

Abstract
Patient-reported outcomes (PROs) are an important endpoint in orthopedics providing comprehensive information about patients' perspectives on treatment outcome. Computer-adaptive test (CAT) measures are an advanced method for assessing PROs using item sets that are tailored to the individual patient. This provides increased measurement precision and reduces the number of items. We developed a CAT version of the Forgotten Joint Score (FJS), a measure of joint awareness in everyday life. CAT development was based on FJS data from 580 patients after THA or TKA (808 assessments). The CAT version reduced the number of items by half at comparable measurement precision. In a feasibility study we administered the newly developed CAT measure on tablet PCs and found that patients actually preferred electronic questionnaires over paper–pencil questionnaires.
Keywords: patient-reported outcomes, forgotten joint score, electronic data capture, computer-adaptive testing, total knee arthroplasty, total hip arthroplasty
Background
Patient-reported outcome (PRO) measures are widely used in orthopedic outcome research as they provide important and detailed information on patients' perception of symptoms and function in everyday life [1,2]. Currently, various modes of administration of PRO measures are in use. Most frequently, PROs are assessed via paper–pencil questionnaires, but electronic PRO questionnaire administration is increasingly employed in clinical studies and daily clinical practice [3,4].
The recently developed Forgotten Joint Score (FJS, [5] assesses patients' awareness of their knee or hip joint during activities of daily living, representing a specific but very subjective PRO measure. It was developed as we considered joint awareness a very important and highly discriminative outcome parameter especially in patients with good to excellent joint function.
Traditional PRO measures, such as the FJS, the WOMAC osteoarthritis index [6] or the SF-36 quality of life questionnaire [7] use the same questions for all patients which is unfavorable for several reasons.
First, questionnaire length poses a certain burden to a patient as these measures require a considerable number of questions to cover the whole measurement range of the outcome parameter of interest. Second, patients find themselves confronted with questions that are not appropriate to their current condition. Inappropriate questions can be inconvenient to the patients interfering with their compliance. Third, these inappropriate questions provide no or little additional information neither to the clinician nor the researcher (e.g. if a patient reports barely being able to walk, further questions on various sports activities provide little or no further information).
To overcome this limitation of traditional PRO measures, a major focus of current research activities in PRO methodology is the development of computer-adaptive test (CAT) measures [8-10]. Computer-adaptive testing (CAT) is a sophisticated method for the assessment of PROs using individually tailored sets of questions to increase measurement precision and reduce the number of questions administered to each patient. CAT requires an item bank (i.e. a set of questions and their psychometric characteristics) and an algorithm for tailoring individual sets of questions.
