

Abstract
The semiparametric partially linear model allows flexible modeling of covariate effects on the response variable in regression. It combines the flexibility of nonparametric regression and parsimony of linear regression. The most important assumption in the existing methods for the estimation in this model is to assume a priori that it is known which covariates have a linear effect and which do not. However, in applied work, this is rarely known in advance. We consider the problem of estimation in the partially linear models without assuming a priori which covariates have linear effects. We propose a semiparametric regression pursuit method for identifying the covariates with a linear effect. Our proposed method is a penalized regression approach using a group minimax concave penalty. Under suitable conditions we show that the proposed approach is model-pursuit consistent, meaning that it can correctly determine which covariates have a linear effect and which do not with high probability. The performance of the proposed method is evaluated using simulation studies, which support our theoretical results. A real data example is used to illustrated the application of the proposed method.
Keywords: Group selection, Minimax concave penalty, Model-pursuit consistency, Penalized regression, Semiparametric models
1. Introduction
Suppose we have a random sample (yi, xi1, …, xip), 1 ≤ i ≤ n, where yi is the response variable and (xi1, …, xip) is a p-dimensional covariate vector. Consider the semiparametric partially linear model
| (1) |
where S1 and S2 are mutually exclusive and complementary subsets of {1, …, p}, {βj: j ∈ S1} are regression coefficients of the covariates with indices in S1, and (fj: j ∈ S2) are unknown functions. In this model, the mean response is linearly related to the covariates in S1, while its relation with the remaining covariates is not specified up to any finite number of parameters. This model combines the flexibility of nonparametric regression and parsimony of linear regression. When the relation between yi and {xij: j ∈ S1} is of main interest and can be approximated by a linear function, it offers more interpretability than a purely nonparametric additive model.
There is a large literature on the estimation in partially linear models. Examples include the partial spline estimator (Wahba 1984; Engle, Granger, Rice and Weiss 1986 and Heckman 1986) and the partial residual estimator (Robinson 1988, Speckman 1988) and polynomial spline estimator (Chen 1988). An excellent discussion of partially linear models can be found in the book by Härdle, Liang and Gao (2000), which also contains an extensive list of references on this model. A comprehensive treatment of general semiparametric theory and many related models can be found in Bickle, Klaassen, Ritov and Wellner (1993).
The most important assumption in the existing methods for the estimation in partially linear models is to assume that it is known a priori which covariates have a linear form and which do not in the model. This assumption underlies the construction of the estimators and investigation of their theoretical properties in the existing methods. However, in applied work, it is rarely known in advance which covariates have linear effects and which have nonlinear effects.
Recently, Zhang, Cheng and Liu (2010) proposed a novel method for determining the zero, linear and nonlinear components in partially linear models. Their method is a two-step regularization method in the smoothing spline ANOVA framework. In the first step, they obtain an initial consistent estimator for the components in a nonparametric additive model, and then use the initial estimator as the weights in their proposed regularized smoothing spline method in a way similar to the adaptive Lasso (Zou 2006). They obtained the rate of convergence of their proposed estimator. They also showed that their method is selection consistent in the special case of tensor product design. However, they did not prove any selection consistency results for general partially linear models. Also, in their two-step approach, a total of four penalty parameters need to be selected, which may be difficult to implement in practice.
We consider the problem of estimation in partially linear models without assuming a priori which covariates have a linear effect and which have nonlinear effects. We propose a semiparametric regression pursuit method for identifying the covariates with linear effects and those with nonlinear effects. We embed partially linear models into a nonparametric additive model. By approximating the nonparametric components using spline series expansions, we transform the problem of model specification into a group variable selection problem. We then determine the linear and nonlinear components with a penalized approach, using the minimax concave penalty (MCP, Zhang 2010) imposed on the norm of the coefficients in the spline expansion. We refer to this penalized approach as the group MCP method. We show that, under suitable conditions, the proposed approach is model pursuit consistent, meaning that it can correctly determine which covariates have a linear effect and which do not with high probability. We allow the possibility that the underlying true model is not partially linear. Then the proposed approach has the same asymptotic property as the nonparametric estimator in the nonparametric additive model. We also show that the estimated coefficients of linear effects are asymptotically normal, with the same distribution as the estimator assuming the true model were known in advance.
Some of the techniques used in this paper are similar to those in Huang, Horowitz and Wei (2010), in which the problem of variable selection in nonparametric additive models is considered. In particular, after transforming the present problem of model pursuit into a group selection problem based on spline approximation, some of the techniques in obtaining rate of convergence for the group Lasso estimator in the context of nonparametric additive models in Huang et al. (2010) can be applied here with some modiffcations, see the proof of Theorem 2 in the Appendix. However, the problem of model pursuit considered in this paper is very different from that in Huang et al. (2010). Also, here we use the group MCP rather than the group Lasso, which requires different treatment at the technical level as well.
This article is organized as follows. In Section 2 we describe our proposed semi-parametric regression pursuit (SRP) method. We transform the problem of identifying linear and nonlinear components into an group selection problem using the group MCP. In Section 3 we derived a group coordinate descent algorithm to implement the proposed method. In Section 4 we state the theoretical results concerning the selection and estimation properties of the proposed method. Section 5 includes simulation studies and an illustration of the proposed method on a data example. Proofs of the results stated in Section 3 are given in the Appendix.
