

Summary
In this paper, we study panel count data with informative observation times. We assume nonparametric and semiparametric proportional rate models for the underlying event process, where the form of the baseline rate function is left unspecified and a subject-specific frailty variable inflates or deflates the rate function multiplicatively. The proposed models allow the event processes and observation times to be correlated through their connections with the unobserved frailty; moreover, the distributions of both the frailty variable and observation times are considered as nuisance parameters. The baseline rate function and the regression parameters are estimated by maximising a conditional likelihood function of observed event counts and solving estimation equations. Large-sample properties of the proposed estimators are studied. Numerical studies demonstrate that the proposed estimation procedures perform well for moderate sample sizes. An application to a bladder tumour study is presented.
Keywords: Dependent censoring, Frailty, Poisson process, Rate function, Serial events
1. Introduction
In longitudinal studies of serial events such as repeated tumour occurrences or graft rejection episodes the cumulative number of these events experienced by each subject may be observed only at several distinct and random observation times, specific to each subject. Data of this type are commonly referred to as panel count data; see Thall & Lachin (1988) and Balshaw & Dean (2002). Statistical methodology for panel count data has developed slowly. Sun & Kalbfleisch (1995) derived a one-sample nonparametric maximum pseudolikelihood estimator of the rate function for the serial event process. Wellner & Zhang (2000) studied the asymptotics of the nonparametric maximum pseudolikelihood estimator and showed that it is less efficient than the nonparametric maximum likelihood estimator through some simulation studies. For semiparametric modelling, the derivation of the semiparametric maximum likelihood estimator is computationally intensive, and Zhang (2002) proposed an inference procedure based on a semiparametric pseudolikelihood function. Wellner et al. (2004) compared the large-sample properties of the semiparametric maximum pseudolikelihood estimator with the semiparametric maximum likelihood estimator, and showed that the former can be very inefficient when the distribution of the number of observation times is heavy-tailed. Sun & Wei (2000) formulated estimation equations for regression parameters in the semiparametric proportional rate models. However, the Sun–Wei estimator is inefficient as it ignores correlations among event counts in the estimation equations, and its validity relies heavily on correct modelling of the observation pattern.
Most proposed statistical models for panel count data assume that the observation times are independent of the serial events, conditioning on observed covariates such as treatment assignments. However, such an assumption can be violated in many applications. No existing method can handle panel count data with informative observation times. Motivated by Wang et al. (2001), we study nonparametric and semiparametric models that allow observation times to be correlated with the event process, where the correlation is induced by a frailty variable. Estimation procedures that require no parametric assumption about the distributions of the frailty variable and the observation time process are proposed for nonparametric and semiparametric models.
2. Notation and models
This paper focuses on statistical inference for the rate function for the underlying event process in a fixed time interval [0, τ]. Let N(t) denote the number of serial events that have occurred at or before time t, and assume that observations on a subject are collected at K random time points 0<t1< … <tK≤τ, where K is a random variable that takes positive integer values and y = tK is the last observation time, i.e. the censoring time. Let mj= N(tj)−N(tj−1) be the number of serial events in the time interval (tj−1, tj] and m = N(y) the total number of events observed in [0, τ]. We denote the observed data by D = {t1, t2, …, tK, K, y; m1, m2, …, mK, m}.
We consider the following nonparametric model for the event process N(·).
Model 1
Let Z be a nonnegative latent variable with E(Z)=1, so that, given Z=z, N(·) is a nonhomogeneous Poisson process with intensity function
where λ0(t) is an unspecified function. Given Z, the event process N(·) is independent of K and the random observation times {t1, …, tK}.
Define the function . Model 1 implies that the cumulative rate function of the event process in the disease population is given by E(Z)Λ0(t)=Λ0(t). Under Model 1, the event process N(·) and the observation times {t1, …, tK} are correlated through the frailty variable Z. Unlike most frailty models in the literature, Model 1 makes no parametric assumption about the distribution of Z.
Let x be a p×1 vector of covariates. When the effects of x on the rate function of the event process are of interest, a semiparametric extension of Model 1 for the event process N(·) is given below.
Model 2
There exists a nonnegative latent variable Z with E(Z|x)=1 so that, conditioning on x and Z=z, N(·) is a nonhomogeneous Poisson process with intensity function
where β is a p×1 vector of parameters and λ0(t) is unspecified. Moreover, given x and z, the event process N(·) is independent of the number of observation time points, K, and the observation times {t1, …, tK}.
