

Abstract
There is increasing interest in discovering individualized treatment rules for patients who have heterogeneous responses to treatment. In particular, one aims to find an optimal individualized treatment rule which is a deterministic function of patient specific characteristics maximizing expected clinical outcome. In this paper, we first show that estimating such an optimal treatment rule is equivalent to a classification problem where each subject is weighted proportional to his or her clinical outcome. We then propose an outcome weighted learning approach based on the support vector machine framework. We show that the resulting estimator of the treatment rule is consistent. We further obtain a finite sample bound for the difference between the expected outcome using the estimated individualized treatment rule and that of the optimal treatment rule. The performance of the proposed approach is demonstrated via simulation studies and an analysis of chronic depression data.
Keywords: Dynamic Treatment Regime, Individualized Treatment Rule, Weighted Support Vector Machine, RKHS, Risk Bound, Bayes Classifier, Cross Validation
1. INTRODUCTION
In many different diseases, patients can show significant heterogeneity in response to treatments. In some cases, a drug that works for a majority of individuals may not work for a subset of patients with certain characteristics. For example, molecularly targeted cancer drugs are only effective for patients with tumors expressing targets (Grünwald & Hidalgo 2003; Buzdar 2009), and significant heterogeneity exists in responses among patients with different levels of psychiatric symptoms (Piper et al. 1995; Crits-Christoph et al. 1999). Thus significant improvements in public health could potentially result from judiciously treating individuals based on his or her prognostic or genomic data rather than a “one size fits all” approach. Treatments and clinical trials tailored for patients have enjoyed recent popularity in clinical practice and medical research, and, in some cases, have provided high quality recommendations accounting for individual heterogeneity (Sargent et al. 2005; Flume et al. 2007; Insel 2009). These proposals have focused on smaller, specific and well-defined subgroups, sought to provide guidance in clinical decision making based on individual differences, and have attempted to achieve better risk minimization and benefit maximization.
One statistical approach for developing individual-adaptive interventions is to classify subjects into different risk levels estimated by a parametric or semiparametric regression model using prognostic factors, and then to assign therapy according to risk level (Eagle et al. 2004; Marlowe et al. 2007; Cai et al. 2010). However, the parametric or semiparametric model assumptions may not be valid due to the complexity of the disease mechanism and individual heterogeneity. Moreover, these approaches require preknowledge in allocating the optimal treatment to each risk category. There is also a significant literature examining discovery and development of personalized treatment relying on predicting patient responses to optional regimens (Rosenwald et al. 2002; van’t Veer & Bernards 2008), where the optimal decision leads to the best predicted outcome. One recent paper by Qian & Murphy (2011) applies a two-step procedure which first estimates a conditional mean for the response and then estimates the rule maximizing this conditional mean. A rich linear model is used to sufficiently approximate the conditional mean, with the estimated rule derived via l1 penalized least squares (l1-PLS). The method includes variable selection to facilitate parsimony and ease of interpretation. The conditional mean approximation requires estimating a prediction model of the relationship between pretreatment prognostic variables, treatments and clinical outcome using a prediction model. Reduction in the mean response is related to the excess prediction error, through which an upper bound can be constructed for the mean reduction of the associated treatment rule. However, by inverting the model to find the optimal treatment rule, this method emphasizes prediction accuracy of the clinical response model instead of directly optimizing the decision rule.
In this paper, we proposed a new method for solving this problem which circumvents the need for conditional mean modeling followed by inversion by directly estimating the decision rule which maximizes clinical response. Specifically, we demonstrate that the optimal treatment rule can be estimated within a weighted classification framework, where the weights are determined from the clinical outcomes. We then alleviate the computational problem by substituting the 0–1 loss in the classification with a convex surrogate loss as is done with the support vector machine (SVM) via the hinge loss (Cortes & Vapnik 1995). The directness of this outcome weighted learning (OWL) approach enables us to better select targeted therapy while making full use of available information.
The remainder of the paper is organized as follows. In Section 2, we provide the mathematical concepts and framework for individualized treatment rules, and then formulate the problem as OWL. The proposed weighted SVM approach for constructing the optimal ITR is then developed in detail. In Section 3, consistency and risk bound results are established for the estimated rules. Faster convergence rates can be achieved with additional marginal assumptions on the data generating distribution. We present simulation studies to evaluate performance of the proposed method in Section 4. The method is then illustrated on the Nefazodone-CBASP data (Keller et al. 2000) in Section 5. In Section 6, we discuss future work. The proofs of theoretical results are given in the Appendix.
2. METHODOLOGY
2.1 Individualized Treatment Rule (ITR)
We assume the data are collected from a two-arm randomized trial. That is, treatment assignments, denoted by A ∈
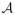 = {−1, 1}, are independent of any patient’s prognostic variables, which are denoted as a d-dimensional vector X = (X1, …, Xd)T ∈
= {−1, 1}, are independent of any patient’s prognostic variables, which are denoted as a d-dimensional vector X = (X1, …, Xd)T ∈
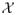 . We let R be the observed clinical outcome, also called the “reward,” and assume that R is bounded, with larger values of R being more desirable. Thus an individualized treatment rule (ITR) is a map from the space of prognostic variables,
, to the space of treatments,
. An optimal ITR is a rule that maximizes the expected reward if implemented.
. We let R be the observed clinical outcome, also called the “reward,” and assume that R is bounded, with larger values of R being more desirable. Thus an individualized treatment rule (ITR) is a map from the space of prognostic variables,
, to the space of treatments,
. An optimal ITR is a rule that maximizes the expected reward if implemented.
Mathematically, we can quantify the optimal ITR in terms of the relationship among (X, A, R). To see this, denote the distribution of (X, A, R) by P and expectation with respect to the P is denoted by E. For any given ITR
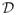 , we let
, we let
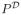 denote the distribution of (X, A, R) given that A =
(X), i.e., the treatments are chosen according to the rule
; correspondingly, the expectation with respect to
is denoted by
denote the distribution of (X, A, R) given that A =
(X), i.e., the treatments are chosen according to the rule
; correspondingly, the expectation with respect to
is denoted by
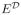 . Then under the assumption that P(A = a) > 0 for a = 1 and −1, it is clear that
is absolutely continuous with respect to P and d
/dP = I(a =
(x))/P(A = a), where I(·) is the indicator function. Thus, the expected reward under the ITR
is given as
. Then under the assumption that P(A = a) > 0 for a = 1 and −1, it is clear that
is absolutely continuous with respect to P and d
/dP = I(a =
(x))/P(A = a), where I(·) is the indicator function. Thus, the expected reward under the ITR
is given as
where π = P(A = 1). This expectation is called the value function associated with
and is denoted
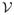 (
). Consequently, an optimal ITR,
(
). Consequently, an optimal ITR,
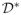 , is a rule that maximizes
(
), i.e.,
, is a rule that maximizes
(
), i.e.,
Note that
does not change if R is replaced by R + c for any constant c. Thus, without loss of generality, we assume that R is nonnegative in the following.
2.2 Outcome Weighted Learning (OWL) for Estimating Optimal ITR
Assume that we observe i.i.d data (Xi, Ai, Ri), i = 1, …, n from the two-arm randomized trial described above. Previous approaches to estimating optimal ITR first estimate E(R|X, A), using the observed data via parametric or semiparametric models, and then estimate the optimal decision rule by comparing the predicted value E(R|X, A = 1) versus E(R|X, A = −1) (Robins 2004; Moodie et al. 2009; Qian & Murphy 2011). As discussed before, these approaches indirectly estimate the optimal ITR, and are likely to produce a suboptimal ITR if the model for R given (X, A) is overfitted. As an alternative, we propose a nonparametric approach which directly maximizes the value function based on an outcome weighted learning method.
