

Abstract
During much of the past century, it was widely believed that phonemes—the human speech sounds that constitute words—have no inherent semantic meaning, and that the relationship between a combination of phonemes (a word) and its referent is simply arbitrary. Although recent work has challenged this picture by revealing psychological associations between certain phonemes and particular semantic contents, the precise mechanisms underlying these associations have not been fully elucidated. Here we provide novel evidence that certain phonemes have an inherent, non-arbitrary emotional quality. Moreover, we show that the perceived emotional valence of certain phoneme combinations depends on a specific acoustic feature—namely, the dynamic shift within the phonemes' first two frequency components. These data suggest a phoneme-relevant acoustic property influencing the communication of emotion in humans, and provide further evidence against previously held assumptions regarding the structure of human language. This finding has potential applications for a variety of social, educational, clinical, and marketing contexts.
Keywords: Language, Emotion, Speech, Phoneme
INTRODUCTION
Human vocalizations can convey emotion through the semantic content of particular phoneme combinations (words), as well as through the prosodic features of a vocalization (accentuation, intonation, rhythm). Throughout much of the past century, it was generally accepted that a string of phonemes (word) constitutes a linguistic sign via an arbitrary relationship between the phonemes and the referent, whereas prosody is thought to have an inherent, non-arbitrary emotional quality that is wholly independent from the semantic content (or lack thereof) in the vocalization. To illustrate, the string of phonemes used to identify a particular object may vary widely between languages, while a particular prosody can be universally understood to convey a particular emotion. Recent work, however, has begun to challenge this picture. In this study, we demonstrate for the first time that certain strings of English phonemes have an inherent, non-arbitrary emotional valence that can be predicted on the basis of dynamic changes in acoustic features.
Although previous studies have identified a number of psychological associations between certain phonemes and particular semantic or perceptual characteristics, these studies differ from ours by employing a classification scheme based either on articulation features (i.e., configurations of the vocal tract during the production of phonemes) or on the relative position and dispersion of phonemes' acoustic frequency components (also known as their formant frequencies). In contrast, our study employs a classification scheme that is based on the dynamic shifts in the phonemes' formant frequencies.
One of the most consistent findings is that nonsense words consisting of front phonemes—i.e., phonemes articulated toward the front of the mouth—are perceived as smaller, faster, lighter, and more pleasant than nonsense words consisting of back phonemes (Folkins & Lenrow, 1966; Miron, 1961; Newman, 1933; Sapir, 1929; Shrum & Lowrey, 2007; Thompson & Estes, 2011). Such differences have also been found when comparing voiced and voiceless phonemes (Folkins & Lenrow, 1966; Klink, 2000; Newman, 1933; Thompson & Estes, 2011), rounded and unrounded phonemes (Kohler, 1929; Ramachandran & Hubbard, 2001), plosives and continuants (Westbury, 2005), and plosives and fricatives (Klink, 2000). Moreover, these results are not unique to English speaking subjects, nor to adults (Davis, 1961; Hinton, Nichols, & Ohala, 1994; Maurer, Pathman, & Mondloch, 2006; though see I. K. Taylor & Taylor, 1965).
These findings raise the question of whether such effects result from some idiosyncratic physical feature of articulation (e.g., proprioceptive awareness of vocal-tract position, or the visual perception of associated facial expressions), or whether these effects are instead strictly related to the listener's auditory experience of acoustic features. The previous articulation-based findings do not resolve this issue; the main confounding factor is that differences in articulation features correspond systematically to differences in acoustic features. For example, as one moves from front to back vowels, the position of the second formant frequency (i.e., F2), as well as the dispersion between the first and second formants (i.e., F1 and F2), decreases at each step (Delattre, Liberman, & Cooper, 1955). Thus, the articulation-based finding—that nonsense words consisting of front phonemes are perceived as smaller, faster, lighter, and more pleasant than nonsense words consisting of back phonemes—could alternatively be described as an acoustic-based finding that nonsense words with a lower F2-position (or a smaller dispersion between F1 and F2) are perceived as smaller, faster, lighter, and more pleasant than nonsense words with higher F2-positions (or a greater dispersion between F1 and F2). To avoid such confounds, we employ a classification scheme that (i) is based on the acoustic features of phonemes and (ii) does not correspond to any single classification scheme regarding articulation features (e.g., the front-back continuum).
