

Abstract
Recent years have seen the developments of several methods for sparse principal component analysis due to its importance in the analysis of high dimensional data. Despite the demonstration of their usefulness in practical applications, they are limited in terms of lack of orthogonality in the loadings (coefficients) of different principal components, the existence of correlation in the principal components, the expensive computation needed, and the lack of theoretical results such as consistency in high-dimensional situations. In this paper, we propose a new sparse principal component analysis method by introducing a new norm to replace the usual norm in traditional eigenvalue problems, and propose an efficient iterative algorithm to solve the optimization problems. With this method, we can efficiently obtain uncorrelated principal components or orthogonal loadings, and achieve the goal of explaining a high percentage of variations with sparse linear combinations. Due to the strict convexity of the new norm, we can prove the convergence of the iterative method and provide the detailed characterization of the limits. We also prove that the obtained principal component is consistent for a single component model in high dimensional situations. As illustration, we apply this method to real gene expression data with competitive results.
Keywords: sparse principal component analysis, high-dimensional data, uncorrelated or orthogonal principal components, iterative algorithm, consistency in high-dimensional
1. Introduction
Principal components analysis (PCA), as a popular feature extraction and dimension reduction tool, seeks the linear combinations of the original variables (principal components, PCs) such that the derived PCs capture maximal variance and guarantee minimal information loss. However, the classic PCA has major practical and theoretical drawbacks when it is applied to high-dimensional data. The classic PCA produces inconsistent estimates in high-dimensional situations (see Paul [11], Nadler [10] and Johnstone and Lu [7]). The loadings of PCs are typically non-zero. This often makes it difficult to interpret the PCs and identify important variables.
To address the drawbacks of classic PCA, various modified PCA methods have been proposed to form PCs where each PC is the linear combination of a small subset of the variables that can still explain high percentage of variance. SCoTLASS proposed in Jolliffe, Trendafilov and Uddin [8], a quite natural extension to classic PCA, maximizes the explained variances with l1 constraints on the loadings, as well as orthogonal conditions on subsequent loadings. The nonconvexity of its objective function and feasible region leads to difficulties in computation, especially for higher order principal components. Trendafilov and Jolliffe [14] proposed a globally convergent algorithm to solve the optimization problem in the SCoTLASS based on the projected gradient approach. D’Aspremont, Bach and Ghaoui [4] suggested a semidefinite programming problem as a relaxation to the l0-penalty for sparse covariance matrix. Amini and Wainwright [1] studied the asymptotic properties of the leading eigenvector of the covariance estimator obtained by D’Aspremont et al. [4]. The SPCA developed by Zou, Hastie and Tibshirani [16] formulates PCA as a regression-type optimization problem (SPCA), and then to obtain sparse loadings by imposing the lasso or elastic net penalty on the regression coefficients. Compared to SCotLASS, this method has more complicated objective function, but it is computationally efficient. The sparse PCs obtained from SPCA are neither orthogonal nor uncorrelated. Applications of SPCA to simulated and real examples indicated that different sparse PCs may be highly correlated, which makes it difficult in differentiating the variances explained by different PCs. To ease this difficulty, Zou and his colleagues proposed a new approach to computing the total variance explained by sparse PCs. However, without orthogonality or uncorrelation constraints, there are infinitely many sparse linear combinations which can achieve the same level of explained variances as the higher order PCs obtained by SPCA. Furthermore, the obtained PCs by SPCA appear to be sensitive to the choice of the number of PCs and all the sparsity parameters. Shen and Huang [13] proposed a sequential method (sPCA-rSVD) to find the sparse PCs via regularized singular value decomposition which extracts the PCs through solving low rank matrix approximation problems. Compared to SPCA, this method does not have the sensitivity problem as SPCA to the number of PCs and its higher order PCs are not affected by the sparsity parameters of the lower order PCs. But the nonorthogonality and correlation in PCs remain a problem. Based on their penalized matrix decomposition method, Witten, Tibshirani and Hastie [15] proposed an iterative method for obtaining sparse PCs, which yields an efficient algorithm to obtain the first PC of SCoTLASS. However, it is hard to study the convergence of this iterative method and to extend it to get orthogonal or uncorrelated higher order PCs. Johnstone and Lu [7] proposed a thresholding method and proved its consistency for a single component model in high dimensional situations. As pointed out by Cadima and Jolliffe [3], the thresholding approach can be potentially misleading in various respects.
In this paper, we propose a new criterion-based sequential sparse PCA method by replacing the l2-norm in traditional eigenvalue problems with a new norm, which is a convex combination of l1 and l2 norms. Hence, the optimization problems in our methods are natural extensions of those in classic PCA and have relatively simple forms. We propose an efficient iterative algorithms to solve these optimization problems. Due to the strict convexity of the new norm, we can prove the convergence of this iterative algorithm and provide the detailed characterization of the limits. With this method, we can efficiently obtain un-correlated PCs or orthogonal loadings, and achieve the goal of explaining high percentage of variations with sparse loadings. Our method is almost as fast as SPCA and sPCA-rSVD for high-dimensional data such as gene expression data and single-nucleotide polymorphism (SNP) data. This new framework can be easily extended to other statistical techniques and methodologies involve solving eigenvalue problems (such as partial least square regression), generalized eigenvalue problems (such as linear discriminant analysis) and singular value decomposition problems (such as canonical correlation analysis), where the different components are required to be orthogonal or uncorrelated. They are our future research directions. We also prove that the obtained PC is consistent in the single component model proposed by Johnstone and Lu [7] when the ratio of the number of variables to the sample size goes to a nonnegative constant.
The paper is organized as follows. In Section 2, we describe our method, propose algorithms and provide the theoretical characterizations. We show the consistency result in Section 3, and conduct simulation studies and apply our method to the well-studied pitprop data set and a gene expression dataset in Section 4. The proofs of all theorems are given in Section 5. The proofs of some technical lemmas are given in the Appendix.
2. Sparse PCA by choice of norm
Let X be a n × p data matrix where n and p are the number of the observations and the number of the variables, respectively. Without loss of generality, assume the column means (sample means) of X are all 0. We will use Σ to denote the p × p sample covariance matrix throughout this paper except in Section 3 where the sample covariance matrix is denoted by Σ̂(n) because we want to study the asymptotic property of our method as n → ∞. XT is the transpose of the matrix X. For any v = (v1, · · ·, vp)T ∈ ℝp and u = (u1, · · ·, up)T ∈ ℝp, let be the l2-norm of v, 〈u, v〉 = uTv be the inner product between u and v, and be the l1-norm of v. If u and v are orthogonal under l2-norm, that is, 〈u, v〉 = uTv = 0, we write u ⊥ v.
For any λ ∈ [0, 1], we define a “mixed norm” ||·||λ in ℝp space by
If λ = 0, this norm reduces to the l2 norm, and if λ = 1, it is the l1 norm. Our definitions for the first and the higher order sparse PCs are given as follows.
Definition 1
The coefficient vector v1 ∈ ℝp of the first sparse principal component is the solution to the following optimization problem,
| (2.1) |
where 0 ≤ λ1 ≤ 1 is the tuning parameter for the first sparse principal component.
λ1 controls the sparsity of v1. A larger λ1 leads to sparser coefficients, but reduces the proportion of variations explained by the first PC. In practice, we need to choose an appropriate value of the tuning parameter to make a balance between sparsity and high percentage of explained variance. Because the objective function in (2.1) is homogeneous, that is, the objective function has the same values at v and av, where a is any nonzero real number, the optimization problem (2.1) is equivalent to the following problem,
| (2.2) |
The solutions to (2.1) and (2.2) differ only by a multiplicative constant. The solution to (2.2) always has the mixed norm equal to one, because Σ, the covariance matrix, is nonnegative definite, and hence uT Σu is always nonnegative for any u. We will propose an efficient algorithm to solve (2.2). However, it is more convenient to consider the form (2.1) in studying the asymptotic consistency of our sparse PCs.
We now compare our method with SCoTLASS which solves the following problem,
| (2.3) |
When , the l1 constraint in (2.3) is not active. In this case, (2.3) is just the usual eigenvalue problem and equivalent to (2.2) with λ1 = 0. When t < 1, the feasible region of (2.3) is empty. When , the difference of the feasible regions between (2.2) and (2.3) is shown in Figure 1 for the two dimensional case. The left plot in Figure 1 shows the pattern of the feasible region for (2.3) with . The feasible region of (2.3) is the collection of the solid green lines and is nonconvex. The right plot in Figure 1 shows the feasible regions in (2.2) for different λ1. The regions are strictly convex for 0 ≤ λ < 1, which plays a key role in the development of our method.
Figure 1.

Left: the feasible region ||u||2 = 1, ||u||1 ≤ t of SCoTLASS (where t = 1.3) is the collection of the solid green lines. Right: the feasible regions ||u||λ ≤ 1 of our method for λ = 0, 0.1, 0.5 and 1 are the regions bounded by the lines with different colors.
The classic PCs possess two properties simultaneously: coefficient vectors of different PCs are orthogonal and different PCs are uncorrelated. However, for sparse PCA, at most one of the two properties can be possessed by principal components. Therefore, we consider two alternative definitions for higher order PCs. In the following definitions, vk, k ≥ 1, denotes the coefficient vector of the k-th sparse PC.
Definition 2
Suppose that we have obtained vj, 1 ≤ j ≤ k − 1, then vk solves the following optimization problem,
| (2.4) |
where λk is the tuning parameter for vk.
Definition 3
Suppose that we have obtained vj, 1 ≤ j ≤ k − 1, then vk solves the following optimization problem,
| (2.5) |
Under Definition 2, vk, k ≥ 1, are orthogonal to each other and under Definition 3, different PCs are uncorrelated to each other. Our algorithm can be applied to both definitions. Different tuning parameters can be used for different PCs in our method. We first propose an algorithm to solve the problem (2.2) for the first PC.
Before we introduce our algorithm, in order to facilitate comparison among various sparse PCA methods, we summarize the criteria of the methods we can find as follows. It is definitely not a complete list.