2. Semiparametric regression pursuit via group minimax concave penalization
2.1. Method
The semiparametric partially linear model (1) can be embedded into the nonparametric additive model (Hastie and Tibshirani 1990),
| (2) |
Suppose that xij takes values in [a, b] where a < b are finite constants. To ensure unique identification of the fj’s, we assume that Efj(xij) = 0, 1 ≤ j ≤ p. If some of the fj’s are linear, then (2) becomes the partially linear additive model (1). The problem becomes that of determineing which fj’s have a linear form and which do not. For this purpose, we decompose fj into a linear part and a nonparametric part
Consider a truncated series expansion for approximating gj,
| (3) |
where φ1, …, φmn are basis functions and mn → ∞ at certain rate as n → ∞. If θjk = 0, 1 ≤ k ≤ mn, then fj has the linear form. Therefore, with this formulation, the problem now is to determine which groups of {θjk, 1 ≤ k ≤ mn} are zero.
Let β = (β1, …, βp)′ and , where θjn = (θj1, …, θjmn)′. Define the penalized least squares criterion
| (4) |
where ρ is a penalty function depending on the penalty parameter λ ≥ 0 and a regularization parameter γ. Here without causing confusing, we still use μ to denote the intercept. The norm for a given positive definite matrix Aj. In theory, any positive definite matrix can be used as Aj, since ||θjn||Aj = 0 if and only if θjn = 0 as long as Aj is positive definite. However, it is important to choose a suitable choice of Aj to make the amount of penalization comparable across the groups and to facilitate the computation. We will specify Aj in (9) below.
We use the minimax concave penalty, or MCP introduced by Zhang (2010). This penalty function is defined by
| (5) |
where γ is a parameter that controls the concavity of ρ and λ is the penalty parameter. Here x+ denotes the nonnegative part of x, that is, x+ = x1{x≥0}. We require λ ≥ 0 and γ > 1. The term MCP comes from the fact that it minimizes the maximum concavity measure defined in (2.2) of Zhang (2010) subject to conditions on unbiasedness and selection features. The MCP can be easily understood by considering its derivative
| (6) |
It begins by applying the same rate of penalization as the lasso, but continuously relaxes that penalization until, when t > γλ, the rate of penalization drops to 0. It provides a continuum of penalties with the ℓ1 penalty at γ = ∞ and the hard-thresholding penalty as γ → 1+. In particular, it includes the Lasso penalty as a special case at γ = ∞. Detailed discussions on the MCP can be found in Zhang (2010).
The penalty in (4) is a composite of the penalty function ργ (·; λ) and a weighted ℓ2-norm of θj. The ργ (·; λ) is a penalty for individual variable selection. When it is applied to a norm of θj, it selects the coefficients in θj as a group. This is desirable, since the nonlinear components are represented by the coefficients in the θj’s as groups. Based on the definition of the penalty function in (4), it is natural to call it the group minimax concave penalty, or group MCP.
For a given (λ, γ), the penalized least squares solution is defined by
subject to the constraints
| (7) |
These centering constraints are sample analogs of the identifying restriction Efj(xij) = 0, 1 ≤ i ≤ n, 1 ≤ j ≤ p.
We convert (7) to an unconstrained optimization problem by centering the response and the covariate functions. Specifically, we center the responses and covariates and standardize the covariates by imposing
We also center the basis functions. Let
| (8) |
Define
So the zij consists of the centered basis functions at the ith observation of the jth covariate. Let Z = (Z1, …, Zp), where Zj = (z1j, …, znj)′ is the n × mn ‘design’ matrix corresponding to the jth expansion. Let y = (y1, …, yn)′, xj = (x1j, …, xnj)′ and X = (x1, …, xp). We can write
Here we dropped μ from the arguments of L, since the intercept is zero due to centering. With the centering, the constrained optimization problem becomes an unconstrained one.
2.2 Penalized profile least squares
To compute (β̂n, θ̂n), we can use a penalized profile least squares approach. For any given θn, the β̂ that minimizes L necessarily satisfies
Thus β = (X′X)−1X′(y − Zθn). Let Q = I − PX, where PX = X(X′X)−1X′ is the projection matrix onto the column space of X. The profile objective function of θn is
| (9) |
As noted above, any positive definite matrix can be used for Aj. Here we use . The rationale for this choice is based on the following considerations. First, in the profile objective function (9), the covariate matrix for group j is QZj. The Gram matrix associated with it is , since Q is an orthonormal matrix. Although the original covariates xij’s are standardized, the covariate matrices for the groups are not necessarily so. Therefore, this choice of Aj standardizes the covariate matrices associated with θnj’s and makes the amount of penalization comparable across the groups comparable. Second, this leads to an explicit expression in the update steps in the group coordinate algorithm described below. This facilitates the implementation of the algorithm, since computation in each update step can be carried out using explicit expressions. For any given (λ, γ), the penalized profile least squares solution is defined by θ̂n = arg minθn L(θn; λ, γ). We compute θ̂n using a group coordinate descent algorithm described in Section 3.
