

Abstract
We analyse two models describing disease transmission and control on regular and small-world networks. We use simulations to find a control strategy that minimizes the total cost of an outbreak, thus balancing the costs of disease against that of the preventive treatment. The models are similar in their epidemiological part, but differ in how the removed/recovered individuals are treated. The differences in models affect choice of the strategy only for very cheap treatment and slow spreading disease. However for the combinations of parameters that are important from the epidemiological perspective (high infectiousness and expensive treatment) the models give similar results. Moreover, even where the choice of the strategy is different, the total cost spent on controlling the epidemic is very similar for both models.
Introduction
Networks can provide a good representation of how individuals interact [1]–[3]. Despite many simplifications, models based upon network structures have successfully been used in many applications [4], [5] including spread of rumours and news [3] and computer viruses [1]. A particularly important application of network models has been in epidemiology [6]–[10] of plant, animal and human pathogens [11]–[13]. Modelling in epidemiology plays an important role: It allows us to estimate the scale of the epidemic, to predict how far the disease could spread and to design effective ways of control. All these tasks need to be achieved despite the fact that in many cases we are not able to observe the whole process and/or measure all relevant parameters [14]. The state of individuals, whether they are susceptible, infected and pre-symptomatic, infected and symptomatic or recovered, is in particular often difficult to ascertain [15]. Despite these uncertainties it is possible to use modelling to design effective control measures leading to the lowest overall cost of the epidemic outbreak [16]–[19] and a number of studies have used network models to address this issue [14], [20]–[23].
Economic and behavioural aspects influence the spread of disease and affect the choice of a control strategy. For instance, if the treatment does not cost anything, the best strategy is to control the whole population. Contrarily, for very expensive control measures it might be better to refrain from treatment at all. Optimisation of total disease costs, including palliative cost associated with disease cases and cost of appropriate control measures, leads to appearance of three basic strategies [20]: The Global Strategy (GS) whereby all individuals are treated regardless of their status can be contrasted with the Null Strategy (NS) when the public authorities completely refrain from preventive treatment and concentrate on palliative treatment of cases. The Local Strategy (LS) emerges for intermediate costs of treatment. In this case, not only detected symptomatic individuals are treated preventively, but the treatment includes also their neighbours.
The work so far has concentrated on the role of processes associated with disease spread on the broad choice of the treatment strategy [20] and on the details of the local strategy [21]. However, the spontaneous recovery also may affect the results and in the current paper we explore this dependence in detail.
We extend our results to two contrasting and yet complementary models in which we either treat individuals that have been through the disease or not. Whether the removed individuals (i.e. those who have been through the disease but then spontaneously recover or die) are part of the treatment plan depends on the type of the disease agent. The key factor in choosing the right model is whether it is possible – and desirable – to distinguish such individuals from those who are susceptible. If the removed class is identified with dead individuals, the distinction is very clear. However, if the removal means recovery and immunity, it might not be possible to identify those who are immune. For example, many people might not want to report that they have been through the infection, or the disease symptoms might be relatively mild. For animal diseases, immunological testing might be the only way to identify such individuals, but this leads to increased costs and test results might not be reliable. In other situations, we might know the status of the individual, but might not be able to target the treatment to susceptible and infected individuals. Plant and crop diseases might serve as an example here, whereby it might be easier to treat the whole field regardless of whether some plants there are already immune to the disease.
Although such individuals do not contribute to the spread of the disease, the cost of treating them affects the economic side of the evaluation and therefore leads to changes in the design of the optimal strategy. We study this case in our paper and show that although there is a difference in the choice of the strategy (LS vs. GS) and the resulting number of treated individuals, there is only a small difference in the overall total cost of the epidemic.
Methods
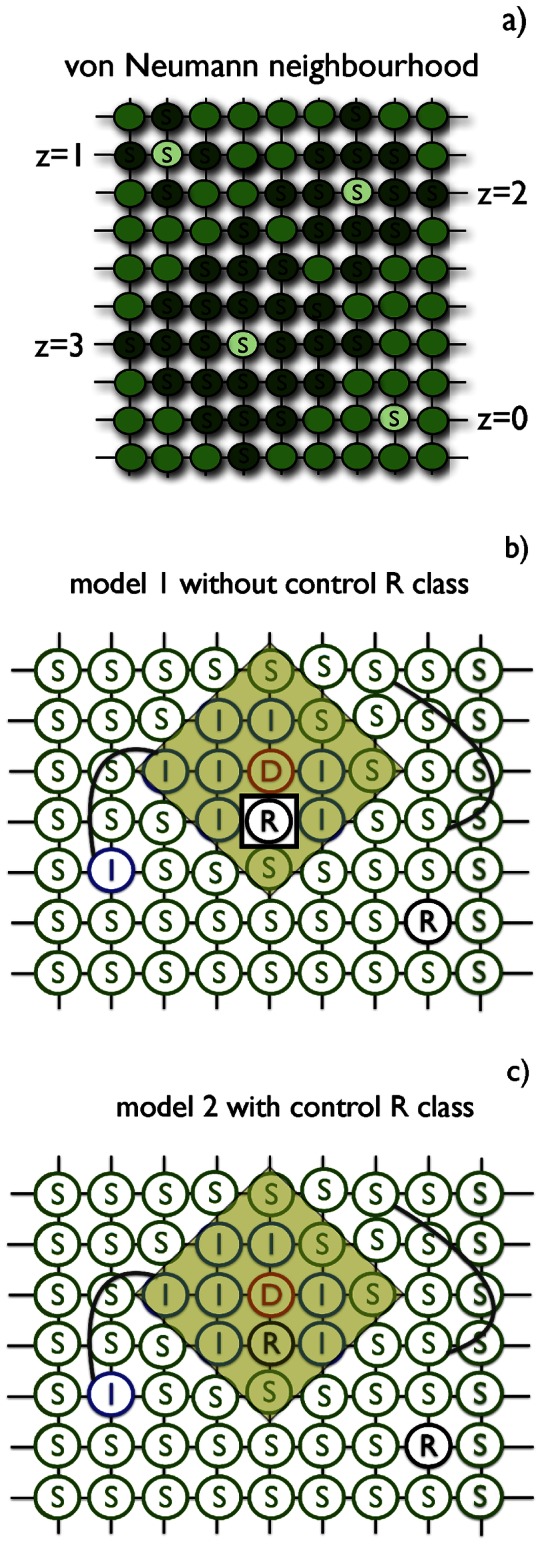
We assume that individuals are located at nodes of a square lattice that represents geographical distribution of hosts, see fig. 1. On this lattice, we define a local infection neighbourhood of order 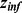 as a von Neumann neighbourhood. In that neighbourhood
as a von Neumann neighbourhood. In that neighbourhood 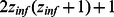 individuals are included, involving the central one. We additionally define
individuals are included, involving the central one. We additionally define 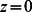 as corresponding to this central individual, which means that this individual is not in contact with anyone, while
