

Abstract
We performed a genome-wide association study (GWAS) and a multistage meta-analysis of type 2 diabetes (T2D) in Punjabi Sikhs from India. Our discovery GWAS in 1,616 individuals (842 case subjects) was followed by in silico replication of the top 513 independent single nucleotide polymorphisms (SNPs) (P < 10−3) in Punjabi Sikhs (n = 2,819; 801 case subjects). We further replicated 66 SNPs (P < 10−4) through genotyping in a Punjabi Sikh sample (n = 2,894; 1,711 case subjects). On combined meta-analysis in Sikh populations (n = 7,329; 3,354 case subjects), we identified a novel locus in association with T2D at 13q12 represented by a directly genotyped intronic SNP (rs9552911, P = 1.82 × 10−8) in the SGCG gene. Next, we undertook in silico replication (stage 2b) of the top 513 signals (P < 10−3) in 29,157 non-Sikh South Asians (10,971 case subjects) and de novo genotyping of up to 31 top signals (P < 10−4) in 10,817 South Asians (5,157 case subjects) (stage 3b). In combined South Asian meta-analysis, we observed six suggestive associations (P < 10−5 to < 10−7), including SNPs at HMG1L1/CTCFL, PLXNA4, SCAP, and chr5p11. Further evaluation of 31 top SNPs in 33,707 East Asians (16,746 case subjects) (stage 3c) and 47,117 Europeans (8,130 case subjects) (stage 3d), and joint meta-analysis of 128,127 individuals (44,358 case subjects) from 27 multiethnic studies, did not reveal any additional loci nor was there any evidence of replication for the new variant. Our findings provide new evidence on the presence of a population-specific signal in relation to T2D, which may provide additional insights into T2D pathogenesis.
South Asians (people originating from the Indian subcontinent) comprise more than a quarter of the global population and contribute the highest number of patients with type 2 diabetes (T2D) (1). According to latest estimates, ∼61 million people in India alone are currently afflicted with T2D, and their number is projected to increase to ∼101 million by 2030 (2). Consequently, ∼60% of the world’s coronary artery disease (CAD), a principal cause of mortality in individuals with T2D, is expected to occur in India (3). There is considerable ethnic difference in the prevalence and progression of T2D and CAD. In addition to environmental factors, genetic factors influence disease susceptibility (4). The incidence of T2D and CAD is about three to five times higher in immigrant South Asians compared with Euro-Caucasians, and the age of onset of T2D is roughly a decade earlier in South Asians than in Europeans (5–7). The higher prevalence of T2D among South Asians settled in developed countries compared with the host population reflects the genetic and ethnic predisposition to cardiometabolic disease under an adverse environment and the joint effects of genes and environment in the predisposition to T2D (8). For these reasons, we conducted ethnic-specific genetic studies in a Sikh population to dissect genetic pathways that may contribute to T2D etiology in different ethnic groups.
The vast majority of genome-wide association studies (GWAS) on T2D so far have been performed on Europeans. Studies on non-European populations, especially those with unique demographic and cultural histories, are important for identifying population-specific linkage disequilibrium (LD) patterns and environmental factors that may modulate disease risk or protection (9). Interestingly, many, but not all, of the common loci originally identified in Europeans have been replicated in non-European groups (10–18). Recent GWAS in non-European populations have yielded intriguing new variants (19–21), including six novel signals in South Asians represented by single nucleotide polymorphisms (SNPs) near GRB14, ST6GAL1, VPS26A, HMG20A, AP3S2, and HNF4A in our recent meta-analysis of GWAS (22). Given the existence of marked genetic variability among South Asian communities, in addition to diversity in culture, language, caste system, physical appearance, and diet, they do not constitute a single homogeneous community (23). Therefore, screening populations with a different genetic and racial background or environmental exposures may improve insights about the disease and genetic risk factors (24).
People from India have a complex racial history complicated by the presence of a caste system that has prohibited interbreeding to a great extent and consequently separated people into numerous endogamous groups (25). The Sikhs, a relatively young, inbred population of ∼26 million (2% of the Indian population), are from the northwestern province of India and follow a distinct and unique religion born ∼500 years ago in Punjab. They have an interesting background for “nontraditional” disease enrichment in the absence of conventional risk factors such as smoking, obesity, and a diet rich in meats (26). Sikhs do not smoke or chew tobacco because of religious and cultural compulsions, and ∼50% of them are lifelong vegetarians. Despite the absence of these lifestyle-related risk factors, T2D and CAD have reached epidemic proportions in Sikhs. Our initial genetic studies in a Sikh cohort as part of the Asian Indian Diabetic Heart Study (AIDHS) or the Sikh Diabetes Study (SDS) revealed an association of FTO and MTNR1B, ADIPOQ, and PPARG polymorphisms with T2D and risk factors in the absence of obesity (11,27,28). In this investigation, we conducted a GWAS in a relatively homogenous Punjabi Sikh population of 1,850 individuals and performed multistage replication in up to 27 case-control studies of Punjabi, other South Asian, East Asian, and Caucasian ancestries (total n = 128,127; 44,358 T2D case and 83,769 control subjects) (Supplementary Tables 1 and 2). Study design of the discovery, replication, and meta-analysis phases was optimized to detect new population-specific and multiethnic T2D loci (Fig. 1). One important difference in the current study from our previous South Asian GWAS (22) is that in the previous study, the SNPs that were common between South Asians and Europeans were selected for replication based on the European Diabetes Genetics Replication and Meta-analysis (DIAGRAM) sample. However, in this study, the SNP selection was prioritized based on the top signals (P < 10−3) from our discovery Sikh cohort.
FIG. 1.

Summary of study design and outcome of key findings.
RESEARCH DESIGN AND METHODS
Participants.
Participants were part of the Punjabi Sikh GWAS.
Study sample and characteristics.