The set of indices of the covariates that are estimated to have the linear form in the regression model (1) is Ŝ1 ≡ {j: ||θ̂nj|| = 0}. Thus,
Denote X̂(1) = (xj, j ∈ Ŝ1), Ẑ(2)= (Zj: j ∉ Ŝ1) and . We have β̂n = (X′X)−1X′(y − Ẑ(2)θ̂n(2)). The estimator of the coefficients of the linear components is β̂n1 = (β̂j: j ∈ Ŝ1)′. Let
Denote f̂nj(xj) = (f̂nj(x1j), …, f̂nj(xnj))′. Then the estimator of the coefficient vector of the linear components can also be written as
2.3 Spline approximation
We use polynomial splines to approximate the non-parametric components gj, 1 ≤ j ≤ p. Let a = t0 < t1 < ··· < tK < tK+1 = b be a partition of [a, b] into K subintervals IKk = [tk, tk+1), k = 0, …, K − 1 and IKK = [tK, tK+1], where K ≡ Kn = O(nv) with 0 < v < 0.5 is a positive integer such that max1≤k≤K+1 |tk − tk−1| = O(n−v). Let Sn be the space of polynomial splines of degree l ≥ 1 consisting of functions s satisfying: (i) the restriction of s to IKk is a polynomial of degree l for 1 ≤ k ≤ K; (ii) for l ≥ 2 and 0 ≤ l′ ≤ l − 2, s is l′ times continuously differentiable on [a, b] (Schumaker 1981). There exists normalized B-spline basis functions {φk, 1 ≤ k ≤ mn} for Sn, where mn ≡ Kn + l (Schumaker 1981). We can use these basis functions in the approximation (3).
3. Computation
We derive a group coordinate descent algorithm for computing θ̂ n. This algorithm is a natural extension of the standard coordinate descent algorithm (Fu 1998; Friedman et al. 2007; Wu and Lange 2007) used in optimization problems with convex penalties such as the Lasso. It has also been used in calculating the penalized estimates based on concave penalty functions (Breheny and Huang 2010).
The group coordinate descent algorithm optimizes a target function with respect to a single group at a time, iteratively cycling through all groups until convergence is reached. This algorithm is particularly suitable for computing θ̂n, since it has a simple closed form expression for a single-group model as given in (10) below.
We write for an mn × mn upper triangular matrix Rj via the Cholesky decomposition. Let bj = Rjθj, ỹ = Qy and . Simple algebra shows that
Note that . Let . Denote
Let . For γ > 1, it can be verified that the value that minimizes Lj with respect to bj is
| (10) |
In particular, when γ = ∞, we have
which is the group Lasso estimate for a single-group model (Yuan and Lin 2006).
With the above expressions, the group coordinate descent algorithm can be implemented as follows. Suppose the current values for the group coefficients , k ≠ j are given. We want to minimize L with respect to bj. Define
Denote and . Let b̃j denote the minimizer of . When γ > 1, we have , where M is defined in (10).
For any given (λ, γ), we use (10) to cycle through one component at a time. Let be the initial value. The proposed coordinate descent algorithm is as follows.
Initialize vector of residuals r = y − ỹ, where . For s = 0, 1, …, carry out the following calculation until convergence. For j = 1, …, p, repeat the following steps:
Calculate .
Update .
Update and j ← j + 1.
The last step ensures that r always holds the current values of the residuals. Although the objective function is not necessarily convex, it is convex with respect to a single group when the coefficients of all the other groups are fixed. Thus, Theorem 5.1 of Tseng (2001) implies that the group coordinate descent algorithm described above always converges.
4. Theoretical properties
We present the results on the model-pursuit consistency, rate of convergence and asymptotic normality of the proposed SRP estimator. In particular, our model-pursuit consistency result shows that the proposed method can correctly determine the linear and nonlinear components in the partially linear model with high probability.
Denote the underlying regression components by f0j and write
Suppose the series expansion for approximating g0j is
Let θ0jn = (θ0j1, …, θ0jmn)′. Denote for any square integrable function g on [a, b]. We have S1 = {j: ||g0j||2 = 0} and ||θ0nj|| = 0 for j ∈ S1. Let .
Let q = |S1| be the cardinality of S1, which is the number of linear components in the regression model. Define
| (11) |
This is the oracle estimator of θ0n assuming the identity of the linear components were known. We note that the oracle estimator is not computable since S1 is unknown. We use it as the benchmark for our proposed estimator.
Analogous to the actual estimates defined at the end of Section 2.2, define the oracle estimators
Denote X(1) = (xj, j ∈ S1), X(2) = (xj: j ∈ S2) and . Let
Denote f̃nj(xj) = (f̃nj(x1j), …, f̃nj(xnj))′. The oracle estimator of the coefficients of the linear components is
Without loss of generality, suppose that S1 = {1, …, q}. Write , where 0qmn is a (qmn)-dimensional vector of zeros and
| (12) |
Define θ*= minj∈S1 ||θ0nj||, which is the smallest norm of the coefficients in the spline expansions of the nonlinear components.
Let k be a non-negative integer, and let α ∈ (0, 1] be such that d = k + α > 0.5. Let
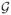 be the class of functions g on [0, 1] whose kth derivative g(k) exists and satisfies a Lipschitz condition of order α:
be the class of functions g on [0, 1] whose kth derivative g(k) exists and satisfies a Lipschitz condition of order α:
Define for any function g, whenever the integral exists.
We make the following assumptions.
(A1) The p and q are fixed and ε1, …, εn are independent and identically distributed with Eεi = 0 and Var(εi) = σ2. Furthermore, P(|εi| > x) ≤ K exp(−Cx2), i = 1, …, n, for all x ≥ 0 for some constants C and K.
(A2) Egj(xj) = 0 and gj ∈
, j = q + 1, …, p.
(A3) The covariate vector X has a continuous density and there exist constants C1 and C2 such that the density function ηj of xj satisfies 0 < C1 ≤ ηj(x) ≤ C2 < ∞ on [a, b] for every 1 ≤ j ≤ p.
