

Abstract
Background
Segmenting cell nuclei in microscopic images has become one of the most important routines in modern biological applications. With the vast amount of data, automatic localization, i.e. detection and segmentation, of cell nuclei is highly desirable compared to time-consuming manual processes. However, automated segmentation is challenging due to large intensity inhomogeneities in the cell nuclei and the background.
Results
We present a new method for automated progressive localization of cell nuclei using data-adaptive models that can better handle the inhomogeneity problem. We perform localization in a three-stage approach: first identify all interest regions with contrast-enhanced salient region detection, then process the clusters to identify true cell nuclei with probability estimation via feature-distance profiles of reference regions, and finally refine the contours of detected regions with regional contrast-based graphical model. The proposed region-based progressive localization (RPL) method is evaluated on three different datasets, with the first two containing grayscale images, and the third one comprising of color images with cytoplasm in addition to cell nuclei. We demonstrate performance improvement over the state-of-the-art. For example, compared to the second best approach, on the first dataset, our method achieves 2.8 and 3.7 reduction in Hausdorff distance and false negatives; on the second dataset that has larger intensity inhomogeneity, our method achieves 5% increase in Dice coefficient and Rand index; on the third dataset, our method achieves 4% increase in object-level accuracy.
Conclusions
To tackle the intensity inhomogeneities in cell nuclei and background, a region-based progressive localization method is proposed for cell nuclei localization in fluorescence microscopy images. The RPL method is demonstrated highly effective on three different public datasets, with on average 3.5% and 7% improvement of region- and contour-based segmentation performance over the state-of-the-art.
Background
Microscopic image analysis is becoming an enabling technology for modern systems-biology research, and cell nucleus segmentation is often the first step in the pipeline. Despite recent advances, the segmentation performance remains unsatisfactory in many cases. For example, on the popular public databases [1], the state-of-the-art segmentation accuracies are just around 85%.
The challenges of automated cell nucleus segmentation mainly arise from two imaging artifacts, as shown in Figure 1. First, the cell nuclei regions are inhomogeneous – the pixels of a cell nucleus exhibit non-uniform intensities and different cell nuclei also display varying patterns. Second, the background is also inhomogeneous and certain regions might have very similar appearance to the cell nuclei. These problems imply that: (1) precise delineation of boundaries between cell nuclei and the background is difficult; (2) some background areas could be mistaken as cell nuclei; and (3) certain cell nuclei could be missed. The segmentation problem can be characterized as a localization issue that includes both object detection and pixel-wise segmentation.
Figure 1.

An example image (left) and corresponding segmentation ground truth (right) from data set [1]. It can be seen that besides the pixel-wise inhomogeneity within a cell nucleus, some cell nuclei exhibit much lower intensities than the others; and although the background looks generally dark, it is indeed highly inhomogeneous, with some fairly bright areas and also a few noisy regions displaying very high intensities.
Related work
Numerous works have been conducted on segmenting various structures in cell images [2,3], and unsupervised approaches appear to dominate. For example, the morphological methods based on thresholding, k-means clustering or watershed [4-8] can be quite effective, as long as the objects exhibit good contrast with the background. Watershed methods are also effective in separating touching cells, although the results might deviate from the actual contours slightly. A more popular trend of unsupervised segmentation is the energy-based deformable models, based on active contours [9] or level sets [10-15]. Compared with modeling contours explicitly, level sets have the advantage of being non-parametric and free from topology constraints. It is also relatively easy to incorporate continuous object-level regularization into level sets, such as shape priors. Another type of energy-based model is based on graph search [16,17], graph cuts [18,19] or normalized cuts [20]. Such methods attempt to derive the segmentation with global constraints, using well-defined graphical structures to represent the spatial relationships between regions. Many of these methods require good initial seeds or contours. However, the usual initialization techniques, such as thresholding and watershed, would not handle images with high inhomogeneities well, hence causing extra or missing detection of cell regions. Such detection errors during initialization could propagate into the final segmentation outputs.
It has been shown that intensity inhomogeneities can be tackled by integrating convex Bayesian functional with the Chan-Vese model [14], and discrete region-competition [15] based on the piecewise-smooth Mumford-Shah model [>[21]. However, without performing cell detection explicitly, the deformable models might become very complicated in order to filter background regions with cell-like features while keeping cell regions with background-like features. To detect cells from inhomogeneous background, one way is to reconstruct the ideal image [22,23], which however, requires specific imaging modeling. Reconstruction can also be built into active contours with constrained iterative deconvolution without explicitly computing the inverse problem [24,25]; however, it requires the point-spread function of a microscope, which is measured or modeled. Another way is to enhance the objects using h-dome transformation [26]; however, it might have difficulties with inhomogeneous foreground. The inhomogeneity can also be reduced with reference-based intensity normalization [27]; however, the image-level normalization would not well handle the intra-image variation. In addition, shape-based nucleus detection has been proposed, with Laplacian of Gaussian (LoG) [28] or sliding band filter (SBF) [29]. While the latter method is less sensitive to low contrast and better representative of irregular shapes, the detection accuracy partially relies on validation from the corresponding cytoplasm image, which is not always available.
Different from the unsupervised approaches, classification-based methods have also been proposed to incorporate prior information from labeled images. These classifiers include Bayesian [30], k-nearest neighbor (kNN) [31], support vector machine (SVM) [32], and atlas-based approaches [33]. Since the apparent difference between the foreground and background is their intensities, simple intensity-based features, such as histograms [30], have been widely used. On the other hand, the effectiveness of classification-based methods depends highly on the separation of feature spaces between foreground and background. Therefore, approaches based on a bag of local classifiers [30], and more complex features such as the local Fourier transform (LFT) [31], spatial information [33], and combination of appearance, shape and context features [32], have been proposed.
While most such supervised approaches describe the pixel- or region-level features, there are methods that tackle intensity inhomogeneity by explicitly modeling the inter-cell variations as more structural features. One way is to perform color standardization within pixelwise classification [34] to account for the inter-image intensity variations. To also address the intra-image variations, contrast information between an image region and the global foreground and local interest regions is computed [35]. A similar approach is to estimate foreground probabilities based on intensity distributions derived from global images and local detection outputs [36]. While both approaches introduce cell-adaptive features, the methods for global feature representation and local region detection might not work well with large feature overlapping between the foreground and the background. An additional false positive reduction step has also been proposed to remove bright background regions that are misidentified as cell nuclei [37]. However, this approach requires a learned classifier, whose performance could be affected by inter-image feature variation. More differently, registration-based approach has also been studied, by creating a template set from training images and segmenting the testing image based on best matches [38]; such templates however, might have difficulties capturing large varieties of object shapes and textures.
Our contribution
The contribution of our work is to localize the cell nuclei in images with high intensity inhomogeneity with various data-adaptive modeling techniques in a progressive manner. Specifically, we design a three-stage cell nucleus localization method that: (1) salient regions representing cell nuclei and cell clusters are extracted with image-adaptive contrast enhancement; (2) the clusters are further processed to identify true cell nuclei based on feature-distance profiles of reference regions with cluster-adaptive probability estimates; and (3) the contours of detected cell nuclei are refined in a graphical model with region-adaptive contrast information. Figure 2 gives an overview of the proposed method.
Figure 2.

