to the remarkable R-package SuperLearner [12] and the possibility to rely on the library of R-packages [13] built by the statistical community. As for the base predictors, they involve (by alphabetical order):
Generalized additive models: we use the gam R-package [4], with its default values.
Generalized linear models: we use the glm R-function with identity link (for learning θ (P0) and μ (P0)) and logit link (for learning g(P0)), and with linear combinations of (1, X, W) or (1, X, W, XW) (for learning θ (P0)) and linear combinations of (1, W) or (1, W, W2) (for learning μ (P0) and g(P0)).
Piecewise linear splines: we use polymars R-function from the polspline R-package [6], with its default values.
Random forests: we use the randomForest R-package [9], with its default values.
Support vector machines: we use the svm R-function from the e1071 R-package [3], with its default values.
Note that none of the statistical models associated to the above estimation procedures contains Ps (see Lemma 7).
6.6. Simulation study
We conduct twice a simulation study where B′ = 103 datasets of n = 200 independent observed data structures are (independently) generated under Ps (i.e., under the simulation scheme described in Section 6.4). In each simulation study and for every simulated dataset, we perform the TMLE methodology for the purpose of estimating the target parameter Ψ (Ps). From one simulation study to the other, we only change the setup of the super-learning procedure, by modifying the library of algorithms involved in the super-learning of the features of interest:
the first time, we proceed exactly as described in Section 6.5 (we say that the full-SL is undertaken);
the second time, we decide to include only algorithms based on generalized linear models (we say that the light-SL is undertaken).
We do not use any index to refer to the super-learning setup (full-SL or light-SL) for the sake of alleviating notations.
In each simulation study (i.e., for each setup of the super-learning procedure full-SL and light-SL) and for each b ≤ B′, we record the values of the initial substitution estimator (k = 0) and subsequent updated substitution estimators (k = 1, 2, 3) targeting Ψ (Ps), as derived on the bth simulated dataset (whose empirical measure is denoted by Pn,b). The targeted update steps rely on the Gaussian fluctuations presented in Section 5.2 (the results are very similar when one applies either the general one-step updating procedure of Section 3.2 or the second tailored alternative two-step updating procedure of Section 5.2). We do not record the next updates because the ad hoc stopping criterion that we devise systematically indicates that this is not necessary (heuristically, the criterion elaborates on the gains in likelihood and the variations in the resulting estimates).
The value of Ψ (Ps) is evaluated by simulations, following (5) in Section 3.1 with Ps substituted for (we rely on B = 105 simulated observed data structures, whose empirical measure is denoted by PB; the features θ (Ps) and σ2 (Ps) are explicitly known, see Lemma 7). In order to get a sense of how accurate our evaluation of Ψ (Ps) is, we also use the same large simulated dataset to evaluate VarPsD★ (Ps)(O) (as the empirical variance Var PB D★ (Ps)(O); again, D★ (Ps) is known explicitly by Lemma 7). Denoting by ψB(Ps) and vB(Ps) the latter evaluations, we interpret the intervals and as (1 − α)-accuracy intervals for the evaluation of Ψ (Ps) based on n = 200 and B = 105 independent observed data structures. The gray intervals in Figure 3 represent these accuracy intervals for α = 5%, n = 200 (light gray) and B = 105 (dark gray). Note that (by the convolution theorem) the length of is the optimal length of a 95%-confidence interval based on an efficient (regular) estimator of Ψ (Ps) relying on n observations (assuming that the asymptotic regime is reached). The numerical values are reported in Table 2.
Fig 3.
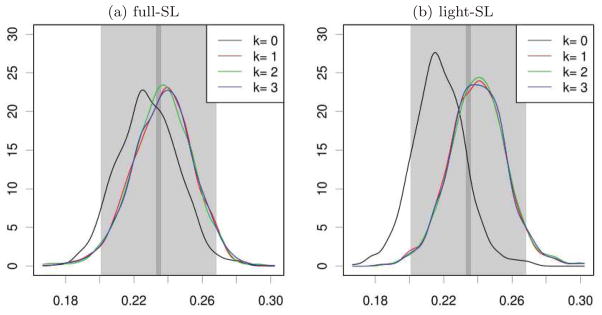
Empirical distribution of { } based on n = 200 independent observed data structures for k = 0 (initial estimator) and k iterations of the updating procedure (k = 1, 2, 3), as obtained from B′ = 103 independent replications of the simulation study (using a Gaussian kernel density estimator). (a). The super-learning procedure involves all algorithms described in Section 6.5. (b). The super-learning procedure only involves algorithms based on generalized linear models. In both graphics, gray rectangles represent 95%-accuracy intervals and for the true parameter Ψ (Ps) based on 200 observed data structures (light gray) and B = 105 observed data structures (dark p gray). The length of is the optimal length of a 95%-confidence interval based on an efficient (regular) estimator of Ψ (Ps) relying on n observations (assuming that the asymptotic regime is reached).