Theorem 1
Suppose that mn = O(n1/(2d+1)), is less than the smallest eigen-value of Z′QZ/n, and
| (13) |
Then under (A1)–(A3),
Consequently,
Therefore, under the conditions of Theorem 1, the proposed estimator can correctly distinguish linear and nonlinear components with high probability. Furthermore, the proposed estimator has the oracle property in the sense that it is the same as the oracle estimator assuming the identity of the linear and nonlinear components were known, except on an event with probability tending to zero.
We note that, except the assumption on the tail probabilities in (A1), (A1)–(A3) are standard conditions for nonparametric additive models. They would be needed to estimate the additive components at the optimal ℓ2 rate of convergence in standard nonparametric additive model setting. The main extra condition needed here is (13), which requires λ = o(n−1/2) and for some an → ∞ simultaneously. The first part of this requirement ensures that the bias resulting from the penalty is small so that it does not interfere with selection, and the second part requires that the smallest norm θ* of the coefficients in the spline expansions of the (nonzero) nonlinear components should be larger than the penalty level plus a term due to the spline approximation error.
Theorem 2
Suppose (A1)–(A3) hold. Under model (2), we have
This theorem gives rate of convergence of the proposed estimator under the non-parametric additive model (2), which contains the partially linear models as special cases. In particular, if we assume that each component in (2) is second order differentiable (d = 2) and take mn = O(n1/5) and λ = n−1/2+δ for a small δ > 0, then , which is the optimal rate of convergence in nonparametric regression.
We now consider the asymptotic distribution of β̂n1. Denote
Each element of Hj is a |S1|-vector of square integrable functions with mean zero. Denote the sumspace
The projection of the centered covariate vector x(1) − E(x(1)) ∈ Rq onto the sumspace H is defined to be the with , j ≤ Ŝ2 that minimizes
| (14) |
For x(2) = (xj: j ∈ S2), denote
| (15) |
Under condition (A3), by Lemma 1 of Stone (1985) and Proposition 2 in Appendix 4 of Bickel, Ritov, Klaassen and Wellner (1993), the sumspace H is closed. Thus the orthogonal projection h* onto H is well defined and unique. Furthermore, each individual component is also well defined and unique. In addition to (A1)–(A3), we also need the following condition for asymptotic normality of the linear component estimator.
(A4) Let w ≥ 1 be a positive integer. The wth partial derivatives of the joint density of x(2) = (xj, j ∈ S2) are bounded by a constant and the qth derivative of each component of ξ(v) = E(x(1)|xj = v), j ∈ S2 is bounded by a constant.
Let A = E[x(1) − E(x(1) − h* (x(2))]⊗2, where h* is defined in (15). Here x⊗2 = xx′ for any column vector x ∈ Rd.
Theorem 3
Suppose that the conditions in Theorem 1 and (A4) are satisfied and that A is nonsingular. Then,
where β(1) = (βj: j ∈ S1)′ and Σ = σ2A−1.
Theorem 3 provides sufficient conditions under which the proposed estimator β̂n1 of the linear components in the model is asymptotically normal with same the limit normal distribution as the oracle estimator β̃n1.
5. Numerical studies
5.1 Simulation studies
We use simulation to evaluate the finite sample performance of the proposed method. Two examples are considered in the simulation. In each of the simulated models, two sample sizes (n=100, 200) are considered and a total of 100 replications are conducted. Consider the following six functions defined on [0, 1]:
In the implementation, we use cubic B-spline with seven basis functions to approximate each function.
Example 1
Let p = 6. Consider the model
In this model, the first three variables have linear effect and the last three variables have nonlinear effect. The p covariates are simulated in the following way. First we simulate w1, ···, wp and u independently from U [0, 1]. Then xik = (wk + u)/2 for k = 1, ···, p. The correlation among predictors is Corr(xij, xik) = 0.5. The error term ε is chosen from N(0, 1.572) to give a signal to noise ratio 3.
Example 2
Let p = 10. Consider the model
In this model, the first 5 components are linear and the remaining 5 are nonlinear. The covariates are simulated in the same way as in Example 1. The error term ε ~ N(0, 1.802), which gives a signal to noise ratio 3.
The group coordinate descent algorithm described in Section 3 is used repeatedly to compute θ̂n over a grid of (λ, γ) values in a rectangle [λmax, λmin] × [γmax, γmin]. Here , which is the smallest value of λ that forces all the solutions to be zero, and we take λmin = 0.0001λmax. We use a set of 100 equally spaced grid points on the logarithmic scale in [λmax, λmin]. For the γ parameter in the group MCP, we consider a grid of equally spaced points in the interval [γmax, γmin] = [8.0, 1.1] with grid size 0.1. We note that Zhang (2010) suggested using γ = 2.7 for standardized covariates in linear regression. In our simulation studies, we found that the value of γ also has considerable impact on the results. Thus instead of using a fixed γ value, we consider a range of γ values.
For the group Lasso, which can be considered a special case of the group MCP with γ= ∞, the algorithm starts at λmax where θ̂n equals 0 and proceeds along the grid values of λ, using the previous solution as the initial value at each grid point. For the group MCP, for each value of λ in the λ-grid and the corresponding initial value from the group Lasso, the algorithm proceeds along the grids of γ in [8.0, 1.1], that is, for each λ grid value, we start the algorithm at γ = 8 using the group Lasso solution as the initial value. This approach follows that of Mazumder, Friedman and Hastie (2009). We then apply the BIC (Schwarz 1978) to select (λ, γ). Here the BIC is defined as
where RSSλ; γ is the residual sum of squares and dfλ; γ is the number of the nonzero selected groups for a given (λ, γ). Recall mn is the number of spline basis functions given in (3). The optimal value of (λ, γ) is chosen to be the one that minimizes the BIC.