-
SCoTLASS (Jolliffe et al. [8] and Trendafilov and Jolliffe [14]): the coefficient vector for the k-th sparse principal component is the solution to
where uj is the coefficient vector for the j-th sparse principal component and t is tuning parameter.
-
Semidefinite-programming relaxation (D’Aspremont et al. [4]): find the symmetric and nonnegative-definite matrix X which
where Tr(·) denotes the trace of a matrix and k is the tuning parameter. Then the estimate of the coefficient vector for the first principal component is the leading eigenvector of X.
-
SPCA (Zou et al. [16]): solve the following regression-type problem,
where x1, · · ·, xn are the sample, A is a p × k matrix, B = (β1, β2, · · ·, βk) is a p × k matrix and I is the identity matrix. Let (Â, B̂) be the solution to the above optimization problem. Then the columns of B̂, are the estimates of the coefficient vectors for the first k principal components.
-
sPCA-rSVD (Shen and Huang [13]): solve the following problem,
where X is the data matrix, u = (u1, · · ·, un)T and v = (v1, · · ·, vp)T, and Pλ(v) is the penalty term. Let (û, v̂) be the solution to the above optimization problem. The estimator of the coefficient vector for the first sparse principal component is v̂.
In addition to the above criterion-based methods, there are thresholding methods such as the method proposed in Johnstone and Lu [7].
2.1. First sparse principal component
We propose the following iterative algorithm to solve (2.2).
Algorithm 2.1 (For solving (2.2))
Choose an initial vector u(0) ∈ ℝp such that Σu(0) ≠ 0.
- Iteratively compute u(1), u(2), · · ·, until convergence as follows: for any i ≥ 1, if we have obtained u(i−1), define w(i−1) = Σu(i−1), then u(i) is the solution to
(2.6)
We first observe that if λ = 0, Algorithm 2.1 is the power iteration method for finding the largest eigenvalue of a symmetric matrix (see Section 5.3 in Quarteroni, Sacco and Saleri [12]). The power method is efficient to find the first eigenvector and has been applied to many real-life problems, such as calculating the page rank of documents in the search engine of Google. The convergence of the power method has been well studied. Algorithm 2.1 can be regarded as a generalized power method. The convergence of Algorithm 2.1 will be established at the end of this subsection. A second observation is that the key step of Algorithm 2.1 is the iteration step (2.6). Hence, in order to make Algorithm 2.1 fast, we will propose an efficient algorithm to solve the iteration step (2.6). The optimization problem (2.6) can be written in a general form: given a nonzero vector a ≠ 0, solve
| (2.7) |
where 0 ≤ λ < 1. The following theorem establishes the uniqueness of the solution to (2.7).
Theorem 2.1
For any 0 ≤ λ < 1, the space (ℝp, ||·||λ) is a strictly convex Banach space, that is, its unit ball {u: ||u||λ ≤ 1} is a strictly convex set. Moreover, the solution to (2.7) is unique and is a continuous function of a.
Remark
When λ = 1, the norm is just the l1-norm, hence the feasible region is convex but not strongly convex. Therefore, in this case, the solution to (2.7) may not be unique.
Theorem 2.1 is important for studying the convergence and limits of Algorithm 2.1. A similar algorithm to Algorithm 2.1 has been proposed in Witten et al. [15] to solve the optimization problem (2.3) in SCoTLASS for the first PC. However, the feasible region in (2.3) is convex but not strictly convex, hence the solution to each iteration step may not be unique and thus it is not a function of a. Therefore, it is not easy to study the convergence and limits of the iterative algorithm and they did not propose the similar iterative algorithm for higher order PCs of SCoTLASS.
Note that (2.7) is a convex optimization problem. We first derive an explicit solution to a special case of (2.7) based on the Karush-Kuhn-Tucker (KKT) conditions in Theorem 2.2. Then the solutions to general cases of (2.7) can be easily derived. We introduce some notations. Let A[λ] be the p × p matrix with diagonal elements equal to 1 and off-diagonal elements equal to λ. That is,
Suppose that I is a subset of {1, 2, · · ·, p} and the size of I is k. Let Ic be the complement of I. For any p × p matrix B, we use BI to denote the k × k submatrix formed by the rows and columns which original indices are in I. For any u ∈ ℝp, we use uI to denote the k-vector formed by the coordinates which original indices are in I.
Lemma 1
Let 0 ≤ λ < 1 and a = (a1, · · ·, ap)T ≠ 0 with a1 ≥ a2 · · · ≥ ap ≥ 0. Define the partial sums , i = 1, · · ·, p. Then there exists a unique m ∈ {1, 2 · · ·, p} satisfying
| (2.8) |
where we set ap+1 = 0. Moreover, we have
| (2.9) |
Remark
For a special case where a1 = a2 = · · · = ap > 0, it can be derived from the lemma that m = p.
Theorem 2.2
Let 0 ≤ λ < 1. Suppose that in (2.7), a = (a1, · · ·, ap)T ≠ 0 with a1 ≥ a2 · · · ≥ ap ≥ 0. Define the partial sums , i = 1, · · ·, p. Then the unique solution to (2.7) satisfies
| (2.10) |
where m, the number of nonzero coordinates of u*, is the unique integer satisfying (2.8) and ν is a positive scale constant chosen to make ||u*||λ = 1. Furthermore, let I = {1, 2, · · ·, m} be the index set of nonzero coordinates of u*, we have , where ν̃ is a positive constant.
The solution to (2.7) for general cases can be easily obtained from Lemma 1 and Theorem 2.2.
Corollary 2.1
Let 0 ≤ λ < 1 and k1, k2, · · ·, kp be a permutation of 1, 2, · · ·, p such that |ak1| ≥ |ak2| ≥ · · · ≥ |akp| is the sorted sequence of (a1, · · ·, ap) by their absolute values. Define the partial sums , i = 1, · · ·, p, of the sorted sequence. Then there exists a unique m ∈ {1, 2 · · ·, p} satisfying
| (2.11) |
where we set |akp+1| = 0, and the unique solution of (2.7) satisfies
| (2.12) |
where sgn is the sign function, I = {k1, · · ·, km} and ν is a positive constant chosen to make ||u*||λ = 1. Furthermore, let
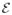 be the p × p diagonal matrix with the i-th diagonal element equal to the sign of ai for all 1 ≤ i ≤ p, we have
be the p × p diagonal matrix with the i-th diagonal element equal to the sign of ai for all 1 ≤ i ≤ p, we have
| (2.13) |
where ν̃ is a positive constant.
Now we propose the following algorithm to solve the optimization problem (2.7) in general cases based on Corollary 2.1.
Algorithm 2.2. (For solving (2.7))
Sort the coordinates ai’s of a by their absolute values: |ak1|≥ |ak2|≥ · · · ≥ |akp|. Let bi = |aki|, 1 ≤ i ≤ p.
-
Compute and find the unique m ∈ {1, 2 · · ·, p} satisfying
where bp+1 = 0.
- Compute
Let û = (û1, · · ·, ûp) with ûki = sgn(aki)yi for 1 ≤ i ≤ p. Then the solution is u* = û/||û||λ.
The following corollary is useful in our proof of consistency results.
Corollary 2.2
Suppose that a is the same as in Corollary 2.1 and is the solution to (2.7) and satisfies (2.12). Let δ > 0 satisfy δ/2ν < 1, where ν is the constant in (2.12). Then the solution to the following problem,
| (2.14) |
is u* multiplied by a positive constant, where .
In the following, we study the convergence and limits of Algorithm 2.1. Let fλ(a) denote the unique solution to (2.7). By Theorem 2.1, for a fixed λ, fλ is a continuous function of a. Since λ is fixed in the following theorems, for simplicity, we omit the subscript λ of fλ hereafter. As a function from ℝp\{0} to the unit sphere {u: ||u||λ = 1} in (ℝp, ||·||λ), f has the following property,
Noting that u(k+1) = f (Σu(k)) in Algorithm 2.1, we define a subset
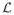 of {u: ||u||λ = 1},
of {u: ||u||λ = 1},
| (2.15) |
Then
is the collection of all fixed points of the function f ∘ Σ. If the initial vector u(0) in Algorithm 2.1 is a point in
, we have u(0) = u(1) = u(2) = · · ·. In this case, Algorithm 2.1 converges to u(0). Hence, any point in
is a possible limit of Algorithm 2.1. We will prove that the iterative procedure in Algorithm 2.1 with any initial vector that satisfies Σu(0) ≠ 0 will converge to one point in
. The limit may depend on the initial vector. The following theorem provides a characterization of the points in
.
Theorem 2.3
Assume that 0 ≤ λ < 1. Let u* be a point in {u: ||u||λ = 1}. Suppose that the number of nonzero coordinates of u* is m and Σu* = (c1, c2, · · ·, cp)T. Let |ck1| ≥ |ck2| ≥ · · · ≥ |ckp| be the sorted sequence of ci’s by their absolute values. Define ai = |cki|, 1 ≤ i ≤ p. Then u* ∈
if and only if
(a1, a2, · · ·, ap) satisfy (2.8) in Lemma 1.
-
The index set I of nonzero coordinates of u* is equal to {k1, k2, · · ·, km} and is an eigenvector with nonzero eigenvalue of the following generalized eigenvalue problem
(2.16) where
is the diagonal matrix with the i-th diagonal element equal to the sign of
for all 1 ≤ i ≤ p.
Now we study the convergence of the iteration in Algorithm 2.1 and its limits.
Theorem 2.4
Assume that 0 ≤ λ < 1. Suppose that for any subset J of {1, 2, · · ·, p}, and any p × p diagonal matrix
with diagonal elements in {1, −1, 0} and the diagonal elements of
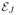 nonzero, all the positive eigenvalues of the following generalized eigenvalue problem have multiplicities 1,
nonzero, all the positive eigenvalues of the following generalized eigenvalue problem have multiplicities 1,
| (2.17) |
Assume that for any u* ∈
,
| (2.18) |
where (c1, c2, · · ·, cp)T = Σu*, I is the index set of nonzero coordinates of u* and m is the size of I. Then the iteration in Algorithm 2.1 converges to a point in
(the limit depends on the initial vector). Furthermore, only those u* ∈
with
being the leading eigenvector of (2.16) are stable limits.
