

Abstract
Many biological and man-made networked systems are characterized by the simultaneous presence of different sub-networks organized in separate layers, with links and nodes of qualitatively different types. While during the past few years theoretical studies have examined a variety of structural features of complex networks, the outstanding question is whether such features are characterizing all single layers, or rather emerge as a result of coarse-graining, i.e. when going from the multilayered to the aggregate network representation. Here we address this issue with the help of real data. We analyze the structural properties of an intrinsically multilayered real network, the European Air Transportation Multiplex Network in which each commercial airline defines a network layer. We examine how several structural measures evolve as layers are progressively merged together. In particular, we discuss how the topology of each layer affects the emergence of structural properties in the aggregate network.
In the past fifteen years, network theory1,2,3 has successfully characterized the interaction among the constituents of a variety of complex systems4,5, ranging from biological6 to technological7, and social8 systems. However, up until recently, attention was almost exclusively given to networks in which all components were treated on equivalent footing, while neglecting all the extra information about the temporal- or context-related properties of the interactions under study. Only in the last three years, taking advantage of the enhanced resolution in real data sets, network scientists have directed their attention to the multiplex character of real-world systems, and explicitly considered the time-varying9,10,11,12,13,14 and multi-layered15,16,17,18,19,20,21,22,23,24,25,26 nature of networks.
A paradigmatic example of intrinsically multiplex system is represented by the Air Transportation Network (ATN). The ATNs have undergone a very significant growth during the last decades, giving rise to the dense and redundant system we know nowadays27. In the ATN, nodes represent airports, while links stand for direct flights between two airports. On the other hand, each commercial airline corresponds to a different layer, containing all the connections operated by the same company. While a considerable effort has recently been devoted to the characterization of the structural properties28,29,30 of ATNs and their role in the dynamical processes taking place on them31,32,33,34, their multiplex nature has remained almost unexplored.
When studying systems that can be represented as a graph made of diverse relationships (layers) between its constituents, an important question, typical of complex systems analysis, arises: can the topological properties of the whole system be traced to those of its layers or do they emerge from the simultaneous presence of multiple layers? Emergence is said to happen when the focus is switched from one scale to a coarser level of description. This question can be addressed by comparing the most usual structural properties of the multiple layers composing a network35 and their analogue in the aggregate representation of the network, in which the layer structure is disregarded.
To address the above question we resort to the European ATN data set. Taking advantage of the high-resolution of these data, comprising a number of airlines (layers) operating in Europe during the year 2011, we succeed to extract the multiplex character of the system, and we investigate how the structural properties usually observed in the ATN are here emerging as a result of progressive layer merging. To this end, we quantify various topological measures, such as the degree distribution, the clustering coefficient or the presence of rich-club effect, in networks obtained by merging together a growing number of layers, from the lowest level of resolution of a single layer, up to the fully aggregate network. In addition, we compare two different types of layers, those corresponding to major (national) airlines and those labeled as low-cost companies. We analyze their structural differences, and their different contribution to the properties of the global ATN.
Results
The European ATN can be represented as a graph composed of M = 37 different layers each representing a different European airline (see Methods for details). Each layer m has the same number of nodes, N, as all European airports are represented in each layer. Furthermore, the data set allows extracting two main subsets, comprising all major, and low-cost airlines, with 18 and 10 layers respectively (See Fig. 1). In particular, panels (a) and (b) display the structure of the aggregate network focusing first on its redundancy by sketching those links belonging to more than one layer and on its unicity by reporting those links that only exist in a specific layer. Panels (c) and (d) show, instead, the single-layer ATN corresponding to a given major and low-cost airlines, respectively. In each of the panels we highlighted the nodes with the highest number of connections.
Figure 1. Visual representation of the ATN.
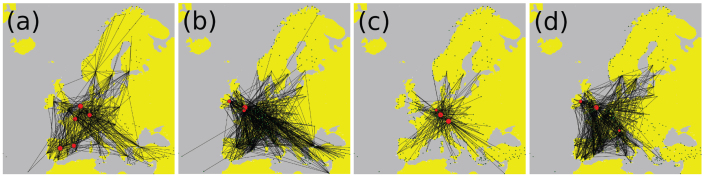
From left to right: the aggregate network of all the layers in which only links belonging to more than one layer are displayed. The same network but in which we display those links which belongs to only one layer and connecting at least one node with degree greater than or equal to 75. An example of ATN network of a major airline and, finally, the network of a low-fare (low-cost) airline. In each network, the airports with the highest degree are highlighted.