The simulation results based on 100 replications are presented in Tables 1–3. The columns in Table 1 are: the average number of nonlinear components being selected (NL), the average model error (ER), the percentage of occasions on which the correct nonlinear components are included in the selected model (IN%) and the percentage of occasions on which the exactly nonlinear components are selected (CS%) in the final model. Enclosed in parentheses are the corresponding standard errors. Table 2 includes the number of times each component being estimated as nonlinear function. Table 3 shows the average mean square error for each function. Enclosed in parentheses are the corresponding standard errors.
Table 1.
Simulation results for Examples 1–2. NL, the average number of the nonlinear components being selected; ER, the average model error; IN%, the percentage of occasions on which the correct nonlinear components are included in the selected model; CS%, the percentage of occasions on which exactly correct nonlinear components are selected, averaged over 100 replications. Enclosed in parentheses are the corresponding standard errors.
| n = 100 | n = 200 | |||||||
|---|---|---|---|---|---|---|---|---|
|
| ||||||||
| NL | ER | IN% | CS% | NL | ER | IN% | CS% | |
| Example 1, Group Lasso | 3.46 (0.76) | 2.66 (0.66) | 100 (0.00) | 67 (0.47) | 3.10 (0.39) | 2.71 (0.39) | 100 (0.00) | 92 (0.27) |
| Group MCP | 3.18 (0.39) | 2.28 (0.47) | 100 (0.00) | 82 (0.39) | 3.01 (0.10) | 2.43 (0.30) | 100 (0.00) | 99 (0.10) |
|
| ||||||||
| Example 2, Group Lasso | 4.37 (2.90) | 6.26 (4.84) | 51 (0.50) | 17 (0.38) | 5.41 (0.71) | 3.55 (0.59) | 98 (0.14) | 62 (0.49) |
| Group MCP | 5.25 (1.37) | 2.98 (1.22) | 76 (0.43) | 43 (0.50) | 5.22 (0.54) | 3.09 (0.38) | 98 (0.14) | 78 (0.42) |
Table 3.
The average mean square error for each component based on 100 replications by the group Lasso and group MCP methods in Examples 1–2.
| f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 | f10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n = 100 | ||||||||||
| Example 1, Group Lasso | 0.64 (0.93) | 0.66 (0.79) | 0.67 (1.05) | 7.52 (1.48) | 12.23 (6.68) | 25.50 (10.02) | ||||
| Group MCP | 0.54 (0.83) | 0.55 (0.70) | 0.49 (0.65) | 7.51 (1.45) | 11.39 (6.72) | 25.34 (9.77) | ||||
| Oracle | 0.11 (0.25) | 0.11 (0.17) | 0.12 (0.23) | 2.22 (1.07) | 0.76 (0.46) | 10.05 (2.39) | ||||
|
| ||||||||||
| n = 200 | ||||||||||
|
| ||||||||||
| Group Lasso | 0.21 (0.28) | 0.19 (0.27) | 0.20 (0.26) | 7.29 (1.05) | 12.08 (4.47) | 27.24 (7.04) | ||||
| Group MCP | 0.20 (0.28) | 0.16 (0.21) | 0.19 (0.26) | 7.25 (1.03) | 11.35 (4.77) | 27.08 (7.12) | ||||
| Oracle | 0.09 (0.07) | 0.08 (0.06) | 0.09 (0.07) | 1.88 (0.65) | 0.50 (0.18) | 9.93 (1.72) | ||||
|
| ||||||||||
| Example 2, Group Lasso | 1.22 (1.45) | 1.55 (2.63) | 1.58 (2.08) | 1.40 (2.06) | 1.87 (2.95) | 3.66 (1.43) | 10.24 (7.17) | 23.80 (12.7) | 3.03 (2.76) | 10.09 (5.80) |
| Group MCP | 0.87 (1.02) | 1.05 (1.91) | 0.90 (1.16) | 0.89 (1.51) | 1.03 (1.33) | 3.55 (1.24) | 9.27 (6.88) | 22.30 (10.6) | 1.96 (1.98) | 9.85 (5.08) |
| Oracle | 0.52 (1.00) | 0.17 (0.60) | 0.27 (0.36) | 0.31 (0.63) | 0.44 (0.79) | 2.57 (0.90) | 1.09 (1.54) | 13.31 (13.9) | 1.28 (1.80) | 1.85 (10.45) |
|
| ||||||||||
| n = 200 | ||||||||||
|
| ||||||||||
| Group Lasso | 0.34 (0.45) | 0.36 (0.40) | 0.30 (0.41) | 0.38 (0.61) | 0.39 (0.56) | 3.34 (0.71) | 8.55 (3.19) | 20.09 (6.61) | 0.95 (0.81) | 9.26 (3.86) |
| Group MCP | 0.30 (0.40) | 0.32 (0.39) | 0.28 (0.39) | 0.31 (0.55) | 0.34 (0.52) | 3.32 (0.70) | 8.52 (3.24) | 19.91 (6.50) | 0.87 (0.81) | 9.19 (3.66) |
| Oracle | 0.23 (0.20) | 0.16 (0.23) | 0.05 (0.02) | 0.16 (0.33) | 0.16 (0.41) | 0.88 (0.30) | 0.36 (0.14) | 9.83 (1.68) | 0.50 (0.17) | 0.33 (0.14) |
Table 2.
