

Abstract
Background
Head and neck cancer (HNC) belongs to a group of heterogeneous disease with distinct patterns of behavior and presentation. TNFRSF10B, a tumor suppressor gene mapped on chromosome 8. Mutation in candidate gene is responsible for the loss of chromosome p arm which is frequently observed in head and neck tumors. TNFRSF10B inhibits tumor formation through apoptosis but deregulation encourages metastasis, migration and invasion of tumor cell tissues.
Results
Structural modeling was performed by employing MODELLER (9v10). A suitable template [2ZB9] was retrieved from protein databank with query coverage and sequence identity of 84% and 30% respectively. Predicted Model evaluation form Rampage revealed 93.2% residues in favoured region, 5.7% in allowed region while only 1 residue is in outlier region. ERRAT and ProSA demonstrated 51.85% overall quality with a −1.08 Z-score of predicted model. Molecular Evolutionary Genetics Analysis (MEGA 5) tool was executed to infer an evolutionary history of TNFRSF10B candidate gene. Orthologs and paralogs [TNFRSF10A & TNFRSF10D] protein sequences of TNFRSF10B gene were retrieved for developed ancestral relationship. Topology of tree presenting TNFRSF10A gene considered as outgroup. Human and gorilla shared more than 90% similarities with conserved amino acid sequence. Virtual screening approach was appliedfor identification of novel inhibitors. Library (Mcule) was screened for novel inhibitors and utilized the scrutinized lead compounds for protein ligand docking. Screened lead compounds were further investigated for molecular docking studies. STRING server was employed to explore protein-protein interactions of TNFRSF10B target protein. TNFSF10 protein showed highest 0.999 confidence score and selected protein-protein docking by utilizing GRAMM-X server. In-silico docking results revealed I-58, S-90 and A-62 as most active interacting residues of TNFRSF10B receptor protein with R-130, S-156 and R-130 of TNFSF10B ligand protein.
Conclusion
Current research may provide a backbone for understanding structural and functional insights of TNFRSF10B protein. The designed novel inhibitors and predicted interactions might serve to inhibit the disease. Effective in-vitro potent ligands are required which will be helpful in future to design a drug to against Head and neck cancer disease. There is an urgent need for affective drug designing of head and neck cancer and computational tools for examining candidate genes more efficiently and accurately are required.
Keywords: Head and neck cancer, Modeling, Tumor necrosis factor, TNFRSF10B, Docking, MODELLER, Phylogenetic, Virtual screening, Inhibitors, Bioinformatics
Background
HNC is the sixth most occurring cancers worldwide [1] whereas in Pakistan, the second most prevalent cancer affecting the pharynx, larynx and oral cavity [2]. Multigenic nature and environmental agents made heterogeneous and complex epidemiology of disease [3]. Different genetic polymorphisms are reported in enzymes involved in the metabolization of alcohol and tobacco greatly increases the risk of Squamous Cell Carcinoma of Head and Neck cancer (SCCHN) [4,5]. Morbidity and prognosis differ from patient to patient depending on causative agents, anatomical site and the stage of disease.
DNA modifications and structural variations in the genomic content of cell controlling gene expression are responsible for cancers. Deletions and duplications of chromosomal segments or even whole chromosome lead to the genomic instability causing genetic alterations [6]. DNA modifications are greatly responsible for change in expression level of HNC [6,7]. Genetic events result in the activation of proto-oncogenes and inactivation of tumor suppressor genes or both, leading to the development of SCCHN [7,8].
Tumor Necrosis Factor (TNF) is a mediator pro-inflammatory cytokine involved in the progression and development of cancer. The family of TNF inhibits tumor formation through apoptosis but TNFs deregulation encourages metastasis, migration and invasion of tumor cell tissues [9]. TNFRSF10B gene consists of 10 gene coding exons. Sequence analysis of all exons suggested allelic loss of 8p was in 20 primary HNCs. A number of putative tumors suppressor genes are located on 8p region which is a frequent site of translocations in head and neck tumors. In 1998, 2-bp insertion in this gene at residue 1065 was found that introduces a premature stop codon lead to truncated protein in SCCHN. Sequence comparison between patient and normal tissues confirmed that germ line contains truncating mutation in the absence of p53 mutation [10].