To illustrate our approach, we first notice that searching for the optimal ITR,
, which maximizes
(
), is equivalent to finding
that minimizes
The latter can be viewed as a weighted classification error, for which we want to classify A using X but we also weigh each misclassification event by R/(Aπ + (1 − A)/2). Hence, using the observed data, we approximate the weighted classification error by
and seek to minimize this expression to estimate
. Since
(x) can always be represented as sign(f(x)), for some decision function f, minimizing the above expression for
is equivalent to minimizing
| (2.1) |
to obtain the optimal f*, and then setting
(x) = sign(f*(x)).
The above minimization also has the following interpretation. That is, we intend to find a decision rule which assigns treatments to each subject only based on their prognostic information. For subjects observed to have a large reward, this rule is apt to recommend the same treatment assignments that the subject has actually received; however, for subjects with small rewards, the rule is more likely to give the opposite treatment assignment to what they received. In other words, if we stratify subjects into different strata based on the rewards, we will expect that the optimal ITR misclassifies less subjects in the high reward stratum as compared to the low reward stratum.
In the machine learning literature, (2.1) can be viewed as a weighted summation of 0–1 loss. It is well known that minimizing (2.1) is difficult due to the discontinuity and non-convexity of 0–1 loss. To alleviate this difficulty, one common approach is to find a convex surrogate loss for the 0–1 loss in (2.1) and develop a tractable estimation procedure (Zhang 2004; Lugosi & Vayatis 2004; Steinwart 2005). Among many choices of surrogate loss, one of the most popular is the hinge loss used in the context of the support vector machine (Cortes & Vapnik 1995), which we will adopt in this paper. Furthermore, we penalize the complexity of the decision function in order to avoid overfitting. In other words, instead of minimizing (2.1), we aim to minimize
| (2.2) |
where x+ = max(x, 0) and ||f|| is some norm for f. In this way, we cast the problem of estimating the optimal ITR into a weighted classification problem using support vector machine techniques.
2.3 Linear Decision Rule for Optimal ITR
Suppose that the decision function f(x) minimizing (2.2) is a linear function of x, that is, f(x) = 〈β, x〉 + β0, where 〈·,·〉 denotes the inner product in Euclidean space. Then the corresponding ITR will assign a subject with prognostic value X into treatment 1 if 〈β, X〉 + β0 > 0 and −1 otherwise.
In (2.2), we define ||f|| as the Euclidean norm of β. Following the usual SVM, we introduce a slack variable ξi for subject i to allow a small portion of wrong classification. Denote C > 0 as the classifier margin. Then minimizing (2.2) can be rewritten as
where πi = πI(Ai = 1)+(1 − π)I(Ai = −1) and s is a constant depending on λn. This is equivalent to
that is
where κ > 0 is a tuning parameter and Ri/πi is the weight for the ith point. We observe that the main difference compared to standard SVM is that we weigh each slack variable ξi with Ri/πi.
After introducing Lagrange multipliers, the Lagrange function becomes:
with αi ≥ 0, μi ≥ 0. Taking derivatives with respect to (β, β0) and ξi, we have and αi = κRi/πi − μi. Plugging these equations into the Lagrange function, we obtain the dual problem
subject to 0 ≤ αi ≤ κRi/πi, i = 1, …, n, and . Quadratic programming algorithms from many widely available software packages can be used to solve this dual problem. Finally, we obtain that
and β̂0 can be solved using the margin points (0 < α̂i, ξ̂i = 0) subject to the Karush-Kuhn-Tucker conditions (Page 421, Hastie, Tibshirani & Friedman 2009). The decision rule is given by sign{〈β̂, X〉 + β̂0}. Similar to the traditional SVM, the estimated decision rule is determined by the support vectors with α̂ > 0.
2.4 Nonlinear Decision Rule for Optimal ITR
The previous section targets a linear boundary of prognostic variables. This may not be practically useful since the dimension of the prognostic variables can be quite high and complicated relationships may be involved between the desired treatments and these variables. However, we can easily generalize the previous approach to obtain a nonlinear decision rule for obtaining the optimal ITR.
We let k :
×
→ ℝ, called a kernel function, be continuous, symmetric and positive semidefinite. Given a real-valued kernel function k, we can associate with it a reproducing kernel Hilbert space (RKHS)
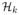 , which is the completion of the linear span of all functions {k(·, x), x ∈
}. The norm in
, denoted by ||·||k, is induced by the following inner product,
, which is the completion of the linear span of all functions {k(·, x), x ∈
}. The norm in
, denoted by ||·||k, is induced by the following inner product,
for and .
We note that our decision function f(x) is from
equipped with norm ||·||k. Thus since any function in
takes the form
, it can be shown that the optimal decision function is given by
where (α̂1, …, α̂n) solves
subject to 0 ≤ αi ≤ κRi/πi, i = 1, …, n, and . We note that if we choose k(x, y) = 〈x, y〉, then the obtained rule reduces to the previous linear rule.
3. THEORETICAL RESULTS
In this section, we establish consistency of the optimal ITR estimated using OWL. We further obtain a risk bound for the estimated ITR and show how the bound can be improved for certain specific, realistic situations.
3.1 Notation
For any ITR
(x) = sign(f(x)) associated with decision function f(x), we define
and the minimal risk (called Bayes risk in the learning literature) as
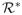 = inff {
= inff {
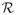 (f)|f:
→ ℝ}. Thus, for the optimal ITR
(x) = sign(f*(x)) (called the Bayes classifier in the learning literature),
=
(f*). In terms of the value function, we note that
(
) −
(
) =
(f) −
(f*).
(f)|f:
→ ℝ}. Thus, for the optimal ITR
(x) = sign(f*(x)) (called the Bayes classifier in the learning literature),
=
(f*). In terms of the value function, we note that
(
) −
(
) =
(f) −
(f*).
In the OWL approach, we substitute 0–1 loss I(A ≠ sign(f(X))) by a surrogate loss, φ(Af(X)), where φ(t) = (1 − t)+. Thus we define the φ-risk
and, similarly, the minimal φ–risk as .
Recall that the estimated optimal ITR is given by sign(f̂n(X)), where
| (3.1) |
3.2 Fisher Consistency
We establish Fisher consistency of the decision function based on surrogate loss φ(t). Specifically, the following result holds:
Proposition 3.1
For any measurable function f, if f̃ minimizes Rφ(f), then
(x) = sign(f̃(x)). Proof. First, we note
Next, for each x ∈
,
Therefore, f̃(x), which minimizes
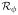 (f), should be positive if E(R|A = 1, X = x) > E(R|A = −1, X = x) and negative if E(R|A = 1, X = x) < E(R|A = −1, X = x). That is, f̃(x) has the same sign as
(x). The result holds.
(f), should be positive if E(R|A = 1, X = x) > E(R|A = −1, X = x) and negative if E(R|A = 1, X = x) < E(R|A = −1, X = x). That is, f̃(x) has the same sign as
(x). The result holds.
The proposition is analogous to results for SVM, for example, Lin (2002). This theorem justifies the validity of using φ(t) as the surrogate loss in OWL.