as corresponding to this central individual, which means that this individual is not in contact with anyone, while 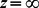 corresponds to the whole population, see fig. 1. To increase realism of our analysis, we also consider the small-world model [24], [25] which adds a certain number of links among randomly chosen nodes, thus adding some long-range connections to the regular lattice ones [24]. Although the disease can spread along these long-range links, we assume that they are so difficult to identify that they are not included in any treatment strategy (see below).
corresponds to the whole population, see fig. 1. To increase realism of our analysis, we also consider the small-world model [24], [25] which adds a certain number of links among randomly chosen nodes, thus adding some long-range connections to the regular lattice ones [24]. Although the disease can spread along these long-range links, we assume that they are so difficult to identify that they are not included in any treatment strategy (see below).
Figure 1. (a) Definition of the von Neumann neighborhood of different values of order  , as used in the simulations and analysis.
, as used in the simulations and analysis.
(b) Illustration of spread of a disease (model 1) on a regular network with additional randomly chosen long-range links represented by curved lines (approximation of a small-world network). The applied control of radius  is centered on node D (yellow shaded area). Note that in model 1 the R individuals are excluded from the control and thus non-treated. (c) Representation of model 2: All individuals contained in the control neighbourhood of order
is centered on node D (yellow shaded area). Note that in model 1 the R individuals are excluded from the control and thus non-treated. (c) Representation of model 2: All individuals contained in the control neighbourhood of order  are preventively treated and moved to V class. In both models treatment does not take into account individuals connected by additional long-range links. S, I, D, R symbols stand for Susceptible, Pre-symptomatic, Symptomatic and Recovered, respectively. The order
are preventively treated and moved to V class. In both models treatment does not take into account individuals connected by additional long-range links. S, I, D, R symbols stand for Susceptible, Pre-symptomatic, Symptomatic and Recovered, respectively. The order  of infection neighbourhood equals
of infection neighbourhood equals 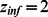 in (b) and (c).
in (b) and (c).
The epidemiological SIDRV model is a standard SIR (Susceptible-Infected-Removed) model [26], modified to account for latent period and preventive and responsive treatment (fig. 2), see also [21]. Taking into consideration the latent period, the infectious class is now composed of two separate, pre-symptomatic and symptomatic classes (S, I, D, R and V, respectively). Number of individuals in each class is denoted by 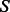 ,
, 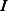 ,
, 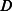 ,
, 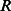 , and
, and  , respectively, and
, respectively, and 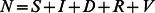 is the total constant number of individuals in the population.
is the total constant number of individuals in the population.
Figure 2. Model scheme of disease transition (black lines) and control (orange lines).

In model 2 there is a possible transition between recovered (R) and treated (V) class when R-individual is in the control neighbourhood of any symptomatic D-individual.
Initially, all individuals are assumed to be susceptible (S). The epidemic is initiated by an introduction of few infected but pre-symptomatic (I) individuals, which are located randomly and uniformly over the whole network. Each infected individual is in contact with a fixed number of other individuals in its infection neighbourhood 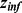 . These connections do not change during the epidemic. The disease is transmitted along these contact routes with probability
. These connections do not change during the epidemic. The disease is transmitted along these contact routes with probability 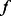 per contact. Upon a successful infection, the susceptible individual moves to the pre-symptomatic class.
per contact. Upon a successful infection, the susceptible individual moves to the pre-symptomatic class.
Each infected pre-symptomatic individual moves to a symptomatic class (D) with probability 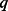 . Detected individuals still can infect other individuals. Subsequently, each detected individual can spontaneously move to a removed class (R) with probability
. Detected individuals still can infect other individuals. Subsequently, each detected individual can spontaneously move to a removed class (R) with probability  . However, detection also triggers a control event with probability
. However, detection also triggers a control event with probability  and subsequently a number of individuals selected from the von Neumann neighbourhood of order
and subsequently a number of individuals selected from the von Neumann neighbourhood of order  centered at the detected individual move to a treated class (V); for details see below. Neither R nor V can infect or be re-infected any more.
centered at the detected individual move to a treated class (V); for details see below. Neither R nor V can infect or be re-infected any more.
According to the responsive treatment two versions of the SIDRV model have considered: (i) model 1 with control of all individuals in selected area except removed (R class), see fig. 1b, and (ii) model 2 with control of all individuals in selected area regardless of their status (and thus including R), see fig. 1c.