The high-level flow chart of our proposed region-based progressive localization method. In this example, the cell nuclei and clusters are first extracted during initial segmentation with contrast-enhanced salient region detector, then missed or falsely detected cell nuclei are further processed in decluster processing with classification-based candidate identification and probability estimation via distance profile for candidate validation, and better contour delineation is finally achieved with regional contrast-based graphical model. For easier viewing, a quadrant of the original image is shown here, and similarly for Figure 3 and 4. The meaning of the color coding is described in Figures 3, 4 and 5.
We also design distinctive data-adaptive priors that can be categorized by the level of generalization: (1) global-level features modeled as support vectors from training images; (2) image-level features representing the distribution of varying appearances of the nearby cell nuclei; and (3) region-level features computed at all three stages of the method for interest region detection, candidate validation and contour refinement. Being adaptive to the specific image or interest region, the image- and region-level features are especially effective in accommodating the intensity inhomogeneities.
Compared to localization methods based on global criteria (e.g. thresholding or feature-based classification), our approach is more capable of accommodating (1) intensity variations between cell nuclei (intra- and inter-images) and (2) feature overlapping between cell nuclei and background areas. Compared to the energy-based techniques that target pixel-wise segmentation (e.g. level sets and graph cuts), our method has a stronger focus on cell nuclei detection with explicit modeling of cell-specific characteristics, to effectively filter cell-like background regions and identify obscure cell nuclei.
We suggest that the proposed region-based progressive localization (RPL) method can be potentially extended to other localization problems, if the objects of interest can be modeled as regions with distinct features from the surrounding background. A similar three-stage approach would be used, and the application-specific modifications would mainly focus on the feature design. One example could be tumor localization in functional images.
Methods
Initial segmentation
While cell nuclei might appear similar to the background, there is always some degree of contrast between them. Such an observation motivates us to localize the cell nuclei by extracting salient regions. During initial segmentation, we do not have strict requirements about the extracted regions. In particular, if multiple cell nuclei are tightly connected, or cell nuclei are surrounded by high-intensity background and difficult to differentiate, identifying them as a single region is acceptable. We design a contrast-enhanced salient region detector for initial segmentation.
Specifically, an iterative approach is developed based on the maximally stable extremal region (MSER) method [39]. Since MSER does not require any initial contour and the region stability is constrained by local regional information, it is easy to use and able to accommodate large intra-image variations. However, the effectiveness of MSER depends highly on the intensity contrast between the foreground and background. If the contrast is low, some regions would not be detected (e.g. Figure 3c). It is intuitive to add contrast enhancement. However, basic approaches such as intensity stretching would not work due to large intensity span. Instead, we design an iterative approach by alternating between the following two steps. First, interest regions {R} are detected using MSER, as shown in Figure 3c. Second, based on the detection result, the image is enhanced (Figure 3d) by:
Figure 3.

Illustration of initial segmentation.(a) The original image. (b) The segmentation ground truth. (c) The interest regions detected without iterative contrast enhancement, and darker blue denotes upper-level regions. (d) The image after iterative enhancement. (e) The final interest regions detected. After the initial segmentation, decluster processing is performed, with outputs shown in (f) and dark gray indicating the detected cell nuclei.
| (1) |
where {R}0 and {R}2 denote the minimum and mean intensities of the detected interest regions in I, and C is a scaling constant. The normalization factor 0.5({R}0+{R}2) is chosen based on: (1) it should normally be smaller than C so that all pixels in I are scaled up with contrast between pixels increased proportionally; and (2) it should not be so small that the image becomes distorted from the original patterns with intensities capped at 255 for grayscale images. The iteration stops when the number of regions created does not change any further. With such a contrast-enhanced approach, better region detection output can be seen in Figure 3e. The resultant regions are either single-level, or form a hierarchy of lower- and upper-level regions.
It is also observed that during each iteration, the parameter MaxVariation in MSER (using VLFeat library [40]) needs to vary for individual images to better accommodate the inter-image variations. Therefore, the parameter value is determined at runtime by first setting MaxVariation to v1 then gradually reducing it by a certain step Δv until it reaches v2 or the number of region levels is larger than one. Furthermore, while the resultant single- and upper-level regions are mostly cell nuclei, occasionally under-segmentation happens. In other words, a single cell nucleus could be divided into two nested regions and the upper-level region would become a under-segmented portion of the cell nucleus. To reduce such under-segmentation, we find that if the combined area of two nested regions is roughly elliptical with a suitable size, they can be merged as a single region. The shape and size criteria are determined using a linear-kernel binary SVM obtained from the training data. The overall process of initial segmentation is listed in Algorithm 1.
Algorithm 1: Initial segmentation
Decluster processing
As seen in Figure 3e, the detected single- and upper-level regions usually represent the cell nuclei, and lower-level regions usually represent the background with elevated intensities. However, the upper-level regions could contain false positives caused by bright background, and lower-level regions could also include undetected cell nuclei. It is also observed that such incorrect detections are mainly present among the two-level nested regions (i.e. clusters), while the single-level regions are normally true cell nuclei. Therefore, in the second stage, we focus on further processing on the detected clusters, with two objectives. First, we expect to identify any cell nucleus that has not been detected after the initial segmentation. Such cell nuclei typically exhibit similar intensities to the surrounding background, and hence would not be highlighted as salient regions. Second, we need to filter out high-intensity background regions, which usually have rounded or irregular shapes, and could be easily confused as cell nuclei. A two-step approach is designed, using candidate identification then candidate validation. An example output is shown in Figure 3f.
Formally, let U = {ui : i = 1,...,NU} be a detected cluster, with NU pixels ui. Define the set of labels {F,B} representing the foreground (i.e. cell nuclei) and background respectively, and a foreground region as a connected component Gx ⊂ U with ∀ui ∈ Gx : li=F. The problem is to label each pixel ui∈U as li = {F,B}, with the object-level constraint that any detected foreground region Gx should have suitable characteristics as a cell nucleus.
Candidate identification
In the first step, we try to identify a set of non-overlapping candidate foreground regions {Gx} from each cluster U by labeling each pixel ui as foreground or background. We specify that any upper-level region enclosed in a cluster U is a candidate region Gx. To identify more candidates from the cluster U itself, it is observed that to differentiate between F and B pixels, the texture feature in a local patch is more discriminative than pixel intensities. For example, compared with cell nuclei, the background usually has more homogeneous texture that might be dark or bright. In this work, we choose to use the scale-invariant feature transform (SIFT) descriptor [41], which describes the gradient distribution within a local patch and is invariant to scale, translation and rotation. SIFT feature of each pixel ui is computed, and then labeled using a binary SVM. The SVM kernel is polynomial, with other default settings in LIBSVM [42]. A connected component of F pixels is identified as a candidate region Gx.
While most of the candidate regions are true cell nuclei, some are actually bright background areas with round shapes (e.g. the first example in Figure 4). To filter out the false detections, we pass them to the candidate validation stage.
Figure 4.