Remark
We say that a limit point is stable if there exists a neighborhood of this point such that once the iteration falls in the neighborhood, it will converge to the limit point.
From the proof of Theorem 2.4, for any unstable limit in
, only an iteration sequence with all but finite points belonging to an affine subspace through that point with dimension strictly less than p can converge to it. Therefore, in practice, due to the rounding errors, the iteration sequence can only converge to stable limits. The solution to (2.2) is one of stable limits in
. Although the stable limits may not be unique, due to the stringent conditions for stable limits in Theorem 2.3, there are only a few stable limits. Note that if u* is a stable limit, so is −u*. We do not differentiate the two limits. Our simulation studies and applications to real data suggest that when λ is small or the differences between the adjacent eigenvalues of covariance matrix are large, there is only one stable limit. For the cases with large λ and the close adjacent eigenvalues of covariance matrix, there can be two or three stable limits. For high dimensional data, a small λ is typically enough to achieve sparsity of the coefficients and high percentage of explained variance. In the case that there is more than one limit, if the initial vector is randomly chosen, our simulations suggest that with larger probability, the iteration converges to the solution to (2.2) than any other limit. These observations are also true for higher order sparse PCs.
2.2. Higher order sparse principal components
Now we propose a similar iterative algorithm for solving the optimization problem (2.4) or (2.5) for the higher order PCs. We will consider the following more general problem of which (2.4) and (2.5) are special cases:
| (2.19) |
where M is a linear subspace of ℝp. M is the subspace spanned by {v1, · · ·, vk−1} for Definition 2, and M is spanned by {Σv1, · · ·, Σvk−1} for Definition 3. We propose the following algorithm to solve (2.19).
Algorithm 2.3. (For solving (2.19))
Choose an initial vector u(0) ∈ ℝp such that Σu(0) ∉ M.
- Iteratively compute u(1), u(2), · · ·, until convergence as follows: for any i ≥ 1, let w(i−1) = Σu(i−1), then u(i) solves the following problem
The optimization problem in the second step of Algorithm 2.3 is a special case of the following problem: given a ∉ M,
| (2.20) |
For a general M, we cannot give an explicit solution to (2.20) as in Theorem 2.2. We will develop a method to solve (2.20) by relating the optimization problem (2.20) to the optimization problem (2.7) which has an explicit solution and can be solved quickly. Recall that f (a) is the solution to the optimization problem (2.7) and is a continuous function of a.
Theorem 2.5
Assume that a ∉ M. Let a⊥ be the orthogonal projection of a onto the orthogonal complement of M. Let q be the dimension of M and {ψ1, · · ·, ψq} be an orthonormal basis of M. Then there exists such that . Moreover, is the unique solution to (2.20).
By Theorem 2.5, solving (2.20) is equivalent to finding t* ∈ ℝq such that . For any t = (t1, · · ·, tq)T ∈ ℝq, we define H(t) to be the squared norm of the orthogonal projection of f (a⊥ + t1ψ1 + · · ·+ tq ψq) onto M. Let Ψ = (ψ1, …, ψq), where ψj = (ψ1j, · · ·, ψpj)T, 1 ≤ j ≤ q, are basis vectors, and x(t) = f (a⊥ + t1ψ1 + · · · + tq ψq) = f (a⊥ + Ψt). Then
| (2.21) |
and H(t) is a continuous function of t. It follows from Theorem 2.5 that H(t*) = 0 and t* is also the minimum point of H(t). We will show that H(t) is a piecewise smooth function. Let
| (2.22) |
ci(t)’s are linear functions of t. Let |ck1(t)| ≥ |ck2(t)| ≥ · · · ≥ |ckq(t)| be the sorted sequence of {c1(t), · · ·, cp(t)} by their absolute values. Note that ki, 1 ≤ i ≤ p, depends on t. Define the following subsets of ℝq,
| (2.23) |
each of which is a union of faces of a finite number of polyhedrons.
Theorem 2.6
H(t) is smooth at any point . Suppose that
is the solution to the following optimization problem
| (2.24) |
Then the first and the second partial derivatives of H(t) are
where
I is the p-dimensional identity matrix, 1 is the p vector with all coordinates equal to 1, and N(t) is the p-dimensional diagonal matrix with the i-th diagonal element equal to sgn(xi(t)), 1 ≤ i ≤ p. 2ν is a scale constant which is the same as that in (2.12) with a and u* replaced with a⊥ + Ψt and x(t), respectively.
By Theorem 2.6, the first and the second partial derivatives of H(t) only involve c(t) and x(t) which can be obtained quickly from Algorithm 2.2. Hence, based on Theorems 2.5 and 2.6, we propose the following algorithm to solve (2.20) by using the Newton method. It is worth to point out that algorithms based on other numerical methods can also be proposed to get the zero point and minimum point t* of H(t), which is equivalent to solving (2.20). Some of them do not use the second derivative of H(t).
Algorithm 2.4. (For solving (2.20))
Compute the projection matrix P = ΨΨT onto M.
Compute the orthogonal projection a⊥ = (I − P)a of a onto the rthogonal complement space M⊥ of M, where I is the identity matrix.
Set the initial value of t equal to zero.
Compute the solution x(t) to (2.24) using Algorithm 2.2.
Compute the first and the second partial derivatives, ∇H(t) and ∇2H(t), of H(t) using Theorem 2.6.
Compute Δt = −(∇2H(t))−1 ∇H(t).
Update the value of t by setting t = t + Δt. Then go back to Step 4 and repeat the procedure until convergence.
In some cases, the second derivatives ∇2H(t) can be nearly singular. We can use the following formula
to calculate Δt in Step 6 of Algorithm 2.4, where ε is the sum of two times of the absolute value of the smallest eigenvalue of ∇2H(t) and a small number (for example, 0.001).
Now we will give the convergence results for Algorithm 2.3 which are very similar to those for the first PC. For any subspace M, define f M(a) to be the solution to (2.20). Then f M is a continuous function from ℝp\M to M⊥∩{u: ||u||λ = 1}, where M⊥ is the orthogonal complement of M. Let
| (2.25) |
The following theorem involves some technical conditions which will be given in its proof.
Theorem 2.7
Assume that 0 ≤ λ < 1. Suppose that all u* ∈
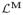 satisfy (5.47). Then the iteration in Algorithm 2.3 converges to one point in
(the limit depends on the initial vector). Furthermore, only u* ∈
with
being a leading eigenvector of problem (5.48) are stable limits, where I is the index set of nonzero coordinates of u*.
satisfy (5.47). Then the iteration in Algorithm 2.3 converges to one point in
(the limit depends on the initial vector). Furthermore, only u* ∈
with
being a leading eigenvector of problem (5.48) are stable limits, where I is the index set of nonzero coordinates of u*.
2.3. Choice of the tuning parameters
The selection of tuning parameters is crucial for the performance of any penalized procedure. The main purpose of sparse PCA is twofold. On the one hand, we want to find principal components which can explain as much as possible variations in data sets. On the other hand, we want to make the coefficients of the principal components as sparse as possible. However, as the tuning parameters increases, sparsity increases, but variation explained decreases. We have to achieve a suitable tradeoff between these two goals. Hence we design the following criteria to choose appropriate tuning parameters. The criteria are similar to the AIC and BIC criteria for linear models. Since we have one tuning parameter for each component, we choose the tuning parameters sequentially from low-order components to high-order components.
For the first principal component, we choose λ1 which maximize
| (2.26) |
where p is the dimension of the coefficients, q1(λ) is the ratio of the explained variances by the first PCs when the tuning parameter is λ to the explained variances when it is zero (the classic PCA), k1(λ) is the number of zeros in the coefficients of the first PC when the tuning parameter is λ. a ∈ (0, 1) is the weight which is chosen based on the purpose of the researchers, that is, the relative importance of sparsity and the explained variations. We choose a larger a if we need sparser principal components.
Suppose that we have chosen the tuning parameters for the first m − 1 components and obtained the first m − 1 principal components v1, · · ·, vm−1. Then the tuning parameter λm of the m-th principal component is chosen by maximizing
| (2.27) |
where a is the same as in (2.26) (that is, a is the same for all components), qm(λ, v1, · · ·, vm−1) is the ratio of the explained variances by the m-th PCs when the tuning parameter is λ to the explained variances when it is zero (the m-th PC should be orthogonal to or uncorrelated with the first m − 1 components), km(λ) is the number of zeros in the coefficients of the m-th PCs when the tuning parameter is λ.
For the total number K of the principal components, we can choose K such that the total variations explained by the first K components is greater than a given large number, or the K + 1 component explain variance less than a given small number.
3. Consistency in high dimensions
In this section, we consider the single component model discussed in John-stone and Lu [7]. We will prove that the PC obtained by our method is consistent under this model when the ratio of the number of variables to the sample size goes to a nonnegative constant.
For each n ≥ 1, we assume that n i.i.d. random samples, , 1 ≤ i ≤ n, are drawn from the following model,
| (3.1) |
where , the single component, is a nonrandom vector. { , 1 ≤ i ≤ n, 1 ≤ n} is a set of i.i.d. standard normal variables and are the noise vectors with { : 1 ≤ j ≤ pn, 1 ≤ i ≤ n} a set of i.i.d. standard normal variables. In this paper, for simplicity, we assume that the variance of noise, σ2, does not depend on n. However, the main result can be easily extended to the cases where σ2 depends on n and is bounded. In Johnstone and Lu [7], ||ρ(n)||2 is assumed to converge to some positive constant. Without loss of generality, we will assume that ||ρ (n)||2 = 1 for simplicity. Our proof can be revised to give the consistency result for the case where the sequence, {||ρ(n)||2: 1 ≤ n}, is bounded.