In-silico analysis of TNFRSF10B gene was conducted to elucidate the novel molecules, interacting partners, their binding interactions and to find a most plausible functions. The main objective of our study was to design novel inhibitors. The aim of research was to elucidate the interactions of TNFRSF10B protein with novel inhibitors and to identify the relation of gene with disease.
Results
The current work presents bioinformatics analysis of TNFRSF10B, a candidate gene of HNC. TNFRSF10B gene mapped on chromosome 8, started from 22877646 bp and ends with 22926692 bp. Molecular functions, biological processes and cellular locations of TNFRSF10B gene are mentioned in Table 1.
Table 1.
Molecular functions, biological processes and cellular locations of TNFRSF10B gene
| Gene | Molecular function | Biological process | Cellular location |
|---|---|---|---|
| |
|
Apoptotic process |
|
| |
Receptor activity |
|
Plasma membrane |
| |
|
Extrinsic apoptotic signalling pathway via death domain receptors. |
|
| |
Protein binding |
|
Integral to membrane |
|
TNFRSF10B |
|
Regulation of apoptotic process. |
|
| |
TRAIL binding |
|
|
| Activation of cysteine-type endopeptidase activity involved in the apoptotic process. |
Protein sequence of TNFRSF10B in FASTA format was retrieved from UniprotKB with accession number E9PBT3. Table 2 represents the templates of TNFRSF10B protein selected on overall quality, total score and query coverage. All the three selected templates were used for three dimensional structure predictions by comparative modeling. The best model was built by MODELLER (9v10) [11] by using 2ZB9 template with optimal alignment. Predicted model was visualized by Chimera 1.6 [12] shown in Figure 1. Assessment of predicted structure by Rampage, ERRAT and ProSA is shown from Figures 2, 3 and 4 respectively.
Table 2.
Template aligned by high score and query coverage
| Accession ID | Total score | Query coverage | E-value | Sequence identity |
|---|---|---|---|---|
|
2ZB9 |
25.8 |
84% |
5.4 |
30% |
|
3NKE |
25.8 |
46% |
4.1 |
32% |
| 3NKD | 25.0 | 46% | 8.1 | 32% |
Figure 1.
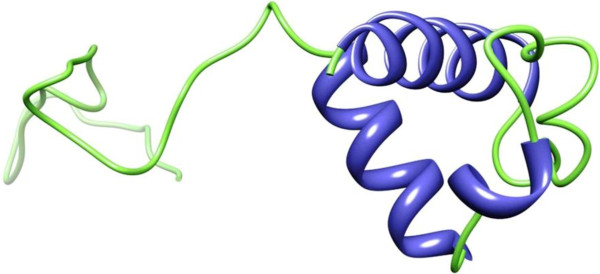
3D structure of TNFRSF10B protein visualized by the UCSF CHIMERA visualizing tool. A model is presented in smoothing ribbons and sticks. Helixes are represented by blue colour and coils by green colour.
Figure 2.

RAMPAGE result of TNFRSF10B protein showing the distribution of residues in favored, allowed and outlier regions.
Figure 3.

ERRAT result of TNFRSF10B model showing the 51.85% overall quality of model. X-axis shows the number of resides while the Y-axis represents error values of residues.
Figure 4.

ProSA results of TNFRSF10B model (A) Plot showing −1.08 Z-score representing the overall quality of the model. (B) Local model quality plot of model showing position of sequences against knowledge based energy in both window sizes 10 and 40.
The evolutionary tool MEGA 5 [13] was employed to construct a neighbor-joining tree of TNFRSF10B gene. Ensembl BLAST (http://www.ensembl.org/Multi/blastview) was performed to identify paralogs of the target gene. Protein sequences of TNFRSF10A, TNFRSF10D and TNFRSF10B were retrieved to determine the evolutionary relationship between paralogs and orthologs. Numbers of bootstrap replications were 1000 in bootstrap method. P-distance method and complete deletion option were used in the construction of neighbor-joining tree shown in Figure 5.
Figure 5.
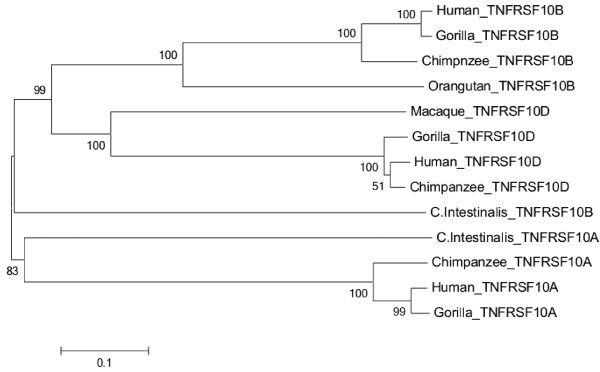
Neighbor-joining tree of TNFRSF10B gene showing TNFRSF10A gene as ancestral gene. Topology of tree showing TNFRSF10A gene is out group of tree. Species having >50% bootstrap values are presented in this tree.
