

Abstract
Microarray experiments are capable of determining the relative expression of tens of thousands of genes simultaneously, thus resulting in very large databases. The analysis of these databases and the extraction of biologically relevant knowledge from them are challenging tasks. The identification of potential cancer biomarker genes is one of the most important aims for microarray analysis and, as such, has been widely targeted in the literature. However, identifying a set of these genes consistently across different experiments, researches, microarray platforms, or cancer types is still an elusive endeavor. Besides the inherent difficulty of the large and nonconstant variability in these experiments and the incommensurability between different microarray technologies, there is the issue of the users having to adjust a series of parameters that significantly affect the outcome of the analyses and that do not have a biological or medical meaning. In this study, the identification of potential cancer biomarkers from microarray data is casted as a multiple criteria optimization (MCO) problem. The efficient solutions to this problem, found here through data envelopment analysis (DEA), are associated to genes that are proposed as potential cancer biomarkers. The method does not require any parameter adjustment by the user, and thus fosters repeatability. The approach also allows the analysis of different microarray experiments, microarray platforms, and cancer types simultaneously. The results include the analysis of three publicly available microarray databases related to cervix cancer. This study points to the feasibility of modeling the selection of potential cancer biomarkers from microarray data as an MCO problem and solve it using DEA. Using MCO entails a new optic to the identification of potential cancer biomarkers as it does not require the definition of a threshold value to establish significance for a particular gene and the selection of a normalization procedure to compare different experiments is no longer necessary.
Keywords: Cancer biomarkers, cervical cancer, data envelopment analysis, microarray data analysis, multiple criteria optimization
Introduction
Microarrays are frequently used to simultaneously analyze the expression level of tens of thousands of genes. Analysis of microarray data has become a useful tool for the study of different illnesses including all types of cancer 1–3. Microarray analyses are carried out, essentially, with the objective to detect variation patterns of genetic expression. In cancer research, these patterns can be used for various purposes such as eliciting a diagnosis or prognosis, characterizing a particular illness stage, or detecting and proposing the role of specific genes in the development of cancer. In this last classification, lies the detection of cancer biomarkers. Because biomarker genes detected using only microarray data are not experimentally validated yet, at that point they are deemed potential biomarkers.
Microarray experiments generate large amounts of information whose analysis and interpretation are nontrivial 4. Traditional statistical approaches are challenged by large variances, incommensurability, nonnormality, and the small number or replicates frequently present in these experiments. These challenges hamper finding consistent analysis results 5, thereby leading to a large number of potential biomarkers to be investigated, the research of which could prove lengthy and very expensive.
An example that illustrates the difficulties of obtaining cancer biomarkers consistently is the 70-gene signature for identification of patients with a high probability for breast cancer relapse after its eradication. The original results are reported previously 6. A 76-gene signature is reported in Wang et al. 7 with the same purpose; however, there are only three genes that intersect with the original signature. This issue has been also reported for the specific case of breast cancer by Ein-Dor et al. 8.
It is also notorious that truly integrated work across disciplines is not frequent in most microarray analysis works. Biology and Medicine experts are usually left with the burden of using coded analysis tools with a series of parameters – of statistical, computational, or mathematical nature – that significantly affect the outcome of the software packages 4. This leads to issues in results' reproducibility and comparability between studies.
These challenges motivate the search for microarray analysis techniques from which consistent results can be achieved across several experiments and researches, particularly for the identification of potential cancer biomarkers. In this study, a multiple criteria optimization (MCO) approach is proposed for the identification of potential cancer biomarkers from microarray data. An MCO problem aims to find the best compromises between two or more conflicting criteria 9. The best compromises are located in the so-called Pareto-efficient frontier. It is proposed that the genes in the efficient frontier of the MCO problem, built with performance measures relating to the significant change in gene expression, are potential cancer biomarkers.
The potential of an MCO analysis for the identification of relevant genes has been recognized before 10 through the use of ranking methods. Here, the proposed MCO problem is solved through the use of data envelopment analysis (DEA) 11. DEA has been used to find the convex efficient frontier of MCO problems 12. DEA is a very computationally convenient technique that is capable to deal with multiple and incommensurable performance measures. A clear applicability to meta-analysis follows from these characteristics. Using MCO provides a new optic to the identification of potential cancer biomarkers as it does not require the definition of a threshold value to establish significance for a particular gene and the selection of a normalization procedure to compare different experiments is no longer necessary.
The proposed method is tested here through its initial application to a microarray database related to cervix cancer 13 and the results are successfully validated through the information available in the literature for the selected genes. Furthermore, two additional studies involving two independent experiments using the same microarray 14,15 platform further corroborate the performance of the proposed method. Finally, the novelty of this approach is contrasted with the use of a single criterion – or performance measure – to find potential biomarkers.
Methods
Potential biomarkers through MCO
In microarray experiments, it is critical to be able to quantify changes in genetic expression. A series of measurements have been proposed in the literature that include variations of pure magnitude of relative change of expression versus a control 16 as well as P-values obtained from various statistical tests 17. A P-value, in statistical comparison procedures, can be understood as the probability associated with finding – by pure chance – a difference in the populations being compared that is at least as large as the observed difference of the samples involved. Lower P-values indicate larger differences and therefore show stronger evidence favoring statistical significance. Due to their interpretation capabilities, P-values have been a favored performance measure in microarray experiments in recent years. Obtaining a P-value for a particular gene is illustrated in Figure 1.
Figure 1.
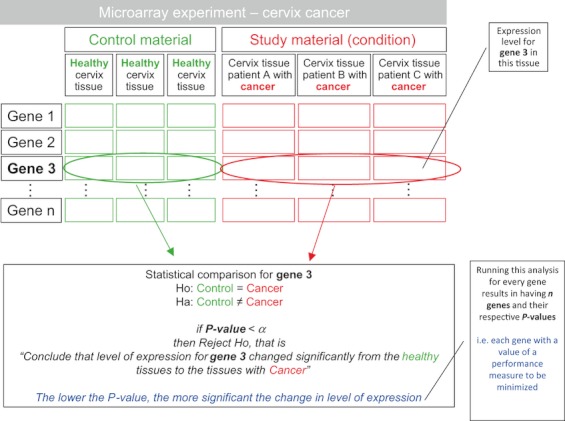
Schematic example of how to obtain a P-value. This is a schematic example of how to obtain one P-value for a particular gene in a microarray experiment with l = 3 healthy tissues as controls and m = 3 tissues with cancer. If statistical comparison is carried out for each gene, then at the end one has n genes each one with an associated P-value.
A P-value, when obtained for a particular gene in a microarray experiment, can be thought of as a criterion to be minimized since the smaller the P-value the more important the change in expression of the gene under consideration. Now, if more than one P-value is available for a particular gene, then the task at hand is one of multiple criteria minimization. An illustrative example with a series of genes is shown in Figure 2. In this figure, each gene is represented by a pair of P-values. Because low P-values are attractive, the ideal gene would be found in the southwest corner of the graph. When no single gene is best in all criteria under consideration, a conflict exists.
Figure 2.
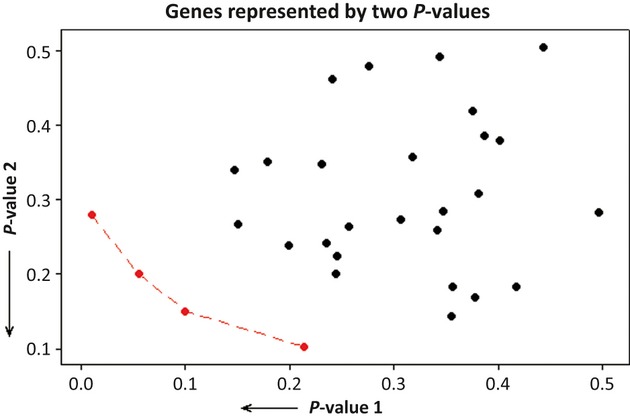
Pareto-efficient frontier. The existence of conflict causes that different genes be attractive when lying in the southwest envelope of the gene set. In general, in multiple criteria optimization (MCO), that envelope is called a Pareto-efficient frontier and it is conformed by Pareto-efficient solutions.