Our estimate ρ̂(n) of the single component ρ(n) is the solution to the following optimization problem,
| (3.2) |
where and 0 ≤ λ(n) < 1 is the tuning parameter. We will show that ||ρ̂(n) − ρ(n)||2 → 0 as n → ∞ under some conditions. An essential condition for consistency of the method in Johnstone and Lu [7] is the uniform “weak lq decay” condition which is equivalent to the concentration of energy in a few coordinates. Suppose that
are the ordered absolute values of the coordinates of ρ(n). Then the uniform “weak lq decay” condition is that for some 0 < q < 2 and C > 0,
| (3.3) |
where C and q do not depend on n. In addition to this, we need another technical condition. For each n, we define the partial sum , 1 ≤ i ≤ pn. For notational reason, for all i > pn, we define . Then the technical condition is
| (3.4) |
We conjecture that our method is consistent even without this condition. This condition implies that the sequences |ρ(n)|(1) ≥ |ρ(n)|(2) ≥ · · · have a uniform asymptotic decreasing rate. Note that if the condition (3.3) with 0 < q < 1 is satisfied, then (3.4) is automatically true with the limit equal to 0. However, if 1 ≤ q < 2, the condition (3.4) can not be derived from (3.3). Here is an example. Suppose that 1 ≤ q < 2, for each n, let pn = 2n, and |ρ(n)|(2) = · · · = |ρ(n)|(pn) = (2n)−1/q, then the condition (3.3) is satisfied with C = 1. However, a simple calculation shows that the limit in (3.4) is 1 and hence the condition (3.4) is not true in this case. If |ρ(n)|(ν) decrease with order ν−1/q uniformly in the sense that
where cn, n ≥ 1, are positive numbers with infn cn > 0, the condition (3.4) holds. Now we give the main consistency result in high dimension for our method.
Theorem 3.1
Suppose that ||ρ (n)||2 = 1 for all n ≥ 1 and satisfies the conditions (3.3) and (3.4). Assume that pn is a nonrandom sequence such that pn/n → c as n → ∞, where c is a real number. Suppose that c satisfies the following condition,
| (3.5) |
and there exists 0 < α < 1/3 such that
| (3.6) |
Then we have limn→∞||ρ̂(n) − ρ (n)||2 = 0. Moreover, the number of nonzero coordinates of ρ̂(n) is Op(1/λ(n)).
4. Examples
4.1. Pitprops data
The pitprops data, with 180 observations and 13 measured variables, was first introduced by Jeffers [6]. It is a classic example showing the difficulty of interpreting PCs. To illustrate the performance of their sparse PCA methods, several authors have studied the pitprops data, such as Jolliffe et al. [8] (SCot-LASS), Zou et al. [16] (SPCA), and Shen and Huang [13] (sPCA-rSVD).
We first compare our method with SPCA and sPCA-rSVD. We apply our method to this data set and take (0.1, 0.1, 0.13, 0.12, 0.2, 0.2) as the values of λ for the first six PCs. The obtained sparse PC loadings are shown in Table 1. We use Definition 3 for higher order PCs. Then the six sparse PCs are uncorrelated and the explained variances by these PCs can be clearly distiguished. The percentages of the explained variances are listed in Table 1. They are close to the percentages achieved by the classical PCA: 32.4, 18.3, 14.4, 8.5, 7.0, 6.3, respectively. We can obtain sparser PCs by increasing the value of λ, but the percentages of explained variances will decrease.
Table 1.
Loadings of the first six PCs by our method on the pitprops data
| Variables | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 |
|---|---|---|---|---|---|---|
| topdiam | −0.471 | 0 | 0.197 | 0 | 0 | 0 |
| length | −0.484 | 0 | 0.222 | 0 | −0.045 | 0 |
| moist | 0 | −0.684 | 0 | 0.060 | 0.261 | 0 |
| testsg | 0 | −0.659 | −0.072 | 0.063 | 0.189 | −0.121 |
| ovensg | 0 | 0 | −0.745 | 0 | 0 | −0.455 |
| ringtop | −0.134 | 0 | −0.400 | 0 | −0.137 | 0.345 |
| ringbut | −0.383 | 0 | −0.110 | 0 | −0.139 | 0.299 |
| bowmax | −0.254 | 0.137 | 0 | −0.092 | 0 | −0.679 |
| bowdist | −0.383 | 0 | 0 | 0 | −0.080 | 0 |
| whorls | −0.410 | 0.163 | 0 | 0.035 | 0 | 0 |
| clear | 0 | 0 | 0 | −0.978 | −0.040 | −0.091 |
| knots | 0 | −0.229 | 0 | 0 | −0.921 | −0.318 |
| diaknot | 0 | 0 | 0.424 | 0.163 | 0 | 0 |
|
| ||||||
| Variance(%) | 0.301 | 0.156 | 0.132 | 0.078 | 0.065 | 0.046 |
| Cum. var.(%) | 0.301 | 0.457 | 0.589 | 0.666 | 0.731 | 0.778 |
The sparse PCs produced by SPCA and sPCA-rSVD are neither uncorrelated nor orthogonal. We calculate the correlation matrices of the first six sparse PCs obtained in Zou et al. [16] and Shen and Huang [13], respectively. The first matrix in the following is the correlation matrix for SPCA and the second one is for sPCA-rSVD:
We can see that some PCs in both methods are strongly correlated and there is no clear pattern in these correlation matrices. For example, in the second matrix, the third PC is strongly correlated to the first, but weakly correlated with the second and the sixth PCs.
We also compare our method with SCotLASS. In Table 2 (provided by one of the anonymous referees), the loadings of principal components produced by SCotLASS for the pitprops data are listed. The loading are orthogonal to each other and all have l2 norms equal to one. However, the principal components are correlated. In order to make a fair comparison between our method and SCotLASS, we also produce principal components with orthonormal loadings. The loadings by our method with the tuning parameters equal to 0.1, 0.12, 0.12, 0.3, 0.3, 0.3 are listed in Table 3. One can see that two sets of principal components explain almost the same variances, however, the loadings by our method are sparser than those by SCotLASS.
Table 2.
Loadings of the first six PCs by SCotLASS on the pitprops data
| Variables | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 |
|---|---|---|---|---|---|---|
| topdiam | 0.471 | 0 | −0.081 | 0.001 | 0 | 0 |
| length | 0.484 | 0 | −0.101 | 0.030 | 0 | 0 |
| moist | 0 | −0.705 | −0.013 | 0 | 0 | 0 |
| testsg | 0 | −0.709 | 0 | 0 | −0.001 | 0 |
| ovensg | 0 | 0 | 0.590 | 0 | 0 | −0.762 |
| ringtop | 0.135 | −0.026 | 0.358 | 0.009 | 0 | 0 |
| ringbut | 0.383 | 0 | 0.101 | 0 | 0 | 0 |
| bowmax | 0.254 | 0 | 0 | −0.062 | 0 | 0 |
| bowdist | 0.383 | 0 | 0 | 0 | 0.051 | 0 |
| whorls | 0.410 | 0.009 | 0 | 0 | −0.049 | 0 |
| clear | 0 | 0 | 0 | 0 | 0.997 | 0 |
| knots | 0 | 0 | 0 | 0.998 | 0 | 0 |
| diaknot | 0 | 0 | −0.704 | 0 | 0 | −0.638 |
|
| ||||||
| Variance(%) | 0.301 | 0.146 | 0.129 | 0.08 | 0.08 | 0.060 |
| Cum. var.(%) | 0.301 | 0.447 | 0.576 | 0.656 | 0.736 | 0.796 |
Table 3.
Orthonormal loadings of the first six PCs by our method on the pitprops data
| Variables | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 |
|---|---|---|---|---|---|---|
| topdiam | 0.471 | 0 | −0.16 | 0 | 0 | 0 |
| length | 0.484 | 0 | −0.175 | 0 | 0 | 0 |
| moist | 0 | −0.705 | −0.013 | 0 | 0 | 0 |
| testsg | 0 | −0.708 | 0 | 0 | 0 | 0 |
| ovensg | 0 | 0 | 0.542 | 0 | 0 | −0.744 |
| ringtop | 0.134 | −0.02 | 0.470 | 0 | 0 | 0 |
| ringbut | 0.383 | 0 | 0.253 | 0 | 0 | 0 |
| bowmax | 0.254 | 0 | 0 | 0 | 0 | 0 |
| bowdist | 0.383 | 0 | 0 | 0 | 0 | 0 |
| whorls | 0.410 | 0.007 | 0 | 0 | 0 | 0 |
| clear | 0 | 0 | 0 | 0 | 1 | 0 |
| knots | 0 | 0 | 0 | 1 | 0 | 0 |
| diaknot | 0 | 0 | −0.604 | 0 | 0 | −0.669 |
|
| ||||||
| Variance(%) | 0.301 | 0.146 | 0.146 | 0.077 | 0.077 | 0.061 |
| Cum. var.(%) | 0.301 | 0.447 | 0.593 | 0.671 | 0.748 | 0.809 |
Finally, we use the criteria (2.26) and (2.27) to choose the tuning parameters for the first six principal components, respectively. Suppose that sparsity and the variance explained are equally important. We choose a = 0.5 in (2.26) and (2.27). Then the tuning parameters chosen by these criteria are 0.10, 0.35, 0.05, 0.15, 0.30, 0.40. The corresponding loadings of the uncorrelated principal components and the proportions of variances explained are listed in Table 4. There are 44 zeros in the loadings and 78.2% variance is explained by the first six principal components.
