

Abstract
Functional data analysis has received considerable recent attention and a number of successful applications have been reported. In this paper, asymptotically simultaneous confidence bands are obtained for the mean function of the functional regression model, using piecewise constant spline estimation. Simulation experiments corroborate the asymptotic theory. The confidence band procedure is illustrated by analyzing CD4 cell counts of HIV infected patients.
Key words and phrases: B spline, confidence band, functional data, Karhunen-Loève L2 representation, knots, longitudinal data, strong approximation
1. Introduction
Functional data analysis (FDA) has in recent years become a focal area in statistics research, and much has been published in this area. An incomplete list includes Cardot, Ferraty, and Sarda (2003), Cardot and Sarda (2005), Ferraty and Vieu (2006), Hall and Heckman (2002), Hall, Müller, and Wang (2006), Izem and Marron (2007), James, Hastie, and Sugar (2000), James (2002), James and Silverman (2005), James and Sugar (2003), Li and Hsing (2007), Li and Hsing (2009), Morris and Carroll (2006), Müller and Stadtmüller (2005), Müller, Stadtmüller, and Yao (2006), Müller and Yao (2008), Ramsay and Silverman (2005), Wang, Carroll, and Lin (2005), Yao and Lee (2006), Yao, Müller, and Wang (2005a), Yao, Müller, and Wang (2005b), Yao (2007), Zhang and Chen (2007), Zhao, Marron, and Wells (2004), and Zhou, Huang, and Carroll (2008). According to Ferraty and Vieu (2006), a functional data set consists of iid realizations {ξi (x), x ∈ χ}, 1 ≤ i ≤ n, of a smooth stochastic process (random curve) {ξ (x), x ∈ χ} over an entire interval χ. A more data oriented alternative in Ramsay and Silverman (2005) emphasizes smooth functional features inherent in discretely observed longitudinal data, so that the recording of each random curve ξi(x) is over a finite number of points in χ, and contaminated with noise. This second view is taken in this paper.
A typical functional data set therefore has the form {Xij, Yij}, 1 ≤ i ≤ n, 1 ≤ j ≤ Ni, in which Ni observations are taken for the ith subject, with Xij and Yij the jth predictor and response variables, respectively, for the ith subject. Generally, the predictor Xij takes values in a compact interval χ = [a, b]. For the ith subject, its sample path {Xij, Yij} is the noisy realization of a continuous time stochastic process ξi(x) in the sense that
| (1.1) |
with errors εij satisfying E (εij) = 0, , and {ξi(x), x ∈ χ} are iid copies of a process {ξ(x), x ∈ χ} which is L2, i.e., E ∫χ ξ2(x)dx < +∞.
For the standard process {ξ(x), x ∈ χ}, one defines the mean function m(x) = E{ξ(x)} and the covariance function G(x, x′) = cov {ξ(x), ξ(x′)}. Let sequences be the eigenvalues and eigenfunctions of G(x, x′), respectively, in which λ1 ≥ λ2 ≥ ⋯ ≥ 0, form an orthonormal basis of L2 (χ) and , which implies that ∫ G(x, x′) ψk (x′) dx′ = λkψk(x).
The process {ξi(x), x ∈ χ} allows the Karhunen-Loève L2 representation
where the random coefficients ξik are uncorrelated with mean 0 and variances 1, and the functions . In what follows, we assume that λk = 0, for k > κ, where κ is a positive integer, thus and the data generating process is now written as
| (1.2) |
The sequences and the random coefficients ξik exist mathematically, but are unknown and unobservable.
Two distinct types of functional data have been studied. Li and Hsing (2007), and Li and Hsing (2009) concern dense functional data, which in the context of model (1.1) means min1≤i≤n Ni → ∞ as n → ∞. On the other hand, Yao, Müller, and Wang (2005a), Yao, Müller, and Wang (2005b), and Yao (2007) studied sparse longitudinal data for which Ni’s are i.i.d. copies of an integer-valued positive random variable. Pointwise asymptotic distributions were obtained in Yao (2007) for local polynomial estimators of m(x) based on sparse functional data, but without uniform confidence bands. Nonparametric simultaneous confidence bands are a powerful tool of global inference for functions, see Claeskens and Van Keilegom (2003), Fan and Zhang (2000), Hall and Titterington (1988), Härdle (1989), Härdle and Marron (1991), Huang, Wang, Yang, and Kravchenko (2008), Ma and Yang (2010), Song and Yang (2009), Wang and Yang (2009), Wu and Zhao (2007), Zhao and Wu (2008), and Zhou, Shen, and Wolfe (1998) for its theory and applications. The fact that a simultaneous confidence band has not been established for functional data analysis is certainly not due to lack of interesting applications, but to the greater technical difficulty in formulating such bands for functional data and establishing their theoretical properties. Specifically, the strong approximation results used to establish the asymptotic confidence level in nearly all published works on confidence bands, commonly known as “Hungarian embedding”, are unavailable for sparse functional data.
In this paper, we present simultaneous confidence bands for m(x) in sparse functional data via a piecewise-constant spline smoothing approach. While there exist a number of smoothing methods for estimating m(x) and G(x, x′) such as kernels (Yao, Müller and, Wang (2005a); Yao, Müller, and Wang (2005b); Yao (2007)), penalized splines (Cardot, Ferraty, and Sarda (2003); Cardot and Sarda (2005); Yao and Lee (2006)), wavelets Morris and Carroll (2006), and parametric splines James (2002), we choose B splines (Zhou, Huang, and Carroll (2008)) for simple implementation, fast computation and explicit expression, see Huang and Yang (2004), Wang and Yang (2007), and Xue and Yang (2006) for discussion of the relative merits of various smoothing methods.
We organize our paper as follows. In Section 2 we state our main results on confidence bands constructed from piecewise constant splines. In Section 3 we provide further insights into the error structure of spline estimators. Section 4 describes the actual steps to implement the confidence bands. Section 5 reports findings of a simulation study. An empirical example in Section 6 illustrates how to use the proposed confidence band for inference. Proofs of technical lemmas are in the Appendix.