This focus on acoustic features also has the advantage of linking our study to previous proposals that have emphasized a key role for acoustic features. Work on animal vocalization, for instance, suggests an important role for acoustic features in some of the previous findings on the semantic qualities of nonsense words. Several studies reveal a positive correlation between vocal-tract length and body size, in both human and non-human animals (Fitch, 1997, 1999; Riede & Fitch, 1999). Moreover, animals with longer vocal tracts (and thus larger body sizes) tend to produce vocalizations with lower formant frequencies and a smaller dispersion between formants (Charlton et al., 2011; Charlton, Reby, & McComb, 2008; Fitch, 2000; Fitch & Reby, 2001). A variety of species—including human, red deer, domestic dog, and koala—rely on these acoustic features to approximate the body size of other organisms (Charlton, Ellis, Larkin, & Tecumseh Fitch, 2012; Reby et al., 2005; Smith, Patterson, Turner, Kawahara, & Irino, 2005; A. M. Taylor, Reby, & McComb, 2010). Thus, a parallel can be drawn between people's tendency to associate certain nonsense words with particular semantic properties and the tendency of animals (human and nonhuman) to use formant features as cues for body size. Specifically, just as front vowels (i.e., vowels characterized by a higher F2-position and a greater dispersion between F1 and F2) are perceived as smaller and lighter than back vowels (i.e., vowels characterized by a lower F2-position and a smaller dispersion between F1 and F2), a similar point can be made about certain animal vocalizations: namely, that animal vocalizations characterized by higher formant positions and a greater formant dispersion are perceived as originating from a smaller organism than vocalizations characterized by lower formant positions and a smaller formant dispersion. Accordingly, some authors have suggested that people's tendency to perceive front vowels as smaller and lighter than back vowels may be evolutionarily rooted in this use of formant position and dispersion as a cue for body size (for review, see Shrum & Lowrey, 2007). In light of such proposals, the question arises as to whether there might be other acoustic features that play a similar type of dual role as that played by formant position and dispersion; i.e., serving as both the characteristic feature used to identify particular human phonemes (in the way that formant position and dispersion are used to identify vowel sounds) and the characteristic feature used to identify certain semantic properties in animal vocalizations (in the way that formant position and dispersion are also used as cues for body size). If an additional feature along these lines were found, it would raise the possibility that the semantic properties associated with this feature's expression in animal vocalizations might also be associated with this feature's expression in nonsense words (e.g., just as the semantic property of smallness is associated both with animal vocalizations characterized by high formant position and dispersion and with nonsense words characterized by high formant position and dispersion). One candidate for an additional feature along these lines is the transition patterns of formant frequencies (also known as formant shifts).
Our study's hypothesis is predicated on three observations. First, numerous non-human animal species lower their vocal tracts (thereby lowering the frequencies of their vocalizations) in order to appear larger and more threatening to antagonists or competitors (Fitch, 1999; Reby et al., 2005). Second, if vocal-tract is dynamically lengthened and pitch dynamically lowered during the presentation of a given vowel sound, humans perceive the vowel as originating from an angrier organism, whereas if vocal-tract is dynamically shortened and pitch dynamically raised during the presentation of the vowel sound, humans perceive the vowel as originating from a happier organism (Chuenwattanapranithi, Xu, Thipakorn, & Maneewongvatana, 2008). Third, in humans, the categorical perception of phonetic sounds is mediated not only by the relative position and dispersion of the first and second formant frequencies (F1 and F2), but also by the transition patterns of F1 and F2 (Delattre et al., 1955; Stevens, Blumstein, Glicksman, Burton, & Kurowski, 1992). Thus, we predicted that human vocalizations exhibiting a downward shift in F1/F2 formants (perhaps evolutionarily rooted in antagonistic/competitive behavior) would be associated with negative emotion, whereas vocalizations exhibiting an upward shift in F1/F2 formants (perhaps evolutionarily rooted in conciliatory/submissive behavior) would be associated with positive emotion. This prediction differs from the findings of Chuenwattanapranithi et al. (2008) in that Chuenwattanapranithi et al. examined changes in acoustic properties (such as pitch) that had no effect on subjects' differentiation between phonemes. In contrast, our study focuses on certain acoustic properties (i.e., F1/F2 formant shifts) that play a key role in the differentiation between phonemes. This difference in focus allows us to explore the novel hypothesis that certain phoneme-relevant acoustic features exhibit a non-arbitrary emotional quality.