Topological measures
To characterize the structural properties of both the aggregate ATN and its layers, we consider several features widely used in network literature35, i.e. cumulative degree distribution P>(k), clustering coefficient C, size of the giant component S, average path length L and Rich-club coefficient R. We briefly describe below the specific meaning of each of these measures in our context. The interested reader will find a complete description of all those quantities in the Methods section.
The cumulative degree distribution P>(k), gives the probability of finding a node with a number of connections (or degree) equal or greater than k. The degree distribution is a powerful tool which allows understanding both structural and dynamical characteristics of a system as, for instance, its tolerance to attacks or failures36,37 so it represents a cornerstone in the characterization of critical infrastructures, such as the ATN.
The average path length 〈L〉, measures the average number of hops one has to make to go from a node to another. In the context of ATNs, it indicates the average number of flights a passenger has to take to go from his/her origin to his/her destination. However, if the system is not connected, this quantity diverges and it is preferable to restrict attention to the giant (largest) component of the system (see below).
The clustering coefficient C, measures the probability, C
 [0, 1], that two nodes with a common neighbor are connected together. C is a typical measure in systems made of social acquaintances8, but in our case it is useful to estimate the density of triangular motifs (denoting the possibility of performing round trips of length 3).
[0, 1], that two nodes with a common neighbor are connected together. C is a typical measure in systems made of social acquaintances8, but in our case it is useful to estimate the density of triangular motifs (denoting the possibility of performing round trips of length 3). The size of the giant component38 S, denotes the largest fraction of overall nodes such that any pair of them is connected through a path of finite length. In our case, it estimates the largest coverage that a given airline (or a combination of them) provides in terms of the available destinations that a passenger can reach from an origin inside the giant component.
The Rich-club coefficient39 R, measures the tendency of highly connected nodes, i.e. the hubs, to be connected among themselves. To measure it, one has to compute the abundance of links,
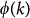 , among nodes with a number of connections equal or greater than a certain value k, and the maximum possible number of links among those nodes,
, among nodes with a number of connections equal or greater than a certain value k, and the maximum possible number of links among those nodes, 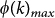 . Then, the ratio between these two quantities gives the relative abundance of links among nodes with at least k connections. Finally, R(k) is given by the ratio between the abundance of links in the real case
. Then, the ratio between these two quantities gives the relative abundance of links among nodes with at least k connections. Finally, R(k) is given by the ratio between the abundance of links in the real case 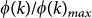 and the same quantity calculated in a proper randomized version of the original network. Colizza et al.28 measured R for the ATN, and found that world air transportation network displays indeed a Rich-club effect, i.e. for large values of k the value of R(k) is larger than 1.
and the same quantity calculated in a proper randomized version of the original network. Colizza et al.28 measured R for the ATN, and found that world air transportation network displays indeed a Rich-club effect, i.e. for large values of k the value of R(k) is larger than 1.
Emergence of topological properties of the European ATN
We now analyze the evolution of the former measures as more and more layers are merged (independently of whether they do correspond to major or low-cost companies), until the complete aggregate ATN, comprising all the available layers, is reached (see the Methods section for the details on the layer merging procedure). The results are shown in Fig. 2.
Figure 2. Evolution of topological properties of the complete ATN network.

(a) Average cumulative degree distribution P>(k) for groups of layers merged together: single layers ( ), five layers (
), five layers ( ), twenty layers (
), twenty layers ( ) and the aggregate (
) and the aggregate ( ). (b–c–d) Average clustering 〈C〉, size of giant component 〈S〉, path length 〈L〉 as a function of m. (e) Link abundance for nodes of degree k or greater,
). (b–c–d) Average clustering 〈C〉, size of giant component 〈S〉, path length 〈L〉 as a function of m. (e) Link abundance for nodes of degree k or greater, 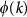 divided by its maximum
divided by its maximum 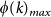 for the aggregate network in both real case (
for the aggregate network in both real case ( ) and its randomized version (
) and its randomized version ( ). The vertical dashed line represent the value of k at which the difference among the two curves is maximal. (f) A subset of the aggregate network showing the connections among those nodes whose degree is greater than (or equal to) 47. The size of the nodes is proportional to the degree.
). The vertical dashed line represent the value of k at which the difference among the two curves is maximal. (f) A subset of the aggregate network showing the connections among those nodes whose degree is greater than (or equal to) 47. The size of the nodes is proportional to the degree.