In our formulation the distribution of the frailty variables and the conditional distribution of the observation times given the frailty can be arbitrary and are left unspecified.
3. The estimators and their asymptotic properties
3·1. Estimation procedure for model 1
We use subscript i for a subject, i=1, …, n. Let zi be the individual frailty value, ki the number of observation times and tij the jth observation time for the ith subject, where j=1, …, ki and 0≡ti0< … <tiki≤τ. Let yi denote the last observation time point, that is, yi=tiki. Let Ni be the underlying individual counting process and let mij= Ni(tij)−Ni(tij−1) be the number of serial events in the time interval (tij−1, tij]. Finally, let mi = N(yi) be the total number of events occurring during follow-up. For ease of notation we use mij and mi to represent both random variables and realisations. We denote the observed data of the ith subject by Di={ti1, ti2, …, tiki, ki, yi; mi1, mi2, …, miki, mi}, for i=1, 2, …, n, and assume that D1, …, Dn are independent and identically distributed copies of D.
Model 1 implies that, given mi and yi, the mi event times are order statistics of independent and identically distributed random variables with density function ziλ0(t)/ziΛ0(yi). The likelihood of the event times is proportional to the truncation likelihood given in Wang et al. (2001). If we further condition on {tij, j=1, …, ki}, the conditional likelihood function can be derived by integrating out the probability density function of the order statistics. Assuming that Λ0(τ) is bounded, we define the shape function for the event process N(·) on [0, τ] as F(t)=Λ0(t)/Λ0(τ), for t≤τ. Thus F defines a proper cumulative distribution function on [0, τ] with F(τ)=1. The conditional likelihood function, conditioning on zi, ki, mi and {tij, j=1, …, ki}, is
| (1) |
Interestingly, no information from the frailty variable Z is required to form (1). Note that, if , the right-hand side of (1) is exactly the likelihood function of a set of independent interval censored and right-truncated data. Therefore, the estimation of F(t) in (1) can be implemented by the self-consistency algorithm proposed by Turnbull (1976).
Turnbull’s self-consistency algorithm is equivalent to the Expectation-Maximisation algorithm. When applied to the conditional likelihood function Q, the E-step and M-step have simple closed solutions as described below. Let be the ordered and distinct observation times from {tij; ki>1, 1≤i≤n, 1 ≤ j ≤ki}. For 1≤ l ≤L, define . We maximise Q subject to the constraint . Define aijk=1 if and 0 otherwise. Additionally, we define bik=1 if and 0 otherwise. Given the estimates in the lth iteration, the E-step is to compute
where in the lth iteration. Given the updated , in the M-step we update the estimate of pk with . Note that is the expected number of events in the time interval [ ] and is the projected total number of serial events in the time interval [0, τ]. Finally, the estimate of F(t) is updated with . We alternate between the E-step and M-step until convergence to obtain the estimate F̂n of F.
The cumulative rate function Λ0(t) is related to F through the equation Λ0(t)= F(t)Λ0(τ), where Λ0(τ) is interpreted as the expected number of serial events occurring in the time interval [0, τ]. If we condition on zi and yi, mi has the expected value E(mi|zi, yi) = ziΛ0(yi) = ziF(yi)Λ0(τ). Thus we have E{miF(yi)−1}=Λ0(τ), since E(Z)=1; that is, the ratio of mi to F(yi) projects the number of events in [0, τ]. If we substitute F with F̂n, an estimator of Λ0(τ) is given by . Hence Λ0(t) can be estimated by Λ̂n(t)=F̂n(t)Λ̂n(τ).
Let
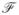 be the class of functions defined by
be the class of functions defined by
Then the L2(ν) metric d on
is defined as
where
The strong consistency property of Λ̂0 is stated in Theorem 1 with the following conditions.
Condition 1. There exists an integer k0<∞ such that the number of observation times, K, satisfies pr(K ≤ k0) = 1 and pr(K>1)>0.
Condition 2. The cumulative rate function Λ0 satisfies Λ0(τ)≤M for some M ∈ (0, ∞).
-
Condition 3. The random function satisfies E[M0]<∞.
Condition 4. There exists a τ1>0 such that pr(Y ≥τ1)=1 and Λ0(τ1)≥C* for some C*>0.
