

Abstract
Perceptual training with spectrally degraded environmental sounds results in improved environmental sound identification, with benefits shown to extend to untrained speech perception as well. The present study extended those findings to examine longer-term training effects as well as effects of mere repeated exposure to sounds over time. Participants received two pretests (1 week apart) prior to a week-long environmental sound training regimen, which was followed by two posttest sessions, separated by another week without training. Spectrally degraded stimuli, processed with a four-channel vocoder, consisted of a 160-item environmental sound test, word and sentence tests, and a battery of basic auditory abilities and cognitive tests. Results indicated significant improvements in all speech and environmental sound scores between the initial pretest and the last posttest with performance increments following both exposure and training. For environmental sounds (the stimulus class that was trained), the magnitude of positive change that accompanied training was much greater than that due to exposure alone, with improvement for untrained sounds roughly comparable to the speech benefit from exposure. Additional tests of auditory and cognitive abilities showed that speech and environmental sound performance were differentially correlated with tests of spectral and temporal-fine-structure processing, whereas working memory and executive function were correlated with speech, but not environmental sound perception. These findings indicate generalizability of environmental sound training and provide a basis for implementing environmental sound training programs for cochlear implant (CI) patients.
Keywords: environmental sound training, speech perception, auditory and cognitive factors
Introduction
Most everyday listening environments are rich with sounds of interacting objects and events. Although speech is the most important means of everyday human communication, other sounds aid the listener in navigating the environment. These sounds, referred to as environmental sounds, exclude the more extensively studied sound classes of speech and music (as defined in Shafiro & Gygi, 2004). Environmental sounds serve many ecological functions: They help the listener to avoid danger (e.g., car honks, fire alarms), inform about ongoing events (e.g., tea kettle boiling, footsteps at the door), provide a sense of aesthetic satisfaction (e.g., listening to waves or singing birds), and contribute to overall well-being (Jenkins, 1985; Ramsdell, 1978). Normal-hearing (NH) listeners are able to identify a great number of sound sources in their environment (Ballas, 1993; Gygi, Kidd, & Watson, 2004; Marcell, Borella, Greene, Kerr, & Rogers, 2000; Shafiro, 2008a) and can often obtain very detailed knowledge about many source properties and behaviors through sound alone, such as identifying a person by the sound of his or her footsteps (Li, Logan, & Pastore, 1991) or determining the fullness of a vessel from the sound of pouring water into it (Cabe & Pittenger, 2000). However, as with speech, environmental sound identification can be compromised by hearing impairments and may significantly affect the individual’s quality of life (Ramsdell, 1978). Specifically, it is not uncommon for cochlear implant (CI) patients with high accuracy in speech perception tests to have considerably reduced environmental sound perception scores. As a group, CI users’ environmental sound identification often suffers even after years of implant use (Inverso & Limb, 2010; Shafiro, Gygi, Cheng, Vachhani, & Mulvey, 2011).
Training of Spectrally Degraded Environmental Sounds
Among the factors that can affect CI user performance, a considerable amount of attention has been paid to the reduction of spectral resolution, a major consequence of CI processing. Studies with simulated vocoder-based CI processors indicate that accurate speech perception can be obtained with 4 to 12 spectral channels, with some variation observed as resulting from the use of different test materials and differing levels of listener experience (Dorman, 1993; Shannon, Zeng, Kamath, Wigonski, & Ekelid, 1995). On the other hand, greater spectral resolution is required for the perception of many common everyday environmental sounds (Gygi et al., 2004; Shafiro, 2008a). Varying the number of frequency channels in a vocoder simulation of CI processing, Shafiro (2008a) demonstrated that while some environmental sounds remain highly identifiable with only four spectral channels or less (e.g., “helicopter”), many others require spectral resolution of 24 channels or greater to be identified correctly (e.g., “cow mooing,” “church bell,” “train whistle”). Nevertheless, the detrimental effects of reduced spectral resolution for both speech and environmental sounds can be partially ameliorated by listener experience with spectrally degraded stimuli. Some perceptual improvements can be achieved by extended exposure during repeated presentation of spectrally degraded stimuli, even without feedback, but even more so by providing listeners with systematic training with feedback (Fu & Galvin, 2007; Gygi et al., 2004; Hervais-Adelman, Davis, Johnsrude, & Carlyon, 2008; Hervais-Adelman, Davis, Johnsrude, Taylor, & Carlyon, 2011; Loebach & Pisoni, 2008; Shafiro, 2008b).
Using four-channel vocoded environmental sounds, Shafiro (2008b) demonstrated an overall perceptual improvement in NH listeners’ ability to identify a large set of 160 familiar environmental sounds subsequent to training. Listener performance was assessed by comparing environmental sound identification without feedback during the pretest and posttest, separated by a week-long training interval that consisted of five training sessions during which subjects received trial and block feedback using a subset of poorly identified sounds. More important, the positive changes in listener performance generalized beyond the sounds included in the training set, so that improved performance was obtained for sounds that were never used during training.
Similar positive perceptual changes following a three-session environmental sound training regimen, based on Shafiro (2008b), were reported in a poster by Markee and colleagues (Markee, Chandrasekaran, Nicol, Shafiro, & Kraus, 2009). However, in addition to the comparison between environmental sound performance before and after week-long training, Markee et al. evaluated potential effects of exposure to spectrally degraded sounds with no feedback. Subjects in the Markee study completed two environmental sound pretests that were separated by 1 week without any training, prior to beginning their training regimen. This manipulation enabled Markee et al. to assess how much simple repeated exposure to the same stimuli and experimental procedure may contribute to overall improvement. Indeed, the researchers found that a significant improvement in environmental sound identification was obtained even between the two pretests, although the magnitude of improvement was substantially greater following training. The results of Shafiro (2008b) and Markee et al. indicate positive effects of both training (defined here as repeated presentations with immediate performance feedback) and exposure (presentations with minimal repetition and no feedback) on the perception of spectrally degraded environmental sounds. These results also show that improvement in performance can generalize to environmental sounds not included in the training set.
Further evidence for an even broader generalization of training effects following environmental sound training was obtained by Loebach and Pisoni (2008). Using eight-channel sinewave-vocoded speech and environmental sounds, these researchers found a significant improvement in speech scores for two different types of word and two different types of sentence materials following a brief (about 15-20 min.) environmental sound training session. When tested on the environmental sounds, the largest improvements were observed for both novel and training sounds, followed by pretest sounds, a generalization effect largely consistent with the findings of Shafiro (2008b) and Markee et al. (2009). Curiously, in a reverse training design, no improvement in environmental sound perception was observed following similarly structured training with different kinds of speech materials: words, sentences, or semantically anomalous sentences. This may suggest that training effects obtained with a semantically and acoustically broader sound class, such as environmental sounds, are easier to generalize to a more structured and less variable sound class such as speech, than the other way around. During training, focusing listeners’ attention on acoustic cues from a broader spectral and temporal range of environmental sounds, compared to speech, could have made them more attentive to perceptually salient dimension of speech signals. Also consistent with previous studies with CI patients (Inverso & Limb, 2010; Shafiro, Gygi et al., 2011; Tyler, Moore, & Kuk, 1989), Loebach and Pisoni found significant moderate correlations in the .45 to .57 range between environmental sound and speech test scores. However, Loebach and Pisoni did not find any positive changes due to mere exposure to the environmental sounds when participants were tested repeatedly without feedback—neither the control group nor the speech training groups showed any improvement for environmental sounds.
The lack of beneficial effects from simple exposure in the work of Loebach and Pisoni (2008) might be attributed to the considerably smaller amount of exposure to environmental sounds compared to that in Shafiro (2008b) and Markee et al. (2009). Consistent with that interpretation, recent evidence demonstrates that large accuracy increases can occur after a single brief training session. The intelligibility of vocoded speech by naïve listeners has been shown to undergo rapid positive changes during short periods of initial exposure to vocoded stimuli even without feedback (Davis, Johnsrude, Hervais-Adelman, Taylor, & McGettingan, 2005; Hervais-Adelman et al., 2008) and also to generalize to untrained speech frequency regions including, with some variation, to different vocoder carriers (Hervais-Adelman et al., 2011). However, it is not clear whether the benefits of such rapid learning can be retained over longer time periods. It is conceivable that learning processes over longer time periods, with a greater amount of training and exposure, may follow a different time course from short-term learning effects.
Basic Auditory and Cognitive Abilities
Performance on any perceptual task always represents the result of at least four main interacting factors: stimulus materials, listener characteristics, the nature of experimental tasks used to assess performance, and specifics of experimental context such as instructions and experimental setting (Jenkins, 1979; Roediger, 2008). Each factor can be represented by a number of variables, which can all influence the ultimate perceptual outcome. In particular, in addition to stimulus-specific variables such as spectral resolution or listener-specific variables such as the amount of experience with degraded stimuli, performance may be also affected by a number of other listener-specific central and peripheral factors. When perceiving speech and environmental sounds, low-level peripheral auditory processing abilities (here referred to as basic auditory abilities; Kidd, Watson, & Gygi, 2007) may affect the quality of sensory input, while central factors may be involved in higher-level cognitive processing of information. A number of higher-order cognitive factors, which refer to listeners’ existing knowledge and the ability to store and manipulate information to execute perceptual tasks, have been shown to influence speech perception in NH and hearing-impaired listeners (see Akeroyd, 2008; Gordon-Salant & Fitzgibbons, 1997; Lunner, 2003; Wingfield & Tun, 2007). Among these, working memory capacity as well as the ability to use sentence context have been consistently linked to speech perception abilities in the hearing-impaired and older adult CI patients (Gygi & Shafiro, 2012; Kronenberger, Pisoni, Henning, Colson, & Hazzard, 2011; Pichora-Fuller & Singh, 2006; Pisoni & Cleary, 2003; Pisoni & Geers, 2000; Pisoni, Kronenberger, Roman, & Geers, 2011; Schvartz, Chatterjee, & Gordon-Salant, 2008). The role played by cognitive factors in speech perception becomes particularly important as the quality of the sensory input deteriorates (Humes, Burk, Coughlin, Busey, & Strauser, 2007; Pichora-Fuller, 2003). Listeners’ prior knowledge, personality traits, perceptual skills, and the ability to use contextual cues from both the speech materials and the communicative setting can influence speech perception outcome. These decision-making processes can be modeled by Bayesian logic (Boothroyd, 2010; Boothroyd & Nitrrouer, 1988) in which an a priori hypothesis based on higher-order knowledge can be confirmed or rejected by sensory evidence. On the other hand, although the role of context and other cognitive factors is less clear for environmental sounds (see Aydelott, Leech, & Crinion, 2010; Ballas & Mullins, 1991; Chiu, 2000; Chiu & Schacter, 1995; Gygi & Shafiro, 2011), it is reasonable to expect that some of the factors involved in the processing of rule-based speech may be also involved in the perception of similarly semantically and acoustically complex environmental sounds.
Peripherally, several measures of basic auditory abilities that assess lower-level spectral and temporal processing have been shown to be associated with speech perception in NH and hearing-impaired listeners. In CI patients, speech perception was correlated with measures of temporal envelope processing, including gap detection (Muchnik, Taitelbaum, Tene, & Hildesheimer, 1994; Tyler et al., 1989), temporal modulation thresholds (Cazals, Pelizzone, Saudan, & Boex, 1994; Fu, 2002), and temporal fine structure (Drennan, Longnion, Ruffin, & Rubinstein, 2008); relevant measures of spectral processing included judging the direction of pitch change (Gfeller, Woodworth, Robin, Witt, & Knutson, 1997; Shafiro, Gygi et al., 2011), place-pitch sensitivity (Donaldson & Nelson, 2000), discrimination of spectral ripple density (Henry, Turner, & Behrens, 2005; Won, Drennan, & Rubinstein, 2007), and detection of spectral modulation (Litvak, Spahr, Saoji, & Fridman, 2007; Saoji et al., 2009). An indication that at least some of these factors may be also involved in the perception of environmental sounds has been obtained in a recent study by Shafiro, Gygi et al. who found a moderate correlation between CI patients’ environmental sound identification scores and their ability to detect a change in pitch direction as the duration of the tonal sequences was progressively shortened.