Our primary Sikh GWAS (discovery) cohort used in this investigation is comprised of 1,616 individuals from the Punjabi Sikh population that was a part of the AIDHS (also named the SDS). The AIDHS/SDS has unique characteristics that are ideal for genetic studies. Sikhs are strictly a nonsmoking population, and ∼50% of participants are teetotalers and life-long vegetarians. All individuals for the GWAS discovery cohort were recruited from one geographical location. Diagnosis of T2D was confirmed by scrutinizing medical records for symptoms and use of medication and measuring fasting glucose levels according to the guidelines of the American Diabetes Association (29), as described previously (11). Data on lipids, insulin, glucose, anthropometric measurements, education, socioeconomic status, job grade, diet, and physical activity were available on >95% of the AIDHS/SDS individuals selected for this study. Dietary questions involving alcohol consumption were scored using a scale from 0 to 5; details are described elsewhere (26). T2D is often asymptomatic and remains undiagnosed for many years, especially in people from the developing world due to poor healthcare provisions. Therefore, it is reasonable to assume that the actual age of onset of T2D in Sikhs may range from 39 to 42 years of age compared with the observed age at diagnosis (46 years). This age is in sharp contrast to the mean age at onset of 60 years or above in developed countries (5,26,30). A medical record indicating either 1) a fasting plasma glucose level ≥7.0 mmol/L (≥126 mg/dL) after a minimum 12-h fast or 2) a 2-h postglucose level of ≥11.1 mmol/L (≥200 mg/dL) estimated during a 2-h oral glucose tolerance test on more than one occasion, combined with symptoms of diabetes, confirmed the diagnosis. Impaired fasting glucose is defined as a fasting blood glucose level ≥5.6 mmol/L (≥100 mg/dL) but ≤7.0 mmol/L (≤126 mg/dL). Impaired glucose tolerance is defined as a 2-h OGTT >7.8 mmol/L (>140 mg/dL) but <11.1 mmol/L (<200 mg/dL). The 2-h OGTTs were performed according to the criteria of the World Health Organization (75-g oral load of glucose). BMI was calculated as weight (kg)/height (m)2, and waist-to-hip ratio was calculated as the ratio of abdomen or waist circumference to hip circumference. Subjects with type 1 diabetes, or those with a family member with type 1 diabetes, or rare forms of T2D subtypes (maturity-onset diabetes of the young) or secondary diabetes (from, e.g., hemochromatosis or pancreatitis) were excluded from the study. The selection of control subjects was based on a fasting glucose <100.8 mg/dL or a 2-h glucose <141.0 mg/dL. Subjects with impaired fasting glucose or impaired glucose tolerance were excluded when data were analyzed for association of the variants with T2D. All blood samples were obtained at the baseline visits. All participants signed a written informed consent for the investigations. The study was reviewed and approved by the University of Oklahoma Health Sciences Center Institutional Review Board, as well as the Human Subject Protection Committee at the participating hospitals and institutes in India.
South Asian cohorts.
For stage 2a replication, the Sikh component of the London Life Sciences Population (LOLIPOP) study (22) comprised 2,919 individuals (801 T2D case and 2,018 control subjects). For stage 2b, the non-Sikh South Asian components of the LOLIPOP and the Pakistan Risk of Myocardial Infarction Study (PROMIS; and the Risk Assessment of Cerebrovascular Events [RACE] study) GWAS (22) comprised 29,157 individuals (10,971 case and 18,186 control subjects) (22). Stage 3a Punjabi-specific replication was carried out on 2,894 individuals (1,711 case and 1,183 control subjects) of Punjabi ancestry from India as part of AIDHS/SDS, and replication testing among South Asians for stage 3b was carried out among 10,817 participants (5,157 case and 5,660 control subjects), which were part of the following studies: Asian Indians from the Singapore Indian Eye (SINDI) study (31), the Chennai Urban Rural Epidemiology Study (CURES) (32), the Diabetes Genetics in Pakistan (DGP) study, the UK Asian Diabetes Study (UKADS) (33), and the Sri Lankan Diabetes Study (SLDS) (34). Details of the contributing cohorts are provided in the Supplementary Data.
East Asian cohorts.
Replication testing for stage 3c was carried out on a total of 33,707 East Asians, comprising 14,890 Japanese from RIKEN (n = 7,480 genotyped) and BioBank Japan (n = 7,410 GWAS) (19,35) and 18,817 individuals of East Asian ancestry as part of the Asian Genetic Epidemiology Network (AGEN) with genotype data available from eight GWAS (21).
DIAGRAM (Euro-Caucasians).
Associations of SNPs with T2D among Europeans were tested in silico using results from the genome-wide association phase of the DIAGRAM study comprising 47,117 subjects (36).
Genotyping and quality control.
Genomic DNA was extracted from buffy coats using QiaAmp blood kits (Qiagen, Chatsworth, CA) or by the salting-out procedure (37). Stage 1 genome-wide genotyping was performed using a Human 660W-Quad BeadChip panel (Illumina, Inc., San Diego, CA). We performed pairwise identity-by-state clustering in PLINK across all individuals to assess population stratification; no population outliers were detected. Related individuals with pi-hat >0.3 and samples with <93% call rate were excluded, as were SNPs with call rate <95%. Also excluded were SNPs with Hardy-Weinberg equilibrium (HWE) P < 10−6 or minor allele frequency (MAF) <1%. After quality control, 524,216 directly genotyped SNPs in 1,616 subjects (842 case and 774 control subjects) were available for association testing.
Genotyping for de novo SNPs in the replication samples was performed by Sequenom MassArray (BioMark HD MX/HX Genetic Analysis System; Fluidigm) or KASPAR (LGC Genomics KBioscience, London, U.K.). Samples and SNPs with <95% call rate were excluded, as were those that deviated from HWE at P < 10−3. The associations of SNPs with T2D were tested in each cohort separately.
Statistical analyses
Association testing.
Associations of SNPs with T2D were tested using logistic regression and an additive genetic model. Age, sex, BMI, and 5 or 10 principal components to adjust for residual population stratification were included as covariates. As the existing HapMap2 or HapMap3 and 1000 Genomes data do not include Sikhs, the 5 or 10 principal components used for this correction were estimated using our Sikh population sample and not the HapMap populations. After association analyses, the genomic control inflation factor (λ) was 1.0, so no adjustments were made (Supplementary Fig. 2A and B).