Theorem 1
We assume that Conditions 1–4 hold. Define τ2=sup{t: pr(Y ≥t)>0}. Then, for every t such that t ≤τ2, d(Λ̂n1[0,t], Λ01[0,t])→0 almost surely when n → ∞.
Since the estimation of Λ0 shares similarities with the estimation of a distribution function under random interval censoring and truncation, the convergence rate of Λ̂n(t) is expected to be nonregular, i.e. not of n1/2-convergence rate. For the purpose of systematically studying the convergence rate of Λ̂n(t), we consider the following technical conditions.
Condition 5. There exists a constant η>0 such that adjacent observation times are separated by η, that is tj−tj−1≥η for j=1, 2, …, K.
-
Condition 6. The baseline cumulative rate function Λ0∈C1[0, τ] and there exists a constant γ>0 such that for t ∈ [0, τ].
Condition 7. For any α=oP(1), there exists a constant C** such that E(zieαz)≤C** for i =0, 1, 2.
Theorem 2
We assume that Conditions 1–7 hold, and we suppress the indicator, 1[0,t], in our expression by assuming that the metric d is defined with t ≤τ2. Then we have that n1/2 d(Λ̂n, Λ0)=Op(1).
The proofs of the theorems are sketched in the Appendix using modern empirical process theory. We leave the study of the asymptotic distribution of Λ̂ to future research.
Remark
Conditions 1–7 are sufficient, but may not all be necessary. In particular, Condition 7 may be stronger than necessary, but it does hold for the Gamma frailty variable.
3·2. Estimation procedure for model 2
Under Model 2 the conditional likelihood for the ith individual, given zi, xi, ki, mi and observation times {ti1, …, tiki}, is proportional to
where F(t)=Λ0(t)/Λ0(τ). Note that the unobserved frailty zi and the observed covariates xi are cancelled out in the formula, yielding the same conditional likelihood function given by (1) in § 3·1. Thus the baseline cumulative rate function can be estimated in the same way as that in Model 1. Intuitively, if all subjects are under observation up to time τ the total number of events of each subject contains all the information about β. Note that . Following E(zi|xi)=1 we have
that is, the ratio of mi to F(yi) projects the number of events in [0, τ]. We can derive the inferential results for β based on a class of unbiased estimating equations given by
| (2) |
where , γ = (η,β′)′, η=log Λ0(τ), and wi is a weight function depending on (xi, β, Λ0). If Λ0 is a known function, the optimal weight is given by
(Godambe, 1960). In practice, however, F is estimated with a convergence rate of n1/3, and hence the efficiency gain is unknown when F̂n is used to replace F in the optimal weight function.
We denote the solutions of (2), with F replaced by F̂n, by . In the Appendix we show that, under Conditions 1–4, |β̂n−β|2→0 almost surely as n→∞, where |·| represents the usual Euclidean L2-norm. Moreover, using the estimator obtained by solving (2), we estimate the baseline cumulative rate function Λ0(t)=F(t)Λ0(τ) by Λ̂n(t)=F̂n(t)eη̂n. The estimator Λ̂n satisfies the following strong consistency property: d(Λ̂n1[0,t], Λ01[0,t])→0 almost surely for all t∈[0, τ2] as n→0. The derivation of the asymptotic distribution of β̂n and Λ̂n(t) is a challenging problem and is left for future research.
4. Simulations and data analysis
4·1. Monte Carlo simulations
Four sets of simulation studies with moderate, n=100, and large, n=1000, sample sizes were conducted to evaluate the performance of the proposed nonparametric and semiparametric estimators. We used Λ0(t)=2t for t∈[0, 10] and conducted the simulations using 1000 replications. The first simulation study compared the efficiency of the proposed nonparametric estimator to that of the nonparametric maximum likelihood estimator (Wellner & Zhang, 2000) and the nonparametric maximum pseudolikelihood estimator (Sun & Kalbfleisch, 1995) under the assumption of independent observation process. To be specific, we set z≡1 and generated K from a discrete uniform distribution on {1, 2, …, 6}. The K distinct observation times t1, …, tK were order statistics of independent and identically distributed uniform random variables on [0, 10], and observation times were rounded to the second decimal place. The second set of simulation studies examined the bias in these three nonparametric estimators when the independence assumption is violated. Let . For z>1, K was generated from a discrete uniform distribution on {1, 2, …, 8} and t1, …, tK were order statistics of K independent and identically distributed exponential random variables with mean 2; for z≤1, K was generated from a discrete uniform distribution on {1, …, 6} and t1, …, tK were order statistics of K independent and identically distributed uniform random variables on [0, 10]. Thus, subjects with z>1 have a higher event rate and tend to be observed more frequently than patients with z≤1.