The key idea in this study is that the potential biomarker genes can be identified as efficient solutions of the MCO problem that results from representing each gene under analysis through a series of associated P-values. In order to develop the idea, two issues must be addressed (i) how can one obtain several P-values for one gene? and (ii) which method can be used to solve the MCO problem.
Obtaining multiple P-values for a particular gene
Consider the results of a microarray experiment laid out on a table where the first column contains the names of the n genes under study; the columns to the right contain the measurements for l healthy tissues followed by m cancer tissues. Thus, for each gene, there are l replicated measurements of relative expression for state 1 (healthy) and m replicates for state 2 (cancer).
A statistical comparison procedure can be used to obtain a P-value when contrasting parameters from the two states – cancer and healthy – for a particular gene. A common interest is to compare the population centers, which are estimated either through sample means or sample medians. For MCO purposes, however, more than one P-value per gene is necessary. Two cases can be distinguished here: (c1) having a single microarray experiment to study one type of cancer and (c2) having several microarray experiments to study one type of cancer. In c1, if a leave-one-out strategy is applied to the tissues pertaining to one state, then it is possible to obtain several P-values. In c2, an additional P-value can be obtained for the genes that are common to both experiments. This study focuses on c1 to introduce the proposed analysis strategy, leaving c2 for future publication.
For c1, the leave-one-tissue-out strategy implies extracting a particular tissue associated with one state (“leaving one column out”). By removing a vector (column), a replicate is deleted from the set, thereby forcing a P-value that is different from the original one. Thus, two different P-values are effectively created. The selection of the tissue to be removed to create a distinct matrix is performed considering the variance of expression on each tissue (stored in each column). Then, a first matrix is built leaving out the tissues (columns) with the highest variance for each state and the second matrix by leaving out the tissues with the lowest variance for each state. Through this strategy, the resulting matrices show extreme cases in terms of data variance. Any other combination of tissues to leave out would have statistical differences lying between these two “extreme” cases.
Thus, two extreme cases span all the possible cases in terms of variance for the leave-one-out cases. This fact can be used to avoid unnecessary computational effort and, by using just two dimensions, it is possible to illustrate the problem graphically.
c1 is important because the vast majority of published microarray experiments are instances of this type, and – as explained previously – it is the subject of study in this manuscript. c2 can be built from several c1 instances, however, it is envisioned that this case becomes an archetype for a study designed to keep the same genes throughout all microarrays experiments involved. c2 will also represent the case where meta-analysis must be addressed and will be approached in a future publication.
Solving the MCO problem
The decision that must result from the solution of the MCO problem can be stated as “a selection of those genes that show the highest possible expression change in all experimental instances when considered simultaneously.” Due to the large variability encountered in microarray experiments, this is a nontrivial decision that will lead to a set of genes that will have very low P-values in certain instances, although not necessarily in all of them, that is, the genes that are Pareto-efficient as illustrated in Figure 2.
DEA is a technique that has been shown capable to identify the efficient solutions located in the convex hull of an MCO problem 11. In its most popular form, DEA finds the Pareto-efficient solutions through the sequential solution of a series of linear optimization models. One of the most popular and effective DEA formulations is the Banker–Charnes–Cooper model (BCC), which is shown next in its two formulations (input oriented and output oriented):
 |
where μ and ν are vectors containing nonnegative multipliers and 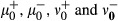 are scalar numbers to be determined optimally,
are scalar numbers to be determined optimally, 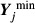 and
and 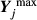 are vectors containing the values of performance measures to be minimized and maximized, respectively, for the jth solution. The subindex 0 is used to denote the solution currently under analysis, and ε is a small constant usually set to a value of 1 × 10−6. The results of solving these two linear optimization problems, for the n genes in a set, are a series of hyperplanes that forms a convex envelope around this set, as depicted in Figure 2.
are vectors containing the values of performance measures to be minimized and maximized, respectively, for the jth solution. The subindex 0 is used to denote the solution currently under analysis, and ε is a small constant usually set to a value of 1 × 10−6. The results of solving these two linear optimization problems, for the n genes in a set, are a series of hyperplanes that forms a convex envelope around this set, as depicted in Figure 2.
Because of the nature of DEA, the model needs at least one performance measure to be maximized. For the case under consideration, a transformation of at least one set of P-values is required. The following transformation is applied to switch from minimization to maximization in a set of n P-values:
| (1) |
where the transformation is carried out for the ith gene. Maximizing the transformed performance measure is fully equivalent to minimizing the original P-value.
DEA has several advantages including (i) computational efficiency owing to its linear optimization structure; (ii) objectivity and consistency of results, which follows from not requiring the adjustment of parameters or assigning weights to the different performance measures; and (iii) capability of analyzing several microarray experiments with incommensurate units. Furthermore, linear optimization is – by far – the most coded type of optimization. Algorithms for linear programing (as this type of optimization is known as) are available in modules from the very common MS Excel package to the mathematically oriented software Matlab 18 and to the very specialized solvers like Lingo 19. There are also DEA solvers like DEA Solver Pro 20 that make adopting the proposed approach even easier. So, in order to use the approach proposed here, all the user needs is a list of genes, with one P-value obtained as usual, and a second P-value transformed using equation (1), and an optimization solver capable to deal with linear programing to use the DEA formulations outlined above.
One limitation of DEA is that of depending on a series of local linear approximations, as shown in Figure 2. Every time that a hyperplane is superimposed over the set under analysis, there are genes lying in the nonconvex part of the set frontier that escape detection. These genes could be potential biomarkers, however.
In order to circumvent this limitation, it is proposed that DEA be applied successively 10 times, each time removing the genes found in a particular iteration from the set for subsequent analyses. This strategy results in 10 frontiers, as seen in Figure 3.
Figure 3.
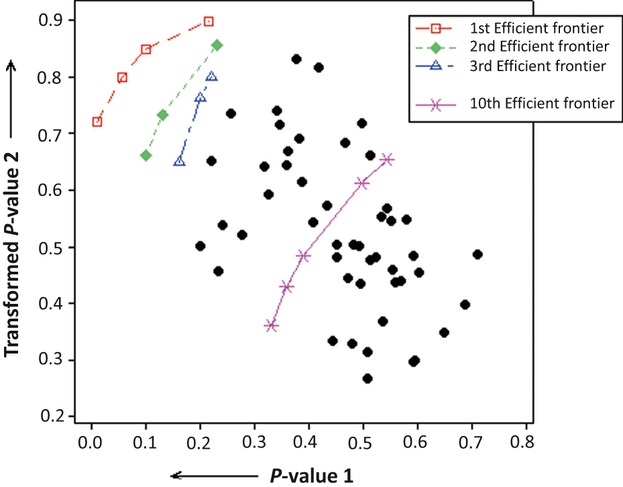
The two performance measures for each gene. This figure schematically shows a case with genes characterized by two performance measures: an untransformed P-value and a transformed one with equation (1). Referring to this figure, and following the proposed method, at this point it is recommended to identify the first 10 efficient frontiers. This can be easily done by identifying the genes in the first efficient frontier through data envelopment analysis (DEA), then removing them from the set and continuing with a second DEA iteration. This is repeated until the tenth frontier is identified. A method to determine the number of adequate frontiers to be analyzed is currently under development by our research group.
Results
Analysis of a single microarray experiment to study one type of cancer
The first results on the application of the proposed method include the analysis of the microarray database used by Wong et al. 13 related to cervix cancer. The database consists of eight healthy tissues and 25 cervix cancer tissues, all of them with expression level readings for 10,692 genes from a cDNA microarray. The Mann–Whitney nonparametric two-sided test for comparison of medians was used to generate two different P-values per gene 21, following the leave-one-tissue-out strategy as outlined in the methods section. Both formulations were applied to each gene characterized by a P-value as an input and as a transformation of the other P-value as an output (equation 1). The first 10 frontiers were identified, and they contained 28 potential biomarkers. Numerically, reducing 10,692 genes to only 28 of them evidences the screening power of the proposed method. Table 1 outlines the genes identified in the analysis. These were then investigated in the literature to assess their cervix cancer biomarking potential as discussed next.
