

Abstract
Community detection helps us simplify the complex configuration of networks, but communities are reliable only if they are statistically significant. To detect statistically significant communities, a common approach is to resample the original network and analyze the communities. But resampling assumes independence between samples, while the components of a network are inherently dependent. Therefore, we must understand how breaking dependencies between resampled components affects the results of the significance analysis. Here we use scientific communication as a model system to analyze this effect. Our dataset includes citations among articles published in journals in the years 1984–2010. We compare parametric resampling of citations with non-parametric article resampling. While citation resampling breaks link dependencies, article resampling maintains such dependencies. We find that citation resampling underestimates the variance of link weights. Moreover, this underestimation explains most of the differences in the significance analysis of ranking and clustering. Therefore, when only link weights are available and article resampling is not an option, we suggest a simple parametric resampling scheme that generates link-weight variances close to the link-weight variances of article resampling. Nevertheless, when we highlight and summarize important structural changes in science, the more dependencies we can maintain in the resampling scheme, the earlier we can predict structural change.
Introduction
Researchers use network theory [1] to better understand complex systems [2]–[5] with many interacting components [6]–[10]. In network theory, there is great interest in detecting the tightly interconnected structural patterns of the network, so-called communities [11]–[21]. Community detection helps us simplify the structure of the network because the communities often correspond to functional units of the system. However, communities are reliable only if they are statistically significant [22]–[25]. Detecting statistically significant communities is possible when we have many instances of the network, because we can first identify communities in each of the instances and then assess the significance of each community. But most often, we only have a single observation of the real network. To overcome this challenge and detect significant communities of real networks, we need a statistically sound procedure that generates instances of the single raw network.
A common approach to generating instances of the raw network is to use resampling techniques [26]–[29]. The idea behind the resampling approach is fairly simple, since we can view a network as the aggregation of many natural events. When resampling, we simply imitate the process of the network formation and generate various realizations of the raw network. With numerous resampled networks, we can aggregate the community information and determine which communities of the raw network are significant and to what degree. The catch, however, is that we must assume that the events that generate the observed network are independent. Therefore, it is important to raise the question: How much do the results of the significance analysis depend on the different assumptions about independent events? Specifically, how important are the link correlations in the resampling scheme?
When resampling weighted networks, the significance of communities depends not only on the weights of the links but also on their individual link-weight variances and their neighbor link-weight correlations across the resamples (two links are neighbors if they share a common node). Here we aim to explore how much the link-weight variances and correlations in different resampling schemes affect the results of significance analysis for weighted, directed citation networks aggregated at the journal level. In previous work, and with data limited to citation counts between journals, we used Poisson resampling without link-weight correlations to generate bootstrap networks [28]. That is, independently from other links, we resampled the weight of each weighted directed link from a Poisson distribution with mean equal to the original link weight. This independent citation resampling is an oversimplification. Citations in the same article depend on each other and introduce correlations: Citations to articles published in the same journal introduce within-link correlations that affect the link-weight variance of individual links. Citations to articles published in different journals introduce between-link correlations that affect the interdependence of the weights of neighbor links. With access to article-level data, we now can resample articles and maintain link correlations to better assess the significance of communities as well as journal rankings. At the same time, we can better understand the effects of eliminated link correlations in Poisson resampling.
Our dataset includes citations between scientific articles published in journals in all areas of science in the years 1984–2010. For a specific year, we can build a weighted, directed network of scientific journals in which the weight of each link between two journals A and B represents the number of times that articles published in journal A cite articles published in journal B. Because we are interested in the frontier of science, we only include citations to articles published no more than three years back in time. For example, in the 2009 data set, there are 961,542 scientific articles and 11,373 journals. This gives a citation network of journals with 11,373 nodes and 1,195,928 weighted, directed links. As in many other citation networks, the degree distribution is skewed with a power-law exponent just below two. We use the network from 2009 in most of our analysis, except when analyzing change over time. Since science is continuously growing, the network from 2009 is the largest in our data set.
Materials and Methods
To understand what effect the link correlations of the resampling scheme have on assessing significant communities, we compared a resampling scheme that maintains between-link and within-link correlations (article resampling), a resampling scheme that only maintains within-link correlations (multinomial resampling), and a resampling scheme that maintains no link correlations (Poisson resampling), as shown in Fig. 1. In between-link correlations, the link weights of neighbor links are correlated. That is, in a resampled network, the weight of a link is not independent of the weight of a neighbor link. In within-link correlations, each link weight in a resampled network is the outcome of dependent events. Below we explain the three resampling methods: article resampling, multinomial resampling, and Poisson resampling. We also clarify the role of link-weight correlations in each method.