3.3 Excess Risk for
(f) and
(f)
The following result shows that for any decision function f, the excess risk of f under 0–1 loss is no larger than the excess risk of f under the hinge loss. Thus, the loss of the value function due to the ITR associated with f can be bounded by the excess risk under the hinge loss. The proof of the theorem can be found in the Appendix.
Theorem 3.2
For any measurable f:
→ ℝ and any probability distribution for (X, A, R),
| (3.2) |
The proof follows the general arguments of Bartlett, Jordan & McAuliffe (2006), in which they bound the risk associated with 0–1 loss in terms of the risk from surrogate loss, utilizing a convexified variational transform of the surrogate loss. In our proof, we extend this concept to our setting by establishing the validity of a weighted version of such a transformation.
3.4 Consistency and Risk Bounds
The purpose of this section is to establish the consistency of f̂n, and, moreover, to derive the convergence rate of
(f̂n) −
.
First, the following theorem shows that the risk due to f̂n does converge to
, and, equivalently, the value of f̂n converges to the optimal value function. Results on consistency of the SVM have been shown in current literature, for example, Zhang (2004). Here we apply the empirical process techniques to show that the proposed OWL estimator is consistent. The proof of the theorem is deferred to the Appendix.
Theorem 3.3
Assume that we choose a sequence λn > 0 such that λn → 0 and λnn → ∞. Then for all distributions P, we have that in probability,
where
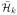 denotes the closure of
k. Thus, if f* belongs to the closure of lim supn→∞
, where
can potentially depend on n, we have
in probability. It then follows that limn→∞
(f̂n) =
in probability.
denotes the closure of
k. Thus, if f* belongs to the closure of lim supn→∞
, where
can potentially depend on n, we have
in probability. It then follows that limn→∞
(f̂n) =
in probability.
One special situation where f* belongs to the limit space of
is when we choose
to be an RKHS with Gaussian kernel and let the kernel bandwidth decrease to zero as n → ∞. This will be shown in Theorem 3.4 below.
We now wish to derive the convergence rate of
(f̂n) −
under certain regularity conditions on the distribution P. Specifically, we need the following “geometric noise” assumption for P (Steinwart & Scovel 2007): Let
| (3.3) |
then 2η(x) − 1 is the decision boundary for the optimal ITR. We further define
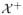 = {x ∈
: 2η(x) − 1 > 0}, and
= {x ∈
: 2η(x) − 1 > 0}, and
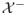 = {x ∈
: 2η(x) − 1 < 0}. A distance function to the boundary between
and
is Δ(x) = d̃(x,
) if x ∈
, Δ(x) = d̃(x,
) if x ∈
and Δ(x) = 0 otherwise, where d̃(x,
= {x ∈
: 2η(x) − 1 < 0}. A distance function to the boundary between
and
is Δ(x) = d̃(x,
) if x ∈
, Δ(x) = d̃(x,
) if x ∈
and Δ(x) = 0 otherwise, where d̃(x,
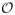 ) denotes the distance of x to a set
with respect to the Euclidean norm. Then the distribution P is said to have geometric noise exponent 0 < q < ∞, if there exists a constant C > 0 such that
) denotes the distance of x to a set
with respect to the Euclidean norm. Then the distribution P is said to have geometric noise exponent 0 < q < ∞, if there exists a constant C > 0 such that
| (3.4) |
In some sense, this geometric noise exponent describes the behavior of the distribution in a neighborhood of the decision boundary. It is affected by how fast the density of the distance Δ(X) decays along the boundary. For example, assume the boundary is linear, in which case Δ(x) = |2η(x)−1|. If for the density of Δ(X), defined as f(u), we have f(u) ~ up when u is close to 0, then we can show q = (p + 2)/d. Larger p corresponds to a faster decaying rate of the density, resulting in a larger q accordingly. Another example is distinctly separable data, i.e., when |2η(x) − 1| > δ > 0, for some constant δ, and η is continuous, q can be arbitrarily large.
In addition to this specific assumption for P, we also restrict the choice of RKHS to the space associated with Gaussian Radial Basis Function (RBF) kernels, i.e.,
where σn > 0 is a parameter varying with n. The tuning parameter σn is related to approximation properties of Gaussian RBF kernels. When σn goes large, only observations in the small neighborhood contribute to the prediction, in which case we obtain a non-linear decision boundary or even non-parametric decision rule. If σn does not diverge, then points further away can contribute to the prediction, resulting in a nearly linear boundary. One advantage of using the Gaussian kernel is that we can determine the complexity of
in terms of capacity bounds with respect to the empirical L2-norm, defined as
For any ε > 0, the covering number of functional class
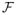 with respect to L2(Pn), N (
, ε, L2(Pn)), is the smallest number of L2(Pn) ε-balls needed to cover
, where an L2(Pn) ε-ball around a function g ∈
is the set {f ∈
: ||f − g||L2(Pn) < ε}.
with respect to L2(Pn), N (
, ε, L2(Pn)), is the smallest number of L2(Pn) ε-balls needed to cover
, where an L2(Pn) ε-ball around a function g ∈
is the set {f ∈
: ||f − g||L2(Pn) < ε}.
Specifically, according to Theorem 2.1 in Steinwart & Scovel (2007), we have that for any ε > 0,
| (3.5) |
where
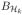 is the closed unit ball of
, and ν and δ are any numbers satisfying 0 < ν ≤ 2 and δ > 0.
is the closed unit ball of
, and ν and δ are any numbers satisfying 0 < ν ≤ 2 and δ > 0.
Under the above conditions, we obtain the following theorem:
Theorem 3.4
Let P be a distribution of (X, A, R) satisfying condition (3.4) with noise exponent q > 0. Then for any δ > 0, 0 < ν < 2, there exists a constant C (depending on ν, δ, d and π) such that for all τ ≥ 1 and ,
where Pr* denotes the outer probability for possibly nonmeasurable sets, and
The first two terms bound the stochastic error, which arises from the variability inherent in a finite sample size and which depends on the complexity of
in terms of covering numbers, while the third term controls the approximation error due to using
, which depends on both σn and the noise behavior in the underlying distribution. We expect better approximation properties when the RKHS is more complex, but, conversely, we also expect larger stochastic variability. Using the above expression, an optimal choice of λn that balances bias and variance is given by
so the optimal rate for the risk is
In particular, when data are well separated, q can be sufficiently large and we can let (δ, ν) be sufficiently small. Then the convergence rate almost achieves the rate n−1/2. However, if the marginal distribution of
has continuous density along the boundary, it can be calculated that q = 2/d. In this case, the convergence rate is approximately n−2/(d+2). Clearly, the speed of convergence is slower with larger dimension of the prognostic variable space.
To prove Theorem 3.4, we note that according to Theorem 3.2, it suffices to prove the result for the excess φ risk. We also use the fact that
We will then bound the first difference on the right-hand side using the empirical counterpart plus the stochastic variability due to the finite sample approximation. The latter can be controlled using large deviation results from empirical processes and some preliminary bound for ||f̂n||k. The second difference on the right-hand side will be bounded by using the approximation property of the RHKS and the geometric noise assumption of the underlying distribution P. The proof is modified based on Vert & Vert (2006) and Steinwart & Scovel (2007), where the weights in the loss function are taken into consideration. The details are provided in the Appendix.