Table 4.
loadings of the first six PCs corresponding to the tuning parameters chosen based on criteria (2.26) and (2.27)
| Variables | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 |
|---|---|---|---|---|---|---|
| topdiam | 0.471 | 0 | 0.246 | 0 | 0 | 0 |
| length | 0.484 | 0 | 0.268 | 0 | 0 | −0.266 |
| moist | 0 | −0.717 | 0 | 0.089 | 0 | 0.330 |
| testsg | 0 | −0.618 | −0.106 | 0.088 | 0 | 0 |
| ovensg | 0 | 0 | −0.576 | 0 | −0.555 | −0.396 |
| ringtop | 0.134 | 0 | −0.450 | 0 | 0 | 0 |
| ringbut | 0.383 | 0 | −0.262 | 0 | 0 | 0 |
| bowmax | 0.254 | 0 | 0 | −0.064 | 0 | 0 |
| bowdist | 0.383 | 0 | 0.093 | 0 | 0 | 0 |
| whorls | 0.410 | 0.323 | 0 | 0 | 0.017 | 0 |
| clear | 0 | 0 | 0 | −0.977 | −0.126 | −0.093 |
| knots | 0 | 0 | 0 | 0 | 0.476 | −0.782 |
| diaknot | 0 | 0 | 0.494 | 0.157 | −0.670 | −0.208 |
|
| ||||||
| Variance(%) | 0.301 | 0.140 | 0.145 | 0.076 | 0.061 | 0.058 |
| Cum. var.(%) | 0.301 | 0.441 | 0.587 | 0.662 | 0.723 | 0.782 |
4.2. NCI cell line data
We apply the three methods to the NCI60 dataset which has n = 60 samples and p = 7129 genes (http://www-genome.wi.mit.edu/mpr/NCI60/). We list the percentages of explained variances and the number of nonzero loadings for different tuning parameters in our method in Table 5. We display, in Figure 2, the percentage of explained variances and the sparsity of the first PCs obtained from the three methods for different tuning parameters. The three curves are almost the same. Actually, the variables selected by the three methods are almost identical. For example, when the numbers of nonzero loadings are all 62 for the three methods, the variables selected by sPCA-rSVD and our method are exactly the same and differ from those selected from SPCA only by 4 variables.
Table 5.
Percentages of variations and the number of nonzero coefficients for different tuning parameters in NCI cell line data
| λ | 0 | 0.001 | 0.005 | 0.01 |
|---|---|---|---|---|
| 1st PC | 15.9%(7129) | 15.1%(411) | 13.3%(155) | 12%(101) |
| 2nd PC | 11.6% (7129) | 10.2%(565) | 8.4%(155) | 7.8% (70) |
| 3rd PC | 7.9% (7129) | 7.7% (579) | 6.7%(216) | 5.7%(149) |
| 4th PC | 5.6%(7129) | 5.2% (437) | 4.6%(142) | 4.2% (86) |
| 5th PC | 4.9%(7129) | 4.5%(522) | 3.9% (164) | 3.4%(110) |
| 6th PC | 4.2% (7129) | 4.0%(403) | 3.6%(123) | 3.4%(79) |
Figure 2.

Plot of percentages of explained variances versus the sparsity of the first PCs of the three methods for the NCI60 data.
For higher order PCs, the three methods have quite different results. For SPCA, the first PC is strongly affected by the tuning parameter for the second PC, which is shown in Figure 3. It is hard to tune the parameters simultaneously for SPCA. The sPCA-rSVD and our method are sequential methods, that is, the tuning of parameters for higher order PCs does not affect the lower order PCs. To compare these two methods, we choose the tuning parameters for the first six PCs such that the numbers of nonzero loadings are the same for the two methods and equal to 101, 70, 149, 86, 110, 79, respectively. Our method provides uncorrelated PCs. But there exist strong correlations between some PCs obtained from sPCA-rSVD as shown in the following correlation matrix. Furthermore, in this case, the two methods selected different sets of variables. The numbers of common variables selected by the two methods are 101, 69, 137, 73, 33, 41 for the first six PCs, respectively.
Figure 3.

Influence of the parameter for the 2nd PC on the first PC in SPCA.
5. Proofs
Proof of Theorem 2.1
We first show that ||·||λ is a norm. It is easy to see that for any η ∈ ℝ and u ∈ ℝp, we have that ||ηu||λ = |η|||u||λ, ||u||λ ≥ 0 and ||u||λ = 0 if and only if u = 0. Hence, we only need to show the triangle inequality. For any u, v ∈ ℝp,
| (5.1) |
where the equality in the inequality in the third line of (5.1) holds if and only if for each 1 ≤ i ≤ p, the coordinates ui and vi have the same signs if both of them are nonzero. The inequality in the second line from the last is due to Cauchy-Schwartz inequality and the equality holds if and only if v is a nonnegative scalar multiple of u or vice versa. Therefore, we have the triangle inequality,
| (5.2) |
with equality if and only if v is a nonnegative scalar multiple of u or vice versa. The completeness of (ℝp, ||·||λ) follows from the fact that ||u||2 ≤ ||u||λ ≤ ||u||1 for any u ∈ ℝp. Hence, (ℝp, ||·||λ) is a Banach space.
Now we show the unit ball of (ℝp, ||·||λ) is a strictly convex set, that is, for any 0 < η < 1 and u ≠ v with ||u||λ = ||v||λ = 1, ||ηu + (1 − η)v||λ < 1. Note that ||ηu + (1 − η)v||λ ≤ η||u||λ + (1 − η) ||v||λ = 1 and the equality holds if and only if v is a nonnegative scalar multiple of u by the arguments in the last paragraph. Because ||u||λ = ||v||λ = 1 and u ≠ v, ||ηu + (1 − η)v||λ = 1 if and only if u = v. Thus, we have ||ηu + (1 − η)v||λ < 1.
(2.7) has at least one solution because its objective function is continuous and its feasible region is a compact set. Now suppose that we have two different solutions u1 ≠ u2 to (2.7). Then aTu1 = aTu2 = max||u||λ≤ 1 aT u. It is obvious that ||u1||λ = ||u2||λ = 1. Let . We have ||ū||λ < 1 by the strict convexness. Hence,
We have obtained a contradiction. Therefore, the sulotion to (2.7) is unique.
Let f (a) denote the unique solution to (2.7). Then f is a function from ℝp\{0} to {u: ||u||λ = 1}. We show that f is a continuous function. Assume contrary, that is, there exist a point a ∈ ℝp\{0} such that f is discontinuous at a. By the compactness of {u: ||u||λ = 1}, we can find a sequence {an, n ≥ 1} in ℝp\{0} such that an → a and f (an) → û ≠ f (a). By the definition of f, we have . Let n → ∞, then we have aT û ≥ aT f (a) = max||u||λ≤ 1 aT u. Therefore, both û and f (a) are solutions to (2.7), which contradicts to the uniqueness of the solution to (2.7). Thus f is a continuous function.
Proof of Lemma 1
Define
| (5.3) |
Since we have set ap+1 = 0, p belongs to the subset in the right hand side of (5.3). Hence, this subset is nonempty. By the definition (5.3), we have (define S0 = 0 if m = 1)
Therefore,
| (5.4) |
and (2.8) follows from (5.3) and (5.4). By similar arguments as in (5.4), we can show that
| (5.5) |
By the definition (5.3), for any i < m, we have
| (5.6) |
(5.4), (5.5) and (5.6) lead to (2.9). The uniqueness of m follows from (2.9) and the definition (5.3).
Proof of Theorem 2.2
Due to the conditions on a in this theorem, we have , for all 1 ≤ i ≤ p. Hence, u* is also the unique solution to the following convex optimization problem,
| (5.7) |
The condition can be written as uT A[λ]u − 1 ≤ 0. Because (5.7) is a convex optimization problem, u* is the solution to (5.7) if and only if it satisfies the following Karush-Kuhn-Tucker (KKT) conditions (see Section 5.5.3 of Boyd and Vandenberghe [2]),
| (5.8) |
where μ = (μ1, · · ·, μp)T and ν̃ are unknown multipliers. From the equalities in the first line of (5.8), we obtain a set of linear equations
| (5.9) |
The solution to this set of linear equations is
| (5.10) |
where and
| (5.11) |
Because for all 1 ≤ i ≤ p, if , then μi = 0 and if μi > 0, then . Therefore, by (5.10), we have either or . Thus, we have . Define
| (5.12) |
We will show that m satisfies (2.8). Because and μi = 0 for all i ≤ m, and for all i > m, by (5.10),
from which we obtain
| (5.13) |
It follows from (5.10), and μm = 0 that [(α + β)am − β(Sp + Δ)]/2ν̃ > 0, and hence by (5.13), . Similarly, from (5.10), andμm+1 ≥ 0, we can obtain . Hence, m satisfies (2.8). The expressions of the solutions in (2.10) can be obtained from (5.10) with ν = ν̃/(α + β). Since I = {1, 2, · · ·, m}, , μi = 0 for all i ∈ I and for all i ∈ Ic. By (5.9), we have .
Proof of Corollary 2.2
Without loss of generality, we assume that a1 ≥ a2 ≥ · · · ≥ ap ≥ 0. Let ã = (ã1, · · ·, ãp) = a − δu* and S̃i = ã1 + · · · + ãi. Then u* satisfies (2.10) and
Let be the solution to (2.14). A simple calculation shows that
Hence, by Theorem 2.2, for i > m and
for i ≤ m, where ν̃ is a scale constant.
Proof of Theorem 2.3
Because u* ∈
if and only if u* is the solution to the optimization problem (2.7) with a replaced by Σu*, this theorem follows from Corollary 2.1 and (2.16) can be derived from (2.13) by noticing that
and ci have the same sign for all i ∈ I.
Proof of Theorem 2.4
Recall that u(0), u(1), u(2), · · · is the iteration sequence in Algorithm 2.1.
Lemma 2
For any u with ||u||λ = 1. Let u′ = f(Σu). Then we have uTΣu ≤ u′T Σu′, where equality holds if and only if u = u′. Hence, u(k)T Σu(k), k ≥ 1, is an increasing sequence.
Proof of Lemma 2
Because Σ is a nonnegative definite symmetric matrix, we can find a matrix B such that Σ = BT B. By the definition of f and Cauchy-Schwarz inequality, we have
| (5.14) |
Thus uT Σu ≤ u′T Σu′, where equality holds if and only if u = u′ because equality in the first inequality of (5.14) holds if and only if u = u′.