Figure 1. Link correlation preservation in different resampling schemes.
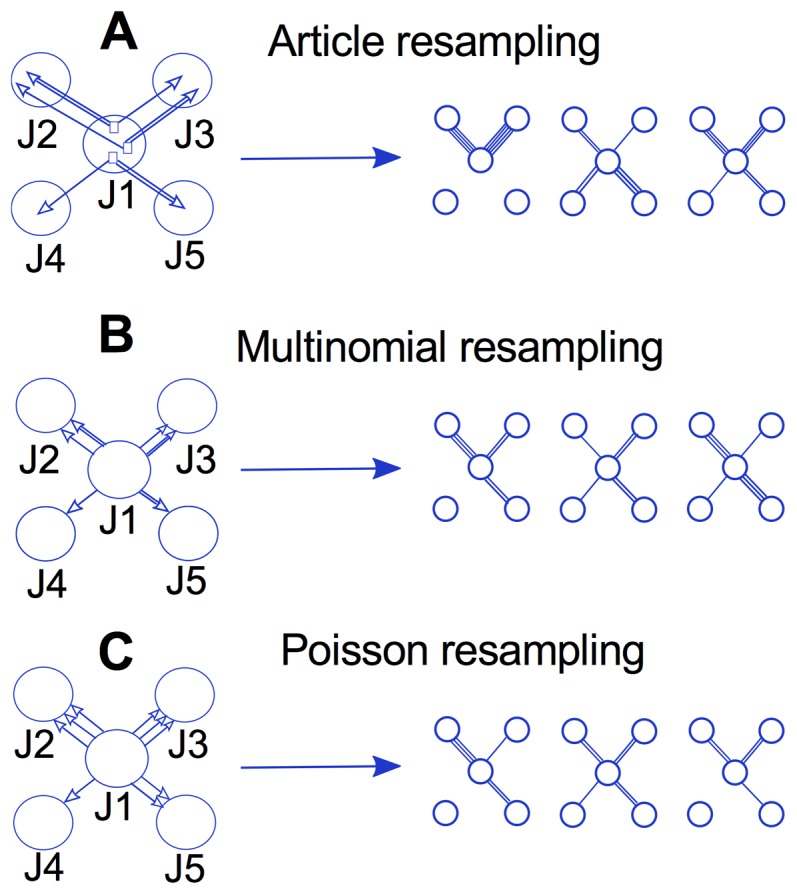
A Article resampling maintains correlations between links and also correlations within links. For example, an article in journal J1 might cite articles from journal J2 together with articles in journal J3 (correlations between links). An article in journal J1 might also cite another journal J2 more than once (correlations within links). The right-hand side shows some examples of possible resampled networks that necessarily keep correlation between and within links. B Multinomial resampling only maintains the correlations within links. The examples of resampled networks on the right-hand side show that they could be generated without keeping between-links correlations. C Poisson resampling does not maintain any link correlation. Every link of a resampled networks is generated independently of others.
Article resampling is based on the assumption that articles can be treated independently of each other. That is, whether an article is published does not depend on whether other articles are published. Assuming that we have a pool of all the articles that participate in our citation network, the process of article resampling to create bootstrap networks is simple. We randomly pick an article from the pool and add its citations from the journal in which the article was published to the cited journals. Then we put this article back in the pool. We continue this process as many times as the number of articles in the original network. Since one article might cite articles in different journals, article resampling automatically introduces correlations between the link-weights of the bootstrap networks. As Fig. 1A shows, the links J1-J2 and J1-J3 are correlated because, for example, it is not possible to have a link J1-J2 and not a link J1-J3.
Article resampling also introduces within-link correlations, because an article might cite articles of a specific journal more than once. In Fig. 1A, for example, the link weight between J1 and J2 is three. This weight is not the outcome of three independent single citations, but rather is generated from one double and one single citation. Because the two citations in the double citation are dependent, and two, not three, events generated the link weight, the link variance will be higher over resampled networks than if the citations were sampled independently. To investigate how these correlations affect the significance analysis, we compare article resampling with multinomial resampling, which keeps the correlations within link weights but destroys the correlations between link weights.