3.5 Improved Rate with Data Completely Separated
In this section, we show that a faster convergence rate can be obtained if the data are completely separated. We assume
-
(A1)
∀x ∈
, |η(x) − 1/2| ≥ η0, where η(x) is defined in (3.3), and η is continuous. -
(A2)
∀x ∈
, min(η(x), 1 − η(x)) ≥ η1.
Assumption (A1) can be referred as a “low noise” condition equivalent to |E(R|A = 1, X) − E(R|A = −1, X)| ≥ η0. Thus, a jump of η (x) at the level of 1/2 requires a gap between the rewards gained from treatment 1 and −1 on the same patient. This assumption is an adaptation of the noise condition used in classical SVM to obtain fast learning rates and it is essentially equivalent to one of the conditions in Blanchard et al. (2008).
Theorem 3.5
Assume that (A1) and (A2) are satisfied. For any ν ∈ (0, 1) and q ∈ (0, ∞), let λn = O(n−1/(ν+1)) and . Then
We can let q go to ∞ and ν go to zero, and this theorem shows that the convergence rate for
(f̂n) −
(f*) is almost n−1, a much faster rate compared to what was given in Theorem 3.4. This result is similar to results for SVM described in Tsybakov (2004), Steinwart & Scovel (2007), and Blanchard et al. (2008).
To prove Theorem 3.5, we can rewrite the minimization problem in (3.1) as:
Thus the problem can be viewed in the model selection framework: a collection of models are balls in
, and for each model, we solve the penalized empirical φ-risk minimization to obtain an estimator f̂n. We can utilize a result for model selection, presented in Theorem 4.3 of Blanchard et al. (2008), to choose the model which yields the minimal penalized empirical φ-risk among all the models. We need to verify the conditions required for the theorem based on the weighted hinge loss and the condition on the covering number of functional class
with respect to L2(Pn), i.e., condition (3.5). Proof details are provided in the Appendix.
4. SIMULATION STUDY
We have conducted extensive simulations to assess the small-sample performance of the proposed method. In these simulations, we generate 50-dimensional vectors of prognostic variables X1, …, X50, consisting of independent U [−1, 1] variates. The treatment A is generated from {−1, 1} independently of X with P(A = 1) = 1/2. The response R is normally distributed with mean Q0 = 1 + 2X1 + X2 + 0.5X3 + T0(X, A) and standard deviation 1, where T0(X, A) reflects the interaction between treatment and prognostic variables and is chosen to vary according to the following four different scenarios:
T0(X, A) = 0.442(1 − X1 − X2)A.
.
.
.
The decision boundaries in the first three scenarios are determined by X1 and X2. Scenario 1 corresponds to a linear decision boundary in truth, where the shape of the boundary in Scenario 2 is a parabola. The third is a ring example, where the patients on the ring are assigned to one treatment, and another if inside or outside the ring. The decision boundary in the fourth example is fairly nonlinear in covariates, depending on covariates other than X1 and X2. For each scenario, we estimate the optimal ITR by applying OWL. We use the Gaussian kernel in the weighted SVM algorithm. There are two tuning parameters: λn, the parameter for penalty, and σn, the inverse bandwidth of the kernel. Since λn plays a role in controlling the severity of the penalty on the functions and σn determines the complexity of the function class utilized, σn should be chosen adaptively from the data simultaneously with λn. To illustrate this, Figure 1 shows the contours of the value function for the first scenario with different combinations of (λn, σn) when n = 30. We can see that λn interacts with σn, with larger λn generally coupled with smaller σn for equivalent value function levels. In our simulations, we apply a 5-fold cross validation procedure, in which we search over a pre-specified finite set of (λn, σn) to select the pair maximizing the average of the estimated values from the validation data. In case of tied values for parameter pair choices, we first choose the set of pairs with smallest λn and then select the one with largest σn.
Figure 1.

Contour Plots of Value Function for Example 1 with λn ∈ (0, 10) and σn ∈ (0, 10)
Additionally, comparison is made among the following four methods:
the proposed OWL using Gaussian kernel (OWL-Gaussian)
the proposed OWL using linear kernel (OWL-Linear)
the l1 penalized least squares method (l1-PLS) developed by Qian & Murphy (2011), which approximates E(R|X, A) using the basis function set (1, X, A, XA) and applies the LASSO method for variable selection, and
ordinary least squares method (OLS), which estimates the conditional mean response using the same basis function set as in 3 but without variable selection.
We consider the OWL with linear kernel (method 2) mainly to assess the impact of different kernels in the weighted SVM algorithm. In this case, there is only one tuning parameter, λn, which can be chosen to maximize the value function in a cross-validation procedure. The selection of the tuning parameters in the l1-PLS approach follows similarly. The last two approaches estimate the optimal ITR using the sign of the difference between the predicted E(R|X, A = 1) and the predicted E(R|X, A = −1). In the comparisons, the performances of the four methods are assessed by two criteria: the first criterion is to evaluate the value function using the estimated optimal ITR when applying to an independent and large validation data; the second criterion is to evaluate the misclassification rates of the estimated optimal ITR from the true optimal ITR using the validation data. Specifically, a validation set with 10000 observations is simulated to assess the performance of the approaches. The estimated value function using any ITR
is given by
(Murphy et al. 2001), where
denotes the empirical average using the validation data and P(A) is the probability of being assigned treatment A.
For each scenario, we vary sample sizes for training datasets from 30 to 100, 200, 400 and 800, and repeat the simulation 1,000 times. The simulation results are presented in Figures 2 and 3, where we report the mean square errors (MSE) of both value functions and misclassification rates. Simulations show there are no large differences in the performance if we replace the Gaussian kernel with the linear kernel in the OWL. However, there are examples presenting advantages of the Gaussian kernel, which suggests that under certain circumstances, it is useful to have a flexible nonparametric estimation procedure to identify the optimal ITR for the underlying nonparametric structures. As demonstrated in Figure 2 and Figure 3, the OWL with either Gaussian kernel or linear kernel has better performance, especially for small samples, than the other two methods, from the points of view of producing larger value functions, smaller misclassification rates, and lower variability of the value function estimates. Specifically, when the approximation models used in the l1-PLS and OLS are correct in the first scenario, the competing methods perform well with large sample size; however, the OWL still provides satisfactory results even if we use a Gaussian kernel. When the optimal ITR is nonlinear in X in the other scenarios, the OWL tends to give higher values and smaller misclassification rates. OLS generally fails unless the sample size is large enough since it encounters severe bias for small sample sizes. This is due to the fact that without variable selection for OLS, there is insufficient data to fit an accurate model with all 50 variables included. We also note that l1-PLS has comparatively larger MSE, resulted from high variance of the method, which may be explained by the conflicting goals of maximizing the value function and minimizing the prediction error (Qian & Murphy 2011). Note that a richer class of basis functions can be used for fitting the regression models. We have tried a polynomial basis and a wavelet basis to see if they could improve the performance. However, as a larger set of basis functions enters the model, we need to take into account higher dimensional interactions which do not necessarily yield better results. Also, we noted that higher variability is introduced with a richer basis for the approximation space (results not shown).
Figure 2.

MSE for Value Functions of Individualized Treatment Rules
Figure 3.

MSE for Misclassification Rates of Individualized Treatment Rules
Additional simulations are performed by generating binary outcomes from a logit model. It turns out the OWL procedures outperform a traditional logistic regression procedure (results not shown). Finally, using empirical results, we also verify that the cross validation procedure can indeed identify the optimal pairs (λn, σn) with the order desired by the theoretical results, i.e., . The numerical results indicate that log2 σn is linear in log2 λn and the ratio between the slopes is close to the reciprocal ratio between the dimensions of the covariate spaces.