Table 2.
Values of ψB(Ps) and vB(Ps), estimators of Ψ (Ps) and VarPsD★ (Ps)(O), and 95%-accuracy intervals (n = 200, B = 105)
| ψB(Ps) | vB(Ps) |
|
||
|---|---|---|---|---|
| N = 200 | N = 105 | |||
| 0.2345 | 0.05980232 | [0.2006; 0.2684] | [0.2329; 0.2360] | |
The results of this joint simulation study are summarized by Figure 3 (which shows kernel density estimates of the empirical distributions of { } for 0 ≤ k ≤ 3) and Table 3. They illustrate some of the fundamental characteristics of the TMLE estimator and related confidence intervals: convergence of the iterative updating procedure, robustness, asymptotic normality, and coverage.
Table 3.
Testing the asymptotic normality of and the validity of the coverage provided by , with for k = 0, 1, 2, 3, (a) for the full-SL procedure and (b) for the light-SL procedure. We report the gains in relative error and mean square error (first and second rows), the test statistics and corresponding p-values of Lilliefors tests of normality (third and fourth rows), the test statistics of the KS test of normality with null mean and variance equal to ψB(Ps) and vB(Ps) (fifth rows; the corresponding p-values are all smaller than 10−4), and finally the empirical coverages as well as their optimistic counterparts (sixth and seventh rows)
| (a) full-SL
| ||||
|---|---|---|---|---|
| iteration of the TMLE procedure | k = 0 | k = 1 | k = 2 | k = 3 |
| gain in relative error | 0 | 0.0469 | 0.0625 | 0.0335 |
| gain in relative mean square error | 0 | 0.0365 | 0.0369 | 0.0035 |
|
| ||||
| Lilliefors test statistic | 0.0183 | 0.0269 | 0.0298 | 0.0282 |
| Lilliefors test p-value | 0.5718 | 0.0861 | 0.0365 | 0.0582 |
|
| ||||
| KS test statistic | 0.1566 | 0.0782 | 0.0743 | 0.0786 |
|
| ||||
| empirical coverage | – | 0.896 | 0.905 | 0.898 |
| empirical coverage (optimistic) | – | 0.914 | 0.920 | 0.916 |
|
| ||||
| (b) light-SL
| ||||
| iteration of the TMLE procedure | k = 0 | k = 1 | k = 2 | k = 3 |
|
| ||||
| gain in relative error | 0 | 0.2871 | 0.2837 | 0.2866 |
| gain in mean square error | 0 | 0.2352 | 0.2293 | 0.2305 |
|
| ||||
| Lilliefors test statistic | 0.0253 | 0.0224 | 0.0218 | 0.0295 |
| Lilliefors test p-value | 0.1251 | 0.2620 | 0.2999 | 0.0400 |
|
| ||||
| KS test statistic | 0.4227 | 0.1327 | 0.1451 | 0.1377 |
|
| ||||
| empirical coverage | – | 0.936 | 0.938 | 0.929 |
| empirical coverage (optimistic) | – | 0.945 | 0.948 | 0.941 |
Convergence of the iterative updating procedure, and robustness
A substantial bias in the initial estimation is revealed by the location of the mode of { } in Figure 3, both for the full-SL and light-SL procedures. We see that the full-SL initial estimator is less biased than its light-SL counterpart. As one can judge visually or by the first rows of Tables 3(a) and 3(b), this initial bias is diminished (if not perfectly corrected) at the first updating step of the TMLE procedure, illustrating the robustness of the targeted estimator. The empirical distributions of { } for k = 1, 2, 3 are not (visually) markedly different, an empirical indication that the TMLE procedure converges quickly.
