

Abstract
Previous studies have demonstrated that speech understanding in reverberant rooms improves when listeners are given prior exposure to the room. Results from these room-adaptation studies are limited, however, because they were conducted with materials that are not representative of the high acoustic variability observed in speech signals during everyday communication. Here, room adaptation effects were measured using an open-set speech corpus with high lexical and indexical variability and virtual auditory space techniques to simulate binaural listening in rooms. Room adaptation effects of comparable magnitude to previous studies were observed, suggesting general importance for facilitating speech intelligibility in reverberation.
Introduction
In many everyday listening situations, room acoustics can profoundly affect the sound reaching a listener's ears. Although strong early reflections (occurring <50 ms following the direct path) have been linked to improve speech intelligibility (Lochner and Burger, 1964) by increasing the level of the signal that reaches the ear, later-arriving reverberant sound of sufficient magnitude has long been known to limit speech understanding (Knudsen, 1929). The perceptual effects of reverberation are particularly pronounced for individuals with hearing impairment (Helfer and Wilber, 1990; Nabelek and Mason, 1981) and can be compounded by background noise (Helfer and Wilber, 1990; Nabelek and Mason, 1981). More moderate amounts of reverberation typically have minimal effects on speech understanding for normal hearing listeners (Plomp, 1976). This is surprising given that substantial distortions to speech signal reaching the ears results even from moderate reverberation.
One possible explanation for this is that the normally functioning auditory system is capable of adapting to listening environments with moderate amounts of reverberation. Support for this hypothesis has been provided by a series of studies in which shifts in speech perception are measured using a categorical perception task with a continuum of speech sounds from “sir” to “stir” (Watkins, 2005a,b). The results suggest that when the auditory system is given prior exposure to a reverberant room, it can compensate for the degrading effects of reverberation. This effect appears to depend critically on the amplitude characteristics of the speech waveform's temporal envelope (Watkins et al., 2011), although the effect has also been demonstrated for non-speech sounds (Watkins and Makin, 2007).
Additional support for this room adaptation hypothesis has been provided by results from Brandewie and Zahorik (2010), which demonstrated objective improvements in speech intelligibility of approximately 18% on average, following brief exposure to a reverberant room. Although these results provide important generalization of the room adaptation effect from categorical “sir/stir” perception to objective speech intelligibility, the CRM speech materials (Boila et al., 2000) used by Brandewie and Zahorik (2010) are still not representative of everyday connected speech discourse. It is therefore important to test whether the previously observed room adaptation effects generalize to more natural and phonetically diverse speech materials.
The goal of this study is to determine if prior listening exposure to a reverberant room can improve the intelligibility of everyday speech. Speech stimuli from the Perceptually Robust English Sentence Test Open-set (PRESTO) speech corpus (Gilbert et al., 2013; Tamati et al., 2013) were used. This corpus contains sentences sampled from the TIMIT database (Garofolo et al., 1993), specifically selected to create lists of sentences that are highly variable in terms of linguistic and indexical properties of the speech, but balanced for keyword frequency and familiarity. Performance in two listening conditions was compared: a “blocked” condition in which the listening environment was kept constant throughout a block of sentence trials, and an “unblocked” condition in which the listening environment was varied from trial to trial. If room adaptation effects generalize to these listening situations, then one would predict improved intelligibility in the blocked condition relative to the unblocked condition because the former provides consistent exposure over time to a single listening environment where the latter does not. Testing of this effect was conducted at two signal-to-noise ratios (SNRs) in order to evaluate any interactions between overall performance level, and also in anechoic space as a control to determine the necessity of room reverberation for the effect.
Methods
Subjects
Sixty normal-hearing (pure-tome air-conduction thresholds ≤ 20 dB HL (hearing level) from 250 to 8000 Hz) adults (ages ranged from 18.1 to 31.1 yr with an average age of 21.9 yr) participated in this experiment. The subjects were either paid or given course credit for their participation. None had prior experience with the speech corpus materials used in the study. All procedures involving human subjects were reviewed and approved by the University of Louisville Institutional Review Board.