The control event is localized within a von Neumann neighbourhood of order  centred on a symptomatic individual. The order of control neighbourhood,
centred on a symptomatic individual. The order of control neighbourhood,  , can be different than the order of the infection neighbourhood,
, can be different than the order of the infection neighbourhood, 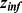 , and is typically found larger. Thus, a group of individuals in the treatment neighbourhood consists of a mixture of susceptible, infected pre-symptomatic, infected symptomatic and recovered individuals (preventive treatment). We have extended the definition of control neighborhood size in order to include the situation when no control is applied,
, and is typically found larger. Thus, a group of individuals in the treatment neighbourhood consists of a mixture of susceptible, infected pre-symptomatic, infected symptomatic and recovered individuals (preventive treatment). We have extended the definition of control neighborhood size in order to include the situation when no control is applied, 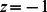 .
.
Simulations
All simulations have been performed on the lattice of 200 by 200 individuals with periodic boundary conditions. Simulations started with 40 initial infected foci, which corresponds to 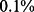 of the total population.
of the total population.
Control size,  , has been varied, while other parameters (such as
, has been varied, while other parameters (such as 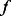 ,
, 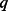 ,
,  ,
,  ,
, 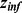 ,) have been kept constant. Each simulation has been run until
,) have been kept constant. Each simulation has been run until 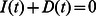 , which means that no infection can occur afterwards. At the end of the run all
, which means that no infection can occur afterwards. At the end of the run all 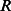 and
and 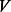 individuals have been counted, yielding information about severity of the epidemic as well as effectiveness of the treatment involved.
individuals have been counted, yielding information about severity of the epidemic as well as effectiveness of the treatment involved.
Effectiveness of control strategies
The effective control strategy is found by taking into account severity of the epidemic and its financial implications. In order to quantify the effectiveness of different control strategies we introduce the severity index, 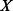 [15], [20]. By seeking the minimum values of
[15], [20]. By seeking the minimum values of 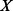 , we find which strategy is optimal.
, we find which strategy is optimal.
The severity index, 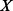 , includes two terms corresponding to the cost of infection and control. First term describes costs associated with death, absence in work, lower productivity etc., whereas second term includes costs of vaccine, quarantine, transport of drugs to infection foci, etc. We assume that
, includes two terms corresponding to the cost of infection and control. First term describes costs associated with death, absence in work, lower productivity etc., whereas second term includes costs of vaccine, quarantine, transport of drugs to infection foci, etc. We assume that 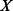 is a linear combination of number of individuals which have gone through disease and recovered (R) and treated individuals (V).
is a linear combination of number of individuals which have gone through disease and recovered (R) and treated individuals (V).
We measure 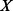 in units of a number of single infected individuals, so that:
in units of a number of single infected individuals, so that:
| (1) |
Here  represents a cost of treatment relative to the cost of infection and
represents a cost of treatment relative to the cost of infection and  stands for the control neighbourhood size. Both
stands for the control neighbourhood size. Both 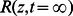 and
and 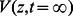 are counted at the end of a single simulation run.
are counted at the end of a single simulation run.
Effective strategy is equivalent to the minimal value of 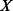 , which means that the epidemic is stopped at the manageable cost. In our simulation, the minimization of the severity index has been achieved by sweeping through different values of control neighbourhood size,
, which means that the epidemic is stopped at the manageable cost. In our simulation, the minimization of the severity index has been achieved by sweeping through different values of control neighbourhood size,  while keeping other parameters constant. Once
while keeping other parameters constant. Once  is set, we let the system evolve and then compute the value of
is set, we let the system evolve and then compute the value of 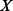 in the stationary state. We repeat this operation 100 times and then we denote with
in the stationary state. We repeat this operation 100 times and then we denote with 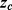 and
and 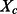 the average values, of
the average values, of  and
and 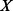 , corresponding to the minimum of
, corresponding to the minimum of 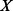 , so that
, so that
| (2) |
Results
In the absence of control, the disease will either progress through the population until it exhausts a large part of initially susceptible population (for large values of the infection probability 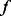 ) or it will quickly stop spreading (for small values of
) or it will quickly stop spreading (for small values of 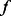 ). As control is applied in extended neighbourhood of radius
). As control is applied in extended neighbourhood of radius 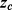 centred at a symptomatic individual, the number of recovered (R) individuals declines rapidly, see fig. 3a. Models 1 and 2 examined in this work differ in the way they treat or not treat the recovered class, R, cf fig. 1 We observe the same behaviour for both considered models (with and without treating R class). However, when we allow the control of R individuals (model 2), the proportion of recovered declines faster than in model 2, see fig. 3a (insert). The proportion of preventively treated individuals, V, in both models is similar for the whole range of control size,
centred at a symptomatic individual, the number of recovered (R) individuals declines rapidly, see fig. 3a. Models 1 and 2 examined in this work differ in the way they treat or not treat the recovered class, R, cf fig. 1 We observe the same behaviour for both considered models (with and without treating R class). However, when we allow the control of R individuals (model 2), the proportion of recovered declines faster than in model 2, see fig. 3a (insert). The proportion of preventively treated individuals, V, in both models is similar for the whole range of control size,  . With increasing control neighbourhood, V(z) grows very quickly, then drops near
. With increasing control neighbourhood, V(z) grows very quickly, then drops near 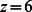 and finally rises monotonically till
and finally rises monotonically till 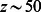 (fig. 3b). Combination of these two relationships,
(fig. 3b). Combination of these two relationships, 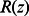 and
and 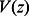 , according to eq(1), gives total cost of epidemic,
, according to eq(1), gives total cost of epidemic, 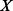 , as a function of
, as a function of  , see fig. 3c. For a very low treatment cost, e.g.