Multinomial resampling assumes that information about multiple citations from single articles to journals is known and can be treated independently. To generate the bootstrap networks, we maintain the topology of the raw network and, independently for each link, resample its weight from a multinomial distribution with the set of multiple citations given by the article-level data. We emphasize that multinomial resampling does not maintain correlations between link weights, but it does maintain the correlations within link weights (Fig. 1B). As a result, multinomial resampling creates an intermediate stage between a completely destroyed link correlation (Poisson resampling) and a fully maintained link correlation (article resampling). For example, in generating each link weight, multinomial resampling only includes the articles that contribute to that link weight and disregards other links that those articles might contain. The question is: how much do the destroyed between-link correlations of multinomial resampling affect the significance analysis? In section Results and Discussion , we show that significant clusters generated with multinomial resampling are close to the significant clusters of article resampling. This result demonstrates that the role of between-link dependency on significance analysis of clusters is relatively small. Poisson resampling assumes that citations can be treated independently of each other. The process of Poisson resampling for generating bootstrap networks is as follows: we maintain the topology of the raw network and, independently for each link, resample its weight from a Poisson distribution with mean equal to the original link weight.
Poisson resampling not only automatically ignores the correlation between link weights, but also ignores the correlations within link weights (Fig. 1C). The question is: how much does the assumption about fully independent link weights affect the results of the significance analysis? In section Results and Discussion , we show that Poisson resampling underestimates the variance of link weights compared to article resampling, and that within-link dependency does matter for the significance analysis of clustering and ranking.
Results and Discussion
In order to investigate the effect of link correlations on the significance analysis of clusters, we create 1000 bootstrap networks based on a resampling scheme. Then we search for significant clusters, or cluster cores, which we define as the biggest subset of nodes in each cluster that gathered together in more than 90% of the bootstrap networks. Correspondingly, a non-significant part of a cluster would be the subset of nodes in the cluster that is separated from the core in more than 10% of bootstrap networks. For clustering, we use infomap, an information-theoretic algorithm that reveals regularities in a given network based on how information flows on that network [30]. Figure 2 shows the difference between significant cluster cores of article, multinomial, and Poisson resampling in terms of normalized information distance. The normalized information distance is defined as one minus the normalized mutual information:
| (1) |
where 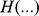 refers to Shannon entropy and
refers to Shannon entropy and 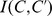 is the mutual information between the significant cores of the two resampling schemes that tells us how similar they are. Mutual information between two clusters
is the mutual information between the significant cores of the two resampling schemes that tells us how similar they are. Mutual information between two clusters  and
and 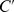 is described as:
is described as:
| (2) |
where 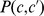 is the joint probability distribution between two clusterings
is the joint probability distribution between two clusterings  and
and 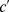 .
. 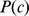 and
and 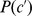 refer to the marginal probability distributions.
refer to the marginal probability distributions.
Figure 2. The differences between significant clusters' cores in different resampling schemes.

We calculate normalized information distance (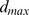 ) between the significant cores of the two corresponding methods with respect to the PageRank. All values correspond to an average over at least 2000 runs.
) between the significant cores of the two corresponding methods with respect to the PageRank. All values correspond to an average over at least 2000 runs.
If  and
and 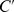 are identical, then the normalized mutual information is equal to 1, which means that, by knowing one cluster structure, we know the other one. Conversely, if
are identical, then the normalized mutual information is equal to 1, which means that, by knowing one cluster structure, we know the other one. Conversely, if  and
and 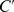 are completely independent, by knowing one, we learn nothing about the other one and the normalized mutual information between them would be 0. We use normalized information distance for comparing clusterings because it is a sound metric [31]. Figure 2 shows that the difference between significant cores of article and multinomial resampling is of the same order as the difference between two iterations of each of these schemes, and both of them are considerably different from Poisson resampling. Although multinomial resampling does not hold the correlation between citations and article resampling does, our results show that between-link dependency does not have a great impact on the significance analysis of clusters.
are completely independent, by knowing one, we learn nothing about the other one and the normalized mutual information between them would be 0. We use normalized information distance for comparing clusterings because it is a sound metric [31]. Figure 2 shows that the difference between significant cores of article and multinomial resampling is of the same order as the difference between two iterations of each of these schemes, and both of them are considerably different from Poisson resampling. Although multinomial resampling does not hold the correlation between citations and article resampling does, our results show that between-link dependency does not have a great impact on the significance analysis of clusters.
