

Abstract
Min-cut clustering, based on minimizing one of two heuristic cost-functions proposed by Shi and Malik nearly a decade ago, has spawned tremendous research, both analytic and algorithmic, in the graph partitioning and image segmentation communities over the last decade. It is however unclear if these heuristics can be derived from a more general principle facilitating generalization to new problem settings. Motivated by an existing graph partitioning framework, we derive relationships between optimizing relevance information, as defined in the Information Bottleneck method, and the regularized cut in a K-partitioned graph. For fast-mixing graphs, we show that the cost functions introduced by Shi and Malik can be well approximated as the rate of loss of predictive information about the location of random walkers on the graph. For graphs drawn from a generative model designed to describe community structure, the optimal information-theoretic partition and the optimal min-cut partition are shown to be the same with high probability.
Keywords: graphs, clustering, information theory, min-cut, information bottleneck, graph diffusion
1 Introduction
MIN-CUT based graph partitioning has been used successfully to find clusters in networks, with applications in image segmentation as well as clustering biological and sociological networks. The central idea is to develop fast and efficient algorithms that optimally cut the edges between graph nodes, resulting in a separation of graph nodes into clusters. Particularly, since Shi and Malik successfully showed [1] that the average cut and the normalized cut (defined below) were useful heuristics to be optimized, there has been tremendous research in constructing the best normalized-cut-based cost function in the image segmentation community.
Additionally, several insightful works have focused on providing an interpretation and a justification for min-cut based clustering, within the framework of graph diffusion. Meila et al. [2] showed rigorous connections between normalized min-cut based clustering and the lumpability of the Markov chains underlying the corresponding discrete-diffusion operator. More recently, Lafon et al. [3] and Nadler et al. [4] showed the close relationship between the problem of spectral clustering and that of learning locality-preserving embeddings of data, using diffusion maps.
The Information Bottleneck (IB) method [5], [6] is a clustering technique, based on rate-distortion theory [7], that has been successfully applied in a wide variety of contexts including clustering word documents and gene-expression profiles [8]. The IB method is also capable of learning clusters in graphs and has been used successfully for synthetic and natural networks [9]. In the hard clustering case, given the diffusive probability distribution over a graph, IB optimally assigns probability distributions, associated with nodes, into distinct groups. These assignment rules define a separation of the graph nodes into clusters.
We here illustrate how minimizing the two cut-based heuristics introduced by Shi and Malik can be well-approximated by the rate of loss of relevance information, defined in the IB method applied to clustering graphs. To establish these relations, we must first define the graphs to be partitioned; we assume hard-clustering and the cluster cardinality to be K. We show, numerically, that maximizing mutual information and minimizing regularized cut amount to the same partition with high probability, for more modular 32-node graphs, where modularity is defined by the probability of inter-cluster edge connections in the Stochastic Block Model for graphs (See NUMERICAL EXPERIMENTS). We also show that the optimization goal of maximizing relevance information is equivalent to minimizing the regularized cut for 16-node graphs.1
2 The Min-Cut Problem
Following [10], for an undirected, unweighted graph with n nodes and m edges, represented2 by its adjacency matrix A := {Axy = 1 ⇔ x ~ y}, we define for two not necessarily disjoint sets of nodes V+, V− ⊆ V, the association
| (2.1) |
We define a bisection of V into V± if V+ ∪ V− = V and V+ ∩ V− = ∅. For a bisection of V into V+ and V−, the `cut' is defined as c(V+, V−) = W (V+, V−). We also quantify the size of a set V+ ⊆ V in terms of the number of nodes in the set V+ or the number of edges with at least one node in the set V+:
| (2.2) |
where dx is the degree of node x.
Shi and Malik [1] defined a pair of regularized cuts, for a bisection of V into V+ and V−; the average cut was defined as
| (2.3) |
and the normalized cut was defined as
| (2.4) |
This definition can be generalized, for a K-partition of V into V1, V2, …, VK [10], to
| (2.5) |
| (2.6) |
where .