In panel (a) we show the evolution for the cumulative degree distribution of the aggregate ATN and those networks obtained by merging 1, 5 and 20 randomly chosen layers. Since right-skewed distributions often display high noise levels at the end of their tails due to the lack of statistics, it is convenient to consider the cumulative distribution instead of the distribution P(k) itself35. A power-law behavior P>(k) ∝ k−α is observed in all the situations considered, with a decrease in the exponent α, ranging from α = 1.84 in the single layer case (m = 1) to α = 1.39 for the aggregate ATN. The increase in heterogeneity with the number of layers considered points to a richer-gets-richer phenomenon different from the one seen in classical models for growing scale-free networks: while in the latter case, it results from the addition of new nodes, in the present case it emerges from the addition new layers.
In panel (b) we report the clustering coefficient. In this case, we show the behavior of 〈C〉 as a function of the number of layers used to construct the aggregate ATN, averaged over the number of different combinations of m elements (m = 1, …, M). Interestingly, we see how the clustering suddenly increases as we merge just a few layers: to achieve more than 80% of the final clustering value, we only need to randomly merge together five layers. This result indicates that the large density of triangles present in the ATN is a consequence of the merging of different layers rather than a single-layer property. Thus, in order to make round trips of length 3 one should make use, most of the times, of more than one airline.
The former result contrasts with the picture obtained for the evolution of the size of the giant component 〈S〉. Panel (c) describes a monotonous and progressive increase of the coverage as more layers are aggregated. In fact, around 40% of the European cities are covered when merging together five randomly chosen layers. It is worth noticing that 〈S〉 also tells us that we are considering a system which is already above the percolation threshold, so that every step towards the aggregate network produces an increment in the collection of reachable destinations (see the value of 〈S〉 for m = 1). However, the behavior of the transition for the average path length 〈L〉 (restricted to those nodes in the giant component) in panel (d) shows a rise-and-fall behavior indicating that combining few layers results in the merging of unconnected components at the aggregate level, causing a fast increase in its length. On the other hand, after the maximum for L is reached, the addition of new layers has a twofold effect on the giant components: it incorporates new nodes, but also creates alternative links between already present nodes. Thus, the average path length of the giant component balances the addition of new destinations with the creation of new links, and suffers a slow decrease when increasing m.
Finally, panel (e) shows, only for the aggregate network, the existence of a Rich-club effect quantifying the abundance of links between nodes with degree larger or equal to k, 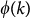 , normalized with respect to its maximum. This quantity is computed both for the real ATN and for a set of randomized versions of the network in which all the links are rewired keeping the same degree sequence of the original network. This randomization aims at destroying any kind of correlation between the local properties of connected nodes. From the figure it is clear that initially the two curves coincide indicating that the existence of flights between airports with few connections (less than k = 30) is equally probable in the ATN and in its randomized version. Instead, for
, normalized with respect to its maximum. This quantity is computed both for the real ATN and for a set of randomized versions of the network in which all the links are rewired keeping the same degree sequence of the original network. This randomization aims at destroying any kind of correlation between the local properties of connected nodes. From the figure it is clear that initially the two curves coincide indicating that the existence of flights between airports with few connections (less than k = 30) is equally probable in the ATN and in its randomized version. Instead, for 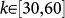 the points corresponding to the real ATN stand above those corresponding to the randomized network. This result points out that the aggregate ATN displays Rich-club effect (the largest effect being found for k = 47), thus confirming for the European case the findings of Colizza et al.28 for the ATN. The existence of such effect is quite logical, as usually highly connected nodes correspond to the principal airports of the main European cities which, in most of the cases, are connected among themselves via direct flights. Finally, for k>60 the fluctuations of the randomized case are too large for any statement to be made on the existence of a Rich-club effect.
the points corresponding to the real ATN stand above those corresponding to the randomized network. This result points out that the aggregate ATN displays Rich-club effect (the largest effect being found for k = 47), thus confirming for the European case the findings of Colizza et al.28 for the ATN. The existence of such effect is quite logical, as usually highly connected nodes correspond to the principal airports of the main European cities which, in most of the cases, are connected among themselves via direct flights. Finally, for k>60 the fluctuations of the randomized case are too large for any statement to be made on the existence of a Rich-club effect.