Based on the response to the initial item the CAT algorithm calculates a first estimate of the PRO score and selects the next most appropriate item to be administered to the patient. This procedure continues until a predefined measurement precision has been reached or a maximum number of items have been asked. Fig. 1 provides details on the various steps of the CAT procedure.
Fig. 1.
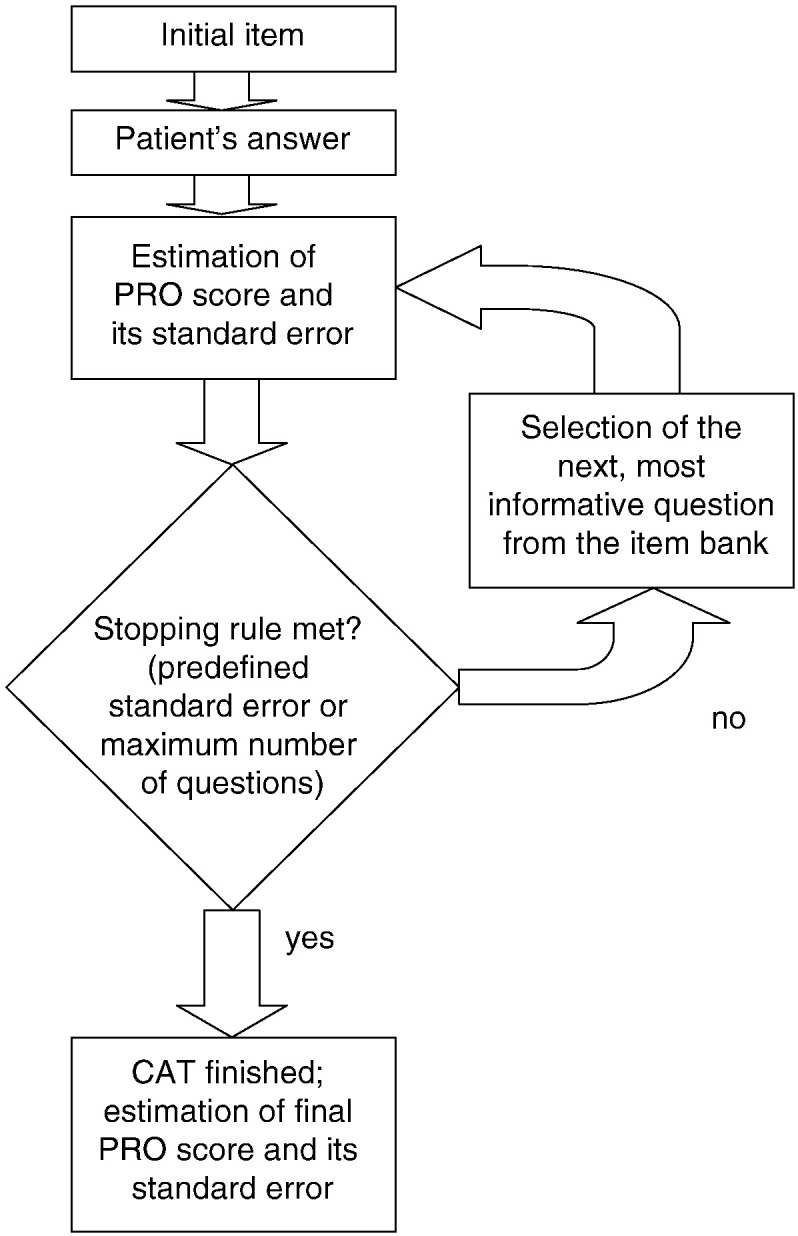
Flowchart showing the CAT procedure.
A crucial prerequisite for CAT is the availability of strictly unidimensional item sets that allow to fit complex item response theory (IRT) measurement models [11]. Since internal consistency (i.e. unidimensionality) of orthopedic questionnaires is generally very high [12] they lend themselves very well to IRT model application and CAT measure development. Consequently, a few studies have applied IRT modeling approaches to orthopedic outcome measures for functional status, pain, and rehabilitation outcome [13-16] including studies on various aspects of CAT measures [13,17,18].
Patients and Methods
Objectives
Our study aimed at shortening the recently published Forgotten Joint Score [5]. Therefore, we developed a computer-adaptive version from its paper–pencil form, the FJS-CAT. In detail, we addressed the following aims:
-
A.
to develop an item response theory measurement model and an item bank for computer-adaptive testing of joint awareness
-
B.
to derive measurement characteristics of the FJS-CAT from a large patient sample
-
C.
to implement the FJS-CAT in a software package and evaluate its feasibility and efficiency in clinical routine (touch tablet PC)
Sample
Development of the FJS-CAT (Aim A) was based on the analysis of FJS-12 data collected at the orthopedic outpatient unit of the Kantonsspital St. Gallen (Switzerland) between August 2007 and 2011.
Inclusion criteria for patient recruitment were the following:
-
•
primary THA or primary TKA within the last 5 years
(minimum of 1 year postoperatively)
-
•
age between 18 and 90 years
-
•
no obvious cognitive impairments
-
•
written informed consent
To evaluate feasibility and efficiency (Aim C) we recruited 60 patients according to the same criteria. The study was approved by the local ethics committee.
The Forgotten Joint Score
Item bank development was based on the above-mentioned 12-item version of the FJS [5]. It uses a 5-point Likert response format and the raw score is transformed to range from 0 to 100 points. High scores indicate good outcome, i.e. a high degree of forgetting the joint in everyday life (forgotten joint phenomenon).
The FJS has a low ceiling effect and was designed to especially discriminate between good, very good and excellent outcome after THA and TKA. The validation study [5] showed high internal consistency (Cronbach's alpha 0.95) and the FJS score proved to discriminate well between patient groups known to show different outcome (i.e. known-group comparisons).