Virtual screening technique
Virtual screening approach was employed to identify competitive compounds that inhibit the mutated TNFRSF10B activity. In pharmaceutical industry, the approach has become progressively more popular for lead identification. The main objective of virtual screening is to screen a large set of compounds against specific receptor protein to identify the manageable number of inhibitors for possibly chance of lead to drug candidate [14]. Four lead compounds (A, B, C and D) structures were screened for further analysis shown in Figure 6.
Figure 6.

Chemical structures of screened lead compounds (A, B, C and D) used in docking analysis.
Bioavailability and membrane permeability are the molecular properties that always connected with molecular weight, partition coefficient (logP), number of hydrogen bond donors and number of H-bond acceptors as a basic molecular descriptors [15]. Lipinski “Rule of Five” was formulated by using these molecular properties [16]. According to this rule, molecules with good membrane permeability have log P≤5, molecular weight ≤500, hydrogen bond acceptors ≤10 and donors ≤5 [17]. Therefore, Lipinski’s Rule of Five was applied to check the bioavailability characteristics such as absorption, distribution, metabolism, elimination (ADME) of the lead compounds. In present work, these properties were determined by Mcule tool [18] mentioned in Table 3.
Table 3.
Drug related properties of the designed molecules
| Inhibitors | Molecular mass | LogP | Rotatable bonds | H-bond donors | H-bond acceptor | RoF violation | Interacting residues |
|---|---|---|---|---|---|---|---|
|
A |
130.077 |
−0.7977 |
0 |
2 |
4 |
0 |
ARG-23, GLU-24, ALA-25, ARG-26, GLY-27, ALA-28, VAL-39, VAL-41, LEU-46 |
|
B |
158.303 |
−0.776 |
0 |
0 |
4 |
0 |
ARG-23, GLU-24, VAL-39, LEU-40, VAL-41, ALA-43, LEU-46 |
|
C |
789.86 |
3.5317 |
14 |
5 |
14 |
2 |
ILE-58, ALA-59, SER-60, ALA-62, MET-73, ILE-85, GLN-86, TRP-89, SER-90 |
| D | 807.877 | 3.65.05 | 14 | 5 | 15 | 2 | PRO-9, ALA-10, SER-12, GLY-13, LYS-16, ARG-17 PRO-30, GLN-53, LYS-54, GLU-57 |
Toxicity
High quality lead structures are the requirement for the successful drug discovery and structures of drug properties are more acceptable than common [19]. In the early steps of drug discovery, poor pharmacokinetics and toxicity should be eradicated. Toxicity and drug score characteristics were further used to screen the hits [20].
Docking analysis of TNFRSF10B protein with screened lead compounds was performed by AutoDock and post dock analysis by Chimera 1.6v and Discovery Studio. The amino acids present in the active sites of the protein were identified by observing those amino acids in the vicinity of 4 Å. Residues of receptor protein interacting with compounds were calculated and presented in Figures 7 and 8 by Chimera and Discovery Studio respectively.
Figure 7.

Binding views of lead compounds (A, B, C and D) with TNFRSF10B receptor protein. The compounds are depicted in pink sticks while protein structures in brown hetromeric surfaces. Interacting residues of receptor protein docked with respective four (A, B, C and D) compounds are determined and presented by Chimera.
Figure 8.

Post dock analysis of complexes by Discovery Studio tool. Chemical structures of compounds with interactions of receptor protein are shown. A) Interactions of novel designed compound A with receptor protein. B) Compound B interacted with TNFRSF10B. C) Interacted complex of TNFRSF10B with designed C inhibitor. D) Binding residues of compound D with receptor protein.
A functional partner network of TNFRSF10B protein was generated by the STRING [21] and STITCH3 [22] databases to explore the highly interacting proteins of the target protein. TNFSF10 protein having highest interaction score 0.999 with receptor protein was used as a ligand protein in protein-protein docking by GRAMM-X [23] and Hex [24]. Interaction network and protein-protein docked complex are shown in Figures 9 and 10 respectively. Interactions of interacting residues were determined and analyzed by PyMol mentioned in Table 4.
