

Summary
Linearity, sometimes jointly with constant variance, is routinely assumed in the context of sufficient dimension reduction. It is well understood that, when these conditions do not hold, blindly using them may lead to inconsistency in estimating the central subspace and the central mean subspace. Surprisingly, we discover that even if these conditions do hold, using them will bring efficiency loss. This paradoxical phenomenon is illustrated through sliced inverse regression and principal Hessian directions. The efficiency loss also applies to other dimension reduction procedures. We explain this empirical discovery by theoretical investigation.
Keywords: Constant variance condition, Dimension reduction, Estimating equation, Inverse regression, Linearity condition, Semiparametric efficiency
1. Introduction
In the sufficient dimension reduction literature, two essential conditions are linearity and constant variance. Denote X the p-dimensional random covariate vector, and let the dimension reduction subspace be the column space of a full rank p × d matrix β. The linearity condition assumes E(X | βTX) = PX, where P = ∑β(βT∑β)−1 βT is a p × p matrix and ∑ = cov(X). The constant variance condition assumes cov (X | βTX) = Q, where Q = ∑ – P∑PT. These two conditions have played a central role throughout the development of the sufficient dimension reduction literature. For example, the linearity condition, sometimes jointly with the constant variance condition, permitted the establishment of sliced inverse regression (Li, 1991), sliced average variance estimation (Cook and Weisberg, 1991), directional regression (Li and Wang, 2007), discretization-expectation estimation (Zhu, et al, 2010b), cumulative slicing estimation (Zhu, et al, 2010a), ordinary least squares (Li and Duan, 1989), and principal Hessian directions (Li, 1992; Cook and Li, 2002), etc. It is no exaggeration to call linearity and constant variance the fundamental conditions of dimension reduction.
It is a different story regarding the validity of the linearity and constant variance conditions and how to verify them in practice. Hall and Li (1993) showed that the linearity condition would hold in an asymptotic sense when p goes to infinity. Yet whether the asymptotically true result suffices for a finite dimensional problem remains unclear. This has prompted researchers to relax these conditions. For example, Li and Dong (2009) and Dong and Li (2010) replaced the linearity condition by a polynomial condition. Ma and Zhu (2012) completely eliminated both conditions.
Following the relaxation of the linearity and constant variance conditions, a natural question arises: What do we lose by ignoring these conditions when they hold? It is natural to conjecture that this will cause estimation variance inflation. However, our discovery is exactly the opposite.
We illustrate this paradoxical phenomenon empirically. Consider
where β1 = 10−1/2(1, 1, 1, 1, 1, 1, 1, 1, 1, 1)T, β2 = 10−1/2(1,−1, 1,−1, 1,−1, 1,−1, 1,−1)T and ε is a standard normal random variable. Thus, p = 10, d = 2 and β = (β1, β2) in these models. We generate X from a multivariate standard normal distribution. Thus both the linearity and the constant variance conditions hold. For Model I, we implement classical sliced inverse regression and its semi-parametric counterpart where the linearity condition is not used. For Model II, we compare classical principal Hessian directions and its semi-parametric counterpart where neither condition is used. Here, the sliced inverse regression and principal Hessian directions are identical to their semi-parametric counterparts, except that the sliced inverse regression and principal Hessian directions utilize the linearity and the constant variance conditions to obtain E(X | βTX) and cov(X | βTX), while their semi-parametric counterparts estimate E(X | βTX) and cov(X | βTX) nonparametrically. See Ma and Zhu (2012) for details on these semi-parametric estimators. We generate 1000 data sets each of size n = 200, and summarize the results in Figure 1. To make a fair comparison, we estimate the kernel matrix of the classical sliced inverse regression by using kernel smoothing rather than the usual slicing estimation. This allows us to avoid selecting the number of slices, which usually adversely affects the performance. Thus, sliced inverse regression is implemented in its improved form.
Fig. 1.