Psychometric and Statistical Analysis
The 12 items of the FJS were considered for inclusion in the FJS-CAT item bank and analyzed with regard to unidimensionality and fit to an IRT model. For investigation of unidimensionality we calculated Cronbach's alpha and conducted a principal component factor analysis. Analysis of fit to an IRT model was based on infit and outfit mean square statistics and root mean squared error of approximation (RMSEA). According to Linacre and Wright [19] we considered infit and outfit mean square values for individual items between 0.5 and 1.5 as an indicator of sufficient model data fit. Analysis of differential item functioning (DIF, i.e. differences in item difficulty between patient subgroups) was done with regard to sex, THA/TKA, and age (above/below 70 years). Uniform DIF was considered to be substantial if log odds ratios exceeded 0.64 with P < .001 and non-uniform DIF if increase in R2 was larger than 0.035 [20].
As a measure of local independence of items we calculated inter-item residual correlations after fitting a unidimensional IRT model. According to Fliege et al. [21] residual correlations below 0.25 were considered an indicator of local independence.
We performed statistical analyses with SPSS 20.0 (SPSS Inc.), IRT analyses with Winsteps 3.42 [22] and CAT simulation with Firestar 1.2 [23].
Pilot Study On The Use Of FJS-CAT
To evaluate the feasibility of data collection with the newly developed electronic FJS-CAT we collected patient feedback within a pilot sample of 60 patients after THA or TKA. We administered the FJS-CAT version together with additional questions on usability, preferences for questionnaire administration mode and computer literacy. Time for CAT completion was recorded by the software. A software package (Computer-based Health Evaluation System (CHES) [24] was used to administer the FJS-CAT to the patients on a touch tablet PC.
Results
Patient Characteristics
FJS data from 580 patients who had undergone THA (n = 154, 26.6%) or TKA (n = 426, 73.4%) surgery at the Kantonsspital St. Gallen (Switzerland) were available for analysis. Mean age at surgery was 68.1 years (SD 10.4) and 56.7% were women. Data from a total of 808 assessments were available for IRT analysis. On the assessment date patients were 18.7 months after surgery on average (SD 14.4). Further details on patient characteristics are given in Table 1.
Table 1.
Sociodemographic and Clinical Sample Characteristics (n = 580)
| TKA Patients (n = 426) | THA Patients (n = 154) | ||
|---|---|---|---|
| Age at surgery (years) | Mean (SD) | 68.1 (9.9) | 68.1 (11.8) |
| Range | 29–87 | 30–89 | |
| Sex | Men | 39.0% | 55.2% |
| Women | 61.0% | 44.8% | |
| Side | Left | 45.3% | 45.5% |
| Right | 54.7% | 54.5% | |
| Time since surgery (months)⁎ | Mean (SD) | 16.3 (14.0) | 29.2 (11.0) |
| Range | 12–60 | 14–52 | |
Refers to the number of assessments (TKA n = 651; THA n = 157; total n = 808).
For feasibility testing of the FJS-CAT (Aim C) we recruited a sample of 60 patients (30 THA patients, 30 TKA patients). Mean age was 67.9 years (SD 10.7) and mean time since surgery was 4.2 years (SD 3.5).
Development Of The FJS-CAT Item Bank
Classical test theory parameters indicated very good unidimensionality for all of the 12 FJS items (Cronbach's alpha 0.97, corrected item-total correlations 0.73–0.88).
Principal component analysis resulted in a single factor explaining 72.4% of variance (factor 1:2 eigenvalue ratio = 9.0). Consequently, none of the items were dropped at this stage leaving 12 items for IRT modeling.
For initial IRT modeling, we applied a Partial Credit Model [25] to the data to investigate if category thresholds are uniform across the various items and to analyze potential DIF. We found substantial uniform DIF with regard to THA/TKA for the following items (see Table 2 for item content): 1, 2, 3, 4, and 8 (log odds ratio > 0.64 and P < .001). No non-uniform DIF was observed.
Table 2.