5. DATA ANALYSIS
We apply the proposed method to analyze real data from the Nefazodone-CBASP clinical trial (Keller et al. 2000). The study randomized 681 outpatients with non-psychotic chronic major depressive disorder (MDD), in a 1:1:1 ratio to either Nafazodone, Cognitive Behavioral-Analysis System of Psychotherapy (CBASP) or the combination of Nefazodone and CBASP. The score on the 24-item Hamilton Rating Scale for Depression (HRSD) was the primary outcome, where higher scores indicate more severe depression. After excluding some patients with missing observations, we use a subset with 647 patients for analysis. Among them, 216, 220 and 211 patients were assigned to Nafazodone, CBASP and the combined treatment group respectively. Overall comparisons using t-tests show that the combination treatment had significant advantages over the other treatments with respect to HRSD scores obtained at end of the trial, while there are no significant differences between the nefazodone group and the psychotherapy group.
To estimate the optimal ITR, we perform pairwise comparisons between all combinations of two treatment arms, and, for each two-arm comparison, we apply the OWL approach. We only present the results from the Gaussian kernel, since the analysis shows a similarity with that of the linear kernel. Rewards used in the analyses are reversed HRSD scores and the prognostic variables X consist of 50 pretreatment variables. The results based on OWL are compared to results obtained using the l1-PLS and OLS methods which use (1, X, A, XA) in their regression models. For comparison between methods, we calculate the value function from a cross-validation type analysis. Specifically, the data is partitioned into 5 roughly equal-sized parts. We perform the analysis on 4 parts of the data, and obtain the estimated optimal ITRs using different methods. We then compute the estimated value functions using the remaining fifth part. The value functions calculated this way should better represent expected value functions for future subjects, as compared to calculating value functions based on the training data. The averages of the cross-validation value functions from the three methods are presented in Table 1.
Table 1.
Mean Depression Scores (the Smaller, the Better) from Cross Validation Procedure with Different Methods
| OLS | l1-PLS | OWL | |
|---|---|---|---|
|
| |||
| Nefazodone vs CBASP | 15.87 | 15.95 | 15.74 |
| Combination vs Nefazodone | 11.75 | 11.28 | 10.71 |
| Combination vs CBASP | 12.22 | 10.97 | 10.86 |
From the table, we observe that OLS produces smaller value functions (corresponding to larger HRSD in the table) than the other two methods, possibly because of the high dimensional prognostic variable space. OWL performs similarly to l1-PLS, but gives a 5% larger value function than l1-PLS when comparing the Combination arm to the Nefazodone arm. In fact, when comparing combination treatment with nefazodone only, OWL recommends the combination treatment to all the patients in the validation data in each round of the cross validation procedure; the OLS assigns the combination treatment to around 70% of the patients in each validation subset; while the l1-PLS recommends the combination to all the patients in three out of five validation sets, and 7% and 28% to the patients for the other two, indicating a very large variability. If we need to select treatment between combination and psychotherapy alone, the OWL approach recommends the combination treatment for all patients in the validation process. In contrast, the l1-PLS chooses psychotherapy for 10 out of 86 patients in one round of validation, and recommends the combination for all patients in the other rounds. The percentages of patients who are recommended the combination treatment range from 66% to 85% across the five validation data sets when applying OLS. When the two single treatments are studied, there are only negligible differences in the estimated value functions from the three methods and the selection results also indicate an insignificant difference between them. Thus OWL not only yields ITRs with the best clinical outcomes, but the ITRs also have lowest variability compared to the other methods.
6. DISCUSSION
The proposed OWL procedure appears to be more effective, across a broad range of possible forms of the interaction between prognostic variables and treatment, compared to previous methods. A two-stage procedure is likely to overfit the regression model, and thus cause troubles for value function approximation. The OWL provides a nonparametric approach which sidesteps the inversion of the predicted model required in other methods and benefits from directly maximizing the value function. The convergence rates for the OWL, aiming to identify the best ITR, nearly reach the optimal for the nonparametric SVM with the same type of assumptions on the separations. The rates, however, are not directly comparable to Qian & Murphy’s (2011), because we allow for complex multivariate interactions and formulate the problem in a nonparametric framework. The proposed estimator will lead to consistency and fast rate results, but not necessarily the most efficient approach. In some cases when we have knowledge of the specific parametric form, a likelihood based method may be more efficient and aid in the improvement of the estimation. Other possible surrogate loss functions, for example, the negative log-likelihood for logistic regression, can also be useful for finding the desired optimal individualized treatment rules.
Several improvements and extensions are important to consider. An important extension we are currently pursuing is to right-censored clinical outcomes. Another extension involves alleviating potential challenges arising from high dimensional prognostic variables. Recall that the proposed OWL is based on a weighted SVM which minimizes the weighted hinge loss function subject to an l2 penalty. If the dimension of the covariate space is sufficiently large, not all the variables would be essential for optimal ITR construction. By eliminating the unimportant variables from the rule, we could simplify interpretations and reduce health care costs by only requiring collection of a small number of significant prognostic variables. For standard SVM, the l1 penalty has been shown to be effective in selecting relevant variables via shrinking small coefficients to zero (Bradley & Mangasarian 1998; Zhu et al. 2003). It outperforms the l2 penalty when there are many noisy variables and sparse models are preferred. Other forms of penalty have been proposed such as the F∞ norm (Zou & Yuan 2008) and the adaptive lq penalty (Liu et al. 2007). In the future, we will examine use of these sparse penalties in the OWL method.
In this paper, we only considered binary options for treatment. When there are more than two treatment classes, although we could do a series of pairwise comparisons as done in Section 5 above, this approach may not be optimal in terms of identifying the best rule considering all treatments simultaneously. It would thus be worthwhile to extend the OWL approach to settings involving three or more treatments. The case of multicategory SVM has been studied recently (Lee, Lin & Wahba 2004; Wang & Shen 2006), and a similar generalization may be possible for finding ITRs involving three or more treatments. Another setting to consider is optimal ITR discovery for continuous treatments such as, for example, a continuous range of dose levels. In this situation, we could potentially utilize ideas underlying support vector regression (Vapnik 1995), where the goal is to find a function that has at most ε deviation from the response. Using a similar rationale as the proposed OWL, we could develop corresponding procedures for continuous treatment spaces through weighing each subject by his/her clinical outcome.
Obtaining inference for individualized treatment regimens is also important and challenging. Due to high heterogeneities among individuals, there may be large variations in the estimated treatment rules across different training sets. Laber & Murphy (2011) construct an adaptive confidence interval for the test error under the non-regular framework. Confidence intervals for value functions help us determine whether essential differences exist among different decision rules. Thus an important future research topic is to derive the limiting distribution of
(
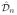 ) −
(
) and to derive corresponding sample size formulas to aid in design of personalized medicine clinical trials.
) −
(
) and to derive corresponding sample size formulas to aid in design of personalized medicine clinical trials.