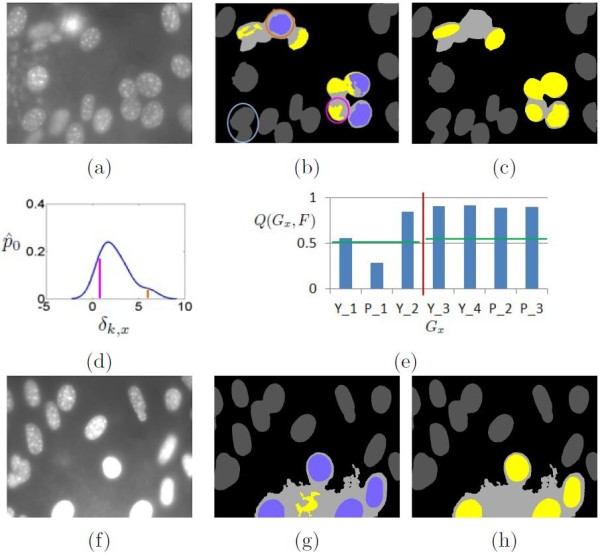
Illustration of decluster processing.(a) The example image (after iterative enhancement). (b) Newly identified candidate regions are shown in yellow, with purple indicating the ones detected during initial segmentation, and both gray and purple denoting the reference regions; here to illustrate the probability inference, the light blue circle highlights one reference Gk, and pink and orange circles indicate two candidate regions Gx. (c) The candidates validated shown as yellow. (d) The KDE plot generated for Gk, in which the pink and orange lines represent for the pink and orange circled candidates. (e) The probabilities Q(Gx,F) derived for all candidate regions, with P_1 and Y_4 corresponding to the orange and pink circled candidate regions, the red vertical line separating the two clusters, and green horizontal lines indicating the thresholds for l(Gx) = F. (f)-(h): A second example with the same annotations to show that different from the first example, the real cell nuclei here are bright while the filtered candidate region is darker.
Candidate validation
In the second step, we validate if the identified candidate region Gx in image I is a cell nucleus. There are two reasons that motivate this step. First, there might be misclassification during candidate identification due to inter-image intensity variations (e.g. different appearances of the cell nuclei between the two examples in Figure 4). The labeling performance could be improved based on reference information gathered from the testing image itself. Second, pixel-level labeling based on SIFT features has limited spatial information and often does not represent the overall region Gx. We design a probability estimation via distance profile method to derive the probability Q(Gx,F) of Gx being a valid cell nucleus based on the feature-distance profiles of other reference cell nuclei, as detailed below.
Probability inference Although cell nuclei in an image could have varying characteristics, we expect that Gx, if representing a true cell nucleus, should have similar features to the other cell nuclei in the same image, especially those spatially adjacent to Gx, as can be seen from the examples in Figure 4. Therefore, if we have a set of determined cell nuclei in I, we can use them as references to validate Gx. To cope with inter-image variations, we would only select references from the image I in which Gx resides. This means we could not use the ground truths for reference construction. Instead, we use the single- and upper-level regions that are detected during initial segmentation as references.
We use these references by first creating a distance profile per reference, and computing the probability of Gx being a cell nucleus based on its feature distance to each reference. Specifically, assume within an area near Gx, there are K reference regions . Here near is defined as both Gx and Gk being in the same quadrant of image I. Let fx describe the region-level feature of Gx, and the feature distance between Gx and Gk as δ(fk,fx) (details of f and δ in the next two subsections). Intuitively, the more similar Gx and Gk are, the more likely Gx is a cell nucleus. However, since Gk may be a false positive detection, decision based on direct feature distance δ(fk,fx) might be error prone. Therefore, we devise an alternative hypothesis that, if δ(fk,fx) is comparable with , then Gx is likely a cell nucleus.
To measure if δ(fk,fx) is comparable with , we use the non-parametric kernel density estimation (KDE):
| (2) |
where δk,x is short for δ(fk,fx), is the Gaussian kernel and hk is the bandwidth approximation following normal distribution of all data samples . The density value is then normalized by the maximum density of the distribution to obtain the comparability measure in terms of probability :
| (3) |
With this model, is larger when δk,x approaches the Gaussian mean of the samples, which means that Gx is more likely a cell nucleus if the distance between Gx and Gk is similar to how the other references vary from Gk.
Next, by combining the estimates from all references {Gk}, the final probability of Gx being a cell nucleus is derived:
| (4) |
The averaging operation helps to ensure that a single reference Gk with very different features from Gx would not affect the overall probability Q(Gx,F) significantly.
Then, based on Q(Gx,F), we define a thresholding rule to determine if Gx is a valid cell nucleus:
| (5) |
where denotes other candidate regions that are within the same cluster U as Gx and x′ ≠ x; α1 and α2 are predefined thresholds. Examples of the density computation and probability derivation are shown in Figure 4, and the overall process of candidate validation is listed in Algorithm 2.
Algorithm 2: Candidate validation
Appearance feature We observe that a region tends to comprise patches of similar textures and repetitive patterns. Therefore, we choose to represent Gx with bag-of-features. First, the image I that contains Gx is divided into a grid of patches {P}. Then for each patch, we represent its texture feature by its minimum, maximum, mean intensity, standard deviation, and a histogram of intensity differences between each pair of pixels. Each patch-wise feature is then assigned a feature word. A histogram summarizing the occurrence frequencies of such feature words in Gx is defined as fx. Here each feature vector is normalized by the size of Gx, to represent the percentages of various intensities and feature words in Gx.
Note that if Gx is a newly identified candidate during decluster processing, Gx might only represent a small under-segmented portion of the actual cell nucleus due to the pixel-level labeling. Therefore, to have a good summary of the actual candidate feature, we first estimate an elliptical region that is a minimum volume ellipsoid covering Gx[43]. To avoid including many background pixels into , we ensure is part of the cluster U in which Gx is detected: . is then used in place of Gx as the detected candidate, from which fx is computed. The refined elliptical regions are shown in Figure 4c.
Appearance distance To compute the distances δ(fk,fx) between two histogram features, the diffusion distance [44] is used. The diffusion distance models the distance between histogram-based descriptors as heat diffusion process on a temperature field. Compared to the bin-to-bin histogram distances, such as Euclidean distance, the diffusion distance is able to measure cross-bin distances, avoiding explicit computation of histogram alignment. While the earth mover’s distance (EMD) [45] has similar advantages, the computation of diffusion distance is much faster, with O(H) complexity only, where H is the number of histogram bins.
Contour refinement
At this stage, a detected region could contain a single or multiple cell nuclei, which could be under-segmented or include extra background. We thus expect to achieve better contour delineation of cell nuclei. Our idea is that, while the foreground and background are often inhomogeneous, there is always relatively good contrast between them in a local area. Therefore, by performing contour refinement for each detected cell region G individually, the foreground and background can be better differentiated by analyzing the localized contrast information. We employ a regional contrast-based graphical model for the contour refinement.
Specifically, a conditional random field (CRF) [46] with the following energy function is designed:
| (6) |
where denotes the detected region G plus its surrounding area of a fixed width (half of the short axis of G) (Figure 5b), and L denotes the labeling vector of all pixels in . Then, the model attempts to refine the contour of G by relabeling each pixel as li = {F,B}. Here η(li) is the unary contrast-based intensity term, η(lG) combined with φ(·) is the contrast-based detection term with lG representing the detected region G, and ϕ(·) is the spatial term associating neighboring pixels ui and . The constant 0.5 is set to obtain equal contributions from the unary costs () and the combined pairwise costs (). Graph cut [47] method is used to derive the most probable labeling L that minimizes the energy function, to produce the final segmentation of cell nuclei from . Here our customized definition of the intensity term and inclusion of the detection term are the main distinctions from the other CRF constructs [35,48,49].