Item Characteristics Based on a Rating Scale Model (FJS-CAT hip version)
| # Item Content | MNSQ |
Item Difficulty | Category Thresholds |
||||
|---|---|---|---|---|---|---|---|
| Infit | Outfit | 1–2 | 2–3 | 3–4 | 4–5 | ||
| 01 in bed at night | 1.36 | 1.24 | 0.33 | − 0.68 | 0.03 | 0.24 | 1.74 |
| 02 sitting > 1 h | 1.02 | 0.95 | 0.24 | − 0.77 | − 0.06 | 0.15 | 1.65 |
| 03 walking > 15 min | 1.06 | 0.95 | − 0.08 | − 1.09 | − 0.38 | − 0.17 | 1.33 |
| 04 taking a bath/shower | 1.11 | 1.04 | 1.07 | 0.06 | 0.77 | 0.98 | 2.48 |
| 05 travelling in a car | 1.07 | 0.98 | 0.69 | − 0.32 | 0.39 | 0.60 | 2.10 |
| 06 climbing stairs | 0.88 | 0.76 | − 0.31 | − 1.32 | − 0.61 | − 0.40 | 1.10 |
| 07 walking on uneven ground | 0.78 | 0.75 | − 0.21 | − 1.22 | − 0.51 | − 0.30 | 1.20 |
| 08 getting up from a low sitting position | 0.98 | 1.02 | − 0.08 | − 1.09 | − 0.38 | − 0.17 | 1.33 |
| 09 standing for longer | 1.04 | 1.23 | − 0.18 | − 1.19 | − 0.48 | − 0.27 | 1.23 |
| 10 housework or gardening | 0.86 | 0.95 | − 0.29 | − 1.30 | − 0.59 | − 0.38 | 1.12 |
| 11 taking a walk/hiking | 0.87 | 0.93 | − 0.71 | − 1.72 | − 1.01 | − 0.80 | 0.70 |
| 12 favorite sport | 1.31 | 1.46 | − 0.49 | − 1.50 | − 0.79 | − 0.58 | 0.92 |
Final 12-item model: RMSEA 0.11.
RMSEA of this initial model was 0.05 and all items with the exception of item 2 had MNSQ statistics within the desired range of 0.5–1.5. Due to the occurrence of considerable DIF with regard to THA/TKA we developed separate IRT models for THA and TKA patients. This finding reflects that the level of function required for certain activities differs substantially between hip and knee patients.
As category thresholds in the initial Partial Credit Model were similar across items, we decided to employ a Rating Scale Model [26], as it contains less item parameters to be estimated. For THA patients all items could be fitted to a Rating Scale Model (RMSEA = 0.11). For TKA patients the Rating Scale Model showed good model data fit (RMSEA = 0.06) after discarding items 1 and 2.
For the THA model RMSEA slightly exceeded suggested thresholds for sufficient model data fit (RMSEA = 0.10) [27], however, we decided to keep this item set as MNSQ statistics on item level were satisfactory (RMSEA for a Partial Credit Model was 0.11). In the final THA model inter-item residual correlations as a measure of local independence of items were below 0.25 for all items, with the exception of the correlations of item 1 with 7 (r = − 0.36), item 3 with 5 (r = − 0.31), item 4 with 10 (r = − 0.27) and item 2 with 7 (r = − 0.25). In the final TKA model all inter-item residual correlations were below 0.25 with the exception of item 11 with 12 (r = 0.35), item 3 with 8 (r = − 0.27) and item 4 with 12 (r = − 0.25). Details on item characteristics in the final model are given in Tables 2 and 3 (separately for THA and TKA patients).
Table 3.