In some complex diseases, dynamic treatment regimes may be more useful than the single-decision treatment rules studied in this paper. Dynamic treatment regimes are customized sequential decision rules for individual patients which can adapt over time to an evolving illness. Recently, this research area has been of great interest in long term management of chronic disease. See, for example, Murphy et al. (2001), Thall, Sung & Estey (2002), Murphy (2003), Robins (2004), Moodie, Richardson & Stephens (2007), Zhao, Zeng, Socinski & Kosorok (2011). Extension of the proposed OWL approach to the dynamic setting would be of great interest.
Acknowledgments
The first, second and fourth authors were partially funded by NCI Grant P01 CA142538.
APPENDIX A. PROOFS
Proof of Theorem 3.2
We consider the case where rewards are discrete. Arguments for the continuous rewards setting follow similarly. Let ηr(x) = p(A = 1|R = r, X = x) and qr(x) = rp(R = r|X = x). We can write
| (A.1) |
where c0(x) = Σr qr(x)[ηr(x)/π + (1 − ηr(x))/(1 − π)], and η(x), defined previously in (3.3), is equal to Σr qr(x) ηr(x)/πc0(x). Similarly,
We define C(η, α) = ηφ(α) + (1 − η)φ (−α). Then the optimal φ-risk satisfies
and
By a result in Bartlett et al. (2006) for a convexified transform of hinge loss, we have
| (A.2) |
Thus, according to (A.1) and (A.2), we have
The last inequality holds because we always have C(η(x), f(x)) ≥ infα ∈ ℝ C(η(x), α) on the set where sign(f(x)) = sign[c0(x)(η(x) − 1/2)] and C(η(x), f (x)) ≥ infα:α(2η (x)−1)≤0 C(η(x), α) when sign(f(x)) ≠ sign[c0(x)(η(x) − 1/2)].
Proof of Theorem 3.3
Define Lφ(f) = Rφ(Af)/(Aπ + (1 − A)/2). By the definition of f̂n, we have for any f ∈
,
where ℙn denotes the empirical measure of the observed data. Thus lim supn ℙn(Lφ(f̂n)) ≤ ℙ(Lφ(f)). It leads to lim supn ℙn(Lφ(f̂n)) ≤ inff
∈
ℙ(Lφ(f)). Theorem 3.3 holds if we can show ℙn(Lφ(f̂n))− ℙ(Lφ(f̂n)) → 0 in probability.
To this end, we first obtain a bound for
. Since
for any f ∈
, we can select f = 0 to obtain
Let M = 2E(R)/min{π, 1 − π} so that the
norm of
is bounded by
. Note that the class {
} is contained in a Donsker class. Thus,
is also P-Donsker because (1 − Af(X))+ is Lipschitz continuous with respect to f. Therefore,
Consequently, from nλn → ∞, ℙn(Lφ(f̂n)) − ℙ(Lφ(f̂n)) → 0 in probability.
Proof of Theorem 3.4
First, we have
| (A.3) |
We will bound each term on the right-hand-side separately in the following arguments.
For the second term on the right-hand-side of (A.3), we use Theorem 2.7 in Steinwart & Scovel (2007) to conclude that
| (A.4) |
when we set .
Now we proceed to obtain a bound for the first term on the right-hand-side of (A.3). To do this, we need the useful Theorem 5.6 of Steinwart & Scovel (2007) presented below: Theorem 5.6, Steinwart & Scovel (2007). Let
be a convex set of bounded measurable functions from Z to ℝ and let L :
× Z → [0, ∞) be a convex and line-continuous loss function. For a probability measure P on Z we define
Suppose that there are constants c ≥ 0, 0 < α < 1, δ ≥ 0 and B > 0 with EP g2 ≤ c(EP g)α + δ and ||g||∞ ≤ B for all g ∈
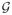 . Furthermore, assume that
is separable with respect to || · ||∞ and that there are constants a ≥ 1 and 0 < p < 2 with
. Furthermore, assume that
is separable with respect to || · ||∞ and that there are constants a ≥ 1 and 0 < p < 2 with
for all ε > 0. Then there exists a constant cp > 0 depending only on p such that for all n ≥ 1 and all τ ≥ 1 we have
where
In their paper,
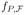 ∈
is a minimizer of
∈
is a minimizer of
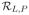 (f) = E(L(f, z)), and
(f) = E(L(f, z)), and
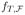 is similarly defined when T is an empirical measure. To use this theorem, we define
, Z, T,
,
and
according to our setting. It suffices to consider the subspace of
, denoted by
, as the ball of
of radius
. Specifically, we let
be
and Z be
. The loss function we consider here is
and
is the function class
is similarly defined when T is an empirical measure. To use this theorem, we define
, Z, T,
,
and
according to our setting. It suffices to consider the subspace of
, denoted by
, as the ball of
of radius
. Specifically, we let
be
and Z be
. The loss function we consider here is
and
is the function class
where
.
and
correspond to
and f̂n, respectively. Therefore, to apply this theorem, we will show that there are constants c ≥ 0 and B > 0, which can possibly depend on n, such that E(g2) ≤ cE(g) and ||g||∞ ≤ B, ∀g ∈
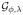 . Moreover, there are constants c̃ and 0 < ν < 2 with
. Moreover, there are constants c̃ and 0 < ν < 2 with
for all ε > 0.
Let CL denote sup{R/min(π, 1 − π)}, which is finite provided that R is bounded. Since the weighted hinge loss is Lipschitz continuous with respect to f, with Lipschitz constant CL, and since ||f||∞ ≤ ||f||k given that k(x, x) ≤ 1, for any g ∈
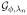 , we have
, we have
| (A.5) |
Therefore, we can set .
For any g ∈
, we have
Squaring both sides and taking expectations yields
| (A.6) |
On the other hand, from the convexity of Lφ, we have
Taking expectations on both sides leads to . Combining this with (A.6), we conclude that E(g2) ≤ cE (g), where
| (A.7) |
To estimate the bound for N(B−1
, ε, L2(Pn)), we first have
From the sub-additivity of the entropy,
| (A.8) |
Using the Lipschitz-continuity of the weighted hinge loss, we now have that if u, with corresponding f, , then ||u − u′||L2(Pn) ≤ B−1CL|| f − f′||L2(Pn), and therefore the first term on the right-hand-side of (A.8) satisfies
The last inequality follows because . It is trivial to see that for the second term on the right hand side of (A.8),
Thus,
Using (3.5) and a given choice for B, we obtain for all σn > 0, 0 < ν < 2, δ > 0, ε > 0,
where c2 depends on ν, δ and d.
Consequently, from Theorem 5.6 in Steinwart & Scovel (2007), there exists a constant cν > 0 depending only on ν such that for all n ≥ 1 and all τ ≥ 1, we have the bound for the first term
where
With B and c as defined in (A.5) and (A.7), i.e., and , we obtain
| (A.9) |
where C1 and C2 are constants depending on ν, δ, d, M and π. We complete the proof of Theorem 3.4 by plugging (A.4) and (A.9) into (A.3).