For the graph , we can define the graph Laplacian Δ = D − A where D is a diagonal matrix of vertex degrees. For a bisection of V, we also define the partition indicator vector h [11]
| (2.7) |
Specifying two `prior' probability distributions over the set of nodes V : (i) p(x) ∝ 1 and (ii) p(x) ∝ dx, we then define the average of h to be
| (2.8) |
The cut, as defined by Fiedler [11], and the regularized cuts, as defined by Shi and Malik [1], can then be written in terms of h as (See Appendix A)
| (2.9) |
More generally, for a K-partition, we define the partition indicator matrix Q as
| (2.10) |
where z ∈ {V1, V2, …, VK and define P as a diagonal matrix of thew `prior' probability distribution over the nodes. The regularized cut can then be generalized as
| (2.11) |
where for ; and for .
Inferring the optimal h (or Q) however, has been shown to be an NP-hard combinatorial optimization problem [12].
3 Information Bottleneck
Rate-distortion theory, which provides the foundations for lossy data compression, formulates clustering in terms of a compression problem; it determines the code with minimum average length such that information can be transmitted without exceeding some specified distortion. Here, the model-complexity, or rate, is measured by the mutual information between the data and their representative codewords (average number of bits used to store a data point). Simpler models correspond to smaller rates but typically suffer from relatively high distortion. The distortion measure, which can be identified with loss functions, usually depends on the problem; in the simplest of cases, it is the variance of the difference between an example and its cluster representative.
The Information Bottleneck (IB) method [6] proposes the use of mutual information as a natural distortion measure. In this method, the data are compressed into clusters while maximizing the amount of information that the `cluster representation' preserves about some specified relevance variable.3 For example, in clustering word documents, one could use the `topic' of a document as the relevance variable.
For a graph , let X be a random variable over graph nodes, Y be the relevance variable and Z be the random variable over clusters. Graph partitioning using the IB method [9] learns a probabilistic cluster assignment function p(z|x) which gives the probability that a given node x belongs to cluster z. The optimal p(z|x) minimizes the mutual information between X and Z, while minimizing the loss of predictive information between Z and Y . This complexity-fidelity trade-off can be expressed in terms of a functional to be minimized
| (3.1) |
where the temperature T parameterizes the relative importance of precision over complexity. As T → 0, we reach the `hard clustering' limit where each node is assigned with unit probability to one cluster (i.e. p(z|x) ∈ {0, 1}).
Graph clustering, as formulated in terms of the IB method, requires a joint distribution p(y, x) to be defined on the graph; we use the distribution given by continuous-time graph diffusion4 as it naturally captures topological information about the network [9]. The relevance variable Y then ranges over the nodes of the graph and is defined as the node at which a random walker ends at time t if the random walker starts at node x at time 0. For continuous-time diffusion, the conditional distribution p(y|x) is given as
| (3.2) |
where Δ is the positive semi-definite graph Laplacian and P is a diagonal matrix of the prior distribution over the graph nodes, as described earlier. Note that the diagonal matrix P can be any prior distribution over the graph nodes. The characteristic diffusion time scale τ of the system is given by the inverse of the smallest non-zero eigenvalue of the diffusion operator exponent ΔP−1 and characterizes the slowest decaying mode in the system. A more common convention for matrix operations in graph theory is to use left eigenvectors. However, since our analysis is within a probabilistic framework, we use right eigenvectors throughout this paper to conform to conventions used in probability theory (particularly with regard to conditional and marginal distributions).
To calculate the joint distribution p(y, x) from the conditional Gt, we must specify an initial or prior distribution5; we use the two different priors p(x), used in Eq. (2.8) to calculate and 〈h〉 : (i) p(x) ∝ 1 and (ii) p(x) ∝ dx. Throughout this paper, time dependence needs to be considered only when the conditional distribution p(y|x) is replaced by the diffusion Green's function G; thus, time dependence will be explicitly denoted only once G is invoked.
4 Rate of Information Loss in Graph Diffusion
We analyze here the rate of loss of predictive information between the relevance variable Y and the cluster variable Z, during diffusion on a graph , after the graph nodes have been hard-partitioned into K clusters.