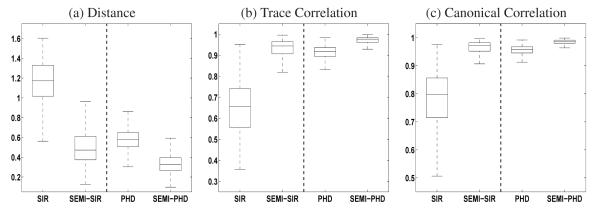
Comparison of sliced inverse regression (SIR) and principal Hessian directions (PHD) with their semiparametric counter parts (SEMI-SIR, SEMI-PHD) in model (I) (left half in each panel) and model (II) (right half in each panel). Results are based on 1000 simulated data sets with sample size n = 200.
Figure 1(a) contains the box plots of the four estimation procedure results, measured by a distance between the estimated and the true dimension reduction subspaces. This distance is defined as the Frobenius norm of , where P is as defined before, and is obtained from the aforementioned estimation procedures. This distance criterion is widely used to evaluate the performance of different estimation procedures, with a smaller distance indicating better estimation of the dimension reduction subspace. Figure 1(a) shows clearly that the semi-parametric counterparts outperform their classical versions. Thus, not taking advantage of the linearity condition or the constant variance condition, although both are satisfied, seems to bring a gain in estimating the dimension reduction subspaces.
Figure 1(b) contains the box plots of the same results measured by the trace correlation, defined as trace . A larger value of this criterion indicates better performance. Figure 1(b) demonstrates again that the semi-parametric counterparts outperform their classical versions respectively, once again indicating that not taking advantage of the linearity or the constant variance condition, even though both hold, brings a gain.
Finally, Figure 1(c) shows the results by yet another popular criterion, the canonical correlation, defined as the average of d canonical correlation coefficients between and βTX. Under this measure, larger values indicate better estimation results, and the conclusion from Figure 1(c) is consistent with those from Figure 1(a) and Figure 1(b).
Having observed these unexpected results, our goal here is to demonstrate that the improvement is not merely a sporadic phenomenon. This improvement is theoretically verifiable. Because it is already well understood that using the linearity and the constant variance conditions when they do not hold causes bias, here we consider exclusively the case when the covariate vector satisfies the linearity condition and, if required, the constant variance condition. This means that the aforementioned original methods, such as sliced inverse regression and principal Hessian directions, are valid and will provide consistent estimation. Although this is the classical setting of the dimension reduction literature and seems well understood, we will formally establish that if we ignore the linearity and the constant variance conditions, and instead, estimate the conditional expectation E(X | βTX) or more generally E{a(X) | βTX} nonparametrically, then the performance of sufficient dimension reduction methods will improve. The improvement is in the asymptotic variance of the estimated dimension reduction subspace, in that not using the linearity or the constant variance condition will yield a more efficient estimator than using them, even when these conditions are indeed true.
2. Some Preliminaries
We first lay out the central subspace and the central mean subspace models and some notation we use throughout. Let Y be a univariate response variable and X and β be defined as in Section 1. Throughout this paper we assume that X satisfies both the linearity and the constant variance conditions. Using an invariance property (Cook, 1998, page 106), we assume without loss of generality that E(X) = 0 and cov(X) = Ip. The essence of the sufficient dimension reduction literature is to assume that Y depends on X only through a few linear combinations βTX, then to identify the space spanned by the columns of β. There are mainly two types of links between Y and X that are commonly studied, one is the conditional distribution, and the other is the conditional mean function. Specifically, in the first model type (Li, 1991; Cook, 1998), one assumes that
| (1) |
where F (y | X) = pr(Y ≤ y | X) denotes the conditional distribution function of Y given X. The smallest column space of β satisfying (1) is called the central subspace, SY |X. In the second model type (Cook and Li, 2002), one assumes that the conditional mean function satisfies
| (2) |
The corresponding smallest column space of β is called the central mean subspace SE(Y|X). Estimating SY|X and SE(Y|X) is the main purpose of sufficient dimension reduction. In the following development, we focus on the classical sliced inverse regression and principal Hessian directions methods as representative estimators for SY|X and SE(Y|X) respectively, although the conclusion applies to other sufficient dimension reduction method as well.