Figure 5.
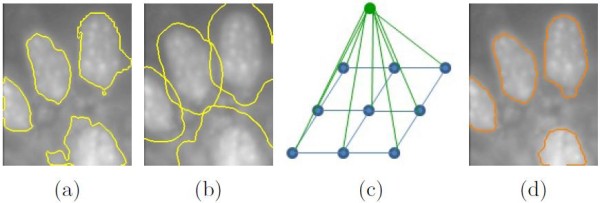
Illustration of contour refinement.(a) Segmentation output after the decluster processing shown with yellow contours. (b) indicated with yellow contours. (c) Visualization of the graphical model, with blue nodes representing li and green node lG, and the blue and green edges denoting the pairwise relationships. (d) Results of contour refinement with orange contours.
The contrast-based intensity term η(li) describes the unary costs of pixel ui labeled as li ∈ {F,B}. Basically, the costs of li = F and li = B represent the inverse probabilities, and the probability pr(ui,F) of li = F is computed by:
| (7) |
| (8) |
| (9) |
where IG denotes the mean intensity of G, and pr(ui,F) follows a sigmoid probability distribution based on the contrast feature fi. We expect pixels with fi > λG to more likely represent the foreground. λG is computed based on fG and , which are the mean and minimum of all feature values {fi : ui ∈ G}, and is adjusted by γG for a balance of foreground and background partitioning in G. The parameter γG is calculated at runtime, by gradually increasing it from γ1 to γ2 with a step value Δγ, and choosing the smallest γG ∈ [ γ1,γ2] that does not cause the entire G to be labeled as B. With pr(ui,B) = 1 - pr(ui,F), the cost values for both labels are:
| (10) |
Note that since λG would be closer to fG in most cases with small γG, it would cause portions of G to have pr(ui,F) < 0.5 (i.e. ui labeled as background), resulting in possible under-segmentation. It is however not advisable to lower λG, due to considerable overlap between low-intensity areas in G and the background. Therefore, we introduce a second contrast-based detection term to encourage labeling of li = F. An auxiliary node lG is first included to the graph with the following unary costs:
| (11) |
where is the number of pixels in , and such a large cost of lG = B ensures lG is assigned 1. Then for each pixel ui, a pairwise cost φ(li,lG) is computed based on the contrast ν(Ii,IG) between Ii and the mean intensity of G:
| (12) |
with δ(li - lG) = 1 if li ≠ lG and 0 otherwise, and ν(Ii,IG) = 1 if Ii > IG, or:
| (13) |
where 〈 · 〉 denotes the average Euclidean distances of all such pairwise distances in . In this way, pixels with pr(ui,F) ≈ 0.5 could be better labeled with the additional cost factor; and obvious background pixels would still obtain the correct B label, with φ(li,lG) much lower than η(li).
The spatial term then further enhances the delineation by encouraging spatial labeling consistencies between neighboring pixels ui and . A pairwise cost for is thus defined as:
| (14) |
where δ(·) and ν(·) follow Eq. (12). Such a cost function implies that pixels with more similar intensities would be more penalized if they take different labels.
Materials and evaluation methods
Three different datasets that are publicly available with segmentation ground truth are used in this study. Their main properties are summarized in Table 1. The images in the first two datasets were acquired with nuclear markers whereas the third dataset also includes the cytoplasm. Detailed information can be found in [1,50]. Among the three, dataset 1 has higher contrast between cell nuclei and background. Datasets 2 and 3 have large intensity inhomogeneity and considerable degree of intensity overlapping between the cell nuclei and the background. The inclusion of cytoplasm in dataset 3 poses more challenges. The images in dataset 3 are preprocessed to remove the pink areas and converted to grayscale. Figure 6 shows an example image after the preprocessing.
Table 1.
Summary of the datasets used
Figure 6.
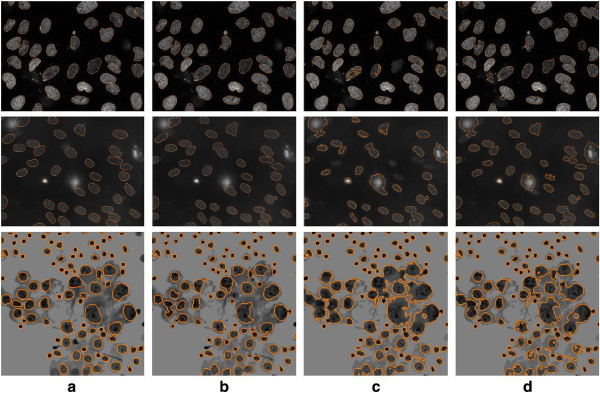
Example localization results. The top row from dataset 1, the middle row from dataset 2 and the bottom row from dataset 3. (a) Image with ground truth contours in orange. (b) Results using our proposed RPL method. (c) Results using OT. (d) Results using LS.
Most parameters used in this study are set to the same values for all three datasets: (1) in Initial Segmentation, v1 = 0.7, v2 = 0.4 and Δv = 0.1; (2) in Probability Inference, α1 = 0.6 and α2 = 0.4; (3) in Appearance Feature, the number of histogram bins is 64, and the number of feature words is 12; and (4) in Contour Refinement, γ1 = 0.25, γ2 = 1 and Δγ = 0.25. While these settings are chosen empirically, using a common setting for all three datasets suggests that the method is robust to different image acquisition and manual tuning of parameters can be minimal. There are only two dataset-specific parameters. One is the patch size in Appearance Feature, which is 8×8 pixels for datasets 1 and 2, and 4×4 pixels for dataset 3. The smaller size for dataset 3 is chosen due to its smaller cell nuclei compared to datasets 1 and 2. The other parameter is C in Initial Segmentation, which is set to 128 for datasets 1 and 2, and 64 for dataset 3. This ensures the contrast enhanced images in dataset 3 would not become too bright to cause distortion.
For dataset 1, four representative images are selected to train two SVM classifiers, for the cell-cluster differentiation and candidate identification. While testing is performed on all images to make the results directly comparable with the state-of-the-art [14,38], we note that the testing results are not sensitive to the selection of training data, with very similar testing results observed based on different training sets. Similar procedures are performed for dataset 2. For dataset 3, in order to have comparable performance evaluation with [32,35], half of the images are used for training (images # 2, 3, 4, 5, and 7) and the rest for testing.
We evaluate the localization of cell nuclei by two measures. First, performance of object-level detection is evaluated by recall (R), precision (P), and accuracy (A):
| (15) |
| (16) |
| (17) |
where TP, FN, and FP are the numbers of true positive, false negative and false positive detections of cell nuclei. Given a detected region Od and the ground truth mask Ogt, if the overlap ratio R(Od) is at least 0.5:
| (18) |
then the detection is considered TP [51]; and correspondingly FN and FP are determined.
Second, the segmentation performance is evaluated by both region- and contour-based measures, including Dice, normalized sum of distances (NSD) and Hausdorff distance (HD):
| (19) |
| (20) |
| (21) |
Here F represents the foreground pixels identified, M is the ground truth mask, and D(ui) is the minimal Euclidean distance of pixel ui to ∂M of the corresponding reference nuclei, with ∂ indicating the contour.