2. Main results
For convenience, we denote the supremum norm of a function r on [a, b] by ∥r∥∞ = supx∈[a,b] |r(x)|, and the modulus of continuity of a continuous function r on [a, b] by ω (r, δ) = maxx,x′∈[a,b],|x−x′|≤δ |r(x) − r(x′)|. Denote by ∥g∥2 the theoretical L2 norm of a function g on [a, b], , where f(x) is the density function of X, and the empirical L2 norm as , where we denote the total sample size by . Without loss of generality, we take the range of X, χ = [a, b], to be [0, 1]. For any β ∈ (0, 1], we denote the collection of order β Hõlder continuous function on [0, 1] by
in which ∥ϕ∥0,β is the C0,β-seminorm of ϕ. Let C [0, 1] be the collection of continuous function on [0, 1]. Clearly, C0,β [0, 1] ⊂ C [0, 1] and, if ϕ ∈ C0,β [0, 1], then ω (ϕ, δ) ≤ ∥ϕ∥0,β δβ.
To introduce the spline functions, divide the finite interval [0, 1] into (Ns+1) equal subintervals χJ = [tJ, tJ+1), J = 0, …., Ns − 1, χNs = [tNs, 1]. A sequence of equally-spaced points , called interior knots, are given as
in which hs is the distance between neighboring knots. We denote by G(−1) = G(−1) [0, 1] the space of functions that are constant on each χJ. For any x ∈ [0, 1], define its location index as J(x) = Jn(x) = min {[x/hs], Ns} so that tJn(x) ≤ x < tJn(x)+1, ∀x ∈ [0, 1]. We propose to estimate the mean function m(x) by
| (2.1) |
The technical assumptions we need are as follows
-
(A1)
The regression function m(x) ∈ C0,1 [0, 1].
-
(A2)
The functions f(x), σ(x), and ϕk(x) ∈ C0,β [0, 1] for some β ∈ (2/3, 1] with f(x) ∈ [cf, Cf], σ(x) ∈ [cσ, Cσ], x ∈ [0, 1], for constants 0 < cf ≤ Cf < ∞, 0 < cσ ≤ Cσ < ∞.
-
(A3)
The set of random variables is a subset of consisting of independent variables Ni, the numbers of observations made for the i-th subject, i = 1, 2, …, with Ni ~ N, where N > 0 is a positive integer-valued random variable with , r = 2, 3, … for some constant cN > 0. The set of random variables is a subset of in which are iid. The number κ of nonzero eigenvalues is finite and the random coefficients ξik, k = 1, …, κ, i = 1, …, ∞ are iid N (0, 1). The variables are independent.
-
(A4)
As n → ∞, the number of interior knots Ns = o (nϑ) for some ϑ ∈ (1/3, 2β − 1) while . The subinterval length .
-
(A5)
There exists r > 2/ {β − (1 + ϑ) /2} such that E |ε11|r < ∞.
Assumptions (A1), (A2), (A4) and (A5) are similar to (A1)–(A4) in Wang and Yang (2009), with (A1) weaker than its counterpart. Assumption (A3) is the same as (A1.1), (A1.2), and (A5) in Yao, Müller, and Wang (2005b), without requiring joint normality of the measurement errors εij.
We now introduce the B-spline basis of G(−1), the space of piecewise constant splines, as , which are simply indicator functions of intervals χJ, bJ(x) = IχJ (x), J = 0, 1, …, Ns. Define
| (2.2) |
| (2.3) |
In addition, define ,
| (2.4) |
for any α ∈ (0, 1). We now state our main results.
Theorem 1
Under Assumptions (A1)-(A5), for any α ∈ (0, 1),
where σn(x) and QNs+1 (α) are given in (2.3) and (2.4), respectively, while Z1−α/2 is the 100 (1 − α/2)th percentile of the standard normal distribution.
The definition of σn(x) in (2.3) does not allow for practical use. The next proposition provides two data-driven alternatives
Proposition 1
Under Assumptions (A2), (A3), and (A5), as n → ∞,
in which for x ∈ [0, 1], σn,IID (x) ≡ σY (x) {f(x)hsnE(N1)}−1/2 and
Using σn,IID(x) instead of σn(x) means to treat the (Xij, Yij) as iid data rather than as sparse longitudinal data, while using σn,LONG(x) means to correctly account for the longitudinal correlation structure. The difference of the two approaches, although asymptotically negligible uniformly for x ∈ [0, 1] according to Proposition 1, is significant in finite samples, as shown in the simulation results of Section 5. For similar phenomenon with kernel smoothing, see Wang, Carroll, and Lin (2005).
Corollary 1
Under Assumptions (A1)-(A5), for any α ∈ (0, 1), as n → ∞, an asymptotic 100 (1 − α) % simultaneous confidence band for m(x), x ∈ [0, 1] is
while an asymptotic 100 (1 − α) % pointwise confidence interval for m(x), x ∈ [0, 1], is m̂(x) ± σn(x)Z1−α/2.
3. Decomposition
In this section, we decompose the estimation error m̂(x) − m(x) by the representation of Yij as the sum of m (Xij), , and σ (Xij) εij.
We introduce the rescaled B-spline basis for G(−1), which is , J = 0, …, Ns. Therefore,
| (3.1) |
It is easily verified that , J = 0, 1, …, Ns, 〈BJ, BJ′〉 ≡ 0, J ≠ J′.
The definition of m̂(x) in (2.1) means that
| (3.2) |
with coefficients as solutions of the least squares problem
Simple linear algebra shows that , where the coefficients {λ̂0, …, λ̂Ns}T are solutions of the least squares problem
| (3.3) |
Projecting the relationship in model (1.2) onto the linear subspace of spanned by {BJ (Xij)}1≤j≤Ni,1≤i≤n,0≤J≤Ns, we obtain the following crucial decomposition in the space G(−1) of spline functions:
| (3.4) |
| (3.5) |
The vectors {λ̃0, …, λ̃Ns}T, {ã0, …, ãNs}T, and {τ̃k,0, …, τ̃k,Ns}T are solutions to (3.3) with Yij replaced by m(Xij), σ (Xij) εij, and ξikϕk (Xij), respectively. We cite next an important result concerning the function m̃(x). The first part is from de Boor (2001), p. 149, and the second is from Theorem 5.1 of Huang (2003).