Asymptotic normality
In order to check the asymptotic normality of the TMLE estimator (e.g. under the conditions of Corollary 1), we first perform Lilliefors tests of normality based on the empirical distributions of { } for k = 0, 1, 2, 3 (i.e., we perform Kolmogorov-Smirnov tests of normality without specification of the means and variances under the null). We report the values of the test statistics and corresponding p-values in the third and fourth rows of Tables 3(a) and 3(b). If we take into account the multiplicity of tests, there is no clear indication that the limit distributions are not Gaussian.
Second, we test the fit of the empirical distributions of { } to a Gaussian distribution with mean and variance given by the estimates ψB(Ps) and vB(Ps) (which are independent of { }). We report in the fifth rows of Tables 3(a) and 3(b) the obtained values of the KS test statistics. If all p-values are smaller than 10−4, one notices that the test statistics are strikingly smaller for k ≥ 1 than for k = 0. Performing Anderson-Darling tests of normality with only the null mean or the null variance specified (i.e., KS tests of normality with specified null mean, equal to ψB(Ps), and unspecified null variance or specified null variance, equal to vB(Ps), and unspecified null mean) teaches us that it is mainly the little remaining bias and not the choice of the variance under the null that makes the KS tests have so small p-values [values not shown].
Coverage
The theoretical convergence in distribution of the TMLE estimator to a Gaussian limit (e.g. under the conditions of Corollary 1) promotes the use of intervals [ ] as (1 − α)-confidence intervals for Ψ (Ps) (k = 1, 2, 3), with . Interestingly, the theoretical result of Corollary 1 does not guarantee that it is safe to estimate the limit variance by (additional assumptions on the construction and convergence of and would be required to get such a result). We nonetheless check whether the latter intervals provide the desired coverage or not. For this purpose, we compute and report in the sixth and seventh rows of Tables 3(a) and 3(b) the empirical coverages and their optimistic counterpart (the latter incorporates the remaining uncertainty of the true value of Ψ (Ps)). We conclude that the provided coverage is good for the light-SL procedure (with excellent optimistic coverage), but disappointing for the full-SL procedure (even for the optimistic coverage). The results may have been better if one had relied on the bootstrap in order to estimate the asymptotic variance of the TMLE. We will investigate this issue in future work.
6.7. Real data application
For the real data application, we focus the set
 of all 130 genes on chromosome 18 in the OvCa dataset. This choice is notably motivated by the associated sample size, approximately equal to 500 (thus much larger than the sample size associated to the GBM dataset). We estimate the non-parametric variable importance measure of X on Y accounting for W for each gene g separately (i.e.,
where
is the true distribution of O = (W, X, Y) for gene g), following exactly one of the statistical methodologies developed in the simulation study. Specifically, the targeted update step relies on the Gaussian fluctuations presented in Section 5.2, and the super-learning involves the library of algorithms that we report in Section 6.5. In particular, we estimate for each gene g the asymptotic variance of the TMLE
of
with the empirical variance
of the efficient influence curve at
. In a future work solely devoted to this real data application, we will use the bootstrap in order to derive a more robust estimator of the asymptotic variance (again, Corollary 1 requires some conditions on
and
in order to guarantee that
is a consistent estimator). We will also “extend” W, by adding to the DNA methylation of the gene of interest the DNA methylations, DNA copy numbers and gene expressions of its neighboring genes.
of all 130 genes on chromosome 18 in the OvCa dataset. This choice is notably motivated by the associated sample size, approximately equal to 500 (thus much larger than the sample size associated to the GBM dataset). We estimate the non-parametric variable importance measure of X on Y accounting for W for each gene g separately (i.e.,
where
is the true distribution of O = (W, X, Y) for gene g), following exactly one of the statistical methodologies developed in the simulation study. Specifically, the targeted update step relies on the Gaussian fluctuations presented in Section 5.2, and the super-learning involves the library of algorithms that we report in Section 6.5. In particular, we estimate for each gene g the asymptotic variance of the TMLE
of
with the empirical variance
of the efficient influence curve at
. In a future work solely devoted to this real data application, we will use the bootstrap in order to derive a more robust estimator of the asymptotic variance (again, Corollary 1 requires some conditions on
and
in order to guarantee that
is a consistent estimator). We will also “extend” W, by adding to the DNA methylation of the gene of interest the DNA methylations, DNA copy numbers and gene expressions of its neighboring genes.