Table 1.
List of the 28 genes identified in the first 10 frontiers of the proposed multiple criteria optimization (MCO) problem
| Frontier | Accession number | Symbol | Name | Expression in cervix cancer (using data from Wong et al. 13) |
|---|---|---|---|---|
| 1 | AA488645 | NAB1 | NGFI-A-binding protein 1 (EGR1 binding protein 1) | Underexpressed |
| 2 | H22826 | LMO7 | LIM domain 7 | Overexpressed |
| 3 | AI553969 | KPNA6 | Karyopherin α6 (importin α7) | Overexpressed |
| 3 | T71316 | ARF4 | ADP-ribosylation factor 4 | Overexpressed |
| 3 | AA243749 | DDR2 | Discoidin domain receptor tyrosine kinase 2 | Overexpressed |
| 3 | AA460827 | PPP1R1A | Protein phosphatase 1, regulatory (inhibitor) subunit 1A | Underexpressed |
| 4 | AA454831 | EST: zx79c10.s1 | Overexpressed | |
| 4 | AA913408, AA913864 | RAD52 | DNA damage repair and recombination protein RAD52 pseudogene | Overexpressed |
| 5 | AA487237 | UBE3A | Ubiquitin protein ligase E3A | Underexpressed |
| 5 | AA446565 | RBM25 | RNA-binding motif protein 25 | Overexpressed |
| 6 | H23187 | CA2 | Carbonic anhydrase II | Overexpressed |
| 7 | AI221445 | KCNE3 | Potassium voltage-gated channel, Isk-related family, member 3 | Overexpressed |
| 7 | R36086 | EST: yh88d01.s1 | Underexpressed | |
| 7 | AA282537 | LOC729991 | Hypothetical protein LOC729991 | Overexpressed |
| 8 | N93686 | ALDH3B1 | Aldehyde dehydrogenase 3 family, member B1 | Underexpressed |
| 8 | R91078 | CYP3A7 | Cytochrome P450, family 3, subfamily A, polypeptide 7 | Overexpressed |
| 8 | R44822 | PRPSAP1 | Phosphoribosyl pyrophosphate synthetase-associated protein 1 | Underexpressed |
| 9 | AI334914 | ITGA2B | Integrin, alpha 2b (platelet glycoprotein IIb of IIb/IIIa complex, antigen CD41) | Overexpressed |
| 9 | R93394 | Transcribed locus | Overexpressed | |
| 9 | AA621155 | MSH5 | MutS homolog 5 (Escherichia coli) | Underexpressed |
| 9 | AA705112 | MOCS1 | Molybdenum cofactor synthesis 1 | Overexpressed |
| 9 | R52794 | PTPRT | Protein tyrosine phosphatase, receptor type, T | Underexpressed |
| 10 | AA424344 | UROD | Uroporphyrinogen decarboxylase | Overexpressed |
| 10 | H69876 | LOC100132707 | Hypothetical LOC100132707 | Underexpressed |
| 10 | H55909 | SRSF1 | Serine/arginine-rich splicing factor 1 | Underexpressed |
| 10 | W74657 | KLF2 | Kruppel-like factor 2 (lung) | Overexpressed |
| 10 | AI017398 | ACCN2 | Amiloride-sensitive cation channel 2, neuronal | Overexpressed |
| 10 | H99699 | POLR3H | Polymerase (RNA) III (DNA directed) polypeptide H (22.9 kD) | Overexpressed |
The table shows complete list of genes identified in the first 10 efficient frontiers. In the last column, the expression change from the normal state to the cancer state is shown.
In the first efficient frontier there is only one gene: the NAB1 gene that codes for EGR1-binding protein 1, which has been reported as a potential tumor suppressor in different cancer types including prostate cancer 22, breast cancer 23, esophageal cancer 24, hepatoma 25, and leukemia 26.
The LIM domain 7 (LMO7) gene was selected in the second frontier. The protein product of the LMO7 belongs to the PDZ-LIM family. Regulation problems with these proteins can support the development of cancer 27.
Third frontier holds DDR2, PPP1R1A, ARF4, and KPNA6. Changes in expression of DDR2 have been linked to several human cancers, for example, in non-small cell lung carcinoma (NSCLC) 28 and in nasopharyngeal carcinoma 29. The PPP1R1A product is the protein phosphatase 1, regulatory (inhibitor) subunit 1A. In a recent study, the PPP1R1A expression in lung, colorectal, and gastric cancer cell lines was different from that of the normal tissues 30, as well as in some cell lines developed from different pediatric tumors 31. The ADP-ribosylation factor 4 (ARF4) gene protein product interacts with epidermal growth factor receptor (EGFR) mediating the EGF-dependent cellular activation of phospholipase D2 (PLD2) 32. An increased PLD2 activity has been reported for human cancers including breast, colon, gastric, and kidney 33. The ARF4 has also been proposed as an antiapoptotic gene in human glioblastoma-derived U373MG cells 34. The product of the KPNA6 gene has been reported to play an important role in the antioxidant response and in keeping the redox homeostasis of the cell 35. Its downregulation was reported to inhibit HeLa cell proliferation 36.
The fourth frontier holds RAD52 along with an expressed sequence tag (EST). RAD52 codes for a protein that is homolog to the Saccharomyces cerevisiae Rad52. The overexpression of RAD52, along with RAD51 and TOP2A, all three DNA repair genes, has been reported to be predictive of poor relapse-free survival for melanoma 37.
The genes in the fifth frontier are RBM25 and UBE3A. The product of the RBM25 gene is an RNA-binding protein that acts as a splicing factor and has been shown to act on the alternative splicing of apoptotic factors 38. The product of the UBE3A gene is an E3 ubiquitin protein ligase, the E6-associated protein (E6AP). This protein is used by the E6 oncoprotein, from high-risk human papillomavirus (HPV) types, to produce the proteolysis of the tumor suppressor p53 39. The E6AP is also used by E6 to stimulate the telomerase activity, generally present in cancer cell lines 40.
CA II, the gene in the sixth frontier, has been reported to be expressed in the neovessel endothelium and the tumor cell cytoplasm of medulloblastomas and primitive neuroectodermal tumors 41 and has been proposed as a biomarker gene for gastrointestinal stromal tumors 42.
In the seventh frontier KCNE3, the uncharacterized conserved protein LOC729991, and the EST yh88d01.s1 were selected. The KCNE3 gene codes for the potassium voltage-gated channel, Isk-related family, member 3. An increase in the activity of plasma membrane voltage-gated potassium channels promote neuronal cell death by apoptosis 43.
The genes in the eighth frontier are ALDH3B1, CYP3A7, and PRPSAP1. In a recent study, the expression of ALDH3B1 was found to be tissue dependent, being upregulated in a high percentage of tumors used in the study (lung > breast = ovarian > colon) 44. CYP3A7 codes for a protein from the cytochrome P450 superfamily of enzymes. Proteins of this family play an important role in carcinogenesis because they metabolically activate precarcinogens and can metabolize anticancer drugs. The product of the PRPSAP1 gene has been suggested to play a negative regulatory role in 5-phosphoribose 1-diphosphate synthesis and to bind to PRPS1 and PRPS2 , enzymes involved in the synthesis of purine and pyrimidine nucleotides.