Table 1 gives the Monte Carlo bias and standard error estimates of these three nonparametric estimators at selected time points. Table 1(a) shows that the bias in these three nonparametric estimators is very small when observation times are independent of the event process. The proposed estimator Λ̂n(t) is more efficient, with smaller Monte Carlo standard errors, than the nonparametric maximum pseudolikelihood estimator, and is slightly less efficient than the nonparametric maximum likelihood estimator. When the sample size is large, the proposed estimator is highly efficient relative to the nonparametric maximum pseudolikelihood estimator. In Table 1(b), where the pattern of observation is correlated with the distribution of serial events, the nonparametric maximum likelihood estimator and the nonparametric maximum pseudolikelihood estimator are substantially biased, while the proposed estimator still gives valid results.
Table 1.
Simulation results for nonparametric estimators under the assumptions of independent and informative observation times
| (a) Independent observation times | ||||||||
|---|---|---|---|---|---|---|---|---|
| n | t | Λ0(t) | Proposed | NPMLE | NPMPLE | |||
| Bias | SE | Bias | SE | Bias | SE | |||
| 100 | 1·0 | 2 | −0·031 | 0·397 | −0·030 | 0·392 | −0·060 | 0·418 |
| 3·0 | 6 | −0·006 | 0·488 | −0·019 | 0·476 | −0·058 | 0·633 | |
| 5·0 | 10 | −0·024 | 0·542 | −0·047 | 0·505 | −0·063 | 0·723 | |
| 7·0 | 14 | −0·015 | 0·654 | −0·055 | 0·559 | −0·065 | 0·844 | |
| 9·0 | 18 | 0·004 | 0·804 | −0·051 | 0·643 | −0·045 | 0·904 | |
| 1000 | 1·0 | 2 | 0·011 | 0·156 | 0·010 | 0·154 | 0·007 | 0·200 |
| 3·0 | 6 | 0·005 | 0·202 | −0·002 | 0·189 | −0·017 | 0·276 | |
| 5·0 | 10 | 0·014 | 0·210 | −0·002 | 0·193 | −0·030 | 0·336 | |
| 7·0 | 14 | 0·011 | 0·241 | −0·009 | 0·211 | −0·019 | 0·374 | |
| 9·0 | 18 | 0·025 | 0·277 | −0·003 | 0·218 | −0·023 | 0·408 | |
| (b) Informative observation times | ||||||||
|---|---|---|---|---|---|---|---|---|
| n | t | Λ0(t) | Proposed | NPMLE | NPMPLE | |||
| Bias | SE | Bias | SE | Bias | SE | |||
| 100 | 1·0 | 2 | −0·009 | 0·271 | 0·015 | 0·271 | 0·447 | 0·454 |
| 3·0 | 6 | −0·007 | 0·553 | −0·040 | 0·512 | 0·361 | 0·795 | |
| 5·0 | 10 | 0·049 | 0·874 | −0·543 | 0·722 | −1·183 | 0·949 | |
| 7·0 | 14 | 0·008 | 1·198 | −1·699 | 0·859 | −3·395 | 1·067 | |
| 9·0 | 18 | 0·127 | 1·532 | −2·987 | 1·021 | −5·324 | 1·349 | |
| 1000 | 1·0 | 2 | 0·000 | 0·104 | 0·021 | 0·101 | 0·484 | 0·194 |
| 3·0 | 6 | 0·015 | 0·214 | −0·021 | 0·182 | 0·431 | 0·345 | |
| 5·0 | 10 | 0·031 | 0·343 | −0·509 | 0·258 | −1·157 | 0·407 | |
| 7·0 | 14 | 0·035 | 0·459 | −1·580 | 0·309 | −3·321 | 0·459 | |
| 9·0 | 18 | 0·038 | 0·564 | −2·901 | 0·340 | −5·448 | 0·508 | |
NPMLE, nonparametric maximum likelihood estimator; NPMPLE, nonparametric maximum pseudolikelihood estimator; Bias and SE are the Monte Carlo sample mean and standard deviation of the 1000 estimates of Λ0(t).