Proof of Theorem 3.5
We apply Theorem 4.3 in Blanchard et al. (2008) on the scaled loss function L̃φ(f) = Lφ(f)/CL to obtain the rates in Theorem 3.5. Without loss of generality, we can assume that the Bayes classifier f* ∈
, since we can always find g ∈
such that
, provided that
is dense in C(
). Let
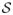 be a countable and dense subset of ℝ+, and let
(S) denote the ball of
of radius S. Then
(S), S ∈
is a countable collection of classes of functions. We can then use Theorem 4.3 in Blanchard et al. (2008) after we verify the following conditions (H1)–(H4):
be a countable and dense subset of ℝ+, and let
(S) denote the ball of
of radius S. Then
(S), S ∈
is a countable collection of classes of functions. We can then use Theorem 4.3 in Blanchard et al. (2008) after we verify the following conditions (H1)–(H4):
-
(H1)
∀S ∈
, ∀f ∈
(S), ||L̃φ(f)||∞ ≤ bS, bS = 1+ S; -
(H2)
∀f, f′ ∈
, Var(L̃φ(f) − L̃φ(f′)) ≤ d2(f, f′), d(f, f′) = ||f − f′||L2(P); -
(H3)
∀S ∈
, ∀f ∈
(S), d2(f, f*) ≤ CS
E(L̃φ(f) − L̃φ(f*)), CS = 2(S/η0 + 1/η1); -
(H4)LetWe have
ψS, S ∈
, is a sequence of sub-root functions, that is, ψS is non-negative, nondecreasing, and
is non-increasing for r > 0. Denote x* as the solution of the equation
- . If denotes the solution of ψS(r) = r/CS, then
Under these conditions, we define for n ∈ ℕ the following quantity:
Given
is associated with the Gaussian kernel, we can show that ξ(x) ⪯ ε1−ν for any 0 < ν < 2. Thus, γn ⪯ max(n−1/2ν, n−1/(ν+1)). By the choice of λn = O(n−1/(ν+1)) for any ν ∈ (0, 1), this satisfies
Therefore, according to Theorem 4.3 in Blanchard et al. (2008), the following bound holds with probability at least 1 − τ, where τ > 0 is a fixed real number:
The result does not change after we scale back to the original loss Lφ(f). We have shown that in the proof of Theorem 3.4. Thus
The remainder of the proof is to verify conditions (H1)–(H4).
For condition (H1), ||L̃φ(f)||∞ ≤ sup{R/(Aπ + (1 − A)/2)}(1 + S)/CL ≤ 1 + S, ||f||k ≤ S.
For condition (H2), let d(f, f′) = ||f − f′||L2(P). Lφ(f) is a Lipschitz function with respect to f with Lipschitz constant CL. Then L̃φ(f) − L̃φ(f′) ≤ |f(x) − f′(x)|. Hence (H2) is easily satisfied.
For condition (H3), the proof is similar to to Lemma 6.4 of Blanchard et al. (2008) with CS = 2(S/η1 + 1/η0), where η0 and η1 are as defined in Assumptions (A1) and (A2) of Section 3.5.
For condition (H4), we introduce the notation for Rademacher averages: let ε1,…, εn be n i.i.d Rademacher random variables, independent of (Xi, Ai, Ri), i = 1, …, n. For any measurable real-valued function f, the Rademacher average is defined as
. Also let
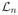 (
) be the empirical Rademacher complexity of function class
,
= supf∈
f.
(
) be the empirical Rademacher complexity of function class
,
= supf∈
f.
First we have from Lemma 6.7 of Blanchard et al. (2008) that for f′ ∈
,
Thus for the set {f ∈
: ||f||k ≤ S, d2(f, f′) ≤ r} and f′ ∈
(S),
the right-hand-side of which is equivalent to . Now we proceed to show that
by slightly modifying the procedure in obtaining Dudley’s Entropy Integral for Rademacher complexity of sets of functions. For j ≥ 0, let
and Tj be a rj-cover of
(2S) with respect to the L2(Pn)-norm. For each f ∈
(2S), we can find an f̃j ∈ Tj, such that ||f − f̃j||L2(Pn) ≤ rj. For any N, we express f as
, where f̃0 = 0. Note f̃0 = 0 is an r0-approximation of f. Hence,
Note that
We therefore have
For any ϑ > 0, we can choose N = sup{j : rj > 2ϑ}. Therefore, ϑ < rN+1 < 2ϑ, and rN < 4ϑ. We therefore conclude that
The function ψS is sub-root because log N (
, ε, L2(Pn)) is a decreasing function of ε.
To show the upperbound of r*, let . Then , CS/S ≥ 1. Assuming that c ≥ 2, we have . Since x−1 ξ(x) is a decreasing function, it follows that
Therefore, by selecting an appropriate constant c,
The desired result follows from the property of sub-root functions, which states that if ψ : [0, ∞) → [0, ∞) is a sub-root function, then the unique positive solution of ψ(r) = r, denoted by r*, exists, and for all r > 0, r ≥ ψ(r) if and only if r* ≤ r (Bartlett et al. 2005).
Contributor Information
Yingqi Zhao, Email: yqzhao@live.unc.edu, Department of Biostatistics, University of North Carolina at Chapel Hill, NC 27599.
Donglin Zeng, Email: dzeng@email.unc.edu, Department of Biostatistics, University of North Carolina at Chapel Hill, NC 27599.
A. John Rush, Email: john.rush@duke-nus.edu.sg, Office of Clinical Sciences, Duke-National University of Singapore Graduate Medical School, Singapore 169857.
Michael R. Kosorok, Email: kosorok@unc.edu, Department of Biostatistics, and Professor, Department of Statistics and Operations Research, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599.
References
- Bartlett PL, Bousquet O, Mendelson S. Local Rademacher Complexities. The Annals of Statistics. 2005;33(4):1497–1537. [Google Scholar]
- Bartlett PL, Jordan MI, McAuliffe JD. Convexity, Classification, and Risk Bounds. J of American Statistical Association. 2006;101(473):138–156. [Google Scholar]
- Blanchard G, Bousquet O, Massart P. Statistical Performance of Support Vector Machines. Annals of Statistics. 2008;36:489–531. [Google Scholar]
- Bradley PS, Mangasarian OL. Feature Selection via Concave Minimization and Support Vector Machines. Proc. 15th International Conf. on Machine Learning; San Francisco, CA, USA: Morgan Kaufmann Publishers Inc; 1998. [Google Scholar]
- Buzdar AU. Role of Biologic Therapy and Chemotherapy in Hormone Receptor and HER2-Positive Breast Cancer. Annals of Oncology. 2009;20:993–999. doi: 10.1093/annonc/mdn739. [DOI] [PubMed] [Google Scholar]
- Cai T, Tian L, Uno H, Solomon SD. Calibrating parametric subject-specific risk estimation. Biometrika. 2010;97(2):389–404. doi: 10.1093/biomet/asq012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cortes C, Vapnik V. Support-Vector Networks. Machine Learning. 1995:273–297. [Google Scholar]
- Crits-Christoph P, Siqueland L, Blaine J, Frank A, Luborsky L, Onken LS, Muenz LR, Thase ME, Weiss RD, Gastfriend DR, Woody GE, Barber JP, Butler SF, Daley D, Salloum I, Bishop S, Najavits LM, Lis J, Mercer D, Griffin ML, Moras K, Beck AT. Psychosocial Treatments for Cocaine Dependence. Arch Gen Psychiatry. 1999;56:493–502. doi: 10.1001/archpsyc.56.6.493. [DOI] [PubMed] [Google Scholar]
- Eagle KA, Lim MJ, Dabbous OH, Pieper KS, Goldberg RJ, de Werf FV, Goodman SG, Granger CB, Steg PG, Joel M, Gore M, Budaj A, Avezum A, Flather MD, Fox KAA GRACE Investigators. A Validated Prediction Model for All Forms of Acute Coronary Syndrome: Estimating the Risk of 6-Month Postdischarge Death in an International Registry. J Am Med Assoc. 2004;291:2727–33. doi: 10.1001/jama.291.22.2727. [DOI] [PubMed] [Google Scholar]