We have compared with popular cell imaging segmentation techniques, including Otsu thresholding, k-means clustering and watershed [8]. Furthermore, in view of the popularity of level set for cell imaging and our design on tackling the intensity inhomogeneities, we have experimented with a level set method that has a similar focus, using the authors’ released code [52], with initial contours generated using watershed method. For all methods, post-processing is conducted to remove isolated segments that are smaller than 1/10 of the average size of foreground regions detected in the image. In addition, we report direct performance comparisons with the state-of-the-art results reported on the same datasets [14,32,35,38], by including the same performance measures as used in these works.
Results and discussion
Cell detection
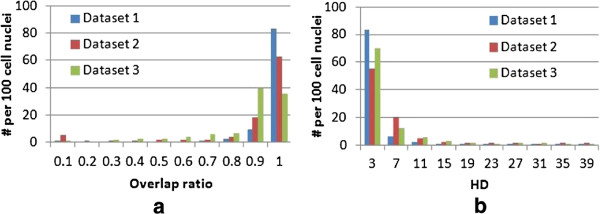
We report the object-level detection results in Table 2. Comparing the results at various stages of the methodology, the improvement is larger on dataset 2 than dataset 1, e.g. 8.3% increase in detection accuracy on dataset 2 vs 0.8% increase on dataset 1. This is because inhomogeneity is more prominent on dataset 2 while dataset 1 exhibits clearer contrast between the cell nuclei and the background in most images. In our evaluation, a detection is only considered as TP if the overlap ratio in Eq. (18) is at least 0.5. Therefore, a largely over- or under-segmented object would be counted as FN for the second stage, and corrected after the contour refinement. This explains why although cell nuclei are detected after the decluster processing, the recall results only improve significantly after the third stage. On dataset 3, the presence of cytoplasm causes many cell nuclei to clutter into one region during the initial segmentation; this leads to FN. The third stage better differentiates the cell nuclei and cytoplasm, and the improvement is significant with 18.7% and 3.4% increase in detection recall and precision. Figure 7a gives a better overview of the overlap ratios obtained from the final localization outputs. While most cell nuclei exhibit ratios not less than 0.5, less optimal results are observed on dataset 3 again due to the influence from the cytoplasm.
Table 2.
Detection results
| |
Dataset 1 |
Dataset 2 |
Dataset 3 |
||||||
|---|---|---|---|---|---|---|---|---|---|
| S-1 | S-2 | S-3 | S-1 | S-2 | S-3 | S-1 | S-2 | S-3 | |
| R |
0.967 |
0.973 |
0.975 |
0.814 |
0.834 |
0.886 |
0.734 |
0.770 |
0.957 |
| P |
0.929 |
0.935 |
0.940 |
0.933 |
0.941 |
0.955 |
0.915 |
0.941 |
0.975 |
| A | 0.908 | 0.914 | 0.916 | 0.769 | 0.792 | 0.852 | 0.691 | 0.736 | 0.934 |
After initial segmentation (S-1), decluster processing (S-2), and contour refinement (S-3).
Figure 7.
Cell detection results. Histograms with y-axis as numbers from per 100 cell nuclei, and x-axis as (a) the object-level overlap ratio and (b) the Hausdorff distance, both between the segmented foreground and ground truth.
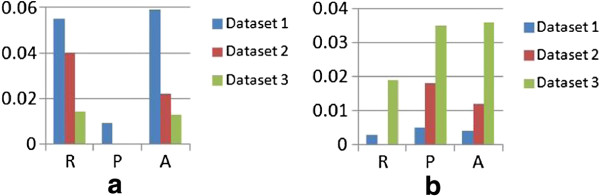
The performance improvement introduced by the iterative process of interleaving interest region extraction and image enhancement are shown in Figure 8a. The higher recall (i.e. on average 3.6% increase) suggests that such an approach is especially useful for identifying foreground regions that originally display low contrast from the background. The benefits of having candidate validation are shown in Figure 8b. By filtering out interest regions that are very different from the reference regions, the detection precision thus improves by on average 2%. The recall improves by on average 0.7% only, mainly because of the same constraints imposed by the overlap ratio.
Figure 8.

Cell detection results. Improvement on detection from (a) iterative image enhancement and interest-region extraction, and (b) candidate validation.
To evaluate the effect of the default threshold setting α1 for candidate validation, the receiver operating characteristics (ROC) curves are plotted by varying the threshold value. The probability estimates from all candidate regions are included in the plot, and candidate regions with at least 0.5 overlapping ratio with the ground truth are marked as foreground class and the rest as the background class. As shown in Figure 9, the 0.6 threshold setting provides a good balance between the TP and FP detections, with close to maximum TP rates. Note that the numbers of true negatives here are small (about 1/5 of positive samples), hence the FP rates appear relatively high.
Figure 9.
ROC curves of candidate validation. The purple dots indicate the position with the decision threshold α1 = 0.6.
Nucleus segmentation
Table 3 summarizes the region- and contour-based segmentation results. On datasets 2 and 3, the decluster processing improves the Dice measure by about 3% and 4%, due to better object-level labeling of candidate regions. The contour-based measures, however, are mainly enhanced at the third stage of the methodology, with on average more than half reduction in NSD and HD. This is attributed to better contour delineations based on the detection results from the first two stages. Besides the mean values listed in the table, the distributions of Hausdorff distances on the final localization results are also shown in Figure 7b.
Table 3.
Segmentation results
| |
Dataset 1 |
Dataset 2 |
Dataset 3 |
||||||
|---|---|---|---|---|---|---|---|---|---|
| S-1 | S-2 | S-3 | S-1 | S-2 | S-3 | S-1 | S-2 | S-3 | |
| Dice |
0.948 |
0.954 |
0.958 |
0.847 |
0.876 |
0.906 |
0.815 |
0.853 |
0.924 |
| NSD |
0.026 |
0.023 |
0.017 |
0.175 |
0.141 |
0.090 |
0.338 |
0.327 |
0.052 |
| HD | 10.72 | 10.60 | 10.01 | 22.55 | 20.76 | 14.10 | 20.96 | 18.03 | 5.51 |
After initial segmentation (S-1), decluster processing (S-2), and contour refinement (S-3).
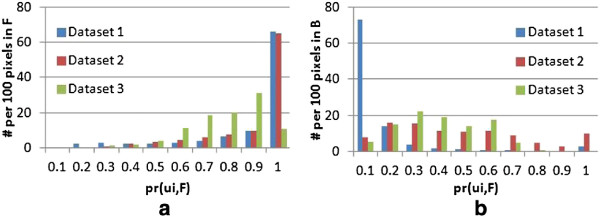
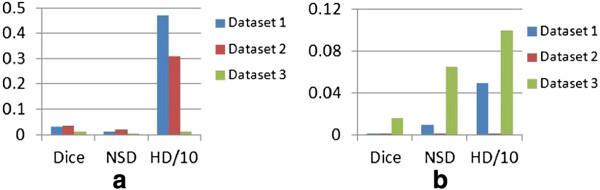
To further evaluate the design of the graphical model for contour refinement, the foreground probabilities for all pixels of interest are computed with the intensity term, as summarized in Figure 10. While many pixels exhibit suitable probabilities, some background pixels, especially those in datasets 2 and 3, have larger foreground probabilities and would lead to misclassification. The pixel-level classification is improved by introducing the contrast-based detection and spatial terms, as shown in Figure 11.