We only briefly summarize the results of the real data application. For this purpose, we report in Figure 4 the values of the test statistics derived from the TMLE after three updates, using two different reference values . Here,
Fig 4.
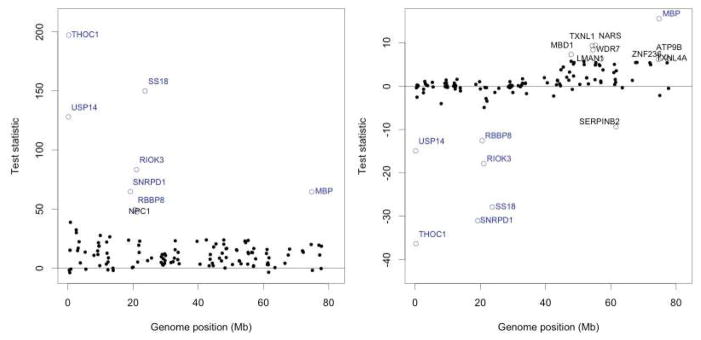
Real data application to the 130 genes of chromosome 18 in the OvCa dataset (ovarian cancers). We represent the test statistics for (left graphic) and (right graphic) along the position of gene g on the genome. We report the names of the genes such that (left graphic) and (right graphic), the cut-offs being arbitrarily chosen.
is the least square (substitution, asymptotically efficient) estimator of parameter
, see (4), a parameter which overlooks the role potentially played by W while quantifying the influence of X on Y. We know that
is also path-wise differentiable at all P ∈
, with an efficient influence curve Δ ★ (P) at P characterized by Δ ★ (P)(O) = (XY −
(P)X2)/σ2(P). We acknowledge that the variance of (
) would be best approximated by the empirical variance of
rather than
.
The reference value is a natural null value to rely on from a testing perspective. Using as another null value is relevant because that allows us to identify those genes for which the (possibly intricate) role played by W in quantifying the influence of X on Y is especially important and results in a stark deviation of from .
Looking at the left graphic in Figure 4 teaches us that a majority of the are likely positive. Eight genes stand up (by having a test statistic ): two genes at 18p11.32 (USP14 and THOC1), a cluster of five genes at 18q11.2 (SNRPD1, RBBP8, RIOK3, NPC1, SS18), and gene MBP at 18q23. This suggests that the region 18q11.2 (especially 19–24 Mb) is of particular relevance in this set of ovarian cancers. Seven out of the latter eight genes (specifically: all of them but gene NPC1) also stand up in the right graphic of Figure 4: six out of the latter seven genes standing up in both graphics (specifically: all of them but gene MBP) exhibit a significantly small test statistic (by having ), as does the additional gene SERPINB2, while gene MBP exhibits a significantly large test statistic (by having ), as do eight additional genes (MBD1, TXNL1, LMAN1, WDR7, NARS, ZNF236, ATP9B, TXNL4A). All genes standing up in the right graphic of Figure 4 are located at 18q2 (41–76 Mb).
Acknowledgments
The topic of this article originates from a presentation [16] by Terry Speed (Department of Statistics, UC Berkeley) in the UC Berkeley Statistics and Genomics Seminar. We would like to thank him for a series of instructive discussions that followed. We also would like to thank The Cancer Genome Atlas project [2] for kindly providing the datasets and for funding PN.
We want to thank two anonymous referees for their comments which helped to improve on the presentation.
Mark van der Laan was supported by NIAID grant R01 AI074345-05.
Appendix A: Appendix
A.1. Miscellanea
Recall that Ps denotes the data-generating distribution of the synthetic observed data structure O = (W, X, Y) described in Section 6.6. We easily derive the following closed-form expressions for the features of interest θ (Ps), μ (Ps), g(Ps), and σ2(Ps).
Lemma 7
Let ϕ denote the density of the standard normal distribution. The following equalities hold:
where, for each u = 1, 2, 3,
A.2. Proofs of Lemmas 1, 6 and Proposition 1
Proof of Lemma 1
Consider (10). For any non-negative measurable function f of (X, W), it holds that
for h(X, W) equal to the right-hand side expression of (10), since (9) implies
The function f being arbitrarily chosen, the latter equalities yield (10). The remaining relationships are easily proven in the same spirit.