Present Study
The present study further investigated the influence of training as well as listener-specific factors that can affect the perception of spectrally degraded speech and environmental sounds. In a pretest–posttest design, similar to Shafiro (2008b) and Markee et al. (2009), the changes in environmental sound and speech perception following a period of week-long environmental sound training were examined. Three specific questions were addressed. First, would speech and environmental sound scores improve following mere repeated exposure to spectrally degraded stimuli without feedback, as could be expected from the preliminary findings of Markee et al. (2009); or would environmental sound performance remain unchanged, as could be expected based on the findings of Loebach and Pisoni (2008)? Second, would perceptual learning generalize beyond novel environmental sounds to include speech when using a more extensive and protracted testing and training regimen than that used by Loebach and Pisoni? If the generalization effects reported by Loebach and Pisoni were due mainly to the acute perceptual adaptation that results from initial response to degraded sensory input, these effects might be absent when a more chronic stimulation is used. Increasing the duration of the training regimen and allowing for more exposure to spectrally degraded stimuli may indicate the time course of learning to listen to degraded speech and environmental sounds. Finally, whether similar central and peripheral factors are involved in the perception of spectrally degraded speech and environmental sounds was investigated by examining associations of speech and environmental sounds with listeners’ spectral-temporal processing abilities and cognitive factors.
Method
Stimuli and Design
To examine the effects of exposure and training, a multiple baseline pretest–posttest design, similar to that used by Markee et al. (2009), was used (Figure 1). First, all subjects participated in two pretest sessions, separated by a 1-week interval without training. Next, following the second pretest, subjects participated in four environmental sound training sessions, conducted over 1 week, and were then administered a posttest. Finally, following another week without training, their performance was assessed again in a retention session. All four testing sessions (Pretests 1 and 2, Posttest, Retention) followed the same format and included a 160-item environmental sound test (Shafiro, 2008b) and a word and a sentence speech test. The stimuli for four environmental sound training sessions were selected individually for each subject based on his or her performance on the second pretest, as described below. In addition, all subjects were administered tests of basic auditory abilities and cognitive factors to determine their role in the perception of spectrally degraded speech and environmental sounds.
Figure 1.

A diagram of the testing–training sequence used in the study.
To simulate effects of CI processing, the spectral resolution of all speech and environmental sounds used during testing and training was reduced to four frequency channels using a noise-based vocoder, similar to spectral degradation techniques used in previous studies (Loizou, 1997; Shafiro, 2008a, 2008b; Shannon et al., 1995). The stimuli were (a) filtered with sixth-order Butterworth filters (overlapping at −3dB) into four log-spaced frequency bands within the 300 to 5500 Hz range, (b) envelopes from each band were obtained via half-wave rectification followed by low-pass filtering at 160 Hz, (c) white noise was modulated with the envelope of each band and filtered using the original filter settings, and (d) the four modulated noise bands were combined.
Familiar environmental sound test (FEST; Shafiro, 2008b) consisted of a large collection of common and familiar environmental sounds selected based on their ecological frequency of occurrence (Ballas, 1993), familiarity to NH and CI listeners (Shafiro, Gygi et al., 2011), and broad representation of different taxonomic categories of environmental sounds established in previous research (Ballas, 1993; Gaver, 1993; Gygi, Kidd, & Watson, 2007). It included 160 familiar environmental sounds (40 sound sources, 4 tokens each), administered in a 60-item closed-set test (40 sound-source labels and 20 foils). Sounds corresponded to five overall categories: human/animal vocalizations and bodily sounds, mechanical sounds, water sounds, aerodynamic sounds, and signaling sounds. When presented without distortion, all sounds in the test have been found to be easily identifiable and highly familiar to NH listeners (Shafiro, 2008b). As in Shafiro (2008b), a greater number of response labels than that of sound sources were used to minimize potential set effects and more closely approximate open-set identification. The choice of a closed-set format in speech and environmental sound testing was motivated primarily by its practical utility in computerized assessment, which avoids the need for an additional human examiner for accuracy scoring. This increases accessibility of home-based computer training, which was in line with the goal of the present study, and avoids the additional variability introduced by an independent scorer. Although the closed-set format may not involve exactly the same perceptual processes as open-set testing, which is more typical of everyday speech perception tasks (Clopper, Pisoni, & Tierney, 2006), the greater experimental control and greater ease of use of the participants provide a practical trade-off for the potential loss of generalizability.
Speech tests included a Consonant–Nucleus–Consonant (CNC) monosyllabic word test (Peterson & Lehiste, 1962) and the Speech-in-Noise (SPIN-R) sentence test (Elliott, 1995); both tests were administered in a closed-set response format with 50 response options with no foils.
For the CNC words, listeners were asked to indicate each word that they heard, and for the SPIN-R sentences, listeners were asked to indicate the last word of each sentence. The CNC test was included to provide information on listeners’ ability to perceive individual words in isolation, whereas the SPIN-R test was included to examine the effect of high- and low-probability sentence context on word identification. When sensory input is degraded, adult listeners can often use semantic and syntactic context to identify the correct word (Divenyi, Stark, & Haupt, 2005; Humes et al., 2007; Pichora-Fuller, 2003). Thus, it was of interest to examine whether listeners’ ability to use contextual information when perceiving spectrally degraded input improves over time to compensate for poor sensory quality.
Tests of cognitive abilities
Assessments of cognitive abilities, a heterogeneous category comprised of a large number of often distinct higher-level information processing operations, were limited to those tests that have previously shown associations with speech and language processing. Although the associations between cognitive abilities and environmental sound perception have not been systematically explored, it was expected that some of the tests previously shown to correlate with speech processing may be also involved in the processing of another acoustically and semantically complex sound class, namely, environmental sounds.
Forward and backward auditory digit-memory span tests to assess working memory function (Wechsler, 1997). These tests required the subject to repeat digits spoken at a rate of approximately one per second. Following a successful repetition of four sequences, the number of presented digits was increased by one. In the forward condition, subjects were instructed to repeat the digits in the same order as spoken; in the backward condition the digits were repeated in reversed order. The forward task has been linked to phonological processing and verbal rehearsal required for maintaining information in short-term memory. The backward task has been linked to attention and higher-level executive functions involved in more complex manipulations of verbal information (Pisoni, 2005; Rosen & Engle, 1997; Rudel & Denckla, 1974).
Reading span test (Ronnberg, 1990) assesses parallel operations of both memory storage and semantic processing abilities (Foo, Rudner, Ronnberg, & Lunner, 2008). It involves visual presentation of sentences, word by word, on a computer screen. Upon presentation of each sentence the subject decided whether the sentence was semantically reasonable or not (e.g., “The horse sang loudly” vs. “The girl played on the beach”). After a number of sentences were presented, the subject was asked to repeat either the first or the last word that occurred in each of the sentences presented (without knowing in advance which word would be asked). The number of sentences presented in one sequence before recall gradually increased from three to six, with each number-of-sentence condition repeated 3 times. The number of words correctly recalled across all sentences provided each subject’s reading span score. Although a recent study by Baldwin and Ash (2011) suggested some dissociation between complex reading span measures and complex listening span measures in older adult listeners, the Reading Span test was selected as a commonly used assessment tool for visual component of working memory abilities. It was also of interest to examine whether experimental effects obtained in the auditory modality may be associated cross-modally with visual language processing abilities.
Letter-number sequencing (LNS), is a working memory and attention subtest of WAIS-III (Wechsler, 1997) in which subjects are presented orally with random strings of letters and digits of gradually increasing length and are required to repeat back the numbers in the ascending order and letters in the alphabetical order. Although closely related to the digit span tests, LNS is also uniquely associated with information processing of speech and visual spatial working memory (Crowe, 2000) and has been found to be the strongest predictor for intelligibility of temporally compressed speech among the older adults (Vaughan, Storzbach, & Furukawa, 2008).
Cloze test, initially developed by Treisman (1965), evaluates subjects’ ability to infer missing words within written sentences based on semantic and syntactic context. Although typically associated with reading comprehension research in education, the underlying processing necessary to perform a Cloze procedure may involve a more general ability to complete perceptual wholes from incomplete sensory input, which has been linked to speech and environmental sound perception (Kidd et al., 2007). In the current version of the procedure, adopted from practice tests in the Cambridge English for Speakers of Other Languages certificate program, participants were presented with four paragraphs of about 150 to 180 words and asked to fill in the missing words (15 words per paragraph) that belong to different lexical categories. For two paragraphs, subjects were tested in a multiple-choice format, selecting one of four possible options for each missing word. For the remaining two paragraphs, subjects could respond with any word they deemed suitable, which was then scored against preselected acceptable response options. The total number of correct responses across all texts is combined to obtain the total Cloze score. Subjects were asked to perform the task as quickly and as accurately as possible and were timed with a stop watch.
Tests of basic auditory ability included five psychoacoustic tests that measured detection and discrimination abilities for assessing both temporal and spectral processing. With the exception of temporal gap detection, a commonly accepted measure of gross temporal processing abilities, the selected tests were designed specifically to assess processing of complex stochastic spectral-temporal patterns, so as to approximate perceptual processing of complex acoustic patterns found in speech and environmental sounds (Sheft, Risley, & Shafiro, 2011; Sheft, Shafiro, Lorenzi, McMullen, & Farrell, in press; Sheft, Yost, Shafiro, & Risley, 2011). Performance was measured with a two-interval forced-choice (2IFC) adaptive procedure (Levitt, 1971) with threshold estimates based on the average of the last 8 of the required 12 tracking reversals per run. The adaptive procedure followed the 2-down-1-up rule for all five tests. A cued 2IFC protocol was used in all but the gap detection procedure.
1. Temporal gap detection threshold was measured for 500-ms Gaussian noise bursts low-pass filtered at 8 kHz. The task was to detect a temporally centered silent interval introduced into the stimulus presented during one of the two observation intervals. On each trial gap duration was adaptively varied to estimate the minimum duration needed for gap detection. Presentation level was 70-dB SPL.
2 & 3. Frequency modulation (FM) pattern discrimination measured thresholds with a 1-kHz pure-tone carrier modulated by different low-pass noise samples drawn from the same underlying noise distribution. The bandwidth of the low-pass noise modulator, which determines the average FM rate, was constant at 5 Hz. The peak magnitude of the modulator was also constant so that the maximum frequency excursion (ΔF) was fixed at 400 Hz with pattern fluctuation centered about the 1-kHz carrier frequency. As a cued 2IFC sample discrimination procedure, discrimination was based on sensitivity to the temporal pattern of frequency fluctuation rather than variations in long-term stimulus characteristics. One FM task measured FM pattern discrimination in the presence of a continuous four-talker speech-babble masker (SNR). Figure 2 illustrates the instantaneous frequency functions of a contrasting stimulus pair of a discrimination trial. With the average masker level fixed at 80-dB SPL, the level of the FM tones was adaptively varied in the FM SNR task to determine the signal-to-noise ratio needed to discriminate the FM patterns. In the second FM task, the modulated carrier was presented at 70-dB SPL without a masker, while the duration of the FM tones was adaptively varied, beginning at 11 ms, to estimate the shortest duration needed for discrimination (FM DUR). With these brief stimulus durations, listeners do not perceive stimulus frequency fluctuations but rather perform discrimination based on change in global timbre due to the effect of modulator shape on the arrival time of energy by frequency. As such, the task, similar to gap detection, provides a measure of auditory temporal resolution.