4.1 Well-mixed limit of graph diffusion
For a given partition Q of the graph, defined in Eq. (2.10), we approximate the mutual information I [Y ;Z] when diffusion on the graph reaches its well-mixed limit. We introduce the linear dependence η(y, z) such that
| (4.1) |
This implies 〈η〉y = 〈η〉z = 0 and 〈〈η〉z〉y = 〈η〉 where 〈〉 denote expectation over the joint distribution and 〈〉y and 〈〉z denote expection over the corresponding marginals.
In the well-mixed limit, we have |η| ⪡ 1. The predictive information (expressed in nats) can then be approximated as:
| (4.2) |
| (4.3) |
Here, we define ι as a first-order approximation to I [Y ;Z] in the well-mixed limit of graph diffusion. This quadratic approximation for I [Y ;Z] is known as the χ2-approximation.
Note that the joint and marginal distributions can also be related by the exponential dependence θ(y, z) defined by
Under this definition, the domain of the dependence is unbounded (i.e. ) and the mutual information is easily expressed as I [Y ;Z] = 〈θ〉. We also have
However, in the well-mixed limit |θ| ⪡ 1, to first non-trivial order, θ ≈ η and the expression for I [Y ;Z] in terms of θ has the same form as Eq. (4.2).
We also have
| (4.4) |
Thus, η(y, z) is bounded from below by −1 (by definition) and from above as shown in Eq. (4.4). However, θ(y, z) is unbounded and negatively divergent for short times. Since η is much better behaved than θ for short times, and for the sake of simplicity, we choose to use the linear dependence instead of the exponential dependence.
4.1.1 Well-mixed K-partitioned graph
As in the IB method, the Markov condition Z – X – Y allows us to make several simplifications for the conditional distributions and associated information theoretic measures. For a K-partition Q of the graph, we have
| (4.5) |
| (4.6) |
| (4.7) |
Graph diffusion being a Markov process, we have . Using this and Bayes rule , we have
| (4.8) |
In the hard clustering case, ΣxQzxPx = p(z) = [QPQT]zz and we have
| (4.9) |
4.1.2 Well-mixed 2-partitioned graph
We can re-write ι as
| (4.10) |
For a bisection h of the graph, z ∈ {+1, −1} and we have
| (4.11) |
| (4.12) |
| (4.13) |
| (4.14) |
We then have
| (4.15) |
The mutual information I [Y ;Z] can then be approximated as
| (4.16) |
Using Bayes rule p(x|y)p(y) = p(y|x)p(x), we have
| (4.17) |
| (4.18) |
Again, graph diffusion being a Markov process,
| (4.19) |
Time dependence is explicitly denoted here to highlight the fact that diffusion on the graph is till time 2t. Substituting 〈h|y〉 in Eq. (4.16), we get
| (4.20) |
| (4.21) |
4.2 Fast-mixing graphs
When diffusion on a graph reaches its well-mixed limit in short times, we have G2t ≈ I – 2tΔP−1. Thus, for a K-partition of a graph
| (4.22) |
For bisections, the short-time approximation of 〈hxhx′〉2t can be written as
| (4.23) |
Note that this approximation to 〈hxhx′〉2t makes no assumption about the choice of prior distribution P on the nodes of the graph. Furthermore, if the discrete-time diffusion operator is used instead, 〈hxhx′〉2t does not approximate to hTΔh in such a simple manner (See Appendix B).
For fast-mixing graphs, the long-time and short-time approximations for I [Y ;Z] and 〈hxhx′〉2t, respectively, hold simultaneously.
| (4.24) |
We have shown analytically that, for fast mixing graphs, the heuristics introduced by Shi and Malik are proportional to the rate of loss of relevance information. The error incurred in the approximations I [Y ;Z] ≈ ι and 〈hxhx′〉2t ≈ 1 – 2thT Δh can be defined as
| (4.25) |
| (4.26) |
5 Numerical Experiments
The validity of the two approximations can be seen in a typical plot of ε1(t) and ε0(t) as a function of normalized diffusion time , for the two different choices of prior distributions over the nodes. ε1, as seen in Fig. 1, is often found to be non-monotonic and sometimes exhibits oscillations. This suggests defining ε∞, a modified monotonic `ε1':
| (5.1) |
ε∞(t) is the maximum of ε1 over all time greater than or equal to t. We do not need to define a monotonic form for ε0 since this error is always found to be monotonically increasing in time.