Room simulation
Virtual acoustic techniques were used to simulate the six listening environments in this study. The listening conditions were: anechoic space (R0) and five simulated reverberant rooms (R1–R5) with broad band (125–4000 Hz) reverberation times (T60) of 0.3, 0.49, 1.22, 2.32, and 2.94 s. All the rooms had identical dimensions of 5.7 m (length) × 4.3 m (width) × 2.6 m (height) but varied in the absorptive properties of the reflective surfaces. Room simulation techniques were based on methods described by Zahorik (2009). Briefly, the simulation methods used an image model to compute directions, delays, and attenuations of the early reflections, which were then, along with the direct-path, spatially rendered using non-individualized head-related transfer functions. The late reverberant energy was simulated statistically using exponentially decaying independent Gaussian noise samples in octave bands from 125 to 4000 Hz for each ear. Overall, this simplified method of room simulation has been found to produce binaural room impulse responses (BRIRs) that are reasonable physical and perceptual approximations of those measured in real rooms (Zahorik, 2009).
Within each simulated room, the speech source was positioned at a distance of 1.4 m in front of the listener. A spatially separated masker was presented on all conditions and was positioned at a distance of 1.4 m from the listener's position directly opposite to the listener's right ear (90° azimuth angle). The masking signal was a broadband (0–8000 Hz) Gaussian noise.
Speech stimuli
Speech stimuli consisted of 16 individual lists from the PRESTO speech corpus (Felty, 2008) which is a subset of the TIMIT database. Each list contained 18 sentences of varying length and syntactic structure with a total of 76 key words. Within a list, no sentence or talker was repeated.
Design
All the listeners were tested in two listening presentation conditions: one blocked by simulated room and another unblocked by room. In the unblocked condition, the room environment was selected at random from trial to trial from one of the six simulated rooms (R0, R1, R2, R3, R4, and R5). This was done to minimize the exposure to different listening conditions from trial to trial. The stimulus presentation was controlled to insure that the same room listening environment did not occur on successive trials. In the blocked condition, the listening environment (either R0 or R1) was fixed within a block of trials. This provided consistent exposure to a single room (either R0 or R1) over the trial block. Two SNRs were tested in each condition: −8 dB and −12 dB. SNR was manipulated by adjusting the gain of the speech signal prior to convolution with the BRIRs, and was always kept fixed within a block of trials.
Over the course of the experiment, each participant was presented with a total of 288 sentences split up into 10 sets of trials. Table Table 1. diagrams the design for these 10 sets which resulted in 18 sentences in all possible stimulus presentation conditions. The first four sets (1–4) each consisted of 18 sentences from a single PRESTO list and were blocked by room and SNR. The remaining sets were all unblocked by room. In sets 5, 7, and 9, listeners were presented with six sentences each from R0, R1, R2, R3, R4, and R5 with presentation order randomized within the set. SNR for these sets was −8 dB. Sets 6, 8, and 10 were analogous to sets 5, 7, and 9, but involved sentence lists presented at −12 dB SNR. The sentences in different listening environments of interest (R0 and R1) were taken from the same list so that the number of key words was equated. No speech material was repeated during the entire study. Each listener completed the experiment in a single session which lasted approximately 1.5 h. Since individual lists in PRESTO speech corpus are not equated for intelligibility, the listeners were divided into two groups of 30 listeners and each group was tested using different PRESTO sentence lists (presentation order randomized) for each condition, as shown in Table Table 2..
Table 1.
Block diagram illustrating the experimental design. A sequence of trials is shown for each set, where R0 denotes speech presented in anechoic listening environment and R1 denotes speech presented in a simulated reverberant listening environment (T60 = 0.3 s). Signal-to-noise ratio (SNR) is indicated (in dB) for each trial. Sets 1–4 (18 trials each) were blocked by room. In the remaining unblocked sets (36 trials each), room was selected at random (equal probability) from a set of six rooms, which included R0 and R1.