- Flume PA, OSullivan BP, Goss CH, Peter J, Mogayzel J, Willey-Courand DB, Bujan J, Finder J, Lester M, Quittell L, Rosenblatt R, Vender RL, Hazle L, Sabadosa K, Marshall B. Cystic Fibrosis Pulmonary Guidelines: Chronic Medications for Maintenance of Lung Health. Am J Respir Crit Care Med. 2007;176(1):957–969. doi: 10.1164/rccm.200705-664OC. [DOI] [PubMed] [Google Scholar]
- Grünwald V, Hidalgo M. Developing Inhibitors of the Epidermal Growth Factor Receptor for Cancer Treatment. J Natl Cancer Inst. 2003;95(12):851–867. doi: 10.1093/jnci/95.12.851. [DOI] [PubMed] [Google Scholar]
- Hastie T, Tibshirani R, Friedman JH. The Elements of Statistical Learning. 2. New York: Springer-Verlag New York, Inc; 2009. [Google Scholar]
- Insel TR. Translating scientific opportunity into public health impact: a strategic plan for research on mental illness. Archives of General Psychiatry. 2009;66(2):128–133. doi: 10.1001/archgenpsychiatry.2008.540. [DOI] [PubMed] [Google Scholar]
- Keller MB, Mccullough JP, Klein DN, Arnow B, Dunner DL, Gelenberg AJ, Markowitz JC, Nemeroff CB, Russell JM, Thase ME, Trivedi MH, Zajecka J. A Comparison of Nefazodone, The Cognitive Behavioral-Analysis System of Psychotherapy, and Their Combination for the Treatment of Chronic Depression. The New England Journal of Medicine. 2000;342(20):1462–70. doi: 10.1056/NEJM200005183422001. [DOI] [PubMed] [Google Scholar]
- Laber EB, Murphy SA. Adaptive Confidence Intervals for the Test Error in Classification. To apper in Journal of the American Statistical Association. 2011 doi: 10.1198/jasa.2010.tm10053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee Y, Lin Y, Wahba G. Multicategory Support Vector Machines, theory, and application to the classification of microarray data and satellite radiance data. Journal of the American Statistical Association. 2004;99:67–81. [Google Scholar]
- Lin Y. Support vector machines and the Bayes rule in classification. Data Mining and Knowledge Discovery. 2002;6:259–275. [Google Scholar]
- Liu Y, Helen Zhang H, Park C, Ahn J. Support vector machines with adaptive Lq penalty. Comput Stat Data Anal. 2007;51(12):6380–94. [Google Scholar]
- Lugosi G, Vayatis N. On the Bayes-risk consistency of regularized boosting methods. The Annals of Statistics. 2004;32:30–55. [Google Scholar]
- Marlowe DB, Festinger DS, Dugosh KL, Lee PA, Benasutti KM. Adapting Judicial Supervision to the Risk Level of Drug Offenders: Discharge and 6-month Outcomes from a Prospective Matching Study. Drug and Alcohol Dependence. 2007;88(Suppl 2 2):S4–S13. doi: 10.1016/j.drugalcdep.2006.10.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moodie EEM, Platt RW, Kramer MS. Estimating Response-Maximized Decision Rules With Applications to Breastfeeding. Journal of the American Statistical Association. 2009;104(485):155–165. [Google Scholar]
- Moodie EEM, Richardson TS, Stephens DA. Demystifying Optimal Dynamic Treatment Regimes. Biometrics. 2007;63(2):447–455. doi: 10.1111/j.1541-0420.2006.00686.x. [DOI] [PubMed] [Google Scholar]
- Murphy SA. Optimal Dynamic Treatment Regimes. Journal of the Royal Statistical Society, Series B. 2003;65:331–366. [Google Scholar]
- Murphy SA, van der Laan MJ, Robins JM, CPPRG Marginal Mean Models for Dynamic Regimes. Journal of the American Statistical Association. 2001;96:1410–23. doi: 10.1198/016214501753382327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piper WE, Boroto DR, Joyce AS, McCallum M, Azim HFA. Pattern of alliance and outcome in short-term individual psychotherapy. Psychotherapy. 1995;32:639–647. [Google Scholar]
- Qian M, Murphy SA. Performance Guarantees for Individualized Treatment Rules. To appear in the Annals of Statistics. 2011 doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins JM. Optimal Structural Nested Models for Optimal Sequential Decisions. Proceedings of the Second Seattle Symposium on Biostatistics; Springer; 2004. pp. 189–326. [Google Scholar]
- Rosenwald A, Wright G, Chan WC, Connors JM, Campo E, et al. The use of molecular profiling to predict survival after chemotherapy for diffuse large B-cell lymphoma. New England J of Medicine. 2002:1937–47. doi: 10.1056/NEJMoa012914. [DOI] [PubMed] [Google Scholar]
- Sargent DJ, Conley BA, Allegra C, Collette L. Clinical Trial Designs for Predictive Marker Validation in Cancer Treatment Trials. Journal of Clinical Oncology. 2005;32:2020–27. doi: 10.1200/JCO.2005.01.112. [DOI] [PubMed] [Google Scholar]
- Steinwart I. Consistency of Support Vector Machines and Other Regularized Kernel Classifiers. IEEE Transactions on Information Theory. 2005;51:128–142. [Google Scholar]
- Steinwart I, Scovel C. Fast Rates for Support Vector Machines using Gaussian Kernels. The Annals of Statistics. 2007;35:575–607. [Google Scholar]
- Thall PF, Sung H-G, Estey EH. Selecting Therapeutic Strategies Based on Efficacy and Death in Multicourse Clinical Trials. Journal of the American Statistical Association. 2002;97:29–39. [Google Scholar]
- Tsybakov AB. Optimal Aggregation of Classifiers in Statistical Learning. Annals of Statistics. 2004;32:135–166. [Google Scholar]
- van’t Veer LJ, Bernards R. Enabling Personalized Cancer Medicine through Analysis of Gene-Expression Patterns. Nature. 2008;452:564–570. doi: 10.1038/nature06915. [DOI] [PubMed] [Google Scholar]
- Vapnik VN. The nature of statistical learning theory. New York: Springer-Verlag New York, Inc; 1995. [Google Scholar]
- Vert R, Vert J-P. Consistency and Convergence Rates of One-Class SVMs and Related Algorithms. Journal of Machine Learning Research. 2006;7:817–854. [Google Scholar]
- Wang L, Shen X. Multi-category Support vector machines, feature selection, and solution path. Statistica Sinica. Statistica Sinica. 2006;16:617–633. [Google Scholar]
- Zhang T. Statistical behavior and consistency of classification methods based on convex risk minimization. Annals of Statistics. 2004;32(1):56–85. [Google Scholar]
- Zhao Y, Zeng D, Socinski MA, Kosorok MR. Reinforcement Learning Strategies for Clinical Trials in Nonsmall Cell Lung Cancer. Biometrics. 2011;67:1422–1433. doi: 10.1111/j.1541-0420.2011.01572.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu J, Rosset S, Hastie T, Tibshirani R. 1-norm Support Vector Machines. Neural Information Processing Systems. 2003:16. [Google Scholar]
- Zou H, Yuan M. The F∞-norm Support Vector Machine. Statistica Sinica. 2008;18:379–398. [Google Scholar]