Major versus low-cost layers
The European ATN is composed of layers corresponding to airlines of different types. In particular, we find among them major (national, such as Lufthansa), low-cost fares (such as Easyjet), regional (such as Norwegian Air Shuttle) or cargo (such as Fed-Ex) airlines. These kinds of airlines have developed according to different structural/commercial constraints. For instance, it is known that major airlines are designed following the so-called hub and spoke structure, to provide an almost complete coverage of the airports belonging to a given country40,41 and maximize efficiency in terms of national transportation interests. Low-cost companies, instead, tend to avoid overly centralized structures and, to be more competitive, typically cover more than one country simultaneously. To unveil the role that each type of airline plays in the emergence of the topological features of the aggregate ATN, we considered two subsets of layers respectively comprising only it majors and low-cost airlines. The results of this study are shown in Fig. 3.
Figure 3. Evolution of topological properties of major (▪) and low-cost (▴) subsets.

(a–b) Average cumulative degree distribution P>(k) for different number of layers merged together. (c–d–e–f) Average clustering 〈C〉, number of triangles 〈n3〉, size of giant component 〈S〉, path length 〈L〉 as a function of the number of layers merged. The insets display the same quantities in the case of the complete set. (g–h) link abundance for the aggregate network. The vertical dashed line represents the value of k at which the difference among the two curves is maximal.
We first address the cumulative degree distribution P>(k). In the two panels (a) and (b) we show the distributions P>(k) for major (a) and low-cost (b) layers when considering different levels for the merging of the layers of the same kind. For major airlines, the typical trend of a single layer (m = 1) displays a plateau for moderate values of k, indicating a centralized character of this kind of layers, with few hubs having remarkably higher than average connectivity. In addition, when merging more layers (m = 10 or all the major airlines) the trend shows a rather continuous decay due to the combination of hubs of different size (depending on the nation of the airline). Notice that a hub of a single layer (a single national airline) is highly connected within the same country, but also has some flights to capitals of other European countries which, in turn, are hubs of their corresponding major layers. On the other hand, the cumulative distribution of typical low-cost airlines shows a rather different pattern, as its decay is rather progressive, and airports of different size coexist within the same layer.
The differences in organization of low-cost and major airlines is further highlighted by the behavior of the clustering coefficient 〈C〉. Panel (c) shows how major airlines display sharp increases in 〈C〉 as more major layers are merged, followed by a plateau for m > 5. This saturation of C is due to the fact that, when merging major layers randomly, national hubs tend to connect together (we have already discussed this fact when introducing the Rich-club effect) in the aggregate network. The saturation of clustering is, however, not observed for the aggregate ATN [see Fig. 2.(b) or the inset in panel (c)] for which C(m) always increases. This is due to the fact that the merging of low-cost layers leads to a continuous formation of new triangles, thus increasing the clustering with m. In addition, in panel (d) we show the evolution with m of the average number of triangles, 〈n3〉, normalized with respect to the total number of triads in the aggregate network for both major and low-cost layers. Interestingly, the monotonic growth of 〈n3〉 reveals that the saturation of the clustering coefficient when m = 5 for major layers is not due to the fact that new triangles are not added when m > 5 but to a balance between the new triads and the new connections added when merging additional layers.
The behavior of the giant component 〈S〉, normalized with respect to the total number of destinations covered by each kind of airline (see panel (e)), does not give any particular insight in terms of differences between low-cost and major airlines, except for the fact that in the low-cost case we observe larger fluctuations, mainly due to the large variability in size of the giant component of single layers. On the other hand, the picture described by the average path length 〈L〉 in panel (f) is very interesting. Major and low-cost subsets behave rather differently not only between them, but also with respect to the evolution of the complete set (see inset). For layers corresponding to major companies, 〈L〉 increases with the number of merged layers. The interpretation of this continuous growth is straightforward: each time a layer corresponding to a major airline is added, even if it shares some common destinations (say some European capitals having their corresponding major airlines within the original set of merged layers), the number of new available nodes (small destinations only available through the new added major layer) is large enough to generate an increase in L. On the contrary, the case of low-cost displays a rise-and-fall in the behavior of 〈L〉, due to the large coverage of European countries/cities that already each single low-cost layer displays. Thus, as we merge some of them together, they already cover nearly all the low-cost destinations, and merging of additional layers just adds new connections between them. When combined into the original ATN, these two different trends lead to the saturated evolution of 〈L〉(m) shown in the inset.
Finally, we examine once again the onset of the Rich-club effect. From panels (g) and (h) we notice how the graph corresponding to the aggregate network constructed by merging layers corresponding to major airlines (g) displays the presence of a rich club for k = 38 (almost the same value as in the case of the total aggregate ATN). Interestingly, the Rich-club effect is absent when merging low-cost layers so that, while in the case of major airlines the merge of layers containing large hubs ends up in a system composed of a connected core of highly connected nodes, the more distributed nature of the low-cost layers prevents the formation of a Rich-club. Thus, a relevant conclusion is that the well-known28 Rich-club effect observed in ATNs is exclusively related to the presence of major airlines.