To further ensure that the identifiability of SY|X or SE(Y|X) implies the identifiability of β, we require the upper d × d sub-matrix of β to be the identity matrix. Through this parameterization, estimating SY|X or SE(Y|X) is equivalent to estimating the lower (p – d) × d sub-matrix in β. This sub-matrix contains all the unknown parameters involved in the estimation of SY|X or SE(Y|X) and uniquely defines the corresponding space SY|X or SE(Y|X). The particular parameterization is simple and enables us to study the properties of the space estimation through studying the properties in estimating the parameters in β. Other parameterizations can also be used.
We further introduce two matrix operators. We use vecl(β) to denote the length (p – d)d vector formed by the concatenation of the columns in the lower (p – d) × d sub-matrix of β, and use vec(M) to denote the concatenation of the columns of an arbitrary matrix M.
3. Theoretical Explanation of the Paradoxical Phenomenon
Following Ma and Zhu (2012), to identify SY|X in model (1), the sliced inverse regression solves for the parameters contained in β from an estimating equation based on the relation
| (3) |
When the linearity condition holds, (3) simplifies to
where Q = Ip – P = Ip – β (βTβ) βT. Consequently, solving (3) is equivalent to calculating the eigen-space of the matrix cov{E(X | Y)} associated with its d nonzero eigenvalues.
Similarly, to identify in SE(Y|X) in model (2), the principle Hessian directions method solves for the parameters contained in β from an estimating equation based on the relation
| (4) |
When both the linearity and the constant variance conditions hold, (4) simplifies to
Thus, solving (4) is equivalent to computing the eigen-space of the matrix E [{Y – E(Y)} XXT] associated with its d nonzero eigenvalues.
To simultaneously consider both the sliced inverse regression in (3) and the principal Hessian directions in (4), we consider a unified form
| (5) |
where g* is a fixed function of Y that satisfies E(g* | X) = E(g* | βTX), and a* is a fixed function of X. Clearly (5) contains both sliced inverse regression and principal Hessian directions as special cases, by choosing g* = E(X | Y) and a* = XT to yield (3) or g* = Y – E(Y) and a* = XXT to yield (4). Denote the observations by (Xi,Yi)(i = 1,…,n). To facilitate our subsequent inference procedure, we further perform the following operations. We first vectorize the sample version of (5), then we perform a generalized method of moment treatment to reduce the number of estimating equations to (p – d)d, then finally we simplify these estimation equations to obtain
| (6) |
where gj(Y) is a scalar or column vector that satisfies E(gj | X) = E(gj | βTX), and aj is a row vector, for j = 1,…,q. A more detailed description of how to obtain (6) from (5) is given in the Appendix. We also assume (6) has a unique solution when n → ∞. We remark here that (6) is equivalent to (5) when n → ∞, hence we can view (6) as a compact expression of the sample version of (5).
We now study the asymptotic properties of the estimating equation (6), both when the E(aj | βTX)s are known and when they are estimated nonparametrically. The analysis of (6) for q > 1 can be readily obtained after we study (6) for q = 1, so in the sequel, whenever appropriate, we shall focus on the case q = 1 in (6) and ignore the subscript j.