Proof of Lemma 6
Note that
where KL(p, q) is the Kullback-Leibler divergence between the Bernoulli distributions of parameters p, q ∈ (0, 1) and c(P0) is a constant depending on P0 only. Since KL(p, q) ≥ 0 with equality iff p = q, we obtain that θ (P0) minimizes P ↦ P0La,b(P) and also that another minimizer must satisfy θ (P)(X, W) = θ (P0)(X, W) P0-almost surely. The second equality is easily obtained by differentiating.
Recall that Ψ is pathwise differentiable at every P ∈
with respect to the maximal tangent space
with an efficient influence curve at P equal to
if, for all
with ||s||∞ < ∞ and
characterized by (9), the mapping ε ↦ Ψ (Pε) is differentiable at ε = 0 with a derivative satisfying
We refer to van der Vaart [25, Chapter 25] for an introduction to the theory of semiparametric models.
Proof of Proposition 1
By expanding the squared sum in (1), we obtain that
which straightforwardly yields (2). It is easily seen that , or in other words that the two components are orthogonal in .
Regarding the pathwise differentiability, it is sufficient to consider paths of the form (9) for arbitrarily chosen with ||s||∞ < ∞. Set such a s and . Using the telescopic equality a1/b1 − a0/b0 = (a1 − a0)/b1 − (a0/b0)(b1 − b0)/b1 yields
| (19) |
with
| (20) |
by (13). Now, the same telescopic equality also yields that
By (10) and the dominated convergence theorem (indeed, { } is bounded),
Furthermore, (10) also yields that
Consequently, applying the dominated convergence theorem finally yields (by using the above telescopic equality and (10), one easily checks the boundedness of { })
| (21) |
where we emphasize that
Combining (19), (20), (21) and (13) teaches us that, for all with ||s||∞ < ∞,
where D★ (P) is defined in the statement of the proposition. In particular, Ψ is pathwise differentiable at P wrt the described collection of paths, and D★ (P) is a gradient of Ψ at P. Since the related tangent space is itself, it is necessarily the efficient influence curve.
It remains to prove that D★ (P) is double-robust. For this purpose, note that
Now, the right-hand side expression vanishes as soon as either θ (P′)(0, ·) = θ (P)(0,) or (μ(P′) = μ (P) and g(P′) = g(P)). The conclusion readily follows.
A.3. Proof of Lemma 5
Proof of Lemma 5
Assume for the time being that, for all W ∈
, there exists λn such that (17) holds with λn substituted for λ. Then, for all W ∈
, the point with coordinates (
) lies in the convex envelope of the set {(X(i), X(i)2): i ≤ n}\{(0, 0)}. Equivalently, there exist for all W ∈
three non-negative weights p1, p2, p3 summing up to 1 and three different values x(1), x(2), x(3) ∈ {X(i): i ≤ n}\{0} such that
the right-hand side expressions being, respectively, the mean and second order moment of the distribution . Thus, there exists such that (i) and (ii) hold.
Set W ∈
. Combining (6), (7) and (17) yields that if there exists λn such that (17) holds with λn substituted for λ, then it must be equal to
, where
and
. In order to conclude, it is therefore sufficient to check that ℓn ∈ [0, 1].
By Jensen’s inequality, it holds that , which yields in turn with (6) and (7) that . Finally, using again (6) and (7), equals
hence . Thus, ℓn ∈ [0, 1], which completes the proof.
A.4. Proofs of Lemmas 2, 3 and 4
Proof of Lemma 2
It is sufficient to verify that, under the stated assumptions,
Now, the absolute value above is straightforwardly upper-bounded by
This trivially entails the wished convergence, hence the result.
Introduce, for all k ≥ 0 and |ε| ≤ ρ, and
Obviously, the normalized log-likelihood under is twice differentiable wrt ε, with first derivative at ε = 0 equal to and second derivative at ε equal to .
Proof of Lemma 3, first part
We first show that under the stated assumptions, by contradiction. Suppose that does not converge to 0 as k → ∞: there exist η > 0 and an increasing function ϕ: ℕ → ℕ such that, for all k ≥ 0,
| (22) |
We show that necessarily limk→∞ εϕ(k) = 0, hence by Lemma 2, contradicting (22).