Theorem 2
There is an absolute constant Cg > 0 such that for every ϕ ∈ C [0, 1], there exists a function g ∈ G(−1) [0, 1] that satisfies ∥g − ϕ∥∞ ≤ Cgω (ϕ, hs). In particular, if ϕ ∈ C0,β [0, 1] for some β ∈ (0, 1], then . Under Assumptions (A1) and (A4), with probability approaching 1, the function m̃(x) defined in (3.5) satisfies ∥m̃(x) − m(x)∥∞ = O (hs).
The next proposition concerns the function ẽ(x) given in (3.4).
Proposition 2
Under Assumptions (A2)-(A5), for any τ ∈ R, and σn(x), aNs+1, and bNs+1 as given in (2.3) and (2.4),
4. Implementation
In this section, we describe procedures to implement the confidence bands and intervals given in Corollary 1. Given any data set from model (1.2), the spline estimator m̂(x) is obtained by (3.2), and the number of interior knots in (3.2) is taken to be , in which [a] denotes the integer part of a and c is a positive constant. When constructing the confidence bands, one needs to evaluate the function by estimating the unknown functions f(x), , and G (x, x), and then plugging in these estimators: the same approach is taken in Wang and Yang (2009).
The number of interior knots for pilot estimation of f(x), , and G (x, x) is taken to be , and . The histogram pilot estimator of the density function f(x) is
Defining the vector , the estimation of is , where the coefficients are solutions of the least squares problem:
The pilot estimator of covariance function G (x, x′) is
where Cijj′ = {Yij − m̂ (Xij)} {Yij′ − m̂ (Xij′)}, 1 ≤ j, j′ ≤ Ni, 1 ≤ i ≤ n. The function σn(x) is estimated by either σ̂n,IID(x) ≡ σ̂Y(x) {f̂(x)hsNT}−1/2 or
We now state a result. That is easily proved by standard theory of kernel and spline smoothing, as in Wang and Yang (2009).
Proposition 3
Under Assumptions (A1)-(A5), as n → ∞
Proposition 1, about how σn,IID(x) and σn,LONG(x) uniformly approximate σn(x), and Proposition 3 together imply that both σ̂n,IID(x) and σ̂n,LONG(x) approximate σn(x) uniformly at a rate faster than (n−1/2+1/3 (logn)1/2−1/3), according to Assumption (A5). Therefore as n → ∞, the confidence bands
| (4.1) |
| (4.2) |
with QNs+1 (α) given in (2.4), and the pointwise intervals m̂(x) ± σ̂n,IID(x)Z1−α/2, m̂(x) ± σ̂n,LONG(x)Z1−α/2 have asymptotic confidence level 1 − α.
5. Simulation
To illustrate the finite-sample performance of the spline approach, we generated data from the model
with X ~ Uniform[0, 1], ξk ~ Normal(0, 1), k = 1, 2, ε ~ Normal(0, 1), Ni having a discrete uniform distribution from 25, … , 35, for 1 ≤ i ≤ n, and , thus λ1 = 2/5, λ2 = 1/10. The noise levels were σ = 0.5, 1.0, the number of subjects n was taken to be 20, 50, 100, 200, the confidence levels were 1 − α = 0.95, 0.99, and the constant c in the definition of Ns in Section 4 was taken to be 1, 2, 3. We found that the confidence band (4.1) did not have good coverage rates for moderate sample sizes, and hence in Table 1 we report the coverage as the percentage out of the total 200 replications for which the true curve was covered by (4.2) at the 101 points {k/100, k = 0, …, 100}.
Table 1.
Uniform coverage rates from 200 replications using the confidence band (4.2). For each sample size n, the first row is the coverage of a nominal 95% confidence band, while the second row is for a 99% confidence band.
| σ | n | 1 − α | c = 1 | c = 2 | c = 3 |
|---|---|---|---|---|---|
| 0.5 | 20 | 0.950 | 0.920 | 0.930 | 0.800 |
| 0.990 | 0.990 | 0.990 | 0.900 | ||
| 50 | 0.950 | 0.960 | 0.965 | 0.910 | |
| 0.990 | 0.995 | 0.995 | 0.965 | ||
| 100 | 0.950 | 0.955 | 0.955 | 0.955 | |
| 0.990 | 1.000 | 1.000 | 0.985 | ||
| 200 | 0.950 | 0.950 | 0.965 | 0.975 | |
| 0.990 | 0.985 | 0.985 | 0.990 | ||
| 1.0 | 20 | 0.950 | 0.935 | 0.930 | 0.735 |
| 0.990 | 0.990 | 0.990 | 0.870 | ||
| 50 | 0.950 | 0.975 | 0.960 | 0.895 | |
| 0.990 | 0.995 | 0.995 | 0.980 | ||
| 100 | 0.950 | 0.950 | 0.940 | 0.935 | |
| 0.990 | 0.995 | 0.990 | 0.990 | ||
| 200 | 0.950 | 0.940 | 0.965 | 0.960 | |
| 0.990 | 0.985 | 0.995 | 0.995 | ||
At all noise levels, the coverage percentages for the confidence band (4.2) are very close to the nominal confidence levels 0.95 and 0.99 for c = 1, 2, but decline for c = 3 when n = 20, 50. The coverage percentages thus depend on the choice of Ns, and the dependency becomes stronger when sample sizes decrease. For large sample sizes n = 100, 200, the effect of the choice of Ns on the coverage percentages is insignificant. Because Ns varies with Ni, for 1 ≤ i ≤ n, the data-driven selection of some “optimal” Ns remains an open problem.
We next examine two alternative methods to compute the confidence band, based on the observation that the estimated mean function m̂(x) and the confidence intervals are step functions that remain the same on each subinterval χJ, 0 ≤ J ≤ Ns. Follwing an associate editor’s suggestion, locally weighted smoothing was applied to the upper and lower confidence limits to generate a smoothed confidence band. Following a referee’s suggestion to treat the number (Ns + 1) of subintervals as fixed instead of growing to infinity, a naive parametric confidence band was computed as
| (5.1) |
in which Q1−α.Ns+1 = Z{1+(1−α)1/(Ns+1)}/2 is the (1 − α) quantile of the maximal absolute values of (Ns + 1) iid N (0, 1) random variables. We compare the performance of the confidence band in (4.2), the smoothed band and naive parametric band in (5.1). Given n = 20 with Ns = 8, 12, and n = 50 Ns = 44 (by taking c = 1 in the definition of Ns in Section 4), σ = 0.5, 1.0, and 1 − α = 0.99, Table 2 reports the coverage percentages P̂, P̂naive, P̂smooth and the average maximal widths W, Wnaive, Wsmooth of Ns + 1 intervals out of 200 replications calculated from confidence bands (4.2), (5.1), and the smoothed confidence bands, respectively.