Number of times each component being selected as nonlinear component in the 100 replications by the group Lasso and group MCP methods in Examples 1–2.
| f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 | f10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n = 100 | ||||||||||
| Example 1, Group Lasso | 21 | 13 | 12 | 100 | 100 | 100 | ||||
| Group MCP | 9 | 4 | 5 | 100 | 100 | 100 | ||||
|
| ||||||||||
| n = 200 | ||||||||||
| Group Lasso | 3 | 4 | 3 | 100 | 100 | 100 | ||||
| Group MCP | 1 | 0 | 0 | 100 | 100 | 100 | ||||
|
| ||||||||||
| n = 100 | ||||||||||
| Example 2, Group Lasso | 19 | 21 | 14 | 17 | 18 | 54 | 73 | 95 | 69 | 57 |
| Group MCP | 16 | 13 | 9 | 9 | 11 | 89 | 99 | 100 | 97 | 82 |
|
| ||||||||||
| n = 200 | ||||||||||
| Group Lasso | 9 | 8 | 7 | 9 | 11 | 99 | 100 | 100 | 100 | 98 |
| Group MCP | 5 | 6 | 6 | 5 | 2 | 99 | 100 | 100 | 100 | 99 |
Several observations can be made from Tables 1 and 2. Table 1 shows that the proposed method with the group MCP performs better than the proposed method with the group Lasso in terms of the percentage of occasions on which the correct nonlinear components are included in the selected model (IN%) and the percentage of occasions on which the exactly nonlinear components are selected (CS%) in the final model. For instance, in Example 1, when n = 100, the percentage of correct selection (CS%) is 82% with the group MCP and is 67% with the group Lasso. Also, when the sample size increases from 100 to 200, the percentage of including all the nonlinear components (IN%) and selecting the exactly correct model (CS%) by both methods are increased. This is not surprising since data with a larger sample size contain more information about the underlying model. Table 2 shows that the group MCP is more accurate in distinguishing the linear functions from the nonlinear functions than the group Lasso. When n = 200, the group MCP can correctly distinguish the linear from nonlinear components 99% of the times in Example 1 and 78% of the times in Example 2. In Table 3, we examine the performance of the proposed method for estimating the linear and nonlinear components in the simulated models. In general, the proposed method with the group MCP have smaller mean square errors. Overall, the proposed method with the group MCP is effective in distinguishing the linear components from the nonlinear ones in the simulation models.
5.2 Diabetes data example
This data set is from a study reported in Willems et al. (1997). The data consist of 19 variables on 403 subjects from 1046 African Americans who were interviewed in a study to understand the prevalence of obesity, diabetes, and other cardiovascular risk factors in central Virginia. Diabetes Mellitus Type II (adult onset diabetes) is associated with obesity. The 403 subjects were the ones who were screened for diabetes. Glycosolated hemoglobin > 7.0 is usually taken as a positive diagnosis of this disease.
We consider Glycosolated hemoglobin as the response variable and the other 15 variables as the covariates excluding. These 15 variables are: cholesterol (chol), stabilized glucose (stab.glu), high density lipoprotein (hdl), cholesterol/hdl ratio (ratio), location, age, gender, height, height, weight, frame, first systolic blood pressure (bp.1s), first diastolic blood pressure (bp.1d), waist, hip, postprandial time when labs were drawn (time.ppn). Among these 15 variables, 3 are categorial variables (location, gender, frame), 12 are continuous variables. We are interested in finding which continuous covariates have nonlinear effects on the response variable. In our study, we only consider the subjects which have all the information, without missing values. Thus the number of subjects are n = 366, p = 15.
The results are summarized in Tables 4 and 5. The top panel of Table 4 lists the 12 continuous variables being selected by the group MCP and the group Lasso as linear or nonlinear variables, indicated by 0/1 (1, nonlinear; 0, linear). The top panel of Table 5 shows the number of variables being selected as nonlinear variables and the residual sum of squares by both the group MCP and the group Lasso methods.
Table 4.
Diabetes data: Number of each component being selected by the group Lasso and group MCP methods as nonlinear components. The top panel of Table lists the 12 continuous variables being selected by the group MCP and the group Lasso as linear or nonlinear variables, indicated by 0 or 1 (0, linear; 1, nonlinear). The bottom panel shows the number of times a variable has a nonlinear effect in the 100 partitions.
| chol | stab.glu | hdl | ratio | age | height | weight | bp.1s | bp.1d | waist | hip | time.ppn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| whole data set | ||||||||||||
| group Lasso | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| group MCP | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
|
| ||||||||||||
| training and testing sets | ||||||||||||
|
| ||||||||||||
| group Lasso | 29 | 66 | 7 | 1 | 0 | 72 | 0 | 0 | 0 | 0 | 0 | 0 |
| group MCP | 89 | 100 | 30 | 99 | 65 | 100 | 9 | 2 | 0 | 0 | 4 | 89 |
Table 5.