We illustrate the effects of link-weight variance on clustering in a concrete example. Figure 3 shows the alluvial diagram of the three resampling schemes over the years 1989–1993. Each block represents a specific module in a given year, and the height of a block represents its importance in terms of PageRank [32]. Based on the areas of specialization of the journals clustered together in each module, we manually label the modules. In a block, the lighter colors correspond to the non-significant part of the module; the bigger this area is, the more non-significant nodes that module has. The white vertical gap between blocks separates the modules, and the numbers under each block correspond to the year. Blocks in a given year might merge as a single block in the next year, or a subset of a block might diverge from it in the next year. The changes that happen to a block from one year to the next are shown by the stream field between the two blocks.
Figure 3. The separation of Nuclear & particle physics from the Physics module.

In this diagram, each block in a given year corresponds to a specific module. In a block, the lighter colors represent the non-significant part of the module and the white vertical gap between blocks separates modules. The stream field between two blocks in consecutive years shows changes that happen to a block. While all three resampling schemes agree on the separation of Nuclear & particle physics from General physics into an independent stand-alone module by 1993, article resampling emits a signal about this change sooner than multinomial or Poisson resampling.
As shown in the figure, all three resampling schemes agree on the separation of Nuclear & particle physics from General physics as an independent stand-alone module in 1993. The exact year will depend on the citation window and data at hand, and by no means do we conclude that we see the emergence of a new field in 1993. While Nuclear & particle physics was considered a research area long before 1993, it takes time before it shows up in the structure of the journal citation network. Instead of singling out a particular year for the emergence of a scientific field, our main focus here is instead to show that different resampling schemes identify fields at different times (Fig. 3). For example, in article resampling, the Nuclear & particle physics module is highlighted as a non-significant part of General physics in 1989, while in Poisson and multinomial resampling, this happens later. In this way, the process of becoming non-significant could provide us a signal about important changes that might happen in the future; apparently, article resampling can give this signal sooner than multinomial resampling, and multinomial resampling can give it sooner than Poisson resampling. We conclude that for significance analysis of communities, within-link correlations play a more important role than between-link correlations. Moreover, maintaining link correlations in a resampling scheme can help us to identify the changes in a network earlier.
As another example of significance analysis of an aggregated network measure, we analyze the effects of the different resampling schemes on PageRank. In calculating PageRank, the importance of a node (a journal in our citation network) corresponds to the importance of nodes that cite this node, so the full network indirectly participates in calculating the PageRank of a node. Figure 4 shows how much the PageRank of some top journals would vary based on the resampling scheme. The length of each line corresponds to an interval that covers the variation of PageRank for a given journal in a given resampling scheme. The numbers on the left/right hand side of each line correspond to the minimum/maximum rank order of each journal for a resampling scheme. Science has the largest PageRank value in the raw network, and so it is the first journal in the rank order. In Poisson resampling, Science always maintains its first position in the ranking list. But in multinomial and article resampling, Science sometimes drops to the second position. In a similar fashion, the rank order of PRL (Physical Review Letters), NEJM (New England Journal of Medicine), and J Neurosci (Journal of Neuroscience) changes based on the resampling scheme that is used. In general, the PageRank of a node varies more in article resampling than in Poisson or multinomial resampling. In this respect, we study the effect of resampling schemes on the rank order of all nodes in the network. We sample pairs of nodes 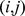 from the rank order that we obtain from a resampling scheme and compare them with the rank order that we obtain from another resampling scheme. We sample pairs of nodes proportional to their PageRank and measure the similarity between the two rank orders in terms of normalized mutual information. If, for all possible pairs in the two-rank order, the node with the highest rank in one order is the same in the other order, the mutual information between the two rank orders would be one. The more different the two rank orders are, the smaller the mutual information between them would be. If the two rank orders do not have any common pair orders, the mutual information between them would be zero. In a quantitative analysis of the rank order for the different resampling schemes, we find that the normalized information distance (Eq. 1) between two different rankings generated with the same resampling scheme is, on average, about 26 percent larger for article resampling than for Poisson resampling and 23 percent larger for multinomial resampling than for Poisson resampling. For ranking, article resampling has the biggest variation, but multinomial resampling without correlations between links varies almost as much as article resampling. Multinomial resampling can explain almost all ranking variances of article resampling with correlations between links.