Figure 9.

Interaction network of TNFRSF10B generated by STRING database. In this network TNFSF10B protein showed the highest interaction score 0.999 with TNFSF10 protein. TNFSF10 protein is used in protein-protein docking of TNFRSF10B.
Figure 10.

Interaction analysis of TNFRSF10B and TNFSF10 visualized by PyMol tool.
Table 4.
Interacting residues between TNFRSF10B and TNFSF10 proteins
| Receptor protein | Interacting protein | Interactions type | Interactions (Receptor residue → Interacting protein residue | Bond distance (Å) |
|---|---|---|---|---|
| TNFRSF10B | TNFSF10 | Ionic bonding (N-O) | ILE-58/O → ARG-130/NH1 |
2.9 |
| SER-90/O → SER-156/N |
3.2 |
|||
| ALA-62/N → ARG-130/O | 3.2 |
Discussion
Head and neck cancer remains a disfiguring disease associated with a high mortality rate [25]. Progressive accumulation of genetic aberrations leads to SCCHN but exact nature is still unknown. Candidate gene identification approach may provide key factors to pinpoint candidate genes involved in different carcinomas, which leads to explore the receptor-ligand or protein-protein interactions recognize these carcinomas that might lead to the development of effective therapeutic strategies [26].
For head and neck candidate gene TNFRSF10B, 2ZB9, 3NKE and 3NKD templates were retrieved from PDB. Out of these three templates, 2ZB9 showed optimal alignment and query coverage. Rampage showed the 93.2% residues in favored region and 5.7% in the allowing region whereas only 1 residue was in outlier region. 51.852% quality factor and −1.08 Z-score were shown by ERRAT and ProSA evaluation tools respectively.
In literature, TNFRSF10B gene and its paralogs genes are predicted in primates and human. MEGA 5 was employed using neighbor-joining method to determine evolutionary relationship of genes among teleosts, rodents, birds, primates and mammals. TNFRSF10D and TNFRSF10A are the paralogs of TNFRSF10B gene that are used in the construction of a phylogenetic tree. TNFRSF10A gene is outgroup in TNFRSF10B tree that presents TNFRSF10A gene as an origin of other genes. TNFRSF10A gene gave rise to TNFRSF10B gene in Ciona Intestinalis and other cluster is further diverged into TNFRSF10D and TNFRSF10B genes. Human and gorilla are closely related in TNFRSF10B and TNFRSF10A genes while in TNFRSF10D, human is closely related with chimpanzee. Bootstrap replication values >50 are presented in phylogenetic tree representing the reliability of topology.
Novel designed molecules have drug related properties and served as inhibitors for candidate gene. Interactions were observed in binding pocket of TNFRSF10B showing polar nature of binding domain. The designed compounds fulfill the properties of a competent drug and have no toxicity, mutagenic, irritants and carcinogenic property.
TNFSF10 protein showed highest interacting score 0.999 with TNFRSF10B target protein belonging to the same protein family. TNFSF10 protein was used as a ligand for protein-protein docking with TNFRSF10B receptor protein. Post docking analysis was performed by PyMol to analyze the hydrogen, ionic and hydrophobic interactions. Only ionic interactions were found in docked complex. Isoleucine-58 of receptor protein TNFRSF10B showed ionic interactions with Arginine-130 of ligand protein TNFSF10 with the distance of 2.9 Å. The nitrogen atom of arginine showed interaction with oxygen atom of isoleucine. Serine-90 of TNFRSF10B receptor protein showed ionic interactions with Serine-156 of ligand protein with a bond distance of 3.2 Å. Nitrogen of serine of ligand protein TNFSF10 interacted with the oxygen of serine of receptor protein. Alanine-62 nitrogen of receptor protein TNFRSF10B interacted with arginine-130 oxygen of ligand protein TNFSF10 with 3.2 Å bond distance.
Conclusion
For protein-protein interaction and novel designed molecules, both functional and expressional studies of TNFRSF10B showed significant interaction. In-vivo experimentation could be performed in animal model to check the effect of selected protein interactions which may leads to the approved drug of head and neck cancer. More than 80% homology between human and primates are strong evidence to build ancestral relationship which will help in prediction of protein functions and family. Current research suggested a baseline for novel ligand screening, docking and ancestral hierarchy for development and validation of novel drugs in particular function prediction of candidate gene TNFRSF10B.