The genes in the ninth frontier are ITGA2B, MSH5, MOCS1, and PTPRT. The ITGA2B gene codes for the integrin alpha chain 2b. Integrins can activate protein kinases involved in the regulation of cell growth, division, survival, differentiation, migration, and apoptosis. The MSH5 gene codes for a member of the mutS family of proteins. These proteins are involved in promoting ionizing radiation-induced apoptosis 46. A recent study found that the level of mRNA for genes involved in mismatching repair, including MSH5, was lower in colorectal cancer samples than in normal tissues 47. The product of the MOCS1 gene is involved in the molybdenum cofactor biosynthesis. Deficiency in molybdenum cofactor produces deficiency in the sulfite oxidase, xanthine dehydrogenase, and aldehyde oxidase 48. Xanthine oxidoreductase has been associated with various forms of cancers as well as other human diseases (reviewed in 49). The PTPRT gene codes for a tyrosine phosphatase protein, receptor type T, and has been suggested that its product has tumor suppression functions 50.
In the 10th frontier, the genes selected by the analysis method used in this study are UROD, LOC100132707, SRSF1, KLF2, ACCN2, and POLR3H. The UROD gene has been reported to be overexpressed in biopsies from patients with head and neck cancer 51. LOC100132707 is a hypothetical gene, the product of which is uncharacterized. The SRSF1 gene codes for a member of the arginine/serine-rich splicing factor protein family, its product works activating or repressing splicing of pre-mRNA . It has been proposed that KLF2 could have a tumor suppressor activity in the MCF-7 mammary carcinoma cells 53. Also, the expression of KLF2 has been reported to inhibit Jurkat T leukemia cell growth 54. The ACCN2 product is an acid-sensing ion channel (ASIC) shown to have higher expression in human glioblastoma multiforme cells as compared with primary human astrocytes 55. The POLR3H gene codes for the polymerase (RNA) III (DNA-directed) polypeptide H. RNA polymerase (pol) III synthesizes several products required for protein synthesis, and there have been detected high rates of pol III transcription in several cancers (reviewed in 56).
As it can be seen, the literature marshaled about the genes detected by the proposed method evidences the biological relevance of the analysis output. The following section presents cross-validation studies that support analysis consistency.
Cross-validation studies of results in cervix cancer
The proposed method is capable to importantly accelerate the detection of potential cancer biomarkers, as shown in the previous study. In the following studies, the objective was to cross-validate the use of the method following (1) a genetic signature approach and (2) a statistical classification procedure.
Two independent cervix cancer databases using the same microarray platform, the Affymetrix U133A (with 22,283 probe set), were identified [14, 15]. Using the proposed method as in the previous study, and considering only the healthy and cancer data, a series of potential biomarkers was selected using solely database 1 14. These genes were then identified in database 2 15 and the change in expression was compared between the datasets. Table 2 shows the overlap between the reference signature behavior from database 1 and the behavior of genes in database 2. The overlap amounts to 28 genes (29 probes with two probes for gene SMC4), which is 71.8% of the original signature, evidencing the effectiveness of the method. Table 2 also summarizes evidence found in the literature to support the genes' potential biomarking role in cervix cancer or in other types of cancer.
Table 2.
List of genes from the cross-validation study
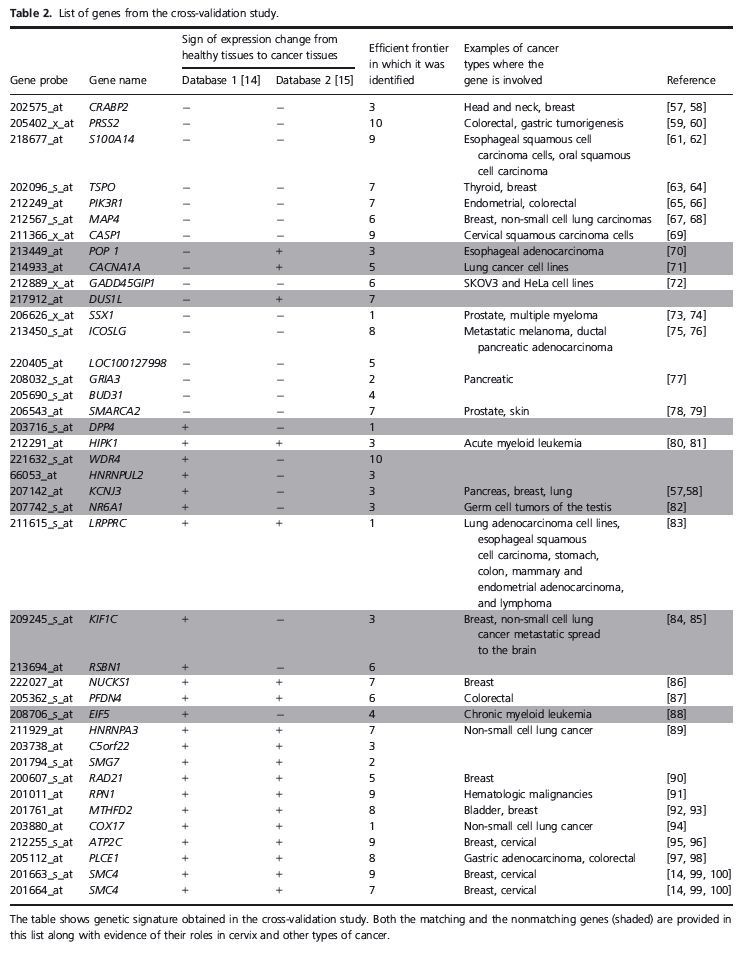 |
An important fact to emphasize in this study is, also, that of the discrimination power of the tool. The microarray platform used by both databases involved in the validation study contained 22,283 probes set. The fact that a signature of 39 genes was feasible to be built and tested evidences the advantage of using the proposed method.
A second cross-validation study entailed building a linear classifier with the set of genes identified as potential biomarkers in database 1, but applying it to classify the tissues in database 2. The classification rate in the 56 tissues of database 2 (24 healthy tissues and 32 cancer tissues) was 100%. The classifier was built with linear discriminant analysis and the results imply that the selection of potential biomarkers in database 1 achieved perfect linear separability in database 2. This provides solid evidence on the competitiveness of the proposed method.
Contrast with the single performance measure strategy
The single performance measure strategy is prevalent in the literature for the selection of genes that change their expression significantly between the conditions under comparison. It generally involves defining a threshold to select a number of potential biomarkers based on a single measurable criterion. The definition of such threshold may vary from experimenter to experimenter, however.
In this section, a multiple simultaneous hypothesis testing approach with a Bonferroni correction by Holms 101 was used to contrast a single performance measure strategy with the multiple performance measure strategy proposed here. For each gene in database 1 14, a P-value was obtained based upon the Mann–Whitney nonparametric test for difference of medians between two groups. All genes and their associated P-values were sorted in increasing order in terms of P-value. To decide whether a gene in the (i)th place of the ordered sequence shows significantly different relative expression levels with the presence of cancer, the following criterion is evaluated:
| (2) |
where α is the family-wise error rate and q is the number of total hypothesis tests being carried out, which in this instance, corresponds to the number of genes under evaluation.
The choice of the value of α is habitually left to the user. With database 1, when α < 0.1280, no gene is deemed to change its relative expression significantly. At α = 0.1280, a total of 86 genes are deemed to have changed their relative expression significantly. The number of genes in this category goes up to 116 at α = 0.1530. The choice of α by the user, as it can be seen, greatly affects the number of genes that are considered important.
To make a fair comparison with the proposed multiple criteria method in this study, only the top 39 genes were chosen to build a linear classifier to be applied to database 2 15 as in the previous section. The classification rate was also of 100% in both healthy tissues and cancer tissues. It is important to notice that although both methods achieved 100% classification rate in an independent database, the proposed multiple criteria method did not require for the user to set any parameter.
Conclusions
The search for potential cancer biomarkers can be greatly enhanced through the use of optimization techniques. In this study, a multiple criteria representation of the gene expression changes identification problem using microarray data is proposed. As a first case, the analysis of a single microarray experiment has been used to extract biologically relevant information in terms of potential biomarkers. The methodology can be extended to find the best compromises between data from different experiments for the same cancer type.