METHODS
To test this prediction, we adapted a two-alternative forced-choice test in which subjects were instructed to match strings of phonemes (comprising nonsense words) with pictures (Kohler, 1929). The non-words were constructed so as to exhibit either an overall upward or downward shift in F1/F2 frequencies (Figure 1, Table 1), and the pictures were selected on the basis of eliciting positive or negative emotion (Bradley, Codispoti, Cuthbert, & Lang, 2001) (Table S1). Non-word pairs were matched for other acoustic and speech features (volume, intonation, accentuation, plosives, fricatives, nasals, vowels, number of syllables, number of phonemes, number of graphemes; Table S2), and pictures were matched for arousal. We ran two versions of the task with two different sets of healthy adult participants. In one version the word pairs were presented visually (n=32 adult subjects, 15 males, mean age 35.5±15.2), and in the other version the word pairs were presented auditorily (n=20 adult subjects, 10 males, mean age 53.3±11.7).
Figure 1.
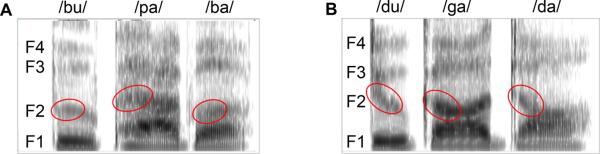
Spectrograms illustrating the first four formants (F1–F4) of the example nonsense words “bupaba” (A) and “dugada” (B) as obtained with Praat software (version 5.1.20). The differentiation between these non-words is largely mediated by the F2 transitions from consonants to vowels (outlined in red), which move upward for “bupaba” and downward for “dugada”.
Table 1.
Non-word pairs used in the study. Each of the 35 non-word pairs was used in the visual task. The subset of 22 italicized non-word pairs was used in the auditory task. Non-word pairs had opposing F1/F2 shifts, but were otherwise matched for acoustic and speech features (volume, intonation, accentuation, plosives, fricatives, nasals, vowels, number of syllables, number of phonemes, number of graphemes; for more detail see Methods and Table S2).