Table 2.
Uniform coverage rates and average maximal widths of confidence intervals from 200 replications using the confidence bands (4.2), (5.1), and the smoothed bands respectively, for 1 − α = 0.99.
| n | σ | Ns | P̂ | P̂naive | P̂smooth | W | Wnaive | Wsmooth |
|---|---|---|---|---|---|---|---|---|
| 20 | 0.5 | 8 | 0.820 | 0.505 | 0.910 | 1.490 | 1.210 | 1.480 |
| 12 | 0.930 | 0.765 | 0.955 | 1.644 | 1.363 | 1.628 | ||
| 1.0 | 8 | 0.910 | 0.655 | 0.970 | 1.725 | 1.401 | 1.721 | |
| 12 | 0.960 | 0.820 | 0.985 | 1.937 | 1.606 | 1.928 | ||
| 50 | 0.5 | 44 | 0.990 | 0.960 | 0.990 | 1.651 | 1.522 | 1.609 |
| 1.0 | 44 | 0.990 | 0.975 | 1.000 | 2.054 | 1.893 | 2.016 | |
In all experiments, one has P̂smooth > P̂ > P̂naive and W > Wsmooth > Wnaive. The coverage percentages for both the confidence bands in (4.2) and the smoothed bands are much closer to the nominal level than those of the naive bands in (5.1), while the smoothed bands perform slightly better than the constant spline bands in (4.2), with coverage percentages closer to the nominal and smaller widths. Based on these observations, the naive band is not recommended due to poor coverage. As for the smoothed band, although it has slightly better coverage than the constant spline band, its asymptotic property has yet to be established, and the second step smoothing adds to its conceptual complexity and computational burden. Therefore with everything considered, the constant spline band is recommended for its satisfactory theoretical property, fast computing, and conceptual simplicity.
For visualization of the actual function estimates, at σ = 0.5 with n = 20, 50, Figure 1 depicts the simulated data points and the true curve, and Figure 2 shows the true curve, the estimated curve, the uniform confidence band, and the pointwise confidence intervals.
Figure 1.
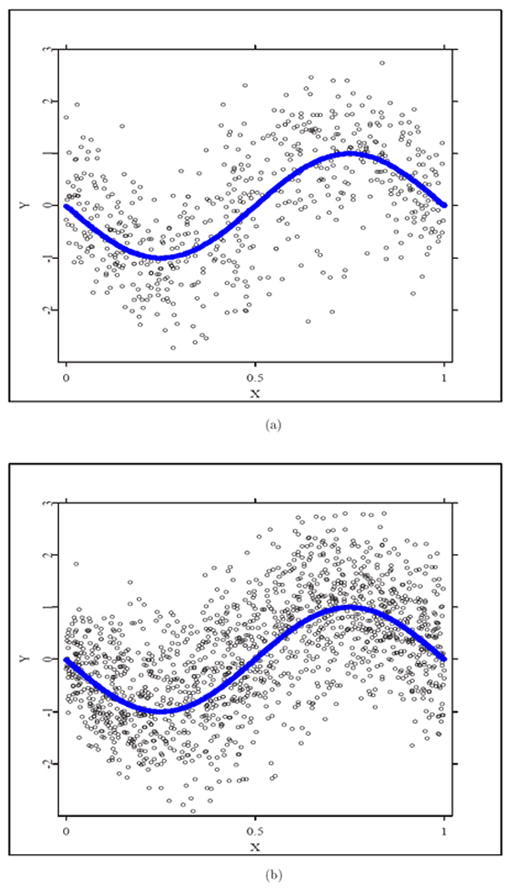
Plots of simulated data scatter points at σ = 0.5: (a) n = 20, (b) n = 50, and the true curve.
Figure 2.
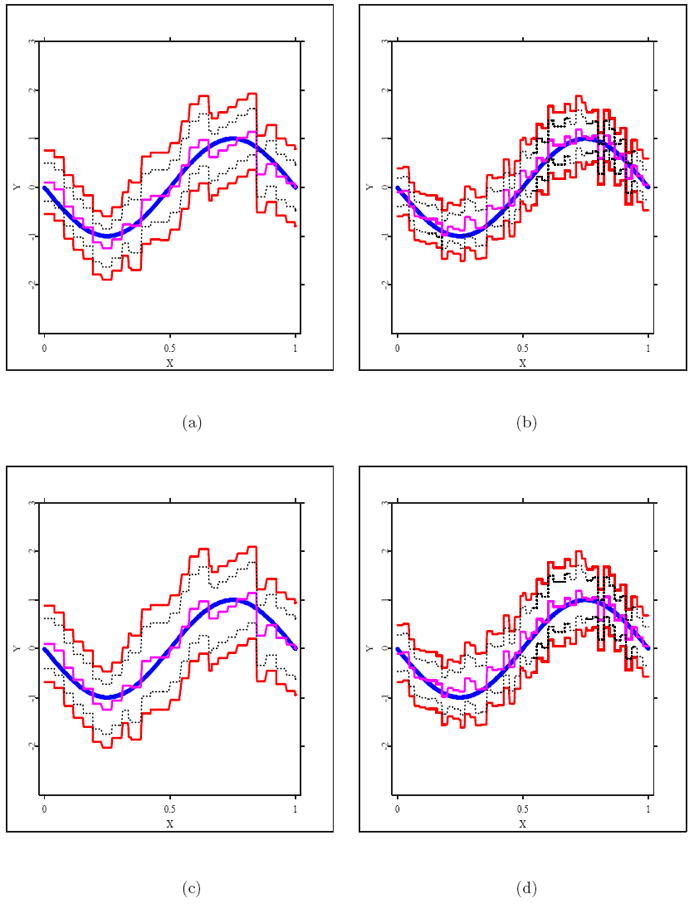
Plots of confidence bands (4.2) (upper and lower solid lines), pointwise confidence intervals (upper and lower dashed lines), the spline estimator (middle thin line), and the true function (middle thick line): (a) 1 − α = 0.95, n = 20, (b) 1 − α = 0.95, n = 50, (c) 1 − α = 0.99, n = 20,(d) 1 − α = 0.99, n = 50.