Figure 10.
Nucleus segmentation results. Histograms with x-axis as the foreground probability derived from the intensity term,and y-axis as the numbers from per 100 pixels in for (a) the real cell nuclei and (b) background.
Figure 11.
Nucleus segmentation results. Improvement on segmentation from (a) contrast-based detection term and (b) spatial term.
Performance comparison
The localization results using the standard approaches are listed in Table 4, with example outputs shown in Figure 6. Compared to our proposed method, the level set and watershed techniques produce the second best results for dataset 1, especially with good contour-based measures. However, without explicitly handling high-intensity background regions, both methods result in about 3% lower detection precision. On dataset 2, our proposed method demonstrates stronger advantages, with 8.5% increase in detection accuracy,10.2% increase in Dice coefficient and 10.8 decrease in HD over the second best approach (i.e. level set). Both the level set and watershed approaches face the following challenges: (1) difficulty separating cell nuclei from surrounding background areas with low contrast, and (2) incapability of classifying background regions that resemble cell nuclei. On dataset 3, the intensity inhomogeneities within the cell nuclei and the cytoplasm make it particularly difficult to achieve good segmentation. As a result, the watershed method tends to largely over-segment the cell nuclei, generating many clusters and cause low detection recall and more errors in contour delineation. The level set method based on localized energy optimization is quite effective in splitting the clusters, but is less optimal for areas with high similarity between the cell nuclei and cytoplasm. The thresholding method does not perform as well as the level set or watershed approaches, but it does outperform the clustering-based approach. Compared to level set, our method achieves 7% increase in detection accuracy, 2.7% increase in Dice coefficient and 1.8 decrease in HD. Tables 2, 3 and 4 show that our proposed method delivers better localization even using only the initial segmentation step. Higher performance margins are obtained with decluster processing and contour refinement, especially on datasets 2 and 3.
Table 4.
Comparison of localization results
| |
Dataset 1 |
|||||
|---|---|---|---|---|---|---|
| R | P | A | Dice | NSD | HD | |
| RPL |
0.975 |
0.940 |
0.916 |
0.958 |
0.017 |
10.01 |
| OT |
0.928 |
0.807 |
0.767 |
0.876 |
0.068 |
17.52 |
| KM |
0.758 |
0.657 |
0.626 |
0.727 |
0.237 |
19.11 |
| WS |
0.974 |
0.915 |
0.893 |
0.945 |
0.022 |
11.21 |
| LS |
0.970 |
0.910 |
0.886 |
0.932 |
0.022 |
9.58 |
| |
Dataset 2 |
|||||
| |
R |
P |
A |
Dice |
NSD |
HD |
| RPL |
0.886 |
0.955 |
0.852 |
0.906 |
0.090 |
14.10 |
| OT |
0.598 |
0.750 |
0.530 |
0.601 |
0.419 |
36.72 |
| KM |
0.508 |
0.601 |
0.437 |
0.521 |
0.503 |
134.5 |
| WS |
0.714 |
0.817 |
0.636 |
0.789 |
0.337 |
47.67 |
| LS |
0.832 |
0.899 |
0.767 |
0.804 |
0.207 |
24.96 |
| |
Dataset 3 |
|||||
| |
R |
P |
A |
Dice |
NSD |
HD |
| RPL |
0.957 |
0.975 |
0.934 |
0.924 |
0.052 |
5.51 |
| OT |
0.712 |
0.961 |
0.685 |
0.873 |
0.188 |
31.80 |
| KM |
0.722 |
0.824 |
0.604 |
0.872 |
0.189 |
38.12 |
| WS |
0.584 |
0.989 |
0.575 |
0.819 |
0.335 |
34.53 |
| LS | 0.914 | 0.939 | 0.865 | 0.897 | 0.094 | 7.35 |
Comparison between our proposed region-based progressive localization method (RPL), Otsu thresholding (OT), k-means clustering (KM), watershed (WS) and level set [52] (LS).
A comparison with the state-of-the-art results reported for the same datasets is summarized in Table 5. Our method achieves better results in most measures, as bold-faced in the table. On dataset 1, 0.93 more FP cell nuclei are detected compared to the level set method [14]. It is possible that such false detections are caused by accidental highlighting of background regions during the iterative image enhancement for the initial segmentation stage. However, our method exhibits overall much better detection performance with minimal numbers of FNs (3.68 fewer than [14]) and only 1.43 FPs. The accuracy of pixel-level segmentation on dataset 2 improves significantly, as indicated by the 5% increase in Dice and Rand indices over [14]. 4.1% performance improvement of object-level accuracy over [35] on dataset 3 is also obtained. These observations suggest that our method is indeed quite effective in handling the intensity inhomogeneity issue that is the major cause hindering satisfactory segmentation on datasets 2 and 3. The improvement on the contour-based measures, i.e. on average 0.03 NSD decrease and 1.45 HD decrease over [14], also demonstrate the suitability of boundary delineation using region-based designs, i.e. the salient region extraction and graphical model-based contour refinement.
Table 5.
Comparison with the state-of-the-art results
| |
Dataset 1 |
|||||
|---|---|---|---|---|---|---|
| Dice | Rand | NSD | HD | Add | Miss | |
| RPL |
0.958 |
0.959 |
0.017 |
10.01 |
1.43 |
0.12 |
| [14] |
0.94 |
– |
0.05 |
12.8 |
0.5 |
3.8 |
| [38] |
– |
0.94 |
0.086 |
95.8 |
1.6 |
4.3 |
| |
Dataset 2 |
|||||
| |
Dice |
Rand |
NSD |
HD |
Add |
Miss |
| RPL |
0.906 |
0.932 |
0.090 |
14.10 |
1.47 |
1.17 |
| [14] |
0.85 |
– |
0.12 |
14.2 |
2.8 |
6.1 |
| [38] |
– |
0.88 |
0.29 |
134.1 |
3.3 |
3.8 |
| |
Dataset 3 |
|
||||
| |
Pix |
Obj |
|
|||
| RPL |
0.862 |
0.934 |
|
|||
| [32] |
0.851 |
0.840 |
|
|||
| [35] | 0.856 | 0.893 | ||||
‘–’ means not available.
Our method is currently implemented in Matlab, running on a standard PC with a 2.66-GHz dual core CPU and 3.6 GB RAM. The computational time is related to the number of cells and the size of cells in an image. On a 1344 ×1024 pixel image with about 40 cell nuclei, an average 35 s is needed for the entire localization process. This is faster than applying the level set method [52], which requires about 45 s with 10 iterations.