4 & 5. Spectral ripple discrimination was measured in the fourth and fifth tasks that evaluated auditory spectral processing. Again using a cued 2IFC procedure, stimuli were based on 500-ms Gaussian noise bursts band-pass filtered between 100 to 8000 Hz. The fourth task measured the ability to detect a logarithmically scaled sinusoidal ripple of the stimulus spectral envelope in terms of ripple depth, the peak-to-trough difference in dB (RIP DET). The ripple density was held constant at 0.75 ripples per octave. The fifth and final task measured the ability to discriminate a change in the phase of the sinusoidal spectral ripple with ripple depth fixed at 30 dB and density at 0.75 ripples per octave (RIP PHASE, see Figure 3). The starting phase of the spectral ripple of the cue stimulus was varied on each trial. To discourage performance based on listening for level changes within individual auditory channels, in both the fourth and fifth tasks, the overall level of each stimulus presentation was randomized by ± 4 dB about a mean level of 70-dB SPL.
Figure 2.
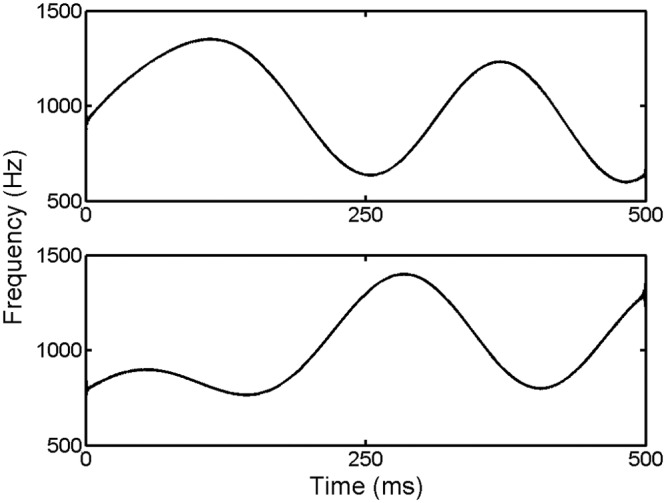
A schematic illustration of two stochastic frequency modulation (FM) patterns to be discriminated in a single trial. These FM patterns were obtained by using a 5-Hz low-pass noise as the modulator of a 500-ms 1-kHz pure-tone carrier with the maximum frequency excursion from the carrier fixed at 400 Hz.
Figure 3.
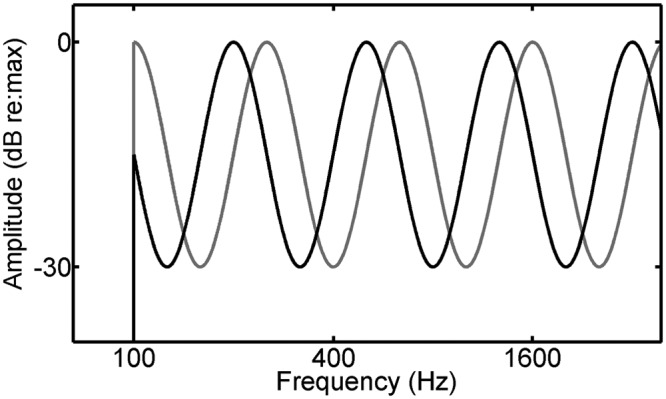
A schematic illustration of two spectral ripples of 0.75 cycles per octave and a 30-dB peak-to-trough-level difference. With a random starting phase at each trial, listeners discriminated stimuli based on the difference in ripple phase, which was adaptively varied to estimate the just-detectable phase difference.
Speech and Environmental Sound Procedures
Pretests 1 and 2, Posttest, Retention sessions followed the same general format and were separated by 1-week time intervals (Figure 1). During these four sessions, subjects were administered the full environmental sound test in quiet, two vocoded CNC lists presented at a 16-dB SNR, and two vocoded SPIN-R lists at a 12-dB SNR (two new CNC and SPIN-R lists were used for each session). All speech and environmental sound testing was performed in a closed-set format with 60 and 50 response options for environmental sounds and speech, respectively. Except for cognitive tests, all stimuli were presented through Sennheiser HD 250 II headphones with environmental and speech sounds at 65-dB SPL levels in the psychoacoustic tests as noted above.
Environmental sound training (based on Shafiro, 2008b) consisted of four training sessions of about 30 to 40 min each, conducted within 1 week between Pretest 2 and Posttest. Training was performed at subjects’ homes using a laptop computer and, as stated above, using Sennheiser HD 250 II headphones. During home training sessions, the output was set at a comfortable listening level selected by the participant.
The training stimuli, selected individually for each subject as illustrated in Table 1, consisted of half of the sound sources that were identified with an accuracy of 50% or lower during Pretest 2 (leaving the second half of poorly identified sound sources to assess generalization of training effects). Each sound source selected for training was represented by four tokens: two randomly selected test tokens and two novel tokens that were not included in the original 160-item test. The two novel tokens of each source were added to increase intra-token variation in order to maximize generalization of training effects. The number of sources selected for training ranged from 11 to 14 per participant. Thus, following the nomenclature of Shafiro (2008b), there were three overall sound source categories: (1) “easy-not trained” (E-NT)—sound sources with more than 50% correct identification, none of which was used during the training; (2) “difficult-not trained” (D-NT)—sound sources with 50% correct or less identification, which were not used during training; and (3) “difficult-trained” (D-T)—sound sources with 50% correct or less identification, which were used during training. The D-T sound sources were further divided into two token subgroups: (1) “difficult-trained-used” (D-T-used), which consisted of two tokens of each D-T sound source used during the training, and (2) “difficult-trained-alternative” (D-T-alt), which consisted of two alternative tokens of each D-T sound source that were not used during the training.
Table 1.
Environmental Sound Categories Used to Separate the Sounds Based on the Results of Pretest 2 for Training Evaluating Subsequent Training Effects
| Source Category | “Easy-Not Trained” (E-NT) | “Difficult-Not Trained” (D-NT) | “Difficult-Trained” (D-T) | |
|---|---|---|---|---|
| Pretest 2 p(c) | > 50% | ≤ 50% | ≤ 50% | ≤ 50% |
| Token subcategories | — | — | “Difficult-trained-used” (D-T-used) | “Difficult-trained- alternative” (D-T-alt) |
| Trained | No | No | Yes | No |
During each training session, the training stimuli were presented at random in three consecutive blocks with feedback given onscreen after every trial. After an incorrect response, subjects were provided with the name of correct response and required to replay the vocoded test stimulus 3 times before proceeding to the next trial. A display of ongoing percent correct for the current block was updated after every subject response during training, with participants also receiving percent-correct feedback in the form of a bar graph upon block completion.
Subjects
Twelve NH young adults, native speakers of American English, who passed a hearing screening at 25-dB HL (500 Hz, 1000 Hz, 2000 Hz, and 4000 Hz) participated. Their median age was 26 (range 24-27 years); six were female. All subjects received financial compensation for participating in the study.
Results
Percent-correct scores obtained on the speech and environmental sounds tests were transformed into rationalized arcsine units (RAU; Studebaker, 1985). To examine overall changes in perceptual accuracy throughout the study, RAU scores were evaluated using three one-way analyses of variance (ANOVAs), one each for environmental sounds and SPIN-R and CNC with test session as the grouping variable. Next, planned comparisons were conducted to evaluate changes in speech and environmental sound performance between individual testing sessions to examine contributions of environmental sound training and stimulus exposure during retests. Generalization of training effects between environmental sounds was further examined by comparing changes in performance for environmental sound sources and sound tokens that were used during training versus those that were not. Finally, correlational and regression analyses were conducted to examine factors underlying performance on speech and environmental sound tests in relation to participants’ cognitive and basic auditory abilities.
As shown in Figure 4, listener performance on both environmental sound and speech tests improved monotonically during the course of the study. The largest significant (p < .05) improvement between Pretest 1 and Retention of 31.2 percentage points was observed for environmental sounds, that is, the sound class that was trained. A significant linear trend (p < .05) was also observed for improvements in both CNC words and SPIN-R sentences, which changed by 10.5 and 5.8 percentage points, respectively, between Pretest 1 and Retention sessions. However, for both environmental sound and speech tests, performance levels and training benefits varied considerably across individual listeners (Table 2), suggesting that factors other than the training regimen could influence training effectiveness. Although all listeners demonstrated an improved performance between the first and the last test sessions of the study for environmental sounds and CNC words, 3 of the 12 listeners showed no improvement or a slight, 1 to 2 percentage point, decline for the SPIN-R sentences. Curiously, these three listeners were among the top performers on the initial pretest in terms of their absolute scores, suggesting that they might have reached a kind of a learning plateau during their first session while others, who initially scored lower, continued to improve. The analysis of low- and high-predictability SPIN-R sentences (Table 3) revealed a consistent and significant (p < .01) difference in scores of about 7 to 8 percentage points for all 4 testing sessions, with both scores improving steadily across sessions. This suggests that linguistic context facilitated comprehension of high-probability words, though its influence was not affected by environmental sound training. This may be due to the lack of explicit context training in the present training regimen or different processing mechanisms for context information for speech and environmental sounds.
Figure 4.
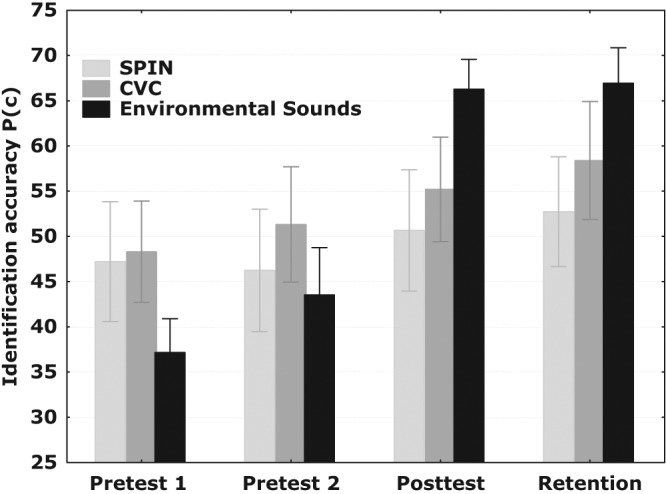
Performance accuracy across testing sessions for speech (speech-in-noise sentence test [SPIN-R] and consonant-nucleus-consonant monosyllabic word test [CNC]) and environmental sounds. Following environmental sound training (between Pretest 2 and Posttest), the biggest improvement is evident for environmental sounds, with both sentences and words also showing improvement to a smaller degree. Error bars represent ± 1 standard deviation.
Table 2.
Performance of Individual Subjects (Percent Correct) on Environmental Sound and Speech Tests Between the First (Pretest 1) and the Last (Retention) Sessions of the Study
| Subject Number | FEST Pretest 1 | Retention | Improve | CNC Pretest 1 | Retention | Improve | SPIN-R Pretest 1 | Retention | Improve |
|---|---|---|---|---|---|---|---|---|---|
| S1 | 44 | 71 | 27 | 51 | 60 | 9 | 42 | 49 | 7 |
| S2 | 36 | 70 | 34 | 51 | 72 | 21 | 61 | 59 | −2 |
| S3 | 41 | 67 | 26 | 48 | 58 | 10 | 36 | 48 | 12 |
| S4 | 38 | 68 | 30 | 49 | 59 | 10 | 42 | 51 | 9 |
| S5 | 41 | 68 | 28 | 47 | 54 | 7 | 54 | 53 | −1 |
| S6 | 32 | 68 | 36 | 44 | 53 | 9 | 44 | 48 | 4 |
| S7 | 38 | 72 | 34 | 51 | 65 | 14 | 53 | 59 | 6 |
| S8 | 38 | 58 | 20 | 50 | 59 | 9 | 51 | 58 | 7 |
| S9 | 43 | 77 | 34 | 65 | 80 | 15 | 59 | 71 | 12 |
| S10 | 33 | 69 | 36 | 56 | 59 | 3 | 61 | 61 | 0 |
| S11 | 22 | 54 | 32 | 26 | 42 | 16 | 29 | 30 | 1 |
| S12 | 33 | 71 | 38 | 41 | 44 | 3 | 33 | 48 | 15 |
| M | 36.49 | 67.71 | 31.22 | 48.25 | 58.75 | 10.50 | 47.08 | 52.92 | 5.83 |
| SD | 5.91 | 6.28 | 5.25 | 9.22 | 10.54 | 5.27 | 11.02 | 10.04 | 5.57 |
Note: FEST = familiar environmental sound test; CNC = consonant–nucleus–consonant monosyllabic word test; SPIN-R = speech-in-noise sentence test.