, see fig. 3c. For a very low treatment cost, e.g. 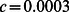 , total cost of control of epidemic,
, total cost of control of epidemic, 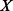 , is almost equal for both models, with difference less than
, is almost equal for both models, with difference less than 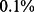 , see fig. 3c (insert). The choice of optimal strategies is different for model 1 (GS) than for model 2 (LS), although the corresponding X values are similar. In model 1 the minimal value of X corresponds to the highest value of control size,
, see fig. 3c (insert). The choice of optimal strategies is different for model 1 (GS) than for model 2 (LS), although the corresponding X values are similar. In model 1 the minimal value of X corresponds to the highest value of control size, 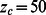 (GS), whereas in model 2, the minimum is identified with
(GS), whereas in model 2, the minimum is identified with 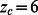 , (LS) fig. 3c.
, (LS) fig. 3c.
Figure 3. (a) The proportion of recovered individuals, 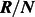 , (b) the fraction of treated (controlled) individuals,
, (b) the fraction of treated (controlled) individuals, 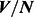 and (c) the total cost of epidemic as a fraction of the system size,
and (c) the total cost of epidemic as a fraction of the system size, 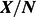 , for
, for 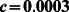 and various control sizes
and various control sizes  .
.
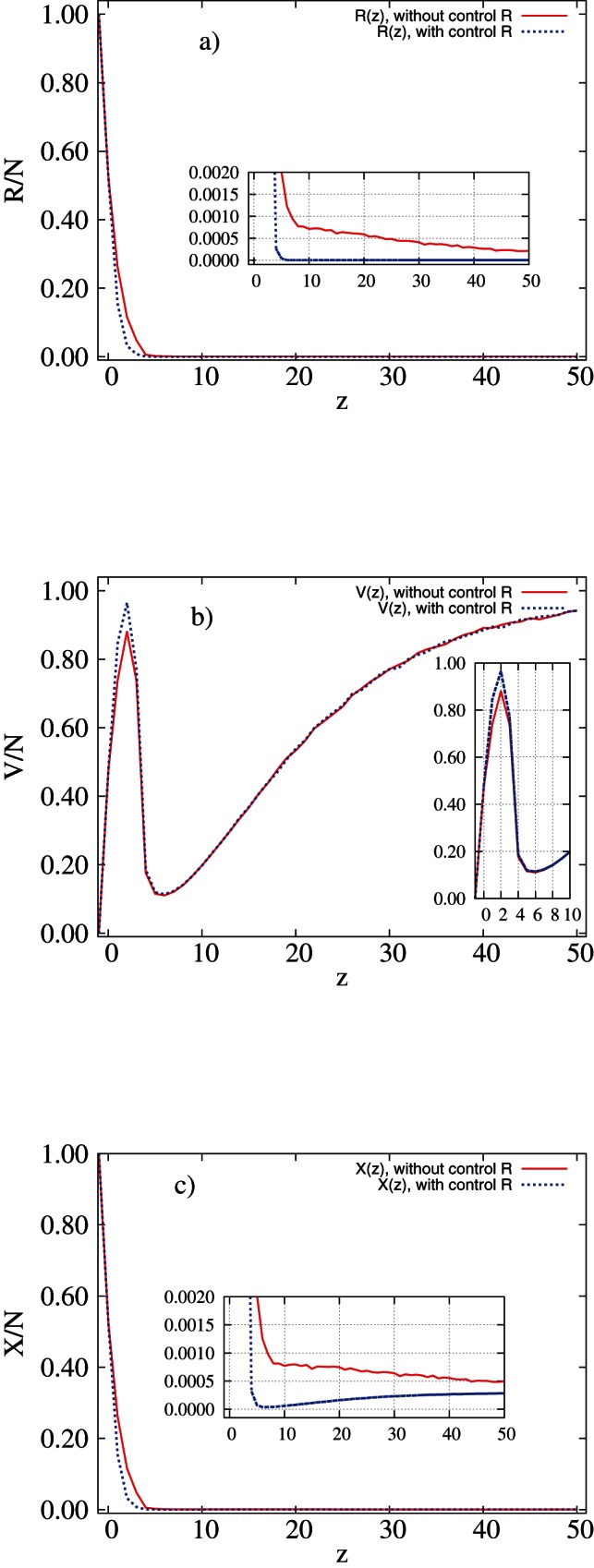
Red solid line: model 1; blue dotted line: model 2. Results of simulations with parameters 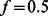 ,
, 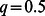 ,
, 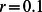 ,
, 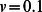 and
and 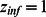 performed on regular networks. Inserts show the relevant magnifications of the graph.
performed on regular networks. Inserts show the relevant magnifications of the graph.