Fig. 1.
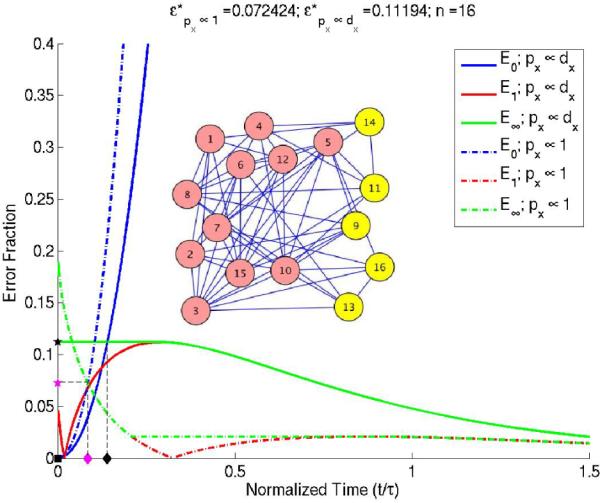
ε1 and ε0 vs normalized diffusion time for two choices of priors over the graph nodes. ε1 (red) typically tends to have a non-monotonic behavior which motivates defining a monotonic ε∝ (green). ★ – ε*, ▪ – , ◆ – . Black – px ∝ dx, Magenta – px ∝ 1.
By fast-mixing graphs, we mean graphs which become well-mixed in short times, i.e. graphs for which both the long-time and short-time approximations hold simultaneously within a certain range of time , as illustrated Fig. 1, where we define
| (5.2) |
| (5.3) |
| (5.4) |
| (5.5) |
ε(t) is the larger of the modified long- and short-time errors, ε∞ and ε0, at time t. ε* is the minimum of ε(t) over all time. For some graphs, the plot of ε(t) at its minimum might exhibit a plateau instead of a single point, as in Fig. 1 (for prior proportional to degree). t*− and t*+ denote the left– and right– limits of this plateau. Note that the use of ε∞ instead of ε1 overestimates the value of ε*; the ε* calculated is an upper bound.
Graphs were drawn randomly from a Stochastic Block Model (SBM) distribution [14], with block cardinality 2, to analyze the distribution of ε*, and . As is commonly done in community detection [15], for a graph of n nodes, the average degree per node is fixed at n/4 for graphs drawn from the SBM distribution: two nodes are connected with probability p+ if they belong to the same block, but with probability p− < p+, if they belong to different blocks. The two probabilities are, thus, constrained by the relation
| (5.6) |
leaving only one free parameter p− that tunes the `modularity' of graphs in the distribution. Starting with a graph drawn from a distribution specified by a p− value and specifying an initial cluster assignment as given by the SBM distribution, we make local moves — adding or deleting an edge in the graph and/or reassigning a node's cluster label — and search exhaustively over this move-set for local minima of ε*. Fig. 2 compares the values of ε* and for graphs obtained in this systematic search, starting with a graph drawn from a distribution with p− = 0.02 and n = {16, 32, 64}. We note that the scatter plots for graphs of different sizes collapse on one another when ε* is plotted against normalized time, confirming the Fiedler value 1/τ to be an appropriate characteristic diffusion time-scale as used in [9]. A plot of ε* against actual diffusion time shows that the scatter plots of graphs of different sizes no longer collapse (see Supplemental Material).
Fig. 2.

ε* vs for graphs of different sizes and different prior distributions over the graph nodes. In the above plot, and are represented by · and ο, respectively.
Having shown analytically that, for fast mixing graphs, the regularized mincut is approximately the rate of loss of relevance information, it would be instructive to compare the actual partitions that optimize these goals. Graphs of size n = 32 were drawn from the SBM distribution with p− = {0.1, 0.12, 0.14, 0.16}. Starting with an equal-sized partition specified by the model itself, we performed iterative coordinate descent to search (independently) for the partition that minimized the regularized cut (hcut) and one that minimized the relevance information (hinf(t)); i.e. we reassigned each node's cluster label and searched for the reassignment that gave the new lowest value for the cost function being optimized. Plots comparing the partitions hinf(t) and hcut, learnt by optimizing the two goals (averaged over 500 graphs drawn from each distribution), are shown in Fig. 3.