Diabetes data: The top panel shows that the number of selected nonlinear components (NL) and the residual sum of squares (RSS) based on the whole data. The bottom panel shows the NL, the RSS and the prediction error (PE), averaged over 100 replications. Enclosed in parentheses are the corresponding standard errors.
| NL | RSS | PE | |
|---|---|---|---|
|
| |||
| whole data | |||
| group Lasso | 2.00 | 3.06 | |
| group MCP | 6.00 | 2.53 | |
|
| |||
| training and testing sets | |||
|
| |||
| group Lasso | 1.75 (0.76) | 3.01 (0.19) | 3.44 (1.02) |
| group MCP | 5.87 (0.87) | 2.53 (0.16) | 3.27 (0.89) |
To evaluate the prediction performance of the methods, we randomly select a training set with 300 subjects from the data to do the estimation and selection and use the remaining 66 subjects at the test set for prediction. We repeat this process 100 times and the results are summarized in the bottom panel of Tables 4 and 5. The bottom panel of Table 4 shows the number of times a variable has a nonlinear effect. The bottom panel of Table 5 shows the number of variables being selected (NL) as nonlinear components, the residual sum of squares (RSS) and the prediction error (PE), averaged over 100 replications with standard error in the parentheses. Table 5 shows that the proposed method with the group MCP performs better than with the group Lasso in terms of the residual sum of squares and the prediction error.
6. Concluding remarks
In this paper, we proposed a semiparametric regression pursuit method for distinguishing linear from nonlinear components in semi-parametric partially linear models. This approach determines the parametric and non-parametric components in a semiparametric model adaptively based on the data. Our proposed method is fundamentally different from the standard semiparametric inference approach where the parametric and nonparametric components in a model are pre-specified. We showed that our method has the asymptotic oracle properties, meaning that it is the same as the standard semiparametric estimator assuming the model structure were known with high probability. The asymptotic rates of the penalty parameters required for our theoretical results are derived. However, as in many recent studies, it is not clear whether the penalty parameters selected using the BIC or other procedures can match the asymptotic rates. This is an important and challenging problem that requires further investigation, but is beyond the scope of the current paper. Our simulation study indicates that the proposed method works well in finite sample situations.
We have only considered the proposed semiparametric regression pursuit method in the partially linear model with fixed p. In many applications such as genomic data analysis, it is possible to have data with p > n. In this case, our proposed method is not directly applicable. In the p > n case, assuming the model is sparse in the sense the number of important covariates is much smaller than n, we can first reduce the model dimension and then apply the proposed method. For example, we can first use the adaptive group Lasso method to select the important variables in the nonparametric additive model (Huang, Horowitz and Wei 2010). We then use the proposed method in this paper to determine linear and nonlinear components in the model. Under the conditions given in Huang et al. (2010) and those given in this paper, this two-step approach has the asymptotic oracle property even in p > n settings. Further work is needed to evaluate the finite sample performance and spelled out the technical details of this two-step approach in p > n settings.
The proposed semiparametric regression pursuit method extends the scope of the application of penalized methods from variable selection to model specification. We have focused on the proposed method in the context of semiparametric partially linear models. This method can be extended to other models, such as the generalized partially linear and partially linear proportional hazards models (Huang 1999). It would be interesting to generalized the results of this paper to these more complicated models.
Acknowledgments
J. Huang wishes to thank Professor Guang Cheng for sharing with us their unpublished manuscript (Zhang, Cheng and Liu 2010) and Professor Cun-Hui Zhang for sharing his insights on the properties of the minimax concave penalty. We also thank an anonymous referee, the associate editor and editor for their helpful comments which led to considerable improvements in the paper. The research of Huang is partially supported by NIH grants R01CA120988, R01CA142774 and NSF grant DMS 0805670. The research of Ma is partially supported by NIH grants R01CA120988 and R01CA142774.
Appendix
Proof of Theorem 1
Since is less than the smallest eigenvalue of Z′QZ/n, L(·; λ, γ) in (9) is a convex function. By the Karush-Kuhn-Tucker conditions, a necessary and sufficient condition for θ̂n is
| (16) |
For j ∉ S1, if ||θ̃nj|| ≥ γλ then ρ̇(||θ̃nj||; λ) = 0. Thus θ̃n satisfies (16) if also for j ∈ S1. Therefore, θ̂n = θ̃n in the intersection of the events
| (17) |
Let g0j(xj) = (g0j(x1j), …, g0j(xnj))′ and δn = Σj∉S1g0j(xj) − Z(2)θn(2). By the approximation properties of splines to a smooth function, we have
| (18) |
Let and . By (12),
| (19) |
and
| (20) |
Recall θ* = minj∈S1 ||θnj||. If ||θnj − θnj|| ≤ θ* − γλ, then minj∉S1||θ̃nj|| ≥ γλ. Therefore,
We also have
Lemma 1 below shows that, when
and Lemma 2 below shows that, when
Note that when mn = n1/(2d+1), we have . Therefore, under the conditions of Theorem 1, we have P(θ̂n ≠ θ̃n) → 0. This completes the proof.
Lemma 1
Suppose that
| (21) |
Proof of Lemma 1
Let Tnj be an mn × (p − q)mn matrix with the form
where 0mn is an mn × mn matrix of zeros and Imn is an mn × mn identity matrix in the jth block. By the triangle inequality,
| (22) |
Let C be a generic constant independent of n. For the first term on the right-hand side, we have
| (23) |
| (24) |
Thus
By (18), the second term
| (25) |
Therefore, when
(21) holds. This proves the lemma.