We evaluated the performance of the proposed semiparametric estimator in the last two sets of simulation studies. The covariate x was generated from a Ber(0·5) random variable, and z was from a Ga(2, 0·5) distribution. We set the cumulative intensity function to be zexβΛ0(t) with β=−1. In the third simulation study we compared the efficiency of the proposed semiparametric estimator to that of the Sun–Wei estimator under the assumption that the observation time process is a nonhomogeneous Poisson process with cumulative intensity function given by log(1+2t)ex/2. Thus, the observation pattern depends only on observed covariates but not on the subject’s risk of serial events. The proposed semiparametric estimation procedure, with unit weights, wi=1, in the estimating equations (2), and the Sun–Wei estimator, with and without assuming that the observation process follows a proportional rate model, were applied to each simulated dataset. Table 2 gives the Monte Carlo bias and standard error of the estimated β, and Table 3 gives estimates of Λ0(t) at selected time points using the proposed semiparametric method. As shown in Table 2, both estimators have small biases; moreover, the proposed semiparametric estimator outperforms the Sun–Wei estimators in that it gives smaller Monte Carlo standard errors.
Table 2.
Bias and standard error of β̂ using the proposed semi-parametric method and the Sun–Wei estimators when the observation time process depends only on observed covariates
| n=100 | n=1000 | |||||
|---|---|---|---|---|---|---|
| Proposed | SWa | SWb | Proposed | SWa | SWb | |
| Bias | −0·005 | 0·464 | −0·036 | −0·003 | 0·460 | −0·040 |
| SE | 0·161 | 0·219 | 0·191 | 0·052 | 0·067 | 0·059 |
SWa, the Sun–Wei estimator of β without modelling the observation pattern; SWb, the Sun–Wei estimator with modelling the observation pattern; Bias and SE, Monte Carlo sample mean and standard deviation for the 1000 estimates.
Table 3.
Bias and standard error of Λ̂0(t) using the proposed semiparametric method when the observation time process depends only on observed covariates
| t | Λ0(t) | n=100 | n=1000 | ||
|---|---|---|---|---|---|
| Bias | SE | Bias | SE | ||
| 1·0 | 2 | 0·005 | 0·394 | 0·006 | 0·136 |
| 3·0 | 6 | 0·024 | 0·879 | 0·004 | 0·301 |
| 5·0 | 10 | 0·093 | 1·352 | 0·033 | 0·464 |
| 7·0 | 14 | 0·175 | 1·887 | 0·073 | 0·594 |
| 9·0 | 18 | 0·204 | 2·550 | 0·082 | 0·814 |
Bias and SE, the Monte Carlo sample mean and standard deviation of the 1000 estimates of Λ0(t).
The last simulation study examined the validity of the two semiparametric estimators in a setting where both the event process and the observation pattern are correlated with z. For x=1 and z>1, K was generated from a discrete uniform distribution on {1, 2, …, 8} and t1, …, tK were order statistics of K independent and identically distributed exponential random variables with mean 2; otherwise, K was generated from a discrete uniform distribution on {1, …, 6} and t1, …, tK were order statistics of K independent and identically distributed uniform random variables on [0, 10]. Tables 4 and 5 show that bias in the proposed estimator is almost ignorable, while the Sun–Wei estimators yield substantial bias in estimating regression parameters.
Table 4.
Bias and standard error of β̂ from the proposed semiparametric method and the Sun–Wei estimators when the observation times are informative
| n=100 | n=1000 | |||||
|---|---|---|---|---|---|---|
| Proposed | SWa | SWb | Proposed | SWa | SWb | |
| Bias | −0·009 | 0·246 | 0·932 | −0·001 | 0·245 | 0·928 |
| SE | 0·123 | 0·153 | 0·153 | 0·033 | 0·049 | 0·048 |
SWa, the Sun–Wei estimator without modelling the observation pattern; SWb, the Sun–Wei estimator with modelling the observation pattern; Bias and SE, Monte Carlo sample mean and standard deviation for the 1000 estimates of β.
Table 5.
Bias and standard error of Λ̂0(t) using the proposed semiparametric method when the observation times are informative
| t | Λ0(t) | n=100 | n=1000 | ||
|---|---|---|---|---|---|
| Bias | SE | Bias | SE | ||
| 1·0 | 2 | 0·001 | 0·525 | −0·005 | 0·132 |
| 3·0 | 6 | 0·045 | 1·698 | 0·003 | 0·220 |
| 5·0 | 10 | 0·088 | 2·560 | 0·036 | 0·296 |
| 7·0 | 14 | 0·142 | 3·663 | 0·010 | 0·375 |
| 9·0 | 18 | 0·217 | 4·529 | 0·033 | 0·463 |
Bias and SE, the Monte Carlo sample mean and standard deviation of the 1000 estimates of Λ0(t).