When we decide to give up using any properties of the covariate X such as linearity or constant variance, we need to estimate E(a | βTX) nonparametrically. For example, we can estimate E(a | βTX) through
Here Kh(·) = K(·/h)/h is a kernel function and h is a bandwidth which can be estimated by leave-one-out cross-validation. Replacing E(a | βTX) in (6) with , we obtain an estimator by solving the equation
| (7) |
Cross-validation is one possible way of selecting h, and its validity in the nonparametric context can be found in Härdle, et al (1988). In the semiparametric context, the final estimate is insensitive to the bandwidth choice. This is reflected in the condition (C4), where a range of bandwidths is allowed, all of which will yield the same first order asymptotic property of the estimation on β. In terms of finite sample performance, bandwidth has also been observed to have low impact, see for example Maity et al (2007). Theorem 1 states the asymptotic properties of .
Theorem 1
Under the regularity conditions given in the Appendix, satisfies
| (8) |
where
Hence, when in distribution, where
Remark 1
We consider only the situation where g* and hence g are fixed functions. In practice, sometimes g* and hence g are estimated, thus more careful notation is and . However, as long as the estimated function converges to g at a proper rate (Mack and Silverman, 1982), the first order result in Theorem 1 stays unchanged if we replace g with .
Alternatively, E(a* | βTX) may have a known form, say E(a* | βTX) = h*(βTX, β), where h*(·) is a known function. This will further yield a known form for E(aj | βTX) in (6), which we denote hj(βTX, β) (j = 1,…, q). For example, under the linearity condition, for a*(X) = XT, h*(βTX, β) = PX = βT(βTβ)−1(βTX); under both the linearity and the constant variance conditions, for a*(X) = XXT, h*(βTX, β) = Q + PXXTP = Ip – β(βTβ)−1βT + β(βTβ)−1(βTX)(βTX)T(βTβ)−1β. This allows us to solve a simplified version of (6). For q = 1 and ignoring the subscript j, we only need to solve
| (9) |
to obtain an estimator . The asymptotic properties of are given in Theorem 2.
Theorem 2
Assume h is differentiable with respect to β, then satisfies
| (10) |
where A is given in Theorem 1. Hence, when n → ∞, in distribution, where
A direct comparison between B1 and B2 reveals the difference between from solving (7) and from solving (9), as stated in Proposition 1.
Proposition 1
Under the conditions in Theorems 1 and 2, is positive definite when n → ∞.
Combining the results in Theorems 1, 2 and Proposition 1, we are now ready to state the main results in Theorem 3. Its proof combines that of Theorems 1, 2 and Proposition 1, and is omitted to avoid redundancy.
Theorem 3
Let and solve (6) with E(aj | βTX) replaced by hj(βTX, β) and by its nonparametric kernel estimator respectively. Under the regularity conditions given in the Appendix, is positive definite when n → ∞.
We emphasize that and solve the same estimating equation (6), except that takes advantage of the known forms of E(aj | βTX) while does not. They are estimators of the same parameter β. Therefore, Theorem 3 states the interesting result that by giving up using the linearity and constant variance conditions, we enjoy a decreased estimation variance.
In estimating the central subspace SY|X, any function of Y is a qualified g* function, because E(g* | X) = E(g* | βTX) by the model assumption (1). Specifically, choose g*(Y ) = E(X | Y), a*(X) = XT, and h*(βTX,β) = βT(βTβ)−1(βTX). After vectorizing and using a generalized method of moments to reduce the number of estimating equations, the over-identified estimating equation reduces to (6). Theorem 3 then directly shows that giving up using the hj functions, hence giving up the linearity condition, will reduce the variance of sliced inverse regression. In estimating the central mean subspace SE(Y|X) defined in (2), Y – c is the only qualified g* function, where c is an arbitrary constant. Specifically, choose g*(Y) = Y – E(Y), a*(X) = XXT, h*(βTX,β) = Ip – β(βTβ)−1βT + β(βTβ)−1(βTX)(βTX)T(βTβ)−1β. Vectorizing the estimating equations and using the generalized method of moments to reduce the number of estimating equations will again yield an estimating equation of the form (6). Theorem 3 shows that giving up the linearity and constant variance conditions will reduce the variance of principal Hessian directions.