6. Empirical example
In this section, we apply the confidence band procedure of Section 4 to the data collected from a study by the AIDS Clinical Trials Group, ACTG 315 (Zhou, Huang, and Carroll (2008)). In this study, 46 HIV 1 infected patients were treated with potent antiviral therapy consisting of ritonavir, 3TC and AZT. After initiation of the treatment on day 0, patients were followed for up to 10 visits. Scheduled visit times common for all patients were 7, 14, 21, 28, 35, 42, 56, 70, 84, and 168 days. Since the patients did not follow exactly the scheduled times and/or missed some visits, the actual visit times Tij were irregularly spaced and varied from day 0 to day 196. The CD4+ cell counts during HIV/AIDS treatments are taken as the response variable Y from day 0 to day 196. Figure 3 shows that the data points (dots) are extremely sparse between day 100 and 150, thus we first transform the data by . A histogram (not shown) indicates that the Xij-values are distributed fairly uniformly. The number of interior knots in (3.2) is taken to be Ns = 6, so that the range for visit time T, which is [0, 196], is divided into seven unequal subintervals, and in each subinterval, the mean CD4+ cell counts and the confidence bands remain the same. Table 3 gives the mean CD4+ cell counts and the confidence limits on each subinterval at simultaneous confidence level 0.95. For instance, from day 4 to 14, the mean CD4+ cell counts is 241.62 with lower and upper limits 171.81 and 311.43 respectively.
Figure 3.
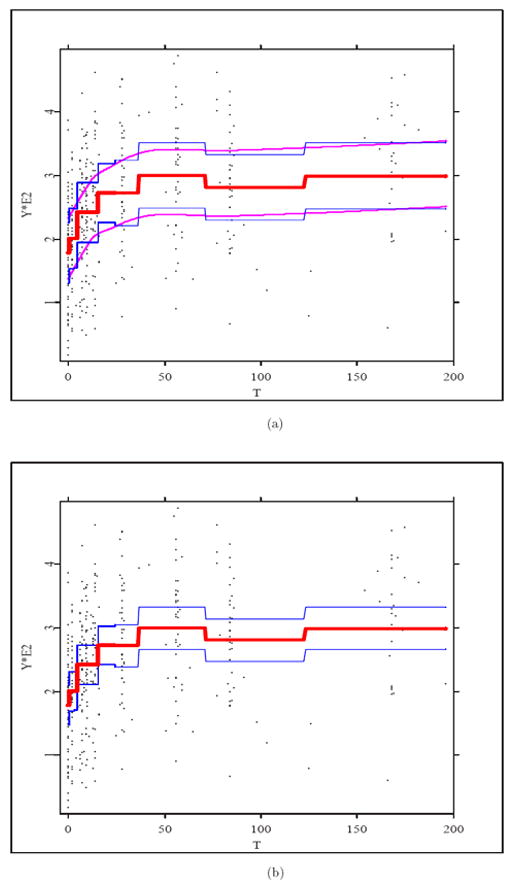
Plots of the piecewise-constant spline estimator (thick line), the data (dots), and (a) confidence band (4.2) (upper and lower solid lines), the smoothed band (upper and lower thin lines), (b) pointwise confidence intervals (upper and lower thin lines) at confidence level 0.95.
Table 3.
The mean CD4+ cell counts and the confidence limits on each subinterval at simultaneous confidence level 0.95.
| Days | Mean CD4+ cell counts | Confidence limits |
|---|---|---|
| [0, 1) | 178.23 | [106.73, 249.72] |
| [1, 4) | 20.32 | [130.51, 270.13] |
| [4, 15) | 24.62 | [171.81, 311.43] |
| [15, 36) | 27.87 | [194.70, 349.04] |
| [36, 71) | 299.51 | [222.34, 376.68] |
| [71, 123) | 280.78 | [203.50, 358.06] |
| [123, 196] | 299.27 | [221.99, 376.55] |
Figure 3 depicts (a) the 95% simultaneous (smoothed) confidence band according to (4.2) in (median) thin lines, and (b) the pointwise 95% confidence intervals in thin lines. The center thick line is the piecewise-constant spline fit m̂(x). It can be seen that the pointwise confidence intervals are of course narrower than the uniform confidence band by the same ratio. Figure 3 is essentially a graphical representation of Table 3; both confirm that the mean CD4+ cell counts generally increases over time as Zhou, Huang, and Carroll (2008) pointed out. The advantage of the current method is that such inference on the overall trend is made with predetermined type I error probability, in this case 0.05.
7. Discussion
In this paper, we have constructed a simultaneous confidence band for the mean function m(x) for sparse longitudinal data via piecewise-constant spline fitting. Our approach extends the asymptotic results in Wang and Yang (2009) for i.i.d. random designs to a much more complicated data structure by allowing dependence of measurements within each subject. The proposed estimator has good asymptotic behavior, and the confidence band had coverage very close to the nominal in our simulation study. An empirical study for the mean CD4+ cell counts illustrates the practical use of the confidence band.
Clearly the simultaneous confidence band in (4.2) can be improved in terms of both theoretical and numerical performance if higher order spline or local linear estimators are used. Constant piecewise spline estimators are less appealing and have sub-optimal convergence rates in the sense of Hall, Müller, and Wang (2006), which uses local linear approaches. Establishing the asymptotic confidence level for such extensions, however, requires highly sophisticated extreme value theory, for sequences of non-stationary Gaussian processes over intervals growing to infinity. That is much more difficult than the proofs of this paper. We consider the confidence band in (4.2) significant because it is the first of its kind for the longitudinal case with complete theoretical justification, and with satisfactory numerical performance for commonly encountered data sizes.
Our methodology can be applied to construct simultaneous confidence bands for other functional objects, such as the covariance function G(x, x′) and its eigenfunctions, see Yao (2007). It can also be adapted to the estimation of regression functions in the functional linear model, as in Li and Hsing (2007). We expect further research along these lines to yield deep theoretical results with interesting applications.