Item Characteristics Based on a Rating Scale Model (FJS-CAT knee version)
| # Item Content | MNSQ |
Item Difficulty | Category Thresholds |
||||
|---|---|---|---|---|---|---|---|
| Infit | Outfit | 1–2 | 2–3 | 3–4 | 4–5 | ||
| 01 ⁎in bed at night | 1.48 | 2.67 | 1.03 | ||||
| 02 ⁎sitting > 1 h | 1.33 | 2.21 | 0.86 | ||||
| 03 walking > 15 min | 1.05 | 0.96 | 0.75 | − 0.01 | 0.52 | 0.80 | 1.69 |
| 04 taking a bath/shower | 1.32 | 1.53 | 2.00 | 1.24 | 1.77 | 2.05 | 2.94 |
| 05 travelling in a car | 1.20 | 1.62 | 1.25 | 0.49 | 1.02 | 1.30 | 2.19 |
| 06 climbing stairs | 1.24 | 1.22 | − 0.60 | − 1.36 | − 0.83 | − 0.55 | 0.34 |
| 07 walking on uneven ground | 0.81 | 0.76 | − 0.43 | − 1.19 | − 0.66 | − 0.38 | 0.51 |
| 08 getting up from a low sitting position | 1.24 | 1.17 | − 1.53 | − 2.29 | − 1.76 | − 1.48 | − 0.59 |
| 09 standing for longer | 0.99 | 0.88 | − 0.27 | − 1.03 | − 0.5 | − 0.22 | 0.67 |
| 10 housework or gardening | 1.03 | 1.00 | 0.26 | − 0.50 | 0.03 | 0.31 | 1.20 |
| 11 taking a walk/hiking | 0.87 | 0.77 | − 0.69 | − 1.45 | − 0.92 | − 0.64 | 0.25 |
| 12 favorite sport | 0.94 | 0.94 | − 0.75 | − 1.51 | − 0.98 | − 0.70 | 0.19 |
Final 10-item model: RMSEA 0.06.
Item discarded due to poor model data fit.
Further analysis of DIF was done separately for THA and TKA patients with regard to sex, age at surgery (above/below 70 years), and time since surgery (above/below 12 months). None of the items exceeded the thresholds for substantial DIF given above.
Measurement Characteristics Of The FJS-CAT
To analyze the relation between CAT lengths, i.e. number of items administered to a patient, and standard error of measurement we ran CAT simulations with the collected data with help of the software Firestar [23]. Again, this was done separately for THA and TKA patients. As an initial item we chose the item with an item difficulty closest to zero, i.e. an item in the middle of the measurement range of the respective item banks. Selection criterion for subsequent items was Fisher's information [23], estimation of person parameters (FJS score) was done with an expected a posteriori (EAP) estimation algorithm.
For THA patients we found a standard error of 0.39 logits for the full item bank (12 items), compared to an standard error of 0.48 for a 6-item CAT, 0.62 for a 3-item CAT and 1.05 for a single item. Correlations with the FJS score derived from the total item bank were above 0.95 for all CAT versions with at least two items.
For TKA patients we found that the full item bank (10 items) had a standard error of 0.46 logits, compared to a standard error of 0.50 for a 6-item CAT, 0.61 for a 3-item CAT and 1.05 for a single item. CAT versions with more than at least four items showed correlations of the FJS score with the full item bank of more than 0.95.
Further details are given in Table 4 and Fig. 2.
Table 4.
CAT Simulation on FJS Score Standard Errors in Relation to CAT Length and Correlations with Full Item Bank
| CAT Length | Mean Standard Error |
Correlation with Full Item Bank |
||
|---|---|---|---|---|
| Hip | Knee | Hip | Knee | |
| 1 item | 1.05 | 1.05 | 0.80 | 0.89 |
| 2 items | 0.74 | 0.74 | 0.90 | 0.96 |
| 3 items | 0.62 | 0.61 | 0.92 | 0.98 |
| 4 items | 0.56 | 0.55 | 0.95 | 0.98 |
| 5 items | 0.51 | 0.52 | 0.96 | 0.99 |
| 6 items | 0.48 | 0.50 | 0.98 | 0.99 |
| 7 items | 0.45 | 0.48 | 0.99 | 1.00 |
| 8 items | 0.44 | 0.47 | 0.99 | 1.00 |
| 9 items | 0.42 | 0.47 | 0.99 | 1.00 |
| 10 items | 0.40 | 0.46 | 1.00 | 1.00 |
| 11 items | 0.39 | 1.00 | ||
| 12 items | 0.39 | 1.00 | ||
Fig. 2.

Measurement precision and CAT lengths for THA and TKA patients: box plots show median and quartiles for standard error of measurement of individual FJS-CAT scores dependent on number of administered items.
Pilot Testing Of The FJS-CAT
With regard to computer literacy, 53.3% of the patients answered “never,” 11.7% “rarely,” 1.7% “several times a month,” 10.0% “several times a week,” and 23.3% “daily” to use a computer.