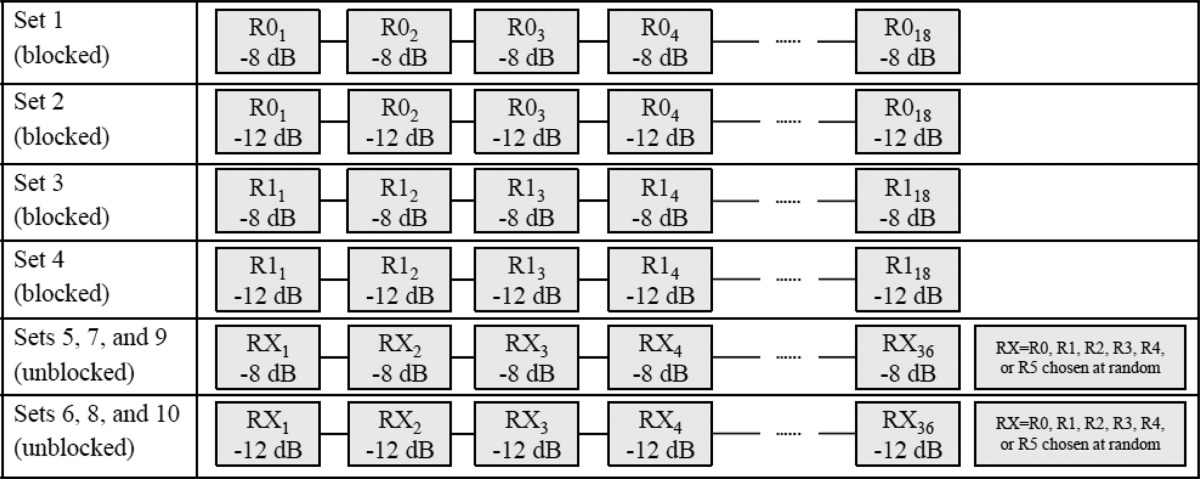 |
Table 2.
Individual PRESTO sentence lists used in different listening conditions (Room and SNR) for listener groups 1 and 2 (n = 30 for each group). B denotes blocked presentation and U denotes unblocked presentation. Presentation order within each list was randomized.
| R0 (Anechoic) | R1 (T60 = 0.3 s) | |||||||
|---|---|---|---|---|---|---|---|---|
| −8 dB | −12 dB | −8 dB | −12 dB | |||||
| B | U | B | U | B | U | B | U | |
| Group 1 | List 8 | List 11 | List 12 | List 14 | List 15 | List 13 | List 18 | List 17 |
| Group 2 | List 2 | List 13 | List 20 | List 4 | List 3 | List 23 | List 17 | List 18 |
Procedure
The listeners were seated in a sound-attenuating chamber (Acoustic Systems, Austin, TX, custom double wall) and listened to speech stimuli via headphones (Beyerdynamic–DT990 Pro, Heilbronn, Germany). The speech stimuli were presented to the listeners at an A-weighted sound level of approximately 68 dB SPL (sound pressure level) at the ear. The listeners were instructed to listen to the speech stimulus presented and type all the words they understood. No feedback was provided regarding the number of words they correctly entered during each trial. The listeners were encouraged to guess if they were unsure about the auditory input. Data collection was self-paced, and the listeners were instructed to take breaks whenever they felt fatigued. All stimulus presentation and data collection was implemented using MATLAB software and statistical analyses were performed using SPSS.
Scoring
The percentage of key words correctly reported was scored as a measure of speech intelligibility for each combination of room, SNR, and blocking conditions. The percent correct speech intelligibility scores were transformed to rationalized arcsine units (RAUs) (Studebaker, 1985) prior to subsequent statistical analyses. Separate repeated measures-analysis of variance tests were conducted to evaluate differences in RAU intelligibility scores across different listening conditions.
Results and discussion
Two analysis of variance (ANOVA) tests were conducted on the data from R0 and R1, with factors of SNR (within-subjects), blocked/unblocked presentation (within-subjects), and sentence lists (between-subjects; see Table Table 2.). No statistically significant main effects or interactions involving the sentence list factor were found in either test. This suggests that effects observed between listening conditions do not depend on the particular PRESTO list presented in the given listening condition. Data from the two groups of listeners that received different lists were therefore pooled for all subsequent analyses.