Regular networks – influence of recovery rate,  on control strategies
on control strategies
Increasing cost of treatment,  , decreases the optimal control neighbourhood,
, decreases the optimal control neighbourhood, 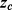 . For very cheap control the optimal scenario is identified with
. For very cheap control the optimal scenario is identified with 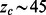 (GS) for model 1, regardless of the recovery rate,
(GS) for model 1, regardless of the recovery rate,  (fig. 4a). The more expensive the treatment, the higher the total costs spent on controlling outbreaks. This leads to change in optimal strategy, see fig. 4a, b. We cannot afford the preventive control of the whole population (GS) and have to shift into treating in neighbourhood of symptomatic individuals. We observe that
(fig. 4a). The more expensive the treatment, the higher the total costs spent on controlling outbreaks. This leads to change in optimal strategy, see fig. 4a, b. We cannot afford the preventive control of the whole population (GS) and have to shift into treating in neighbourhood of symptomatic individuals. We observe that 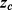 rapidly decreases with increasing costs, especially for model 1. For intermediate values of
rapidly decreases with increasing costs, especially for model 1. For intermediate values of  ,
, 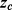 drops to
drops to 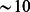 depending on recovery rate,
depending on recovery rate,  . Higher recovery rate,
. Higher recovery rate,  , results not only in a shorter plateaux for LS (see fig. 4a, b) but also moves the plateaux towards larger control size,
, results not only in a shorter plateaux for LS (see fig. 4a, b) but also moves the plateaux towards larger control size, 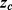 . As treatment becomes more expensive, second threshold is observed that describes change from LS to NS. Although for model 2 the global strategy is selected rather than the local one as for model 1 (fig. 4b, d) for the high values of recovery rate,
. As treatment becomes more expensive, second threshold is observed that describes change from LS to NS. Although for model 2 the global strategy is selected rather than the local one as for model 1 (fig. 4b, d) for the high values of recovery rate,  and low
and low  , the total cost of epidemic,
, the total cost of epidemic, 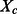 , does not differ much between the two models, see fig. 5. The highest costs are associated with fast spreading diseases (large
, does not differ much between the two models, see fig. 5. The highest costs are associated with fast spreading diseases (large 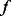 ) and expensive treatment (large
) and expensive treatment (large  ) for both models (upper right part of plots in fig. 5). Slow spreading disease does not significantly affect the budget for control regardless of treatment costs (lower part of plots in fig. 5) and model selected. For model 2 the global strategy is predominantly selected for high values of recovery rate
) for both models (upper right part of plots in fig. 5). Slow spreading disease does not significantly affect the budget for control regardless of treatment costs (lower part of plots in fig. 5) and model selected. For model 2 the global strategy is predominantly selected for high values of recovery rate  and at low
and at low  , in contrast to model 1 (fig. 4b, d) where the local strategy prevails. Despite these differences, the total cost of epidemic,
, in contrast to model 1 (fig. 4b, d) where the local strategy prevails. Despite these differences, the total cost of epidemic, 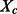 , does not differ between the two models, see fig. 5.
, does not differ between the two models, see fig. 5.
Figure 4. Control size 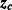 as a function of the treatment cost
as a function of the treatment cost  ((a) and (b)) and as a function of the recovery rate,
((a) and (b)) and as a function of the recovery rate,  , and the treatment cost,
, and the treatment cost,  ((c) and (d)) for model 1 (left column) and model 2 (right column).
((c) and (d)) for model 1 (left column) and model 2 (right column).

In (a) and (b) 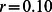 (red line),
(red line), 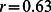 (green dashed line),
(green dashed line), 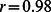 (blue dotted line). All simulations done on regular networks with parameters
(blue dotted line). All simulations done on regular networks with parameters 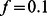 ,
, 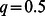 ,
, 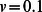 ,
, 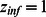 .
.
Figure 5. Total cost of epidemic at optimum, 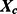 , as a function of the treatment cost
, as a function of the treatment cost  ((a) and (b)) and as a function of both infectiousnes,
((a) and (b)) and as a function of both infectiousnes, 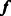 , and cost,
, and cost,  ((c) and (d)) for model 1 (left column) and model 2 (right column).
((c) and (d)) for model 1 (left column) and model 2 (right column).

In (a) and (b) 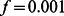 (red line),
(red line), 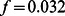 (green dashed line),
(green dashed line), 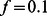 (blue dotted line). All simulations done with parameters
(blue dotted line). All simulations done with parameters 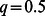 ,
, 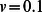 ,
, 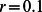 ,
, 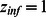 . Disease spreading on regular networks.
. Disease spreading on regular networks.
Regular networks – control strategies
Control size, 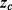 depends strongly on the cost of treatment,
depends strongly on the cost of treatment,  , and on the infectiousness of the disease,
, and on the infectiousness of the disease, 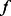 (fig. 6). For small
(fig. 6). For small 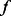 and
and  , both models suggest preventive control extended to the whole population (GS) (lower left part of each plot in fig. 6). In case of highly infectious disease and low treatment costs, model 1 predicts higher effectiveness of GS whereas model 2 selects LS as an optimal solution, upper left part of each plot in fig. 6. However, in both examined models the total cost of epidemic, X, is approximately the same, see fig. 3. As treatment cost,
, both models suggest preventive control extended to the whole population (GS) (lower left part of each plot in fig. 6). In case of highly infectious disease and low treatment costs, model 1 predicts higher effectiveness of GS whereas model 2 selects LS as an optimal solution, upper left part of each plot in fig. 6. However, in both examined models the total cost of epidemic, X, is approximately the same, see fig. 3. As treatment cost,  , increases, LS becomes the most cost-effective strategy. LS changes to NS when
, increases, LS becomes the most cost-effective strategy. LS changes to NS when  is of order 1 for small
is of order 1 for small 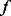 and of order 10 for high
and of order 10 for high 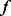 , regardless of the choice of the model or the exact value of
, regardless of the choice of the model or the exact value of  , compare fig. 6a, b with fig. 6c, d.
, compare fig. 6a, b with fig. 6c, d.
Figure 6. Control size, 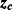 , as a function of both infectiousness,
, as a function of both infectiousness, 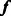 , and treatment cost,
, and treatment cost,  , for model 1 (left column) and model 2 (right column).
, for model 1 (left column) and model 2 (right column).