DEA is shown as a promising first approach to characterize the convex-efficient frontier of the MCO problem, and therefore to point toward potential biomarkers in a parameter-free and consistent fashion.
The proposed method, when applied to a publicly available microarray database from cervix cancer, identified genes already reported as relevant for different cancer types or cellular processes related to cancer. When the behavior of a selected gene was contrary to what was expected (NAB1 [AA488645], RBM25 [AA446565], UBE3A [AA487237], ALDH3B1 [N93686], PRPSAP1 [R44822]), the original data were reexamined. For those genes the readings showed great dispersion, from one run to the next, making the signal very noisy, which can explain the odd observed behavior. Genes without previous report of their relevance can be proposed for further in vitro validation.
Similarly, in the cross-validation studies, 39 genes were identified as potential cervix cancer biomarkers in a database. Of these genes, there was an overlap of 29 genes with similar behavior in a second database using the same microarray platform. These genes are proposed in this study as potential cervix biomarkers. A second cross-validation study showed that the proposed selection of potential biomarkers achieved perfect linear separability in an independent database, adding evidence in favor of the performance of the proposed approach. Furthermore, the convenience of not requiring the user to set parameters that affect the output of the analysis was demonstrated through a comparison with a commonly used strategy based on a single performance measure.
New methodologies for biological characterization have emerged after microarrays. The issues in handling large amounts of data, analysis reproducibility, and consistency, as well as computational convenience will continue to be challenges. This situates the proposed approach as a promising tool capable to accelerate biological discovery and to facilitate meta-analysis.
Acknowledgments
This study is based on study supported by the National Science Foundation (NSF) under Grant HRD 0833112 (CREST program), as well as the National Institutes of Health (NIH) MARC Grant 5T36GM095335-02 “Bioinformatics Programs at Minority Institutions.” UPRM BioSEI Grant 330103080301 awarded to M. Cabrera-Ríos and PROMEP Grant 103.5/07/2523 awarded to C. Isaza were also critical to the development of this study. M. Sanchez Peña was supported through a research fellowship in the Department of Industrial Engineering at UPRM.
Conflict of Interest
None declared.
References
- Ho L, Sharma N, Blackman L, Festa E, Reddy G, Pasinetti GM. From proteomics to biomarker discovery in Alzheimer's disease. Brain Res. Rev. 2005;48:360–369. doi: 10.1016/j.brainresrev.2004.12.025. [DOI] [PubMed] [Google Scholar]
- Riker AI, Enkemann SA, Fodstad O, Liu S, Ren S, Morris C, et al. The gene expression profiles of primary and metastatic melanoma yields a transition point of tumor progression and metastasis. BMC Med. Genomics. 2008;1:13. doi: 10.1186/1755-8794-1-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Di Valentin E, Crahay C, Garbacki N, Hennuy B, Guéders M, Noël A, et al. New asthma biomarkers: lessons from murine models of acute and chronic asthma. Am. J. Physiol. Lung Cell. Mol. Physiol. 2009;296:L185–L197. doi: 10.1152/ajplung.90367.2008. [DOI] [PubMed] [Google Scholar]
- Olson NE. The microarray data analysis process: from raw data to biological significance. NeuroRX. 2006;3:373–383. doi: 10.1016/j.nurx.2006.05.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ioannidis JP, Allison DB, Ball CA, Coulibaly I, Cui X, Culhane AC, et al. Repeatability of published microarray gene expression analyses. Nat. Genet. 2009;41:149–155. doi: 10.1038/ng.295. [DOI] [PubMed] [Google Scholar]
- van ‘t Veer LJ, Dai H, He MJ, van de Vijver YD, Hart AA, Mao M, et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature. 2002;415:530–536. doi: 10.1038/415530a. [DOI] [PubMed] [Google Scholar]
- Wang Y, Klijn JG, Zhang Y, Sieuwerts AM, Look MP, Yang F, et al. Gene-expression profiles to predict distant metastasis of lymph-node-negative primary breast cancer. Lancet. 2005;365:671–679. doi: 10.1016/S0140-6736(05)17947-1. [DOI] [PubMed] [Google Scholar]
- Ein-Dor L, Kela I, Getz G, Givol D, Domany E. Outcome signature genes in breast cancer: is there a unique set? Bioinformatics. 2005;21:171–178. doi: 10.1093/bioinformatics/bth469. [DOI] [PubMed] [Google Scholar]
- Ehrgott M. Multicriteria optimization. Heidelberg, New York: Springer; 2005. [Google Scholar]
- Hero AO, Fleury G. Pareto-optimal methods for gene ranking. J. VLSI Signal Process. Syst. 2004;38:259–275. [Google Scholar]
- Charnes A, Cooper W, Lewin A, Seiford L. Data envelopment analysis theory, methodology and applications. Norwell, MA: Kluwer Academic Publishers; 1995. [Google Scholar]
- Marroquín MGV, Peña MLS, Castro CE, Castro JM, Cabrera-Ríos M. Use of data envelopment analysis and clustering in multiple criteria optimization. Intell. Data Anal. 2008;12:89–101. [Google Scholar]
- Wong YF, Selvanayagam ZE, Wei N, Porter J, Vittal R, Hu R, et al. Expression genomics of cervical cancer. Molecular classification and prediction of radiotherapy response by DNA microarray. Clin. Cancer Res. 2003;9:5486–5492. [PubMed] [Google Scholar]
- Zhai Y, Kuick R, Nan B, Ota I, Weiss SJ, Trimble CL, et al. Gene expression analysis of preinvasive and invasive cervical squamous cell carcinomas identifies HOXC10 as a key mediator of invasion. Cancer Res. 2007;67:10163–10172. doi: 10.1158/0008-5472.CAN-07-2056. [DOI] [PubMed] [Google Scholar]
- Scotto L, Narayan G, Nandula SV, Arias-Pulido H, Subramaniyam S, Schneider A, et al. Identification of copy number gain and overexpressed genes on chromosome arm 20q by an integrative genomic approach in cervical cancer: potential role in progression. Genes Chromosom. Cancer. 2008;47:755–765. doi: 10.1002/gcc.20577. [DOI] [PubMed] [Google Scholar]
- Chen Y, Dougherty ER, Bittner ML. Ratio-based decisions and the quantitative analysis of cDNA microarray images. J. Biomed. Opt. 1997;2:364–374. doi: 10.1117/12.281504. [DOI] [PubMed] [Google Scholar]
- Pan W. A comparative review of statistical methods for discovering differentially expressed genes in replicated microarray experiments. Bioinformatics. 2002;18:546–554. doi: 10.1093/bioinformatics/18.4.546. [DOI] [PubMed] [Google Scholar]
- Matlab Software. Available at http://www.mathworks.com/ (accessed 23 February 2013)
- Lingo Software. Available at http://www.lindo.com (accessed 23 February 2013)
- DEA Solver Pro Software. Available at http://www.saitech-inc.com (accessed 23 February 2013)
- Hollander M, Wolfe DA. Nonparametric statistical methods. New York, NY: Wiley-Interscience, John Wiley & Sons, Inc; 1999. [Google Scholar]
- Virolle T, Krones-Herzig A, Baron V, Adamson G, De Gregorio ED, Mercola D. Egr1 promotes growth and survival of prostate cancer cells. J. Biol. Chem. 2003;278:11802–11810. doi: 10.1074/jbc.M210279200. [DOI] [PubMed] [Google Scholar]