Set k ≥ 0. For any , a Taylor expansion of yields the existence of such that
| (23) |
By assumption (iii) and since
| (24) |
there exists a constant κ > 0 (depending on Pn) such that the right-hand side term of (24) is upper-bounded by −κ, hence simultaneously for all k′ ≥ 0 and |ε| ≤ ρ.
The function being decreasing and equal to at ε = 0, it necessarily holds that (i.e., and share the same sign), hence too. Furthermore, combining (23) and the left-hand side of (24) yields
| (25) |
The conclusion is now at hand. Assume that the sequence does not converge to 0: there exist c > 0 and another increasing function ψ: ℕ → ℕ such that, for all k ≥ 0, . Note that c can be chosen small enough to guarantee in addition that cη − 2M2c2 > 0. Impose now for all k ≥ 0 (this uniquely defines ). According to (25), for all k ≥ 0,
Using (a) for all k′ ≥ 0 and (b) for every k′ ≥ 1, one obtains that for all k ≥ 0,
This contradicts assumption (iv). So the sequence must converge to 0, Lemma 2 applies, and (22) is contradicted.
Proof of Lemma 3, second part
For all k ≥ 0, another Taylor expansion of yields the existence of such that
We derive from these inequalities that
where the right-hand side converges to 0 as k → ∞ by virtue of the first part of the lemma. This completes the proof.
Proof of Lemma 4
We first show that the sequence converges in total variation. For this purpose, note that is dominated by , with a density characterized by . Since (a) the functions are uniformly bounded by a common constant M, and (b) the series converges, the sequence of densities converges wrt the ||·||∞-norm to a limit density ( ) that we denote . Density gives rise to a data-generating distribution , the limit of in total variation (hence its weak limit too).
Now, it holds that
The observed data structure O being bounded, the functions O = (W, X, Y) ↦ XY and O = (W, X, Y) ↦ X2 are continuous and bounded, hence and respectively converge to and by weak convergence. Furthermore, the convergence of to wrt the ||·||∞-norm trivially entails the pointwise convergence of to , then the wished convergence of to by the dominated convergence theorem. This completes the proof.
A.5. Proof of Propositions 2 and 3 and of Corollary 1
Denote . Let D1 (σ2, θ) be characterized by D1 (σ2, θ) (O) = (X(θ(X, W) − θ (0, W)))/σ2, and denote D1 (P) = D1 (σ2 (P), θ(P)). We use the notation a ≲ b for “a smaller than b up to a multiplicative constant”. We start with a useful lemma.
Lemma 8
Suppose that the assumptions of Proposition 2 are met. There exists ψ0 ∈ ℝ such that (i.e., the TMLE converges in probability). Moreover, it holds that
| (26) |
| (27) |
| (28) |
Proof
Recall that ||O|| is bounded under P0 and that . Using repeatedly the telescopic equality a1/b1 − a0/b0 = (a1 − a0)/b1 − (a0/b0)(b1 − b0)/b1 and inequality (a + b)2 ≤ 2(a2 + b2) yields that, under P0, , and therefore that
| (29) |
Similarly, the same tricks as above and the facts that (a) both random variables and are upper-bounded under P0, and (b) , g0(0|W) ≥ c imply that, under P0, , hence (27).
Now, rewrite as
| (30) |
and consider the two first right-hand side terms. Since we have and the class {O ↦ X2ψ/σ2: (ψ, σ2) ∈ ℝ × [c, ∞]} is P0-Donsker, it holds that both and belong to a P0-Donsker class with P0-probability tending to 1, hence so does . Therefore, by (29), (27) and Lemma 19.24 in [25], the first term is . Combining (29) and (27) with the Cauchy-Schwarz inequality yields in turn that the second term is oP (1). Finally, the law of large numbers and the fact that entail that . Consequently, we deduce from (30) that there exists ψ0 ∈ ℝ such that ψn = ψ0 + oP (1).
Because , (26) easily follows from (29) and the convergence in probability of ψn and to ψ0 and . Finally (26) and (27) imply (28), thus concluding the proof.