from the rank order that we obtain from a resampling scheme and compare them with the rank order that we obtain from another resampling scheme. We sample pairs of nodes proportional to their PageRank and measure the similarity between the two rank orders in terms of normalized mutual information. If, for all possible pairs in the two-rank order, the node with the highest rank in one order is the same in the other order, the mutual information between the two rank orders would be one. The more different the two rank orders are, the smaller the mutual information between them would be. If the two rank orders do not have any common pair orders, the mutual information between them would be zero. In a quantitative analysis of the rank order for the different resampling schemes, we find that the normalized information distance (Eq. 1) between two different rankings generated with the same resampling scheme is, on average, about 26 percent larger for article resampling than for Poisson resampling and 23 percent larger for multinomial resampling than for Poisson resampling. For ranking, article resampling has the biggest variation, but multinomial resampling without correlations between links varies almost as much as article resampling. Multinomial resampling can explain almost all ranking variances of article resampling with correlations between links.
Figure 4. The variation of the PageRank for top-rank journals based on different resampling schemes.

In agreement with the result of single link-weight variance analysis, our analysis shows that core structures in article and multinomial resampling are much more similar to each other than in the Poisson resampling. The article resampling is the biggest perturbation, in which the 95% confidence interval for the PageRank is broader than in multinomial or article resampling. Multinomial and article resampling were second and third, respectively.
The between-link correlations of article resampling seem to play a minor role on significance analysis on ranking (Fig. 4) and clustering (Fig. 2). To better understand the effects of between-link and within-link correlations generated by article resampling, we quantify and compare for the different resampling schemes the correlations between the weights of neighbor links and the variance of individual link weights. Our results show that between-link correlations of article resampling indeed are weak, but that the within-link correlations strongly affects the link-weight variance. Because multinomial resampling is almost as effective as article resampling, we propose a simple model that estimates the probabilities of multinomial resampling when full article-level data are not available.
Between-link correlations
Article resampling introduces dependencies between link weights: an article may cite papers in different journals, so choosing that article adds citations to more than one journal simultaneously. Here we want to measure how much these neighbor links are correlated in the resampled networks. Figure 5 shows that, in article resampling, only a fraction of neighbor links are weakly correlated. To check if these correlations are significant or not, we compare article resampling with multinomial resampling without between-link correlations. Figure 5 confirms that between-link correlations are weak in article resampling. In fact, we could say that most neighbor links are not correlated, and that those few neighbor links that are correlated tend to be positively correlated. As we saw in the beginning of section Results and Discussion , this slight correlation doesn't have a great impact on the significant cluster cores or ranking of nodes. As shown, the dependency between links has a small effect on significant cluster cores, but nevertheless it influences the time that non-significant clusters emerge and can give a clue about important changes that might happen in the future.
Figure 5. Neighbor links are only weakly dependent in article resampling.

The correlation distribution for a pair of neighbor links where at least one of them has a specific weight. By definition, article resampling introduces correlation to the neighboring links and multinomial resampling ignores any correlation. By comparing, we see that the result of correlation distribution confirms that most correlations of article resampling are not significant, when we compare them with the multinomial resampling as null mode. All points correspond to an average of at least 50 runs.
Within-link correlations
Figure 6 shows how much a specific link weight,  , varies based on the resampling scheme. When the link weight is very small, for example,
, varies based on the resampling scheme. When the link weight is very small, for example, 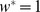 , we see that the variance of link weights in Poisson resampling perfectly matches with the variance in the article resampling (Fig. 6A). The link weight equal to one means that only one article contributes to the citation between two journals, so the chance of picking that article is
, we see that the variance of link weights in Poisson resampling perfectly matches with the variance in the article resampling (Fig. 6A). The link weight equal to one means that only one article contributes to the citation between two journals, so the chance of picking that article is 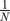 , where
, where 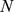 is the total number of articles. Therefore, after resampling
is the total number of articles. Therefore, after resampling 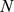 articles, the chance of getting that specific paper
articles, the chance of getting that specific paper 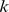 times is
times is 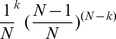 , which, in the limit of large
, which, in the limit of large 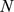 , coincides with the definition of
, coincides with the definition of 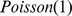 . But when the link weight between two journals is higher than one, for example, medium values such as
. But when the link weight between two journals is higher than one, for example, medium values such as 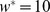 in Fig. 6B or high values such as
in Fig. 6B or high values such as 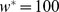 in Fig. 6C, we see that the variance of Poisson resampling underestimates the variance of article resampling. This happens because citations can come in groups: for a link where its weight
in Fig. 6C, we see that the variance of Poisson resampling underestimates the variance of article resampling. This happens because citations can come in groups: for a link where its weight 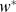 is medium/high, there are
is medium/high, there are 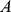 articles (
articles (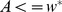 ) that contribute to that weight, and sometimes articles might add more than one citation. So, although article resampling gives the same average weight as Poisson resampling, the variance of that weight in article resampling would be higher than for Poisson resampling. In summary, high link weights result in greater differences between the variance of article resampling and Poisson resampling (Fig. 6D).