In addition to the analysis of directly genotyped SNPs, we performed imputation using the Impute 2 program (38–40), which determines the probability distribution of missing genotypes based on a set of known haplotypes and an estimated fine-scale recombination map. Imputation was based on the entire multiethnic HapMap3 reference panel of ∼1.5 million autosomal SNPs with MAF >1% in 1,011 individuals from Africa, Asia, Europe, and the Americas (including 1,362,138 SNPs from the Indian population of 100 Gujaratis from Houston [GIH]). Imputation yielded a total of 1,232,008 passing SNPs with MAF >1% in the Sikh GWAS. Imputed SNPs were analyzed using SNPTEST (38,40), adjusted for the covariates age, sex, BMI, and five principal components, which implements frequentist tests that calculate P values and parameter estimates and their standard errors that account for the uncertainty due to the probability distributions of the imputed genotypes, and included only those SNPs with an information score ≥0.5 in the discovery sample as well as in all GWAS used for replication, a measure of the relative statistical information about the additive genetic effect being estimated. The genomic control value for imputed SNPs was 1.02. The inbreeding coefficient and measures of autozygosity were determined using the program PLINK. We identified runs of homozygosity using the metrics defined in Nalls et al. (41), evaluating 1-Mb autosomal regions with at least 50 adjacent SNPs, with a sliding window of 50 SNPs including no more than 2 SNPs with missing genotypes and one possible heterozygous genotype.
Stage 2 replication.
We selected all independent association signals (r2 <0.25) with P < 10−3 for lookup in GWAS of 1) the Sikh component of the LOLIPOP GWAS (22) and 2) the non-Sikh South Asian components of the LOLIPOP and PROMIS GWAS (22). A fixed-effect, inverse-variance meta-analysis (as implemented in METAL) (42) was used to combine the results for individual studies.
Stage 3 replication.
Significant association results with P < 10−3 based on meta-analysis of stages 1, 2a, and 2b were selected for de novo or in silico replication in Sikh, South Asian, other Asian, and European populations. In addition, we selected SNPs from a Sikh-only meta-analysis of stages 1a and 2a for genotyping in an in-house Punjabi Sikh T2D case-control population. In our previous South Asian GWAS by Kooner et al. (22), 300 of the 3,200 samples of the AIDHS/SDS (used in replication) were genotyped using Illumina 660 Quad arrays, and the remaining samples (from 1,187 case and 1,632 control subjects) were genotyped using Sequenom MassARRAYs. However, in this study, in addition to GWAS set (n = 1,616), SNPs were genotyped de novo on our remaining replication set (n = 2,894). Signals with P < 10−4 after meta-analysis of stages 1, 2a, and 3a were also genotyped in the South Asian, other Asian, and European populations to test if they were specific to the Sikh ethnic group or spanned ethnicities. All meta-analyses were performed using a fixed-effects, inverse-variance meta-analysis implemented in METAL.
MuTHER Consortium.
The Multiple Tissue Human Expression Resource (MuTHER; www.muther.ac.uk) includes lymphoblastic cell lines and skin and adipose tissue derived simultaneously from a subset of well-phenotyped healthy female twins from the Twins UK adult registry. Whole-genome expression profiling of the samples, each with either two or three technical replicates, was performed using the Illumina HumanHT-12 v3 BeadChips according to the protocol supplied by the manufacturer. Log2-transformed expression signals were normalized separately per tissue as follows. Quantile normalization was performed across technical replicates of each individual followed by quantile normalization across all individuals. Genotyping was performed with a combination of Illumina arrays HumanHap300, HumanHap610Q, 1M-Duo, and 1.2MDuo 1M. Untyped HapMap2 SNPs were imputed using the IMPUTE software package (v2). The number of adipose samples with genotypes and expression values is 776. Association between all SNPs (MAF >5%; IMPUTE info >0.8) within a gene or within 1 Mb of the gene transcription start or end site and normalized expression values was performed with the GenABEL/ProbABEL packages using the polygenic linear model incorporating a kinship matrix in GenABEL followed by the ProbABEL mmscore score test with imputed genotypes. Age and experimental batch were included as cofactors.
RESULTS
Punjabi Sikh discovery GWAS.
Clinical characteristics of the stage 1 Punjabi Sikh T2D GWAS cohort and stage 2a and 2b (replication) cohorts are described in Supplementary Table 3. Principal components analysis revealed little population structure (Supplementary Fig. 1). After quality control, 524,216 directly genotyped SNPs in 1,616 subjects (842 case and 774 control subjects) from 1,850 total subjects were available for association testing after removing samples showing cryptic relatedness through identity-by-descent sharing. To increase genome coverage, genotypes were imputed for untyped SNPs using the HapMap3 multiethnic reference panel (see research design and methods), yielding a total of 1,232,008 SNPs for association analyses. The reason for choosing a more cosmopolitan panel and not restricting to the GIH was based on our own data showing equal diversity of the Sikhs from GIH and CEU, and based on previously described advantages of using a worldwide reference panel (39). We performed a GWAS for T2D adjusted for covariates age, sex, BMI, and five principal components (Supplementary Fig. 1); no evidence of inflation was observed (Supplementary Fig. 2A and B) (see RESEARCH DESIGN AND METHODS).
Replication and meta-analyses in Punjabi Sikh participants.
We undertook a two-stage replication in T2D case-control samples of Punjabi Sikh ancestry (stages 2a and 3a in Fig. 1). Lead SNPs representing 513 novel, independent (r2 <0.25) association signals with P < 10−3 in the discovery GWAS (including only two previously known GWAS SNPs from TCF7L2 and IGF2BP2 and excluding 62 SNPs with P < 10−3 from other known T2D loci) were tested for in silico replication in the Punjabi Sikh subcomponent of the LOLIPOP GWAS comprising 801 T2D case and 2,018 control subjects (Supplementary Table 1). Top SNPs representing 66 putatively novel signals with P < 10−4 after stage 1 and 2a meta-analysis using a fixed effects, inverse-variance approach were directly genotyped in the stage 3a sample of 2,894 Punjabi Sikh individuals (1,711 T2D case and 1,183 control subjects) (Fig. 1 and Supplementary Table 2).