4·2. Data analysis
We used a subset of data from the bladder tumour study conducted by the Veterans Administration Cooperative Urological Research Group (Byar, 1980) to illustrate the proposed methods. All the recruited patients had superficial bladder tumours before entering the study, and were randomly allocated into one of the three treatment groups; namely placebo, thiotepa and pyridoxine. Many patients experienced multiple tumour occurrences after enrolment, and new tumours were removed at follow-up clinic visits. We set τ=30 months and compared the thiotepa group with the placebo group in tumour occurrence rate during the first 30 months.
Figure 1(a) shows the estimated cumulative rate function for placebo and thiotepa groups using the proposed nonparametric method, the nonparametric maximum likelihood estimator and the nonparametric maximum pseudolikelihood estimator. Patients treated with thiotepa had a lower tumour occurrence rate, indicating the effectiveness of thiotepa in the first 30 months. Next, we applied the proposed semiparametric method and the Sun–Wei estimators to the bladder tumour data, with x an indicator of whether or not a patient was in the thiotepa group. With the proposed method, the estimate of the regression coefficient of the treatment indicator is −0·62 with a bootstrap standard error of 0·43, yielding an estimated tumour occurrence rate in the thiotepa group of 0·54=e−0·62 times that of the placebo group during the first 30 months of follow-up. The estimated baseline cumulative rate function with 95% pointwise bootstrapped confidence interval at selected time points is given in Fig. 1(b). With the Sun–Wei estimators, the estimated coefficient of the treatment indicator is −0·88 with a bootstrap standard error of 0·41 under the assumption that the observation pattern is the same for both treatment groups, and is −1·48 with a bootstrap standard error of 0·40 under the assumption that the observation process follows a proportional rate model. The proposed method estimates a smaller treatment effect in the tumour occurrence rate than do the Sun–Wei estimators.
Fig. 1.

Bladder tumour study. (a) Nonparametric estimation of cumulative rate function by treatment group; (b) Semiparametric estimation of baseline cumulative rate function with pointwise bootstrap 95% confidence intervals.
5. Final remarks
We have applied our method to data generated from other than the working Poisson process, and concluded that the inferential results, not shown here, are still valid. Moreover, the Poisson process assumption is not required in our proof for the strong consistency. This indicates that the proposed methods have the same robustness property as those proposed by Wellner & Zhang (2000) and Zhang (2002), namely that the validity of the proposed methods does not depend on the underlying counting process conditioning on the frailty variable under Model 1 or conditioning on the frailty variables and covariates under Model 2. We have also considered in our simulation studies scenarios where the scheduled visits are fixed by design and the chance of missing a visit depends on the frailty z. The results, not shown, suggest that the proposed method gives valid results, while the nonparametric maximum likelihood estimator and the nonparametric pseudolikelihood estimator are substantially biased.
The standard asymptotic theory applies to the proposed method when the schedules of visits are fixed by study design: instead of maximising a nonparametric conditional likelihood with infinite-dimensional parameters, the proposed estimation procedure maximises a conditional likelihood with finite number of parameters. This asymptotic normality with a convergence rate of n1/2 is expected for the proposed estimators.
It is important to indicate that the proposed methodology relies on the assumption that the effect of frailty on the intensity function is multiplicative. This assumption is widely used in modelling clustered survival times, where a parametric assumption for the frailty distribution is usually required for statistical inference. The estimation procedure proposed in this paper does not rely on the frailty distribution and hence is more robust against departure from the true frailty distribution. While the use of multiplicative frailty is crucial to our methodology, the technique for checking the multiplicative assumption needs to be developed in future research.
Acknowledgments
The authors thank Professor Wei Pan for useful discussions and Yan Zheng and Tai Feng for the computing support. The authors thanks the editor and the associate editor, whose comments greatly improved the paper.
Appendix
Proofs
Sketch proof of Theorem 1
We only state the main results for the proof of Theorem 1. Readers are referred to the technical report available at http://www.bepress.com/jhubiostat/paper90 for details. The proof of strong consistency of F̂n closely follows Wellner & Zhang (2000). Arguing as in the proof of Theorem 4·2 in Wellner & Zhang (2000), we can show that d(F̂n1[0,t], cF1[0,t])→ 0 almost surely for any t ∈ [0, τ2], where τ2=sup{t : pr(Y ≥t)>0} and c is a fixed constant.