Discussion
The characterization of the interaction patterns in large systems has recently been spurred by the incorporation of the paradigm of multiplexity. Taking advantage of the European ATN data set, with details of the airlines operating each flight, we showed that the topological properties of the ATN are generally not present in single layers, rather they are the consequence of an emerging phenomenon intimately related to the multilayer character of the system. We also pointed out that the merging of low-cost and major (national) layers leads to the emergence of qualitatively different aggregate networks. Finally, we demonstrated that the combination of these two different behaviors accounts for the many important structural features of the global ATN, such as the Rich-club effect (mainly due to the layers of major airlines), path redundancy (resulting from a cooperative combination of the clustering of low-cost and major layers), or small-worldness (remarkably enhanced by the presence low-cost layers).
Our study highlights the importance of considering the multiplex character of most real networked systems, and shows that considering layers as relevant entities of a network (such as nodes and links at the micro-scale or communities at the meso-scale) will contribute to a better understanding and modeling of dynamical processes taking place at the level of aggregate network.
Methods
Dataset
The data analyzed in this paper are taken from the complete list of airlines operating Instrumental Flight Rules (IFR) flights between European airports on a certain day obtained from EUROCON-TROL and the Complex World Network in the context of the SESAR Work Package E42. We selected only those airlines whose number of destinations is above the average (which is 32), obtaining 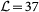 different airlines (layers), that include both major companies (like Lufthansa or Air France), and low-fares (low-cost) companies (as Ryanair or Easyjet). Each layer
different airlines (layers), that include both major companies (like Lufthansa or Air France), and low-fares (low-cost) companies (as Ryanair or Easyjet). Each layer 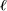 in this multiplex representation is a graph
in this multiplex representation is a graph 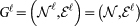 with
with 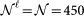 nodes and
nodes and 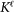 links that models a single airline. An example of such networks is shown in Fig. 1. The ensemble of all these layers constitutes our multilayer system, that we will call the complete set. We will also consider the subset of major airlines, that will be a multiplex network made of
links that models a single airline. An example of such networks is shown in Fig. 1. The ensemble of all these layers constitutes our multilayer system, that we will call the complete set. We will also consider the subset of major airlines, that will be a multiplex network made of 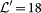 layers, and the subset of low-cost companies, with
layers, and the subset of low-cost companies, with 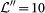 layers. Note that the remaining airlines, such as cargo airlines, constitutes a marginal small subset and therefore its analysis is residual.
layers. Note that the remaining airlines, such as cargo airlines, constitutes a marginal small subset and therefore its analysis is residual.
Topological indexes
In this section, we present a summary of the topological measures used throughout the paper. Note that the considered topological measures are essentially defined for classic monoplex networks, and their extensions to the multiplex setting is an exercise, whose details are here shown.
One of the most basic topological parameter of a complex network 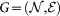 is the degree distribution P(k) which is defined as the probability that a node chosen uniformly at random has degree k, or equivalently the fraction of nodes in the network having degree k3,35. Since broad distributions often display high noise levels at the end of their tails, here related to the low abundance of highly connected nodes, it is convenient to consider the cumulative distribution P>(k). Cumulative distribution P>(k) is the probability that a randomly chosen node has a degree equal or greater than k, i.e.
is the degree distribution P(k) which is defined as the probability that a node chosen uniformly at random has degree k, or equivalently the fraction of nodes in the network having degree k3,35. Since broad distributions often display high noise levels at the end of their tails, here related to the low abundance of highly connected nodes, it is convenient to consider the cumulative distribution P>(k). Cumulative distribution P>(k) is the probability that a randomly chosen node has a degree equal or greater than k, i.e.
where N(k) is the number of nodes with degree k and 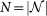 is the total number of nodes in the network.
is the total number of nodes in the network.
The average path length4 L(G) is the average length of the shortest paths among all the couples of nodes in the network, i.e.
where dij is the minimum number of hops one has to make to go from node i to node j in G (the distance from i to j). Note that this definition diverges if G is not connected, since dij may be infinite. One way to avoid this divergence is considering the average only on the largest connected component, and an alternative approach that has been shown very useful in many cases is considering the harmonic mean of the distances.