We first assume that
is the leading eigenvector of (2.16) where I is the index set of nonzero coordinates of u*. We will find a neighborhood
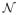 of u* such that if u(k) ∈
∩ {u: ||u||λ = 1} for some k ≥ 1, then the iteration will converge to u*. Without loss of generality, we assume that
of u* such that if u(k) ∈
∩ {u: ||u||λ = 1} for some k ≥ 1, then the iteration will converge to u*. Without loss of generality, we assume that
| (5.15) |
We decompose the matrix Σ as follows
| (5.16) |
where Ic = {1, 2, · · ·, p}\I, ΣI and ΣIc are m × m and (p − m) × (p − m) matrices, respectively, and Λ is a m × (p − m) matrix. It follows from (2.16) and (5.15), is the leading eigenvector of the following generalized eigenvalue problem,
| (5.17) |
Recall that A[λ] is the p × p matrix with diagonal elements equal to 1 and off-diagonal elements equal to λ.
Lemma 3
Suppose that g, g′ ∈ ℝm are two eigenvectors of (5.17) corresponding to different eigenvalues. Then we have .
Proof of Lemma 3
Suppose that the eigenvalues corresponding to g and g′ are μ and μ′, respectively. Because
| (5.18) |
and
| (5.19) |
by subtracting (5.18) from (5.19), we obtain
Since μ ≠ μ′, we have .
Suppose that μ1 ≥ μ2 ≥ · · · ≥ μm ≥ 0 are eigenvalues of (5.17) and the corresponding eigenvectors g1, g2, · · ·, gm ∈ ℝm satisfying
| (5.20) |
Note that if μi ≠ μj, then by Lemma 3, the second equality in (5.20) is true. For μi = μj, we can apply the Gram-Schmidt orthogonalization procedure to choose the eigenvectors satisfying (5.20). Since is the leading eigenvector of (5.17), by the condition (2) in Theorem 2.3, we have μ1 ≠ 0. By the assumption of this theorem, the multiplicity of μ1 is one, hence is equal to g1 multiplied by a constant. By (5.15), without loss of generality, we can assume that all coordinates of g1 are positive. For 1 ≤ i ≤ m, define hi to be the p-vector with the first m coordinates equal to gi and the last p −m coordinates equal to zeros, that is,
| (5.21) |
Define hm+j, 1 ≤ j ≤ p − m, to be the p-vectors with the m + j-th coordinate equal to 1 and other coordinates equal to 0. Then {h1, · · ·, hp} form a basis of ℝp and it follows from the following lemma that
| (5.22) |
Lemma 4
There exists δ1 > 0 such that for any u = ηh1 + ε2h2 + · · · + εmhm with |1 − η| < δ1 and , we have
| (5.23) |
Hence, in this case, ||u||λ = 1 if and only if .
Proof of Lemma 4
By the definition (5.21), the last p −m coordinates of u are zeros. The first m coordinates of h1 are equal to coordinates of g1 which are positive. Therefore, if η is close enough to 1 and ε2, · · ·, εp−m are small enough, the first m coordinates of u are positive. Thus, by (5.20),
| (5.24) |
Recall that Σu* = c = (c1, · · ·, cp)T. We sort the absolute values of ci’s into an decreasing sequence |ck1| ≥ |ck2| ≥ · · · ≥ |ckp| and define ai = |cki|, 1 ≤ i ≤ p. Since u* →
, that is, u* = f (Σu*) = f (c), by Corollary 2.1 and (5.15), I = {k1, k2, · · ·, km} = {1, 2, · · ·, m}, that is, {k1, k2, · · ·, km} is a permutation of {1, 2, · · ·, m}, and
, 1 ≤ i ≤ m, has the same sign as ci, that is
| (5.25) |
Let , 1 ≤ i ≤ p. By the condition (2.18),
| (5.26) |
It follows from (5.26) and the condition (2.11) in Corollary 2.1 that
| (5.27) |
Lemma 5
There exists a positive number δ2 ≤ δ1 (δ1 is defined in Lemma 4) such that if there is a vector in the iteration sequence of Algorithm 2.1 belonging to the following subset
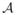 of {u: ||u||λ = 1},
of {u: ||u||λ = 1},
| (5.28) |
then the iteration sequence converges to u* = h1.
Proof of Lemma 5
Without loss of generality, we assume that u(0) ∈
. Suppose that
Define . Then as , by (5.22),
| (5.29) |
Hence, by (5.25), when is small enough, we have
| (5.30) |
Let be the sorted sequence. Define , 1 ≤ i ≤ p and , 1 ≤ i ≤ p. Then, we have and , 1 ≤ j ≤ p, as . Because by (5.27), maxm+1≤ i ≤ p|ci| = maxi∉I |ci| = am+1 < am = mini∈I |ci| = min1≤i≤m |ci|, when is samll enough, we have . Hence, { } is a permutation of { } and { } is a permutation of { }. In another word,
| (5.31) |
and . Therefore, we can choose δ2 ≤ δ1 small enough such that (5.30), (5.31) and the following inequality (due to (5.27)) hold,
| (5.32) |
Now by (5.31), (5.32), and Corollary 2.1, the coordinates of u(1) with indices in are zeros. It follows from (2.13) that
| (5.33) |
where ν a positive scale constant chosen to make ||u(1)||λ = 1. Since is invertible, we have . Hence, . By (5.30) and (5.33), . Hence, . we have
where and , 2 ≤ i ≤ m. By the assumptions of this theorem, the nonnegative eigenvalues have multiplicities 1, so μ1 > μ2 ≥ · · · ≥ μp. Then we have
Hence, u(1) ∈
. Similarly, all the iteration sequence
where and
Therefore u(k) ∈ h1 as k → ∞.
Now define a neighborhood of u* = h1 as follows
| (5.34) |
By a similar argument as that in the proof of Lemma 5, we can choose δ3 small enough such that if u(k) ∈
∩ {u: ||u||λ = 1} for some k ≥ 1, then u(k+1) ∈
and the iteration will converge to u* by Lemma 5.
Now we assume that is not the leading eigenvector of the problem (2.16). Without loss of generality, we assume that is the eigenvector corresponding to the second largest eigenvalue. For other cases, we have the similar results and proofs. We will adapt the same notations as above and still assume that the first m coordinates of u are positive and the last p −m coordinates are zeros. Hence, in this case, we have u* = h2 and . By the assumptions of this theorem, both μ1 and μ2 have multiplicities 1. Therefore, we have μ1 > μ2 > μ3 ≥ · · ·. We define the following two subsets of {u: ||u||λ = 1} around u* = h2,
The only difference between
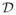 and
and
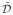 is the ranges of ε1. Note that
⊂
is the ranges of ε1. Note that
⊂
Lemma 6
For
small enough and any u ∈
, we have
| (5.35) |
where
. Furthermore, f (Σu) ∈
.
Recall that f (Σu) is the solution to optimization problem (2.7) with a replaced with Σu.
Proof of Lemma 6
(5.35) can be derived by the same arguments as in the case that
is the leading eigenvector. Now we show that f (Σu) ∈
. Since
and
where the last inequality is due to the definition of
. Thus f (Σu) ∈
.
Now without loss of generality, we assume that u(0) ∈
. Let u(0) = ε1h1 + ηh2 + ε3h3 + · · · + εmhm. If ε1 = 0, by (5.35) in Lemma 6, the coefficient of h1 in u(1) = f (Σu(0)) is also zero. This fact is true for all vectors in the iteration sequence. We can use the same arguments as in the case that
is the leading eigenvector to show that the iteration sequence converges to
. However, if ε1 ≠ 0, we have a different result.
Lemma 7
For any u ∈
\
, we have uT
Σu > (u*)T
Σ(u*).
Proof of Lemma 7
Let u = ε1h1 + ηh2 + ε3h3 + · · · + εmhm. Since u ∈
\
, we have
| (5.36) |
Because the last p − m coordinates of u are zeros, we have
Now if ε1 ≠ 0, by (5.35), we can obtain that the coefficient of h1 in u(k) is
which is strictly increasing. Hence, when k is large enough, u(k) will leave the subset
. Suppose that k0 is the index with u(k0) ∈
and u(k0+1) ∉
. Then by Lemmas 6 and 7, we have that u(k0+1) ∈
\
and (u(k0+1))T
Σu(k0+1> (u*)T
Σ(u*). Now by Lemma 2, {(u(k))T
Σu(k): k ≥ 1} is an increasing sequence, hence {u(k): k ≥ 1} can not converge to u*.
Now define a neighborhood of u* = h2 as follows
| (5.37) |
By the same arguments as in the case that
is the leading eigenvector, we can show that when δ5 small enough we have if u(k) ∈
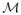 , then u(k+1) ∈
. In this case, let u(k) = ω1h1 + (1 + ω2)h2 + · · · + ωmhm + · · · + ωphp. We will compute the coefficient of h1 in u(k+1). By the decomposition (5.16) of Σ and the following decompositions,
, then u(k+1) ∈
. In this case, let u(k) = ω1h1 + (1 + ω2)h2 + · · · + ωmhm + · · · + ωphp. We will compute the coefficient of h1 in u(k+1). By the decomposition (5.16) of Σ and the following decompositions,
where .
It follows from (2.13) that
where ν is a positive scale constant. Then the coefficient of h1 in u(k+1) is equal to
Now define the following affine subspace passing through u* = h2 in ℝp with dimension strictly less than p,
| (5.38) |
Then if u(k) ∈
∩
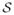 ∩ {{u: ||u||λ = 1} for some k ≥ 1, then all u(k+1), u(k+2), · · ·, will belong to
∩ {{u: ||u||λ = 1} and their coefficients of h1 are all zeros. Hence, the iteration sequence converges to u*. If u(k) ∈
∩
∩ {{u: ||u||λ = 1} for some k ≥ 1, then all u(k+1), u(k+2), · · ·, will belong to
∩ {{u: ||u||λ = 1} and their coefficients of h1 are all zeros. Hence, the iteration sequence converges to u*. If u(k) ∈
∩
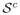 ∩ {{u: ||u||λ = 1} for some k ≥ 1, all u(k+1), u(k+2), · · ·, will belong to
∩ {{u: ||u||λ = 1}, but their coefficients of h1 are all nonzero. The iteration sequence can not converge to u*. Therefore, in this case, u* is not a stable limit.
∩ {{u: ||u||λ = 1} for some k ≥ 1, all u(k+1), u(k+2), · · ·, will belong to
∩ {{u: ||u||λ = 1}, but their coefficients of h1 are all nonzero. The iteration sequence can not converge to u*. Therefore, in this case, u* is not a stable limit.