Table 3.
SPIN-R High- Versus. Low-Predictability Average Scores for Each Testing Session
| Pretest 1 | Pretest 2 | Posttest | Retention | |
|---|---|---|---|---|
| Low predictability | 39.85 | 38.46 | 43.08 | 45.23 |
| High predictability | 47.08 | 47.08 | 51.23 | 52.46 |
| Difference | −7.23 | −8.62 | −8.15 | −7.23 |
Note: SPIN-R = speech-in-noise sentence test.
Listener performance on the SPIN-R and CNC tests within each session also revealed pronounced effects of initial perceptual adaptation1 to spectrally degraded speech, which was different from the overall improvements obtained across several sessions. In every test session, scores on both SPIN-R and CNC tests were consistently lower on the first list than on the second list (based on 50 words per list). In the first test session (Pretest 1), the difference between the lists was 11.8 and 7 percentage points for SPIN-R and CNC, respectively. These differences between the first and second list in the session persisted throughout the following three testing sessions 1 week apart, although they were somewhat attenuated for SPIN-R (range: 1.8-5.3 points) compared to CNC (4.1-8.7 points). Having not heard degraded speech in the interim, the NH listeners seemed to undergo a rapid perceptual adaptation in the beginning of every session. The magnitude of these adaptation effects is similar to that previously reported by others for comparable sets of speech materials (Davis et al., 2005; Hervais-Adelman et al., 2008, 2011; Loebach & Pisoni, 2008).
Planned comparisons between Pretest 1 and Pretest 2, the most direct measure of exposure effects without training for all three tests, revealed a significant improvement (p < .05) in performance of 6.7 percentage points for environmental sounds only. No significant improvement between the first and second testing sessions were found for SPIN-R sentences or CNC words, with difference scores of −1.0 and 3.2 percentage points, respectively. However, planned comparisons of the testing session immediately preceding the training (Pretest 2), and the posttest session immediately following the training (Posttest 1), confirmed a significant positive change (p < .05) for all three tests, indicating significant, if smaller, gains in speech perception concurrent with environmental sound training.
Contributions of training to environmental sound scores on the posttest were further confirmed by a significant difference (p < .01) between the amount of improvement (i.e., the difference in scores) between Pretest 1 and Pretest 2 versus that between Pretest 2 and Posttest. This indicates that additional exposure alone could not account for the improvement in environmental sound perception. Although a similar comparison was not significant for either speech test, there was a significant improvement in scores between Pretest 2 and Retention sessions for both speech tests, suggesting a potentially more extended temporal trajectory for learning spectrally degraded speech. A longer trajectory for speech would not be surprising given that no direct speech training was provided. Continuous improvement in performance on both speech tests may have been augmented by environmental sound training as well as by the continuous experience with the test materials.
Significant effects of training were also observed for different environmental sound training categories, using post hoc t tests with a Bonferroni correction conducted on the Pretest 2 and Posttest scores. Performance improved (p < .05) in two of the three sound source categories, D-T and D-NT, but no change was observed in the E-NT performance, which is likely due to a ceiling effect (Figure 5). Consistent with previous findings by Shafiro (2008b) and Markee et al. (2009), the highest improvement in performance of 68 percentage points was observed for the D-T sound sources, and a substantially smaller significant improvement of 8 percentage points was observed for the D-NT sound sources. In addition to sound sources, there was a significant (p < .05) improvement of similar magnitude for both D-T-used training tokens and D-T-alternative sound tokens of 66.1 and 65.7 points, respectively (see Figure 6). Thus, training effects generalized to sound sources and tokens that were not used during training.
Figure 5.
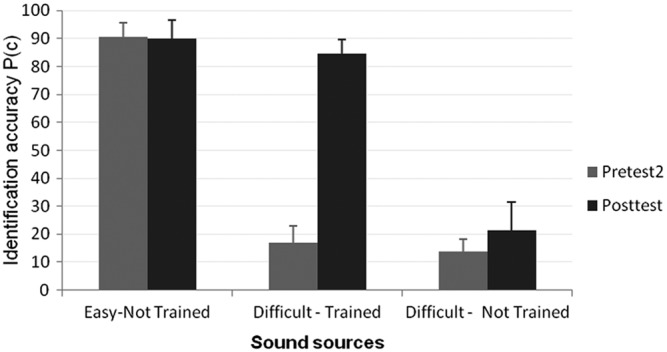
Environmental sound identification accuracy between Pretest 2 and Posttest for three sound source categories: (a) low-accuracy sounds that were later used during training (difficult-trained), (b) low-accuracy sounds that were not trained (difficult-not trained), and (c) high-accuracy sounds that were not trained (easy-not trained). Error bars represent 1 standard deviation of the mean.
Figure 6.
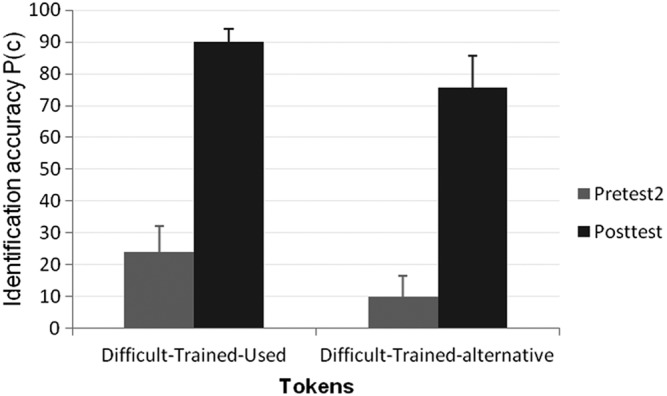
Identification accuracy on Pretest 2 and Posttest for the two subgroups of the difficult-trained (D-T) sound sources: difficult-trained-used (D-T-used), that is, two exemplars of each source selected for training and used during training and difficult-trained-alternative (D-T-alt), that is, two exemplars of each source selected for training but not used during training. Error bars represent 1 standard deviation of the mean.
There was considerable variability in identification accuracy and the amount of improvement among environmental sounds across testing sessions (Table 4). In general, the most accurately identified environmental sounds, such as “clapping,” “machine gun,” and “footsteps” were relatively long duration, temporally patterned, and consisting largely of broadband bursts. The least identifiable were sounds with distinct and time-varying spectral components or sounds of brief duration. Sound sources whose identification accuracy improved the most appeared to be relatively long sounds that, in addition to harmonic spectra, also had a distinct envelope (e.g., “baby crying,” “cow mooing,” “birds chirping”). It is possible that during the study listeners were learning to give greater perceptual weights to the most informative stimulus dimensions, selectively focusing their attention on temporal cues, while learning to ignore spectral ones. This kind of learning has been shown to take place in a number of experimental paradigms across modalities (Kruschke, 2011). Although quantitative data to support this possibility are presently lacking, it is possible to generate specific hypotheses for future studies regarding training-induced changes in the perceptual salience of temporal and spectral cues in the vocoded speech. Given the acoustic heterogeneity of environmental sounds, they can be differentiated a priori based on existing work that distinguishes sounds with respect to perceptual salience of temporal versus spectral information (Gygi et al., 2004; Shafiro, 2008a). It could be expected that those sounds in which temporal information is perceptually important before vocoding will be easier to learn in the vocoded form than those sounds in which spectral information is more perceptually salient before the vocoding. Learning to ignore spectral information for such sounds may be more challenging if spectral cues were perceptually important even prior to vocoding. This expectation is indirectly supported by the findings of Hervais-Adelman et al. (2008), who found only partial generalization of learning for speech stimuli vocoded with different carriers. Apparently, learning to rely on spectral and temporal-fine-structure cues in speech perception was a limiting factor even though this dimension was not informative in the vocoded stimuli.
Table 4.
Average Environmental Sound Identification Accuracy and Associated Accuracy Change Between the First (Pretest 1) and the Last (Retention) Testing Sessions
| Sound Name | Pretest 1 | Retention | Improvement | ||
|---|---|---|---|---|---|
| Siren | 0.0 | (0.0) | 35.4 | (45.8) | 35.4 |
| Telephone ringing | 0.0 | (0.0) | 20.8 | (25.7) | 20.8 |
| Yawning | 0.0 | (0.0) | 14.6 | (19.8) | 14.6 |
| Baby crying | 2.1 | (7.2) | 52.1 | (40.5) | 50.0 |
| Car horn | 4.2 | (9.7) | 18.8 | (26.4) | 14.6 |
| Cow mooing | 4.2 | (9.7) | 81.3 | (38.6) | 77.1 |
| Wind blowing | 6.3 | (11.3) | 35.4 | (44.5) | 29.2 |
| Airplane flying | 8.3 | (12.3) | 22.9 | (29.1) | 14.6 |
| Birds chirping | 10.4 | (16.7) | 64.6 | (41.9) | 54.2 |
| Doorbell | 10.4 | (24.9) | 52.1 | (50.5) | 41.7 |
| Ice cubes into glass | 10.4 | (16.7) | 52.1 | (37.6) | 41.7 |
| Sighing | 10.4 | (22.5) | 68.8 | (35.6) | 58.3 |
| Blowing nose | 12.5 | (25.0) | 29.2 | (23.4) | 16.7 |
| Brushing teeth | 16.7 | (24.6) | 75.0 | (41.3) | 58.3 |
| Burp | 20.8 | (29.8) | 45.8 | (46.3) | 25.0 |
| Clearing throat | 20.8 | (29.8) | 62.5 | (36.1) | 41.7 |
| Rooster | 20.8 | (33.4) | 70.8 | (43.7) | 50.0 |
| Toilet flushing | 20.8 | (17.9) | 37.5 | (37.7) | 16.7 |
| Coughing | 22.9 | (29.1) | 85.4 | (22.5) | 62.5 |
| Ppouring soda | 25.0 | (30.2) | 66.7 | (38.9) | 41.7 |
| Zipper | 25.0 | (21.3) | 68.8 | (30.4) | 43.8 |
| Gargling | 29.2 | (23.4) | 58.3 | (43.1) | 29.2 |
| Dog barking | 35.4 | (37.6) | 85.4 | (29.1) | 50.0 |
| Clock ticking | 37.5 | (36.1) | 64.6 | (37.6) | 27.1 |
| Snoring | 41.7 | (28.9) | 75.0 | (18.5) | 33.3 |
| Car starting | 43.8 | (30.4) | 91.7 | (12.3) | 47.9 |
| Horse neighing | 52.1 | (27.1) | 91.7 | (22.2) | 39.6 |
| Glass breaking | 56.3 | (26.4) | 91.7 | (16.3) | 35.4 |
| Sneezing | 58.3 | (26.8) | 91.7 | (16.3) | 33.3 |
| Laughing | 60.4 | (32.8) | 95.8 | (9.7) | 35.4 |
| Phone busy signal | 64.6 | (40.5) | 81.3 | (38.6) | 16.7 |
| Bowling strike | 68.8 | (18.8) | 81.3 | (21.7) | 12.5 |
| Camera | 75.0 | (23.8) | 100.0 | (0.0) | 25.0 |
| Typing | 77.1 | (27.1) | 95.8 | (14.4) | 18.8 |
| Helicopter flying | 79.2 | (20.9) | 83.3 | (16.3) | 4.2 |
| Thunder | 79.2 | (17.9) | 79.2 | (23.4) | 0.0 |
| Footsteps | 83.3 | (22.2) | 95.8 | (14.4) | 12.5 |
| Door closing | 85.4 | (16.7) | 97.9 | (7.2) | 12.5 |
| Machine gun | 87.5 | (19.9) | 91.7 | (16.3) | 4.2 |
| Clapping | 93.8 | (11.3) | 95.8 | (9.7) | 2.1 |
| M | 36.5 | 67.7 | 31.2 | ||
| SD | 29.9 | 25.3 | 18.5 | ||
Note: Sounds are arranged from lowest to highest accuracy on Pretest 1. Standard deviations are shown in parenthesis.