The across subject average of percent key words correct (RAU units) is shown in Fig. 1a for R0 (anechoic) and R1 (T60 = 0.3 s) listening environments during blocked and unblocked listening conditions at both −8 dB and −12 dB SNRs. Of primary interest is the improvement in performance between the unblocked and the blocked conditions. Such an improvement is observed in the reverberant room listening condition at both SNRs. In anechoic space, however, these effects are absent. These observations were confirmed using separate 2-way repeated-measures ANOVA tests for each listening environment with factors of presentation condition (blocked/unblocked) and SNR. There was a significant main effect of SNR in both the R0 [F(1,59) = 74.045, p < 0.0001, Mse = 71.383] and R1 [F(1,59) = 179.314, p < 0.0001, Mse = 42.609] environments. This relationship between speech understanding and SNR for a spatially separated masker is, of course, well-known (Plomp, 1976), as is the overall decrement in performance between anechoic and reverberant space (Knudsen, 1929; Lochner and Burger, 1964). Neither of these effects are therefore of particular interest in this study. Much more important is the significant main effect of listening condition in R1 [F(1,59) = 415.923, p < 0.0001, Mse = 46.145], but not in R0 [F(1,59) = 0.033, p = 0.857, Mse = 70.524]. Also of interest is a significant interaction between listening condition and SNR in R1 [F(1,59) = 12.110, p < 0.001, Mse = 63.446], but not in R0 [F(1,59) = 1.207, p = 0.276, Mse = 90.928]. Overall, these results are consistent with past research that used more phonetically homogeneous speech materials (Brandewie and Zahorik, 2010; Srinivasan and Zahorik, 2011). The results suggest that consistent prior listening exposure to a reverberant room improves speech intelligibility, and that the improvement magnitude is inversely related to SNR: approximately 16% at −8 dB SNR and 22% at −12 dB SNR. The magnitude of these exposure effects is particularly striking when compared to that observed for the SNR manipulation alone [see Fig. 1a], which in this study improves performance by at most 15 percentage points (unblocked condition).
Figure 1.

(Color online) Speech intelligibility results from anechoic (R0) and reverberant room (R1) listening environments at −8 dB and −12 dB SNR. Results from three types of analyses are shown. (a) Mean (n = 60) transformed speech intelligibility for blocked (filled bars: “B”) and unblocked (unfilled bars: “U”) conditions in R0 (upper panel) and R1 (lower panel) listening environments as a function of SNR. Error bars show 95% confidence intervals for each mean. (b) Scatter plot of speech intelligibility during blocked and unblocked listening conditions for R0 and R1environments. Each point indicates data from one listener at a given SNR. For R1, the majority of listeners demonstrate improved intelligibility when consistent room exposure is provided (blocked condition) relative to when room varies from trial to trial (unblocked condition). (c) Mean (n = 60) transformed speech intelligibility as a function of exposure time, measured in six-sentence epochs. Data are shown for blocked (B) and unblocked (U) conditions at −8 dB and −12 dB SNRs in R0 and R1. Error bars show 95% confidence intervals for each mean.
The patterns of results observed in the group-averaged data [Fig. 1a] are also observable in nearly all individuals. Figure 1b shows scatter plots of transformed speech intelligibility for blocked versus unblocked presentation, for both R0 and R1 listening environments. Each plot displays data from both SNRs. Although substantial individual variability may be observed, nearly all listeners demonstrated improved intelligibility in blocked versus unblocked listening in the reverberant environment. At −8 dB, 53 out of 60 listeners showed improvement, and at −12 dB all 60 listeners improved. Similar results were not observed in anechoic space for the same listeners, further suggesting that the exposure effects of interest are specific to reverberant space. The consistency of the results over the relatively large sample of listeners tested in this study is also a notable extension of past work that was conducted with smaller samples (Brandewie and Zahorik, 2010).
An additional and important question relates to the amount of listening exposure required for intelligibility improvement. To address this question, intelligibility was analyzed over six-sentence time epochs in the experiment. The results of this analysis are shown in Fig. 1c. Results from separate repeated-measures ANOVAs for each condition confirmed that there were no significant differences in performance in any of the conditions over time. These results suggest that the processes underlying the intelligibility improvement are relatively rapid (within the first six sentences), and once the improvements are realized, there is little additional longer-term improvement. This too is consistent with results from past work using less-diverse speech materials (Brandewie and Zahorik, 2010).
Conclusions
Results from this study confirm that prior listening exposure to a reverberant room improves speech intelligibility and that the processes of underlying this effect are relatively rapid—on the order of seconds—and do not show longer-term improvement. The magnitude of the effect (average intelligibility improvement of 16 to 22 percentage points, depending on SNR) was also comparable to that observed in a past study (Brandewie and Zahorik, 2010). This study represents an important extension of past work for two reasons: (i) Results from this study demonstrate that the room adaptation effect generalizes to speech materials that are much more representative of natural speech in terms of phonetic, lexical, and indexical variability, and (ii) the results are consistent across a large sample of normal-hearing listeners. Additional study of these effects may have important implications for understanding why individuals with hearing impairment have difficulty with speech intelligibility and spoken language understanding in reverberation, and how these difficulties may be mitigated.