Proof of Proposition 2
We first rewrite as
| (31) |
Since and belong to a P0-Donsker class with P0-probability tending to 1, so does . Therefore, (28) of Lemma 8 and Lemma 19.24 in [25] yield that the first right-hand term in (31) is . Moreover, (28) of Lemma 8 and the Cauchy-Schwarz inequality imply that the second right-hand side term is oP (1). Consequently, the deterministic quantity is equal to 0, and the conditions on (θ0, μ0, g0) ensure that necessarily ψ0 = Ψ (P0) i.e., that the TMLE is consistent.
Proof of Proposition 3
We resume the previous proof where we left it. The fundamental relationship of this proof, derived from and , is
| (32) |
where the left-hand side term obviously equals . Consider now the first right-hand term in (32). Since (a) { } is a P0-Donsker class and (b) , it holds that by Lemma 19.24 in [25]. Regarding the second right-hand side term in (32), note (a) that
(b) that we have already shown that the first random function between parentheses belongs to a P0-Donsker class with P0-probability tending to 1, (c) that second random function between parentheses belongs to the P0-Donsker class { }, and (d) that the last function of the decomposition is deterministic. Therefore, belongs to a P0-Donsker class with P0-probability tending to 1. Now, by applying repeatedly the inequality (a + b)2 ≤ 2(a2 + b2) we deduce that
But ||O|| is bounded under P0 and , so that . This fact combined with (29), (27) and yield that . Consequently, Lemma 19.24 in [25] implies that the second right-hand side term in (32) is . We now turn to the last right-hand side term in (32). It is easily seen that
where . Using that , the previous display yields that the third right-hand side term in (32) equals
In summary, we just showed that
hence the stated relationship.
Proof of Corollary 1
This result relies on the decomposition:
where we use that P0D★ (σ2 (P0), θ0, μ0, g0, Ψ (P0)) = 0. Following the lines of the proof of Lemma 8 and using the Cauchy-Schwarz inequality yield that the first term of the left-hand side decomposition is upper-bounded (up to a multiplicative constant) by square-root of , while the second term equals zero. Thus the latter left-hand side expression is by assumption, (32) yields the asymptotic linear expansion, and the central limit theorem completes the proof.
Contributor Information
Antoine Chambaz, Email: antoine.chambaz@parisdescartes.fr, MAP5, Université Paris Descartes and CNRS.
Pierre Neuvial, Email: pierre.neuvial@genopole.cnrs.fr, Laboratoire Statistique et Génome, Université d’Évry Val d’Essonne, UMR CNRS 8071 – USC INRA.
Mark J. van der Laan, Email: laan@stat.berkeley.edu, Division of Biostatistics and Department of Statistics University of California at Berkeley Berkeley, CA 94720.
References
- 1.Andrews J, Kennette W, Pilon J, Hodgson A, Tuck AB, Chambers AF, Rodenhiser DI. Multi-platform whole-genome microarray analyses refine the epigenetic signature of breast cancer metastasis with gene expression and copy number. PLoS ONE. 2010;5(1):e8665.01. doi: 10.1371/journal.pone.0008665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Collins FS, Barker AD. Mapping the cancer genome. Scientific American. 2007 Mar;296(3):50–57. [PubMed] [Google Scholar]
- 3.Dimitriadou E, Hornik K, Leisch F, Meyer D, WeingeSsel A. Misc Functions of the Department of Statistics (e1071) TU Wien. 2011 URL http://cran.r-project.org/web/packages/e1071/index.html. R package version 1.6.
- 4. Hastie T. Generalized additive models. 2011 doi: 10.1177/096228029500400302. URL http://cran.r-project.org/web/packages/gam/index.html. R package version 1.04.1. [DOI] [PubMed]
- 5.Jones PA, Baylin SB. The epigenomics of cancer. Cell. 2007 Feb;128(4):683–692. doi: 10.1016/j.cell.2007.01.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kooperberg C. Polynomial spline routines. 2010 URL http://cran.r-project.org/web/packages/polspline/index.html. R package version 1.1.5.