Correlational analyses of speech and environmental sound scores at each testing stage with the measures of basic auditory and cognitive factors were conducted to determine which abilities predict performance for each sound category (speech and environmental sounds) and whether these associations change following training. The pairwise correlations of all tests, shown in Table 5, revealed that environmental sounds and speech overlap in some processing abilities and that they also differ in others. Both environmental sounds and speech were associated with tests of working memory and executive function: Forward and Backward Digit Span test as well as the LNS had significant correlations with the speech tests, suggesting a trend for involvement of working memory (also found in Schvartz et al., 2009), whereas Cloze results correlated with the environmental sound performance. Among the tests of basic auditory abilities, scores on both speech tests and FEST were associated with measures of spectral processing and temporal-fine-structure processing. Specifically, all three tests (SPIN-R, CNC, FEST) showed moderate-to-strong correlations with the ability to detect a low-density spectral ripple (RIP DET), spectral processing acuity assessed through discrimination of changes in the phase of spectral ripple (RIP PHASE), and discrimination of FM pattern duration and FM patterns in noise (FM DUR and FM SNR). Neither speech test nor FEST correlated with the gap detection scores.
Table 5.
Correlations Between the Speech and Environmental Sounds Tests Scores With the Cognitive and Perceptual Measures Described in the Methods
| SPIN 1 | SPIN 2 | SPIN 3 | SPIN 4 | CNC 1 | CNC 2 | CNC 3 | CNC 4 | FEST 1 | FEST 2 | FEST 3 | FEST 4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ReadingSpn | 0.31 | 0.46 | 0.43 | 0.57 | 0.48 | 0.61 | 0.45 | 0.56 | 0.33 | 0.33 | 0.06 | 0.31 |
| Frwd DS | 0.45 | 0.54 | 0.70 | 0.61 | 0.49 | 0.62 | 0.58 | 0.55 | 0.14 | 0.20 | 0.16 | 0.36 |
| Bkwrd DS | 0.64 | 0.45 | 0.54 | 0.52 | 0.49 | 0.57 | 0.74 | 0.59 | 0.43 | 0.55 | 0.60 | 0.60 |
| LNS | 0.35 | 0.51 | 0.53 | 0.64 | 0.60 | 0.59 | 0.63 | 0.48 | 0.47 | 0.49 | 0.32 | 0.57 |
| Cloze | 0.10 | 0.01 | 0.20 | 0.25 | 0.45 | 0.47 | 0.37 | 0.52 | 0.59 | 0.58 | 0.70 | 0.57 |
| FM SNR | −0.62 | −0.69 | −0.58 | −0.83 | −0.90 | −0.73 | −0.71 | −0.65 | −0.85 | −0.78 | −0.60 | −0.67 |
| FM DUR | −0.58 | −0.59 | −0.43 | −0.68 | −0.70 | −0.41 | −0.64 | −0.38 | −0.54 | −0.54 | −0.53 | −0.62 |
| RIP DET | −0.55 | −0.52 | −0.61 | −0.59 | −0.68 | −0.57 | −0.62 | −0.45 | −0.53 | −0.61 | −0.64 | −0.61 |
| RIP PHASE | −0.72 | −0.68 | −0.90 | −0.83 | −0.85 | −0.78 | −0.84 | −0.85 | −0.45 | −0.47 | −0.65 | −0.67 |
| GAP | 0.15 | −0.02 | 0.23 | 0.14 | 0.18 | 0.37 | 0.36 | 0.48 | 0.39 | 0.35 | 0.42 | 0.35 |
Note: FEST = familiar environmental sound test; CNC = consonant–nucleus–consonant monosyllabic word test; SPIN-R = speech-in-noise sentence test.; ReadingSpn = Reading Span; Frwd DS = Forward Digit Span; Bkwrd DS = Backward Digit Span; LNS = Letter Number Sequencing Test; FM SNR = Frequency Modulation Pattern Discrimination in Noise; FM DUR = Frequency Modulation Pattern Discrimination with Variable Duration; RIP DET = Spectral Ripple Depth Detection; RIP Phase = Spectral Ripple Phase Discrimination; GAP = Temporal Gap Detection.
However, an examination of the residuals revealed a great deal of redundancy in many measures that were highly intercorrelated. To determine the underlying structure in the data, a factor analysis was performed on the four test stages (Pretests 1 & 2, Posttest, Retention) for the three stimulus categories (SPIN-R, CNC, and FEST). The rotated solution yielded two factors that accounted for 86% of the variance on the 7 variables, the factor loadings for which are listed in Table 6. The SPIN-R and CNC results loaded on Factor 1, and FEST results on Factor 2. So it appears that Factor 1 represents the speech tests, and Factor 2 the FEST data.
Table 6.
Factor Loadings (Varimax Rotated and Normalized) for the Tests Used in the Study
| Factor 1 | Factor 2 | |
|---|---|---|
| SPIN Pretest 1 | 0.898 | 0.215 |
| SPIN Pretest 2 | 0.950 | 0.138 |
| SPIN Posttest 1 | 0.888 | 0.218 |
| SPIN retention | 0.852 | 0.442 |
| CNC Pretest 1 | 0.740 | 0.624 |
| CNC Pretest 2 | 0.790 | 0.497 |
| CNC Posttest | 0.778 | 0.545 |
| CNC Retention | 0.801 | 0.477 |
| FEST Pretest 1 | 0.283 | 0.852 |
| FEST Pretest 2 | 0.373 | 0.816 |
| FEST Posttest 1 | 0.182 | 0.868 |
| FEST retention | 0.271 | 0.846 |
| Explained variance | 5.968 | 4.329 |
| Proportion total | 0.497 | 0.361 |
Note: FEST = familiar environmental sound test; CNC = consonant–nucleus–consonant monosyllabic word test; SPIN-R = speech-in-noise sentence test. Significant loadings are in italics.
To examine whether the tests of basic auditory abilities and cognitive factors could account for the factor analysis results, multiple regression analyses were performed to predict the factor loadings from the peripheral and cognitive tests. The results, included in Table 7, revealed two tests that were strong predictors of both factor scores, the Cloze and RIP PHASE. This is somewhat surprising given the relatively modest correlations of the Cloze results with the speech tests, but it does show that Cloze was the main independent cognitive predictor. Thus, a cognitive ability (the ability to make a whole from separate parts) and a basic spectral processing ability can account for a large amount of the variance in performance with both speech and environmental sounds. Tellingly, a third significant predictor from regression analysis differed for the two factors: For the speech tests (Factor 1) it was a cognitive measure, Reading span test scores, with the three predictors accounting for 80% of the variance in the Speech Test factor. But for the environmental sound test (Factor 2), the third predictor was a peripheral measure, the ability to discriminate patterns of frequency changes in noise (FM SNR). In that case the three predictors accounted for 86% of the variance in Factor 2.
Table 7.
Stepwise Regression Results for the Factor Scores From Table 4 as Predicted by the Subjects’ Peripheral and Cognitive Test Results (Described in Text)
| Step +In/−Out | Multiple R | Multiple R2 | R2 Change | |
|---|---|---|---|---|
| Summary of stepwise regression: Dependent variable: Factor 1 | ||||
| RIP PHASE | 1 | 0.75 | 0.56 | 0.56 |
| Cloze | 2 | 0.86 | 0.74 | 0.18 |
| Reading span | 3 | 0.89 | 0.80 | 0.06 |
| Summary of stepwise regression: Dependent variable: Factor 2 | ||||
| Cloze | 1 | 0.75 | 0.56 | 0.56 |
| FM SNR | 2 | 0.89 | 0.79 | 0.23 |
| RIP PHASE | 3 | 0.93 | 0.86 | 0.07 |
Note: RIP PHASE = phase of spectral ripple; FM SNR= four-talker speech-babble masker.
Furthermore, as shown in Table 8, both speech tests correlated strongly with the environmental sound test across test sessions. This is in line with the previous findings in simulated and actual CI users demonstrating an association between the abilities to perceive speech and environmental sounds (Inverso & Limb, 2010; Shafiro, 2008b; Shafiro, Gygi et al., 2011; Tyler et al., 1989), suggesting an overlap in the perceptual processing of these two acoustically and semantically complex sound classes.
Table 8.
Correlations of the SPIN-R, CNC, and Familiar Environmental Sounds (FEST) Tests in the First and Last Test Session (Pretest 1 and Retention, Respectively)
| Pretest 1 | Retention | |
|---|---|---|
| SPIN/CNC | 0.77 | 0.85 |
| SPIN/FEST | 0.41 | 0.66 |
| CNC/FEST | 0.77 | 0.60 |
Note: CNC = consonant–nucleus–consonant monosyllabic word test; FEST = familiar environmental sound test; SPIN-R = speech-in-noise sentence test.
Discussion
Changes in Environmental Sound Perception Following Training
The present results indicated positive effects of both structured training and exposure on the perception of environmental sounds. As expected, the largest training effects were observed for environmental sounds, the class of sounds trained on, as evidenced by the significant improvement in environmental sound identification from Pretest 2 to Posttest, a mean of 22 percentage points. In addition to the training effects, environmental sound perception also benefited from simple repeated exposure, as shown by the overall improvement of 6.3 percentage points from Pretest 1 to Pretest 2.
The training effects observed with environmental sounds are largely consistent with previous findings by Shafiro (2008b) and Markee et al. (2009). In both the past and present work, overall environmental sound identification accuracy before and after training was within the range of several percentage points of each other, despite some variation in the study designs, the number of training sessions, and the stimuli. In addition, in these studies following training with a small subset of initially poorly identified environmental sounds, there was an improvement in performance in other sounds as well. Specifically, there was a significant improvement in scores for D-T-alternative sound tokens that were not used in training but referred to the same sound sources as the training tokens. This could result from the fact that the D-T-alternative sound tokens were similar enough to the D-T tokens that were actually trained that the dimensions that subjects learned for identification of the D-T tokens were applicable to the alternative tokens as well.
Similarly, all three studies demonstrated an improvement in the D-NT (i.e., sound sources that were matched in identification accuracy to the training sound sources but were not used during training). However, the magnitude of improvement for the D-NT sources in the present study was considerably lower than reported by Shafiro (2008b), a difference of 7.0 vs. 18.0 percentage points, respectively. This difference in scores may reflect the differences in study design. Whereas in Shafiro (2008b) only a single pretest was given before training, in the present study, two pretests were conducted prior to training, allowing for a separate assessment of exposure and training effects. Thus, the larger improvement in D-NT in Shafiro (2008b) may reflect the compounded effects of training and exposure to a greater degree than in the present study. This interpretation is supported by the similar magnitude of D-NT improvement between the present study and that by Markee et al. (2009), who also used two pretests before starting training (i.e., 7.0 vs. 8.0 percentage points, respectively).