| Upward F1/F2 shifts (Predicted Positive) | Downward F1/F2 shifts (Predicted Negative) | |
|---|---|---|
| 1 | babopu | tatoku |
| 2 | pabu | dagu |
| 3 | bopo | koto |
| 4 | mobapo | nodago |
| 5 | bibapo | didago |
| 6 | masa | naza |
| 7 | pabapo | katako |
| 8 | mabapu | nadaku |
| 9 | bafaso | gavazo |
| 10 | mabo | nago |
| 11 | bafapo | davako |
| 12 | bepabo | degado |
| 13 | pasobi | tazogi |
| 14 | bopa | koga |
| 15 | bobipa | dodiga |
| 16 | pafabi | davagi |
| 17 | bupaba | dugada |
| 18 | bobipu | dodigu |
| 19 | mesabo | nezago |
| 20 | bepaso | tekazo |
| 21 | bapafo | katavo |
| 22 | mipaba | nidaga |
| 23 | besa | teza |
| 24 | pafobu | tavoku |
| 25 | pasa | kaza |
| 26 | besapa | dezaga |
| 27 | asofi | azovi |
| 28 | bofoba | kovoka |
| 29 | asaba | azaga |
| 30 | bobapu | kokatu |
| 31 | befosa | kevoza |
| 32 | mabapu | nataku |
| 33 | ousa | ouza |
| 34 | posabu | kozagu |
| 35 | bapibu | gadigu |
The visual test consisted of 35 trials (20 experimental, 15 control), corresponding to the 35 non-word pairs (Table 1) as well as the 35 image pairs (Table S1). For each of the 20 experimental trials, there was a distinct pair of non-words with opposing F1/F2 frequency shifts (one with upward shifts, one with downward shifts) and a distinct pair of pictures with opposing valences (one positive, one negative). For each of the 15 control trials, there was a distinct pair of non-words with opposing F1/F2 frequency shifts (one upward, one downward) and a distinct pair of pictures with matched valences (5 of the pairs were neutral/neutral, 5 were negative/negative, and 5 were positive/positive). The 15 control trials (which were randomly interspersed among the experimental trails) had image pairs with matched (rather than opposing) valences in order to mask the semantic feature under scrutiny (i.e., valence). Thus, for control trials, the nonwords within each pair were matched to positive, negative, and neutral images equally often.
The auditory test consisted of 22 trials. For each trial, there was a distinct pair of non-words with opposing F1/F2 frequency shifts (one upward, one downward) and an individual picture (11 trials had a positively-valenced picture, and 11 had a negatively-valenced picture). The non-words were pronounced by an automated computer voice program (AT&T Natural Voices). For each of the non-word pairs used in the auditory task, spectrograms were obtained with Praat software (version 5.1.20) to ensure that the non-words in each pair differed with respect to direction of F1/F2 shift. The 22 non-word pairs used in the auditory task are italicized in Table 1. The 22 pictures used in the auditory task are italicized in Table S1. Given that the auditory task used individual pictures (rather than image pairs), there was no need to include control trials that matched image pairs for valence (as was done in the visual task).
In both the visual and auditory tests, the non-word pairs remained constant across all subjects. To illustrate, the two non-words in the first pair from Table 1—“babopu” and “tatoku”—were always paired together. However, the place at which each non-word appeared on the screen (top left or bottom right, for the visual task; bottom left or bottom right, for the auditory task) was randomized for each subject, as was the image pair (or the individual image, for the auditory task) that appeared with the non-words and the particular trial in which the non-word pair was presented.
Non-word pairs were constructed on the basis of the following general points:
-
(1)
The differentiation between bilabial plosives (/b/, /p/), alveolar plosives (/d/, /t/), and velar plosives (/g/, /k/) is largely mediated by the F2 transitions from the plosive to the subsequent vowel sound. In short, the F2 transitions of bilabial plosives tend to move upward, while the F2 transitions of alveolar and velar plosives tend to move downward (Blumstein & Stevens, 1979; Delattre et al., 1955; Stevens & Blumstein, 1978; Sussman, Bessell, Dalston, & Majors, 1997).
-
(2)
The differentiation between the nasal phonemes, /m/ and /n/, is largely mediated by the F2 transitions from the nasal to the subsequent vowel sound. Furthermore, the F2 transitions of /m/ and /n/ closely resemble the F2 transitions of /b/ and /d/, respectively (Delattre et al., 1955; Liberman, Delattre, Cooper, & Gerstman, 1954; Repp & Svastikula, 1988).
-
(3)
The differentiation between voiced intervocalic fricatives (particularly, /z/ and /v/) and their voiceless counterparts (/s/ and /f/, respectively) is largely mediated by the F1 transitions between the fricative and the adjacent vowels. Moreover, for the voiced fricatives /z/ and /v/, the downward F1 transition from the preceding vowel to the fricative tends to be greater than the upward F1 transition from the fricative to the subsequent vowel. For the voiceless fricatives /s/ and /f/, however, the downward F1 transition from the preceding vowel to the fricative tends to be less than the upward F1 transition from the fricative to the subsequent vowel. Furthermore, the downward F1 transition of fricatives tends to be more salient than the upward F1 transition; and the voiced fricatives (/z/ and /v/) exhibit a greater downward F1 transition than their voiceless counterparts (/s/ and /f/, respectively) (Stevens et al., 1992).