) that contribute to that weight, and sometimes articles might add more than one citation. So, although article resampling gives the same average weight as Poisson resampling, the variance of that weight in article resampling would be higher than for Poisson resampling. In summary, high link weights result in greater differences between the variance of article resampling and Poisson resampling (Fig. 6D).
Figure 6. Comparing the probability distribution of link weights in article resampling with Poisson resampling and multinomial resampling.

A For low link weight (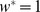 ), Poisson resampling precisely coincides with article resampling. B,C For medium values of link weight (
), Poisson resampling precisely coincides with article resampling. B,C For medium values of link weight (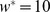 ) and high values of link weight (
) and high values of link weight (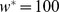 ), Poisson resampling underestimates article resampling. The variance of the distribution in article resampling is much higher than in Poisson resampling. For example, for
), Poisson resampling underestimates article resampling. The variance of the distribution in article resampling is much higher than in Poisson resampling. For example, for 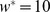 , the variance in article resampling is
, the variance in article resampling is 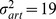 , while the variance in Poisson resampling is
, while the variance in Poisson resampling is 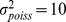 . Similarly, for link weight
. Similarly, for link weight 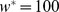 , the variance in article resampling is
, the variance in article resampling is 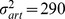 , while the variance in Poisson resampling is
, while the variance in Poisson resampling is 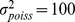 . The variance in multinomial resampling is quite close to article resampling, which confirms that the multinomial model imitates article resampling and make the distribution broader than Poisson resampling. D The variance of link weights in article resampling and Poisson resampling averaged over all resamples. All points correspond to averaging over 1000 runs.
. The variance in multinomial resampling is quite close to article resampling, which confirms that the multinomial model imitates article resampling and make the distribution broader than Poisson resampling. D The variance of link weights in article resampling and Poisson resampling averaged over all resamples. All points correspond to averaging over 1000 runs.
Indeed, although Poisson resampling assumes an enormous number of binomial events that produce a specific link weight, article resampling tells us that the observed link weight is the outcome of multinomial events. In multinomial resampling, every link weight is generated from a multinomial distribution independently from other links. Although multinomial resampling assumes independency between links' weights and article resampling does not, Fig. 6(B,C) shows that multinomial resampling completely matches article resampling on the link level. Multinomial resampling intrinsically considers group citations, and therefore it can generate higher variance than Poisson resampling.
But what if the probabilities of different link weights are unknown for a given network? To estimate the probabilities, we look at the number of papers that contribute to a link with a specific weight. Figure 7A shows that, when the link weight 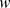 is high, the number of papers that contribute to generating that link weight
is high, the number of papers that contribute to generating that link weight 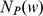 is far from the value of the weight itself. Figure 7B shows that, when the link weight increases, the fraction of single citations that contribute to that weight is reduced. As Fig. 7A shows, the number of papers that contribute to generating a link weight
is far from the value of the weight itself. Figure 7B shows that, when the link weight increases, the fraction of single citations that contribute to that weight is reduced. As Fig. 7A shows, the number of papers that contribute to generating a link weight 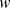 scales as
scales as 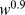 for all years. We use this information to build a model for estimating the multinomial distribution when the probabilities of different link weights in a given network are not known. We assume that each weight
for all years. We use this information to build a model for estimating the multinomial distribution when the probabilities of different link weights in a given network are not known. We assume that each weight 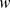 is generated from papers with only one or two citations. We can simply estimate the number of papers with one citation
is generated from papers with only one or two citations. We can simply estimate the number of papers with one citation 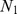 and the number of contributing papers with two citations
and the number of contributing papers with two citations 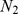 by solving the following linear equation system:
by solving the following linear equation system:
 |
(3) |
After estimating  and
and  , we suggest resampling every link weight by using the following minimal model:
, we suggest resampling every link weight by using the following minimal model:
| (4) |
The variance that we could get from this model is:
| (5) |
In Fig. 7C, we show the probability distribution of link weight 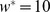 for four cases: Poisson resampling, article resampling, multinomial resampling, and the proposed minimal model. As shown, the high variance of article and multinomial resampling could be estimated by the minimal model. However, this estimation is not exact because the minimal model does not take into account group citations with three or more citations. In summary, the model can generate higher variance than Poisson resampling for different link weights, but it can not generate exactly as high a variance as article resampling (Fig. 7D).