- 7.Lawson CL, Hanson RJ. Solving least squares problems. Vol. 15. Society for Industrial Mathematics; 1995. MR1349828. [Google Scholar]
- 8.Le Cam LM. Séminaire de Mathématiques Supérieures, No 33 (Été, 1968) Les Presses de l’Université de Montréal; Montreal, Que: 1969. Théorie asymptotique de la décision statistique. MR0260085. [Google Scholar]
- 9.Liaw A, Wiener M. Classification and regression by randomforest. R News. 2002;2(3):18–22. URL http://CRAN.R-project.org/doc/Rnews/ [Google Scholar]
- 10.Louhimo R, Hautaniemi S. CNAmet: an R package for integrating copy number, methylation and expression data. Bioinformatics. 2011;27(6):887. doi: 10.1093/bioinformatics/btr019. [DOI] [PubMed] [Google Scholar]
- 11.Pollack JR, Sørlie T, Perou CM, Rees CA, Jeffrey SS, Lonning PE, Tibshirani R, Botstein D, Børresen-Dale AL, Brown PO. Microarray analysis reveals a major direct role of DNA copy number alteration in the transcriptional program of human breast tumors. Proc Natl Acad Sci U S A. 2002 Oct;99(20):12963–12968. doi: 10.1073/pnas.162471999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Polley E, van der Laan MJ. SuperLearner. 2011 URL http://CRAN.R-project.org/package=SuperLearner. R package version 2.0-4.
- 13.R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; Vienna, Austria: 2010. URL http://www.R-project.org. [Google Scholar]
- 14.Robins JM, Rotnitzky A. Comment on Inference for semiparametric models: some questions and an answer. In: Bickel PJ, Kwon J, editors. Statistica Sinica. Vol. 11. 2001. pp. 920–935. [Google Scholar]
- 15.Robins JM, Mark SD, Newey WK. Estimating exposure effects by modelling the expectation of exposure conditional on confounders. Biometrics. 1992;48(2):479–495. MR1173493. [PubMed] [Google Scholar]
- 16.Speed TP. From expression profiling to putative master regulators. UC Berkeley Statistics and Genomics Seminar; February 5th, 2009. [Google Scholar]
- 17.Sun Z, Asmann YW, Kalari KR, Bot B, Eckel-Passow JE, Baker TR, Carr JM, Khrebtukova I, Luo S, Zhang L, et al. Integrated analysis of gene expression, CpG island methylation, and gene copy number in breast cancer cells by deep sequencing. PLoS One. 2011;6(2):e17490. doi: 10.1371/journal.pone.0017490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.The Cancer Genome Atlas (TGCA) research Network. Comprehensive genomic characterization defines human glioblastoma genes and core pathways. Nature. 2008;455:1061–1068. doi: 10.1038/nature07385. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.The Cancer Genome Atlas (TGCA) research Network. Integrated genomic analyses of ovarian carcinoma. Nature. 2011;474(7353):609–615. doi: 10.1038/nature10166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Tuglus C, van der Laan MJ. chapter Targeted methods for biomarker discovery. Springer Verlag; 2011. Targeted Learning: Causal Inference for Observational and Experimental Data. MR2867111. [Google Scholar]
- 21.van der Laan MJ. Statistical inference for variable importance. Int J Biostat. 2006;2:Article 2. MR2275897. [Google Scholar]
- 22.van der Laan MJ, Rose S. Targeted Learning: Causal Inference for Observational and Experimental Data. Springer Verlag; 2011. MR2867111. [Google Scholar]
- 23.van der Laan MJ, Rubin D. Targeted maximum likelihood learning. Int J Biostat. 2006;2:Article 11. [Google Scholar]
- 24. van der Laan MJ, Polley EC, Hubbard AE. Super learner. Stat Appl Genet Mol Biol. 2007;6:Article 25. doi: 10.2202/1544-6115.1309. MR2349918. [DOI] [PubMed] [Google Scholar]
- 25.van der Vaart AW. Asymptotic statistics, volume 3 of Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press; Cambridge: 1998. MR1652247. [Google Scholar]
- 26.van Wieringen WN, van de Wiel MA. Nonparametric testing for DNA copy number induced differential mRNA gene expression. Biometrics. 2008 Mar;5(1):19–29. doi: 10.1111/j.1541-0420.2008.01052.x. [DOI] [PubMed] [Google Scholar]
- 27.Wang XV, Verhaak RGW, Purdom E, Spellman PT, Speed TP. Unifying gene expression measures from multiple platforms using factor analysis. PloS one. 2011;6(3):e17691. doi: 10.1371/journal.pone.0017691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.YU Z, van der Laan MJ. Technical report. Division of Biostatistics, University of California; Berkeley: 2003. Measuring treatment effects using semi-parametric models. [Google Scholar]