Simulation parameters for top panel ((a) and (b)): 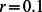 ; for bottom panel ((c) and (d)):
; for bottom panel ((c) and (d)): 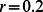 ; other parameters:
; other parameters: 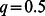 ,
, 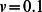 ,
, 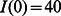 ,
, 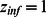 . Disease spreading on regular networks.
. Disease spreading on regular networks.
The main difference in selection of the optimal strategy occurs for small  . Changes in
. Changes in  affect only low
affect only low  regions. Increasing
regions. Increasing  from
from 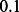 to
to 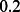 extends the region of validity of GS and moves it towards marginally larger values of
extends the region of validity of GS and moves it towards marginally larger values of  and high values of
and high values of 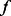 , fig. 6c, d. This trend is continued for larger values of
, fig. 6c, d. This trend is continued for larger values of  , see fig. 4, and can be associated with faster removal of individuals without triggering control events.
, see fig. 4, and can be associated with faster removal of individuals without triggering control events.
Small world networks – control strategies
Addition of small-world links does not change the behaviour for small 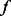 and
and  . However, there are substantial differences for large
. However, there are substantial differences for large 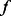 and the effect differs for the two models. Introducing disorder into the topology by adding long-range links changes ranges of optimal strategy for both considered models, compare fig. 6a, b with fig. 7. In model 1 small number of links, e.g.
and the effect differs for the two models. Introducing disorder into the topology by adding long-range links changes ranges of optimal strategy for both considered models, compare fig. 6a, b with fig. 7. In model 1 small number of links, e.g.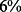 , fig. 7a, extends GS when disease spreads fast and costs are higher. The small number of links
, fig. 7a, extends GS when disease spreads fast and costs are higher. The small number of links 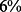 in model 2 does not change choice of control strategy, compare fig. 6b with fig. 7b, as in model 1 (top panel in fig. 7). Nonetheless, the total cost of epidemic remains almost the same. For large values of
in model 2 does not change choice of control strategy, compare fig. 6b with fig. 7b, as in model 1 (top panel in fig. 7). Nonetheless, the total cost of epidemic remains almost the same. For large values of 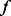 , destroying spatial structure by adding
, destroying spatial structure by adding 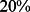 links results in only two effective strategies for highly infectious disease, GS for
links results in only two effective strategies for highly infectious disease, GS for 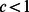 and NS otherwise, fig. 7c. The higher disorder (
and NS otherwise, fig. 7c. The higher disorder (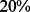 of long range links) in model 2, introduces GS when probability of spreading the epidemic,
of long range links) in model 2, introduces GS when probability of spreading the epidemic, 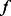 , increases, fig. 7d.
, increases, fig. 7d.
Figure 7. Control size, 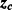 as a function of both infectiousness,
as a function of both infectiousness, 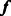 , and treatment cost,
, and treatment cost,  , for model 1 (left column) and model 2 (right column).
, for model 1 (left column) and model 2 (right column).

Number of additional links with respect to all the ones that can be added, on the top panel ((a) and (b)): 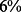 , on the bottom panel ((c) and (d)) –
, on the bottom panel ((c) and (d)) –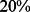 . Other simulation parameters:
. Other simulation parameters: 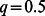 ,
, 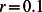 ,
, 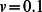 ,
, 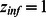 . Disease spreading on small-world networks.
. Disease spreading on small-world networks.
Discussion
The goal in designing cost-effective control strategy is to stop the epidemic outbreak very quickly at a minimal possible cost. In order to achieve this by using the local strategy (LS) we need to catch in the preventive control neighbourhood as many infected but pre-symptomatic individuals and to form a fire-break by treating around the infection focus. The extend of control is a crucial factor; however, it is not obvious by how much we need to enlarge the neighborhood in which preventive treatment is applied. We need to balance epidemiological and economic aspects of disease spread and control [27]. When we extend prevention to the whole population we might be able to successfully protect population from epidemic outbreaks but we will need to spend a lot of resources. On the other hand, when we apply control to too small neighbourhood, we will spend a lot but the disease will still invade the whole population. Under some conditions an optimal solution emerges in between these two extremes and can be associated with the Local Strategy; in other cases the extreme solutions (Global Strategy and Null Strategy) are optimal. As we have already shown [20], [21], the effective control neighbourhood can be chosen based on combined epidemiological and economic analysis.
The previous analyses [20], [21] left three key questions unanswered. Firstly, should we treat individuals that are already immune? Although the answer clearly depends on the nature of the disease and the treatment, some general principles can be established. This depends on the relative – economic, social and medical – cost of the preventive treatment compared to the palliative care (when we just let the disease to run its natural course). Secondly, are our results stable with respect to structural changes of the model? We illustrate the stability by considering two versions of the same model, with and without treating recovered R individuals. Finally, it is the dependence of the results on the actual recovery rate,  . In real-life applications it is difficult to distinguish between individuals that have been through the disease and those who do not. It is therefore very important to check whether the model and the resulting policy implications are robust with respect to the potential uncertainties. We show that this is the case in general but also identify the region of the parameters when the two models have different behavior (small
. In real-life applications it is difficult to distinguish between individuals that have been through the disease and those who do not. It is therefore very important to check whether the model and the resulting policy implications are robust with respect to the potential uncertainties. We show that this is the case in general but also identify the region of the parameters when the two models have different behavior (small  , large
, large 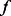 ).
).
Two contrasting cases can be distinguished in answer to the first question. If the treatment is costly and/or may lead to complications, the authorities might want to invest in testing individuals in order to find out who is and who is not naturally immune. This would identify individuals in the R class who then might not be offered the treatment. Contrariwise, if it is not immediately obvious what the actual status of the individual is and testing is expensive, lengthy or unreliable, the authorities might decide to treat all individuals regardless of their status. Our results from this paper suggest that the choice of the strategy depends on whether treatment includes or excludes R but the total budget spent on controlling epidemic remains similar for both models.