for four cases: Poisson resampling, article resampling, multinomial resampling, and the proposed minimal model. As shown, the high variance of article and multinomial resampling could be estimated by the minimal model. However, this estimation is not exact because the minimal model does not take into account group citations with three or more citations. In summary, the model can generate higher variance than Poisson resampling for different link weights, but it can not generate exactly as high a variance as article resampling (Fig. 7D).
Figure 7. The high variance of article and multinomial resampling can be estimated by a simple model that extends Possion resampling to account for papers that contribute multiple citations to the same journal.

A Average number of papers that contribute to a specific link weight in logarithmic scale. For all years, the number of papers with weight 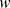 (
(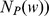 fits to the function
fits to the function 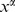 with exponent
with exponent 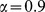 . B The fraction of 1, 2, 3 and 4 citations that contribute to building a specific link weight
. B The fraction of 1, 2, 3 and 4 citations that contribute to building a specific link weight 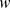 . Compared to low link weights, high link weights have a lower fraction of papers with only one citation and a higher fraction of papers with 2, 3 or 4 citations. C The probability distribution of link weight
. Compared to low link weights, high link weights have a lower fraction of papers with only one citation and a higher fraction of papers with 2, 3 or 4 citations. C The probability distribution of link weight 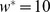 for 4 cases: Poisson resampling, article resampling, multinomial resampling, and the minimal model. The high variance of article/multinomial resampling could be estimated by the model. D The model can generate higher variance than Poisson resampling for different link weights. However, it could not generate exactly as high a variance as article resampling.
for 4 cases: Poisson resampling, article resampling, multinomial resampling, and the minimal model. The high variance of article/multinomial resampling could be estimated by the model. D The model can generate higher variance than Poisson resampling for different link weights. However, it could not generate exactly as high a variance as article resampling.
Conclusion
Link correlation of a resampling scheme influences the significance analysis of communities and ranking. We compare three scenarios: fully maintained correlations between and within links (article resampling), no correlations between links (multinomial resampling), and completely broken link correlations (Poisson resampling). We found that the result of significance analysis in multinomial resampling almost matches with article resampling. We conclude that the role of variance of individual links is greater than the role of correlation between links. Nevertheless, we found that conserving link correlation in a resampling scheme can provide an early hint of possible changes to the network in the future. The basic approach that we have laid out here, resampling the more or less independent components of a network for significance analysis, can be applied to other networks than citation networks. We speculate that the variance of link weights will play the major role also in those networks. These findings can help researchers to better understand and asses reliable significant communities and structural changes for a given weighted network.
Acknowledgments
We are grateful to Sara de Luna and Deborah Kolp for many valuable discussions.
Funding Statement
MR was supported by the Swedish Research Council grant 2009-5344. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Newman MEJ (2010) Networks: An Introduction. Oxford: OxfordUniversity Press.