- Ronski K, Sanders M, Burleson JA, Moyo V, Benn P, Fang M. Early growth response gene 1 (EGR1) is deleted in estrogen receptor-negative human breast carcinoma. Cancer. 2005;104:925–930. doi: 10.1002/cncr.21262. [DOI] [PubMed] [Google Scholar]
- Wu MY, Chen MH, Liang YR, Meng GZ, Yang HX, Zhuang CX. Experimental and clinic-opathologic study on the relationship between transcription factor Egr-1 and esophageal carcinoma. World J. Gastroenterol. 2001;7:490–495. doi: 10.3748/wjg.v7.i4.490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hao MW, Liang YR, Liu YF, Liu L, Wu MY, Yang HX. Transcription factor EGR-1 inhibits growth of hepatocellular carcinoma and esophageal carcinoma cell lines. World J. Gastroenterol. 2002;8:203–207. doi: 10.3748/wjg.v8.i2.203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shafarenko M, Liebermann DA, Hoffman B. Egr-1 abrogates the block imparted by c-Myc on terminal M1 myeloid differentiation. Blood. 2005;106:871–878. doi: 10.1182/blood-2004-08-3056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krcmery J, Camarata T, Kulisz A, Simon HG. Nucleocytoplasmic functions of the PDZ-LIM protein family: new insights into organ development. BioEssays. 2010;32:100–108. doi: 10.1002/bies.200900148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ford CE, Lau SK, Zhu CQ, Andersson T, Tsao MS, Vogel WF. Expression and mutation analysis of the discoidin domain receptors 1 and 2 in non-small cell lung carcinoma. Br. J. Cancer. 2007;96:808–814. doi: 10.1038/sj.bjc.6603614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chua HH, Yeh TH, Wang YP, Huang YT, Sheen TS, Lo YC, et al. Upregulation of discoidin domain receptor 2 in nasopharyngeal carcinoma. Head Neck. 2008;30:427–436. doi: 10.1002/hed.20724. [DOI] [PubMed] [Google Scholar]
- Takakura S, Kohno T, Manda R, Okamoto A, Tanaka T, Yokota J. Genetic alterations and expression of the protein phosphatase 1 genes in human cancers. Int. J. Oncol. 2001;18:817–824. doi: 10.3892/ijo.18.4.817. [DOI] [PubMed] [Google Scholar]
- Wai DH, Schaefer KL, Schramm A, Korsching E, Ozaki F, Van Valen T, et al. Expression analysis of pediatric solid tumor cell lines using oligonucleotide microarrays. Int. J. Oncol. 2002;20:441–451. [PubMed] [Google Scholar]
- Kim SW, Hayashi M, Lo JF, Yang Y, Yoo JS, Lee JD. ADP-ribosylation factor 4 small GTPase mediates epidermal growth factor receptor-dependent phospholipase D2 activation. J. Biol. Chem. 2003;278:2661–2668. doi: 10.1074/jbc.M205819200. [DOI] [PubMed] [Google Scholar]
- Su W, Chen Q, Frohman MA. Targeting phospholipase D with small-molecule inhibitors as a potential therapeutic approach for cancer metastasis. Future Oncol. 2009;5:1477–1486. doi: 10.2217/fon.09.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Woo IS, Eun SY, Jang HS, Kang ES, Kim GH, Kim HJ, et al. Identification of ADP-ribosylation factor 4 as a suppressor of N-(4-hydroxyphenyl)retinamide-induced cell death. Cancer Lett. 2009;276:53–60. doi: 10.1016/j.canlet.2008.10.031. [DOI] [PubMed] [Google Scholar]
- Sun Z, Wu T, Zhao F, Lau A, Birch CM, Zhang DD. KPNA6 (importin {alpha}7)-mediated nuclear import of KEAP1 represses the NRF2-dependent antioxidant response. Mol. Cell. Biol. 2011;31:1800–1811. doi: 10.1128/MCB.05036-11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quensel C, Friedrich B, Sommer T, Hartmann E, Kohler M. In vivo analysis of importin alpha proteins reveals cellular proliferation inhibition and substrate specificity. Mol. Cell. Biol. 2004;24:10246–10255. doi: 10.1128/MCB.24.23.10246-10255.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jewell R, Conway C, Mitra A, Randerson-Moor J, Lobo S, Nsengimana J, et al. Patterns of expression of DNA repair genes and relapse from melanoma. Clin. Cancer Res. 2010;16:5211–5221. doi: 10.1158/1078-0432.CCR-10-1521. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou A, Ou AC, Cho A, Benz EJ, Jr, Huang SC. Novel splicing factor RBM25 modulates Bcl-x pre-mRNA 5′ splice site selection. Mol. Cell. Biol. 2008;28:5924–5936. doi: 10.1128/MCB.00560-08. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scheffner M, Werness BA, Huibregtse JM, Levine AJ, Howley PM. The E6 oncoprotein encoded by human papillomavirus types 16 and 18 promotes the degradation of p53. Cell. 1990;63:1129–1136. doi: 10.1016/0092-8674(90)90409-8. [DOI] [PubMed] [Google Scholar]
- Kelley ML, Keiger KE, Lee CJ, Huibregtse JM. The global transcriptional effects of the human papillomavirus E6 protein in cervical carcinoma cell lines are mediated by the E6AP ubiquitin ligase. J. Virol. 2005;79:3737–3747. doi: 10.1128/JVI.79.6.3737-3747.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nordfors K, Haapasalo J, Korja M, Niemelä A, Laine J, Parkkila AK, et al. The tumour-associated carbonic anhydrases CA II, CA IX and CA XII in a group of medulloblastomas and supratentorial primitive neuroectodermal tumours: an association of CA IX with poor prognosis. BMC Cancer. 2010;10:148. doi: 10.1186/1471-2407-10-148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parkkila S, Lasota J, Fletcher JA, Ou WB, Kivelä AJ, Nuorva K, et al. Carbonic anhydrase II. A novel biomarker for gastrointestinal stromal tumors. Mod. Pathol. 2010;23:743–750. doi: 10.1038/modpathol.2009.189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lauritzen I, Zanzouri M, Honoré E, Duprat F, Ehrengruber MU, Lazdunski M, et al. K+-dependent cerebellar granule neuron apoptosis. J. Biol. Chem. 2003;278:32068–32076. doi: 10.1074/jbc.M302631200. [DOI] [PubMed] [Google Scholar]
- Marchitti SA, Orlicky DJ, Brocker C, Vasiliou V. Aldehyde dehydrogenase 3B1 (ALDH3B1): immunohistochemical tissue distribution and cellular-specific localization in normal and cancerous human tissues. J. Histochem. Cytochem. 2010;58:765–783. doi: 10.1369/jhc.2010.955773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Uniprot. Available at http://www.uniprot.org/ (accessed 23 February 2013)
- Tompkins JD, Wu X, Chu YL, Her C. Evidence for a direct involvement of hMSH5 in promoting ionizing radiation induced apoptosis. Exp. Cell Res. 2009;315:2420–2432. doi: 10.1016/j.yexcr.2009.05.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ioana M, Angelescu C, Burada F, Mixich F, Riza A, Dumitrescu T, et al. Gene expression pattern in sporadic colorectal cancer. J. Gastrointestin. Liver Dis. 2010;19:155–159. [PubMed] [Google Scholar]
- Reiss J, Johnson JL. Mutations in the molybdenum cofactor biosynthetic genes MOCS1, MOCS2, and GEPH. Hum. Mutat. 2003;21:569–576. doi: 10.1002/humu.10223. [DOI] [PubMed] [Google Scholar]
- Lin J, Xu P, LaVallee P, Hoidal JR. Identification of proteins binding to E-Box/Ku86 sites and function of the tumor suppressor SAFB1 in transcriptional regulation of the human xanthine oxidoreductase gene. J. Biol. Chem. 2008;283:29681–29689. doi: 10.1074/jbc.M802076200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scott A, Wang Z. Tumour suppressor function of protein tyrosine phosphatase receptor-T. Biosci. Rep. 2011;31:303–307. doi: 10.1042/BSR20100134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ito E, Yue S, Moriyama EH, Hui AB, Kim I, Shi W, et al. Uroporphyrinogen decarboxylase is a radiosensitizing target for head and neck cancer. Sci. Transl. Med. 2011;3:67ra7. doi: 10.1126/scitranslmed.3001922. [DOI] [PubMed] [Google Scholar]