Lemma 2
Suppose that
we have
| (26) |
Proof of Lemma 2
Write
| (27) |
By Lemma 2 of Huang et al. (2010),
| (28) |
Therefore,
| (29) |
By (18), the second term on the right hand side of (27)
| (30) |
Therefore, when
Proof of Theorem 2
By the definition of ,
| (31) |
Let ηn = Q(y − Zθn) and νn = QZ(θ̂n − θn). Write
We have . We can rewrite (31) as
| (32) |
Since
| (33) |
combining (32) and (33), we get
| (34) |
Let . By the Cauchy-Schwartz inequality,
| (35) |
Let cn* be the smallest eigenvalue of Z′QZ/n. By Lemma 1 of Huang, Horowitz and Wei (2010), . Since and 2ab ≤ a2 + b2,
It follows that
| (36) |
Let . Write
Since | μ − ȳ|2 = Op(n−1) and , we have
| (37) |
where is the projection of εn = (ε1, …, εn)′ to the span of QZ. We have
| (38) |
Combining (36), (37), and (38), we get
Since and , we have
Now the result follows from the properties of polynomial splines (Schumaker 2001). This completes the proof of the theorem.
Proof of Theorem 3
Let θ̃n be the oracle estimator defined in (11). Define
Let
Denote f̃nj(xj) = (f̃nj(x1j), …, f̃nj(xnj))′. The estimator of the coefficients of the linear components is
Using the standard techniques in semiparametric models such as those described in Huang (1996), we can show that
By Theorem 1, P(β̂n1 = β̃n1) → 1, which implies . Therefore, by Slutsky’s lemma, we also have
This completes the proof of Theorem 3.
References
- Bickel PJ, Klaassen CAJ, Ritov Y, Wellner JA. Efficient and Adaptive Estimation for Semiparametric Models. Johns Hopkins University Press; Baltimore: 1993. [Google Scholar]
- Breheny P, Huang J. Coordinate Descent Algorithms for Nonconvex Penalized Regression Methods. Ann Appl Statist. 2010;5:232–253. doi: 10.1214/10-AOAS388. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen H. Convergence rates for parametric components in a partly linear model. Ann Statist. 1988;16:136–146. [Google Scholar]
- Chen H. Asymptotically efficient estimation in semiparametric generalized linear models. Ann Statist. 1995;23:1102–1129. [Google Scholar]
- Engle RF, Granger CWJ, Rice J, Weiss A. Semiparametric estimates of the relation between weather and electricity sales. J Amer Statist Assoc. 1986;81:310–320. [Google Scholar]
- Friedman J, Hastie, Hoefling H, Tibshirani R. Pathwise coordinate optimization. Ann Appl Statist. 2007;35:302–332. [Google Scholar]
- Fu WJ. Penalized regressions: the bridge versus the lasso. J Comp Graph Statist. 1998;7:397–416. [Google Scholar]
- Härdle W, Liang H, Gao J. Partially Linear Models. Physica-Verlag; Heidelberg: 2000. [Google Scholar]
- Hastie T, Tibshirani R. Generalized additive models. Chapman & Hall; 1990. [DOI] [PubMed] [Google Scholar]
- Heckman N. Spline smoothing in partly linear model. J Roy Statist Soc Ser B. 1986;48:244–248. [Google Scholar]
- Huang J. Efficient estimation for the Cox model with interval censoring. Ann Statist. 1996;24:540–568. [Google Scholar]
- Huang J. Efficient estimation of the partly linear additive Cox model. Ann Statist. 1999;27:1536–1563. [Google Scholar]
- Huang J, Horowitz JL, Wei FR. Variable selection in nonparametric additive models. Ann Statist. 2010;38:2282–2313. doi: 10.1214/09-AOS781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mazumder R, Friedman J, Hastie T. Preprint. Department of Statistics, Stanford University; 2009. SparseNet: Coordinate descent with non-convex penalties. [Google Scholar]
- Rice J. Convergence rates for partially spline models. Statist & Probab Lett. 1986;4:203–208. [Google Scholar]
- Shen X, Wong WH. Convergence rate of sieve estimates. Ann Statist. 1994;22:580–615. [Google Scholar]
- Schumaker L. Spline Functions: Basic Theory. Wiley; New York: 1981. [Google Scholar]
- Speckman P. Spline smoothing and optimal rates of convergence in nonparametric regression models. Ann Statist. 1985;13:970–983. [Google Scholar]
- Stone CJ. Additive regression and other nonparametric models. Ann Statist. 1985;13:689–705. [Google Scholar]
- Tseng P. Convergence of a block coordinate descent method for nondifferentiable minimization. J Opt Th & Appl. 2001;109:475–494. [Google Scholar]
- Van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer Verlag; New York: 1996. [Google Scholar]
- Wahba G. Analyses for Time Series, Japan-US Joint Seminar. Tokyo: Institute of Statistical Mathematics; 1984. Partial spline models for the semiparametric estimation of functions of several variables; p. 319329. [Google Scholar]
- Willems JP, Saunders JT, Hunt DE, Schorling JB. Prevalence of coronary heart disease risk factors among rural blacks: A community-based study. Southern Med J. 1997;90:814–820. doi: 10.1097/00007611-199708000-00008. [DOI] [PubMed] [Google Scholar]
- Wu T, Lange K. Coordinate descent procedures for lasso penalized regression. Ann Appl Statist. 2007;2:224–244. [Google Scholar]
- Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. J R Statist Soc B. 2006;68:49–67. [Google Scholar]
- Zhang CH. Nearly unbiased variable selection under minimax concave penalty. Ann Statist. 2010;38:894–942. [Google Scholar]
- Zhang HH, Cheng G, Liu Y. Linear or nonlinear? Automatic structure discovery for partially linear models. Preprint Under revision for J Amer Statist Assoc. 2010 doi: 10.1198/jasa.2011.tm10281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H. The adaptive Lasso and its oracle properties. J Amer Statist Assoc. 2006;101:1418–1429. [Google Scholar]