- 2. Vespignani A (2012) Modelling dynamical processes in complex socio-technical systems. Nat Phys 8: 32–39. [Google Scholar]
- 3. Jeong H, Tombor B, Albert R, Oltvai Z, Barabási AL (2000) The large-scale organization of metabolic networks. Nature 407: 651–4. [DOI] [PubMed] [Google Scholar]
- 4. Kleinberg J (2000) Navigation in a small world. Nature 406: 845. [DOI] [PubMed] [Google Scholar]
- 5. Milo R, Shen-Orr S, Itzkovitz S, Kashtan N, Chklovskii D, et al. (2002) Network Motifs: Simple Building Blocks of Complex Networks. Science 298: 824–827. [DOI] [PubMed] [Google Scholar]
- 6. Albert R, Barabási AL (2002) Statistical mechanics of complex networks. Rev Mod Phys 74: 47–97. [Google Scholar]
- 7. Newman MEJ (2003) The structure and function of complex networks. SIAM Rev 45: 167–256. [Google Scholar]
- 8. Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang DU (2006) Complex networks : Structure and dynamics. Phys Rep 424: 175–308. [Google Scholar]
- 9. Sales-Pardo M, Guimerà R, Moreira AA, Amaral LAN (2007) Extracting the hierarchical organization of complex systems. Proc Natl Acad Sci USA 104: 15224–15229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Clauset A, Moore C, Newman MEJ (2008) Hierarchical structure and the prediction of missing links in networks. Nature 453: 98–101. [DOI] [PubMed] [Google Scholar]
- 11. Girvan M, Newman MEJ (2002) Community structure in social and biological networks. Proc Natl Acad Sci USA 99: 7821–7826. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Radicchi F, Castellano C, Cecconi F, Loreto V, Parisi D (2004) Defining and identifying communities in networks. Proc Natl Acad Sci USA 101: 2658–2663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Newman MEJ (2004) Fast algorithm for detecting community structure in networks. Phys Rev E 69: 066133. [DOI] [PubMed] [Google Scholar]
- 14. Danon L, Daz-Guilera A, Arenas A (2006) The effect of size heterogeneity on community identification in complex networks. Stat Mech 2006: P11010. [Google Scholar]
- 15. Blondel VB, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. Stat Mech 2008: P10008. [Google Scholar]
- 16. Hastings MB (2006) Community detection as an inference problem. Phys Rev E 74: 035102. [DOI] [PubMed] [Google Scholar]
- 17. Rosvall M, Bergstrom CT (2007) An information-theoretic framework for resolving community structure in complex networks. Proc Natl Acad Sci USA 104: 7327–7331. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Palla G, Derényi I, Farkas I, Vicsek T (2005) Uncovering the overlapping community structure of complex networks in nature and society. Nature 435: 814–818. [DOI] [PubMed] [Google Scholar]
- 19. Ahn YY, Bagrow JP, Lehmann S (2010) Link communities reveal multiscale complexity in networks. Nature 466: 761–764. [DOI] [PubMed] [Google Scholar]
- 20. Newman MEJ (2006) Modularity and community structure in networks. Proc Natl Acad Sci USA 103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Fortunato S (2010) Community detection in graphs. Physics Reports 486: 75–174. [Google Scholar]
- 22. Spirin V, Mirny LA (2003) Protein complexes and functional modules in molecular networks. Proc Natl Acad Sci USA 100: 12123–12128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Hu Y, Nie Y, Yang H, Cheng J, Fan Y, et al. (2010) Measuring the significance of community structure in complex networks. Phys Rev E 82: 066106. [DOI] [PubMed] [Google Scholar]
- 24. Lancichinetti A, Radicchi F, Ramasco J (2010) Statistical significance of communities in networks. Phys Rev E 81: 046110. [DOI] [PubMed] [Google Scholar]
- 25. Lancichinetti A, Radicchi F, Ramasco JJ, Fortunato S (2011) Finding statistically significant communities in networks. PLoS ONE 6: e18961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Gfeller D, Chappelier JC, De Los Rios P (2005) Finding instabilities in the community structure of complex networks. Phys Rev E 72: 056135. [DOI] [PubMed] [Google Scholar]
- 27. Karrer B, Levina E, Newman MEJ (2008) Robustness of community structure in networks. Phys Rev E 77: 046119. [DOI] [PubMed] [Google Scholar]
- 28. Rosvall M, Bergstrom CT (2010) Mapping change in large networks. PLoS ONE 5: e8694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Mirshahvalad A, Lindholm J, Derlén M, Rosvall M (2012) Significant communities in large sparse networks. PLoS ONE 7: e33721. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Rosvall M, Bergstrom CT (2008) Maps of random walks on complex networks reveal community structure. Proc Natl Acad Sci USA 105: 1118–1123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Vinh NX, Epps K, Bailey J (2010) Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. Mach Learn Res 11: 2837–2854. [Google Scholar]
- 32. Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems 30: 107–117. [Google Scholar]