The (local) clustering coefficient4
ci of a node 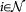 is defined as
is defined as
where ei is the number of neighbors of i which are mutual neighbors, and ki is the degree of node i. Therefore the (local) clustering coefficient of a node i is the ratio between the number of neighbors of i which are mutual neighbors and the maximal possible number of edges between neighbors of i. The (average) clustering coefficient C of a graph is the arithmetic mean of ci over all its nodes.
The giant component S(G) is the largest connected component of G and the size of the giant component is the proportion of nodes in the network that belong to the giant component, i.e.,
where Ni is the number of nodes of the maximal connected subnetwork of G containing node i.
If we take a node with degree
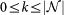 , the Rich-club coefficient R(k)39 is given by
, the Rich-club coefficient R(k)39 is given by
where
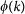 is the number of edges connecting nodes of degree greater or equal to k (called the link abundance),
is the number of edges connecting nodes of degree greater or equal to k (called the link abundance), 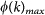 is the maximum number of links that can exist between nodes of degree k,
is the maximum number of links that can exist between nodes of degree k, 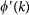 is the link abundance on a network with the same degree sequence of the original but with connections randomly shuffled.
is the link abundance on a network with the same degree sequence of the original but with connections randomly shuffled. 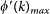 is the maximum number of links that can exist between nodes of degree k on a network with the same degree sequence of the original but with connections randomly shuffled.
is the maximum number of links that can exist between nodes of degree k on a network with the same degree sequence of the original but with connections randomly shuffled. N>k is the number of nodes with degree greater or equal to k.
If, for a certain value of k, R(k) > 1 for some 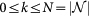 , then we say that G has a Rich-club. Note that in the plots presented in this paper, we decided to present the ratios
, then we say that G has a Rich-club. Note that in the plots presented in this paper, we decided to present the ratios 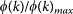 and
and 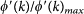 instead of R(k). The randomization, in our case, is repeated 1,000 times, while the shuffling is repeated 10,000 times to ensure a robust statistical sampling. Note that for the ATN network, having a size of N = 450 nodes, the number of random shuffling steps is large enough to guarantee that the resulting network is fully randomized. This randomization method is known as Markov Chain Monte Carlo Algorithm43. However, for bigger graphs other methods are recommended so to minimize the computation cost for producing reliable randomized networks, see the work by Del Genio et al.44.
instead of R(k). The randomization, in our case, is repeated 1,000 times, while the shuffling is repeated 10,000 times to ensure a robust statistical sampling. Note that for the ATN network, having a size of N = 450 nodes, the number of random shuffling steps is large enough to guarantee that the resulting network is fully randomized. This randomization method is known as Markov Chain Monte Carlo Algorithm43. However, for bigger graphs other methods are recommended so to minimize the computation cost for producing reliable randomized networks, see the work by Del Genio et al.44.
Next, we describe the layer merging procedure used to study the evolution of the topological measures and the behavior of the layers in the major airline and low-cost multiplex sub-networks.
If we fix a subset of layers 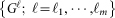 to merge together, we construct a monoplex network
to merge together, we construct a monoplex network 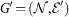 (i.e. a classic network with only one layer) given by
(i.e. a classic network with only one layer) given by
This network G′ is obtained by projecting all the m layers onto one and by converting multiple links into single ones.
Now if we fix m, we look for all the possible mergings of m layers, The number of different configurations to arrange n layers into groups of size m without repetitions is given by 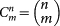 , therefore if we want to compute a topological measure on the ensemble of m layers, we should first compute it on each of the
, therefore if we want to compute a topological measure on the ensemble of m layers, we should first compute it on each of the 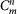 mergings, and then average over all
mergings, and then average over all 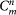 possible configurations. However, when the number of possible configurations exceeded a certain threshold, we operated a random sampling over 500,000 mergings in order to avoid the growth of the computation time. Throughout the paper the operator 〈·〉 denotes the average over the elements of the ensemble. As an example, if we want to compute the clustering coefficient over an ensemble
possible configurations. However, when the number of possible configurations exceeded a certain threshold, we operated a random sampling over 500,000 mergings in order to avoid the growth of the computation time. Throughout the paper the operator 〈·〉 denotes the average over the elements of the ensemble. As an example, if we want to compute the clustering coefficient over an ensemble 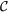 , we compute:
, we compute:
where Ncomb is the number of elements of 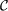 and Ci is the average clustering of the network obtained merging together the layers corresponding to
and Ci is the average clustering of the network obtained merging together the layers corresponding to  .
.
Author Contributions
A.C., J.G.G., M.Z., M.R. and S.B. devised the model and designed the study. A.C. carried out the numerical simulations. A.C., J.G.G., F.d.P. and M.Z. analyzed the data and prepared the figures. A.C., J.G.G., D.P. and S.B. wrote the main text of the manuscript.