Also consistent with previous findings on the perception of spectrally degraded environmental sounds are the large differences in accuracy among individual sound sources. Environmental sounds that contain distinct dynamic narrowband spectral components generally require higher spectral resolution to be perceived than broadband sounds with dynamic energy envelopes (Gygi et al., 2004; Shafiro, 2008a). Spectral degradation generally leads to the smearing of narrowband spectral cues but has relatively small effect on the noisy broadband sounds typically identified through their temporal cues. This could lead to the consistent differences in identification accuracy among some spectrally degraded sounds observed across studies (Gygi et al., 2004; Shafiro, 2008a, 2008b). Nevertheless, with training, identifiability of many spectrally rich sounds can improve substantially, suggesting that when spectral cues are not available listeners can make perceptual decisions based on an alternative set of temporal cues. This interpretation agrees with the earlier findings of Inverso and Limb (2010) and Shafiro et al. (Shafiro, Gygi et al., 2011) for CI patients who accurately identified environmental sounds with narrowband dynamic components (such as “doorbell,” “bird chirping,” “laughing”) that NH listeners only mastered following training. Collectively, these results provide further evidence for auditory system plasticity in selecting perceptually salient acoustic cues for a given level of signal representation.
Changes in Speech Perception Following Environmental Sound Training
Improvements in environmental sound perception following training were accompanied by significant positive changes in speech perception. Although no significant changes were obtained between Pretests 1 and 2 for either speech test before the beginning of training, performance on both speech tests improved significantly between Pretest 2 and Posttest sessions following environmental sound training. At face value, this finding seems to support the conclusion of Loebach and Pisoni (2008) that environmental sound training effects generalize across sound classes to include spoken words and sentences. There are further indications that the effects of environmental sound training on speech may be long lasting, as there were also significant positive differences between Pretest 2 and the Retention sessions. The magnitude of perceptual learning of speech is, in fact, comparable in magnitude to that of the D-NT environmental sound sources, suggesting that the improvement in speech perception is part of a more generalized improvement for novel sound sources (i.e., those not used during training).
However, this interpretation of generalization effects also carries some caveats. For one, the gradual improvement in speech scores, particularly for the CNC test, is also consistent with a linear trend indicating a gradual incremental improvement that might have taken place simply due to repeated application of the tests, even with different word lists each time and without any environmental sound training. The general magnitude of speech improvement of less than 10 percentage points in the current work appears to fall within the range of improvements that have been previously shown to occur through mere repeated exposure to speech stimuli without feedback (Davis et al., 2005; Loebach, Bent, & Pisoni, 2008; Loebach & Pisoni, 2008). One notable difference between this past work and the present study, however, is that in the present study these improvements were obtained over a course of several weeks, whereas the previous work was based on single short training sessions of 1 hour or less.
The long-term gains in speech performance obtained in the present study further contrast with the acute improvements in performance that occurred on a shorter time scale in the course of every session as shown by the rapid improvement in performance between the second and first SPIN-R and CNC lists. The significant learning effects within training sessions suggest perceptual adaptation to the specific stimuli used in the test and may differ in underlying mechanism from the learning effects across sessions. Consistent with the Hebbian learning theory (Hebb, 1949), the latter may indicate longer-term perceptual learning of a broader class of sounds and may involve slower but more fundamental and longer-lasting neuroplastic changes for the processing of spectrally degraded stimuli.
In the speech tests, the overall improvement for isolated words across test sessions was slightly greater than the improvement for words in sentences (i.e., 10.5 vs. 5.8 percentage points). This difference in improvement scores was unexpected given the additional syntactic and semantic information available in the sentences. However, because the CNC words were presented at a more favorable SNR than the SPIN-R sentences (+16 vs. +12 dB) and, accordingly, had higher absolute performance levels, sensory encoding of the CNC words might have been more robust than the SPIN-R sentences. As suggested by Boothroyd (2010), this argument presumes that the perceptual advantages of sentence context can be influenced by the overall perceptual difficulty of sensory input. Considerably impoverished sensory input may prevent robust encoding of most individual words in the sentences, thus attenuating the strength of context effects and potentially requiring greater cognitive resources such as working memory in order to process a sentence-length stimulus (Shafiro, Sheft, & Risley, 2011).
The Role of Basic Auditory Abilities and Cognitive Factors
The present findings point to a number of basic auditory abilities and general cognitive factors associated with the perception of spectrally degraded speech and environmental sounds. Because both speech and environmental sounds provide acoustically complex and ecologically important information, some overlap in their perceptual processing can be expected. Neuroimaging studies show overlapping patterns of activation for speech and environmental sounds (Lewis et al., 2004) as well as shared perceptual deficits in both sound classes in patients with cerebral damage (Baddeley & Wilson, 1993; Piccirilli, Scarab, & Luzzi, 2000; Schindler et al., 1994). Thus, significant intercorrelations between scores on the environmental sound and speech tests in the present study as well as in previous research with CI patients (Inverso & Limb, 2010; Shafiro, Gygi et al., 2011; Tyler et al., 1989) further indicate an overlap in the perceptual processing of all complex meaningful sounds that represent information about distal objects and events in the environment.
Cognitively, both sound classes were associated with a measure of working memory and executive function—the Backward Digit Span test and, to a smaller extent, the Letter-Number-Sequencing test—whereas Forward Digit Span was associated primarily with the speech tests. This indicates the influence of cognitive factors, which was also shown in Humes et al. (Humes, Lee, & Coughlin, 2006) and Schvartz et al. (2009). Certainly the cognitive load is large: When dealing with spectrally degraded sensory input, listeners need to perform more exhaustive perceptual searches in order to match the distorted stimulus with an appropriate mental representation of the sound source. Being able to maintain the image of the stimulus in working memory longer during the search or performing a greater number of searches faster before the decay of the stimulus image may lead to better accuracy. Correlations between working memory measures and processing of spectrally degraded speech and environmental sounds are also consistent with recent CI findings that indicate the central involvement of working memory in speech and language processing (Pisoni et al., 2011).
However, a multiple regression solution showed that the cognitive measure that best accounted for the common variance in the speech and environmental sound tasks was the Cloze test, which is commonly used to assess language comprehension abilities by tapping into the use of sentence context. Although this finding was unexpected, it may be indicative of a greater reliance on semantic processing in the perception of spectrally degraded complex auditory stimuli. The fact that the Cloze test was administered in the visual modality while environmental sounds were presented aurally may suggest that the factors underlying the association between the tests are modality independent.
Peripherally, both speech and environmental sounds were associated with measures of spectral processing and sensitivity to changes in the patterns of temporal fine structure. In the multiple regression solution, ripple phase discrimination was a strong predictor of both the speech and environmental sound test results. For the spectrally degraded stimuli in which the spectral profile is grossly smeared, sensitivity to minute spectral and temporal changes may provide an additional cue to sound identification. For instance, greater sensitivity for detection of a spectral ripple and discrimination of ripple phase may be related to the ability to follow subtle changes in the spectrum of the degraded signal, potentially indicating rapid spectral changes such as formant transitions. On the other hand, gap detection in noise, a measure of gross temporal envelope processing, was not a critical differentiating factor for NH listeners tested with spectrally degraded speech and environmental sounds.
There were, however, some differences between the speech tests and the environmental sound tests in terms of the correlated variables. Speech test scores were best predicted in the multiple regression solution by an additional cognitive factor, Reading Span test, which, unlike speech, was administered in the visual modality. On the other hand, a measure of FM pattern discrimination ability (FM SNR), when added as a third variable in the multiple regressions, best accounted for the FEST results. This distinction suggests that greater cognitive demands are put on the auditory system by speech rather than environmental sounds and highlights the differences in the perceptual processing of these two sound classes. Accurate identification of isolated spectrally degraded environmental sounds appears to involve more complex spectrotemporal processing than speech, which is understandable given the greater acoustical variation found in environmental sounds (Gygi et al., 2004).
Theoretically, the findings of interrelatedness of basic auditory abilities and higher-level cognitive factors are generally consistent with a number of recent speech-language processing models that posit different perceptual processing routes, depending on the quality of sensory input. For instance, within the Ease of Language Understanding framework, or ELU (Ronnberg, Rudner, Foo, & Lunner, 2008), robustly encoded phonological representations can be matched directly with long-term memory representations using implicit processing with little involvement of working memory. However, when the quality of the input is degraded, whether due to peripheral hearing loss or other external factors such as noise, listening becomes effortful and requires explicit processing that relies heavily on working memory. A similar principle is found in the reversed hierarchy theory (RHT) account of speech perception (Ahissar, Nahum, Nelken, & Hochstein, 2008; Nahum, Nelken, & Ahissar, 2008). According to RHT, perception of robustly encoded input with multiple acoustic cues, such as speech in quiet, proceeds in a top-down manner, from global to local levels, since numerous redundant acoustic cues provide almost instant access to higher-level response categories such as words. However, direct word-level access is impaired when input is degraded due to hearing loss or faulty signal transmission. In that case, speech perception proceeds through a slow recursive backward search in which low-level stimulus details are matched with higher-level categories. The successes of the later processing route would be strongly affected by individual working memory capacity where input would be maintained during a slow backward search until an appropriate long-term memory match is found or the input representation decays. A similar role for working memory as a mediator in a time-sensitive interplay of lower-level sensory and higher-level contextual information is assigned by Boothroyd (2010). Although these models do not explicitly address environmental sound perception, the distinction between fast, effortless, and automatic perceptual processing of robust sensory input and the slow, effortful, explicit processing of degraded input could be cautiously extended to environmental sounds as well, given many similarities between speech and environmental sounds, described above, in terms of acoustic and semantic structure. Future studies could demonstrate whether the involvement of working memory and other cognitive factors changes as the sensory representation of speech and environmental sound stimuli is varied (e.g., through manipulation of number of vocoder channels).
Perceptual Learning of Spectrally Degraded Speech and Environmental Sounds
The current findings that speech perception improved over time without explicit speech training are consistent with conclusions of previous studies, which suggested that perceptual learning could involve multiple routes (Loebach et al., 2008). Listeners never heard the same word more than once throughout the study while their speech performance continued to improve. This suggests that some speech plasticity occurs at the sublexical level (Bent, Loebach, Phillips, & Pisoni, 2011; Davis et al., 2005; Hervais-Adelman et al., 2008; Loebach et al., 2008; Loebach & Pisoni, 2008). Thus, simple remembering of specific lexical items, which could straighten immediate neural connections based on the classic Hebbian theory of learning (Hebb, 1949), was not the exclusive basis for the improvement in performance. Some more general top-down factors were likely to be involved (Hervais-Adelman et al., 2008, 2011). This conclusion is in line with the present findings of correlations between working memory and executive function in speech and environmental sound performance.
The present findings also extend previous research on the generalization of perceptual learning of spectrally degraded speech and environmental sounds (Bent et al., 2011; Hervais-Adelman et al., 2008, 2011; Loebach & Pisoni, 2008) and suggest that learning is not limited to a single sound class: speech or environmental sounds. Based on current models of attentional learning (see Kruschke, 2011, for a review), perceptual learning may involve increased selective attention to information-bearing dimensions of the vocoded stimuli coupled with learning to ignore irrelevant dimensions. Because both speech and environmental sounds are acoustically and semantically complex real-world signals, there may be a considerable overlap in their information-bearing acoustic properties. Even more global cues that can affect the accuracy of speech and environmental sound perception are likely to be available to listeners in real-life settings from multimodal environmental and social context. Words and sounds one is likely to encounter walking in the woods are not the same as those likely to be heard at a formal black-tie reception. Overtime, listeners may learn to rely on such non–stimulus-specific cues that can provide a basis for a priori probabilities for specific types of sounds, making it possible to use Bayesian models to predict perceptual outcomes (Boothroyd, 2010; Kruschke, 2011).