Ma and Zhu (2012) studied many other forms of the sufficient dimension reduction estimators that use the linearity and constant variance conditions. Those estimators can all be written in the form (6). Following Theorem 3, these estimators suffer the same efficiency loss as sliced inverse regression and principal Hessian directions, in that their estimation variance can be decreased by nonparametric estimation of E(aj | βTX). Since we work in the semiparametric framework, our analysis does not apply when Y is categorical and X is multivariate normal given Y. Under these two conditions, the model is parametric and the sliced inverse regression is the maximum likelihood estimator and cannot be further improved.
To keep the vital information simple and clear, we have presented the inverse regression methods in their idealistic forms, where the knowledge E(X) = 0 and cov(X) = I is directly incorporated into estimation. In practice, one might need to replace E(X) with and cov(X) with , and proceed with the estimation. Denote the resulting estimator . However, the estimation of E(X) and cov(X) does not recover the efficiency loss caused by using the linearity and constant variance conditions. In other words, is still a positive definite matrix. We omit the proof because it is very similar to the proofs of Theorems 1, 2, Proposition 1 and Theorem 3.
4. Discussion
The surprising discovery that the linearity and constant variance conditions cause efficiency loss reminds us of the situation widely experienced in using inverse probability weighting idea to handle missing covariates. There it is well known that using the true weights yields a less efficient estimator than using the estimated weights. Such a phenomenon has been well studied in Henmi and Eguchi (2004), and a nice geometrical explanation was provided there. However, our problem shows several important differences. First, the efficiency improvement in the inverse probability weighting scheme can be obtained through any valid parametric estimation of the weights, while the efficiency improvement is not guaranteed when we view the linearity condition as a truth, and replace it with an arbitrary valid parametric estimation. This makes the geometric explanation in Henmi and Eguchi (2004) invalid in our context. Second, our efficiency gain is achieved through replacing the linearity condition with a nonparametric estimation, while only parametric estimation is considered in Henmi and Eguchi (2004).
Finally, having focused on the drawback of using the linearity and the constant variance conditions when they do hold, we acknowledge that using these conditions does ease the computation. When these conditions hold, a nonparametric estimation procedure can be avoided, which results in less programming effort and fast computation. However, nonparametric estimation is more or less routine in modern statistics, while the linearity and constant variance conditions remain uncheckable. As estimation is the eventual goal and this is better achieved without using the linearity or constant variance conditions, whether or not they hold, one would expect that giving up computational convenience for better statistical results can be sensible.
Appendix 1.
A.1. Obtaining (6) from (5)
We first vectorize the estimating function in (6) to obtain
| (A.1) |
Here we assume a* contains l columns, denoted . Assume contains l’ rows. We then perform the generalized method of moments step to obtain
where
has (p – d)d rows and Dj is a (p – d)d × l’ matrix, j = 1,…,l. Here D* is an arbitrary positive-definite ll’ × ll’ matrix, with the optimal choice being D* = E(ffT)−1, and gj(Y) = Djg*(Y). In (A.1) is either a scalar, such as in sliced inverse regression, or a column vector, such as in principal Hessian directions. When the are column vectors, we further expand the matrix multiplication so that eventually, after simplification through combining terms that are redundant, each summand contains a scalar function and a scalar or column vector gj(Y). We use q to denote the total number of summands. By now the form of Df(Y,XβTX) is almost the desired form in (6), except that if several different are multiplied by the same gj(Y) functions, we can write them more concisely by forming a row vector of the corresponding ’s and this is what we name aj in (6). For example, writing X = (X1,…,Xp)T, for sliced inverse regression, we have
hence q = p, gj(Y) = DjE(X | Y), which is a column vector, and aj(X) = Xj, which is a scalar, in (6). For principal Hessian directions, we have
| (A.2) |
where Dj has dimension (p – d)d × p, and Djk stands for the kth column of Dj. We rewrite (A.2) into a matrix form as
| (A.3) |
where D·,k is a p × (p – d)d matrix with jth row . Using (A.3) to form (6), we hence have q = p, gj(Y) = Y – E(Y), a scalar, and aj(X) = XTD·,jXj, a row vector, in (6).