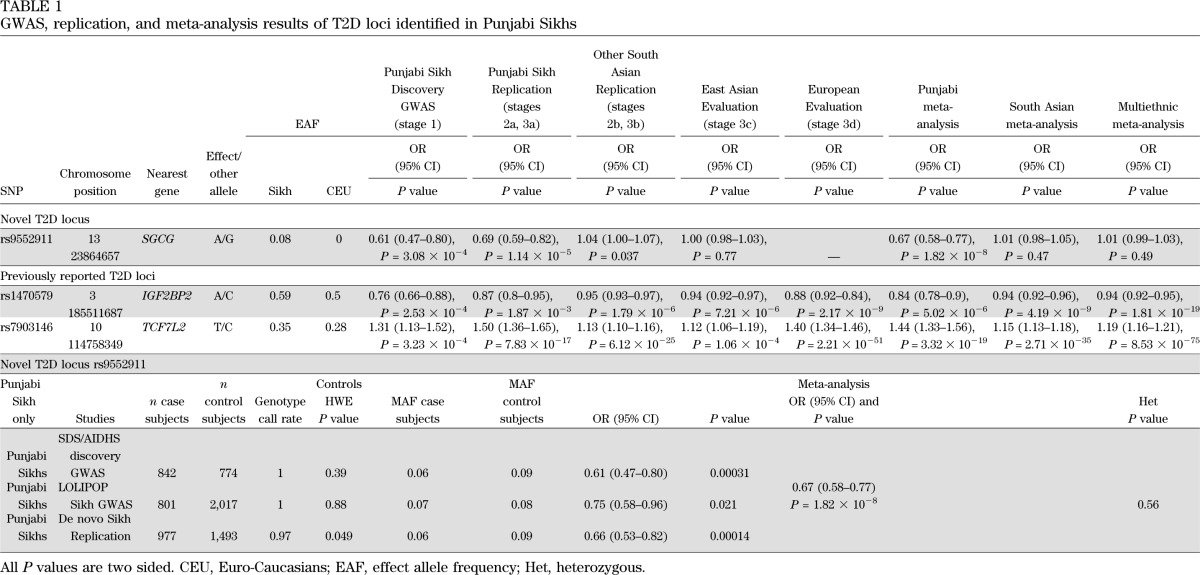
In a combined meta-analysis of the three Punjabi studies (n = 7,329), we identified one new locus reaching genome-wide significance (P < 5 × 10−8) along with robust replication of the established SNP rs7903146 in TCF7L2 (P = 3.32 × 10−19) in Sikhs (Figs. 2, 3, and 4). This novel association signal lies in a 164-kb region of strong LD at 13q12 (harboring genes gamma-sarcoglycan [SGCG] and sacsin [SACS]) and is represented by a directly genotyped intronic SNP, rs9552911 in SGCG (odds ratio [OR] 0.67 [95% CI 0.58–0.77], P = 1.82 × 10−8 for the minor “A” allele) (Table 1, Fig. 4, and Supplementary Table 5). Excluding BMI from the logistic regression model did not affect the association (Supplementary Table 6). Furthermore, including five additional principal components in the model did not attenuate the signal; indeed, the effect and significance were slightly improved (Supplementary Table 6). The genetic variance (R2) explained by this variant for the T2D phenotype in Punjabi Sikh discovery and replication sets was 1.57 and 1.34%, respectively. There were 15 additional independent loci with suggestive evidence (P < 10−5 to < 10−7) of association, including six unknown regions along with IGF2BP2, originally identified in Caucasians (43) (Supplementary Table 5). Meta-analysis results including non-Sikh Punjabis from PROMIS (Pakistan) revealed suggestive association (P < 10−5 to < 10−7) at SNPs from three new regions: chromosome 18q21 ZBTB7C (rs1893835), 20q13, near HMG1L1/CTCFL/RBM38/PCK1 (rs328506), and 5q33 (rs17053082) (Supplementary Table 7). Association results for 42 previously reported T2D loci in the Punjabi cohort are summarized in Supplementary Table 14. Most loci showed consistent effect in the same direction and 33 out of 42 were associated with T2D at P < 0.05 in Sikhs.
FIG. 2.

A: Manhattan plot showing primary genome-wide association analysis of the Punjabi Sikh discovery cohort using directly genotyped (524,216) SNPs. B: Manhattan plot shows imputed 1,232,008 SNPs on the x-axis and −log10 P value of association on the y-axis. Locations of the three loci (including one novel locus at SGCG) reached genome-wide significance after combined analysis of the GWAS and replication data in Punjabi Sikhs.
FIG. 3.

A: Regional association plot for a new T2D locus detected at 13q12 in the SGCG gene from the genome-wide meta-analysis in Sikhs. B: A strong confirmation of SNPs in the TCF7L2 gene in Sikh meta-analysis. In these plots, the SNPs showing the most strongly associated signal are depicted as a red diamond with blue border for the combined stage 1, 2a, and 3a results for meta-analysis, and the red diamond with black border shows evidence of association for the stage 1 results. Each square in color shows a SNP with the color scale relating the r2 value for that SNP and the top SNP taken from the HapMap 3 GIH panel. We present LD using the GIH panel, the closest HapMap population to the Sikhs; however, we note that there could still be differential LD between the reference panel and the Sikh population. At the bottom of the plot, the locations of known genes in the region are shown.
FIG. 4.