Acknowledgments
The authors thank Shuzhuan Zheng and the seminar participants at the University of Michigan, Georgia Institute of Technology, Georgia State University, University of Toledo, University of Georgia, Soochow University, University of Science and Technology of China, and Peking University for their comments on the paper. Ma and Yang’s research was supported in part by NSF Awards DMS 0706518, DMS 1007594, an MSU Summer Support Fellowship and a grant from Risk Management Institute, National University of Singapore. Carroll’s research was supported by a grant from the National Cancer Institute (CA57030) and by Award Number KUS-CI-016-04, made by King Abdullah University of Science and Technology (KAUST). The detailed and insightful comments from an associate editor and two referees are gratefully acknowledged.
Appendix
Throughout this section, an ~ bn means , where c is some nonzero constant, and for functions an(x), bn(x), an(x) = u {bn(x)} means an(x)/bn(x) → 0 as n → ∞ uniformly for x ∈ [0, 1].
A.1. Preliminaries
We first state some results on strong approximation, extreme value theory and the classic Bernstein inequality. These are used in the proofs of Lemma A.7, Theorem 1, and Lemma A.6.
Lemma A.1
(Theorem 2.6.7 of Csőrgő and Révész (1981)) Suppose that ξi, 1 ≤ i ≤ n are iid with E(ξ1) = 0, , and H(x) > 0 (x ≥ 0) is an increasing continuous function such that x−2−γ H(x) is increasing for some γ > 0 and x−1 logH (x) is decreasing with EH (|ξ1|) < ∞. Then there exists a Wiener process {W (t), 0 ≤ t < ∞} that is a Borel function of ξi, 1 ≤ i ≤ n, and constants C1, C2, a > 0 which depend only on the distribution of ξ1, such that for any satisfying H−1 (n) < xn < C1 (nlogn)1/2 and ,
Lemma A.2
Let , 1 ≤ i ≤ n, be jointly normal with . Let be such that for γ > 0, Cr > 0, , i ≠ j. Then for τ ∈ R, as n → ∞, P{Mn,ξ ≤ τ/an + bn} → exp (−2e−τ), in which and an, bn are as in (2.4) with Ns + 1 replaced by n.
Proof
Let be i.i.d. standard normal r.v.’s, be vectors of real numbers, and ω = min (|u1|,…, |un| , |υ1|,…, |υn|). By the Normal Comparison Lemma (Leadbetter, Lindgren and Rootzén (1983), Lemma 11.1.2),
If u1 = ⋯ = un = υ1 = ⋯ = υn = τ/an + bn = τn, it is clear that , as n → ∞. Then , for any ε > 0 and large n. Since as n → ∞, i ≠ j, for i ≠ j, ∃Cr2 > 0 such that and for any ∊ > 0 and large n. Let Mn,η = max {|η1|,…, |ηn|}. By Leadbetter, Lindgren and Rootzén (1983), Theorem 1.5.3, P {Mn,η ≤ τn} → exp (−2e−τ) as n → ∞, while the above results entail
as n → ∞. Hence P {Mn,ξ ≤ τn} → exp (−2e−τ), as n → ∞.
Lemma A.3
(Theorem 1.2 of Bosq (1998)) Suppose that are iid with E(ξ1) = 0, , and there exists c > 0 such that for r = 3, 4, …, . Then for each n > 1, t > 0, , in which .
Lemma A.4
Under Assumption (A2), as n → ∞ for cJ,n defined in (2.2), cJ,n = f (tJ) hs (1 + rJ,n), 〈bJ, bJ′〉 ≡ 0, J ≠ J′, where max0≤J≤Ns |rJ,n| ≤ Cω (f,hs). There exist constants CB > cB > 0 such that for r = 1, 2, … and 1 ≤ J ≤ Ns + 1, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n.
Proof
By the definition of cJ,n in (2.2),
Hence for all J = 0, …, Ns, |cJ,n − f (tJ) hs| ≤ ∫[tJ, tJ+1]| f(x) − f (tJ)| dx ≤ ω (f, hs) hs, or |rJ,n| = |cJ,n − f (tJ) hs| {f (tJ) hs}−1 ≤ Cω (f, hs), J = 0, …, Ns. By (3.1), .
Proof of Proposition 1
By Lemma A.4 and Assumption (A2) on the continuity of functions , σ2(x) and f(x) on [0, 1], for any x ∈ [0, 1]
Hence,
A.2. Proof of Theorem 1
Note that , so the terms ξ̃k(x) and ε̃(x) defined in (3.5) are
Let
| (8.1) |
where
| (8.2) |
Lemma A.5
Under Assumption (A3), for ẽ(x) given in (3.4) and ξ̂k(x), ε̂(x) given in (8.1), we have
where . There exists CA > 0, such that for large n, . as n → ∞.
See the supplement of Wang and Yang (2009) for a detailed proof.
Lemma A.6
Under Assumptions (A2) and (A3), for R1k,ξ,J, R11, ε,J in (8.2),
there exist 0 < cR < CR < ∞, such that for 0 ≤ J ≤ Ns, as n → ∞.
Proof
By independence of X1j, 1 ≤ j ≤ N1 and N1 and (3.1),
It is easily shown that ∃ 0 < cR < CR < ∞ such that . Let for r ≥ 1 and large n,
by Lemma A.4. So {E(ζ1,J)}r ~ 1, E (ζi,J)r ≫ {E(ζ1,J)}r for r ≥ 2, and such that , for . We obtain with , which implies that satisfies Cramér’s condition. Applying Lemma A.3 to , for r > 2 and any large enough δ > 0, is bounded by
Hence . Thus, as n → ∞ by Borel-Cantelli Lemma. The properties of Rij,ε,J are obtained similarly.
Order all Xij, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n from large to small as X(t), X(1) ≥ … ≥ X(NT), and denote the εij corresponding to X(t) as ε(t). By (8.1),
where and S0 = 0.