Materials and methods
The sequence of TNFRSF10B protein in FASTA format was retrieved from Uniprot Knowledge base (http://www.uniprot.org/) of accession number E9PBT3. The retrieved amino acid sequence of TNFRSF10B was subjected to a protein-protein BLAST (BLASTp) search against the Protein Data Bank (PDB) (http://www.rcsb.org/) [27] to recognize a suitable template structure. Suitable template [PDB ID: 2ZB9] having 84% query coverage, 30% sequence identity and 5.1 E-value was used in comparative modeling of TNFRSF10B protein. The homology modeling program MODELLER 9v10 was applied to generate 3D models. TNFRSF10B 3D model having lowest objective function was further assessed by Rampage [28], ERRAT [29] and ProSA [30] evaluation tools for the reliability of predicted structure.
Molecular Evolutionary Genetic Algorithm (MEGA 5) was used to infer ancestral history and species relationship of TNFRSF10B gene. Distance based approach through neighbor-joining technique was applied to construct the phylogenetic tree by using 1000 bootstrap replicates.
The compounds obtained through virtual screening were used in docking analysis by AutoDock Vina [31]. The ligand molecules of target protein were not reported in earlier studies and also not found in biological databases, hence virtual screening technique was used to screen drug like lead compounds for TNFRSF10B docking calculations. Four novel lead compounds (as A, B, C and D) were screened. Mcule suit was employed for virtual screening and to predict the bioactivity and molecular properties of lead compounds.
LogP value is an important predictor of per oral bioavailability of drug molecules [32]. Therefore, physiochemical properties such as LogP, molecular mass, rotatable bonds, hydrogen bond acceptor and donors of 4 selected lead compounds were determined. Results showed that compounds (C and D) showed violations of two rules of lipinski rule of five suggesting that lead compounds have good bioavailability. The selected top scrutinized compounds were minimized through VegaZZ [33] and ChemDraw Ultra [34]. Subsequent analysis on selected lead compounds were carried out and docking analysis was performed to identify the binding affinities by AutoDock. Parameters of AutoDock used in docking are mentioned in Table 5.
Table 5.
Parameters of AutoDock used in docking analysis
| Lead compounds |
Centre |
Size (X-axis* Y-axis* Z-axis) | Rate of gene mutation | Rate of crossover | Binding affinity (Kcal/mol) | ||
|---|---|---|---|---|---|---|---|
| X-axis | Y-axis | Z-axis | |||||
|
A |
5.52 |
61.778 |
35.2 |
40*40*40 |
0.02 |
0.8 |
−4.8 |
|
B |
5.846 |
61.933 |
35.423 |
40*40*40 |
0.02 |
0.8 |
−4.9 |
|
C |
5.846 |
61.933 |
35.423 |
40*40*40 |
0.02 |
0.8 |
−8.6 |
| D | 5.846 | 61.933 | 35.423 | 40*40*40 | 0.02 | 0.8 | −9.9 |
The STRING and STITCH3 servers were employed to identify the functional partners of TNFRSF10B. These databases are online database of known and predicted protein interactions including direct (physical) and indirect (functional) relationships. Gramm-X and Hex online servers were applied in protein docking of TNFRSF10B protein with its interactive partner TNFSF10 protein. Post docking analysis of docked complex was performed by PyMol tool.
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
RAT and SAS has equal contribution. RAT and SAS carried out analysis and drafted the manuscript under the supervision of NAK. AM and NAK defined the research theme, designed methods, and analyzed the data. JZKK, AM and NAK critically studied the manuscript. All authors have contributed to, seen, read and approved the manuscript.
Contributor Information
Rana Adnan Tahir, Email: adnantahir8@live.com.
Sheikh Arslan Sehgal, Email: arslansehgal@yahoo.com.
Naureen Aslam Khattak, Email: naureen.aslam@uaar.edu.pk.
Jabar Zaman Khan Khattak, Email: jabar.khattak@iiu.edu.pk.
Asif Mir, Email: asif.mir@iiu.edu.pk.
Acknowledgements
We are thankful to Babar Ashraf Sheikh, Sajjad Ahmad Larra, Syed Babar Jamal and Muhammad Waqar Arshad for assistance.