Forest plot showing the association of lead SNP in the SGCG (rs9552911) gene with T2D. For each study, the estimates of the ORs with 95% CI are shown. In addition, meta-analyses of Sikhs and South Asians and multiethnic studies are shown at the bottom. Meta-analysis in Sikhs shows a significant association of rs9552911 with T2D (OR 0.67 [0.58–0.77], P = 1.82 × 10−8). The red diamond signifies the OR and CI across all multiethnic samples.
TABLE 1.
GWAS, replication, and meta-analysis results of T2D loci identified in Punjabi Sikhs
Replication/evaluation and meta-analysis in other South Asians.
In order to identify T2D association signals common to Punjabi and other South Asian populations, we tested the association of the 513 top independent signals (P < 10−3) derived from the discovery cohort in GWAS from the LOLIPOP, PROMIS, and RACE studies as part of stage 2b replication (10,971 T2D case and 18,186 control subjects) (Fig. 1 and Supplementary Table 1). Thirty-one signals (P < 10−4 from an interim analysis with stage 2b) were further genotyped in 10,817 South Asians (5,157 T2D and 5,660 control subjects) (Fig. 1) as part of stage 3b replication. Clinical characteristics of the stage 3 replication cohorts are described in Supplementary Table 4. Combined South Asian meta-analysis revealed nominally significant association in six SNPs with MAF >5% (P ≤ 10−4), but only the two previously known SNPs in TCF7L2 and IGF2BP2 reached genome-wide significance (Table 1 and Supplementary Table 8). Suggestive novel signals included SNPs at chromosome 20q13, near HMG1L1/CTCFL/RBM38/PCK1 (rs328506), 7q32 near PLXNA4 (rs1593304), 3p21 in SCAP (rs4858889), and 5p11 (rs13155082) (Supplementary Table 8). Further studies and replication in a larger sample will be required to validate these results and identify causal variants at these loci.
Multiethnic replication and meta-analysis.
To identify T2D signals spanning ethnicities, we extended the replication of 31 SNPs with P < 10−4 in Punjabis and South Asians (stage 3b) to East Asians (AGEN+) and Europeans (DIAGRAM+) in stages 3c and 3d, respectively (Fig. 1). Upon meta-analysis of 31 loci in Asians (South Asians and AGEN+), genome-wide associations were only seen in TCF7L2 (rs7903146, P = 1.93 × 10−38) and IGF2BP2 (rs1470579, P = 1.54 × 10−13) (Supplementary Table 9). In joint multiethnic meta-analysis on 128,127 individuals from 27 studies, only two previously known loci, TCF7L2 (rs7903146, P = 8.53 × 10−75) and IGF2BP2 (rs1470579, P = 1.81 × 10−19), showed robust associations. Interestingly, none of the Punjabi hits could be independently confirmed in AGEN+ or DIAGRAM+ (notably, the lead rs9552911 variant from SGCG was monomorphic in DIAGRAM+) (Table 1 and Supplementary Table 10). Lookup of 50 kb upstream and downstream of SNPs within the SGCG locus in the publicly available data of the Meta-Analyses of Glucose and Insulin-Related Traits Consortium (MAGIC) study on glycemic trait GWAS (44,45) revealed several nominal associations of SNPs with fasting blood glucose and 2-h glucose levels (Supplementary Fig. 3). Some of these SNPs also showed an association with fasting blood glucose and waist or waist-to-hip ratio in Sikhs (Supplementary Table 11), but none of these were in LD (r2 >0.20) with our lead SNP.
Gene expression studies.
We examined the expression of SGCG and neighboring genes (FLJ46358, MIPEP, SACS, and sTNFRSF19) within 1 Mb of the index SNP by cis expression quantitative trait locus (eQTL) analysis using adipose tissue, skin, and lymphoblastic cell line gene expression data from the MuTHER Consortium, comprising healthy female twins of European ancestry from Britain. Several SNPs in the SGCG region were associated with significantly elevated (PeQTL < 10−4 to < 10−9) expression of SGCG mRNA in adipose tissues (Supplementary Table 12 and Supplementary Fig. 4). One adipose eQTL from MuTHER (rs572303, PeQTL = 5.47 × 10−4) located within SGCG showed a nominally significant association with increased waist circumference in Sikhs (β = 0.67, P = 5.2 × 10−2) (Supplementary Table 11). As shown in Supplementary Fig. 4, the LD patterns in the region (∼1.46 Mb) surrounding the SGCG variant (rs9552911) varied in East Asians (JPT), Africans (YRI), Caucasians (CEU), Gujarati Indians (GIH), and Sikhs. Interestingly, in Caucasians and Yorubians, this variant was monomorphic. However, several alternative SNPs from this region in Europeans were nominally associated with fasting blood glucose (MAGIC study, r2 ranging from 0.10 to 0.20 with the index SNP [rs9552911]) and mRNA expression of adipose cells in the MuTHER study (r2 ranging from 0.14 to 0.26 with the index SNP). These data suggest that population differences may underlie the weak LD. It is possible that a single causal variant may be responsible for these associations, but LD may differ between Sikhs, Europeans, and other populations.
Comparative analysis of autozygosity.
We further looked to compare the distributions of inbreeding coefficients and autozygosity as described by Nalls et al. (41). As expected, the inbreeding coefficients in our sample were higher compared with two outbred populations of European Americans, Coriell, and Baltimore Longitudinal Study of Aging (BLSA) (F = 0.041 ± 0.018 in Sikhs vs. F = 0.007 ± 0.019 in Coriell and F = −0.3 ± 0.012 in BLSA), as assessed by Nalls et al. (41). However, these results were similar to other Indian populations previously reported by Reich et al. (46). No significant difference in inbreeding was observed between case and control subjects (P = 0.59). Autozygosity analysis determined that there were 19 ± 7 homozygous segments >1 Mb in length, with an average length of 2.0 ± 0.95 Mb. Hence, fewer but longer autozygous segments were found in our population than in outbred populations. No correlation of measures of autozygosity to age was observed (P > 0.05) across decades of age.
DISCUSSION
In this GWAS and multistage meta-analysis, a novel locus at 13q12 in the SGCG gene (rs9552911, P = 1.82 × 10−8) was identified as associated with T2D susceptibility in Punjabi Sikhs from Northern India.