During training and exposure to vocoded stimuli, listeners may be learning to attend to temporal dimensions of the signals transmitted by energy envelopes and ignore perceptually irrelevant spectral information. The perceptual importance of temporal information was shown in Gygi et al. (2004) by a number of temporal measures that were the best predictors of NH subject performance with noise-vocoded environmental sounds. Even without explicit training such increased selective attention to information-bearing stimulus dimensions may operate based on the input from less ambiguous and easily identifiable words or environmental sounds (Hervais-Adelman et al., 2008). On the other hand, global auditory changes for the perception of semantically and acoustically complex input are also consistent with previous findings of Kidd et al. (2007), who suggested that a general auditory ability for putting “parts into wholes” may underlie the relationship between environmental sound and speech perception, which accords well with the importance of the Cloze data in predicting subject performance.
On the other hand, this more general auditory learning mechanism is likely to be but one among several routes of perceptual learning (Bent et al., 2011; Loebach et al., 2005). Some perceptual learning may be stimulus specific, involving episodic memory, and other, more global, factors, involving greater abstraction of ecologically significant properties of real-world sounds. Stimulus-specific episodic learning may be fast and highly effective for a specific set of stimuli, consistent with the highest improvement in the present data observed for the D-T sounds that were part of the training set. However, when stimuli vary across tests, listeners cannot rely on simple changes in associations between stimulus and response. In this case, perceptual learning continues, although slower and less effectively, through more general routes, as indicated by positive changes in the D-NT environmental sounds and speech. This hybrid account of episodic and more abstract changes in perceptual processing of vocoded speech and environmental sounds is similar in some ways to mid-20th-century views of learning and memory as a two-stage process (Hebb, 1949). It is also consistent with recent findings by Harvais-Adelman et al. (2011) who showed generalization of the learning of vocoded speech across frequency regions and variable generalization of learning across different noise carriers. Generalization of learning beyond specific items has been also shown by Bent et al., who demonstrated improved perception of vocoded speech in one language following training with vocoded speech materials in another language. It is noteworthy, however, that for environmental sounds, there remained a great deal of variability in the amount of posttraining improvement among individual D-NT sounds (Table 4). This seems to indicate that some dimensions of environmental sounds were likely more susceptible to generalization than others, a conclusion consistent with the current learning models that posit variable learnability of different stimulus dimensions (Kruschke, 2011). Further studies with greater control of stimulus properties and response measures can indicate the fundamental mechanism underlying the generalization effects. More global abstract-level learning may occur in parallel with acute perceptual learning on the order of minutes, as, for instance, observed by Davis et al. (2005) when listeners demonstrated continuous improvements in intelligibility of sets of 10 sentences, after being presented with spectrally degraded stimuli for the first time. Such rapid changes are compounded in the overall percent-correct speech scores for each session that consisted of 100 SPIN-R sentences and 100 words, but can be clearly seen in the differences between the first two 50-item lists for SPIN-R and CNC in each session (Table 3). It is further likely that these rapid accuracy changes during each session are more indicative of perceptual rather than procedural learning because participants were already quite familiar with the simple and straightforward close-set procedure following the first pretest (Hawkey, Amitay, & Moore, 2004). On the other hand, the rapid perceptual learning effects might have dissipated relatively quickly, whereas the slower learning effects, when listeners were not actively engaged with spectrally degraded stimuli for a period of 1 week between sessions, might have involved more fundamental and longer-lasting neurocognitive changes. Similar perceptual learning effects in the perception of synthetic speech can take place when people are performing unrelated tasks or even sleeping as have been observed for other learning tasks (Fenn, Nusbaum, & Margoliash, 2003).
Summary
The present study demonstrated the role of several factors in the perception of spectrally degraded speech and environmental sounds. Results confirmed and extended the previous findings of Loebach and Pisoni (2008), demonstrating improvements in both speech and environmental sound perception following a week-long course of environmental sound training. Training benefits were most pronounced for the class of sounds which were trained, with some generalization to novel sounds and, to a lesser extent, speech. Cognitive factors and basic auditory abilities were also shown to be involved. Working memory and executive function, on one hand, and spectral processing acuity, on the other, were related to the perception of both speech and environmental sounds. Associations between environmental sound and speech perception are in general agreement with existing results for CI patients (Inverso & Limb, 2010; Shafiro, Gygi et al. 2011). Further research will determine for CI patients the extent of training effects and whether the same cognitive factors and basic auditory abilities play a similar role as for NH listeners in the perception of speech and environmental sounds.
Acknowledgments
We are grateful to Sejal Kuvadia for her assistance with subject testing and to an anonymous reviewer for helpful comments.
“Adaptation” is being used here to refer to adapting listening strategies to maximize performance (see Boothroyd, 2010), rather than to the behaviorist sense of a diminished response to a frequently presented stimulus.
Footnotes
Author’s Note: Portions of the data were presented at the 160th Meeting of the Acoustical Society of America, Cancun, Mexico, and the First International Conference on Cognitive Hearing Science for Communication, Linkoping, Sweden.
Declaration of Conflicting Interests: The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
- Ahissar M., Nahum M., Nelken I., Hochstein S. (2008). Reverse hierarchies and sensory learning. Philosophical Transactions of the Royal Society: Biological Sciences, 364, 285-299 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Akeroyd M. A. (2008). Are individual differences in speech reception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing-impaired adults. International Journal of Audiology, 47, 125-143 [DOI] [PubMed] [Google Scholar]
- Aydelott J., Leech R., Crinion J. (2010). Normal adult aging and contextual influences affecting speech and meaningful sound perception. Trends in Amplification, 14(4), 218-232 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baddeley A. D., Wilson B. A. (1993). A case of word deafness with preserved span: Implications for the structure and function of short-term memory. Cortex, 29, 741-748 [DOI] [PubMed] [Google Scholar]
- Baldwin C. L., Ash I. K. (2011). Impact of sensory acuity on auditory working memory span in young and old adults. Psychology and Aging, 26(1), 85-91 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ballas J. A. (1993). Common factors in the identification of an assortment of brief everyday Sounds. Journal of Experimental Psychology: Human Perception and Performance, 19, 250-267 [DOI] [PubMed] [Google Scholar]
- Ballas J. A., Mullins T. (1991). Effects of context on the identification of everyday sounds. Human Performance, 4, 199-219 [Google Scholar]
- Bent T., Loebach J. L., Phillips L., Pisoni D. B. (2011). Perceptual adaptation to sinewave-vocoded speech across languages. Journal of Experimental Psychology: Human Perception and Performance, 37(5), 1607-1616 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boothroyd A. (2010). Adapting to changed hearing: The potential role of formal training. Journal of the American Academy of Audiology, 21, 601-611 [DOI] [PubMed] [Google Scholar]
- Cabe P. A., Pittenger J. B. (2000). Human sensitivity to acoustic information from vessel filling. Journal of Experimental Psychology: Human Perception and Performance, 26, 313-324 [DOI] [PubMed] [Google Scholar]
- Cazals Y., Pelizzone M., Saudan O., Boex C. (1994). Low-pass filtering in amplitude modulation detection associated with vowel and consonants identification in subjects with cochlear implants. Journal of the Acoustical Society of America, 96, 2048-2054 [DOI] [PubMed] [Google Scholar]
- Chiu C.-Y. P. (2000). Specificity of auditory implicit and explicit memory: Is perceptual priming for environmental sounds exemplar specific? Memory & Cognition, 28, 1126-1139 [DOI] [PubMed] [Google Scholar]
- Chiu C.-Y. P., Schacter D. L. (1995). Auditory priming for nonverbal information: Implicit and explicit memory for environmental sounds. Consciousness and Cognition, 4, 440-458 [DOI] [PubMed] [Google Scholar]
- Clopper C. G., Pisoni D. B., Tierney A. T. (2006). Effects of open-set and closed-set task demands on spoken word recognition. Journal of the American Academy of Audiology, 17(5), 331-349 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crowe S. F. (2000). Does the letter number sequencing task measure anything more than digit span? Assessment, 7, 113-117 [DOI] [PubMed] [Google Scholar]
- Davis M. H., Johnsrude I. S., Hervais-Adelman A. G., Taylor K., McGettingan C. (2005). Lexical information drives perceptual learning of distorted speech: Evidence from the comprehension of noise vocoded sentences. Journal of Experimental Psychology: General, 134, 222-241 [DOI] [PubMed] [Google Scholar]
- Divenyi P. L., Stark P. B., Haupt K. M. (2005). Decline of speech understanding and auditory thresholds in the elderly. Journal of the Acoustical Society of America, 118, 1089-1100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donaldson G. S., Nelson D. A. (2000). Place-pitch sensitivity and its relation to consonant recognition by cochlear implant listeners using the MPEAK and SPEAK speech processing strategies. Journal of the Acoustical Society of America, 107, 1645-1658 [DOI] [PubMed] [Google Scholar]
- Dorman M. F. (1993). Speech perception by adults. In Tyler R. S. (Eds.), Cochlear implants: Audiological foundations. San Diego, CA: Singular Publishing Group [Google Scholar]
- Drennan W. R., Longnion J. K., Ruffin C., Rubinstein J. (2008). Discrimination of Schroeder-phase harmonic complexes by normal-hearing and cochlear-implant listeners. Journal of the Association for Research in Otolaryngology, 9, 138-149 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott L. L. (1995). Verbal auditory closure and the Speech Perception in Noise (SPIN) test. Journal of Speech and Hearing Research, 38, 1363-1376 [DOI] [PubMed] [Google Scholar]
- Fenn K. M., Nusbaum H. C., Margoliash D. (2003). Consolidation during sleep of perceptual learning of spoken language. Nature, 425, 614-616 [DOI] [PubMed] [Google Scholar]
- Foo C., Rudner M., Ronnberg J., Lunner T. (2008). Recognition of speech in noise with new hearing instrument: Compression release setting requires explicit cognitive storage and processing capacity. Journal of the American Academy of Audiology, 18, 618-631 [DOI] [PubMed] [Google Scholar]
- Fu Q. (2002). Temporal processing and speech recognition in cochlear implant users. Neuroreport, 13, 1635-1639 [DOI] [PubMed] [Google Scholar]
- Fu Q. J., Galvin J. J. (2007). Perceptual learning and auditory training in cochlear implant recipients. Trends in Amplification, 11, 193-205 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gaver W. W. (1993). What in the world do we hear? An ecological approach to auditory event perception. Ecological Psychology, 5, 1-29 [Google Scholar]
- Gfeller K., Woodworth G., Robin D. A., Witt S., Knutson J. F. (1997). Perception of rhythmic and sequential pitch patterns by normally hearing adults and adult cochlear implant users. Ear and Hearing, 18, 252-260 [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S., Fitzgibbons P. J. (1997). Selected cognitive factors and speech recognition performance among young and elderly listeners. Journal of Speech, Language, and Hearing Research, 40, 423-431 [DOI] [PubMed] [Google Scholar]