In accordance with (1)–(3), all non-words were paired so that (i) bilabial plosives were matched with alveolar or velars plosives, (ii) the nasal phoneme /m/ was matched with /n/, (iii) the voiced fricatives (/z/ and /v/) were matched with their voiceless counterparts (/s/ and /f/, respectively), and (iv) all fricatives were situated between two vowels (hence, making them intervocalic fricatives). Also, given that the extent (and in some cases, the direction) of F1/F2 transitions can vary depending on the adjacent vowel sound (Delattre et al., 1955), and given that certain changes in vowel sounds can create changes in the perceived meaning of a nonsense word (Folkins & Lenrow, 1966; Miron, 1961; Newman, 1933; Sapir, 1929), all non-word pairs were matched for vowel sounds (as seen in Table 1).
RESULTS
As predicted, subjects reliably paired the downward F1/F2 shift non-words with the negative images and the upward F1/F2 shift non-words with the positive images. In the visual task (n=32 adult subjects, 15 males, mean age 35.5±15.2), subjects made the predicted choice on 80% of trials (chance performance is 50%). The proportion of individuals selecting a majority of predicted responses (i.e., on more than 10 out of the 20 trials) was significantly greater than expected by chance (Yates' χ2= 23.8; p=0.000001) (Figure 2).
Figure 2.
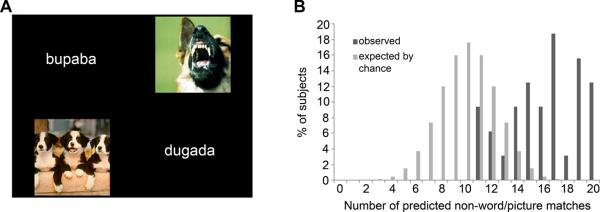
Visual task. A: Example of a trial from the visual task. Subjects pressed a vertical arrow button to match the non-words/pictures vertically, or a horizontal arrow button to match the non-words/pictures horizontally. B: Data from the visual task.
To ensure that this effect did not result merely from the words' visual properties, we ran an auditory version of the test with a different set of subjects (n=20 adult subjects, 10 males, mean age 53.3±11.7), and again found the predicted pattern. In particular, subjects made the predicted choice on 65.5% of trials (chance performance is 50%). The proportion of individuals selecting a majority of predicted responses (i.e., on more than 11 out of the 22 trials) was again significantly greater than expected by chance (Yates' χ2= 4.7; p=0.03) (Figure 3).
Figure 3.
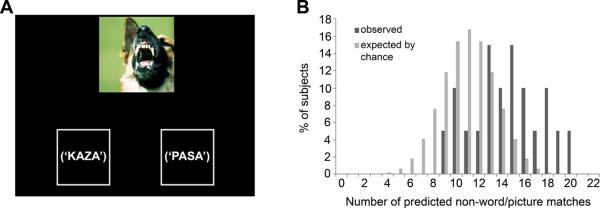
Auditory task. A: Example of a trial from the auditory task. Subjects heard two non-words (the non-words were not actually displayed visually during the task), then pressed a button (left or right) to select the first or second word, respectively. B: Data from the auditory task.
DISCUSSION
These results suggest that certain strings of English phonemes have a non-arbitrary emotional quality, and moreover, that the emotional quality can be predicted on the basis of specific acoustic features. This study moves beyond previous research by employing a classification scheme that is based solely on the acoustic features of phonemes, such that the scheme cannot be equivalently re-described in terms of articulation features (e.g., the front-back continuum). Moreover, the present results differ from previous findings relating phoneme-irrelevant properties (such as pitch) to emotional valence (Chuenwattanapranithi et al. 2008); and also from findings relating certain acoustic features (e.g., amplitude) to emotional arousal, irrespective of valence (Bachorowski & Owren, 1995, 1996). This study is thus the first to identify phoneme-relevant formant shifts as a critical determinant of emotional valence in human speech.