SGCG is a member of the sarcoglycan complex of transmembrane glycoproteins mutated in autosomal recessive muscular dystrophy, in particular limb-girdle muscular dystrophy type 2C (LGMD2C). SGCG is expressed in skeletal muscle, and its high expression is also seen in vascular smooth muscle cells as well as in breast cancer cell lines (47,48). Founder mutations in SGCG that cause LGMD2C predate migration of the Romani gypsies of Europe out of India around 1100 AD (49). Due to complete endogamy, this genetically isolated community had an increased incidence of autosomal recessive LGMD2C. SGCG-targeted knockout mice displayed a variety of phenotypes, including dystrophic cardiomyopathy and defects in skeletal muscle, metabolism, homeostasis, growth, apoptosis, aging, and behavior (50–53). Mice lacking the sarcoglycan complex including SGCG in adipose and skeletal muscle were shown to be glucose intolerant and exhibited whole-body insulin resistance due to impaired insulin-stimulated glucose uptake in skeletal muscle (54).
The allelic distribution of the less common “A” (protective) allele of rs9552911 ranged from 0.06 to 0.15 in South Asians and differed between other South Asians (0.11) and Punjabi Sikhs (0.08) (see details in Supplementary Table 13). Further replication in large independent datasets of South Asians and Punjabi Sikhs would be needed to confirm the pattern of observed association. In view of the complex racial history complicated by a well-defined caste system, Indian populations display a great deal of genetic and cultural diversity (55). Studies suggest that genetic affinity among endogamous communities in India is inversely correlated with geographic distance between them (23). Therefore, it is possible that undetected causal variant(s) or multiple rare variants in LD with this marker arose on a haplotype tagged by rs9552911 in Punjabi Sikhs after divergence from other South and West Indian populations. This variation in the index SNP rs9552911 does not appear to be of recent origin, as suggested by comparative genomic analysis (Supplementary Fig. 5). Two important nuclear hormone receptors and transcription factors (peroxisome proliferator–activated receptor-γ [PPAR-γ] [1 and 2] and PPAR-α) bind to the promoter and intron 1 of the SGCG gene. Further, the maturity-onset diabetes of young 4 (MODY4) locus at chromosome 13q12, represented by insulin promoter factor 1 or PDX-1, lies next to the SGCG locus. Therefore, further in-depth examination by targeted resequencing in the extended region and functional studies may reveal putative causative variants in this extended region and provide insight into the physiological relevance of the observed association.
In summary, our study identified a novel locus associated with T2D in a population of Punjabi Sikh ancestry from Northern India. These findings not only provide new information on previously unknown regions associated with T2D but demonstrate a putative population-specific association that could lead to additional biological insights into T2D pathogenesis.
Supplementary Material
ACKNOWLEDGMENTS
This work was supported by National Institutes of Health/National Institute of Diabetes and Digestive and Kidney Diseases Grant R01-DK-082766 and a seed grant from the University of Oklahoma Health Sciences Center.
No potential conflicts of interest relevant to this article were reported. Manuscript preparation: R.S. and L.F.B. performed the analysis. R.S., D.S., and D.K.S. wrote the manuscript. Data collection and analysis in the participating studies: AIDHS/SDS: R.S., L.F.B., M.L.G., T.B., A.Bj., G.S.W., J.R.S., N.K.M., S.R., M.I.K., J.J.M., and D.K.S.; PROMIS and RACE study: D.S., R.Y., W.K.H., A.R., P.F., P.D., D.J.R., and J.D.; Singapore Indian Eye Study: X.S., D.P.-K.N., T.-Y.W., and E.S.T.; SLDS: N.H., M.I.M., P.K., and D.M.; CURES: V.R., M.C., S.L., and V.M.; DGP and UKADS: S.D.R., A.Ba., A.H.B., and M.A.K.; BioBank Japan and RIKEN T2D study: T.Y., K.H., Y.T., H.H., H.M., K.T., S.M., and T.K.; AGEN Consortium: Y.S.C.; LOLIPOP: J.C.C. and J.S.K. Association results among Europeans in DIAGRAM: M.I.M. and A.P.M. eQTL analyses in MuTHER: M.I.M. All authors read and provided critical comments on the manuscript. D.K.S. is the guarantor of this work and, as such, had full access to all the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis.
The authors thank the research participants for their contribution and support for making this study possible. The authors also thank Bansari Mehta and Braden Juengel (University of Oklahoma Health Sciences Center) and Jackie Lane (Harvard Medical School) for their superb technical support in this study. The authors thank the collaborating groups of all the contributing sites including Dr. Nadereh Jafari and staff at the Northwestern University Genomics Core (Evanston, IL) for performing genome-wide genotyping and Dr. Andrew Brooks and staff at Rutgers University (New Brunswick, NJ) for replication genotyping. Study-specific acknowledgments are provided in the Supplementary Data.
Footnotes
This article contains Supplementary Data online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db12-1077/-/DC1.
*Complete lists of the members of the DIAGRAM, MuTHER, and AGEN study groups can be found in the Supplementary Data online.
See accompanying commentary, p. 1369.