Now we prove that Λ̂n(t) is a consistent estimator of Λ0(t) for t in [0, τ2]. We write
Let
 denote the Borel sets in
denote the Borel sets in
 . We define a new measure ν2 on ([τ1, τ],
. We define a new measure ν2 on ([τ1, τ],
 ) by ν2(B)=E1[yi∈B]. Obviously, ν2 is dominated by the measure ν. For a δn>0 with δn→0 as n → ∞, we define a class
={ f : f (t)=N(t){g−1(t)−c−1F−1(t)}, where g is nondecreasing and nonnegative with positive lower bound in [τ1, τ] and d(g1[0,tau;], cF1[0,tau;])≤δn. For a sufficiently large n,
) by ν2(B)=E1[yi∈B]. Obviously, ν2 is dominated by the measure ν. For a δn>0 with δn→0 as n → ∞, we define a class
={ f : f (t)=N(t){g−1(t)−c−1F−1(t)}, where g is nondecreasing and nonnegative with positive lower bound in [τ1, τ] and d(g1[0,tau;], cF1[0,tau;])≤δn. For a sufficiently large n,
where ℙn denotes the empirical measure and P denotes the probability measure.
Under Condition 4 and applying Theorems 2·7·5 and 2·4·1 in van der Vaart & Wellner (1996), we can show that
is a Glivenko–Cantelli class. Thus ||ℙn−P|| →0 almost surely. Moreover,
→0 almost surely. Moreover,
for some c>0 following from the fact that ν2 is dominated by ν and the Hölder inequality. This implies that I→0 almost surely. The quantity II converges to 0 almost surely because E{mi/F(yi)}=Λ0(τ) and by the law of large numbers. Thus we show that Λ̂n(τ)−c−1Λ0(τ) converges to 0 almost surely. It is easy to see that Λ̂n(t)−Λ0(t)→0 almost surely for ν-almost-all t∈[0, τ2], and it follows from the dominated convergence theroem, with dominating functions Λ0(τ2) since ν is a finite measure, that d(Λ̂n1[0,t], Λ01[0,t])→0 almost surely for any t∈[0, τ2].
Sketch proof of Theorem 2
We apply Theorem 3·2·5 of van der Vaart & Wellner (1996) to derive the rate of convergence. To do so, we verify that the conditions of that theorem hold in our problem with Conditions 1–7.
We rewrite , where Λ*(tj)=Λ(tj)/Λ(y) for j=1, 2, …, k. We define
| (A1) |
where ΔΛ0(tj)=Λ0(tj)−Λ0(tj−1) and ΔΛ*(tj)=Λ*(tj)−Λ*(tj−1).
First, we show that performing Taylor expansion on the right-hand side of (A1) along with Conditions 5 and 6 yields for any Λ in a neighbourhood of Λ0. Here C represents a generic constant.
Next, we consider a class
 ={q(Λ; D)−q(Λ0; D) : d(Λ, Λ0)<δ} for some δ>0 and δ=o(1). For any f=q(Λ; D)−q(Λ0; D)∈
, using Conditions 1 and 7, we can obtain || f ||P,B≤Cδ, where ||·||P,B is the Bernstein norm defined as || f ||P,B={2P(e|f|−1−| f |}1/2. Hence, by Lemma 3·4·3 of van der Vaart & Wellner (1996),
={q(Λ; D)−q(Λ0; D) : d(Λ, Λ0)<δ} for some δ>0 and δ=o(1). For any f=q(Λ; D)−q(Λ0; D)∈
, using Conditions 1 and 7, we can obtain || f ||P,B≤Cδ, where ||·||P,B is the Bernstein norm defined as || f ||P,B={2P(e|f|−1−| f |}1/2. Hence, by Lemma 3·4·3 of van der Vaart & Wellner (1996),
where J̃
[](δ,
, ||·||P,B) is the bracketing integral of the class of functions
and is defined by
Finally, using Conditions 5–7, we can argue that the ε-bracketing number of class
with Bernstein norm is controlled by e1/ε, that is N[](ε,
, ||·||P,B) = O(ε1/ε). Hence
This implies that the function φn(δ), which is critical for the rate of convergence based on Theorem 3·2·5 of van der Vaart & Wellner (1996), is given by
It can be easily verified that φn(δ)/δ is a decreasing function of δ and n2/3φn(n−1/3)=2n1/2, so that n1/3d(Λ̂n, Λ0)=OP(1) because of Theorem 3·2·5 of van der Vaart & Wellner (1996). %
Consistency of β̂n
The consistency of F̂n under Model 2 can be established by arguing in the same way as described above, except for replacing zi with . We now examine the consistency of β ^n obtained by solving the estimating function (2). The consistency property of the estimator obtained from the alternative estimating function can be proven using a similar argument. Define the function . It can be shown that the function U converges to 0 almost surely when evaluated at γ=(log{Λ0(τ)/c}, β′) ′. Furthermore, it is easy to see that the derivative of U evaluated at (log{Λ0(τ)/c}, β ′) ′ is negative definite. Applying Taylor expansion to U(γ), one can show that the solution of (2), that is , converges to γ=(log{Λ0(τ)/c}, β ′) ′ almost surely. Thus we prove that β̂n converges to β almost surely.