Lemma A.7
Under Assumptions (A2)-(A5), there is a Wiener process {W (t), 0 ≤ t < ∞} independent of {Ni, Xij, 1 ≤ j ≤ Ni, ξik, 1 ≤ k ≤ κ, 1 ≤ i ≤ n}, such that as n → ∞, for some t < − (1 − ϑ) /2 < 0, where ε̂(0) (x) is
| (8.3) |
Proof
Define MNT = max1≤q≤NT |Sq − W (q)|, in which {W (t), 0 ≤ t ≤ ∞} is the Wiener process as in Lemma A.1 that as a Borel function of the set of variables {ε(t) 1 ≤ t ≤ NT} is independent of {Ni, Xij, 1 ≤ j ≤ Ni, ξik, 1 ≤ k ≤ κ, 1 ≤ i ≤ n} since {ε(t) 1 ≤ t ≤ NT} is. Further,
which, by the Hölder continuity of σ in Assumption (A2), is bounded by
where , 0 ≤ J ≤ Ns + 1, has a binomial distribution with parameters (NT, pJ,n), where pJ,n = ∫χJ f (x) dx. Simple application of Lemma A.3 entails . Meanwhile, by letting H(x) = xr, xn = nt′, t′ ∈ (2/r, β − (1 + ϑ) /2), the existence of which is due to the Assumption (A4) that r > 2/ {β − (1 + ϑ) /2}. It is clear that satisfies the conditions in Lemma A.1. Since for some γ1 > 1, one can use the probability inequality in Lemma A.1 and the Borel-Cantelli Lemma to obtain MNT = Oa.s. (xn) = Oa.s. (nt′). Hence Lemma A.4 and the above imply
since t′ < β − (1 + ϑ) /2 by definition, implying t′ − 1 ≤ t′ − β < − (1 + ϑ) /2. The Lemma follows by setting t = t′ − β + ϑ.
Now
| (8.4) |
where Z(t) = W (t) − W (t − 1), 1 ≤ t ≤ NT, are i.i.d N (0, 1), ξik, Zij, Xij, Ni are independent, for 1 ≤ k ≤ κ, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n, and ξ̂k(x), ε̂(0)(x) are conditional independent of Xij, Ni, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n. If the conditional variances of ξ̂k(x), ε̂(0)(x) on (Xij, Ni)1≤j≤Ni,1≤i≤n are , we have
| (8.5) |
where Rik,ξ,J(x), Rij,ε,J(x), and cJ(x),n are given in (8.2) and (2.2).
Lemma A.8
Under Assumptions (A2) and (A3), let
| (8.6) |
with σξk,n(x), σε,n(x), ξ̂k(x), ε̂(0)(x), and cJ(x),n given in (8.5), (8.1), (8.3), and (2.2). Then η(x) is a Gaussian process consisting of (Ns + 1) standard normal variables such that η(x) = ηJ(x) for x ∈ [0, 1], and there exists a constant C > 0 such that for large n, sup0≤J≠J′≤Ns |EηJηJ′| ≤ Chs.
Proof
It is apparent that ℒ {ηJ |(Xij, Ni), 1 ≤ j ≤ Ni, 1 ≤ i ≤ n} = N (0, 1) for 0 ≤ J ≤ Ns, so ℒ {ηJ} = N (0, 1), for 0 ≤ J ≤ Ns. For J ≠ J′, by (8.2) and (3.1), Rij,ε,J Rij,ε,J′ = BJ (Xij) BJ′ (Xij) σ2 (Xij) = 0, along with (8.4), (8.3), the conditional independence of ξ̂k(x), ε̂(0)(x) on Xij, Ni, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n, and independence of ξik, Zij, Xij, Ni, 1 ≤ k ≤ κ, 1 ≤ j ≤ Ni, 1 ≤ i ≤ n, E (ηJηJ′) is
in which .Note that according to definitions of Rik,ξ,J, Rij,ε,J, and Lemma A.5,
, for 0 ≤ J ≤ Ns,
by Lemma A.5. Thus for large n, with probability ≥ 1 − 2n−3, the numerator of Cn,J,J′ is uniformly greater than . Applying Bernstein’s inequality to , there exists C0 > 0 such that, for large n,
Putting the above together, for large n, ,
Note that as a continuous random variable, sup0≤J≠J′≤Ns|Cn,J,J′| ∈ [0, 1], thus
For large n, C1hs < 1 and then E (sup0≤J≠J′≤Ns |Cn,J,J′|) is
for some C > 0 and large enough n. The lemma now follows from
By Lemma A.8, the (Ns + 1) standard normal variables η0, …, ηNs satisfy the conditions of Lemma A.2 Hence for any τ ∈ R,
| (8.7) |
For x ∈ [0, 1], Rik,ξ,J, Rij,ε,J given in (8.2), define the ratio of population and sample quantities as rn(x) = {nE (N1) / NT}1/2 {R̄n(x) / R̄(x)}1/2, with
Lemma A.9
Under Assumptions (A2), (A3), for η(x), σn(x) in (8.6), (2.3),
| (8.8) |
as n → ∞, .
Proof
Equation (8.8) follows from the definitions of η(x) and σn(x). By Lemma A.6, ,
and there exist constants 0 < cR̄ < CR̄ < ∞ such that for all x ∈ [0,1], cR̄ < R̄(x) < CR̄. Thus, supx∈[0,1] |R̄n(x) − R̄(x)| is bounded by
Thus . Then supx∈[0,1] {aNs+1 |rn(x) − 1|} is bounded by
Proof of Proposition 2
The proof follows from Lemmas A.5, A.7, A.9, (8.7), and Slutsky’s Theorem.
Proof of Theorem 1
By Theorem 2, ∥m̃(x) − m(x)∥∞ = Op (hs), so
Meanwhile, (3.4) and Proposition 2 entail that, for any τ ∈ R,
Thus Slutsky’s Theorem implies that
Let , definitions of aNs+1, bNs+1, and QNs+1 (α) in (2.4) entail
by (3.4). That σn(x)−1 {m̂(x) − m(x)} →d N (0, 1) for any x ∈ [0, 1] follows by directly using η(x) ~ N (0, 1), without reference to supx∈[0,1] |η(x)|.
Contributor Information
Shujie Ma, Email: mashujie@stt.msu.edu.
Lijian Yang, Email: yanglijian@suda.edu.cn.
Raymond J. Carroll, Email: carroll@stat.tamu.edu.