Fig. 3.
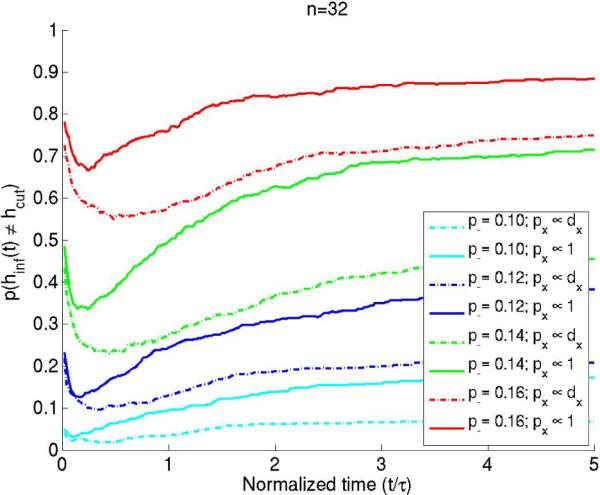
p(hinf(t) ≠ hcut) vs normalized diffusion time, averaged over 500 graphs drawn from a distribution parameterized by a given p— value, is plotted for different graph distributions
6 Concluding Remarks
We have shown that the normalized cut and average cut, introduced by Shi and Malik as useful heuristics to be minimized when partitioning graphs, are well approximated by the rate of loss of predictive information for fast-mixing graphs. Deriving these cut-based cost functions from rate-distortion theory gives them a more principled setting, makes them interpretable, and facilitates generalization to appropriate cut-based cost functions in new problem settings. We have also shown (see Fig. 2) that the inverse Fiedler value is an appropriate normalization for diffusion time, justifying its use in [9] to capture long-time behaviors on the network.
Absent from this manuscript is a discussion of how not to overpartition a graph, i.e. a criterion for selecting K. It is hoped that by showing how these heuristics can be derived from a more general problem setting, lessons learnt by investigating stablilty, cross-validation or other approaches may benefit those using min-cut based approaches as well. Furthermore, a derivation of some rigorous bounds on the magnitude of the approximation errors, under some conditions, and analysis of algorithms used in rate-distortion theory and min-cut minimization are highly promising avenues for research.
Supplementary Material
{kind=link}
{kind=link}
Acknowledgments
Chris H. Wiggins was supported by grants NIH 1U54CA121852-01A1 and NIH 5PN2EY016586-03 from the National Institutes of Health, and NSF IIS-0705580 from the National Science Foundation.
Biographies

Anil Raj received his Bachelor of Technology in Aerospace Engineering from the Indian Institute of Technology Madras, Chennai, in 2005, his MS degree in Applied Physics and his MPhil degree in Applied Mathematics from Columbia University in the city of New York in 2006 and 2009, respectively. He is currently working toward his PhD degree under the supervision of Dr. Chris Wiggins. His research interests include information theory, graph theory, statistical learning theory and machine learning, and their application to problems in pattern recognition, data mining and computational biology.

Chris H. Wiggins received his PhD degree in physics from Princeton University in 1998. Between 1998 and 2001, he was an NSF Mathematical Sciences Foundation Postdoctoral Research Fellow at the Courant Institute, NYU. Since 2001, he has been a member of the Department of Applied Physics and Applied Mathematics of Columbia University in the city of New York, where he is currently an associate professor. His research interests include applications of machine learning, statistical inference, and information theory for the inference, analysis, and organization of biological networks. He is also affiliated with the Center for Computational Biology and Bioinformatics and the NanoMedicine Center for Mechanical Biology at Columbia University.
Appendix A Normalized and Average Cut
Using the definition of Δ, for any general vector f over the graph nodes, we have for symmetric A
| (A.1) |
When f = h, with hx ∈ {−1, 1}, we have
| (A.2) |
The factor disappears because summation over all nodes counts each adjacent pair of nodes twice.