Conclusions
A fully automatic localization method for cell nuclei in microscopic images is presented in this paper. Intensity inhomogeneities in cell nuclei and the background often cause unsatisfactory localization performance. Not many works have been reported to address this problem in a robust manner. We propose a method that exploits various scales of data-adaptive information to tackle the intensity inhomogeneity. First, the regions of interest, i.e. cell nuclei or clusters, are extracted as salient regions with iterative contrast enhancement. Then with feature-based classification and reference-based probability inference, the clusters are further processed to detect more cell nuclei and filter out spurious regions. Lastly, based on regional contrast information encoded in a graphical model, the pixel-level segmentation is enhanced to create the final contours. This region-based progressive localization (RPL) method has been successfully applied to three publicly available datasets, showing good object-level detection and region- and contour-based segmentation results. Compared to popular approaches in this problem domain such as level sets, our method achieved consistently better performance, with on average 5.2% increase in Dice coefficient and 6% increase in object-level detection accuracy. Our method also outperformed the state-of-the-art with on average 3.5% and 7% improvement of region- and contour-based segmentation measures. We also suggest that the proposed method is general in nature and can be applied to other localization problems, as long as the objects of interest can be modeled as salient regions with measurable contrast from the background.
As a future study, we will investigate improving the graphical model for better contour delineation. A potential approach is to incorporate an additional term as the cost of difference between the model image and the measured image, as inspired by [24]. The model image could be derived as a convolution of a point-spread function of the microscope with an object intensity function defined based on the pixel labels. We will also investigate replacing the pixel-wise labeling with region-level processing for computational efficiency while maintaining the segmentation accuracy. Other future work could explore the applicability of the proposed method on other types of images. Images with nuclear membrane marker and different nuclear markers such as the green fluorescent protein (GFP), and those with higher resolution or dimension, are of particular interest. To accommodate the specific characteristics of these images, possible changes to the method are to design more comprehensive intensity and texture features to differentiate among cell structures and background, and to enhance the contour refinement with boundary constraints.
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
YS designed and carried out research and drafted the manuscript. WC discussed and helped to design the methodology and draft the manuscript. HH, YW and MC helped with the draft manuscript. DF coordinated the designed research. All authors read and approved the final manuscript.
Contributor Information
Yang Song, Email: yson1723@uni.sydney.edu.au.
Weidong Cai, Email: tom.cai@sydney.edu.au.
Heng Huang, Email: heng@uta.edu.
Yue Wang, Email: yuewang@vt.edu.
David Dagan Feng, Email: dagan.feng@sydney.edu.au.
Mei Chen, Email: mei.chen@intel.com.
Acknowledgements
This work was supported in part by ARC grants.
References
- Coelho LP, Shariff A, Murphy RF. Nuclear segmentation in microscope cell images: a hand-segmented dataset and comparison of algorithms. IEEE International Symposium on Biomedical Imaging. 2009. pp. 518–521. [DOI] [PMC free article] [PubMed]
- Peng H. Bioimage informatics: a new area of engineering biology. Bioinformatics. 2008;24(17):1827–1836. doi: 10.1093/bioinformatics/btn346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meijering E. Cell segmentation: 50 years down the road [life sciences] IEEE Signal Process Mag. 2012;29(5):140–145. [Google Scholar]
- Long F, Peng H, Myers E. Automatic segmentation of nuclei in 3D, microscopy images of C.elegans. IEEE International Symposium on Biomedical Imaging. 2007. pp. 536–539.
- Yan P, Zhou X, Shah M, Wong STC. Automatic segmentation of high-throughput RNAi fluorescent cellular images. IEEE Trans. Inf Technol Biomed. 2008;12:109–117. doi: 10.1109/TITB.2007.898006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang H, DeFilippis RA, Tlsty TD, Parvin B. Graphical methods for quantifying macromolecules through bright field imaging. Bioinformatics. 2009;25(8):1070–1075. doi: 10.1093/bioinformatics/btn426. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Zhou X, Ma J, Wong STC. Multiple nuclei tracking using integer programming for quantitative cancer cell cycle analysis. IEEE Trans Med Imag. 2010;29:96–105. doi: 10.1109/TMI.2009.2027813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hagwood C, Bernal J, Halter M, Elliott J. Evaluation of segmentation algorithms on cell populations using CDF curves. IEEE Trans Med Imag. 2012;31(2):380–390. doi: 10.1109/TMI.2011.2169806. [DOI] [PubMed] [Google Scholar]
- Yang L, Meer P, Foran D. Unsupervised segmentation based on robust estimation and color active contour models. IEEE Trans Inf Technol Biomed. 2005;9(3):475–486. doi: 10.1109/TITB.2005.847515. [DOI] [PubMed] [Google Scholar]
- Mosaliganti K, Gelas A, Gouaillard A, Noche R, Obholzer N, Megason S. Detection of spatially correlated objects in 3D images using appearance models and coupled active contours. International Conference on Medical Image Computing and Computer Assisted Intervention. 2009. pp. 641–648. [DOI] [PMC free article] [PubMed]
- Dzyubachyk O, van Cappellen WA, Essers J, Niessen WJ, Meijering E. Advanced level-set-based cell tracking in time-lapse fluorescence microscopy. IEEE Trans Med Imag. 2010;29(3):852–867. doi: 10.1109/TMI.2009.2038693. [DOI] [PubMed] [Google Scholar]
- Bergeest JP, Rohr K. Fast Globally Optimal Segmentation of Cells in Fluorescence Microscopy Images. International Conference on Medical Image Computing and Computer Assisted Intervention. 2011. pp. 645–652. [DOI] [PubMed]
- Ali S, Madabhushi A. An integrated region, boundary, shape based active contour for multiple object overlap resolution in histological imagery. IEEE Trans Med Imag. 2012;31(7):1–14. doi: 10.1109/TMI.2012.2190089. [DOI] [PubMed] [Google Scholar]
- Bergeest JP, Rohr K. Efficient globally optimal segmentation of cells in flurorescence microscopy images using level sets and convex energy functionals. Med Image Anal. 2012;16:1436–1444. doi: 10.1016/j.media.2012.05.012. [DOI] [PubMed] [Google Scholar]
- Cardinale J, Paul G, Sbalzarini IF. Discrete region competition for unknown numbers of connected regions. IEEE Trans Image Process. 2012;21(8):3531–3545. doi: 10.1109/TIP.2012.2192129. [DOI] [PubMed] [Google Scholar]
- Wahlby C, Raviv TR, Ljosa V, Conery AL, Golland P, Ausubel FM, Carpenter AE. Resolving clustered worms via probabilistic shape models. IEEE International Symposium on Biomedical Imaging. 2010. pp. 552–555. [DOI] [PMC free article] [PubMed]
- Raviv TR, Ljosa V, Conery AL, Ausubel FM, Carpenter AE, Golland P, Wahlby C. Morphology-guided graph search for untangling objects: C.elegans analysis. International Conference on Medical Image Computing and Computer Assisted Intervention. 2010. pp. 635–642. [DOI] [PMC free article] [PubMed]
- Yang HF, Choe Y. Cell tracking and segmentation in electron microscopy images using graph cuts. IEEE International Symposium on Biomedical Imaging. 2009. pp. 306–309.
- Lou X, Koethe U, Wittbrodt J, Hamprecht FA. Learning to segment dense cell nuclei with shape prior. IEEE Conference on Computer Vision and Pattern Recognition. 2012. pp. 1012–1018.