The present results also link nicely to previous proposals that emphasize an important role for acoustic features. As noted, some authors have suggested that people's tendency to perceive front vowels as smaller and lighter than back vowels may be explained in terms of the parallel finding that animal vocalizations characterized by higher formant positions and a greater formant dispersion are perceived as originating from a smaller organism than vocalizations characterized by lower formant positions and a smaller formant dispersion. In a similar fashion, the present findings that strings of phonemes characterized by downward F1/F2 shifts are perceived as more aversive than those characterized by upward F1/F2 shifts may be explained in terms of parallel data suggesting that animal vocalizations characterized by a dynamic lowering of the vocal tract are perceived as angrier than vocalizations characterized by a dynamic raising of the vocal tract.
One limitation of the present study is that all subjects were English-speaking adults. Thus, future work would do well to examine whether the effect also holds in non-English speaking subjects and in younger children; especially since some of the key previous findings on the semantic properties of nonsense words have been found to extend to both non-English speaking subjects and toddlers (Davis, 1961; Hinton et al., 1994; Maurer et al., 2006).
The data presented here effectively outline a formula for constructing words and non-words that implicitly conjure positive or negative emotion. Accordingly, we see potential applications of this study to a variety of social, educational, clinical, and marketing contexts. Consider a few examples. Advertising campaigns, whether for commercial products or political candidates, attempt to enhance emotional salience or appeal through carefully chosen language (Lerman & Garbarino, 2002; Robertson, 1989). Likewise, educational and mental health professionals seek to destigmatize certain conditions or activities through more sensitive labeling (Ben-Zeev, Young, & Corrigan, 2010; Siperstein, Pociask, & Collins, 2010). Even in artistic contexts, such as film and literature, these acoustic principles could be applied to evoke a particular emotional subtext. (Indeed, our data suggest that “Darth Vader” (Lucas, 1977) is an acoustically more appropriate name for an intergalactic miscreant than “Barth Faber”, by virtue of the downward frequency shifts and thus inherently negative emotional connotation). The results of this study elucidate an acoustic mechanism by which the characteristic properties of phonemes may communicate emotion.
Supplementary Material
REFERENCES
- Bachorowski JA, Owren MJ. Vocal Expression of Emotion - Acoustic Properties of Speech Are Associated with Emotional Intensity and Context. Psychological Science. 1995;6(4):219–224. [Google Scholar]
- Bachorowski JA, Owren MJ. Vocal expression of emotion is associated with vocal fold vibration and vocal tract resonance. Psychophysiology. 1996;33:S20–S20. [Google Scholar]
- Ben-Zeev D, Young MA, Corrigan PW. DSM-V and the stigma of mental illness. J Ment Health. 2010;19(4):318–327. doi: 10.3109/09638237.2010.492484. doi:10.3109/09638237.2010.492484. [DOI] [PubMed] [Google Scholar]
- Blumstein SE, Stevens KN. Acoustic invariance in speech production: evidence from measurements of the spectral characteristics of stop consonants. J Acoust Soc Am. 1979;66:1001–1017. doi: 10.1121/1.383319. [DOI] [PubMed] [Google Scholar]