- NCBI gene SRSF1 serine/arginine-rich splicing factor 1 [Homo sapiens] Available at http://www.ncbi.nlm.nih.gov/pubmed?Db=gene&Cmd=retrieve&dopt=full_report&list_uids=6426 (accessed 23 February 2013)
- Kannan-Thulasiraman P, Seachrist DD, Mahabeleshwar GH, Jain MK, Noy N. Fatty acid-binding protein 5 and PPARβ/δ are critical mediators of epidermal growth factor receptor-induced carcinoma cell growth. J. Biol. Chem. 2010;285:19106–19115. doi: 10.1074/jbc.M109.099770. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu J, Lingrel JB. KLF2 inhibits Jurkat T leukemia cell growth via upregulation of cyclin-dependent kinase inhibitor p21WAF1/CIP1. Oncogene. 2004;23:8088–8096. doi: 10.1038/sj.onc.1207996. [DOI] [PubMed] [Google Scholar]
- Kapoor N, Bartoszewski R, Qadri YJ, Bebok Z, Bubien JK, Fuller CM, et al. Knockdown of ASIC1 and epithelial sodium channel subunits inhibits glioblastoma whole cell current and cell migration. J. Biol. Chem. 2009;284:24526–24541. doi: 10.1074/jbc.M109.037390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- White RJ. RNA polymerase III transcription and cancer. Oncogene. 2004;23:3208–3216. doi: 10.1038/sj.onc.1207547. [DOI] [PubMed] [Google Scholar]
- Calmon MF, Rodrigues RV, Kaneto CM, Moura RP, Silva SD, Mota LD, et al. Epigenetic silencing of CRABP2 and MX1 in head and neck tumors. Neoplasia. 2009;11:1329–1339. doi: 10.1593/neo.91110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Geiger T, Madden SF, Gallagher WM, Cox J, Mann M. Proteomic portrait of human breast cancer progression identifies novel prognostic markers. Cancer Res. 2012;72:2428–2439. doi: 10.1158/0008-5472.CAN-11-3711. [DOI] [PubMed] [Google Scholar]
- Williams SJ, Gotley DC, Antalis TM. Human trypsinogen in colorectal cancer. Int. J. Cancer. 2001;93:67–73. doi: 10.1002/ijc.1304. [DOI] [PubMed] [Google Scholar]
- Rajkumar T, Vijayalakshmi N, Gopal G, Sabitha K, Shirley S, Raja UM, et al. Identification and validation of genes involved in gastric tumorigenesis. Cancer Cell Int. 2010;10:45. doi: 10.1186/1475-2867-10-45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen H, Yuan Y, Zhang C, Luo A, Ding F, Ma J, et al. Involvement of S100A14 protein in cell invasion by affecting expression and function of matrix metalloproteinase (MMP)-2 via p53-dependent transcriptional regulation. J. Biol. Chem. 2012;287:17109–17119. doi: 10.1074/jbc.M111.326975. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sapkota D, Bruland O, Costea DE, Haugen H, Vasstrand EN, Ibrahim SO. S100A14 regulates the invasive potential of oral squamous cell carcinoma derived cell-lines in vitro by modulating expression of matrix metalloproteinases, MMP1 and MMP9. Eur. J. Cancer. 2011;47:600–610. doi: 10.1016/j.ejca.2010.10.012. [DOI] [PubMed] [Google Scholar]
- Klubo-Gwiezdzinska J, Jensen K, Bauer A, Patel A, Costello J, Burman K, et al. The expression of translocator protein in human thyroid cancer and its role in the response of thyroid cancer cells to oxidative stress. J. Endocrinol. 2012;214:207–216. doi: 10.1530/JOE-12-0081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mukherjee S, Das SK. Translocator protein (TSPO) in breast cancer. Curr. Mol. Med. 2012;12:443–457. [PubMed] [Google Scholar]
- Cheung LW, Hennessy BT, Li J, Yu S, Myers AP, Djordjevic B, et al. High frequency of PIK3R1 and PIK3R2 mutations in endometrial cancer elucidates a novel mechanism for regulation of PTEN protein stability. Cancer Discov. 2011;1:170–185. doi: 10.1158/2159-8290.CD-11-0039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nowakowska-Zajdel E, Mazurek U, Ziółko E, Niedworok E, Fatyga E, Kokot T, et al. Analysis of expression profile of gene encoding proteins of signal cascades activated by insulin-like growth factors in colorectal cancer. Int. J. Immunopathol. Pharmacol. 2011;24:781–787. doi: 10.1177/039463201102400324. [DOI] [PubMed] [Google Scholar]
- Chen X, Wu J, Lu H, Huang O, Shen K. Measuring β-tubulin III, Bcl-2, and ERCC1 improves pathological complete remission predictive accuracy in breast cancer. Cancer Sci. 2012;103:262–268. doi: 10.1111/j.1349-7006.2011.02135.x. [DOI] [PubMed] [Google Scholar]
- Cucchiarelli V, Hiser L, Smith H, Frankfurter A, Spano A, Correia JJ, et al. Beta-tubulin isotype classes II and V expression patterns in nonsmall cell lung carcinomas. Cell Motil. Cytoskeleton. 2008;65:675–685. doi: 10.1002/cm.20297. [DOI] [PubMed] [Google Scholar]
- Arany I, Ember IA, Tyring SK. All-trans-retinoic acid activates caspase-1 in a dose-dependent manner in cervical squamous carcinoma cells. Anticancer Res. 2003;23:471–473. [PubMed] [Google Scholar]
- Liu CY, Wu MC, Chen F, Ter-Minassian M, Asomaning K, Zhai R, et al. A large-scale genetic association study of esophageal adenocarcinoma risk. Carcinogenesis. 2010;31:1259–1263. doi: 10.1093/carcin/bgq092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Castro M, Grau L, Puerta P, Gimenez L, Venditti J, Quadrelli S, et al. Multiplexed methylation profiles of tumor suppressor genes and clinical outcome in lung cancer. J. Transl. Med. 2010;8:86. doi: 10.1186/1479-5876-8-86. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nakayama K, Nakayama N, Wang TL, Shih IeM. NAC-1 controls cell growth and survival by repressing transcription of Gadd45GIP1, a candidate tumor suppressor. Cancer Res. 2007;67:8058–8064. doi: 10.1158/0008-5472.CAN-07-1357. [DOI] [PubMed] [Google Scholar]
- Smith HA, Cronk RJ, Lang JM, McNeel DG. Expression and immunotherapeutic targeting of the SSX family of cancer-testis antigens in prostate cancer. Cancer Res. 2011;71:6785–6795. doi: 10.1158/0008-5472.CAN-11-2127. [DOI] [PubMed] [Google Scholar]
- Van Duin M, Broyl A, Goldschmidt Y, de Knegt H, Richardson PG, Hop WC, et al. Cancer testis antigens in newly diagnosed and relapse multiple myeloma: prognostic markers and potential targets for immunotherapy. Haematologica. 2011;96:1662–1669. doi: 10.3324/haematol.2010.037978. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fu T, He Q, Sharma P. The ICOS/ICOSL pathway is required for optimal antitumor responses mediated by anti-CTLA-4 therapy. Cancer Res. 2011;71:5445–5454. doi: 10.1158/0008-5472.CAN-11-1138. [DOI] [PubMed] [Google Scholar]
- Tjomsland V, Spångeus A, Sandström P, Borch K, Messmer D, Larsson M. Semi mature blood dendritic cells exist in patients with ductal pancreatic adenocarcinoma owing to inflammatory factors released from the tumor. PLoS ONE. 2010;5:e13441. doi: 10.1371/journal.pone.0013441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ripka S, Riedel J, Neesse A, Griesmann H, Buchholz M, Ellenrieder V, et al. Glutamate receptor GRIA3–target of CUX1 and mediator of tumor progression in pancreatic cancer. Neoplasia. 2010;12:659–667. doi: 10.1593/neo.10486. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun A, Tawfik O, Gayed B, Thrasher JB, Hoestje S, Li C, et al. Aberrant expression of SWI/SNF catalytic subunits BRG1/BRM is associated with tumor development and increased invasiveness in prostate cancers. Prostate. 2007;67:203–213. doi: 10.1002/pros.20521. [DOI] [PubMed] [Google Scholar]