References
- Bosq D. Nonparametric Statistics for Stochastic Processes. Springer-Verlag; New York: 1998. [Google Scholar]
- Cardot H, Ferraty F, Sarda P. Spline estimators for the functional linear model. Statistica Sinica. 2003;13:571–591. [Google Scholar]
- Cardot H, Sarda P. Estimation in generalized linear models for functional data via penalized likelihood. Journal of Multivariate Analysis. 2005;92:24–41. [Google Scholar]
- Claeskens G, Van Keilegom I. Bootstrap confidence bands for regression curves and their derivatives. Annals of Statistics. 2003;31:1852–1884. [Google Scholar]
- Csőrgő M, Révész P. Strong Approximations in Probability and Statistics. Academic Press; New York-London: 1981. [Google Scholar]
- de Boor C. A Practical Guide to Splines. Springer-Verlag; New York: 2001. [Google Scholar]
- Fan J, Zhang WY. Simultaneous confidence bands and hypothesis testing in varying-coefficient models. Scandinavian Journal of Statistics. 2000;27:715–731. [Google Scholar]
- Ferraty F, Vieu P. Nonparametric Functional Data Analysis: Theory and Practice. Springer; Berlin: 2006. [Google Scholar]
- Hall P, Heckman N. Estimating and depicting the structure of a distribution of random functions. Biometrika. 2002;89:145–158. [Google Scholar]
- Hall P, Müller HG, Wang JL. Properties of principal component methods for functional and longitudinal data analysis. Annals of Statistics. 2006;34:1493–1517. [Google Scholar]
- Hall P, Titterington DM. On confidence bands in nonparametric density estimation and regression. Journal of Multivariate Analysis. 1988;27:228–254. [Google Scholar]
- Härdle W. Asymptotic maximal deviation of M-smoothers. Journal of Multivariate Analysis. 1989;29:163–179. [Google Scholar]
- Härdle W, Marron JS. Bootstrap simultaneous error bars for nonparametric regression. Annals of Statistics. 1991;19:778–796. [Google Scholar]
- Huang J. Local asymptotics for polynomial spline regression. Annals of Statistics. 2003;31:1600–1635. [Google Scholar]
- Huang J, Yang L. Identification of nonlinear additive autoregressive models. Journal of the Royal Statistical Society B. 2004;66:463–477. [Google Scholar]
- Huang X, Wang L, Yang L, Kravchenko AN. Management practice effects on relationships of grain yields with topography and precipitation. Agronomy Journal. 2008;100:1463–1471. [Google Scholar]
- Izem R, Marron JS. Analysis of nonlinear modes of variation for functional data. Electronic Journal of Statistics. 2007;1:641–676. [Google Scholar]
- James GM, Hastie T, Sugar C. Principal component models for sparse functional data. Biometrika. 2000;87:587–602. [Google Scholar]
- James GM. Generalized linear models with functional predictors. Journal of the Royal Statistical Society B. 2002;64:411–432. [Google Scholar]
- James GM, Silverman BW. Functional adaptive model estimation. Journal of the American Statistical Association. 2005;100:565–576. [Google Scholar]
- James GM, Sugar CA. Clustering for sparsely sampled functional data. Journal of the American Statistical Association. 2003;98:397–408. [Google Scholar]
- Leadbetter MR, Lindgren G, Rootzén H. Extremes and Related Properties of Random Sequences and Processes. Springer-Verlag; New York: 1983. [Google Scholar]
- Li Y, Hsing T. On rates of convergence in functional linear regression. Journal of Multivariate Analysis. 2007;98:1782–1804. [Google Scholar]
- Li Y, Hsing T. Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data. Annals of Statistics. 2009 forthcoming. [Google Scholar]
- Ma S, Yang L. A jump-detecting procedure based on spline estimation. Journal of Nonparametric Statistics. 2010 in press. [Google Scholar]
- Morris JS, Carroll RJ. Wavelet-based functional mixed models. Journal of the Royal Statistical Society B. 2006;68:179–199. doi: 10.1111/j.1467-9868.2006.00539.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Müller HG, Stadtmüller U. Generalized functional linear models. Annals of Statistics. 2005;33:774–805. [Google Scholar]
- Müller HG, Stadtmüller U, Yao F. Functional variance processes. Journal of the American Statistical Association. 2006;101:1007–1018. [Google Scholar]
- Müller HG, Yao F. Functional additive models. Journal of American Statistical Association. 2008;103:1534–1544. [Google Scholar]
- Ramsay JO, Silverman BW. Functional Data Analysis. Second Edition. Springer; New York: 2005. [Google Scholar]
- Song Q, Yang L. Spline confidence bands for variance function. Journal of Nonparametric Statistics. 2009;21:589–609. [Google Scholar]
- Wang N, Carroll RJ, Lin X. Efficient semiparametric marginal estimation for longitudinal/clustered data. Journal of the American Statistical Association. 2005;100:147–157. [Google Scholar]
- Wang L, Yang L. Spline-backfitted kernel smoothing of nonlinear additive autoregression model. Annals of Statistics. 2007;35:2474–2503. [Google Scholar]
- Wang J, Yang L. Polynomial spline confidence bands for regression curves. Statistica Sinica. 2009;19:325–342. [Google Scholar]
- Wu W, Zhao Z. Inference of trends in time series. Journal of the Royal Statistical Society B. 2007;69:391–410. [Google Scholar]
- Xue L, Yang L. Additive coefficient modelling via polynomial spline. Statistica Sinica. 2006;16:1423–1446. [Google Scholar]
- Yao F, Lee TCM. Penalized spline models for functional principal component analysis. Journal of the Royal Statistical Society B. 2006;68:3–25. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional linear regression analysis for longitudinal data. Annals of Statistics. 2005a;33:2873–2903. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005b;100:577–590. [Google Scholar]
- Yao F. Asymptotic distributions of nonparametric regression estimators for longitudinal or functional data. Journal of Multivariate Analysis. 2007;98:40–56. [Google Scholar]
- Zhang JT, Chen J. Statistical inferences for functional data. Annals of Statistics. 2007;35:1052–1079. [Google Scholar]
- Zhao X, Marron JS, Wells MT. The functional data analysis view of longitudinal data. Statistica Sinica. 2004;14:789–808. [Google Scholar]
- Zhao Z, Wu W. Confidence bands in nonparametric time series regression. Annals of Statistics. 2008;36:1854–1878. [Google Scholar]
- Zhou L, Huang J, Carroll RJ. Joint modelling of paired sparse functional data using principal components. Biometrika. 2008;95:601–619. doi: 10.1093/biomet/asn035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou S, Shen X, Wolfe DA. Local asymptotics of regression splines and confidence regions. Annals of Statistics. 1998;26:1760–1782. [Google Scholar]