- Bradley MM, Codispoti M, Cuthbert BN, Lang PJ. Emotion and motivation I: defensive and appetitive reactions in picture processing. Emotion. 2001;1(3):276–298. [PubMed] [Google Scholar]
- Charlton BD, Ellis WA, Larkin R, Tecumseh Fitch W. Perception of size-related formant information in male koalas (Phascolarctos cinereus) Anim Cogn. 2012 doi: 10.1007/s10071-012-0527-5. doi: 10.1007/s10071-012-0527-5. [DOI] [PubMed] [Google Scholar]
- Charlton BD, Ellis WA, McKinnon AJ, Cowin GJ, Brumm J, Nilsson K, Fitch WT. Cues to body size in the formant spacing of male koala (Phascolarctos cinereus) bellows: honesty in an exaggerated trait. J Exp Biol. 2011;214(Pt 20):3414–3422. doi: 10.1242/jeb.061358. [DOI] [PubMed] [Google Scholar]
- Charlton BD, Reby D, McComb K. Effect of combined source (F0) and filter (formant) variation on red deer hind responses to male roars. J Acoust Soc Am. 2008;123(5):2936–2943. doi: 10.1121/1.2896758. [DOI] [PubMed] [Google Scholar]
- Chuenwattanapranithi S, Xu Y, Thipakorn B, Maneewongvatana S. Encoding emotions in speech with the size code. A perceptual investigation. Phonetica. 2008;65(4):210–230. doi: 10.1159/000192793. [DOI] [PubMed] [Google Scholar]
- Davis R. The fitness of names to drawings. A cross-cultural study in Tanganyika. British journal of psychology. 1961;52:259–268. doi: 10.1111/j.2044-8295.1961.tb00788.x. [DOI] [PubMed] [Google Scholar]
- Delattre P, Liberman A, Cooper F. Acoustic loci and transitional cues for consonants. J Acoust Soc Am. 1955;27:769–773. [Google Scholar]
- Fitch WT. Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaques. J Acoust Soc Am. 1997;102(2 Pt 1):1213–1222. doi: 10.1121/1.421048. [DOI] [PubMed] [Google Scholar]
- Fitch WT. Acoustic exaggeration of size in birds by tracheal elongation: Comparative and theoretical analyses. Journal of Zoology. 1999;248:31–49. [Google Scholar]
- Fitch WT. The evolution of speech: a comparative review. Trends in cognitive sciences. 2000;4(7):258–267. doi: 10.1016/s1364-6613(00)01494-7. [DOI] [PubMed] [Google Scholar]
- Fitch WT, Reby D. The descended larynx is not uniquely human. Proceedings of the Royal Society of London, B. 2001;268:1669–1675. doi: 10.1098/rspb.2001.1704. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Folkins C, Lenrow P. An investigation of the expressive values of graphemes. The Psychological Record. 1966;16:193–200. [Google Scholar]
- Hinton L, Nichols J, Ohala JJ. Sound symbolism. Cambridge University Press; Cambridge: 1994. [Google Scholar]
- Klink RR. Creating brand names with meaning: The use of sound symbolism. Marketing Letters. 2000;11(1):5–20. [Google Scholar]
- Kohler W. Gestalt Psychology. Liveright; New York: 1929. [Google Scholar]
- Lerman D, Garbarino E. Recall and recognition of brand names: A comparison of word and nonword name types. Psychology and Marketing. 2002;19:621–639. [Google Scholar]
- Liberman A, Delattre P, Cooper F, Gerstman L. The role of consonant-vowel transitions in the perception of the stop and nasal consonants. Psychol Monogr. 1954;68:1–13. [Google Scholar]
- Lucas G. Star Wars: 20th Century Fox. 1977. [Google Scholar]
- Maurer D, Pathman T, Mondloch CJ. The shape of boubas: sound-shape correspondences in toddlers and adults. [Research Support, Non-U.S. Gov't] Developmental science. 2006;9(3):316–322. doi: 10.1111/j.1467-7687.2006.00495.x. doi: 10.1111/j.1467-7687.2006.00495.x. [DOI] [PubMed] [Google Scholar]