At last, we prove the iteration sequence converges. Because {u: ||u||λ = 1} is a compact set, we can find a convergent subsequence {ukj: k1 < k2 < · · ·} of the iteration sequence. Suppose that ukj → u* as j → ∞. We first show that u* ∈
which is defined in (2.15). Because ukj+1 = f (Σkj) and f is a continuous function, ukj+1 → f (Σu*). Let ū′ = f (Σu*). Then we have
and
. By Lemma 2, {
} is an increasing sequence. Hence, u*T
Σu* = (ū′)T
Σū′ and by Lemma 2, u* = ū′, that is, u* ∈
. Now if u*I is a leading vector of (2.16). Let
be the neighborhood of u* defined in (5.34). Then when kj is large enough, ukj ∈
. Hence, the iteration sequence converges to u*. If u*I is not a leading vector. Let
and
be the subsets defined in (5.37) and (5.38). Since ukj → u*, we must have that when kj is large enough, ukj ∈
∩
. Hence, the iteration sequence converges to u*.
Proof of Theorem 2.5
Let Ψ = (ψ1, …, ψq) be a p × q matrix, where the basis ψj = (ψ1j, · · ·, ψpj)T ∈ Rp, 1 ≤ j ≤ q. Then t1ψ1 + · · · + tq ψq = Ψt, ∀t = (t1, · · ·, tq)T ∈ ℝq. We first show that if for some t* ∈ ℝp, f (a⊥ + Ψt*) ⊥ M, then f (a⊥ + Ψt*) is the solution to (2.20). Actually, for any u with u ⊥ M and ||u||λ = 1, we have
where the inequality follows from the definition of f. The uniqueness of the solution to (2.20) is due to the strict convexness of {u: ||u||λ = 1}. For any t = (t1, · · ·, tq)T ∈ ℝq, let the orthogonal projection of f (a⊥ + Ψt) onto M have the basis expansion Ψs = s1ψ1 + · · · + sq ψq, where s = (s1, · · ·, sq)T ∈ ℝq is a function of t. Hence, we define s = Γ(t). Then Γ is a continous function from Rq to Rq because f is a continuous function. We only need to show that there exists t* such that Γ(t*) = 0. We first prove a technical lemma.
Lemma 8
If , we have tTΓ(t) > 0. Moreover, if ||t||2 → ∞, we have .
Proof of Lemma 8
We will proceed by contradiction. Assume that tT Γ(t) ≤ 0. Let f (a⊥ + Ψt) = ΨΓ(t) + u⊥, where u⊥ ⊥ M. Hence, . Note that {ψ1, · · ·, ψq} is an orthonormal basis. Then we have
It is a contradiction because, by the definition of f, (a⊥ + Ψt)T f (a⊥ + Ψt) is the largest among all (a⊥ + Ψt)T u with ||u||λ = 1. The last statement in this lemma follows from
Now if q = 1, t is the real number. By Lemma 8, we can choose t > 0 so large that tΓ(t) > 0 and (−t)Γ(−t) > 0. Hence, we have Γ(−t) < 0 < Γ(t). Because Γ is a continuous function, the intermediate value theorem implies that for some −t ≤ t* ≤ t, Γ(t*) = 0.
If q > 1, we need some basic results from topology. We first give a definition (see Section 51 in Munkres [9]). Suppose that ρ0 and ρ1 are continuous maps of from a space X into X, we say that ρ0 is homotopic to ρ1 if there is a continuous map F: X ×[0, 1] → X such that F (x, 0) = ρ0(x) and F (x, 1) = ρ1(x), ∀x ∈ X. If ρ1 maps all points in X into a fixed point in X, we say that ρ0 is null homotopic. It is well known that the identity map from the unit sphere Sq−1 of ℝq (with l2-norm) onto Sq−1 is not null homotopic (see Exercise 4(a), after Section 55 in Munkres [9]). We will proceed by contradiction. Assume that Γ(t) ≠ 0 for all t ∈ ℝq. By Lemma 8, we can choose a large M > 0 such that if ||t̃||2 = M, we have t̃TΓ(t̃) > 0. Hence, for any t ∈ Sq−1, tTΓ(M t) > 0. Now we define a continuous map F: Sq−1 × [0, 1] → Sq−1 as follows,
where (1 −2θ)t + 2θΓ(Mt) ≠ 0 for all . It is easy to see that F(t, 0) is the identity map from Sq−1 to Sq−1 and F (t, 1) maps every t to Γ(0)/||Γ(0)||2, which contradict to the fact that the identity map from Sq−1 onto Sq−1 is not null homotopic.
Proof of Theorem 2.6
Recall that Ψ = (ψ1, …, ψq), where the basis ψj = (ψ1j, · · ·, ψpj)T ∈ Rp, 1 ≤ j ≤ q. Suppose that . We will calculate the first and second order partial derivatives of H at point t̄. Let , 1 ≤ i ≤ p, where ci(t̄)’s are define in (2.22). Let m be the number of nonzero coordinates of f (a⊥ + Ψt̄). Then by (2.11) in Corollary 2.1
and the set I of indices of nonzero coordinates of f (a⊥ + Ψt̄) is equal to {k1, · · ·, km}. By the definition of
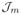 , we have the following strict inequalities,
, we have the following strict inequalities,
| (5.39) |
Let Δt = (Δt1, Δ2, · · ·, Δtq) and be the sorted sequence. Define , 1 ≤ i ≤ p. By similar arguments as in the proof of Lemma 5, it follows from (5.39) that when ||Δt||2 is small enough, we have
| (5.40) |
and . Recall that we have defined x(t) = (x1(t), · · ·, xq (t))T = f (a⊥ + Ψt̄). It follows from (5.40) and Corollary 2.1 that
| (5.41) |
where ν and ν′ are the scale constants. Since ci(t̄ + Δt) = ci(t̄) + (ΨΔt)i, when ||Δt||2 is small enough, we have sgn(ci(t̄ + Δt)) = sgn(ci(t̄)) ≠ 0 for i ∈ I. In this case,
Hence, for i ∈ I, we have
| (5.42) |
where the last two equalities follows from the facts that xi(t̄) and ci(t̄) have the same signs for i ∈ I and the signs of xi(t̄) are zeros for all i ∈ Ic. Note that the last line in (5.42) is equal to xi(t̄ + Δt) even if i ∈ Ic because both of them are equal to zero. Thus, we have
| (5.43) |
where the p × q matrix
| (5.44) |
I is the p-dimensional identity matrix, 1 is the p vector with all coordinates equal to 1, and N(t̄) is the p-dimensional diagonal matrix with the i-th diagonal element equal to sgn(xi(t̄)), 1 ≤ i ≤ p. Now by the definition of H, we have H(t̄) = x(t̄)T ΨΨT x(t̄) and
| (5.45) |
where the q-vector G(t̄) = K(t̄)T ΨΨT x(t̄) and the q × q matrix Π(t̄) = K(t̄)T ΨΨT K(t̄). Now we compute (2ν′)2. From (5.43), we have
where the q-vector E and the q × q matrix F are
Since ||x(t̄)||λ = 1,
Now by (5.45),
Hence we have
Proof of Theorem 2.7
Recall that Ψ = (ψ1, …, ψq) is the matrix of basis vectors of M, where q is the dimension of M. For any 1 ≤ j ≤ p, let ej be the vector with q-th coordinate equal to 1 and other coordinates equal zeros. {e1, · · ·, ep} is a basis of ℝp. For any subset I of {1, · · ·, p}, we choose a subset J = J(I) of Ic such that {ei: i ∈ J} ∪ {ψj: 1 ≤ j ≤ q} is a basis for the subspace spanned by {ei: i ∈ Ic} ∪ {ψj: 1 ≤ j ≤ q}. For any u* ∈
, let I be the index set of nonzero coordinates of u*. Since u* is the solution to
it is also the solution to
which is equivalent to the problem
By the Karush-Kuhn-Tucker condition, we have
| (5.46) |
where ν̃ > 0, μi and βj are multipliers and
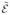 is the p-dimensional diagonal matrix with the i-th diagonal element equal to
if i ∈ I and 1 if i ∈ I c. We will assume that for all u* ∈
,
is the p-dimensional diagonal matrix with the i-th diagonal element equal to
if i ∈ I and 1 if i ∈ I c. We will assume that for all u* ∈
,
| (5.47) |
From (5.46), we have
and thus
| (5.48) |
where
is the orthogonal projection matrix onto the orthogonal complement of the space spanned by (ψj)I, 1 ≥ j ≥ q. Hence,
is an eigenvector of the generalized eigenvalue problem (5.48) corresponding nonzero eigenvaules. Now we can use the same arguments as in the proof of Theorem 2.4 to prove the convergence of Algorithm 2.3. Moreover, we can show that only u* ∈
with
being a leading eigenvector of problem (5.48) are stable limits.
Proof of Theorem 3.1
Since , we can find a positive number β such that
| (5.49) |
Without loss of generality, we assume that for each n,
| (5.50) |
Then the uniform “weak lq decay” condition (3.3) becomes
| (5.51) |
and the partial sum , 1 ≤ i ≤ pn. Let , and be the pn × n noise matrix. Then the pn × pn sample covariance matrix is
| (5.52) |
where I is the pn-dimensional identity matrix, is a pn-dimensional random vector and Π(n) = Z(n)(Z(n))T is a pn × pn random matrix and has a Wishart distribution with n degrees of freedom. By the condition (3.4), we can choose a positive integer m0 (independent of n) and a real number 0 < τ < 1 such that for any m ≥ m0,
| (5.53) |
Define
| (5.54) |
We first provide several technical lemmas whose proofs are given in Appendix. Recall that for any two vectors u and v, we use 〈u, v〉 = uT v to denote the inner product between u and v. By the condition (3.5), we have and . Thus, we can find κ1 > 0 and κ2 > 0 small enough such that
| (5.55) |
| (5.56) |
Lemma 9
Suppose that κ1 and κ2 satisfy (5.55) and (5.56), respectively, we have
| (5.57) |
| (5.58) |
Lemma 10
If μ̂ (n) > (1 + κ2)σ2 and λ(n) ≤ κ2/(1 + κ2), then ρ̂(n) is the solution to the following optimization problem multiplied by a constant,
where I is the identity matrix and .