A.2. List of regularity conditions
(C1) The univariate kernel function K(·) is symmetric, has compact support and is Lipschitz continuous on its support. It satisfies
Thus K is a m-th order kernel. The d-dimensional kernel function is a product of d univariate kernel functions, that is, for u = (u1,…, ud)T. Here we abuse notation and use the same K regardless of the dimension of its argument.
(C2) The probability density function of βTX, denoted by f(βTX), is bounded away from zero and infinity.
(C3) Let r(βTX) = E{a(X) | βTX}f(βTX). The (m – 1)-th derivatives of r(βTX) and f(βTX) are locally Lipschitz-continuous as functions of βTX.
(C4) The bandwidth h = O(n−κ) for (2m)−1 < κ < (2d)−1. This implies m > d.
A.3. Technical details
Let and . Write ,
Lemma A1
Assume E (ε | η) = 0. Under Conditions (C1)-(C3), we have
Proof of Lemma A1
Recall that from condition (C3), and . We write
| (A.4) |
By the uniform convergence of nonparametric regression (Mack and Silverman, 1982), the third and the fourth summations are order . The first two summations in the right hand side of (A.4) have similar structures, thus we explain in detail only the first one. We write as a second-order U-statistic:
By using Lemma 5.2.1.A of Serfling (1980, page 183), it follows that
| (A.5) |
because the difference on the left hand side is a degenerate U-statistic. Next we show that
| (A.6) |
Following similar arguments in Lemma 3.3 of Zhu and Fang (1996) for calculating the bias term, we easily have by assuming that the (m – 1)-th derivative of r(η) is locally Lipschitz-continuous. This proves (A.6). Combining (A.5) and (A.6), we obtain
This result together with (A.4) entails the desired result, which completes the proof.
Lemma A2
Under Conditions (C1)-(C4), we have
Proof of Lemma A2
Using the definition of the function r(·) in condition (C3), and the bandwidth conditions nh2d → ∞ and nh4m → 0 in (C4), we obtain
Furthermore, since the bandwidth h satisfies nh2m → 0 under condition (C4), Lemma A.2 of Zhu and Zhu (2007) yields
| (A.7) |
Similarly, invoking Lemma A.3 of Zhu and Zhu (2007), we obtain
| (A.8) |
Combining (A.7) and (A.8), we obtain the results of Lamma A2.
Proof of Theorem 1
We rewrite the estimating equation to obtain
| (A.9) |
We first study the left hand side of (A.9):
| (A.10) |
From Lemma A2, the summation of the first two terms on the right hand side of (A.10) is op(n1/2). Using Taylor’s expansion and the weak law of large numbers, denoting Kronecker product as ⊗, i.e. M ⊗ B = (mijB) for any matrices M and B, we rewrite the vectorized form of the third summation on the right hand side of (A.10) as
Using , we obtain that
where the last equality is because E(g | X) = E(g | η). Hence
since E [E (g | η) {a(X) – E(a | η)}] = 0 for all β. Thus, the vectorized form of the left hand side of (A.9) is . Next we study the right hand side of (A.9). We write
Because E {g(Yi) – E(g | ηi) | ηi} = 0, a direct application of Lemma A1 entails that the second term is of order OP {n1/2hm + nh2m + (log2 n)h−d}, which is op(n1/2) when nh2d → ∞ and nh4m → 0. By Taylor expansion, the vectorized form of the third term is
where the last equality is again because E(g | X) = E(g | η). The proof of Theorem 1 is completed by combining the results concerning the left and right hand sides of (A.9).
Proof of Theorem 2
A standard Taylor expansion around β yields
where β* is on the line connecting and β. From the proof of Theorem 1, we have
Thus, we have
hence the theorem is proven.