- Miron M. A cross-linguistic investigation of phonetic symbolism. J Abnorm Soc Psychol. 1961;62:623–630. doi: 10.1037/h0045212. [DOI] [PubMed] [Google Scholar]
- Newman S. Further experiments in phonetic symbolism. Amer J Psychol. 1933;45:53–75. [Google Scholar]
- Ramachandran VS, Hubbard EM. Synaesthesia - a window into perception, thought, and language. Journal of Consciousness Studies. 2001;8(12):3–34. [Google Scholar]
- Reby D, McComb K, Cargnelutti B, Darwin C, Fitch WT, Clutton-Brock T. Red deer stags use formants as assessment cues during intrasexual agonistic interactions. Proc Biol Sci. 2005;272(1566):941–947. doi: 10.1098/rspb.2004.2954. doi: QWEU7P6HQ0BE5QP1 [pii] 10.1098/rspb.2004.2954. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Repp BH, Svastikula K. Perception of the [m]-[n] distinction in VC syllables. J Acoust Soc Am. 1988;83(1):237–247. doi: 10.1121/1.396529. [DOI] [PubMed] [Google Scholar]
- Riede T, Fitch T. Vocal tract length and acoustics of vocalization in the domestic dog (Canis familiaris) The Journal of experimental biology. 1999;202(Pt 20):2859–2867. doi: 10.1242/jeb.202.20.2859. [DOI] [PubMed] [Google Scholar]
- Robertson K. Strategically desirable brand name characteristics. Journal of Consumer Marketing. 1989;6:61–71. [Google Scholar]
- Sapir E. A study in phonetic symbolism. J Exper Psychol. 1929;12:225–239. [Google Scholar]
- Shrum LJ, Lowrey TM. Sounds Convey Meaning: The Implications of Phonetic Symbolism for Brand Name Construction. In: Lowrey TM, editor. Psycholinguistic Phenomena in Marketing Communications. Lawrence Erlbaum; Mahwah, NJ: 2007. pp. 39–58. [Google Scholar]
- Siperstein GN, Pociask SE, Collins MA. Sticks, stones, and stigma: a study of students' use of the derogatory term “retard”. Intellectual and developmental disabilities. 2010;48(2):126–134. doi: 10.1352/1934-9556-48.2.126. [DOI] [PubMed] [Google Scholar]
- Smith DR, Patterson RD, Turner R, Kawahara H, Irino T. The processing and perception of size information in speech sounds. J Acoust Soc Am. 2005;117(1):305–318. doi: 10.1121/1.1828637. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stevens KN, Blumstein SE. Invariant cues for place of articulation in stop consonants. J Acoust Soc Am. 1978;64(5):1358–1368. doi: 10.1121/1.382102. [DOI] [PubMed] [Google Scholar]
- Stevens KN, Blumstein SE, Glicksman L, Burton M, Kurowski K. Acoustic and perceptual characteristics of voicing in fricatives and fricative clusters. J Acoust Soc Am. 1992;91(5):2979–3000. doi: 10.1121/1.402933. [DOI] [PubMed] [Google Scholar]
- Sussman HM, Bessell N, Dalston E, Majors T. An investigation of stop place of articulation as a function of syllable position: a locus equation perspective. J Acoust Soc Am. 1997;101(5 Pt 1):2826–2838. doi: 10.1121/1.418567. [DOI] [PubMed] [Google Scholar]
- Taylor AM, Reby D, McComb K. Size communication in domestic dog, Canis familiaris, growls. Animal Behaviour. 2010;79(1):205–210. [Google Scholar]
- Taylor IK, Taylor MM. Another look at phonetic symbolism. Psychological bulletin. 1965;64(6):413–427. doi: 10.1037/h0022737. [DOI] [PubMed] [Google Scholar]
- Thompson PD, Estes Z. Sound symbolic naming of novel objects is a graded function. Quarterly journal of experimental psychology. 2011;64(12):2392–2404. doi: 10.1080/17470218.2011.605898. [DOI] [PubMed] [Google Scholar]
- Westbury C. Implicit sound symbolism in lexical access: evidence from an interference task. Brain and language. 2005;93(1):10–19. doi: 10.1016/j.bandl.2004.07.006. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.