Secondly, in the most important region of parameter space, corresponding to expensive preventive treatment and a highly infectious disease, both models yield very similar scenarios (right part of fig. 4c, d). Thus, the results appear to be stable with respect to structural changes of the model. Where the difference is marked, for low  and high
and high 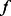 , the models suggest a different choice of strategy (GS for model 1 and LS for model 2). However, we also found that in this case the economic outcome of either GS or LS is very similar (see fig. 3c).
, the models suggest a different choice of strategy (GS for model 1 and LS for model 2). However, we also found that in this case the economic outcome of either GS or LS is very similar (see fig. 3c).
Thirdly, the main effect of increasing  is to shift the boundary between the GS and LS for small
is to shift the boundary between the GS and LS for small  , rendering the GS less attractive as
, rendering the GS less attractive as  decreases – and the infectious period increases. For model 2 (without treatment of R) the area of preference of GS over LS is limited to very small values of
decreases – and the infectious period increases. For model 2 (without treatment of R) the area of preference of GS over LS is limited to very small values of  . Thus, the longer the infectious period, the more likely the local strategy is to work. The boundary between LS and NS for large values of
. Thus, the longer the infectious period, the more likely the local strategy is to work. The boundary between LS and NS for large values of  remains unchanged.
remains unchanged.
Addition of long-range links enlarges the region of applicability of GS towards higher 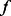 and
and  for both models. The large number of randomly placed long-range links destroys spatial structure of spreading the pathogen and causes that it spreads mostly globally so that LS is no longer effective option of control the epidemic.
for both models. The large number of randomly placed long-range links destroys spatial structure of spreading the pathogen and causes that it spreads mostly globally so that LS is no longer effective option of control the epidemic.
The results obtained in this paper can be used for those diseases for which spread is dominated by local transmission or by a mixture of local and long-range links. Examples include human (notably SARS [28] and influenza [29]–[31]), animal (foot-and-mouth disease [32]) and plant diseases (citrus canker [33], sudden oak death [34]–[36] and rhizomania of sugar beet [37], [38]). Although our model assumes a simple network structure, we believe that the results can be generalised to more complex, but also more realistic networks, including social networks [31]. This work can also be extended in several ways. The most interesting will be the SIRS model, in which after some period of immunity to the disease individuals become susceptible again and could catch a disease few times; with influenza [29]–[31] and sexually-transmitted diseases [39], [40] being the best examples.
Funding Statement
Project operated within the Foundation for Polish Science International Ph.D. Projects Programme co-financed by the European Regional Development Fund covering, under the agreement no. MPD/2009/6, the Jagiellonian University International Ph.D. Studies in Physics of Complex Systems and was co-financed by the European Development Fund in the framework of the “Innovative Economy Programme” and within the framework of “Exploring the Physics of Small Devices (EPSD)” of European Science Foundation (ESF). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Newman M (2003) The structure and function of complex networks. SIAM Review 45: 167–256. [Google Scholar]
- 2.Keeling MJ, Rohani P (2007) Modeling Infectious Diseases in Humans and Animals. Princeton University Press, 408 p.
- 3.Newman M (2010) Networks: An introduction. Oxford Univ Press.
- 4. Aleksiejuk A, Hołyst J, Stauffer D (2002) Ferromagnetic phase transition in Barabási-Albert networks. Physica A: Statistical Mechanics and its Applications 310: 260–266. [Google Scholar]
- 5. Bianconi G, Barabási A (2001) Bose-Einstein condensation in complex networks. Physical Review Letters 86: 5632–5635. [DOI] [PubMed] [Google Scholar]
- 6. Andersson H (1999) Epidemic models and social networks. Mathematical Scientist 24: 128–147. [Google Scholar]
- 7. Keeling M, Eames K (2005) Networks and epidemic models. Journal of the Royal Society Interface 2: 295–307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Pastor-Satorras R, Vespignani A (2001) Epidemic spreading in scale-free networks. Physical review letters 86: 3200–3203. [DOI] [PubMed] [Google Scholar]
- 9. Moreno Y, Pastor-Satorras R, Vespignani A (2002) Epidemic outbreaks in complex heterogeneous networks. The European Physical Journal B-Condensed Matter and Complex Systems 26: 521–529. [Google Scholar]
- 10.Meloni S, Perra N, Arenas A, Gómez S, Moreno Y, et al.. (2011) Modeling human mobility responses to the large-scale spreading of infectious diseases. Scientific reports 1. [DOI] [PMC free article] [PubMed]
- 11. Keeling M (2005) Models of foot-and-mouth disease. Proceedings of the Royal Society B: Biological Sciences 272: 1195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Jeger M, Pautasso M, Holdenrieder O, Shaw M (2007) Modelling disease spread and control in networks: implications for plant sciences. New Phytologist 174: 279–297. [DOI] [PubMed] [Google Scholar]
- 13. Ferguson N, Donnelly C, Anderson R (2001) The foot-and-mouth epidemic in Great Britain: pattern of spread and impact of interventions. Science 292: 1155. [DOI] [PubMed] [Google Scholar]