Using the definitions of and , we have
| (A.3) |
| (A.4) |
Appendix B Discrete Time Diffusion
For discrete-time diffusion, the conditional distribution p(y|x) is given as
| (B.1) |
where D is the diagonal matrix of node degrees, A is the adjacency matrix and s is the number of time steps. For any s, substituting A = D − Δ and expanding the binomial gives
| (B.2) |
Thus, for p(x) ∝ dx, the expression for 〈hxhx′〉2s becomes
| (B.3) |
From the above equation, we see that even when s = 1, unlike in the continuous-time diffusion case, 〈hxhx′〉2s does not approximate as simply to the cut and ι does not approximate to the normalized or average cut.
Footnotes
We chose 16-node graphs so the network and its partitions could be parsed visually with ease.
We use the shorthand x ~ y to mean x is adjacent to y.
See [8] for a detailed discussion on the relevance variable.
See [13] for a detailed discussion on graph diffusion and mixing.
Strictly speaking, any diagonal matrix P that we specify determines the steady-state distribution. Since we are modeling the distribution of random walkers at statistical equilibrium, we always use this distribution as our initial or prior distribution.
References
- [1].Shi J, Malik J. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence. Jan, 2000. [Online]. Available: http://doi.ieeecomputersociety.org/10.1109/34.868688.
- [2].Meila M, Shi J. A random walks view of spectral segmentation. AI and STATISTICS. 2001 [Google Scholar]
- [3].Lafon S, Lee AB. Diffusion maps and coarse-graining: A unified framework for dimensionality reduction, graph partitioning, and data set parameterization. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2006;28(9):1393–1403. doi: 10.1109/TPAMI.2006.184. [DOI] [PubMed] [Google Scholar]
- [4].Nadler B, Lafon S, Coifman RR, Kevrekidis IG. Advances in Neural Information Processing Systems 18. MIT Press; 2005. Diffusion maps, spectral clustering and eigenfunctions of fokker-planck operators; pp. 955–962. [Google Scholar]
- [5].Tishby N, Pereira FC, Bialek W. The information bottleneck method. arXiv preprint physics. Jan, 2000. [Online]. Available: http://arxiv.org/abs/physics/0004057.
- [6].Tishby N, Slonim N. Data clustering by markovian relaxation and the information bottleneck method. Advances in Neural Information Processing Systems. Jan, 2000. [Online]. Available: http://www.cs.cmu.edu/Web/Groups/NIPS/00papers-pub-on-web/TishbySlonim.ps.gz.
- [7].Shannon C. A mathematical theory of communication. ACM SIGMOBILE Mobile Computing and Communications Review. 2001 Jan;5(1) [Online]. Available: http://portal.acm.org/citation.cfm?id=584091.584093. [Google Scholar]
- [8].Slonim N. Ph.D. dissertation. The Hebrew University of Jerusalem; 2002. The information bottleneck: Theory and applications. [Google Scholar]
- [9].Ziv E, Middendorf M, Wiggins CH. Information-theoretic approach to network modularity. Physical Review E. Jan, 2005. [Online]. Available: http://link.aps.org/doi/10.1103/PhysRevE. 71.046117. [DOI] [PubMed]
- [10].von Luxburg U. A tutorial on spectral clustering. arXiv. 2007 Nov;cs.DS [Online]. Available: http://arxiv.org/abs/0711. 0189v1. [Google Scholar]
- [11].Fiedler M. Algebraic connectivity of graphs. Czechoslovak Mathematical Journal. 1973 [Google Scholar]
- [12].Wagner D, Wagner F. Between min cut and graph bisection. MFCS '93: Proceedings of the 18th International Symposium on Mathematical Foundations of Computer Science; London, UK: Springer-Verlag; 1993. pp. 744–750. [Google Scholar]
- [13].Chung FR. Spectral Graph Theory. American Mathematical Society; 1997. [Google Scholar]
- [14].Holland PW, Leinhardt S. Local structure in social networks. Sociological Methodology. Jan, 1976. [Online]. Available: http://www.cs.cmu.edu/Web/Groups/NIPS/00papers-pub-on-web/TishbySlonim.ps.gz.
- [15].Danon L, Diaz-Guilera A, Duch J, Arenas A. Comparing community structure identification. Journal of Statistical Mechanics: Theory and Experiment. 2005 Jan; [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.