Let
Then we have the following lemma.
Lemma 11
If (5.58) holds for some positive κ2, we have
| (5.59) |
We choose and fix κ1 > 0 and κ2 > 0 such that (5.55) and (5.56) hold. Define ζ(n) = ξ(n)/(〈ρ̂(n), ρ(n)〉 + 〈ρ̂(n), y(n)〉) and
then
It follows from (5.57) and (5.59) that
| (5.60) |
where . Define a sequence of measurable subsets of the probability space
| (5.61) |
It follows from Lemma 9 and (5.60) that
| (5.62) |
where (Ω(n))c is the complement of Ω(n). Hence by Borel-Cantelli Lemma, it holds almost surely that for all but finitely many n, the event Ω(n) happens. Therefore, in the following, we will assume that the inequalities in the definition (5.61) of Ω(n) hold for all n large enough. By Lemma 10, ρ̂(n) is the solution to the following optimization problem multiplied by a constant,
Let |â(n)|(1) ≥ |â(n)|(2) ≥ · · · ≥ |â(n)|(pn) be the sorted sequence of the co-ordinates ( ) of â(n) by their absolute values. Define the partial sums , 1 ≤ i ≤ pn. Since , from which and (5.50) we can obtain that
| (5.63) |
Let m̂(n) be the number of nonzero coordinates of ρ̂(n). We will give an upper bound for m̂(n). Define
| (5.64) |
where τ is the constant defined in (5.53), λ̃ (n) is defined in Lemma 10. For any real number x, ⌊x⌋ denotes the largest integer number smaller than x.
Lemma 12
With probability 1, m̂(n) ≤ m(n) when n is large enough.
By Corollary 2.1, we have
| (5.65) |
where and
| (5.66) |
(x)+ denotes the function which is equal to zero if x < 0 and equal to x if x ≥ 0. We will show as n → ∞. Let
| (5.67) |
Then I0 ∪ I1 ∪ I2 = {1, 2, · · ·, pn} and the number of elements in I1 ∪ I2 is m̂(n). It can be seen that for any i ∈ I0, we have
| (5.68) |
for any i ∈ I1,
| (5.69) |
and for any i ∈ I2,
| (5.70) |
First we calculate
By the condition (5.51), we have
Hence, by Lemma 12, if 1 < q < 2,
Similarly, for other two cases. Since n−2βm̂(n) ≤ n−2βm (n) = O(n−2β/λ̃(n)) = O(n−2β+α) → 0 by (5.49),
| (5.71) |
| (5.72) |
| (5.73) |
It follows from (5.71) that
Because each term in the sum (5.72) converges to zero as n → ∞ and the sequence dominated by {Ci−1/q: i ≥ 1} which is square summable, by the Dominated Convergence Theorem, the sum (5.72) converges to zero. Hence, we have proved that . Since ||ρ(n)||2 = 1, .
the right hand side goes to zero.
Supplementary Material
Acknowledgments
Supported in part by NSF grant DMS 0714817 and NIH grants P30 DA18343 and R01 GM59507.
The authors want to thank the Editors and the reviewers whose comments have greatly improved the scope and presentation of the paper.
6. Appendix
We will use the following large deviation inequalities for chi-square distribution (see (A.2) and (A.3) in Johnstone and Lu [7]).
| (6.1) |
Proof of Lemma 9
By (5.55), we can pick small enough such that
| (6.2) |
and
| (6.3) |
| (6.4) |
because the two sides of (6.2) and (6.3) converge to the two sides of (5.55) and (5.56), the left side of (6.4) goes to which is smaller than 3 by (5.56), as ε → 0. We choose an integer N > 0 (independent of n) such that . We define , then by the condition (5.51),
| (6.5) |
Since ρ̂(n) is the solution to (3.2), we have
| (6.6) |
By a simple calculation, it follows from (5.52) that
| (6.7) |
where γ̂(n) is the largest eigenvalue of . Similarly, by (6.5),
| (6.8) |
Now it follows from (6.6) − (6.8) that
| (6.9) |
Since and as n → 0, we have when n is large enough. Therefore, it follows from (6.9) that when n is large enough,
| (6.10) |
Since , we have when n is large enough. If and , then by (6.10) and (6.2), when n is large enough, we have
| (6.11) |
moreover, by the definition (5.54) of μ̂ (n), (6.8) and (6.3),
| (6.12) |
and by (6.6), (6.7), (6.12) and (6.4),
| (6.13) |
Hence, when n is large enough, by (6.11) − (6.13), we have
| (6.14) |
| (6.15) |
and
| (6.16) |
has -distribution and has the distribution where and are independent (see (24) in Johnstone and Lu [7]). It follows from (6.1) that
| (6.17) |
Now we consider the term for ||y(n) ||2. If c > 0, then pn → ∞ and thus
| (6.18) |
If c = 0, let , the largest integer less than or equal to .
| (6.19) |
where is independent of . By (2) in Geman [5], because γ̂(n) + 1 is the largest eigenvalue of Π(n)/n, we have
| (6.20) |
Proof of Lemma 10
First note that ρ̂(n)/||ρ̂(n)||λ(n) is the solution to the following optimization problem,
We will verify the conditions in Corollary 2.2. Then this lemma follows from Corollary 2.2. Let â (n) = Σ̂ (n)ρ̂(n). Without loss of generality, in this proof, we assume that . Let I = {1, 2, · · ·, m}. Then by Theorem 2.3, we have , from which we can obtain that
where and . Under the conditions of this lemma, σ2/μ̂ (n)(1 − λ (n)) < 1, that is, the conditions of Corollary 2.2 are satisfied.
Proof of Lemma 11
By (5.52),
Hence,
where yi and are the i-th coordinates of y(n) and , respectively. First, we calculate
| (6.21) |
Since
where and are two independent variables, the probability in (6.21) is less than or equal to
Since by (5.49), it follows from (6.1) and (5.58) that
| (6.22) |
Second, because
where and are two independent variables, by the same argument, we have
| (6.23) |
Then the lemma follows.
Proof of Lemma 12
Recall the partial sums
By Theorem 2.2 and Lemma 1, we only need to show that
| (6.24) |
Let . Since m(n) → ∞ as n → ∞, when n is large, we have k > m0, where m0 is defined in (5.53). Hence, the inequality (5.53) is true for k. From the definition (5.64) of m(n), we can obtain that
| (6.25) |
Then
| (6.26) |
where the inequality in the third line is due to (5.53) and the last inequality is due to (6.25). It follows from (5.63) that
| (6.27) |
We will consider the following two cases separately. If , by (6.26) and (6.27),
If , let us compute
| (6.28) |
where the last inequality follows from the condition (5.51). Hence,
where the inequality in the last line is due to (6.25) and . By (6.28) and the definition (5.64) of m(n), which is lager than when n is large by (5.49). Therefore, we have proved (6.24).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Xin Qi, Email: xqi3@gsu.edu, Department of Mathematics and Statistics, Georgia State University, 30 Pryor Stree, Atlanta, GA 30303-3083.
Ruiyan Luo, Email: rluo@gsu.edu, Department of Mathematics and Statistics, Georgia State University, 30 Pryor Stree, Atlanta, GA 30303-3083.
Hongyu Zhao, Email: hongyu.zhao@yale.edu, Department of Epidemiology and Public Health, Yale University, New Haven, CT 06520-8034.
References
- 1.Amini A, Wainwright M. High-dimensional analysis of semidefinite relaxations for sparse principal components. Annals of Statistics. 2009;37:2877–2921. [Google Scholar]
- 2.Boyd S, Vandenberghe L. Convex Optimization. chap 5. Cambridge University Press; 2004. [Google Scholar]
- 3.Cadima J, Jolliffe I. Loadings and correlations in the interpretation of principal components. Journal of Applied Statistics. 1995;22:203–214. [Google Scholar]
- 4.D’Aspremont A, Bach F, Ghaoui LE. A direct formulation of sparse PCA using semidefinite programming. SIAM Riew. 2007;49:434–448. [Google Scholar]
- 5.Geman S. A limit theorem for the norm of random matrices. The Annals of Probability. 1980;8:252–261. [Google Scholar]
- 6.Jeffers J. Two case studies in the application of principal component. Applied Statistics. 1967;16:225–236. [Google Scholar]
- 7.Johnstone IM, Lu AY. On consistency and sparsity for principal components analysis in high dimensions. Journal of the American Statistical Association. 2009;104(486):682–693. doi: 10.1198/jasa.2009.0121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Jolliffe IT, Trendafilov NT, Uddin M. A modified principal component technique based on the LASSO. Journal of Computional and Graphical Statistics. 2003;12:531–547. [Google Scholar]
- 9.Munkres J. Topology. 2. Prentice Hall; 2000. [Google Scholar]
- 10.Nadler B. Finite sample approximation results for principal component analysis: A matrix perturbation approach. The Annals of Statistics. 2008;36:2791–2817. [Google Scholar]
- 11.Paul D. Asymptotics of sample eigenstructure for a large dimensional spiked covariance model. Statistica Sinica. 2007;17:1617–1642. [Google Scholar]
- 12.Quarteroni A, Sacco R, Saleri F. Numerical Mathematics (Graduate Texts in Mathematics) 2. Springer; 2006. [Google Scholar]
- 13.Shen H, Huang J. Sparse principal component analysis via regularized low rank matrix approximation. Journal of Multivariate Analysis. 2008;99 [Google Scholar]
- 14.Trendafilov NT, Jolliffe IT. Projected gradient approach to the numerical solution of the scotlass. Computational Statistics and Data Analysis. 2006;50:242–253. [Google Scholar]
- 15.Witten DM, Tibshirani R, Hastie T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics. 2009;10:515–534. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Zou H, Hastie T, Tibshirani R. Sparse principal component analysis. Journal of omputational and Graphical Statistics. 2006;15:265–286. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.