- 14. Cohen R, Havlin S, Ben-Avraham D (2003) Efficient immunization strategies for computer networks and populations. Physical review letters 91: 247901. [DOI] [PubMed] [Google Scholar]
- 15. Dybiec B, Kleczkowski A, Gilligan C (2004) Controlling disease spread on networks with incomplete knowledge. Physical Review E 70: 066145. [DOI] [PubMed] [Google Scholar]
- 16. Kao R (2002) The role of mathematical modelling in the control of the 2001 FMD epidemic in the UK. Trends In Microbiology 10: 279–286. [DOI] [PubMed] [Google Scholar]
- 17. Forster GA, Gilligan CA (2007) Optimizing the control of disease infestations at the landscape scale. Proceedings of the National Academy of Sciences of the United States of America 104: 4984–4989. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Klepac P, Laxminarayan R, Grenfell B (2011) Synthesizing epidemiological and economic optima for control of immunizing infections. Proceedings of the National Academy of Sciences 108: 14366–14370. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Hollingsworth TD, Klinkenberg D, Heesterbeek H, Anderson RM (2011) Mitigation Strategies for Pandemic Influenza A: Balancing Conflicting Policy Objectives. PLoS Computational Biology 7: e1001076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Kleczkowski A, Oleś K, Gudowska-Nowak E, Gilligan C (2012) Searching for the most cost-effective strategy for controlling epidemics spreading on regular and small-world networks. Journal of The Royal Society Interface 9: 158–169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Oleś K, Gudowska-Nowak E, Kleczkowski A (2012) Understanding disease control: influence of epidemiological and economic factors. PloS One 7: e36026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Dybiec B, Kleczkowski A, Gilligan C (2005) Optimising control of disease spread on networks. Acta Physica Polonica B 36: 1509–1526. [Google Scholar]
- 23. Gomez-Gardenes J, Echenique P, Moreno Y (2006) Immunization of real complex communication networks. The European Physical Journal B-Condensed Matter and Complex Systems 49: 259–264. [Google Scholar]
- 24.Watts D (2003) Small worlds: the dynamics of networks between order and randomness. Princeton University Press.
- 25. Verdasca J, Telo da Gama M, Nunes A, Bernardino N, Pacheco J, et al. (2005) Recurrent epidemics in small world networks. Journal of Theoretical Biology 233: 553–561. [DOI] [PubMed] [Google Scholar]
- 26. KermackWO, McKendrick AG (1927) A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London Series A 115: 700–721. [Google Scholar]
- 27. Gersovitz M, Hammer J (2004) The Economical Control of Infectious Diseases. The Economic Journal 114: 1–27. [Google Scholar]
- 28. Dye C, Gay N (2003) Modeling the SARS epidemic. Science 300: 1884–1885. [DOI] [PubMed] [Google Scholar]
- 29. Ferguson NM, Cummings DAT, Cauchemez S, Fraser C, Riley S, et al. (2005) Strategies for containing an emerging influenza pandemic in Southeast Asia. Nature 437: 209–214. [DOI] [PubMed] [Google Scholar]
- 30. Halloran ME, Ferguson NM, Eubank S, Longini IM, Cummings DaT, et al. (2008) Modeling targeted layered containment of an influenza pandemic in the United States. Proceedings of the National Academy of Sciences of the United States of America 105: 4639–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Cauchemez S, Bhattarai A, Marchbanks TL, Fagan RP, Ostroff S, et al. (2011) Role of social networks in shaping disease transmission during a community outbreak of 2009 H1N1 pandemic influenza. Proceedings of the National Academy of Sciences of the United States of America 108: 2825–2830. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Woolhouse MEJ, Chase-Topping M, Haydon D, Friar J, Matthews L, et al. (2001) Epidemiology – Footand-mouth disease under control in the UK. Nature 411: 258–259. [DOI] [PubMed] [Google Scholar]
- 33. Gottwald T, Hughes G, Graham J, Sun X, Riley T (2001) The citrus canker epidemic in Florida: the scientific basis of regulatory eradication policy for an invasive species. Phytopathology 91: 30–4. [DOI] [PubMed] [Google Scholar]
- 34. Rizzo DM, Garbelotto M, Davidson JM, Slaughter GW, Koike ST (2002) Phytophthora ramorum as the cause of extensive mortality of quercus spp. and lithocarpus densiflorus in California. Plant Disease 86: 205–214. [DOI] [PubMed] [Google Scholar]
- 35.Meentemeyer RK, Cunniffe NJ, Cook AR, Filipe JA, Hunter RD, et al.. (2011) Epidemiological modeling of invasion in heterogeneous landscapes: spread of sudden oak death in California (1990-2030). Ecosphere 2.
- 36. Filipe JA, Cobb RC, Meentemeyer RK, Lee CA, Valachovic YS, et al. (2012) Landscape epidemiology and control of pathogens with cryptic and long-distance dispersal: sudden oak death in northern Californian forests. PLoS computational biology 8: e1002328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Stacey AJ, Truscott JE, Asher MJC, Gilligan CA (2004) A model for the invasion and spread of rhizomania in the United Kingdom: Implications for disease control strategies. Phytopathology 94: 209–215. [DOI] [PubMed] [Google Scholar]
- 38. Gilligan C, Truscott J, Stacey A (2007) Impact of scale on the effectiveness of disease control strategies for epidemics with cryptic infection in a dynamical landscape: an example for a crop disease. Journal of the Royal Society Interface 4: 925–934. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Wylie JL, Cabral T, Jolly AM (2005) Identification of networks of sexually transmitted infection: a molecular, geographic, and social network analysis. Journal of Infectious Diseases 191: 899–906. [DOI] [PubMed] [Google Scholar]
- 40. Stoner BP, Whittington W, Hughes JP, Aral SO, Holmes KK (2000) Comparative epidemiology of heterosexual gonococcal and chlamydial networks: implications for transmission patterns. Sexually transmitted diseases 27: 215–223. [DOI] [PubMed] [Google Scholar]