The CAT algorithm was configured to stop at a measurement precision of 0.5 logits and administer three items at minimum and nine items at maximum. The median number of administered items was 5 (mean 6.2, SD 2.8).
Time for CAT completion was 1.6 min (SD 0.8, range 0.5–5.5) excluding explanations of the study nurse and handing over the touch tablet PC. Fifty percent completed the questions on the touch tablet PC themselves, and 50.0% preferred the study nurse to work the touch tablet PC. Concerning patient feedback we found high acceptance of the electronic CAT administration. Ninety percent of patients preferred the electronic mode over paper–pencil questionnaires, whereas 10% preferred paper–pencil questionnaires. Moreover, 98.3% reported no difficulties with answering the questions on the touch tablet PC and 98.3% indicated to be willing to complete electronic questionnaires in the future. See Fig. 3 for a screen shot of the electronic CAT questionnaire.
Fig. 3.
Screen shot of the CHES interface for web-based CAT administration.
Discussion
Within this study we developed a knee-specific and a hip-specific computer-adaptive test version of the FJS-12 score, the so-called FJS-CAT. The FJS-CAT is among the first CAT measures emerging in the orthopedic field and it is the first joint-specific CAT measure. The original FJS was developed to overcome limited discriminatory abilities that have been shown for several PRO measures (WOMAC, Knee Society Score) in patients with good to excellent outcome. The CAT version presented in this paper can be considered a computer-adaptive short form of the original FJS (12 questions) providing adaptable measurement precision, reduced test length and a more patient-friendly PRO assessment mode. Concerning test length and measurement precision, we found that increasing the number of questions e.g. by the factor of 4 decreased mean measurement precision only by the factor of 1.4. This indicates that test length can be considerably shortened through CAT without substantial loss of measurement precision.
As mentioned above CAT allows adapting the desired measurement precision to study requirements. Since measurement precision is inversely related to sample size in power analyses, measurement precision (corresponding to the number of items administered to a patient) can be increased to optimize statistical power if only a limited number of patients are available for recruitment. On the other hand, if the CAT measure is used as a secondary study outcome (e.g. additional to implant survival in registers) the number of items may be reduced as in those studies PRO analyses are commonly overpowered. A recent study by Fries et al. [28] on the relation between measurement precision provided by CAT, sample size and study costs respectively, suggests a substantial potential for reduction in sample size in future PRO studies.
A limitation of our study was that we developed the FJS-CAT from the 12 questions from the current FJS questionnaire. This rather small original item set required to be rather inclusive within IRT modeling in order to provide sufficient coverage of the measurement range in the FJS-CAT item bank. In addition, due to a substantial DIF we had to develop different models for THA and TKA patients, which proved problematic because of the limited number of THA patients in our sample. However, we believe the FJS-CAT is preferable to the FJS as it is a shorter and more flexible instrument covering the same outcome.
As a next step we plan to extend the item bank with targeted items covering more strenuous activities which results in higher measurement precision in patients with excellent outcome. The possibility of extending an existing item bank without annihilating comparability with previous versions of a score demonstrates one of the major strengths of IRT modeling.
Regarding patients' acceptance of electronic CAT administration in daily clinical practice we found a strong patient preference for computer-based assessment when compared to paper–pencil assessment. This was surprising, considering the mean age of an average arthroplasty population. In the literature a considerable number of studies indicate good feasibility and high patient acceptance of electronic PRO assessments, also in elderly patient groups [3,29].
Beyond the orthopedic field, the large US-based initiative PROMIS (Patient-reported Outcome Measure Information System) funded by the National Institutes of Health (NIH) is developing generic CAT measures applicable to a wide range of medical fields. For orthopedic outcome research PROMIS provides useful measures for physical function (including versions for upper extremity, mobility, and mobility aid users) [30].
Naturally, the administration of CAT measures requires a software package to administer questionnaires electronically, to manage item banks and to employ the CAT algorithm for item administration. As IT infrastructure for electronic PRO data capture is increasingly available in hospital settings, the use of CAT measures becomes more feasible and efficient.