Acknowledgments
The authors wish to thank Regina Collecchia, Noah Jacobs, and Chris Wheeler for their assistance in data collection and scoring. This research was supported by NIH-NIDCD (Grant No. R01DC008168).
References and links
- Boila, R. S., Nelson, W. T., Ericson, M. A., and Simpson, B. D. (2000). “A speech corpus for multitalker communications research,” J. Acoust. Soc. Am. 107(2), 1065–1066. 10.1121/1.428288 [DOI] [PubMed] [Google Scholar]
- Brandewie, E. J., and Zahorik, P. (2010). “Prior listening in rooms improves speech intelligibility,” J. Acoust. Soc. Am. 128(1), 291–299. 10.1121/1.3436565 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Felty, R. (2008). “Perceptually robust English sentence test (open-set),” Unpublished manuscript, Indiana University, Bloomington, IN.
- Garofolo, J., Lamel, L. F., Fisher, W. M., Fiscus, J. G., Pallett, D. S., Dahlgren, N. L., and Zue, V. (1993). “DARPA TIMIT acoustic-phonetic continuous speech corpus,” Linguistic Data Consortium, Philadelphia, PA. [Google Scholar]
- Gilbert, J. L., Tamati, T. N., and Pisoni, D. B. (2013). “Development, reliability, and validity of PRESTO: A new high-variability sentence recognition test,” J. Am. Acad. Audiol. 24, 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer, K. S., and Wilber, L. A. (1990). “Hearing loss, aging, and speech perception in reverberation and noise,” J. Speech Hear. Res. 33(1), 149–155. [DOI] [PubMed] [Google Scholar]
- Knudsen, V. O. (1929). “The hearing of speech in auditoriums,” J. Acoust. Soc. Am. 1, 56–82. 10.1121/1.1901470 [DOI] [Google Scholar]
- Lochner, J., and Burger, J. (1964). “The influence of reflections in auditorium acoustics,” J. Sound Vib. 1(4), 426–454. 10.1016/0022-460X(64)90057-4 [DOI] [Google Scholar]
- Nabelek, A. K., and Mason, D. (1981). “Effect of noise and reverberation on binaural and monaural word identification by subjects with various audiograms,” J. Speech Hear. Res 24(2), 375–383. [DOI] [PubMed] [Google Scholar]
- Plomp, R. (1976). “Binaural and monaural speech intelligibility of connected discourse in reverberation as a function of azimuth of a single competing sound source (speech or noise),” Acustica 34, 200–211. [Google Scholar]
- Srinivasan, N. K., and Zahorik, P. (2011). “The effect of semantic context on speech intelligibility in reverberant rooms,” Proc. Meet. Acoust. 12, 060001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Studebaker, G. A. (1985). “A rationalized arcsine transform,” J. Speech Hear. Res. 28(3), 455–462. [DOI] [PubMed] [Google Scholar]
- Tamati, T. N., Gilbert, J. L., and Pisoni, D. B. (2013). “Some factors underlying individual differences in speech recognition on PRESTO: A first report,” J. Am. Acad. Audiol. In press. [DOI] [PMC free article] [PubMed]
- Watkins, A. J. (2005a). “Perceptual compensation for effects of echo and of reverberation on speech identification,” Acta Acust. 91, 892–901. [DOI] [PubMed] [Google Scholar]
- Watkins, A. J. (2005b). “Perceptual compensation for effects of reverberation in speech identification,” J. Acoust. Soc. Am. 118(1), 249–262. 10.1121/1.1923369 [DOI] [PubMed] [Google Scholar]
- Watkins, A. J., and Makin, S. J. (2007). “Steady-spectrum contexts and perceptual compensation for reverberation in speech identification,” J. Acoust. Soc. Am. 121(1), 257–266. 10.1121/1.2387134 [DOI] [PubMed] [Google Scholar]
- Watkins, A. J., Raimond, A. P., and Makin, S. J. (2011). “Temporal-envelope constancy of speech in rooms and the perceptual weighting of frequency bands,” J. Acoust. Soc. Am. 130(5), 2777–2788. 10.1121/1.3641399 [DOI] [PubMed] [Google Scholar]
- Zahorik, P. (2009). “Perceptually relevant parameters for virtual listening simulation of small room acoustics,” J. Acoust. Soc. Am. 126(2), 776–791. 10.1121/1.3167842 [DOI] [PMC free article] [PubMed] [Google Scholar]