REFERENCES
- 1.Basnyat B, Rajapaksa LC. Cardiovascular and infectious diseases in South Asia: the double whammy. BMJ 2004;328:781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.International Diabetes Federation. Diabetes Atlas Belgium, International Diabetes Federation, 2011
- 3.Ghaffar A, Reddy KS, Singhi M. Burden of non-communicable diseases in South Asia. BMJ 2004;328:807–810 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Zimmet P. Type 2 (non-insulin-dependent) diabetes—an epidemiological overview. Diabetologia 1982;22:399–411 [DOI] [PubMed] [Google Scholar]
- 5.McKeigue PM, Pierpoint T, Ferrie JE, Marmot MG. Relationship of glucose intolerance and hyperinsulinaemia to body fat pattern in south Asians and Europeans. Diabetologia 1992;35:785–791 [DOI] [PubMed] [Google Scholar]
- 6.Oldroyd J, Banerjee M, Heald A, Cruickshank K. Diabetes and ethnic minorities. Postgrad Med J 2005;81:486–490 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Nakagami T, Qiao Q, Carstensen B, et al. DECODE-DECODA Study Group Age, body mass index and type 2 diabetes-associations modified by ethnicity. Diabetologia 2003;46:1063–1070 [DOI] [PubMed] [Google Scholar]
- 8.Zimmet PZ. Kelly West Lecture 1991. Challenges in diabetes epidemiology—from West to the rest. Diabetes Care 1992;15:232–252 [DOI] [PubMed] [Google Scholar]
- 9.McCarthy MI, Abecasis GR, Cardon LR, et al. Genome-wide association studies for complex traits: consensus, uncertainty and challenges. Nat Rev Genet 2008;9:356–369 [DOI] [PubMed] [Google Scholar]
- 10.Sanghera DK, Nath SK, Ortega L, et al. TCF7L2 polymorphisms are associated with type 2 diabetes in Khatri Sikhs from North India: genetic variation affects lipid levels. Ann Hum Genet 2008;72:499–509 [DOI] [PubMed] [Google Scholar]
- 11.Sanghera DK, Ortega L, Han S, et al. Impact of nine common type 2 diabetes risk polymorphisms in Asian Indian Sikhs: PPARG2 (Pro12Ala), IGF2BP2, TCF7L2 and FTO variants confer a significant risk. BMC Med Genet 2008;9:59. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Hu C, Zhang R, Wang C, et al. A genetic variant of G6PC2 is associated with type 2 diabetes and fasting plasma glucose level in the Chinese population. Diabetologia 2009;52:451–456 [DOI] [PubMed] [Google Scholar]
- 13.Hu C, Zhang R, Wang C, et al. PPARG, KCNJ11, CDKAL1, CDKN2A-CDKN2B, IDE-KIF11-HHEX, IGF2BP2 and SLC30A8 are associated with type 2 diabetes in a Chinese population. PLoS ONE 2009;4:e7643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Ng MC, Park KS, Oh B, et al. Implication of genetic variants near TCF7L2, SLC30A8, HHEX, CDKAL1, CDKN2A/B, IGF2BP2, and FTO in type 2 diabetes and obesity in 6,719 Asians. Diabetes 2008;57:2226–2233 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Sanghera DK, Been L, Ortega L, et al. Testing the association of novel meta-analysis-derived diabetes risk genes with type II diabetes and related metabolic traits in Asian Indian Sikhs. J Hum Genet 2009;54:162–168 [DOI] [PubMed] [Google Scholar]
- 16.Omori S, Tanaka Y, Horikoshi M, et al. Replication study for the association of new meta-analysis-derived risk loci with susceptibility to type 2 diabetes in 6,244 Japanese individuals. Diabetologia 2009;52:1554–1560 [DOI] [PubMed] [Google Scholar]
- 17.Schleinitz D, Tönjes A, Böttcher Y, et al. Lack of significant effects of the type 2 diabetes susceptibility loci JAZF1, CDC123/CAMK1D, NOTCH2, ADAMTS9, THADA, and TSPAN8/LGR5 on diabetes and quantitative metabolic traits. Horm Metab Res 2010;42:14–22 [DOI] [PubMed] [Google Scholar]
- 18.Rees SD, Hydrie MZ, Shera AS, et al. Replication of 13 genome-wide association (GWA)-validated risk variants for type 2 diabetes in Pakistani populations. Diabetologia 2011;54:1368–1374 [DOI] [PubMed] [Google Scholar]
- 19.Yamauchi T, Hara K, Maeda S, et al. A genome-wide association study in the Japanese population identifies susceptibility loci for type 2 diabetes at UBE2E2 and C2CD4A-C2CD4B. Nat Genet 2010;42:864–868 [DOI] [PubMed] [Google Scholar]
- 20.Unoki H, Takahashi A, Kawaguchi T, et al. SNPs in KCNQ1 are associated with susceptibility to type 2 diabetes in East Asian and European populations. Nat Genet 2008;40:1098–1102 [DOI] [PubMed] [Google Scholar]
- 21.Cho YS, Chen CH, Hu C, et al. DIAGRAM Consortium. MuTHER Consortium Meta-analysis of genome-wide association studies identifies eight new loci for type 2 diabetes in east Asians. Nat Genet 2012;44:67–72 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Kooner JS, Saleheen D, Sim X, et al. DIAGRAM. MuTHER Genome-wide association study in individuals of South Asian ancestry identifies six new type 2 diabetes susceptibility loci. Nat Genet 2011;43:984–989 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Kivisild T, Bamshad MJ, Kaldma K, et al. Deep common ancestry of Indian and Western-Eurasian mitochondrial DNA lineages. Curr Biol 1999;9:1331–1334 [DOI] [PubMed] [Google Scholar]
- 24.Mathew CG. New links to the pathogenesis of Crohn disease provided by genome-wide association scans. Nat Rev Genet 2008;9:9–14 [DOI] [PubMed] [Google Scholar]
- 25.Singh K, Bhalla V, Kaul L. People of India. Vol. X. Oxford, Oxford University Press, 1994, p. 1–3 [Google Scholar]
- 26.Sanghera DK, Bhatti JS, Bhatti GK, et al. The Khatri Sikh Diabetes Study (SDS): study design, methodology, sample collection, and initial results. Hum Biol 2006;78:43–63 [DOI] [PubMed] [Google Scholar]
- 27.Sanghera DK, Demirci FY, Been L, et al. PPARG and ADIPOQ gene polymorphisms increase type 2 diabetes mellitus risk in Asian Indian Sikhs: Pro12Ala still remains as the strongest predictor. Metabolism 2010;59:492–501 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Been LF, Hatfield JL, Shankar A, et al. A low frequency variant within the GWAS locus of MTNR1B affects fasting glucose concentrations: Genetic risk is modulated by obesity. Nutr Metab Cardiovasc Dis 2012; 22:944–951 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.American Diabetes Association Diagnosis and classification of diabetes mellitus. Diabetes Care 2004;27(Suppl. 1):S5–S10 [DOI] [PubMed] [Google Scholar]