In conclusion we believe that combining electronic PRO data capture and computer-adaptive assessment allows for a significant improvement of outcome assessment in the orthopedic field. The CAT measure for joint awareness developed within in this study showed satisfactory psychometric properties. It is well accepted by the patients and significantly reduces time for PRO assessment in clinical routine. Targeted extension of the item bank can further improve measurement precision of the instrument across the whole measurement range.
Conflict of Interest Statements
COI Giesinger JOA.
COI Kuster JOA.
COI Holzner JOA.
COI Giesinger KM JOA.
Acknowledgments
This study was kindly supported by a grant from the Swiss Society of orthopedic Surgery and Traumatology. The work of Johannes M. Giesinger was funded by a grant from the Austrian Science Fund (FWF #502). We would like to thank Annelise Spitz for her help with data collection.
Footnotes
The Conflict of Interest statement associated with this article can be found at http://dx.doi.org/10.1016/j.arth.2012.08.026.
References
- 1.Chapman J.R., Norvell D.C., Hermsmeyer J.T. Evaluating common outcomes for measuring treatment success for chronic low back pain. Spine (Phila Pa 1976) 2011;36(21 Suppl):S54. doi: 10.1097/BRS.0b013e31822ef74d. [DOI] [PubMed] [Google Scholar]
- 2.Wright R.W. Knee injury outcomes measures. J Am Acad Orthop Surg. 2009;17(1):31. doi: 10.5435/00124635-200901000-00005. [DOI] [PubMed] [Google Scholar]
- 3.Dixon S., Bunker T., Chan D. Outcome scores collected by touchscreen: medical audit as it should be in the 21st century? Ann R Coll Surg Engl. 2007;89(7):689. doi: 10.1308/003588407X205422. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Theiler R., Bischoff-Ferrari H.A., Good M. Responsiveness of the electronic touch screen WOMAC 3.1 OA Index in a short term clinical trial with rofecoxib. Osteoarthritis Cartilage. 2004;12(11):912. doi: 10.1016/j.joca.2004.08.006. [DOI] [PubMed] [Google Scholar]
- 5.Behrend H., Giesinger K., Giesinger J.M. The “Forgotten Joint” as the ultimate goal in joint arthroplasty validation of a new patient-reported outcome measure. J Arthroplasty. 2011 doi: 10.1016/j.arth.2011.06.035. [DOI] [PubMed] [Google Scholar]
- 6.Bellamy N., Buchanan W.W., Goldsmith C.H. Validation study of WOMAC: a health status instrument for measuring clinically important patient relevant outcomes to antirheumatic drug therapy in patients with osteoarthritis of the hip or knee. J Rheumatol. 1988;15(12):1833. [PubMed] [Google Scholar]
- 7.Ware J.E., Jr., Sherbourne C.D. The MOS 36-item short-form health survey (SF-36). I. Conceptual framework and item selection. Med Care. 1992;30(6):473. [PubMed] [Google Scholar]
- 8.Bjorner J., Chang C., Thissen D. Developing tailored instruments: item banking and computerized adaptive assessment. Qual Life Res. 2007;16(Suppl 1):95. doi: 10.1007/s11136-007-9168-6. [DOI] [PubMed] [Google Scholar]
- 9.Petersen M.A., Groenvold M., Aaronson N.K. Development of computerised adaptive testing (CAT) for the EORTC QLQ-C30 dimensions—general approach and initial results for physical functioning. Eur J Cancer. 2010;46(8):1352. doi: 10.1016/j.ejca.2010.02.011. [DOI] [PubMed] [Google Scholar]
- 10.The PROMIS network Patient-Reported Outcomes Measurement Information System (PROMIS) 2011. http://www.nihpromis.org Retrieved 30 Nov 2011, 2010, from.