- Bernardis E, Yu SX. Pop out many small structures from a very large microscopic image. Med Image Anal. 2011;15:690–707. doi: 10.1016/j.media.2011.06.009. [DOI] [PubMed] [Google Scholar]
- Mumford D, Shah J. Optimal approximations by piecewise smooth functions and associated variational problems. Comm Pure Appl Math. 1989;42:577–685. doi: 10.1002/cpa.3160420503. [DOI] [Google Scholar]
- Li K, Kanade T. Nonnegative Mixed-Norm Preconditioning for Microscopy Image Segmentation. International Conference on Information Processing in Medical Imaging. 2009. pp. 362–373. [DOI] [PubMed]
- Yin Z, Kanade T, Chen M. Understanding the phase contrast optics to restore artifact-free microscopy images for segmentation. Med Image Anal. 2012;16:1047–1062. doi: 10.1016/j.media.2011.12.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helmuth JA, Sbalzarini IF. Deconvolving active contours for fluorescence microscopy images. International Symposium on Visual Computing. 2009. pp. 544–553.
- Helmuth JA, Burckhardt CJ, Greber UF, Sbalzarini IF. Shape reconstruction of subcellular structures from live cell fluorescence microscopy images. J Struct Biol. 2009;167:1–10. doi: 10.1016/j.jsb.2009.03.017. [DOI] [PubMed] [Google Scholar]
- Rezatofighi SH, Hartley R, Hughes WE. A new approach for spot detection in total internal reflection fluorescence microscopy. IEEE International Symposium on Biomedical Imaging. 2012. pp. 860–863.
- Song Y, Cai W, Feng DD. Microscopic Image Segmentation with Two-Level Enhancement of Feature Discriminability. International Conference on Digital Image Computing Techniques and Applications. 2012. pp. 1–6.
- Smith K, Carleton A, Lepetit V. General constraints for batch multiple-target tracking applied to large-scale videomicroscopy. IEEE Conference on Computer Vision and Pattern Recognition. 2008. pp. 1–8.
- Quelhas P, Marcuzzo M, Mendonca AM, Campilho A. Cell nuclei and cytoplasm joint segmentation using the sliding band filter. IEEE Trans Med Imag. 2010;29(8):1463–1473. doi: 10.1109/TMI.2010.2048253. [DOI] [PubMed] [Google Scholar]
- Yin Z, Bise R, Chen M, Kanade T. Cell Segmentation in Microscopy Imagery Using a Bag of Local Bayesian Classifiers. IEEE International Symposium on Biomedical Imaging. 2010. pp. 125–128.
- Kong H, Gurcan M, Belkacem-Boussaid K. Partitioning histopathological images: an integrated framework for supervised color-texture segmentation and cell splitting. IEEE Trans Med Imag. 2011;30(9):1661–1677. doi: 10.1109/TMI.2011.2141674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng L, Ye N, Yu W, Cheah A. Discriminative Segmentation of Microscopic Cellular Images. International Conference on Medical Image Computing and Computer Assisted Intervention. 2011. pp. 637–644. [DOI] [PubMed]
- Qu L, Long F, Liu X, Kim S, Myers E, Peng H. Simultaneous recognition and segmentation of cells: application in C.elegans. Bioinformatics. 2011;27(20):2895–2902. doi: 10.1093/bioinformatics/btr480. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Monaco J, Raess P, Chawla R, Bagg A, Weiss M, Choi J, Madabhushi A. Image segmentation with implicit color standardization using cascaded EM: detection of myelodysplastic syndromes. IEEE International Symposium on Biomedical Imaging. 2012. pp. 740–743.
- Song Y, Cai W, Huang H, Wang Y, Feng DD. Object localization in medical images based on graphical model with contrast and interest-region terms. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. 2012. pp. 1–7.
- Chang H, Loss LA, Spellman PT, Borowsky A, Parvin B. Batch-invariant nuclear segmentation in whole mount histology sections. IEEE International Symposium on Biomedical Imaging. 2012. pp. 856–859.
- Song Y, Cai W, Feng DD, Chen M. Cell Nuclei Segmentation in Fluorescence Microscopy Images Using Inter- and Intra-Region Discriminative Information. International Conference of the IEEE Engineering in Medicine and Biology Society. 2013. pp. 1–4. [DOI] [PubMed]
- Chen C, Wang W, Ozolek JA, Lages N, Altschuler SJ, Wu LF, Rohde GK. A template matching approach for segmenting microscopy images. IEEE International Symposium on Biomedical Imaging. 2012. pp. 768–771.
- Matas J, Chum O, Urban M, Pajdla T. Robust wide baseline stereo from maximally stable extremal regions. British Machine Vision Conference. 2002. pp. 384–393.
- Vedaldi A, Fulkerson B. Vlfeat: an open and portable library of computer vision algorithms. ACM International Conference on Multimedia. 2010. pp. 1469–1472.
- Lowe DG. Distinctive image features from scale-invariant keypoints. Int J Comput Vis. 2004;60(2):91–110. [Google Scholar]
- Chang CC, Lin CJ. LIBSVM: A library for support vector machines. ACM Trans Intell Syst Technol. 2011;2:1–27. [Google Scholar]
- Boyd S, Vandenberghe L. Convex optimization. Cambridge University Press; 2004. [Google Scholar]
- Ling H, Okada K. Diffusion distance for histogram comparison. IEEE Conference on Computer Vision and Pattern Recognition. 2006. pp. 246–253.
- Rubner Y, Tomasi C, Guibas LJ. The earth mover’s distance as a metric for image retrieval. Int J Comput Vis. 2000;40(2):99–121. doi: 10.1023/A:1026543900054. [DOI] [Google Scholar]
- Lafferty J, McCallum A, Pereira F. Conditional random fields: probabilistic models for segmenting and labeling sequence data. International Conference on Machine Learning. 2001. pp. 282–289.
- Kolmogorov V, Zabih R. What energy functions can be minimized via graph cuts? IEEE Trans Pattern Anal Mach Intell. 2004;26(2):147–159. doi: 10.1109/TPAMI.2004.1262177. [DOI] [PubMed] [Google Scholar]
- Huh S, Ker DFE, Bise R, Chen M, Kanade T. Automated mitosis detection of stem cell populations in phase-contrast microscopy images. IEEE Trans Med Imag. 2011;30(3):586–596. doi: 10.1109/TMI.2010.2089384. [DOI] [PubMed] [Google Scholar]
- Song Y, Cai W, Kim J, Feng DD. A multistage discriminative model for tumor and lymph node detection in thoracic images. IEEE Trans Med Imag. 2012;31(5):1061–1075. doi: 10.1109/TMI.2012.2185057. [DOI] [PubMed] [Google Scholar]
- Lezoray O, Cardot H. Cooperation of color pixel classification schemes and color watershed: a study for microscopic images. IEEE Trans Image Proc. 2002;11(7):783–789. doi: 10.1109/TIP.2002.800889. [DOI] [PubMed] [Google Scholar]
- Everingham M, Gool L, Williams C, Winn J, Zisserman A. The pascal visual object classes (VOC) challenge. Int J Comput Vis. 2010;88(2):303–338. doi: 10.1007/s11263-009-0275-4. [DOI] [Google Scholar]
- Li C, Huang R, Ding Z, Gatenby JC, Metaxas DN, Gore JC. A level set method for image segmentation in the presence of intensity Inhomogeneities with application to MRI. IEEE Trans Image Proc. 2011;20(7):2007–2016. doi: 10.1109/TIP.2011.2146190. [DOI] [PMC free article] [PubMed] [Google Scholar]