- Moloney FJ, Lyons JG, Bock VL, Huang XX, Bugeja MJ, Halliday GM. Hotspot mutation of Brahma in non-melanoma skin cancer. J. Invest. Dermatol. 2009;129:1012–1015. doi: 10.1038/jid.2008.319. [DOI] [PubMed] [Google Scholar]
- Mougeot JL, Bahrani-Mougeot FK, Lockhart PB, Brennan MT. Microarray analyses of oral punch biopsies from acute myeloid leukemia (AML) patients treated with chemotherapy. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. Endod. 2011;112:446–452. doi: 10.1016/j.tripleo.2011.05.009. [DOI] [PubMed] [Google Scholar]
- Aikawa Y, Nguyen LA, Isono K, Takakura N, Tagata Y, Schmitz ML, et al. Roles of HIPK1 and HIPK2 in AML1- and p300-dependent transcription, hematopoiesis and blood vessel formation. EMBO J. 2006;25:3955–3965. doi: 10.1038/sj.emboj.7601273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Juric D, Sale S, Hromas RA, Yu R, Wang Y, Duran GE, et al. Gene expression profiling differentiates germ cell tumors from other cancers and defines subtype-specific signatures. Proc. Natl. Acad. Sci. USA. 2005;102:17763–17768. doi: 10.1073/pnas.0509082102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tian T, Ikeda JI, Wang Y, Mamat S, Luo W, Aozasa K, et al. Role of leucine-rich pentatricopeptide repeat motif-containing protein (LRPPRC) for anti-apoptosis and tumourigenesis in cancers. Eur. J. Cancer. 2012;48:2462–2473. doi: 10.1016/j.ejca.2012.01.018. [DOI] [PubMed] [Google Scholar]
- De S, Cipriano R, Jackson MW, Stark GR. Overexpression of kinesins mediates docetaxel resistance in breast cancer cells. Cancer Res. 2009;69:8035–8042. doi: 10.1158/0008-5472.CAN-09-1224. [DOI] [PubMed] [Google Scholar]
- Grinberg-Rashi H, Ofek E, Perelman M, Skarda J, Yaron P, Hajdúch M, et al. The expression of three genes in primary non-small cell lung cancer is associated with metastatic spread to the brain. Clin. Cancer Res. 2009;15:1755–1761. doi: 10.1158/1078-0432.CCR-08-2124. [DOI] [PubMed] [Google Scholar]
- Ziółkowski P, Gamian E, Osiecka B, Zougman A, Wiśniewski JR. Immunohistochemical and proteomic evaluation of nuclear ubiquitous casein and cyclin-dependent kinases substrate in invasive ductal carcinoma of the breast. J. Biomed. Biotechnol. 2009;2009:919645. doi: 10.1155/2009/919645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miyoshi N, Ishii H, Mimori K, Nishida N, Tokuoka M, Akita H, et al. Abnormal expression of PFDN4 in colorectal cancer: a novel marker for prognosis. Ann. Surg. Oncol. 2010;17:3030–3036. doi: 10.1245/s10434-010-1138-5. [DOI] [PubMed] [Google Scholar]
- Balabanov S, Gontarewicz A, Ziegler P, Hartmann U, Kammer W, Copland M, et al. Hypusination of eukaryotic initiation factor 5A (eIF5A): a novel therapeutic target in BCR-ABL-positive leukemias identified by a proteomics approach. Blood. 2007;109:1701–1711. doi: 10.1182/blood-2005-03-037648. [DOI] [PubMed] [Google Scholar]
- Boukakis G, Patrinou-Georgoula M, Lekarakou M, Valavanis C, Guialis A. Deregulated expression of hnRNP A/B proteins in human non-small cell lung cancer: parallel assessment of protein and mRNA levels in paired tumour/non-tumour tissues. BMC Cancer. 2010;10:434. doi: 10.1186/1471-2407-10-434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Atienza JM, Roth RB, Rosette C, Smylie KJ, Kammerer S, Rehbock J, et al. Suppression of RAD21 gene expression decreases cell growth and enhances cytotoxicity of etoposide and bleomycin in human breast cancer cells. Mol. Cancer Ther. 2005;4:361–368. doi: 10.1158/1535-7163.MCT-04-0241. [DOI] [PubMed] [Google Scholar]
- Shimizu S, Suzukawa K, Kodera T, Nagasawa T, Abe T, Taniwaki M, et al. Identification of breakpoint cluster regions at 1p36.3 and 3q21 in hematologic malignancies with t(1;3)(p36;q21) Genes Chromosom. Cancer. 2000;27:229–238. doi: 10.1002/(sici)1098-2264(200003)27:3<229::aid-gcc2>3.0.co;2-0. [DOI] [PubMed] [Google Scholar]
- Andrew AS, Gui J, Sanderson AC, Mason RA, Morlock EV, Schned AR, et al. Bladder cancer SNP panel predicts susceptibility and survival. Hum. Genet. 2009;125:527–539. doi: 10.1007/s00439-009-0645-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu X, Qiao M, Zhang Y, Jiang Y, Wei P, Yao J, et al. Quantitative proteomics study of breast cancer cell lines isolated from a single patient: discovery of TIMM17A as a marker for breast cancer. Proteomics. 2010;10:1374–1390. doi: 10.1002/pmic.200900380. [DOI] [PubMed] [Google Scholar]
- Suzuki C, Daigo Y, Kikuchi T, Katagiri T, Nakamura Y. Identification of COX17 as a therapeutic target for non-small cell lung cancer. Cancer Res. 2003;63:7038–7041. [PubMed] [Google Scholar]
- Grice DM, Vetter I, Faddy HM, Kenny PA, Roberts-Thomson SJ, Monteith GR. Golgi calcium pump secretory pathway calcium ATPase 1 (SPCA1) is a key regulator of insulin-like growth factor receptor (IGF1R) processing in the basal-like breast cancer cell line MDA-MB-231. J. Biol. Chem. 2010;285:37458–3766. doi: 10.1074/jbc.M110.163329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilting SM, Meijer J, de Wilde CJ, Berkhof J, Yi Y, van Wieringen WN, et al. Integrated genomic and transcriptional profiling identifies chromosomal loci with altered gene expression in cervical cancer. Genes Chromosom. Cancer. 2008;47:890–8905. doi: 10.1002/gcc.20590. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang M, Zhang R, He J, Qiu L, Li J, Wang Y, et al. Potentially functional variants of PLCE1 identified by GWASs contribute to gastric adenocarcinoma susceptibility in an eastern Chinese population. PLoS ONE. 2012;7:e31932. doi: 10.1371/journal.pone.0031932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Danielsen SA, Cekaite L, Ågesen TH, Sveen A, Nesbakken A, Thiis-Evensen E, et al. Phospholipase C isozymes are deregulated in colorectal cancer – insights gained from gene set enrichment analysis of the transcriptome. PLoS ONE. 2011;6:e24419. doi: 10.1371/journal.pone.0024419. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang H, Jeung HC, Jung JJ, Kim TS, Rha SY, Chung HC. Identification of genes associated with chemosensitivity to SAHA/taxane combination treatment in taxane-resistant breast cancer cells. Breast Cancer Res. Treat. 2011;125:55–63. doi: 10.1007/s10549-010-0825-z. [DOI] [PubMed] [Google Scholar]
- Kulawiec M, Safina A, Desouki MM, Still I, Matsui S, Bakin A, et al. Tumorigenic transformation of human breast epithelial cells induced by mitochondrial DNA depletion. Cancer Biol. Ther. 2008;7:1732–1743. doi: 10.4161/cbt.7.11.6729. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holm S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979;6:65–70. [Google Scholar]