References
- Devasena A, Pranay MC, Sadhana K, Rajani AB, Manoj BM. Susceptibility to oral cancer by genetic polymorphisms at CYP1A1, GSTM1 and GSTT1 loci among Indians: tobacco exposure as a risk modulator. Carcinogenesis. 2007;28:1455–1462. doi: 10.1093/carcin/bgm038. [DOI] [PubMed] [Google Scholar]
- Hanif M, Zaidi P, Kamal S, Hameed A. Institution-based cancer incidence in a local population in Pakistan: nine year data analysis. Asia Pac J Cancer Prev. 2009;10:227–230. [PubMed] [Google Scholar]
- Vokes EE, Weichselbaum RR, Lippman SM, Hong WK. Head and neck cancer. N Eng J Med. 1993;328:184–194. doi: 10.1056/NEJM199301213280306. [DOI] [PubMed] [Google Scholar]
- Sturgis EM, Wei Q. Genetic susceptibility—molecular epidemiology of head and neck cancer. Curr Opin Oncol. 2002;14:310–317. doi: 10.1097/00001622-200205000-00010. [DOI] [PubMed] [Google Scholar]
- Hashibe M, Boffetta P, Zaridze D. Evidence for an important role of alcohol- and aldehyde-metabolizing genes in cancers of the upper aerodigestive tract. Cancer Epidemiol Biomarkers Prev. 2006;15:696–703. doi: 10.1158/1055-9965.EPI-05-0710. [DOI] [PubMed] [Google Scholar]
- Hittelman WN. Genetic instability in epithelial tissues at risk for cancer. Ann N Y Acad Sci. 2001;952:1–12. doi: 10.1111/j.1749-6632.2001.tb02723.x. [DOI] [PubMed] [Google Scholar]
- Ha PK, Califano JA. Promoter methylation and inactivation of tumour-suppressor genes in oral squamous-cell carcinoma. Lancet Oncol. 2006;7:77–82. doi: 10.1016/S1470-2045(05)70540-4. [DOI] [PubMed] [Google Scholar]
- Perez-Ordonez B, Beauchemin M, Jordan RC. Molecular biology of squamous cell carcinoma of the head and neck. J Clin Pathol. 2006;59:445–453. doi: 10.1136/jcp.2003.007641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schabath MB, Giuliano AR, Thompson Z, Fenstermacher D, Jonathan K, Sellers TA, Haura E. TNFRSF10B polymorphisms and haplotypes predicts survival in non-small cell lung cancer patients. Cancer Res. 2012;72:4506–4520. [Google Scholar]
- Pai SI, Wu GS, Ozoren N, Wu L, Jen J, Sidransky D, El-Deiry WS. Rare loss-of-function mutation of a death receptor gene in head and neck cancer. Cancer Res. 1998;58:3513–3518. [PubMed] [Google Scholar]
- Eswar N, Eramian D, Webb B, Shen MY, Sali A. Protein structure modeling with MODELLER. Methods Mol Biol. 2008;426:145–159. doi: 10.1007/978-1-60327-058-8_8. [DOI] [PubMed] [Google Scholar]
- Pettersen EF, Goddard TD, Huang CC, Couch GS, Greenblatt DM, Meng EC, Ferrin TE. UCSF Chimera–a visualization system for exploratory research and analysis. J Comput Chem. 2004;25:1605–1612. doi: 10.1002/jcc.20084. [DOI] [PubMed] [Google Scholar]
- Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S. MEGA5: molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol. 2011;28:2731–2739. doi: 10.1093/molbev/msr121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tondi D, Slomczynska U, Costi MP, Watterson DM, Ghelli S, Shoichet BK. Structure-based discovery and in-parallel optimization of novel competitive inhibitors of thymidylate synthase. Chem Biol. 1999;6:319–331. doi: 10.1016/S1074-5521(99)80077-5. [DOI] [PubMed] [Google Scholar]
- Ertl P, Rohde B, Selzer P. Fast calculation of molecular polar surface area as a sum of fragment based contributions and its application to the prediction of drug transport properties. J Med Chem. 2000;43:3714–3717. doi: 10.1021/jm000942e. [DOI] [PubMed] [Google Scholar]
- Lipinski CA, Lombardo F, Dominy BW, Feeney PJ. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings. Adv Drug Deliv Rev. 1997;23:3–25. doi: 10.1016/s0169-409x(00)00129-0. [DOI] [PubMed] [Google Scholar]
- Muegge I. Selection criteria for drug-like compounds. Med Res Rev. 2003;23:302–321. doi: 10.1002/med.10041. [DOI] [PubMed] [Google Scholar]