Based on the above sketch proof, η̂n converges to log{Λ0(τ)/c} almost surely. Along with the fact that d(F̂n1[0,t], cF1[0,t])→ 0 almost surely for any t∈[0, τ2], it can be shown that d(Λ̂n1[0,t], Λ01[0,t])=d(F̂n1[0,t]eη̂n, Λ01[0,t])→0 for any t∈[0, τ2].
Contributor Information
CHIUNG-YU HUANG, Email: huangchi@niaid.nih.gov, Biostatistics Research Branch, National Institute of Allergy and Infectious Diseases, National Institutes of Health, Bethesda, Maryland 20892, U.S.A.
MEI-CHENG WANG, Email: ncwang@jhsph.edu, Department of Biostatistics, Bloomberg School of Public Health, Johns Hopkins University, Baltimore, Maryland 21205, U.S.A.
YING ZHANG, Email: ying-j-zhang@uiowa.edu, Department of Biostatistics, University of Iowa, Iowa City, Iowa 52242, U.S.A.
References
- Balshaw RF, Dean CB. A semiparametric model for the analysis of recurrent-event panel data. Biometrics. 2002;58:324–31. doi: 10.1111/j.0006-341x.2002.00324.x. [DOI] [PubMed] [Google Scholar]
- Byar DP. The veterans administration study of chemoprophylaxis for recurrent stage I bladder tumors: comparisons of placebo, pyridoxine, and topical thiotepa. In: Pavone-Macaluso M, Smith PH, Edsmyr F, editors. Bladder Tumors and Other Topics in Urological Oncology. New York: Plenum; 1980. pp. 363–70. [Google Scholar]
- Godambe VP. An optimum property of regular maximum likelihood estimation. Ann Math Statist. 1960;31:1208–12. [Google Scholar]
- Sun J, Kalbfleisch JD. Estimation of the mean function of point processes based on panel count data. Statist Sinica. 1995;5:279–89. [Google Scholar]
- Sun J, Wei LJ. Regression analysis of panel count data with covariate-dependent observation and censoring times. J R Statist Soc B. 2000;62:293–302. [Google Scholar]
- Thall PF, Lachin JM. Analysis of recurrent events: nonparametric methods for random-interval count data. J Am Statist Assoc. 1988;83:339–47. [Google Scholar]
- Turnbull BW. The empirical distribution function with arbitrarily grouped, censored and truncated data. J R Statist Soc B. 1976;38:290–5. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer-Verlag; New York: 1996. [Google Scholar]
- Wang MC, Qin J, Chiang CT. Analyzing recurrent event data with informative censoring. J Am Statist Assoc. 2001;96:1057–65. doi: 10.1198/016214501753209031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wellner JA, Zhang Y. Two estimators of the mean of a counting process with panel count data. Ann Statist. 2000;28:779–814. [Google Scholar]
- Wellner JA, Zhang Y, Liu H. A semiparametric regression model for panel count data: when do pseudo-likelihood estimators become badly inefficient? In: Lin DY, Heagerty PJ, editors. Proceedings of the Second Seattle Biostatistical Symposium: Analysis of Correlated Data. New York: Springer-Verlag; 2004. pp. 143–74. [Google Scholar]
- Zhang Y. A semiparametric pseudolikelihood estimation method for panel count data. Biometrika. 2002;89:39–48. [Google Scholar]