- Gygi B., Kidd G., Watson C. (2004). Spectral-temporal factors in the identification of environmental sounds. Journal of the Acoustical Society of America, 115, 1252-1265 [DOI] [PubMed] [Google Scholar]
- Gygi B., Kidd G. R., Watson C. S. (2007). Similarity and categorization of environmental Sounds. Perception and Psychophysics, 69, 839-855 [DOI] [PubMed] [Google Scholar]
- Gygi B., Shafiro V. (2011). The incongruency advantage for environmental sounds presented in natural auditory scenes. Journal of Experimental Psychology: Human Perception and Performance, 37, 551-565 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gygi B., Shafiro V. (2012). Spatial and temporal factors in a multitalker dual listening task. Acta Acustica united with Acustica, 98(1), 142-157 [Google Scholar]
- Hebb D. O. (1949). The organization of behaviour. New York, NY: John Wiley [Google Scholar]
- Henry B. A., Turner C. W., Behrens A. (2005). Spectral peak resolution and speech recognition in quiet: Normal hearing, hearing impaired, and cochlear implant listeners. Journal of the Acoustical Society of America, 118, 1111-1121 [DOI] [PubMed] [Google Scholar]
- Hervais-Adelman A., Davis M. H., Johnsrude I. S., Carlyon R. P. (2008). Perceptual learning of noise vocoded words: Effects of feedback and lexicality. Journal of Experimental Psychology: Human Perception and Performance, 34, 460-474 [DOI] [PubMed] [Google Scholar]
- Hervais-Adelman A., Davis M. H., Johnsrude I. S., Taylor K. J., Carlyon R. P. (2011). Generalization of perceptual learning of vocoded speech. Journal of Experimental Psychology: Human Perception and Performance. Published Ahead of Print. 10.1037/a0020772 [DOI] [PubMed] [Google Scholar]
- Hawkey D. J. C., Amitay S., Moore D. R. (2004). Early and rapid perceptual learning. Nature Neuroscience, 7, 1055-1056 [DOI] [PubMed] [Google Scholar]
- Humes L. E., Burk M. H., Coughlin M. P., Busey T. A., Strauser L. E. (2007). Auditory speech recognition and visual text recognition in younger and older adults: Similarities and differences between modalities and the effects of presentation rate. Journal of Speech, Language, and Hearing Research, 50, 283-303 [DOI] [PubMed] [Google Scholar]
- Humes L. E., Lee J. H., Coughlin M. P. (2006). Auditory measures of selective and divided attention in young and older adults using single-talker competition. Journal of the Acoustical Society of America, 120, 2926-2937 [DOI] [PubMed] [Google Scholar]
- Inverso Y., Limb C. J. (2010). Cochlear implant-mediated perception of nonlinguistic Sounds. Ear and Hearing, 31, 505-514 [DOI] [PubMed] [Google Scholar]
- Jenkins J. J. (1979). Four points to remember: A tetrahedral model of memory experiments. In Cermak L. S., Craik F. I. M. (Eds.), Levels of processing in human memory (pp. 429-446). Hillsdale, NJ: Lawrence Erlbaum [Google Scholar]
- Jenkins J. J. (1985). Acoustic information for objects, places and events. In Warren W. H., Shaw R. E. (Eds.), Persistence and change (pp. 115-138). Hillsdale, NJ: Lawrence Erlbaum [Google Scholar]
- Kidd G. R., Watson C. S., Gygi B. (2007). Individual differences in auditory abilities. Journal of the Acoustical Society of America, 122, 418-435 [DOI] [PubMed] [Google Scholar]
- Kronenberger W. G., Pisoni D. B., Henning S. C., Colson B. G., Hazzard L. M. (2011). Working memory training for children with cochlear implants: A pilot study. Journal of Speech, Language, and Hearing Research, 54, 1182-1196 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kruschke J. K. (2011). Models of attentional learning. In Pothos E. M., Wills A. J. (Eds.), Formal approaches in categorization (pp. 120-152). Cambridge, UK: Cambridge University Press [Google Scholar]
- Levitt H. (1971). Transformed up-down methods in psychoacoustics. Journal of the Acoustical Society of America, 49, 467-477 [PubMed] [Google Scholar]
- Lewis J. W., Wightman F. L., Brefczynski J. A., Phinney R.E., Binder J.R., DeYoe E.A. (2004). Human brain regions involved in recognizing environmental stimuli. Cerebral Cortex, 14, 1008-1021 [DOI] [PubMed] [Google Scholar]
- Li X., Logan R. J., Pastore R. E. (1991). Perception of acoustic source characteristics: Walking sounds. Journal of the Acoustical Society of America, 90, 3036-3049 [DOI] [PubMed] [Google Scholar]
- Litvak L. M., Spahr A. J., Saoji A. A., Fridman G. Y. (2007). Relationship between perception of spectral ripple and speech recognition in cochlear implant and vocoder listeners. Journal of the Acoustical Society of America, 122, 982-991 [DOI] [PubMed] [Google Scholar]
- Loebach J. L., Bent T., Pisoni D. B. (2008). Multiple routes to the perceptual learning of Speech. Journal of the Acoustical Society of America, 124, 552-561 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loebach J. L., Pisoni D. B. (2008). Perceptual learning of spectrally degraded speech and environmental sounds. Journal of the Acoustical Society of America, 123, 1126-1139 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loizou P. (1997, August). Signal processing for cochlear prosthesis: A tutorial review. 40th Midwest Symposium on Circuits and Systems, Sacramento, CA [Google Scholar]
- Lunner T. (2003). Cognitive function in relation to hearing aid use. International of Journal of Audiology, 42(Suppl. 1), 49-58 [DOI] [PubMed] [Google Scholar]
- Marcell M. M., Borella D., Greene M., Kerr E., Rogers S. (2000). Confrontation naming of environmental sounds. Journal of Clinical and Experimental Neuropsychology, 22, 830-864 [DOI] [PubMed] [Google Scholar]
- Markee J., Chandrasekaran B., Nicol T., Shafiro V., Kraus N. (2009, April). The effect of training on brainstem and cortical auditory evoked responses to spectrally degraded environmental sounds. Poster presented at the American Academy of Audiology Convention, Dallas, TX [Google Scholar]
- Muchnik C., Taitelbaum R., Tene S., Hildesheimer M. (1994). Auditory temporal resolution and open speech recognition in cochlear implant recipients. Scandinavian Audiology, 23, 105-109 [DOI] [PubMed] [Google Scholar]
- Nahum M., Nelken I., Ahissar M. (2008). Low-level information and high-level perception: The case of speech in noise. PLoS Biology, 6, 978-991 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peterson G., Lehiste I. (1962). Revised CNC list for auditory tests. Journal of Speech and Hearing Disorders, 27, 62-70 [DOI] [PubMed] [Google Scholar]
- Piccirilli M., Scarab T., Luzzi S. (2000). Modularity of music: Evidence from a case of pure amusia. Journal of Neurology, 69, 541-545 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pichora-Fuller M. K. (2003). Cognitive aging and auditory information processing. International Journal of Audiology, 42, 26-32 [PubMed] [Google Scholar]
- Pichora-Fuller K., Singh G. (2006). Effects of age on auditory and cognitive processing: Implications for hearing aid fitting and audiologic rehabilitation. Trends in Amplification, 10, 29-59 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pisoni D. B. (2005). Speech perception in deaf children with cochlear implants. In Pisoni D. B., Remez R. E. (Eds.), The handbook of speech perception (pp. 494-523). Oxford, UK: Blackwell [Google Scholar]
- Pisoni D. B., Cleary M. (2003). Measures of working memory span and verbal rehearsal speed in deaf children after cochlear implantation, Ear and Hearing, 24, 106-120 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pisoni D. B., Geers A. (2000). Working memory in deaf children with cochlear implants: Correlations between digit span and measures of spoken language processing. Annals of Otology, Rhinology, and Laryngology, 109, 92-93 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pisoni D. B., Kronenberger W. G., Roman A. S., Geers A. E. (2011). Measures of digit span and verbal rehearsal speed in deaf children after more than 10 years of cochlear implantation. Ear and Hearing, 32, 60-74 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramsdell D. A. (1978). The psychology of the hard-of-hearing and the deafened adult. In Davis H., Silverman S. R. (Eds.), Hearing and deafness (pp. 499-510). New York, NY: Holt, Rinehart and Winston [Google Scholar]
- Roediger H. L. (2008). Relativity of remembering: Why the laws of memory vanished. Annual Review of Psychology, 59, 225-254 [DOI] [PubMed] [Google Scholar]
- Ronnberg J. (1990). Cognitive and communicative function: The effects of chronological age and “handicap age.” European Journal of Cognitive Psychology, 2, 253-273 [Google Scholar]
- Ronnberg J., Rudner M., Foo C., Lunner T. (2008). Cognition counts: A working memory system for ease of language understanding (ELU). International Journal of Audiology, 47(Suppl. 2), 99-105 [DOI] [PubMed] [Google Scholar]
- Rosen V. M., Engle R. W. (1997). Forward and backward serial recall. Intelligence, 25, 37 47 [Google Scholar]
- Rudel R. G., Denckla M. B. (1974). Relation of forward and backward digit repetition to neurological impairment in children with learning disability. Neuropsychologia, 12, 109-118 [DOI] [PubMed] [Google Scholar]
- Saoji A.A., Litvak L., Spahr A.J., Eddins D.A. (2009). Spectral modulation detection and vowel and consonant identifications in cochlear implant listeners. Journal of the Acoustical Society of America, 126, 955-958 [DOI] [PubMed] [Google Scholar]
- Schvartz K. C., Chatterjee M., Gordon-Salant S. (2008). Recognition of spectrally degraded phonemes by younger, middle-aged, and older normal-hearing listeners. Journal of the Acoustical Society of America, 124, 3972-3988 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shafiro V. (2008a). Identification of environmental sounds with varying spectral resolution. Ear and Hearing, 29, 401-420 [DOI] [PubMed] [Google Scholar]
- Shafiro V. (2008b). Development of a large-item environmental sound test and the effects of short-term training with spectrally-degraded stimuli. Ear and Hearing, 29, 775-790 [DOI] [PubMed] [Google Scholar]
- Shafiro V., Gygi B. (2004). How to select stimuli for environmental sound research and where to find them? Behavioral Research Methods, Instruments, and Computers, 36, 590-598 [DOI] [PubMed] [Google Scholar]
- Shafiro V., Gygi B., Cheng M., Vachhani J., Mulvey M. (2011). Perception of environmental sounds by experienced cochlear implant patients. Ear and Hearing, 32, 511-523 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shafiro V., Sheft S., Risley R. (2011). Perception of interrupted speech: Effects of dual rate gating on the intelligibility of words and sentences. Journal of the Acoustical Society of America, 130, 2076-2087 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shannon R. V., Zeng F., Kamath V., Wigonski J., Ekelid M. (1995). Speech recognition with primarily temporal cues. Science, 270, 303-304 [DOI] [PubMed] [Google Scholar]
- Sheft S., Risley R., Shafiro V. (2011, August). Clinical measures of static and dynamic spectral pattern discrimination in relationship to speech perception. Proceedings of the International Symposium on Auditory and Audiological Research (ISAAR), Nyborg, Denmark [Google Scholar]
- Sheft S., Shafiro V., Lorenzi C., McMullen R., Farrell C. (in press). Effects of age and hearing loss on the relationship between discrimination of stochastic frequency modulation and speech perception. Ear and Hearing. 10.1097/AUD.0b013e31825aab15 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sheft S., Yost W. A., Shafiro V., Risley R. (2011, March). Discrimination of periodic spectral ripples in relationship to speech perception. American Auditory Society Conference, Scottsdale, AZ [Google Scholar]
- Treisman A., (1965). Verbal responses and contextual constraints in language. Journal of Verbal Learning and Verbal Behavior, 4, 118-128 [Google Scholar]
- Tyler R. S., Moore B., Kuk F. (1989). Performance of some of the better cochlear-implant Patients. Journal of Speech, Language, and Hearing Research, 32, 887-911 [DOI] [PubMed] [Google Scholar]
- Wechsler D. (1997). Wechsler adult intelligence scale (3rd ed., WAIS-3®) San Antonio, TX: Harcourt Assessment [Google Scholar]
- Wingfield A., Tun P. A. (2007). Cognitive supports and cognitive constraints on comprehension of spoken language. Journal of the American Academy of Audiology, 18,567-577 [DOI] [PubMed] [Google Scholar]
- Won J. H., Drennan W. R., Rubinstein J. T. (2007). Spectral-ripple resolution correlates with speech reception in noise in cochlear implant users. Journal of the Association for Research in Otolaryngology, 8, 384-392 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vaughan N., Storzbach D., Furukawa I. (2008). Investigation of potential cognitive tests for use with older adults in audiology clinics. Journal of the American Academy of Audiology, 19, 533-541 [DOI] [PubMed] [Google Scholar]