- Kiss R, Sandor M, Szalai FA. http://Mcule.com: a public web service for drug discovery. J Chem Inform. 2012;4:17. [Google Scholar]
- Proudfoot JR. Drugs, leads, and drug-likeness: an analysis of some recently launched drugs. Bioorg Med Chem Lett. 2002;12:1647–1650. doi: 10.1016/s0960-894x(02)00244-5. [DOI] [PubMed] [Google Scholar]
- OSIRIS. 2001. http://www.organic-chemistry.org/prog/peo/
- Franceschini A, Szklarczyk D, Frankild S, Kuhn M, Simonovic M, Roth A, Lin J, Minguez P, Bork P, von-Mering C, Jensen LJ. STRING v9.1: protein-protein interaction networks, with increased coverage and integration. Nucleic Acids Res. 2013;41:808–815. doi: 10.1093/nar/gks1094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuhn M, Szklarczyk D, Franceschini A, Mering CV, Jensen LJ, Bork P. STITCH 3: zooming in on protein–chemical interactions. Nucl Acids Res. 2012;40:876–880. doi: 10.1093/nar/gkr1011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tovchigrechko A, Vakser IA. GRAMM-X public web server for protein-protein docking. Nucleic Acids Res. 2006;34:310–314. doi: 10.1093/nar/gkl206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macindoe G, Mavridis L, Venkatraman V, Devignes MD, Ritchie DW. HexServer: an FFT-based protein docking server powered by graphics processors. Nucleic Acids Res. 2010;38:445–449. doi: 10.1093/nar/gkq311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Forastiere A, Koch W, Trotti A, Sidransky D. Head and neck cancer. N Engl J Med. 2001;345:1890–1900. doi: 10.1056/NEJMra001375. [DOI] [PubMed] [Google Scholar]
- Scully C, Field JK, Tanzawa H. Genetic aberrations in oral or head and neck squamous cell carcinoma (SCCHN): 1. Carcinogen metabolism, DNA repair and cell cycle control. Oral Oncol. 2000;36:256–263. doi: 10.1016/s1368-8375(00)00007-5. [DOI] [PubMed] [Google Scholar]
- Berman HM, Westbrook J, Feng Z, Gilliland G, Bhat TN, Weissig H, Shindyalov IN, Bourne PE. The protein data bank. Nucleic Acids Res. 2000;28:235–242. doi: 10.1093/nar/28.1.235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lovell SC, Davis IW, Arendall WB III, de Bakker PIW, Word JM, Prisant MG, Richardson JS, Richardson DC. Structure validation by Cαgeometry: φ/ψ and Cβ deviation. Proteins: Structure, Function Genetics. 2002;50:437–450. doi: 10.1002/prot.10286. [DOI] [PubMed] [Google Scholar]
- Colovos C, Yeates TO. Verification of protein structures: patterns of nonbonded atomic interactions. Protein Sci. 1993;2:1511–1519. doi: 10.1002/pro.5560020916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiederstein & Sippl. ProSA-web: interactive web service for the recognition of errors in three-dimensional structures of proteins. Nucleic Acids Res. 2007;35:407–410. doi: 10.1093/nar/gkm290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trott O, Olson AJ. AutoDock Vina: improving the speed and accuracy of docking with a new scoring function, efficient optimization and multithreading. J Comput Chem. 2010;31:455–461. doi: 10.1002/jcc.21334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang LCW, Spanjersberg RF, von Frijtag DK, Unzel JK, Mulder-Krieger T, van den Hout G. 2,4,6-Trisubstituted pyrimidines as a new class of selective adenosine A, receptor antagonists. J Med Chem. 2004;47:6529–6540. doi: 10.1021/jm049448r. [DOI] [PubMed] [Google Scholar]
- Pedretti A, Villa L, Vistoli G. VEGA – An open platform to develop chemo-bio-informatics applications, using plug-in architecture and script ”programming“. J Comput Aided Mol Des. 2004;18:167–173. doi: 10.1023/b:jcam.0000035186.90683.f2. [DOI] [PubMed] [Google Scholar]
- Mendelsohn LD. ChemDraw 8 ultra: windows and Macintosh versions. J Chem Inf Comput Sci. 2004;44:2225–2226. [Google Scholar]