Proof of Proposition 1
From Theorem 1 and 2, we can easily obtain that
which is clearly positive definite. The last equality holds because E(g | X) = E(g | η). Hence is positive definite.
Contributor Information
MA Yanyuan, Department of Statistics, Texas A&M University, College Station Texas 77843, U.S.A ma@stat.tamu.edu.
ZHU Liping, School of Statistics and Management, Shanghai University of Finance and Economics, Shanghai 200433, China. zhu.liping@mail.shufe.edu.cn.
References
- Cook RD. Regression Graphics: Ideas for Studying Regressions through Graphics. Wiley; New York: 1998. [Google Scholar]
- Cook RD, Li B. Dimension reduction for conditional mean in regression. Ann. Statist. 2002;30:455–474. [Google Scholar]
- Cook RD, Weisberg S. Discussion of “Sliced inverse regression for dimension reduction” by Li, K. C. J. Am. Statist. Assoc. 1991;86:28–33. [Google Scholar]
- Dong Y, Li B. Dimension reduction for non-elliptically distributed predictors: second-order moments. Biometrika. 2010;97:279–294. [Google Scholar]
- Hall P, Li KC. On almost linearity of low dimensional projections from high dimensional data. Ann. Statist. 1993;21:867–889. [Google Scholar]
- Härdle W, Hall P, Marron JS. How far are automatically chosen regression smoothing parameters from their optimum? (with discussion) J. Am. Statist. Assoc. 1988;83:86–99. [Google Scholar]
- Henmi M, Eguchi S. A paradox concerning nuisance parameters and projected estimating functions. Biometrika. 2004;91:929–941. [Google Scholar]
- Li B, Dong Y. Dimension reduction for non-elliptically distributed predictors. Ann. Statist. 2009;37:1272–1298. [Google Scholar]
- Li B, Wang S. On directional regression for dimension reduction. J. Am. Statist. Assoc. 2007;102:997–1008. [Google Scholar]
- Li KC. Sliced inverse regression for dimension reduction (with discussion) J. Am. Statist. Assoc. 1991;86:316–342. [Google Scholar]
- Li KC. On principal Hessian directions for data visualization and dimension reduction: another application of Stein’s lemma. J. Am. Statist. Assoc. 1992;87:1025–1039. [Google Scholar]
- Li KC, Duan N. Regression analysis under link violation. Ann. Statist. 1989;17:1009–1052. [Google Scholar]
- Ma Y, Zhu LP. A semiparametric approach to dimension reduction. J. Am. Statist. Assoc. 2012;107:168–179. doi: 10.1080/01621459.2011.646925. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mack YP, Silverman BW. Weak and strong uniform consistency of kernel regression estimates. Probability Theory and Related Fields. 1982;61:405–415. [Google Scholar]
- Maity A, Ma Y, Carroll RJ. Efficient estimation of population-level summaries in general semiparametric regression models. J. Am. Statist. Assoc. 2007;102:123–139. [Google Scholar]
- Serfling RJ. Approximation Theorems of Mathematical Statistics. John Wiley; New York: 1980. [Google Scholar]
- Zhu LP, Zhu LX, Feng ZH. Dimension reduction in regressions through cumulative slicing estimation. J. Am. Statist. Assoc. 2010;105:1455–1466. [Google Scholar]
- Zhu LP, Wang T, Zhu LX, Ferré L. Sufficient dimension reduction through discretization-expectation estimation. Biometrika. 2010;97:295–304. [Google Scholar]
- Zhu LP, Zhu LX. On kernel method for sliced average variance estimation. J. Multi. Anal. 2007;98:970–991. [Google Scholar]
- Zhu LX, Fang KT. Asymptotics for kernel estimate of sliced inverse regression. Ann. Statist. 1996;24:1053–1068. [Google Scholar]