- 30.McKeigue PM, Marmot MG, Syndercombe Court YD, Cottier DE, Rahman S, Riemersma RA. Diabetes, hyperinsulinaemia, and coronary risk factors in Bangladeshis in east London. Br Heart J 1988;60:390–396 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Lavanya R, Jeganathan VS, Zheng Y, et al. Methodology of the Singapore Indian Chinese Cohort (SICC) eye study: quantifying ethnic variations in the epidemiology of eye diseases in Asians. Ophthalmic Epidemiol 2009;16:325–336 [DOI] [PubMed] [Google Scholar]
- 32.Chidambaram M, Radha V, Mohan V. Replication of recently described type 2 diabetes gene variants in a South Indian population. Metabolism 2010;59:1760–1766 [DOI] [PubMed] [Google Scholar]
- 33.Rees SD, Islam M, Hydrie MZ, et al. An FTO variant is associated with type 2 diabetes in South Asian populations after accounting for body mass index and waist circumference. Diabet Med 2011;28:673–680 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Katulanda P, Constantine GR, Mahesh JG, et al. Prevalence and projections of diabetes and pre-diabetes in adults in Sri Lanka—Sri Lanka Diabetes, Cardiovascular Study (SLDCS). Diabet Med 2008;25:1062–1069 [DOI] [PubMed] [Google Scholar]
- 35.Gille H, Strahl T, Shaw PE. Activation of ternary complex factor Elk-1 by stress-activated protein kinases. Curr Biol 1995;5:1191–1200 [DOI] [PubMed] [Google Scholar]
- 36.Voight BF, Scott LJ, Steinthorsdottir V, et al. MAGIC investigators. GIANT Consortium Twelve type 2 diabetes susceptibility loci identified through large-scale association analysis. Nat Genet 2010;42:579–589 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Miller SA, Dykes DD, Polesky HF. A simple salting out procedure for extracting DNA from human nucleated cells. Nucleic Acids Res 1988;16:1215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Marchini J, Howie B, Myers S, McVean G, Donnelly P. A new multipoint method for genome-wide association studies by imputation of genotypes. Nat Genet 2007;39:906–913 [DOI] [PubMed] [Google Scholar]
- 39.Howie B, Marchini J, Stephens M. Genotype imputation with thousands of genomes. G3 (Bethesda) 2011;1:457–470 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Marchini J, Howie B. Genotype imputation for genome-wide association studies. Nat Rev Genet 2010;11:499–511 [DOI] [PubMed] [Google Scholar]
- 41.Nalls MA, Simon-Sanchez J, Gibbs JR, et al. Measures of autozygosity in decline: globalization, urbanization, and its implications for medical genetics. PLoS Genet 2009;5:e1000415. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Willer CJ, Li Y, Abecasis GR. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 2010;26:2190–2191 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Sladek R, Rocheleau G, Rung J, et al. A genome-wide association study identifies novel risk loci for type 2 diabetes. Nature 2007;445:881–885 [DOI] [PubMed] [Google Scholar]
- 44.Dupuis J, Langenberg C, Prokopenko I, et al. DIAGRAM Consortium. GIANT Consortium. Global BPgen Consortium. Anders Hamsten on behalf of Procardis Consortium. MAGIC investigators New genetic loci implicated in fasting glucose homeostasis and their impact on type 2 diabetes risk. Nat Genet 2010;42:105–116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Saxena R, Hivert MF, Langenberg C, et al. GIANT consortium. MAGIC investigators Genetic variation in GIPR influences the glucose and insulin responses to an oral glucose challenge. Nat Genet 2010;42:142–148 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Reich D, Thangaraj K, Patterson N, Price AL, Singh L. Reconstructing Indian population history. Nature 2009;461:489–494 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Avondo F, Roncaglia P, Crescenzio N, et al. Fibroblasts from patients with Diamond-Blackfan anaemia show abnormal expression of genes involved in protein synthesis, amino acid metabolism and cancer. BMC Genomics 2009;10:442. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Barresi R, Moore SA, Stolle CA, Mendell JR, Campbell KP. Expression of gamma-sarcoglycan in smooth muscle and its interaction with the smooth muscle sarcoglycan-sarcospan complex. J Biol Chem 2000;275:38554–38560 [DOI] [PubMed] [Google Scholar]
- 49.Piccolo F, Jeanpierre M, Leturcq F, et al. A founder mutation in the gamma-sarcoglycan gene of gypsies possibly predating their migration out of India. Hum Mol Genet 1996;5:2019–2022 [DOI] [PubMed] [Google Scholar]
- 50.Goldstein JA, Kelly SM, LoPresti PP, et al. SMAD signaling drives heart and muscle dysfunction in a Drosophila model of muscular dystrophy. Hum Mol Genet 2011;20:894–904 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Townsend D, Yasuda S, McNally E, Metzger JM. Distinct pathophysiological mechanisms of cardiomyopathy in hearts lacking dystrophin or the sarcoglycan complex. FASEB J 2011;25:3106–3114 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Wheeler MT, Korcarz CE, Collins KA, et al. Secondary coronary artery vasospasm promotes cardiomyopathy progression. Am J Pathol 2004;164:1063–1071 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Hack AA, Ly CT, Jiang F, et al. Gamma-sarcoglycan deficiency leads to muscle membrane defects and apoptosis independent of dystrophin. J Cell Biol 1998;142:1279–1287 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Groh S, Zong H, Goddeeris MM, et al. Sarcoglycan complex: implications for metabolic defects in muscular dystrophies. J Biol Chem 2009;284:19178–19182 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Bamshad M, Kivisild T, Watkins WS, et al. Genetic evidence on the origins of Indian caste populations. Genome Res 2001;11:994–1004 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.