Acknowledgments
This work has been partially supported by the Spanish MINECO under projects FIS2011-25167 and FIS2012-38266-C02-01; European FET project MULTIPLEX (317532); and by the Comunidad de Aragon (FENOL group). J.G.G is supported by MINECO through the Ramon y Cajal program.
References
- Albert R. & Barabási A.-L. Statistical mechanics of complex networks. Rev. Mod. Phys. 74, 47–97 (2002). [Google Scholar]
- Newman M. E. J. The Structure and Function of Complex Networks. SIAM Rev. 45, 167–256 (2003). [Google Scholar]
- Boccaletti S., Latora V., Moreno Y., Chavez M. & Hwang D. Complex networks: Structure and dynamics. Physics Reports 424, 175–308 (2006). [Google Scholar]
- Watts D. J. & Strogatz S. H. Collective dynamics of small-world networks. Nature 393, 440–442 (1998). [DOI] [PubMed] [Google Scholar]
- Strogatz S. H. Exploring complex networks. Nature 410, 268–276 (2001). [DOI] [PubMed] [Google Scholar]
- Milo R., Shen-Orr S., Itzkovitz S., Kashtan N., Chklovskii D. & Alon U. Network motifs: simple building blocks of complex networks. Science 298, 824–827 (2002). [DOI] [PubMed] [Google Scholar]
- Albert R., Jeong H. & Barabási A.-L. Diameter of the World-Wide Web. Nature 401, 398–399 (1999). [Google Scholar]
- Wasserman S. & Faust K. Social Network analysis. Cambridge University Press Cambridge (1994). [Google Scholar]
- Onnela J.-P., Saramaki J., Hyvonen J., Szabó G., Lazer D., Kaski K., Kertesz J. & Barabási A.-L. Structure and tie strengths in mobile communication networks. Proc. Nat. Acad. Sci. U.S.A. 104, 7332–7336 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tang J., Scellato S., Musolesi M., Mascolo C. & Latora V. Small-world behavior in time-varying graphs. Phys. Rev. E 81, 055101R) (2010). [DOI] [PubMed] [Google Scholar]
- Zhao K., Stehlé J., Bianconi G. & Barrat A. Social network dynamics of face-to-face interactions. Phys. Rev. E 83, 056109 (2011). [DOI] [PubMed] [Google Scholar]
- Isella L., Stehlé J., Barrat A., Cattuto C., Pinton J.-F. & Van den Broeck W. What's in a crowd? Analysis of face-to-face behavioral networks. J. Theor. Biol. 271, 166–180 (2011). [DOI] [PubMed] [Google Scholar]
- Mucha P. J., Richardson T., Macon K., Porter M. A. & Onnela J.-P. Community structure in time-dependent, multiscale, and multiplex networks. Science 328, 876–878 (2010). [DOI] [PubMed] [Google Scholar]
- Szell M., Lambiotte R. & Thurner S. Multi-relational Organization of Large-scale Social Networks in an Online World. Proc. Natl. Acad. Sci. (U.S.A.) 107, 13636–13641 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kurant M. & Thiran P. Layered complex networks. Phys. Rev. Lett. 96, 138701 (2006). [DOI] [PubMed] [Google Scholar]
- Buldyrev S. V., Parshani R., Paul G., Stanley H. E. & Havlin S. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028 (2010). [DOI] [PubMed] [Google Scholar]
- Parshani R., Buldyrev S. & Havlin S. Critical effect of dependency groups on the function of networks. Proc. Natl. Acad. Sci. (U.S.A.) 108, 1007–1010 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J., Buldyrev S. V., Stanley H. E. & Havlin S. Networks formed from interdependent networks. Nature Phys. 8, 40–48 (2012). [DOI] [PubMed] [Google Scholar]
- Lee K.-M., Kim J. Y., Cho W.-K., Goh K.-I. & Kim I.-M. Correlated multiplexity and connectivity of multiplex random networks. New J. Phys. 14, 033027 (2012). [Google Scholar]
- Brummitt C. D., D'Souza R. M. & Leicht E. A. Suppressing casades of load in interdependent networks. Proc. Natl. Acad. Sci. (U.S.A.) 109, E680–E689 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brummitt C. D., Lee K.-M. & Goh K.-I. Multiplexity-facilitated cascades in networks. Phys. Rev. E 85, 045102(R) (2012). [DOI] [PubMed] [Google Scholar]