- 11.Hambleton R., Swaminathan H., Rogers H. Sage Publications; Newbury Park: 1991. Fundamentals of item response theory. [Google Scholar]
- 12.Impellizzeri F.M., Mannion A.F., Leunig M. Comparison of the reliability, responsiveness, and construct validity of 4 different questionnaires for evaluating outcomes after total knee arthroplasty. J Arthroplasty. 2011;26(6):861. doi: 10.1016/j.arth.2010.07.027. [DOI] [PubMed] [Google Scholar]
- 13.Jette A.M., Haley S.M., Ni P. Adaptive short forms for outpatient rehabilitation outcome assessment. Am J Phys Med Rehabil. 2008;87(10):842. doi: 10.1097/PHM.0b013e318186b7ca. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Jette A.M., McDonough C.M., Ni P. A functional difficulty and functional pain instrument for hip and knee osteoarthritis. Arthritis Res Ther. 2009;11(4):R107. doi: 10.1186/ar2760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ryser L., Wright B.D., Aeschlimann A. A new look at the Western Ontario and McMaster Universities Osteoarthritis Index using Rasch analysis. Arthritis Care Res. 1999;12(5):331. doi: 10.1002/1529-0131(199910)12:5<331::aid-art4>3.0.co;2-w. [DOI] [PubMed] [Google Scholar]
- 16.Wolfe F., Kong S.X. Rasch analysis of the Western Ontario MacMaster questionnaire (WOMAC) in 2205 patients with osteoarthritis, rheumatoid arthritis, and fibromyalgia. Ann Rheum Dis. 1999;58(9):563. doi: 10.1136/ard.58.9.563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Haley S.M., Gandek B., Siebens H. Computerized adaptive testing for follow-up after discharge from inpatient rehabilitation: II. Participation outcomes. Arch Phys Med Rehabil. 2008;89(2):275. doi: 10.1016/j.apmr.2007.08.150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Hart D.L., Mioduski J.E., Stratford P.W. Simulated computerized adaptive tests for measuring functional status were efficient with good discriminant validity in patients with hip, knee, or foot/ankle impairments. J Clin Epidemiol. 2005;58(6):629. doi: 10.1016/j.jclinepi.2004.12.004. [DOI] [PubMed] [Google Scholar]
- 19.Linacre J., Wright B. MESA Press; Chicago: 2001. A user's guide to WINSTEPS. [Google Scholar]
- 20.Scott N.W., Fayers P.M., Aaronson N.K. Differential item functioning (DIF) analyses of health-related quality of life instruments using logistic regression. Health Qual Life Outcomes. 2010;8:81. doi: 10.1186/1477-7525-8-81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Fliege H., Becker J., Walter O.B. Development of a computer-adaptive test for depression (D-CAT) Qual Life Res. 2005;14(10):2277. doi: 10.1007/s11136-005-6651-9. [DOI] [PubMed] [Google Scholar]
- 22.Linacre J. 2003. WINSTEPS (version 3.42) [Google Scholar]
- 23.Choi S. 2009. FIRESTAR: computerized adaptive testing (CAT) simulation program for polytomous IRT models. [Google Scholar]
- 24.Holzner B., Giesinger J.M., Pinggera J. The computer-based health evaluation system (CHES): a software for electronic patient-reported outcome monitoring. BMC Med Inform Decis Mak. 2012;12(1):126. doi: 10.1186/1472-6947-12-126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Masters G., Wright B. In: The partial credit model. Handbook of modern item response theory. Van der Linden W., Hambleton R., editors. Springer; New York: 1997. p. 101. [Google Scholar]
- 26.Andrich D. Application of a psychometric rating model to ordered categories which are scored with successive integers. Appl Psychol Meas. 1978;2:581. [Google Scholar]
- 27.Browne M., Cudeck R. Alternative ways of assessing model fit. Sociol Methods Res. 1992;21:230. [Google Scholar]
- 28.Fries J.F., Krishnan E., Rose M. Improved responsiveness and reduced sample size requirements of PROMIS physical function scales with item response theory. Arthritis Res Ther. 2011;13(5):R147. doi: 10.1186/ar3461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Bellamy N., Wilson C., Hendrikz J. Electronic data capture (EDC) using cellular technology: implications for clinical trials and practice, and preliminary experience with the m-Womac Index in hip and knee OA patients. Inflammopharmacology. 2009;17(2):93. doi: 10.1007/s10787-008-8045-4. [DOI] [PubMed] [Google Scholar]
- 30.Hung M., Clegg D.O., Greene T. Evaluation of the PROMIS physical function item bank in orthopaedic patients. J Orthop Res. 2011;29(6):947. doi: 10.1002/jor.21308. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
COI Giesinger JOA.
COI Kuster JOA.
COI Holzner JOA.
COI Giesinger KM JOA.