- Gómez-Gardeñes J., Reinares I., Arenas A. & Floría L. M. Evolution of cooperation in Multiplex Networks. Scientific Rep. 2, 620 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gómez S., Diaz-Guilera A., Gómez-Gardeñes J., Perez-Vicente C., Moreno Y. & Arenas A. Diffusion Dynamics on Multiplex Networks. Phys. Rev. Lett. 110, 028701 (2013). [DOI] [PubMed] [Google Scholar]
- Criado R., Flores J., García del Amo A., Gómez-Gardeñes J. & Romance J. A mathematical model for networks with structures in the mesoscale. Int. J. Comp. Math. 89 (3), 291–309 (2012). [Google Scholar]
- Ronhovde P. & Nussinov Z. Multiresolution community detection for megascale networks by information-based replica correlations. Phys. Rev. E 80, 016109 (2009). [DOI] [PubMed] [Google Scholar]
- Ronhovde P., Chakrabarty S., Hu D., Sahu M., Sahu K. K., Kelton K. F., Mauro N. A. & Nussinov Z. Detecting hidden spatial and spatio-temporal structures in glasses and complex physical systems by multiresolution network clustering. Eur. Phys. J. E 34, 105 (2011). [DOI] [PubMed] [Google Scholar]
- EUROCONTROL, Long-Term Forecast of Annual Number of IFR Flights (2010–2030) (2010). Available at: http://www.eurocontrol.int/articles/forecasts. Accessed on June 2012.
- Colizza V., Flammini A., Serrano M. A. & Vespignani A. Detecting rich-club ordering in complex networks. Nature Physics 2, 110–115 (2006). [Google Scholar]
- Guimera R., Mossa S., Turtschi A. & Amaral L. A. N. The worldwide air transportation network: Anomalous centrality, community structure, and cities' global roles. Proc. Nat. Acad. Sci. (U.S.A.) 102, 7794–7799 (2005). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wuellner D., Roy S. & D'Souza R. M. Resilience and rewiring of the passenger airline networks in the United States. Phys. Rev. E 82, 056101 (2010). [DOI] [PubMed] [Google Scholar]
- Colizza V., Pastor-Satorras R. & Vespignani A. Reaction-diffusion processes and metapopulation models in heterogeneous networks. Nature Phys. 3, 276–282 (2007). [Google Scholar]
- Colizza V. & Vespignani A. Epidemic modeling in metapopulation systems with heterogeneous coupling pattern: Theory and simulations. J. Theor. Biol. 251, 450–467 (2008). [DOI] [PubMed] [Google Scholar]
- Lacasa L., Cea M. & Zanin M. Jamming transition in air transportation networks. Physica A 388, 3948–3954 (2009). [Google Scholar]
- Meloni S., Perra N., Arenas A., Gómez S., Moreno Y. & Vespignani A. Modeling human mobility responses to the large-scale spreading of infectious diseases. Scientific Rep. 1, 62 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Newman M. Networks: An Introduction. Oxford University Press (2010). [Google Scholar]
- Cohen R., Erez K., ben Avraham D. & Havlin S. Resilience of the Internet to Random Breakdowns. Phys. Rev. Lett. 85, 4626 (2000). [DOI] [PubMed] [Google Scholar]
- Cohen R., Erez K., ben Avraham D. & Havlin S. Breakdown of the Internet under Intentional Attack. Phys. Rev. Lett. 86, 3682 (2001). [DOI] [PubMed] [Google Scholar]
- Stauffer D. & Aharony A. Introduction to percolation theory. Taylor & Francis, London, UK (1994). [Google Scholar]
- Zhou S. & Mondragon R. J. The rich-club phenomenon in the Internet topology. IEEE Commun. Lett. 8, 180–182 (2004). [Google Scholar]
- Barthélemy M. Spatial networks. Physics Reports 499, 1–101 (2011). [Google Scholar]
- Bryan D. L. & O'kelly M. E. Hub-and-spoke networks in air transportation: an analytical review. J. Reg. Sci. 39, 275–295 (1999). [Google Scholar]
- SESAR and WP-E. Available at: http://www.complexworld.eu/sesar-and-wp-e/. Accessed on February 2012.
- Blitzstein J. & Diaconis P. A sequential importance sampling algorithm for generating random graphs with prescribed degrees. Internet Math. 6, 489 (2011). [Google Scholar]
- Del Genio C. I., Kim H., Toroczkai Z. & Bassler K. E. Efficient and exact sampling of simple graphs with given arbitrary degree sequence. PloS one 5, e10012 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]